


Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 نعم يمكننا ذلك، ففي كيراس تم تعريف ال CosineSimilarity كدالة تكلفة لمهام التوقع. المعادلة الرياضية: loss = -sum(l2_norm(y_true) * l2_norm(y_pred)) يكون الخرج بين ال 1 و -1، بحيث كلما اقتربت القيم من ال -1 يكون التشابه أعظم وكلما اقترب من 1 يكون أقل تشابه وتشير ال 0 إلى حالة التعامد. وهذا مايجعلها قابلة للاستخدام كدالة تكلفة. يمكن استيرادها من الموديول: keras.losses لاستخدامها مع نموذج نمررها للدالة compile كما في المثال التالي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss=keras.losses.CosineSimilarity(axis=1), metrics=['mae']) #model.compile(optimizer='rmsprop', loss='CosineSimilarity', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64)
نعم يمكننا ذلك، ففي كيراس تم تعريف ال CosineSimilarity كدالة تكلفة لمهام التوقع. المعادلة الرياضية: loss = -sum(l2_norm(y_true) * l2_norm(y_pred)) يكون الخرج بين ال 1 و -1، بحيث كلما اقتربت القيم من ال -1 يكون التشابه أعظم وكلما اقترب من 1 يكون أقل تشابه وتشير ال 0 إلى حالة التعامد. وهذا مايجعلها قابلة للاستخدام كدالة تكلفة. يمكن استيرادها من الموديول: keras.losses لاستخدامها مع نموذج نمررها للدالة compile كما في المثال التالي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss=keras.losses.CosineSimilarity(axis=1), metrics=['mae']) #model.compile(optimizer='rmsprop', loss='CosineSimilarity', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64)- 2 اجابة
-
- 2
-

-
إضافة للإجابات في الأعلى. سأتحدث عن مكتبة psutil كونها تعمل على مختلف أنظمة التشغيل، حيث توفر واجهة لاسترداد المعلومات حول العمليات الجارية واستخدام النظام (وحدة المعالجة المركزية والذاكرة). import psutil # استخدام المعالج print(psutil.cpu_percent()) # 15.3 # عرض نسبة استخدام الذاكرة print(psutil.virtual_memory().percent) # 71.1 # حساب المساحة المتوفرة من الذاكرة psutil.virtual_memory().available * 100 / psutil.virtual_memory().total # 28.76908537555775 # يمكنك عرض معلومات كاملة psutil.virtual_memory() # svmem(total=4169424896, available=1228451840, percent=70.5, used=2940973056, free=1228451840) ولمستخدمي لينوكس يمكنهم أيضاً استخدام مكتبة os: import os # استخدام المعالج cpu=str(round(float(os.popen('''grep 'cpu ' /proc/stat | awk '{usage=($2+$4)*100/($2+$4+$5)} END {print usage }' ''').readline()),2)) #print results print("usage :" + cpu) # استخدام الذاكرة # os.popen() # الحصول على كل معلومات الذاكرة total_memory, used_memory, free_memory = map( int, os.popen('free -t -m').readlines()[-1].split()[1:]) # استخدام الذاكرة print("RAM memory % used:", round((used_memory/total_memory) * 100, 2)) ويمكنك الحصول على معلومات مفصلة للتحليل ولعرض استخدام الذاكرة لكل سطر باستخدام وحدتي profile line_profiler وmemory_profiler بالطريقة التالية: اكتب برنامج python المراد اختباره ، والوظيفة المراد اختبارها وأضف أعلاها @ profile ، ثم احفظها كملف py. ثم ضع في سطر الأوامر commandline أو في محرر الأكواد: kernprof -l -v *.py ستتم طباعة تحليل الأداء وطباعة نتائج البرنامج. مثال، سنكتب تابع صغير ثم سنحفظه باسم ali.py @profile def com(): for i in range(10): print(i**4) if __name__=='__main__': com() ثم ضع في سطر الأوامر Command Line أو في محرر الأكواد. kernprof -l -v ali.py ''' Wrote profile results to test.py.lprof Timer unit: 1e-06 s Total time: 0.012405 s File: test.py Function: compute at line 1 Line # Hits Time Per Hit % Time Line Contents ============================================================== 1 @profile 2 def compute(): 3 101 74.0 0.7 0.6 for i in range(10): 4 100 12331.0 123.3 99.4 print(i**4) ''' Timer unit : وحدة الموقت ، ميكروثانية Total time :إجمالي وقت تشغيل الكود Time : زمن تشغيل السطر Hits: Number of runs % Time: النسبة المئوية لزمن تشغيل السطر ويمكنك استخدام بنفس الطريقة لكن نضع: python -m memory_profiler ali.py ''' Line # Mem usage Increment Line Contents ================================================ 2 39.08 MiB 39.08 MiB @profile(precision=2) 3 def compute(): 4 39.08 MiB 0.00 MiB for i in range(100): 5 39.08 MiB 0.00 MiB print(i**3) ''' Increment: زيادة الذاكرة أو نقصانها بعد تشغيل كل سطر من التعليمات البرمجية Mem usage: استخدام الذاكؤة لكل سطر يمكنك تثبيت المكتبات كالتالي: pip install line_profiler pip install memory_profiler
- 3 اجابة
-
- 2
-
-
هناك عدة طرق من بينها الطرق التي ذكرها الزملاء في الأعلى، لكن إذا أردت إيجادها باستخدام نمباي يمكنك القيام بذلك كالتالي: import numpy as np np.r_[True, arr[1:] < arr[:-1]] & numpy.r_[arr[:-1] < arr[1:], True] لكن يجب أن تقوم بعملية smooth على مصفوفتك قبل ذلك باستخدام التابع convolve. مثال عن هذا التابع: np.convolve([1, 2, 3], [0, 1, 0.5]) #array([0. , 1. , 2.5, 4. , 1.5])
- 3 اجابة
-
- 1
-
-
هناك عدة طرق للقيام بذلك، وتختلف باختلاف زمن التنفيذ كما في الرسم البياني الذي قدمته Reem. إليك أفضل الطرق للقيام بذلك: import numpy as np a = np.array([ [1, 2,], [3, 4] ]) n=1 b = np.random.random((n,a.shape[1])) # طريقة1 np.ascontiguousarray(np.vstack([a.T, b]).T) # طريقة 2 np.c_[a, b.T] # طريقة 4 # تكديس المصفوفات في تسلسل عمودي (حسب الصف). np.vstack([a.T, b]).T # 5 طريقة # سلسلة من المصفوفات على طول محور موجود np.concatenate([a.T, b]).T # 6 طريقة # 1D إضافة مصفوفة # يتم إضافتها كعمود np.column_stack([a, b.T]) # 7 تكديس المصفوفات في تسلسل أفقي أي حسب الصف np.hstack([a, b.T]) #append و insert يمكن أيضاً استخدام التابع # لكنهما أقل سرعة # الخرج """ array([[1. , 2. , 0.11709763], [3. , 4. , 0.65841792]]) """ مثال عن concatenate لتوضيح عمله: # numpy.concatenate((a1, a2, ...), axis=0, dtype=None) a = np.array([[1, 2], [3, 4]]) b = np.array([[5, 6]]) np.concatenate((a, b), axis=0) """array([[1, 2], [3, 4], [5, 6]]) """ np.concatenate((a, b.T), axis=1) """array([[1, 2, 5], [3, 4, 6]])""" np.concatenate((a, b), axis=None) """array( [1, 2, 3, 4, 5, 6] )""" استخدام hstack و vstack يبدو الحل الأسرع (التخزين بشكل contiguous أي تخزين المصفوفات بشكل متجاور بشكل عام بعتبر أسرع من ناحية إجراء العمليات عليه لكن هذه الطرق-أقصد stack بأنواعها- لاتخزن المصفوفات بشكل متجاور، لذا نستخدم التابع ascontiguousarray لتحويلها لكن هذا سيكلفنا المزيد من الوقت وهذا مايتضح لنا في الرسم البياني الذي قدمته Reem، لذا لا أفضله). أفضل استخدام concat أو column_stack فهو مريح أكثر ومناسب وسرعته مناسبة كما ترى في الرسم البياني الذي أرفقته Reem
