


Mustafa Suleiman
-
المساهمات
20540 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
496
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
 كل عام وأنتي بخير هبة. تلك الوسائط يتم تحميلها من مواقع توفر فيديوهات مجانية أو مدفوعة، وتستطيعي أنتي أيضًا تنزيل فيديوهات احترافية واستخدامها في تصميمك من المصادر التالية: Pexels Coverr Pixabay Mixkit كل ما عليكِ هو تنزيل الفيديو بصيغة mp4 واستبدال ملف الفيديو القديم في مجلد القالب بالفيديو الجديد بنفس الاسم أو تغيير المسار في الكود. الفيديو في لغة HTML يعمل كطبقة تعلو الخلفية العادية، ولو وضعتي background-image في الـ CSS، فتوضع خلف الفيديو، وبالتالي لا تظهر لأن الفيديو يغطيها. لذا يجب حذف الفيديو في كود HTML بحذف التالي: <video autoplay muted loop id="myVideo"> <source src="video.mp4" type="video/mp4"> </video> ثم التوجه لملف CSS وتحديد العنصر الأب الذي كان يحتوي الفيديو، وغالبًا اسمه header أو hero أو banner ثم إضافة التنسيق التالي: .hero-section { background-image: url('../images/background.jpg'); background-size: cover; background-position: center; background-repeat: no-repeat; } بالطبع مع تعديل مسار الصورة بالمسار لديكِ
كل عام وأنتي بخير هبة. تلك الوسائط يتم تحميلها من مواقع توفر فيديوهات مجانية أو مدفوعة، وتستطيعي أنتي أيضًا تنزيل فيديوهات احترافية واستخدامها في تصميمك من المصادر التالية: Pexels Coverr Pixabay Mixkit كل ما عليكِ هو تنزيل الفيديو بصيغة mp4 واستبدال ملف الفيديو القديم في مجلد القالب بالفيديو الجديد بنفس الاسم أو تغيير المسار في الكود. الفيديو في لغة HTML يعمل كطبقة تعلو الخلفية العادية، ولو وضعتي background-image في الـ CSS، فتوضع خلف الفيديو، وبالتالي لا تظهر لأن الفيديو يغطيها. لذا يجب حذف الفيديو في كود HTML بحذف التالي: <video autoplay muted loop id="myVideo"> <source src="video.mp4" type="video/mp4"> </video> ثم التوجه لملف CSS وتحديد العنصر الأب الذي كان يحتوي الفيديو، وغالبًا اسمه header أو hero أو banner ثم إضافة التنسيق التالي: .hero-section { background-image: url('../images/background.jpg'); background-size: cover; background-position: center; background-repeat: no-repeat; } بالطبع مع تعديل مسار الصورة بالمسار لديكِ -
كلاهما مختصين بمجال مختلف تمامًا عن الآخر، أرجو توضيح هل تريد التخصص في مجال تطوير الويب أم تريد التخصص في مجال تعلم الآلة؟ في حال تعلم الآلة، إذن ستحتاج إلى استبدال دورة جافاسكريبت بدورة علوم الحاسوب لتتناسب مع دورة الذكاء الاصطناعي، وذلك عن طريق التحدث لمركز المساعدة.
