Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 هو طريقة لتسريع خوارزمية GD وتخفيف التذبذب وهي فعالة من الناحية الحسابية وتأخذ ذاكرة قليلة ومناسبة للمشكلات الكبيرة في التعلم الآلي التي تكون فيها البيانات كبيرة أو عدد الأوزان في الشبكة كبير جداً، تعتمد على حساب متوسط الأوزان الأسية للمشتقات السابقة وتخزينها في متحول v وكذلك حساب متوسط الأوزان الأسية لمربعات المشتقات السابقة ووضعها في متحول s و تقوم أيضاً بالخلط بين الطريقتين. يتم حساب متوسط الأوزان الأسية للمشتقات السابقة عن طريق القوانين: vdw = B1* vdw + (1-B1)*dw vdb = B1*vdb + (1-B1)*db حيث vdw هيي متوسط الأوزان اأاسي لجميع الأوزان في الشبكة. و vdb متوسط الأوزان اأاسي لل bias في الشبكة. و B1 يمثل معدل الاضمخلال الأسي. يتم حساب متوسط الاوزان الاسية لمربعات المشتقات السابقة عن طريق القوانين: Sdw = B2*Sdw + (1-B2)*dw^2 Sdb = B2*Sdb + (1-B2)*db^2 حيث vdw هيي متوسط الأوزان الاسي لجميع الأوزان في الشبكة. و vdb متوسط الأوزان الاسي لل bias في الشبكة. و B2 معدل التضاؤل الأسي. في كيراس يتم استيراده من خلال الموديول: keras.optimizers لاستخدامه في نموذج نمرره للدالة compile بإحدى الطريقتين: model.compile( optimizer=Adam(learning_rate=0.001) ... ) # أو model.compile( optimizer='adam' ... ) # لاحظ أنه في الطريقة الثانية سيستخدم معمل الخطوة الافتراضي # لذا إذا أردت تغييرها استخدم الصيغة الأولى مثال عن طريقه الاستخدام حيث يأخذ adam الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة. # استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import Adam # تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() # تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 بناء الشبكه العصبونيه بطبقه واحده وطبقة خرج ب 10 أصناف model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) #مع معامل تعلم 0.001 adam استخدام model.compile(optimizer=Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) # تدريب الموديل model.fit(X_train,y_train)
هو طريقة لتسريع خوارزمية GD وتخفيف التذبذب وهي فعالة من الناحية الحسابية وتأخذ ذاكرة قليلة ومناسبة للمشكلات الكبيرة في التعلم الآلي التي تكون فيها البيانات كبيرة أو عدد الأوزان في الشبكة كبير جداً، تعتمد على حساب متوسط الأوزان الأسية للمشتقات السابقة وتخزينها في متحول v وكذلك حساب متوسط الأوزان الأسية لمربعات المشتقات السابقة ووضعها في متحول s و تقوم أيضاً بالخلط بين الطريقتين. يتم حساب متوسط الأوزان الأسية للمشتقات السابقة عن طريق القوانين: vdw = B1* vdw + (1-B1)*dw vdb = B1*vdb + (1-B1)*db حيث vdw هيي متوسط الأوزان اأاسي لجميع الأوزان في الشبكة. و vdb متوسط الأوزان اأاسي لل bias في الشبكة. و B1 يمثل معدل الاضمخلال الأسي. يتم حساب متوسط الاوزان الاسية لمربعات المشتقات السابقة عن طريق القوانين: Sdw = B2*Sdw + (1-B2)*dw^2 Sdb = B2*Sdb + (1-B2)*db^2 حيث vdw هيي متوسط الأوزان الاسي لجميع الأوزان في الشبكة. و vdb متوسط الأوزان الاسي لل bias في الشبكة. و B2 معدل التضاؤل الأسي. في كيراس يتم استيراده من خلال الموديول: keras.optimizers لاستخدامه في نموذج نمرره للدالة compile بإحدى الطريقتين: model.compile( optimizer=Adam(learning_rate=0.001) ... ) # أو model.compile( optimizer='adam' ... ) # لاحظ أنه في الطريقة الثانية سيستخدم معمل الخطوة الافتراضي # لذا إذا أردت تغييرها استخدم الصيغة الأولى مثال عن طريقه الاستخدام حيث يأخذ adam الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة. # استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import Adam # تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() # تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 بناء الشبكه العصبونيه بطبقه واحده وطبقة خرج ب 10 أصناف model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) #مع معامل تعلم 0.001 adam استخدام model.compile(optimizer=Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) # تدريب الموديل model.fit(X_train,y_train)- 3 اجابة
-
- 1
-

-
لقد تغيرت الوحدة التي يتم منها استخدام الموديل VGG16 حيث أصبح موجود في applications.vgg16 بدلا من applications لذلك سوف تكون كالأتي: import keras import numpy as np import pandas as pd import matplotlib.pyplot # تصحيح الكود from keras.applications.vgg16 import VGG16
- 2 اجابة
-
- 2
-
-
المشكلة تحدث عند محاولة إدخال خرج طبقة ال RNN الأولى إلى طبقة RNN الثانية. إليك مايلي: طبقات ال RNN بأنواعها المختلفة تعمل في وضعين: الأول يرد كامل الخرج كسلسلة متتابعة من ال timestep وبالتالي يكون الخرج هو مصفوفة tensor ثلاثية الأبعاد (batch_size, timesteps, output_features). أما الوضع الثاني فيرد فقط آخر خرج لكل سلسلة إدخال، وبالتالي يكون الخرج ثنائي الأبعاد (batch_size, output_features). ويتم التحكم بنمط الإخراج باستخدام الوسيط return_sequences الذي يأخذ قيمة بوليانية، في حالة True فيكون الخرج هو الوضع الأول وفي حالة False يكون الوضع الثاني، وافتراضياً يكون False ، أي الوضع الثاني. وكما نعلم أن طبقات الRNN تحتاج كدخل (batch_size, sequence_length, features) وأنت تقوم بتكديس طبقتي RNN وبالتالي خرج الأولى سيكون دخل الثانية لذلك يجب أن يكون خرج الأولى 3D أي يجب أن يكون الوضع الأول. لكن أنت تشغل الوضع الأول وبالتالي سيعطي خطأ، لأنها تحتاج 3D وتعتطيها 2D، لذا لحل المشكلة يجب أن نضبط return_sequences على True. from keras.layers import Dense,Embedding,SimpleRNN from keras.datasets import imdb from keras.preprocessing import sequence from keras.models import Sequential max_features = 1000 maxlen = 20 batch_size = 64 print('Loading data...') (input_train, y_train), (input_test, y_test) = imdb.load_data( num_words=max_features) print(len(input_train), 'train sequences') print(len(input_test), 'test sequences') print('Pad sequences (samples x time)') input_train = sequence.pad_sequences(input_train, maxlen=maxlen) input_test = sequence.pad_sequences(input_test, maxlen=maxlen) print('input_train shape:', input_train.shape) model = Sequential() model.add(Embedding(max_features, 16)) model.add(SimpleRNN(16, return_sequences=True)) model.add(SimpleRNN(16)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(input_train, y_train, epochs=2, batch_size=128, validation_split=0.2) ''' Loading data... 25000 train sequences 25000 test sequences Pad sequences (samples x time) input_train shape: (25000, 20) Epoch 1/2 157/157 [==============================] - 4s 14ms/step - loss: 0.6751 - acc: 0.5501 - val_loss: 0.5692 - val_acc: 0.7026 Epoch 2/2 157/157 [==============================] - 2s 10ms/step - loss: 0.5229 - acc: 0.7427 - val_loss: 0.5801 - val_acc: 0.6912 '''