- 5 اجابة
-
- 1
-
-
هذا المفهوم هو مفهوم عام وغير محصور بلغة برمجية محددة، أي من الممكن أن تراه في لغات أخرى. في البداية تعددية الأشكال تعني قدرة الغرض أن يأخذ عدة أشكال، حيث أن الاستخدام الشائع لهذا المفهوم في البرمجة غرضية التوجه يحدث عندما يكون لدينا مرجع من صف أب (نسميه مقبض)يشير إلى كائن من صف ابن.. لاشك أنك تعرف الوراثة في جافا !! العكس لا يصح .. أي أن الغرض من الصف الأب و يشير إلى كائن من نفس الصف أو من الصف الابن حصراً ، مثلاً: class Human { ….. } class Student extends Human { ……. } //العبارات التالية صحيحة Human H ; //مقبض من الصف الأب H = new Human() ; // المقبض يشير إلى كائن من نفس الصف H = new Student () ; // المقبض يشير إلى كائن من الصف الابن // العبارات التالية خاطئة Student st = new Human ; // مقبض من الصف الابن يشير الى كائن من الصف الأب (لايجوز) الآن لفهم الكلام السابق سنعطي مثال ، نشرحه ثم نكتب كود برمجي يعبرعنه .. لنفرض مثلاً لدينا شاحنة ونريد نقل مجموعة سيارات بحيث كل شاحنة تتسع ل 10 سيارات ، وتنقل نوع واحد من السيارات .. ( يمكن تشبيه الشاحنة بمصفوفة تضم عناصر من نمط واحد ) .. لنفرض لدينا نوعين من السيارات نريد أن ننقلهم 4:BMW و 4:AUDI حسب الشروط المفروضة سنحتاج شاحنتين في كل واحدة سنضع 4 من نفس النوع .. الفكرة أن الشاحنة الواحدة (مصفوفة ) لا تحمل نوعين لكنها تتسع للعدد الكلي ، أي أننا قمنا بعملية نقل صحيحة لكنها مكلفة ( حجزنا شاحنة ويوجد أماكن فارغة بالأولى + ماذا لو كان لدينا أكثر من نوعين .. ) الحل : يجب أن نبحث عن شاحنة ( مصفوفة) تحمل النوعين .. ونعلم أن المصفوفة لا تحمل الا نوع واحد .. ما العمل هنا تأتي " تعددية الأشكال" بأن نعرف صف أب للصفين السابقين وليكن Carونرث منه الصفين BMW و AUDI ونأخذ مصفوفة مقابض من Car ( نمط واحد ) وكل عنصر (مقبض) نجعله يشير الى الكائن المطلوب .. BMW أو AUDI .. وهكذا نكون قد حللنا المشكلة و خزنا كائنات من صفوف مختلفة بمصفوفة واحدة مثال : (يمكن نسخ الكود وتنفيذه لملاحظة النتائج): package javaapplication29; class Car { void type () { System.out.println("car");} } class BMW extends Car { @Override void type () { System.out.println("BMW");} } class AUDI extends Car { @Override void type () { System.out.println("AUDI");} } public class JavaApplication29 { public static void main(String[]args ){ Car[]c =new Car[8]; //نعبئ أربع سيارات BMW for( int i=0; i<4 ; ++i ) c[i] = new BMW(); //نعبئ أربع سيارات AUDI for( int i=4; i<8 ; ++i ) c[i] = new AUDI(); //تعليمة طباعة للتأكد من أنه تم تعبئة النوعين for( int i=0; i<8 ; ++i ) c[i].type(); } }
- 3 اجابة
-
- 1
-
-
بما أنك تتعامل مع شبكة عصبونية التفافية CNN يجب أن تكون الصورة من الشكل: الطول*العرض*عدد القنوات. أي يجب تحويل الأبعاد الخاصة بالداتا كالآتي: x_train = x_train.reshape(60000, 28, 28, 1) x_test = x_test.reshape(10000, 28, 28, 1)
- 2 اجابة
-
- 2
-
-
هو طريقة تحسين مشابهه ل Adam التي تقوم بتسريع GD وتخفف التذبذب وامتداد لها ويكون adamax أفضل من adam أو أكثر فعالية في بعض المشكلات يقوم adam بتحدث الأوزان اعتمادا على متوسط الأوزان الأسية للمشتقات السابقع ومتوسط الأوزان الاسية لمربعات المشتقات السابقة في حين أن adamax يقوم بتوسيع الحد الأقصى للمشتقات السابقة ويقوم إيضا بتكييف معدل تعلم لكل معلمة في عملية التحسين بشكل منفصل لاستخدامها في كبراس نمررها إلى الدالة compile: model.compile( optimizer=Adamax(learning_rate=0.001) ... ) # أو model.compile( optimizer='Adamax' ... ) # لاحظ أنه في الطريقة الثانية سيستخدم معمل الخطوة الافتراضي. # لذا إذا أردت تغييرها استخدم الصيغة الأولى. مثال عن طريقة الاستخدام حيث يأخذ Adamax الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة: #استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import Adamax #تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() #تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 #بناء الشبكه العصبونيه بطبقه واحده وطبقة خرج ب 10 أصناف model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) #0.001مع معامل تعلم Adamax استخدام model.compile(optimizer=Adamax(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) #تدريب الموديل model.fit(X_train,y_train)
- 2 اجابة
-
- 1
-
-
يمكنك ذلك عبر مايسمى بالوسطاء الموضعية أو الاختيارية *args. def echo(*args): for i in args: print(i) myLits = [1, 2, 3, 4] echo(myLits) حيث يمكن تعريف دالة قادرة على أخذ عدد اختياري من الوسطاء عن طريق وسيط واحد مع إضافة الرمز * له، وهذا مفيد عندما لاتعلم عدد الوسطاء التي سوف يتم تمريرها إلى الدالة، وبهذه الطريقة ستكون الدالة قادرة على تلقي مجموعة من الوسطاء، مع إمكانية الوصول إلى أي منها، حيث يفهم مترجم بايثون أن هذا المتحول هو مجموعة من الوسطاء، وبالتالي مهما وضعنا وسطاء سوف يقبلها. def func(*args): # argswill be a tuple containing all values that are passed in for i in args: print(i) func(1, 2, 3) # Calling it with 3 arguments # Out: 1 # 2 # 3 list_of_arg_values = [1, 2, 3] func(*list_of_arg_values) # Calling it with list of values, * expands the list # Out: 1 # 2 # 3 func() # Calling it without arguments # No Output للتنويه: لايمكنك تمرير عدد افتراضي من الوسطاء، فمثلاً: (func(*args=[1, 2, 3]) # خطأ ولايمكن التمرير بالاسم عند استدعاء الدالة: (func(*args=[1, 2, 3]) ولكن إذا كان لديك بالفعل وسطاء كمصفوفة (أو أي نوع آخر)، تستطيع عندها استدعاء الدالة بالشكل: func(*my_stuff) ويمكن الوصول إلى هذه الوسطاء (*args) عن طريق الفهرس، فمثلاُ: args[0] # ترجع قيمة العنص الأول يمكنك تمرير مجموعة من الوسطاء العادية والاختيارية لكن يجب التقيد في التعريف، أي الوسطاء العادية أولاً ثم الاختيارية: def func(p1, p2=10 , *args): #p1 يجب أن نمرر أولاً قيمة ل pass
