
البحث في الموقع
المحتوى عن 'تطبيقات scikit learn'.
تم العثور على 4 نتائج
-

 تعرفنا في المقال السابق على خوارزمية أقرب الجيران K-Nearest Neighbors، ووضحنا كيفية استخدامها عمليًا من خلال تمارين وتطبيقات متنوعة، وسنشرح اليوم خوارزمية أساسية من خوارزميات الذكاء الاصطناعي وهي خوارزمية الانحدار اللوجيستي Logistic Regression مع تطبيقات عملية باستخدام مكتبة ساي كيت ليرن ومجموعة بيانات أزهار آيرس Iris dataset. سنمر في البداية على جميع الخطوات التي تدربنا عليها في الأجزاء السابقة بإيجاز، ثم سنشرح آلية عمل خوارزمية الانحدار اللوجيستي المستخدمة بشكل أساسي في مهام التصنيف الثنائي binary classification، كما سنتطرق لبعض الطرق التي تسمح لنا باستخدام هذه الخوارزمية مع مهام التصنيف المتعدد multi classification. مفهوم الانحدار اللوجيستي تحليل الانحدار regression analysis هو أداة إحصائية مفيدة لفهم العلاقة بين متغيرات مختلفة، يساعدنا على تخمين أو توقع كيف يؤثر شيء ما يسمى المتغير المستقل independent variable على شيء آخر يسمى المتغير المعتمد dependent variable. مثلًا يمكننا معرفة كيف يؤثر عدد ساعات الدراسة على درجات الطلاب في الامتحان من خلال تحليل الانحدار واكتشاف العلاقة بين هذين المتغيرين وتحديد إن كان عدد الساعات يؤثر فعلاً في الدرجات أم لا، وفي مجموعة بيانات أزهار آيرس يمكننا استخدامه لاستكشاف العلاقة بين طول السبلة Sepal length وعرض البتلة Petal width على سبيل المثال. هناك نوع خاص من الانحدار يطلق عليه اسم الانحدار اللوجيستي Logistic Regression نستخدمه عندما نريد التنبؤ بنتيجة تصنيف ثنائي binary classification نتيجته إما نعم أو لا، حيث تستخدم خوارزمية الانحدار اللوجيستي logistic regression دالة سينية sigmoid function تسمى بالدالة اللوجيستية logistic function والتي تحوّل المدخلات إلى قيم تقع بين الصفر والواحد مما يجعلها مناسبة لمهام التصنيف الثنائي. يمكننا أن ننظر إلى طريقة عمل خوارزمية الانحدار اللوجيستي على أنها خوارزمية تتكون من خطوتين الأولى هي إيجاد أفضل معادلة خطية تربط بين المدخلات أو المتغيرات المستقلة وبين المخرجات أي المتغيرات المعتمدة، بحيث نوجد أفضل خط يساير fitting البيانات، كما في خوارزمية توقع الانحدار الخطي. الخطوة الثانية هي تحويل القيمة المستمرة الخارجة من خوارزمية توقع الانحدار الخطي إلى احتمالية بين الصفر والواحد باستخدام الدالة اللوجيستية logistic function، والتصنيف ذو الاحتمال الأكبر هو توقع النموذج. يمكننا كذلك استخدام خوارزمية الانحدار اللوجيستي مع مشكلات التصنيف المتعدد multi classification باستخدام خدعة بسيطة تسمى واحد ضد الجميع One Vs All والتي تعرف اختصارًا OVA، حيث نعمل على تدريب عدد من المصنفات الثنائية binary classifiers يساوي عدد التصنيفات classes الموجودة في البيانات، وتكون مهمة كل مصنف classifier التمييز بين تصنيف محدد ونرمز له رقميًا بواحد 1 وما دون ذلك من التصنيفات نرمز لها جميعًا بصفر 0. يمكننا في مكتبة scikit-learn، استخدام خوارزمية الانحدار اللوجستي لمهام التصنيف المتعدد باستخدام الدالة softmax التي تحدد احتمالية انتماء كل عينة إلى إحدى التصنيفات المتعددة، بحيث يكون مجموع الاحتمالات لجميع التصنيفات classes مساويًا لواحد، بينما نستخدم الدالة sigmoid في مهام التصنيف الثنائي فقط. استكشاف مجموعة البيانات Data Exploring سنكتب برنامج بايثون لعرض المعلومات الإحصائية الأساسية لفصائل أزهار آيرس المختلفة Iris-setosa و Iris-versicolor و Iris-virginica على النحو التالي: import pandas as pd iris = pd.read_csv("iris.csv") # قائمة بجميع الفصائل SpeciesList = iris.Species.value_counts().index # حلقة تكرارية لحساب الإحصائيات لكل فصيلة for s in SpeciesList: print(f"Statistics about {s}") # حساب الإحصائيات لشريحة البيانات التي تنتمي للفصيلة الحالية print(iris[iris.Species == s].describe()) يعمل الكود السابق على توليد إحصائيات وصفية لكل فصيلة من فصائل الأزهار الموجودة في المجموعة. حيث يسمح لنا الشرط [iris[iris.Species == s باختيار العينات التي تحقق هذا الشرط، أي أننا سنختار في كل تكرار للحلقة العينات التي تنتمي للفصيلة s ثم سنستخدام التابع data.describe() للحصول على معلومات إحصائية تخص هذه العينات، مثل أكبر وأصغر قيمة في البيانات والمتوسط الحسابي للقيم والانحراف المعياري. عند تنفيذ الكود سنحصل على الخرج التالي: Statistics about Iris-setosa Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.00000 50.000000 50.000000 50.00000 mean 25.50000 5.00600 3.418000 1.464000 0.24400 std 14.57738 0.35249 0.381024 0.173511 0.10721 min 1.00000 4.30000 2.300000 1.000000 0.10000 25% 13.25000 4.80000 3.125000 1.400000 0.20000 50% 25.50000 5.00000 3.400000 1.500000 0.20000 75% 37.75000 5.20000 3.675000 1.575000 0.30000 max 50.00000 5.80000 4.400000 1.900000 0.60000 Statistics about Iris-versicolor Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.000000 50.000000 50.000000 50.000000 mean 75.50000 5.936000 2.770000 4.260000 1.326000 std 14.57738 0.516171 0.313798 0.469911 0.197753 min 51.00000 4.900000 2.000000 3.000000 1.000000 25% 63.25000 5.600000 2.525000 4.000000 1.200000 50% 75.50000 5.900000 2.800000 4.350000 1.300000 75% 87.75000 6.300000 3.000000 4.600000 1.500000 max 100.00000 7.000000 3.400000 5.100000 1.800000 Statistics about Iris-virginica Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.00000 50.000000 50.000000 50.00000 mean 125.50000 6.58800 2.974000 5.552000 2.02600 std 14.57738 0.63588 0.322497 0.551895 0.27465 min 101.00000 4.90000 2.200000 4.500000 1.40000 25% 113.25000 6.22500 2.800000 5.100000 1.80000 50% 125.50000 6.50000 3.000000 5.550000 2.00000 75% 137.75000 6.90000 3.175000 5.875000 2.30000 max 150.00000 7.90000 3.800000 6.900000 2.50000 Index(['Id', 'SepalLengthCm', 'SepalWidth عرض العلاقة بين البيانات باستخدام التمثيل المرئي Data Visualization سننشئ الآن رسم بياني نقطي Scatter plot لعرض العلاقة بين طول السبلة Sepal length وعرض البتلة Petal width، لنحقق ذلك نكتب الكود التالي: import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(7,7), dpi=150) sns.scatterplot(data=iris, x="SepalLengthCm", y="PetalWidthCm", hue="Species") plt.show() استوردنا في هذا الكود مكتبة matplotlib لضبط إعدادات الرسم البياني من أبعاد الشكل ودقة الصورة الناتجة، كما استوردنا مكتبة seaborn التي توفر واجهة استخدام سهلة ومرنة للرسم. بعدها مررنا للدالة sns.scatterplot المعامل data لتحديد مجموعة البيانات التي سنعمل عليها، وحددنا بأن المحور الأفقي سيكون طول السبلات، وأن المحور العمودي سيكون عرض البتلات، ستمثل كل زهرة بنقطة في الشكل الناتج وتلون كل نقطة وفقًا لانتمائها لأحد الفصائل الثلاثة في مجموعة بيانات أزهار آيرس. عند تنفيذ الكود سنحصل على الرسم البياني التالي: تصنيف فصائل الأزهار باستخدام خوارزمية الانحدار اللوجستي سنكتب الآن برنامج بايثون لتدريب نموذج الانحدار اللوجيستي Logistic Regression على مجموعة بيانات أزهار آيرس التي تحتوي على ثلاثة فصائل من الأزهار للتمييز فيما بينها، ثم نقيم أداء النموذج على مجموعة الاختبار. import pandas as pd from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.linear_model import LogisticRegression iris = pd.read_csv("iris.csv") # Id احذف عمود # لعدم أهميته في عملية التعلم iris = iris.drop('Id',axis=1) # خواص الأزهار X = iris.iloc[:, :-1].values # وسم الأزهار y = iris.iloc[:, 4].values # تقسيم مجموعة البيانات إلى مجموعة بيانات تدريب ومجموعة بيانات اختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # إنشاء نموذج model = LogisticRegression(random_state=0, multi_class='multinomial') model.fit(X_train,y_train) prediction=model.predict(X_test) print('The accuracy of the Logistic Regression is', metrics.accuracy_score(prediction,y_test)) استوردنا في البداية عددًا من الدوال والمكتبات التي ستساعدنا في تدريب وتقييم النموذج، واستدعينا الدالة train_test_split لتقسم خاصيات مجموعة البيانات dataset features ووسوم البيانات dataset labels إلى مجموعتي تدريب واختبار كل منها يمتلك جزءًا من خاصيات مجموعة البيانات والوسوم المقابلة للعينات المختارة، وحددنا نسبة التقسيم باستخدام التعليمة test_size=0.20 لجعل عشرين بالمائة من مجموعة البيانات مجموعة اختبار، والنسبة الباقية للتدريب، ستُقسَم البيانات بشكل عشوائي في كل مرة نشغل بها الكود، ثم عرفنا كائن model يطبق خوارزمية الانحدار اللوجيستي ومررنا له المتغير random_state=0 لنضمن ثبات نتيجة تدريب النموذج عند تشغيل الكود أكثر من مرة، وحددنا نوع المشكلة بأنه تصنيف متعدد بضبط قيمة المعامل multi_class إلى multinomial. بعد أن هيئنا إعدادات النموذج سندربه على مجموعة بيانات التدريب باستخدام الدالة model.fit(X_train,y_train)، وبعد تدريب النموذج يمكننا استخدامه في تخمين الوسوم لمجموعة الاختبار باستخدام الدالة model.predict(X_test). نخزن الناتج في القائمة prediction التي تحتوي محاولة النموذج لتوقع قيم y_test، ولتقييم دقة النموذج في هذه المحاولة نستخدم الدالة metrics.accuracy_score(prediction,y_test) التي تحصي نسبة القيم التي توقعها النموذج بشكل صحيح إلى إجمالي جميع القيم. عند تنفيذ الكود سنحصل على الخرج التالي: The accuracy of the Logistic Regression is 0.9333333333333333 تعني النتيجة التي حصلنا عليها أن النموذج جيد جدًا في التنبؤ، لأنه أصاب في أكثر من 93% من الحالات فهذه النسبة تمثل نسبة العينات التي صنفها النموذج بشكل صحيح وتعرف باسم دقة النموذج، لكن الدقة ليست دائمًا المقياس الوحيد الكافي، خصوصًا في المشكلات التي يكون فيها عدد العينات في كل فئة غير متوازن لذا قد نحتاج لمقاييس إضافية لتقييم النموذج بشكل عادل. الخاتمة تعرفنا في هذه المقالة على خوارزمية الانحدار اللوجيستي Logistic Regression وكيف تعمل، وطبقناها باستخدام مكتبة ساي كيت ليرن على مجموعة بيانات أزهار إيرس، وقيمنا دقة النموذج على مجموعة بيانات اختبارية، يمكن مواصلة التدريب على مجموعات بيانات مختلفة أكبر في الحجم وتحتاج للمزيد من المعالجة، حيث تتوفر الكثير من مجموعات البيانات مفتوحة المصدر على موقع Kaggle. اقرأ أيضًا المقال السابق: استخدام خوارزمية أقرب الجيران k-Nearest Neighbors في Scikit-Learn تعرف على مكتبة Scikit learn وأهم خوارزمياتها الانحدار الإحصائي regression ودوره في ملاءمة النماذج المختلفة مع أنواع البيانات المتاحة العلاقات بين المتغيرات الإحصائية وكيفية تنفيذها في بايثون