- 2 اجابة
-
- 2
-
-
هي دالة تكلفة (loss) في كيراس وتنسرفلو ويتم استخدامها مع مسائل التصنيف المتعدد أي عندما يكون لدينا أكثر من فئة (Class label). تتوقع منك مصفوفتين كدخل، واحدة تعبر عن القيم الحقيقية (مصفوفة من الأعداد integer)، والأخرى تعبر عن القيم المتوقعة (float). تعتمد هذه الدالة على المفهوم الشهير في نظرية المعلومات والمعروف ب Cross Entropy أو الإنتروبيا المتقطعة، وهي مقياس لمدى تشابه توزعين احتماليين مختلفين لنفس الحدث وفي ال ML نستخدم هذا التعريف وقانونه لكي نقوم بحساب ال Loss (التكلفة Cost). حيث يكون الخرج الخاص بالشبكة العصبية هو توزيع احتمالي لعدة فئات classes. تابع التنشيط هنا إما Sigmoid أو Softmax فهما تابعي التنشيط الوحيدين المتوافقين مع دالة التكلفة SCCE. الفرق الوحيد بينها وبين CategoricalCrossentropy هو في طريقة تمثيل القيم الحقيقية أو label classes (فئات البيانات)، فهناك نمثلها بأشعة Spare باستخدام الترميز One-Hot أما هنا فلسنا بحاجة للقيام بذلك (ويعتبر هذا الترميز أفضل من ناحية التعقيد الزماني والمكاني كونه لايستهلك دفقات معالجة لافائدة منها كما في ال CCE). أبعاد المدخلات: y_true [batch_size] y_pred [batch_size, num_classes] يتم استيرادها من الموديول: tensorflow.keras.losses مثال: # استيرادها from tensorflow.keras.losses import SparseCategoricalCrossentropy # تشكيل داتامزيفة تعبر عن قيم حقيقية وقيم متوقعة y_true = [2,1,0] # تم تحديد ثلاث أصناف و3 عينات y_pred1 = [[0.1, 0.0,0.9], [0.2, 0.8, 0.0],[0.8, 0.2, 0.0]] # مصفوفة تعبر عن القيم المتوقعة y_pred2 = [[0.0, 0.01,0.99], [0.01, 0.99, 0.0],[0.99, 0.01, 0.0]] # مصفوفة ثانية تعبر عن القيم المتوقعة #SparseCategoricalCrossentropy إنشاء غرض من الكلاس scce = SparseCategoricalCrossentropy() # تمرير القيم الحقيقية والمتوقعة إلى الغرض ليحسب لنا التكلفة scce(y_true, y_pred1).numpy() # 0.18388261 scce(y_true, y_pred2).numpy() # 0.010050405 لاستخدامها ضمن نموذجك كدالة خسارة، نقوم بتمريرها إلى الدالة compile بإحدى الشكلين التاليين، ويمكنك استخدامها ممعيار لنموذجك (لكن في الواقع لا أحد يقوم بذلك): model.compile( loss=tf.keras.losses.SparseCategoricalCrossentropy(), ... ) # أو يمكن تمريرها بسهولة بالشكل التالي model.compile( loss='sparse_categorical_crossentropy', ... ) # لاستخدامها كمعيار model.compile( metrics=['sparse_categorical_accuracy'], ... ) سأقوم بتطبيقها مع مجموعة بيانات routers، حيث أن هذه البيانات لديها 46 فئة (صنف) مختلف: # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) #integer فئات البيانات يجب أن تكون print(train_labels[0:5]) # [3 4 3 4 4] # الآن لنقم بترميز بيانات التدريب import numpy as np #One-Hot قمت بإنشاء تابع يقوم بتحويل بياناتي إلى الترميز # بإمكانك أيضاً استخدام تابع تحويل جاهز def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # لاحظ كيف قمنا بتمرير دالة التكلفة إلى النموذج # التدريب history = model.fit(x_train, train_labels, epochs=8, batch_size=512, validation_split=0.2) # الخرج ''' Epoch 1/8 15/15 [==============================] - 3s 53ms/step - loss: 3.3317 - accuracy: 0.2863 - val_loss: 2.0840 - val_accuracy: 0.5687 Epoch 2/8 15/15 [==============================] - 0s 14ms/step - loss: 1.9193 - accuracy: 0.5986 - val_loss: 1.6421 - val_accuracy: 0.6221 Epoch 3/8 15/15 [==============================] - 0s 14ms/step - loss: 1.4877 - accuracy: 0.6641 - val_loss: 1.3978 - val_accuracy: 0.6956 Epoch 4/8 15/15 [==============================] - 0s 14ms/step - loss: 1.3094 - accuracy: 0.7072 - val_loss: 1.3088 - val_accuracy: 0.7040 Epoch 5/8 15/15 [==============================] - 0s 14ms/step - loss: 1.1608 - accuracy: 0.7329 - val_loss: 1.2279 - val_accuracy: 0.7234 Epoch 6/8 15/15 [==============================] - 0s 13ms/step - loss: 1.0447 - accuracy: 0.7597 - val_loss: 1.2365 - val_accuracy: 0.7067 Epoch 7/8 15/15 [==============================] - 0s 21ms/step - loss: 0.9647 - accuracy: 0.7750 - val_loss: 1.2022 - val_accuracy: 0.7179 Epoch 8/8 15/15 [==============================] - 0s 12ms/step - loss: 0.9104 - accuracy: 0.7882 - val_loss: 1.1006 - val_accuracy: 0.7390 '''
- 2 اجابة
-
- 1
-
-
يجب أن تكون الأبعاد متوافقة مع الطبقة أي يجب أن تكون (1,4) بدلا من (,4). import numpy as np from keras.models import Sequential from keras import layers # إصلاح الكود وتغيير الأبعاد inputx= np.random.randint(0,40, (1,4)) model = Sequential() model.add(layers.Embedding(input_dim=40, output_dim=32, input_length=4)) model.add(layers.Flatten()) model.add(layers.Dense(units=5, activation='sigmoid')) print(model(inputx))
- 2 اجابة
-
- 1
-
-