- 4 اجابة
-
- 1
-
-
حسناً أنت محظوظ فهذا النوع من البرمجة كان اختصاصي خلال مشاركاتي في المسابقات البرمجية. عندما تتحدث عن ال memoization فهذا يعني أنك دخلت حقل البرمجة الديناميكية "Dynamic Programming" كبداية سأعرفك بالبرمجة الديناميكية: البرمجة الديناميكية هي أسلوب أو نهج في حل المسائل لتحسين التعقيد الزمني للمسائل التي تحوي "العودية". الفكرة هي ببساطة تخزين نتائج المشكلات الفرعية "Subproblems"، حتى لا نضطر إلى إعادة حسابها عند الحاجة لها لاحقاً. وهذا مايؤدي إلى تقليل التعقيد الزمني للعديد من المسائل من تعقيد أسي إلى تعقيد خطي polynomail. على سبيل المثال، إذا كتبنا حلًا عودياً بسيطًا لأرقام فيبوناتشي، فإننا نحصل على تعقيد زمني أسي، وإذا قمنا بتحسينه عن طريق تخزين حلول المشكلات الفرعية، فإن تعقيد الوقت ينخفض إلى خطي. # تايع لحساب أعداد فيبوناتشي بالطريقة العودية def Fib(n): if n<0: print("error") elif n==0: return 0 elif n==1: return 1 else: return Fib(n-1)+Fib(n-2) print(Fib(5)) # هذا الكود تعقيده أسي وهذا سيئ وغير فعال fib(5) / \ fib(4) fib(3) / \ / \ fib(3) fib(2) fib(2) fib(1) / \ / \ / \ fib(2) fib(1) fib(1) fib(0) fib(1) fib(0) / \ fib(1) fib(0) #تستدعى مرتين fib 3 يمكن مثلاً ملاحظة أنّ الدالة #وإن تسنّى لنا تخزين القيمة الناتجة عن استدعاء هذه الدالة، فستنتفي الحاجة إلى إعادة حساب هذه القيمة وسيكون بالإمكان استخدام القيمة المخزّنة سابقًا عوضًا عن ذلك. أما عند حله باستخدام مفهوم البرمجة الديناميكية: # Dynamic Programming def Fib(n): dp = [0, 1] for i in range(2, n+1): dp.append(dp[i-1] + dp[i-2]) return dp[n] print(Fib(5)) لكن يجب أن تعلم أن ليس كل مسألة عودية أو أي مسألة تحوي استدعاءات متكررة يمكن أن يكون لها حل باستخدام البرمجة الديناميكية، هناك شرطين يجب أن تحققهما أي مسألة قبل أن نحاول حلها باستخدام هذا المفهوم، فإذا تحققا هذا يعني أنه يمكن حلها في ال DP، وإلا فلا تحاول، وهما: مسائل فرعية متداخلة "Overlapping Subproblems": أي هل يمكن تقسيم المسألة إلى مسائل فرعية أصغر، أو إلى مهام أصغر، أو بمعنى آخر هل يمكننا تقسيم المسألة إلى مسائل أصغر بحيث تجتمع هذه المسائل لحل المسألة الأكبر. حيث أن البرمجة الديناميكية تشبه نموذج فرّق تسد في أنها تدمج حلول المسائل الفرعية بعضها ببعض. تستخدم البرمجة الديناميكية عمومًا عندما تظهر الحاجة إلى استخدام حلول مجموعة معينة من المسائل الفرعية مرة بعد أخرى. تخزّن حلول المسائل الفرعية في البرمجة الديناميكية في مصفوفة وذلك لتجنّب حسابها مرة أخرى. هذا يعني أنّ البرمجة الديناميكية غير مفيدة عندما لا تكون هناك مسائل فرعية متداخلة؛ إذ لا فائدة من تخزين الحلول إن لم تكن الخوارزمية بحاجة إليها مرة أخرى. قمثلاً تتضمن عملية حساب أعداد فيبوناتشي بطريقة تعاودية العديد من المسائل الفرعية التي يجري حلّها مرة تلو الأخرى مثل fib3 كما رأينا. بنية فرعية مثالية "Optimal Substructure":نقول أنّ مسألة معيّنة تمتلك بنية فرعية مثالية إذا كان بالإمكان الحصول على الحل المثالي للمسألة المعطاة بجمع الحلول المثالية للمسائل المتفرّعة عن المسألة الرئيسية. الآن سأنتقل لك لمفهوم ال Memoization.. نحن قلنا أنه سيتم تخزين الحلول، حسناً كيف سيتم تخزينها؟ هناك طريقتين للقيام بذلك: التحفيظ Memoization (من الأعلى إلى الأسفل): تشبه طريقة التحفيظ في حل مسألة معينة الطريقة التعاودية ولكن مع تعديل بسيط، وهو أنّ هذه الطريقة تبحث في جدول البحث lookup table معين قبل حساب الحلول. تبدأ العملية بتهيئة مصفوفة بحث تحمل القيمة NIL كقيمة أولية. وفي كل مرّة نحتاج فيها إلى إيجاد حلٍّ لمسألة فرعية، نبدأ بالبحث في جدول البحث، فإن كانت القيمة محسوبة مسبقًا موجودة فيه فسنعيد حينئذٍ تلك القيمة، وإلا سنحسب القيمة ونضع النتيجة في جدول البحث ليتسنى لنا إعادة استخدامها في وقت لاحق. مثال لاستخدام هذه الطريقة مع المسألة السابقة: # الدالة المسؤولة عن حساب العدد ذي الترتيب المعطى في متتالية فيبوناتشي def fib(n, lookup): # الحالة الأساس if n == 0 or n == 1 : lookup[n] = n # إن لم تكن القيمة محسوبة مسبقًا فسنحسبها الآن if lookup[n] is None: lookup[n] = fib(n-1 , lookup) + fib(n-2 , lookup) # n تعيد الدالة القيمة المرتبطة بالقيمة المعطاة return lookup[n] # اختبار الدالة السابقة def main(): n = 34 # إنشاء جدول البحث # يستوعب الجدول 100 عنصر lookup = [None]*(101) print "Fibonacci Number is ", fib(n, lookup) if __name__=="__main__": main() 2.الجدولة Tabulation (من الأسفل إلى الأعلى): تبني هذه الطريقة جدولًا من الأسفل إلى الأعلى وتعيد آخر قيمة من الجدول عند الحاجة. فعلى سبيل المثال، تحسب دالة فيبوناتشي الأعداد في المتتالية حسب التسلسل fib(0) ثم fib(1) ثم fib(2) ثم fib(3) وهكذا. وهذا يعني أنّنا نبني جدول الحلول للمسائل الفرعية من الأسفل إلى الأعلى حرفياً. وهي ذات الطريقة التي استخدماتها لتخزين الحلول للمسألة في البداية. مثال آخر للتحفيظ: لنفترض أن لدينا الأعداد {1, 3, 5} والمطلوب هو إيجاد عدد الطرق التي يمكن استخدام هذه الأرقام فيها لحساب رقم معيّن (ليكن N) وذلك بإجراء عملية الجمع مع السماح بتكرار الأعداد وتغيير ترتيبها. لكي نتمكّن من حلّ هذه المسألة ديناميكيًا يجب في البداية اتخاذ قرار بشأن الحالة الخاصة بالمسألة المعطاة، وسنستخدم معاملًا (ليكن n) لاتخاذ القرار بشأن الحالة الراهنة وذلك لإمكانية استخدام هذه المعامل في تشخيص أي مسألة فرعية بطريقة فريدة. وبهذا تكون الحالة في هذه المسألة هي state(n)، والتي تمثّل هنا العدد الكلي للترتيبات التي يمكن استخدامها لتكوين العدد n باستخدام العناصر {1, 3, 5}. ولمّا كان بالإمكان استخدام الأعداد 1 و 3 و 5 فقط لتكوين العدد المعطى، سنفترض أنّنا نعرف نتائج الأعداد n = 1, 2, 3, 4 , 5, 6 مسبقًا، وبمعنى آخر فإنّنا نعرف نتائج كلّ من state (n = 1), state (n = 2), state (n = 3) ……… state (n = 6). // تعيد الدالة عدد الترتيبات لتكوين العدد المعطى int solve(int n) { // الحالة الأساس if (n < 0) return 0; if (n == 0) return 1; return solve(n-1) + solve(n-3) + solve(n-5); } تعمل الشيفرة السابقة بتعقيد زمني أسّي وتحسب الحالة نفسها مرارًا وتكرارًا؛ ولهذا يجب إضافة عملية التحفيظ memoization. إضافة عملية التحفيظ إليها:: // تهيئة القيمة لتكون -1 int dp[MAXN]; // تعيد هذه الدالة عدد الترتيبات لتكوين العدد `n` int solve(int n) { // الحالة الأساس if (n < 0) return 0; if (n == 0) return 1; // التحقق من أنّ الحالة الراهنة محسوبة مسبقًا if (dp[n]!=-1) return dp[n]; // تخزين النتيجة وإعادتها return dp[n] = solve(n-1) + solve(n-3) + solve(n-5); }