-
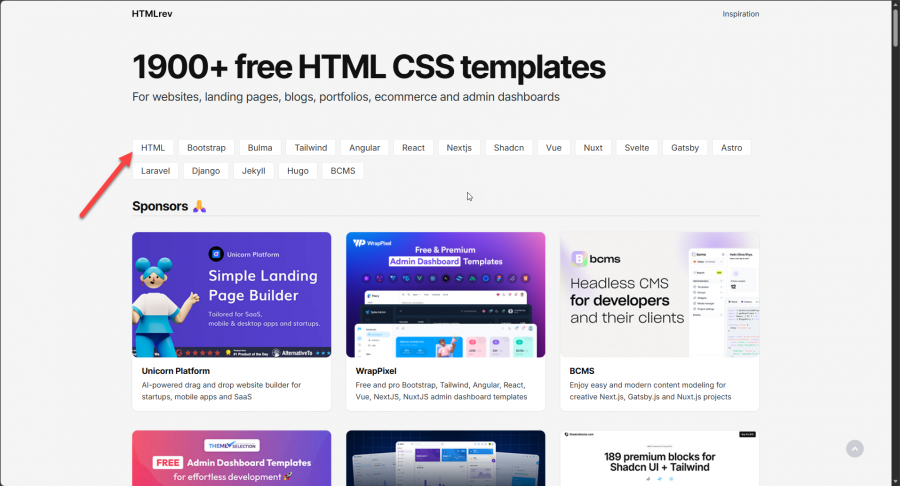
يتوفر موقع HTMLrev.com ويوجد به فلاتر لتصفية القوالب بناءًا عليها، بمعنى لإختيار قالب HTML, CSS فقط، قومي بتحديد فلتر HTML: ونفس الأمر لو أردتي قالب مُطور من خلال بوتستراب، فقومي بالضغط على فلتر Boostrap وستحصلين على HTML, CSS, JS, Boostrap ثم اختاري القالب الذي تريدينه وانزلي لأسفل الصفحة وستجد زر التحميل، ولو أردتي المعاينة قبل التحميل اضغطي على Live view كذلك المواقع التالية: https://startbootstrap.com/themes https://bootstrapmade.com/ https://bootswatch.com/
-
تقصدين قالب html, css, js جاهز؟ أم تريدين قالب منسق بواسطة بوتستراب؟ وفي أي مشروع سيتم استخدام القالب؟
-
طالما سوق العمل فالأمر راجع إذن للمطلوب في سوق العمل لديك، ستحتاج إلى تفقد الوظائف المعروضة على مواقع التوظيف مثل LinkedIn وIndeed وغيرهم، وذلك بالنسبة لمستوى Junior وعلى أساسها تقرر وليس العكس. https://academy.hsoub.com/questions/24823-ماهي-لغة-البرمجة-الأنسب-بالنسبة-لسوق-العمل-والحصول-على-وظيفة؟/#findComment-75480
-
كلا الإطارين مختلفين من حيث اللغة البرمجية، المقارنة هنا على أي أساس؟ هل لمشروع شخصي أم من أجل سوق العمل؟ وكذلك هل لديك إلمام بلغة PHP؟
-
لا مشكلة في الاستضاف ومن الجيد أنها بالعملة المحلية لديك، لكن ما الحاجة إلى ذلك، تتوفر استضافة مجانية من خلال Vercel الشركة المطورة لـ Next.js أو Netlify أو Cloudflare Pages أيضًا تقدم استضافة للمواقع الساكنة، مع ربط مباشر بـ GitHub و CDN عالمي لتحسين سرعة الموقع. وللواجهة الخلفية استخدم استخدم Render أو Railway أو Fly.io والتي تدعم Node.js و Python وغيرها، وتوفر خطط مجانية أو تبدأ من 5 دولارات شهريًا. كذلك لقواعد البيانات لديك Supabase والتي توفر PostgreSQL كذلك لديك MongoDB Atlas وكلاهما يوفر خطة مجانية.
- 1 جواب
-
- 1
-

-
الأفضل إطار عام للمشروع، وأنت تبحث في التفاصيل للجمع بين الفائدتين، والمتطلبات الأساسية MVP التي ستبدأ بها هي ما يلي: نظام تسجيل دخول وإنشاء حساب صفحة عرض الفعاليات سواء حفلات، مباريات، سينما، قم باختيار نوع واحد. صفحة تفاصيل الفعالية وبها التاريخ، المكان، السعر، المقاعد المتاحة. إمكانية اختيار المقاعد أو عدد التذاكر. سلة حجز بسيطة. صفحة تأكيد الحجز. لوحة تحكم المستخدم وبها الحجوزات. لوحة تحكم الأدمن لإدارة الفعاليات. وفيما بعد تستطيع إضافة المزايا التالية: نظام دفع وهمي أو حقيقي مثل Stripe. إرسال التذكرة بالإيميل أو PDF نظام بحث وفلترة الفعاليات تقييم الفعاليات نظام كوبونات خصم QR Code للتذكرة إشعارات تذكير بموعد الفعالية. يجب التخطيط قبل كتابة الكود، قم برسم الصفحات على ورقة أي إنشاء Wireframes أ واستخدم أداة رقمية لذلك. ثم حدد الـ Models وعلاقاتها، ثم اكتب قائمة بكل الـ URLs، وقسم المشروع لمراحل صغيرة ولا تنظر إليه