


Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 تظهر هذه المشكلة لأن TensorFlow أو Keras لا يمكنها العمل مع h5py v3 والإصدارات الأحدث. لذا قم بتثبيت نسخة أقدم منها كالتالي: pip install 'h5py==2.10.0' --force-reinstall ثم أعد تشغيل الKernal (أي قم بإغلاق المحرر وأعد تشغيله أو قم بإعادة تشغيل الحاسب) غالباً سوف يتم جعل تنسرفلو وكيراس يعملان مع النسخ الأحدث منها قريباً.
تظهر هذه المشكلة لأن TensorFlow أو Keras لا يمكنها العمل مع h5py v3 والإصدارات الأحدث. لذا قم بتثبيت نسخة أقدم منها كالتالي: pip install 'h5py==2.10.0' --force-reinstall ثم أعد تشغيل الKernal (أي قم بإغلاق المحرر وأعد تشغيله أو قم بإعادة تشغيل الحاسب) غالباً سوف يتم جعل تنسرفلو وكيراس يعملان مع النسخ الأحدث منها قريباً.- 2 اجابة
-
- 2
-

-
في جافا: package javaapplication19; import java.util.*; public class JavaApplication19 { public static void main(String[] args) { Scanner sc=new Scanner(System.in); // إدخال عدد الأسطر وعدد الأعمدة int rows=sc.nextInt(); int cols=sc.nextInt(); // تعريف مصفوفة من الأعداد الصحيحة int arr[][]=new int[rows][cols]; // إدخال العناصر for(int i=0; i<rows;i++) { for(int j=0; j<cols;j++) { arr[i][j]=sc.nextInt(); } } int sumC=0,sumR=0; // مجموع كل سطر for(int i = 0; i < cols; i++){ sumR=0; for(int j = 0; j < rows; j++){ sumR = sumR + arr[i][j]; } System.out.println("row"+(i+1)+": " + sumR); } // مجموع كل عمود for(int i = 0; i < cols; i++){ sumC=0; for(int j = 0; j < rows; j++){ sumC = sumC + arr[j][i]; } System.out.println("column"+(i+1)+": " + sumC); } } } بايثون: #تعرف مصفوفة import numpy as np # إدخال عدد الأسطر فقط r=int(input()) # إدخال عناصر المصفوفة arr = [list(map(int,input().split())) for i in range(r)] # حساب مجموع عناصر كل عمود for i in range(0, r): sum_ = 0; for j in range(0, c): sum_ = sum_ + arr[j][i]; print(" column"+str(i+1)+": " + str(sum_)); print("\n") # حساب مجموع عناصر كل صف for i in range(0, r): sum_ = 0; for j in range(0, c): sum_ = sum_ + arr[i][j]; print(" row"+str(i+1)+": " + str(sum_)); هناك طرق أخرى للإدخال في بايثون لكنني أخترت لك طريقتي التي كنت استخدمها (وهي الأفضل) في مسابقات البرمجة التنافسية وعلى موقع CodeForces لكن انتبه، هنا يكون إدخال عناصر المصفوفة بشكل مختلف قليلاً حيث يتم الإدخال سطر سطر ولهذا السبب لم نطلب إدخال عدد الأعمدة.أي مثلاُ حددنا 3 أسطر وبالتالي ندخل قيم كامل السطر الأول دفعة واحدة ونفصل بينهم بفراغات، أي مثلاً: 1 2 3 ثم نضغط enter ثم 5 6 4 ثم Enter ثم 4 6 6 ثم Enter وبالتالي نكون أدخلنا مصفوفة ب 3 أسطر و 3 أعمدة.
- 4 اجابة
-
- 2
-
-
يمكنك معرفة ذلك من خلال التعليمة التالية: model.count_params() مثال: model = Sequential() model.add(Embedding(1000, 50, input_length=30, trainable=True)) model.add(GRU(150, recurrent_dropout=0.1, dropout=0.1)) model.add(Dense(10, activation='softmax')) model.count_params() #142410 ويمكنك أيضاً استخدام: model.summary() حيث تعطيك الطريقة الثانية ملخص كامل عن الطبقات الموجودة في نموذجك وعدد المعاملات في كل منها وأبعاد كل طبقة والمعاملات القابلة للتدريب والغير قابلة للتدريب. # مثال model = Sequential() model.add(Embedding(1000, 50, input_length=30, trainable=True)) model.add(GRU(150, recurrent_dropout=0.1, dropout=0.1)) model.add(Dense(10, activation='softmax')) model.summary() Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 30, 50) 50000 _________________________________________________________________ gru_1 (GRU) (None, 150) 90900 _________________________________________________________________ dense (Dense) (None, 10) 1510 ================================================================= Total params: 142,410 Trainable params: 142,410 Non-trainable params: 0 _________________________________________________________________
- 3 اجابة
-
- 1
-
-
هذا الخطأ شائع ومثير للحيرة عند المبتدئين، المشكلة في ال input_shape حيث يجب أن يحتوي 3 أبعاد فقط والبعد الرابع يقوم بإضافته كيراس تلقائياً ويمثل بعد الدفعة batch_size، لكن أنت أضفت البعد الرابع الذي يمثل ال batch وبالتالي أضاف كيراس بعداً آخر فأصبح لدينا 5 أبعاد، لذلك لايجب أن نضيف البعد الرابع والذي يمثل ال batch أي الحل يكون فقط بتغيير الinput_shape كالتالي: input_shape=(32,32,1)
- 1 جواب
-
- 1
-
-
اذهب إلى التيرمينال ونفذ الأوامر التالية: conda uninstall PIL conda uninstall Pillow conda install Pillow ثم: conda install keras conda install tensorflow وأخيراً قم بإغلاق كل شيء ثم أعد تشغيل الجوبيتر.