- 2 اجابة
-
- 3
-
-
عند التعامل مع المسائل التي تندرج تحت ال NLP هناك خطوة مهمة يجب القيام بها قبل إرسال ال Data إلى الطبقات للتدرب عليها وهي وضع القيم في مصفوفة ذات أبعاد ثابتة. أثناء تجهيز البيانات النصية (النصوص، حيث كل عينة تكون عبارة عن نص) وترميزها رقمياً (إسناد عدد صحيح يمثل كل كلمة ثم تمثيل النص كسلسلة من الأعداد الصحيحة) ستكون بعض النصوص أطول من الأخرى وهذا شيء مؤكد وبديهي (أي أول عينة قد يكون طولها 500 والأخرى 1000 وو). لذا لإدخالها إلى شبكة عصبية يجب علينا أولاً توحيد طول كل عينة (طول كل نص أو طول كل سلسلة رقمية كوننا قمنا بترميزها رقمياً)، وهذا التوحيد يكون عبر اختيارنا للحجم الذي نراه مناسياً لكل سلسلة وليكن x، ثم نمر على كل العينات ونقطع كل سلسلة طولها أكبر من (بالتالي نجعلها 500 فقط)، أما إذا كانت أقل من x فنقوم (بحشوها) بأصفار، وهذا مايتم من خلال التابع pad_sequences كما سترى في المثال، وهذا مايجب عليك القيام به قبل إدخالالبيانات إلى شبكتك، فهذا هو سبب الخطأ الذي ظهر ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type list). فهو غير قادر على تحويل list لإى tensor بأبعاد مختلفة، يجب أن تقوم بتوحيد الأبعاد لكل العينات. التصحيح: from keras.datasets import imdb from keras.layers import Embedding, SimpleRNN from keras.models import Sequential (input_train, y_train), (input_test, y_test) = imdb.load_data( num_words=max_features) print(len(input_train), 'train sequences') print(len(input_test), 'test sequences') ################ نضيف################### from keras.preprocessing import sequence maxlen = 500 print('Pad sequences (samples x time)') input_train = sequence.pad_sequences(input_train, maxlen=maxlen) input_test = sequence.pad_sequences(input_test, maxlen=maxlen) ############# انتهى#################### print('input_train shape:', input_train.shape) print('input_test shape:', input_test.shape) from keras.layers import Dense model = Sequential() model.add(Embedding(10000, 32)) model.add(SimpleRNN(32)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(input_train, y_train, epochs=2, batch_size=32, validation_split=0.2) ------------------------------------------------- 25000 train sequences 25000 test sequences Pad sequences (samples x time) input_train shape: (25000, 500) input_test shape: (25000, 500) Epoch 1/2 625/625 [==============================] - 79s 111ms/step - loss: 0.6659 - acc: 0.5671 - val_loss: 0.4343 - val_acc: 0.8116 Epoch 2/2 625/625 [==============================] - 67s 108ms/step - loss: 0.3630 - acc: 0.8477 - val_loss: 0.3880 - val_acc: 0.8262
- 2 اجابة
-
- 2
-
-
تقوم بإيقاف جميع التعليمات التي تأتي بعدها ضمن الكود حتى يتم تنفيذ ال thread الذي يقوم بالاستدعاء، لفهم ذلك : في البداية و كما نعلم أن ال thread هو طريق إلى وحدة المعالج، ففي حال لدينا كود ما كبير وكان هنالك إمكانية للتفريع، و قمنا بإنشاء عدد من ال Threads، فإن كل thread منها يصل إلى نواة من أموية المعالج، وبالتالي كل نواة تنفذ جزء من الكود، و بالتالي تنفيذ الكود يكون بشكل متساير ( متوازي) مما يؤدي لتسريع تنفيذ الكود. إذن مجال التنفيذ سيكون متداخل، فلو أخذنا المثال البسيط التالي (سنقتصر على ذكر الأفكار اللازمة لفهم الطريقة join() فقط) : ( الصف Helper يحوي الطريقتين printA تقوم بطباعة A مئة مرة، printB تقوم بطباعة B مئة مرة). Class Helper { Public void PrintA(){ for ( int i=0 ; i<100 ; i++ ) { console.WriteLine("A"); } } Public void PrintB(){ for ( int i=0 ; i<100 ; i++ ) { console.WriteLine("B"); } } } ( في ال main class أخذنا غرض من الصف Helper واستدعينا طرائقه ، ثم أنشئنا لكل طريقة thread خاص ، لا ننسى أن ال التابع main() عبارة عن thread أساسي يتم تنفيذه). Class program { Public static void main() { Helper h = new Helper (); Thread th1 = new Thread (h.printA()); Thread th2 = new Thread (h.printB()); Th1.start(); Th2.start (); for ( int i =0 ; i < 100; i++ ) { console.WriteLine ( "C" ); } } } الآن أصبح لدينا ثلاثة نياسب (th1 يطبع A مئة مرة، th2يطبع B مئة مرة، thread mainيطبع C مئة مرة). التنفيذ متداخل و يكون الخرج هنا بعد التنفيذ: ( طباعة A مئة مرة و B مئة مرة و C مئة مرة ) بشكل متداخل. الآن الجزء المهم لمعرفة وظيفة الطريقة join(): ماذا نفعل اذا أردنا أن نطبع A مئة ثم طباعة B مئة مرة ثم طباعة C مئة مرة ؟ الجواب نستخدم التعليمة join() بالشكل : th1.start(); th1.join(); th2.start(); th2.join(); for(int i=0;i<100;++i){ onsole.WriteLine("C"); } سؤال بطريقة أخرى لفهم join() ، ماهو الخرج في حال كانت التعليمات بالشكل : th1.start(); th2.start(); th1.join(); th2.join(); for(int i=0;i<100;++i){ onsole.WriteLine("C"); } الخرج : طباعة C مئة مرة بعد طباعة كل من A,B بشكل متداخل ، بشكل مفصل: التعليمة th1.join() تقوم بإيقاف ال main(طباعة C)حتى يتم طباعة A مئة مرة. (إلى هنا يكون المتوقع حتى الآن طباعة A و B بشكل متداخل وعندما تتم طباعة A مئة مرة يبدأ تنفيذ النيسب main بالتالي بدئ طباعة C بشكل متداخل مع B إن لم تكن منتهية ) لكن لدينا التعليمة التالية وهي th2.join()تقوم بإيقاف ال main(طباعة C)حتى يتم طباعة B مئة مرة .. بالتالي أصبح الخرج المتوقع (طباعة Aمئة مرة و B مئة مرة ) بشكل متداخل ومن ثم طباعة C مئة مرة .