ككل ولا تحاول بناء كل شيء دفعة واحدة بل ابدأ بأبسط نسخة تعمل. ةاستخدم Git من اليوم الأول ويجب تسجيل كل تغيير بـ commit واضح، واختبر كل ميزة فور بنائها ولا تبني 5 ميزات ثم تختبر. واتبع منهج التطوير التدريجي، كالتالي: المرحلة الأولى Models و Admin Panel. الثانية صفحة عرض الفعاليات صفحة التفاصيل نظام المستخدمين نظام الحجز لوحة تحكم المستخدم التنسيق والتحسين ولا تقارن مشروعك بمشاريع المحترفي، ركز على التعلم وليس الكمال. الأفضل استخدم Bootstrap لأنّ tailwind يتطلب معرفة بـ CSS، ويوجد قوالب Bootstrap جاهزة تفقد startbootstrap.com أو bootstrapmade.com وعندما تحتاج تعديل بسيط، ابحث عنه. لكن في حال تريد أن تصبح مطور ويب فيجب تعلم CSS وليس تجنبها. عامًة لا تضيع وقتك في التصميم في البداية اجعل الموقع يعمل أولاً ثم عدل التنسيق. لم تذكر الوقت المخصص يوميًا، على إفتراض 3 ساعات يوميًا ستحتاج إلى أسبوعين أو ثلاثة للإنتهاء من MVP. لكن الهدف هو التعلم وليس السرعة، ومن الطبيعي أن تقضي يوم كامل على مشكلة واحدة.
- 1 جواب
-
- 1
-
-
سوق العمل ستحتاج إلى تفقده بنفسك من خلال تفقد الوظائف المعروضة على مواقع التوظيف مثل LinkedIn وIndeed، أي البحث بالكلمات المفتاحية الخاصة بمجال بايثون مثل Python Django Backend Developer بالنسبة لما يمكنك العمل به بعد الإنتهاء من الدورة،: مطور Full-stack لبناء مواقع الويب والمتاجر الإلكترونية أي قادر على تطوير الواجهة الأمامية والخلفية أيضًا من خلال Django و Flask. مطور واجهة خلفية Back-End فقط. مجال تعلم الآلة ولكن هنا أنت بحاجة إلى تعلم المزيد وعدم الإكتفاء بالدورة والأمر بحاجة إلى وقت أكثر من أي مجال آخر. محلل بيانات (Data Analyst )، حيث ستتمكن من استخدام مهارات البرمجة الخاصة بك للتحليل واستخراج البيانات من مصادر متنوعة، ومعالجة البيانات، وإجراء التحليلات الإحصائية والتعلم الآلي باستخدام مكتبات Python مثل pandas و NumPy و scikit-learn. مطور odoo ستجد تفصيل أكثر هنا:
-
في أغلب الأحيان ستجد السبب هو الذاكرة العشوائية، وهو أمر لا يتضح لك عند دراسة لغات مرتفعة المستوى مثل جافاسكربيت وبايثون والتي تقوم بتجريد الكثير من الأمور أي إخفائها عنك. السبب هو الـ Memory Offset أو إزاحة الذاكرة، حيث الذاكرة RAM شكلها كالتالي تقريبًا: العنوان: 1000 1001 1002 1003 1004 القيمة: 'H' 'e' 'l' 'l' 'o' وذلك عند تخزين المتغير: let str = "Hello"; فالكمبيوتر يحفظ أول حرف في عنوان أساسي base address مثلاً 1000 وللوصول لباقي الأحرف نستخدم الإزاحة: عنوان الحرف = العنوان الأساسي + الإزاحة (offset) أي ما يحدث في الخلفية عند كتابة str[0] : str[0] 1000 + 0 = 1000 str[1] 1000 + 1 = 1001 str[2] 1000 + 2 = 1002 لو بدأنا من 1 كنا نحتاج إلى تنفيذ طرح في كل مرة: str[1] 1000 + (1-1) = 1000 وتلك عملية زائدة لا حاجة إليها.