- 1 جواب
-
- 1
-
-
في بايثون: #تعرف مصفوفة import numpy as np arr =np.array([[8, 2, 7],[0, 4, 1],[1, 9, 0]]) # حساب عدد الأسطر والأعمدة في المصفوفة r,c=arr.shape # حساب مجموع عناصر كل عمود for i in range(0, r): sum_ = 0; for j in range(0, c): sum_ = sum_ + arr[j][i]; print(" column"+str(i+1)+": " + str(sum_)); print("\n") # حساب مجموع عناصر كل صف for i in range(0, r): sum_ = 0; for j in range(0, c): sum_ = sum_ + arr[i][j]; print(" row"+str(i+1)+": " + str(sum_)); """ column1: 9 column2: 15 column3: 8 row1: 17 row2: 5 row3: 10 """ جافا: public class javaapplication1 { public static void main(String[] args) { int r, c; // تعريف المصفوفة int arr[][] = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} }; // مجموع كل عمود for(int i = 0; i < cols; i++){ for(int j = 0; j < rows; j++){ sumC = sumC + a[j][i]; } System.out.println(" column"+(i+1)+": " + sumC); } // مجموع كل سطر int sumC=0,sumR=0; for(int i = 0; i < arr.length; i++){ for(int j = 0; j < arr[0].length; j++){ sumR = sumR + a[i][j]; } System.out.println(" row"+(i+1)+": " + sumR); } } } وفي ++C وباقي اللغات يكون بنفس الطريقة
- 4 اجابة
-
- 1
-
-
الطبقة الكثيفة أو "Dense" هي مجرد طبقة مكونة من وحدات منتظمة نسميها خلايا عصبية في الشبكة العصبية. تتلقى كل خلية عصبية مدخلات من جميع الخلايا العصبية في الطبقة السابقة، وبالتالي نقول عنها "متصلة بكثافة" أو "Densely Connected". تحتوي هذه الطبقة على مصفوفة وزن W ومتجه يمثل الانحراف b بالإضافة لخرج الطبقة السابقة أي خرج تنشيط الطبقة السابقة a. هذه الطبقة تؤدي العملية التالية (حسب وثائق كيراس): output = activation(dot(input, kernel) + bias) حيث أن ال activation هو تابع التنشيط المستخدم. و ال kernel هي مصفوفة الأوزان الخاصة بهذه الطبقة وال bias هو الانحراف "weights matrix". لها الشكل التالي: keras.layers.Dense( units, activation=None, use_bias=True, kernel_initializer="glorot_uniform", bias_initializer="zeros", ) حيث أن units هي عدد الخلايا في الطبقة، و activation هو تابع التنشيط، و use bias لتحديد فيما إذا كنت تريد تفعيل الانحراف أم تجاهله، kernel_initializer مُهيئ لمصفوفة أوزان النواة. bias_initializer أيضاً نفس الأمر لكن لشعاع الانحراف. وعادةً نتركهم على الحالة الافتراضية أي انسى أمرهم، فلا أحد يغيرهم. أما دخل هذه الطبقة هو : (batch_size, ..., input_dim) أي N-D tensor لكن غالباً يكون الإدخال 2D من الشكل (batch_size, input_dim). أما الإخراج (batch_size, ..., units) وفي حالة 2D يكون الخرج (batch_size, units). مثال: #Dense ثم أضفنا طبقات Sequential قمنا بإنشاء نموذج من النوع model = tf.keras.models.Sequential() # 16 نحدد دخل النموذج ب (None, 16) model.add(tf.keras.Input(shape=(16,))) #relu تعريف طبقة كثيفة ب32 خلية وتابع تنشيط model.add(tf.keras.layers.Dense(32, activation='tanh')) # الخرج سيكون(None, 32). # طبعاً بعد أول طبقة لاداعي لتحديد أبعاد المدخلات إذ يتم استنتاجهم تلقائياً # طبقة أخر model.add(tf.keras.layers.Dense(32)) # أبعاد الإخراج model.output_shape (None, 32)
- 1 جواب
-
- 1
-
-
تيح لنا طبقة التضمين تحويل كل كلمة إلى متجه بطول ثابت وبحجم محدد. المتجه الناتج هو متجه كثيف "Dense" له قيم حقيقية بدلاً من 0 و 1 فقط كما في الترميز One-Hot. يساعدنا الطول الثابت لمتجهات الكلمات على تمثيل الكلمات بطريقة أفضل وأكثر فعالية مع أبعاد مخفضة. وهذه المتجهات تكون ممثلة في فضاء Vector space مهيكل ويعكس المعاني الدلالية لكل كلمة وهذا مايجعل هذا التمثيل فعال للغاية. إن أفضل فهم لطبقة التضمين هو اعتبارها كقاموس يقوم بربط أعداد صحيحة (كل كلمة ترمز في البداية كعدد صحيح) بمتجه كثيف. أي أنها تأخذ كدخل أعداد صحيحة ثم تبحث في هذا القاموس على المتجه الذي يقابله في القاموس الداخلي، ويعيد هذا القاموس. Word index --> Embedding layer --> Corresponding word vector في كيراس نستخدمها كأول طبقة من طبقات النماذج التي تتعامل مع مهام NLP. هذه الطبقة تأخذ وسيطين على الأقل الأول هو عدد ال tokens (المفردات) الموجودة في بياناتك أي (1 + maximum word index) والثاني هو dimensionality of the embeddings أي أبعاد التضمين. وفي