


أروى عفان
-
المساهمات
46 -
تاريخ الانضمام
-
تاريخ آخر زيارة
4 متابعين




آخر الزوار
2140 زيارة للملف الشخصي



إنجازات أروى عفان
عضو نشيط (3/3)
5
السمعة بالموقع
-
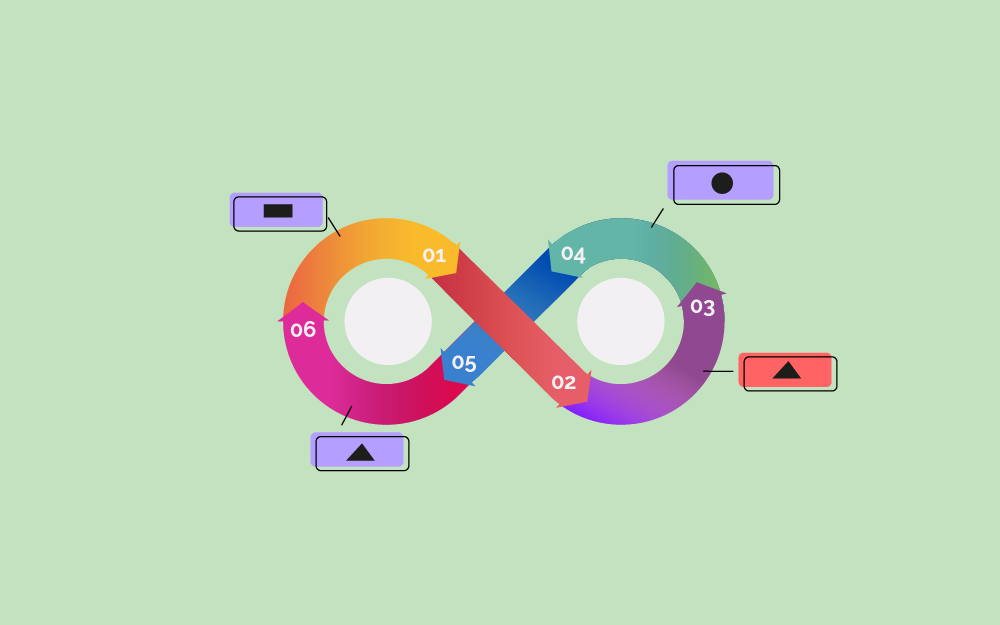 أصبح اعتماد منهجية DevOps هو الحل البديهي لتحسين البرامج البطيئة وغير الناجحة وأتمتة المهام اليدوية. ولذلك، سنشرح في هذا المقال ما هي منهجية عمل إنتاج البرمجيات في DevOps أو ما يُعرف بمصطلح DevOps pipeline وما هي خطوات إنشائها. مقدمة عن منهجية DevOps وخطوط التكامل والتسليم المستمر CI/CD تطورت منهجية DevOps لتشتمل على عديد من التخصصات المختلفة، ولكن معظم الناس يتفقون على أن DevOps هي منهجية لتطوير البرمجيات أو دورة حياة تطوير البرمجيات SDLC، ومبدؤها الأساسي هو تغيير ثقافة العمل واعتماد أتمتة المهام اليدوية لزيادة الإنتاجية وتحسين مرونة تنفيذ المهام. هناك بعض الأدوات الضرورية لتحقيق بيئة DevOps، لكن المفتاح الرئيسي هو إنشاء منهجية عمل Pipeline يُطبّق فيها التكامل المستمر والنشر المستمر CI/CD، بحيث تحتوي على مراحل مختلفة مثل مرحلة التطوير DEV، والتكامل INT، والاختبار TST، والتحقق من الجودة QA، واختبار قبول المستخدم UAT، والتحضير STG، والانتاج PROD؛ وتؤتمت فيها المهام اليدوية، لكي يستطيع المطورون العمل بمرونة وكتابة شيفرة عالية الجودة، والنشر مرات عديدة. يقدّم هذا المقال طريقةً مكونةً من خمس خطوات لإنشاء منهجية عمل لإنتاج البرمجيات بأسلوب DevOps باستخدام أدوات مفتوحة المصدر، مثل ماهو موضح في الصورة التالية: 1. استخدام اُطر عمل التكامل والنشر المستمر CI/CD أول ما نحتاج إليه هو إحدى أدوات التكامل والنشر المستمر CI/CD، ويُنصح لهذا الغرض باستخدام أداة جنكينز Jenkins، وهي أداة مفتوحة المصدر ومبنية على لغة جافا Java وترخيص MIT، وهي ما ساهم في نشر منهجية DevOps لتصبح المعيار الأساسي. ولتبسيط الأمر، يمكننا تخيل أن أداة Jenkins هي جهاز تحكم عن بعد يمكنه التخاطب مع خدمات وأدوات عدة المختلفة وإدارتها، وهي عديمة النفع بمفردها، ولكنها تصير أكثر قوةً عند استخدامها مع أدوات وخدمات مختلفة. وهي واحدة من العديد من أدوات CI/CD مفتوحة المصدر التي يمكن الاستفادة منها لإنشاء منهجية عمل DevOps. فيما يلي بعض الأدوات الأخرى: الأداة الرخصة Jenkins المشاع الإبداعي و MIT Travis CI MIT CruiseControl BSD Buildbot GPL Apache Gump Apache 2.0 Cabie GNU توضح الصورة التالية سير عمليات DevOps باستخدام أدوات التكامل والنشر المستمر CI/CD: وبهذا تكون قد أصبحت لدينا أداة CI/CD قيد التشغيل في مضيفنا المحلي، ولكن لا يمكن الاستفادة منها في شيء الآن. سنتابع شرح باقي الخطوات كي نتعلم كيفية استخدام الأدوات لبناء منهجية عمل DevOps. 2. إدارة الشيفرة المصدرية Source Code Management إن أفضل وأسهل طريقة للتأكد من أن أدوات CI/CD تعمل جيدًا هي استخدامها مع إحدى أدوات إدارة الشفرة المصدرية Source Code Management أو اختصارًا: SCM، وذلك لأن الشيفرة التي نكتبها عند تطوير تطبيق ما باستخدام إحدى لغات البرمجة مثل لغة جافا Java أو بايثون Python أو C++ أو لغة جو Go، أو جافاسكربت Javascript، أو غيرها، يطلق عليها اسم الشيفرة المصدرية Source Code. عند العمل بمفردنا، سيكون من الأسهل هو حفظ كل ما يلزمنا في مجلد واحد على جهازنا؛ ولكن عند العمل على مشروع كبير يتم فيه التعاون مع الآخرين، فسوف نحتاج إلى طريقة لمشاركة التعديلات على الشيفرة بفعالية وتجنب التعارض عند التعديل؛ كما سنحتاج أيضًا إلى طريقة لاستعادة النسخ السابقة من الشيفرة، وأحدث من طريقة النسخ الاحتياطي أو طريقة النسخ واللصق التقليدية. هنا علينا استخدام أدوات إدارة الشيفرة المصدرية SCM التي تساعد في تخزين الشيفرة في مستودعات، والتحكم في إصدار الشيفرة، والتنسيق بين أعضاء المشروع. ثمة أدوات عدة لإدارة الشيفرة المصدرية، لكن غيت Git أفضلها، وفيما يلي ذكر لأدوات أخرى مفتوحة المصدر: الأداة الرخصة غيت GPLv2 & LGPL v2.1 Subversion Apache 2.0 Concurrent Versions System (CVS) GNU Vesta LGPL Mercurial GNU GPL v2+ توضح الصورة الآتية كيف تبدو منهجية عمل DevOps عند استخدام إحدى أدوات إدارة الشيفرة المصدرية SCM: وكما هو واضح، يمكن لأداة التكامل والنشر المستمر CI/CD أتمتة التعديلات على الشيفرة المصدرية وتسهيل التعاون بين أعضاء الفريق. وسنتعرف في باقي الخطوات على كيفية الاستفادة من ذلك في تطبيق عملي حتى يتمكن العديد من الناس من استخدامه. 3. إنشاء أداة لأتمتة عمليات بناء الشيفرة يمكن الآن الإطلاع على تعديلات الشيفرة وإضافة تعديلاتنا، كما يمكن التعاون مع مطورين آخرين في كتابة الشيفرة. للتأكيد، يجب علينا تجميع التطبيق قبل ذلك ووضعه في تنسيق حزمة قابلة للنشر أو تشغيله كملف قابل للتنفيذ Executable لجعله تطبيق ويب. يمكننا ملاحظة أن لغات البرمجة المُفسَّرة مثل جافاسكربت JavaScript أو PHP لا تحتاج إلى تجميع Compilation، وهنا علينا استخدام إحدى أدوات أتمتة عمليات بناء البرامج Build Automation Tool، والتي تهدف إلى إنشاء شيفرة مصدرية بتنسيق معين، وأتمتة عمليات تنظيف الشيفرة وتجميعها واختبارها ونشرها في موقع معين. تختلف أدوات البناء وفقًا للغة البرمجة، وفيما يلي بعض الأدوات الشائعة مفتوحة المصدر: الأداة الرخصة لغة البرمجة Maven أباتشي Apache 2.0 جافا Java Ant أباتشي Apache 2.0 جافا Java Gradle أباتشي Apache 2.0 جافا Java Bazel أباتشي Apache 2.0 جافا Java Make GNU --- Grunt MIT جافا سكربت JavaScript Gulp MIT جافا سكربت JavaScript Rake MIT Ruby Buildr Apache Ruby A-A-P GNU بايثون Python SCons MIT بايثون Python BitBake GPLv2 بايثون Python Cake MIT C# ASDF Expat (MIT) LISP Cabal BSD Haskell يمكننا الآن إضافة ملفات إعدادات أداة أتمتة بناء الشيفرة إلى أداة إدارة الشيفرة المصدرية SCM وستتولى أداة التكامل والنشر المستمر CI/CD أمر بنائها. 4. اختيار خادم تطبيقات الويب للحصول على فائدة من التطبيق، يجب أن يكون التطبيق قادرًا على توفير خدمة أو واجهة ما، كما يجب استضافته على خادم تطبيقات ويب؛ إذ يوفر الخادم بيئةً قادرةً على قراءة المنطق البرمجي داخل الحزمة القابلة للنشر، وعرض واجهة التطبيق، وتقديم خدمات الويب عن طريق إتاحة مآخذ هذه الخدمات، ولذلك ستحتاج إلى خادم HTTP وآلة افتراضية Virtual machine لتثبيت خادم التطبيقات. فيما يلي عدد من خوادم تطبيقات الويب مفتوحة المصدر التي يمكن المفاضلة بينها واختيار الأنسب بينها: الأداة الرخصة لغة البرمجة Tomcat Apache 2.0 جافا Jetty Apache 2.0 جافا WildFly GNU Lesser Public جافا GlassFish CDDL & GNU Less Public جافا Django 3-Clause BSD بايثون Python Paste MIT بايثون Rails MIT Ruby Node.js MIT جافا سكربت بعد تحديد خادم الويب المناسب، نستطيع القول أنه قد أصبحت لدينا منهجية عمل DevOps شبه مُعَدّة للاستخدام. يمكن التوقف هنا عند هذه الخطوة والمتابعة بمفردنا، لكن سنخصص الخطوة التالية للتحدث عن جودة الشيفرة لأهميتها. 5. اختبار تغطية الشيفرة Code Testing Coverage قد يكون اختبار الشيفرة أمرًا مرهقًا ولكنه ضروري ويجب إجراؤه باكرًا لاكتشاف الأخطاء ورفع جودة الشيفرة وضمان رضا العملاء؛ ولكن توجد أدوات عدة مفتوحة المصدر لاختبار الشيفرة وتحسين جودتها, ويمكن توصيل معظم أدوات التكامل والنشر المستمر CI/CD مع أدوات الاختبار وأتمتة العملية. أُطُر اختبار الشيفرة البرمجية Code Test Frameworks هناك نوعان من أدوات اختبار الشيفرة، هما: أُطُر اختبار الشيفرة البرمجية Code test framework: وتساعد في كتابة الاختبارات وتشغيلها أدوات تحسين الجودة Code Quality Suggestion Tools: وتقدم اقتراحات تساعد على تحسين جودة الشيفرة البرمجية في الآتي جدول مكون من أهم أُطُر الاختبار: إطار العمل الرخصة لغة البرمجة JUnit Eclipse Public License جافا EasyMock أباتشي Apache جافا Pytest MIT Python Tox MIT Python أما عن أدوات تحسين الجودة Code Quality Suggestion Tools، فيمكن ذكر الأدوات الآتية: الأداة الرخصة لغة البرمجة Cobertura GNU جافا Emma common Public License جافا Coverage.py Apache 2.0 بايثون Tox MIT Python Jasmine MIT جافا سكربت Jest MIT جافا سكربت وكما نلاحظ، معظم الأدوات والأطر التي ذكرناها مكتوبة بلغة جافا، أو بايثون، أو جافا سكربت؛ أما لغتا C++ وC# فهما من لغات البرمجة الخاصة Proprietary لكن المُترجِم المستخدم لترجمتهما GCC مفتوح المصدر. والآن بعد تطبيق أدوات اختبار التغطية، يجب أن يكون لدينا منهجية عمل DevOps تشبه المنهجية الموضحة في بداية مقالنا. خطوات إضافية لتحسين المنهجية سنوضح فيما يلي بعض الخطوات الإضافية التي يمكن القيام بها لتحسين منهجية عمل DevOps الخاصة بنا. استخدام الحاويات Containers ذكرنا سابقًا أن بإمكاننا استضافة خادم التطبيقات على آلة افتراضية أو خادم، كما يمكن استخدام الحاويات containers أيضًا. يقوم مفهوم الحاويات باختصار على أن الآلة الافتراضية تحتاج إلى مساحة كبيرة لنظام التشغيل تفوق حجم التطبيق، بينما تحتاج الحاوية فقط إلى عدد قليل من المكتبات والإعدادات لتشغيل التطبيق. لا تزال هناك استخدامات مهمة للآلات الافتراضية، ولكن الحاويات توّفر حلًا خفيف الوزن لاستضافة التطبيقات، بما في ذلك خادم التطبيقات. توجد خيارات مختلفة للحاويات، لكن دوكر Docker وكوبرنيتس Kubernetes هما الأكثر شيوعًا. الأداة الرخصة Docker Apache 2.0 Kubernetes Apache 2.0 أدوات الأتمتة الوسيطة Middleware automation tools تركز منهجية عمل DevOps التي نفّذناه على إنشاء تطبيق ونشره بصورة تعاونية، ولكن هناك أمور أخرى عدّة يمكننا تنفيذها باستخدام أدوات DevOps، وأحدها هو الاستفادة من أدوات إدارة البنية التحتية باستخدام الشيفرة Infrastructure as Code واختصارًا IaC، والتي تُعرف أيضًا باسم أدوات الأتمتة الوسيطة. تساعد هذه الأدوات في أتمتة عمليات التثبيت والإدارة ومهام البرامج الوسيطة، حيث يمكن لأداة الأتمتة مثلًا أن تسحب الاعدادات المناسبة للتطبيقات، مثل خادم تطبيقات الويب وقواعد البيانات وأدوات المراقبة، ونشرها على خادم التطبيقات. وفيما يلي بعض أدوات الأتمتة الوسيطة مفتوحة المصدر: الأداة الرخصة SaltStack Apache 2.0 Chef Apache 2.0 Ansible GNU Public Puppet Apache أو GPL الخلاصة تعلّمنا في هذا المقال كيفية إنشاء منهجية عمل لإنتاج البرمجيات بأسلوب DevOps باستخدام أدوات مفتوحة المصدر، وتعرفنا على أشهر أدوات التكامل والنشر المستمر CI/CD مفتوحة المصدر وأدوات إدارة الشيفرة المصدرية واختبارها، ويمكنك من الآن بدء تجربة إنشاء منهجية DevOps لمشروعك البرمجي الحقيقي. ترجمة، وبتصرّف، للمقال A beginner's guide to building DevOps pipelines with open source tools لكاتبه Bryant Son. اقرأ أيضًا دليل المبتدئين في مجال DevOps وأهم ممارساته وأدواته المدخل الشامل لتعلم DevOps ما هي الغاية من DevOps؟ أفضل 5 لغات برمجة لـ DevOps
أصبح اعتماد منهجية DevOps هو الحل البديهي لتحسين البرامج البطيئة وغير الناجحة وأتمتة المهام اليدوية. ولذلك، سنشرح في هذا المقال ما هي منهجية عمل إنتاج البرمجيات في DevOps أو ما يُعرف بمصطلح DevOps pipeline وما هي خطوات إنشائها. مقدمة عن منهجية DevOps وخطوط التكامل والتسليم المستمر CI/CD تطورت منهجية DevOps لتشتمل على عديد من التخصصات المختلفة، ولكن معظم الناس يتفقون على أن DevOps هي منهجية لتطوير البرمجيات أو دورة حياة تطوير البرمجيات SDLC، ومبدؤها الأساسي هو تغيير ثقافة العمل واعتماد أتمتة المهام اليدوية لزيادة الإنتاجية وتحسين مرونة تنفيذ المهام. هناك بعض الأدوات الضرورية لتحقيق بيئة DevOps، لكن المفتاح الرئيسي هو إنشاء منهجية عمل Pipeline يُطبّق فيها التكامل المستمر والنشر المستمر CI/CD، بحيث تحتوي على مراحل مختلفة مثل مرحلة التطوير DEV، والتكامل INT، والاختبار TST، والتحقق من الجودة QA، واختبار قبول المستخدم UAT، والتحضير STG، والانتاج PROD؛ وتؤتمت فيها المهام اليدوية، لكي يستطيع المطورون العمل بمرونة وكتابة شيفرة عالية الجودة، والنشر مرات عديدة. يقدّم هذا المقال طريقةً مكونةً من خمس خطوات لإنشاء منهجية عمل لإنتاج البرمجيات بأسلوب DevOps باستخدام أدوات مفتوحة المصدر، مثل ماهو موضح في الصورة التالية: 1. استخدام اُطر عمل التكامل والنشر المستمر CI/CD أول ما نحتاج إليه هو إحدى أدوات التكامل والنشر المستمر CI/CD، ويُنصح لهذا الغرض باستخدام أداة جنكينز Jenkins، وهي أداة مفتوحة المصدر ومبنية على لغة جافا Java وترخيص MIT، وهي ما ساهم في نشر منهجية DevOps لتصبح المعيار الأساسي. ولتبسيط الأمر، يمكننا تخيل أن أداة Jenkins هي جهاز تحكم عن بعد يمكنه التخاطب مع خدمات وأدوات عدة المختلفة وإدارتها، وهي عديمة النفع بمفردها، ولكنها تصير أكثر قوةً عند استخدامها مع أدوات وخدمات مختلفة. وهي واحدة من العديد من أدوات CI/CD مفتوحة المصدر التي يمكن الاستفادة منها لإنشاء منهجية عمل DevOps. فيما يلي بعض الأدوات الأخرى: الأداة الرخصة Jenkins المشاع الإبداعي و MIT Travis CI MIT CruiseControl BSD Buildbot GPL Apache Gump Apache 2.0 Cabie GNU توضح الصورة التالية سير عمليات DevOps باستخدام أدوات التكامل والنشر المستمر CI/CD: وبهذا تكون قد أصبحت لدينا أداة CI/CD قيد التشغيل في مضيفنا المحلي، ولكن لا يمكن الاستفادة منها في شيء الآن. سنتابع شرح باقي الخطوات كي نتعلم كيفية استخدام الأدوات لبناء منهجية عمل DevOps. 2. إدارة الشيفرة المصدرية Source Code Management إن أفضل وأسهل طريقة للتأكد من أن أدوات CI/CD تعمل جيدًا هي استخدامها مع إحدى أدوات إدارة الشفرة المصدرية Source Code Management أو اختصارًا: SCM، وذلك لأن الشيفرة التي نكتبها عند تطوير تطبيق ما باستخدام إحدى لغات البرمجة مثل لغة جافا Java أو بايثون Python أو C++ أو لغة جو Go، أو جافاسكربت Javascript، أو غيرها، يطلق عليها اسم الشيفرة المصدرية Source Code. عند العمل بمفردنا، سيكون من الأسهل هو حفظ كل ما يلزمنا في مجلد واحد على جهازنا؛ ولكن عند العمل على مشروع كبير يتم فيه التعاون مع الآخرين، فسوف نحتاج إلى طريقة لمشاركة التعديلات على الشيفرة بفعالية وتجنب التعارض عند التعديل؛ كما سنحتاج أيضًا إلى طريقة لاستعادة النسخ السابقة من الشيفرة، وأحدث من طريقة النسخ الاحتياطي أو طريقة النسخ واللصق التقليدية. هنا علينا استخدام أدوات إدارة الشيفرة المصدرية SCM التي تساعد في تخزين الشيفرة في مستودعات، والتحكم في إصدار الشيفرة، والتنسيق بين أعضاء المشروع. ثمة أدوات عدة لإدارة الشيفرة المصدرية، لكن غيت Git أفضلها، وفيما يلي ذكر لأدوات أخرى مفتوحة المصدر: الأداة الرخصة غيت GPLv2 & LGPL v2.1 Subversion Apache 2.0 Concurrent Versions System (CVS) GNU Vesta LGPL Mercurial GNU GPL v2+ توضح الصورة الآتية كيف تبدو منهجية عمل DevOps عند استخدام إحدى أدوات إدارة الشيفرة المصدرية SCM: وكما هو واضح، يمكن لأداة التكامل والنشر المستمر CI/CD أتمتة التعديلات على الشيفرة المصدرية وتسهيل التعاون بين أعضاء الفريق. وسنتعرف في باقي الخطوات على كيفية الاستفادة من ذلك في تطبيق عملي حتى يتمكن العديد من الناس من استخدامه. 3. إنشاء أداة لأتمتة عمليات بناء الشيفرة يمكن الآن الإطلاع على تعديلات الشيفرة وإضافة تعديلاتنا، كما يمكن التعاون مع مطورين آخرين في كتابة الشيفرة. للتأكيد، يجب علينا تجميع التطبيق قبل ذلك ووضعه في تنسيق حزمة قابلة للنشر أو تشغيله كملف قابل للتنفيذ Executable لجعله تطبيق ويب. يمكننا ملاحظة أن لغات البرمجة المُفسَّرة مثل جافاسكربت JavaScript أو PHP لا تحتاج إلى تجميع Compilation، وهنا علينا استخدام إحدى أدوات أتمتة عمليات بناء البرامج Build Automation Tool، والتي تهدف إلى إنشاء شيفرة مصدرية بتنسيق معين، وأتمتة عمليات تنظيف الشيفرة وتجميعها واختبارها ونشرها في موقع معين. تختلف أدوات البناء وفقًا للغة البرمجة، وفيما يلي بعض الأدوات الشائعة مفتوحة المصدر: الأداة الرخصة لغة البرمجة Maven أباتشي Apache 2.0 جافا Java Ant أباتشي Apache 2.0 جافا Java Gradle أباتشي Apache 2.0 جافا Java Bazel أباتشي Apache 2.0 جافا Java Make GNU --- Grunt MIT جافا سكربت JavaScript Gulp MIT جافا سكربت JavaScript Rake MIT Ruby Buildr Apache Ruby A-A-P GNU بايثون Python SCons MIT بايثون Python BitBake GPLv2 بايثون Python Cake MIT C# ASDF Expat (MIT) LISP Cabal BSD Haskell يمكننا الآن إضافة ملفات إعدادات أداة أتمتة بناء الشيفرة إلى أداة إدارة الشيفرة المصدرية SCM وستتولى أداة التكامل والنشر المستمر CI/CD أمر بنائها. 4. اختيار خادم تطبيقات الويب للحصول على فائدة من التطبيق، يجب أن يكون التطبيق قادرًا على توفير خدمة أو واجهة ما، كما يجب استضافته على خادم تطبيقات ويب؛ إذ يوفر الخادم بيئةً قادرةً على قراءة المنطق البرمجي داخل الحزمة القابلة للنشر، وعرض واجهة التطبيق، وتقديم خدمات الويب عن طريق إتاحة مآخذ هذه الخدمات، ولذلك ستحتاج إلى خادم HTTP وآلة افتراضية Virtual machine لتثبيت خادم التطبيقات. فيما يلي عدد من خوادم تطبيقات الويب مفتوحة المصدر التي يمكن المفاضلة بينها واختيار الأنسب بينها: الأداة الرخصة لغة البرمجة Tomcat Apache 2.0 جافا Jetty Apache 2.0 جافا WildFly GNU Lesser Public جافا GlassFish CDDL & GNU Less Public جافا Django 3-Clause BSD بايثون Python Paste MIT بايثون Rails MIT Ruby Node.js MIT جافا سكربت بعد تحديد خادم الويب المناسب، نستطيع القول أنه قد أصبحت لدينا منهجية عمل DevOps شبه مُعَدّة للاستخدام. يمكن التوقف هنا عند هذه الخطوة والمتابعة بمفردنا، لكن سنخصص الخطوة التالية للتحدث عن جودة الشيفرة لأهميتها. 5. اختبار تغطية الشيفرة Code Testing Coverage قد يكون اختبار الشيفرة أمرًا مرهقًا ولكنه ضروري ويجب إجراؤه باكرًا لاكتشاف الأخطاء ورفع جودة الشيفرة وضمان رضا العملاء؛ ولكن توجد أدوات عدة مفتوحة المصدر لاختبار الشيفرة وتحسين جودتها, ويمكن توصيل معظم أدوات التكامل والنشر المستمر CI/CD مع أدوات الاختبار وأتمتة العملية. أُطُر اختبار الشيفرة البرمجية Code Test Frameworks هناك نوعان من أدوات اختبار الشيفرة، هما: أُطُر اختبار الشيفرة البرمجية Code test framework: وتساعد في كتابة الاختبارات وتشغيلها أدوات تحسين الجودة Code Quality Suggestion Tools: وتقدم اقتراحات تساعد على تحسين جودة الشيفرة البرمجية في الآتي جدول مكون من أهم أُطُر الاختبار: إطار العمل الرخصة لغة البرمجة JUnit Eclipse Public License جافا EasyMock أباتشي Apache جافا Pytest MIT Python Tox MIT Python أما عن أدوات تحسين الجودة Code Quality Suggestion Tools، فيمكن ذكر الأدوات الآتية: الأداة الرخصة لغة البرمجة Cobertura GNU جافا Emma common Public License جافا Coverage.py Apache 2.0 بايثون Tox MIT Python Jasmine MIT جافا سكربت Jest MIT جافا سكربت وكما نلاحظ، معظم الأدوات والأطر التي ذكرناها مكتوبة بلغة جافا، أو بايثون، أو جافا سكربت؛ أما لغتا C++ وC# فهما من لغات البرمجة الخاصة Proprietary لكن المُترجِم المستخدم لترجمتهما GCC مفتوح المصدر. والآن بعد تطبيق أدوات اختبار التغطية، يجب أن يكون لدينا منهجية عمل DevOps تشبه المنهجية الموضحة في بداية مقالنا. خطوات إضافية لتحسين المنهجية سنوضح فيما يلي بعض الخطوات الإضافية التي يمكن القيام بها لتحسين منهجية عمل DevOps الخاصة بنا. استخدام الحاويات Containers ذكرنا سابقًا أن بإمكاننا استضافة خادم التطبيقات على آلة افتراضية أو خادم، كما يمكن استخدام الحاويات containers أيضًا. يقوم مفهوم الحاويات باختصار على أن الآلة الافتراضية تحتاج إلى مساحة كبيرة لنظام التشغيل تفوق حجم التطبيق، بينما تحتاج الحاوية فقط إلى عدد قليل من المكتبات والإعدادات لتشغيل التطبيق. لا تزال هناك استخدامات مهمة للآلات الافتراضية، ولكن الحاويات توّفر حلًا خفيف الوزن لاستضافة التطبيقات، بما في ذلك خادم التطبيقات. توجد خيارات مختلفة للحاويات، لكن دوكر Docker وكوبرنيتس Kubernetes هما الأكثر شيوعًا. الأداة الرخصة Docker Apache 2.0 Kubernetes Apache 2.0 أدوات الأتمتة الوسيطة Middleware automation tools تركز منهجية عمل DevOps التي نفّذناه على إنشاء تطبيق ونشره بصورة تعاونية، ولكن هناك أمور أخرى عدّة يمكننا تنفيذها باستخدام أدوات DevOps، وأحدها هو الاستفادة من أدوات إدارة البنية التحتية باستخدام الشيفرة Infrastructure as Code واختصارًا IaC، والتي تُعرف أيضًا باسم أدوات الأتمتة الوسيطة. تساعد هذه الأدوات في أتمتة عمليات التثبيت والإدارة ومهام البرامج الوسيطة، حيث يمكن لأداة الأتمتة مثلًا أن تسحب الاعدادات المناسبة للتطبيقات، مثل خادم تطبيقات الويب وقواعد البيانات وأدوات المراقبة، ونشرها على خادم التطبيقات. وفيما يلي بعض أدوات الأتمتة الوسيطة مفتوحة المصدر: الأداة الرخصة SaltStack Apache 2.0 Chef Apache 2.0 Ansible GNU Public Puppet Apache أو GPL الخلاصة تعلّمنا في هذا المقال كيفية إنشاء منهجية عمل لإنتاج البرمجيات بأسلوب DevOps باستخدام أدوات مفتوحة المصدر، وتعرفنا على أشهر أدوات التكامل والنشر المستمر CI/CD مفتوحة المصدر وأدوات إدارة الشيفرة المصدرية واختبارها، ويمكنك من الآن بدء تجربة إنشاء منهجية DevOps لمشروعك البرمجي الحقيقي. ترجمة، وبتصرّف، للمقال A beginner's guide to building DevOps pipelines with open source tools لكاتبه Bryant Son. اقرأ أيضًا دليل المبتدئين في مجال DevOps وأهم ممارساته وأدواته المدخل الشامل لتعلم DevOps ما هي الغاية من DevOps؟ أفضل 5 لغات برمجة لـ DevOps -
 طرأت تطورات كثيرة منذ أن أصبح مصطلح DevOps شائعًا في عالم تقنية المعلومات. ونظرًا لكثرة المصادر المفتوحة في هذا المجال، فمن المفيد الاطلاع على نشأة هذا المصطلح وأهميته في المهن التقنية. سنلقي الضوء في مقالنا هذا على مفهوم تخصص DevOps وأهميته، ونستعرض أساليبه، وأطر عمله، وأدواته. ما هو تخصص DevOps لا يوجد تعريف واحد لمصطلح DevOps، لكن يمكن أن نعُدّه إطار عمل يضمن التعاون بين فرق التطوير Development المسؤولة عن كتابة الشيفرة البرمجية للتطبيق، وفرق العمليات Operations المسؤولة عن نشر الشيفرات والبرامج في بيئات الإنتاج بسرعة وبطريقة مؤتمتة Automated وقابلة للتكرار أي يمكن تشغيلها عدة مرات دون مشكلات. ومصطلح DevOps هو دمج لكلمتي تطوير Development وعمليات Operations. وهو تقنية مهمة جدًا تساعد على زيادة سرعة تسليم التطبيقات والخدمات، وتتيح للمؤسسات خدمة عملائها بكفاءة أعلى، وتزيد قدرتها على المنافسة في السوق. يركّز منهج DevOps على نشر ثقافة التوافق بين فرق التطوير وفرق تقنية المعلومات وتحسين التواصل والتعاون بينهما، ويولد تطبيق ممارسات DevOps في المؤسسة قيمة مستمرة للعملاء، ويعتمد على ثلاث ركائز أساسية هي الأشخاص People، والعمليات Processes، والأدوات Tools. فالأشخاص هم الذين يقومون بالعمل، والعمليات هي الطريقة التي ينجز بها العمل، أما الأدوات فهي البرامج التي تساعد على تنفيذ العمل بشكل أسرع وأسهل من خلال الأتمتة والتي سنوضحها بمزيد من التفصيل لاحقًا. يزيد تطبيق ممارسات DevOps من قدرة المؤسسات على تقديم حلول برمجية عالية الجودة بوتيرة سريعة، وذلك من خلال أتمتة جميع العمليات الخاصة بتطبيق أو منتج ما، بدءًا من إنشائه، وحتى نشره إلى المستخدمين. التحديات التي يواجهها فريق التطوير يكون المطورون متحمسين عادةً ومستعدين لتبني أساليب وتقنيات جديدة لحل المشكلات، لكنهم قد يواجهون التحديات التالية: يخلق السوق التنافسي ضغطًا كبيرًا على المطورين لتسليم المشروع في الوقت المحدد يجب على المطورين الالتزام بجعل الشيفرة البرمجية جاهزة ومناسبة لبيئات الإنتاج وتطبيق المميزات الجديدة يتعين على فريق التطوير وضع عدة توقعات قبل نشر التطبيق بسبب طول دورة إصدار التطبيقات، لذا يستغرق حل المشكلات التي تحدث أثناء النشر مزيدًا من الوقت في بيئات الإنتاج أو في مرحلة التهيئة الأخيرة قبل النشر Staging Environment. التحديات التي يواجهها فريق العمليات فريق العمليات هو المسؤول عن تشغيل التطبيقات بشكل مستقر وآمن على الخوادم أو الخدمات السحابية، وضمان أن تعمل التطبيقات كما ينبغي بعد نشرها للمستخدمين النهائيين، ويركّز هذا الفريق على استقرار وموثوقية الخدمات التقنية. ولذلك نجدهم يهتمون بإجراء تغييرات على الموارد أو التقنيات أو الأساليب المتبعة لتحقيق استقرار التطبيقات، وقد يواجهون التحديات التالية: إدارة التنافس على الموارد، وتوفير موارد كافية عند زيادة الطلب عليها التعامل مع عمليات إعادة تصميم البنية التحتية للتطبيق وإجراء التعديلات المطلوبة لتنفيذ التطبيق في بيئة الإنتاج تشخيص المشكلات التي قد تظهر في بيئة الإنتاج، وحلّها بصورة منفصلة بعد نشر التطبيق كيف تعالج منهجية DevOps تحديات فريقي التطوير والعمليات بدلًا من إطلاق ميزات كثيرة للتطبيق في وقت واحد، تحاول الشركات طرح عدد صغير من الميزات لعملائها من خلال سلسلة من تكرارات الإصدار Release Iterations، ولهذا الأمر عدة مزايا، مثل تحقيق جودة أعلى للبرامج، والحصول على تقييمات العملاء بصورة أسرع وهذا يضمن رضاهم. ولتحقيق هذه الأهداف يجب على الشركات تحقيق التالي: تقليل احتمالية فشل الإصدارات الجديدة بجعل كل تحديث أصغر وأسهل في الاختبار زيادة وتيرة النشر عن طريق إطلاق نسخ محدثة بوتيرة أسرع وبشكل منتظم تقصير وقت التعافي MTTR في حال حدوث خلل بعد نشر إصدار جديد، لتعود الخدمة لطبيعتها بسرعة تسريع وقت التسليم Lead Time، أي تقليل المدة بين اكتشاف المشكلة وإطلاق الإصلاح الخاص بها تحقق منهجية DevOps كل هذه الأهداف، وتساعدنا على تحقيق التسليم السلس للمشاريع والتطبيقات. لذا تتبنى المؤسسات منهجية DevOps لتحقق مستويات من الأداء لم تكن ممكنة قبل بضع سنوات إذ يمكنها من خلالها نشر عشرات أو مئات أو حتى آلاف من التحديثات يوميًا، إلى جانب توفير موثوقية واستقرار وأمان على مستوى عالٍ. يهتم نهج DevOps بمعالجة مجموعة متنوعة من المشكلات التي تنتج عن المنهجيات السابقة، بما في ذلك: مشكلة عمل فرق التطوير والتشغيل بصورة منفصلة عن بعضهم مشكلة إنجاز مرحلتي الاختبار والنشر كلّ على حدة بعد انتهاء مرحلتي التصميم والبناء، وذلك يتطلب وقتًا أطول من دورات البناء مشكلة قضاء أعضاء الفريق وقتًا طويلًا في الاختبار والنشر والتصميم بدلًا من التركيز على إنشاء خدمات للأعمال مشكلة حدوث أخطاء الإنتاج عند النشر اليدوي للكود مشكلة عمل فرق التطوير والعمليات وفق جداول زمنية منفصلة وغير متزامنة، مما يسبب تأخيرات إضافية في العمل مقارنة بين منهجية أجايل Agile و DevOps وتقنية Waterfall التقليدية تُقارَن DevOps مع المنهجيات الأخرى في مجال تقنية المعلومات، ولا سيّما منهجيّتي أجايل Agile والشلال Waterfall. تتكون أجايل Agile من مجموعة من المبادئ والقيم والأساليب المُتّبعة لإنتاج البرمجيات. فمثلًا، إن أردنا تحويل فكرة إلى برنامج، فيمكننا الاستفادة من مبادئ وقيم أجايل، لكن هذا البرنامج قد يعمل فقط في بيئة التطوير أو الاختبار، لذا سنحتاج إلى طريقة لنقل البرنامج بسرعة وتكرار إلى بيئة الإنتاج بطريقة بسيطة وآمنة، والطريقة هي استخدام أدوات وتقنيات DevOps؛ إذ تركّز منهجية أجايل لتطوير البرمجيات على عمليات التطوير، عكس منهجية DevOps المسؤولة عن التطوير والنشر بطريقة أكثر أمانًا وموثوقية. والآن لنقارن بين منهجية الشلال أو تدفق المياه Waterfall التقليدية ومنهجية DevOps لفهم الفوائد التي تقدمها DevOps. سنفترض أن لدينا السيناريو التالي: لدينا تطبيق سيُشغَّل بعد أربعة أسابيع، واكتملت عملية كتابة الشيفرة بنسبة 85%، وبدأت عملية شراء الخوادم التي ستُرفع الشيفرة البرمجية عليها. يوضّح الجدول التالي الفروقات بين تطبيق المنهجيتين في هذه الحالة: النهج التقليدي نهج DevOps يعمل فريق التطوير على الاختبار بعد تقديم طلب لشراء الخوادم الجديدة، ويعمل فريق العمليات على تجهيز الأعمال الورقية اللازم لنشر البنية التحتية بعد تقديم طلب شراء الخوادم، يعمل فريق التطوير والعمليات معًا على العمليات والأوراق اللازمة لإعداد الخوادم الجديدة. ويؤدي هذا إلى فهم أفضل لمتطلبات البنية التحتية لا تكون المعلومات المتعّلقة بتجاوز الفشل والتكرار ومواقع مراكز البيانات، ومتطلبات التخزين دقيقة بسبب عدم توفر مدخلات من فريق التطوير الذي لديه معرفة عميقة بالتطبيق المعلومات المتعّلقة بتجاوز الفشل والتكرار والتعافي من الكوارث ومواقع مراكز البيانات ومتطلبات التخزين معروفة وصحيحة بسبب مدخلات فريق التطوير لا يعلم فريق العمليات بالتقدم الذي أحرزه فريق التطوير، إذ يضع فريق العمليات خطة مراقبة بناءً على فهمهم يطّلع فريق العمليات على تقدم فريق التطوير، ويتعاون الفريقان في وضع خطة مراقبة تلبي احتياجات تقنية المعلومات والأعمال. ويستخدمون أدوات مراقبة أداء التطبيقيات APM Tools يؤدي اختبار التحميل Load Test قبل إتاحة التطبيق للعموم إلى تعطل التطبيق، مما يؤدي إلى تأخير إصداره يؤدي اختبار التحميل قبل إتاحة التطبيق إلى بطء التطبيق. يُصلَح فريق التطوير الاختناقات بسرعة، ويُصدَر التطبيق في الوقت المحدد دورة حياة المشاريع في DevOps سنستعرض فيما يلي بعض الممارسات الشائعة في منهجية DevOps. التخطيط المستمر Continuous Planning يعتمد التخطيط المستمر على مبادئ تطوير البرمجيات المرن lean للعمل بخطوات صغيرة، وذلك من خلال تحديد الموارد والنتائج اللازمة لاختبار قيم العمل أو رؤيته، والتكيف باستمرار، وقياس التقدم، والتعلم من احتياجات العملاء، وتعديل العمل بسرعة وفقًا للحاجة وتحديث خطة العمل. التطوير التعاوني Collaborative Development تتيح عملية التطوير التعاوني Collaborative Development إمكانية التعاون بين الفريق التجاري وفريق التطوير وفريق الاختبار المنتشرين في مناطق مختلفة لتقديم برامج ذات جودة عالية باستمرار، ويتضمن ذلك تطوير منصات متعددة، ودعم البرمجة متعددة اللغات، وإنشاء قصص المستخدمين، ووضع الأفكار، وإدارة دورة حياة المشروع. يشتمل التطوير التعاوني على عملية التكامل المستمر، مما يعزز دمج الشيفرة البرمجية Code Integration بتكرار، ويؤدي ذلك إلى تحديد مشكلات التكامل في وقت مبكر من دورة الحياة التطبيق حيث يكون إصلاحها أسهل، ويُخفّض جهد التكامل الإجمالي من خلال الآراء والتقييمات المستمرة، لأن المشروع يُظهر تقدمًا مستمرًا ومثبتًا. الاختبار المستمر Continuous Testing يؤدي الاختبار المستمر إلى تقليل تكلفة الاختبار ومساعد فرق التطوير على تحقيق التوازن بين سرعة الإنجاز والجودة، كما يزيل اختناقات الاختبار Testing Bottlenecks من خلال الخدمات الافتراضية ويبسط إنشاء بيئات اختبار افتراضية يمكن مشاركتها ونشرها وتحديثها بسهولة عند تغيير الأنظمة. تخفّض هذه الميزات تكلفة توفير بيئات الاختبار وصيانتها، وتقصّر المدة اللازمة لإتمام دورات الاختبار من خلال إتاحة اختبار التكامل في وقت مبكر من دورة حياة المشروع. الإصدار المستمر Continuous Release والنشر المستمر Continuous Deployment يوفر الإصدار والنشر المستمران خطوط إنتاج مستمرة تعمل على أتمتة العمليات الرئيسية، ويقللان من العمليات اليدوية وأوقات انتظار إتاحة الموارد وكمية العمل، وذلك من خلال تفعيل خاصيّة النشر بضغطة زر، مما يتيح زيادة عدد الإصدارات وتقليل الأخطاء. تلعب الأتمتة دورًا رئيسيًا في ضمان إصدار البرنامج بتكرار وموثوقية؛ إذ إن أحد الأهداف الرئيسية هو أتمتة العمليات اليدوية مثل عملية بناء التطبيقات والانحدار Regression والنشر وتوفير البنية التحتية. ويتطلب هذا إدارة إصدارات الشيفرة المصدرية، مثل استخدام البرامج النصية لأتمتة عمليات الاختبار والنشر، وأتمتة إعدادات التطبيقات والبنية التحتية، والمكتبات والحزم التي يعتمد عليها التطبيق؛ إذ تُعدّ القدرة على الاستعلام عن حالة جميع البيئات عاملًا مهمًا. المراقبة المستمرة Continuous Monitoring توفر المراقبة المستمرة إمكانية إعداد التقارير على مستوى المؤسسة، ويساعد ذلك فرق التطوير على الإطلاع على أداء التطبيقات ومدى توفرها في بيئة الإنتاج، قبل نشرها. تُعَدّ التقييمات والآراء Feedback التي توفرها المراقبة المستمرة في مراحل مبكّرة ذات أهمية كبيرة في خفض الأخطاء وتوجيه المشاريع في الاتجاه الصحيح. وغالبًا ما تتضمن هذه المرحلة أدوات المراقبة التي تكشف عن المقاييس المتعلقة بأداء التطبيق. المراجعة والتقييم والتحسين Optimization توفر التقييمات والآراء المستمرة Continuous Feedback من العملاء وسائل مساعدة لتحليل تجربتهم للتطبيق وتحديد النقاط التي يجب تحسينها. ويمكن إتاحتهما قبل الإنتاج وبعده لزيادة الاستفادة إلى أقصى حد وضمان إتمام مزيد من المعاملات بنجاح إذ يُتيح ذلك معرفة السبب الجذري للمشكلات التي يواجهها العملاء، والتي تؤثر على السلوك من جهة، وعلى العمل من جهة أخرى. فوائد تطبيق منهجية DevOps في بيئة العمل يؤمّن تطبيق منهجية DevOps بيئة عمل يتعاون فيها فريق التطوير وفريق إدارة البرمجيات ويعملان كفريق واحد لتحقيق أهداف مشتركة. ويتميز ذلك بتنفيذ التكامل المستمر والتسليم المستمر CI/CD، مما يتيح إصدار البرامج بسرعة وأخطاء أقل ويعود علينا بجملة من الفوائد تشمل: القدرة على التنبؤ بنتائج الإصدارات الجديدة: عند تطبيق ممارسات DevOps في بيئة العمل، سينخفض معدل فشل الإصدارات الجديدة للتطبيقات كثيرًا قابلية الصيانة: سنتمكن من استرداد التطبيق بسهولة في حالة عدم عمل الإصدار الجديد أو تعطل التطبيق إمكانية التكرار: فبفضل أدوات إدارة الإصدارات، سنتمكن من تتبع التغييرات بدقة والرجوع إلى إصدارات سابقة بسهولة عند الحاجة جودة أعلى للتطبيقات: تؤدي إدارة مشكلات البنية التحتية لتحسين جودة التطبيقات تقصير وقت إطلاق التطبيق: يؤدي تسليم البرامج المبسط إلى تقليل الوقت اللازم لتسليمه وتوفره في السوق بنسبة 50% تقليل المخاطر: وذلك عن طريق تعزيز الأمان في دورة حياة البرنامج، مما يؤدي إلى تقليل الأخطاء والعيوب التي قد تظهر فعالية التكلفة: تؤدي ممارسات DevOps لتخفيض تكلفة تطوير البرمجيات المرونة: يكون نظام البرمجيات أكثر استقرارًا وأمانًا، مع إمكانية تتبع التغييرات وتدقيقها بسهولة تقسيم قاعدة الشيفرات البرمجية الكبيرة لأجزاء أصغر: تتكامل ممارسات DevOps مع منهجيات أجايل، مما يساعد على تقسيم الكود لأجزاء صغيرة يسهل إدارتها واختبارها ونشرها مبادئ DevOps مبادئ DevOps كثيرة، وهي تتطور مع الوقت حسب احتياجات كل شركة. فبعض الشركات تضيف تغييرات خاصة بها، لكن في النهاية، تشكل هذه المبادئ طريقة عمل شاملة تساعد الفرق على التعاون بشكل أفضل، وتسليم البرامج بسرعة وجودة. ومن أهم هذه المبادئ نذكر: 1. التطوير والاختبار في بيئة شبيهة ببيئة الإنتاج الهدف من هذا المبدأ هو السماح لفرق التطوير وفرق ضمان الجودة Quality Assurance -أو اختصارًا QA- بتطوير البرمجيات واختبارها في بيئات قريبة من بيئات الإنتاج Production Systems، كي يعاينوا أداء التطبيقات قبل أن تصبح جاهزة للنشر. يجب أن يتعرض التطبيق لأنظمة شبيهة بالإنتاج في وقت مبكر قدر الإمكان من دورة حياته لمعالجة الأمور التالية: اختبار التطبيق في بيئة قريبة من البيئة الفعلية السماح باختبار عمليات تسليم التطبيق والتحقق من صحته مقدمًا تمكين فريق العمليات من اختبار أداء البيئة عند نشر التطبيق في مرحلة مبكرة من دورة حياته وتعديل البيئة بما يناسب التطبيق 2. النشر باستخدام عمليات موثوقة وقابلة للتكرار يسمح هذا المبدأ لفرق التطوير والعمليات بتنفيذ منهجية أجايل المرنة في تطوير البرمجيات طوال دورة حياة المشروع، إذ تُعدّ الأتمتة مهمةً لإنشاء عمليات متكررة وموثوقة ولذلك يجب على المؤسسات إنشاء خط تسليم Delivery Pipeline يتيح إمكانية النشر والاختبار المستمر والمؤتمت، مما يضمن أن كل تحديث جرى اختباره قبل أن نشره بشكل فعلي، وبالتالي تقليل مخاطر فشل النشر أثناء الإصدار الفعلي للتطبيق. 3. مراقبة الجودة التشغيلية Operational Quality تُجيد المؤسسات مراقبة أداء التطبيقات في بيئة الإنتاج لأن لديها أدوات لمراقبة المقاييس ومؤشرات الأداء الرئيسية KPIs في الوقت الفعلي. ويُطبَق هذا المبدأ في وقت مبكر من دورة حياة التطبيق، مما يضمن أن الاختبارات الآلية تراقب السمات الوظيفية وغير الوظيفية للتطبيق في وقت مبكر. يجب جمع مقاييس الجودة وتحليلها عند اختبار تطبيق ما ونشره، إذ يضمن ذلك كشف مشكلات التشغيل التي قد تحدث أثناء الإنتاج. ويجب جمع هذه المقاييس وصياغتها بطريقة يمكن لجميع المشاركين في المشروع ومالكي الأسهم فهمها. 4. جمع تقييمات وآراء موسعة حول التطبيق إن أحد أهداف عمليات DevOps هو تمكين المؤسسات من التفاعل وإجراء التغييرات بسرعة أكبر. يتطلب تحقيق هذا الهدف في مجال تسليم البرمجيات جمع تقييمات وآراء Feedback مبكرة، ومن ثم التعلم بسرعة من كل إجراء. يدعو هذا المبدأ المؤسسات إلى إنشاء قنوات اتصال تسمح لمالكي الأسهم وأصحاب المشروع بإجراء التقييمات والتصرف بناءً عليها، ومن ثم قد يعدل فريق التطوير خطط المشروع، أو قد يجري تعديلات على بيئات الإنتاج و يحسنها. قائمة بأهم أدوات DevOps من أهم أدوات DevOps مفتوحة المصدر في مجال تطوير البرمجيات وإدارة العمليات نذكر الآتي: أهم أدوات عملية التطوير Development مرحلة التخطيط: أداة Kanboard وWekan وأنا وGitLab وTuleap و Redmine وبدائل جيرا JIRA مثل Mattermost و Roit.im و IRC. مرحلة كتابة الشيفرة: غيت Git و Gerrit و Bugzilla و جينكينز Jenkins. مرحلة بناء التطبيق: Apache Maven و Gradle و Apache Ant و Packer مرحلة الاختبار: JUnit و Cucumbe و Selenium و Apache JMeter أهم أدوات عملية إدارة العمليات Operations مرحلة الإصدار والنشر والتشغيل: Kubernetes و Nomad و جينكينز Jenkins و Zuul و Spinnaker و Ansible و Apache ZooKeeper و etcd و Netflix Archaius و Terrafo مرحلة المراقبة: Prometheus و Nagios و InfluxDB و Fluentd وكما هو موضح، فقد دمجنا مرحلة التشغيل الأخيرة مع مرحلتي الإصدار والنشر بسبب تشابه أدواتها. الخاتمة بهذا نصل لختام مقالنا الذي وضحنا فيه منهجية DevOps التي تهدف لربط فريق تطوير التطبيقات وفريق العمليات في وحدة متماسكة، وهي منهجية ذات شعبية متزايدة تختلف عن الطرق القديمة والتقليدية المستخدمة في إدارة الأنظمة وتطوير البرمجيات حيث كانت الفرق تعمل بمعزل عن بعضها، وتشبه كما وضحنا منهجية أجايل في بعض النقاط ولكنها ليست مثلها تمامًا. ترجمة، وبتصرّف، للمقال A beginner's guide to everything DevOps لكاتبه Sameer S Paradkar. اقرأ أيضًا المدخل الشامل لتعلم DevOps كيفية تحقيق نهج DevSecOps بنجاح دليلك الشامل عن النشر المستمر Continuous Delivery دليل المبتدئين لمنهجية أجايل Agile ما هو إطار عمل تطوير البرمجيات المرن Lean Software Development