تعرفنا في المقال السابق على خوارزمية أقرب الجيران K-Nearest Neighbors، ووضحنا كيفية استخدامها عمليًا من خلال تمارين وتطبيقات متنوعة، وسنشرح اليوم خوارزمية أساسية من خوارزميات الذكاء الاصطناعي وهي خوارزمية الانحدار اللوجيستي Logistic Regression مع تطبيقات عملية باستخدام مكتبة ساي كيت ليرن ومجموعة بيانات أزهار آيرس Iris dataset. سنمر في البداية على جميع الخطوات التي تدربنا عليها في الأجزاء السابقة بإيجاز، ثم سنشرح آلية عمل خوارزمية الانحدار اللوجيستي المستخدمة بشكل أساسي في مهام التصنيف الثنائي binary classification، كما سنتطرق لبعض الطرق التي تسمح لنا باستخدام هذه الخوارزمية مع مهام التصنيف المتعدد multi classification. مفهوم الانحدار اللوجيستي تحليل الانحدار regression analysis هو أداة إحصائية مفيدة لفهم العلاقة بين متغيرات مختلفة، يساعدنا على تخمين أو توقع كيف يؤثر شيء ما يسمى المتغير المستقل independent variable على شيء آخر يسمى المتغير المعتمد dependent variable. مثلًا يمكننا معرفة كيف يؤثر عدد ساعات الدراسة على درجات الطلاب في الامتحان من خلال تحليل الانحدار واكتشاف العلاقة بين هذين المتغيرين وتحديد إن كان عدد الساعات يؤثر فعلاً في الدرجات أم لا، وفي مجموعة بيانات أزهار آيرس يمكننا استخدامه لاستكشاف العلاقة بين طول السبلة Sepal length وعرض البتلة Petal width على سبيل المثال. هناك نوع خاص من الانحدار يطلق عليه اسم الانحدار اللوجيستي Logistic Regression نستخدمه عندما نريد التنبؤ بنتيجة تصنيف ثنائي binary classification نتيجته إما نعم أو لا، حيث تستخدم خوارزمية الانحدار اللوجيستي logistic regression دالة سينية sigmoid function تسمى بالدالة اللوجيستية logistic function والتي تحوّل المدخلات إلى قيم تقع بين الصفر والواحد مما يجعلها مناسبة لمهام التصنيف الثنائي. يمكننا أن ننظر إلى طريقة عمل خوارزمية الانحدار اللوجيستي على أنها خوارزمية تتكون من خطوتين الأولى هي إيجاد أفضل معادلة خطية تربط بين المدخلات أو المتغيرات المستقلة وبين المخرجات أي المتغيرات المعتمدة، بحيث نوجد أفضل خط يساير fitting البيانات، كما في خوارزمية توقع الانحدار الخطي. الخطوة الثانية هي تحويل القيمة المستمرة الخارجة من خوارزمية توقع الانحدار الخطي إلى احتمالية بين الصفر والواحد باستخدام الدالة اللوجيستية logistic function، والتصنيف ذو الاحتمال الأكبر هو توقع النموذج. يمكننا كذلك استخدام خوارزمية الانحدار اللوجيستي مع مشكلات التصنيف المتعدد multi classification باستخدام خدعة بسيطة تسمى واحد ضد الجميع One Vs All والتي تعرف اختصارًا OVA، حيث نعمل على تدريب عدد من المصنفات الثنائية binary classifiers يساوي عدد التصنيفات classes الموجودة في البيانات، وتكون مهمة كل مصنف classifier التمييز بين تصنيف محدد ونرمز له رقميًا بواحد 1 وما دون ذلك من التصنيفات نرمز لها جميعًا بصفر 0. يمكننا في مكتبة scikit-learn، استخدام خوارزمية الانحدار اللوجستي لمهام التصنيف المتعدد باستخدام الدالة softmax التي تحدد احتمالية انتماء كل عينة إلى إحدى التصنيفات المتعددة، بحيث يكون مجموع الاحتمالات لجميع التصنيفات classes مساويًا لواحد، بينما نستخدم الدالة sigmoid في مهام التصنيف الثنائي فقط. استكشاف مجموعة البيانات Data Exploring سنكتب برنامج بايثون لعرض المعلومات الإحصائية الأساسية لفصائل أزهار آيرس المختلفة Iris-setosa و Iris-versicolor و Iris-virginica على النحو التالي: import pandas as pd iris = pd.read_csv("iris.csv") # قائمة بجميع الفصائل SpeciesList = iris.Species.value_counts().index # حلقة تكرارية لحساب الإحصائيات لكل فصيلة for s in SpeciesList: print(f"Statistics about {s}") # حساب الإحصائيات لشريحة البيانات التي تنتمي للفصيلة الحالية print(iris[iris.Species == s].describe()) يعمل الكود السابق على توليد إحصائيات وصفية لكل فصيلة من فصائل الأزهار الموجودة في المجموعة. حيث يسمح لنا الشرط [iris[iris.Species == s باختيار العينات التي تحقق هذا الشرط، أي أننا سنختار في كل تكرار للحلقة العينات التي تنتمي للفصيلة s ثم سنستخدام التابع data.describe() للحصول على معلومات إحصائية تخص هذه العينات، مثل أكبر وأصغر قيمة في البيانات والمتوسط الحسابي للقيم والانحراف المعياري. عند تنفيذ الكود سنحصل على الخرج التالي: Statistics about Iris-setosa Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.00000 50.000000 50.000000 50.00000 mean 25.50000 5.00600 3.418000 1.464000 0.24400 std 14.57738 0.35249 0.381024 0.173511 0.10721 min 1.00000 4.30000 2.300000 1.000000 0.10000 25% 13.25000 4.80000 3.125000 1.400000 0.20000 50% 25.50000 5.00000 3.400000 1.500000 0.20000 75% 37.75000 5.20000 3.675000 1.575000 0.30000 max 50.00000 5.80000 4.400000 1.900000 0.60000 Statistics about Iris-versicolor Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.000000 50.000000 50.000000 50.000000 mean 75.50000 5.936000 2.770000 4.260000 1.326000 std 14.57738 0.516171 0.313798 0.469911 0.197753 min 51.00000 4.900000 2.000000 3.000000 1.000000 25% 63.25000 5.600000 2.525000 4.000000 1.200000 50% 75.50000 5.900000 2.800000 4.350000 1.300000 75% 87.75000 6.300000 3.000000 4.600000 1.500000 max 100.00000 7.000000 3.400000 5.100000 1.800000 Statistics about Iris-virginica Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.00000 50.000000 50.000000 50.00000 mean 125.50000 6.58800 2.974000 5.552000 2.02600 std 14.57738 0.63588 0.322497 0.551895 0.27465 min 101.00000 4.90000 2.200000 4.500000 1.40000 25% 113.25000 6.22500 2.800000 5.100000 1.80000 50% 125.50000 6.50000 3.000000 5.550000 2.00000 75% 137.75000 6.90000 3.175000 5.875000 2.30000 max 150.00000 7.90000 3.800000 6.900000 2.50000 Index(['Id', 'SepalLengthCm', 'SepalWidth عرض العلاقة بين البيانات باستخدام التمثيل المرئي Data Visualization سننشئ الآن رسم بياني نقطي Scatter plot لعرض العلاقة بين طول السبلة Sepal length وعرض البتلة Petal width، لنحقق ذلك نكتب الكود التالي: import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(7,7), dpi=150) sns.scatterplot(data=iris, x="SepalLengthCm", y="PetalWidthCm", hue="Species") plt.show() استوردنا في هذا الكود مكتبة matplotlib لضبط إعدادات الرسم البياني من أبعاد الشكل ودقة الصورة الناتجة، كما استوردنا مكتبة seaborn التي توفر واجهة استخدام سهلة ومرنة للرسم. بعدها مررنا للدالة sns.scatterplot المعامل data لتحديد مجموعة البيانات التي سنعمل عليها، وحددنا بأن المحور الأفقي سيكون طول السبلات، وأن المحور العمودي سيكون عرض البتلات، ستمثل كل زهرة بنقطة في الشكل الناتج وتلون كل نقطة وفقًا لانتمائها لأحد الفصائل الثلاثة في مجموعة بيانات أزهار آيرس. عند تنفيذ الكود سنحصل على الرسم البياني التالي: تصنيف فصائل الأزهار باستخدام خوارزمية الانحدار اللوجستي سنكتب الآن برنامج بايثون لتدريب نموذج الانحدار اللوجيستي Logistic Regression على مجموعة بيانات أزهار آيرس التي تحتوي على ثلاثة فصائل من الأزهار للتمييز فيما بينها، ثم نقيم أداء النموذج على مجموعة الاختبار. import pandas as pd from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.linear_model import LogisticRegression iris = pd.read_csv("iris.csv") # Id احذف عمود # لعدم أهميته في عملية التعلم iris = iris.drop('Id',axis=1) # خواص الأزهار X = iris.iloc[:, :-1].values # وسم الأزهار y = iris.iloc[:, 4].values # تقسيم مجموعة البيانات إلى مجموعة بيانات تدريب ومجموعة بيانات اختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # إنشاء نموذج model = LogisticRegression(random_state=0, multi_class='multinomial') model.fit(X_train,y_train) prediction=model.predict(X_test) print('The accuracy of the Logistic Regression is', metrics.accuracy_score(prediction,y_test)) استوردنا في البداية عددًا من الدوال والمكتبات التي ستساعدنا في تدريب وتقييم النموذج، واستدعينا الدالة train_test_split لتقسم خاصيات مجموعة البيانات dataset features ووسوم البيانات dataset labels إلى مجموعتي تدريب واختبار كل منها يمتلك جزءًا من خاصيات مجموعة البيانات والوسوم المقابلة للعينات المختارة، وحددنا نسبة التقسيم باستخدام التعليمة test_size=0.20 لجعل عشرين بالمائة من مجموعة البيانات مجموعة اختبار، والنسبة الباقية للتدريب، ستُقسَم البيانات بشكل عشوائي في كل مرة نشغل بها الكود، ثم عرفنا كائن model يطبق خوارزمية الانحدار اللوجيستي ومررنا له المتغير random_state=0 لنضمن ثبات نتيجة تدريب النموذج عند تشغيل الكود أكثر من مرة، وحددنا نوع المشكلة بأنه تصنيف متعدد بضبط قيمة المعامل multi_class إلى multinomial. بعد أن هيئنا إعدادات النموذج سندربه على مجموعة بيانات التدريب باستخدام الدالة model.fit(X_train,y_train)، وبعد تدريب النموذج يمكننا استخدامه في تخمين الوسوم لمجموعة الاختبار باستخدام الدالة model.predict(X_test). نخزن الناتج في القائمة prediction التي تحتوي محاولة النموذج لتوقع قيم y_test، ولتقييم دقة النموذج في هذه المحاولة نستخدم الدالة metrics.accuracy_score(prediction,y_test) التي تحصي نسبة القيم التي توقعها النموذج بشكل صحيح إلى إجمالي جميع القيم. عند تنفيذ الكود سنحصل على الخرج التالي: The accuracy of the Logistic Regression is 0.9333333333333333 تعني النتيجة التي حصلنا عليها أن النموذج جيد جدًا في التنبؤ، لأنه أصاب في أكثر من 93% من الحالات فهذه النسبة تمثل نسبة العينات التي صنفها النموذج بشكل صحيح وتعرف باسم دقة النموذج، لكن الدقة ليست دائمًا المقياس الوحيد الكافي، خصوصًا في المشكلات التي يكون فيها عدد العينات في كل فئة غير متوازن لذا قد نحتاج لمقاييس إضافية لتقييم النموذج بشكل عادل. الخاتمة تعرفنا في هذه المقالة على خوارزمية الانحدار اللوجيستي Logistic Regression وكيف تعمل، وطبقناها باستخدام مكتبة ساي كيت ليرن على مجموعة بيانات أزهار إيرس، وقيمنا دقة النموذج على مجموعة بيانات اختبارية، يمكن مواصلة التدريب على مجموعات بيانات مختلفة أكبر في الحجم وتحتاج للمزيد من المعالجة، حيث تتوفر الكثير من مجموعات البيانات مفتوحة المصدر على موقع Kaggle. اقرأ أيضًا المقال السابق: استخدام خوارزمية أقرب الجيران k-Nearest Neighbors في Scikit-Learn تعرف على مكتبة Scikit learn وأهم خوارزمياتها الانحدار الإحصائي regression ودوره في ملاءمة النماذج المختلفة مع أنواع البيانات المتاحة العلاقات بين المتغيرات الإحصائية وكيفية تنفيذها في بايثون -
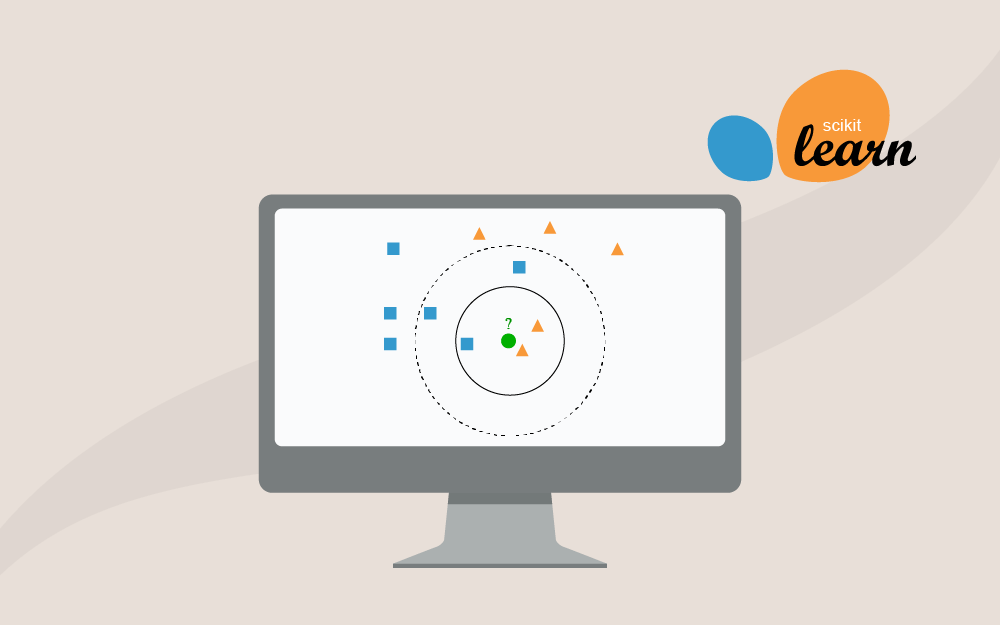 في هذا المقال من سلسلة تطبيقات عملية على استخدام مكتبة ساي كيت ليرن سنستعرض خطوة بخطوة كيفية تطبيق واحدة من أشهر خوارزميات تعلم الآلة وهي خوارزمية أقرب الجيران k-Nearest Neighbors -أو KNN اختصارًا- لتصنيف الأنواع المختلفة من الأزهار الموجودة ضمن مجموعة بيانات آيرس Iris dataset إحدى أكثر مجموعات البيانات استخدامًا في مجال تعلم الآلة والتي تعرفنا عليها في مقال سابق بعنوان أساسيات تحليل البيانات باستخدام Scikit-Learn. آلية عمل خوارزمية k-Nearest Neighbors يمكننا تعريف خوارزمية أقرب جار K-Nearest Neighbors على أنها خوارزمية لا معاملية non-parametric بمعنى أنها لا تملك أوزان أو معاملات تحاول تحسينها كما تتبع خوارزميات ذكاء اصطناعي أخرى، فهي تستخدم في مهام التصنيف Classification وتوقع الانحدار Regression، وفي كلا الحالتين تعتمد على المعلومات المتاحة لدى أقرب k من النقاط المجاورة لمجموعة بيانات التدريب، وتختلف طريقة حساب المخرجات حسب مهمة التعلم. في حالة التصنيف Classification يكون خرج النموذج أحد التصنيفات المحددة، ونقرره بناءً على تصويت الأغلبية من عدد k نقطة مجاورة لها حق التصويت أي يسمح لها بالمشاركة في اتخاذ القرار بشأن تصنيف نقطة معينة، ويكون هذا العدد المحدد k من النقاط المجاورة عددًا صحيحًا موجبًا ويفضل أن يكون فرديًا لمنع أي حالات تعادل في التصويت. من المهم اختيار قيمة k مناسبة في خوارزمية الجار الأقرب، ويفضل أن تكون قيمة صغيرة نسبيًا، فعندما نحدد عدد النقاط المجاورة k=1 سيتأثر قرار النموذج بالضجيج noise في البيانات والنقاط الخارجة outliers وغير المألوفة بشكل كبير، مما يحدث حالة إفراط في التخصيص Overfitting ويضعف قدرته على التعميم لبيانات جديدة، بينما عندما نحدد عدد النقاط المجاورة برقم كبير n يساوي عدد العينات بمجموعة بيانات التدريب سيصبح النموذج أبسط من اللازم وتحدث لديه حالة إفراط في التبسيط Underfitting بالتالي لن يكون قادر على التعبير عن العلاقات المعقدة الموجودة في البيانات وسيأخذ قرارات اعتمادًا على نقاط بعيدة جدًا ولا تؤثر على نقطة الاستفسار الحالية. في حالة توقع الانحدار Regression يكون خرج النموذج عدد مستمر ناتج عن أخذ متوسط القيم من عدد محدد k من النقاط المجاورة لتقرير قيمة نقطة الاستفسار الحالية. تعرض الصورة السابقة مثالًا على خوارزمية KNN لمهمة التصنيف، وتمثل النقطة الخضراء نقطة الاستفسار الحالية query point والتي نريد تصنيفها إما لصنف المربعات الزرقاء أو المثلثات الحمراء، فإذا قررنا أن عدد النقاط المجاورة k=3 تصبح النقاط الداخلة في القرار هي النقاط المحاطة بالدائرة المتصلة، وكما نرى فالأغلبية في هذا النطاق للمثلثات الحمراء 2 بينما الأقلية هي المربعات الزرقاء 1، بالتالي يمكننا تصنيف نقطة الاستفسار query point بأنها مثلث أحمر، بينما عند زيادة k لتصبح 5 ننظر للنقاط المحاطة بالدائرة المنقطة فنجد أن الأغلبية صارت للمربعات الزرقاء 3 مقابل 2 من المثلثات الحمراء، بالتالي يصبح التصنيف لنقطة الاستفسار مربع أزرق. بعد أن تعرفنا على آلية عمل الخوارزمية، لنستعرض مجموعة من التدريبات العملية التي تساعدنا على فهم كيفية استخدام هذه الخوارزمية بشكل فعّال باستخدام مكتبة scikit-learn. فصل مجموعة البيانات من أولى خطوات التحضير لبناء أي نموذج تعلم آلة هي فصل الخصائص Features وهي البيانات التي نستخدمها لتوقع شيء ما عن الوسوم Labels وهي القيم التي نحاول التنبؤ بها، لنكتب برنامج بايثون لتقسيم مجموعة بيانات أزهار آيرس إلى خصائصها كطول و عرض بتلة الزهرة وسبلتها والتي سنخزنها في متغير X ، والوسوم التي سنخزنها في متغير Y. سيحتوي المتغير X أول أربعة أعمدة بينما يحتوي المتغير Y وسم كل زهرة بفصيلتها مثل Setosa أو Versicolor أو Virginica. import pandas as pd iris = pd.read_csv("iris.csv") # Idاحذف عمود iris = iris.drop('Id',axis=1) # iloc : تسمح باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values print("الخصائص:") print(X) print("\nالوسوم:") print(y) كما نلاحظ فقد حذفنا في هذه الخطوة عمود المعرف Id من مجموعة البيانات، كونه لا يحمل أي معنى يتعلق بخصائص الأزهار، واستخدامه قد يؤدي لنموذج متحيز وغير دقيق. واستخدمنا التابع iloc لتحديد الخصائص X، والوسوم Y وأخيرًا، طبعنا كلًا من X و Y للتأكد من صحة التقسيم. عند تنفيذ الكود سنحصل على الخرج التالي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] ... [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] تقسيم مجموعة البيانات لمجموعة تدريب ومجموعة اختبار نحتاج لتقسيم البيانات إلى بيانات تدريب training وبيانات اختبار testing حتى نتمكن من معرفة فيما إذا كان النموذج يعمل جيدًا على بيانات جديدة لم يرها من قبل، سنكتب كود لتقسيم مجموعة بيانات آيرس إلى مجموعة تدريب تحتوي 80% من البيانات ومجموعة اختبار تحتوي 20%، بحيث يكون عدد العينات المستخدمة في التدريب هو 120 عينة والمستخدمة في الاختبار 30 عينة، ونطبع كلا المجموعتين. import pandas as pd from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") # Id احذف العمود iris = iris.drop('Id',axis=1) # iloc : تسمح لنا باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسم هذه الدالة مجموعة البيانات عشوائيًا وفقًا للنسب المحددة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n70% train data:") print(X_train) print(y_train) print("\n30% test data:") print(X_test) print(y_test) فصلنا في البداية مجموعة البيانات إلى خاصيات X ووسوم Y كما في فعلنا في التطبيق السابق، ثم استدعينا الدالة train_test_split التي تقسم خاصيات ووسوم المجموعة إلى مجموعة تدريب ومجموعة اختبار، وحددنا نسبة التقسيم باستخدام test_size=0.20 لجعل 20% من مجموعة البيانات مخصصة للاختبار، بينما 80% منها للتدريب، سيجري تقسيم البيانات عشوائيًا في كل مرة نشغل بها الكود. عند تنفيذ الكود السابق سنحصل على خرج مشابه لما يلي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [4.8 3. 1.4 0.1] [6. 2.7 5.1 1.6] [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] ترقيم الفصائل النصية الأن سنعمل على تطبيق يحوّل فصائل الأزهار في مجموعة بيانات آيرس من أسماء نصية إلى قيم رقمية، ولنفعل ذلك سنحتاج لتحويل كل قيمة إلى رقم ثابت لهذه القيمة، فمثلًا نجعل Iris-setosa:0 و Iris-versicolor:1 و Iris-virginica:2، ثم نطبع مجموعة بيانات التدريب ومجموعة بيانات الاختبار. import pandas as pd from sklearn.model_selection import train_test_split # LabelEncoder استدعي # والذي سوف نستخدمه لتحويل الفصائل من قيم نصية إلى أرقام ثابته لكل فصيلة from sklearn.preprocessing import LabelEncoder iris = pd.read_csv("iris.csv") # labelEncoder نهيئ الصنف البرمجي le = LabelEncoder() # labelEncoder نستخدم الصنف البرمجي # لتحويل التصنيفات النصية إلى أرقم iris.Species = le.fit_transform(iris.Species) # Id نحذف العمود # حيث لا يحتوي معلومات مهمة للتعلم iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # نقسم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار # كل منهما له خصائص ووسوم منفصلة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n80% train data:") print(X_train) print(y_train) print("\n20% test data:") print(X_test) print(y_test) استخدمناLabelEncoder() لنهيئ الكائن le والذي سنستخدمه لتحويل الفصائل النصية categorical classes لأرقام، حيث نرمز لكل صنف أو اسم برقم ثابت لهذا الصنف، ونستدعي هذا الكائن ليطبّق على البيانات باستخدام le.fit_transform(iris.Species) حيث تتعرف هذه الدالة في البداية على الأصناف في عمود Species وتحدد القيم التي ستعطى لكل فصيل category وتسمى هذه العملية fit ويمكن تنفيذها بشكل مستقل، ومن ثم يتم تحويل القيم النصية القديمة إلى الأرقام المقابلة عند تنفيذ عملية transform التي يمكن فصلها لكي تنفّذ بعد عملية fit على أكثر من مجموعة من البيانات التي تتضمن نفس الفصائل، ولكن في كثير من الأحيان نستخدم الدالة التي تدمج الخطوتين معًا. عند تنفيذ الكود سنحصل على الخرج التالي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] 80% train data: [[7.7 2.8 6.7 2. ] [6.7 3.1 5.6 2.4] [5.7 2.6 3.5 1. ] [6.3 2.8 5.1 1.5] [4.9 3.1 1.5 0.1] … [4.8 3. 1.4 0.3] [6.4 2.9 4.3 1.3] [4.8 3. 1.4 0.1] [5.5 2.6 4.4 1.2] [6.3 2.3 4.4 1.3]] [2 2 1 2 0 0 0 2 2 2 2 2 0 0 2 2 1 2 1 0 1 2 0 1 2 0 1 2 2 0 1 1 1 2 0 1 0 1 0 2 2 2 0 2 1 1 0 2 1 2 1 0 0 1 1 2 0 0 2 1 1 2 0 1 1 0 0 2 0 0 1 1 2 1 0 1 2 2 0 1 0 0 2 0 0 2 0 1 1 2 2 0 0 1 2 0 1 1 1 0 0 1 0 2 2 0 0 0 2 2 0 2 2 0 2 0 1 0 1 1] 20% test data: [[6.8 3.2 5.9 2.3] [5.4 3. 4.5 1.5] [4.3 3. 1.1 0.1] [5.6 3. 4.1 1.3] [6.7 3. 5. 1.7] … [5.8 2.7 3.9 1.2] [6.3 2.5 5. 1.9] [6.3 3.3 4.7 1.6] [5.1 3.7 1.5 0.4] [6.9 3.2 5.7 2.3]] [2 1 0 1 1 0 2 2 2 1 0 2 1 1 1 1 1 2 1 1 1 0 2 0 0 1 2 1 0 2] بناء نموذج K-Nearest Neighbors باستخدام ساي كيت ليرن Scikit-Learn لنكتب كود برمجي لجعل نسبة تقسيم مجموعات البيانات 70% لمجموعة التدريب و30% لمجموعة الاختبار، حيث يصبح عدد العينات المستخدمة في التدريب 105 عينة وعدد عينات الاختبار 45، ثم نتوقع باستخدام نموذج KNN تصنيفات الفصائل لمجموعة الاختبار مع تحديد عدد النقاط المجاورة ليكون 5. import pandas as pd from sklearn.model_selection import train_test_split # نستدعي المُصنف من مكتبة ساي كيت ليرن from sklearn.neighbors import KNeighborsClassifier iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم مجموعات البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30) # KNN Classifier استدعي # القيمة الافتراضية لعدد النقاط المجاورة التي لها حق التصويت هي 5 knn = KNeighborsClassifier(n_neighbors=5) # درب النموذج باستخدام مجموعة بيانات التدريب # في عملية التدريب الخاضع للإشراف يستطيع النموذج أن يستخدم وسم البيانات knn.fit(X_train, y_train) # استخدم النموذج المدرب لتوقع مجموعة بيانات الاختبار print("Response for test dataset:") y_pred = knn.predict(X_test) print(y_pred) استخدمنا دالة knn.fit(X_train, y_train) لتدريب الكائن الذي يُطبق خوارزمية KNN في مكتبة ساي كيت ليرن، ولتدريب النموذج استخدمنا مجموعة خاصيات التدريب X_train والوسوم المقابلة لها y_train، وأثناء تهيئة الكائن عرفنا بعض الإعدادات والمعاملات مثل عدد النقاط المجاورة n_neighbors، وبعد تدريب النموذج استخدمناه لتوقع وسوم خاصيات مجموعة الاختبار X_test. عند تنفيذ الكود سنحصل على الخرج التالي: Response for test dataset: ['Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica'] نلاحظ أن النموذج استطاع التعامل مع القيم النصية لتصنيفات الفصائل بشكل مباشر، وهذا ليس السائد في نماذج تعلم الآلة حيث أغلبها يتوقع فقط قيمًا رقمية حيث أن أغلب الخوارزميات تقوم بعمليات رياضية، ولكن كما ذكرنا من قبل فإن خوارزمية KNN لا معاملية non-parametric ولا تقوم بأي عمليات رياضية معقدة، فقط عملية التصويت في حالة التصنيف. نلاحظ أيضًا أن هذا يعمل فقط مع القيم النصية للوسوم وليس للخاصيات أو الأعمدة الأخرى المستخدمة في التدريب، حيث يحتاج النموذج لحساب المسافة بين نقطة الاستفسار query points وبين جميع النقاط في مجموعة التدريب المخزنة في الذاكرة ليستطيع تقرير أقرب k من النقاط المجاورة مسافةً. اختبار تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN سنكتب تطبيق لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب دقة النموذج لكل قيمة. import pandas as pd from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) print("For k = %d accuracy is"%k,knn.score(X_test,y_test)) أنشأنا حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها. عند تنفيذ الكود سنحصل على الخرج التالي: For k = 1 accuracy is 0.9666666666666667 For k = 2 accuracy is 0.9666666666666667 For k = 3 accuracy is 0.9666666666666667 For k = 4 accuracy is 0.9333333333333333 For k = 5 accuracy is 0.9666666666666667 For k = 6 accuracy is 0.9666666666666667 For k = 7 accuracy is 0.9666666666666667 For k = 8 accuracy is 0.9333333333333333 For k = 9 accuracy is 0.9666666666666667 رسم بياني لدراسة تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN لنقسم الآن مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k. import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=10) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) score = knn.score(X_test,y_test) acc.append(score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], acc) plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.show() أنشانا في الكود السابق حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها، وقد حفظنا دقة النموذج عند كل نقطة k في القائمة acc لنستخدمها في الرسم البياني، ويمكن أن نلاحظ أننا استخدمنا random_state=10 لتثبيت تقسيم البيانات العشوائي وجعل الكود يخرج نفس الرسم البياني في كل مرة. عند تنفيذ الكود سنحصل على الرسم البياني التالي: مقارنة أداء النموذج بين مجموعة بيانات التدريب ومجموعة بيانات الاختبار سنكتب برنامج لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم درب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، وكذلك دقته في توقع وسوم مجموعة التدريب، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k، سنستخدم هذا الرسم البياني للمقارنة بين أداء النموذج على مجموعة التدريب أمام أدائه على مجموعة الاختبار. import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=21) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة test_acc = [] train_acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) test_score = knn.score(X_test,y_test) train_score = knn.score(X_train, y_train) test_acc.append(test_score) train_acc.append(train_score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], test_acc, label=get_display(reshape("دقة النموذج على بيانات الاختبار")), color='salmon') plt.plot([k for k in range(1, 10)], train_acc, label=get_display(reshape("دقة النموذج على بيانات التدريب")), color="skyblue") plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.legend() plt.show() يختلف هذا التدريب عن السابق في أنه يحسب الدقة على مجموعة التدريب ومجموعة الاختبار وهي استراتيجية شائعة تستخدم لاختبار مدى قدرة النموذج على التعميم generalization، حيث لا ينبغي أن يكون الفرق المطلق بين أداء النموذج على مجموعة التدريب ومجموعة الاختبار كبيرًا، فأن كان أداء النموذج جيد جدًا في مجموعة التدريب وسيئ للغاية فهذا النموذج ليس قابلًا للاستخدام في العالم الحقيقي على البيانات التي لم يرها من قبل، يمكن تشبيه هذه الحالة بالطالب الذي حفظ أسئلة الاختبار وعند تخرجه ليواجه المشاكل الحقيقية فشل فشلًا ذريعًا لأنه في واقع الأمر حفظ البيانات ولم يتعلم منها وتعرف هذه الحالة بالمسايرة المفرطة أو فرط التخصيص overfitting، وفي الحالة التي يكون أداء النموذج سئيًا على كل من مجموعة بيانات الاختبار والتدريب فتعرف هذه الحالة بقلة التخصيص underfitting وهي بساطة النموذج لدرجة تمنعه من تعلم الأنماط المعقدة الموجودة في مجموعة البيانات. عند تنفيذ الكود سنحصل على الرسم البياني التالي: الخاتمة تناولنا في المقال الثالث من سلسلة تطبيقات ساي كيت ليرن مجموعة تدريبات على خوارزمية أقرب الجيران K-Nearest Neighbors واستخدمناها لتصنيف فصائل أزهار آيرس، ودرسنا كيفية تقسيم البيانات لمجموعة تدريب ومجموعة اختبار مع تقييم النموذج وحساب دقة التوقعات،كما تعرفنا على تأثير عدد النقاط المجاورة في هذه الخوارزمية، سنتدرب في المقال القادم على استخدام خوارزمية الانحدار اللوجيستي Logistic Regression وهي أيضًا خوارزمية أساسية من خوازرميات التصنيف Classification وتستخدم في مهام عديدة مثل تشخيص الأمراض وتصنيف رسائل البريد. اقرأ أيضًا المقال السابق: التمثيل المرئي للبيانات باستخدام Scikit-Learn مع Matplotlib و Seaborn تقييم واختيار نماذج تعلم الآلة مصطلحات الذكاء الاصطناعي للمبتدئين بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون واستخدام Scikit-Learn