حالة كانت الطبقة التالية هي طبقة flatten ثم Dense فيجب عليك استخدام وسيط ثالث هو input_length أي طول مدخلاتك أو بمعنى أوضح، طول السلاسل النصية التي تعالجها. وفي كيراس لها الشكل التالي: keras.layers.Embedding( input_dim, output_dim, input_length=None, ) هذه الطبقة تأخذ كمدخلات مصفوفة 2D من الشكل:(batch_size, input_length) وتعيد مصفوفة من الشكل: (batch_size, input_length, output_dim) مثال: >>> model = tf.keras.Sequential() # طول السلاسل هو 120 وأبعاد التضمين 128 وعدد الكلمات 10000 >>> model.add(tf.keras.layers.Embedding(10000, 128, input_length=120)) >>> input_array = np.random.randint(1000, size=(32, 10)) >>> model.compile('rmsprop', 'mse') >>> output_array = model.predict(input_array) >>> print(output_array.shape) # (32, 10, 64)
- 2 اجابة
-
- 2
-
-
الخوارزمية الجشعة هي الخوارزمية التي تبني الحل خطوة خطوة أو قطعة قطعة وتعتمد على اختيار الخيار الأمثل (يعظم الربح) عند كل نقطة اختيار, أي أنها تخلق خيار مثالي محلي على أمل أن هذا السلوك سيقودنا الى حل مثالي شامل (أي حل مثالي لكامل المسألة). كما أنه لا يمكننا اثبات صحة حل مسألة تعتمد على الخوارزمية الجشعة ولكن يكفي إعطاء مثال لإثبات أن الخوارزمية خاطئة. لنأخذ المثال التالي ولنحاول حلها بطريقة الخوارزمية الجشعة: لنفرض لدينا قاعة وعدد من المقررات التي نريد اعطاء محاضرة منها في هذه القاعة مع توقيت بداية و نهاية كل من هذه المحاضرات والمطلوب ما هو أكبر عدد من الأنشطة او المحاضرات التي نستيطع القيام بها في هذه القاعة؟ تذكر أن يكفي إعطاء مثال لاثبات ان الخوارزمية خاطئة. 1_سنحاول حل هذه المسألة بختيار الأنشطة ذات الامتداد الزمني(توقيت النهاية-توقيت البداية) الأقصر,ولكن هذه الفكرة خاطئة ويمكن اعطاء هذا المثال لاثبات ذلك: النشاط الاول من 8 الى 11. النشاط الثاني من 10:30 الى 12. النشاط الثالث من 11:30 الى 3. بناءان على الفكرة السابقة سيتم اختيار النشاط الثاني فقط بينما من الأفضل اختيار النشاطين الأول و الثالث. 2_سنحاول هذه المرة باختيار الأنشطة ذات الزمن البداية الأصغر,ولكن هذه الفكرة خاطئة ايضا ويمكن اعطاء هذا المثال لأثبات ذلك: النشاط الأول من 8 الى 1. النشاط الثاني من 9 الى 10. النشاط الثالث من 10 الى 11. النشاط الرابع من 11:30 الى 12:30 بناءان على الفكرة السابقة سيتم اختيار النشاط الأول فقط بينما من الأفضل اختيار النشاط الثاني و الثالث و الرابع. إذاً ما هي فكرة حل هذه المسألة؟ يتم حل هذه المسألة بأخذ الأحداث التي تنتهي أولا مع مراعاة عدم تداخل تواقيتها، أي أقوم بترتيب الأنشطة حسب زمن انتهائها (من النشاط الذي ينتهي أولا الى النشاط الذي ينتهي اخيرا) ثم أقوم بأخذ النشاط الذي ينتهي أولا و من ثم أبحث عن اول نشاط يبدأ بعد انتهائه(كي لا يحدث تداخل في تواقيت الأنشطة) ومن ثم أبحث عن أول نشاط يبدأ بعد انتهاء أخر نشاط أخذناه وهكذا... ويكون pseudocode الخاص بالمسألة كالتالي: input: n activities output: a max size subset of compatible activities sort activities by increasing finish time A1,A2,A3 where F1<F2<F3<..<Fn E<-{1} T<-F1 for i=2 to n do { if(Si>=T)then { add i to E T<-Fi } } output E
- 2 اجابة
-
- 2
-
-
بشكل افتراضي وتلقائي، يتم تشغيل طبقة التضمين على ال GPU في حال كانت متوفرة، من أجل الحصول على أفضل أداء، هذا يعني أن مصفوفة التضمين "embedding matrix"ستم وضعها في ال GPU وهنا قد تنتج المشكلة في حال كانت مصفوفة التضمين ضخمة وبالتالي لايمكن عمل fitting لها في ال GPU فيظهر هذا الخطأ، ولحل هذه المشكلة يجب أن تقوم بوضعها في ال "CPU memory" ويمكنك القيام بذلك بالشكل التالي: with tf.device('cpu:0'): embedding_layer = Embedding(...) embedding_layer.build() ثم بعد ذلك يمكنك أن تضيفها إلى نموذجك بالشكل التالي: model.add(embedding_layer) # Wherever_there_is_artificial_intelligence,_there is me
- 2 اجابة
-
- 1
-
-
في مسائل التصنيف المتعدد يجب أن تكون حذراً مع اختيار دالة الخسارة، والمشكلة هنا هي في اختيارك لدالة الخسارة، فعندما تكون بيانات y_true مرمزة بترميز One-Hot يجب أن نختار categorical_crossentropy أما إذا كانت بيانات y_true تتبع ترميزاً عادياً (أي كل صنف تم تمثيله بعدد صحيح 1,2,3...,class_n) فهنا يجب أن نختار دالة الخسارة sparse_categorical_crossentropy.