هي اختصار لـ Root Mean Squared prop وهي خوارزمية تحسين تستخدم لتسريع خوارزمية gradient descent، وتحسين مسار التدرج. نعلم خوارزمية mini-batch gradient descent تتقدم بشكل أسرع من خوارزمية gradient descent الأساسية ولكن يكون الطريق الذي تسلكه هذه الخوارزمية متذبذب، لذلك لتخفيف هذا التذبذب تقوم هذه الخوارزمية بالتقدم مع الأخذ بعين الاعتبار الـ exponentially weighted average للمشتقات السابقة في الحسبان. يتم في الخطوه الأولى حساب exponentially weighted average عن طريق القوانين: Sdw = B2*Sdw + (1-B2)*dw^2 Sdb = B2*Sdb + (1-B2)*db^2 حيث Sdw هيي متوسط الأوزان الأسي لجميع الأوزان في الشبكة. و Sdb متوسط الأوزان الاسي لل bias في الشبكة. و B هي معامل من المعاملات العليا و يسمى الزخم يتراوح من 0 إلى 1 يستخدم لحساب المتوسط الاسي الجديد، وتحدد الوزن بين متوسط القيمة السابقة والقيمة الحالية. بعد ذلك نقوم بتحديث الأوزان كما في gradient descent عن طريق القوانين: w = w - a * dw / sqrt(Sdw) b= b - a * db / sqrt(Sdb) حيث w أوزان الشبكه العصبونية و b تمثل ال bias في الشبكة العصبونية. و dw التغيير في الأوزان و db التغيير في ال bias. و Sdw هيي متوسط الأوزان الاسي لجميع الأوزان في الشبكة. و Sdb متوسط الأوزان الاسي لل bias في الشبكة. و B هي معامل من المعاملات العليا و يسمى الزخم يتراوح من 0 إلى 1 يستخدم لحساب المتوسط الاسي الجديد، فإنها تحدد الوزن بين متوسط القيمة السابقة والقيمة الحالية. أي أن الفرق الوحيد بين Rmsprop و gradient descent هو أنه في GD يتم تعديل الأوزان بالشكل التالي: w = w - a * dw b= b - a * db و Rmsprop نفس الشئ مع قسمة كل من dw,db على جذر exponentially weighted average يتم استيراد RMSprop في keras من خلال الوحدة optimizer لاستخدامه مع النموذج نقوم بتمريره إلى الدالة compile بإحدى الطريقتين: model.compile( optimizer=RMSprop(learning_rate=0.001), ... ) # أو model.compile( optimizer='rmsprop', ... ) #0.001 لاحظ أنه في الطريقة الثانية سيتم استخدام معامل الخطوة الافتراضي وهو # لذا إذا أردت تغييره فعليك باستخدام الطريقة الأولى مثال عملي لطريقة الاستخدام حيث يأخذ RMSprop الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة. # استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import RMSprop # تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() # تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 # بناء الشبكة العصبونية بطبقة واحدة وطبقة خرج ب 10 أصناف. model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) # استخدام compile مع Rmsprop مع معامل تعلم 0.001 model.compile(optimizer=RMSprop(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) # تدريب الموديل model.fit(X_train,y_train)
- 2 اجابة
-
- 1
-
-
الكود بسيط عليك فقط المحاولة، لذا جرب بنفسك وأرسل (((الكود))) لنا و سنساعدك في إصلاحه وتوجيهك للحل الصحيح.
- 2 اجابة
-
- 1
-
-
أول فرق يكمن بالحجم التخزيني، فمصفوفات نمباي تخزن البيانات بشكل أكثر فعالية وتستهلك عدد أقل من البايتات لكل عنصر: import numpy as np import sys # إنشاء قائمة بألفي عنصر l= range(2000) # حجم كل عنصر من عناصر القائمة بالبايت print("Size of each element : ",sys.getsizeof(l),"bytes") # حجم كامل القائمة print("Size of the whole list : ",sys.getsizeof(l)*len(l),"bytes") # إنشاء مصفوفة نمباي بألفي عنصر D= np.arange(2000) # حجم كل عنصر بالمصفوفة print("Size of each element: ",D.itemsize,"bytes") # حجم كامل المصفوفة print("Size of the whole array : ",D.size*D.itemsize,"bytes") ''' Size of each element : 48 bytes Size of the whole list : 96000 bytes Size of each element: 4 bytes Size of the whole array : 8000 bytes ''' الفرق الثاني بزمن التنفيذ حيث أن استخدام مصفوفات نمباي يعد أكثر فعالية في زمن التنفيذ، في المثال التالي ستعرض الفرق بزمن تنفيذ العمليات عندما نستخدم مصفوفات نمباي و القوائم: import numpy as np import time # تعريف قائمتين l1 = range (200000) l2 = range(200000) # تعريف مصفوفتين arr1 = np.arange(2000000) arr2 = np.arange(2000000) # حساب الزمن اللازم لمضاعفة عناصر القائمة start = time.time() r = [(x * y) for x, y in zip(l1, l2)] print("Time when we use lists :",(time.time() - start),"sec") #حساب الزمن اللازم لمضاعفة عناصر المصفوفة start = time.time() r = arr1 * arr2 print("Time when we use numpy arrays :",(time.time() - start),"sec") ''' Time when we use lists : 0.04999589920043945 sec Time when we use numpy arrays : 0.0069963932037353516 sec ''' لذا فهي أكثر كفاءة في التخزين والزمن اللازم لإجراء العمليات عليها، ويعود السبب الأساسي لذلك في طريقة تخزين العناصر في نمباي (تخزن العناصر بشكل متجاور على عكس القوائم)
- 3 اجابة
-
- 2
-
-
عند استخدام دالة التكلفة categorical_crossentropy يجب أن تقوم بترميز الفئات لديك باستخدام الترميز One-Hot فهي معرفة للتعامل فقط مع هذا الترميز للبيانات. لذا يكون الحل في ترميز فئات البيانات لديك باستخدام One-Hot ويمكنك القيام بذلك عن طريق استخدام الوظيفة to_categorical في كيراس كالتالي: # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) #ترميز الفئات المختلفة للبيانات #كما أشرنا One-Hot-Enoding نستخدم الترميز from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) #أي الفئات target انتهينا من ترميز قيم ال import numpy as np def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # التدريب history = model.fit(x_train, one_hot_train_labels, epochs=8, batch_size=512, validation_split=0.2) أو يمكنك استخدام دالة التكلفة sparse_categorial_crossentropy بدلاً من categorial_crossentropy، فهي تستطيع التعامل مع الترميز العددي بدون الحاجة إلى الترميز الفئوي One-Hot. # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) import numpy as np def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # التدريب history = model.fit(x_train, train_labels, epochs=8, batch_size=512, validation_split=0.2)
-
يمكنك تنفيذ الجداءالديكارتي باستخدام التابع التالي اعتماداً على الدالة meshgrid في مكتبة نمباي : import numpy as np x = np.array([0, 1, 2]) y = np.array([3, 4, 5]) # تعريف تابع يقوم بعملية الجداء الديكارتي def cartesian(*arrays): g = np.meshgrid(*arrays) coord = [x.ravel() for x in g] p = np.vstack(coord).T return p # استدعاء التابع وطباعة الخرج print(cartesian(x,y)) # الخرج ''' [[0 3] [1 3] [2 3] [0 4] [1 4] [2 4] [0 5] [1 5] [2 5]] '''
- 3 اجابة
-
- 3
-
-