في هذا المقال من سلسلة تطبيقات عملية على استخدام مكتبة ساي كيت ليرن سنستعرض خطوة بخطوة كيفية تطبيق واحدة من أشهر خوارزميات تعلم الآلة وهي خوارزمية أقرب الجيران k-Nearest Neighbors -أو KNN اختصارًا- لتصنيف الأنواع المختلفة من الأزهار الموجودة ضمن مجموعة بيانات آيرس Iris dataset إحدى أكثر مجموعات البيانات استخدامًا في مجال تعلم الآلة والتي تعرفنا عليها في مقال سابق بعنوان أساسيات تحليل البيانات باستخدام Scikit-Learn. آلية عمل خوارزمية k-Nearest Neighbors يمكننا تعريف خوارزمية أقرب جار K-Nearest Neighbors على أنها خوارزمية لا معاملية non-parametric بمعنى أنها لا تملك أوزان أو معاملات تحاول تحسينها كما تتبع خوارزميات ذكاء اصطناعي أخرى، فهي تستخدم في مهام التصنيف Classification وتوقع الانحدار Regression، وفي كلا الحالتين تعتمد على المعلومات المتاحة لدى أقرب k من النقاط المجاورة لمجموعة بيانات التدريب، وتختلف طريقة حساب المخرجات حسب مهمة التعلم. في حالة التصنيف Classification يكون خرج النموذج أحد التصنيفات المحددة، ونقرره بناءً على تصويت الأغلبية من عدد k نقطة مجاورة لها حق التصويت أي يسمح لها بالمشاركة في اتخاذ القرار بشأن تصنيف نقطة معينة، ويكون هذا العدد المحدد k من النقاط المجاورة عددًا صحيحًا موجبًا ويفضل أن يكون فرديًا لمنع أي حالات تعادل في التصويت. من المهم اختيار قيمة k مناسبة في خوارزمية الجار الأقرب، ويفضل أن تكون قيمة صغيرة نسبيًا، فعندما نحدد عدد النقاط المجاورة k=1 سيتأثر قرار النموذج بالضجيج noise في البيانات والنقاط الخارجة outliers وغير المألوفة بشكل كبير، مما يحدث حالة إفراط في التخصيص Overfitting ويضعف قدرته على التعميم لبيانات جديدة، بينما عندما نحدد عدد النقاط المجاورة برقم كبير n يساوي عدد العينات بمجموعة بيانات التدريب سيصبح النموذج أبسط من اللازم وتحدث لديه حالة إفراط في التبسيط Underfitting بالتالي لن يكون قادر على التعبير عن العلاقات المعقدة الموجودة في البيانات وسيأخذ قرارات اعتمادًا على نقاط بعيدة جدًا ولا تؤثر على نقطة الاستفسار الحالية. في حالة توقع الانحدار Regression يكون خرج النموذج عدد مستمر ناتج عن أخذ متوسط القيم من عدد محدد k من النقاط المجاورة لتقرير قيمة نقطة الاستفسار الحالية. تعرض الصورة السابقة مثالًا على خوارزمية KNN لمهمة التصنيف، وتمثل النقطة الخضراء نقطة الاستفسار الحالية query point والتي نريد تصنيفها إما لصنف المربعات الزرقاء أو المثلثات الحمراء، فإذا قررنا أن عدد النقاط المجاورة k=3 تصبح النقاط الداخلة في القرار هي النقاط المحاطة بالدائرة المتصلة، وكما نرى فالأغلبية في هذا النطاق للمثلثات الحمراء 2 بينما الأقلية هي المربعات الزرقاء 1، بالتالي يمكننا تصنيف نقطة الاستفسار query point بأنها مثلث أحمر، بينما عند زيادة k لتصبح 5 ننظر للنقاط المحاطة بالدائرة المنقطة فنجد أن الأغلبية صارت للمربعات الزرقاء 3 مقابل 2 من المثلثات الحمراء، بالتالي يصبح التصنيف لنقطة الاستفسار مربع أزرق. بعد أن تعرفنا على آلية عمل الخوارزمية، لنستعرض مجموعة من التدريبات العملية التي تساعدنا على فهم كيفية استخدام هذه الخوارزمية بشكل فعّال باستخدام مكتبة scikit-learn. فصل مجموعة البيانات من أولى خطوات التحضير لبناء أي نموذج تعلم آلة هي فصل الخصائص Features وهي البيانات التي نستخدمها لتوقع شيء ما عن الوسوم Labels وهي القيم التي نحاول التنبؤ بها، لنكتب برنامج بايثون لتقسيم مجموعة بيانات أزهار آيرس إلى خصائصها كطول و عرض بتلة الزهرة وسبلتها والتي سنخزنها في متغير X ، والوسوم التي سنخزنها في متغير Y. سيحتوي المتغير X أول أربعة أعمدة بينما يحتوي المتغير Y وسم كل زهرة بفصيلتها مثل Setosa أو Versicolor أو Virginica. import pandas as pd iris = pd.read_csv("iris.csv") # Idاحذف عمود iris = iris.drop('Id',axis=1) # iloc : تسمح باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values print("الخصائص:") print(X) print("\nالوسوم:") print(y) كما نلاحظ فقد حذفنا في هذه الخطوة عمود المعرف Id من مجموعة البيانات، كونه لا يحمل أي معنى يتعلق بخصائص الأزهار، واستخدامه قد يؤدي لنموذج متحيز وغير دقيق. واستخدمنا التابع iloc لتحديد الخصائص X، والوسوم Y وأخيرًا، طبعنا كلًا من X و Y للتأكد من صحة التقسيم. عند تنفيذ الكود سنحصل على الخرج التالي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] ... [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] تقسيم مجموعة البيانات لمجموعة تدريب ومجموعة اختبار نحتاج لتقسيم البيانات إلى بيانات تدريب training وبيانات اختبار testing حتى نتمكن من معرفة فيما إذا كان النموذج يعمل جيدًا على بيانات جديدة لم يرها من قبل، سنكتب كود لتقسيم مجموعة بيانات آيرس إلى مجموعة تدريب تحتوي 80% من البيانات ومجموعة اختبار تحتوي 20%، بحيث يكون عدد العينات المستخدمة في التدريب هو 120 عينة والمستخدمة في الاختبار 30 عينة، ونطبع كلا المجموعتين. import pandas as pd from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") # Id احذف العمود iris = iris.drop('Id',axis=1) # iloc : تسمح لنا باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسم هذه الدالة مجموعة البيانات عشوائيًا وفقًا للنسب المحددة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n70% train data:") print(X_train) print(y_train) print("\n30% test data:") print(X_test) print(y_test) فصلنا في البداية مجموعة البيانات إلى خاصيات X ووسوم Y كما في فعلنا في التطبيق السابق، ثم استدعينا الدالة train_test_split التي تقسم خاصيات ووسوم المجموعة إلى مجموعة تدريب ومجموعة اختبار، وحددنا نسبة التقسيم باستخدام test_size=0.20 لجعل 20% من مجموعة البيانات مخصصة للاختبار، بينما 80% منها للتدريب، سيجري تقسيم البيانات عشوائيًا في كل مرة نشغل بها الكود. عند تنفيذ الكود السابق سنحصل على خرج مشابه لما يلي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [4.8 3. 1.4 0.1] [6. 2.7 5.1 1.6] [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] ترقيم الفصائل النصية الأن سنعمل على تطبيق يحوّل فصائل الأزهار في مجموعة بيانات آيرس من أسماء نصية إلى قيم رقمية، ولنفعل ذلك سنحتاج لتحويل كل قيمة إلى رقم ثابت لهذه القيمة، فمثلًا نجعل Iris-setosa:0 و Iris-versicolor:1 و Iris-virginica:2، ثم نطبع مجموعة بيانات التدريب ومجموعة بيانات الاختبار. import pandas as pd from sklearn.model_selection import train_test_split # LabelEncoder استدعي # والذي سوف نستخدمه لتحويل الفصائل من قيم نصية إلى أرقام ثابته لكل فصيلة from sklearn.preprocessing import LabelEncoder iris = pd.read_csv("iris.csv") # labelEncoder نهيئ الصنف البرمجي le = LabelEncoder() # labelEncoder نستخدم الصنف البرمجي # لتحويل التصنيفات النصية إلى أرقم iris.Species = le.fit_transform(iris.Species) # Id نحذف العمود # حيث لا يحتوي معلومات مهمة للتعلم iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # نقسم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار # كل منهما له خصائص ووسوم منفصلة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n80% train data:") print(X_train) print(y_train) print("\n20% test data:") print(X_test) print(y_test) استخدمناLabelEncoder() لنهيئ الكائن le والذي سنستخدمه لتحويل الفصائل النصية categorical classes لأرقام، حيث نرمز لكل صنف أو اسم برقم ثابت لهذا الصنف، ونستدعي هذا الكائن ليطبّق على البيانات باستخدام le.fit_transform(iris.Species) حيث تتعرف هذه الدالة في البداية على الأصناف في عمود Species وتحدد القيم التي ستعطى لكل فصيل category وتسمى هذه العملية fit ويمكن تنفيذها بشكل مستقل، ومن ثم يتم تحويل القيم النصية القديمة إلى الأرقام المقابلة عند تنفيذ عملية transform التي يمكن فصلها لكي تنفّذ بعد عملية fit على أكثر من مجموعة من البيانات التي تتضمن نفس الفصائل، ولكن في كثير من الأحيان نستخدم الدالة التي تدمج الخطوتين معًا. عند تنفيذ الكود سنحصل على الخرج التالي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] 80% train data: [[7.7 2.8 6.7 2. ] [6.7 3.1 5.6 2.4] [5.7 2.6 3.5 1. ] [6.3 2.8 5.1 1.5] [4.9 3.1 1.5 0.1] … [4.8 3. 1.4 0.3] [6.4 2.9 4.3 1.3] [4.8 3. 1.4 0.1] [5.5 2.6 4.4 1.2] [6.3 2.3 4.4 1.3]] [2 2 1 2 0 0 0 2 2 2 2 2 0 0 2 2 1 2 1 0 1 2 0 1 2 0 1 2 2 0 1 1 1 2 0 1 0 1 0 2 2 2 0 2 1 1 0 2 1 2 1 0 0 1 1 2 0 0 2 1 1 2 0 1 1 0 0 2 0 0 1 1 2 1 0 1 2 2 0 1 0 0 2 0 0 2 0 1 1 2 2 0 0 1 2 0 1 1 1 0 0 1 0 2 2 0 0 0 2 2 0 2 2 0 2 0 1 0 1 1] 20% test data: [[6.8 3.2 5.9 2.3] [5.4 3. 4.5 1.5] [4.3 3. 1.1 0.1] [5.6 3. 4.1 1.3] [6.7 3. 5. 1.7] … [5.8 2.7 3.9 1.2] [6.3 2.5 5. 1.9] [6.3 3.3 4.7 1.6] [5.1 3.7 1.5 0.4] [6.9 3.2 5.7 2.3]] [2 1 0 1 1 0 2 2 2 1 0 2 1 1 1 1 1 2 1 1 1 0 2 0 0 1 2 1 0 2] بناء نموذج K-Nearest Neighbors باستخدام ساي كيت ليرن Scikit-Learn لنكتب كود برمجي لجعل نسبة تقسيم مجموعات البيانات 70% لمجموعة التدريب و30% لمجموعة الاختبار، حيث يصبح عدد العينات المستخدمة في التدريب 105 عينة وعدد عينات الاختبار 45، ثم نتوقع باستخدام نموذج KNN تصنيفات الفصائل لمجموعة الاختبار مع تحديد عدد النقاط المجاورة ليكون 5. import pandas as pd from sklearn.model_selection import train_test_split # نستدعي المُصنف من مكتبة ساي كيت ليرن from sklearn.neighbors import KNeighborsClassifier iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم مجموعات البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30) # KNN Classifier استدعي # القيمة الافتراضية لعدد النقاط المجاورة التي لها حق التصويت هي 5 knn = KNeighborsClassifier(n_neighbors=5) # درب النموذج باستخدام مجموعة بيانات التدريب # في عملية التدريب الخاضع للإشراف يستطيع النموذج أن يستخدم وسم البيانات knn.fit(X_train, y_train) # استخدم النموذج المدرب لتوقع مجموعة بيانات الاختبار print("Response for test dataset:") y_pred = knn.predict(X_test) print(y_pred) استخدمنا دالة knn.fit(X_train, y_train) لتدريب الكائن الذي يُطبق خوارزمية KNN في مكتبة ساي كيت ليرن، ولتدريب النموذج استخدمنا مجموعة خاصيات التدريب X_train والوسوم المقابلة لها y_train، وأثناء تهيئة الكائن عرفنا بعض الإعدادات والمعاملات مثل عدد النقاط المجاورة n_neighbors، وبعد تدريب النموذج استخدمناه لتوقع وسوم خاصيات مجموعة الاختبار X_test. عند تنفيذ الكود سنحصل على الخرج التالي: Response for test dataset: ['Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica'] نلاحظ أن النموذج استطاع التعامل مع القيم النصية لتصنيفات الفصائل بشكل مباشر، وهذا ليس السائد في نماذج تعلم الآلة حيث أغلبها يتوقع فقط قيمًا رقمية حيث أن أغلب الخوارزميات تقوم بعمليات رياضية، ولكن كما ذكرنا من قبل فإن خوارزمية KNN لا معاملية non-parametric ولا تقوم بأي عمليات رياضية معقدة، فقط عملية التصويت في حالة التصنيف. نلاحظ أيضًا أن هذا يعمل فقط مع القيم النصية للوسوم وليس للخاصيات أو الأعمدة الأخرى المستخدمة في التدريب، حيث يحتاج النموذج لحساب المسافة بين نقطة الاستفسار query points وبين جميع النقاط في مجموعة التدريب المخزنة في الذاكرة ليستطيع تقرير أقرب k من النقاط المجاورة مسافةً. اختبار تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN سنكتب تطبيق لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب دقة النموذج لكل قيمة. import pandas as pd from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) print("For k = %d accuracy is"%k,knn.score(X_test,y_test)) أنشأنا حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها. عند تنفيذ الكود سنحصل على الخرج التالي: For k = 1 accuracy is 0.9666666666666667 For k = 2 accuracy is 0.9666666666666667 For k = 3 accuracy is 0.9666666666666667 For k = 4 accuracy is 0.9333333333333333 For k = 5 accuracy is 0.9666666666666667 For k = 6 accuracy is 0.9666666666666667 For k = 7 accuracy is 0.9666666666666667 For k = 8 accuracy is 0.9333333333333333 For k = 9 accuracy is 0.9666666666666667 رسم بياني لدراسة تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN لنقسم الآن مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k. import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=10) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) score = knn.score(X_test,y_test) acc.append(score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], acc) plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.show() أنشانا في الكود السابق حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها، وقد حفظنا دقة النموذج