- 2 اجابة
-
- 2
-
-
بما أنه لديك 3 أصناف فيجب أن تقوم بتحويل ال y_train و y_test إلى الترميز الفئوي أي One-Hot أي: from keras.utils import to_categorical y_test = to_categorical(y_test, 4) y_train = to_categorical(y_train, 4) وأيضاً يجب أن تتحقق من أبعاد المدخلات لديك في طبقة LSTM حيث أن الدخل المتوقع لهذه الطبقة يجب أن يكون: (batch_size, timesteps, input_dim) # 3D tensor
- 2 اجابة
-
- 1
-
-
الخطأ هو أن شكل الخرج Y في البيانات هو (,60000) يجب أن يكون شكل الخرج في البيانات مطابق لشكل الخرج في الموديل حيث شكل الخرج في الموديل الذي تقوم بتدريبه هو (32,2) وشكل المخرجات التي تظهر في خرج البيانات باعتبار انها 0 أو 1 هو (32,1) لذلك يجيب تغير الموديل لإخراج قيمة واحدة بدلاً من 2 واستخدام تابع التفعيل sigmoid مع تابع الخسارة binary_crossentropy أي يصبح الكود كالتالي: import numpy as np import pandas as pd from keras.models import Sequential from keras.layers import Dense , Activation, Dropout from keras.models import Sequential from keras.utils.np_utils import to_categorical from keras.datasets import mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() y_train[y_train<=5]=0 y_train[y_train>5]=1 y_train=y_train.astype('int64') print(x_train.shape, y_train.shape) image_size = x_train.shape[1] input_size = image_size * image_size x_train = np.reshape(x_train, [-1, input_size]) x_train = x_train.astype('float32') / 255 x_test = np.reshape(x_test, [-1, input_size]) x_test = x_test.astype('float32') / 255 batch_size = 32 hidden_units = 256 model = Sequential() model.add(Dense(hidden_units, input_shape=(input_size,))) model.add(Activation('relu')) model.add(Dropout(0.45)) model.add(Dense(hidden_units)) model.add(Activation('relu')) model.add(Dropout(0.45)) #إصلاح model.add(Dense(1)) #إصلاح model.add(Activation('sigmoid')) #إصلاح model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5, batch_size=batch_size)
- 2 اجابة
-
- 1
-
-
أنت قمت بتعيين الطبقة الأولى بحيث تتوقع منك أبعاد الإدخال (،300) عن طريق ضبطك للوسيط input_shape على input_shape = (300،) ثم أعطيت النموذج لاحقاً أبعاداً مختلفة مساوية لأبعاد البيانات التي تريد التدريب عليه، وهذا خاطئ. الوسيط input_shape يحدد أبعاد المدخلات للطبقة، لذا يجب أن يكون مطابقاً لأبعاد بياناتك. لحل المشكلة استخدم train_data.shape[1] أي تصبح input_shape=(train_data.shape[1],) بدلاً من تحديد الأبعاد بشكل يدوي أي بدلاً من (,input_shape = (300: from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss="mse", metrics=['mae']) #بالشكل التالي compile هنا استخدمناها كدالة تكلفة وكمعيار عن طريق تمريره إلى الدالة #model.compile(optimizer='rmsprop', loss='mse', metrics=['mse']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64)
- 2 اجابة
-
- 1
-
-
يمكنك القيام بذلك من خلال التابع format في المكتبة locale كالتالي: import locale locale.format("%d", 123456789 , grouping=True)# '123,456,789' أو باستخدام التعابير المنطقية من مكتبة regex: import re re.sub("(\d)(?=(\d{3})+(?!\d))", r"\1,", "%d" % 123456789) # '123,456,789' أوكما أشار الأستاذ سمير في إجابته: x=123456789 '{:0,.2f}'.format(x) # '123,456,789.00' يمكنك أيضاً القيام بذلك بشكل يدوي من خلال التابع التالي: def sp(x): l = [] g = '%d' % x while g and g[-1].isdigit(): l.append(g[-3:]) g = g[:-3] return g + ','.join(reversed(l)) sp(123456789) # '123,456,789'
- 4 اجابة
-
- 2
-
-
الطريقة WaitAll(): هي طريقة ستاتيكية تستدعى لأجل الصف، دخلها مصفوفة عناصر من النمط Task، مهمتها إيقاف الأب، مثلاً لو استدعيناها في ال mian سيتم إيقافه (ينتظر) حتى تنفيذ كل التاسكات الموجودة ضمن هذه المصفوفة فقط . مثال : هنا مثال عن الطريقة فقط ، باعتبار الصف Test صف يحوي طريقتين وهما MethodA تقوم بطباعة A خمسين مرة، والطريقة MethodB تطبع B خمسين مرة: var TaskA = new Task.Factory.StartNew(Test.MethodA); var TaskB = new Task.Factory.StartNew(Test.MethodB); Task [] stopmain = { TaskA , TaskB }; Task.WaitAll(stopmain); هنا سيتوقف ال main حتى يتم تنفيذ جميع ال task في المصفوفة stopmain. For (int i=0 ; i<50;i++){ console.WriteLine("Main");} الخرج : طباعة A و B خمسين مرة بشكل متداخل(ترتيب غير معلوم) ومن ثم طباعة Main خمسين مرة. الطريقة WaitAny() : هي أيضا طريقة ستاتيكية و تقبل مصفوفة تاسكات كسابقتها اذاً هي شبيها بالطريقة السابقة ولكن لو استدعيناها في ال main مثلاً