- 2 اجابة
-
- 1
-
-
يوجد خطأن الأول في dropout هو فقط ضع مكان السطر model.add(Dropout(0,45)) السطر التالي: model.add(Dropout(0.45)) والثاني أنه في مجموعة التحقق validation_data في السطر التالي: model.fit(x_train, y_train, epochs=5,validation_data=[x_vaild, y_vaild], batch_size=batch_size) يأخذ tuple و ليس مصفوفة أي يصبح السطر هكذا: model.fit(x_train, y_train, epochs=5,validation_data=(x_vaild, y_vaild), batch_size=batch_size)
- 2 اجابة
-
- 1
-
-
في الاحصاء الرياضي، فإن تباعد كولباك - ليبلير هو مقياس لمدى اختلاف توزيع احتمالي p عن توزيع احتمالي مرجعي آخر q، وهو مجرد تعديل طفيف لمعادلة الإنتروبيا، ويستخدم في تعلم الآلة كمقياس لأداء نموذج، عن طريق مقارنة اختلاف y_pred (التوزيع الاحتمالي الذي أنتجته الخوارزمية) ب y_true (توزيع احتمالي مرجعي). يمكنك استخدامه عبر الموديول:tf.keras.losses tensorflow.keras.losses مثال: import tensorflow as tf y_true = [[0, 1], [1, 0]] y_pred = [[0.2, 0.8], [0.9, 0.1]] kl = tf.keras.losses.KLDivergence() kl(y_true, y_pred).numpy() #0.16425064 لاستخدامه في نموذجك، قم بتمريره إلى دالة compile كالتالي: model.compile( loss=tf.keras.losses.KLDivergence() ... ) # أو model.compile( loss='KLDivergence' ... ) مثال على مجموعة بيانات راوترز (تصنيف متعدد 46 فئة): للتنويه: لاستخدامه يجب أن تقوم بترميز بيانات ال target لديك بترميز فئوي One-Hot، ويمكنك استخدام الدالة to_categorical كما في المثال للقيام بالأمر. # تحميل الداتا from keras.datasets import reuters import tensorflow as tf (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) #ترميز الفئات المختلفة للبيانات #كما أشرنا One-Hot-Enoding طبعاً يجب أن نستخدم الترميز from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) #أي الفئات target انتهينا من ترميز قيم ال # الآن لنقم بترميز بيانات التدريب import numpy as np #One-Hot قمت بإنشاء تابع يقوم بتحويل بياناتي إلى الترميز # بإمكانك أيضاً استخدام تابع تحويل جاهز def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss=tf.keras.losses.KLDivergence(), metrics=['accuracy']) # لاحظ كيف قمنا بتمرير دالة التكلفة إلى النموذج # التدريب history = model.fit(x_train, one_hot_train_labels, epochs=8, batch_size=512, validation_split=0.2) -------------------------------------------------------------------------- Epoch 1/8 15/15 [==============================] - 1s 31ms/step - loss: 3.2545 - accuracy: 0.2897 - val_loss: 2.0523 - val_accuracy: 0.5704 Epoch 2/8 15/15 [==============================] - 0s 14ms/step - loss: 1.9090 - accuracy: 0.5904 - val_loss: 1.6599 - val_accuracy: 0.6210 Epoch 3/8 15/15 [==============================] - 0s 14ms/step - loss: 1.5475 - accuracy: 0.6557 - val_loss: 1.4534 - val_accuracy: 0.6772 Epoch 4/8 15/15 [==============================] - 0s 20ms/step - loss: 1.3430 - accuracy: 0.7036 - val_loss: 1.3452 - val_accuracy: 0.6962 Epoch 5/8 15/15 [==============================] - 0s 34ms/step - loss: 1.2310 - accuracy: 0.7298 - val_loss: 1.2695 - val_accuracy: 0.7151 Epoch 6/8 15/15 [==============================] - 0s 14ms/step - loss: 1.1037 - accuracy: 0.7569 - val_loss: 1.1704 - val_accuracy: 0.7446 Epoch 7/8 15/15 [==============================] - 0s 17ms/step - loss: 1.0003 - accuracy: 0.7809 - val_loss: 1.1225 - val_accuracy: 0.7607 Epoch 8/8 15/15 [==============================] - 0s 15ms/step - loss: 0.9435 - accuracy: 0.7911 - val_loss: 1.0866 - val_accuracy: 0.7590
- 2 اجابة
-
- 1
-
-
يمكنك ذلك باستخدام الكلاس make_regression من مكتبة Sklearn : sklearn.datasets.make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, shuffle=True, random_state=None) الوسيط الأول يحدد عدد العينات التي تريدها. افتراضياً 100 الوسيط الثاني يحدد عدد الميزات features التي تريدها. افتراضياً 20 الوسيط الثالث يحدد عدد الميزات لبناء النموذج الخطي المستخدم لتوليد الخرج افتراضيا 10 الوسيط الرابع عدد أهداف التوقع أي أبعاد الخرج y الوسيط الخامس قيمة bias في نموذج التوقع الوسيط السادس لخلط البيانات بعد إنشائها. الوسيط الثامن هو وسيط التحكم بنظام العشوائية في التقسيم. مثال: from sklearn.datasets import make_regression X, y = make_regression(n_samples=1000, n_features=4, n_informative=10, n_targets=1, bias=0.0, shuffle=False, random_state=0) print(X.shape) #(1000, 4) print(y.shape,end='\n\n') # (1000,) print(X) # الخرج (1000, 4) (1000,) [[ 1.76405235 0.40015721 0.97873798 2.2408932 ] [ 1.86755799 -0.97727788 0.95008842 -0.15135721] [-0.10321885 0.4105985 0.14404357 1.45427351] ... [ 0.10672049 -0.9118813 -1.46836696 0.5764787 ] [ 0.06530561 -0.7735128 0.39494819 -0.50388989] [ 1.77955908 -0.03057244 1.57708821 -0.8128021 ]]
- 2 اجابة
-
- 1
-
-
يمكنك استخدامه عن طريق الموديول: sklearn.ensemble الصيغة العامة: sklearn.ensemble.ExtraTreesRegressor(n_estimators=100, criterion='mse', max_depth=None, min_samples_split=2, min_samples_leaf=1, max_features='auto', max_leaf_nodes=None, bootstrap=False, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None) n_estimators : عدد أشجار القرار المستخدمة.default=100 criterion: معيار قياس جودة التقسيم وتكون {“mse”, “mae”}, default=”mse” max_depth : عمق الأشجار. min_samples_split:الحد الأدنى لعدد العينات المطلوبة لتقسيم عقدة داخلية. int , default=2. min_samples_leaf: الحد الأدنى لعدد العينات المطلوبة في العقدة التي تمثل الاوراق. default=1. max_features:العدد المناسب من الفيتشرز التي يتم احتسابها {“auto”, “sqrt”, “log2”}. في حال auto: max_features=sqrt(n_features). sqrt: ax_features=sqrt(n_features). log2: max_features=log2(n_features). None: max_features=n_features. إذا