-
آلية الإختبار هي كالتالي، بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل وذلك أفضل في حال كنتي مبتدئة، عليكِ رفع المشاريع التي قمتي بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريدين التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتيها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصلين على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد. وبعد الحصول على الشهادة ستحصلين على المزايا التالية: إن لم تحصلين على عمل خلال 6 أشهر يغطي قيمة الدورة التي دفعتها، فسنعيد لك ما دفعتيه. موقع إلكتروني لمدة سنة مقدم من سنديان مع نطاق مخصص لعرض أعمالك وبناء تواجدك الرقمي على الإنترنت. اشتراك لمدة سنة في العضوية المميزة على منصة مستقل لمساعدتك على الانطلاق في العمل الحر وحصولك على أول عميل. استشارة توظيف فردية، وسيرة ذاتية احترافية من موقع بعيد تعزز فرصك في الحصول على الوظيفة التي تتطلعين إليها. بالنسبة لطريقة الدراسة ستجدين تفصيل هنا:
-
الطريقة الحديثة حاليًا هي من خلال القالب النصي Template Literals، والصيغة الخاصة به هي علامة تنصيص مائلة ` ` تستطيع كتابتها بالضغط على حرف ذ أعلى اليسار في لوحة المفاتيح لكن قم بتحويلها إلى الإنجليزية أولاً. const newLineString = `Up up down down`; console.log(newLineString); وبدونها ستحتاج إلى استخدام رمز السطر الجديد n\ const newLineString = 'Up up\n down down'; console.log(newLineString); والأفضل القالب النصي، لأنه يسمح أيضًا بإضافة متغيرات لتكوين النص كالتالي: const name = 'mustafa' const newLineString = `Up up down down ${name}`; console.log(newLineString);
-
دورة علوم الحاسب غير مخصصة لتعليمك مجال محدد في البرمجة من أجل سوق العمل، بل غرضها هو تأهيلك لتعلم البرمجة بشكل سليم ودخول سوق العمل بقوة، حيث أنك ستمتلك أفضلية بالطبع بسبب تعلمك لأساسيات البرمجة من خلال بايثون وجافاسكريبت وأيضًا علوم الحاسب والتي تتضمن التالي: أساسيات الحاسوب وعلومه والتفكير المنطقي وما هي الخوارزميات وكيف تفيد في البرمجة تطبيقات عملية على أساسيات التفكير المنطقي باستخدام بيئة سكراتش Scratch التفاعلية أساسيات أنظمة التشغيل المختلفة وكيفية تثبيت البرمجيات اللازمة للبرمجة عليها أساسيات سطر الأوامر في نظام لينكس، وشرح الأسس التي بني عليها النظام مع تطبيقها عمليًا أنظمة قواعد البيانات المختلفة، مع شرح تفصيلي للغة SQL للتعامل معها مبادئ أساسية في أنظمة قواعد البيانات NoSQL المفاهيم الأساسية التي تبنى فيها صفحات الويب مفاهيم أساسية في الشبكات والخوادم، وكيف يتم استقبال الطلبيات إلى الخادم والرد عليها مبادئ الحماية والأمان في الويب وبالتالي يصبح لديك قاعدة معرفة قوية ووعي ودراية بمجالات البرمجة، الأمر الذي يؤهلك للخطوة القادمة وهي إختيار مجال البرمجة الذي تريده، حيث سيتم توجيهك بعد إنتهاء الدورة وإجتياز الإختبار إلى كيفية تعلم المجال الذي تريده لدخول سوق العمل أو إقتراح مجالات ومنها الويب أو تطوير تطبيقات الهاتف أو مجال الواجهة الخلفية Back-End أو الجمع بين الواجهة الأمامية والخلفية لتصبح مطور Full-stack. وأيضًا ستجد نفسك قادر على حل المشكلات التي تواجهك ولديك مهارة التفكير المنطقي أي مستواك أفضل من أي شخص قام ببدأ المسار التعليمي في مجال معين دون تعلم الأساسيات. وبخصوص التوظيف وسوق العمل، فأرجو مناقشة ذلك مع مركز المساعدة وسيتم إرشادك لما يجب فعله.