لن تنتظر انتهاء كل التاسكات، بل تنتظر انتهاء أول task وعند اكتمال تنفيذ هذا التاسك يستأنف ال main العمل بالتوازي مع التاسكات الأخرى مع الملاحظة أن هذه الطريقة ترد قيمة وهي index يمثل موقع التاسك الذي انتهى من المصفوفة. مثال : var TaskA = new Task.Factory.StartNew(Test.MethodA); var TaskB = new Task.Factory.StartNew(Test.MethodB); Task [] stopmain = new Task[] { TaskA , TaskB }; Int id = Task.WaitAny(stopmain); هنا سيتوقف ال main حتى يتم تنفيذ إحدى تاسكات المصفوفة لا على التعيين و ترد هذه الطريقة ال index للتاسك الذي اكتمل تنفيذه أولاً إلى المتحول id ، حيث أن المصفوفة هنا تحوي عنصرين فال index إما 0 أو 1. For (int i=0 ; i<50;i++){ console.WriteLine("Main");} الخرج : طباعة A خمسين مرة و طباعة B خمسين مرة بترتيب غير معلوم ولكن طباعة الكلمة main لا تبدأ إلا بعد انتهاء طباعة إحدى العبارات "ِA" أو "B".
- 1 جواب
-
- 2
-
-
Hinge loss هي دالة تكلفة تستخدم لمصنفات التدريب مثل SVM تقوم هذه الدالة بحساب خسارة هاينغ بين القيم المتوقعة والقيم الحققية للنموذج. يتم استخدامها عبر الموديول: keras.losses loss = maximum(1 - y_true * y_pred, 0) مثال: y_true = [[1., 0.], [0., 0.]] y_pred = [[0.3, 0.5], [0.2, 0.6]] h = tf.keras.losses.Hinge() h(y_true, y_pred).numpy() لاستخدامها في تدريب نموذجك نقوم بتمريرها إلى الدالة compile كالتالي: model.compile( loss=keras.losses.hinge(), ... ) # أو model.compile( loss="hinge", ... ) سأعطي الآن مثال لاستخدمها في بناء نموذج في في كيراس يحاكي خوارزمية SVM: #SVM النموذج التالي يعمل بشكل مشابه لل #RandomFourierFeatures نقوم باستخدام طبقات SVM لتحقيق from tensorflow.keras.layers.experimental import RandomFourierFeatures from tensorflow import keras from keras.datasets import mnist from tensorflow.keras import layers (x_train, y_train), (x_test, y_test) =mnist.load_data() # معالجة البيانات x_train = x_train.reshape(-1, 784).astype("float32") / 255 x_test = x_test.reshape(-1, 784).astype("float32") / 255 y_train = keras.utils.to_categorical(y_train) y_test = keras.utils.to_categorical(y_test) # بناء النموذج model = keras.Sequential( [ keras.Input(shape=(784,)), RandomFourierFeatures( output_dim=4096, scale=10.0, kernel_initializer="gaussian" ), layers.Dense(units=10), ] ) model.compile( optimizer="rmsprop", loss=keras.losses.hinge(), metrics=["acc"], ) # تدريب النموذج model.fit(x_train, y_train, epochs=2, batch_size=64, validation_split=0.2)
- 1 جواب
-
- 1
-
-
ببساطة ال destructor عبارة عن تابع لا يرد أية قيمة ولا يحوي على return ولا نمرر له أي وسيط. يتم تعريفه بأن نكتب ( اسم الصف مسبوق بالإشارة ~ ) ثم فتح قوسين فارغين، و من الممكن أن يحوي تعليمات أو أن لا يحوي. مثال : Class A{ Public : // تعريف باني افتراضي A() { cout<<"A"; } // destructor ~ A() { cout<<" Destructor is call " ; } } لكل صف يتم إنشاؤه يكون هناك destructor افتراضي (يتم تعريفه تلقائياً حتى ولو لم تقم بالتصريح عنه واستدعائه ). مثلاً في حال تم انشاء كائن ضمن دالة وتم تنفيذ محتوى هذه الدالة سيتم استدعاء التابع destructor (وببساطة سيتم حذف أي شيء تم تعريفه ضمن الدالة بعد أن تنفذ). يتم الاستفادة من التابع destructor عندما يكون ضمن الصف حقول معطيات ديناميكية مثل (مؤشرات ، مصفوفات ديناميكية ..إلخ) حيث أننا ضمن جسم التابع نقوم بتحرير المواقع المحجوزة من قبل هذه المتحولات الديناميكية عن طريق استخدام التعليمة delete. مثال : ليكن لدينا الصف dynamic يحتوي على المصفوفة الديناميكية A ،من النمط int و باني افتراضي للتهيئة بالصفر وطريقة لإدخال عناصر المصفوفة و هادم ( destructor). عندئذ يجب استخدام التعليمة delete في الهادم لتحرير المواقع المحجوزة من قبل المصفوفة الديناميكية. #include <iostream> using namespace std; class dynamic { private : int *A ; int size ; public : // البان الافتراضي dynamic (){ cout<<" constructor is called " ; size = 0; A=new int [0]; } //طريقة لادخال عناصر المصوفة void input(s){ size = s; A=new int [size]; for (int i=0;i<size;i++){ cin>>A[i]; } //هادم لتحرير الذاكرة ~dnamic() { Cout<< " destructor is called " ; Delete[]A; } }; int main() { dynamic d //غرض من الصف السابق int n; cin>>n ; //ادخال عدد العناصر d.input(n); return 0 ; } //الخرج constructor is called 5 1 2 55 57 69 destructor is called إذاً تم استدعاء التابع Destructor بعد الانتهاء من تنفيذ جميع تعليمات البرنامج الموضوعة ضمن ال main، ليقوم بتحرير المواقع المحجوزة.