طرأت تطورات كثيرة منذ أن أصبح مصطلح DevOps شائعًا في عالم تقنية المعلومات. ونظرًا لكثرة المصادر المفتوحة في هذا المجال، فمن المفيد الاطلاع على نشأة هذا المصطلح وأهميته في المهن التقنية. سنلقي الضوء في مقالنا هذا على مفهوم تخصص DevOps وأهميته، ونستعرض أساليبه، وأطر عمله، وأدواته. ما هو تخصص DevOps لا يوجد تعريف واحد لمصطلح DevOps، لكن يمكن أن نعُدّه إطار عمل يضمن التعاون بين فرق التطوير Development المسؤولة عن كتابة الشيفرة البرمجية للتطبيق، وفرق العمليات Operations المسؤولة عن نشر الشيفرات والبرامج في بيئات الإنتاج بسرعة وبطريقة مؤتمتة Automated وقابلة للتكرار أي يمكن تشغيلها عدة مرات دون مشكلات. ومصطلح DevOps هو دمج لكلمتي تطوير Development وعمليات Operations. وهو تقنية مهمة جدًا تساعد على زيادة سرعة تسليم التطبيقات والخدمات، وتتيح للمؤسسات خدمة عملائها بكفاءة أعلى، وتزيد قدرتها على المنافسة في السوق. يركّز منهج DevOps على نشر ثقافة التوافق بين فرق التطوير وفرق تقنية المعلومات وتحسين التواصل والتعاون بينهما، ويولد تطبيق ممارسات DevOps في المؤسسة قيمة مستمرة للعملاء، ويعتمد على ثلاث ركائز أساسية هي الأشخاص People، والعمليات Processes، والأدوات Tools. فالأشخاص هم الذين يقومون بالعمل، والعمليات هي الطريقة التي ينجز بها العمل، أما الأدوات فهي البرامج التي تساعد على تنفيذ العمل بشكل أسرع وأسهل من خلال الأتمتة والتي سنوضحها بمزيد من التفصيل لاحقًا. يزيد تطبيق ممارسات DevOps من قدرة المؤسسات على تقديم حلول برمجية عالية الجودة بوتيرة سريعة، وذلك من خلال أتمتة جميع العمليات الخاصة بتطبيق أو منتج ما، بدءًا من إنشائه، وحتى نشره إلى المستخدمين. التحديات التي يواجهها فريق التطوير يكون المطورون متحمسين عادةً ومستعدين لتبني أساليب وتقنيات جديدة لحل المشكلات، لكنهم قد يواجهون التحديات التالية: يخلق السوق التنافسي ضغطًا كبيرًا على المطورين لتسليم المشروع في الوقت المحدد يجب على المطورين الالتزام بجعل الشيفرة البرمجية جاهزة ومناسبة لبيئات الإنتاج وتطبيق المميزات الجديدة يتعين على فريق التطوير وضع عدة توقعات قبل نشر التطبيق بسبب طول دورة إصدار التطبيقات، لذا يستغرق حل المشكلات التي تحدث أثناء النشر مزيدًا من الوقت في بيئات الإنتاج أو في مرحلة التهيئة الأخيرة قبل النشر Staging Environment. التحديات التي يواجهها فريق العمليات فريق العمليات هو المسؤول عن تشغيل التطبيقات بشكل مستقر وآمن على الخوادم أو الخدمات السحابية، وضمان أن تعمل التطبيقات كما ينبغي بعد نشرها للمستخدمين النهائيين، ويركّز هذا الفريق على استقرار وموثوقية الخدمات التقنية. ولذلك نجدهم يهتمون بإجراء تغييرات على الموارد أو التقنيات أو الأساليب المتبعة لتحقيق استقرار التطبيقات، وقد يواجهون التحديات التالية: إدارة التنافس على الموارد، وتوفير موارد كافية عند زيادة الطلب عليها التعامل مع عمليات إعادة تصميم البنية التحتية للتطبيق وإجراء التعديلات المطلوبة لتنفيذ التطبيق في بيئة الإنتاج تشخيص المشكلات التي قد تظهر في بيئة الإنتاج، وحلّها بصورة منفصلة بعد نشر التطبيق كيف تعالج منهجية DevOps تحديات فريقي التطوير والعمليات بدلًا من إطلاق ميزات كثيرة للتطبيق في وقت واحد، تحاول الشركات طرح عدد صغير من الميزات لعملائها من خلال سلسلة من تكرارات الإصدار Release Iterations، ولهذا الأمر عدة مزايا، مثل تحقيق جودة أعلى للبرامج، والحصول على تقييمات العملاء بصورة أسرع وهذا يضمن رضاهم. ولتحقيق هذه الأهداف يجب على الشركات تحقيق التالي: تقليل احتمالية فشل الإصدارات الجديدة بجعل كل تحديث أصغر وأسهل في الاختبار زيادة وتيرة النشر عن طريق إطلاق نسخ محدثة بوتيرة أسرع وبشكل منتظم تقصير وقت التعافي MTTR في حال حدوث خلل بعد نشر إصدار جديد، لتعود الخدمة لطبيعتها بسرعة تسريع وقت التسليم Lead Time، أي تقليل المدة بين اكتشاف المشكلة وإطلاق الإصلاح الخاص بها تحقق منهجية DevOps كل هذه الأهداف، وتساعدنا على تحقيق التسليم السلس للمشاريع والتطبيقات. لذا تتبنى المؤسسات منهجية DevOps لتحقق مستويات من الأداء لم تكن ممكنة قبل بضع سنوات إذ يمكنها من خلالها نشر عشرات أو مئات أو حتى آلاف من التحديثات يوميًا، إلى جانب توفير موثوقية واستقرار وأمان على مستوى عالٍ. يهتم نهج DevOps بمعالجة مجموعة متنوعة من المشكلات التي تنتج عن المنهجيات السابقة، بما في ذلك: مشكلة عمل فرق التطوير والتشغيل بصورة منفصلة عن بعضهم مشكلة إنجاز مرحلتي الاختبار والنشر كلّ على حدة بعد انتهاء مرحلتي التصميم والبناء، وذلك يتطلب وقتًا أطول من دورات البناء مشكلة قضاء أعضاء الفريق وقتًا طويلًا في الاختبار والنشر والتصميم بدلًا من التركيز على إنشاء خدمات للأعمال مشكلة حدوث أخطاء الإنتاج عند النشر اليدوي للكود مشكلة عمل فرق التطوير والعمليات وفق جداول زمنية منفصلة وغير متزامنة، مما يسبب تأخيرات إضافية في العمل مقارنة بين منهجية أجايل Agile و DevOps وتقنية Waterfall التقليدية تُقارَن DevOps مع المنهجيات الأخرى في مجال تقنية المعلومات، ولا سيّما منهجيّتي أجايل Agile والشلال Waterfall. تتكون أجايل Agile من مجموعة من المبادئ والقيم والأساليب المُتّبعة لإنتاج البرمجيات. فمثلًا، إن أردنا تحويل فكرة إلى برنامج، فيمكننا الاستفادة من مبادئ وقيم أجايل، لكن هذا البرنامج قد يعمل فقط في بيئة التطوير أو الاختبار، لذا سنحتاج إلى طريقة لنقل البرنامج بسرعة وتكرار إلى بيئة الإنتاج بطريقة بسيطة وآمنة، والطريقة هي استخدام أدوات وتقنيات DevOps؛ إذ تركّز منهجية أجايل لتطوير البرمجيات على عمليات التطوير، عكس منهجية DevOps المسؤولة عن التطوير والنشر بطريقة أكثر أمانًا وموثوقية. والآن لنقارن بين منهجية الشلال أو تدفق المياه Waterfall التقليدية ومنهجية DevOps لفهم الفوائد التي تقدمها DevOps. سنفترض أن لدينا السيناريو التالي: لدينا تطبيق سيُشغَّل بعد أربعة أسابيع، واكتملت عملية كتابة الشيفرة بنسبة 85%، وبدأت عملية شراء الخوادم التي ستُرفع الشيفرة البرمجية عليها. يوضّح الجدول التالي الفروقات بين تطبيق المنهجيتين في هذه الحالة: النهج التقليدي نهج DevOps يعمل فريق التطوير على الاختبار بعد تقديم طلب لشراء الخوادم الجديدة، ويعمل فريق العمليات على تجهيز الأعمال الورقية اللازم لنشر البنية التحتية بعد تقديم طلب شراء الخوادم، يعمل فريق التطوير والعمليات معًا على العمليات والأوراق اللازمة لإعداد الخوادم الجديدة. ويؤدي هذا إلى فهم أفضل لمتطلبات البنية التحتية لا تكون المعلومات المتعّلقة بتجاوز الفشل والتكرار ومواقع مراكز البيانات، ومتطلبات التخزين دقيقة بسبب عدم توفر مدخلات من فريق التطوير الذي لديه معرفة عميقة بالتطبيق المعلومات المتعّلقة بتجاوز الفشل والتكرار والتعافي من الكوارث ومواقع مراكز البيانات ومتطلبات التخزين معروفة وصحيحة بسبب مدخلات فريق التطوير لا يعلم فريق العمليات بالتقدم الذي أحرزه فريق التطوير، إذ يضع فريق العمليات خطة مراقبة بناءً على فهمهم يطّلع فريق العمليات على تقدم فريق التطوير، ويتعاون الفريقان في وضع خطة مراقبة تلبي احتياجات تقنية المعلومات والأعمال. ويستخدمون أدوات مراقبة أداء التطبيقيات APM Tools يؤدي اختبار التحميل Load Test قبل إتاحة التطبيق للعموم إلى تعطل التطبيق، مما يؤدي إلى تأخير إصداره يؤدي اختبار التحميل قبل إتاحة التطبيق إلى بطء التطبيق. يُصلَح فريق التطوير الاختناقات بسرعة، ويُصدَر التطبيق في الوقت المحدد دورة حياة المشاريع في DevOps سنستعرض فيما يلي بعض الممارسات الشائعة في منهجية DevOps. التخطيط المستمر Continuous Planning يعتمد التخطيط المستمر على مبادئ تطوير البرمجيات المرن lean للعمل بخطوات صغيرة، وذلك من خلال تحديد الموارد والنتائج اللازمة لاختبار قيم العمل أو رؤيته، والتكيف باستمرار، وقياس التقدم، والتعلم من احتياجات العملاء، وتعديل العمل بسرعة وفقًا للحاجة وتحديث خطة العمل. التطوير التعاوني Collaborative Development تتيح عملية التطوير التعاوني Collaborative Development إمكانية التعاون بين الفريق التجاري وفريق التطوير وفريق الاختبار المنتشرين في مناطق مختلفة لتقديم برامج ذات جودة عالية باستمرار، ويتضمن ذلك تطوير منصات متعددة، ودعم البرمجة متعددة اللغات، وإنشاء قصص المستخدمين، ووضع الأفكار، وإدارة دورة حياة المشروع. يشتمل التطوير التعاوني على عملية التكامل المستمر، مما يعزز دمج الشيفرة البرمجية Code Integration بتكرار، ويؤدي ذلك إلى تحديد مشكلات التكامل في وقت مبكر من دورة الحياة التطبيق حيث يكون إصلاحها أسهل، ويُخفّض جهد التكامل الإجمالي من خلال الآراء والتقييمات المستمرة، لأن المشروع يُظهر تقدمًا مستمرًا ومثبتًا. الاختبار المستمر Continuous Testing يؤدي الاختبار المستمر إلى تقليل تكلفة الاختبار ومساعد فرق التطوير على تحقيق التوازن بين سرعة الإنجاز والجودة، كما يزيل اختناقات الاختبار Testing Bottlenecks من خلال الخدمات الافتراضية ويبسط إنشاء بيئات اختبار افتراضية يمكن مشاركتها ونشرها وتحديثها بسهولة عند تغيير الأنظمة. تخفّض هذه الميزات تكلفة توفير بيئات الاختبار وصيانتها، وتقصّر المدة اللازمة لإتمام دورات الاختبار من خلال إتاحة اختبار التكامل في وقت مبكر من دورة حياة المشروع. الإصدار المستمر Continuous Release والنشر المستمر Continuous Deployment يوفر الإصدار والنشر المستمران خطوط إنتاج مستمرة تعمل على أتمتة العمليات الرئيسية، ويقللان من العمليات اليدوية وأوقات انتظار إتاحة الموارد وكمية العمل، وذلك من خلال تفعيل خاصيّة النشر بضغطة زر، مما يتيح زيادة عدد الإصدارات وتقليل الأخطاء. تلعب الأتمتة دورًا رئيسيًا في ضمان إصدار البرنامج بتكرار وموثوقية؛ إذ إن أحد الأهداف الرئيسية هو أتمتة العمليات اليدوية مثل عملية بناء التطبيقات والانحدار Regression والنشر وتوفير البنية التحتية. ويتطلب هذا إدارة إصدارات الشيفرة المصدرية، مثل استخدام البرامج النصية لأتمتة عمليات الاختبار والنشر، وأتمتة إعدادات التطبيقات والبنية التحتية، والمكتبات والحزم التي يعتمد عليها التطبيق؛ إذ تُعدّ القدرة على الاستعلام عن حالة جميع البيئات عاملًا مهمًا. المراقبة المستمرة Continuous Monitoring توفر المراقبة المستمرة إمكانية إعداد التقارير على مستوى المؤسسة، ويساعد ذلك فرق التطوير على الإطلاع على أداء التطبيقات ومدى توفرها في بيئة الإنتاج، قبل نشرها. تُعَدّ التقييمات والآراء Feedback التي توفرها المراقبة المستمرة في مراحل مبكّرة ذات أهمية كبيرة في خفض الأخطاء وتوجيه المشاريع في الاتجاه الصحيح. وغالبًا ما تتضمن هذه المرحلة أدوات المراقبة التي تكشف عن المقاييس المتعلقة بأداء التطبيق. المراجعة والتقييم والتحسين Optimization توفر التقييمات والآراء المستمرة Continuous Feedback من العملاء وسائل مساعدة لتحليل تجربتهم للتطبيق وتحديد النقاط التي يجب تحسينها. ويمكن إتاحتهما قبل الإنتاج وبعده لزيادة الاستفادة إلى أقصى حد وضمان إتمام مزيد من المعاملات بنجاح إذ يُتيح ذلك معرفة السبب الجذري للمشكلات التي يواجهها العملاء، والتي تؤثر على السلوك من جهة، وعلى العمل من جهة أخرى. فوائد تطبيق منهجية DevOps في بيئة العمل يؤمّن تطبيق منهجية DevOps بيئة عمل يتعاون فيها فريق التطوير وفريق إدارة البرمجيات ويعملان كفريق واحد لتحقيق أهداف مشتركة. ويتميز ذلك بتنفيذ التكامل المستمر والتسليم المستمر CI/CD، مما يتيح إصدار البرامج بسرعة وأخطاء أقل ويعود علينا بجملة من الفوائد تشمل: القدرة على التنبؤ بنتائج الإصدارات الجديدة: عند تطبيق ممارسات DevOps في بيئة العمل، سينخفض معدل فشل الإصدارات الجديدة للتطبيقات كثيرًا قابلية الصيانة: سنتمكن من استرداد التطبيق بسهولة في حالة عدم عمل الإصدار الجديد أو تعطل التطبيق إمكانية التكرار: فبفضل أدوات إدارة الإصدارات، سنتمكن من تتبع التغييرات بدقة والرجوع إلى إصدارات سابقة بسهولة عند الحاجة جودة أعلى للتطبيقات: تؤدي إدارة مشكلات البنية التحتية لتحسين جودة التطبيقات تقصير وقت إطلاق التطبيق: يؤدي تسليم البرامج المبسط إلى تقليل الوقت اللازم لتسليمه وتوفره في السوق بنسبة 50% تقليل المخاطر: وذلك عن طريق تعزيز الأمان في دورة حياة البرنامج، مما يؤدي إلى تقليل الأخطاء والعيوب التي قد تظهر فعالية التكلفة: تؤدي ممارسات DevOps لتخفيض تكلفة تطوير البرمجيات المرونة: يكون نظام البرمجيات أكثر استقرارًا وأمانًا، مع إمكانية تتبع التغييرات وتدقيقها بسهولة تقسيم قاعدة الشيفرات البرمجية الكبيرة لأجزاء أصغر: تتكامل ممارسات DevOps مع منهجيات أجايل، مما يساعد على تقسيم الكود لأجزاء صغيرة يسهل إدارتها واختبارها ونشرها مبادئ DevOps مبادئ DevOps كثيرة، وهي تتطور مع الوقت حسب احتياجات كل شركة. فبعض الشركات تضيف تغييرات خاصة بها، لكن في النهاية، تشكل هذه المبادئ طريقة عمل شاملة تساعد الفرق على التعاون بشكل أفضل، وتسليم البرامج بسرعة وجودة. ومن أهم هذه المبادئ نذكر: 1. التطوير والاختبار في بيئة شبيهة ببيئة الإنتاج الهدف من هذا المبدأ هو السماح لفرق التطوير وفرق ضمان الجودة Quality Assurance -أو اختصارًا QA- بتطوير البرمجيات واختبارها في بيئات قريبة من بيئات الإنتاج Production Systems، كي يعاينوا أداء التطبيقات قبل أن تصبح جاهزة للنشر. يجب أن يتعرض التطبيق لأنظمة شبيهة بالإنتاج في وقت مبكر قدر الإمكان من دورة حياته لمعالجة الأمور التالية: اختبار التطبيق في بيئة قريبة من البيئة الفعلية السماح باختبار عمليات تسليم التطبيق والتحقق من صحته مقدمًا تمكين فريق العمليات من اختبار أداء البيئة عند نشر التطبيق في مرحلة مبكرة من دورة حياته وتعديل البيئة بما يناسب التطبيق 2. النشر باستخدام عمليات موثوقة وقابلة للتكرار يسمح هذا المبدأ لفرق التطوير والعمليات بتنفيذ منهجية أجايل المرنة في تطوير البرمجيات طوال دورة حياة المشروع، إذ تُعدّ الأتمتة مهمةً لإنشاء عمليات متكررة وموثوقة ولذلك يجب على المؤسسات إنشاء خط تسليم Delivery Pipeline يتيح إمكانية النشر والاختبار المستمر والمؤتمت، مما يضمن أن كل تحديث جرى اختباره قبل أن نشره بشكل فعلي، وبالتالي تقليل مخاطر فشل النشر أثناء الإصدار الفعلي للتطبيق. 3. مراقبة الجودة التشغيلية Operational Quality تُجيد المؤسسات مراقبة أداء التطبيقات في بيئة الإنتاج لأن لديها أدوات لمراقبة المقاييس ومؤشرات الأداء الرئيسية KPIs في الوقت الفعلي. ويُطبَق هذا المبدأ في وقت مبكر من دورة حياة التطبيق، مما يضمن أن الاختبارات الآلية تراقب السمات الوظيفية وغير الوظيفية للتطبيق في وقت مبكر. يجب جمع مقاييس الجودة وتحليلها عند اختبار تطبيق ما ونشره، إذ يضمن ذلك كشف مشكلات التشغيل التي قد تحدث أثناء الإنتاج. ويجب جمع هذه المقاييس وصياغتها بطريقة يمكن لجميع المشاركين في المشروع ومالكي الأسهم فهمها. 4. جمع تقييمات وآراء موسعة حول التطبيق إن أحد أهداف عمليات DevOps هو تمكين المؤسسات من التفاعل وإجراء التغييرات بسرعة أكبر. يتطلب تحقيق هذا الهدف في مجال تسليم البرمجيات جمع تقييمات وآراء Feedback مبكرة، ومن ثم التعلم بسرعة من كل إجراء. يدعو هذا المبدأ المؤسسات إلى إنشاء قنوات اتصال تسمح لمالكي الأسهم وأصحاب المشروع بإجراء التقييمات والتصرف بناءً عليها، ومن ثم قد يعدل فريق التطوير خطط المشروع، أو قد يجري تعديلات على بيئات الإنتاج و يحسنها. قائمة بأهم أدوات DevOps من أهم أدوات DevOps مفتوحة المصدر في مجال تطوير البرمجيات وإدارة العمليات نذكر الآتي: أهم أدوات عملية التطوير Development مرحلة التخطيط: أداة Kanboard وWekan وأنا وGitLab وTuleap و Redmine وبدائل جيرا JIRA مثل Mattermost و Roit.im و IRC. مرحلة كتابة الشيفرة: غيت Git و Gerrit و Bugzilla و جينكينز Jenkins. مرحلة بناء التطبيق: Apache Maven و Gradle و Apache Ant و Packer مرحلة الاختبار: JUnit و Cucumbe و Selenium و Apache JMeter أهم أدوات عملية إدارة العمليات Operations مرحلة الإصدار والنشر والتشغيل: Kubernetes و Nomad و جينكينز Jenkins و Zuul و Spinnaker و Ansible و Apache ZooKeeper و etcd و Netflix Archaius و Terrafo مرحلة المراقبة: Prometheus و Nagios و InfluxDB و Fluentd وكما هو موضح، فقد دمجنا مرحلة التشغيل الأخيرة مع مرحلتي الإصدار والنشر بسبب تشابه أدواتها. الخاتمة بهذا نصل لختام مقالنا الذي وضحنا فيه منهجية DevOps التي تهدف لربط فريق تطوير التطبيقات وفريق العمليات في وحدة متماسكة، وهي منهجية ذات شعبية متزايدة تختلف عن الطرق القديمة والتقليدية المستخدمة في إدارة الأنظمة وتطوير البرمجيات حيث كانت الفرق تعمل بمعزل عن بعضها، وتشبه كما وضحنا منهجية أجايل في بعض النقاط ولكنها ليست مثلها تمامًا. ترجمة، وبتصرّف، للمقال A beginner's guide to everything DevOps لكاتبه Sameer S Paradkar. اقرأ أيضًا المدخل الشامل لتعلم DevOps كيفية تحقيق نهج DevSecOps بنجاح دليلك الشامل عن النشر المستمر Continuous Delivery دليل المبتدئين لمنهجية أجايل Agile ما هو إطار عمل تطوير البرمجيات المرن Lean Software Development -
 عند إعادة تشغيل الخادم سنحتاج لإعادة تشغيل حاويات دوكر Docker من أجل ضمان استمرار تشغيل الخدمات داخل هذه الحاويات وتجنب توقفها. في هذا المقال سنوضح ثلاثة طرق مختلفة لبدء تشغيل حاويات دوكر تلقائيًا بعد إعادة تشغيل النظام، حيث ستعتمد الطريقة الأولى والثانية على وجود خدمة دوكر على مستوى الجهاز أي أنها تتطلب وجود عملية dockerd تعمل في الخلفية وتدير الحاويات وإلا سنواجه أخطاء في تطبيقها. لنشرح الطرق الثلاثة بالتفصيل في الفقرات التالية: الطريقة الأولى: استخدام خيار --restart always هذه الطريقة هي الإعداد الافتراضي لتشغيل الحاوية، فعندما نشغل حاوية دوكر باستخدام الأمر docker run يمكننا تحديد الخيار restart always-- لنقرر تشغيل الحاوية تلقائيًا عند إعادة تشغيل الخادم، أو عند توقف الحاوية لأي سبب كان. يوضح المثال التالي تشغيل حاوية أباتشي مع تفعيل إعادة التشغيل التلقائي: docker run -p 8080:80 --name apache -v "${PWD}":/usr/local/apache2/htdocs -d --restart always httpd هنالك عدة احتمالات ممكنة للخيار restart-- نتحكم من خلالها في كيفية إعادة تشغيل الحاوية تلقائيًا تشمل التالي: restart no-- وهو الإعداد الافتراضي، ويعني عدم تشغيل الحاوية تلقائيًا عند توقف الحاوية لأي سبب كان restart always-- إعادة تشغيل الحاوية تلقائيًا بمجرد توقفها، وسيعاد تشغيل جميع الحاويات التي بدأ تشغيلها سابقًا باستخدام هذا الخيار تحذير: إذا كانت الحاوية تحتوي على خطأ برمجي تسبب في توقفها، فيتسبب هذا الخيار في محاولة إعادة تشغيلها بصورة مستمرة ومتكررة، إلا لو أوقفناها يدويًا باستخدام الأمر docker stop فعندها سيتوقف تشغيلها في نفس الجلسة، لكن ستعاد محاولة تشغيلها من جديد عند إعادة تشغيل الخادم restart unless-stopped-- يعمل هذا الخيار بشكل مشابه لخيار restart always-- الفرق هنا هو عدم إعادة تشغيل الحاوية التي أوقفناها يدويًا باستخدام docker stop restart on-failure-- إعادة تشغيل الحاوية تلقائيًا فقط في حالة توقفها بسبب خطأ ما يمكننا معرفة سلوك إعادة التشغيل حاوية باستخدام الأمر docker inspect: docker inspect <containername> ... "RestartPolicy": { "Name": "always", "MaximumRetryCount": 0 }, ... لتغيير سلوك إعادة تشغيل الحاوية أثناء تشغيلها بالفعل، يمكننا استخدام الأمر docker update، على سبيل المثال، إذا كنا نحتاج لتغيير أسلوب إعادة تشغيل حاوية معينة ونريد إعادة تشغيلها فقط في حالة حدوث خطأ في الحاوية سنكتب الأمر التالي: docker update --restart on-failure <containername> الطريقة الثانية: استخدام Docker Compose يمكننا أيضًا تحديد طريقة إعادة التشغيل التلقائي للحاوية من خلال ملف docker-compose.yml باستخدام الكلمة المفتاحية restart كما يلي: services: db: image: mariadb:latest restart: always هناك أربعة إعدادات مسموح بها هنا وهي: no وهو الخيار الافتراضي ويعني إعادة تشغيل الحاوية يدويًا فقط always لإعادة تشغيل الحاوية دائمًا unless-stopped لإعادة تشغيل الحاوية في كافة الأحوال، إلا في حال أوقفناها يدويًا on-failure لإعادة تشغيل الحاوية فقط في حال توقفت نتيجة لحدوث خطأ تتشابه دلالة الخيارات السابقة مع الخيارات المشروحة في الطريقة الأولى التي تستخدم الخيار restart-- مع الأمر docker run، لكن هنا سيكون المعامل restart: always ساري المفعول حتى نوقف الحاويات الموجودة في الملف docker-compose.yml ونحذفها يدويًا باستخدام الأمر docker-compose down. ملاحظة: ينبغي التأكد من تحديد الكلمة المفتاحية restart في المستوى الصحيح داخل إعدادات الحاوية المعنية وهي db في المثال. services: db: image: mariadb:latest volumes: - vol-db:/var/lib/mysql environment: MYSQL_USER: wpuser MYSQL_PASSWORD: password restart: always الطريقة الثالثة: إعادة تشغيل الحاوية باستخدام systemd الطريقة الأساسية لبدء تشغيل حاويات Docker هي عن باستخدام الأمر docker run والذي يسمح لنا بإنشاء حاوية من صورة دوكر Docker image وتشغيلها، لكن هناك مشكلة في هذه الطريقة ففي حال حدوث أي مشكلة تتسبب في توقف الخادم أو إعادة تشغيله فستتوقف الحاوية التي شغلناها عبر هذا الأمر ولن يعاد تشغيلها تلقائيًا، مما يؤدي إلى توقف الخدمة و التطبيق الذي توفره. يمكننا حل هذه المشكلة وضمان استمرار عمل الحاوية بتحويل الأمر docker run إلى خدمة نظام لضمان مواصلة عملها بعد إعادة تشغيل الخادم، فالحاوية في هذه الحالة ستكون جزءًا من خدمة وبالتالي يمكن تشغيلها تلقائيًا عند إقلاع الخادم، وإعادة تشغيلها تلقائيًا إذا توقفت لأي سبب كان. يمكن تحقيق ذلك باستخدام مدير الخدمات systemd، كما يمكننا استخدام supervisord أيضًا أو أي نظام مشابه آخر لإدارة الخدمات، ولكننا اخترنا systemd في مقالنا الحالي لكونه الأكثر استخدمًا وهو معتمد في معظم توزيعات لينكس. سنغلف حاوية دوكر في خدمة systemd، كي نتمكن من إدارة هذه الحاوية بنفس الطريقة التي ندير بها التطبيقات والخدمات الأخرى على جهازنا، وضمان الأمور التالية: إمكانية بدء الخدمة بشكل صحيح عند تشغيل الجهاز إمكانية إعادة تشغيل الحاوية تلقائيًا في حال توقفت لأي سبب كان باستخدام إعداد Restart=always في ملف خدمة systemd سهولة مراجعة وإدارة سجلات الحاوية stdout بواسطة نظام تسجيل السجلات Journald استخدام كامل نظام systemd لإدارة المتطلبات كالتبعيات والأوامر التي يجب أن تنفذ قبل وبعد تشغيل الحاوية وتعريف متغيرات البيئة التي تحتاجها الحاوية بكفاءة يعرض الكود التالي الحد الأدنى لمحتوى ملف خدمة systemd لتشغيل حاوية دوكر تحتوي على خادم nginx والموجود في المسار /etc/systemd/system/nginx.service: [Unit] Description=Docker container [Service] ExecStart=/usr/bin/docker run --name nginx \ --net host \ -v /srv/nginx/conf.d:/etc/nginx/conf.d \ -v /srv/nginx/index.html:/usr/share/nginx/html/index.html \ nginx ExecStop=/usr/bin/docker stop nginx ExecStopPost=/usr/bin/docker rm -f nginx [Install] WantedBy=multi-user.target يحدد هذا الملف الأمور التالية: تشغيل الحاوية التي تحتوي على خادم nginx تلقائيًا عند تشغيل النظام إيقاف الحاوية بشكل صحيح عند إيقاف الخدمة حذف الحاوية بعد إيقافها تشغيل الخدمة تلقائيًا عند تشغيل النظام ووصوله لمرحلة multi-user target لكن هذه الطريقة لها بعض السلبيات، ونحتاج لإجراء بعض التعديلات على ملف الخدمة لضمان عمله بشكل صحيح، فهنا بدأنا تشغيل حاوية Docker باسم nginx، وسحبنا أحدث صورة nginx من المستودع الرسمي مع تمرير مجلد الإعدادات على شكل volume داخل الحاوية،وفي حال لم يكن موجودًا ستنشئه حاوية دوكر على الخادم. سيعمل جزء WantedBy فقط عند تنفيذ الأمر systemctl enable nginx، وفي هذه الحالة ستفعَّل الخدمة عند بدء التشغيل لأنها ستكون مرتبطة بالوصول لمرحلة multi-user target في systemd، هذا يعني أنه عند تشغيل النظام، ستفعّل الخدمة تلقائيًا. الحل هو بإضافة الأسطر BindsTo و After في ملف الخدمة لضمان أن الخدمة تعتمد على دوكر. بمعنى آخر، إذا توقفت خدمة دوكر أو لم تكن تعمل بعد، فإن هذه الخدمة لن تبدأ بالعمل إلا بعد أن نضمن تشغيل دوكر بنجاح، وسيجري إيقافها أولًا إذا توقفت حاوية دوكر في أي وقت. أيضًا، في حالتنا nginx التي هي خدمة عديمة الحالة stateless أي أنها لا تحفظ حالتها بين عمليات التشغيل المختلفة، لذا سيكون من الأفضل تحديث صورة دوكر الخاصة بالخدمة لأحدث إصدار متاح كلما شغلنا هذه الخدمة لنضمن بأنها تعمل بأحدث نسخة من الحاوية، ولتحقيق سنضيف أمر ExecStartPre المسؤول عن تنفيذ docker pull كي يعمل قبل الأمر ExecStart. كما يمكننا فرض إعادة تشغيل الخدمة دائمًا في حال تعرضت لخطأ، وذلك كل 10 ثوانٍ مثلًا، من خلال الأسطر Restart و RestartSec والتي تشابه في تأثيرها الخيار restart=on-failure في أمر docker run الذي شرحناه في الطريقة الأولى. أخيرًا هناك مشكلة أخرى سنواجهها في حال استخدمنا systemd لإدارة الحاويات. فعند تشغيل خدمة حاوية دوكر عبر systemd، سنحتاج لتحديد سلوك إعادة التشغيل يدويًا عند إعادة تشغيل الخدمة أو توقفها لأن systemd يفترض بأننا نرغب في الاحتفاظ بالأسلوب المستخدم لإعادة التشغيل، حيث سيوقف الخدمة أولاً ثم يعيد تشغيلها مرة أخرى. لحل هذه المشكلة يمكن استخدام حل بسيط وهو استخدام الأمر ExecReload لإعادة تحميل عملية nginx داخل الحاوية فهذا يساعدنا عند الحاجة لتحديث إعدادات nginx أو إعادة تحميلها دون توقف الخدمة بالكامل، كما يمكننا استخدام حل بديل وهو إرسال إشارة باستخدام الأمر kill -s HUP، لنخبر nginx بأن يعيد تحميل إعداداته دون إيقافه بالكامل. أخيرًا، يمكننا تغيير الأسماء المستخدمة في ملف الخدمة باستخدام متغيرات البيئة في السطر Environment. وفي حال وجدنا أن المتغيرات أصبحت كثيرة أو كانت مشتركة بين عدة ملفات خدمة على نفس الخادم، فيمكن استخدام ملف منفصل للمتغيرات باستخدام الخيار EnvironmentFile. فيما يلي ملف الخدمة بعد إجراء التحسينات السابقة: [Unit] Description=Docker container BindsTo=docker.service After=docker.service [Service] Environment=NAME=%N Environment=IMG=nginx Restart=on-failure RestartSec=10 ExecStartPre=-/usr/bin/docker kill ${NAME} ExecStartPre=-/usr/bin/docker rm ${NAME} ExecStart=/usr/bin/docker run --name ${NAME} \ -p 80:80 \ -p 443:443 \ -v /srv/nginx/conf.d:/etc/nginx/conf.d \ -v /srv/nginx/html:/usr/share/nginx/html/ \ ${IMG} ExecStop=/usr/bin/docker stop ${NAME} ExecReload=/usr/bin/docker exec ${NAME} nginx -s reload [Install] WantedBy=multi-user.target ملاحظة: يجري استبدال N% تلقائيًا باسم ملف الخدمة، وعلينا أن لا ننسى تشغيل الأمر systemctl daemon-reload في كل مرة نغير فيها إعدادات ملف الخدمة. مراقبة سجلات الخدمة عند تشغيل الخدمات باستخدام systemd مثل خدمة nginx في المثال السابق، ستوجه السجلات التي تنتج عن الخدمة إلى سجلات النظام journald، وهذا يسهل علينا الوصول لها وتحليلها. على سبيل المثال، يمكننا الوصول إلى سجلات nginx ببساطة لمراقبتها وعرضها في الزمن الحقيقي من خلال الأمر التالي: journalctl -fu nginx لا يمنعنا هذا الأسلوب من الحصول على ملفات سجلات منفصلة، فقد نحتاج لذلك كما في حالة استخدام virtualhosts لإدارة عدة مواقع ويب على نفس الخادم باستخدام nginx، في هذه الحالة سيكون من الأنسب لنا مشاركة مجلد السجلات الخاص بالحاوية وهو بشكل افتراضي /var/log/nginx مع جهاز المضيف حتى لا نفقدها عند إعادة التشغيل. الخاتمة تعرفنا في هذا المقال على ثلاث طرق مختلفة لإعادة تشغيل حاويات دوكر تلقائيًا بعد إعادة تشغيل الخادم، يعتمد اختيار الطريقة المناسبة على البئية ومتطلبات العمل، ففي الحالات البسيطة وإعدادات الحاوية الواحدة قد تكون طريقة restart-- في أمر docker run أو طريقة Docker Compose كافية. لكن في البيئات المعقدة التي تتضمن عدة خدمات ستوفر لنا طريقة systemd تحكمًا أكبر بالحاوية. ترجمة -وبتصرف- للمقال Restart Docker Container Automatically After Reboot لكاتبه Umair Khurshid اقرأ أيضًا ثلاث نصائح لتسمية حاويات Docker استخدام الأمر docker exec في حاويات Docker أساسيات تنسيق الحاويات مدخل إلى الحاويات
عند إعادة تشغيل الخادم سنحتاج لإعادة تشغيل حاويات دوكر Docker من أجل ضمان استمرار تشغيل الخدمات داخل هذه الحاويات وتجنب توقفها. في هذا المقال سنوضح ثلاثة طرق مختلفة لبدء تشغيل حاويات دوكر تلقائيًا بعد إعادة تشغيل النظام، حيث ستعتمد الطريقة الأولى والثانية على وجود خدمة دوكر على مستوى الجهاز أي أنها تتطلب وجود عملية dockerd تعمل في الخلفية وتدير الحاويات وإلا سنواجه أخطاء في تطبيقها. لنشرح الطرق الثلاثة بالتفصيل في الفقرات التالية: الطريقة الأولى: استخدام خيار --restart always هذه الطريقة هي الإعداد الافتراضي لتشغيل الحاوية، فعندما نشغل حاوية دوكر باستخدام الأمر docker run يمكننا تحديد الخيار restart always-- لنقرر تشغيل الحاوية تلقائيًا عند إعادة تشغيل الخادم، أو عند توقف الحاوية لأي سبب كان. يوضح المثال التالي تشغيل حاوية أباتشي مع تفعيل إعادة التشغيل التلقائي: docker run -p 8080:80 --name apache -v "${PWD}":/usr/local/apache2/htdocs -d --restart always httpd هنالك عدة احتمالات ممكنة للخيار restart-- نتحكم من خلالها في كيفية إعادة تشغيل الحاوية تلقائيًا تشمل التالي: restart no-- وهو الإعداد الافتراضي، ويعني عدم تشغيل الحاوية تلقائيًا عند توقف الحاوية لأي سبب كان restart always-- إعادة تشغيل الحاوية تلقائيًا بمجرد توقفها، وسيعاد تشغيل جميع الحاويات التي بدأ تشغيلها سابقًا باستخدام هذا الخيار تحذير: إذا كانت الحاوية تحتوي على خطأ برمجي تسبب في توقفها، فيتسبب هذا الخيار في محاولة إعادة تشغيلها بصورة مستمرة ومتكررة، إلا لو أوقفناها يدويًا باستخدام الأمر docker stop فعندها سيتوقف تشغيلها في نفس الجلسة، لكن ستعاد محاولة تشغيلها من جديد عند إعادة تشغيل الخادم restart unless-stopped-- يعمل هذا الخيار بشكل مشابه لخيار restart always-- الفرق هنا هو عدم إعادة تشغيل الحاوية التي أوقفناها يدويًا باستخدام docker stop restart on-failure-- إعادة تشغيل الحاوية تلقائيًا فقط في حالة توقفها بسبب خطأ ما يمكننا معرفة سلوك إعادة التشغيل حاوية باستخدام الأمر docker inspect: docker inspect <containername> ... "RestartPolicy": { "Name": "always", "MaximumRetryCount": 0 }, ... لتغيير سلوك إعادة تشغيل الحاوية أثناء تشغيلها بالفعل، يمكننا استخدام الأمر docker update، على سبيل المثال، إذا كنا نحتاج لتغيير أسلوب إعادة تشغيل حاوية معينة ونريد إعادة تشغيلها فقط في حالة حدوث خطأ في الحاوية سنكتب الأمر التالي: docker update --restart on-failure <containername> الطريقة الثانية: استخدام Docker Compose يمكننا أيضًا تحديد طريقة إعادة التشغيل التلقائي للحاوية من خلال ملف docker-compose.yml باستخدام الكلمة المفتاحية restart كما يلي: services: db: image: mariadb:latest restart: always هناك أربعة إعدادات مسموح بها هنا وهي: no وهو الخيار الافتراضي ويعني إعادة تشغيل الحاوية يدويًا فقط always لإعادة تشغيل الحاوية دائمًا unless-stopped لإعادة تشغيل الحاوية في كافة الأحوال، إلا في حال أوقفناها يدويًا on-failure لإعادة تشغيل الحاوية فقط في حال توقفت نتيجة لحدوث خطأ تتشابه دلالة الخيارات السابقة مع الخيارات المشروحة في الطريقة الأولى التي تستخدم الخيار restart-- مع الأمر docker run، لكن هنا سيكون المعامل restart: always ساري المفعول حتى نوقف الحاويات الموجودة في الملف docker-compose.yml ونحذفها يدويًا باستخدام الأمر docker-compose down. ملاحظة: ينبغي التأكد من تحديد الكلمة المفتاحية restart في المستوى الصحيح داخل إعدادات الحاوية المعنية وهي db في المثال. services: db: image: mariadb:latest volumes: - vol-db:/var/lib/mysql environment: MYSQL_USER: wpuser MYSQL_PASSWORD: password restart: always الطريقة الثالثة: إعادة تشغيل الحاوية باستخدام systemd الطريقة الأساسية لبدء تشغيل حاويات Docker هي عن باستخدام الأمر docker run والذي يسمح لنا بإنشاء حاوية من صورة دوكر Docker image وتشغيلها، لكن هناك مشكلة في هذه الطريقة ففي حال حدوث أي مشكلة تتسبب في توقف الخادم أو إعادة تشغيله فستتوقف الحاوية التي شغلناها عبر هذا الأمر ولن يعاد تشغيلها تلقائيًا، مما يؤدي إلى توقف الخدمة و التطبيق الذي توفره. يمكننا حل هذه المشكلة وضمان استمرار عمل الحاوية بتحويل الأمر docker run إلى خدمة نظام لضمان مواصلة عملها بعد إعادة تشغيل الخادم، فالحاوية في هذه الحالة ستكون جزءًا من خدمة وبالتالي يمكن تشغيلها تلقائيًا عند إقلاع الخادم، وإعادة تشغيلها تلقائيًا إذا توقفت لأي سبب كان. يمكن تحقيق ذلك باستخدام مدير الخدمات systemd، كما يمكننا استخدام supervisord أيضًا أو أي نظام مشابه آخر لإدارة الخدمات، ولكننا اخترنا systemd في مقالنا الحالي لكونه الأكثر استخدمًا وهو معتمد في معظم توزيعات لينكس. سنغلف حاوية دوكر في خدمة systemd، كي نتمكن من إدارة هذه الحاوية بنفس الطريقة التي ندير بها التطبيقات والخدمات الأخرى على جهازنا، وضمان الأمور التالية: إمكانية بدء الخدمة بشكل صحيح عند تشغيل الجهاز إمكانية إعادة تشغيل الحاوية تلقائيًا في حال توقفت لأي سبب كان باستخدام إعداد Restart=always في ملف خدمة systemd سهولة مراجعة وإدارة سجلات الحاوية stdout بواسطة نظام تسجيل السجلات Journald استخدام كامل نظام systemd لإدارة المتطلبات كالتبعيات والأوامر التي يجب أن تنفذ قبل وبعد تشغيل الحاوية وتعريف متغيرات البيئة التي تحتاجها الحاوية بكفاءة يعرض الكود التالي الحد الأدنى لمحتوى ملف خدمة systemd لتشغيل حاوية دوكر تحتوي على خادم nginx والموجود في المسار /etc/systemd/system/nginx.service: [Unit] Description=Docker container [Service] ExecStart=/usr/bin/docker run --name nginx \ --net host \ -v /srv/nginx/conf.d:/etc/nginx/conf.d \ -v /srv/nginx/index.html:/usr/share/nginx/html/index.html \ nginx ExecStop=/usr/bin/docker stop nginx ExecStopPost=/usr/bin/docker rm -f nginx [Install] WantedBy=multi-user.target يحدد هذا الملف الأمور التالية: تشغيل الحاوية التي تحتوي على خادم nginx تلقائيًا عند تشغيل النظام إيقاف الحاوية بشكل صحيح عند إيقاف الخدمة حذف الحاوية بعد إيقافها تشغيل الخدمة تلقائيًا عند تشغيل النظام ووصوله لمرحلة multi-user target لكن هذه الطريقة لها بعض السلبيات، ونحتاج لإجراء بعض التعديلات على ملف الخدمة لضمان عمله بشكل صحيح، فهنا بدأنا تشغيل حاوية Docker باسم nginx، وسحبنا أحدث صورة nginx من المستودع الرسمي مع تمرير مجلد الإعدادات على شكل volume داخل الحاوية،وفي حال لم يكن موجودًا ستنشئه حاوية دوكر على الخادم. سيعمل جزء WantedBy فقط عند تنفيذ الأمر systemctl enable nginx، وفي هذه الحالة ستفعَّل الخدمة عند بدء التشغيل لأنها ستكون مرتبطة بالوصول لمرحلة multi-user target في systemd، هذا يعني أنه عند تشغيل النظام، ستفعّل الخدمة تلقائيًا. الحل هو بإضافة الأسطر BindsTo و After في ملف الخدمة لضمان أن الخدمة تعتمد على دوكر. بمعنى آخر، إذا توقفت خدمة دوكر أو لم تكن تعمل بعد، فإن هذه الخدمة لن تبدأ بالعمل إلا بعد أن نضمن تشغيل دوكر بنجاح، وسيجري إيقافها أولًا إذا توقفت حاوية دوكر في أي وقت. أيضًا، في حالتنا nginx التي هي خدمة عديمة الحالة stateless أي أنها لا تحفظ حالتها بين عمليات التشغيل المختلفة، لذا سيكون من الأفضل تحديث صورة دوكر الخاصة بالخدمة لأحدث إصدار متاح كلما شغلنا هذه الخدمة لنضمن بأنها تعمل بأحدث نسخة من الحاوية، ولتحقيق سنضيف أمر ExecStartPre المسؤول عن تنفيذ docker pull كي يعمل قبل الأمر ExecStart. كما يمكننا فرض إعادة تشغيل الخدمة دائمًا في حال تعرضت لخطأ، وذلك كل 10 ثوانٍ مثلًا، من خلال الأسطر Restart و RestartSec والتي تشابه في تأثيرها الخيار restart=on-failure في أمر docker run الذي شرحناه في الطريقة الأولى. أخيرًا هناك مشكلة أخرى سنواجهها في حال استخدمنا systemd لإدارة الحاويات. فعند تشغيل خدمة حاوية دوكر عبر systemd، سنحتاج لتحديد سلوك إعادة التشغيل يدويًا عند إعادة تشغيل الخدمة أو توقفها لأن systemd يفترض بأننا نرغب في الاحتفاظ بالأسلوب المستخدم لإعادة التشغيل، حيث سيوقف الخدمة أولاً ثم يعيد تشغيلها مرة أخرى. لحل هذه المشكلة يمكن استخدام حل بسيط وهو استخدام الأمر ExecReload لإعادة تحميل عملية nginx داخل الحاوية فهذا يساعدنا عند الحاجة لتحديث إعدادات nginx أو إعادة تحميلها دون توقف الخدمة بالكامل، كما يمكننا استخدام حل بديل وهو إرسال إشارة باستخدام الأمر kill -s HUP، لنخبر nginx بأن يعيد تحميل إعداداته دون إيقافه بالكامل. أخيرًا، يمكننا تغيير الأسماء المستخدمة في ملف الخدمة باستخدام متغيرات البيئة في السطر Environment. وفي حال وجدنا أن المتغيرات أصبحت كثيرة أو كانت مشتركة بين عدة ملفات خدمة على نفس الخادم، فيمكن استخدام ملف منفصل للمتغيرات باستخدام الخيار EnvironmentFile. فيما يلي ملف الخدمة بعد إجراء التحسينات السابقة: [Unit] Description=Docker container BindsTo=docker.service After=docker.service [Service] Environment=NAME=%N Environment=IMG=nginx Restart=on-failure RestartSec=10 ExecStartPre=-/usr/bin/docker kill ${NAME} ExecStartPre=-/usr/bin/docker rm ${NAME} ExecStart=/usr/bin/docker run --name ${NAME} \ -p 80:80 \ -p 443:443 \ -v /srv/nginx/conf.d:/etc/nginx/conf.d \ -v /srv/nginx/html:/usr/share/nginx/html/ \ ${IMG} ExecStop=/usr/bin/docker stop ${NAME} ExecReload=/usr/bin/docker exec ${NAME} nginx -s reload [Install] WantedBy=multi-user.target ملاحظة: يجري استبدال N% تلقائيًا باسم ملف الخدمة، وعلينا أن لا ننسى تشغيل الأمر systemctl daemon-reload في كل مرة نغير فيها إعدادات ملف الخدمة. مراقبة سجلات الخدمة عند تشغيل الخدمات باستخدام systemd مثل خدمة nginx في المثال السابق، ستوجه السجلات التي تنتج عن الخدمة إلى سجلات النظام journald، وهذا يسهل علينا الوصول لها وتحليلها. على سبيل المثال، يمكننا الوصول إلى سجلات nginx ببساطة لمراقبتها وعرضها في الزمن الحقيقي من خلال الأمر التالي: journalctl -fu nginx لا يمنعنا هذا الأسلوب من الحصول على ملفات سجلات منفصلة، فقد نحتاج لذلك كما في حالة استخدام virtualhosts لإدارة عدة مواقع ويب على نفس الخادم باستخدام nginx، في هذه الحالة سيكون من الأنسب لنا مشاركة مجلد السجلات الخاص بالحاوية وهو بشكل افتراضي /var/log/nginx مع جهاز المضيف حتى لا نفقدها عند إعادة التشغيل. الخاتمة تعرفنا في هذا المقال على ثلاث طرق مختلفة لإعادة تشغيل حاويات دوكر تلقائيًا بعد إعادة تشغيل الخادم، يعتمد اختيار الطريقة المناسبة على البئية ومتطلبات العمل، ففي الحالات البسيطة وإعدادات الحاوية الواحدة قد تكون طريقة restart-- في أمر docker run أو طريقة Docker Compose كافية. لكن في البيئات المعقدة التي تتضمن عدة خدمات ستوفر لنا طريقة systemd تحكمًا أكبر بالحاوية. ترجمة -وبتصرف- للمقال Restart Docker Container Automatically After Reboot لكاتبه Umair Khurshid اقرأ أيضًا ثلاث نصائح لتسمية حاويات Docker استخدام الأمر docker exec في حاويات Docker أساسيات تنسيق الحاويات مدخل إلى الحاويات -

 نشرح في هذا المقال إنشاء تطبيق مكتوب بلغة بايثون Python على كوبرنتس Kubernetes باستخدام منصة أوكتيتو Okteto التي تسهل عملية تطوير تطبيقات كوبرنتس Kubernetes، فهي تسمح للمطورين ببناء التطبيقات واختبارها مباشرة في عناقيد كوبرنتس Kubernetes clusters دون الحاجة لإعداد بيئات تطوير معقدة، كما توّفر منصة Okteto ميزة التحديثات المباشرة live updates للتطبيقات التي تعمل في عناقيد كوبرنتس مما يسمح للمطورين رؤية التعديلات على الشيفرة في الوقت الفعلي دون الحاجة إلى إعادة بناء التطبيقات أو إعادة نشرها. المتطلبات الأساسية لمتابعة خطوات هذا المقال، سنحتاج إلى ما يلي: عنقود كوبرنتس النسخة 1.28، وسنستخدم في مقالنا عنقود من منصة DigitalOcean، يحتوي على 3 عقد على الأقل تثبيت واجهة سطر الأوامر kubectl وضبطها للتواصل مع عنقود كوبرنتس حساب على مستودع دوكر هب تثبيت دوكر Docker على جهازنا المحلي مفتاح ترخيص لاستخدام منصة Okteto، ويمكن التسجيل في الإصدار التجريبي المجاني. تثبيت مدير الحزم Helm لتطوير التطبيقات ضمن عناقيد Kubernetes، باتباع الخطوة الأولى من المقال التالي. نطاق Domain مسجَّل ومربوط مع Load Balancer لإدارة حركة مرور التطبيقات، وإنشاء سجل A record باسم * وعنوان IP موازن الحِمل. إنشاء تطبيق بايثون علينا التأكد أولًا بأن بايثون مثبّت على جهاز يعمل بنظام التشغيل أوبنتو بكتابة الأمر التالي في الطرفية: python3 --version إذا كانت حزم بايثون مثبّتة على الجهاز فسيعرضالأمر السابق نسختها، وإلّا نستخدم الأمر التالي لتثبيتها: sudo apt install python3 python3-venv python3-pip -y بعدها، ننشئ مجلد لتخزين شيفرة البرنامج وإعداداته: mkdir my-app ثم ننشئ بيئة افتراضية داخل مجلد التطبيق لوضع اعتماديات المشروع فيها: cd my-app python3 -m venv python-env والآن نفعّل البيئة الافتراضية باستخدام الأمر التالي: source python-env/bin/activate ثم ننشئ ملف بايثون لكتابة شيفرة التطبيق فيه: nano app.py ونضيف له الشيفرة التالية: from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return "Hello, This is a simple Python App!" if __name__ == '__main__': app.run(debug=True, host='0.0.0.0') ثم نثبّت إطار عمل فلاسك Flask: pip install flask نشغّل التطبيق الآن باستخدام الأمر التالي: python3 app.py سنحصل على هذا الخرج: Output * Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:5000 * Running on http://172.20.10.2:5000 Press CTRL+C to quit * Restarting with stat * Debugger is active! * Debugger PIN: 311-959-468 أصبح إطار فلاسك Flask يعمل على جهازنا المحلي، نتأكّد من ذلك باستخدام الأمر curl: curl -X GET -H "Content-Type: application/json" http://localhost:5000 سنحصل على الرد التالي من تطبيق فلاسك: Output Hello, This is a simple Python App! يدل هذا الخرج على أن تطبيق فلاسك قد نُفّذ بنجاح دون أخطاء. يمكن إيقاف تفعيل البيئة الافتراضية عند الانتهاء من العمل على مشروعنا، باستخدام الأمر التالي: deactivate وبهذا تكون أنشأنا تطبيقنا واختبرنا عمله محليًا، وحان وقت الخطوة الثانية لتشغيل هذا التطبيق داخل دوكر Docker. تشغيل تطبيق بايثون داخل دوكر Docker يتطلب تشغيل تطبيق بايثون داخل حاوية دوكر إنشاء صورة دوكر Docker image تحتوي على بيئة بايثون والاعتماديات اللازمة لتشغيل التطبيق. ننشئ أولًا ملفًا باسم Dockerfile في المجلد الأساسي للتطبيق: nano Dockerfile ثم نضيف عليه التعليمات التالية: # Use an official Python runtime as a parent image FROM python:3.8-slim # Set the working directory in the container WORKDIR /app # Copy the current directory contents into the container at /app ADD . /app # Install any needed dependencies specified in requirements.txt RUN pip install flask # Make port 5000 available to the world outside this container EXPOSE 5000 # Define environment variable ENV NAME DockerizedPythonApp # Run app.py when the container launches CMD ["python3", "./app.py"] فيما يلي شرح تعليمات ملف دوكر السابقة: تحدد التعليمة FROM python:3.8-slim الصورة الأساسية التي نحتاجها تضبط WORKDIR /app المجلد /app مجلدًا للعمل داخل الحاوية container تنسخ التعليمة ADD . /app محتوى المجلد الحالي لمجلد حاوية التطبيق /app تثبّت RUN pip install flask إطار العمل فلاسك Flask تستمع التعليمة EXPOSE 5000 على المنفذ 5000 للسماح بالاتصال يحدد CMD ["python3", "app.py"] الأمر الذي سينفذ عند تشغيل الحاوية وهو هنا الأمر app.py بعدها سنشغّل الأمر التالي لبناء صورة دوكر وفقًا للتعليمات السابقة: docker build -t my-app . نستطيع تشغيل التطبيق الآن في الحاوية باستخدام الصورة التي أنشأناها: docker run -dit -p 5000:5000 my-app:latest يُشَغّل الأمر السابق حاوية من الصورة my-app ويضبط منفذ الحاوية على المنفذ المضيف 5000. نكتب الأمر التالي للتأكد من عمل الحاوية: docker ps وسنحصل على الخرج التالي: Output CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 761c54c77411 my-app:latest "python3 ./app.py" 3 seconds ago Up 3 seconds 0.0.0.0:5000->5000/tcp, :::5000->5000/tcp pedantic_wescoff نفتح متصفح الويب أو نستعمل موجّه الأوامر curl للوصول إلى التطبيق باستخدام العنوان http://your-server-ip:5000/، وستظهر رسالة Hello, This is a simple Python App! التي تشير لأن التطبيق يعمل داخل حاوية دوكر. وبهذا نكون شغّلنا تطبيق بايثون في حاوية دوكر بنجاح. رفع صورة تطبيق بايثون إلى سجل DockerHub لتنفيذ هذه الخطوة يجب أن يكون لدينا حساب على موقع دوكر هب DockerHub، بعدها نستخدم الأمر docker login لتسجيل الدخول، وسيُطلب منا إدخال اسم المستخدم وكلمة المرور. docker login سنحصل على الخرج التالي: Output Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one. Username: username@gmail.com Password: WARNING! Your password will be stored unencrypted in /root/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded يجب وسم الصورة باسم حسابنا ومجلد الاعتمادية المطلوب قبل رفعها push لمستودع دوكر هب: docker tag my-app yourusername/my-app:latest يمكن الآن رفع الصورة إلى دوكر هب باستخدام الأمر docker push: docker push yourusername/my-app:latest نتأكّد بعدها أن الصورة أصبحت موجودة بالبحث عنها باستخدام طرفية دوكر هب Docker Hub CLI: docker search yourusername/my-app وهكذا أصبحت صورة تطبيقنا مرفوعةً على منصة دوكر هب ويمكن للآخرين سحبها أو نشرها في عدّة بيئات. إنشاء ملف Kubernetes Manifests لنشر التطبيق علينا الآن إنشاء ملف Kubernetes Manifests باستخدام منصة Okteto لضبط عملية التطوير والخدمات وموارد Ingressللتطبيق. نكتب الأمر التالي لإنشاء الملف: nano k8s.yaml ثم نضيف الإعدادات التالية إليه: apiVersion: apps/v1 kind: Deployment metadata: name: my-app spec: selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: containers: - image: yourusername/my-app name: my-app --- apiVersion: v1 kind: Service metadata: name: my-app spec: type: ClusterIP ports: - name: "my-app" port: 5000 selector: app: my-app --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: my-app annotations: dev.okteto.com/generate-host: my-app spec: rules: - http: paths: - backend: service: name: my-app port: number: 5000 path: / pathType: ImplementationSpecific سينشر الملف السابق تطبيقنا بالاسم my-app باستخدام منصة Okteto، وسينشره داخليًا عبر خدمة ClusterIP على المنفذ 5000، ثم سيُعدّ مورد Ingress لتوجيه حركة مرور HTTP إلى التطبيق. وهنا استخدمنا التعليقات التوضيحية الخاصة بـمنصة Okteto لتفعيل بعض الميزات التي تقدمها مثل إنشاء اسم المضيف hostname تلقائيًا. تثبيت Okteto باستخدام مدير الحزم Helm لتثبيت Okteto باستخدام مدير الحزم Helm علينا أولًا إضافة مستودع Okteto Helm إلى عميل Helm: helm repo add okteto https://charts.okteto.com وبعد ذلك علينا تحديث مستودعات مدير الحزم Helm لنضمن أن لدينا معلومات حديثة عن المخططات أو الحزم التي تحتوي على تعريفات موارد Kubernetes اللازمة لتشغيل التطبيق: helm repo update ثم ننشئ ملف config.yaml: nano config.yaml ونضيف بعدها مفتاح رخصة استخدام Okteto الخاص بنا، والنطاق الفرعي والإعدادات، كما هو موضح أدناه: license: INSERTYOURKEYHERE subdomain: okteto.example.com buildkit: persistence: enabled: true registry: storage: filesystem: persistence: enabled: true ثم نثبّت أحدث نسخة من Okteto باستخدام ملف الإعدادات config.yaml: helm install okteto okteto/okteto -f config.yaml --namespace okteto --create-namespace سنحصل على الخرج التالي عند انتهاء التثبيت: Output NAME: okteto LAST DEPLOYED: Tue Mar 12 20:27:21 2024 NAMESPACE: okteto STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Congratulations! Okteto is successfully installed! Follow these steps to complete your domain configuration: 1. Create a wildcard A record "*.okteto.example.com", pointing it to the Okteto NGINX ingress controller External-IP: $ kubectl get service -l=app.kubernetes.io/name=ingress-nginx,app.kubernetes.io/component=controller --namespace=okteto 2. Access your Okteto instance at `https://okteto.okteto.example.com/login#token=88f8cc11` ملاحظة: علينا الاحتفاظ برمز الوصول الشخصي Personal Access Tokens ذو القيمة 88f8cc11 من الشيفرة أعلاه لأننا سنحتاجه لتوثيق حسابنا في Okteto. ننتظر قليلًا ثم نجلب عنوان IP لخادم NGINX Ingress: kubectl get service -l=app.kubernetes.io/name=ingress-nginx,app.kubernetes.io/component=controller --namespace=okteto سنحصل على الخرج التالي: Output NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE okteto-ingress-nginx-controller LoadBalancer 10.101.31.239 45.76.14.191 80:31150/TCP,443:31793/TCP 3m21s علينا إضافة العنوان الخارجي EXTERNAL-IP إلى سجل A تحت الاسم * في إعدادات بروتوكول DNS. والآن، نفتح المتصفح للوصول إلى Okteto باستخدام الرابط التالي: https://okteto.okteto.example.com/login#token=88f8cc11. تثبيت وضبط إعدادات واجهة أوامر Okteto تُتيح لنا واجهة أوامر Okteto مفتوحة المصدر تطوير التطبيقات مباشرة على Kubernetes. بإمكاننا تثبيت واجهة الأوامر على نظامي لينوكس Linux وماك MacOS باستخدام الأمر curl التالي: sudo curl https://get.okteto.com -sSfL | sh نتأكد من تثبيت واجهة أوامر Okteto باستخدام الأمر التالي الذي سيعرض تانسخة المثبّتة على جهازنا Output okteto version 2.25.2 والآن علينا استخدام رمز الوصول الشخصي Personal Access Tokens للمصادقة: okteto context use https://okteto.okteto.example.com --token 88f8cc11 --insecure-skip-tls-verify وسنحصل على الخرج التالي: Output ✓ Using okteto-admin @ okteto.okteto.example.com نشغّل الأمر التالي للتأكد من إعدادات واجهة الأوامر: okteto context list وسنحصل على الخرج التالي: Output Name Namespace Builder Registry https://okteto.okteto.example.com * okteto-admin tcp://buildkit.okteto.example.com:443 registry.okteto.example.com vke-4b7aaaa6-78fa-4a19-9fb3-cf7b8c1ec678 default docker - إنشاء Okteto Manifest علينا إنشاء ملف Okteto Manifest وضبط إعدادات بيئة التطوير لنتمكن من إنشاء تطبيقات بلغة بايثون. أولًا، ننشئ ملف okteto.yaml مخصص لتطبيق بايثون بسيط. nano okteto.yaml ثم نضيف الإعدادات التالية: deploy: - kubectl apply -f k8s.yaml dev: my-app: command: bash environment: - FLASK_ENV=development sync: - .:/app reverse: - 9000:9000 volumes: - /root/.cache/pip فيما يلي شرح الأوامر السابقة: يتضمن القسم deploy إعدادات النشر. وعند تشغيل الأمر okteto up أو okteto deploy يُنَفَّذ الأمر kubectl apply -f k8s.yaml الذي ينشر موارد Kubernetes الموجودة في الملف k8s.yaml، ويُتيح ذلك فصل إعدادات النشر عن إعدادات التطوير. يُحدد command: bash الأمر الذي يجب تشغيله عند بدء تشغيل بيئة التطوير ويحدد environment متغيرات البيئة التي يجب أن تكون في بيئة التطوير. وهنا صرّحنا أن متغيرات فلاسك FLASK_ENV يجب أن تكون في بيئة التطوير FLASK_ENV=development. يحدد القسم sync القسم الملفات التي يجب مزامنتها من جهازنا المحلي مع ملفات بيئة التطوير، إذ يجب مزامنة المجلد (.) مع المجلد /app من بيئة التطوير. ويوّضح reverse قواعد توجيه المنافذ بين بيئة التطوير وجهازك المحلي. وفي مثالنا، يوجّه المنفذ 9000 من بيئة التطوير إلى المنفذ 9000 على جهازنا المحلي. أخيرًا يوّضح v وحدات التخزين الإضافية التي ستُضاف إلى بيئة التطوير. وهنا سنضيف المجلد /root/.cache/pip، لنستخدمه لتخزين حزم pip في بيئة التطوير مؤقتًا. الآن علينا نشر تطبيق بايثون إلى عنقود كوبرنيتس باستخدام الأمر التالي: okteto deploy وسنحصل على الخرج التالي عند نجاح عملية النشر: Output deployment.apps/my-app created service/my-app created ingress.networking.k8s.io/my-app created i There are no available endpoints for 'Okteto'. Follow this link to know more about how to create public endpoints for your application: https://www.okteto.com/docs/cloud/ssl/ ✓ Development environment 'Okteto' successfully deployed i Run 'okteto up' to activate your development container ثم نحدّث لوحة تحكم Okteto من المتصفح لتعاين التطبيق بعد نشره: كما يمكننا الوصول إلى التطبيق من الرابط التالي: https://my-app-okteto-admin.okteto.example.com. تطوير تطبيق بايثون في منصة كوبرنتس مباشرة سنستخدم الأمر okteto up لنشر التطبيق مباشرةً على كوبرنتس، إذ يزامن هذا الأمر الشيفرة المحلية مع بيئة التطوير. وبإمكاننا تعديل الشيفرة باستخدام أي بيئة تطوير أو محرر أكواد على جهازنا، وستجري مزامنة التغييرات تلقائيًا مع بيئة التطوير في كوبرنيتس. علينا أولًا تشغيل بيئة التطوير باستخدام Okteto: okteto up يُنشئ هذا الأمر بيئة تطوير وفقًا للإعدادات الموجودة في ملف okteto.yaml: Output i Using okteto-admin @ okteto.okteto.example.com as context i 'Okteto' was already deployed. To redeploy run 'okteto deploy' or 'okteto up --deploy' i Build section is not defined in your okteto manifest ✓ Persistent volume successfully attached ✓ Images successfully pulled ✓ Files synchronized Context: okteto.okteto.example.com Namespace: okteto-admin Name: my-app Reverse: 9000 <- 9000 root@my-app-okteto-7767588c8d-ndzj7:/app# نشغّل بعدها تطبيق بايثون: python3 app.py وسنحصل على الخرج التالي: * Serving Flask app 'app' * Debug mode: on WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:5000 * Running on http://10.244.97.92:5000 Press CTRL+C to quit * Restarting with stat * Debugger is active! * Debugger PIN: 126-620-675 ثم نعدّل ملف التطبيق app.py: nano app.py وعدّل السطر التالي: return "Hello, This is a simple Python App Deployed on Kubernetes" نحفظ الملف ثم نغلقه، وستٌطبَق التعديلات على الشيفرة البرمجية تلقائيًا في كوبرنتس. ثم نعيد تحميل صفحة التطبيق من متصفح الويب لتعاين التطبيق بعد التعديل. الخاتمة تعلمنا في هذا المقال كيفية إنشاء تطبيق بايثون بسيط وكيفية نشرته ضمن عناقيد كوبرنتس باستخدام منصة Okteto التي تتيح خاصية مزامنة التعديلات على الشيفرة المحلية مع بيئة التطوير، كما تسمح لنا بالتركيز على بناء تطبيقات بايثون عالية الجودة دون القلق حيال بنية كوبرنتس المعقّدة. ترجمة -وبتصرّف- للمقال How to Deploy Python Application on Kubernetes with Okteto لكاتبيه hitjethva وEasha Abid. اقرأ أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون نشر تطبيق جانغو آمن وقابل للتوسيع باستخدام كوبيرنتس Kubernetes تثبيت بايثون 3 وإعداد بيئتها البرمجية تعرّف على كوبرنيتس Kubernetes