وضعت قيمة float: max_features=int(max_features * n_features) قيمة int: سيتم أخذ ال features عند كل تقسيمة ك max_features. bootstrap: لتحديد فيما إذا كان سيتم استخدام عينات ال bootstrap عند بناء الأشجار. في حال ضبطها على true سيتم استخدام كامل البيانات لبناء كل شجرة. افتراضياً تكون False. oob_score: لتحديد فيما إذا كان سيتم استخدام عينات out-of-bag لتقدير قيمة التعميم "generalization score". ويجب أن تكون bootstrap مضبوطة على True لاستخدامها. n_jobs: عدد المهام التي يتم تنفيذها بالتوازي. -1 للتنفيذ بأقصى سرعة ممكنة. random_state: يتحكم بعملية التقسيم افتراضياً يكون None. verbose: لعرض التفاصيل التي تحدث في التدريب. افاراضياً 0 أي لايظهر شيء، أما وضع أي قيمة أكبر من الصفر سيعرض التفاصيل int. ccp_alpha: معامل تعقيد يستخدم لتقليل التكلفة الزمانية والمكانية. non-negative float, default=0.0 التوابع: fit(data): للقيام بعملية التدريب. predict(data): لتوقع القيم. score(data): لتقييم كفاءة النموذج. ()get_depth: يرد عمق الشجرة. ال attributtes: n_outputs_: عدد المرخرجات الناتجة عن عملية ال fitting. estimators_: عرض معلومات عن كل الأشجار التي تم تشكيلها. base_estimator_:عرض معلومات الشجرة الأساسية. n_features_: عدد الفيتشرز. مثال: # بيانات أسعار المنازل في مدينة بوسطن from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.ensemble import ExtraTreesRegressor # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=2021) # DecisionTreeRegressor تطبيق extra = ExtraTreesRegressor(random_state=20) extra.fit(X_train, y_train) #حساب الدقة print('Train Score is : ' , extra.score(X_train, y_train)) # Train Score is : 1.0 print('Test Score is : ' , extra.score(X_test, y_test)) # Test Score is : 0.8465469931793999 #حعرض التوقعات y_pred = extra.predict(X_test) print(y_pred)
- 1 جواب
-
- 1
-
-
تفترض خوارزميات التعلم الآلي مثل Linear Regression و Gaussian Naive Bayes أن المتغيرات العددية لها توزيع احتمالي غاوسي. قد لا تحتوي بياناتك على توزيع غاوسي وبدلاً من ذلك قد يكون لها توزيع يشبه Gaussian (على سبيل المثال تقريبًا Gaussian ولكن مع القيم المتطرفة أو الانحراف) أو توزيع مختلف تمامًا (على سبيل المثال الأسي). وعلى هذا النحو قد تكون قادراً على تحقيق أداء أفضل على نطاق واسع من خوارزميات التعلم الآلي عن طريق تحويل متغيرات الإدخال و/ أو الإخراج للحصول على توزيع غاوسي. توفر تحويلات Power transforms مثل تحويل Box-Cox وتحويل Yeo-Johnson طريقة تلقائية لإجراء هذه التحولات على بياناتك ويتم توفيرها في مكتبة التعلم الآلي لـ scikit-Learn Python. لاستخدامه، يجب أن يتم استيراده عبر الموديول: sklearn.preprocessing الصيغة العامة: sklearn.preprocessing.PowerTransformer(method='yeo-johnson', standardize=True, copy=True) method: خوارزمية التحويل التي ذكرناها {‘yeo-johnson’, ‘box-cox’} وافتراضيا ’yeo-johnson’ مع الانتباه إلى أن ال box-cox تعمل فقط مع القيم الموجبة. standardize:لتطبيق تطبيع متوسط التباين الصفري على الناتج المحول في حالة True. copy: لإنشاء نسخة، أي لكي لايتم التعديل على البيانات الأصلية. مثال: # سنشكل بيانات تبع توزيعاً أسياً from sklearn.preprocessing import PowerTransformer from numpy import exp from numpy.random import randn from matplotlib import pyplot # تشكيل بيانات غاوصية data = randn(2000) # تحويلها لبيانات أسية data = exp(data) # رسم الهستوغرام للبيانات الأسية pyplot.hist(data, bins=50) pyplot.show() #على البيانات PowerTransformer الآن سنجري تحويل data = data.reshape((len(data),1)) power = PowerTransformer(method='yeo-johnson', standardize=True) data_trans = power.fit_transform(data) # عرض الهستوغرام للبيانات بعد القيام بالتحويل pyplot.hist(data_trans, bins=25) pyplot.show()
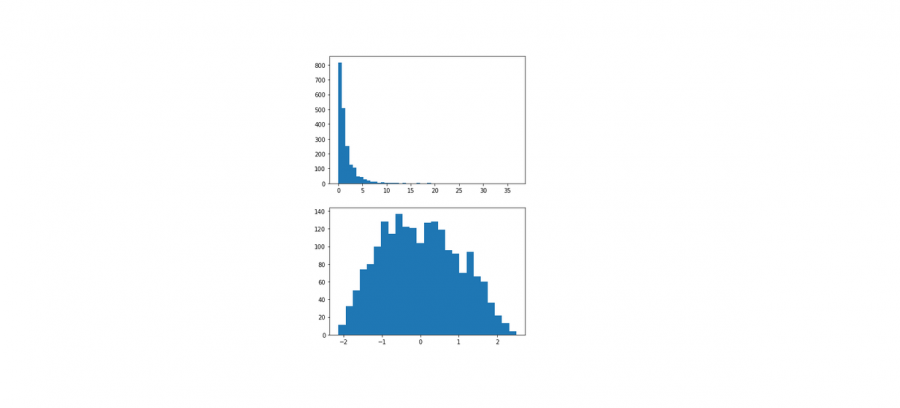
- 2 اجابة
-
- 1
-
-
AdaBoost "adaptive boosting" : فكرة هذه الخوارزمية أن وزن العينات المتوقعة بشكل سيئ بواسطة ال base_estimator السابق يزداد (وبالتالي يصبح أكثر أهمية)، بينما سينخفض وزن العينات المتوقعة بشكل جيد وهذه الأوزان تستخدم مرة أخرى لتدريب ال base_estimator التالي. و في كل تكرار، تتم إضافة learner ضعيف جديد، ولا يتم تحديد ال learner النهائي الأفضل حتى يتم الوصول إلى معدل خطأ صغير معين أو الانتهاء من التكرارات. يمكنك استخدامها عبر الموديول: sklearn.ensemble.AdaBoostRegressor الصيغة العامة: sklearn.ensemble.AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None الوسطاء: base_estimator: ال estimator الأساسي الذي تبنى منه باقي المجموعة المعززة (boosted ensemble). افتراضياً None. ويفضل تركه none ليعطي أفضل النتائج في حال لم تكن لديك خبرة، افتراضياً يكون DecisionTreeRegressor. random_state: يتحكم بعملية التقسيم افتراضياً يكون None. n_estimators : عدد الخوارزميات أو ال estimator المستخدمة. default=50. learning_rate: مقدار معامل التعلم (حجم الخطوة)، ويأخذ فيمة من النمط float. loss: تابع التكلفة الذي يجب استخدامه عند تحديث الأوزان بعد كل تكرار معزز. ويمكن اختيار {‘linear’, ‘square’, ‘exponential’} وافتراضياً linear. Attributes: estimator_weights_: أوزان كل estimator تم تطبيقه. estimators_: عرض معلومات عن ال estimator التي تم تشكيلها. base_estimator_:عرض معلومات ال estimator الأساسية. estimator_errors_: خطأ التوقع في كل estimator من المجموعة المعززة. أهم التوابع: fit(data): للقيام بعملية التدريب. predict(data): لتوقع القيم. score(data): لتقييم كفاءة النموذج. مثال: # بيانات أسعار المنازل في مدينة بوسطن from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostRegressor # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=2021) # DecisionTreeRegressor تطبيق Ada = AdaBoostRegressor(random_state=20) Ada.fit(X_train, y_train) #حساب الدقة print('Train Score is : ' , Ada.score(X_train, y_train)) print('Test Score is : ' , Ada.score(X_test, y_test)) #حعرض التوقعات y_pred = Ada.predict(X_test) print(y_pred)