- 2 اجابة
-
- 2
-
-
هي دالة خسارة (تكلفة) وتستخدم لنماذج التوقع، وهو يمثل متوسط مجموع الفروق بين القيم الحقيقية والمتوقعة بالقيمة المطلقة. loss = abs(y_true - y_pred) يعد MAE مفيدًا في حالة تلف بيانات التدريب بسبب القيم المتطرفة (أي أننا نتلقى بشكل خاطئ قيمًا سلبية / إيجابية ضخمة بشكل غير واقعي في بيئة التدريب لدينا ، ولكن لانتلقاها في بيئة الاختبار). بشكل عام لا أحبذ استخدامه كدالة تكلفة لأن الدوال من الشكل |x| أي دوال القيمة المطلقة يكون لها شكل مشابه تماماً لحرف V وبالتالي فإن قيمة المشتقة في أي نقطة ستكون كبيرة وهذا أمر غير مناسب، ويمكن إصلاح هذه المشكلة لكن لاداعي لإضاعة الوقت عليها، حيث يمكنك استخدام MSE فهي دالة ممتازة مع مهام التوقع. إن أفضل ايستخدام لها بالنسبة لي هو استخدامها كمعيار (مقياس) لأداء نماذج التوقع. في المثال التالي سأقوم باستخدامها كدالة خسارة وكمعيار: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss=keras.losses., metrics=['mae']) #بالشكل التالي compile هنا استخدمناها كدالة تكلفة وكمعيار عن طريق تمريره إلى الدالة model.compile(optimizer='rmsprop', loss='mae', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64)
- 2 اجابة
-
- 1
-
-
Log-cosh هي دالة أخرى من دوال التكلفة المستخدمة مع مهام التوقع وهي أكثر سلاسة من MSE، وهي لوغاريتم جيب التمام الزائدي لخطأ التنبؤ "hyperbolic cosine of the prediction error". log(cosh(x)) تساوي تقريباً: (x ** 2) / 2 #صغيرة x عندما تكون abs(x) - log(2) # عندما تكون كبيرة هذا يعني أنها تعمل في الغالب مثل MSE، ولكنها لا تتأثر بالتنبؤ غير الصحيح إلى حد كبير. ولديها كل مزايا دالة هوبر، إضافة إلى إمكانية تفاضلها مرتين، على عكس دالة هوبر. وهذا مهم مع العديد من الخوارزميات التحسين مثل Newton’s. في كيراس يمكن استخدامها من الموديول: keras.losses الصيغة الرياضية: # logcosh = log((exp(x) + exp(-x))/2); x= y_pred - y_true مثال: import keras y_true = [[0., 1.], [0., 0.]] y_pred = [[1., 1.], [0., 0.]] l = keras.losses.LogCosh() l(y_true, y_pred).numpy() # 0.1084452 ولاستخدامها في نموذجك نمررها إلى الدالة compile كالتالي: model.compile( loss='LogCosh' ... ) # أو model.compile( loss=keras.losses.LogCosh() ... ) مثال عملي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss='LogCosh', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64) -----------------------------------------------------------------------Epoch 1/8 7/7 [==============================] - 1s 5ms/step - loss: 21.0908 - mae: 21.7840 Epoch 2/8 7/7 [==============================] - 0s 6ms/step - loss: 20.3744 - mae: 21.0669 Epoch 3/8 7/7 [==============================] - 0s 4ms/step - loss: 18.8925 - mae: 19.5840 Epoch 4/8 7/7 [==============================] - 0s 2ms/step - loss: 17.1608 - mae: 17.8454 Epoch 5/8 7/7 [==============================] - 0s 3ms/step - loss: 16.1519 - mae: 16.8398 Epoch 6/8 7/7 [==============================] - 0s 3ms/step - loss: 14.0706 - mae: 14.7509 Epoch 7/8 7/7 [==============================] - 0s 3ms/step - loss: 13.2366 - mae: 13.9173 Epoch 8/8 7/7 [==============================] - 0s 3ms/step - loss: 11.4787 - mae: 12.1537
- 2 اجابة
-
- 1
-
-
حسناً اعتدنا على تمرير وسيطين إلى طبقة التضمين، الأول هو عدد ال tokens (المفردات) الموجودة في بياناتك أي (1 + maximum word index) والثاني هو dimensionality of the embeddings أي أبعاد التضمين. وكان ذلك كافياً عندما تكون الطبقة التالية هي طبقة تكرارية (أحد أنواع RNN). لكنك هنا تستخدم طبقة Flatten بعدها، لذا في هذه الحالة يجب أن نقوم بتمرير وسيط إضافي إلى طبقة التضمين وهو input_length أي طول سلاسل الإدخال لديك: from keras.datasets import imdb from keras.layers import Embedding, SimpleRNN,Flatten,Dense from keras.models import Sequential (input_train, y_train), (input_test, y_test) = imdb.load_data( num_words=10000) print(len(input_train), 'train sequences') print(len(input_test), 'test sequences') ################ نضيف################### from keras.preprocessing import