نشرح في هذا المقال إنشاء تطبيق مكتوب بلغة بايثون Python على كوبرنتس Kubernetes باستخدام منصة أوكتيتو Okteto التي تسهل عملية تطوير تطبيقات كوبرنتس Kubernetes، فهي تسمح للمطورين ببناء التطبيقات واختبارها مباشرة في عناقيد كوبرنتس Kubernetes clusters دون الحاجة لإعداد بيئات تطوير معقدة، كما توّفر منصة Okteto ميزة التحديثات المباشرة live updates للتطبيقات التي تعمل في عناقيد كوبرنتس مما يسمح للمطورين رؤية التعديلات على الشيفرة في الوقت الفعلي دون الحاجة إلى إعادة بناء التطبيقات أو إعادة نشرها. المتطلبات الأساسية لمتابعة خطوات هذا المقال، سنحتاج إلى ما يلي: عنقود كوبرنتس النسخة 1.28، وسنستخدم في مقالنا عنقود من منصة DigitalOcean، يحتوي على 3 عقد على الأقل تثبيت واجهة سطر الأوامر kubectl وضبطها للتواصل مع عنقود كوبرنتس حساب على مستودع دوكر هب تثبيت دوكر Docker على جهازنا المحلي مفتاح ترخيص لاستخدام منصة Okteto، ويمكن التسجيل في الإصدار التجريبي المجاني. تثبيت مدير الحزم Helm لتطوير التطبيقات ضمن عناقيد Kubernetes، باتباع الخطوة الأولى من المقال التالي. نطاق Domain مسجَّل ومربوط مع Load Balancer لإدارة حركة مرور التطبيقات، وإنشاء سجل A record باسم * وعنوان IP موازن الحِمل. إنشاء تطبيق بايثون علينا التأكد أولًا بأن بايثون مثبّت على جهاز يعمل بنظام التشغيل أوبنتو بكتابة الأمر التالي في الطرفية: python3 --version إذا كانت حزم بايثون مثبّتة على الجهاز فسيعرضالأمر السابق نسختها، وإلّا نستخدم الأمر التالي لتثبيتها: sudo apt install python3 python3-venv python3-pip -y بعدها، ننشئ مجلد لتخزين شيفرة البرنامج وإعداداته: mkdir my-app ثم ننشئ بيئة افتراضية داخل مجلد التطبيق لوضع اعتماديات المشروع فيها: cd my-app python3 -m venv python-env والآن نفعّل البيئة الافتراضية باستخدام الأمر التالي: source python-env/bin/activate ثم ننشئ ملف بايثون لكتابة شيفرة التطبيق فيه: nano app.py ونضيف له الشيفرة التالية: from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return "Hello, This is a simple Python App!" if __name__ == '__main__': app.run(debug=True, host='0.0.0.0') ثم نثبّت إطار عمل فلاسك Flask: pip install flask نشغّل التطبيق الآن باستخدام الأمر التالي: python3 app.py سنحصل على هذا الخرج: Output * Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:5000 * Running on http://172.20.10.2:5000 Press CTRL+C to quit * Restarting with stat * Debugger is active! * Debugger PIN: 311-959-468 أصبح إطار فلاسك Flask يعمل على جهازنا المحلي، نتأكّد من ذلك باستخدام الأمر curl: curl -X GET -H "Content-Type: application/json" http://localhost:5000 سنحصل على الرد التالي من تطبيق فلاسك: Output Hello, This is a simple Python App! يدل هذا الخرج على أن تطبيق فلاسك قد نُفّذ بنجاح دون أخطاء. يمكن إيقاف تفعيل البيئة الافتراضية عند الانتهاء من العمل على مشروعنا، باستخدام الأمر التالي: deactivate وبهذا تكون أنشأنا تطبيقنا واختبرنا عمله محليًا، وحان وقت الخطوة الثانية لتشغيل هذا التطبيق داخل دوكر Docker. تشغيل تطبيق بايثون داخل دوكر Docker يتطلب تشغيل تطبيق بايثون داخل حاوية دوكر إنشاء صورة دوكر Docker image تحتوي على بيئة بايثون والاعتماديات اللازمة لتشغيل التطبيق. ننشئ أولًا ملفًا باسم Dockerfile في المجلد الأساسي للتطبيق: nano Dockerfile ثم نضيف عليه التعليمات التالية: # Use an official Python runtime as a parent image FROM python:3.8-slim # Set the working directory in the container WORKDIR /app # Copy the current directory contents into the container at /app ADD . /app # Install any needed dependencies specified in requirements.txt RUN pip install flask # Make port 5000 available to the world outside this container EXPOSE 5000 # Define environment variable ENV NAME DockerizedPythonApp # Run app.py when the container launches CMD ["python3", "./app.py"] فيما يلي شرح تعليمات ملف دوكر السابقة: تحدد التعليمة FROM python:3.8-slim الصورة الأساسية التي نحتاجها تضبط WORKDIR /app المجلد /app مجلدًا للعمل داخل الحاوية container تنسخ التعليمة ADD . /app محتوى المجلد الحالي لمجلد حاوية التطبيق /app تثبّت RUN pip install flask إطار العمل فلاسك Flask تستمع التعليمة EXPOSE 5000 على المنفذ 5000 للسماح بالاتصال يحدد CMD ["python3", "app.py"] الأمر الذي سينفذ عند تشغيل الحاوية وهو هنا الأمر app.py بعدها سنشغّل الأمر التالي لبناء صورة دوكر وفقًا للتعليمات السابقة: docker build -t my-app . نستطيع تشغيل التطبيق الآن في الحاوية باستخدام الصورة التي أنشأناها: docker run -dit -p 5000:5000 my-app:latest يُشَغّل الأمر السابق حاوية من الصورة my-app ويضبط منفذ الحاوية على المنفذ المضيف 5000. نكتب الأمر التالي للتأكد من عمل الحاوية: docker ps وسنحصل على الخرج التالي: Output CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 761c54c77411 my-app:latest "python3 ./app.py" 3 seconds ago Up 3 seconds 0.0.0.0:5000->5000/tcp, :::5000->5000/tcp pedantic_wescoff نفتح متصفح الويب أو نستعمل موجّه الأوامر curl للوصول إلى التطبيق باستخدام العنوان http://your-server-ip:5000/، وستظهر رسالة Hello, This is a simple Python App! التي تشير لأن التطبيق يعمل داخل حاوية دوكر. وبهذا نكون شغّلنا تطبيق بايثون في حاوية دوكر بنجاح. رفع صورة تطبيق بايثون إلى سجل DockerHub لتنفيذ هذه الخطوة يجب أن يكون لدينا حساب على موقع دوكر هب DockerHub، بعدها نستخدم الأمر docker login لتسجيل الدخول، وسيُطلب منا إدخال اسم المستخدم وكلمة المرور. docker login سنحصل على الخرج التالي: Output Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one. Username: username@gmail.com Password: WARNING! Your password will be stored unencrypted in /root/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded يجب وسم الصورة باسم حسابنا ومجلد الاعتمادية المطلوب قبل رفعها push لمستودع دوكر هب: docker tag my-app yourusername/my-app:latest يمكن الآن رفع الصورة إلى دوكر هب باستخدام الأمر docker push: docker push yourusername/my-app:latest نتأكّد بعدها أن الصورة أصبحت موجودة بالبحث عنها باستخدام طرفية دوكر هب Docker Hub CLI: docker search yourusername/my-app وهكذا أصبحت صورة تطبيقنا مرفوعةً على منصة دوكر هب ويمكن للآخرين سحبها أو نشرها في عدّة بيئات. إنشاء ملف Kubernetes Manifests لنشر التطبيق علينا الآن إنشاء ملف Kubernetes Manifests باستخدام منصة Okteto لضبط عملية التطوير والخدمات وموارد Ingressللتطبيق. نكتب الأمر التالي لإنشاء الملف: nano k8s.yaml ثم نضيف الإعدادات التالية إليه: apiVersion: apps/v1 kind: Deployment metadata: name: my-app spec: selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: containers: - image: yourusername/my-app name: my-app --- apiVersion: v1 kind: Service metadata: name: my-app spec: type: ClusterIP ports: - name: "my-app" port: 5000 selector: app: my-app --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: my-app annotations: dev.okteto.com/generate-host: my-app spec: rules: - http: paths: - backend: service: name: my-app port: number: 5000 path: / pathType: ImplementationSpecific سينشر الملف السابق تطبيقنا بالاسم my-app باستخدام منصة Okteto، وسينشره داخليًا عبر خدمة ClusterIP على المنفذ 5000، ثم سيُعدّ مورد Ingress لتوجيه حركة مرور HTTP إلى التطبيق. وهنا استخدمنا التعليقات التوضيحية الخاصة بـمنصة Okteto لتفعيل بعض الميزات التي تقدمها مثل إنشاء اسم المضيف hostname تلقائيًا. تثبيت Okteto باستخدام مدير الحزم Helm لتثبيت Okteto باستخدام مدير الحزم Helm علينا أولًا إضافة مستودع Okteto Helm إلى عميل Helm: helm repo add okteto https://charts.okteto.com وبعد ذلك علينا تحديث مستودعات مدير الحزم Helm لنضمن أن لدينا معلومات حديثة عن المخططات أو الحزم التي تحتوي على تعريفات موارد Kubernetes اللازمة لتشغيل التطبيق: helm repo update ثم ننشئ ملف config.yaml: nano config.yaml ونضيف بعدها مفتاح رخصة استخدام Okteto الخاص بنا، والنطاق الفرعي والإعدادات، كما هو موضح أدناه: license: INSERTYOURKEYHERE subdomain: okteto.example.com buildkit: persistence: enabled: true registry: storage: filesystem: persistence: enabled: true ثم نثبّت أحدث نسخة من Okteto باستخدام ملف الإعدادات config.yaml: helm install okteto okteto/okteto -f config.yaml --namespace okteto --create-namespace سنحصل على الخرج التالي عند انتهاء التثبيت: Output NAME: okteto LAST DEPLOYED: Tue Mar 12 20:27:21 2024 NAMESPACE: okteto STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Congratulations! Okteto is successfully installed! Follow these steps to complete your domain configuration: 1. Create a wildcard A record "*.okteto.example.com", pointing it to the Okteto NGINX ingress controller External-IP: $ kubectl get service -l=app.kubernetes.io/name=ingress-nginx,app.kubernetes.io/component=controller --namespace=okteto 2. Access your Okteto instance at `https://okteto.okteto.example.com/login#token=88f8cc11` ملاحظة: علينا الاحتفاظ برمز الوصول الشخصي Personal Access Tokens ذو القيمة 88f8cc11 من الشيفرة أعلاه لأننا سنحتاجه لتوثيق حسابنا في Okteto. ننتظر قليلًا ثم نجلب عنوان IP لخادم NGINX Ingress: kubectl get service -l=app.kubernetes.io/name=ingress-nginx,app.kubernetes.io/component=controller --namespace=okteto سنحصل على الخرج التالي: Output NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE okteto-ingress-nginx-controller LoadBalancer 10.101.31.239 45.76.14.191 80:31150/TCP,443:31793/TCP 3m21s علينا إضافة العنوان الخارجي EXTERNAL-IP إلى سجل A تحت الاسم * في إعدادات بروتوكول DNS. والآن، نفتح المتصفح للوصول إلى Okteto باستخدام الرابط التالي: https://okteto.okteto.example.com/login#token=88f8cc11. تثبيت وضبط إعدادات واجهة أوامر Okteto تُتيح لنا واجهة أوامر Okteto مفتوحة المصدر تطوير التطبيقات مباشرة على Kubernetes. بإمكاننا تثبيت واجهة الأوامر على نظامي لينوكس Linux وماك MacOS باستخدام الأمر curl التالي: sudo curl https://get.okteto.com -sSfL | sh نتأكد من تثبيت واجهة أوامر Okteto باستخدام الأمر التالي الذي سيعرض تانسخة المثبّتة على جهازنا Output okteto version 2.25.2 والآن علينا استخدام رمز الوصول الشخصي Personal Access Tokens للمصادقة: okteto context use https://okteto.okteto.example.com --token 88f8cc11 --insecure-skip-tls-verify وسنحصل على الخرج التالي: Output ✓ Using okteto-admin @ okteto.okteto.example.com نشغّل الأمر التالي للتأكد من إعدادات واجهة الأوامر: okteto context list وسنحصل على الخرج التالي: Output Name Namespace Builder Registry https://okteto.okteto.example.com * okteto-admin tcp://buildkit.okteto.example.com:443 registry.okteto.example.com vke-4b7aaaa6-78fa-4a19-9fb3-cf7b8c1ec678 default docker - إنشاء Okteto Manifest علينا إنشاء ملف Okteto Manifest وضبط إعدادات بيئة التطوير لنتمكن من إنشاء تطبيقات بلغة بايثون. أولًا، ننشئ ملف okteto.yaml مخصص لتطبيق بايثون بسيط. nano okteto.yaml ثم نضيف الإعدادات التالية: deploy: - kubectl apply -f k8s.yaml dev: my-app: command: bash environment: - FLASK_ENV=development sync: - .:/app reverse: - 9000:9000 volumes: - /root/.cache/pip فيما يلي شرح الأوامر السابقة: يتضمن القسم deploy إعدادات النشر. وعند تشغيل الأمر okteto up أو okteto deploy يُنَفَّذ الأمر kubectl apply -f k8s.yaml الذي ينشر موارد Kubernetes الموجودة في الملف k8s.yaml، ويُتيح ذلك فصل إعدادات النشر عن إعدادات التطوير. يُحدد command: bash الأمر الذي يجب تشغيله عند بدء تشغيل بيئة التطوير ويحدد environment متغيرات البيئة التي يجب أن تكون في بيئة التطوير. وهنا صرّحنا أن متغيرات فلاسك FLASK_ENV يجب أن تكون في بيئة التطوير FLASK_ENV=development. يحدد القسم sync القسم الملفات التي يجب مزامنتها من جهازنا المحلي مع ملفات بيئة التطوير، إذ يجب مزامنة المجلد (.) مع المجلد /app من بيئة التطوير. ويوّضح reverse قواعد توجيه المنافذ بين بيئة التطوير وجهازك المحلي. وفي مثالنا، يوجّه المنفذ 9000 من بيئة التطوير إلى المنفذ 9000 على جهازنا المحلي. أخيرًا يوّضح v وحدات التخزين الإضافية التي ستُضاف إلى بيئة التطوير. وهنا سنضيف المجلد /root/.cache/pip، لنستخدمه لتخزين حزم pip في بيئة التطوير مؤقتًا. الآن علينا نشر تطبيق بايثون إلى عنقود كوبرنيتس باستخدام الأمر التالي: okteto deploy وسنحصل على الخرج التالي عند نجاح عملية النشر: Output deployment.apps/my-app created service/my-app created ingress.networking.k8s.io/my-app created i There are no available endpoints for 'Okteto'. Follow this link to know more about how to create public endpoints for your application: https://www.okteto.com/docs/cloud/ssl/ ✓ Development environment 'Okteto' successfully deployed i Run 'okteto up' to activate your development container ثم نحدّث لوحة تحكم Okteto من المتصفح لتعاين التطبيق بعد نشره: كما يمكننا الوصول إلى التطبيق من الرابط التالي: https://my-app-okteto-admin.okteto.example.com. تطوير تطبيق بايثون في منصة كوبرنتس مباشرة سنستخدم الأمر okteto up لنشر التطبيق مباشرةً على كوبرنتس، إذ يزامن هذا الأمر الشيفرة المحلية مع بيئة التطوير. وبإمكاننا تعديل الشيفرة باستخدام أي بيئة تطوير أو محرر أكواد على جهازنا، وستجري مزامنة التغييرات تلقائيًا مع بيئة التطوير في كوبرنيتس. علينا أولًا تشغيل بيئة التطوير باستخدام Okteto: okteto up يُنشئ هذا الأمر بيئة تطوير وفقًا للإعدادات الموجودة في ملف okteto.yaml: Output i Using okteto-admin @ okteto.okteto.example.com as context i 'Okteto' was already deployed. To redeploy run 'okteto deploy' or 'okteto up --deploy' i Build section is not defined in your okteto manifest ✓ Persistent volume successfully attached ✓ Images successfully pulled ✓ Files synchronized Context: okteto.okteto.example.com Namespace: okteto-admin Name: my-app Reverse: 9000 <- 9000 root@my-app-okteto-7767588c8d-ndzj7:/app# نشغّل بعدها تطبيق بايثون: python3 app.py وسنحصل على الخرج التالي: * Serving Flask app 'app' * Debug mode: on WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:5000 * Running on http://10.244.97.92:5000 Press CTRL+C to quit * Restarting with stat * Debugger is active! * Debugger PIN: 126-620-675 ثم نعدّل ملف التطبيق app.py: nano app.py وعدّل السطر التالي: return "Hello, This is a simple Python App Deployed on Kubernetes" نحفظ الملف ثم نغلقه، وستٌطبَق التعديلات على الشيفرة البرمجية تلقائيًا في كوبرنتس. ثم نعيد تحميل صفحة التطبيق من متصفح الويب لتعاين التطبيق بعد التعديل. الخاتمة تعلمنا في هذا المقال كيفية إنشاء تطبيق بايثون بسيط وكيفية نشرته ضمن عناقيد كوبرنتس باستخدام منصة Okteto التي تتيح خاصية مزامنة التعديلات على الشيفرة المحلية مع بيئة التطوير، كما تسمح لنا بالتركيز على بناء تطبيقات بايثون عالية الجودة دون القلق حيال بنية كوبرنتس المعقّدة. ترجمة -وبتصرّف- للمقال How to Deploy Python Application on Kubernetes with Okteto لكاتبيه hitjethva وEasha Abid. اقرأ أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون نشر تطبيق جانغو آمن وقابل للتوسيع باستخدام كوبيرنتس Kubernetes تثبيت بايثون 3 وإعداد بيئتها البرمجية تعرّف على كوبرنيتس Kubernetes -
 يعد بروتوكول النقل الآمن Secure Shell، أو SSH اختصارًا، إحدى الأدوات الأساسية التي يجب على مسؤول النظام إتقانها، حيث يستخدم لتسجيل الدخول الآمن إلى الأجهزة البعيدة عن طريق الطرفية أو سطر الأوامر، وهو من أكثر الطرق شيوعًا للوصول إلى خوادم لينكس، وستتعلم في هذا المقال كيفية التعامل مع بروتوكول SSH للاتصال بنظام بعيد خطوة بخطوة. العمل على نظام تشغيل ويندوز Windows إذا كنا نستخدم نظام التشغيل ويندوز على جهازنا، فسنحتاج إلى تثبيت إحدى إصدارات برنامج OpenSSH لنتمكن من استخدام الأمر ssh من سطر الأوامر. أما إن فضّلنا العمل في برنامج PowerShell، فيمكن قراءة توثيقات مايكروسوفت لإضافة OpenSSH إلى PowerShell. أما في حال العمل في بيئة لينكس Linux كاملة، فيمكن إعداد WSL -أي نظام ويندوز الفرعي لنظام لينكس Windows Subsystem for Linux- وهو طبقة توافق لتشغيل أنظمة لينكس داخل أنظمة ويندوز، مما يتيح لنا تشغيل طرفية حقيقية مباشرةً في نظام ويندوز دون الحاجة لآلة افتراضية ويتضمن الأمر ssh. وأخيرًا، يمكننا تثبيت Git على نظام ويندوز، والذي يوفر طرفية Bash أصلية تتضمن أيضًا الأمر ssh. فجميع هذه البيئات الثلاثة مدعومة والخيار متروك لكم في العمل مع إحداها حسب ما تفضلونه. العمل على نظام تشغيل لينكس Linux أو ماك Mac إن كنا نستخدم نظام لينكس أو ماك فسيكون الأمر ssh جاهزًا في الطرفية، وفيما يلي صيغته الأساسية: ssh remote_host remote_host هو عنوان IP أو اسم النطاق domain الذي نريد الاتصال به. يفترض الأمر السابق أن اسم المستخدم على النظام البعيد هو نفس اسم المستخدم على نظامنا المحلي، أما إن كان اسم المستخدم مختلفًا، فيمكننا تحديده باستخدام الأمر التالي: ssh remote_username@remote_host قد يُطلب منا إدخال كلمة مرور للاتصال بالخادم، وسنتحدث لاحقًا عن كيفية استخدام مفاتيح المصادقة المشفرة keys بدل كلمات المرور passwords. نستخدم الأمر التالي للخروج من جلسة SSH والعودة إلى الصدفة: Exit آلية عمل بروتوكول SSH يعمل بروتوكول SSH عن طريق توصيل برنامج عميل client program يسمى sshd مع خادم ssh، فبالعودة إلى مثالنا السابق، فإن ssh هو بمثابة برنامج العميل، أما خادم ssh فيعمل على الجهاز البعيد remote host الذي حددناه. يجب أن يبدأ خادم sshd بالعمل تلقائيًا في معظم بيئات لينكس. وإذا لم يعمل لسبب ما، فقد نحتاج إلى الوصول إلى الخادم من خلال إحدى طرفيّات المتصفح المعتمدة على الويب web-based console، أوالطرفيّة المحلية local serial console. يعتمد الأمر اللازم لتشغيل خادم ssh على توزيعة لينكس التي نستخدمها، فعند استخدام توزيعة أوبنتو، يمكننا تشغيل الأمر التالي: sudo systemctl start ssh يُشغّل الأمر السابق خادم sshd وبإمكاننا الآن تسجيل الدخول إلى الخادم عن بعد. كيفية ضبط إعدادات بروتوكول SSH عندما نغيّر إعدادات بروتوكول SSH فإننا نغيّر أيضًا إعدادات خادم sshd. سنجد ملف الإعدادات ضمن المسار /etc/ssh/sshd_config. ومن الضروري أخذ نسخة احتياطيةً عن هذا الملف قبل بدء التعديل، باستخدام الأمر التالي: sudo cp /etc/ssh/sshd_config{,.bak} ثم نفتحه باستخدام محرر النصوص nano أو أي محرر آخر: sudo nano /etc/ssh/sshd_config لنطلع على بعض خيارات الملف: Port 22 عند الإعلان عن منفذ جديد port declaration فإننا نحدد المنفذ الذي سيستخدمه خادم sshd للاتصال، والمنفذ الافتراضي لذلك هو 22. يُفضّل ألا نغيّر هذا الإعداد، إلا إن كان لدينا سبب لذلك. وسنوضح لاحقًا كيفية الاتصال بالمنفذ الجديد. HostKey /etc/ssh/ssh_host_rsa_key HostKey /etc/ssh/ssh_host_dsa_key HostKey /etc/ssh/ssh_host_ecdsa_key عند الإعلان عن مفاتيح المضيف host keys فإننا نحدد مكان البحث عن مفاتيح المضيف العامة global host keys. وسنتحدث عن ذلك لاحقًا. SyslogFacility AUTH LogLevel INFO يحدد العنصران السابقان مستوى التسجيل logging level. إذ قد تكون زيادة التسجيل طريقة جيدة لاكتشاف المشكلات في SSH: LoginGraceTime 120 PermitRootLogin yes StrictModes yes تحدد المعاملات السابقة بعض معلومات تسجيل الدخول: يحدد المعامل LoginGraceTime عدد الثواني إبقاء الاتصال قبل تسجيل الدخول، ويُنصح أن نجعل هذا الوقت أكثر بقليل من الوقت اللازم لتسجيل الدخول عادة يحدد المعامل PermitRootLogin هل يُسمح للمستخدم الجذر تسجيل الدخول أم لا، ويجب في معظم الحالات ضبط هذا الإعداد على الخيار no عند إنشاء مستخدم لديه امتيازات الجذر لتقليل خطر حصول أي شخص على امتيازات الجذر والوصول إلى خادمنا المعامل strictModes هو حارس أمان لا يسمح بتسجيل الدخول إذا كانت ملفات المصادقة متاحة القراءة للجميع. وهذا يمنع تسجيل الدخول عندما تكون ملفات الإعدادات غير آمنة X11Forwarding yes X11DisplayOffset 10 تضبط هذه المعاملات خاصيةً تسمى X11 Forwarding تتيح لنا عرض واجهة المستخدم الرسومية GUI للنظام البعيد على النظام المحلي، ويجب تفعيل هذا الخيار على الخادم واستخدامه مع عميل SSH أثناء الاتصال مصحوبًا بالخيار x-. بعد التعديل على الملف نحفظه ثم نغلقه. وإن كنا نستخدم محرر النصوص nano، نضغط على المفتاحين Ctrl+X، ثم Y عندما يُطلب منا ذلك، ثم نضغط على مفتاح Enter. ولا ننسى إعادة تحميل خادم sshd لتنفيذ التعديلات التي أجريناها في الملف باستخدام الأمر التالي: sudo systemctl reload ssh يجب اختبار التعديلات بدقة للتأكد أنها تعمل كما يجب. كما يمكننا فتح بضع جلسات في الطرفية أثناء التعديل على ملف الإعدادات، لإلغاء التعديلات إن لزم الأمر دون الحاجة إلى إعادة تسجيل الدخول. تسجيل الدخول إلى SSH باستخدام مفاتيح المصادقة Keys يُنصح لتسجيل الدخول إلى نظام بعيد استخدام كلمات المرور passwords أو مفاتيح المصادقة keys والتي تتصف بأنها أسرع وأكثر أمانًا من كلمات المرور. آلية عمل المصادقة المعتمدة على المفاتيح تعمل المصادقة المعتمدة على مفاتيح المصادقة عن طريق إنشاء زوج من المفاتيح: مفتاح خاص private key ومفتاح عام public key. يوجد المفتاح الخاص على جهاز العميل وهو سرّي، أما المفتاح العام فيمكن إعطاؤه لأي شخص أو وضعه على أي خادم نرغب الوصول إليه. عندما نحاول الاتصال باستخدام زوج من المفاتيح، نستخدم الخادم المفتاح العام لإنشاء رسالة محمية لحاسوب العميل لا يمكن قراءتها إلا باستخدام المفتاح الخاص. بعد ذلك، يرسل حاسوب العميل الاستجابة المناسبة إلى الخادم وسيعرف الخادم أن العميل يُسمح له بالاتصال. تُنفَّذ هذه العملية تلقائيًا بعد ضبط إعدادات المفاتيح. كيفية إنشاء مفاتيح المصادقة في بروتوكول SSH يجب إنشاء مفاتيح المصادقة في بروتوكول SSH على الحاسوب الذي سنسجل الدخول منه، أي جهازنا المحلي. نكتب ما يلي في سطر الأوامر: ssh-keygen -t rsa قد يُطلب منا تعيين كلمة مرور على ملفات المفاتيح نفسها، ولكن هذا الأمر غير شائع. يجب الضغط على مفتاح Enter لقبول الإعدادات الافتراضية. وستُنشأ المفاتيح في المجلد ~/.ssh/id_rsa.pub و المجلد ~/.ssh/id_rsa. نغيّر مكان إنشاء المفاتيح إلى المجلد .sshباستخدام الأمر التالي: cd ~/.ssh نستعرض سماحيات الملف باستخدام الأمر: ls -l وسنحصل على الخرج التالي: -rw-r--r-- 1 demo demo 807 Sep 9 22:15 authorized_keys -rw------- 1 demo demo 1679 Sep 9 23:13 id_rsa -rw-r--r-- 1 demo demo 396 Sep 9 23:13 id_rsa.pub نلاحظ أن الملف id_rsa قابل القراءة والكتابة بواسطة المالك فقط، مما يساعد على إبقاء الملف سريًّا. أما الملف id_rsa.pub فيمكن مشاركته وله سماحيات تمكّن ذلك. نقل المفاتيح العامة إلى الخادم إن فعّلنا الوصول إلى الخادم باستخدام كلمة المرور، فبإمكاننا نسخ مفتاح المرور العام إلى الخادم باستخدام الأمر التالي: ssh-copy-id remote_host سيؤدي الأمر إلى إنشاء جلسة SSH، وبعد إدخال كلمة المرور، سيُنسخ المفتاح العام إلى ملف المفاتيح المعتمدة authorized keys في الخادم، مما يسمح لنا بتسجيل الدخول دون كلمة المرور في المرة القادمة. الخيارات المتاحة لعميل SSH هناك خيارات عدة عند الاتصال عبر بروتوكول SSH، بعضها قد يكون ضروريًا لمطابقة الإعدادات الموجودة في sshd عند المضيف البعيد remote host. مثلًا، إذا غيّرنا رقم المنفذ في إعدادات sshd، فعلينا تغييره عند العميل باستخدام الأمر التالي: ssh -p port_number remote_host ملاحظة:: يُعدَ تغيير منفذ بروتوكول ssh طريقةً مناسبةً لزيادة الأمان، فإذا كنا نسمح بالاتصال بخادم معروف عبر بروتوكول ssh على المنفذ 22 كالمعتاد، ووضعنا كلمة مرور، فمن المحتمل أن نتعرض لمحاولات تسجيل دخول آلية عديدة automated logins. لكن، لا يُعدّ استخدام مفاتيح المصادقة وتشغيل بروتوكول ssh على منفذ غير المنفذ المعتاد الحل الأمني الأمثل، ولكنه يفيد في الحد من الهجمات الآلية. إذا أردنا تنفيذ أمر واحد فقط على النظام البعيد، فيمكن تحديده بعد المضيف، كما يلي: ssh remote_host command_to_run سنتصل بالنظام البعيد وسيُنَفذ الأمر بعد إدخال مفتاح المرور. إن كانت خاصية X11 Forwarding مفعلةً على كلا الجهازين، فيمكننا تفعيل ميزاتها باستخدام الأمر التالي: ssh -X remote_host بشرط توفر الأدوات المناسبة لذلك على حاسوبنا، فبرامج واجهة المستخدم الرسومية التي نستخدمها على النظام البعيد ستُشَغّل الآن على نظامنا المحلي. إلغاء التحقق من كلمة المرور يمكن عند إنشاء مفاتيح SSH، تحسين أمان الخادم وتعطيل مصادقة كلمة المرور، وتمكين تسجيل الدخول إلى الخادم من خلال المفتاح الخاص المقترن بالمفتاح العام الذي نبّته على الخادم. تنبيه: قبل متابعة هذه الخطوة، يتوجب التأكد من تثبيت مفتاح عام على الخادم. وإلا لن نستطيع تسجيل الدخول! نفتح ملف إعدادات sshd كمستخدم مسؤول root user أو أو مستخدم يتمتع بامتيازات sudo باستخدام الأمر التالي: sudo nano /etc/ssh/sshd_config نبحث عن سطر Password Authentication ثم نزيل التعليق عنه بمسح رمز #، ونغيّر قيمته إلى القيمة no: PasswordAuthentication no أما الخيار PubkeyAuthentication و ChallengeResponseAuthentication فلا يحتاجان إلى تعديل، شريطة ألا نكون عدلنا هذا الملف، إذ يجب تركهما على الضبط الإفتراضي: PubkeyAuthentication yes ChallengeResponseAuthentication no نحفظ الملف ونغلقه بعد الانتهاء من التعديلات. ثم نعيد تحميل برنامج ssh: sudo systemctl reload ssh وبهكذا نكون قد ألغينا التحقق من كلمة المرور، وفعّلنا خيار الوصول إلى الخادم حصرًا عبر مفتاح SSH. الخاتمة شرحنا في هذا المقال كيفية استخدام بروتوكول SSH وهو أمر مفيد جدًا في مجال الحوسبة السحابية، وسنحتاج أثناء استخدام الخيارات المتنوعة مزيدًا من الميزات المتقدمة التي من شأنها تسهيل عملنا. لهذا بقي بروتوكول SSH شائع الاستخدام لأنه آمن وصغير الحجم ومفيد في الكثير من الحالات. ترجمة ، وبتصرّف، للمقال How To Use SSH to Connect to a Remote Server لكاتبه Justin Ellingwood. اقرأ أيضًا ما هي تقنية SSH؟ أنفاق SSH، ماهيتها وكيفية إعدادها كيفيّة منع SSH من فصل الجلسات مدخل إلى طرفيّة لينكس Linux Terminal
يعد بروتوكول النقل الآمن Secure Shell، أو SSH اختصارًا، إحدى الأدوات الأساسية التي يجب على مسؤول النظام إتقانها، حيث يستخدم لتسجيل الدخول الآمن إلى الأجهزة البعيدة عن طريق الطرفية أو سطر الأوامر، وهو من أكثر الطرق شيوعًا للوصول إلى خوادم لينكس، وستتعلم في هذا المقال كيفية التعامل مع بروتوكول SSH للاتصال بنظام بعيد خطوة بخطوة. العمل على نظام تشغيل ويندوز Windows إذا كنا نستخدم نظام التشغيل ويندوز على جهازنا، فسنحتاج إلى تثبيت إحدى إصدارات برنامج OpenSSH لنتمكن من استخدام الأمر ssh من سطر الأوامر. أما إن فضّلنا العمل في برنامج PowerShell، فيمكن قراءة توثيقات مايكروسوفت لإضافة OpenSSH إلى PowerShell. أما في حال العمل في بيئة لينكس Linux كاملة، فيمكن إعداد WSL -أي نظام ويندوز الفرعي لنظام لينكس Windows Subsystem for Linux- وهو طبقة توافق لتشغيل أنظمة لينكس داخل أنظمة ويندوز، مما يتيح لنا تشغيل طرفية حقيقية مباشرةً في نظام ويندوز دون الحاجة لآلة افتراضية ويتضمن الأمر ssh. وأخيرًا، يمكننا تثبيت Git على نظام ويندوز، والذي يوفر طرفية Bash أصلية تتضمن أيضًا الأمر ssh. فجميع هذه البيئات الثلاثة مدعومة والخيار متروك لكم في العمل مع إحداها حسب ما تفضلونه. العمل على نظام تشغيل لينكس Linux أو ماك Mac إن كنا نستخدم نظام لينكس أو ماك فسيكون الأمر ssh جاهزًا في الطرفية، وفيما يلي صيغته الأساسية: ssh remote_host remote_host هو عنوان IP أو اسم النطاق domain الذي نريد الاتصال به. يفترض الأمر السابق أن اسم المستخدم على النظام البعيد هو نفس اسم المستخدم على نظامنا المحلي، أما إن كان اسم المستخدم مختلفًا، فيمكننا تحديده باستخدام الأمر التالي: ssh remote_username@remote_host قد يُطلب منا إدخال كلمة مرور للاتصال بالخادم، وسنتحدث لاحقًا عن كيفية استخدام مفاتيح المصادقة المشفرة keys بدل كلمات المرور passwords. نستخدم الأمر التالي للخروج من جلسة SSH والعودة إلى الصدفة: Exit آلية عمل بروتوكول SSH يعمل بروتوكول SSH عن طريق توصيل برنامج عميل client program يسمى sshd مع خادم ssh، فبالعودة إلى مثالنا السابق، فإن ssh هو بمثابة برنامج العميل، أما خادم ssh فيعمل على الجهاز البعيد remote host الذي حددناه. يجب أن يبدأ خادم sshd بالعمل تلقائيًا في معظم بيئات لينكس. وإذا لم يعمل لسبب ما، فقد نحتاج إلى الوصول إلى الخادم من خلال إحدى طرفيّات المتصفح المعتمدة على الويب web-based console، أوالطرفيّة المحلية local serial console. يعتمد الأمر اللازم لتشغيل خادم ssh على توزيعة لينكس التي نستخدمها، فعند استخدام توزيعة أوبنتو، يمكننا تشغيل الأمر التالي: sudo systemctl start ssh يُشغّل الأمر السابق خادم sshd وبإمكاننا الآن تسجيل الدخول إلى الخادم عن بعد. كيفية ضبط إعدادات بروتوكول SSH عندما نغيّر إعدادات بروتوكول SSH فإننا نغيّر أيضًا إعدادات خادم sshd. سنجد ملف الإعدادات ضمن المسار /etc/ssh/sshd_config. ومن الضروري أخذ نسخة احتياطيةً عن هذا الملف قبل بدء التعديل، باستخدام الأمر التالي: sudo cp /etc/ssh/sshd_config{,.bak} ثم نفتحه باستخدام محرر النصوص nano أو أي محرر آخر: sudo nano /etc/ssh/sshd_config لنطلع على بعض خيارات الملف: Port 22 عند الإعلان عن منفذ جديد port declaration فإننا نحدد المنفذ الذي سيستخدمه خادم sshd للاتصال، والمنفذ الافتراضي لذلك هو 22. يُفضّل ألا نغيّر هذا الإعداد، إلا إن كان لدينا سبب لذلك. وسنوضح لاحقًا كيفية الاتصال بالمنفذ الجديد. HostKey /etc/ssh/ssh_host_rsa_key HostKey /etc/ssh/ssh_host_dsa_key HostKey /etc/ssh/ssh_host_ecdsa_key عند الإعلان عن مفاتيح المضيف host keys فإننا نحدد مكان البحث عن مفاتيح المضيف العامة global host keys. وسنتحدث عن ذلك لاحقًا. SyslogFacility AUTH LogLevel INFO يحدد العنصران السابقان مستوى التسجيل logging level. إذ قد تكون زيادة التسجيل طريقة جيدة لاكتشاف المشكلات في SSH: LoginGraceTime 120 PermitRootLogin yes StrictModes yes تحدد المعاملات السابقة بعض معلومات تسجيل الدخول: يحدد المعامل LoginGraceTime عدد الثواني إبقاء الاتصال قبل تسجيل الدخول، ويُنصح أن نجعل هذا الوقت أكثر بقليل من الوقت اللازم لتسجيل الدخول عادة يحدد المعامل PermitRootLogin هل يُسمح للمستخدم الجذر تسجيل الدخول أم لا، ويجب في معظم الحالات ضبط هذا الإعداد على الخيار no عند إنشاء مستخدم لديه امتيازات الجذر لتقليل خطر حصول أي شخص على امتيازات الجذر والوصول إلى خادمنا المعامل strictModes هو حارس أمان لا يسمح بتسجيل الدخول إذا كانت ملفات المصادقة متاحة القراءة للجميع. وهذا يمنع تسجيل الدخول عندما تكون ملفات الإعدادات غير آمنة X11Forwarding yes X11DisplayOffset 10 تضبط هذه المعاملات خاصيةً تسمى X11 Forwarding تتيح لنا عرض واجهة المستخدم الرسومية GUI للنظام البعيد على النظام المحلي، ويجب تفعيل هذا الخيار على الخادم واستخدامه مع عميل SSH أثناء الاتصال مصحوبًا بالخيار x-. بعد التعديل على الملف نحفظه ثم نغلقه. وإن كنا نستخدم محرر النصوص nano، نضغط على المفتاحين Ctrl+X، ثم Y عندما يُطلب منا ذلك، ثم نضغط على مفتاح Enter. ولا ننسى إعادة تحميل خادم sshd لتنفيذ التعديلات التي أجريناها في الملف باستخدام الأمر التالي: sudo systemctl reload ssh يجب اختبار التعديلات بدقة للتأكد أنها تعمل كما يجب. كما يمكننا فتح بضع جلسات في الطرفية أثناء التعديل على ملف الإعدادات، لإلغاء التعديلات إن لزم الأمر دون الحاجة إلى إعادة تسجيل الدخول. تسجيل الدخول إلى SSH باستخدام مفاتيح المصادقة Keys يُنصح لتسجيل الدخول إلى نظام بعيد استخدام كلمات المرور passwords أو مفاتيح المصادقة keys والتي تتصف بأنها أسرع وأكثر أمانًا من كلمات المرور. آلية عمل المصادقة المعتمدة على المفاتيح تعمل المصادقة المعتمدة على مفاتيح المصادقة عن طريق إنشاء زوج من المفاتيح: مفتاح خاص private key ومفتاح عام public key. يوجد المفتاح الخاص على جهاز العميل وهو سرّي، أما المفتاح العام فيمكن إعطاؤه لأي شخص أو وضعه على أي خادم نرغب الوصول إليه. عندما نحاول الاتصال باستخدام زوج من المفاتيح، نستخدم الخادم المفتاح العام لإنشاء رسالة محمية لحاسوب العميل لا يمكن قراءتها إلا باستخدام المفتاح الخاص. بعد ذلك، يرسل حاسوب العميل الاستجابة المناسبة إلى الخادم وسيعرف الخادم أن العميل يُسمح له بالاتصال. تُنفَّذ هذه العملية تلقائيًا بعد ضبط إعدادات المفاتيح. كيفية إنشاء مفاتيح المصادقة في بروتوكول SSH يجب إنشاء مفاتيح المصادقة في بروتوكول SSH على الحاسوب الذي سنسجل الدخول منه، أي جهازنا المحلي. نكتب ما يلي في سطر الأوامر: ssh-keygen -t rsa قد يُطلب منا تعيين كلمة مرور على ملفات المفاتيح نفسها، ولكن هذا الأمر غير شائع. يجب الضغط على مفتاح Enter لقبول الإعدادات الافتراضية. وستُنشأ المفاتيح في المجلد ~/.ssh/id_rsa.pub و المجلد ~/.ssh/id_rsa. نغيّر مكان إنشاء المفاتيح إلى المجلد .sshباستخدام الأمر التالي: cd ~/.ssh نستعرض سماحيات الملف باستخدام الأمر: ls -l وسنحصل على الخرج التالي: -rw-r--r-- 1 demo demo 807 Sep 9 22:15 authorized_keys -rw------- 1 demo demo 1679 Sep 9 23:13 id_rsa -rw-r--r-- 1 demo demo 396 Sep 9 23:13 id_rsa.pub نلاحظ أن الملف id_rsa قابل القراءة والكتابة بواسطة المالك فقط، مما يساعد على إبقاء الملف سريًّا. أما الملف id_rsa.pub فيمكن مشاركته وله سماحيات تمكّن ذلك. نقل المفاتيح العامة إلى الخادم إن فعّلنا الوصول إلى الخادم باستخدام كلمة المرور، فبإمكاننا نسخ مفتاح المرور العام إلى الخادم باستخدام الأمر التالي: ssh-copy-id remote_host سيؤدي الأمر إلى إنشاء جلسة SSH، وبعد إدخال كلمة المرور، سيُنسخ المفتاح العام إلى ملف المفاتيح المعتمدة authorized keys في الخادم، مما يسمح لنا بتسجيل الدخول دون كلمة المرور في المرة القادمة. الخيارات المتاحة لعميل SSH هناك خيارات عدة عند الاتصال عبر بروتوكول SSH، بعضها قد يكون ضروريًا لمطابقة الإعدادات الموجودة في sshd عند المضيف البعيد remote host. مثلًا، إذا غيّرنا رقم المنفذ في إعدادات sshd، فعلينا تغييره عند العميل باستخدام الأمر التالي: ssh -p port_number remote_host ملاحظة:: يُعدَ تغيير منفذ بروتوكول ssh طريقةً مناسبةً لزيادة الأمان، فإذا كنا نسمح بالاتصال بخادم معروف عبر بروتوكول ssh على المنفذ 22 كالمعتاد، ووضعنا كلمة مرور، فمن المحتمل أن نتعرض لمحاولات تسجيل دخول آلية عديدة automated logins. لكن، لا يُعدّ استخدام مفاتيح المصادقة وتشغيل بروتوكول ssh على منفذ غير المنفذ المعتاد الحل الأمني الأمثل، ولكنه يفيد في الحد من الهجمات الآلية. إذا أردنا تنفيذ أمر واحد فقط على النظام البعيد، فيمكن تحديده بعد المضيف، كما يلي: ssh remote_host command_to_run سنتصل بالنظام البعيد وسيُنَفذ الأمر بعد إدخال مفتاح المرور. إن كانت خاصية X11 Forwarding مفعلةً على كلا الجهازين، فيمكننا تفعيل ميزاتها باستخدام الأمر التالي: ssh -X remote_host بشرط توفر الأدوات المناسبة لذلك على حاسوبنا، فبرامج واجهة المستخدم الرسومية التي نستخدمها على النظام البعيد ستُشَغّل الآن على نظامنا المحلي. إلغاء التحقق من كلمة المرور يمكن عند إنشاء مفاتيح SSH، تحسين أمان الخادم وتعطيل مصادقة كلمة المرور، وتمكين تسجيل الدخول إلى الخادم من خلال المفتاح الخاص المقترن بالمفتاح العام الذي نبّته على الخادم. تنبيه: قبل متابعة هذه الخطوة، يتوجب التأكد من تثبيت مفتاح عام على الخادم. وإلا لن نستطيع تسجيل الدخول! نفتح ملف إعدادات sshd كمستخدم مسؤول root user أو أو مستخدم يتمتع بامتيازات sudo باستخدام الأمر التالي: sudo nano /etc/ssh/sshd_config نبحث عن سطر Password Authentication ثم نزيل التعليق عنه بمسح رمز #، ونغيّر قيمته إلى القيمة no: PasswordAuthentication no أما الخيار PubkeyAuthentication و ChallengeResponseAuthentication فلا يحتاجان إلى تعديل، شريطة ألا نكون عدلنا هذا الملف، إذ يجب تركهما على الضبط الإفتراضي: PubkeyAuthentication yes ChallengeResponseAuthentication no نحفظ الملف ونغلقه بعد الانتهاء من التعديلات. ثم نعيد تحميل برنامج ssh: sudo systemctl reload ssh وبهكذا نكون قد ألغينا التحقق من كلمة المرور، وفعّلنا خيار الوصول إلى الخادم حصرًا عبر مفتاح SSH. الخاتمة شرحنا في هذا المقال كيفية استخدام بروتوكول SSH وهو أمر مفيد جدًا في مجال الحوسبة السحابية، وسنحتاج أثناء استخدام الخيارات المتنوعة مزيدًا من الميزات المتقدمة التي من شأنها تسهيل عملنا. لهذا بقي بروتوكول SSH شائع الاستخدام لأنه آمن وصغير الحجم ومفيد في الكثير من الحالات. ترجمة ، وبتصرّف، للمقال How To Use SSH to Connect to a Remote Server لكاتبه Justin Ellingwood. اقرأ أيضًا ما هي تقنية SSH؟ أنفاق SSH، ماهيتها وكيفية إعدادها كيفيّة منع SSH من فصل الجلسات مدخل إلى طرفيّة لينكس Linux Terminal -