هي دالة تكلفة (loss) في كيراس وتنسرفلو ويتم استخدامها مع مسائل التصنيف المتعدد أي عندما يكون لدينا أكثر من فئة (Class label) الصيغة الرياضية: تعتمد هذه الدالة على المفهوم الشهير في نظرية المعلومات والمعروف ب Cross Entropy أو الإنتروبيا المتقطعة، وهي مقياس لمدى تشابه توزعين احتماليين مختلفين لنفس الحدث وفي ال ML نستخدم هذا التعريف وقانونه لكي نقوم بحساب ال Loss (التكلفة Cost). حيث يكون الخرج الخاص بالشبكة العصبية هو توزيع احتمالي لعدة فئات classes. تابع التنشيط هنا إما Sigmoid أو Softmax فهما تابعي التنشيط الوحيدين المتوافقين مع دالة التكلفة CCE. كنصيحة لنتائج أفضل دوماً اعتمد على ال Softmax. عند استخدامك لهذه الوظيفة يجب عليك أن تقوم أولاً بترميز فئات البيانات لديك باستخدام الترميز One-Hot. يتم استيرادها من الموديول: tensorflow.keras.losses مثال: from tensorflow.keras.losses import CategoricalCrossentropy # إنشاء داتا مزيفة لنجرب عليها # قمنا بتشكيل عينتين ولدينا 3 فئات y_true = [[0, 1, 0], [1, 0, 1]] #تمثل القيم الحقيقية One-Hot مصفوفة من ال y_pred = [[0.01, 0.9, 0], [0.77, 0.6, 0.8]] # مصفوفة القيم المتوقعة # CategoricalCrossentropy إنشاء غرض cce =CategoricalCrossentropy() # حساب الخسارة cce(y_true, y_pred).numpy() # 1.0225062 لاستخدامها في نموذجك: # كالتالي compile لاستخدامه مع النموذج نقوم بتمريره إلى # نقوم أولاً باستيرادها model.compile( loss=tf.keras.losses.CategoricalCrossentropy(), ... ) # أو يمكن تمريرها بسهولة بالشكل التالي model.compile( loss='categorical_crossentropy', ... ) سأقوم بتطبيقها مع مجموعة بيانات routers، حيث أن هذه البيانات لديها 46 فئة (صنف) مختلف: # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) #ترميز الفئات المختلفة للبيانات #كما أشرنا One-Hot-Enoding طبعاً يجب أن نستخدم الترميز from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) # قمنا بعرض فئة أول عينة من بيانات التدريب print('one_hot_train_labels[0]:\n',one_hot_train_labels[0]) ''' one_hot_train_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' # قمنا بعرض فئة أول عينة من بيانات الاختبار print('one_hot_test_labels[0]:\n',one_hot_test_labels[0]) ''' one_hot_test_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' #أي الفئات target انتهينا من ترميز قيم ال # الآن لنقم بترميز بيانات التدريب import numpy as np #One-Hot قمت بإنشاء تابع يقوم بتحويل بياناتي إلى الترميز # بإمكانك أيضاً استخدام تابع تحويل جاهز def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # لاحظ كيف قمنا بتمرير دالة التكلفة إلى النموذج # التدريب history = model.fit(x_train, one_hot_train_labels, epochs=8, batch_size=512, validation_split=0.2) # الخرج ''' one_hot_train_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] one_hot_test_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] Epoch 1/8 15/15 [==============================] - 1s 26ms/step - loss: 3.3072 - accuracy: 0.2687 - val_loss: 2.0882 - val_accuracy: 0.5598 Epoch 2/8 15/15 [==============================] - 0s 14ms/step - loss: 1.9363 - accuracy: 0.5923 - val_loss: 1.6561 - val_accuracy: 0.6689 Epoch 3/8 15/15 [==============================] - 0s 14ms/step - loss: 1.5366 - accuracy: 0.6684 - val_loss: 1.4629 - val_accuracy: 0.6789 Epoch 4/8 15/15 [==============================] - 0s 13ms/step - loss: 1.3725 - accuracy: 0.7010 - val_loss: 1.3563 - val_accuracy: 0.7067 Epoch 5/8 15/15 [==============================] - 0s 13ms/step - loss: 1.1850 - accuracy: 0.7418 - val_loss: 1.2387 - val_accuracy: 0.7329 Epoch 6/8 15/15 [==============================] - 0s 13ms/step - loss: 1.1154 - accuracy: 0.7538 - val_loss: 1.1835 - val_accuracy: 0.7390 Epoch 7/8 15/15 [==============================] - 0s 12ms/step - loss: 1.0090 - accuracy: 0.7659 - val_loss: 1.1342 - val_accuracy: 0.7524 Epoch 8/8 15/15 [==============================] - 0s 26ms/step - loss: 0.9243 - accuracy: 0.7887 - val_loss: 1.0994 - val_accuracy: 0.7618 '''
- 2 اجابة
-
- 1
-
-
النمط String لايقبل الإضافة إليه، بحيث أي طريقة يتم استدعاءها على String تنشئ غرض جديد new String وترده وهذا لأن ال String غير قابل للتعديل، ولا يمكنه تغيير حالته الداخلية. أما StringBuilder فيمكنه ذلك باستخدام الطريقة append. وبالتالي يكون التعامل معه أسرع بكثير وأقل كلفة في الذاكرة فهو لايقوم بإنشاء غرض جديد (استهلاك وقت وذاكرة). مثال يبين أهم فرق بينهما: // String استخدام String s=""; for(int i=0;i<5000;i++) s+=String.valueOf(i); // 4828ms //ٍ StringBuilder أما باستخدام ٍStringBuilder sb=new ٍStringBuilder(); for(int i=0;i<5000;i++) sb.append(String.valueOf(i)); // 4ms باستخدام ال String نحتاح إلى 4828ms على جهازي أما باستخدام Builder فقط 4ms وهذا فرق كبير جداً. أي يمكنك استخدام الاثنين لكن ال StringBuilder أكثر كفاءة مهما كانت المهمة سواءاً قراءة ملف أو التعديل عليه.
- 2 اجابة
-
- 3
-
-
في Keras، طبقة الإدخال هي ال input shape وهي ليست طبقة بحد ذاتها ، لكنها موتر (tensor) أو مصفوفة ترسله إلى أول طبقة مخفية. ويجب أن يكون لهذا الموتر نفس شكل بيانات التدريب الخاصة بك. فمثلاً:إذا كان لديك 20 صورة بحجم 150 × 150 بكسل في RGB (3 قنوات) ، يكون شكل بيانات الإدخال (30،50،50،3). وبالتالي فإن موتر طبقة الإدخال يجب أن يكون متطابقاً معه. كل نوع من الطبقات يتطلب إدخالًا بعدد معين من الأبعاد: Dense: تطلب (batch_size, input_size)، أو (batch_size, optional,...,optional, input_size) 2D convolutional layers: فهناك حالتان وكل منهما يتعلق بترتيب وجود وسيط القنوات. (batch_size, imageside1, imageside2, channels) أو (batch_size, channels, imageside1, imageside2) 1D convolutions: وأيضاً الطبقات المتكررة مثل RNN و LSTM تحتاج إلى (batch_size, sequence_length, features). لذا سيكون حل مشكلتك كل التالي فسببها هو طريقتك الخاطئة بتمرير الأبعاد: #Dense نقوم بإعادة تعيين الأبعاد بطريقة تناسب الدخل الذي تحتاجه الطبقة التي لديك وهي X_train = X_train.reshape((60000, 28 * 28)) X_test = X_test.reshape((10000, 28 * 28)) #وبعد ذلك تدريب البيانات الجديدة على الشبكة التالية model = models.Sequential() model.add(layers.Dense(512, activation='relu', input_shape=(28* 28,))) model.add(layers.Dense(1, activation='softmax')) model.compile(optimizer='Adam',loss='categorical_crossentropy',metrics=['accuracy']) model.fit(X_train,y_train) نقوم بتحديد ال input shape في أول طبقة فقط، ثم بعد ذلك يتم استنتاجه تلقائياُ بدون التصريح عن ذلك بشكل صريح في الطبقات الأخرى.