عند كل نقطة k في القائمة acc لنستخدمها في الرسم البياني، ويمكن أن نلاحظ أننا استخدمنا random_state=10 لتثبيت تقسيم البيانات العشوائي وجعل الكود يخرج نفس الرسم البياني في كل مرة. عند تنفيذ الكود سنحصل على الرسم البياني التالي: مقارنة أداء النموذج بين مجموعة بيانات التدريب ومجموعة بيانات الاختبار سنكتب برنامج لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم درب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، وكذلك دقته في توقع وسوم مجموعة التدريب، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k، سنستخدم هذا الرسم البياني للمقارنة بين أداء النموذج على مجموعة التدريب أمام أدائه على مجموعة الاختبار. import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=21) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة test_acc = [] train_acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) test_score = knn.score(X_test,y_test) train_score = knn.score(X_train, y_train) test_acc.append(test_score) train_acc.append(train_score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], test_acc, label=get_display(reshape("دقة النموذج على بيانات الاختبار")), color='salmon') plt.plot([k for k in range(1, 10)], train_acc, label=get_display(reshape("دقة النموذج على بيانات التدريب")), color="skyblue") plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.legend() plt.show() يختلف هذا التدريب عن السابق في أنه يحسب الدقة على مجموعة التدريب ومجموعة الاختبار وهي استراتيجية شائعة تستخدم لاختبار مدى قدرة النموذج على التعميم generalization، حيث لا ينبغي أن يكون الفرق المطلق بين أداء النموذج على مجموعة التدريب ومجموعة الاختبار كبيرًا، فأن كان أداء النموذج جيد جدًا في مجموعة التدريب وسيئ للغاية فهذا النموذج ليس قابلًا للاستخدام في العالم الحقيقي على البيانات التي لم يرها من قبل، يمكن تشبيه هذه الحالة بالطالب الذي حفظ أسئلة الاختبار وعند تخرجه ليواجه المشاكل الحقيقية فشل فشلًا ذريعًا لأنه في واقع الأمر حفظ البيانات ولم يتعلم منها وتعرف هذه الحالة بالمسايرة المفرطة أو فرط التخصيص overfitting، وفي الحالة التي يكون أداء النموذج سئيًا على كل من مجموعة بيانات الاختبار والتدريب فتعرف هذه الحالة بقلة التخصيص underfitting وهي بساطة النموذج لدرجة تمنعه من تعلم الأنماط المعقدة الموجودة في مجموعة البيانات. عند تنفيذ الكود سنحصل على الرسم البياني التالي: الخاتمة تناولنا في المقال الثالث من سلسلة تطبيقات ساي كيت ليرن مجموعة تدريبات على خوارزمية أقرب الجيران K-Nearest Neighbors واستخدمناها لتصنيف فصائل أزهار آيرس، ودرسنا كيفية تقسيم البيانات لمجموعة تدريب ومجموعة اختبار مع تقييم النموذج وحساب دقة التوقعات،كما تعرفنا على تأثير عدد النقاط المجاورة في هذه الخوارزمية، سنتدرب في المقال القادم على استخدام خوارزمية الانحدار اللوجيستي Logistic Regression وهي أيضًا خوارزمية أساسية من خوازرميات التصنيف Classification وتستخدم في مهام عديدة مثل تشخيص الأمراض وتصنيف رسائل البريد. اقرأ أيضًا المقال السابق: التمثيل المرئي للبيانات باستخدام Scikit-Learn مع Matplotlib و Seaborn تقييم واختيار نماذج تعلم الآلة مصطلحات الذكاء الاصطناعي للمبتدئين بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون واستخدام Scikit-Learn -
 نتناول في هذه السلسلة مجموعة متنوعة من التطبيقات العملية حول تعلم الآلة Machine Learning باستخدام إطار عمل ساي كيت ليرن Scikit-Learn الذي يوفر حزمة من الأدوات البرمجية مفتوحة المصدر تشمل خوارزميات تعلم الآلة كخوارزميات التصنيف Classification وتوقع الانحدار Regression وخوارزميات العنقدة Clustering، وقد صمم هذا الإطار ليعمل بكفاءة مع العديد من مكتبات بايثون القوية مثل NumPy و SciPy. الهدف من هذه السلسلة إرشاد المبتدئين من خلال مجموعة من التدريبات العملية المكتوبة بلغة بايثون وإطار عمل ساي كيت ليرن Scikit-Learn، فالتطبيق وحل التدريبات واحدة من أفضل طرق التعلم واكتساب المهارات لذا ننصح بمحاولة إيجاد الحل بأنفسكم قبل النظر في الأكواد المرفقة لتحقيق استفادة أفضل. ما هي مجموعة بيانات أزهار آيرس؟ سنستخدم في التطبيقات العملية مجموعة بيانات أزهار آيرس أو السوسن Iris dataset وهي مجموعة بيانات من عدة متغيرات استخدمت بواسطة عالم الإحصاء والأحياء رونالد فيشر في ورقته البحثية لعام 1936، وهي تسمى أيضًا مجموعة بيانات اندرسون نسبة للعالم الذي جمعها ليحلل التغيرات الشكلية بين الفصائل الثلاث لهذه الأزهار. تتكون مجموعة البيانات من 50 عينة لكل فصيلة من الفصائل الثلاثة للأزهار، وهي Iris setosa و Iris virginica و Iris versicolor وقيست أربعة خصائص لكل عينة وهي: طول البتلة Petal length عرض البتلة Petal width طول السبلة Sepal length عرض السبلة Sepal width وباستخدام هذه التوليفة من الخصائص استطاع فيشر تطوير نموذج تميز خطي Linear discrimination قادر على التفريق بين الفصائل وبعضها. تطبيقات أساسية باستخدام مكتبة باندا Pandas سنتعرف على مجموعة من التطبيقات التي تستخدم مكتبة باندا Pandas لتحليل واستكشاف مجموعة البيانات والتي تعد خطوة أساسية في أي مشروع لتعلم الآلة. تحميل مجموعة البيانات إلى إطار البيانات DataFrame سنكتب برنامج بلغة برمجة بايثون لتحميل مجموعة بيانات آيرس من ملف csv إلى البنية pandas التي توفرها مكتبة dataframe ونطبع شكل البيانات ونوعها وأول ثلاثة صفوف منها. import pandas as pd data = pd.read_csv("iris.csv") print("Shape of the data:") print(data.shape) print("\nData Type:") print(type(data)) print("\nFirst 3 rows:") print(data.head(3)) النمط DataFrame هو نمط توفره مكتبة pandas لتنظيم البيانات وتخزينها على هيئة جدول، وقد استوردنا في الكود السابق مكتبة pandas وقرأنا البيانات المطلوبة من الملف iris.csv وخزناها في متغير data من النمط DataFrame، ثم عرضنا عدد الأبعاد -أي عدد الصفوف والأعمدة الموجود في هذا الكائن- باستخدام التابع shape ونوع بياناته باستخدام التابع type وعرضنا أول 3 صفوف من البيانات فقط باستخدام التعليمة data.head(3). عند تنفيذ الكود، نحصل على الخرج التالي: Shape of the data: (150, 6) Data Type: <class 'pandas.core.frame.DataFrame'> First 3 rows: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa استعراض خصائص مجموعات بيانات آيرس الآن، سكتب برنامج بايثون باستخدام ساي كيت ليرن Scikit-Learn لطباعة مفاتيح الأعمدة Keys وعدد الصفوف وعدد الأعمدة وأسماء الخاصيات والوصف لمجموعة بيانات آيرس. import pandas as pd iris_data = pd.read_csv("iris.csv") print("\nKeys of Iris dataset:") print(iris_data.keys()) print("\nNumber of rows and columns of Iris dataset:") print(iris_data.shape) استخدمنا هنا أيضًا بنية DataFrame كما في المثال السابق لتخزين البيانات ضمن متغير باسم iris_data وعرضنا المفاتيح أو أسماء الأعمدة في مجموعة البيانات باستخدام الدالة iris_data.keys() والتي تمثل المتغيرات أو الخصائص المختلفة بيانات الأزهار، وعرضنا أخيرًا عدد الصفوف والأعمدة باستخدام الدالة iris_data.shape. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Keys of Iris dataset: Index(['Id', 'SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species'], dtype='object') Number of rows and columns of Iris dataset: (150, 6) عرض عدد العينات وعدد القيم المفقودة في مجموعة بيانات آيرس فيما يلي كود بايثون لمعرفة عدد العينات في مجموعة بيانات الأزهار، وعدد القيم المفقودة فيها. import pandas as pd iris = pd.read_csv("iris.csv") print(iris.info()) استوردنا مجموعة البيانات بشكل بنية جدول DataFrame وخزناها في متغير باسم iris وطبعنا المعلومات التي نحتاجها باستخدام الدالة iris.info() التي تعرض بعض المعلومات المهمة مثل عدد العينات ونوع العمود الفهرسي Index column وكذلك عدد القيم الفعلية non-null ونوع البيانات لكل عمود، بالإضافة للذاكرة RAM المستهلكة لتخزين البيانات. نحصل على الخرج التالي من تنفيذ الكود أعلاه: <class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Id 150 non-null int64 1 SepalLengthCm 150 non-null float64 2 SepalWidthCm 150 non-null float64 3 PetalLengthCm 150 non-null float64 4 PetalWidthCm 150 non-null float64 5 Species 150 non-null object dtypes: float64(4), int64(1), object(1) memory usage: 7.2+ KB None المصفوفات المتناثرة Dense Matrices والمصفوفات عالية الكثافة Dense Matrices باستخدام NumPy و Scipy سنعمل في هذه الفقرة على إنشاء مصفوفة ثنائية الأبعاد 2D array مليئة بالواحد في كل عناصرها لواقعة على القطر الرئيسي والقيمة الصفر فيما دون ذلك، ثم نحول المصفوفة من نوع NumPy array إلى مصفوفة SciPy sparse matrix أي مصفوفة متناثرة بتنسيق CSR هو أحد تنسيقات مكتبة SciPy لتمثيل المصفوفات. وتعرف المصفوفة المتناثرة بأنها مصفوفة تحتوي في الغالب على أصفار Sparse matrix، وعلى النقيض تمامًا فإن المصفوفة الي يكون غالب عناصرها قيم لا تساوي الصفر تسمى مصفوفة عالية الكثافة Dense matrix، ويعرف معدل التناثر sparsity على أنه عدد العناصر الصفرية مقسومة على إجمالي العناصر بالمصفوفة، ويساوي أيضًا 1 مطروحًا منه معدل الكثافة Density للمصفوفة، وباستخدام هذه التعريفات يمكننا تصنيف مصفوفة بأنها متناثرة sparse إن كان معدل تناثرها Sparsity أكبر من 0.5. تكمن فائدة تحويل المصفوفة من NumPy array إلى صيغة مصفوفة متناثرة الصفوف CSR باستخدام SciPy خطوة مفيدة وفعالة وتسرع الوصول إلى العناصر ذات القيمة الفعلية غير الصفرية داخل المصفوفة، حيث تتيح صيغة CSR تخزين المصفوفة بشكل مضغوط دون الحاجة إلى تخزين الأصفار، مما يقلل من استهلاك الذاكرة ويزيد من كفاءة المعالجة. تبرز أهمية هذا التحويل بشكل خاص عند إجراء عمليات رياضية أو تحليل بيانات على مصفوفات كبيرة، حيث يسهم تجاهل الأصفار في تسريع الحسابات دون التأثير على النتائج. import numpy as np from scipy import sparse eye = np.eye(4) print("NumPy array:\n", eye) sparse_matrix = sparse.csr_matrix(eye) print("\nSciPy sparse CSR matrix:\n", sparse_matrix) بعد أن استوردنا مكتبتي NumPy و SciPy استخدمنا الدالة np.eye() لإنشاء مصفوفة ثنائية الأبعاد تتكون جميع عناصرها من أصفار فيما عدا عناصر القطر الرئيسي للمصفوفة حيث تساوي عناصره الواحد، ومررنا للدالة العدد 4 وهو عدد الصفوف، وثم خزنا الناتج في الكائن eye وطبعنا المصفوفة التي يخزنها الكائن قبل أن تحويلها، واستخدمنا الدالة sparse.csr_matrix(eye) لتحويل المصفوفة للصيغة المضغوطة CSR، وطبعنا الكائن الذي يحتوي المصفوفة الجديدة لنقارن بين الصيغتين. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: NumPy array: [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] SciPy sparse CSR matrix: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0 نلاحظ أن صيغة CSR لا تعرض كل عناصر المصفوفة، بل تُظهر العناصر التي تحتوي على أرقام غير صفرية فقط. وبما أن المصفوفة تحتوي على 1 في كل موقع قطري سنجد تساوي دليل الصف مع دليل العمود. عرض الاحصائيات الأساسية عن مجموعة بيانات آيرس باستخدام باندا Pandas لعرض المعلومات الاحصائية الأساسية عن مجموعة البيانات مثل المتوسط والانحراف المعياري والتوزيع وغيرها من المعلومات نكتب الكود التالي: import pandas as pd data = pd.read_csv("iris.csv") print(data.describe()) استخدمنا التابع data.describe() للحصول على إحصائيات عن الكائن data من نوع DataFrame، مثل عدد القيم count والمتوسط الحسابي mean والانحراف المعياري standard deviation والتوزيع المئوي percentiles وهي إحصائية تقيس الترتيب النسبي لموقع نقطة في مجموعة البيانات، فمثلًا عند قولنا أن التوزيع المئوي 25% يساوي 38.25 فهذا يعني أن 25% من القيم الموجودة في البيانات أقل من هذا العدد، وتوجد ثلاث توزيعات مئوية أساسية هي 25% و 50% و75% تمثل الأرباع Q1 و Q2 و Q3 على الترتيب، ويعرف Q2 خاصةً بالوسيط median وهو الرقم الوسيط بين مجموعة من القيم المرتبة، وتعرض أيضًا القيمة العظمى لكل عمود، ولا تأخذ هذه الدالة في الاعتبار القيم المفقودة NAN، ولا تعمل إلا على الأعمدة الرقمية Numerical. نحصل على الخرج التالي من تنفيذ الكود أعلاه: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 150.000000 150.000000 150.000000 150.000000 150.000000 mean 75.500000 5.843333 3.054000 3.758667 1.198667 std 43.445368 0.828066 0.433594 1.764420 0.763161 min 1.000000 4.300000 2.000000 1.000000 0.100000 25% 38.250000 5.100000 2.800000 1.600000 0.300000 50% 75.500000 5.800000 3.000000 4.350000 1.300000 75% 112.750000 6.400000 3.300000 5.100000 1.800000 max 150.000000 7.900000 4.400000 6.900000 2.500000 معرفة عدد عينات كل نوع Categorical values باستخدام Pandas لنحصل على عدد عينات كل فصيلة من الفصائل في مجموعة بيانات الأزهار نكتب الكود على النحو التالي: import pandas as pd data = pd.read_csv("iris.csv") print("Observations of each species:") print(data['Species'].value_counts()) استخدمنا الدالة value_counts() على العمود Species الذي يحتوى وسمًا لكل عينة في مجموعة البيانات، تسمح هذه الدالة بالحصول على عدد العينات في كل تصنيف، بمعنى أخر سنعرف كم عينة تنتمي لكل فصيلة من الأزهار. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Observations of each species: Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 Name: Species, dtype: int64 نلاحظ من الخرج السابق أن البيانات تحتوي على 150 زهرة موزعة بالتساوي على الفصائل الثلاثة. حذف عمود من DataFrame باستخدام Pandas لحذف عمود Id وطباعة أول خمسة صفوف حصلنا عليها بعد حذفه نكتب الكود التالي. import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) لحذف عمود من بنية DataFrame نستخدم الدالة drop() ونمرر لها اسم العمود المطلوب والمعامل axis وهو معامل يقبل قيمتين إما 0 وتعني أننا نريد حذف عمود، أو 1 والتي تعني أننا نريد حذف صف، ثم نستدعي new_data.head() لعرض أول خمسة صفوف من مجموعة البيانات الجديدة التي حصلنا عليها. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa اختيار شرائح معينة من مجموعة البيانات باستخدام Panda للوصول إلى أول أربع خلايا من كل صف في مجموعة البيانات المخزنة في بنية DataFrame واستخدم أسماء الأعمدة بالإضافة للفهرس للوصول للخلايا المحددة سنكتب كود بايثون التالي: import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) x = data.iloc[:, [1, 2, 3, 4]].values print(x) يسمح لنا التابع data.iloc[] باختيار شريحة معينة من مجموعة البيانات، حيث نحدد قبل الفاصلة الأولى الصفوف التي نريد أن تدخل في الاختيار، وبعد الفاصلة الأعمدة التي نريد أن تدخل في الاختيار، وفي حالتنا اخترنا عرض قيم جميع الصفوف باستخدام الرمز : والموجودة في أعمدة محددة [1,2,3,4]. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الخاتمة استكشفنا في هذه المجموعة من التدريبات مجموعة بيانات آيرس، وتعرفنا على خواصها والمعلومات الإحصائية الأساسية عنها، واستعرضنا تطبيقات عملية للتعامل مع بنية DataFrame لتخزين البيانات وتعديلها بطرق مختلفة، يمكن تجربة المزيد من الأكواد لاستكشاف هذه البيانات والتعرف عليها بشكل جيد قبل الانتقال للمقالة القادمة التي سنتدرب بها على إنشاء الرسومات البيانية لفهم العلاقات بين خواص مجموعة بيانات آيرس بشكلٍ مرئي. اقرأ أيضًا بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الأول خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الثاني خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الثالث
نتناول في هذه السلسلة مجموعة متنوعة من التطبيقات العملية حول تعلم الآلة Machine Learning باستخدام إطار عمل ساي كيت ليرن Scikit-Learn الذي يوفر حزمة من الأدوات البرمجية مفتوحة المصدر تشمل خوارزميات تعلم الآلة كخوارزميات التصنيف Classification وتوقع الانحدار Regression وخوارزميات العنقدة Clustering، وقد صمم هذا الإطار ليعمل بكفاءة مع العديد من مكتبات بايثون القوية مثل NumPy و SciPy. الهدف من هذه السلسلة إرشاد المبتدئين من خلال مجموعة من التدريبات العملية المكتوبة بلغة بايثون وإطار عمل ساي كيت ليرن Scikit-Learn، فالتطبيق وحل التدريبات واحدة من أفضل طرق التعلم واكتساب المهارات لذا ننصح بمحاولة إيجاد الحل بأنفسكم قبل النظر في الأكواد المرفقة لتحقيق استفادة أفضل. ما هي مجموعة بيانات أزهار آيرس؟ سنستخدم في التطبيقات العملية مجموعة بيانات أزهار آيرس أو السوسن Iris dataset وهي مجموعة بيانات من عدة متغيرات استخدمت بواسطة عالم الإحصاء والأحياء رونالد فيشر في ورقته البحثية لعام 1936، وهي تسمى أيضًا مجموعة بيانات اندرسون نسبة للعالم الذي جمعها ليحلل التغيرات الشكلية بين الفصائل الثلاث لهذه الأزهار. تتكون مجموعة البيانات من 50 عينة لكل فصيلة من الفصائل الثلاثة للأزهار، وهي Iris setosa و Iris virginica و Iris versicolor وقيست أربعة خصائص لكل عينة وهي: طول البتلة Petal length عرض البتلة Petal width طول السبلة Sepal length عرض السبلة Sepal width وباستخدام هذه التوليفة من الخصائص استطاع فيشر تطوير نموذج تميز خطي Linear discrimination قادر على التفريق بين الفصائل وبعضها. تطبيقات أساسية باستخدام مكتبة باندا Pandas سنتعرف على مجموعة من التطبيقات التي تستخدم مكتبة باندا Pandas لتحليل واستكشاف مجموعة البيانات والتي تعد خطوة أساسية في أي مشروع لتعلم الآلة. تحميل مجموعة البيانات إلى إطار البيانات DataFrame سنكتب برنامج بلغة برمجة بايثون لتحميل مجموعة بيانات آيرس من ملف csv إلى البنية pandas التي توفرها مكتبة dataframe ونطبع شكل البيانات ونوعها وأول ثلاثة صفوف منها. import pandas as pd data = pd.read_csv("iris.csv") print("Shape of the data:") print(data.shape) print("\nData Type:") print(type(data)) print("\nFirst 3 rows:") print(data.head(3)) النمط DataFrame هو نمط توفره مكتبة pandas لتنظيم البيانات وتخزينها على هيئة جدول، وقد استوردنا في الكود السابق مكتبة pandas وقرأنا البيانات المطلوبة من الملف iris.csv وخزناها في متغير data من النمط DataFrame، ثم عرضنا عدد الأبعاد -أي عدد الصفوف والأعمدة الموجود في هذا الكائن- باستخدام التابع shape ونوع بياناته باستخدام التابع type وعرضنا أول 3 صفوف من البيانات فقط باستخدام التعليمة data.head(3). عند تنفيذ الكود، نحصل على الخرج التالي: Shape of the data: (150, 6) Data Type: <class 'pandas.core.frame.DataFrame'> First 3 rows: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa استعراض خصائص مجموعات بيانات آيرس الآن، سكتب برنامج بايثون باستخدام ساي كيت ليرن Scikit-Learn لطباعة مفاتيح الأعمدة Keys وعدد الصفوف وعدد الأعمدة وأسماء الخاصيات والوصف لمجموعة بيانات آيرس. import pandas as pd iris_data = pd.read_csv("iris.csv") print("\nKeys of Iris dataset:") print(iris_data.keys()) print("\nNumber of rows and columns of Iris dataset:") print(iris_data.shape) استخدمنا هنا أيضًا بنية DataFrame كما في المثال السابق لتخزين البيانات ضمن متغير باسم iris_data وعرضنا المفاتيح أو أسماء الأعمدة في مجموعة البيانات باستخدام الدالة iris_data.keys() والتي تمثل المتغيرات أو الخصائص المختلفة بيانات الأزهار، وعرضنا أخيرًا عدد الصفوف والأعمدة باستخدام الدالة iris_data.shape. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Keys of Iris dataset: Index(['Id', 'SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species'], dtype='object') Number of rows and columns of Iris dataset: (150, 6) عرض عدد العينات وعدد القيم المفقودة في مجموعة بيانات آيرس فيما يلي كود بايثون لمعرفة عدد العينات في مجموعة بيانات الأزهار، وعدد القيم المفقودة فيها. import pandas as pd iris = pd.read_csv("iris.csv") print(iris.info()) استوردنا مجموعة البيانات بشكل بنية جدول DataFrame وخزناها في متغير باسم iris وطبعنا المعلومات التي نحتاجها باستخدام الدالة iris.info() التي تعرض بعض المعلومات المهمة مثل عدد العينات ونوع العمود الفهرسي Index column وكذلك عدد القيم الفعلية non-null ونوع البيانات لكل عمود، بالإضافة للذاكرة RAM المستهلكة لتخزين البيانات. نحصل على الخرج التالي من تنفيذ الكود أعلاه: <class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Id 150 non-null int64 1 SepalLengthCm 150 non-null float64 2 SepalWidthCm 150 non-null float64 3 PetalLengthCm 150 non-null float64 4 PetalWidthCm 150 non-null float64 5 Species 150 non-null object dtypes: float64(4), int64(1), object(1) memory usage: 7.2+ KB None المصفوفات المتناثرة Dense Matrices والمصفوفات عالية الكثافة Dense Matrices باستخدام NumPy و Scipy سنعمل في هذه الفقرة على إنشاء مصفوفة ثنائية الأبعاد 2D array مليئة بالواحد في كل عناصرها لواقعة على القطر الرئيسي والقيمة الصفر فيما دون ذلك، ثم نحول المصفوفة من نوع NumPy array إلى مصفوفة SciPy sparse matrix أي مصفوفة متناثرة بتنسيق CSR هو أحد تنسيقات مكتبة SciPy لتمثيل المصفوفات. وتعرف المصفوفة المتناثرة بأنها مصفوفة تحتوي في الغالب على أصفار Sparse matrix، وعلى النقيض تمامًا فإن المصفوفة الي يكون غالب عناصرها قيم لا تساوي الصفر تسمى مصفوفة عالية الكثافة Dense matrix، ويعرف معدل التناثر sparsity على أنه عدد العناصر الصفرية مقسومة على إجمالي العناصر بالمصفوفة، ويساوي أيضًا 1 مطروحًا منه معدل الكثافة Density للمصفوفة، وباستخدام هذه التعريفات يمكننا تصنيف مصفوفة بأنها متناثرة sparse إن كان معدل تناثرها Sparsity أكبر من 0.5. تكمن فائدة تحويل المصفوفة من NumPy array إلى صيغة مصفوفة متناثرة الصفوف CSR باستخدام SciPy خطوة مفيدة وفعالة وتسرع الوصول إلى العناصر ذات القيمة الفعلية غير الصفرية داخل المصفوفة، حيث تتيح صيغة CSR تخزين المصفوفة بشكل مضغوط دون الحاجة إلى تخزين الأصفار، مما يقلل من استهلاك الذاكرة ويزيد من كفاءة المعالجة. تبرز أهمية هذا التحويل بشكل خاص عند إجراء عمليات رياضية أو تحليل بيانات على مصفوفات كبيرة، حيث يسهم تجاهل الأصفار في تسريع الحسابات دون التأثير على النتائج. import numpy as np from scipy import sparse eye = np.eye(4) print("NumPy array:\n", eye) sparse_matrix = sparse.csr_matrix(eye) print("\nSciPy sparse CSR matrix:\n", sparse_matrix) بعد أن استوردنا مكتبتي NumPy و SciPy استخدمنا الدالة np.eye() لإنشاء مصفوفة ثنائية الأبعاد تتكون جميع عناصرها من أصفار فيما عدا عناصر القطر الرئيسي للمصفوفة حيث تساوي عناصره الواحد، ومررنا للدالة العدد 4 وهو عدد الصفوف، وثم خزنا الناتج في الكائن eye وطبعنا المصفوفة التي يخزنها الكائن قبل أن تحويلها، واستخدمنا الدالة sparse.csr_matrix(eye) لتحويل المصفوفة للصيغة المضغوطة CSR، وطبعنا الكائن الذي يحتوي المصفوفة الجديدة لنقارن بين الصيغتين. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: NumPy array: [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] SciPy sparse CSR matrix: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0 نلاحظ أن صيغة CSR لا تعرض كل عناصر المصفوفة، بل تُظهر العناصر التي تحتوي على أرقام غير صفرية فقط. وبما أن المصفوفة تحتوي على 1 في كل موقع قطري سنجد تساوي دليل الصف مع دليل العمود. عرض الاحصائيات الأساسية عن مجموعة بيانات آيرس باستخدام باندا Pandas لعرض المعلومات الاحصائية الأساسية عن مجموعة البيانات مثل المتوسط والانحراف المعياري والتوزيع وغيرها من المعلومات نكتب الكود التالي: import pandas as pd data = pd.read_csv("iris.csv") print(data.describe()) استخدمنا التابع data.describe() للحصول على إحصائيات عن الكائن data من نوع DataFrame، مثل عدد القيم count والمتوسط الحسابي mean والانحراف المعياري standard deviation والتوزيع المئوي percentiles وهي إحصائية تقيس الترتيب النسبي لموقع نقطة في مجموعة البيانات، فمثلًا عند قولنا أن التوزيع المئوي 25% يساوي 38.25 فهذا يعني أن 25% من القيم الموجودة في البيانات أقل من هذا العدد، وتوجد ثلاث توزيعات مئوية أساسية هي 25% و 50% و75% تمثل الأرباع Q1 و Q2 و Q3 على الترتيب، ويعرف Q2 خاصةً بالوسيط median وهو الرقم الوسيط بين مجموعة من القيم المرتبة، وتعرض أيضًا القيمة العظمى لكل عمود، ولا تأخذ هذه الدالة في الاعتبار القيم المفقودة NAN، ولا تعمل إلا على الأعمدة الرقمية Numerical. نحصل على الخرج التالي من تنفيذ الكود أعلاه: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 150.000000 150.000000 150.000000 150.000000 150.000000 mean 75.500000 5.843333 3.054000 3.758667 1.198667 std 43.445368 0.828066 0.433594 1.764420 0.763161 min 1.000000 4.300000 2.000000 1.000000 0.100000 25% 38.250000 5.100000 2.800000 1.600000 0.300000 50% 75.500000 5.800000 3.000000 4.350000 1.300000 75% 112.750000 6.400000 3.300000 5.100000 1.800000 max 150.000000 7.900000 4.400000 6.900000 2.500000 معرفة عدد عينات كل نوع Categorical values باستخدام Pandas لنحصل على عدد عينات كل فصيلة من الفصائل في مجموعة بيانات الأزهار نكتب الكود على النحو التالي: import pandas as pd data = pd.read_csv("iris.csv") print("Observations of each species:") print(data['Species'].value_counts()) استخدمنا الدالة value_counts() على العمود Species الذي يحتوى وسمًا لكل عينة في مجموعة البيانات، تسمح هذه الدالة بالحصول على عدد العينات في كل تصنيف، بمعنى أخر سنعرف كم عينة تنتمي لكل فصيلة من الأزهار. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Observations of each species: Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 Name: Species, dtype: int64 نلاحظ من الخرج السابق أن البيانات تحتوي على 150 زهرة موزعة بالتساوي على الفصائل الثلاثة. حذف عمود من DataFrame باستخدام Pandas لحذف عمود Id وطباعة أول خمسة صفوف حصلنا عليها بعد حذفه نكتب الكود التالي. import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) لحذف عمود من بنية DataFrame نستخدم الدالة drop() ونمرر لها اسم العمود المطلوب والمعامل axis وهو معامل يقبل قيمتين إما 0 وتعني أننا نريد حذف عمود، أو 1 والتي تعني أننا نريد حذف صف، ثم نستدعي new_data.head() لعرض أول خمسة صفوف من مجموعة البيانات الجديدة التي حصلنا عليها. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa اختيار شرائح معينة من مجموعة البيانات باستخدام Panda للوصول إلى أول أربع خلايا من كل صف في مجموعة البيانات المخزنة في بنية DataFrame واستخدم أسماء الأعمدة بالإضافة للفهرس للوصول للخلايا المحددة سنكتب كود بايثون التالي: import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) x = data.iloc[:, [1, 2, 3, 4]].values print(x) يسمح لنا التابع data.iloc[] باختيار شريحة معينة من مجموعة البيانات، حيث نحدد قبل الفاصلة الأولى الصفوف التي نريد أن تدخل في الاختيار، وبعد الفاصلة الأعمدة التي نريد أن تدخل في الاختيار، وفي حالتنا اخترنا عرض قيم جميع الصفوف باستخدام الرمز : والموجودة في أعمدة محددة [1,2,3,4]. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الخاتمة استكشفنا في هذه المجموعة من التدريبات مجموعة بيانات آيرس، وتعرفنا على خواصها والمعلومات الإحصائية الأساسية عنها، واستعرضنا تطبيقات عملية للتعامل مع بنية DataFrame لتخزين البيانات وتعديلها بطرق مختلفة، يمكن تجربة المزيد من الأكواد لاستكشاف هذه البيانات والتعرف عليها بشكل جيد قبل الانتقال للمقالة القادمة التي سنتدرب بها على إنشاء الرسومات البيانية لفهم العلاقات بين خواص مجموعة بيانات آيرس بشكلٍ مرئي. اقرأ أيضًا بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الأول خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الثاني خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الثالث -
 نشرح في هذا المقال التمثيل المرئي لمجموعة بيانات أزهار آيرس Iris dataset باستخدام مكتبة Scikit-Learn ومجموعة من المكتبات المفيدة الأخرى بهدف ملاحظة الأنماط وفهم العلاقات بين الخاصيات المختلفة لمجموعة بيانات الأزهار من خلال عرضها على شكل رسومات بيانية. أهمية التمثيل المرئي للبيانات Data Visualization سنوفر عدة تطبيقات عملية توضح مجموعة مهمة من أنواع الرسومات البيانية plots والتي لا غنى عنها في أي عملية تحليل للبيانات أو التمثيل المرئي للبيانات والنتائج التي تسهل فهم العلاقات واكتشاف الأنماط وعرض نتائج التحليل الإحصائي وتقييم أداء نماذج تعلم الآلة، ليس فقط للمختصين في البرمجة بل للعامة، فالجميع يمكن أن يفهم الرسومات البيانية والتوضيحية التي تسرع من توصيل المعلومات. تمثيل مرئي عام للمعلومات الإحصائية سنكتب برنامج بايثون لإنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('Statistics',) plt.ylabel('Value') plt.title("General Statistics of Iris Dataset") plt.show() استوردنا في الكود السابق المكتبة pandas وهي مكتبة بايثون مفيدة لمعالجة البيانات وتحليلها، ومكتبة matplotlib والتي تتخصص في رسم الرسومات البيانية بمختلف أنواعها، وحمّلنا مجموعة البيانات في الكائن iris، ثم استخدمنا الدالةdescribe() الذي تطرقنا له في الدرس السابق لعرض الإحصائيات الهامة عن مجموعة البيانات، بعدها استدعيناplot() ومررنا له إعدادات الرسم مثل نوع الرسم البياني kind=area، وحجم الخط والألوان المستخدمة وأبعاد الرسم البياني وغيرها من الإعدادت، وأخيرًا عرضنا الرسم البياني باستخدام plt.show(). عند تنفيذ الكود السابق سنحصل على الرسم البياني التالي: رسم بياني شريطي Bar Plot سنكتب الآن برنامج بايثون لإنشاء رسم بياني شريطي لرسم توزيع ثلاث فصائل من الأزهار وبيان تكرار ها في مجموعة البيانات. import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") ax=plt.subplots(1,1,figsize=(10,8)) sns.countplot(data=iris) plt.title("Iris Species Count") plt.show() أنشأنا باستخدام الدالةplt.subplots() شكلًا بيانيًا يمكنه احتواء عدد من الرسومات البيانية الجزئية، ومررنا للدالة عدد الصفوف والأعمدة التي نرغب أن يتكون منها الشكل البياني وهي في حالتنا صف واحد وعمود واحد، أي سيحتوي الشكل البياني على رسم بياني جزئي واحد فقط، ثم ضبطنا أبعاد الرسم البياني، بعدها استخدمنا الدالةsns.countplot() لإنشاء رسم شريطي Bar plot وهذه الدالة جزء من مكتبة seaborn التي تستخدم في الخلفية مكتبة matplotlib ولكنها تختصر العديد من الخطوات وتبسّطها حيث يمكن أن ننشئ العديد من الرسومات البيانية المعقدة بسطر برمجي واحد دون الدخول في تفاصيل معقدة. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني دائري Pie Plot سنكتب الآن برنامج بايثون لإنشاء رسم بياني دائري يوضح توزيع فصائل الأزهار وتكرارها في مجموعة البيانات. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # ضبط أبعاد الرسم البياني plt.figure(figsize=(10,8)) labels = iris['Species'].value_counts().index # وسم كل شريحة # Index(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype='object', name='Species') values = iris['Species'].value_counts().values # تكرار كل فصيلة والتي يحسب منها نسبة كل شريحة # array([50, 50, 50], dtype=int64) plt.pie(x=values, labels=labels, autopct='%1.1f%%', shadow=True, explode=[0.1, 0.1, 0.1]) plt.title("Iris Species %") plt.show() استخدمنا هنا الدالةplt.pie() لإنشاء الرسم البياني المطلوب ومررنا لها قائمة x=values تتضمن العدد في كل شريحة في الرسم البياني وقائمة أخرى labels=labels تتضمن وسم كل شريحة، وقد حصلنا على القيم ووسومها باستخدام iris['Species'].value_counts() فباستخدام التابع index نحصل على القيم الفهرسية أو المفتاحية وهي أسماء فصائل الأزهار وباستخدام التابع values نحصل على عدد كل فصيلة، بينما تحدد باقي العوامل بعض التأثيرات الجمالية مثل طريقة عرض الأرقام في الرسم البياني وإضافة ظل على الرسم، بينما القائمة الممررة للمعامل explode يعبر كل عنصر بها عن مقدار ابتعاد الشريحة عن المركز حيث تجعل القيمة 0.1 كل شريحة تبتعد عن المركز بمسافة قدرها 10% من طول نصف القطر ويمكنكم تجربة تغير هذه القيم وملاحظة التأثير الناتج. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني للنقاط المبعثرة Scatter plot لسبلات الأزهار سنرسم في هذا التطبيق رسم نقطي مبعثر يوضح العلاقة بين أبعاد السبلات أي بين طولها وعرضها. import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(10,8)) # Plotting sns.scatterplot(data=iris, x="SepalLengthCm", y="SepalWidthCm", hue="Species") # Titles plt.xlabel("Sepal Length") plt.ylabel("Sepal Width") plt.title("Sepal Length VS Width") plt.show() استخدمنا الدالةsns.scatterplot() لإنشاء رسم بياني للنقاط المبعثرة بين طول السبلة SepalLengthCm وعرض السبلة SepalWidthCm مع تلوين الفصائل المختلفة للأزهار وفقًا لتصنيفها باستخدام المعامل hue وضبطنا قيمته ليلون النقاط المبعثرة اعتمادًا على الوسوم Species، ثم استخدمنا مكتبة matplotlib لضبط إعدادات الرسم والعناوين. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني للمدرّج التكراري Histogram Plot سننشئ تطبيق يعرض رسم بياني من نوع Histogram ويوضح التوزيع لأبعاد كل من البتلات Petals والسبلات Sepals. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # Drop id column new_data = iris.drop('Id',axis=1) new_data.hist(edgecolor='black', linewidth=1.2) # gcf() -> get current figure fig=plt.gcf() fig.set_size_inches(12,12) plt.show() استخدمنا التابع new_data.hist لإنشاء رسم بياني للمدرّج التكراري، حيث يوضح هذا النوع تكرار القيم في كل متغير، وضبطنا لون الحواف لكل شريط في الرسم البياني ليكون باللون الأسود باستخدام edgecolor، وعرض الحواف باستخدام linewidth، واستخدامنا الدالة plt.gcf للحصول على الشكل البياني الحالي وتخزينه في الكائن fig حتى نتمكن من تعديله بحريّة. مثلًا يمكننا إعادة ضبط أبعاد الشكل البياني باستخدام الدالة fig.set_size_inches(12,12) وهي دالة تابعة للكائن fig، ثم عرضنا الرسم البياني على النحو التالي: رسم بياني مشترك Join Plot سنكتب برنامج لإنشاء رسم بياني مشترك يصف توزيع كل متغير من متغيرات الأزهار بشكل منفرد ثم بشكل مشترك في نفس الرسمة البيانية. import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue') plt.show() عند تنفيذ الكود سنحصل على الرسم البياني التالي: ويمكننا إظهار مزيد من المعلومات باستخدام خاصية hue والتي تعطى لونًا مختلفًا لكل تصنيف. fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue', hue="Species") عند تنفيذ الكود سنحصل على الرسم البياني التالي: شبكة رسومات بيانية لأزواج من المتغيرات سنكتب برنامج بايثون لإنشاء رسم بياني يوضح العلاقة بين أزواج مختلفة من المتغيرات pairplot، وتحديد أي الفصائل يسهل تميزها عن الأخرى وفصلها. # Import necessary modules import pandas as pd import seaborn as sns iris = pd.read_csv("iris.csv") #Drop id column iris = iris.drop('Id',axis=1) sns.pairplot(iris,hue='Species') تسمح لنا الدالةsns.pairplot() برسم العلاقة بين كل المتغيرات في مجموعة البيانات، حيث تقارن كل زوج من المتغيرات برسم بياني لتشكل مصفوفة متكاملة، يمكنك من خلالها ملاحظة العلاقة بين أي زوج من المتغيرات أو الخاصيات في مجموعة البيانات، ونمرر لهذه الدالة بشكل أساسي مجموعة البيانات iris وهذا كافٍ للحصول على نتيجة ولكن يمكننا إضافة المزيد من الألوان والأبعاد في مصفوفة الرسومات البيانية باستخدام معامل hue الذي يميز بين كل تصنيف في مجموعة البيانات بلون مميز في الرسم البياني، مما يسهّل علينا اكتشاف الأنماط المتعلقة بتصنيف محدد، حيث سنلاحظ أن أغلب النقاط التي تنتمي لتصنيف واحد أي لصنف واحد من الأزهار ستتجمع حول بعضها في بعض الأماكن في الرسم البياني. عند تنفيذ الكود سنحصل على الرسم البياني التالي: الخريطة الحرارية Heat map سنكتب برنامج بايثون لإيجاد الترابط Correlation بين المتغيرات في مجموعة بيانات آيرس، باستخدام خريطة حرارية Heatmap. نوجد أولاً مصفوفة الترابط Correlation Matrix import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") corr_matrix = iris.drop(columns=["Id", "Species"]).corr() print(corr_matrix) عند تنفيذ الكود سنحصل على الخرج التالي: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm SepalLengthCm 1.000000 -0.109369 0.871754 0.817954 SepalWidthCm -0.109369 1.000000 -0.420516 -0.356544 PetalLengthCm 0.871754 -0.420516 1.000000 0.962757 PetalWidthCm 0.817954 -0.356544 0.962757 1.000000 بعدها، نرسم الخريطة الحرارية Heat Map المعبرة عن مصفوفة الترابط Correlation Matrix sns.heatmap(corr_matrix, annot=True, cmap="Blues") plt.show() عند تنفيذ الكود سنحصل على الرسم البياني التالي: الرسومات البيانية باللغة العربية إذا حاولنا إنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس، كما فعلنا في التطبيق الأول مع جعل العناوين باللغة العربية، سنلاحظ أن مكتبة Matplotlib لا توفر دعمًا جيدًا للغة العربية وتعرض الأحرف مبعثرة، وكذلك ستظهر كل كلمة معكوسة الاتجاه من اليسار إلى اليمين. لنلاحظ نتيجة تنفيذ الكود التالي عند محاولة عرض العناوين العربية قبل استخدام المكتبات الخارجية: iris.describe().plot(kind = "area",fontsize=15, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('الاحصائيات',) plt.ylabel('القيمة') plt.title("معلومات احصائية عامة لمجموعة بيانات آيرس") plt.show() لتصحيح هذا الخطأ سنستخدم مكتبتين خارجيتين: مكتبة arabic_reshaper لحل مشكلة عدم اتصال الحروف ببعضها مكتبة python-bidi لحل مشكلة اتجاه الحروف المعكوس والسماح بدمج مناسب لنصوص عربية مع نصوص أجنبية نستخدم الأوامر التالية لتثبيت المكتبات: pip install arabic-reshaper pip install python-bidi الآن إذا حاولنا عرض العناوين العربية بعد استخدام المكتبات الخارجية كما يلي: import pandas as pd import matplotlib.pyplot as plt from bidi.algorithm import get_display import arabic_reshaper def arabic(txt): return get_display(arabic_reshaper.reshape(txt)) iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel(arabic('الاحصائيات')) plt.ylabel(arabic('القيمة')) plt.title(arabic("معلومات احصائية عامة لمجموعة بيانات آيرس")) plt.show() الخاتمة تعرفنا في هذا المقال على كيفية تمثيل البيانات بشكل مرئي من خلال أمثلة عملية متنوعة بمكتبة Scikit-Learn والمكتبات المساعدة، وقد اكتفينا بعرض بعض أنواع فقط ونترك لكم استكشاف أنواع الرسومات المختلفة الأخرى والاستفادة منها في تمثيل البيانات وملاحظة الأنماط والعلاقات الموجودة بينها بسرعة وسهولة. ترجمة -وبتصرف- للجزء الثاني من مقال Python: Machine learning - Scikit-learn Exercises, Practice, Solution اقرأ أيضًا المقال السابق: أساسيات تحليل البيانات باستخدام Scikit-Learn مع Pandas تعرف على مكتبة Scikit learn وأهم خوارزمياتها الدليل الشامل إلى تحليل البيانات Data Analysis بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn أفضل أدوات الذكاء الاصطناعي وتعلم الآلة للمطورين المبتدئين