 نتعرف في مقال اليوم على إطار عمل جيست Jest أحد الأطر الشائعة لاختبار الشيفرات المصدرية المكتوبة باستخدام رياكت React ولغة جافا سكريبت، فهو يقدم مجموعة شاملة من المطابِقات Matchers التي تقارن بين القيم المتوقعة والقيم الفعلية أثناء اختبار الشيفرة مما يسمح بكتابة اختبارات لعدة أنواع من المشاريع. كما يُنَظم الاختبارات في مجموعات اختبار test suites ليُحَسّن الصيانة والمقروئية، وينجز الاختبار بكفاءة وسلاسة. ستتعرّف في هذا المقال على عدّة اختبارات شائعة الاستخدام في مجال تطوير البرمجيات، وبعض الممارسات المفيدة في عملية الاختبار. إذ سنكتب توابع جافا سكريبت JavaScript ثم سنختبرها باستخدام إطار عمل جيست Jest على خادم Vultr مع تطبيق نود جي إس NodeJS جاهز من صفحة متجر تطبيقات NodeJS marketplace. أنواع الاختبارات تتضمن عملية تطوير البرمجيات ثلاثة أنواع من الاختبارات لضمان جودة الشيفرة البرمجية وسلامة وظائفها. يخدم كل منها غرضًا محددًا: اختبارات الوحدة Unit tests تركز هذه الاختبارات على اختبار الوحدات أو المكونات الفردية مثل الدوال functions أو التوابع methods أو الصفوف classes. إذ يضمن هذا الاختبار أن كل مكونات الشيفرة البرمجية تعمل بصورة صحيحة من تلقاء نفسها. اختبارات التكامل Integration tests تركز هذه الاختبارات على تقييم تفاعل مكونات التطبيق المختلفة مع بعضها البعض. على عكس اختبارات الوحدة، التي تختبر مكونًا واحدًا، تهتم هذه الاختبارات بالتفاعلات بين عدّة وحدات للتأكد من أنها تعمل كما هو متوقع عند دمجها. الاختبارات الشاملة End-to-end tests تحاكي هذه الاختبارات سيناريوهات الاستخدام الحقيقية عن طريق اختبار التطبيق من البداية إلى النهاية. وتكون مؤتمتة automated عادة، وتتفاعل مع التطبيق كمستخدم حقيقي، مما يضمن أن التطبيق يعمل كما ينبغي. منهجيات شائعة في عملية الاختبار تساعد منهجية الإعداد Arrange واتخاذ الإجراء المناسب Act والتأكيد Assert أو ما يعرف اختصارًا بمهنجية AAA على تقسيم الاختبار إلى مراحل منفصلة، وبذلك يصبح من السهل على المطورين والمراجعين فهم كل جزء من الاختبار على حدة، وتحديد الأخطاء بسرعة أكبر. فيما يلي مثال يوضح المنهجية السابقة، حيث سنختبر فيما إذا كان البريد الإلكتروني للمستخدم مكتوبًا بأبجدية رقمية alphanumeric أي مكون من أحرف وأرقام، ويستخدم النطاق example.com: test("returns false for an invalid domain", () => { const email = "user123@example.net"; const result = isValidEmail(email); expect(result).toBe(false); }); فيما يلي شرح المراحل الثلاثة للاختبار مرحلة الإعداد Arrange علينا في هذه المرحلة إعداد الشرط الأولي وبيئة الاختبار. بما فيه تهيئة الكائنات objects وإعداد الدخل inputs وضبط البيئة لإنشاء حالة الاستخدام التي نرغب في اختبارها، نريد في مثالنا اختبار عمل الدالة isValidEmail ونتحقق فيما إذا كانت تحدد بدّقة رسائل البريد الإلكتروني غير الصالحة. وهنا أسندنا إلى متغير البريد الإلكتروني سلسلة نصية لا تفي بالمعايير التي حددناها حيث تستخدم النطاق .net بدلاً من .com مرحلة اتخاذ الإجراء المناسب Act ننفّذ في هذه المرحلة الإجراء الذي نريد اختباره. قد يتضمن ذلك استدعاء تابع أو التفاعل مع كائن، أو تنفيذ جزء معين من الشيفرة البرمجية. وقد استدعينا في مثالنا الدالة isValidEmail في هذه الخطوة، ثم مررنا متغير البريد الإلكتروني كوسيط. مرحلة التأكيد Assert في هذه المرحلة، علينا التحقق من أن نتيجة المرحلة السابقة تلبي التوقعات، وقد استخدمنا في مثالنا التابع expect الذي يوفره إطار عمل Jest، للتأكد من أن النتيجة التي أرجعتها الدالة isValidEmail محددة بأنها خاطئة، كما هو متوقع بالنسبة لبريد إلكتروني غير صالح. إعداد مجلد المشروع على Vultr سننشر أولًا خادم على Vultr ومن الضروري أن نحرص على تحديد الخيار NodeJS في علامة تبويب تطبيقات المتجر Apps Marketplace. بعدها علينا إعداد مشروع Node.js وتثبيت إطار عمل Jest. ثم تعريف دالتين في ملفي جافا سكريبت منفصلين، حيث سنختبر هاتين الدالتين في الخطوات القادمة. نتأكّد من تثبيت Node.jS باستخدام الأمر التالي: node --version بعدها، ننشئ مجلدًا للمشروع ثم ننتقل إليه: mkdir sample cd sample نبدأ تشغيل المشروع باستخدام الأمر التالي: npm init -y ثم نثبّت إطار عمل Jest: npm install --save-dev jest نلاحظ أننا استخدمنا الراية --save-dev لتثبيت الحزمة كتبعية تطوير development dependency. ويعني هذا أن الحزمة ستُسخدم فقط خلال مرحلتي التطوير والاختبار، وليس في مرحلة الإنتاج. بعد ذلك نفتح ملف package.json باستخدام أحد محررات الأكواد، وسنستخدم في مثالنا محرر النصوص نانو Nano. nano package.json الآن، علينا إضافة سكربت للاختبار "scripts": { "test": "jest" } نغلق الملف باستخدم الاختصار Ctrl+X، ثم ننقر على مفتاح Y لحفظ التغييرات. بعدها سنشئ ملف جافا سكريبت ونطلق عليه اسم token: nano token.js ننسخ الشيفرة التالية ونلصقها في ملف token.js، إذ توضح هذه الشيفرة كيفية حساب تاريخ انتهاء صلاحية مفتاح تشفير ويب JSON Web Token أو JWT اختصارًا، والتحقق من صلاحيته. ملاحظة: إن شيفرة التحقق التالية هي للتوضيح فقط، حيث يوصى الاعتماد على مكتبات معتمدة عند التعامل مع رموز المصادقة في المشاريع الحقيقية مثل مكتبة jsonwebtoken. /** * * @param {string} token * @returns {Date} */ function getTokenExpiryDate(token) { if (!token) return null; const tokenParts = token.split("."); const payload = tokenParts[1]; const decodedPayload = Buffer.from(payload, "base64").toString(); const payloadObject = JSON.parse(decodedPayload); const expiryDate = new Date(payloadObject.exp * 1000); return expiryDate; } /** * * @param {string} token * @returns {boolean} */ function isTokenExpired(token) { const expiryDate = getTokenExpiryDate(token); const currentDate = new Date(); return currentDate > expiryDate; } module.exports = { isTokenExpired }; تُعَرّف الشيفرة السابقة دالتين هما getTokenExpiryDate وisTokenExpired اللتان تحسبان تاريخ انتهاء صلاحية رمز JWT وتعطيان إما القيمة true أو false بناءً على حالة صلاحية الرمز. نحفظ الملف ونغلقه، ثم ننشئ ملف جافا سكريبت آخر باسم email: nano email.js ثم نلصق فيه الشيفرة التالية: function isValidEmail(email) { const emailRegex = /[a-zA-Z0-9]+@example\.com/; return emailRegex.test(email); } module.exports = { isValidEmail }; تُعَرّف الشيفرة السابقة الدالة isValidEmail التي تتحقق من صحة بنية البريد الإلكتروني باستخدام التعابير النمطية regex، والتي تتيح لنا التحقق من أن جميع عناوين البريد الإلكتروني مكتوبة بأبجدية رقمية وتنتهي بـالنطاق @example.com. والآن، علينا حفظ الملف وإغلاقه. كتابة اختبارات الوحدة Unit Tests باستخدام إطار عمل Jest سنتعلم الآن كيفية كتابة اختبارات الوحدة باستخدام إطار عمل جيست Jest لاختبار دوال جافا سكريبت التي عرّفناها سابقًا. سنضع هذه الاختبارات في مجلد منفصل ضمن مجلد المشروع، ونوصي باتباع التسميات الاصطلاحية التي سنعتمدها في مقالنا لأن Jest يتعامل مع الملفات التي تنتهي بالصيغة .test.js كملفات اختبار. أولًا، ننشئ مجلدّا يدعى tests داخل مجلد sample، ثم ننتقل إليه باستخدام الأمر cd على النحو التالي: mkdir tests cd tests بعدها ننشئ ملف جافا سكريبت. nano token.test.js ننسخ الشيفرة التالية ونلصقها في الملف. const { isTokenExpired } = require("/root/sample/token.js"); describe("isTokenExpired", () => { test("should return false if the token is not expired", () => { const token = "eyJ0eXAiOiJKV1QiLCJhbGciOi..."; const result = isTokenExpired(token); expect(result).toBe(false); }); test("should return true if the token is expired", () => { const token = "eyJ0eXAiOiJKV1QiLCJhbGciOi..."; const result = isTokenExpired(token); expect(result).toBe(true); }); }); تستخدم الشيفرة السابقة الدالة isTokenExpired التي عرّفناها سابقًا لتحديد ما إذا كانت الدالة تتصرف كما هو متوقع، وتعيد قيمةً منطقيةً تحدد إن كان رمز JWT منتهي الصلاحية أم لا. ملاحظة: إن أردنا أن تتحقق الدالة isTokenExpired من صحة رموز مصادقة حقيقية، يمكننا إنشاء رموز JWT منتهية الصلاحية وأخرى غير منتهية الصلاحية بواسطة أداة مثل JSON Web Token Builder واستخدامها بدلاً من النصوص المستخدمة في الاختبارات السابقة. نحفظ الملف ونغلقه، ثم ننشئ ملف جافا سكريبت آخر للاختبار. nano email.test.js ننسخ الشيفرة التالية ونلصقها في ملف الاختبار. const { isValidEmail } = require("/root/sample/email.js"); describe("isValidEmail", () => { test("returns true for a valid email", () => { const email = "user123@example.com"; const result = isValidEmail(email); expect(result).toBe(true); }); test("returns false for an invalid domain", () => { const email = "user123@example.net"; const result = isValidEmail(email); expect(result).toBe(false); }); }); تختبر الشيفرة السابقة دالة isValidEmail من خلال توفير بريد إلكتروني صالح وآخر غير صالح. ثم تتحقق من صحة النتائج عن طريق مطابقة المخرجات المتوقعة مع المخرجات الفعلية. تشغيل اختبارات Jest على Vultr سنتعلم الآن كيف نجري اختبارات باستخدام إطار عمل Jest بطريقتين. إذ سنجري في الطريقة الأولى اختبارات وحدة فردية لكل دالة معرّفة سابقًا. أما في الطريقة الثانية، فسنختبر الدالتين في وقت واحد. اختبارات وحدة فردية أولًا: نختبر صحة رمز المصادقة. npm test -- tests/token.test.js إن نجح الاختبار فيجب أن يبدو الخرج على النحو التالي: > sample@1.0.0 test > jest tests/token.test.js PASS tests/token.test.js isTokenExpired ✓ should return false if the token is not expired (2 ms) ✓ should return true if the token is expired (1 ms) Test Suites: 1 passed, 1 total Tests: 2 passed, 2 total Snapshots: 0 total Time: 0.315 s, estimated 1 s Ran all test suites matching /tests\/token.test.js/i. ثانيًا: نختبر صحة البريد الإلكتروني. npm test -- tests/email.test.js إن نجح الاختبار فسيبدو الخرج على النحو التالي: > sample@1.0.0 test > jest tests/email.test.js PASS tests/email.test.js isValidEmail ✓ returns true for a valid email (2 ms) ✓ returns false for an invalid domain (1 ms) Test Suites: 1 passed, 1 total Tests: 2 passed, 2 total Snapshots: 0 total Time: 0.451 s Ran all test suites matching /tests\/email.test.js/i. إجراء جميع الاختبارات في وقت واحد أولًا: نشغّل جميع الاختبارات في وقت واحد. npm test إن نجح الاختبار فسيبدو الخرج على النحو التالي: > sample@1.0.0 test > jest PASS tests/email.test.js PASS tests/token.test.js Test Suites: 2 passed, 2 total Tests: 4 passed, 4 total Snapshots: 0 total Time: 0.225 s, estimated 1 s Ran all test suites. ختامًا تعرّفنا في هذا المقال على أنواع مختلفة من الاختبارات البرمجية، وعلى بعض المنهجيات والممارسات المفيدة في عملية الاختبار. وتعلّمنا كيفية كتابة وتطبيق اختبارات الوحدة باستخدام إطار عمل Jest على خادم Vultr مثبّت عليه Node.js. حيث يمكن زيادة موثوقية وقوة الشيفرة البرمجية من خلال الاستفادة من أدوات الاختبار مثل Jest لتطوير برامج أكثر استقرارًا وقابلة للصيانة. ترجمة -وبتصرّف- للمقال Testing JavaScript with Jest on Vultr. اقرأ أيضًا استراتيجيات اختبارات مشاريع الويب للتوافق مع المتصفحات اختبار الوحدات البرمجية باستخدام Mocha و Assert في Node.js تعرف على أداة TestGrid وأهميتها في أتمتة الاختبارات البرمجية إعداد البيئة للاختبارات الآلية في مشاريع الويب للتوافق مع المتصفحات
نتعرف في مقال اليوم على إطار عمل جيست Jest أحد الأطر الشائعة لاختبار الشيفرات المصدرية المكتوبة باستخدام رياكت React ولغة جافا سكريبت، فهو يقدم مجموعة شاملة من المطابِقات Matchers التي تقارن بين القيم المتوقعة والقيم الفعلية أثناء اختبار الشيفرة مما يسمح بكتابة اختبارات لعدة أنواع من المشاريع. كما يُنَظم الاختبارات في مجموعات اختبار test suites ليُحَسّن الصيانة والمقروئية، وينجز الاختبار بكفاءة وسلاسة. ستتعرّف في هذا المقال على عدّة اختبارات شائعة الاستخدام في مجال تطوير البرمجيات، وبعض الممارسات المفيدة في عملية الاختبار. إذ سنكتب توابع جافا سكريبت JavaScript ثم سنختبرها باستخدام إطار عمل جيست Jest على خادم Vultr مع تطبيق نود جي إس NodeJS جاهز من صفحة متجر تطبيقات NodeJS marketplace. أنواع الاختبارات تتضمن عملية تطوير البرمجيات ثلاثة أنواع من الاختبارات لضمان جودة الشيفرة البرمجية وسلامة وظائفها. يخدم كل منها غرضًا محددًا: اختبارات الوحدة Unit tests تركز هذه الاختبارات على اختبار الوحدات أو المكونات الفردية مثل الدوال functions أو التوابع methods أو الصفوف classes. إذ يضمن هذا الاختبار أن كل مكونات الشيفرة البرمجية تعمل بصورة صحيحة من تلقاء نفسها. اختبارات التكامل Integration tests تركز هذه الاختبارات على تقييم تفاعل مكونات التطبيق المختلفة مع بعضها البعض. على عكس اختبارات الوحدة، التي تختبر مكونًا واحدًا، تهتم هذه الاختبارات بالتفاعلات بين عدّة وحدات للتأكد من أنها تعمل كما هو متوقع عند دمجها. الاختبارات الشاملة End-to-end tests تحاكي هذه الاختبارات سيناريوهات الاستخدام الحقيقية عن طريق اختبار التطبيق من البداية إلى النهاية. وتكون مؤتمتة automated عادة، وتتفاعل مع التطبيق كمستخدم حقيقي، مما يضمن أن التطبيق يعمل كما ينبغي. منهجيات شائعة في عملية الاختبار تساعد منهجية الإعداد Arrange واتخاذ الإجراء المناسب Act والتأكيد Assert أو ما يعرف اختصارًا بمهنجية AAA على تقسيم الاختبار إلى مراحل منفصلة، وبذلك يصبح من السهل على المطورين والمراجعين فهم كل جزء من الاختبار على حدة، وتحديد الأخطاء بسرعة أكبر. فيما يلي مثال يوضح المنهجية السابقة، حيث سنختبر فيما إذا كان البريد الإلكتروني للمستخدم مكتوبًا بأبجدية رقمية alphanumeric أي مكون من أحرف وأرقام، ويستخدم النطاق example.com: test("returns false for an invalid domain", () => { const email = "user123@example.net"; const result = isValidEmail(email); expect(result).toBe(false); }); فيما يلي شرح المراحل الثلاثة للاختبار مرحلة الإعداد Arrange علينا في هذه المرحلة إعداد الشرط الأولي وبيئة الاختبار. بما فيه تهيئة الكائنات objects وإعداد الدخل inputs وضبط البيئة لإنشاء حالة الاستخدام التي نرغب في اختبارها، نريد في مثالنا اختبار عمل الدالة isValidEmail ونتحقق فيما إذا كانت تحدد بدّقة رسائل البريد الإلكتروني غير الصالحة. وهنا أسندنا إلى متغير البريد الإلكتروني سلسلة نصية لا تفي بالمعايير التي حددناها حيث تستخدم النطاق .net بدلاً من .com مرحلة اتخاذ الإجراء المناسب Act ننفّذ في هذه المرحلة الإجراء الذي نريد اختباره. قد يتضمن ذلك استدعاء تابع أو التفاعل مع كائن، أو تنفيذ جزء معين من الشيفرة البرمجية. وقد استدعينا في مثالنا الدالة isValidEmail في هذه الخطوة، ثم مررنا متغير البريد الإلكتروني كوسيط. مرحلة التأكيد Assert في هذه المرحلة، علينا التحقق من أن نتيجة المرحلة السابقة تلبي التوقعات، وقد استخدمنا في مثالنا التابع expect الذي يوفره إطار عمل Jest، للتأكد من أن النتيجة التي أرجعتها الدالة isValidEmail محددة بأنها خاطئة، كما هو متوقع بالنسبة لبريد إلكتروني غير صالح. إعداد مجلد المشروع على Vultr سننشر أولًا خادم على Vultr ومن الضروري أن نحرص على تحديد الخيار NodeJS في علامة تبويب تطبيقات المتجر Apps Marketplace. بعدها علينا إعداد مشروع Node.js وتثبيت إطار عمل Jest. ثم تعريف دالتين في ملفي جافا سكريبت منفصلين، حيث سنختبر هاتين الدالتين في الخطوات القادمة. نتأكّد من تثبيت Node.jS باستخدام الأمر التالي: node --version بعدها، ننشئ مجلدًا للمشروع ثم ننتقل إليه: mkdir sample cd sample نبدأ تشغيل المشروع باستخدام الأمر التالي: npm init -y ثم نثبّت إطار عمل Jest: npm install --save-dev jest نلاحظ أننا استخدمنا الراية --save-dev لتثبيت الحزمة كتبعية تطوير development dependency. ويعني هذا أن الحزمة ستُسخدم فقط خلال مرحلتي التطوير والاختبار، وليس في مرحلة الإنتاج. بعد ذلك نفتح ملف package.json باستخدام أحد محررات الأكواد، وسنستخدم في مثالنا محرر النصوص نانو Nano. nano package.json الآن، علينا إضافة سكربت للاختبار "scripts": { "test": "jest" } نغلق الملف باستخدم الاختصار Ctrl+X، ثم ننقر على مفتاح Y لحفظ التغييرات. بعدها سنشئ ملف جافا سكريبت ونطلق عليه اسم token: nano token.js ننسخ الشيفرة التالية ونلصقها في ملف token.js، إذ توضح هذه الشيفرة كيفية حساب تاريخ انتهاء صلاحية مفتاح تشفير ويب JSON Web Token أو JWT اختصارًا، والتحقق من صلاحيته. ملاحظة: إن شيفرة التحقق التالية هي للتوضيح فقط، حيث يوصى الاعتماد على مكتبات معتمدة عند التعامل مع رموز المصادقة في المشاريع الحقيقية مثل مكتبة jsonwebtoken. /** * * @param {string} token * @returns {Date} */ function getTokenExpiryDate(token) { if (!token) return null; const tokenParts = token.split("."); const payload = tokenParts[1]; const decodedPayload = Buffer.from(payload, "base64").toString(); const payloadObject = JSON.parse(decodedPayload); const expiryDate = new Date(payloadObject.exp * 1000); return expiryDate; } /** * * @param {string} token * @returns {boolean} */ function isTokenExpired(token) { const expiryDate = getTokenExpiryDate(token); const currentDate = new Date(); return currentDate > expiryDate; } module.exports = { isTokenExpired }; تُعَرّف الشيفرة السابقة دالتين هما getTokenExpiryDate وisTokenExpired اللتان تحسبان تاريخ انتهاء صلاحية رمز JWT وتعطيان إما القيمة true أو false بناءً على حالة صلاحية الرمز. نحفظ الملف ونغلقه، ثم ننشئ ملف جافا سكريبت آخر باسم email: nano email.js ثم نلصق فيه الشيفرة التالية: function isValidEmail(email) { const emailRegex = /[a-zA-Z0-9]+@example\.com/; return emailRegex.test(email); } module.exports = { isValidEmail }; تُعَرّف الشيفرة السابقة الدالة isValidEmail التي تتحقق من صحة بنية البريد الإلكتروني باستخدام التعابير النمطية regex، والتي تتيح لنا التحقق من أن جميع عناوين البريد الإلكتروني مكتوبة بأبجدية رقمية وتنتهي بـالنطاق @example.com. والآن، علينا حفظ الملف وإغلاقه. كتابة اختبارات الوحدة Unit Tests باستخدام إطار عمل Jest سنتعلم الآن كيفية كتابة اختبارات الوحدة باستخدام إطار عمل جيست Jest لاختبار دوال جافا سكريبت التي عرّفناها سابقًا. سنضع هذه الاختبارات في مجلد منفصل ضمن مجلد المشروع، ونوصي باتباع التسميات الاصطلاحية التي سنعتمدها في مقالنا لأن Jest يتعامل مع الملفات التي تنتهي بالصيغة .test.js كملفات اختبار. أولًا، ننشئ مجلدّا يدعى tests داخل مجلد sample، ثم ننتقل إليه باستخدام الأمر cd على النحو التالي: mkdir tests cd tests بعدها ننشئ ملف جافا سكريبت. nano token.test.js ننسخ الشيفرة التالية ونلصقها في الملف. const { isTokenExpired } = require("/root/sample/token.js"); describe("isTokenExpired", () => { test("should return false if the token is not expired", () => { const token = "eyJ0eXAiOiJKV1QiLCJhbGciOi..."; const result = isTokenExpired(token); expect(result).toBe(false); }); test("should return true if the token is expired", () => { const token = "eyJ0eXAiOiJKV1QiLCJhbGciOi..."; const result = isTokenExpired(token); expect(result).toBe(true); }); }); تستخدم الشيفرة السابقة الدالة isTokenExpired التي عرّفناها سابقًا لتحديد ما إذا كانت الدالة تتصرف كما هو متوقع، وتعيد قيمةً منطقيةً تحدد إن كان رمز JWT منتهي الصلاحية أم لا. ملاحظة: إن أردنا أن تتحقق الدالة isTokenExpired من صحة رموز مصادقة حقيقية، يمكننا إنشاء رموز JWT منتهية الصلاحية وأخرى غير منتهية الصلاحية بواسطة أداة مثل JSON Web Token Builder واستخدامها بدلاً من النصوص المستخدمة في الاختبارات السابقة. نحفظ الملف ونغلقه، ثم ننشئ ملف جافا سكريبت آخر للاختبار. nano email.test.js ننسخ الشيفرة التالية ونلصقها في ملف الاختبار. const { isValidEmail } = require("/root/sample/email.js"); describe("isValidEmail", () => { test("returns true for a valid email", () => { const email = "user123@example.com"; const result = isValidEmail(email); expect(result).toBe(true); }); test("returns false for an invalid domain", () => { const email = "user123@example.net"; const result = isValidEmail(email); expect(result).toBe(false); }); }); تختبر الشيفرة السابقة دالة isValidEmail من خلال توفير بريد إلكتروني صالح وآخر غير صالح. ثم تتحقق من صحة النتائج عن طريق مطابقة المخرجات المتوقعة مع المخرجات الفعلية. تشغيل اختبارات Jest على Vultr سنتعلم الآن كيف نجري اختبارات باستخدام إطار عمل Jest بطريقتين. إذ سنجري في الطريقة الأولى اختبارات وحدة فردية لكل دالة معرّفة سابقًا. أما في الطريقة الثانية، فسنختبر الدالتين في وقت واحد. اختبارات وحدة فردية أولًا: نختبر صحة رمز المصادقة. npm test -- tests/token.test.js إن نجح الاختبار فيجب أن يبدو الخرج على النحو التالي: > sample@1.0.0 test > jest tests/token.test.js PASS tests/token.test.js isTokenExpired ✓ should return false if the token is not expired (2 ms) ✓ should return true if the token is expired (1 ms) Test Suites: 1 passed, 1 total Tests: 2 passed, 2 total Snapshots: 0 total Time: 0.315 s, estimated 1 s Ran all test suites matching /tests\/token.test.js/i. ثانيًا: نختبر صحة البريد الإلكتروني. npm test -- tests/email.test.js إن نجح الاختبار فسيبدو الخرج على النحو التالي: > sample@1.0.0 test > jest tests/email.test.js PASS tests/email.test.js isValidEmail ✓ returns true for a valid email (2 ms) ✓ returns false for an invalid domain (1 ms) Test Suites: 1 passed, 1 total Tests: 2 passed, 2 total Snapshots: 0 total Time: 0.451 s Ran all test suites matching /tests\/email.test.js/i. إجراء جميع الاختبارات في وقت واحد أولًا: نشغّل جميع الاختبارات في وقت واحد. npm test إن نجح الاختبار فسيبدو الخرج على النحو التالي: > sample@1.0.0 test > jest PASS tests/email.test.js PASS tests/token.test.js Test Suites: 2 passed, 2 total Tests: 4 passed, 4 total Snapshots: 0 total Time: 0.225 s, estimated 1 s Ran all test suites. ختامًا تعرّفنا في هذا المقال على أنواع مختلفة من الاختبارات البرمجية، وعلى بعض المنهجيات والممارسات المفيدة في عملية الاختبار. وتعلّمنا كيفية كتابة وتطبيق اختبارات الوحدة باستخدام إطار عمل Jest على خادم Vultr مثبّت عليه Node.js. حيث يمكن زيادة موثوقية وقوة الشيفرة البرمجية من خلال الاستفادة من أدوات الاختبار مثل Jest لتطوير برامج أكثر استقرارًا وقابلة للصيانة. ترجمة -وبتصرّف- للمقال Testing JavaScript with Jest on Vultr. اقرأ أيضًا استراتيجيات اختبارات مشاريع الويب للتوافق مع المتصفحات اختبار الوحدات البرمجية باستخدام Mocha و Assert في Node.js تعرف على أداة TestGrid وأهميتها في أتمتة الاختبارات البرمجية إعداد البيئة للاختبارات الآلية في مشاريع الويب للتوافق مع المتصفحات -
 يُعَدّ التوثيق التقني أمرًا ضروريًا في تحسين تجربة المستخدم، حيث يوفر إرشادات واضحة حول كيفية استخدام منتج أو تطبيق ويشجعهم على استخدامه وتجربته، يقدم هذا المقال نظرة عامة على المبادئ الأساسية لكتابة التوثيقات التقنية، ويسلّط الضوء على أفضل الممارسات لإنشاء وثائق واضحة وسهلة الفهم. وسواء كنتم بحاجة لتوثيق مشاريعكم أو منتجاتكم البرمجية، أو كتابة أي محتوى تقني آخر، سيساعدكم تطبيق المبادئ التي سنشرحها في الفقرات التالية على كتابة التوثيقات التقنية بجودة عالية. ما هو التوثيق التقني التوثيق التقني هو بمثابة دليل استخدام أو كتيب إرشادات خاص بتقنية ما، حيث يركز على توفير معلومات تفصيلية للمطورين والمستخدمين، ويتضمن وصفًا تفصيليًا حول طريقة التعامل معها، وشرحًا للتفاصيل الفنية الخاصة بها من دوال وواجهات برمجية، ومعلومات عن صيانتها وحل المشكلات الشائعة التي قد تواجههم عند التعامل معها. لنتعرف على أهم النصائح الواجب اتباعها لكتابة التوثيقات التقنية بوضوح واحترافية. أولًا: الالتزام بالوضوح والإيجاز والاتساق تشكل هذه العناصر الثلاثة المبادئ الأساسية لكتابة التوثيقات التقنية، وتساعد في إنشاء وثائق عالية الجودة، ولنوضح كل عنصر من هذه العناصر بمزيد من التفصيل. الوضوح كي يحقق التوثيق التقني سمة الوضوح، يتوجب علينا تطبيق الإرشادات التالية: استخدام كلمات بسيطة ولغة واضحة ووضع الجمهور المستهدف في الحسبان الوضوح عند كتابة تعليمات لتنفيذ دالة ما، ويفضل استخدام الأفعال المبنية للمعلوم لتوضيح الفاعل وتحديد هل ستُشَغّل الدالة بواسطة حدث معين، أم على المستخدم استدعاؤها بشكل صريح شرح المصطلحات الجديدة بوضوح، حيث يساعد ذلك في وضع أساسيات للمفاهيم التي سنتحدث عنها لاحقًا استبدال الضمائر بأسماء علم إن كانت تشير لأكثر من شيء واحد في السياق المحدد تقديم فكرة واحدة في كل جملة لتحسين المقروئية، والالتزام بفكرة رئيسية واحدة في كل فقرة ربط كل جملة منطقيًا بالجمل التي قبلها، كما لو أن كل جملة في الفقرة هي حلقة في سلسلة، فإن فهمنا الحلقة الأولى، فيجب أن تتبعها الحلقات الأخرى في السلسلة، لتشكل سلسلة مترابطة تتدفق فيها الأفكار بسلاسة الإيجاز من الجيد إبقاء الجمل قصيرة وموجزة قدر المستطاع لتعزز وضوح المستند وسهولة قراءته، وتساعد على الفهم السريع، فقد يكون فهم الجمل الطويلة أصعب بسبب بنيتها المعقدة. وبناءً على معايير سهولة القراءة الشائعة، من الأفضل كتابة 15 إلى 20 كلمة وسطيًا في كل جملة. وللحصول على معلومات إضافية حول هذا المعيار ننصح بمطالعة صفحة المقروئية على ويكيبيديا. الاتساق يتوجب علينا استخدام نفس المصطلحات في التوثيق البرمجي لضمان تجربة قراءة سلسة. على سبيل المثال، إذا استخدمنا مصطلح وكلاء المستخدم user agents للإشارة إلى المتصفحات browsers، فعلينا الالتزام بهذا المصطلح في كل السياق، إذ يجنبنا ذلك الالتباس الذي قد ينشأ نتيجة لاستخدام مصطلحات عدة، حتى لو كان لها المعنى نفسه. كما ينبغي اتباع أسلوب تنسيق موحد في جميع الوثائق، والحفاظ على تناسق الكلمات، من حيث استخدام الأحرف الكبيرة والصغيرة -في حال استخدام اللغة الإنجليزية في التوثيق- إذ تُحَسّن هذه الممارسات مقروئية المستند، وتظهره بشكل احترافي. ثانيًا: تنظيم المحتوى ينبغي أن نطبّق نفس القواعد المستخدمة لتنظيم الشيفرات البرمجية عند تنظيم المحتوى التقني، وذلك من خلال تحديد هدف واضح للمحتوى، والتفكير في البنية التي نريد اعتمادها في التوثيقات. والحرص على أن تساهم كلّ الأقسام الفرعية في تحقيق هذا الهدف تدريجيًا، ولنوضح أهم الأقسام التي تساعدنا على تنظيم محتوانا التقني. مقدمة التوثيق أولاً، علينا وصف الميزة التقنية التي سنوثّقها في المقدمة، ونوضّح لماذا سيكون التعرف على تلك الميزة مفيدًا كأن نذكر حالات عملية مفيدة لاستخدامها. فكلما أضفنا حالات واقعية ذات أهمية، سَهُلَ على القراء فهم المحتوى والتفاعل معه. التسلسل المنطقي ستساعدنا الأسئلة التالية في تنظيم المحتوى وفق تسلسل منطقي صحيح: هل التوثيق مصمم لتوجيه القراء بدايةً من المفاهيم الأساسية إلى المفاهيم المتقدمة هل توجد أقسام مخصصة للتعريف بالأساسيات النظرية وكل ما يلزم، قبل الانتقال إلى كيفية التنفيذ هل تُماثِل بنية المستند مسار التعلم الطبيعي للموضوع، فهذا يساعد على بناء المعلومات خطوة خطوة ويعزز تجربة التعلم هل توجد أدلة إرشادية وأمثلة كافية تعزز الأقسام النظرية والمفاهيمية هل يتبع المحتوى تسلسلاً منطقيًا من حيث الجمل والفقرات والأقسام وهل يعتمد كل قسم على المعلومات السابقة، مع تجنب الفجوات في المحتوى استخدام الأمثلة استخدام الأمثلة في التوثيق البرمجي أمر بالغ الأهمية ويساعدنا على توصيل الفكرة بوضوح وسهولة، يمكن أن نتخيل أننا نجلس بجوار شخص ما ونشرح له المفاهيم، كما يمكن أن نستبق أسئلته ونعالجها في الكتابة، ونستخدم هذا الأسلوب لإضافة أكبر عدد ممكن من الأمثلة الواضحة ذات الصلة بما نشرحه. وعند كتابة التوثيق البرمجي، ليس بالضرورة أن نقتصر على تقديم الأمثلة البرمجية فقط بل يمكننا أيضًا تضمين أمثلة عملية وحالات غير برمجية تساعد في توضيح فائدة الميزة وكيفية استخدامها وتطبيقها عمليًا. هذا سيساعد القراء على استيعاب المفاهيم بصورة أفضل ويلبي أيضًا أنماط التعلم المختلفة. ثالثًا: تحسين بنية التوثيق من الضروري تقييم بنية مستندات التوثيق للتأكد من أنها تحافظ على تسلسل هرمي منطقي ومتوازن باتباع الإرشادات التالية: يجب أن يكون لكل قسم رئيسي ولكل قسم فرعي غرض واضح، ولا يجب أن يكون هناك أقسام بلا هدف محدد أو بلا محتوى كافٍ التعامل مع الأقسام اليتيمة Orphan Sections وهي الأقسام الرئيسية التي تحتوي على قسم فرعي واحد فقط، كأن يكون لدينا قسم فرعي واحد من المستوى الثالث H3 ضمن قسم رئيسي من المستوى الثاني H2، هذا يشير لضرورة إعادة توسيع هذا القسم أو دمجه مع قسم آخر التحقق من عدم وجود الكثير من العناوين من المستوى الرابع H4، فكثرة الأقسام الفرعية قد يكون مرهقًا للقراء، وقد يُصعّب عليهم فهم المعلومات الانتباه للطول الإجمالي لكل قسم فإذا كان أحد الأقسام طويلًا جدًا، فقد يشتت القارئ، لذا نقسّم الأقسام الكبيرة لأقسام فرعية منطقية متعددة، أو نعيد هيكلة المحتوى تدقيق المحتوى من أكثر الخطوات أهمية في التوثيق البرمجي هي المراجعة الذاتية وتدقيق المحتوى، سواء كنا بصدد إنشاء مستند كبير أو فقرة قصيرة، فهذه الخطوة ضرورية جدًا. لذا نحتاج لأن نخصص وقتًا مناسبًا لمراجعة العمل كاملًا ونحدد الأقسام التي يمكن تحسينها وتوضيحها أكثر، ونزيل الحشو من الأفكار التي لا تضيف قيمة، ونتخلص من الكلمات والعبارات المكررة. ستضمن هذه التعديلات وضوح النص وتماسكه ووصول الأفكار على النحو المطلوب. كما نحتاج لتدقيق المحتوى لغويًا ويفضل أن نستريح قليلًا قبل مراجعته مرة أخرى، ونبحث عن أي تناقضات في الأسلوب أو أزمنة الأفعال أو التنسيق ثم نعدّل ما يلزم فالمراجعة بعد فترة من الاستراحة تمكننا من ملاحظة الأخطاء التي قد تفوتنا أول مرة. نصائح إضافية نختم بجملة من النصائح التالية لتحسين وضوح الوثائق التقنية: استخدام القوائم ذات التعداد الرقمي عندما يتوجب علينا اتباع الخطوات بترتيب محدد، أو التعداد النقطي عندما لا يكون للعناصر ترتيب محدد، ونسبق القائمة دائمًا بجملة أولية توضح السياق استخدام الفواصل وعلامات الترقيم المناسبة لتحسين المقروئية وتوضيح بنية الجملة وضع نص بديل Alternative text للصور، وإرفاق ملفات الفيديو والصوت بنصوص وصفية لجعل الوثائق مناسبة للجميع الحرص على أن تكون جميع نصوص الروابط واضحة وتشير بوضوح إلى وجهة الرابط لمساعدة الأشخاص الذين يستخدمون برامج قراءة الشاشة على فهم وجهة الروابط. مثلًا، نستخدم الجملة التالية اطلع على بعض الأدوات مجانية لتحسين محركات البحث بدلاً من جملة انقر هنا استخدام لغة مناسبة ومفردات تحترم تنوع الجمهور، وتجعل من الوثائق موضع ترحيب للجميع الخاتمة بهذا وصلنا إلى نهاية مقالنا الذي قدمنا فيه نصائح مفيدة للمطورين والكتّاب التقنيين المهتمين بتحسين جودة التوثيقات التقنية والبرمجية. ولنتذكر في الختام أن إنشاء توثيقات تقنية فعالة وسهلة الاستخدام عملية مهمة تبدأ بفهم الجمهور المستهدف والهدف من الوثائق التي نكتبها، مع الحرص على تطبيق المبادئ التي تعلمناها لتحسين جودة الوثائق وفهمها. ترجمة، وبتصرّف، للمقال Creating effective technical documentation لكاتبته Dipika Bhattacharya. اقرأ أيضًا كيف تكتب كود برمجي مثل مهندسي البرمجيات هل تحتاج لمراجعات تقنية مستقلة قائمة مراجعة المشروع البرمجي أسس القيادة التقنية قواعد البرمجة ببساطة للمبتدئين
يُعَدّ التوثيق التقني أمرًا ضروريًا في تحسين تجربة المستخدم، حيث يوفر إرشادات واضحة حول كيفية استخدام منتج أو تطبيق ويشجعهم على استخدامه وتجربته، يقدم هذا المقال نظرة عامة على المبادئ الأساسية لكتابة التوثيقات التقنية، ويسلّط الضوء على أفضل الممارسات لإنشاء وثائق واضحة وسهلة الفهم. وسواء كنتم بحاجة لتوثيق مشاريعكم أو منتجاتكم البرمجية، أو كتابة أي محتوى تقني آخر، سيساعدكم تطبيق المبادئ التي سنشرحها في الفقرات التالية على كتابة التوثيقات التقنية بجودة عالية. ما هو التوثيق التقني التوثيق التقني هو بمثابة دليل استخدام أو كتيب إرشادات خاص بتقنية ما، حيث يركز على توفير معلومات تفصيلية للمطورين والمستخدمين، ويتضمن وصفًا تفصيليًا حول طريقة التعامل معها، وشرحًا للتفاصيل الفنية الخاصة بها من دوال وواجهات برمجية، ومعلومات عن صيانتها وحل المشكلات الشائعة التي قد تواجههم عند التعامل معها. لنتعرف على أهم النصائح الواجب اتباعها لكتابة التوثيقات التقنية بوضوح واحترافية. أولًا: الالتزام بالوضوح والإيجاز والاتساق تشكل هذه العناصر الثلاثة المبادئ الأساسية لكتابة التوثيقات التقنية، وتساعد في إنشاء وثائق عالية الجودة، ولنوضح كل عنصر من هذه العناصر بمزيد من التفصيل. الوضوح كي يحقق التوثيق التقني سمة الوضوح، يتوجب علينا تطبيق الإرشادات التالية: استخدام كلمات بسيطة ولغة واضحة ووضع الجمهور المستهدف في الحسبان الوضوح عند كتابة تعليمات لتنفيذ دالة ما، ويفضل استخدام الأفعال المبنية للمعلوم لتوضيح الفاعل وتحديد هل ستُشَغّل الدالة بواسطة حدث معين، أم على المستخدم استدعاؤها بشكل صريح شرح المصطلحات الجديدة بوضوح، حيث يساعد ذلك في وضع أساسيات للمفاهيم التي سنتحدث عنها لاحقًا استبدال الضمائر بأسماء علم إن كانت تشير لأكثر من شيء واحد في السياق المحدد تقديم فكرة واحدة في كل جملة لتحسين المقروئية، والالتزام بفكرة رئيسية واحدة في كل فقرة ربط كل جملة منطقيًا بالجمل التي قبلها، كما لو أن كل جملة في الفقرة هي حلقة في سلسلة، فإن فهمنا الحلقة الأولى، فيجب أن تتبعها الحلقات الأخرى في السلسلة، لتشكل سلسلة مترابطة تتدفق فيها الأفكار بسلاسة الإيجاز من الجيد إبقاء الجمل قصيرة وموجزة قدر المستطاع لتعزز وضوح المستند وسهولة قراءته، وتساعد على الفهم السريع، فقد يكون فهم الجمل الطويلة أصعب بسبب بنيتها المعقدة. وبناءً على معايير سهولة القراءة الشائعة، من الأفضل كتابة 15 إلى 20 كلمة وسطيًا في كل جملة. وللحصول على معلومات إضافية حول هذا المعيار ننصح بمطالعة صفحة المقروئية على ويكيبيديا. الاتساق يتوجب علينا استخدام نفس المصطلحات في التوثيق البرمجي لضمان تجربة قراءة سلسة. على سبيل المثال، إذا استخدمنا مصطلح وكلاء المستخدم user agents للإشارة إلى المتصفحات browsers، فعلينا الالتزام بهذا المصطلح في كل السياق، إذ يجنبنا ذلك الالتباس الذي قد ينشأ نتيجة لاستخدام مصطلحات عدة، حتى لو كان لها المعنى نفسه. كما ينبغي اتباع أسلوب تنسيق موحد في جميع الوثائق، والحفاظ على تناسق الكلمات، من حيث استخدام الأحرف الكبيرة والصغيرة -في حال استخدام اللغة الإنجليزية في التوثيق- إذ تُحَسّن هذه الممارسات مقروئية المستند، وتظهره بشكل احترافي. ثانيًا: تنظيم المحتوى ينبغي أن نطبّق نفس القواعد المستخدمة لتنظيم الشيفرات البرمجية عند تنظيم المحتوى التقني، وذلك من خلال تحديد هدف واضح للمحتوى، والتفكير في البنية التي نريد اعتمادها في التوثيقات. والحرص على أن تساهم كلّ الأقسام الفرعية في تحقيق هذا الهدف تدريجيًا، ولنوضح أهم الأقسام التي تساعدنا على تنظيم محتوانا التقني. مقدمة التوثيق أولاً، علينا وصف الميزة التقنية التي سنوثّقها في المقدمة، ونوضّح لماذا سيكون التعرف على تلك الميزة مفيدًا كأن نذكر حالات عملية مفيدة لاستخدامها. فكلما أضفنا حالات واقعية ذات أهمية، سَهُلَ على القراء فهم المحتوى والتفاعل معه. التسلسل المنطقي ستساعدنا الأسئلة التالية في تنظيم المحتوى وفق تسلسل منطقي صحيح: هل التوثيق مصمم لتوجيه القراء بدايةً من المفاهيم الأساسية إلى المفاهيم المتقدمة هل توجد أقسام مخصصة للتعريف بالأساسيات النظرية وكل ما يلزم، قبل الانتقال إلى كيفية التنفيذ هل تُماثِل بنية المستند مسار التعلم الطبيعي للموضوع، فهذا يساعد على بناء المعلومات خطوة خطوة ويعزز تجربة التعلم هل توجد أدلة إرشادية وأمثلة كافية تعزز الأقسام النظرية والمفاهيمية هل يتبع المحتوى تسلسلاً منطقيًا من حيث الجمل والفقرات والأقسام وهل يعتمد كل قسم على المعلومات السابقة، مع تجنب الفجوات في المحتوى استخدام الأمثلة استخدام الأمثلة في التوثيق البرمجي أمر بالغ الأهمية ويساعدنا على توصيل الفكرة بوضوح وسهولة، يمكن أن نتخيل أننا نجلس بجوار شخص ما ونشرح له المفاهيم، كما يمكن أن نستبق أسئلته ونعالجها في الكتابة، ونستخدم هذا الأسلوب لإضافة أكبر عدد ممكن من الأمثلة الواضحة ذات الصلة بما نشرحه. وعند كتابة التوثيق البرمجي، ليس بالضرورة أن نقتصر على تقديم الأمثلة البرمجية فقط بل يمكننا أيضًا تضمين أمثلة عملية وحالات غير برمجية تساعد في توضيح فائدة الميزة وكيفية استخدامها وتطبيقها عمليًا. هذا سيساعد القراء على استيعاب المفاهيم بصورة أفضل ويلبي أيضًا أنماط التعلم المختلفة. ثالثًا: تحسين بنية التوثيق من الضروري تقييم بنية مستندات التوثيق للتأكد من أنها تحافظ على تسلسل هرمي منطقي ومتوازن باتباع الإرشادات التالية: يجب أن يكون لكل قسم رئيسي ولكل قسم فرعي غرض واضح، ولا يجب أن يكون هناك أقسام بلا هدف محدد أو بلا محتوى كافٍ التعامل مع الأقسام اليتيمة Orphan Sections وهي الأقسام الرئيسية التي تحتوي على قسم فرعي واحد فقط، كأن يكون لدينا قسم فرعي واحد من المستوى الثالث H3 ضمن قسم رئيسي من المستوى الثاني H2، هذا يشير لضرورة إعادة توسيع هذا القسم أو دمجه مع قسم آخر التحقق من عدم وجود الكثير من العناوين من المستوى الرابع H4، فكثرة الأقسام الفرعية قد يكون مرهقًا للقراء، وقد يُصعّب عليهم فهم المعلومات الانتباه للطول الإجمالي لكل قسم فإذا كان أحد الأقسام طويلًا جدًا، فقد يشتت القارئ، لذا نقسّم الأقسام الكبيرة لأقسام فرعية منطقية متعددة، أو نعيد هيكلة المحتوى تدقيق المحتوى من أكثر الخطوات أهمية في التوثيق البرمجي هي المراجعة الذاتية وتدقيق المحتوى، سواء كنا بصدد إنشاء مستند كبير أو فقرة قصيرة، فهذه الخطوة ضرورية جدًا. لذا نحتاج لأن نخصص وقتًا مناسبًا لمراجعة العمل كاملًا ونحدد الأقسام التي يمكن تحسينها وتوضيحها أكثر، ونزيل الحشو من الأفكار التي لا تضيف قيمة، ونتخلص من الكلمات والعبارات المكررة. ستضمن هذه التعديلات وضوح النص وتماسكه ووصول الأفكار على النحو المطلوب. كما نحتاج لتدقيق المحتوى لغويًا ويفضل أن نستريح قليلًا قبل مراجعته مرة أخرى، ونبحث عن أي تناقضات في الأسلوب أو أزمنة الأفعال أو التنسيق ثم نعدّل ما يلزم فالمراجعة بعد فترة من الاستراحة تمكننا من ملاحظة الأخطاء التي قد تفوتنا أول مرة. نصائح إضافية نختم بجملة من النصائح التالية لتحسين وضوح الوثائق التقنية: استخدام القوائم ذات التعداد الرقمي عندما يتوجب علينا اتباع الخطوات بترتيب محدد، أو التعداد النقطي عندما لا يكون للعناصر ترتيب محدد، ونسبق القائمة دائمًا بجملة أولية توضح السياق استخدام الفواصل وعلامات الترقيم المناسبة لتحسين المقروئية وتوضيح بنية الجملة وضع نص بديل Alternative text للصور، وإرفاق ملفات الفيديو والصوت بنصوص وصفية لجعل الوثائق مناسبة للجميع الحرص على أن تكون جميع نصوص الروابط واضحة وتشير بوضوح إلى وجهة الرابط لمساعدة الأشخاص الذين يستخدمون برامج قراءة الشاشة على فهم وجهة الروابط. مثلًا، نستخدم الجملة التالية اطلع على بعض الأدوات مجانية لتحسين محركات البحث بدلاً من جملة انقر هنا استخدام لغة مناسبة ومفردات تحترم تنوع الجمهور، وتجعل من الوثائق موضع ترحيب للجميع الخاتمة بهذا وصلنا إلى نهاية مقالنا الذي قدمنا فيه نصائح مفيدة للمطورين والكتّاب التقنيين المهتمين بتحسين جودة التوثيقات التقنية والبرمجية. ولنتذكر في الختام أن إنشاء توثيقات تقنية فعالة وسهلة الاستخدام عملية مهمة تبدأ بفهم الجمهور المستهدف والهدف من الوثائق التي نكتبها، مع الحرص على تطبيق المبادئ التي تعلمناها لتحسين جودة الوثائق وفهمها. ترجمة، وبتصرّف، للمقال Creating effective technical documentation لكاتبته Dipika Bhattacharya. اقرأ أيضًا كيف تكتب كود برمجي مثل مهندسي البرمجيات هل تحتاج لمراجعات تقنية مستقلة قائمة مراجعة المشروع البرمجي أسس القيادة التقنية قواعد البرمجة ببساطة للمبتدئين -
 تتقدم التقنيات بسرعة في أيامنا، ويأتي الذكاء الاصطناعي وتعلم الآلة في طليعة هذه التقنيات، إذ تُطوَّر أدوات الذكاء الاصطناعي الجديدة بانتظام، وتغير من طريقة تنفيذنا للمهام في مختلف الصناعات، وتنوع الأساليب التي يتبعها المطورون لابتكار الحلول البرمجية، فالذكاء الاصطناعي وتعلم الآلة اليوم من الأدوات القوية التي يمكنها أن تساعدنا في حل المشكلات المختلفة، وتحسّن كفاءة عملنا، وتكشف عن قراءات مهمة من بيانات كان من المستحيل اكتشافها في السابق. لكن تنوّع الأدوات المتاحة وكثرتها قد تشعر المبتدئين بالارتباك، لذا سنساعدكم في مقالنا هذا على اختيار الأدوات المناسبة لتحسين مهارات الذكاء الاصطناعي المختلفة وتسريع تنفيذ الحلول العملية مثل إنشاء روبوتات الدردشة، وتطبيقات التعرف على الصور، وتحليل المشاعر، وأنظمة التوصية وغيرها من المهام. وقد اخترنا الأدوات التي سنذكرها أدناه بناءً على مميزاتها وبساطتها ووجود مجتمع داعم لها. أولًا: منصة Paperspace تُعدّ Paperspace منصة ممتازة لبدء رحلة تعلم الذكاء الاصطناعي وتعلم الآلة، فهي توفر وحدة معالجة رسومية سحابية cloud-based GPU منخفضة التكلفة وجاهزة للاستخدام، وبالتالي لن نحتاج لامتلاك جهاز حاسوب قوي لتطوير مشاريع الذكاء الاصطناعي والتعلم العميق ولن نقلق بشأن توفير العتاد الملائم. كما يمكن الاستفادة من Paperspace Gradient، وهي مجموعة أدوات مصممة لتسريع العمل على المشاريع، وتشتمل على أداة قوية لإدارة المهام، ودعم الحاويات ومنصة Jupyter notebook التفاعلية، وتتكامل مع العديد من لغات البرمجة، كما توفر منصة Paperspace إمكانية الوصول إلى أطر عمل التعلم العميق الشائعة مثل تنسرفلو TensorFlow وباي تورش PyTorch مما يجعل التجريب والتطوير أمرًا سهلًا وسلسًا. ومع استحواذ شركة DigitalOcean مؤخرًا على منصة Paperspace يمكن للشركات نشر نماذج تعلم الآلة من خلال استخدام وحدات معالجة الرسوميات NVIDIA H100 GPUs منخفضة التكلفة، والتي تعد من أقوى وحدات معالجة الرسوميات لتدريب نماذج الذكاء الاصطناعي وتعلم الآلة. ثانيًا: منصة Papers with code توفر منصة Papers with Code أحدث الأوراق البحثية مع شيفرتها البرمجية على Github، ومجموعات بياناتها datasets التي ساهم بها المجتمع. ولعل اسم المنصة يعطينا فكرة واضحة عن الغرض منها، وقد اكتسبت هذه المنصة مؤخرًا شعبية كبيرة، ووسعت نظامها لدعم الأبحاث في مجال تعلم الآلة ووفرت بيئة كاملة للمساهمات مفتوحة المصدر تسهل على مهندسي الذكاء الاصطناعي، وعلماء البيانات، والباحثين والطلاب تبادل الأفكار وتعزيز الخبرات التطويرية. تتمثل مهمة منصة Papers with Code في إنشاء مورد مجاني يحتوي على أوراق بحثية في مجال تعلم الآلة مع تضمين الأكواد البرمجية ومجموعات البيانات والدوال، وجداول التقييم المستخدمة مع كل بحث. ويمكن تصفح بعض نماذج State of the Art models للاطلاع على أحدث تطورات هذا المجال. ثالثًا: مكتبة تنسرفلو TensorFlow تُعدّ مكتبة تنسرفلو TensorFlow التي طورتها Google، إحدى المكتبات مفتوحة المصدر الأكثر انتشارًا في مشاريع تعلم الآلة والتعلم العميق. فواجهتها سهلة الاستخدام تجعلها خيارًا مثاليًا للمستخدمين الجدد، كما تتميز مكتبة TensorFlow ببيئة واسعة الموارد، وتتضمن برامج تعليمية وتوثيقات ومجتمع داعم يضم الكثير من المستخدمين وهي خيار مثالي لبدء تعلم الذكاء الاصطناعي وتعلم الآلة باستخدام واجهة برمجة التطبيقات عالية المستوى كيراس Keras، والتي دمجت مع تنسرفلو لتبسيط إنشاء الشبكات العصبية وتدريبها. رابعًا: إطار باي تورش PyTorch يُعدّ باي تورش PyTorch من أطر العمل المفضلة بلغة البرمجة بايثون في مجال التعلم العميق، وهو يشتهر بمرونته وسهولة استخدامه ورسوماته البيانية الديناميكية وقدرته الممتازة على تصحيح الأخطاء. ويمتاز مجتمع باي تورش PyTorch بكونه نشطًا جدًا، ويقدم الكثير من الموارد والبرامج التعليمية لتسهيل تعلم مجال التعلم العميق. خامسًا: مكتبة ساي كيت ليرن Scikit-Learn مكتبة ساي كيت ليرن Scikit-Learn هي إحدى مكتبات لغة بايثون القوية المصممة بدقة لتطبيقات تعلم الآلة البسيطة والفعالة. وهي خيار ممتاز للمبتدئين وتوفر واجهة برمجة تطبيقات API واضحة ومتسقة، كما تقدم مجموعة خوارزميات ذكاء اصطناعي قوية أبرزها خوارزميات التصنيف classification، وخوارزميات الانحدار أو التوقع regression، وخوارزميات العنقدة clustering وغيرها، ويمكن مطالعة التوثيقات الرسمية والأمثلة التوضيحية للمكتبة لفهم هذه الخوارزميات وتنفيذها بفاعلية. سادسًا: منصة Jupyter Notebook منصة Jupyter Notebook هي بيئة تطوير تفاعلية تتيح إنشاء ونشر مستندات تجمع بين الشيفرة البرمجية المباشرة live code والمعادلات equations والتمثيل المرئي للبيانات visualization، ويمكنها التعامل مع لغات برمجية عدة، بما في ذلك لغة بايثون Python ولغة R ما يجعلها أداة مثالية لتجربة مشاريع الذكاء الاصطناعي وتعلم الآلة. سابعًا: منصة IBM Watson Studio منصة IBM Watson Studio هي منصة سحابية تقدم أدوات وخدمات متنوعة لمطوري الذكاء الاصطناعي وعلماء البيانات. فهي تبسِّط عملية تطوير تطبيقات وخدمات الذكاء الاصطناعي وتعلم الآلة من خلال تقديم توفير بيئات معّدة مسبقًا، وميزات تعاونية، وتمنح إمكانية الوصول لخدمات الذكاء الاصطناعي الخاصة بشركة IBM. وبالتالي فهي خيار مناسب للمبتدئين الراغبين في تجربة الذكاء الاصطناعي دون تعقيدات. ثامنًا: منصة Hugging Face تقدم منصة Hugging Face مجموعة أدوات ذكاء اصطناعي متنوعة، بما في ذلك مكتبة المحولات Transformers، وهي مكتبة مخصصة تتضمن أحدث نماذج معالجة اللغات الطبيعية NLP وتتميز ببساطتها وسهولة استخدامها، مما يجعلها خيارًا مناسبًا للمبتدئين الذين يستكشفون طريقهم في مجال معالجة اللغة الطبيعية NLP. كما أن الدعم الواسع الذي تقدمه منصة Hugging Face والنماذج الكثيرة المسبقة التدريب تسهّل عملية التعلم. نصائح لبدء تعلم الذكاء الاصطناعي وتعلم الآلة بعد أن تعرّفنا على مجموعة منتقاة من أفضل أدوات الذكاء الاصطناعي وتعلم الآلة، سنقدم لك بعض النصائح لتحسين رحلتك في تعلم الذكاء الاصطناعي وتعلم الآلة كمبتدئ. تعلم الأساسيات يتوجب البدء بتعلم أساسيات الذكاء الاصطناعي وتعلم الآلة ودراسة مفاهيمه ومصطلحاته، بما في ذلك التعلم الخاضع للإشراف supervised learning، والتعلم غير الخاضع للإشراف unsupervised learning، والشبكات العصبية neural networks. هناك العديد من الدورات التدريبية والبرامج التعليمية المتاحة عبر الإنترنت والتي تساعد على تعلم هذه المفاهيم. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن التدريب العملي إذا اكتفينا بدراسة مفاهيم الذكاء الاصطناعي وتعلم الآلة وركزنا فقط على الجانب النظري فلن نحرز أي تقدم، بل يتوجب علينا تطبيق كل ما نتعلمه وتنفيذ مشاريع صغيرة مع زيادة تعقيدها تدريجيًا. إذ يُعدّ التجريب مفتاحًا لفهم هذه التقنيات، وللاطلاع على مشاريع عديدة تناسب المبتدئين ننصحك بكتاب عشرة مشاريع عملية عن الذكاء الاصطناعي من أكاديمية حسوب. استكشاف مجموعات البيانات Datasets لا يمكن تنفيذ مشاريع الذكاء الاصطناعي مجموعات البيانات فهي حجر الزاوية لبناء النماذج وبدونها لا يمكن للنموذج تعلم الأنماط أو اتخاذ القرارات، لذا سنحتاج للتعرف على مجموعات البيانات ذات الصلة باهتمامنا والاستفادة منها في مشاريعنا. على سبيل المثال تُعدّ منصة Kaggle كنزًا لمجموعات البيانات وهي تستضيف مسابقات عديدة في علوم البيانات من شأنها تعزيز فهمنا وصقل مهاراتنا. الانضمام إلى المجتمعات التقنية لا شك أن طرح الأسئلة والنقاش مع المطورين المختصين في مجتمعات الذكاء الاصطناعي وتعلم الآلة المتخصصة مثل PaperSpace و GitHub و Stack Overflow وReddit ومجتمع حسوب IO يساعدنا كثيرة في حل مشكلاتنا وتسريع رحلتنا التعليمية وتعزيز خبراتنا في هذا التخصص. الاطلاع على كل جديد يتطور مجال الذكاء الاصطناعي وتعلم الآلة بسرعة ولذا لا بد من متابعة أحدث المستجدات عبر الإنترنت، وقراءة الأخبار والتقارير التقنية، والاطلاع على الأوراق البحثية للبقاء على اطلاع بأحدث التطورات في هذا المجال سريع التقادم. الخاتمة يمكن أن تكون رحلتنا في مجال الذكاء الاصطناعي وتعلم الآلة كمبتدئين تجربة مثيرة ومثمرة إذا حرصنا على بناء أساس متين واستخدامنا الأدوات التي تسهل علينا التعلم والفهم. ولنتذكر أن التعلم عملية مستمرة، لذا علينا الحفاظ على حماسنا والتدرب بجد والاستمتاع بما نتعلمه وتطبيقه في مشاريع فعلية تجسد فائدة ما نتعلمه. ترجمة وبتصرّف للمقال Top AI and ML Tools for New Developers to Get Started With لكاتبه Anish Singh Walia. اقرأ أيضًا تعرف على أفضل دورات الذكاء الاصطناعي تعرف على أهم كتب الذكاء الاصطناعي المجانية مكتبات وأطر عمل الذكاء الاصطناعي: القوة الكامنة خلف الأنظمة الذكية لغات برمجة الذكاء الاصطناعي اكتشف بدائل ChatGPT مفتوحة المصدر