- 2 اجابة
-
- 3
-
-
تسطيع حل المشكلة بطريقتن فقط ضع قبل keras مكتبة tensorflow. مكتبة كيراس هي مثل واجهة أمامية ل tensorflow يصبح الكود كالتالي: from tensorflow.keras.utils import to_categorical y_train=to_categorical(y_train) الطريقه الثانيه هي أن to_categorical موجودة في الوحدة الوظيفة np_utils ضمن utils وبتالي يصبح الكود: from keras.utils.np_utils import to_categorical y_train=to_categorical(y_train)
- 1 جواب
-
- 2
-
-
معظم مسائل الـ deep learning تعمل بشكل أفضل عندما تعتمد على داتاست كبيرة الحجم مثلاً من رتبة 10 مليون أو أعلى (big data) وستصبح عملية التدريب في الشبكات العصبونية بطيئة نظراً لضخامة الداتاست وفي هذه الحالات نحتاج لوجود خوارزميات تحسين سريعة والتي تساعد في زيادة الفعالية. خوارزمية Batch Gradient Descent هي النوع المعروف والشكل الأصلي لخوارزمية Gradient Descent حيث تمر على كل الداتاست ثم تتقدم خطوة واحدة (تحدث قيم الأوزان) ثم تمر على كامل الداتاست مرة أخرى ثم تتقدم خطوة ثانية وهكذا حتى يتم التقارب Converge. لكن المشكلة فيها أنه عندما تكون الداتاست كبيرة مثلاً من رتبة 5 مليون (طبعاً هذا الرقم ضخم وفي الحقيقة حتى عندما تكون الداتا من رتبة مئات الآلاف يظهر عيبها) ستصبح الخوارزمية بطيئة في التقدم أو التدرج لأنه في كل تكرار تمر على كامل الداتاست، لذلك في Mini Batch Gradient Descent يتم تقسيم الداتاست إلى مجموعات داتاست أصغر وهذه المجموعات تسمى mini-batches والوسيط batch_size يدل على حجم هذه المجموعة في كيراس وتنسرفلو. إن هذا التقسيم يجعل عملية التقارب أسرع بكثير من الطريقة العادية فهو لاينتظر المرور على كامل الداتاسيت حتى يتقدم خطوة (تحديث الأوزان) وإنما على جزء منها. أما فيما يتعلق بالخوارزمية الأخيرة Stochastic Gradient Descent فهي الأسرع، حيث يتم تحديث الأوزان بعد المرور على عينة واحدة فقط أي من أجل كل عينة في الداتاسيت سيتم تحديث الأوزان، لكن عيبها هو أنها في غالب الأحيان لن تستطيع التقارب من القيم الدنيا للتكلفة. لذا فالخيار الأفضل هو تجنب النوع الأول والثالث واستخدام ال Mini-Batch (فهي توازن بين الاثنين -السرعة والدقة-). Batch Gradient Descent: بطيئة ودقيقة. Stochastic Gradient Descent: سريعة جداً وغير دقيقة. Mini Batch Gradient Descent: توازن بين السرعة والدقة. وفي كيراس نستخدم الوسيط batch_size لتحديد عدد الباتشات (عدد التقسيمات للداتا)، فمثلاً 64 باتش تعني أنه سيتم تقسيم البيانات إلى 64 قسم وكل قسم يحوي عدد عينات يساوي (عدد العينات في الداتا مقسوم على 64). عدم تعيين قيمة لل batch_size يعني أنك ستستخدم Batch Gradient Descent واختيارك ل 1 يعني أنك ستستخدم Stochastic . لنأخذ مثال ونلاحظ الفرق: دربنا الموديل على الداتا المعرفه في keras والتي تدعى mnist وسوف نقوم بتدريب نفس الموديل ولكن مع اختلاف أن الأول ينفذ Batch Gradient Descent والثاني Mini Batch Gradient Descent: from keras.models import Sequential from keras import layers from keras.datasets import mnist (X_train,y_train),(X_test,y_test)=mnist.load_data() X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 model = Sequential() model.add(layers.Dense(512, activation='relu', input_shape=(28*28,))) model.add(layers.Dense(10, activation='softmax')) model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.fit(X_train,y_train,epochs=1) #الخرج ''' 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3400 - accuracy: 0.9004 الكود الثاني نفس السابق مع إضافة batch_size ''' #Mini-Batch model = Sequential() model.add(layers.Dense(512, activation='relu', input_shape=(28*28,))) model.add(layers.Dense(10, activation='softmax')) model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.fit(X_train,y_train, batch_size=60,epochs=1) #الخرج ''' 1000/1000 [==============================] - 5s 5ms/step - loss: 0.3865 - accuracy: 0.8889 الفرق واضح من الخرج في كل كود الأول الذي يحوي gradient descent كان أبطئ واستغرف 8s في حين الثاني الذي يحوي mini-batch gradient descent صحيح أن الدقه ليست كالأول ولكن السرعه كانت أفضل استغرق 5s وطبعا هنا كانت الداتاست صغيره مقارنتا بالداتاست المعياريه '''
- 2 اجابة
-
- 2
-
-
هي دالة تكلفة (loss) في كيراس وتنسرفلو ويتم استخدامها مع مسائل التصنيف الثنائي أي عندما يكون الخرج 1 أو 0. الصيغة الرياضية: تعتمد هذه الدالة على المفهوم الشهير في نظرية المعلومات والمعروف ب Cross Entropy أو الإنتروبيا المتقطعة، وهي مقياس لمدى تشابه توزعين احتماليين مختلفين لنفس الحدث وفي ال ML نستخدم هذا التعريف وقانونه لكي نقوم بحساب ال Loss (التكلفة Cost). حيث يكون الخرج الخاص بالشبكة العصبية هو توزيع احتمالي لعدة فئات classes. تابع التنشيط Sigmoid هو تابع التنشيط الوحيد المتوافق مع دالة التكلفة Binary CE. له الشكل التالي في كيراس: #في كيراس BinaryCrossentropy الكلاس tf.keras.losses.BinaryCrossentropy( from_logits=False, name="binary_crossentropy", ) # True عندما يكون مجال القيم المتوقعة غير محدود # False عندما يكون مجال القيم المتوقعة بين الصفر والواحد مثال: import tensorflow as tf # إنشاء قيم حقيقية وفيم متوقعة y_true = [1, 1, 0] y_pred1 = [0.7, 0.61, 0.04] # قيم متوقعة بين 0 و 1 y_pred2 = [-11.2, 1.51, 3.94] # قيم متوقعة بين الناقص لانهاية والزائد لانهاية # إنشاء كائن من هذا الكلاس c1 = tf.keras.losses.BinaryCrossentropy(from_logits=False) c2 = tf.keras.losses.BinaryCrossentropy(from_logits=True) # استخدامه وطباعة الناتج print(c1(y_true, y_pred1).numpy()) # 0.29726425 print(c2(y_true, y_pred2).numpy()) # 5.1196237 ولاستخدمها مع الدالة Compile: # كالتالي compile لاستخدامه مع النموذج نقوم بتمريره إلى model.compile( loss=tf.keras.losses.BinaryCrossentropy(), ... ) # أو يمكن تمريرها بسهولة بالشكل التالي model.compile( loss='binary_crossentropy', ... ) في المثال التالي سأبين لك استخدامها، سوف أقوم ببناء Baseline لمسألة تصنيف مشاعر ثنائية مع مجموعة بيانات imdb: # مثال بسيط # تحميل وتجهيز البيانات from keras.datasets import imdb from keras import preprocessing max_features = 100 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) # بناء النموذج from keras.models import Sequential from keras.layers import Flatten, Dense,Embedding model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # تجميع النموذج model.compile(optimizer='rmsprop', loss=tf.keras.losses.BinaryCrossentropy(from_logits=False), metrics=['acc']) # لاحظ كيف قمنا بتمرير دالة التكلفة # عرض ملخص للنموذج model.summary() # تدريب النموذج history = model.fit(x_train, y_train, epochs=2, batch_size=32, validation_split=0.2) #---------------------------------------------------------- ''' Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 20, 8) 80000 _________________________________________________________________ flatten_1 (Flatten) (None, 160) 0 _________________________________________________________________ dense_1 (Dense) (None, 1) 161 ================================================================= Total params: 80,161 Trainable params: 80,161 Non-trainable params: 0 _________________________________________________________________ Epoch 1/2 625/625 [==============================] - 2s 2ms/step - loss: 0.6919 - acc: 0.5179 - val_loss: 0.6806 - val_acc: 0.5912 Epoch 2/2 625/625 [==============================] - 1s 2ms/step - loss: 0.6671 - acc: 0.6126 - val_loss: 0.6530 - val_acc: 0.6128 '''
- 1 جواب
-
- 2
-
-
هناك العديد من الحلول لموازنة البيانات غير النصية: هل يمكنك جمع المزيد من البيانات لفئة الأقلية؟ الكثير منا يتجاهل هذا الأمر، رغم أنه قد يكون الحل الأفضل والأسهل لمشكلتنا خصوصاً وأنه يوجد العديد من المصادر على الانترنت. هناك بعض الخوارزميات القوية والتي تتعامل بشكل تلقائي مع البيانات غير المتوازنة مثل أشجار القرار، نظرًا لأنهم يعملون من خلال الخروج بشروط / قواعد في كل مرحلة من مراحل الانقسام ، لذا فينتهي الأمر بأخذ كلا الفئتين في الاعتبار، وأيضاً يمكنك استخدام ال XGBoost. DataAugmentation: هذا المفهوم ليس بالضرورة أن يطبق فقط في مهام الرؤية الحاسوبية وإنما يمكننا أن نطبقه مع البيانات النصية أيضاً لكن بطريقة مختلفة. في الصور هناك توابع جاهزة تقوم لك بهذا الأمر (DataAugmentation)، لكن في البيانات النصية لا أعتقد، لذا يجب أن تقوم بذلك بنفسك واعتماداً على مهاراتك، فمثلاً تتجلى إحدى الطرق بقيامك بتغيير الكلمات و الأفعال والصفات إلى مرادفات لها، ويمكنك أن تستخدم wordnet من مكتبة NLTK لمساعدتك بهذا الأمر (wordnet هي قاموس ضخم من الكلمات ومرادفاتها ومضاداتها و فروعها و معانيها الدلالية ...إلخ). أو مثلاً خلط الجمل وإعادة ترتيبها. ويمكنك أن تبدعي في هذا المحور ففي إحدى مسابقات Kaggle قام أحد المتسابقين بتغيير لغة النص إلى لغة عشوائية ثم إعادة ترجمتها إلى الإنجليزية (عن طريق مترجمات مثل مترجم غوغل)، وحصل على نتائج مبهرة!. حذف نقاط البيانات (العينات) المكررة أو المتشابهة جداً (فمثلاً قد تجدين عينتان تحملان نفس الكلمات والمعنى). إذا كانت مهمتك هي مهمة تصنيف متعدد فقد يكون من الممكن في كثير من الأحيان دمج فئات الأقلية مع بعضها البعض (فمثلاً لديك 3 فئات لتصنيف المنتجات الفئة الأولى ممتاز والفئة الثانية سيئ والثالثة سيئ جداً، والفئة الثانية والثالثة هما فئات أقلية، فهنا يمكن أن نقوم بضم الفئة الثالثة للثانية). Undersampling : حذف عينات بشكل عشوائي من قئة الأغلبية، حتى تتوازن البيانات ( لا أراها فكرة جيدة ). Oversampling : تعتمد على تكرار عينات من فئات الأقلية بشكل عشوائي (أيضاً لا أراها فكرة جيدة لأنها تؤدي إلى Overfitting وسيفشل نموذجك في التعميم generalization ). Penalized Models: يمكنك أن تضيف لنموذجك شيئاً إضافياً وهو مفهوم ال Penalized ويقتضي في أن تقوم بإضافة تكلفة إضافية (عقوبة) عندما يخطئ في التصنيف مع فئات الأقلية، وهذا سيجعل نموذج مجبراً على عدم تجاهل فئات الأقلية وإعطاء أهمية أكبر لها. Anomaly Detection Models: أو نماذج اكتشاف الشذوذ. إذا كانت مهمتك هي مهمة تصنيف ثنائي فيمكنك أن تستخدم هذه النماذج بدلاً من نماذج التصنيف، حيث تعمل هذه النماذج على تشكيل إطار يحيط بفئة الأغلبية وأي عينة لاتنتمي لها تعتبر شذوذاً (تستخدم هذه النماذج في مهام كشف الاحتيال). هذه كانت أشهر وأهم الطرق المستخدمة للتعامل مع هذه المشكلة لكن أحب أن أنوه إلى أن الطريقة التي أشرت لها "SMOTE" ليست فكرة جيدة مع البيانات غير النصية لأن الكلمات يتم تمثيلها في متجهات أبعادها عالية جداً. في النهاية لايوجد طريقة هي الأفضل كما هو الحال مع معظم المواضيع في علوم البيانات وخوارزميات التعلم الآلي، فاعتماداً على بياناتك والفئات ونوع البيانات وماتريد أن تصل إليه تختلف هذه الطرق بين الأفضل و الجيدة والسيئة.