نشرح في هذا المقال التمثيل المرئي لمجموعة بيانات أزهار آيرس Iris dataset باستخدام مكتبة Scikit-Learn ومجموعة من المكتبات المفيدة الأخرى بهدف ملاحظة الأنماط وفهم العلاقات بين الخاصيات المختلفة لمجموعة بيانات الأزهار من خلال عرضها على شكل رسومات بيانية. أهمية التمثيل المرئي للبيانات Data Visualization سنوفر عدة تطبيقات عملية توضح مجموعة مهمة من أنواع الرسومات البيانية plots والتي لا غنى عنها في أي عملية تحليل للبيانات أو التمثيل المرئي للبيانات والنتائج التي تسهل فهم العلاقات واكتشاف الأنماط وعرض نتائج التحليل الإحصائي وتقييم أداء نماذج تعلم الآلة، ليس فقط للمختصين في البرمجة بل للعامة، فالجميع يمكن أن يفهم الرسومات البيانية والتوضيحية التي تسرع من توصيل المعلومات. تمثيل مرئي عام للمعلومات الإحصائية سنكتب برنامج بايثون لإنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('Statistics',) plt.ylabel('Value') plt.title("General Statistics of Iris Dataset") plt.show() استوردنا في الكود السابق المكتبة pandas وهي مكتبة بايثون مفيدة لمعالجة البيانات وتحليلها، ومكتبة matplotlib والتي تتخصص في رسم الرسومات البيانية بمختلف أنواعها، وحمّلنا مجموعة البيانات في الكائن iris، ثم استخدمنا الدالةdescribe() الذي تطرقنا له في الدرس السابق لعرض الإحصائيات الهامة عن مجموعة البيانات، بعدها استدعيناplot() ومررنا له إعدادات الرسم مثل نوع الرسم البياني kind=area، وحجم الخط والألوان المستخدمة وأبعاد الرسم البياني وغيرها من الإعدادت، وأخيرًا عرضنا الرسم البياني باستخدام plt.show(). عند تنفيذ الكود السابق سنحصل على الرسم البياني التالي: رسم بياني شريطي Bar Plot سنكتب الآن برنامج بايثون لإنشاء رسم بياني شريطي لرسم توزيع ثلاث فصائل من الأزهار وبيان تكرار ها في مجموعة البيانات. import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") ax=plt.subplots(1,1,figsize=(10,8)) sns.countplot(data=iris) plt.title("Iris Species Count") plt.show() أنشأنا باستخدام الدالةplt.subplots() شكلًا بيانيًا يمكنه احتواء عدد من الرسومات البيانية الجزئية، ومررنا للدالة عدد الصفوف والأعمدة التي نرغب أن يتكون منها الشكل البياني وهي في حالتنا صف واحد وعمود واحد، أي سيحتوي الشكل البياني على رسم بياني جزئي واحد فقط، ثم ضبطنا أبعاد الرسم البياني، بعدها استخدمنا الدالةsns.countplot() لإنشاء رسم شريطي Bar plot وهذه الدالة جزء من مكتبة seaborn التي تستخدم في الخلفية مكتبة matplotlib ولكنها تختصر العديد من الخطوات وتبسّطها حيث يمكن أن ننشئ العديد من الرسومات البيانية المعقدة بسطر برمجي واحد دون الدخول في تفاصيل معقدة. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني دائري Pie Plot سنكتب الآن برنامج بايثون لإنشاء رسم بياني دائري يوضح توزيع فصائل الأزهار وتكرارها في مجموعة البيانات. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # ضبط أبعاد الرسم البياني plt.figure(figsize=(10,8)) labels = iris['Species'].value_counts().index # وسم كل شريحة # Index(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype='object', name='Species') values = iris['Species'].value_counts().values # تكرار كل فصيلة والتي يحسب منها نسبة كل شريحة # array([50, 50, 50], dtype=int64) plt.pie(x=values, labels=labels, autopct='%1.1f%%', shadow=True, explode=[0.1, 0.1, 0.1]) plt.title("Iris Species %") plt.show() استخدمنا هنا الدالةplt.pie() لإنشاء الرسم البياني المطلوب ومررنا لها قائمة x=values تتضمن العدد في كل شريحة في الرسم البياني وقائمة أخرى labels=labels تتضمن وسم كل شريحة، وقد حصلنا على القيم ووسومها باستخدام iris['Species'].value_counts() فباستخدام التابع index نحصل على القيم الفهرسية أو المفتاحية وهي أسماء فصائل الأزهار وباستخدام التابع values نحصل على عدد كل فصيلة، بينما تحدد باقي العوامل بعض التأثيرات الجمالية مثل طريقة عرض الأرقام في الرسم البياني وإضافة ظل على الرسم، بينما القائمة الممررة للمعامل explode يعبر كل عنصر بها عن مقدار ابتعاد الشريحة عن المركز حيث تجعل القيمة 0.1 كل شريحة تبتعد عن المركز بمسافة قدرها 10% من طول نصف القطر ويمكنكم تجربة تغير هذه القيم وملاحظة التأثير الناتج. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني للنقاط المبعثرة Scatter plot لسبلات الأزهار سنرسم في هذا التطبيق رسم نقطي مبعثر يوضح العلاقة بين أبعاد السبلات أي بين طولها وعرضها. import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(10,8)) # Plotting sns.scatterplot(data=iris, x="SepalLengthCm", y="SepalWidthCm", hue="Species") # Titles plt.xlabel("Sepal Length") plt.ylabel("Sepal Width") plt.title("Sepal Length VS Width") plt.show() استخدمنا الدالةsns.scatterplot() لإنشاء رسم بياني للنقاط المبعثرة بين طول السبلة SepalLengthCm وعرض السبلة SepalWidthCm مع تلوين الفصائل المختلفة للأزهار وفقًا لتصنيفها باستخدام المعامل hue وضبطنا قيمته ليلون النقاط المبعثرة اعتمادًا على الوسوم Species، ثم استخدمنا مكتبة matplotlib لضبط إعدادات الرسم والعناوين. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني للمدرّج التكراري Histogram Plot سننشئ تطبيق يعرض رسم بياني من نوع Histogram ويوضح التوزيع لأبعاد كل من البتلات Petals والسبلات Sepals. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # Drop id column new_data = iris.drop('Id',axis=1) new_data.hist(edgecolor='black', linewidth=1.2) # gcf() -> get current figure fig=plt.gcf() fig.set_size_inches(12,12) plt.show() استخدمنا التابع new_data.hist لإنشاء رسم بياني للمدرّج التكراري، حيث يوضح هذا النوع تكرار القيم في كل متغير، وضبطنا لون الحواف لكل شريط في الرسم البياني ليكون باللون الأسود باستخدام edgecolor، وعرض الحواف باستخدام linewidth، واستخدامنا الدالة plt.gcf للحصول على الشكل البياني الحالي وتخزينه في الكائن fig حتى نتمكن من تعديله بحريّة. مثلًا يمكننا إعادة ضبط أبعاد الشكل البياني باستخدام الدالة fig.set_size_inches(12,12) وهي دالة تابعة للكائن fig، ثم عرضنا الرسم البياني على النحو التالي: رسم بياني مشترك Join Plot سنكتب برنامج لإنشاء رسم بياني مشترك يصف توزيع كل متغير من متغيرات الأزهار بشكل منفرد ثم بشكل مشترك في نفس الرسمة البيانية. import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue') plt.show() عند تنفيذ الكود سنحصل على الرسم البياني التالي: ويمكننا إظهار مزيد من المعلومات باستخدام خاصية hue والتي تعطى لونًا مختلفًا لكل تصنيف. fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue', hue="Species") عند تنفيذ الكود سنحصل على الرسم البياني التالي: شبكة رسومات بيانية لأزواج من المتغيرات سنكتب برنامج بايثون لإنشاء رسم بياني يوضح العلاقة بين أزواج مختلفة من المتغيرات pairplot، وتحديد أي الفصائل يسهل تميزها عن الأخرى وفصلها. # Import necessary modules import pandas as pd import seaborn as sns iris = pd.read_csv("iris.csv") #Drop id column iris = iris.drop('Id',axis=1) sns.pairplot(iris,hue='Species') تسمح لنا الدالةsns.pairplot() برسم العلاقة بين كل المتغيرات في مجموعة البيانات، حيث تقارن كل زوج من المتغيرات برسم بياني لتشكل مصفوفة متكاملة، يمكنك من خلالها ملاحظة العلاقة بين أي زوج من المتغيرات أو الخاصيات في مجموعة البيانات، ونمرر لهذه الدالة بشكل أساسي مجموعة البيانات iris وهذا كافٍ للحصول على نتيجة ولكن يمكننا إضافة المزيد من الألوان والأبعاد في مصفوفة الرسومات البيانية باستخدام معامل hue الذي يميز بين كل تصنيف في مجموعة البيانات بلون مميز في الرسم البياني، مما يسهّل علينا اكتشاف الأنماط المتعلقة بتصنيف محدد، حيث سنلاحظ أن أغلب النقاط التي تنتمي لتصنيف واحد أي لصنف واحد من الأزهار ستتجمع حول بعضها في بعض الأماكن في الرسم البياني. عند تنفيذ الكود سنحصل على الرسم البياني التالي: الخريطة الحرارية Heat map سنكتب برنامج بايثون لإيجاد الترابط Correlation بين المتغيرات في مجموعة بيانات آيرس، باستخدام خريطة حرارية Heatmap. نوجد أولاً مصفوفة الترابط Correlation Matrix import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") corr_matrix = iris.drop(columns=["Id", "Species"]).corr() print(corr_matrix) عند تنفيذ الكود سنحصل على الخرج التالي: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm SepalLengthCm 1.000000 -0.109369 0.871754 0.817954 SepalWidthCm -0.109369 1.000000 -0.420516 -0.356544 PetalLengthCm 0.871754 -0.420516 1.000000 0.962757 PetalWidthCm 0.817954 -0.356544 0.962757 1.000000 بعدها، نرسم الخريطة الحرارية Heat Map المعبرة عن مصفوفة الترابط Correlation Matrix sns.heatmap(corr_matrix, annot=True, cmap="Blues") plt.show() عند تنفيذ الكود سنحصل على الرسم البياني التالي: الرسومات البيانية باللغة العربية إذا حاولنا إنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس، كما فعلنا في التطبيق الأول مع جعل العناوين باللغة العربية، سنلاحظ أن مكتبة Matplotlib لا توفر دعمًا جيدًا للغة العربية وتعرض الأحرف مبعثرة، وكذلك ستظهر كل كلمة معكوسة الاتجاه من اليسار إلى اليمين. لنلاحظ نتيجة تنفيذ الكود التالي عند محاولة عرض العناوين العربية قبل استخدام المكتبات الخارجية: iris.describe().plot(kind = "area",fontsize=15, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('الاحصائيات',) plt.ylabel('القيمة') plt.title("معلومات احصائية عامة لمجموعة بيانات آيرس") plt.show() لتصحيح هذا الخطأ سنستخدم مكتبتين خارجيتين: مكتبة arabic_reshaper لحل مشكلة عدم اتصال الحروف ببعضها مكتبة python-bidi لحل مشكلة اتجاه الحروف المعكوس والسماح بدمج مناسب لنصوص عربية مع نصوص أجنبية نستخدم الأوامر التالية لتثبيت المكتبات: pip install arabic-reshaper pip install python-bidi الآن إذا حاولنا عرض العناوين العربية بعد استخدام المكتبات الخارجية كما يلي: import pandas as pd import matplotlib.pyplot as plt from bidi.algorithm import get_display import arabic_reshaper def arabic(txt): return get_display(arabic_reshaper.reshape(txt)) iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel(arabic('الاحصائيات')) plt.ylabel(arabic('القيمة')) plt.title(arabic("معلومات احصائية عامة لمجموعة بيانات آيرس")) plt.show() الخاتمة تعرفنا في هذا المقال على كيفية تمثيل البيانات بشكل مرئي من خلال أمثلة عملية متنوعة بمكتبة Scikit-Learn والمكتبات المساعدة، وقد اكتفينا بعرض بعض أنواع فقط ونترك لكم استكشاف أنواع الرسومات المختلفة الأخرى والاستفادة منها في تمثيل البيانات وملاحظة الأنماط والعلاقات الموجودة بينها بسرعة وسهولة. ترجمة -وبتصرف- للجزء الثاني من مقال Python: Machine learning - Scikit-learn Exercises, Practice, Solution اقرأ أيضًا المقال السابق: أساسيات تحليل البيانات باستخدام Scikit-Learn مع Pandas تعرف على مكتبة Scikit learn وأهم خوارزمياتها الدليل الشامل إلى تحليل البيانات Data Analysis بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn أفضل أدوات الذكاء الاصطناعي وتعلم الآلة للمطورين المبتدئين