تتقدم التقنيات بسرعة في أيامنا، ويأتي الذكاء الاصطناعي وتعلم الآلة في طليعة هذه التقنيات، إذ تُطوَّر أدوات الذكاء الاصطناعي الجديدة بانتظام، وتغير من طريقة تنفيذنا للمهام في مختلف الصناعات، وتنوع الأساليب التي يتبعها المطورون لابتكار الحلول البرمجية، فالذكاء الاصطناعي وتعلم الآلة اليوم من الأدوات القوية التي يمكنها أن تساعدنا في حل المشكلات المختلفة، وتحسّن كفاءة عملنا، وتكشف عن قراءات مهمة من بيانات كان من المستحيل اكتشافها في السابق. لكن تنوّع الأدوات المتاحة وكثرتها قد تشعر المبتدئين بالارتباك، لذا سنساعدكم في مقالنا هذا على اختيار الأدوات المناسبة لتحسين مهارات الذكاء الاصطناعي المختلفة وتسريع تنفيذ الحلول العملية مثل إنشاء روبوتات الدردشة، وتطبيقات التعرف على الصور، وتحليل المشاعر، وأنظمة التوصية وغيرها من المهام. وقد اخترنا الأدوات التي سنذكرها أدناه بناءً على مميزاتها وبساطتها ووجود مجتمع داعم لها. أولًا: منصة Paperspace تُعدّ Paperspace منصة ممتازة لبدء رحلة تعلم الذكاء الاصطناعي وتعلم الآلة، فهي توفر وحدة معالجة رسومية سحابية cloud-based GPU منخفضة التكلفة وجاهزة للاستخدام، وبالتالي لن نحتاج لامتلاك جهاز حاسوب قوي لتطوير مشاريع الذكاء الاصطناعي والتعلم العميق ولن نقلق بشأن توفير العتاد الملائم. كما يمكن الاستفادة من Paperspace Gradient، وهي مجموعة أدوات مصممة لتسريع العمل على المشاريع، وتشتمل على أداة قوية لإدارة المهام، ودعم الحاويات ومنصة Jupyter notebook التفاعلية، وتتكامل مع العديد من لغات البرمجة، كما توفر منصة Paperspace إمكانية الوصول إلى أطر عمل التعلم العميق الشائعة مثل تنسرفلو TensorFlow وباي تورش PyTorch مما يجعل التجريب والتطوير أمرًا سهلًا وسلسًا. ومع استحواذ شركة DigitalOcean مؤخرًا على منصة Paperspace يمكن للشركات نشر نماذج تعلم الآلة من خلال استخدام وحدات معالجة الرسوميات NVIDIA H100 GPUs منخفضة التكلفة، والتي تعد من أقوى وحدات معالجة الرسوميات لتدريب نماذج الذكاء الاصطناعي وتعلم الآلة. ثانيًا: منصة Papers with code توفر منصة Papers with Code أحدث الأوراق البحثية مع شيفرتها البرمجية على Github، ومجموعات بياناتها datasets التي ساهم بها المجتمع. ولعل اسم المنصة يعطينا فكرة واضحة عن الغرض منها، وقد اكتسبت هذه المنصة مؤخرًا شعبية كبيرة، ووسعت نظامها لدعم الأبحاث في مجال تعلم الآلة ووفرت بيئة كاملة للمساهمات مفتوحة المصدر تسهل على مهندسي الذكاء الاصطناعي، وعلماء البيانات، والباحثين والطلاب تبادل الأفكار وتعزيز الخبرات التطويرية. تتمثل مهمة منصة Papers with Code في إنشاء مورد مجاني يحتوي على أوراق بحثية في مجال تعلم الآلة مع تضمين الأكواد البرمجية ومجموعات البيانات والدوال، وجداول التقييم المستخدمة مع كل بحث. ويمكن تصفح بعض نماذج State of the Art models للاطلاع على أحدث تطورات هذا المجال. ثالثًا: مكتبة تنسرفلو TensorFlow تُعدّ مكتبة تنسرفلو TensorFlow التي طورتها Google، إحدى المكتبات مفتوحة المصدر الأكثر انتشارًا في مشاريع تعلم الآلة والتعلم العميق. فواجهتها سهلة الاستخدام تجعلها خيارًا مثاليًا للمستخدمين الجدد، كما تتميز مكتبة TensorFlow ببيئة واسعة الموارد، وتتضمن برامج تعليمية وتوثيقات ومجتمع داعم يضم الكثير من المستخدمين وهي خيار مثالي لبدء تعلم الذكاء الاصطناعي وتعلم الآلة باستخدام واجهة برمجة التطبيقات عالية المستوى كيراس Keras، والتي دمجت مع تنسرفلو لتبسيط إنشاء الشبكات العصبية وتدريبها. رابعًا: إطار باي تورش PyTorch يُعدّ باي تورش PyTorch من أطر العمل المفضلة بلغة البرمجة بايثون في مجال التعلم العميق، وهو يشتهر بمرونته وسهولة استخدامه ورسوماته البيانية الديناميكية وقدرته الممتازة على تصحيح الأخطاء. ويمتاز مجتمع باي تورش PyTorch بكونه نشطًا جدًا، ويقدم الكثير من الموارد والبرامج التعليمية لتسهيل تعلم مجال التعلم العميق. خامسًا: مكتبة ساي كيت ليرن Scikit-Learn مكتبة ساي كيت ليرن Scikit-Learn هي إحدى مكتبات لغة بايثون القوية المصممة بدقة لتطبيقات تعلم الآلة البسيطة والفعالة. وهي خيار ممتاز للمبتدئين وتوفر واجهة برمجة تطبيقات API واضحة ومتسقة، كما تقدم مجموعة خوارزميات ذكاء اصطناعي قوية أبرزها خوارزميات التصنيف classification، وخوارزميات الانحدار أو التوقع regression، وخوارزميات العنقدة clustering وغيرها، ويمكن مطالعة التوثيقات الرسمية والأمثلة التوضيحية للمكتبة لفهم هذه الخوارزميات وتنفيذها بفاعلية. سادسًا: منصة Jupyter Notebook منصة Jupyter Notebook هي بيئة تطوير تفاعلية تتيح إنشاء ونشر مستندات تجمع بين الشيفرة البرمجية المباشرة live code والمعادلات equations والتمثيل المرئي للبيانات visualization، ويمكنها التعامل مع لغات برمجية عدة، بما في ذلك لغة بايثون Python ولغة R ما يجعلها أداة مثالية لتجربة مشاريع الذكاء الاصطناعي وتعلم الآلة. سابعًا: منصة IBM Watson Studio منصة IBM Watson Studio هي منصة سحابية تقدم أدوات وخدمات متنوعة لمطوري الذكاء الاصطناعي وعلماء البيانات. فهي تبسِّط عملية تطوير تطبيقات وخدمات الذكاء الاصطناعي وتعلم الآلة من خلال تقديم توفير بيئات معّدة مسبقًا، وميزات تعاونية، وتمنح إمكانية الوصول لخدمات الذكاء الاصطناعي الخاصة بشركة IBM. وبالتالي فهي خيار مناسب للمبتدئين الراغبين في تجربة الذكاء الاصطناعي دون تعقيدات. ثامنًا: منصة Hugging Face تقدم منصة Hugging Face مجموعة أدوات ذكاء اصطناعي متنوعة، بما في ذلك مكتبة المحولات Transformers، وهي مكتبة مخصصة تتضمن أحدث نماذج معالجة اللغات الطبيعية NLP وتتميز ببساطتها وسهولة استخدامها، مما يجعلها خيارًا مناسبًا للمبتدئين الذين يستكشفون طريقهم في مجال معالجة اللغة الطبيعية NLP. كما أن الدعم الواسع الذي تقدمه منصة Hugging Face والنماذج الكثيرة المسبقة التدريب تسهّل عملية التعلم. نصائح لبدء تعلم الذكاء الاصطناعي وتعلم الآلة بعد أن تعرّفنا على مجموعة منتقاة من أفضل أدوات الذكاء الاصطناعي وتعلم الآلة، سنقدم لك بعض النصائح لتحسين رحلتك في تعلم الذكاء الاصطناعي وتعلم الآلة كمبتدئ. تعلم الأساسيات يتوجب البدء بتعلم أساسيات الذكاء الاصطناعي وتعلم الآلة ودراسة مفاهيمه ومصطلحاته، بما في ذلك التعلم الخاضع للإشراف supervised learning، والتعلم غير الخاضع للإشراف unsupervised learning، والشبكات العصبية neural networks. هناك العديد من الدورات التدريبية والبرامج التعليمية المتاحة عبر الإنترنت والتي تساعد على تعلم هذه المفاهيم. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن التدريب العملي إذا اكتفينا بدراسة مفاهيم الذكاء الاصطناعي وتعلم الآلة وركزنا فقط على الجانب النظري فلن نحرز أي تقدم، بل يتوجب علينا تطبيق كل ما نتعلمه وتنفيذ مشاريع صغيرة مع زيادة تعقيدها تدريجيًا. إذ يُعدّ التجريب مفتاحًا لفهم هذه التقنيات، وللاطلاع على مشاريع عديدة تناسب المبتدئين ننصحك بكتاب عشرة مشاريع عملية عن الذكاء الاصطناعي من أكاديمية حسوب. استكشاف مجموعات البيانات Datasets لا يمكن تنفيذ مشاريع الذكاء الاصطناعي مجموعات البيانات فهي حجر الزاوية لبناء النماذج وبدونها لا يمكن للنموذج تعلم الأنماط أو اتخاذ القرارات، لذا سنحتاج للتعرف على مجموعات البيانات ذات الصلة باهتمامنا والاستفادة منها في مشاريعنا. على سبيل المثال تُعدّ منصة Kaggle كنزًا لمجموعات البيانات وهي تستضيف مسابقات عديدة في علوم البيانات من شأنها تعزيز فهمنا وصقل مهاراتنا. الانضمام إلى المجتمعات التقنية لا شك أن طرح الأسئلة والنقاش مع المطورين المختصين في مجتمعات الذكاء الاصطناعي وتعلم الآلة المتخصصة مثل PaperSpace و GitHub و Stack Overflow وReddit ومجتمع حسوب IO يساعدنا كثيرة في حل مشكلاتنا وتسريع رحلتنا التعليمية وتعزيز خبراتنا في هذا التخصص. الاطلاع على كل جديد يتطور مجال الذكاء الاصطناعي وتعلم الآلة بسرعة ولذا لا بد من متابعة أحدث المستجدات عبر الإنترنت، وقراءة الأخبار والتقارير التقنية، والاطلاع على الأوراق البحثية للبقاء على اطلاع بأحدث التطورات في هذا المجال سريع التقادم. الخاتمة يمكن أن تكون رحلتنا في مجال الذكاء الاصطناعي وتعلم الآلة كمبتدئين تجربة مثيرة ومثمرة إذا حرصنا على بناء أساس متين واستخدامنا الأدوات التي تسهل علينا التعلم والفهم. ولنتذكر أن التعلم عملية مستمرة، لذا علينا الحفاظ على حماسنا والتدرب بجد والاستمتاع بما نتعلمه وتطبيقه في مشاريع فعلية تجسد فائدة ما نتعلمه. ترجمة وبتصرّف للمقال Top AI and ML Tools for New Developers to Get Started With لكاتبه Anish Singh Walia. اقرأ أيضًا تعرف على أفضل دورات الذكاء الاصطناعي تعرف على أهم كتب الذكاء الاصطناعي المجانية مكتبات وأطر عمل الذكاء الاصطناعي: القوة الكامنة خلف الأنظمة الذكية لغات برمجة الذكاء الاصطناعي اكتشف بدائل ChatGPT مفتوحة المصدر -
 سنغطي في هذا المقال أسئلة واسعة حول تعلم الآلة Machine Learning، ومعالجة اللغات الطبيعية Natural Language Processing، والذكاء الاصطناعي Artificial Intelligence بهدف توسيع المهارات حول هذه التقنيات الحديثة، سنحاول الإجابة على مجموعة من الأسئلة المهمة بدءًا من أساسيات هذا المجال، والتقنيات الموصى بها، وصولًا إلى النماذج اللغوية المتقدمة مثل GPT 4، كما سنتناول التحديات التي تواجه المنتجات والأعمال المرتبطة بمعالجة اللغات الطبيعية ونناقش مستقبل هذا المجال. أسئلة حول أساسيات معالجة اللغات الطبيعية فيما يلي مجموعة أسئلة وإجابات حول أساسيات معالجة اللغات الطبيعية. ما خطوات الانتقال من تطوير التطبيقات التقليدية لاحتراف مجال تعلم الآلة ML في مجال تعلم الآلة، يحتاج المطور إلى استيعاب المفاهيم النظرية أولًا فهي تشكل الأساس الذي يبنى عليه كل شيء. ولكن من المهم أيضًا أن يتعرف على التقنيات واللغات الحديثة التي تدعم هذا المجال ويمكن تحقيق ذلك بحضور دورات تدريبية حول الذكاء الاصطناعي وتعلم الآلة وتنفيذ ما يتعلمه بشكل عملي. أما بالنسبة للغات البرمجة، فلغة بايثون هي الخيار الأمثل للمطورين المبتدئين في تعلم الآلة فهي لغة برمجة عالية المستوى، وتحظى بشعبية واسعة، وتتميز بوجود مجتمع كبير يدعمها، كما تحتوي بايثون على مكتبات قوية في مجال تعلم الآلة مثل تنسرفلو TensorFlow وساي كت ليرن Scikit-learn التي تسهّل الوصول إلى الأدوات اللازمة لتطبيق مفاهيم تعلم الآلة. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن هل تتطلب دراسة معالجة اللغة الطبيعية معرفة بمجال اللغويات Linguistics ونظرية المعلومات تشكل نظرية المعلومات Information Theory الأساس الذي يعتمد عليه الكثيرون في فهم طريقة معالجة البيانات والمعلومات بطريقة منظمة وفعّالة، وهي تستخدم في مجالات متعددة، بما في ذلك معالجة اللغة الطبيعية NLP. فعلم البيانات ونظرية المعلومات يرتبطان ارتباطًا وثيقًا ببعضهما، وبالتالي فإن الفهم الجيد لمفاهيم مثل انتروبية المعلومات Information Entropy سيسهم في تعزيز قدرتنا على تطوير تطبيقات ذكاء اصطناعي احترافية، وسيساعدنا توظيف هذه المبادئ على التعمق في معالجة اللغات الطبيعية. أما بالنسبة للغويات Linguistics وفهم بنية وقواعد اللغة فلا يتطلب الأمر بالضرورة الحصول على شهادة أكاديمية في هذا المجال. ويمكننا الاستفادة من الدورات التدريبية عبر الإنترنت التي توفر محتوى تطبيقي يساعد في تعزيز مهاراتنا، فمن خلال هذه الدورات سنتمكن من اكتساب الخبرة اللازمة لتطبيق تقنيات معالجة اللغات الطبيعية باحترافية. ما هي نماذج BERT وGPT وما الأمثلة الواقعية عنها نماذج BERT وGPT هما نوعان من النماذج اللغوية Language Models المدربة على كميات ضخمة من النصوص بهدف أداء مهام معينة مثل ملء المعلومات الناقصة في النصوص Text Infilling. إن هذه النماذج مهيأة بشكل خاص للاستخدام في التفاعل الحواري، حيث يمكنها فهم السياق اللغوي، والرد على الاستفسارات بطريقة طبيعية مشابهة لطريقة البشر. كما تُظهر نماذج BERT وGPT أداء مذهلًا وتتفوق في العديد من التطبيقات الأخرى غير الحوارية، مثل حل المسائل الرياضية أو ترجمة النصوص. ويُظهِر كل من نموذج BERT الذي يعتمد على المعالجة ثنائية الاتجاه للنصوص Bidirectional Processing ونموذج GPT الذي يعتمد على النماذج اللغوية التوليدية Generative Language Models قدرة فائقة على فهم وتوليد اللغة في العديد من السياقات. وأحد الأمثلة الواقعية على استخدام GPT هو روبوت الدردشة ChatGPT، أما نموذج BERT فيستخدم بشكل رئيسي في تحسين محركات البحث SEO وأنظمة التوصية. ما أبرز الأدوات المفيدة في مجال معالجة اللغات الطبيعية من أبرز أدوات معالجة اللغة الطبيعية NLP نذكر: لغات البرمجة مثل بايثون Python و R الخدمات السحابية مثل Amazon Web Services و Microsoft Azure خدمات تسيير العمل مثل Apache Airflow و Amazon Neptune النماذج اللغوية مثل GPT و BERT أي لغة أفضل في تحليل النصوص لغة بايثون أم R يُفضِّل كثيرون استخدام لغة بايثون في كل شيء، وليس في علم البيانات فقط، فلهذه اللغة مميزات عديدة من أبرزها سهولتها ووجود مجتمع كبير داعم لها، وتوفر العديد من مكتبات تحليل النصوص واستخراج المعلومات مثل NLTK و spaCy و TextBlob. أما لغة R، فهي مختلفة عن لغات البرمجة الأخرى وقد يكون استخدامها صعبًا ومعقدًا في بيئة الإنتاج. لكن قدراتها في مجال الإحصاء الرياضي يعطيها ميزة كبيرة مقارنة بلغة بايثون. ما هي الخدمة السحابية الأفضل لبناء النماذج ونشرها هناك العديد من الخدمات السحابية المتاحة لبناء النماذج Models ونشرها مثل خدمات AWS و Azure و Google، يمكن اختيار الخدمة التي تناسبنا وينصح الكاتب باستخدام منصة AWS لأنها تجنبنا مشكلة احتكار البائع Vendor Lock-in التي قد نواجهها عندما نعتمد على مزود سحابي معين، والتي قد تعيق انتقالنا إلى مزود آخر بسهولة وتكبدنا تكاليف ضخمة وتحديات كبيرة في نقل بيئة العمل. هل يفيدنا استخدام أدوات تسيير العمل في خطوط عمل معالجة اللغة الطبيعية نعم، تفيد أدوات تسيير العمل مثل Prefect أو Airflow أو Luigi أو Neptune بشكل فعّال في خطوط عمل معالجة اللغة الطبيعية NLP pipelines، لاسيما عندما يتطلب الأمر تنسيق عدة عمليات مع الحاجة لإضافة أو تعديل خطوط العمل في المستقبل. فهذه الأدوات ضرورية في حالات معالجة البيانات الضخمة التي تتطلب عمليات استخراج البيانات Extract، وتحويلها Transform، وتحميلها Load، والمعروفة اختصارًا بعمليات ETL، وهي تساهم في إدارة العمليات بثقة ومرونة وتنظم تنفيذ العمليات المعقدة، وتُسهّل التعامل مع تدفقات البيانات وتحسن الكفاءة في مشاريع معالجة اللغة الطبيعية. ما الأدوات التي يُوصى بها في مجال تعلم الآلة ومعالجة اللغات الطبيعية ينصح الكاتب باستخدام التابع style من مكتبة Pandas لعرض البيانات وإجراء مقارنات سريعة بينها. كما ينصح باستخدام MLflow عند الحاجة لمشاركة نتائج تجربة معينة مع فريق من المبرمجين أو علماء البيانات، واستخدام مكتبة ploty بدلًا من matplotlib للحصول على تقارير تفاعلية، ويمكن استخدام منصة Weights & Biases في مجال التعلم العميق Deep Learning، لأن مراقبة الموترات أو التنسورات tensors -وهي البنية الأساسية للبيانات التي تعالجها الشبكة العصبية- أصعب بكثير من مراقبة المقاييس metrics بسبب طبيعة البيانات التي تعمل بها التنسورات، حيث تحتوي على معلومات متعددة الأبعاد قد تكون ضخمة ومعقدة، في حين أن المقاييس، مثل دقة النموذج accuracy و خسارة النموذج Loss فهي قيم واحدة مفردة يجري تحديثها باستمرار وعرضها خلال تدريب النموذج ومن السهل تتبعها وتحليلها. نصائح وأسئلة حول العمل في مجال معالجة اللغة الطبيعية فيما يلي مجموعة أسئلة وإجابات مرتبطة بالعمل في مجال معالجة اللغات الطبيعية. كيف يمكن تقسيم المهام اليومية في تنظيف البيانات وبناء نماذج التطبيقات يعد تنظيف البيانات Data Cleaning وهندسة الميزات Feature Engineering من المهام التي تتطلب وقتًا كبيرًا عند تطوير تطبيقات فعلية، نظرًا لأن جودة البيانات هي الأساس الذي يعتمد عليه تعلم الآلة في تقديم حلول فعّالة. لذا، يُنصح بتخصيص أكبر قدر ممكن من الوقت لبناء النماذج Models، خصوصًا عندما تكون متطلبات التطبيق بسيطة ومحدودة، ولا تحتاج إلى استخدام تقنيات معقدة أو حلول مبتكرة للوصول إلى النتائج المطلوبة. كيف يمكن تحليل جدوى لنموذج تعلم آلة لا يحقق الأداء المطلوب لو طُلب منا العمل على نموذج تعلم آلة لا يحقق الأداء المطلوب مهما درّبناه، وأردنا إجراء تحليل جدوى لتوفير الوقت وتقديم دليل على أن من الأفضل الانتقال إلى طرق أخر فيمكننا استخدام أسلوب التطوير المرن Lean الذي يهدف إلى تحقيق أفضل النتائج بأقل جهد ووقت، يجري ذلك من خلال معالجة بسيطة مسبقة للبيانات Data Preprocessing، واستخدام مجموعة نماذج بسيطة سهلة التنفيذ، واتباع ممارسات من شأنها ضمان عمل النموذ بشكل صحيح مثل فصل مجموعات التدريب، والتحقق من الصحة validation، واستخدام الاختبار والتقويم المتقاطع cross-validation عند الإمكان. فباستخدام هذه الخطوات البسيطة، يمكننا تقييم فيما إذا كان النموذج الحالي قابل للتحسين أو من الأفضل استخدام نماذج أخرى لتحقيق الأداء المطلوب. هل يمكن بناء نماذج تعلم آلة تستخدم موارد أقل وبجودة النماذج الأكبر حجمًا نعم، يمكن بناء نماذج أصغر باستخدام تقنيات مثل التقليم Pruning. والتقليم هو عملية تقليص حجم النموذج عن طريق إزالة العناصر غير المهمة التي لا تؤثر بشكل كبير على أداء النموذج. تساعدنا هذه التقنية في تقليل حجم النموذج وتحسين كفاءته الحسابية وتمكننا من تشغيله على أجهزة أقل قوة مع الحفاظ على نفس مستوى الأداء. من الأمثلة الحديثة على ذلك نموذج Chinchilla من DeepMind، فعلى الرغم من أن هذا النموذج أصغر بكثير من النماذج القوية مثل GPT-3 من حيث الحجم الحسابي، إلا أنه يقدم أداء أفضل. وهذا يثبت أن تقنيات مثل التقليم يمكن أن تساعدنا في تحسين الكفاءة الحسابية وتحقيق نتائج عالية الأداء بنماذج أصغر. أسئلة حول منتجات الذكاء الاصطناعي ورؤى الأعمال فيما يلي مجموعة أمثلة وإجابات حول منتجات الذكاء الاصطناعي ورؤى الأعمال ما هي الخطوات المتبعة في دورة تطوير منتجات تعلم الآلة تتكون دورة تطوير منتجات تعلم الآلة من عدة خطوات أساسية: تبدأ الدورة بتحليل البيانات الاستكشافي Exploratory Data Analysis أو اختصارًا EDA من خلال فحص البيانات بعناية لتحديد ما هو ضروري للعمل على منتج تعلم الآلة، بعدها تُناقش نتائج التحليل مع الفريق وتقيّم أهداف المشروع لضمان وضوح التوجهات بعد تحديد الأهداف، ثم تُستَخدم نماذج بسيطة لتوليد نتائج مرجعية تساعد في تحديد أفضل الحلول، وأخيرًا يجري تحسين النماذج وتعديلها لتحقيق النتائج المثلى وفقًا لمقاييس الأداء. وخلال جميع الخطوات يجب أن يكون هناك تواصل مستمر مع العميل لضمان تطابق الحلول مع احتياجاته. ما تحديات تطبيق الذكاء الاصطناعي وتعلم الآلة في تطوير المنتجات في الوقت الحالي، هناك تحديان رئيسيان في مجال الذكاء الاصطناعي وتعلم الآلة: الأول هو الذكاء الاصطناعي العام Artificial General Intelligence أو AGI اختصارًا، والذي أصبح محور اهتمام كبير فهو نوع من الذكاء الاصطناعي يُفترض أن يكون قادرًا على أداء أي مهمة يمكن أن يؤديها الإنسان. لكن رغم الاهتمام الكبير به، لا زال تحقيقه غير ممكن في الوقت الحالي، وما زال أمامنا وقت طويل للوصول إلى تحقيق مستوى عالي من الكفاءة في أداء مهام متنوعة، ولا زال الذكاء الاصطناعي يواجه صعوبة في التعامل مع مشكلات لم يتعلم كيفية حلها مسبقًا. الحد الثاني في الذكاء الاصطناعي هو التعلم المعزز Reinforcement Learning حيث يعتمد هذا النوع من التعلم على تحسين الأنظمة من خلال المحاولة والتجربة والتفاعل مع البيئة بدلاً من الاعتماد على البيانات الضخمة Big data. ورغم أنه يعد بديلاً للتعلم التقليدي القائم على البيانات الضخمة والتعلم الخاضع للإشراف Supervised learning، إلا أن جمع البيانات اللازمة لتعلم جميع المهام البشرية أمر يستغرق وقتًا طويلاً، وحتى إذا جمعنا البيانات المطلوبة، قد لا تكون كافية لإنشاء نموذج ذكي يعمل بنفس مستوى الكفاءة التي يعمل بها البشر، خاصة عندما تتغير الظروف والبيئات في المستقبل. فهذه التغيرات قد تؤثر على قدرة النموذج على التكيف مع التحديات الجديدة. لذا من غير المحتمل أن يتمكن مجتمع الذكاء الاصطناعي من حل هذه المشكلات قريبًا، وإذا تمكن من ذلك، ستتحول التحديات إلى أمور تتعلق بالكفاءة الحسابية. ما حالات استخدام عمليات تعلم الآلة تعد عمليات تعلم الآلة Machine Learning Operations أو MLOps اختصارًا، ممتازة لعديد من المنتجات والأهداف مثل الحلول المصممة بدون خادم Serverless والتي تُحَصَّل الرسوم فيها مقابل ما نستخدمه والتي لا نحتاج فيها إلى إدارة الخوادم أو القلق بشأن صيانتها، وكذلك تستخدم في واجهات برمجة تطبيقات تعلم الآلة التجارية مثل التنبؤ بالطلب على المنتجات أو تحسين تجربة العملاء، كما تُستخدم خدمات مجانية مثل MLflow لمتابعة ومراقبة التجارب أثناء تطوير النماذج في مراحلها الأولى، ومراقبة الأداء بعد نشر التطبيقات. كيف نقنع العميل أو المدير باستخدام تعلم الآلة في التطبيقات تتمتع عمليات تعلم الآلة بفوائد كبيرة في التطبيقات على مستوى المؤسسات، حيث تساهم في تحسين كفاءة عملية التطوير وتقليل التكاليف التقنية. ومع ذلك، من المهم تقييم مدى ملاءمة الحل المقترح للهدف المطلوب. على سبيل المثال، إذا كان لدينا خادم في مكتبنا ويمكن ضمان تلبية متطلبات اتفاقية مستوى الخدمة Service-level agreement أو اختصارًا SLA، ومعرفة عدد الطلبات المتوقعة، فلن نحتاج لاستخدام خدمات عمليات تعلم الآلة المُدارة managed MLOps service. تحدث المشكلات الشائعة عندما نفترض أن الخدمة المُدارة ستلبي جميع متطلبات المشروع، مثل أداء النموذج، ومتطلبات اتفاقية مستوى الخدمة SLA، وقابلية التوسع، وغيرها. على سبيل المثال، يتطلب إنشاء واجهة برمجة تطبيقات للتعرف الضوئي على الحروف Optical Character Recognition أو OCR اختصارًا إجراء ختبارات دقيقة لتقييم نقاط الفشل وكيفية حدوثها. ويجب استخدام هذه الاختبارات لتحديد العوائق التي قد تعيق الوصول إلى الأداء المطلوب. كيف تحدد المؤسسات احتياجات العميل بدقة وتنشئ نماذج تساعد في اتخاذ القرارات تُضيف أدوات علم البيانات مزيدًا من الغموض للعميل مقارنة بحلول البرمجة التقليدية، لأنها تعتمد غالبًا على التعامل مع حالات عدم اليقين بدلاً من تجنبها. لهذا، من الضروري أن يظل العميل على اطلاع دائم بسير العمل فالعميل هو الأكثر دراية باحتياجات المشروع وهو من يوافق على النتيجة النهائية. أسئلة حول مستقبل معالجة اللغات الطبيعية فيما يلي مجموعة أمثلة وإجابات حول مستقبل معالجة اللغات الطبيعية وتحديات تطبيقها. ما مبرر ارتفاع استهلاك الطاقة الناتج عن الشبكات العصبية التلافيفية الكبيرة CNNs قد يعتقد البعض أن نماذج مثل LLaMA من شركة Meta غير مفيدة وتهدر الموارد. ومع ذلك، بما أن هذه النماذج ستكون متاحة مجانًا للجمهور في المستقبل، فإن الاستثمارات التي تُنفق على تدريب هذه النماذج ستعود بالفائدة على المدى البعيد وستساهم في تقدم الأبحاث والتقنيات، فبتقديم هذه النماذج، نفتح الفرصة للباحثين والمطورين للاستفادة منها في مجالات متنوعة، ونسرع من الابتكار ونعزز من تقدم الذكاء الاصطناعي بشكل عام. هل استطاعت نماذج الذكاء الاصطناعي اكتساب وعي يماثل الوعي البشري إن الوعي في الذكاء الاصطناعي هو مفهوم نظري للغاية، والحديث عن وعي الذكاء الاصطناعي قد يكون غير دقيق في الغالب، ويؤثر سلبًا على فهم معالجة اللغات الطبيعية. بالعموم، تظل مشاريع الذكاء الاصطناعي اصطناعية ولا تمتلك وعيًا مشابهًا للوعي البشري. هل يجب أن نقلق بشأن القضايا الأخلاقية المتعلقة بالذكاء الاصطناعي وتعلم الآلة يجب أن نكون حذرين بشأن ذلك خاصة مع التقدم السريع في أنظمة الذكاء الاصطناعي مثل ChatGPT. ولكن، من المهم أن يكون لدينا تعليم وخبرة كافية لفهم هذه التقنية بشكل جيد. ومن المفترض أن تكون الحكومات هي المسؤولة عن تنظيم الأمور، ما زلنا بحاجة إلى وقت إضافي لتحقيق ذلك، ولعل إحدى القضايا الأخلاقية المهمة هي كيفية تقليل تحيز الذكاء الاصطناعي وتجنبه ومسؤولية ذلك تقع على عاتق المهندسين والشركات، وكذلك على العملاء. لذا يجب بذل جهد كبير لضمان عدم التمييز أو المعاملة غير العادلة لأي شخص، بغض النظر عن تكاليف تحقيق ذلك. الخاتمة ختامًا، لنتذكر أن تعلم الآلة هو المحرك الرئيسي الذي يمكن أن يقود البشرية إلى ثورتها الصناعية القادمة. فقد اختفت وظائف عدة أثناء الثورة الصناعية، ولكن ظهرت وظائف جديدةً أكثر إبداعًا ويمكنها تأدية عمل ينجزه عدد كبير من العمال. وبإمكاننا فعل الشيء نفسه الآن والتكيف مع تعلم الآلة والذكاء الاصطناعي بشكل إيجابي وفعال. ترجمة، وبتصرّف، للمقال Ask an NLP Engineer: From GPT Models to the Ethics of AI، لكاتبه Daniel Pérez Rubio. اقرأ أيضًا المفاهيم الأساسية لتعلم الآلة مجالات الذكاء الاصطناعي الذكاء الاصطناعي: أهم الإنجازات والاختراعات وكيف أثرت في حياتنا اليومية نظرة سريعة على مجال تعلم الآلة كل ما تود معرفته عن دراسة الذكاء الاصطناعي
سنغطي في هذا المقال أسئلة واسعة حول تعلم الآلة Machine Learning، ومعالجة اللغات الطبيعية Natural Language Processing، والذكاء الاصطناعي Artificial Intelligence بهدف توسيع المهارات حول هذه التقنيات الحديثة، سنحاول الإجابة على مجموعة من الأسئلة المهمة بدءًا من أساسيات هذا المجال، والتقنيات الموصى بها، وصولًا إلى النماذج اللغوية المتقدمة مثل GPT 4، كما سنتناول التحديات التي تواجه المنتجات والأعمال المرتبطة بمعالجة اللغات الطبيعية ونناقش مستقبل هذا المجال. أسئلة حول أساسيات معالجة اللغات الطبيعية فيما يلي مجموعة أسئلة وإجابات حول أساسيات معالجة اللغات الطبيعية. ما خطوات الانتقال من تطوير التطبيقات التقليدية لاحتراف مجال تعلم الآلة ML في مجال تعلم الآلة، يحتاج المطور إلى استيعاب المفاهيم النظرية أولًا فهي تشكل الأساس الذي يبنى عليه كل شيء. ولكن من المهم أيضًا أن يتعرف على التقنيات واللغات الحديثة التي تدعم هذا المجال ويمكن تحقيق ذلك بحضور دورات تدريبية حول الذكاء الاصطناعي وتعلم الآلة وتنفيذ ما يتعلمه بشكل عملي. أما بالنسبة للغات البرمجة، فلغة بايثون هي الخيار الأمثل للمطورين المبتدئين في تعلم الآلة فهي لغة برمجة عالية المستوى، وتحظى بشعبية واسعة، وتتميز بوجود مجتمع كبير يدعمها، كما تحتوي بايثون على مكتبات قوية في مجال تعلم الآلة مثل تنسرفلو TensorFlow وساي كت ليرن Scikit-learn التي تسهّل الوصول إلى الأدوات اللازمة لتطبيق مفاهيم تعلم الآلة. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن هل تتطلب دراسة معالجة اللغة الطبيعية معرفة بمجال اللغويات Linguistics ونظرية المعلومات تشكل نظرية المعلومات Information Theory الأساس الذي يعتمد عليه الكثيرون في فهم طريقة معالجة البيانات والمعلومات بطريقة منظمة وفعّالة، وهي تستخدم في مجالات متعددة، بما في ذلك معالجة اللغة الطبيعية NLP. فعلم البيانات ونظرية المعلومات يرتبطان ارتباطًا وثيقًا ببعضهما، وبالتالي فإن الفهم الجيد لمفاهيم مثل انتروبية المعلومات Information Entropy سيسهم في تعزيز قدرتنا على تطوير تطبيقات ذكاء اصطناعي احترافية، وسيساعدنا توظيف هذه المبادئ على التعمق في معالجة اللغات الطبيعية. أما بالنسبة للغويات Linguistics وفهم بنية وقواعد اللغة فلا يتطلب الأمر بالضرورة الحصول على شهادة أكاديمية في هذا المجال. ويمكننا الاستفادة من الدورات التدريبية عبر الإنترنت التي توفر محتوى تطبيقي يساعد في تعزيز مهاراتنا، فمن خلال هذه الدورات سنتمكن من اكتساب الخبرة اللازمة لتطبيق تقنيات معالجة اللغات الطبيعية باحترافية. ما هي نماذج BERT وGPT وما الأمثلة الواقعية عنها نماذج BERT وGPT هما نوعان من النماذج اللغوية Language Models المدربة على كميات ضخمة من النصوص بهدف أداء مهام معينة مثل ملء المعلومات الناقصة في النصوص Text Infilling. إن هذه النماذج مهيأة بشكل خاص للاستخدام في التفاعل الحواري، حيث يمكنها فهم السياق اللغوي، والرد على الاستفسارات بطريقة طبيعية مشابهة لطريقة البشر. كما تُظهر نماذج BERT وGPT أداء مذهلًا وتتفوق في العديد من التطبيقات الأخرى غير الحوارية، مثل حل المسائل الرياضية أو ترجمة النصوص. ويُظهِر كل من نموذج BERT الذي يعتمد على المعالجة ثنائية الاتجاه للنصوص Bidirectional Processing ونموذج GPT الذي يعتمد على النماذج اللغوية التوليدية Generative Language Models قدرة فائقة على فهم وتوليد اللغة في العديد من السياقات. وأحد الأمثلة الواقعية على استخدام GPT هو روبوت الدردشة ChatGPT، أما نموذج BERT فيستخدم بشكل رئيسي في تحسين محركات البحث SEO وأنظمة التوصية. ما أبرز الأدوات المفيدة في مجال معالجة اللغات الطبيعية من أبرز أدوات معالجة اللغة الطبيعية NLP نذكر: لغات البرمجة مثل بايثون Python و R الخدمات السحابية مثل Amazon Web Services و Microsoft Azure خدمات تسيير العمل مثل Apache Airflow و Amazon Neptune النماذج اللغوية مثل GPT و BERT أي لغة أفضل في تحليل النصوص لغة بايثون أم R يُفضِّل كثيرون استخدام لغة بايثون في كل شيء، وليس في علم البيانات فقط، فلهذه اللغة مميزات عديدة من أبرزها سهولتها ووجود مجتمع كبير داعم لها، وتوفر العديد من مكتبات تحليل النصوص واستخراج المعلومات مثل NLTK و spaCy و TextBlob. أما لغة R، فهي مختلفة عن لغات البرمجة الأخرى وقد يكون استخدامها صعبًا ومعقدًا في بيئة الإنتاج. لكن قدراتها في مجال الإحصاء الرياضي يعطيها ميزة كبيرة مقارنة بلغة بايثون. ما هي الخدمة السحابية الأفضل لبناء النماذج ونشرها هناك العديد من الخدمات السحابية المتاحة لبناء النماذج Models ونشرها مثل خدمات AWS و Azure و Google، يمكن اختيار الخدمة التي تناسبنا وينصح الكاتب باستخدام منصة AWS لأنها تجنبنا مشكلة احتكار البائع Vendor Lock-in التي قد نواجهها عندما نعتمد على مزود سحابي معين، والتي قد تعيق انتقالنا إلى مزود آخر بسهولة وتكبدنا تكاليف ضخمة وتحديات كبيرة في نقل بيئة العمل. هل يفيدنا استخدام أدوات تسيير العمل في خطوط عمل معالجة اللغة الطبيعية نعم، تفيد أدوات تسيير العمل مثل Prefect أو Airflow أو Luigi أو Neptune بشكل فعّال في خطوط عمل معالجة اللغة الطبيعية NLP pipelines، لاسيما عندما يتطلب الأمر تنسيق عدة عمليات مع الحاجة لإضافة أو تعديل خطوط العمل في المستقبل. فهذه الأدوات ضرورية في حالات معالجة البيانات الضخمة التي تتطلب عمليات استخراج البيانات Extract، وتحويلها Transform، وتحميلها Load، والمعروفة اختصارًا بعمليات ETL، وهي تساهم في إدارة العمليات بثقة ومرونة وتنظم تنفيذ العمليات المعقدة، وتُسهّل التعامل مع تدفقات البيانات وتحسن الكفاءة في مشاريع معالجة اللغة الطبيعية. ما الأدوات التي يُوصى بها في مجال تعلم الآلة ومعالجة اللغات الطبيعية ينصح الكاتب باستخدام التابع style من مكتبة Pandas لعرض البيانات وإجراء مقارنات سريعة بينها. كما ينصح باستخدام MLflow عند الحاجة لمشاركة نتائج تجربة معينة مع فريق من المبرمجين أو علماء البيانات، واستخدام مكتبة ploty بدلًا من matplotlib للحصول على تقارير تفاعلية، ويمكن استخدام منصة Weights & Biases في مجال التعلم العميق Deep Learning، لأن مراقبة الموترات أو التنسورات tensors -وهي البنية الأساسية للبيانات التي تعالجها الشبكة العصبية- أصعب بكثير من مراقبة المقاييس metrics بسبب طبيعة البيانات التي تعمل بها التنسورات، حيث تحتوي على معلومات متعددة الأبعاد قد تكون ضخمة ومعقدة، في حين أن المقاييس، مثل دقة النموذج accuracy و خسارة النموذج Loss فهي قيم واحدة مفردة يجري تحديثها باستمرار وعرضها خلال تدريب النموذج ومن السهل تتبعها وتحليلها. نصائح وأسئلة حول العمل في مجال معالجة اللغة الطبيعية فيما يلي مجموعة أسئلة وإجابات مرتبطة بالعمل في مجال معالجة اللغات الطبيعية. كيف يمكن تقسيم المهام اليومية في تنظيف البيانات وبناء نماذج التطبيقات يعد تنظيف البيانات Data Cleaning وهندسة الميزات Feature Engineering من المهام التي تتطلب وقتًا كبيرًا عند تطوير تطبيقات فعلية، نظرًا لأن جودة البيانات هي الأساس الذي يعتمد عليه تعلم الآلة في تقديم حلول فعّالة. لذا، يُنصح بتخصيص أكبر قدر ممكن من الوقت لبناء النماذج Models، خصوصًا عندما تكون متطلبات التطبيق بسيطة ومحدودة، ولا تحتاج إلى استخدام تقنيات معقدة أو حلول مبتكرة للوصول إلى النتائج المطلوبة. كيف يمكن تحليل جدوى لنموذج تعلم آلة لا يحقق الأداء المطلوب لو طُلب منا العمل على نموذج تعلم آلة لا يحقق الأداء المطلوب مهما درّبناه، وأردنا إجراء تحليل جدوى لتوفير الوقت وتقديم دليل على أن من الأفضل الانتقال إلى طرق أخر فيمكننا استخدام أسلوب التطوير المرن Lean الذي يهدف إلى تحقيق أفضل النتائج بأقل جهد ووقت، يجري ذلك من خلال معالجة بسيطة مسبقة للبيانات Data Preprocessing، واستخدام مجموعة نماذج بسيطة سهلة التنفيذ، واتباع ممارسات من شأنها ضمان عمل النموذ بشكل صحيح مثل فصل مجموعات التدريب، والتحقق من الصحة validation، واستخدام الاختبار والتقويم المتقاطع cross-validation عند الإمكان. فباستخدام هذه الخطوات البسيطة، يمكننا تقييم فيما إذا كان النموذج الحالي قابل للتحسين أو من الأفضل استخدام نماذج أخرى لتحقيق الأداء المطلوب. هل يمكن بناء نماذج تعلم آلة تستخدم موارد أقل وبجودة النماذج الأكبر حجمًا نعم، يمكن بناء نماذج أصغر باستخدام تقنيات مثل التقليم Pruning. والتقليم هو عملية تقليص حجم النموذج عن طريق إزالة العناصر غير المهمة التي لا تؤثر بشكل كبير على أداء النموذج. تساعدنا هذه التقنية في تقليل حجم النموذج وتحسين كفاءته الحسابية وتمكننا من تشغيله على أجهزة أقل قوة مع الحفاظ على نفس مستوى الأداء. من الأمثلة الحديثة على ذلك نموذج Chinchilla من DeepMind، فعلى الرغم من أن هذا النموذج أصغر بكثير من النماذج القوية مثل GPT-3 من حيث الحجم الحسابي، إلا أنه يقدم أداء أفضل. وهذا يثبت أن تقنيات مثل التقليم يمكن أن تساعدنا في تحسين الكفاءة الحسابية وتحقيق نتائج عالية الأداء بنماذج أصغر. أسئلة حول منتجات الذكاء الاصطناعي ورؤى الأعمال فيما يلي مجموعة أمثلة وإجابات حول منتجات الذكاء الاصطناعي ورؤى الأعمال ما هي الخطوات المتبعة في دورة تطوير منتجات تعلم الآلة تتكون دورة تطوير منتجات تعلم الآلة من عدة خطوات أساسية: تبدأ الدورة بتحليل البيانات الاستكشافي Exploratory Data Analysis أو اختصارًا EDA من خلال فحص البيانات بعناية لتحديد ما هو ضروري للعمل على منتج تعلم الآلة، بعدها تُناقش نتائج التحليل مع الفريق وتقيّم أهداف المشروع لضمان وضوح التوجهات بعد تحديد الأهداف، ثم تُستَخدم نماذج بسيطة لتوليد نتائج مرجعية تساعد في تحديد أفضل الحلول، وأخيرًا يجري تحسين النماذج وتعديلها لتحقيق النتائج المثلى وفقًا لمقاييس الأداء. وخلال جميع الخطوات يجب أن يكون هناك تواصل مستمر مع العميل لضمان تطابق الحلول مع احتياجاته. ما تحديات تطبيق الذكاء الاصطناعي وتعلم الآلة في تطوير المنتجات في الوقت الحالي، هناك تحديان رئيسيان في مجال الذكاء الاصطناعي وتعلم الآلة: الأول هو الذكاء الاصطناعي العام Artificial General Intelligence أو AGI اختصارًا، والذي أصبح محور اهتمام كبير فهو نوع من الذكاء الاصطناعي يُفترض أن يكون قادرًا على أداء أي مهمة يمكن أن يؤديها الإنسان. لكن رغم الاهتمام الكبير به، لا زال تحقيقه غير ممكن في الوقت الحالي، وما زال أمامنا وقت طويل للوصول إلى تحقيق مستوى عالي من الكفاءة في أداء مهام متنوعة، ولا زال الذكاء الاصطناعي يواجه صعوبة في التعامل مع مشكلات لم يتعلم كيفية حلها مسبقًا. الحد الثاني في الذكاء الاصطناعي هو التعلم المعزز Reinforcement Learning حيث يعتمد هذا النوع من التعلم على تحسين الأنظمة من خلال المحاولة والتجربة والتفاعل مع البيئة بدلاً من الاعتماد على البيانات الضخمة Big data. ورغم أنه يعد بديلاً للتعلم التقليدي القائم على البيانات الضخمة والتعلم الخاضع للإشراف Supervised learning، إلا أن جمع البيانات اللازمة لتعلم جميع المهام البشرية أمر يستغرق وقتًا طويلاً، وحتى إذا جمعنا البيانات المطلوبة، قد لا تكون كافية لإنشاء نموذج ذكي يعمل بنفس مستوى الكفاءة التي يعمل بها البشر، خاصة عندما تتغير الظروف والبيئات في المستقبل. فهذه التغيرات قد تؤثر على قدرة النموذج على التكيف مع التحديات الجديدة. لذا من غير المحتمل أن يتمكن مجتمع الذكاء الاصطناعي من حل هذه المشكلات قريبًا، وإذا تمكن من ذلك، ستتحول التحديات إلى أمور تتعلق بالكفاءة الحسابية. ما حالات استخدام عمليات تعلم الآلة تعد عمليات تعلم الآلة Machine Learning Operations أو MLOps اختصارًا، ممتازة لعديد من المنتجات والأهداف مثل الحلول المصممة بدون خادم Serverless والتي تُحَصَّل الرسوم فيها مقابل ما نستخدمه والتي لا نحتاج فيها إلى إدارة الخوادم أو القلق بشأن صيانتها، وكذلك تستخدم في واجهات برمجة تطبيقات تعلم الآلة التجارية مثل التنبؤ بالطلب على المنتجات أو تحسين تجربة العملاء، كما تُستخدم خدمات مجانية مثل MLflow لمتابعة ومراقبة التجارب أثناء تطوير النماذج في مراحلها الأولى، ومراقبة الأداء بعد نشر التطبيقات. كيف نقنع العميل أو المدير باستخدام تعلم الآلة في التطبيقات تتمتع عمليات تعلم الآلة بفوائد كبيرة في التطبيقات على مستوى المؤسسات، حيث تساهم في تحسين كفاءة عملية التطوير وتقليل التكاليف التقنية. ومع ذلك، من المهم تقييم مدى ملاءمة الحل المقترح للهدف المطلوب. على سبيل المثال، إذا كان لدينا خادم في مكتبنا ويمكن ضمان تلبية متطلبات اتفاقية مستوى الخدمة Service-level agreement أو اختصارًا SLA، ومعرفة عدد الطلبات المتوقعة، فلن نحتاج لاستخدام خدمات عمليات تعلم الآلة المُدارة managed MLOps service. تحدث المشكلات الشائعة عندما نفترض أن الخدمة المُدارة ستلبي جميع متطلبات المشروع، مثل أداء النموذج، ومتطلبات اتفاقية مستوى الخدمة SLA، وقابلية التوسع، وغيرها. على سبيل المثال، يتطلب إنشاء واجهة برمجة تطبيقات للتعرف الضوئي على الحروف Optical Character Recognition أو OCR اختصارًا إجراء ختبارات دقيقة لتقييم نقاط الفشل وكيفية حدوثها. ويجب استخدام هذه الاختبارات لتحديد العوائق التي قد تعيق الوصول إلى الأداء المطلوب. كيف تحدد المؤسسات احتياجات العميل بدقة وتنشئ نماذج تساعد في اتخاذ القرارات تُضيف أدوات علم البيانات مزيدًا من الغموض للعميل مقارنة بحلول البرمجة التقليدية، لأنها تعتمد غالبًا على التعامل مع حالات عدم اليقين بدلاً من تجنبها. لهذا، من الضروري أن يظل العميل على اطلاع دائم بسير العمل فالعميل هو الأكثر دراية باحتياجات المشروع وهو من يوافق على النتيجة النهائية. أسئلة حول مستقبل معالجة اللغات الطبيعية فيما يلي مجموعة أمثلة وإجابات حول مستقبل معالجة اللغات الطبيعية وتحديات تطبيقها. ما مبرر ارتفاع استهلاك الطاقة الناتج عن الشبكات العصبية التلافيفية الكبيرة CNNs قد يعتقد البعض أن نماذج مثل LLaMA من شركة Meta غير مفيدة وتهدر الموارد. ومع ذلك، بما أن هذه النماذج ستكون متاحة مجانًا للجمهور في المستقبل، فإن الاستثمارات التي تُنفق على تدريب هذه النماذج ستعود بالفائدة على المدى البعيد وستساهم في تقدم الأبحاث والتقنيات، فبتقديم هذه النماذج، نفتح الفرصة للباحثين والمطورين للاستفادة منها في مجالات متنوعة، ونسرع من الابتكار ونعزز من تقدم الذكاء الاصطناعي بشكل عام. هل استطاعت نماذج الذكاء الاصطناعي اكتساب وعي يماثل الوعي البشري إن الوعي في الذكاء الاصطناعي هو مفهوم نظري للغاية، والحديث عن وعي الذكاء الاصطناعي قد يكون غير دقيق في الغالب، ويؤثر سلبًا على فهم معالجة اللغات الطبيعية. بالعموم، تظل مشاريع الذكاء الاصطناعي اصطناعية ولا تمتلك وعيًا مشابهًا للوعي البشري. هل يجب أن نقلق بشأن القضايا الأخلاقية المتعلقة بالذكاء الاصطناعي وتعلم الآلة يجب أن نكون حذرين بشأن ذلك خاصة مع التقدم السريع في أنظمة الذكاء الاصطناعي مثل ChatGPT. ولكن، من المهم أن يكون لدينا تعليم وخبرة كافية لفهم هذه التقنية بشكل جيد. ومن المفترض أن تكون الحكومات هي المسؤولة عن تنظيم الأمور، ما زلنا بحاجة إلى وقت إضافي لتحقيق ذلك، ولعل إحدى القضايا الأخلاقية المهمة هي كيفية تقليل تحيز الذكاء الاصطناعي وتجنبه ومسؤولية ذلك تقع على عاتق المهندسين والشركات، وكذلك على العملاء. لذا يجب بذل جهد كبير لضمان عدم التمييز أو المعاملة غير العادلة لأي شخص، بغض النظر عن تكاليف تحقيق ذلك. الخاتمة ختامًا، لنتذكر أن تعلم الآلة هو المحرك الرئيسي الذي يمكن أن يقود البشرية إلى ثورتها الصناعية القادمة. فقد اختفت وظائف عدة أثناء الثورة الصناعية، ولكن ظهرت وظائف جديدةً أكثر إبداعًا ويمكنها تأدية عمل ينجزه عدد كبير من العمال. وبإمكاننا فعل الشيء نفسه الآن والتكيف مع تعلم الآلة والذكاء الاصطناعي بشكل إيجابي وفعال. ترجمة، وبتصرّف، للمقال Ask an NLP Engineer: From GPT Models to the Ethics of AI، لكاتبه Daniel Pérez Rubio. اقرأ أيضًا المفاهيم الأساسية لتعلم الآلة مجالات الذكاء الاصطناعي الذكاء الاصطناعي: أهم الإنجازات والاختراعات وكيف أثرت في حياتنا اليومية نظرة سريعة على مجال تعلم الآلة كل ما تود معرفته عن دراسة الذكاء الاصطناعي -