- 2 اجابة
-
- 1
-
-
لتشكيل مصفوفة جديدة بطريقة تسمح لك بتحديد الخطوة وال shape، تمنحك Numpy طريقتين رئيسيتين لبناء منظار جديد "new view" لمخزن الذاكرة المؤقت "memory buffer" ، وذلك عن طريق تحديد سمات المصفوفة الأساسية مثل الخطوات "strides" بشكل مباشرة، هاتين الطريقتين هما: as_strided و ndarray. بشكل عام كلاهما يعتبران طرق خطيرة للاستخدام داخل الكود لأنه قد تنتج (((الكثير))) من الأخطاء أثناء استخدامه حتى ولو كنت مبرمجاً محترفاً، لذا لاينصح أبداً بهما إلا للضرورة القصوى. مثلاً في بعض المسائل الصعبة التي قد يسهل حلها عند التلاعب بشكل المصفوفة بهذه الطرق. قبل البدء ماهي ال strides؟ هو مقدار الخطوة، أو هو عدد البايتات اللازمة للانتقال إلى العنصر الثاني من المصفوفة.(ويشار له أيضاً بال axis) طبعاً في حالة المصوفوفة الثنائية نحدد الخطوة الأفقية والخطوة العمودية فمثلاً(16,4) تعني: array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) # جهازي بخزن كل قيمة ب4 بايت هذا يعني أنه للانتقال من العنصر 1 إلى 2 نحتاج إلى 4 بايت وللانتقال من بداية البعد الأول [ 0, 1, 2, 3] في المصفوفة إلى البعد الثاني [ 4, 5, 6, 7] نحتاج إلى خطوة مقدارها 16 أي 4*4 أي عدد الأعمدة بحجم كل خطوة as_strided : في اللمثال التالي نقوم بإنشاء view باستخدام هذه الطريقة بشكل مكافئ تماماً ل reshape، ثم سأقوم بإنشاء مايكافئ x.reshape # أنشأنا عرضًا جديدًا لمخزن الذاكرة #x.reshape(3, 4) مايلي يكافئ import numpy as np from numpy.lib.stride_tricks import as_strided x = np.arange(12) #array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) print(x.strides) # أي نحتاج 8 بايتات للانتقال في الذاكرة من العنصر1 إلى 2 as_strided(x, shape=(3, 4), strides=(16, 4))# 16=x.strides*4 '''array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]])''' #x.reshape(3, 4) مايلي يكافئ as_strided(x, shape=(3, 4), strides=(4, 16)) # لاحظ كيف أنه من خلال التلاعب بالخطوات يمكنني الحصول على ما أريد القدرات والفائدة الأساسية من as_strided تتجاوز ذلك، فالاستخدام الشائع منها هي ال “sliding window” وهو ما أشرت إليه بسؤالك "إنشاء مصفوفة من x بأبعاد (5,3)" إذاً ماهو ال strides المناسب للقيام بذلك؟ أولاً بالنسبة للأسطر، فالانتقال من عنصر لعنصر يتطلب x.strides أي 4 بايت على جهازي. ثانياً القفز على الأعمدة ( أي للنزول ) كم نحتاج؟ لو ان القيم في الأعمدة متتالية لكنا نحتاج فقط 4 بايت، مثلاً: array([[0, 1, 2, 3, 4], [1, 2, 3, 4, 5], [2, 3, 4, 5, 6]]) # ولو كان بالشكل التالي سنحتاج 4*2 array([[0, 1, 2, 3, 4], [2, 3, 4, 5, 6], [4, 5, 6, 7, 8]]) ولو كان بالشكل التالي لحتجنا 4*3 array([[ 0, 1, 2, 3, 4], [ 3, 4, 5, 6, 7], [ 6, 7, 8, 9, 10]]) #لمعرفتها x.strides حجم الخطوة يختلف من جهاز لآخر اسخدم التعليمة x = np.arange(1,12) as_strided(x, shape=(3, 5), strides=(x.strides*3, x.strides)) """ array([[ 1, 2, 3, 4, 5], [ 4, 5, 6, 7, 8], [ 7, 8, 9, 10, 11]]) """ إن الشيء الرائع فيها هو إنه يمكنك تشكيل مصفوفة أكبر حجماً من المصفوفة x ذاتها بدوم أن يتم استهلاك ذاكرة إضافية، أي أننا هنا احتجنا لتمثيل x في الذاكرة 11*4 =44 bytes ثم شكلنا مصفوفة جديدة منها بأبعاد 4,3 أي قد تظن أن الحجم التخزيني سيكون 4*3*4 لكن أنت مخطئ، سيكون 44 بايت أيضاً!! وذلك لأنها تتشارك البيانات. الآن يمكنك تشكيل تابع يعطيك الخرج بالحالة العامة، حيث نمرر له المصفوفة والطول والعرض: def strided_app(a, L, S ): nrows = ((a.size-L)//S)+1 n = a.strides[0] x=np.lib.stride_tricks.as_strided(a, shape=(nrows,L), strides=(S*n,n)) return x strided_app(x,5,3) """ array([[ 0, 1, 2, 3, 4], [ 3, 4, 5, 6, 7], [ 6, 7, 8, 9, 10]]) """ ndarray: يمكنك استخدامها بطريقة مشابهة كالتالي: np.ndarray(buffer=x.data, shape=(3, 5), strides=(12,4), dtype=int) كما يمكنك استخدام طرق عادية لتشكيل المطلوب باستخدام مفهوم ال broadcasting: def broadcasting_app(a, L, S ): nrows = ((a.size-L)//S)+1 x=a[S*np.arange(nrows)[:,None] + np.arange(L)] return x
- 5 اجابة
-
- 2
-
-
يجب إضافة طبقة Flatten قبل أول طبقة Dense. إن المرحلة الأخيرة من الشبكة العصبية التلافيفية (CNN) هي المصنف. يطلق عليه طبقة/طبقات Dense، وهي مجرد مصنف شبكة عصبية اصطناعية (ANN). ويحتاج مصنف ANN إلى ميزات فردية "individual features" ، تماماً مثل أي مصنف آخر. هذا يعني أنه يحتاج إلى "feature vector". لذلك، تحتاج إلى تحويل خرج الجزء التلافيفي من CNNs إلى Vector1D، ليتم استخدامه بواسطة جزء ANN. هذه العملية تسمى التسطيح "Flatten ". # write your model here, we prefer that you call it model2 to make comparisions easier later: model2 = keras.Sequential() model2.add(layers.Conv2D(filters=6, kernel_size=(3, 3), activation='relu', input_shape=(150,150,3))) model2.add(layers.AveragePooling2D()) model2.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu')) model2.add(layers.AveragePooling2D()) model2.add(layers.Flatten()) # هنا model2.add(layers.Dense(units=120, activation='tanh')) model2.add(layers.Dense(units=84, activation='tanh')) model2.add(layers.Dense(units=6, activation = 'softmax')) model2.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy', metrics=['accuracy']) model2.fit(train_images, train_labels, batch_size=32, epochs=1, validation_split = 0.2)
- 2 اجابة
-
- 2
-
-
الخطأ هو أن keras.engine.Network لم تعد موجودة في إصدار كيراس الاحدث حتى أنها أصبحت في الوحدة keras.engine.network.Network و بعدها لم تعد موجودة هي كذلك في الإصدار، لينوب عنها keras.Model: import keras from keras import backend from keras.models import Sequential from keras import layers from keras.datasets import mnist model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) model.compile(optimizer='Adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # لتصحيح الكود وضع # keras.Model مكان keras.engine.Network def init(model): session = backend.get_session() for layer in model.layers: if isinstance(layer, keras.Model): init(layer) init(model)