sequence maxlen = 20 print('Pad sequences (samples x time)') input_train = sequence.pad_sequences(input_train, maxlen=maxlen) input_test = sequence.pad_sequences(input_test, maxlen=maxlen) ############# انتهى#################### print('input_train shape:', input_train.shape) print('input_test shape:', input_test.shape) from keras.layers import Dense model = Sequential() model.add(Embedding(10000, 16, input_length=maxlen)) model.add(Flatten()) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(input_train, y_train, epochs=2, batch_size=32, validation_split=0.2) --------------------------------------------------------------------------------------------- 25000 train sequences 25000 test sequences Pad sequences (samples x time) input_train shape: (25000, 20) input_test shape: (25000, 20) Epoch 1/2 625/625 [==============================] - 2s 3ms/step - loss: 0.6506 - acc: 0.5996 - val_loss: 0.5080 - val_acc: 0.7414 Epoch 2/2 625/625 [==============================] - 2s 3ms/step - loss: 0.4356 - acc: 0.7957 - val_loss: 0.4968 - val_acc: 0.7534
- 2 اجابة
-
- 1
-
-
الصف object هو جذر كل الصفوف في بايثون أو الأب لكل الصفوف base-class. في بايثون 3 لافرق في كتابة: class hi: pass hi.__bases__ #(<type 'object'>,) أو: class hi(object): pass hi.__bases__ # الخرج #(<type 'object'>,) فكلاهما يؤدي إلى إنشاء صف جديد مع تحديد الصف object كأب له كما تلاحظ من الخرج. أما في بايثون 2 (تحديداً من بعد 2.2) فإن تعريف الكلاس بالشكل: class hi(object): pass يؤدي إلى إنشاء صف جديد مع تحديد الصف object كأب له، ويسمى التعريف بهذا الشكل "new style class"، أي كما في بايثون 3. أما تعريفه بهذا الشكل: class hi: pass # انظر hi.__bases__ # الخرج () فهنا لايكون لدينا object كصف رئيسي. وتسمى بالطريقة الكلاسيكية."old style class". وطبعاً أنت ستهتم بالطريقة الجديدة فكلنا نتبع الطرق الأحدث. طبعاً في كل كم النمط القديم والحديث فإن ال staticmethod و classmethod تعملان بشكل طبيعي، property تعمل مع القراءة في النمط القديم لكنها تفشل مع ال intercept writes وأما __slots__ فتم تحسينها من حيث سرعة الوصول إلى ال attribute وأيضاً توفيرها للذاكرة.
- 2 اجابة
-
- 2
-
-
المشكلة تحدث في طبقة التضمين Embedding. هذه الطبقة تأخذ وسيطين على الأقل الأول هو عدد ال tokens (المفردات) الموجودة في بياناتك أي (1 + maximum word index) والثاني هو dimensionality of the embeddings أي أبعاد التضمين. يمكن اعتبار طبقة التضمين قاموس يقوم بربط أعداد صحيحة (كل عدد يمثل كلمة) بأشعة كثيفة. "maps integer indices,(which stand for specific words) to dense vectors" وبالتالي يأخذ كمدخل له عدد صحيح ثم يبحث عن هذا العدد في قاموسه ثم يرد الشعاع المقابل له. Word index --> Embedding layer --> Corresponding word vector أنت ماذا فعلت؟! أنت قمت بتحديد عدد المفردات بالنص الخاص بك إلى 75000 كلمة فريدة، ثم قمت بتحديد 10000 كلمة في طبقة التضمين وهذا سينتج خطأ لأن الكلمات الموجودة في بياناتك أكثر بكثير وبالتالي لن يجد هذه الكلمات في قاموسه الداخلي وبالتالي ينتج خطأ. لحل المشكلة يجب أن تتم مطابقتهما أي إذا حددت عدد الكلمات التي ستبقى في نصك في مرحلة ال tokenaization ب 75000 فيجب أن تحدد 75000 في طبقة التضمين أيضاً. التصحيح: df_train = pd.read_csv('/content/drive/MyDrive/imdbdataset/Completely_clean_data.csv') df_train.drop(df_train.filter(regex="Unname"),axis=1, inplace=True) df_test = pd.read_csv('/content/drive/MyDrive/imdbdataset/Completely_clean_data_test.csv') df_test.drop(df_test.filter(regex="Unname"),axis=1, inplace=True) max_words = 75000 tokenizer = Tokenizer(num_words=max_words) # fitting tokenizer.fit_on_texts(pd.concat([df_test['review'], df_train['review']])) #max_len=int(df["review_len"].mean()) #231 # do you remember!! train = tokenizer.texts_to_sequences(df_train['review']) test = tokenizer.texts_to_sequences(df_test['review']) train = pad_sequences(train, maxlen=200) test = pad_sequences(test, maxlen=200) print("the shape of data train :",train.shape) print("the shape of data test :",test.shape) # model def modelBiLSTM(): max_words = 75000 #drop_lstm =0.4 embeddings=128 model = Sequential() # الإصلاح model.add(Embedding(max_words, embeddings)) model.add(Bidirectional(LSTM(64, activation='tanh'))) # 2D output model.add(Dense(1, activation='sigmoid')) # binary output return model model=modelBiLSTM() model.summary() # training model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history=model.fit(train, train_label,validation_split=0.12, batch_size=32, epochs=8)