-
يجب أن يتواجد لأنه يحتوي على المترجم والملفات التنفيذية مثل g++.exe. الأفضلالإعتماد على نسخة تثبيت معدلة وجاهزة للتثبيت المباشر وهي متوفرة في المستودع التالي: https://github.com/ehsan18t/easy-mingw-installer كل ما عليكِ هو حذف الإصدار الذي ثبتيه على حاسوبك من خلال لوحة control panel ثم اختيار uninstall programs وحذف المترجم. ثم تثبيت ملف التثبيت من المستودع السابق: EasyMinGW.Installer.v2025.12.23.64-bit.exe ثم الضغط على install فقط.
-
أرجو التوجه للرابط التالي: https://accounts.hsoub.com/settings وبه ستجدين كافة المعلومات عن حسابك وأيضًا تستطيعي تغيير كلمة السر بالضغط على رابط تغيير كلمة المرور، ثم بعد ذلك تسجيل الدخول من خلال الرابط التالي: https://accounts.hsoub.com وبعد تسجيل الدخول اضغطي على منصة أكاديمية حسوب للتوجه إليها.
-
Web Scraping هو المفهوم أو العملية نفسها أو التقنية التي تقوم فيها باستخراج البيانات من المواقع الإلكترونية، بينما BeautifulSoup4 أداة وهي مكتبة بايثون لتنفيذ عملية الـ Web Scraping. قم بتطوير برنامج تضع فيه نص طويل وغير مرتب وليكن نص منسوخ من موقع شركة أو ملف نصي عشوائي، ويقوم البرنامج باستخراج الإيميلات و أرقام الهواتف فقط. أي اطلب من المستخدم إدخال نص طويل، ثم أنشئ Regex Pattern للإيميل وآخر لرقم الهاتف، وابحث في النص واطبع قائمة نظيفة تحتوي فقط على الإيميلات والأرقام المستخرجة. برنامج يعمل في الـ Terminal يسمح لك بإضافة مصاريفك اليومية، وحفظها في ملف دائم بصيغة JSON، بحيث إذا أغلقت البرنامج وفتحته تجد بياناتك السابقة. أي عند تشغيل البرنامج، قم بقراءة ملف expenses.json، وإن لم يتم إجاده أنشئ قائمة فارغة. ثم اعرض قائمة خيارات للمستخدم: (1) إضافة مصروف جديد (الاسم، المبلغ، التاريخ). (2) عرض كل المصروفات. (3) حساب مجموع المصروفات. (4) حفظ وخروج. عند اختيار الحفظ، يتم تحويل القائمة إلى نص JSON وتخزينها في الملف. للتدريب، الأفضل استخدام موقع مخصص للتجربة مثل http://books.toscrape.com لأنه متاح للتعلم. قم بتطوير برنامج يزحف على الموقع، ويجلب عناوين الكتب وأسعارها وتقييمها، ثم يطبعها بشكل مرتب. وكمشروع شامل على ما سبق، قم بتطوير بوت"يقوم بالدخول على موقع وظائف ويقوم بالآتي: يسحب عناوين الوظائف والوصف الوظيفي. يبحث داخل الوصف الوظيفي عن أي بريد إلكتروني للتواصل لأن بعض الشركات تكتبه داخل النص. يقوم بحفظ النتيجة النهائية في ملف jobs.json بهذا الشكل: [ { "title": "Python Developer", "email_contact": "hr@company.com" }, { "title": "Data Analyst", "email_contact": "No email found" } ]
-
لا مشكلة بها ومنطقية، لكن، من الناحية البرمجية ينقصها خطوة وهي استقبال أو قراءة القيمة وتخزينها. فالكمبيوتر يحتاج أن تخبره أن يحفظ الاسم الذي كتبه المستخدم في مكان ما وذلك (يسمى متغير Variable في البرمجة، وذلك لكي يستطيع طباعته لاحقًا. بدء البرنامج. أظهر رسالة للمستخدم: أدخل اسمك. اقرأ الاسم واحفظه في متغير . اطبع المتغير (الاسم) على الشاشة. إنهاء البرنامج.