- 1 جواب
-
- 2
-
-
المشكلة هنا هي أنك تحاول تثبيت Keras مع إصدار من Numpy لا يحتوي على الوظائف التي تتطلبها Keras، لحل المشكلة يجب ترقية numpy وتنسرفلو: pip install -U numpy pip install -U tensorflow
- 2 اجابة
-
- 2
-
-
يمكنك استخدامها عبر الموديول: keras.utils.np_utils يقوم التابع to_categorical بتحويل البيانات العددية إلى بيانات فئوية ممثلة بأصفار و واحدات ، حيث يقوم بترميز كل قيمة عددية مميزة (ال class) في شعاع طوله بعدد الفئات Classes المختلفة الموجودة في بياناتنا. وبشكل أكثر وضوح: بعد أن يتم إعطاء كل class في مجموعة البيانات رقمً تعريف فريد Classid يتراوح بين 1 و | Classes | . حيث Classes هي مجموعة الفئات (الأصناف) الموجودة لدينا . ثم يتم تمثيل كل فئة عبر متجه بأبعاد مقدارها | Classes | مملوء كلها بـ صفر باستثناء الفهرس ، حيث index = Classid. حيث نضع في هذا الفهرس ببساطة 1. ونستخدمه عادة عندما يكون لدينا مهمة تصنيف متعدد (عندما يكون لدينا عدة فئات). في المثال التالي لدي شعاع y فيه 3 كلاسات مختلفة وبالتالي كل كلاس سوف يتم تمثيله بشعاع له 3 أبعاد. # استيراد التابع from keras.utils.np_utils import to_categorical # خرج مزيف y=[0,1,0,2,1,0,1,2,0,1,2] # استخدام المحول الفئوي y=to_categorical(y) #طباعة النتائج print(y) ''' array([[1., 0., 0.], [0., 1., 0.], [1., 0., 0.], [0., 0., 1.], [0., 1., 0.], [1., 0., 0.], [0., 1., 0.], [0., 0., 1.], [1., 0., 0.], [0., 1., 0.], [0., 0., 1.]], dtype=float32) ''' سأقوم بتطبيق هذا التابع لترميز مجموعة بيانات routers، حيث أن هذه البيانات لديها 46 فئة (صنف) مختلف: # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=100) # ترميز الفئات المختلفة للبيانات from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) # قمنا بعرض فئة أول عينة من بيانات التدريب print('one_hot_train_labels[0]:\n',one_hot_train_labels[0]) ''' one_hot_train_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' # قمنا بعرض فئة أول عينة من بيانات الاختبار print('one_hot_test_labels[0]:\n',one_hot_test_labels[0]) ''' one_hot_test_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' ملاحظة: هذا الترميز هو نفسه ال One-Hot-Encoding
- 1 جواب
-
- 2
-
-
نعم منذ Py2.6: قم بتثبيتها أولاً: pip install ordered-set from ordered_set import OrderedSet l = OrderedSet('abraca') print(l) # OrderedSet(['a', 'b', 'r', 'c'])
- 4 اجابة
-
- 4
-
-
أولاً as: يتم استخدامها لإنشاء اسم مستعار # بدون اسم مستعار import numpy a = numpy.array([2, 3, 4]) # array([2, 3, 4]) b=numpy.zeros((3, 4)) # مع استخدام اسم مستعار import numpy as np a = np.array([2, 3, 4]) # array([2, 3, 4]) b=np.zeros((3, 4)) # لاحظ ان استخدام اسم مستعار يكون أكثر أريحية خصوصاً عندما تتعدد الفروع مثل المثال التالي # بدون اسم مستعار import tensorflow.keras.utils tensorflow.keras.utils.plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True) # مع اسم مستعار import tensorflow.keras.utils as pl pl.plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True) ثانياً: with. تم تقديم عبارة with لأول مرة منذ خمس سنوات، في Python 2.5. تُستخدم with عند العمل مع موارد غير مُدارة "unmanaged resources" مثل file streams Open network connections. Unmanaged memory ومع الأقفال Locks و ال sockets وال subprocesses. يسمح لك بالتأكد من "تنظيف" المورد عند انتهاء تشغيل الكود الذي يستخدمه، حتى إذا تم طرح استثناءات. ففي حال استخدمتها مع الملفات فتتمثل ميزة استخدام عبارة with في ضمان إغلاق الملف بشكل آمن بغض النظر عن كيفية الخروج من الكتل البرمجية المتداخلة الموجودة لديك. بحيث إذا حدث استثناء قبل نهاية الكتلة البرمجية، فسيتم إغلاق الملف بشكل مسبق بواسطة معالج استثناء خارجي. وإذا كانت الكتلة المتداخلة تحتوي على تعليمة return ، أو تعليمة continue أو break، فإن تعليمة with ستغلق الملف تلقائياً في تلك الحالات أيضاً. حيث تضمن عبارة with نفسها بالحصول على الموارد وتحريرها بالشكل المناسب. يكون استخدامها مفيداً عندما يكون لديك عمليتان مترابطتان ترغب في تنفيذهما كزوج، مع وجود كتلة من التعليمات البرمجية بينهما. المثال الكلاسيكي هو فتح ملف ومعالجة الملف ثم إغلاقه وهذا ماسنراه في المثال التالي: # وبدون معالجة للاستثناءات التي قد تحدث with بدون استخدام f = open('path', 'w') f.write('hsoub') f.close() # مع معالجة للاستثناءات التي قد تحدث with بدون استخدام f = open('path', 'w') try: f.write('hsoub') finally: f.close() #with استخدام with open('path', 'w') as file: f.write('hsoub') في أول مثال قد يؤدي حدوث استثناء أثناء استدعاء write إلى عدم إغلاق الملف بشكل سليم مما يؤدي إلى حدوث العديد من الأخطاء في الكود. الطريقة الثانية في المثال أعلاه تهتم بجميع الاستثناءات ولكن استخدام تعليمة with يجعل الكود مضغوطاً وقابل للقراءة بشكل أكبر. وبالتالي ، تساعد العبارة في تجنب الأخطاء والتسريبات من خلال ضمان تحرير المورد بشكل صحيح عند تنفيذ التعليمات البرمجية التي تستخدم المورد بالكامل. ولاحظ أنك لن تحتاج لتعليمة close كما في أول حالتين. يمكنك أيضاً استخدام تعليمة with مع كائنات معرفة من قبلك حيث يمكن استخدامها في الكائنات التي يحددها المستخدم وهذا مفيد بالنسبة لك لأن دعم عبارة with في العناصر الخاصة بك سيضمن عدم ترك أي مورد مفتوحًا أبدًا. لاستخدامها مع الكائنات المعرفة من قبل المستخدم، تحتاج فقط إلى إضافة التوابع __enter __ () و __exit __ () في الكائن، مثال: class wr(object): def __init__(self, file_name): self.file_name = file_name def __enter__(self): self.file = open(self.file_name, 'w') return self.file def __exit__(self): self.file.close() #مع الكائن with استخدام التعليمة with wr('file.txt') as f: f.write('hasoub') إن الكلمة المفتاحية with تشكل باني ل wr، وبمجرد وصول التنفيذ لتعليمة with يتم إنشاء كائن من wr، ثم يقوم بايثون باستدعاء التابع enter الذي يقوم بتهيئة المورد الذي تريد أن تستخدمه في ال object الخاص بك، ويجب أن تقوم طريقة __enter __ () دائمًا بإرجاع واصف للمورد "descriptor"(مقبض للوصول للملف) الذي تم الحصول عليه. يتم استخدام f للإشارة لل descriptor الذي تم الحصول عليه من التابع enter، ويتم وضع الكود البرمجي الذي يستخدم المورد بداخل كتلة with وبمجرد تنفيذ الكود الموجود داخل الكتلة with ، يتم استدعاء طريقة __exit __ () ليتم تحرير جميع الموارد.