- 1 جواب
-
- 2
-
-
هو طريقة تدرج عشوائي SGD تعتمد على تحديث معامل التعلم بناء على تحديثات gradient descent يساهم في حل مشكلة التدهور المستمر لمعدلات التعلم خلال عملية التدريب كذلك يعطي معامل تعلم أولي، وهذا يساعد في أن لا نقوم بوضع معامل تعلم يمكن أن يأثر على الموديل سلباً. وهذا يقلل عدد العمليات للوصول إلى المعاملات العليا. لاستخدامها في كبراس نمررها إلى الدالة compile: model.compile( optimizer=Adadelta(learning_rate=0.001) ... ) # أو model.compile( optimizer='adadelta' ... ) # لاحظ أنه في الطريقة الثانية سيستخدم معمل الخطوة الافتراضي # لذا إذا أردت تغييرها استخدم الصيغة الأولى مثال عن طريقة الاستخدام حيث يأخذ Adadelta الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة: #استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import Adadelta #تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() #تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 #بناء الشبكه العصبونيه بطبقه واحده وطبقة خرج ب 10 أصناف model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) #0.001مع معامل تعلم Adadelta استخدام model.compile(optimizer=Adadelta(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) #تدريب الموديل model.fit(X_train,y_train)
- 2 اجابة
-
- 1
-
-
هي دالة خسارة تحسب خسارة بواسون بين القيم الحقيقية والمتوقعة. له الصيغة التالية مع مسائل التصنيف: loss = y_pred - y_true * log(y_pred) توزيع بواسون: هو توزيع احتمالي منفصل، ويعبر عن احتمالية حدوث مجموعة من الأحداث P ضمن فترة زمنية محددة عندما تحدث هذه الأحداث بمعدل وسطي v شرط أن لا تكون متعلقة بزمن حدوث آخر حدث. يكون استخدامها مع مسائل التصنيف (المتعدد) اعتماداً على الصيغة السابقة، وفي كيراس لم يتضمن التوثيق استخدام لها مع مسائل التوقع رغم أنه من الممكن استخدامه مع هذه المسائل عندما تتبع البيانات توزيع بواسون (لكن في هذه الحالة لايتم استخدامها بنفس الصيغة قي الأعلى). يجب أن تقوم بترميز بيانات ال target ترميزاً فئوياً One-Hot. مثال: import tensorflow as tf y_true = [[0, 1, 0], [1, 0, 0]] #تمثل القيم الحقيقية One-Hot مصفوفة من ال y_pred = [[0.01, 0.9, 0], [0.99, 0.0, 0.0]] # مصفوفة القيم المتوقعة p = tf.keras.losses.Poisson() p(y_true, y_pred).numpy()#0.33590174 لاستخدامها مع نموذجك، قم بتمريريها إلى الدالة compile: model.compile( loss=tf.keras.losses.Poisson(), ) # أو model.compile( loss='poisson', ) مثال على مجموعة بيانات راوترز (تصنيف متعدد 46 فئة): # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) #ترميز الفئات المختلفة للبيانات #كما أشرنا One-Hot-Enoding طبعاً يجب أن نستخدم الترميز from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) #أي الفئات target انتهينا من ترميز قيم ال # الآن لنقم بترميز بيانات التدريب import numpy as np #One-Hot قمت بإنشاء تابع يقوم بتحويل بياناتي إلى الترميز # بإمكانك أيضاً استخدام تابع تحويل جاهز def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss=tf.keras.losses.Poisson(), metrics=['accuracy']) # لاحظ كيف قمنا بتمرير دالة التكلفة إلى النموذج # التدريب history = model.fit(x_train, one_hot_train_labels, epochs=8, batch_size=512, validation_split=0.2) ------------------------------------------------------------------ Epoch 1/8 15/15 [==============================] - 1s 25ms/step - loss: 0.0900 - accuracy: 0.3860 - val_loss: 0.0635 - val_accuracy: 0.5704 Epoch 2/8 15/15 [==============================] - 0s 14ms/step - loss: 0.0608 - accuracy: 0.6000 - val_loss: 0.0558 - val_accuracy: 0.6589 Epoch 3/8 15/15 [==============================] - 0s 15ms/step - loss: 0.0544 - accuracy: 0.6672 - val_loss: 0.0536 - val_accuracy: 0.6667 Epoch 4/8 15/15 [==============================] - 0s 14ms/step - loss: 0.0511 - accuracy: 0.6971 - val_loss: 0.0505 - val_accuracy: 0.7134 Epoch 5/8 15/15 [==============================] - 0s 20ms/step - loss: 0.0481 - accuracy: 0.7221 - val_loss: 0.0487 - val_accuracy: 0.7234 Epoch 6/8 15/15 [==============================] - 0s 19ms/step - loss: 0.0457 - accuracy: 0.7484 - val_loss: 0.0475 - val_accuracy: 0.7529 Epoch 7/8 15/15 [==============================] - 0s 20ms/step - loss: 0.0435 - accuracy: 0.7724 - val_loss: 0.0470 - val_accuracy: 0.7513 Epoch 8/8 15/15 [==============================] - 0s 14ms/step - loss: 0.0421 - accuracy: 0.7906 - val_loss: 0.0465 - val_accuracy: 0.7663
- 2 اجابة
-
- 1
-
-
نعم يمكنك
- 5 اجابة
-
- 2
-
-
لاتوجد فروقات مهمة ، لكن هناك فرق في طريقة الاستخدام ، انظر للمثال : #include<bits/stdc++.h> using namespace std; int main() { int x=1; cout<<"The x value is:"<<" "<<x<<endl; printf("The x value is: %d",x); return 0; } // الخرج سوف يكون The x value is: 1 The x value is: 1 نلاحظ لا يوجد أي فرق بين الطريقتين من حيث قيمة الخرج,لكن الفرق هو بطريقة طباعة كل من cout و printf لكن ماذا تعني %d في printf؟ يجيب ان تخبر ال printf بنمط المتحول الذي بداخله وهذه الرموز تعبر عن نمط المتحولات %d=int %c=char %s=string %f=float ومن الضروري وضعه، بدونه لن يطبع قيمة المتحول. مثلا اذا كان الكود كالتالي: #include<bits/stdc++.h> using namespace std; int main() { float x=1.1; printf("The x value is:",x); return 0; } سيكون الخرج The x value is نلاحظ عدم طباعة اي قيمة والتصحيح هو: #include<bits/stdc++.h> using namespace std; int main() { float x=1.1; printf("The x value is: %f",x); return 0; }
- 5 اجابة
-
- 2
-
-
لانجيب عن الأسئلة الامتحانية، إذا كان لديك أي سؤال برمجي أو مشكلة نحن جاهزون دوماً
- 1 جواب
-
- 2
-