-
لست مضطر لتحميل النسخة الكاملة من أوبونتو، حيث تتوفر ميزة WSL في نظام Windows 10 أو 11، والتي تتيح لك تشغيل أوبونتو داخل ويندوز مباشرة دون الحاجة لبرامج مثل VirtualBox. وحجم التحميل أقل من 500 ميجا لأنك تحمل واجهة سطر الأوامر فقط بدون الواجهة الرسومية الثقيلة، وذلك هو ما تحتاجه لتعلم البرمجة والتعامل مع السيرفرات. الخطوات هي: افتح PowerShell كمسؤول Admin. اكتب الأمر wsl --install سيقوم الويندوز بتحميل وتثبيت Ubuntu تلقائيًا بعد إعادة تشغيل الجهاز، ستجد أيقونة Ubuntu وتستطيع استخدام أوامر لينكس كاملة. أو هناك حل آخر، منصة Replit قم بإنشاء مشروع جديد بها واختر Bash لتحصل على بيئة لينكس كاملة لتجربة الأوامر.
- 2 اجابة
-
- 1
-
-
بالطبع لكن الأمر ليس بالسهل ستحتاج إلى بذل مجهود، لكن لتصبح باحث AI Research Scientist ستحتاج أيضًا إلى ماجستير أو دكتوراه PhD في مجال الـ AI/CS فتلك هي المرحلة التي تتعلم فيها كيف تبحث، وكيف تنشر أوراق علمية. وفي البداية تستطيع العمل كـ Research Engineer وتلك وظيفة تجمع بين الاثنين أي تساعد الباحثين الكبار في تحويل معادلاتهم إلى كود. وأثناء الجامعة لا تكتفِ بالكورسات. حاول قراءة أوراق بحثيةومحاولة تطبيقها، وذلك من خلال بايثون فذلك هو هو ما يثبت للشركات أنك باحث ولست مجرد طالب رياضيات. كذلك المعدل التراكمي GPA مهم في تخصص الرياضيات، حاول الحفاظ على معدل عالٍ، لأنه مفتاحك للمنح الدراسية للماجستير والدكتوراه لاحقًا. وعامًة تستطيع دراسة الرياضيات بشكل حر بدون الحاجة للإلتحاق بجامعة مختصة، ستحتاج إلى ذلك فقط في حال تريد التخصص في البحث AI Research تحديدًا، وليس مجرد تطبيق النماذج الجاهزة. وأغلب أوراق البحث العلمي في مؤتمرات مثل NeurIPS أو ICML تعتمد بشكل كلي على الجبر الخطي Linear Algebra، التفاضل والتكامل Calculus، الاحتمالات والإحصاء Probability & Statistics، والـ Optimization. وخريج علوم الحاسوب CS يدرس تلك المواد بشكل سطحي أو تطبيقي، بينما خريج الرياضيات يدرسها بعمق يجعله يستوعب لماذا تعمل الخوارزمية، وليس فقط كيف يستخدمها. لذا علوم الحاسوب أفضل لوظيفة مهندس برمجيات أو مهندس ذكاء اصطناعي AI Engineer، لكون الرياضيات فيه أقل، لكن تستطيع دراستها بنفسك. أما التخصص في الرياضيات يؤهلك لتكون عالم وباحث يبتكر خوارزميات جديدة، لكن ستحتاج بالطبع إلى دراسة البرمجة بجانب ذلك من خلال تعلم الأساسيات فقط عن طريق C++ أو Java ثم التعمق في بايثون.
- 3 اجابة
-
- 1
-

-
أحسنت حقًا، قمت بمراجعة مشروعك، وللتحسين عليك إصلاح الـ Models والمهجرات مع إعادة تهيئة DB من خلال تحديث ipam/models.py بإضافة max_length لحقول CharField أو تحويل description إلى TextField(blank=True). وتوحيد العلاقات والقيود مثل unique=True على ip_address وإضافة related_name مثل: network = ForeignKey( , related_name="ip_addresses") لتسهيل الاستعلامات. وإضافة Model.clean() وCheckConstraint بسيط لتناسق ثم حذف الـ migrations الحالية للتطبيق ipam وإعادة إنشاء migrations نظيفة. ولديك Bug في التحقق من وجود IP لأنّ استخدام ip_address__contains=host أحيانًا سيعطي نتائج خاطئة بمعنى 192.168.1.1 يطابق 192.168.1.10. لذا قم بنقل فحص تداخل الشبكات من forms.clean() الـ view إلى مكان واحد إما Network.clean() وهو أفضل لإعادة الاستخدام في admin/forms أو NetowrkCreateForm.clean() مع استثناء self عند التحديث. وفي حالة التحديث، استبعاد الشبكة الحالية بالـ pk بدلاً من مقارنة network_address. وفي ipam/views.py داخل NetworkUpdateView.form_valid استبدل len(list(current_net.hosts())) بمعادلة ثابتة: current_net.num_addresses - 2 طالما prefix ≤ 30 لديك. وتجنب بناء قائمة كل الـ hosts أي استخدم iterator على current_net.hosts() وتوقف عند الوصول للعدد المطلوب. واستبدل فحص الوجود بـ bulk_create( , ignore_conflicts=True) لتفادي الاستعلام لكل IP، أو على الأقل exists() مع ip_address=host بدل contains. مع تغليف العملية داخل transaction.atomic() لتجنب حالات نصف تحديث. وفي NetworkUpdateView.get_context_data أو override get_queryset استخدم prefetch_related مع select_related('user') لعلاقة IPs لتجنب مشكلة N+1. وبالنسبة لتحسين أمان التطبيق، فقم نقل الأسرار إلى متغيرات بيئة SECRET_KEY, إعدادات DB, وتعطيل debug_toolbar إلا عند عمل DEBUG. كذلك إضافة LoginRequiredMixin لـ IPAddressAssignView، ومنع تعيين IP في حال status != FREE وأيضًا منع overwrite لمالك سابق.