 تعرفنا في مقال سابق على طريقة بناء موقع ثابت كمعرض أعمال باستخدام تقنيات الويب الأساسية، وسنتعلم في هذا المقال أهم الخطوات التي علينا اتباعها لترقية موقعنا من موقع بسيط إلى تطبيق تفاعلي باستخدام لغة جافا سكريبت وإطار عملها Vue.js. متطلبات العمل لإنشاء التطبيق نحتاج إلى تثبيت بيئة نود جي إس Node.js ومدير الحزم npm على حاسوبنا المحلي، للقيام بذلك ننتقل إلى موقع Node.js الرسمي ونحمّل أحدث نسخة، بعد تنزيل وتثبيت Node.js سيثبت npm تلقائيًا. بعد ذلك نفتح موجه الأوامر أو الطرفية ونتحقق من أن Node.js ومدير الحزم npm مثبتان بشكل صحيح باستخدام الأمرين التاليين: node -v npm -v بهذا نكون قد أعددنا متطلبات العمل، ونحن جاهزون للبدء بالخطوات العملية لإنشاء تطبيق معرض الأعمال. إنشاء بنية المشروع يتوجب علينا بداية إنشاء مجلد جديد للمشروع، ثم ننشئ مشروع Vue.js جديد باستخدام الأمر التالي: npm init vue@latest سينشئ هذا الأمر مشروع فيو جديد لكن سيُطلب منا بداية بعض الخيارات مثل اسم المشروع وتهيئة المشروع. بعد الانتهاء من إنشاء المشروع، سوف نتنقل له، ونثبت جميع الحزم أو التبعيات المطلوبة، ثم نشغل الخادم المحلي لعرض مشروعنا في المتصفح من خلال التعليمات التالية: cd <your-project-name> npm install npm run dev يظهر لنا رابط الخادم المحلي localhost في الطرفية، ويمكن فتحه في المتصفح لعرض تطبيق Vue.js الخاص بنا كما في الصورة التالية: بنية المشروع إليك البنية التي سنتبعها لهذا المشروع: يمثل App.vue المكوّن الجذر root component، الذي يحتوي بدوره على خمسة مكونات فرعية child components. من بين هذه المكونات كما تلاحظ المكوّن ProjectListComponent.vue الذي يمكن أن يحتوي بدوره على مكون فرعي آخر هو ProjectComponent.vue. لتشيكل هيكل متداخل بسيط ضمن التطبيق. يمكننا استخدام البنية التي نريدها لتنظيم مكونات المشروع، فمثلًا، يمكن استخدام مكوّن رئيسي MainComponent يحتوي على القسم التعريفي، وقسم المهارات، وقسم النشرة الإخبارية، وقائمة المشاريع كمكوّنات أبناء child components، لجعل البنية أكثر تعقيدًا، كما يمكننا الجمع بين قسم التعريف والمهارات وقسم النشرة الإخبارية بمكوّن واحد، فإطار العمل Vue.js يمنحنا حرية هيكلة مشروعنا بالطريقة التي تريدها. أولاً، علينا تعديل بعض المعلومات الوصفية meta information في ملفIndex.html، وهو نقطة الأساس في المشروع: <!doctype html> <html lang="en"> <head> <meta charset="utf-8" /> <meta name="description" content="My Portfolio" /> <meta name="keywords" content="HTML, CSS, JavaScript" /> <meta name="author" content="Hsoub Academy" /> <title>My Portfolio</title> </head> <body> <div id="app"></div> <script type="module" src="/src/main.js"></script> </body> </html> علينا وضع المكوّن الجذر App.vue في العنصر <div id="app"></div> ضمن الملف index.html. إنشاء المكوّن الجذر ومكوّن الترويسة header component بإمكاننا الآن إنشاء المكوّن الأول HeaderComponent.vue ببساطة، كل ما علينا هو نسخ شيفرة HTML من الملف index.html الذي أنشأناه في مقالنا السابق ولصقه في العنصر <template> ضمن هذا المكون على النحو التالي: <script> export default { props: ["websiteName"], }; </script> <template> <!--Header and Navigation Bar--> <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4 header"> <h1>{{ websiteName }}</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li><a href="/">Root</a></li> <li><a href="portfolio.html">Home1</a></li> <li><a href="/portfolio.html">Home2</a></li> <li><a href="https://academy.hsoub.com/programming/">Lessons</a></li> <li><a href="#project">Projects</a></li> </ul> </nav> </div> </template> ثم نستورد هذا المكوّن الذي أنشأناه للتو داخل المكوّن الجذر App.vue كما يلي: <script> import HeaderComponent from "@/components/HeaderComponent.vue"; export default { data() { return { websiteName: "My Portfolio", }; }, components: { HeaderComponent, }, }; </script> <template> <div class="container"> <HeaderComponent></HeaderComponent> </div> </template> <style> @import "./assets/style.css"; </style> استوردنا أيضًا في نهاية الكود أعلاه شيفرة CSS التي كتباناها في المقال السابق داخل المكوّن الجذر، كي تُطبَّق التنسيقات على جميع المكوّنات، حيث وضعنا ملف CSS في مثالنا في المجلد /src/assets/. الآن إذا فتحنا رابط التطبيق في المتصفح فيجب أن نرى شريط التنقل الذي أضفناه. لدينا مشكلة جديدة لأن كل شيء مكتوب مباشرة في الشيفرة المصدرية، فإن أردنا تغيير شيء ما، فعلينا تغييره في كل مكان ورد فيه ضمن الشيفرة. لكن هدفنا هو جعل صفحة الويب ديناميكية ونسهل تغيير البيانات ولتحقيق ذلك، سنربط بعض معلومات موقعنا مع المتغيرات variables. على سبيل المثال لاحظ كيف كتبنا اسم الموقع وروابط التنقل في شريط التنقل من خلال إضافة الكود التالي للملف HeaderComponent.vue: <script> export default { data() { return { websiteName: "My Portfolio" navLinks: [ { id: 1, name: "Home", link: "#" }, { id: 2, name: "Features", link: "#" }, { id: 3, name: "Pricing", link: "#" }, { id: 4, name: "FAQs", link: "#" }, { id: 5, name: "About", link: "#" }, ], }; }, }; </script> <template> <!--Header and Navigation Bar--> <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4 header"> <h1>{{ websiteName }}</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li class="nav-item" v-for="navLink in navLinks" v-bind:key="navLink.id" > <a href="/portfolio.html" v-bind:href="navLink.link">{{ navLink.name }}</a> </li> </ul> </nav> </div> </template> ولكن هل هذا هو الحل الأمثل؟ سيظهر اسم الموقع مرة أخرى في المكون FooterComponent، وبما أن المكوّنات المختلفة تُعرض منفصلة، فهذا يعني أن اسم الموقع سيُسترد من قاعدة البيانات مرتين، وذلك مضيعة للموارد. الحل البديل هو وضع اسم الموقع websiteName داخل المكوّن الجذر App.vue على شكل خاصية وتمريره إلى المكوّنات الأبناء التي تحتاج إلى استخدامه كما يلي: <script> import HeaderComponent from "@/components/HeaderComponent.vue"; export default { data() { return { websiteName: "My Portfolio", }; }, components: { HeaderComponent, }, }; </script> <template> <div class="container"> <HeaderComponent v-bind:websiteName="websiteName"></HeaderComponent> </div> </template> <style> @import "./assets/style.css"; </style> الآن نحصل على اسم الموقع في شيفرة HeaderComponent.vue كما يلي: <script> export default { data() { return { navLinks: [ { id: 1, name: "Home", link: "#" }, { id: 2, name: "Features", link: "#" }, { id: 3, name: "Pricing", link: "#" }, { id: 4, name: "FAQs", link: "#" }, { id: 5, name: "About", link: "#" }, ], }; }, props: ["websiteName"], }; </script> <template> <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4 header"> <h1>{{ websiteName }}</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li class="nav-item" v-for="navLink in navLinks" :key="navLink.id"> <a :href="navLink.link">{{ navLink.name }}</a> </li> </ul> </nav> </div> </template> مكونات التطبيق شرحنا في الفقرات السابقة طريقة تحقيق مكون الترويسة، ويمكن إنشاء باقي مكونات التطبيق وتخصيصها بنفس الطريقة التي أضفنا فيها الترويسة حيث سيتضمن تطبيقنا المكونات التالية: مكون الترويسة HeaderComponent.vue مكون التعريف IntroComponent.vue مكون النشرة البريدية NewsletterComponent.vue مكون المهارات SkillsComponent.vue مكون المشاريع ProjectsComponent.vue مكون التذييل FooterComponent.vue بعد إنشاء المكونات المطلوبة نعرضها في المكون الجذر App.vue كما يلي: <script> import HeaderComponent from './components/HeaderComponent.vue' import IntroComponent from './components/IntroComponent.vue' import NewsletterComponent from './components/NewsletterComponent.vue' import SkillsComponent from './components/SkillsComponent.vue' import ProjectsComponent from './components/ProjectsComponent.vue' import FooterComponent from './components/FooterComponent.vue' export default { data() { return { websiteName: 'My Portfolio' } }, components: { HeaderComponent, IntroComponent, NewsletterComponent, SkillsComponent, ProjectsComponent, FooterComponent } } </script> <template> <div class="container"> <HeaderComponent :websiteName="websiteName" /> <IntroComponent /> <NewsletterComponent /> <SkillsComponent /> <ProjectsComponent /> <FooterComponent /> </div> </template> <style> @import './assets/style.css'; </style> ملاحظة: هنالك عدة طرق لإضافة الصور للتطبيق، وفي حالتنا سنضيف مجلد الصور images في المجلد public ضمن المشروع لسهولة الوصول لها مباشرة. عند الانتهاء من إضافة كافة الأقسام والصور والتنسيقات سيظهر تطبيقنا كما في الصورة التالية: الخاتمة تعلمنا في هذا المقال أهم خطوات تحويل موقع مطور بواسطة HTML و CSS إلى تطبيق Vue.js. حيث أنشأنا مشروع Vue جديد، ونقلنا التنسيقات والصور إلى المجلدات المناسبة في تطبيقنا، كما قسمنا صفحة HTML إلى مكونات متنوعة تمثل أجزاء الصفحة المختلفة وربطنا المكونات مع بعضها البعض في المكون الجذر. وتعرفنا كذلك على طريقة تحويل البيانات الثابتة إلى ديناميكية، حان دوركم لتجربة تحويل مواقعكم البسيطة إلى تطبيقات جافا سكريبت لجعلها أسهل في الصيانة وأكثر تنظيمًا. ترجمة، وبتصرّف للمقال Create a portfolio Website لكاتبه Eric Hu. اقرأ أيضًا مقدمة إلى Vue.js إنشاء مشاريع Vue.js باستخدام Vue CLI عرض مكونات Vue.js مدخل إلى التعامل مع المكونات في Vue.js
تعرفنا في مقال سابق على طريقة بناء موقع ثابت كمعرض أعمال باستخدام تقنيات الويب الأساسية، وسنتعلم في هذا المقال أهم الخطوات التي علينا اتباعها لترقية موقعنا من موقع بسيط إلى تطبيق تفاعلي باستخدام لغة جافا سكريبت وإطار عملها Vue.js. متطلبات العمل لإنشاء التطبيق نحتاج إلى تثبيت بيئة نود جي إس Node.js ومدير الحزم npm على حاسوبنا المحلي، للقيام بذلك ننتقل إلى موقع Node.js الرسمي ونحمّل أحدث نسخة، بعد تنزيل وتثبيت Node.js سيثبت npm تلقائيًا. بعد ذلك نفتح موجه الأوامر أو الطرفية ونتحقق من أن Node.js ومدير الحزم npm مثبتان بشكل صحيح باستخدام الأمرين التاليين: node -v npm -v بهذا نكون قد أعددنا متطلبات العمل، ونحن جاهزون للبدء بالخطوات العملية لإنشاء تطبيق معرض الأعمال. إنشاء بنية المشروع يتوجب علينا بداية إنشاء مجلد جديد للمشروع، ثم ننشئ مشروع Vue.js جديد باستخدام الأمر التالي: npm init vue@latest سينشئ هذا الأمر مشروع فيو جديد لكن سيُطلب منا بداية بعض الخيارات مثل اسم المشروع وتهيئة المشروع. بعد الانتهاء من إنشاء المشروع، سوف نتنقل له، ونثبت جميع الحزم أو التبعيات المطلوبة، ثم نشغل الخادم المحلي لعرض مشروعنا في المتصفح من خلال التعليمات التالية: cd <your-project-name> npm install npm run dev يظهر لنا رابط الخادم المحلي localhost في الطرفية، ويمكن فتحه في المتصفح لعرض تطبيق Vue.js الخاص بنا كما في الصورة التالية: بنية المشروع إليك البنية التي سنتبعها لهذا المشروع: يمثل App.vue المكوّن الجذر root component، الذي يحتوي بدوره على خمسة مكونات فرعية child components. من بين هذه المكونات كما تلاحظ المكوّن ProjectListComponent.vue الذي يمكن أن يحتوي بدوره على مكون فرعي آخر هو ProjectComponent.vue. لتشيكل هيكل متداخل بسيط ضمن التطبيق. يمكننا استخدام البنية التي نريدها لتنظيم مكونات المشروع، فمثلًا، يمكن استخدام مكوّن رئيسي MainComponent يحتوي على القسم التعريفي، وقسم المهارات، وقسم النشرة الإخبارية، وقائمة المشاريع كمكوّنات أبناء child components، لجعل البنية أكثر تعقيدًا، كما يمكننا الجمع بين قسم التعريف والمهارات وقسم النشرة الإخبارية بمكوّن واحد، فإطار العمل Vue.js يمنحنا حرية هيكلة مشروعنا بالطريقة التي تريدها. أولاً، علينا تعديل بعض المعلومات الوصفية meta information في ملفIndex.html، وهو نقطة الأساس في المشروع: <!doctype html> <html lang="en"> <head> <meta charset="utf-8" /> <meta name="description" content="My Portfolio" /> <meta name="keywords" content="HTML, CSS, JavaScript" /> <meta name="author" content="Hsoub Academy" /> <title>My Portfolio</title> </head> <body> <div id="app"></div> <script type="module" src="/src/main.js"></script> </body> </html> علينا وضع المكوّن الجذر App.vue في العنصر <div id="app"></div> ضمن الملف index.html. إنشاء المكوّن الجذر ومكوّن الترويسة header component بإمكاننا الآن إنشاء المكوّن الأول HeaderComponent.vue ببساطة، كل ما علينا هو نسخ شيفرة HTML من الملف index.html الذي أنشأناه في مقالنا السابق ولصقه في العنصر <template> ضمن هذا المكون على النحو التالي: <script> export default { props: ["websiteName"], }; </script> <template> <!--Header and Navigation Bar--> <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4 header"> <h1>{{ websiteName }}</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li><a href="/">Root</a></li> <li><a href="portfolio.html">Home1</a></li> <li><a href="/portfolio.html">Home2</a></li> <li><a href="https://academy.hsoub.com/programming/">Lessons</a></li> <li><a href="#project">Projects</a></li> </ul> </nav> </div> </template> ثم نستورد هذا المكوّن الذي أنشأناه للتو داخل المكوّن الجذر App.vue كما يلي: <script> import HeaderComponent from "@/components/HeaderComponent.vue"; export default { data() { return { websiteName: "My Portfolio", }; }, components: { HeaderComponent, }, }; </script> <template> <div class="container"> <HeaderComponent></HeaderComponent> </div> </template> <style> @import "./assets/style.css"; </style> استوردنا أيضًا في نهاية الكود أعلاه شيفرة CSS التي كتباناها في المقال السابق داخل المكوّن الجذر، كي تُطبَّق التنسيقات على جميع المكوّنات، حيث وضعنا ملف CSS في مثالنا في المجلد /src/assets/. الآن إذا فتحنا رابط التطبيق في المتصفح فيجب أن نرى شريط التنقل الذي أضفناه. لدينا مشكلة جديدة لأن كل شيء مكتوب مباشرة في الشيفرة المصدرية، فإن أردنا تغيير شيء ما، فعلينا تغييره في كل مكان ورد فيه ضمن الشيفرة. لكن هدفنا هو جعل صفحة الويب ديناميكية ونسهل تغيير البيانات ولتحقيق ذلك، سنربط بعض معلومات موقعنا مع المتغيرات variables. على سبيل المثال لاحظ كيف كتبنا اسم الموقع وروابط التنقل في شريط التنقل من خلال إضافة الكود التالي للملف HeaderComponent.vue: <script> export default { data() { return { websiteName: "My Portfolio" navLinks: [ { id: 1, name: "Home", link: "#" }, { id: 2, name: "Features", link: "#" }, { id: 3, name: "Pricing", link: "#" }, { id: 4, name: "FAQs", link: "#" }, { id: 5, name: "About", link: "#" }, ], }; }, }; </script> <template> <!--Header and Navigation Bar--> <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4 header"> <h1>{{ websiteName }}</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li class="nav-item" v-for="navLink in navLinks" v-bind:key="navLink.id" > <a href="/portfolio.html" v-bind:href="navLink.link">{{ navLink.name }}</a> </li> </ul> </nav> </div> </template> ولكن هل هذا هو الحل الأمثل؟ سيظهر اسم الموقع مرة أخرى في المكون FooterComponent، وبما أن المكوّنات المختلفة تُعرض منفصلة، فهذا يعني أن اسم الموقع سيُسترد من قاعدة البيانات مرتين، وذلك مضيعة للموارد. الحل البديل هو وضع اسم الموقع websiteName داخل المكوّن الجذر App.vue على شكل خاصية وتمريره إلى المكوّنات الأبناء التي تحتاج إلى استخدامه كما يلي: <script> import HeaderComponent from "@/components/HeaderComponent.vue"; export default { data() { return { websiteName: "My Portfolio", }; }, components: { HeaderComponent, }, }; </script> <template> <div class="container"> <HeaderComponent v-bind:websiteName="websiteName"></HeaderComponent> </div> </template> <style> @import "./assets/style.css"; </style> الآن نحصل على اسم الموقع في شيفرة HeaderComponent.vue كما يلي: <script> export default { data() { return { navLinks: [ { id: 1, name: "Home", link: "#" }, { id: 2, name: "Features", link: "#" }, { id: 3, name: "Pricing", link: "#" }, { id: 4, name: "FAQs", link: "#" }, { id: 5, name: "About", link: "#" }, ], }; }, props: ["websiteName"], }; </script> <template> <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4 header"> <h1>{{ websiteName }}</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li class="nav-item" v-for="navLink in navLinks" :key="navLink.id"> <a :href="navLink.link">{{ navLink.name }}</a> </li> </ul> </nav> </div> </template> مكونات التطبيق شرحنا في الفقرات السابقة طريقة تحقيق مكون الترويسة، ويمكن إنشاء باقي مكونات التطبيق وتخصيصها بنفس الطريقة التي أضفنا فيها الترويسة حيث سيتضمن تطبيقنا المكونات التالية: مكون الترويسة HeaderComponent.vue مكون التعريف IntroComponent.vue مكون النشرة البريدية NewsletterComponent.vue مكون المهارات SkillsComponent.vue مكون المشاريع ProjectsComponent.vue مكون التذييل FooterComponent.vue بعد إنشاء المكونات المطلوبة نعرضها في المكون الجذر App.vue كما يلي: <script> import HeaderComponent from './components/HeaderComponent.vue' import IntroComponent from './components/IntroComponent.vue' import NewsletterComponent from './components/NewsletterComponent.vue' import SkillsComponent from './components/SkillsComponent.vue' import ProjectsComponent from './components/ProjectsComponent.vue' import FooterComponent from './components/FooterComponent.vue' export default { data() { return { websiteName: 'My Portfolio' } }, components: { HeaderComponent, IntroComponent, NewsletterComponent, SkillsComponent, ProjectsComponent, FooterComponent } } </script> <template> <div class="container"> <HeaderComponent :websiteName="websiteName" /> <IntroComponent /> <NewsletterComponent /> <SkillsComponent /> <ProjectsComponent /> <FooterComponent /> </div> </template> <style> @import './assets/style.css'; </style> ملاحظة: هنالك عدة طرق لإضافة الصور للتطبيق، وفي حالتنا سنضيف مجلد الصور images في المجلد public ضمن المشروع لسهولة الوصول لها مباشرة. عند الانتهاء من إضافة كافة الأقسام والصور والتنسيقات سيظهر تطبيقنا كما في الصورة التالية: الخاتمة تعلمنا في هذا المقال أهم خطوات تحويل موقع مطور بواسطة HTML و CSS إلى تطبيق Vue.js. حيث أنشأنا مشروع Vue جديد، ونقلنا التنسيقات والصور إلى المجلدات المناسبة في تطبيقنا، كما قسمنا صفحة HTML إلى مكونات متنوعة تمثل أجزاء الصفحة المختلفة وربطنا المكونات مع بعضها البعض في المكون الجذر. وتعرفنا كذلك على طريقة تحويل البيانات الثابتة إلى ديناميكية، حان دوركم لتجربة تحويل مواقعكم البسيطة إلى تطبيقات جافا سكريبت لجعلها أسهل في الصيانة وأكثر تنظيمًا. ترجمة، وبتصرّف للمقال Create a portfolio Website لكاتبه Eric Hu. اقرأ أيضًا مقدمة إلى Vue.js إنشاء مشاريع Vue.js باستخدام Vue CLI عرض مكونات Vue.js مدخل إلى التعامل مع المكونات في Vue.js -
 سنشرح في هذا المقال كيفية توظيف معلوماتك عن تقنيات الويب الأساسية وهي HTML وCSS و JavaScript لإنشاء موقع ويب يكون معرضًا لأعمالك تستخدمه للتعريف بك وبمشاريعك، وسنعمل في مقال لاحق على تحسين هذا الموقع من خلال إطار عمل Vue.js. إنشاء ملف HTML أولاً، ننشئ مجلدًا ونسميه portfolio، حيث سنخزن فيه كل ما يتعلق بمشروع معرض الأعمال. ثم ننشئ داخله ملف HTML، ونطلق عليه اسم Portfolio.html ونفتحه باستخدام أي محرر نصي نفضله، يمكن استخدام أي محرر كالمفكرة، لكن ننصح باستخدام محرر أكواد برمجية مناسب مثل Visual Studio Code. إذا فتحنا الملف في المتصفح واستكشفناه في أدوات المطور سنلاحظ أن له البنية التالية: <!doctype html> <html> <head> . . . </head> <body> . . . </body> </html> لنبدأ بالحديث عن قسم الترويسة <head> والذي يتضمن التالي: <head> <meta charset="utf-8" /> <meta name="description" content="My Portfolio" /> <meta name="keywords" content="HTML, CSS, JavaScript" /> <meta name="author" content="Hsoub Academy" /> <title>My Portfolio</title> </head> الجزء السابق بسيط وواضح، فقد حددنا أولاً مجموعة المحارف التي سيستخدمها الملف، إذ يستخدم المتصفح هذه المعلومات للتأكد من عرض الأحرف والرموز بصورة صحيحة. وبعدها حددنا الوصف والكلمات الرئيسية ومنشئ صفحة الويب، وأخيرًا، صرّحنا عن عنوان صفحة الويب وهو في حالتنا My Portfolio. ملاحظة: لا تُعرض معلومات <head> في موقع الويب، لكنها مهمة لتحسين محركات البحث SEO. . الترويسة Header وشريط التنقل Navigation bar بعدها سنبدأ بإنشاء ترويسة موقعنا، وننشئ شريط التنقل الأساسي من خلال كتابة الكود التالي: <!--Header and Navigation Bar--> <header> <h1>Simple Portfolio</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li class="nav-item"><a href="./portfolio.html">Home</a></li> <li class="nav-item"><a href="https://academy.hsoub.com/programming">Lessons</a></li> <li class="nav-item"><a href="#project">Projects</a></li> </ul> </nav> نلاحظ أننا استخدمنا أنواع روابط مختلفة، فالرابط الأول في قسم التنقل هو عنوان نسبي relative URL سينقلنا إلى جذر الخادم root directory ثم سيبحث عن ملف portfolio.html، والرابط الثاني هو عنوان مطلق absolute URL، أما الرابط الأخير فهو رابط مرساة anchor link وسنتحدث عنه لاحقًا. إضافة القسم التعريفي لمعرض الأعمال نحتاج في معرض الأعمال الاحترافي للتعريف عن نفسنا ونسرد خبراتنا بإيجاز، ولتحقيق ذلك سنضيف الشيفرة التالية، مع تعديل النص الموجود ضمن وسم الفقرة <p>. . .</p> لعرض رسالة قصيرة نعرّف فيها زوار معرض الأعمال عنا: <!--Self Introduction Section--> <section> <h2>Welcome to My Portfolio</h2> <p> Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book </p> </section> قسم الرسائل الإخبارية Newsletter سنضيف بعدها الشيفرة التالية لإتاحة خيار الاشتراك في الرسائل الإخبارية لمتابعي الموقع: <!--Newsletter Sign Up Section--> <section> <h2>Would you like to see more tips and tutorials on web development?</h2> <form> <label for="firstname">First Name:</label> <input type="text" id="firstname" /> <br /><br /> <label for="lastname">Last Name:</label> <input type="text" id="lastname" /> <br /><br /> <label for="email">Enter your email:</label> <input type="email" id="email" name="email" /> </form> </section> قسم الخبرات Skills ثم نضيف الشيفرة التالية لعرض المهارات والخبرات المختلفة: <!--Skills Section--> <section> <h2>My Skills</h2> <ul> <li>HTML (100%)</li> <li>CSS (90%)</li> <li>JavaScript (90%)</li> <li>Python (90%)</li> <li>PHP (100%)</li> <li>Java (90%)</li> <li>Vue.js (80%)</li> <li>Django (90%)</li> <li>Laravel (90%)</li> </ul> </section> نلاحظ استخدام ثلاث طرق لتمثيل إشارة النسبة المئوية % في الكود أعلاه وجميعها تعطي النتيجة نفسها. قسم المشاريع Projects نضيف الشيفرة التالية لعرض المشاريع البرمجية المنجزة: <!--Projects Section--> <section id="project"> <h2>My Projects</h2> <div> <h3>First Project</h3> <img src="./images/first project.jpg" width="500" height="300" /> <p>. . .</p> </div> <div> <h3>Second Project</h3> <img src="./images/second project.jpg" width="500" height="300" /> <p>. . .</p> </div> <div> <h3>Third Project</h3> <img src="./images/third project.jpg" width="500" height="300" /> <p>. . .</p> </div> </section> أضفنا في السطر الثاني معرّفًا id للوسم <section> باسم projects، كي يعمل مع رابط المرساة anchor link الذي ذكرناه سابقًا. <a href="#project">Projects</a> سينقلنا هذا الرابط إلى العنصر ذي المعرّف project. حيث يتوجب عليك دائمًا استخدام المعرف لتحديد العنصر الذي نرغب في الربط به أو الانتقال إليه بحيث يكون فريدًا في صفحة الويب. أما الصور الموجودة في هذا القسم فكلها مخزنة في مجلد يسمى images ضمن مجلد المشروع portfolio. تذييل الصفحة Footer أخيرًا، نضيف الشيفرة التالية لإضافة تذييل إلى الصفحة: <!--Footer--> <footer> <p>Created by Hsoub Academy</p> <p><a href="mailto:example@email.com">example@email.com</a></p> </footer> ستبدو النتيجة النهائية بالشكل التالي، لكنها كما هو ظاهر في الصورة ليست احترافية، ولن تخوّلنا للحصول على وظيفة مناسبة بهيئتها الحالية. لذا سنوضح في الفقرات التالية خطوات تنسيق هذه الصفحة وجعلها أكثر جاذبية. إضافة تنسيقات CSS إلى مستند HTML حان الآن وقت تحسين مظهر الموقع باستخدام لغة CSS، وسنشرح هنا بعض المفاهيم الأساسية لهذه اللغة: أولًا، ننشئ ملف style.css في مجلد المشروع: ثم نستورده import داخل مستند HTML بكتابة وسم <link> داخل الوسم <head> كما يلي: <head> <meta charset="utf-8" /> <meta name="description" content="My Portfolio" /> <meta name="keywords" content="HTML, CSS, JavaScript" /> <meta name="author" content="Hsoub Academy" /> <title>My Portfolio</title> <!-- ربط ملف CSS --> <link rel="stylesheet" href="style.css"> </head> إنشاء تصميم متجاوب علينا تحقيق تصميم متجاوب لمعرض الأعمال، ولتحقيق ذلك يجب أن يحتوي تخطيط الصفحة على مكونين رئيسيين، هما الحاوية container ونظام التخطيط الشبكي grid system. أولاً، يجب أن يكون لدينا حاوية مرنة يتغير عرضها عند تغيير حجم نافذة المتصفح. نعتمد عادة العرض الأعظم على الشاشات الكبيرة كي لا تمتد الحاوية إلى الحافة. أما على الشاشات الأصغر حجمًا، فنضبط عرض الحاوية على القيمة 100% كي نستفيد من أكبر مساحة ممكنة. فيما يلي الشيفرة اللازمة لتحقيق ذلك: <body> <div class="container">. . .</div> </body> /* الشاشات صغيرة الحجم */ .container { max-width: 100%; display: flex; flex-wrap: wrap; } /* الشاشات كبيرة الحجم */ @media only screen and (min-width: 1200px) { .container { max-width: 1140px; margin: auto; display: flex; flex-wrap: wrap; } } نلاحظ أن لدينا نقطة حدّية breakpoint واحدة لتبسيط الأمور، إذا كان عرض الشاشة أقل من 1200 بكسل، فإن الحاوية ستمتد إلى الحواف. أما إن كانت الشاشة أكبر من 1200 بكسل، فسيُضبَط الحد الأقصى لعرض الحاوية على القيمة 1140 بكسل. وفي الحالة الثانية ضبطنا قيمة الهامش على القيمة التلقائية margin: auto; للتأكد من أن الحاوية موجودة داخل حدود الشاشة دائمًا . فيما يلي النتيجة في حالة الشاشات صغيرة الحجم: وفي حالة الشاشات متوسطة الحجم: وفي حالة الشاشات كبيرة الحجم: ثانياً، نحتاج إلى أنظمة تخطيط شبكي مختلفة grid systems للشاشات الصغيرة كشاشات الهواتف المحمولة، والشاشات المتوسطة كشاشات الأجهزة اللوحية، والشاشات الكبيرة كحواسيب سطح المكتب. يحتوي كل نظام شبكي على 12 عمودًا، وقد تشغل العناصر المختلفة أعمدة مختلفة باختلاف أنواع الشاشات، يمكن تحقيق ذلك إما عن طريق نظام الشبكة العادي regular grid system أو الصندوق المرن flexbox. لكننا سنستخدم في مقالنا تخطيط الصندوق المرن: <body> <div class="container"> <div class="col-6 col-s-8">Div1</div> <div class="col-6 col-s-4">Div2</div> <div class="col-2 col-s-10">Div3</div> <div class="col-4 col-s-2">Div4</div> </div> </body> /* للهواتف المحمولة */ [class*="col-"] { width: 100%; } /* للأجهزة اللوحية */ @media only screen and (min-width: 600px) { .col-s-1 { width: 8.33%; } .col-s-2 { width: 16.66%; } .col-s-3 { width: 25%; } .col-s-4 { width: 33.33%; } .col-s-5 { width: 41.66%; } .col-s-6 { width: 50%; } .col-s-7 { width: 58.33%; } .col-s-8 { width: 66.66%; } .col-s-9 { width: 75%; } .col-s-10 { width: 83.33%; } .col-s-11 { width: 91.66%; } .col-s-12 { width: 100%; } } /* للحواسيب المكتبية */ @media only screen and (min-width: 768px) { .col-1 { width: 8.33%; } .col-2 { width: 16.66%; } .col-3 { width: 25%; } .col-4 { width: 33.33%; } .col-5 { width: 41.66%; } .col-6 { width: 50%; } .col-7 { width: 58.33%; } .col-8 { width: 66.66%; } .col-9 { width: 75%; } .col-10 { width: 83.33%; } .col-11 { width: 91.66%; } .col-12 { width: 100%; } } لنرى الآن كيف سيبدو التخطيط السابق: على الشاشات الصغيرة: على الشاشات المتوسطة: على الشاشات الكبيرة: بعد أن انتهينا من تصميم التخطيط العام المتجاوب لموقعنا، سنتطرق إلى التفاصيل. ولكن أولًا، ننصح بالنقر على الروابط أدناه لإلقاء نظرة أوضح على النتيجة التي يجب أن تبدو عليها الصفحة المطلوبة من أجل حجم كل شاشة: تصميم الشاشات الصغيرة تصميم الشاشات المتوسطة تصميم الشاشات الصغيرة اختيار الألوان والخطوط قبل استكمال العمل على تنسيق صفحة الويب، دعونا نفكر في اختيار نظام الألوان والخط الذي ستستخدمه. قد يكون ذلك صعبًا، لكن هناك عديد من الأدوات التي يمكن أن تساعدنا في تحقيق المطلوب،على سبيل المثال يمكن استخدام موقع Coolors الذي يقدم مئات لوحات الألوان المختلفة مع رموزها. أما بالنسبة للخطوط، فننصح باستخدام Google Fonts إذ يمكن تحديد أي خط واستخدامه في ملف CSS. اخترنا في حالتنا الخطوط التالية: Comfortaa بوزن 700 Courier Prime بأوزان 400 و 700 ونوع monospace Crimson Text بأوزان 400 و 600 و 700 Poppins بأوزان 200 و 300 و 400 و 500 و 600 و 700 وكي نتمكن من تطبيق هذه الخطوط على عناصر موقعنا علينا كتابة شيفرة الاستيراد الشيفرة التالية أعلى ملف CSS كما يلي: @import url("https://fonts.googleapis.com/css2?family=Comfortaa:wght@700&family=Courier+Prime:ital,wght@0,400;0,700;1,400;1,700&family=Crimson+Text:ital,wght@0,400;0,600;0,700;1,400;1,600;1,700&family=Poppins:ital,wght@0,200;0,300;0,400;0,500;0,600;0,700;1,200;1,300;1,400;1,500;1,600;1,700&display=swap"); بمجرد استيراد هذه الخطوط عبر @import يمكننا تطبيقها على العناصر في صفحة HTML باستخدام CSS كما يلي: h1 { font-family: "Comfortaa", cursive; } h2, h3, h4 { font-family: "Crimson Text", serif; } p, a { font-family: "Poppins", sans-serif; } تنسيق مظهر أقسام الصفحة لنطبق التنسيقات على كل قسم من الأقسام التي أضفناها لملف HTML تنسيق مظهر شريط التنقل عند تصميم صفحات الويب، يجب عليك دائمًا اتباع قاعدة الجوال أولاً mobile first. أي علينا أولًا البدء بتصميم تخطيط الشاشة الصغيرة. سنبدأ بشريط التنقل. أولاً، نضع العنصر <header> و <nav> داخل العنصر<div>. إذ يقبل العنصر <div> إثني عشر عمودًا في جميع الأجهزة. <div class="col-12 col-s-12 header-and-nav"> <header>. . .</header> <nav>. . .</nav> </div> يجب أن يبقى العنصر <header> في أعلى العنصر <nav> في الشاشات الصغيرة، وفي الشاشات الأكبر حجمًا، نريد وضع العنصر <header> في الجانب الأيسر والعنصر <nav> في الأيمن. ولتنفيذ ذلك، يجب أن نحرص على أن العنصر <div> هو حاوية مرنة flexbox container، وذلك باستخدام الشيفرة التالية: .header-and-nav { display: flex; flex-wrap: wrap; } <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4">. . .</header> <nav class="col-8 col-s-8">. . .</nav> </div> والآن علينا وضع الترويسة وقائمة التنقل في منتصف الصفحة، كما يلي: <!--Header and Navigation Bar--> <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4 header"> <h1>Simple Portfolio</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li class="nav-item"> <a href="./portfolio.html">Home</a> </li> . . . </ul> </nav> </div> .header { text-align: center; } .nav-list { text-align: center; } .nav-item { display: inline-block; } .nav-item a { display: inline-block; } إليك شكل قائمة التنقل الحالية: والآن سنضيف بعض الألوان والحشو paddings والهوامش margins وزخارف نصية للترويسة وقائمة التنقل لجعلها أكثر احترافية: .header { color: white; text-align: center; } .nav-list { list-style-type: none; margin: 0px; padding: 0px; text-align: center; } .nav-item { display: inline-block; } .nav-item a { display: inline-block; color: white; text-decoration: none; padding: 27px 20px; } .nav-item a:hover { background-color: #457b9d; text-decoration: underline; } وستصبح ترويسة الصفحة على النحو التالي: بعدها سنُغيّر شكل قائمة التنقل في الحواسيب المكتبية، ونجري محاذاة للروابط إلى اليمين، باستخدام الشيفرة التالية: @media only screen and (min-width: 768px) { .nav-list { list-style-type: none; margin: 0px; padding: 0px; text-align: right; } } ستصبح الآن على النحو التالي: تنسيق مظهر قسم التعريف الشخصي نستخدم الشيفرة التالية لتنسيق قسم التعريف الشخصي ويمكن استبدال الصورة بأخرى مناسبة: <!--Self Introduction Section--> <section class="col-12 col-s-12 self-intro"> <img src="./images/profile-image.jpg" class="col-4 col-s-4 profile-image" /> <div class="col-8 col-s-8 self-intro-text"> <h2>Welcome to My Portfolio</h2> <p>. . .</p> </div> </section> /* Self Introduction Section */ .self-intro { display: flex; align-items: center; gap: 20px; padding: 20px; background-color: #f8f8f2; } .profile-image { flex: 0 0 40%; height: auto; object-fit: cover; } .self-intro-text { flex: 1; text-align: left; } .self-intro-text h2 { font-size: 1.8rem; font-weight: bold; margin-bottom: 10px; text-decoration: underline; } تنسيق مظهر قسم الرسائل الإخبارية فيما يلي شكل قسم التسجيل في الرسائل الإخبارية والشيفرة اللازمة: على الشاشات الكبيرة: على الشاشات الصغيرة: <!--Newsletter Sign Up Section--> <section class="col-12 col-s-12 newsletter-signup"> <h2 class="col-6 col-s-6">Would you like to see more tips and tutorials on web development?</h2> <form class="col-6 col-s-6 newsletter-signup-form"> <label for="firstname">First Name:</label><br /> <input type="text" id="firstname" /> <br /> <label for="lastname">Last Name:</label><br /> <input type="text" id="lastname" /> <br /> <label for="email">Enter your email:</label><br /> <input type="email" id="email" name="email" /> <button type="submit">Submit</button> </form> </section> /* قسم التسجيل في الرسائل الإخبارية */ .newsletter-signup { background-color: #a8dadc; padding: 10px; display: flex; flex-wrap: wrap; } .newsletter-signup h2 { text-align: center; } .newsletter-signup-form { margin: 0 auto; } .newsletter-signup-form label { font-family: "Poppins", sans-serif; } .newsletter-signup-form input { width: 100%; padding: 12px 20px; margin: 8px 0; box-sizing: border-box; } .newsletter-signup-form button { background-color: #a8dadc; border: solid 3px #e63946; color: #e63946; width: 100%; padding: 10px 0; margin: 10px 0; cursor: pointer; font-family: "Poppins", sans-serif; font-size: 1em; font-weight: 600; } .newsletter-signup-form button:hover { background-color: #e63946; border: solid 3px #e63946; color: white; } @media only screen and (min-width: 768px) { .newsletter-signup { background-color: #a8dadc; padding: 10px; display: flex; flex-wrap: wrap; align-items: center; } .newsletter-signup h2 { text-align: center; padding: 10px; } } تنسيق مظهر قسم المهارات <!--Skills Section--> <section class="col-12 col-s-12 skills-section"> <h2 class="col-12 col-s-12">My Skills</h2> <ul class="col-8 col-s-8 skills-list"> <li>HTML (100%)</li> . . . </ul> </section> /* قسم المهارات */ .skills-section { padding: 10px; display: flex; flex-wrap: wrap; } .skills-section h2 { text-decoration: underline; } .skills-list { column-count: 2; } @media only screen and (min-width: 768px) { .skills-list { column-count: 2; margin: 0 auto; } } لاحظ أننا جعلنا عدد الأعمدة اثنين column-count: 2;، كي نعرض قائمة المهارات في عمودين. تنسيق مظهر قسم المشاريع نريد عرض قسم المشاريع على الشاشة الكبيرة كما يلي: وعرضها على الشاشات الصغيرة كما يلي: وفيما يلي الشيفرة اللازمة لتنسيق عرض قسم المهارات ليبدو بالشكل المطلوب: <!--Projects Section--> <section class="col-12 col-s-12 porject-section" id="project"> <h2 class="col-12 col-s-12">My Projects</h2> <div class="col-4 col-s-4"> <div class="project-card"> <h3>First Project</h3> <img src="/frontend/images/p1.jpg" /> <p>. . .</p> </div> </div> . . . </section> /* قسم المشاريع */ .porject-section { padding: 10px; display: flex; flex-wrap: wrap; background-color: #a8dadc; } .porject-section h2 { text-decoration: underline; } .project-card { border: solid 2px gray; border-radius: 5px; padding: 5px; margin: 5px; } .project-card img { max-width: 100%; object-fit: cover; } تنسيق مظهر تذييل الصفحة نريد عرض تذييل الصفحة بالشكل التالي: <!--Footer--> <footer class="col-12 col-s-12 footer"> <p>Created by Hsoub Academy</p> <p><a href="mailto:example@email.com">example@email.com</a></p> </footer> /*تذييل الصفحة */ .footer { background-color: #1d3557; color: white; text-align: center; } .footer a { color: white; } بهذا نكون قد انتهينا من تصميم موقعنا بالكامل وستبدو الصفحة الرئيسية لموقعنا على النحو التالي: يمكن تحميل الكود البرمجي الكامل لموقع معرض الأعمال وتعديله وفق متطلباتكم من هذا الرابط portfolio-website.zip الخاتمة بهذا نكون أنهينا مقالنا، والذي شرحنا فيه خطوة بخطوة كيفية إنشاء معرض أعمال باستخدام تقنيات الويب الأساسية، وسنتعلم في المقال التالي كيفية ترقية معرض الأعمال الحالي وتحويله إلى تطبيق باستخدام إطار جافا سكريبت Vue.js. ترجمة، وبتصرّف للمقال Create a portfolio Website لكاتبه Eric Hu. اقرأ أيضًا التصميم المتجاوب لصفحات الويب Responsive Web Design عرض محتوى صفحات الويب بتجاوب على الأجهزة المتعددة دليلك إلى استعلامات الوسائط Media Queries في CSS كيف تبرمج موقع ويب بسيط باستخدام HTML و CSS و Bootstrap
سنشرح في هذا المقال كيفية توظيف معلوماتك عن تقنيات الويب الأساسية وهي HTML وCSS و JavaScript لإنشاء موقع ويب يكون معرضًا لأعمالك تستخدمه للتعريف بك وبمشاريعك، وسنعمل في مقال لاحق على تحسين هذا الموقع من خلال إطار عمل Vue.js. إنشاء ملف HTML أولاً، ننشئ مجلدًا ونسميه portfolio، حيث سنخزن فيه كل ما يتعلق بمشروع معرض الأعمال. ثم ننشئ داخله ملف HTML، ونطلق عليه اسم Portfolio.html ونفتحه باستخدام أي محرر نصي نفضله، يمكن استخدام أي محرر كالمفكرة، لكن ننصح باستخدام محرر أكواد برمجية مناسب مثل Visual Studio Code. إذا فتحنا الملف في المتصفح واستكشفناه في أدوات المطور سنلاحظ أن له البنية التالية: <!doctype html> <html> <head> . . . </head> <body> . . . </body> </html> لنبدأ بالحديث عن قسم الترويسة <head> والذي يتضمن التالي: <head> <meta charset="utf-8" /> <meta name="description" content="My Portfolio" /> <meta name="keywords" content="HTML, CSS, JavaScript" /> <meta name="author" content="Hsoub Academy" /> <title>My Portfolio</title> </head> الجزء السابق بسيط وواضح، فقد حددنا أولاً مجموعة المحارف التي سيستخدمها الملف، إذ يستخدم المتصفح هذه المعلومات للتأكد من عرض الأحرف والرموز بصورة صحيحة. وبعدها حددنا الوصف والكلمات الرئيسية ومنشئ صفحة الويب، وأخيرًا، صرّحنا عن عنوان صفحة الويب وهو في حالتنا My Portfolio. ملاحظة: لا تُعرض معلومات <head> في موقع الويب، لكنها مهمة لتحسين محركات البحث SEO. . الترويسة Header وشريط التنقل Navigation bar بعدها سنبدأ بإنشاء ترويسة موقعنا، وننشئ شريط التنقل الأساسي من خلال كتابة الكود التالي: <!--Header and Navigation Bar--> <header> <h1>Simple Portfolio</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li class="nav-item"><a href="./portfolio.html">Home</a></li> <li class="nav-item"><a href="https://academy.hsoub.com/programming">Lessons</a></li> <li class="nav-item"><a href="#project">Projects</a></li> </ul> </nav> نلاحظ أننا استخدمنا أنواع روابط مختلفة، فالرابط الأول في قسم التنقل هو عنوان نسبي relative URL سينقلنا إلى جذر الخادم root directory ثم سيبحث عن ملف portfolio.html، والرابط الثاني هو عنوان مطلق absolute URL، أما الرابط الأخير فهو رابط مرساة anchor link وسنتحدث عنه لاحقًا. إضافة القسم التعريفي لمعرض الأعمال نحتاج في معرض الأعمال الاحترافي للتعريف عن نفسنا ونسرد خبراتنا بإيجاز، ولتحقيق ذلك سنضيف الشيفرة التالية، مع تعديل النص الموجود ضمن وسم الفقرة <p>. . .</p> لعرض رسالة قصيرة نعرّف فيها زوار معرض الأعمال عنا: <!--Self Introduction Section--> <section> <h2>Welcome to My Portfolio</h2> <p> Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book </p> </section> قسم الرسائل الإخبارية Newsletter سنضيف بعدها الشيفرة التالية لإتاحة خيار الاشتراك في الرسائل الإخبارية لمتابعي الموقع: <!--Newsletter Sign Up Section--> <section> <h2>Would you like to see more tips and tutorials on web development?</h2> <form> <label for="firstname">First Name:</label> <input type="text" id="firstname" /> <br /><br /> <label for="lastname">Last Name:</label> <input type="text" id="lastname" /> <br /><br /> <label for="email">Enter your email:</label> <input type="email" id="email" name="email" /> </form> </section> قسم الخبرات Skills ثم نضيف الشيفرة التالية لعرض المهارات والخبرات المختلفة: <!--Skills Section--> <section> <h2>My Skills</h2> <ul> <li>HTML (100%)</li> <li>CSS (90%)</li> <li>JavaScript (90%)</li> <li>Python (90%)</li> <li>PHP (100%)</li> <li>Java (90%)</li> <li>Vue.js (80%)</li> <li>Django (90%)</li> <li>Laravel (90%)</li> </ul> </section> نلاحظ استخدام ثلاث طرق لتمثيل إشارة النسبة المئوية % في الكود أعلاه وجميعها تعطي النتيجة نفسها. قسم المشاريع Projects نضيف الشيفرة التالية لعرض المشاريع البرمجية المنجزة: <!--Projects Section--> <section id="project"> <h2>My Projects</h2> <div> <h3>First Project</h3> <img src="./images/first project.jpg" width="500" height="300" /> <p>. . .</p> </div> <div> <h3>Second Project</h3> <img src="./images/second project.jpg" width="500" height="300" /> <p>. . .</p> </div> <div> <h3>Third Project</h3> <img src="./images/third project.jpg" width="500" height="300" /> <p>. . .</p> </div> </section> أضفنا في السطر الثاني معرّفًا id للوسم <section> باسم projects، كي يعمل مع رابط المرساة anchor link الذي ذكرناه سابقًا. <a href="#project">Projects</a> سينقلنا هذا الرابط إلى العنصر ذي المعرّف project. حيث يتوجب عليك دائمًا استخدام المعرف لتحديد العنصر الذي نرغب في الربط به أو الانتقال إليه بحيث يكون فريدًا في صفحة الويب. أما الصور الموجودة في هذا القسم فكلها مخزنة في مجلد يسمى images ضمن مجلد المشروع portfolio. تذييل الصفحة Footer أخيرًا، نضيف الشيفرة التالية لإضافة تذييل إلى الصفحة: <!--Footer--> <footer> <p>Created by Hsoub Academy</p> <p><a href="mailto:example@email.com">example@email.com</a></p> </footer> ستبدو النتيجة النهائية بالشكل التالي، لكنها كما هو ظاهر في الصورة ليست احترافية، ولن تخوّلنا للحصول على وظيفة مناسبة بهيئتها الحالية. لذا سنوضح في الفقرات التالية خطوات تنسيق هذه الصفحة وجعلها أكثر جاذبية. إضافة تنسيقات CSS إلى مستند HTML حان الآن وقت تحسين مظهر الموقع باستخدام لغة CSS، وسنشرح هنا بعض المفاهيم الأساسية لهذه اللغة: أولًا، ننشئ ملف style.css في مجلد المشروع: ثم نستورده import داخل مستند HTML بكتابة وسم <link> داخل الوسم <head> كما يلي: <head> <meta charset="utf-8" /> <meta name="description" content="My Portfolio" /> <meta name="keywords" content="HTML, CSS, JavaScript" /> <meta name="author" content="Hsoub Academy" /> <title>My Portfolio</title> <!-- ربط ملف CSS --> <link rel="stylesheet" href="style.css"> </head> إنشاء تصميم متجاوب علينا تحقيق تصميم متجاوب لمعرض الأعمال، ولتحقيق ذلك يجب أن يحتوي تخطيط الصفحة على مكونين رئيسيين، هما الحاوية container ونظام التخطيط الشبكي grid system. أولاً، يجب أن يكون لدينا حاوية مرنة يتغير عرضها عند تغيير حجم نافذة المتصفح. نعتمد عادة العرض الأعظم على الشاشات الكبيرة كي لا تمتد الحاوية إلى الحافة. أما على الشاشات الأصغر حجمًا، فنضبط عرض الحاوية على القيمة 100% كي نستفيد من أكبر مساحة ممكنة. فيما يلي الشيفرة اللازمة لتحقيق ذلك: <body> <div class="container">. . .