- 2 اجابة
-
- 1
-
-
يمكن اعتبارها كتحسين لل MSE أو كتطوير لها للتعامل مع حالات معينة، وهي مزيج من ال MSE و MSA. إن ال (MSE) يركز على القيم المتطرفة في مجموعة البيانات، بينما متوسط الخطأ المطلق (MAE) جيد لتجاهل القيم المتطرفة. لكن في بعض الحالات فإن البيانات التي تبدو وكأنها قيم متطرفة، قد لا تشكل مشكلة بالنسبة لك، وأيضاً تلك النقاط من البيانات لا ينبغي أن تحظى بأولوية عالية. وهنا حيث يأتي هوبر لوس. الصيغة الرياضية: كما قلنا فهي مزيج من MSE و MAE مما يعني أنها تربيعية (MSE) عندما يكون الخطأ صغيرًا وإلا فهي MAE. دلتا هنا تعتبر من المعاملات العليا hyperparameter لتحديد نطاق MAE و MSE. من المعادلة نجد أنه عندما يكون الخطأ أقل من دلتا ، يكون الخطأ تربيعيًا وإلا يكون مطلقًا. يمن استخدامها في كيراس بسهولة كالتالي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) #model.compile(optimizer='rmsprop', loss='Huber', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64) """ Epoch 1/8 7/7 [==============================] - 7s 2ms/step - loss: 21.8385 - mae: 22.3385 Epoch 2/8 7/7 [==============================] - 0s 3ms/step - loss: 20.6043 - mae: 21.1043 Epoch 3/8 7/7 [==============================] - 0s 3ms/step - loss: 19.8923 - mae: 20.3920 Epoch 4/8 7/7 [==============================] - 0s 3ms/step - loss: 18.4374 - mae: 18.9368 Epoch 5/8 7/7 [==============================] - 0s 4ms/step - loss: 17.2154 - mae: 17.7146 Epoch 6/8 7/7 [==============================] - 0s 3ms/step - loss: 15.7804 - mae: 16.2756 Epoch 7/8 7/7 [==============================] - 0s 2ms/step - loss: 14.0492 - mae: 14.5466 Epoch 8/8 7/7 [==============================] - 0s 3ms/step - loss: 12.3948 - mae: 12.8905 """
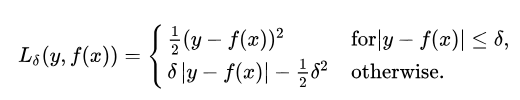
- 2 اجابة
-
- 2
-
-
أشهر دالة تكلفة والأفضل مع مسائل التوقع ويمكن استخدامها أيضاً كمعيار لكن من غير الشائع القيام بذلك، وهي تقوم على حساب متوسط الفرق التربيعي بين القيم المتوقعة من النموذج والقيمة الفعلية. ال MSE قوي في التعامل مع القيم المتطرفة في البيانات. الصيغة الرياضية: ال MSE من أجل عينة ما : # من أجل عينة واحدة loss = square(y_true - y_pred) لاستخدامها نقوم بتمررها إلى الدالة compile في نوذجنا كما في المثال: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss=keras.losses., metrics=['mae']) #بالشكل التالي compile هنا استخدمناها كدالة تكلفة وكمعيار عن طريق تمريره إلى الدالة #model.compile(optimizer='rmsprop', loss='mse', metrics=['mse']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64) """ Epoch 1/8 7/7 [==============================] - 1s 2ms/step - loss: 583.3815 - mse: 583.3815 Epoch 2/8 7/7 [==============================] - 0s 2ms/step - loss: 531.9802 - mse: 531.9802 Epoch 3/8 7/7 [==============================] - 0s 3ms/step - loss: 503.3803 - mse: 503.3803 Epoch 4/8 7/7 [==============================] - 0s 3ms/step - loss: 409.2950 - mse: 409.2950 Epoch 5/8 7/7 [==============================] - 0s 2ms/step - loss: 387.9506 - mse: 387.9506 Epoch 6/8 7/7 [==============================] - 0s 3ms/step - loss: 303.1605 - mse: 303.1605 Epoch 7/8 7/7 [==============================] - 0s 2ms/step - loss: 253.2450 - mse: 253.2450 Epoch 8/8 7/7 [==============================] - 0s 3ms/step - loss: 190.7695 - mse: 190.7695 """
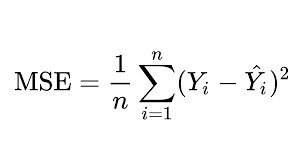
- 2 اجابة
-
- 2
-