- 1 جواب
-
- 1
-
-
الفكرة ليس في التطبيق على كل ساعة، بل في التطبيق على مفهوم معين تعلمته، مثلاً تعلمت أساسيات حلقات التكرار في بايثون، هنا تتوقف وتقوم بتنفيذ تمرين للتطبيق على ذلك المفهوم، وربط التمرين بما تعلمته سابقًا أي القوائم والمتغيرات والجمل الشرطية وهكذا. في حال كان الدرس طويل أو به مفاهيم مختلفة، أرجو قراءة التالي: وكل شخص له أسلوب يُناسبه في الدراسة، لكن المهم هو تجنب المشاهدة السلبية وتخصيص وقت أكبر للتطبيق العملي، فالبرمجة عبارة عن تفكير منطقي لحل مشكلة ثم تنفيذ ذلك من خلال كتابة الكود. بالنسبة لطريقة الدراسة البعض يُفضل كتابة مُلخصات لكل شيء، لكن لا أنصحك بذلك، اكتفي فقط بكتابة ملاحظات ومُلخصات ورسومات للأمور النظرية أو معلومة معينة تريد الإحتفاظ بها للعودة إليها للمراجعة. بينما البرمجة نفسها اكتفي بالتطبيق العملي فهو الأهم وبدونه فلا معنى للمُلخصات النظرية مهما كتبت، ببساطة لن تستطيع قيادة سيارة بمشاهدة فيديو صحيح؟ وحاول تجنب الإنقطاعات المتكررة خاصًة في البداية، حاول الدراسة بإنتظام بحد أدنى ساعتين يوميًا أو شبه يومي. في بعض الدروس ستجد شرح نظري، هنا يتعين عليك الاستيعاب قدر الإمكان والسؤال عن الأمور الغير واضحة لك لتفصيلها وتبسيط، وبعد فترة من التطبيق العملي سيتضح لك الأمر أكثر. ولا يوجد مدة محددة للتطبيق، الأمر كله يعود للوقت المتوفر لك وتحتاج إلى إدارته، عامًة عليك تخصيص 50% من وقتك للتطبيق العملي. وللعلم مجال الذكاء الاصطناعي يعتبر ضمن أكثر مجالات البرمجة تعقيدًا وبحاجة إلى مجهود واستيعاب أكثر من باقي المجالات. لذا يجب دراسة الدورة بهدف الاستيعاب وليس بهدف إنهائها في أسرع وقت، البحث والمشاهدة بجانب ما يتم شرحه أمر لابد منه وذلك حال أي دورة في أي مكان، فلا توجد تلك الدورة التي تقدم لك كل شيء. وإدارة مجهودك بذكاء من خلال معرفة ما يجب عليك تعلمه في البداية وما تحتاجه لاحقًا، فبطبيعة الحال توجد أساسيات ثم أمور خاصة بالمستوى المتوسط ويليها المستوى المتقدم. اتبع قاعدة 20 - 80 وهو مبدأ باريتو، الفكرة الأساسية هي أن 20% من المجهود تغطي 80% من النتائج أو المهام المطلوبة. وبالتطبيق على الدورة، ركز على تعلم أساسيات البرمجة كالمتغيرات، الحلقات، الدوال، والهياكل البيانية (القوائم والمصفوفات) لحل 80% من المشكلات البرمجية البسيطة إلى المتوسطة. وفي التطبيق العملي عليك قضاء 20% من وقتك في تعلم النظريات و80% في كتابة الكود وحل المشكلات العملية يساعد على تثبيت المعرفة. بعد فترة من الوقت لن تصلح تلك القاعدة بسبب تعقيد مجال الذكاء الاصطناعي، ويجب تعميق الفهم لما يتجاوز استيعاب الأساسيات، أي قاعدة 20% لن تجدي نفعًا بعد فترة لكن ستفيدك في البداية.