</div> </body> /* الشاشات صغيرة الحجم */ .container { max-width: 100%; display: flex; flex-wrap: wrap; } /* الشاشات كبيرة الحجم */ @media only screen and (min-width: 1200px) { .container { max-width: 1140px; margin: auto; display: flex; flex-wrap: wrap; } } نلاحظ أن لدينا نقطة حدّية breakpoint واحدة لتبسيط الأمور، إذا كان عرض الشاشة أقل من 1200 بكسل، فإن الحاوية ستمتد إلى الحواف. أما إن كانت الشاشة أكبر من 1200 بكسل، فسيُضبَط الحد الأقصى لعرض الحاوية على القيمة 1140 بكسل. وفي الحالة الثانية ضبطنا قيمة الهامش على القيمة التلقائية margin: auto; للتأكد من أن الحاوية موجودة داخل حدود الشاشة دائمًا . فيما يلي النتيجة في حالة الشاشات صغيرة الحجم: وفي حالة الشاشات متوسطة الحجم: وفي حالة الشاشات كبيرة الحجم: ثانياً، نحتاج إلى أنظمة تخطيط شبكي مختلفة grid systems للشاشات الصغيرة كشاشات الهواتف المحمولة، والشاشات المتوسطة كشاشات الأجهزة اللوحية، والشاشات الكبيرة كحواسيب سطح المكتب. يحتوي كل نظام شبكي على 12 عمودًا، وقد تشغل العناصر المختلفة أعمدة مختلفة باختلاف أنواع الشاشات، يمكن تحقيق ذلك إما عن طريق نظام الشبكة العادي regular grid system أو الصندوق المرن flexbox. لكننا سنستخدم في مقالنا تخطيط الصندوق المرن: <body> <div class="container"> <div class="col-6 col-s-8">Div1</div> <div class="col-6 col-s-4">Div2</div> <div class="col-2 col-s-10">Div3</div> <div class="col-4 col-s-2">Div4</div> </div> </body> /* للهواتف المحمولة */ [class*="col-"] { width: 100%; } /* للأجهزة اللوحية */ @media only screen and (min-width: 600px) { .col-s-1 { width: 8.33%; } .col-s-2 { width: 16.66%; } .col-s-3 { width: 25%; } .col-s-4 { width: 33.33%; } .col-s-5 { width: 41.66%; } .col-s-6 { width: 50%; } .col-s-7 { width: 58.33%; } .col-s-8 { width: 66.66%; } .col-s-9 { width: 75%; } .col-s-10 { width: 83.33%; } .col-s-11 { width: 91.66%; } .col-s-12 { width: 100%; } } /* للحواسيب المكتبية */ @media only screen and (min-width: 768px) { .col-1 { width: 8.33%; } .col-2 { width: 16.66%; } .col-3 { width: 25%; } .col-4 { width: 33.33%; } .col-5 { width: 41.66%; } .col-6 { width: 50%; } .col-7 { width: 58.33%; } .col-8 { width: 66.66%; } .col-9 { width: 75%; } .col-10 { width: 83.33%; } .col-11 { width: 91.66%; } .col-12 { width: 100%; } } لنرى الآن كيف سيبدو التخطيط السابق: على الشاشات الصغيرة: على الشاشات المتوسطة: على الشاشات الكبيرة: بعد أن انتهينا من تصميم التخطيط العام المتجاوب لموقعنا، سنتطرق إلى التفاصيل. ولكن أولًا، ننصح بالنقر على الروابط أدناه لإلقاء نظرة أوضح على النتيجة التي يجب أن تبدو عليها الصفحة المطلوبة من أجل حجم كل شاشة: تصميم الشاشات الصغيرة تصميم الشاشات المتوسطة تصميم الشاشات الصغيرة اختيار الألوان والخطوط قبل استكمال العمل على تنسيق صفحة الويب، دعونا نفكر في اختيار نظام الألوان والخط الذي ستستخدمه. قد يكون ذلك صعبًا، لكن هناك عديد من الأدوات التي يمكن أن تساعدنا في تحقيق المطلوب،على سبيل المثال يمكن استخدام موقع Coolors الذي يقدم مئات لوحات الألوان المختلفة مع رموزها. أما بالنسبة للخطوط، فننصح باستخدام Google Fonts إذ يمكن تحديد أي خط واستخدامه في ملف CSS. اخترنا في حالتنا الخطوط التالية: Comfortaa بوزن 700 Courier Prime بأوزان 400 و 700 ونوع monospace Crimson Text بأوزان 400 و 600 و 700 Poppins بأوزان 200 و 300 و 400 و 500 و 600 و 700 وكي نتمكن من تطبيق هذه الخطوط على عناصر موقعنا علينا كتابة شيفرة الاستيراد الشيفرة التالية أعلى ملف CSS كما يلي: @import url("https://fonts.googleapis.com/css2?family=Comfortaa:wght@700&family=Courier+Prime:ital,wght@0,400;0,700;1,400;1,700&family=Crimson+Text:ital,wght@0,400;0,600;0,700;1,400;1,600;1,700&family=Poppins:ital,wght@0,200;0,300;0,400;0,500;0,600;0,700;1,200;1,300;1,400;1,500;1,600;1,700&display=swap"); بمجرد استيراد هذه الخطوط عبر @import يمكننا تطبيقها على العناصر في صفحة HTML باستخدام CSS كما يلي: h1 { font-family: "Comfortaa", cursive; } h2, h3, h4 { font-family: "Crimson Text", serif; } p, a { font-family: "Poppins", sans-serif; } تنسيق مظهر أقسام الصفحة لنطبق التنسيقات على كل قسم من الأقسام التي أضفناها لملف HTML تنسيق مظهر شريط التنقل عند تصميم صفحات الويب، يجب عليك دائمًا اتباع قاعدة الجوال أولاً mobile first. أي علينا أولًا البدء بتصميم تخطيط الشاشة الصغيرة. سنبدأ بشريط التنقل. أولاً، نضع العنصر <header> و <nav> داخل العنصر<div>. إذ يقبل العنصر <div> إثني عشر عمودًا في جميع الأجهزة. <div class="col-12 col-s-12 header-and-nav"> <header>. . .</header> <nav>. . .</nav> </div> يجب أن يبقى العنصر <header> في أعلى العنصر <nav> في الشاشات الصغيرة، وفي الشاشات الأكبر حجمًا، نريد وضع العنصر <header> في الجانب الأيسر والعنصر <nav> في الأيمن. ولتنفيذ ذلك، يجب أن نحرص على أن العنصر <div> هو حاوية مرنة flexbox container، وذلك باستخدام الشيفرة التالية: .header-and-nav { display: flex; flex-wrap: wrap; } <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4">. . .</header> <nav class="col-8 col-s-8">. . .</nav> </div> والآن علينا وضع الترويسة وقائمة التنقل في منتصف الصفحة، كما يلي: <!--Header and Navigation Bar--> <div class="col-12 col-s-12 header-and-nav"> <header class="col-4 col-s-4 header"> <h1>Simple Portfolio</h1> </header> <nav class="col-8 col-s-8"> <ul class="nav-list"> <li class="nav-item"> <a href="./portfolio.html">Home</a> </li> . . . </ul> </nav> </div> .header { text-align: center; } .nav-list { text-align: center; } .nav-item { display: inline-block; } .nav-item a { display: inline-block; } إليك شكل قائمة التنقل الحالية: والآن سنضيف بعض الألوان والحشو paddings والهوامش margins وزخارف نصية للترويسة وقائمة التنقل لجعلها أكثر احترافية: .header { color: white; text-align: center; } .nav-list { list-style-type: none; margin: 0px; padding: 0px; text-align: center; } .nav-item { display: inline-block; } .nav-item a { display: inline-block; color: white; text-decoration: none; padding: 27px 20px; } .nav-item a:hover { background-color: #457b9d; text-decoration: underline; } وستصبح ترويسة الصفحة على النحو التالي: بعدها سنُغيّر شكل قائمة التنقل في الحواسيب المكتبية، ونجري محاذاة للروابط إلى اليمين، باستخدام الشيفرة التالية: @media only screen and (min-width: 768px) { .nav-list { list-style-type: none; margin: 0px; padding: 0px; text-align: right; } } ستصبح الآن على النحو التالي: تنسيق مظهر قسم التعريف الشخصي نستخدم الشيفرة التالية لتنسيق قسم التعريف الشخصي ويمكن استبدال الصورة بأخرى مناسبة: <!--Self Introduction Section--> <section class="col-12 col-s-12 self-intro"> <img src="./images/profile-image.jpg" class="col-4 col-s-4 profile-image" /> <div class="col-8 col-s-8 self-intro-text"> <h2>Welcome to My Portfolio</h2> <p>. . .</p> </div> </section> /* Self Introduction Section */ .self-intro { display: flex; align-items: center; gap: 20px; padding: 20px; background-color: #f8f8f2; } .profile-image { flex: 0 0 40%; height: auto; object-fit: cover; } .self-intro-text { flex: 1; text-align: left; } .self-intro-text h2 { font-size: 1.8rem; font-weight: bold; margin-bottom: 10px; text-decoration: underline; } تنسيق مظهر قسم الرسائل الإخبارية فيما يلي شكل قسم التسجيل في الرسائل الإخبارية والشيفرة اللازمة: على الشاشات الكبيرة: على الشاشات الصغيرة: <!--Newsletter Sign Up Section--> <section class="col-12 col-s-12 newsletter-signup"> <h2 class="col-6 col-s-6">Would you like to see more tips and tutorials on web development?</h2> <form class="col-6 col-s-6 newsletter-signup-form"> <label for="firstname">First Name:</label><br /> <input type="text" id="firstname" /> <br /> <label for="lastname">Last Name:</label><br /> <input type="text" id="lastname" /> <br /> <label for="email">Enter your email:</label><br /> <input type="email" id="email" name="email" /> <button type="submit">Submit</button> </form> </section> /* قسم التسجيل في الرسائل الإخبارية */ .newsletter-signup { background-color: #a8dadc; padding: 10px; display: flex; flex-wrap: wrap; } .newsletter-signup h2 { text-align: center; } .newsletter-signup-form { margin: 0 auto; } .newsletter-signup-form label { font-family: "Poppins", sans-serif; } .newsletter-signup-form input { width: 100%; padding: 12px 20px; margin: 8px 0; box-sizing: border-box; } .newsletter-signup-form button { background-color: #a8dadc; border: solid 3px #e63946; color: #e63946; width: 100%; padding: 10px 0; margin: 10px 0; cursor: pointer; font-family: "Poppins", sans-serif; font-size: 1em; font-weight: 600; } .newsletter-signup-form button:hover { background-color: #e63946; border: solid 3px #e63946; color: white; } @media only screen and (min-width: 768px) { .newsletter-signup { background-color: #a8dadc; padding: 10px; display: flex; flex-wrap: wrap; align-items: center; } .newsletter-signup h2 { text-align: center; padding: 10px; } } تنسيق مظهر قسم المهارات <!--Skills Section--> <section class="col-12 col-s-12 skills-section"> <h2 class="col-12 col-s-12">My Skills</h2> <ul class="col-8 col-s-8 skills-list"> <li>HTML (100%)</li> . . . </ul> </section> /* قسم المهارات */ .skills-section { padding: 10px; display: flex; flex-wrap: wrap; } .skills-section h2 { text-decoration: underline; } .skills-list { column-count: 2; } @media only screen and (min-width: 768px) { .skills-list { column-count: 2; margin: 0 auto; } } لاحظ أننا جعلنا عدد الأعمدة اثنين column-count: 2;، كي نعرض قائمة المهارات في عمودين. تنسيق مظهر قسم المشاريع نريد عرض قسم المشاريع على الشاشة الكبيرة كما يلي: وعرضها على الشاشات الصغيرة كما يلي: وفيما يلي الشيفرة اللازمة لتنسيق عرض قسم المهارات ليبدو بالشكل المطلوب: <!--Projects Section--> <section class="col-12 col-s-12 porject-section" id="project"> <h2 class="col-12 col-s-12">My Projects</h2> <div class="col-4 col-s-4"> <div class="project-card"> <h3>First Project</h3> <img src="/frontend/images/p1.jpg" /> <p>. . .</p> </div> </div> . . . </section> /* قسم المشاريع */ .porject-section { padding: 10px; display: flex; flex-wrap: wrap; background-color: #a8dadc; } .porject-section h2 { text-decoration: underline; } .project-card { border: solid 2px gray; border-radius: 5px; padding: 5px; margin: 5px; } .project-card img { max-width: 100%; object-fit: cover; } تنسيق مظهر تذييل الصفحة نريد عرض تذييل الصفحة بالشكل التالي: <!--Footer--> <footer class="col-12 col-s-12 footer"> <p>Created by Hsoub Academy</p> <p><a href="mailto:example@email.com">example@email.com</a></p> </footer> /*تذييل الصفحة */ .footer { background-color: #1d3557; color: white; text-align: center; } .footer a { color: white; } بهذا نكون قد انتهينا من تصميم موقعنا بالكامل وستبدو الصفحة الرئيسية لموقعنا على النحو التالي: يمكن تحميل الكود البرمجي الكامل لموقع معرض الأعمال وتعديله وفق متطلباتكم من هذا الرابط portfolio-website.zip الخاتمة بهذا نكون أنهينا مقالنا، والذي شرحنا فيه خطوة بخطوة كيفية إنشاء معرض أعمال باستخدام تقنيات الويب الأساسية، وسنتعلم في المقال التالي كيفية ترقية معرض الأعمال الحالي وتحويله إلى تطبيق باستخدام إطار جافا سكريبت Vue.js. ترجمة، وبتصرّف للمقال Create a portfolio Website لكاتبه Eric Hu. اقرأ أيضًا التصميم المتجاوب لصفحات الويب Responsive Web Design عرض محتوى صفحات الويب بتجاوب على الأجهزة المتعددة دليلك إلى استعلامات الوسائط Media Queries في CSS كيف تبرمج موقع ويب بسيط باستخدام HTML و CSS و Bootstrap -
 تملك أداة بودمان أداة تسمى بودمان كومبوز Podman Compose وهي بديلة عن أداة دوكر كومبوز Docker Compose وتُتيح لك العمل مع ملفاتها. وكما ذكرنا في مقالاتنا السابقة فإن بودمان يُعدّ بديلًا ممتازًا عن دوكر، لكن إحدى مساوئه هي أنه لا يُتيح ميزة سحب الصور وتشغيل الحاويات بدءًا من ملفات كومبوز. سنتعرف في مقالنا على هذه الأداة والفوائد التي تقدمها عند العمل مع الحاويات وكيفية حل هذه المشكلة من خلالها. ما هي أداة بودمان كومبوز Podman Compose تُتيح أداة دوكر خاصيّة تحديد جميع التفاصيل المهمة كاسم الحاوية، والصورة المُستَخدمة، وسياسة إعادة التشغيل restart policy، ووحدات التخزين، والمنافذ، والتسميات، وما شابه، في ملف واحد يدعى عادةً ملف docker-compose.yml. لكن هذه الخاصيّة ليست موجودةً في بودمان. لذلك يجب أن نستخدم أداة بودمان كومبوز لنحصل عليها. تتبع أداة بودمان كومبوز المواصفات نفسها التي تتبعها أداة دوكر Docker، مما يجعلها تتوافق مع ملفات docker-compose.yml (لكن قد توجد بعض الاختلافات البسيطة كوضع القيم بين علامتي الاقتباس المزدوجة (")، ولكن هذه الاختلافات يمكن حلها بمجرد النظر إلى الأخطاء الناتجة عن استعمال الأداة podman-compose.) تثبيت أداة بودمان كومبوز podman-compose تُعد أداة بودمان كومبوز أداةً جديدةً نسبيًا لذلك قد لا تجدها في مستودعات توزيعات لينكس المستقرة وذات الدعم طويل الأمد LTS distributions. لكن إليك الخيارات المتاحة من أجل تثبيتها: يمكنك تثبيت أداة بودمان كومبوز في توزيعة أوبنتو ذات الإصدار 22.10 نسخة كينيتك كودو Kinetic Kudu والنسخ الأحدث، وفي توزيعة ديبيان النسخة الثانية عشر بوكوورم Bookworm والنسخ الأحدث منها، باستخدام مدير الحزم apt على النحو التالي: sudo apt install podman-compose أما بالنسبة لمستخدمي الإصدار السادس والثلاثين من توزيعة فيدورا Fedora والإصدارات الأحدث (إصدار حزمة النسخة الخامسة والثلاثون من فيدورا هو 0.1.7-6.git) فيمكنهم استخدام مدير الحزم dnf لتثبيت أداة بودمان كومبوز كما يلي: sudo dnf install podman-compose أما لتثبيتها على نسخة OpenSUSE Tumbleweed أو Leap الإصدار الخامس عشر أو الإصدارات الأحدث فاستخدم الأمر التالي: sudo zypper install podman-compose أما مستخدمو Arch Linux فعليهم استخدام الأمر التالي: sudo pacman -Syu podman-compose التأكد من نجاح التثبيت للتأكد من نجاح عملية تثبيت أداة بودمان كومبوز وأن مسارها الصحيح موجود ضمن متغير البيئة path استخدم الأمر التالي والذي سيعرض لك نسخة بودمان المُستخدمة: podman-compose --version إليك خرج الأمر السابق على توزيعة فيدورا النسخة السادسة والثلاثون: $ podman-compose --version ['podman', '--version', ''] using podman version: 4.3.1 podman-composer version 1.0.3 podman --version podman version 4.3.1 exit code: 0 أساسيات أداة بودمان كومبوز إليك المقال التالي عن كيفية استخدام دوكر كومبوز. إليك ملف كومبوز الذي سنستخدمه في مقالنا: version: 3.7 services: reverse-proxy: image: docker.io/library/caddy:alpine container_name: caddy-vishwambhar command: caddy run --config /etc/caddy/Caddyfile restart: always ports: - "8080:80" - "8443:443" volumes: - /docker-volumes/caddy/Caddyfile:/etc/caddy/Caddyfile:Z - /docker-volumes/caddy/site:/srv:Z - /docker-volumes/caddy/caddy_data:/data:Z - /docker-volumes/caddy/caddy_config:/config:Z - /docker-volumes/caddy/ssl:/etc/ssl:Z labels: - io.containers.autoupdate=registry - pratham.container.category=proxy environment: - TZ=Asia/Kolkata depends_on: - gitea-web gitea-web: image: docker.io/gitea/gitea:latest container_name: gitea-govinda restart: always ports: - "8010:3000" - "8011:22" volumes: - /docker-volumes/gitea/web:/data:Z - /docker-volumes/gitea/ssh:/data/git/.ssh:Z - /etc/localtime:/etc/localtime:ro labels: - io.containers.autoupdate=registry - pratham.container.category=gitea environment: - RUN_MODE=prod - DISABLE_SSH=false - START_SSH_SERVER=true - SSH_PORT=22 - SSH_LISTEN_PORT=22 - ROOT_URL=https://git.mydomain.com - DOMAIN=git.mydomain.com - SSH_DOMAIN=git.mydomain.com - GITEA__database__DB_TYPE=postgres - GITEA__database__HOST=gitea-db:5432 - GITEA__database__NAME=gitea - GITEA__database__USER=gitea - GITEA__database__PASSWD=/run/secrets/gitea_database_user_password - GITEA__service__DISABLE_REGISTRATION=true - TZ=Asia/Kolkata depends_on: - gitea-db secrets: - gitea_database_user_password gitea-db: image: docker.io/library/postgres:14-alpine container_name: gitea-chitragupta restart: always volumes: - /docker-volumes/gitea/database:/var/lib/postgresql/data:Z labels: - io.containers.autoupdate=registry - pratham.container.category=gitea environment: - POSTGRES_USER=gitea - POSTGRES_PASSWORD=/run/secrets/gitea_database_user_password - POSTGRES_DB=gitea - TZ=Asia/Kolkata secrets: - gitea_database_user_password secrets: gitea_database_user_password: external: true تشغيل كل الحاويات من ملف كومبوز يمكننا باستخدام الأمر up إنشاء الخدمات المذكورة في ملف كومبوز (docker-compose.yml) وتشغيلها: podman-compose up -d يؤدي تشغيل الأمر up إلى تنفيذ كل الإجراءات اللازمة لتشغيل الخدمات والحاويات المذكورة في ملف كومبوز، بما فيه الخطوات التالية: سحب الصور غير المتوفرة محليًا. إنشاء الحاويات مع الخيارات المحددة (المنافذ، ووحدات التخزين، والشبكات، والمعلومات الحساسة secrets). تشغيل الحاويات وفق ترتيب معين (باستخدام القيود constrains مثل depends_on). إذا تمعّنت في المثال السابق ستلاحظ وجود الخيار d- الذي يُشغّل الحاويات في الخلفية ويفصلها عن الصدفة الحالية. يمكنك التأكد من عمل الحاويات بتشغيل الأمر podman ps: $ podman ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d7b7f91c03aa docker.io/library/caddy:alpine caddy run --confi... 4 hours ago Up 4 hours ago 0.0.0.0:8080->80/tcp, 0.0.0.0:8443->443/tcp caddy-vishwambhar 1cfcc6efc0d0 docker.io/library/postgres:14-alpine postgres 4 hours ago Up 4 hours ago gitea-chitragupta 531be3df06d0 docker.io/gitea/gitea:latest /bin/s6-svscan /e... 4 hours ago Up 4 hours ago 0.0.0.0:8010->3000/tcp, 0.0.0.0:8011->22/tcp gitea-govinda إيقاف جميع الحاويات باستخدام ملف كومبوز لإيقاف جميع الحاويات المحددة في ملف كومبوز عليك استخدام الأمر down: podman-compose down يمكنك تحديد وقت إيقاف timeout لتتوقف فيه الحاويات عن العمل من تلقاء نفسها، باستخدام أحد الخيارين التاليين: podman-compose down -t TIMEOUT_IN_SECONDS podman-compose down --timeout TIMEOUT_IN_SECONDS يرجى الانتباه إلى أن الأمر down يوقف عمل الحاويات فقط، أما إن أردت حذف الحاويات فعليك حذفها يدويًا. تشغيل أو إيقاف خدمات معينة إن كررت استخدام المنافذ ووحدات التخزين ومتغيرات البيئة، فمن المحتمل أنك ستستخدم الأمر podman-compose up والأمر podman-compose down بشكل متكرر. لكن هذا سيؤدي إلى تشغيل كل الخدمات وإيقافها، على التوالي. أي إن أردت تشغيل خدمة معينة أو إيقافها، فعليك انتظار تشغيل جميع الخدمات المدرجة في ملف كومبوز وإيقافها، وهذا ليس أمرًا محبّذًا. ولحل هذه المشكلة، يمكنك استخدام الأمر start والأمر stop لتشغيل وإيقاف خدمة معينة. ويمكنك استخدام الأمر restart لإعادة التشغيل. إليك المثال التالي الذي يوضح تشغيل الخدمة gitea-db، وإيقافها ثم إعادة تشغيلها: $ podman-comopse start gitea-db $ podman-compose stop gitea-db $ podman-compose restart gitea-db سحب صور الحاويات الضرورية دفعةً واحدة لنفترض أن لديك عشر خدمات مختلفة في ملف كومبوز وأنك تريد تشغيل الحاويات معًا، إذًا بإمكانك استخدام أمر السحب pull كما يلي: podman-compose pull سيؤدي تشغيل الأمر pull إلى سحب كل الصور المحددة في ملف كومبوز. تغيير اسم ملف كومبوز قد ترغب بتغيير اسم ملف كومبوز (docker-compose.yml) إلى اسم آخر، لتنفيذ ذلك يمكنك استخدام أحد الخيارين التاليين: podman-compose -f COMPOSE_FILE_NAME podman-compose --file COMPOSE_FILE_NAME على النحو التالي: podman-compose --file my-compose-file.yml إن تشغيل الأمر السابق يجعل أداة بودمان كومبوز تغير اسم الملف من docker-compose.yml إلى my-compose-file.yml. الخلاصة تهانينا! لقد وصلت إلى نهاية سلسلتنا التعليمية عن أداة بودمان التي تُعدّ أداةً رائعةً لإدارة الحاويات، وعند استخدامها مع أداة بودمان كومبوز يصبح بإمكانك إنشاء حاويات متعددة وتخصيصها وفق الإعدادات التي تناسبك. بها! ننصحك بتجربتها وشاركنا استفساراتك في قسم الأسئلة والأجوبة في أكاديمية حسوب. ترجمة -وبتصرّف- للمقال Beginner's Guide to Using Podman Compose من موقع Linux Handbook. اقرأ أيضًا المقال السابق: إدارة الحاويات محدودة الصلاحية Rootless Containers باستخدام أداة بودمان Podman تشغيل الحاويات تلقائيًا باستخدام أداة بودمان Podman الفرق بين أداتي دوكر Docker وبودمان Podman نظام كوبيرنتس Kubernetes وكيفية عمله
تملك أداة بودمان أداة تسمى بودمان كومبوز Podman Compose وهي بديلة عن أداة دوكر كومبوز Docker Compose وتُتيح لك العمل مع ملفاتها. وكما ذكرنا في مقالاتنا السابقة فإن بودمان يُعدّ بديلًا ممتازًا عن دوكر، لكن إحدى مساوئه هي أنه لا يُتيح ميزة سحب الصور وتشغيل الحاويات بدءًا من ملفات كومبوز. سنتعرف في مقالنا على هذه الأداة والفوائد التي تقدمها عند العمل مع الحاويات وكيفية حل هذه المشكلة من خلالها. ما هي أداة بودمان كومبوز Podman Compose تُتيح أداة دوكر خاصيّة تحديد جميع التفاصيل المهمة كاسم الحاوية، والصورة المُستَخدمة، وسياسة إعادة التشغيل restart policy، ووحدات التخزين، والمنافذ، والتسميات، وما شابه، في ملف واحد يدعى عادةً ملف docker-compose.yml. لكن هذه الخاصيّة ليست موجودةً في بودمان. لذلك يجب أن نستخدم أداة بودمان كومبوز لنحصل عليها. تتبع أداة بودمان كومبوز المواصفات نفسها التي تتبعها أداة دوكر Docker، مما يجعلها تتوافق مع ملفات docker-compose.yml (لكن قد توجد بعض الاختلافات البسيطة كوضع القيم بين علامتي الاقتباس المزدوجة (")، ولكن هذه الاختلافات يمكن حلها بمجرد النظر إلى الأخطاء الناتجة عن استعمال الأداة podman-compose.) تثبيت أداة بودمان كومبوز podman-compose تُعد أداة بودمان كومبوز أداةً جديدةً نسبيًا لذلك قد لا تجدها في مستودعات توزيعات لينكس المستقرة وذات الدعم طويل الأمد LTS distributions. لكن إليك الخيارات المتاحة من أجل تثبيتها: يمكنك تثبيت أداة بودمان كومبوز في توزيعة أوبنتو ذات الإصدار 22.10 نسخة كينيتك كودو Kinetic Kudu والنسخ الأحدث، وفي توزيعة ديبيان النسخة الثانية عشر بوكوورم Bookworm والنسخ الأحدث منها، باستخدام مدير الحزم apt على النحو التالي: sudo apt install podman-compose أما بالنسبة لمستخدمي الإصدار السادس والثلاثين من توزيعة فيدورا Fedora والإصدارات الأحدث (إصدار حزمة النسخة الخامسة والثلاثون من فيدورا هو 0.1.7-6.git) فيمكنهم استخدام مدير الحزم dnf لتثبيت أداة بودمان كومبوز كما يلي: sudo dnf install podman-compose أما لتثبيتها على نسخة OpenSUSE Tumbleweed أو Leap الإصدار الخامس عشر أو الإصدارات الأحدث فاستخدم الأمر التالي: sudo zypper install podman-compose أما مستخدمو Arch Linux فعليهم استخدام الأمر التالي: sudo pacman -Syu podman-compose التأكد من نجاح التثبيت للتأكد من نجاح عملية تثبيت أداة بودمان كومبوز وأن مسارها الصحيح موجود ضمن متغير البيئة path استخدم الأمر التالي والذي سيعرض لك نسخة بودمان المُستخدمة: podman-compose --version إليك خرج الأمر السابق على توزيعة فيدورا النسخة السادسة والثلاثون: $ podman-compose --version ['podman', '--version', ''] using podman version: 4.3.1 podman-composer version 1.0.3 podman --version podman version 4.3.1 exit code: 0 أساسيات أداة بودمان كومبوز إليك المقال التالي عن كيفية استخدام دوكر كومبوز. إليك ملف كومبوز الذي سنستخدمه في مقالنا: version: 3.7 services: reverse-proxy: image: docker.io/library/caddy:alpine container_name: caddy-vishwambhar command: caddy run --config /etc/caddy/Caddyfile restart: always ports: - "8080:80" - "8443:443" volumes: - /docker-volumes/caddy/Caddyfile:/etc/caddy/Caddyfile:Z - /docker-volumes/caddy/site:/srv:Z - /docker-volumes/caddy/caddy_data:/data:Z - /docker-volumes/caddy/caddy_config:/config:Z - /docker-volumes/caddy/ssl:/etc/ssl:Z labels: - io.containers.autoupdate=registry - pratham.container.category=proxy environment: - TZ=Asia/Kolkata depends_on: - gitea-web gitea-web: image: docker.io/gitea/gitea:latest container_name: gitea-govinda restart: always ports: - "8010:3000" - "8011:22" volumes: - /docker-volumes/gitea/web:/data:Z - /docker-volumes/gitea/ssh:/data/git/.ssh:Z - /etc/localtime:/etc/localtime:ro labels: - io.containers.autoupdate=registry - pratham.container.category=gitea environment: - RUN_MODE=prod - DISABLE_SSH=false - START_SSH_SERVER=true - SSH_PORT=22 - SSH_LISTEN_PORT=22 - ROOT_URL=https://git.mydomain.com - DOMAIN=git.mydomain.com - SSH_DOMAIN=git.mydomain.com - GITEA__database__DB_TYPE=postgres - GITEA__database__HOST=gitea-db:5432 - GITEA__database__NAME=gitea - GITEA__database__USER=gitea - GITEA__database__PASSWD=/run/secrets/gitea_database_user_password - GITEA__service__DISABLE_REGISTRATION=true - TZ=Asia/Kolkata depends_on: - gitea-db secrets: - gitea_database_user_password gitea-db: image: docker.io/library/postgres:14-alpine container_name: gitea-chitragupta restart: always volumes: - /docker-volumes/gitea/database:/var/lib/postgresql/data:Z labels: - io.containers.autoupdate=registry - pratham.container.category=gitea environment: - POSTGRES_USER=gitea - POSTGRES_PASSWORD=/run/secrets/gitea_database_user_password - POSTGRES_DB=gitea - TZ=Asia/Kolkata secrets: - gitea_database_user_password secrets: gitea_database_user_password: external: true تشغيل كل الحاويات من ملف كومبوز يمكننا باستخدام الأمر up إنشاء الخدمات المذكورة في ملف كومبوز (docker-compose.yml) وتشغيلها: podman-compose up -d يؤدي تشغيل الأمر up إلى تنفيذ كل الإجراءات اللازمة لتشغيل الخدمات والحاويات المذكورة في ملف كومبوز، بما فيه الخطوات التالية: سحب الصور غير المتوفرة محليًا. إنشاء الحاويات مع الخيارات المحددة (المنافذ، ووحدات التخزين، والشبكات، والمعلومات الحساسة secrets). تشغيل الحاويات وفق ترتيب معين (باستخدام القيود constrains مثل depends_on). إذا تمعّنت في المثال السابق ستلاحظ وجود الخيار d- الذي يُشغّل الحاويات في الخلفية ويفصلها عن الصدفة الحالية. يمكنك التأكد من عمل الحاويات بتشغيل الأمر podman ps: $ podman ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d7b7f91c03aa docker.io/library/caddy:alpine caddy run --confi... 4 hours ago Up 4 hours ago 0.0.0.0:8080->80/tcp, 0.0.0.0:8443->443/tcp caddy-vishwambhar 1cfcc6efc0d0 docker.io/library/postgres:14-alpine postgres 4 hours ago Up 4 hours ago gitea-chitragupta 531be3df06d0 docker.io/gitea/gitea:latest /bin/s6-svscan /e... 4 hours ago Up 4 hours ago 0.0.0.0:8010->3000/tcp, 0.0.0.0:8011->22/tcp gitea-govinda إيقاف جميع الحاويات باستخدام ملف كومبوز لإيقاف جميع الحاويات المحددة في ملف كومبوز عليك استخدام الأمر down: podman-compose down يمكنك تحديد وقت إيقاف timeout لتتوقف فيه الحاويات عن العمل من تلقاء نفسها، باستخدام أحد الخيارين التاليين: podman-compose down -t TIMEOUT_IN_SECONDS podman-compose down --timeout TIMEOUT_IN_SECONDS يرجى الانتباه إلى أن الأمر down يوقف عمل الحاويات فقط، أما إن أردت حذف الحاويات فعليك حذفها يدويًا. تشغيل أو إيقاف خدمات معينة إن كررت استخدام المنافذ ووحدات التخزين ومتغيرات البيئة، فمن المحتمل أنك ستستخدم الأمر podman-compose up والأمر podman-compose down بشكل متكرر. لكن هذا سيؤدي إلى تشغيل كل الخدمات وإيقافها، على التوالي. أي إن أردت تشغيل خدمة معينة أو إيقافها، فعليك انتظار تشغيل جميع الخدمات المدرجة في ملف كومبوز وإيقافها، وهذا ليس أمرًا محبّذًا. ولحل هذه المشكلة، يمكنك استخدام الأمر start والأمر stop لتشغيل وإيقاف خدمة معينة. ويمكنك استخدام الأمر restart لإعادة التشغيل. إليك المثال التالي الذي يوضح تشغيل الخدمة gitea-db، وإيقافها ثم إعادة تشغيلها: $ podman-comopse start gitea-db $ podman-compose stop gitea-db $ podman-compose restart gitea-db سحب صور الحاويات الضرورية دفعةً واحدة لنفترض أن لديك عشر خدمات مختلفة في ملف كومبوز وأنك تريد تشغيل الحاويات معًا، إذًا بإمكانك استخدام أمر السحب pull كما يلي: podman-compose pull سيؤدي تشغيل الأمر pull إلى سحب كل الصور المحددة في ملف كومبوز. تغيير اسم ملف كومبوز قد ترغب بتغيير اسم ملف كومبوز (docker-compose.yml) إلى اسم آخر، لتنفيذ ذلك يمكنك استخدام أحد الخيارين التاليين: podman-compose -f COMPOSE_FILE_NAME podman-compose --file COMPOSE_FILE_NAME على النحو التالي: podman-compose --file my-compose-file.yml إن تشغيل الأمر السابق يجعل أداة بودمان كومبوز تغير اسم الملف من docker-compose.yml إلى my-compose-file.yml. الخلاصة تهانينا! لقد وصلت إلى نهاية سلسلتنا التعليمية عن أداة بودمان التي تُعدّ أداةً رائعةً لإدارة الحاويات، وعند استخدامها مع أداة بودمان كومبوز يصبح بإمكانك إنشاء حاويات متعددة وتخصيصها وفق الإعدادات التي تناسبك. بها! ننصحك بتجربتها وشاركنا استفساراتك في قسم الأسئلة والأجوبة في أكاديمية حسوب. ترجمة -وبتصرّف- للمقال Beginner's Guide to Using Podman Compose من موقع Linux Handbook. اقرأ أيضًا المقال السابق: إدارة الحاويات محدودة الصلاحية Rootless Containers باستخدام أداة بودمان Podman تشغيل الحاويات تلقائيًا باستخدام أداة بودمان Podman الفرق بين أداتي دوكر Docker وبودمان Podman نظام كوبيرنتس Kubernetes وكيفية عمله -
 ستتعلم في هذا المقال كيفية التعامل مع الحاويات محدودة الصلاحية Rootless Containers باستخدام أداة بودمان. إن كنت تستخدم الحاويات لنشر البرمجيات، أو تستخدم أداة بودمان، أو أنك ترغب في رفع مستوى الأمان عن طريق تشغيل الحاويات محدودة الصلاحية rootless containers، فهذا المقال مناسب لك. ما هي أداة بودمان Podman إن أداة بودمان Podman هي أحد منتجات شركة Red Hat طُرِحَت كبديل فعّال عن أداة دوكر Docker ويمكنها أداء 99% من المهام التي تؤديها أداة دوكر. بعض ميزات بودمان هي دعم الحاويات محدودة الصلاحية rootless containers، واستخدام نموذج fork/exec لتشغيل الحاويات، وأنه لا يعمل وفق مبدأ البرنامج الخفي أي إنه daemon-less، وثمة كثير من الميزات الأخرى. أما مزايا الحاويات محدودة الصلاحية فهي واضحة، فهي لا تحتاج لصلاحيات الجذر الذي يملك وصولًا كاملًا إلى جميع موارد وملفات النظام كي تعمل، لذلك فإن تشغيلها أكثر أمانًا. تشغيل حاويات بودمان محدودة الصلاحية Rootless Containers إذا كنت متمرسًا في مجال تقنية المعلومات، فمن المحتمل أنك وقعت في أحد الخطأين التاليين: تشغيل الأمر docker باستخدام Sudo، وبالتالي زيادة امتيازاته. إضافة مستخدم محدود الصلاحيات non-root إلى مجموعة دوكر docker group. تلك أخطاء تُضِر بأمان النظام بصورة كبيرة؛ لأنك تسمح لبرنامج دوكر الخفي Docker daemon بالوصول إلى جهازك. وهذا يعرضك للخطر بطريقتين: يعمل برنامج دوكر الخفي (dockerd) كجذر، فإذا كانت ثمة ثغرة أمنية فيه، سيكون نظامك بكامله عرضةً للخطر لأن dockerd هي عملية تابعة للمستخدم الجذر. قد تحتوي الصورة التي تستخدمها على ثغرات أمنية. تخيّل ماذا سيحدث عند استخدام هذه الصورة بواسطة حاوية تعمل كعملية للمستخدم الجذر root process. يمكن لأحد المخترقين استخدام هذه الصورة للوصول إلى كافة موراد النظام. الحل بسيط، عليك الامتناع عن تشغيل البرامج بصلاحيات الجذر، حتى لو كنت تثق بها. تذكر أنه لا يوجد شيء آمن بنسبة 100%. وهنا تأتي ميزة بودمان في إدارة الحاويات دون الحاجة إلى الوصول إلى الجذر. فعند تشغيل حاوية باستخدام بودمان كمستخدم غير جذر، لن تحصل تلك الحاوية على امتيازات إضافية، ولن يطلب منك بودمان كلمة مرور sudo. إليك المزايا التي توفرها أداة بودمان عند إدارة الحاويات محدودة الصلاحية root-less containers: يمكنك تخصيص مجموعة من الحاويات المشتركة لكل مستخدم محلي. (على سبيل المثال، بإمكانك تشغيل Nextcloud وMariaDB لدى المستخدم nextcloud_user وتشغيل الحاويات Gitea وPostgreSQL لدى المستخدم gitea_user). حتى لو اختُرِقَت الحاوية، فلا يمكن التحكم بالنظام المضيف بكامله، لأن المستخدم المسؤول عن الحاوية ليس جذرًا. لكنه لن يعود صالحًا للاستخدام. قيود استخدام حاويات بودمان محدودة الصلاحية عند استخدام أداتي بودمان ودوكر مع صلاحيات المستخدم الجذر أي بنمط عمل root-full، فأنت تمنحها امتيازات على مستوى المستخدم المسؤول أو المميز super-user. وهذا ليس أمرًا محمودًا، ولكنه يضمن أن جميع الوظائف تعمل على النحو المطلوب. ومن الناحية الأخرى، ثمة بعض القيود على تشغيل حاويات بودمان بدون امتيازات الجذر، إليك أهمها: لا يمكن تشارك صور الحاويات بين المستخدمين إذا سحب المستخدم user0 صورة الحاوية nginx:stable-alpine فيجب على المستخدم user1 سحبها بنفسه مرةً أخرى. لا توجد لحد الآن طريقة تسمح تشارك الصور بين المستخدمين، لكن يمكنك نسخ الصور من مستخدم لآخر باتباع هذا الدليل من شركة ريد هات Red Hat. لا يمكن ربط المنافذ ports binding ذوات الأرقام الأدنى من 1024، لكن ثمة طريقة لحل هذه المشكلة. لا يمكن للحاوية محدودة الصلاحية إرسال الطلب ping لأي من المضيفين hosts. لكن ثمة طريقة لحل هذه المشكلة. إذا عيّنت معرّفًا مميزًا UID لحاوية بودمان محدودة الصلاحية، فقد يفشل ذلك إن لم تسند المعرّف المميز UID إلى حاوية موجودة مسبقًا. إذًا، من الأفضل تشغيل بودمان من صدفة طرفية (shell) مستخدم موجود، والخيار الأفضل هو إنشاء خدمة systemd لتشغيلها تلقائيًا. تشغيل حاويات محدودة الصلاحية Rootless Containers باستخدام بودمان قبل أن تبدأ بتشغيل الحاويات محدودة الصلاحية، ثمة بعض المتطلبات التي عليك توفيرها. تثبيت حزمة slirp4netns تُستخدم الحزمة slirp4netns لتوفير خيارات الشبكة لوضع المستخدم user-mode networking لفضاءات أسماء الشبكة. يعد هذا الأمر ضروريًا كي تتفاعل الحاوية محدودة الصلاحية مع أي شبكة وبدونها لا يمكن للحاويات محدودة الصلاحية الاتصال بالإنترنت أو الشبكات الداخلية، مما يحد من فائدتها بشكل كبير. يمكنك تثبيت حزمة slirp4netns على التوزيعات المعتمدة على نظامي ديبيان Debian وأوبنتو Ubuntu باستخدام مدير الحزم apt: sudo apt install slirp4netns أما في التوزيعات المعتمدة على نظامي فيدورا Fedora وريد هات Red Hat فاستخدم مدير الحزم dnf لتثبيت الحزمة، على النحو التالي: sudo dnf install slirp4netns بالنسبة لمستخدمي Arch Linux فعليك استخدام الأمر pacman على النحو التالي: sudo pacman -Sy slirp4netns ضبط subuid و subgid على النحو الصحيح نظرًا لأن حاويات بودمان محدودة الصلاحية تُشَغّل بواسطة مستخدم موجود على النظام، فإن المستخدم يحتاج إلى إذن لتشغيل هذه الحاوية بمعرّف مميز UID مختلف عن معرف المستخدم. وهذا ينطبق أيضًا على معرّف المجموعة GID. يُمنح كل مستخدم نطاقًا من المعرفات التي يُسمح له باستخدامها، تذكر المعرفات الفريدة UID في الملف /etc/subuid، أما معرفات المجموعات GID فتذكر في الملف /etc/subgid. وصيغة الملف هي على النحو التالي: username:initial UID/GID allocated to user:range/size of allowed UIDs/GIDs فلنفرض أن اسم المستخدم pratham يريد مئة معرّف مميز، والمستخدم krishna يريد ألفًا، إذًا ستكون صيغة الملف /etc/subuid على النحو التالي: pratham:100000:100 Krishna:100100:1000 يعني هذا أن المستخدم pratham يمكنه استخدام المعرّفات UID من المعرّف 100000 إلى 100100، والمستخدم krishna يمكنه استخدامها بدءً من المعرّف 100100 إلى 101100. يكون هذا عادةً مُعَدًا مسبقًا لكل مستخدم تنشئه، ويُحَدد للنطاق 65536 معرفًا قابلًا للاستخدام سواء كان معرفًا مميزًا UID أم معرّف مجموعة GID. ولكن، يجب أن تضبطه يدويًا في بعض الحالات. ولكن ليس عليك ضبط ذلك يدويًا لكل مستخدم، إذ يمكنك استخدام الأمر usermod لهذا الغرض. إليك صيغة الأمر المطلوبة: sudo usermod --add-subuids START-RANGE --add-subgids START-RANGE USERNAME والآن استبدل كل من السلسلة START و RANGE و USERNAME بما يناسبك. ** تنبيه:** احرص على ضبط سماحيات الملفين /etc/subuid و/etc/subgid على القيمة 644 وأن يكونا تابعين للمستخدم الجذر root:root. ربط المنافذ ذات الأرقام الأدنى من 1024 إن استخدمت وكيلًا عكسيًا reverse proxy لبروتوكول SSL، فأنت تعلم أن المنفذين 80 و443 يجب أن يكونا متاحين لمزود الشهادات مثلLet's Encrypt. إذا حاولت ربط المنافذ الأقل من 1024 بحاوية بودمان محدودة الصلاحية، فستلاحظ أن ذلك غير متاح كميّزة جاهزة out of the box. إذ لا يُسمح للمستخدم غير الجذر بربط أي شيء على المنافذ الأدنى من المنفذ 1024. إذًا، كيف يمكن ربط المنافذ الأدنى بحاويات بودمان محدودة الصلاحية؟ عليك أولاً تحديد المنفذ الأدنى الذي تحتاجه. في حالتنا، تحتاج إلى المنفذين 80 و443 لنشر بروتوكول SSL، لذا فإن أقل منفذ تحتاجه هو المنفذ 80. والآن، أضف السطر التالي إلى الملف /etc/sysctl.conf: net.ipv4.ip_unprivileged_port_start=YOUR_PORT_NUMBER ما ستفعله هو تغيير قيمة net.ipv4.ip_unprivileged_port_start إلى قيمة أدنى منفذ تحتاجه، إذًا عليك استبدال YOUR_PORT_NUMBER بالقيمة 80 كي تربط المنفذ 80 بحاوية محدودة الصلاحية. أين توجد صور الحاويات كما ذكرنا سابقًا فأحد قيود عمل أداة بودمان هي أنها لا تتيح مشاركة الصور بين المستخدمين. فيجب أن يسحب كل مستخدم الصورة، أو يجب نسخ الصورة من مستخدم لآخر. كلا الخيارين سيحجز ضعف أو أضعاف المساحة، حسب عدد نسخ الصور.حيث تُخَزّن صور حاويات المستخدم في المجلد الرئيسي، وبالتحديد داخل المجلد ~/local/share/containers/storage/ والآن، بعد أن تحققتَ من توفر المتطلبات السابقة، يمكنك تشغيل الأمر podman run من صدفة خارجية non-root user's shell وإنشاء حاوية. سنستخدم خادم Caddy في مثالنا لنشر بروتوكول SSL. شغّل خادم Caddy في حاوية محدودة الصلاحية واربطه بمنفذ أدنى من المنفذ 1024 على النحو التالي: $ whoami pratham $ podman run -d --name=prathams-caddy -p 80:80 -p 443:443 caddy:alpine e6ed67eb90e6d0f3475d78b287af941bc873f6d62db60d5c13b1106af80dc5ff $ podman ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e6ed67eb90e6 docker.io/library/caddy:alpine caddy run --confi... 2 seconds ago Up 2 seconds ago 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp prathams-caddy $ ps aux | grep caddy pratham 3022 0.0 0.0 85672 2140 ? Ssl 06:53 0:00 /usr/bin/conmon --api-version 1 -c e6ed67eb90e6d0f3475d78b287af941bc873f6d62db60d5c13b1106af80dc5ff [...] pratham 3025 0.1 0.3 753060 32320 ? Ssl 06:53 0:00 caddy run --config /etc/caddy/Caddyfile --adapter caddyfile لاحظ أن المستخدم pratham ليس جذرًا وأنه لا حاجة لاستخدام الأمر sudo لزيادة صلاحيات المستخدم. إذ استطعت تشغيل حاوية خادم Caddy محدودة الصلاحية باستخدام أداة بودمان. يُظهِر خرج الأمر ps أن رمز العملية PID ذو الرقم 3022هو عملية تابعة للمستخدم pratham وهي حاوية خادم Caddy (لكننا لم نُظهِر الخرج كاملًا في مثالنا). أما العملية 3025 فهي تابعة child process للعملية 3022 وهما تابعتان للمستخدم نفسه. الخلاصة وضّحنا في هذا المقال كيفية إدارة الحاويات محدودة الصلاحية باستخدام أداة بودمان، وتحدثنا عن البرامج الضرورية لذلك، وتطرقنا إلى بعض المشكلات الشائعة التي قد تواجهها وكيفية حلها. إن واجهت مشكلةً لم نأتِ على ذكرها مع حاويات بودمان محدودة الصلاحية، فذلك لأن أداة بودمان لا تزال جديدةً بالنسبة للبرمجيات، لذا من المحتمل ظهور بعض المشكلات، في هذه الحالة، شاركنا استفسارك في قسم الأسئلة والأجوبة في أكاديمية حسوب. كما يمكنك الاطلاع على التوثيق الرسمي من موقع بودمان. ترجمة -وبتصرّف- للمقال Getting Started With Rootless Container Using Podman من Linux Handbook. اقرأ أيضًا المقال السابق: تحديث حاويات بودمان Podman تلقائيًا تعلم الحوسبة السحابيّة: المتطلبات الأساسيّة، وكيف تصبح مهندس حوسبة سحابيّة الفرق بين أداتي دوكر Docker وبودمان Podman الفرق بين دوكر Docker وكوبيرنيتيس Kubernetes؟ ما عليك معرفته عن الفرق بين دوكر والأجهزة الافتراضية أساسيات تنسيق الحاويات