- 3 اجابة
-
- 2
-
-
لقد سبق وظهرت لي ذات المشكلة، غالباً السبب أن هناك مشكلة في عملية التثبيت أو في المسار، قم بمايلي وسيتم حل المشكلة من جذورها. قم بتثبيت كل مما يلي: # قم بحذفهم pip uninstall pydot pip uninstall pydotplus pip uninstall graphviz # ثم أعد تنزيلهم pip install pydot pip install pydotplus pip install graphviz أو باستخدام conda: # قم بحذفهم أولاً conda uninstall pydot conda uninstall pydotplus conda uninstall graphviz # ثم أعد تنزيلهم conda install pydot conda install pydotplus conda install graphviz ثم قم بتثبيت graphviz binaries على جهازك ثم أضف مسار ال graphviz bin في ال system PATH أثناء التثبيت.
- 1 جواب
-
- 1
-
-
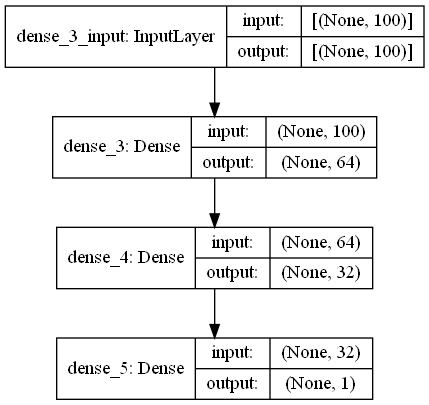
إن بنية المعطيات الأساسية (data structure) في Keras هي "Model" هذا المودل يسمح لنا بتعريف و تصميم وتنظيم طبقات الشبكة العصبية المطلوب بناءها. في كيراس فإن أحد أشكال بنية المعطيات هذه (model) هو الهيكلية التي تسمى Sequential. وهو أبسط أشكال النماذج (طبقات مكدسة فوق بعضها بشكل خطي) وأشهرها وأكثرها استخداماً (مستخدم في أكثر من 95% من النماذج والمهام). إن دخل كل طبقة في هذه البنية هو tensor (مصفوفة) واحدة بالضبط وخرجها tensor واحدة بالضبط (exactly one input tensor and one output tensor). لتعريف بنية المعطيات Sequential واستخدامها لتصميم وتنظيم شبكة عصبية يجب علينا أولاً أن نقوم باستيرادها، ويتم ذلك من خلال الموديول التالي: keras.models هناك طريقتان لإضافة وتنظيم الطبقات إلى هذه البنية الأولى بباستخدام التابع add كما في المثال التالي والأخرى عن طريق تمرير قائمة بالطبقات التي نريدها إلى باني الصف Sequential كما سنرى: #add باستخدام model.add(layers.Dense(64)) model.add(layers.Dense(32)) model.add(layers.Dense(1)) # Sequential طريقة أخرى حيث نمرر قائمة من الطبقات إلى باني الصف model =Sequential( [ layers.Dense(64), layers.Dense(32), layers.Dense(1), ] ) المثال1: هنا سأقوم بتعريف نموذج باستخدام هذه المعمارية وقمت بترجمته وتدريبه (التدريب وكل شيء قمت به هو عشوائي، غايتي هي فقط أن أبين لك شكل المعمارية كيف يتم الأمر). # تحميل الدتا from keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data( num_words=100) # تحضير الداتا import numpy as np def vectorize_sequences(sequences, dimension=100): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) y_train = np.asarray(train_labels).astype('float32') y_test = np.asarray(test_labels).astype('float32') #----------------------------------------------------------------- # استيراد المكتبات from keras import layers # Sequential استيراد المعمارية from keras.models import Sequential # Sequential إنشاء كائن يمثل نموذج من النوع model = Sequential() # سنضيف الآن عدد من الطبقات بشكل عشوائي #إلى هذا النموذج Fully Conected قمنا بإضافة 3 طبقات من نوع model.add(layers.Dense(64, activation='relu', input_shape=(100,))) # features 100 والدخل لهذه الطبقة هو relu طبقة ب32 خلية وتابع تنشيط model.add(layers.Dense(32, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) # طبقة الخرج حددناها بمخرج واحد فقط #---------------------------------------------------------------- # ثم سنرسم شكل المعمارية باستخدام واجهة برمجة التطبيقات من كيراس لتتضح لك # واجهة برمجة تطبيقات Keras الوظيفية أن تفعل ذلك لنا. from tensorflow.keras.utils import plot_model # قم بتشغيل الكود لترى هيكل النموذج إذا أحببت # هيكل النموذج هو الصورة في الأسفل plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True) #----------------------------------------------------------------- # ثم نقوم بترجمة النموذج وتمرير المعلومات التي يحتاجها model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) # وأخيراً تدريب النموذج history = model.fit(x_train, y_train, epochs=4) #---------------------------------------------------------------- # لتقييم النموذج model.evaluate(x_test,y_test) إذا هذا النموذج غير جيد في حال كان لديك أكثر من input أوأكثر من output في أي طبقة من طبقاتك، أو إذا كنت بحاجة إلى تشارك الطبقات أو إذا كنت لاتريد أن تكون طبولوجيا الشبكة خطية. # Writen by: Ali_H_Ahmad
- 1 جواب
-
- 1
-
-
طالما أنه يقوم بتحديد الجسم (وضع إطار حوله) فهذا الأمر يتم باستخدام مفهوم ال Object detection (حقل من حقول الذكاء الصنعي ) ماتبقى أيضا يعتمد على مفاهيم الرؤية الحاسوبية والذكاء الصنعي. أما موضوع تحويل الصورة لشكل 3D فهذا أيضا يندرج تحت مفاهيم الرؤية الحاسوبية ويتم عن طريق التقاط عدة صور للجسم ثم دمجها باستخدام توابع مخصصة والناتج يكون صورة 3D (غالبا يعتمد على وجود عدة عدسات في الكاميرة بحيث كل عدسة تلتقط صورة بزاوية مختلفة ثم يتم دمج هذه الصور لتعطي صورة 3D) هذا بشكل عام الأمر الذي تعتمد عليه هكذا تطبيقات.
- 1 جواب
-
- 1
-
-
نستخدم المعامل in لاختبار وجود substring (سلسلة جزئية) في نص text. string = "board, projects, resources and activities" arr = ['board', 'projects', 'activities'] #lower case نحول حالة كل الكلمات في النص الأساسي إلى حالة الأحرف الصغيرة string=string.lower() # نعرف عداد يعد عدد مرات ظهور نص من القائمة في النص الأساسي count=0 #وتختبر وجودها arr حلقة تمر على كل كلمة في ال for i in arr: if i in string: # إذا كانت موجودة نضيف 1 count+=1 #True نقسم الناتج على 2 فإذا كان أكبر نطبع if count>=len(arr)//2: print(True)