-
في الوقت الحالي لا تتوفر مُلخصات للدروس، تستطيع الإعتماد على موسوعة حسوب كمرجع، وتستطيع الاستفسار أسفل الدروس في التعليقات عما تحتاجه وسيتم توضيحه لك. الملفات المتوفرة هي ملفات المشروع التي سنعمل عليه خلال المسار، وتستطيع تحميل ذلك من خلال درس المقدمة أو المدخل في بداية المسار. عامًة كل شخص له أسلوب يُناسبه في الدراسة، لكن المهم هو تجنب المشاهدة السلبية وتخصيص وقت أكبر للتطبيق العملي، فالبرمجة عبارة عن تفكير منطقي لحل مشكلة ثم تنفيذ ذلك من خلال كتابة الكود. والبعض يُفضل كتابة مُلخصات لكل شيء، لكن لا أنصحك بذلك، اكتفي فقط بكتابة ملاحظات ومُلخصات ورسومات للأمور النظرية أو معلومة معينة تريد الإحتفاظ بها للعودة إليها للمراجعة. بينما البرمجة نفسها اكتفي بالتطبيق العملي فهو الأهم وبدونه فلا معنى للمُلخصات النظرية مهما كتبت، ببساطة لن تستطيع قيادة سيارة بمشاهدة فيديو صحيح؟
-
الإمتحان باللغة العربية، آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.
- 2 اجابة
-
- 1
-
-
تتوفر منصة UniPin وSmile.one، والأفضل منصة UniPin لأنها توفر نظام Merchant API متكامل وواضح ويغطي استرجاع قوائم الألعاب، والتحقق من اسم اللاعب (ID) قبل الشحن، وإنشاء طلبات التعبئة آليًا. كذلك منصة LikeCard بها Merchant API يتيح ربط أكثر من 3000 بطاقة ومنتج رقمي بمتجرك، وتتميز بواجهة إدارة Dashboard لمتابعة العمليات والأرباح، وهي الأنسب للمنطقة العربية. ومنصة Codashop توفر حل Codapay وهو API موحد يربط متجرك بمئات وسائل الدفع والناشرين الرسميين، ولكنه يتطلب تقديم طلب عبر نموذج Reseller Program ليتم مراجعته من قبل فريقهم. ويوجد منصة SEAGM بها تنوع في برامج الشات مثل Mico Live، Poppo Live، Sugo، و Tango، وتستطيع عبر حساب الموزع Partnership الوصول لخدمات الشحن المباشر لتلك التطبيقات بأسعار الجملة.
-
ربما تختزل الطلب على منصة عمل حر معينة، لكن تفقد مختلف المنصات ستجد طلب على مشاريع SaaS، وللعلم تعتمد 82% من الشركات الناشئة في دول الخليج حاليًا على مستقلين لتنفيذ مشاريع محددة، وكذلك نسبة الطلب الأكبر هي من قبل الأجانب. بالنسبة لصاحب مشروع أم مبرمج؟ أعتقد أنك الأخير، لذا الأمر يعتمد على ما تعلمته بالفعل أو تنوي تعلمه، لكن الأصح هو استكشاف سوق العمل وتفقد المهارات المطلوبة وليس العكس. وعامًة كمطور جافاسكريبت، فالأنسب هو إطار Next.js مع Tailwind CSS وكمطور PHP الأنسب هو لارافل، وقاعدة البيانات لكلاهما هي PostgreSQL، وكمنصة سحابية فالأفضل AWS.