ستتعلم في هذا المقال كيفية التعامل مع الحاويات محدودة الصلاحية Rootless Containers باستخدام أداة بودمان. إن كنت تستخدم الحاويات لنشر البرمجيات، أو تستخدم أداة بودمان، أو أنك ترغب في رفع مستوى الأمان عن طريق تشغيل الحاويات محدودة الصلاحية rootless containers، فهذا المقال مناسب لك. ما هي أداة بودمان Podman إن أداة بودمان Podman هي أحد منتجات شركة Red Hat طُرِحَت كبديل فعّال عن أداة دوكر Docker ويمكنها أداء 99% من المهام التي تؤديها أداة دوكر. بعض ميزات بودمان هي دعم الحاويات محدودة الصلاحية rootless containers، واستخدام نموذج fork/exec لتشغيل الحاويات، وأنه لا يعمل وفق مبدأ البرنامج الخفي أي إنه daemon-less، وثمة كثير من الميزات الأخرى. أما مزايا الحاويات محدودة الصلاحية فهي واضحة، فهي لا تحتاج لصلاحيات الجذر الذي يملك وصولًا كاملًا إلى جميع موارد وملفات النظام كي تعمل، لذلك فإن تشغيلها أكثر أمانًا. تشغيل حاويات بودمان محدودة الصلاحية Rootless Containers إذا كنت متمرسًا في مجال تقنية المعلومات، فمن المحتمل أنك وقعت في أحد الخطأين التاليين: تشغيل الأمر docker باستخدام Sudo، وبالتالي زيادة امتيازاته. إضافة مستخدم محدود الصلاحيات non-root إلى مجموعة دوكر docker group. تلك أخطاء تُضِر بأمان النظام بصورة كبيرة؛ لأنك تسمح لبرنامج دوكر الخفي Docker daemon بالوصول إلى جهازك. وهذا يعرضك للخطر بطريقتين: يعمل برنامج دوكر الخفي (dockerd) كجذر، فإذا كانت ثمة ثغرة أمنية فيه، سيكون نظامك بكامله عرضةً للخطر لأن dockerd هي عملية تابعة للمستخدم الجذر. قد تحتوي الصورة التي تستخدمها على ثغرات أمنية. تخيّل ماذا سيحدث عند استخدام هذه الصورة بواسطة حاوية تعمل كعملية للمستخدم الجذر root process. يمكن لأحد المخترقين استخدام هذه الصورة للوصول إلى كافة موراد النظام. الحل بسيط، عليك الامتناع عن تشغيل البرامج بصلاحيات الجذر، حتى لو كنت تثق بها. تذكر أنه لا يوجد شيء آمن بنسبة 100%. وهنا تأتي ميزة بودمان في إدارة الحاويات دون الحاجة إلى الوصول إلى الجذر. فعند تشغيل حاوية باستخدام بودمان كمستخدم غير جذر، لن تحصل تلك الحاوية على امتيازات إضافية، ولن يطلب منك بودمان كلمة مرور sudo. إليك المزايا التي توفرها أداة بودمان عند إدارة الحاويات محدودة الصلاحية root-less containers: يمكنك تخصيص مجموعة من الحاويات المشتركة لكل مستخدم محلي. (على سبيل المثال، بإمكانك تشغيل Nextcloud وMariaDB لدى المستخدم nextcloud_user وتشغيل الحاويات Gitea وPostgreSQL لدى المستخدم gitea_user). حتى لو اختُرِقَت الحاوية، فلا يمكن التحكم بالنظام المضيف بكامله، لأن المستخدم المسؤول عن الحاوية ليس جذرًا. لكنه لن يعود صالحًا للاستخدام. قيود استخدام حاويات بودمان محدودة الصلاحية عند استخدام أداتي بودمان ودوكر مع صلاحيات المستخدم الجذر أي بنمط عمل root-full، فأنت تمنحها امتيازات على مستوى المستخدم المسؤول أو المميز super-user. وهذا ليس أمرًا محمودًا، ولكنه يضمن أن جميع الوظائف تعمل على النحو المطلوب. ومن الناحية الأخرى، ثمة بعض القيود على تشغيل حاويات بودمان بدون امتيازات الجذر، إليك أهمها: لا يمكن تشارك صور الحاويات بين المستخدمين إذا سحب المستخدم user0 صورة الحاوية nginx:stable-alpine فيجب على المستخدم user1 سحبها بنفسه مرةً أخرى. لا توجد لحد الآن طريقة تسمح تشارك الصور بين المستخدمين، لكن يمكنك نسخ الصور من مستخدم لآخر باتباع هذا الدليل من شركة ريد هات Red Hat. لا يمكن ربط المنافذ ports binding ذوات الأرقام الأدنى من 1024، لكن ثمة طريقة لحل هذه المشكلة. لا يمكن للحاوية محدودة الصلاحية إرسال الطلب ping لأي من المضيفين hosts. لكن ثمة طريقة لحل هذه المشكلة. إذا عيّنت معرّفًا مميزًا UID لحاوية بودمان محدودة الصلاحية، فقد يفشل ذلك إن لم تسند المعرّف المميز UID إلى حاوية موجودة مسبقًا. إذًا، من الأفضل تشغيل بودمان من صدفة طرفية (shell) مستخدم موجود، والخيار الأفضل هو إنشاء خدمة systemd لتشغيلها تلقائيًا. تشغيل حاويات محدودة الصلاحية Rootless Containers باستخدام بودمان قبل أن تبدأ بتشغيل الحاويات محدودة الصلاحية، ثمة بعض المتطلبات التي عليك توفيرها. تثبيت حزمة slirp4netns تُستخدم الحزمة slirp4netns لتوفير خيارات الشبكة لوضع المستخدم user-mode networking لفضاءات أسماء الشبكة. يعد هذا الأمر ضروريًا كي تتفاعل الحاوية محدودة الصلاحية مع أي شبكة وبدونها لا يمكن للحاويات محدودة الصلاحية الاتصال بالإنترنت أو الشبكات الداخلية، مما يحد من فائدتها بشكل كبير. يمكنك تثبيت حزمة slirp4netns على التوزيعات المعتمدة على نظامي ديبيان Debian وأوبنتو Ubuntu باستخدام مدير الحزم apt: sudo apt install slirp4netns أما في التوزيعات المعتمدة على نظامي فيدورا Fedora وريد هات Red Hat فاستخدم مدير الحزم dnf لتثبيت الحزمة، على النحو التالي: sudo dnf install slirp4netns بالنسبة لمستخدمي Arch Linux فعليك استخدام الأمر pacman على النحو التالي: sudo pacman -Sy slirp4netns ضبط subuid و subgid على النحو الصحيح نظرًا لأن حاويات بودمان محدودة الصلاحية تُشَغّل بواسطة مستخدم موجود على النظام، فإن المستخدم يحتاج إلى إذن لتشغيل هذه الحاوية بمعرّف مميز UID مختلف عن معرف المستخدم. وهذا ينطبق أيضًا على معرّف المجموعة GID. يُمنح كل مستخدم نطاقًا من المعرفات التي يُسمح له باستخدامها، تذكر المعرفات الفريدة UID في الملف /etc/subuid، أما معرفات المجموعات GID فتذكر في الملف /etc/subgid. وصيغة الملف هي على النحو التالي: username:initial UID/GID allocated to user:range/size of allowed UIDs/GIDs فلنفرض أن اسم المستخدم pratham يريد مئة معرّف مميز، والمستخدم krishna يريد ألفًا، إذًا ستكون صيغة الملف /etc/subuid على النحو التالي: pratham:100000:100 Krishna:100100:1000 يعني هذا أن المستخدم pratham يمكنه استخدام المعرّفات UID من المعرّف 100000 إلى 100100، والمستخدم krishna يمكنه استخدامها بدءً من المعرّف 100100 إلى 101100. يكون هذا عادةً مُعَدًا مسبقًا لكل مستخدم تنشئه، ويُحَدد للنطاق 65536 معرفًا قابلًا للاستخدام سواء كان معرفًا مميزًا UID أم معرّف مجموعة GID. ولكن، يجب أن تضبطه يدويًا في بعض الحالات. ولكن ليس عليك ضبط ذلك يدويًا لكل مستخدم، إذ يمكنك استخدام الأمر usermod لهذا الغرض. إليك صيغة الأمر المطلوبة: sudo usermod --add-subuids START-RANGE --add-subgids START-RANGE USERNAME والآن استبدل كل من السلسلة START و RANGE و USERNAME بما يناسبك. ** تنبيه:** احرص على ضبط سماحيات الملفين /etc/subuid و/etc/subgid على القيمة 644 وأن يكونا تابعين للمستخدم الجذر root:root. ربط المنافذ ذات الأرقام الأدنى من 1024 إن استخدمت وكيلًا عكسيًا reverse proxy لبروتوكول SSL، فأنت تعلم أن المنفذين 80 و443 يجب أن يكونا متاحين لمزود الشهادات مثلLet's Encrypt. إذا حاولت ربط المنافذ الأقل من 1024 بحاوية بودمان محدودة الصلاحية، فستلاحظ أن ذلك غير متاح كميّزة جاهزة out of the box. إذ لا يُسمح للمستخدم غير الجذر بربط أي شيء على المنافذ الأدنى من المنفذ 1024. إذًا، كيف يمكن ربط المنافذ الأدنى بحاويات بودمان محدودة الصلاحية؟ عليك أولاً تحديد المنفذ الأدنى الذي تحتاجه. في حالتنا، تحتاج إلى المنفذين 80 و443 لنشر بروتوكول SSL، لذا فإن أقل منفذ تحتاجه هو المنفذ 80. والآن، أضف السطر التالي إلى الملف /etc/sysctl.conf: net.ipv4.ip_unprivileged_port_start=YOUR_PORT_NUMBER ما ستفعله هو تغيير قيمة net.ipv4.ip_unprivileged_port_start إلى قيمة أدنى منفذ تحتاجه، إذًا عليك استبدال YOUR_PORT_NUMBER بالقيمة 80 كي تربط المنفذ 80 بحاوية محدودة الصلاحية. أين توجد صور الحاويات كما ذكرنا سابقًا فأحد قيود عمل أداة بودمان هي أنها لا تتيح مشاركة الصور بين المستخدمين. فيجب أن يسحب كل مستخدم الصورة، أو يجب نسخ الصورة من مستخدم لآخر. كلا الخيارين سيحجز ضعف أو أضعاف المساحة، حسب عدد نسخ الصور.حيث تُخَزّن صور حاويات المستخدم في المجلد الرئيسي، وبالتحديد داخل المجلد ~/local/share/containers/storage/ والآن، بعد أن تحققتَ من توفر المتطلبات السابقة، يمكنك تشغيل الأمر podman run من صدفة خارجية non-root user's shell وإنشاء حاوية. سنستخدم خادم Caddy في مثالنا لنشر بروتوكول SSL. شغّل خادم Caddy في حاوية محدودة الصلاحية واربطه بمنفذ أدنى من المنفذ 1024 على النحو التالي: $ whoami pratham $ podman run -d --name=prathams-caddy -p 80:80 -p 443:443 caddy:alpine e6ed67eb90e6d0f3475d78b287af941bc873f6d62db60d5c13b1106af80dc5ff $ podman ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e6ed67eb90e6 docker.io/library/caddy:alpine caddy run --confi... 2 seconds ago Up 2 seconds ago 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp prathams-caddy $ ps aux | grep caddy pratham 3022 0.0 0.0 85672 2140 ? Ssl 06:53 0:00 /usr/bin/conmon --api-version 1 -c e6ed67eb90e6d0f3475d78b287af941bc873f6d62db60d5c13b1106af80dc5ff [...] pratham 3025 0.1 0.3 753060 32320 ? Ssl 06:53 0:00 caddy run --config /etc/caddy/Caddyfile --adapter caddyfile لاحظ أن المستخدم pratham ليس جذرًا وأنه لا حاجة لاستخدام الأمر sudo لزيادة صلاحيات المستخدم. إذ استطعت تشغيل حاوية خادم Caddy محدودة الصلاحية باستخدام أداة بودمان. يُظهِر خرج الأمر ps أن رمز العملية PID ذو الرقم 3022هو عملية تابعة للمستخدم pratham وهي حاوية خادم Caddy (لكننا لم نُظهِر الخرج كاملًا في مثالنا). أما العملية 3025 فهي تابعة child process للعملية 3022 وهما تابعتان للمستخدم نفسه. الخلاصة وضّحنا في هذا المقال كيفية إدارة الحاويات محدودة الصلاحية باستخدام أداة بودمان، وتحدثنا عن البرامج الضرورية لذلك، وتطرقنا إلى بعض المشكلات الشائعة التي قد تواجهها وكيفية حلها. إن واجهت مشكلةً لم نأتِ على ذكرها مع حاويات بودمان محدودة الصلاحية، فذلك لأن أداة بودمان لا تزال جديدةً بالنسبة للبرمجيات، لذا من المحتمل ظهور بعض المشكلات، في هذه الحالة، شاركنا استفسارك في قسم الأسئلة والأجوبة في أكاديمية حسوب. كما يمكنك الاطلاع على التوثيق الرسمي من موقع بودمان. ترجمة -وبتصرّف- للمقال Getting Started With Rootless Container Using Podman من Linux Handbook. اقرأ أيضًا المقال السابق: تحديث حاويات بودمان Podman تلقائيًا تعلم الحوسبة السحابيّة: المتطلبات الأساسيّة، وكيف تصبح مهندس حوسبة سحابيّة الفرق بين أداتي دوكر Docker وبودمان Podman الفرق بين دوكر Docker وكوبيرنيتيس Kubernetes؟ ما عليك معرفته عن الفرق بين دوكر والأجهزة الافتراضية أساسيات تنسيق الحاويات -
 سنقدم لك في هذا المقال دليلًا مفصلًا حول كيفية ضبط التحديثات التلقائية للحاويات المُدارة بواسطة أداة بودمان Podman وتفعيلها. فتحديث البرامج أمر محبّذ، لا سيما عندما تحتوي التحديثات على ميزات جديدة أو خيارات لزيادة الأمان. لتسهيل العمل سنستخدم في هذا المقال صورة الخادم Caddy من مستودع Docker Hub. تعيين مصدر جلب صور الحاويات كي تستطيع استخدام صورة حاوية (container image) يجب أولًا سحب هذه الصورة من أحد المصادر باستخدام أداة إدارة الحاويات بودمان، يدعى هذا المصدر بسياسة التحديث التلقائي auto-update policy وهي تتضمن قواعد أو إعدادات تحدد زمان وكيفية تحديث الصور أو الحاويات بشكل تلقائي دون تدخل يدوي، مثلاً عند إصدار تحديث جديد للصورة، يتم تحميل التحديث وتطبيقه بشكل تلقائي دون تدخل المستخدم وذلك على النحو التالي: سجل registry: عند إسناد سجل (موقع) ما إلى سياسة التحديث التلقائي auto-update policy فإن بودمان سيسحب الصورة من سجل خارجي remote registry مثل Docker Hub أو Quay.io. مصدر محلي local: عند إسناد الخيار local إلى سياسة التحديث التلقائي، فإن أداة بودمان ستجلب الصورة من الصور المحلية. يُعدّ هذا الخيار هذا الخيار مفيدًا للمطورين الذين يرغبون في اختبار التعديلات المحلية قبل دفعها إلى سجل بعيد. ملاحظة: نستخدم في أمثلة هذا المقال حاوية محدودة الصلاحية root-less container، وحاولنا قدر الإمكان ذكر الأوامر الخاصة بالحاويات كاملة الصلاحية root-full container. فإن استخدمت حاوية كاملة الصلاحية وواجهك خطأ يتعلق بصلاحيات المستخدم، فعليك استخدام الأمر sudo. تفعيل التحديثات التلقائية لحاويات Podman يمكنك الآن تفعيل التحديثات التلقائية لحاويات بودمان بعد أن أصبحت تعلم ما هو مفهوم سياسة التحديث التلقائي، وذلك باستخدام الأمر التالي: io.containers.autoupdate=AUTO_UPDATE_POLICY والآن استبدل السلسلة AUTO_UPDATE_POLICY بالخيار registry أو local. ولكن كيف ستتحدث الحاوية تلقائيًا وأداة بودمان لا تعمل كبرنامج خفي؟ ضبط خدمة systemd عليك إدارة الحاويات التي تحتاج إلى التحديث التلقائي بواسطة نظام التمهيد systemd، وذلك لأن أداة بودمان لا تعمل كبرنامج خفي. إن أردت تشغيل الحاويات تلقائيًا عند إقلاع النظام، فلا شك أنك تستخدم systemd. سنشرح في الخطوات التالية كيفية دمج حاويات بودمان سواء كانت حاويات كاملة أو محدودة الصلاحية، مع خدمة systemd وتشغيلها تلقائيًا عند الاقلاع. الخطوة التمهيدية، إنشاء الحاوية عليك التأكد أولًا أن لديك حاوية بودمان، سواء كانت قيد العمل أو متوقفة. استخدم الأمر التالي للتحقق من الحاويات الموجودة عندك: podman container list لتوضيح أمثلة هذا المقال، اسحب صورةً قديمةً من خادم Caddy (الإصدار 2.5.2-alpine) ثم أعد تسميتها بالاسم alpine، إذ ستساعد إعادة تسمية الصورة في توضيح عملية التحديث. ويمكنك التحقق من ذلك لأن معرف الصورتين هو نفسه. ثم أنشئ حاويةً من الصورة وسمّها prathams-caddy: $ podman images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/library/caddy 2.5.2-alpine d83af79bf9e2 2 weeks ago 45.5 MB docker.io/library/caddy alpine d83af79bf9e2 2 weeks ago 45.5 MB $ podman container list CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 99d1838dd999 localhost/caddy:alpine caddy run --confi... 5 seconds ago Up 6 seconds ago prathams-caddy كما تلاحظ فإن لدينا حاويةً تدعى prathams-caddy تعمل على صورة Caddy (الإصدار الأقدم). عندما تنشئ الحاوية Prathams-caddy أسند سياسة التحديث التلقائي io.containers.autoupdate على خيار السجل registry كما تعلمنا في الخطوة السابقة. إذا كان لديك حاوية بدون هذا التعديل، فلست بحاجة إلى إعادة إنشاء حاوية جديدة. سنتحدث عن ذلك في الخطوة التالية. الخطوة الأولى، إنشاء ملف خدمة systemd للحاوية كي تتمكن من إدارة حاويات بودمان باستخدام نظام systemd، يجب عليك تحويله إلى خدمة، لتشغيل الحاويات عند إقلاع النظام وإيقافها عند إيقاف تشغيل النظام. إذًا، يجب تشغيل الحاوية كخدمة systemd. ولكن كي لا تضطر إلى كتابة ملف خدمة systemd لكل حاوية، أوجد مطورو أداة بودمان حلًا لذلك، وهو تشغيل أمر معين لكل حاوية. عليك تشغيل الأمر التالي للحاويات كاملة الصلاحية root-full container: sudo podman generate systemd -f --new --name CONTAINER_NAME والأمر التالي للحاويات محدودة الصلاحية root-less container: podman generate systemd -f --new --name CONTAINER_NAME ثم استبدل CONTAINER_NAME باسم حاويتك، وسيتولد بعدها ملف باسم الحاوية كما يلي: $ podman generate systemd -f --new --name prathams-caddy /home/pratham/container-prathams-caddy.service لاحظ من الخرج السابق إنشاء حاوية باسم container-prathams-caddy.service في الملف الحالي. سبق أن ضبطتَ ميزة التحديث التلقائي لهذه الحاوية. أما بالنسبة للحاويات التي لم تضبط فيها هذه الميزة، فليس عليك إعادة إنشاء الحاوية بل يكفي تعديل ملف خدمة systemd وإضافة السطر التالي إلى حقل ExecStart على النحو التالي: [...] ExecStart=/usr/bin/podman run \ [...] --label io.containers.autoupdate=registry [...] وهكذا يستدعي ملف خدمة systemd أمر تشغيل حاويات بودمان podman run. وكل ما عليك فعله هو إضافة io.containers.autoupdate إلى الأمر podman run. الخطوة الثانية، نقل ملف خدمة systemd قبل تفعيل خدمة systemd، يجب عليك نقل ملف الخدمة إلى أحد المجلدين التاليين: /etc/systemd/system/ : إذا كانت الحاوية كاملة الصلاحية وتحتاج إلى امتيازات المستخدم المسؤول superuser. ~/.config/systemd/user/ : إذا كانت الحاوية محدودة الصلاحية، ضعها في مجلد المستخدم الذي سيشغلها. إن الحاوية Prathams-caddy في مثالنا هي حاوية محدودة الصلاحية، لذا عليك نقلها إلى مجلد المستخدم الخاص بك: $ mv -v container-prathams-caddy.service ~/.config/systemd/user/ renamed 'container-prathams-caddy.service' -> '/home/pratham/.config/systemd/user/container-prathams-caddy.service' الخطوة الثالثة، تفعيل خدمة systemd أصبح بإمكانك الآن تفعيل خدمة systemd بعد أن نقلت ملف الخدمة إلى المجلد المناسب. لكن، يجب أولاً إعلام نظام systemd بالخدمة التي أنشأتها قبل إعادة تشغيل حاسوبك. وذلك بإعادة تحميل systemd باستخدام الأمر التالي إذا كانت الخدمة خاصةً بحاوية كاملة الصلاحية: sudo systemctl daemon-reload والأمر التالي للحاويات محدودة الصلاحية: systemctl --user daemon-reload أصبح بإمكانك الآن استخدام الأمر systemctl enable لتفعيل الخدمة: # للحاويات كاملة الصلاحية sudo systemctl enable SERVICE_NAME.service # للحاويات محدودة الصلاحية systemctl --user enable SERVICE_NAME.service تحقق من حالة الخدمة، ستلاحظ أنها غير نشطة inactive (dead) وذلك لأن الخدمة تعمل عند إعادة إقلاع الحاسوب أو النظام، ولم ننفذ ذلك بعد. $ systemctl --user enable container-prathams-caddy.service Created symlink /home/pratham/.config/systemd/user/default.target.wants/container-prathams-caddy.service → /home/pratham/.config/systemd/user/container-prathams-caddy.service. $ systemctl --user status container-prathams-caddy.service ○ container-prathams-caddy.service - Podman container-prathams-caddy.service Loaded: loaded (/home/pratham/.config/systemd/user/container-prathams-caddy.service; enabled; vendor preset: enabled) Active: inactive (dead) Docs: man:podman-generate-systemd(1) والآن أوقف عمل الحاوية ثم استخدم الأمر التالي لحذفها podman container rm وأعد إقلاع جهازك بعدها. $ podman stop prathams-caddy prathams-caddy $ podman container rm prathams-caddy 99d1838dd9990b2f79b4f2c83bc9bc16dfbaf3fdeeb6c6418ddd6e641535ce21 الخطوة الرابعة، تفعيل بقاء المستخدم نشطًا (اختيارية) إذا كانت حاويتك محدودة الصلاحية فمن الأفضل أن يبقى المستخدم المسؤول عنها نشطًا، وذلك باستخدام الأمر التالي: sudo loginctl enable-linger الخطوة الخامسة، تفعيل خدمة التحديث التلقائي كل ما عليك فعله الآن هو تفعيل خدمة التحديث التلقائي في بودمان باستخدام الأمر التالي: sudo systemctl enable podman-auto-update.service بعد تفعيل خدمة التحديث التلقائي podman-auto-update في بودمان، سيتحقق systemd من وجود صورة بحاجة إلى تحديث. إذا كان هناك تحديثات، تُحدّث الصور التي جلبت أولاً، ثم يُعاد تشغيل الحاوية، مع الاحتفاظ بالصورة القديمة في حالة الحاجة إلى التراجع عن التحديث لعدة أسباب. ملاحظة: على الرغم من أن خدمة التحديث التلقائي في بودمان podman-auto-update.service تُفعّل على مستوى النظام، إلا أن أداة بودمان ليست أساسية في عديد من التوزيعات غير التابعة لتوزيعة فيدورا Fedora. لذلك، ربما تحتاج إلى تشغيل الأمر التالي لتفعيل الخدمة عند المستخدمين محدودي الصلاحية: systemctl --user Enable --now podman-auto-update.service التحديث اليدوي إن لم تكن من محبي التحديثات التلقائية، فيمكنك تحديث الحاويات يدويًا باستخدام أمر واحد فقط، بشرط أن تكون مدارةً بواسطة systemd. هذا الأمر هو podman auto-update. وإن أردت التحقق من وجود تحديثات جديدة فقط، فأضف خيار dry-run-- حتى لا تُحَدّث أي حاوية. والآن لنتحقق من إمكانية تحديث صورة الحاوية "2.5.2-alpine" إلى الإصدار "2.6.1-alpine" باستخدام الأمر podman auto-update: $ podman container list CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a712a3c8846b docker.io/library/caddy:alpine caddy run --confi... 2 seconds ago Up 2 seconds ago prathams-caddy $ podman auto-update --dry-run UNIT CONTAINER IMAGE POLICY UPDATED container-prathams-caddy.service a712a3c8846b (prathams-caddy) caddy:alpine registry pending لاحظ أن حالة العمود updated في خرج أمر التحديث التلقائي هي pending أو معلقة وهذا يعني أنه ثم تحديث متوفر. كي تحدّث الحاوية، أزل الخيار dry-run-- من الأمر السابق. الخلاصة قد تبدو عملية تفعيل التحديثات التلقائية لحاويات بودمان معقدةً بعض الشيء، ولكنها ستؤتي ثمارها على المدى الطويل. تُحدّث جميع الحاويات المُدارة عادة بصورة تلقائية عند منتصف الليل في حال وجود التحديثات. وإن حدثت اي مشكلة في الحاوية فإن systemd سيعيدها إلى صورة قديمة، بحيث تستمر الحاوية في العمل. ترجمة وبتصرّف للمقال Automatically Updating Podman Containers من Linux Handbook. اقرأ أيضًا المقال السابق: تشغيل الحاويات تلقائيًا باستخدام أداة بودمان Podman أساسيات تنسيق الحاويات ما الفرق بين دوكر Docker وكوبيرنيتيس Kubernetes؟ ما عليك معرفته عن الفرق بين دوكر والأجهزة الافتراضية
سنقدم لك في هذا المقال دليلًا مفصلًا حول كيفية ضبط التحديثات التلقائية للحاويات المُدارة بواسطة أداة بودمان Podman وتفعيلها. فتحديث البرامج أمر محبّذ، لا سيما عندما تحتوي التحديثات على ميزات جديدة أو خيارات لزيادة الأمان. لتسهيل العمل سنستخدم في هذا المقال صورة الخادم Caddy من مستودع Docker Hub. تعيين مصدر جلب صور الحاويات كي تستطيع استخدام صورة حاوية (container image) يجب أولًا سحب هذه الصورة من أحد المصادر باستخدام أداة إدارة الحاويات بودمان، يدعى هذا المصدر بسياسة التحديث التلقائي auto-update policy وهي تتضمن قواعد أو إعدادات تحدد زمان وكيفية تحديث الصور أو الحاويات بشكل تلقائي دون تدخل يدوي، مثلاً عند إصدار تحديث جديد للصورة، يتم تحميل التحديث وتطبيقه بشكل تلقائي دون تدخل المستخدم وذلك على النحو التالي: سجل registry: عند إسناد سجل (موقع) ما إلى سياسة التحديث التلقائي auto-update policy فإن بودمان سيسحب الصورة من سجل خارجي remote registry مثل Docker Hub أو Quay.io. مصدر محلي local: عند إسناد الخيار local إلى سياسة التحديث التلقائي، فإن أداة بودمان ستجلب الصورة من الصور المحلية. يُعدّ هذا الخيار هذا الخيار مفيدًا للمطورين الذين يرغبون في اختبار التعديلات المحلية قبل دفعها إلى سجل بعيد. ملاحظة: نستخدم في أمثلة هذا المقال حاوية محدودة الصلاحية root-less container، وحاولنا قدر الإمكان ذكر الأوامر الخاصة بالحاويات كاملة الصلاحية root-full container. فإن استخدمت حاوية كاملة الصلاحية وواجهك خطأ يتعلق بصلاحيات المستخدم، فعليك استخدام الأمر sudo. تفعيل التحديثات التلقائية لحاويات Podman يمكنك الآن تفعيل التحديثات التلقائية لحاويات بودمان بعد أن أصبحت تعلم ما هو مفهوم سياسة التحديث التلقائي، وذلك باستخدام الأمر التالي: io.containers.autoupdate=AUTO_UPDATE_POLICY والآن استبدل السلسلة AUTO_UPDATE_POLICY بالخيار registry أو local. ولكن كيف ستتحدث الحاوية تلقائيًا وأداة بودمان لا تعمل كبرنامج خفي؟ ضبط خدمة systemd عليك إدارة الحاويات التي تحتاج إلى التحديث التلقائي بواسطة نظام التمهيد systemd، وذلك لأن أداة بودمان لا تعمل كبرنامج خفي. إن أردت تشغيل الحاويات تلقائيًا عند إقلاع النظام، فلا شك أنك تستخدم systemd. سنشرح في الخطوات التالية كيفية دمج حاويات بودمان سواء كانت حاويات كاملة أو محدودة الصلاحية، مع خدمة systemd وتشغيلها تلقائيًا عند الاقلاع. الخطوة التمهيدية، إنشاء الحاوية عليك التأكد أولًا أن لديك حاوية بودمان، سواء كانت قيد العمل أو متوقفة. استخدم الأمر التالي للتحقق من الحاويات الموجودة عندك: podman container list لتوضيح أمثلة هذا المقال، اسحب صورةً قديمةً من خادم Caddy (الإصدار 2.5.2-alpine) ثم أعد تسميتها بالاسم alpine، إذ ستساعد إعادة تسمية الصورة في توضيح عملية التحديث. ويمكنك التحقق من ذلك لأن معرف الصورتين هو نفسه. ثم أنشئ حاويةً من الصورة وسمّها prathams-caddy: $ podman images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/library/caddy 2.5.2-alpine d83af79bf9e2 2 weeks ago 45.5 MB docker.io/library/caddy alpine d83af79bf9e2 2 weeks ago 45.5 MB $ podman container list CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 99d1838dd999 localhost/caddy:alpine caddy run --confi... 5 seconds ago Up 6 seconds ago prathams-caddy كما تلاحظ فإن لدينا حاويةً تدعى prathams-caddy تعمل على صورة Caddy (الإصدار الأقدم). عندما تنشئ الحاوية Prathams-caddy أسند سياسة التحديث التلقائي io.containers.autoupdate على خيار السجل registry كما تعلمنا في الخطوة السابقة. إذا كان لديك حاوية بدون هذا التعديل، فلست بحاجة إلى إعادة إنشاء حاوية جديدة. سنتحدث عن ذلك في الخطوة التالية. الخطوة الأولى، إنشاء ملف خدمة systemd للحاوية كي تتمكن من إدارة حاويات بودمان باستخدام نظام systemd، يجب عليك تحويله إلى خدمة، لتشغيل الحاويات عند إقلاع النظام وإيقافها عند إيقاف تشغيل النظام. إذًا، يجب تشغيل الحاوية كخدمة systemd. ولكن كي لا تضطر إلى كتابة ملف خدمة systemd لكل حاوية، أوجد مطورو أداة بودمان حلًا لذلك، وهو تشغيل أمر معين لكل حاوية. عليك تشغيل الأمر التالي للحاويات كاملة الصلاحية root-full container: sudo podman generate systemd -f --new --name CONTAINER_NAME والأمر التالي للحاويات محدودة الصلاحية root-less container: podman generate systemd -f --new --name CONTAINER_NAME ثم استبدل CONTAINER_NAME باسم حاويتك، وسيتولد بعدها ملف باسم الحاوية كما يلي: $ podman generate systemd -f --new --name prathams-caddy /home/pratham/container-prathams-caddy.service لاحظ من الخرج السابق إنشاء حاوية باسم container-prathams-caddy.service في الملف الحالي. سبق أن ضبطتَ ميزة التحديث التلقائي لهذه الحاوية. أما بالنسبة للحاويات التي لم تضبط فيها هذه الميزة، فليس عليك إعادة إنشاء الحاوية بل يكفي تعديل ملف خدمة systemd وإضافة السطر التالي إلى حقل ExecStart على النحو التالي: [...] ExecStart=/usr/bin/podman run \ [...] --label io.containers.autoupdate=registry [...] وهكذا يستدعي ملف خدمة systemd أمر تشغيل حاويات بودمان podman run. وكل ما عليك فعله هو إضافة io.containers.autoupdate إلى الأمر podman run. الخطوة الثانية، نقل ملف خدمة systemd قبل تفعيل خدمة systemd، يجب عليك نقل ملف الخدمة إلى أحد المجلدين التاليين: /etc/systemd/system/ : إذا كانت الحاوية كاملة الصلاحية وتحتاج إلى امتيازات المستخدم المسؤول superuser. ~/.config/systemd/user/ : إذا كانت الحاوية محدودة الصلاحية، ضعها في مجلد المستخدم الذي سيشغلها. إن الحاوية Prathams-caddy في مثالنا هي حاوية محدودة الصلاحية، لذا عليك نقلها إلى مجلد المستخدم الخاص بك: $ mv -v container-prathams-caddy.service ~/.config/systemd/user/ renamed 'container-prathams-caddy.service' -> '/home/pratham/.config/systemd/user/container-prathams-caddy.service' الخطوة الثالثة، تفعيل خدمة systemd أصبح بإمكانك الآن تفعيل خدمة systemd بعد أن نقلت ملف الخدمة إلى المجلد المناسب. لكن، يجب أولاً إعلام نظام systemd بالخدمة التي أنشأتها قبل إعادة تشغيل حاسوبك. وذلك بإعادة تحميل systemd باستخدام الأمر التالي إذا كانت الخدمة خاصةً بحاوية كاملة الصلاحية: sudo systemctl daemon-reload والأمر التالي للحاويات محدودة الصلاحية: systemctl --user daemon-reload أصبح بإمكانك الآن استخدام الأمر systemctl enable لتفعيل الخدمة: # للحاويات كاملة الصلاحية sudo systemctl enable SERVICE_NAME.service # للحاويات محدودة الصلاحية systemctl --user enable SERVICE_NAME.service تحقق من حالة الخدمة، ستلاحظ أنها غير نشطة inactive (dead) وذلك لأن الخدمة تعمل عند إعادة إقلاع الحاسوب أو النظام، ولم ننفذ ذلك بعد. $ systemctl --user enable container-prathams-caddy.service Created symlink /home/pratham/.config/systemd/user/default.target.wants/container-prathams-caddy.service → /home/pratham/.config/systemd/user/container-prathams-caddy.service. $ systemctl --user status container-prathams-caddy.service ○ container-prathams-caddy.service - Podman container-prathams-caddy.service Loaded: loaded (/home/pratham/.config/systemd/user/container-prathams-caddy.service; enabled; vendor preset: enabled) Active: inactive (dead) Docs: man:podman-generate-systemd(1) والآن أوقف عمل الحاوية ثم استخدم الأمر التالي لحذفها podman container rm وأعد إقلاع جهازك بعدها. $ podman stop prathams-caddy prathams-caddy $ podman container rm prathams-caddy 99d1838dd9990b2f79b4f2c83bc9bc16dfbaf3fdeeb6c6418ddd6e641535ce21 الخطوة الرابعة، تفعيل بقاء المستخدم نشطًا (اختيارية) إذا كانت حاويتك محدودة الصلاحية فمن الأفضل أن يبقى المستخدم المسؤول عنها نشطًا، وذلك باستخدام الأمر التالي: sudo loginctl enable-linger الخطوة الخامسة، تفعيل خدمة التحديث التلقائي كل ما عليك فعله الآن هو تفعيل خدمة التحديث التلقائي في بودمان باستخدام الأمر التالي: sudo systemctl enable podman-auto-update.service بعد تفعيل خدمة التحديث التلقائي podman-auto-update في بودمان، سيتحقق systemd من وجود صورة بحاجة إلى تحديث. إذا كان هناك تحديثات، تُحدّث الصور التي جلبت أولاً، ثم يُعاد تشغيل الحاوية، مع الاحتفاظ بالصورة القديمة في حالة الحاجة إلى التراجع عن التحديث لعدة أسباب. ملاحظة: على الرغم من أن خدمة التحديث التلقائي في بودمان podman-auto-update.service تُفعّل على مستوى النظام، إلا أن أداة بودمان ليست أساسية في عديد من التوزيعات غير التابعة لتوزيعة فيدورا Fedora. لذلك، ربما تحتاج إلى تشغيل الأمر التالي لتفعيل الخدمة عند المستخدمين محدودي الصلاحية: systemctl --user Enable --now podman-auto-update.service التحديث اليدوي إن لم تكن من محبي التحديثات التلقائية، فيمكنك تحديث الحاويات يدويًا باستخدام أمر واحد فقط، بشرط أن تكون مدارةً بواسطة systemd. هذا الأمر هو podman auto-update. وإن أردت التحقق من وجود تحديثات جديدة فقط، فأضف خيار dry-run-- حتى لا تُحَدّث أي حاوية. والآن لنتحقق من إمكانية تحديث صورة الحاوية "2.5.2-alpine" إلى الإصدار "2.6.1-alpine" باستخدام الأمر podman auto-update: $ podman container list CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a712a3c8846b docker.io/library/caddy:alpine caddy run --confi... 2 seconds ago Up 2 seconds ago prathams-caddy $ podman auto-update --dry-run UNIT CONTAINER IMAGE POLICY UPDATED container-prathams-caddy.service a712a3c8846b (prathams-caddy) caddy:alpine registry pending لاحظ أن حالة العمود updated في خرج أمر التحديث التلقائي هي pending أو معلقة وهذا يعني أنه ثم تحديث متوفر. كي تحدّث الحاوية، أزل الخيار dry-run-- من الأمر السابق. الخلاصة قد تبدو عملية تفعيل التحديثات التلقائية لحاويات بودمان معقدةً بعض الشيء، ولكنها ستؤتي ثمارها على المدى الطويل. تُحدّث جميع الحاويات المُدارة عادة بصورة تلقائية عند منتصف الليل في حال وجود التحديثات. وإن حدثت اي مشكلة في الحاوية فإن systemd سيعيدها إلى صورة قديمة، بحيث تستمر الحاوية في العمل. ترجمة وبتصرّف للمقال Automatically Updating Podman Containers من Linux Handbook. اقرأ أيضًا المقال السابق: تشغيل الحاويات تلقائيًا باستخدام أداة بودمان Podman أساسيات تنسيق الحاويات ما الفرق بين دوكر Docker وكوبيرنيتيس Kubernetes؟ ما عليك معرفته عن الفرق بين دوكر والأجهزة الافتراضية -
 لا شك أن أداة بودمان ممتازة لإدارة الحاويات بما تقدمه من ميزات متعددة، لكنها لا توفر خاصية التشغيل التلقائي للحاويات عند إقلاع النظام، سنتعلم في هذا المقال كيف نجد حلًا لهذه المشكلة. على الرغم من أن أداة بودمان لا تعمل كبرنامج خفي daemon، وتسمح للمستخدم محدود الصلاحيات unprivileged user بتشغيل الحاويات دون الحاجة إلى الوصول إلى الجذر، مما يزيد من أمان النظام. لكنها ليست أداةً مثاليةً بالكامل فهي لا تُتيح إعادة تشغيل الحاويات تلقائيًا بعد إقلاع الخادم. سياسة إعادة تشغيل الحاويات عند الاطلاع على صفحة التعليمات man الخاصة بالأمر podman-run ستجد أن خيار إعادة التشغيل restart-- لا يعيد تشغيل الحاويات عندما يقلع النظام. وسبب هذا يرجع إلى أن بنية بودمان لا تعتمد مبدأ البرنامج الخفي، أي إن بودمان لا يعمل تلقائيًا عند إقلاع النظام، وبالتالي فإن الحاويات لا تعمل عند الإقلاع أيضًا. على عكس أداة دوكر التي تعتمد مبدأ البرنامج الخفي الذي يعمل عند إقلاع النظام ويُشَغّل الحاويات المحددة. حل مشكلة عدم التشغيل التلقائي للحاويات أيًّا كانت توزيعة نظام التشغيل التي تعمل عليها فلا بد أنها تستخدم systemd كنظام تمهيد init، وهذا ما سنحاول الاستفادة منه في إيجاد حل للمشكلة. الخطوة الأولى: إعداد الحاوية وتشغيلها ثمة عدة طرق ممكنة لتشغيل الحاوية. إن كان لديك حاوية بسيطة فبإمكانك استخدام الأمر podman run. أو يمكنك استخدام ملف دوكر إن أردت حاويةً بإعدادات معقدة واحتجت لمزيد من التحكم بهذه الإعدادات. لتوضيح ذلك، سننشئ حاويةً من صورة الحاوية mariadb وسنسميها chitragupta-db. $ podman ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 422eed872347 docker.io/library/mariadb:latest --transaction-iso... 58 seconds ago Up 58 seconds ago chitragupta-db يمكنك إيقاف الحاوية الجديدة لاحقًا. الخطوة الثانية: إنشاء خدمة systemd كما ذكرنا سابقًا، فإن بودمان ليس برنامجًا خفيًا أي إنه daemon-less لإدارة الحاويات. إذًا، فإن تشغيل حاويات بودمان يحتاج إلى تشغيل يدوي أو خارجي. سننفذ ذلك من خلال إنشاء خدمة systemd. حيث إن خدمة systemd هي نظام تمهيد init يدير الخدمات والبرامج الخفية في أنظمة تشغيل لينكس. إنشاء ملف وحدة systemd ليس عليك إنشاء ملف وحدة systemd يدويًا، إذ يمكن تنفيذ ذلك باستخدام الأمر podman generator systemd على النحو التالي: podman generate systemd --new --name CONTAINER_NAME لإنشاء ملف وحدة systemd للحاوية استخدم الأمر podman generate systemd متبوعًا باسم الحاوية، اسم الحاوية في مثالنا هو chitragupta-db: كما تلاحظ فإن الأمر السابق نفّذ العمل المطلوب، ولكننا لم ننته من العمل بعد. إن خرج الأمر podman generate systemd هو ما يجب أن يكون موجودًا في ملف وحدة systemd، لكن ثمة خيار مفيد يمكنك الاستعانة به بدلًا من نسخ الخرج ولصقه، وهو الخيار files -- أو اختصارًا f-. إذ سيؤدي استخدام هذا الخيار أولًا إلى ملء الملف بالمحتوى المطلوب بدلاً من طباعته على الطرفية، وثانيًا، إنشاء ملف باسم Container-CONTAINER_NAME.service في مجلد العمل الحالي. $ podman generate systemd --new --name chitragupta-db -f /home/pratham/container-chitragupta-db.service $ ls *.service Container-chitragupta-db.service لاحظ أن اسم الحاوية في مثالنا هو chitragupta-db، وأنه أصبح لدينا ملف باسم container-chitragupta-db.service في المجلد الحالي. بما أن الأمر podman generate systemd سوف ينشئ ملف وحدة systemd فإن بإمكانك استخدام الخيارات التالية =after=, --requires=, --wants-- لتحديد الاعتماديات للحاويات. نقل ملف خدمة systemd إلى موقع محدد كما لاحظت فإن الأمر السابق سينشئ ملف وحدة systemd جديد في مجلد العمل الحالي، لكن ذلك ليس الخيار الأنسب. إليك المسار المناسب للملف بالنسبة للمستخدم المسؤول superuser: /etc/systemd/system/ أما بالنسبة للمستخدم محدود الصلاحيات non-root user فهو: ~/.config/systemd/user/ والآن عليك نقل الملف إلى المجلد المناسب. بما أن الحاوية في مثالنا هي حاوية محدودة الصلاحية، فعليك نقلها إلى المجلد config/systemd/user/.~. $ mv -v container-chitragupta-db.service ~/.config/systemd/user/ renamed 'container-chitragupta-db.service' -> '/home/pratham/.config/systemd/user/container-chitragupta-db.service' وهكذا بعد أن أنشأت ملف وحدة systemd بالاستعانة بأوامر الطرفية ونقلته إلى المجلد الصحيح، ما تبقى عليك الآن هو تفعيله. الخطوة الثالثة: تفعيل حاوية خدمة systemd عليك الآن أن تعيد إقلاع systemd كي تتفعل الخدمة التي أنشأتها في الخطوة السابقة. استخدم الأمر التالي لإعادة تشغيل خدمة systemd للمستخدم الجذر: sudo systemctl daemon-reload أما بالنسبة للمستخدم محدود الصلاحيات فعليك إزالة الأمر sudo وإضافة الخيار user--، كي يصبح الأمر على الشكل التالي: systemctl --user daemon-reload وهكذا سيُعاد تشغيل خدمة systemd دون إعادة إقلاع النظام، وسيُحدّث وتظهر الخدمة الجديدة container-chitragupta-db.service. والآن أصبح بإمكانك تفعيل الخدمة الجديدة. استخدم الأمر التالي لتفعيل الخدمة للمستخدم الجذر: sudo systemctl enable SERVICE_NAME.service أما بالنسبة للمستخدم محدود الصلاحيات فعليك إزالة الأمر sudo وإضافة الخيار user--، كي يصبح الأمر على الشكل التالي: systemctl --user enable SERVICE_NAME.service ستحصل على الخرج التالي عند تفعيل الحاوية محدودة الصلاحية root-less container: $ systemctl --user enable container-chitragupta-db.service Created symlink /home/pratham/.config/systemd/user/default.target.wants/container-chitragupta-db.service → /home/pratham/.config/systemd/user/container-chitragupta-db.service. يمكنك التحقق من حالة الخدمة بعد تفعيلها بإضافة الأمر status على الأمر السابق للمستخدم الجذر والمستخدم محدود الصلاحية وفقًا لما يلي: # للمستخدم الجذر sudo systemctl status SERVICE_NAME.service # للمستخدم محدود الصلاحية systemctl --user status SERVICE_NAME.service إليك حالة الخدمة container-chitragupta-db: $ systemctl --user status container-chitragupta-db.service ○ container-chitragupta-db.service - Podman container-chitragupta-db.service Loaded: loaded (/home/pratham/.config/systemd/user/container-chitragupta-db.service; enabled; vendor preset: disabled) Active: inactive (dead) Docs: man:podman-generate-systemd(1) لا تقلق لأن حالة الخدمة تظهر غير نشطة inactive (dead)، إذ فعّلنا الخدمة الآن ويجب أن تعمل الخدمة عند إقلاع النظام، وليس الآن، وهذا هو المطلوب. إذا لم توقف الحاوية في الخطوة الأولى، فهذا هو الوقت المناسب لإيقافها عن طريق استخدام الأمر podman stop ثم استخدام الأمر podman container rm لحذفها، وإعادة إقلاع النظام بعدها لتشغيل خدمة الحاوية. الخطوة الرابعة: تفعيل خدمة إعادة التشغيل قد تحتاج في بعض التوزيعات إلى تفعيل خدمة إعادة التشغيل في بودمان أيضًا. ينطبق هذا على التوزيعات غير المعتمدة على نظام فيدورا، وخاصةً توزيعة NixOS. لتفعيل خدمة إعادة التشغيل عليك استخدام الأمر التالي: systemctl --user enable podman-restart.service يحرص الأمر podman-restart على إعادة تشغيل جميع الحاويات التي ضُبطت ليُعاد تشغيل دائمًا أي عند ضبط الأمر restart-policy على الخيار always. الخطوة الخامسة، تفعيل بقاء المستخدم محدود الصلاحية نشطًا (خطوة اختيارية) بما أنك فعّلت هذه الخدمة بواسطة مستخدم عادي محدود الصلاحية وليس المستخدم الجذر، هذا يعني أن المستخدم يحتاج إلى تسجيل الدخول عند التشغيل ويجب أن يظل نشطًا إن خرج من جلسة واجهة المستخدم الرسومية GUI أو من الطرفية. ويمكن تحقيق ذلك باستخدام الأمر loginctl من طرفية المستخدم نفسه، على النحو التالي: sudo loginctl enable-linger يضمن هذا الأمر تفعيل جلسة المستخدم عند الإقلاع وبقاءها نشطةً حتى بعد تسجيل الخروج من واجهة المستخدم الرسومية أو الطرفية. وبهذا تكون قد فعّلتَ إعادة تشغيل حاويات بودمان عند الإقلاع. حيث ستؤدي إعادة تشغيل النظام إلى التشغيل التلقائي للحاويات التي أنشأت لها ملف وحدة systemd. تعديل خدمة systemd نعلم جميعًا أن الإعدادات الافتراضية تفيد المبتدئين دائمًا، إذ تساعد على تخفيف شعور الارتباك لديهم. تُعد الإعدادات الإفتراضية لملف systemd الذي أنشأته مثاليةً لمعظم الأشخاص، لكن إن لم تكن مبتدئًا فبإمكانك إضافة مزيد من التعديلات من خلال تعديل ملف systemd أو إنشاء خدمة مخصصة جديدة من الصفر. الخلاصة تعلمنا في هذا المقال كيفية إنشاء ملفات وحدة systemd للتشغيل التلقائي لحاويات بودمان عند إقلاع النظام. حيث أن استخدام خدمة systemd سيساعدك في مراقبة الحاويات التي تستخدم واجهة systemd. ترجمة وبتصرّف للمقال Autostarting Podman Containers من موقع Linux Handbook. اقرأ أيضًا المقال السابق: إنشاء الحاويات وحذفها باستخدام أداة بودمان Podman نظام كوبيرنتس Kubernetes وكيفية عمله كيفية تأمين الحاويات عن طريق سي لينكس SELinux الفرق بين أداتي دوكر Docker وبودمان Podman
لا شك أن أداة بودمان ممتازة لإدارة الحاويات بما تقدمه من ميزات متعددة، لكنها لا توفر خاصية التشغيل التلقائي للحاويات عند إقلاع النظام، سنتعلم في هذا المقال كيف نجد حلًا لهذه المشكلة. على الرغم من أن أداة بودمان لا تعمل كبرنامج خفي daemon، وتسمح للمستخدم محدود الصلاحيات unprivileged user بتشغيل الحاويات دون الحاجة إلى الوصول إلى الجذر، مما يزيد من أمان النظام. لكنها ليست أداةً مثاليةً بالكامل فهي لا تُتيح إعادة تشغيل الحاويات تلقائيًا بعد إقلاع الخادم. سياسة إعادة تشغيل الحاويات عند الاطلاع على صفحة التعليمات man الخاصة بالأمر podman-run ستجد أن خيار إعادة التشغيل restart-- لا يعيد تشغيل الحاويات عندما يقلع النظام. وسبب هذا يرجع إلى أن بنية بودمان لا تعتمد مبدأ البرنامج الخفي، أي إن بودمان لا يعمل تلقائيًا عند إقلاع النظام، وبالتالي فإن الحاويات لا تعمل عند الإقلاع أيضًا. على عكس أداة دوكر التي تعتمد مبدأ البرنامج الخفي الذي يعمل عند إقلاع النظام ويُشَغّل الحاويات المحددة. حل مشكلة عدم التشغيل التلقائي للحاويات أيًّا كانت توزيعة نظام التشغيل التي تعمل عليها فلا بد أنها تستخدم systemd كنظام تمهيد init، وهذا ما سنحاول الاستفادة منه في إيجاد حل للمشكلة. الخطوة الأولى: إعداد الحاوية وتشغيلها ثمة عدة طرق ممكنة لتشغيل الحاوية. إن كان لديك حاوية بسيطة فبإمكانك استخدام الأمر podman run. أو يمكنك استخدام ملف دوكر إن أردت حاويةً بإعدادات معقدة واحتجت لمزيد من التحكم بهذه الإعدادات. لتوضيح ذلك، سننشئ حاويةً من صورة الحاوية mariadb وسنسميها chitragupta-db. $ podman ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 422eed872347 docker.io/library/mariadb:latest --transaction-iso... 58 seconds ago Up 58 seconds ago chitragupta-db يمكنك إيقاف الحاوية الجديدة لاحقًا. الخطوة الثانية: إنشاء خدمة systemd كما ذكرنا سابقًا، فإن بودمان ليس برنامجًا خفيًا أي إنه daemon-less لإدارة الحاويات. إذًا، فإن تشغيل حاويات بودمان يحتاج إلى تشغيل يدوي أو خارجي. سننفذ ذلك من خلال إنشاء خدمة systemd. حيث إن خدمة systemd هي نظام تمهيد init يدير الخدمات والبرامج الخفية في أنظمة تشغيل لينكس. إنشاء ملف وحدة systemd ليس عليك إنشاء ملف وحدة systemd يدويًا، إذ يمكن تنفيذ ذلك باستخدام الأمر podman generator systemd على النحو التالي: podman generate systemd --new --name CONTAINER_NAME لإنشاء ملف وحدة systemd للحاوية استخدم الأمر podman generate systemd متبوعًا باسم الحاوية، اسم الحاوية في مثالنا هو chitragupta-db: كما تلاحظ فإن الأمر السابق نفّذ العمل المطلوب، ولكننا لم ننته من العمل بعد. إن خرج الأمر podman generate systemd هو ما يجب أن يكون موجودًا في ملف وحدة systemd، لكن ثمة خيار مفيد يمكنك الاستعانة به بدلًا من نسخ الخرج ولصقه، وهو الخيار files -- أو اختصارًا f-. إذ سيؤدي استخدام هذا الخيار أولًا إلى ملء الملف بالمحتوى المطلوب بدلاً من طباعته على الطرفية، وثانيًا، إنشاء ملف باسم Container-CONTAINER_NAME.service في مجلد العمل الحالي. $ podman generate systemd --new --name chitragupta-db -f /home/pratham/container-chitragupta-db.service $ ls *.service Container-chitragupta-db.service لاحظ أن اسم الحاوية في مثالنا هو chitragupta-db، وأنه أصبح لدينا ملف باسم container-chitragupta-db.service في المجلد الحالي. بما أن الأمر podman generate systemd سوف ينشئ ملف وحدة systemd فإن بإمكانك استخدام الخيارات التالية =after=, --requires=, --wants-- لتحديد الاعتماديات للحاويات. نقل ملف خدمة systemd إلى موقع محدد كما لاحظت فإن الأمر السابق سينشئ ملف وحدة systemd جديد في مجلد العمل الحالي، لكن ذلك ليس الخيار الأنسب. إليك المسار المناسب للملف بالنسبة للمستخدم المسؤول superuser: /etc/systemd/system/ أما بالنسبة للمستخدم محدود الصلاحيات non-root user فهو: ~/.config/systemd/user/ والآن عليك نقل الملف إلى المجلد المناسب. بما أن الحاوية في مثالنا هي حاوية محدودة الصلاحية، فعليك نقلها إلى المجلد config/systemd/user/.~. $ mv -v container-chitragupta-db.service ~/.config/systemd/user/ renamed 'container-chitragupta-db.service' -> '/home/pratham/.config/systemd/user/container-chitragupta-db.service' وهكذا بعد أن أنشأت ملف وحدة systemd بالاستعانة بأوامر الطرفية ونقلته إلى المجلد الصحيح، ما تبقى عليك الآن هو تفعيله. الخطوة الثالثة: تفعيل حاوية خدمة systemd عليك الآن أن تعيد إقلاع systemd كي تتفعل الخدمة التي أنشأتها في الخطوة السابقة. استخدم الأمر التالي لإعادة تشغيل خدمة systemd للمستخدم الجذر: sudo systemctl daemon-reload أما بالنسبة للمستخدم محدود الصلاحيات فعليك إزالة الأمر sudo وإضافة الخيار user--، كي يصبح الأمر على الشكل التالي: systemctl --user daemon-reload وهكذا سيُعاد تشغيل خدمة systemd دون إعادة إقلاع النظام، وسيُحدّث وتظهر الخدمة الجديدة container-chitragupta-db.service. والآن أصبح بإمكانك تفعيل الخدمة الجديدة. استخدم الأمر التالي لتفعيل الخدمة للمستخدم الجذر: sudo systemctl enable SERVICE_NAME.service أما بالنسبة للمستخدم محدود الصلاحيات فعليك إزالة الأمر sudo وإضافة الخيار user--، كي يصبح الأمر على الشكل التالي: systemctl --user enable SERVICE_NAME.service ستحصل على الخرج التالي عند تفعيل الحاوية محدودة الصلاحية root-less container: $ systemctl --user enable container-chitragupta-db.service Created symlink /home/pratham/.config/systemd/user/default.target.wants/container-chitragupta-db.service → /home/pratham/.config/systemd/user/container-chitragupta-db.service. يمكنك التحقق من حالة الخدمة بعد تفعيلها بإضافة الأمر status على الأمر السابق للمستخدم الجذر والمستخدم محدود الصلاحية وفقًا لما يلي: # للمستخدم الجذر sudo systemctl status SERVICE_NAME.service # للمستخدم محدود الصلاحية systemctl --user status SERVICE_NAME.service إليك حالة الخدمة container-chitragupta-db: $ systemctl --user status container-chitragupta-db.service ○ container-chitragupta-db.service - Podman container-chitragupta-db.service Loaded: loaded (/home/pratham/.config/systemd/user/container-chitragupta-db.service; enabled; vendor preset: disabled) Active: inactive (dead) Docs: man:podman-generate-systemd(1) لا تقلق لأن حالة الخدمة تظهر غير نشطة inactive (dead)، إذ فعّلنا الخدمة الآن ويجب أن تعمل الخدمة عند إقلاع النظام، وليس الآن، وهذا هو المطلوب. إذا لم توقف الحاوية في الخطوة الأولى، فهذا هو الوقت المناسب لإيقافها عن طريق استخدام الأمر podman stop ثم استخدام الأمر podman container rm لحذفها، وإعادة إقلاع النظام بعدها لتشغيل خدمة الحاوية. الخطوة الرابعة: تفعيل خدمة إعادة التشغيل قد تحتاج في بعض التوزيعات إلى تفعيل خدمة إعادة التشغيل في بودمان أيضًا. ينطبق هذا على التوزيعات غير المعتمدة على نظام فيدورا، وخاصةً توزيعة NixOS. لتفعيل خدمة إعادة التشغيل عليك استخدام الأمر التالي: systemctl --user enable podman-restart.service يحرص الأمر podman-restart على إعادة تشغيل جميع الحاويات التي ضُبطت ليُعاد تشغيل دائمًا أي عند ضبط الأمر restart-policy على الخيار always. الخطوة الخامسة، تفعيل بقاء المستخدم محدود الصلاحية نشطًا (خطوة اختيارية) بما أنك فعّلت هذه الخدمة بواسطة مستخدم عادي محدود الصلاحية وليس المستخدم الجذر، هذا يعني أن المستخدم يحتاج إلى تسجيل الدخول عند التشغيل ويجب أن يظل نشطًا إن خرج من جلسة واجهة المستخدم الرسومية GUI أو من الطرفية. ويمكن تحقيق ذلك باستخدام الأمر loginctl من طرفية المستخدم نفسه، على النحو التالي: sudo loginctl enable-linger يضمن هذا الأمر تفعيل جلسة المستخدم عند الإقلاع وبقاءها نشطةً حتى بعد تسجيل الخروج من واجهة المستخدم الرسومية أو الطرفية. وبهذا تكون قد فعّلتَ إعادة تشغيل حاويات بودمان عند الإقلاع. حيث ستؤدي إعادة تشغيل النظام إلى التشغيل التلقائي للحاويات التي أنشأت لها ملف وحدة systemd. تعديل خدمة systemd نعلم جميعًا أن الإعدادات الافتراضية تفيد المبتدئين دائمًا، إذ تساعد على تخفيف شعور الارتباك لديهم. تُعد الإعدادات الإفتراضية لملف systemd الذي أنشأته مثاليةً لمعظم الأشخاص، لكن إن لم تكن مبتدئًا فبإمكانك إضافة مزيد من التعديلات من خلال تعديل ملف systemd أو إنشاء خدمة مخصصة جديدة من الصفر. الخلاصة تعلمنا في هذا المقال كيفية إنشاء ملفات وحدة systemd للتشغيل التلقائي لحاويات بودمان عند إقلاع النظام. حيث أن استخدام خدمة systemd سيساعدك في مراقبة الحاويات التي تستخدم واجهة systemd. ترجمة وبتصرّف للمقال Autostarting Podman Containers من موقع Linux Handbook. اقرأ أيضًا المقال السابق: إنشاء الحاويات وحذفها باستخدام أداة بودمان Podman نظام كوبيرنتس Kubernetes وكيفية عمله كيفية تأمين الحاويات عن طريق سي لينكس SELinux الفرق بين أداتي دوكر Docker وبودمان Podman