


Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 يمكنك القيام بذلك من خلال الدالة reshape هذه الدالة تمكنك من تعديل أبعاد المصفوفة بالشكل الذي تريده، والشرط الوحيد هو أن كون عدد العناصر في المصفوفة الجديدة التي تريد إعادة تشكيلها = عدد العناصر في المصفوفة الأصلية. أي إذا كانت المصفوفة الأصلية مصفوفة أحادية البعد ب 12 عنصر وأردنا تحويلها لمصفوفة ثنائية ببعدين وبالتالي يجب أن يكون ناتج جداء البعد الأول بالثاني =12 وبالتالي يمكن أن نستنتج أن أبعاد المصفوفة الناتجة إحدى الخيارات التالية: a=np.arange(12) a.reshape(3,4) """ array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) """ a.reshape(4,3) """ array([[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]]) """ a.reshape(6,2) """ array([[ 0, 1], [ 2, 3], [ 4, 5], [ 6, 7], [ 8, 9], [10, 11]]) """ a.reshape(2,6) a.reshape(4,4) # ValueError: cannot reshape array of size 12 into shape (4,4) كما أننا يمكننا أن نمرر له بعد واحد والبعد الآخر نضع مكانه -1 و هو سيستنتجه تلقائياً وفقاُ لمعادلة الجداء: a=np.arange(12) a.reshape(-1,4) # سيستنتج أنه3 """ array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) """ الآن بالتأكيد أصبحت تستطيع معالجة مشكلتك، حيث يمكنك التلاعب بشكل الإخراج بالشكل الذي تريده: arr = np.ones((50,100,25)) arr.shape # (50, 100, 25) arr1=arr.reshape(-1,50) # 100*25 arr1.shape #(2500, 50) arr2=arr.reshape(-1,25) # 100*50 arr2.shape #(5000, 25) arr3=arr.reshape(50,-1) # 100*25 arr3.shape #(50, 2500) arr4=arr.reshape(100,-1) arr4.shape # (100, 1250) arr5=arr.reshape(-1,100) arr5.shape #(1250, 100) أو مثلاً لو لدينا مصفوفة ب 4 أبعاد: arr = np.ones((50,100,25,4)) arr.shape #(50, 100, 25, 4) arr1=arr.reshape(-1,50) # 100*25*4 arr1.shape # (10000, 50) arr2=arr.reshape(50,100,-1) # 25*4 arr2.shape #(50, 100, 100) وهكذا..
يمكنك القيام بذلك من خلال الدالة reshape هذه الدالة تمكنك من تعديل أبعاد المصفوفة بالشكل الذي تريده، والشرط الوحيد هو أن كون عدد العناصر في المصفوفة الجديدة التي تريد إعادة تشكيلها = عدد العناصر في المصفوفة الأصلية. أي إذا كانت المصفوفة الأصلية مصفوفة أحادية البعد ب 12 عنصر وأردنا تحويلها لمصفوفة ثنائية ببعدين وبالتالي يجب أن يكون ناتج جداء البعد الأول بالثاني =12 وبالتالي يمكن أن نستنتج أن أبعاد المصفوفة الناتجة إحدى الخيارات التالية: a=np.arange(12) a.reshape(3,4) """ array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) """ a.reshape(4,3) """ array([[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]]) """ a.reshape(6,2) """ array([[ 0, 1], [ 2, 3], [ 4, 5], [ 6, 7], [ 8, 9], [10, 11]]) """ a.reshape(2,6) a.reshape(4,4) # ValueError: cannot reshape array of size 12 into shape (4,4) كما أننا يمكننا أن نمرر له بعد واحد والبعد الآخر نضع مكانه -1 و هو سيستنتجه تلقائياً وفقاُ لمعادلة الجداء: a=np.arange(12) a.reshape(-1,4) # سيستنتج أنه3 """ array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) """ الآن بالتأكيد أصبحت تستطيع معالجة مشكلتك، حيث يمكنك التلاعب بشكل الإخراج بالشكل الذي تريده: arr = np.ones((50,100,25)) arr.shape # (50, 100, 25) arr1=arr.reshape(-1,50) # 100*25 arr1.shape #(2500, 50) arr2=arr.reshape(-1,25) # 100*50 arr2.shape #(5000, 25) arr3=arr.reshape(50,-1) # 100*25 arr3.shape #(50, 2500) arr4=arr.reshape(100,-1) arr4.shape # (100, 1250) arr5=arr.reshape(-1,100) arr5.shape #(1250, 100) أو مثلاً لو لدينا مصفوفة ب 4 أبعاد: arr = np.ones((50,100,25,4)) arr.shape #(50, 100, 25, 4) arr1=arr.reshape(-1,50) # 100*25*4 arr1.shape # (10000, 50) arr2=arr.reshape(50,100,-1) # 25*4 arr2.shape #(50, 100, 100) وهكذا..- 2 اجابة
-
- 1
-

-
هناك الكثير من الطرق وأولها الدالة flatten وهذه الدالة تعيد نسخة من المصفوفة الأصلية: import numpy as np a = np.array([[1, 2, 3], [45, 4, 7], [9, 6, 10]]) a.flatten() #array([ 1, 2, 3, 45, 4, 7, 9, 6, 10]) إذا كنت تتعامل مع ndarray كبيرة الحجم ، فقد يتسبب استخدام flatten في حدوث مشكلة في الأداء. يوصى بعدم استخدامه في هكذا حالات (كما أنه أبطأ كثيراً). ما لم تكن بحاجة إلى نسخة من البيانات للقيام بشيء آخر.... أيضاً يمكن استخدام الدالة ravel: import numpy as np a = np.array([[1, 2, 3], [45, 4, 7], [9, 6, 10]]) a.ravel() #array([ 1, 2, 3, 45, 4, 7, 9, 6, 10]) أو من خلال الدالة reshape: import numpy as np a = np.array([[1, 2, 3], [45, 4, 7], [9, 6, 10]]) a.reshape(-1) # فقط نمرر لها -1 #array([ 1, 2, 3, 45, 4, 7, 9, 6, 10]) ينصح باستخدام reshape فهي توفر المرونة في إعادة تشكيل الحجم إضافةً إلى أنها هي و ravel سريعتين (بنفس الأداء تقريباً). ويمكنك أيضاً استخدام flat لكن هنا لايعيد لك مصفوفة جديدة وإنما iterator (مكرر) على مصفوفتك (ربما يفيدك): import numpy as np a = np.array([[1, 2, 3], [45, 4, 7], [9, 6, 10]]) arr=a.flat for i in a.flat: print(i,end=" ") #1 2 3 45 4 7 9 6 10
- 2 اجابة
-
- 1
-
-
np.max هو فقط اسم مختصر أو مستعار لـ np.amax . نمرر لهذا التابع المصفوفة التي نريدها ويرد لنا القيمة العظمى فيها. أو يمكننا أن نحدد المحور الذي نريد حساب القيمة العظمى على أساسه وسيجد لنا القيمة العظمى على طول محور مصفوفة الإدخال (يرد مصفوفة جديدة بالقيم العظمى على طول الأسطر أو الأعمدة). ليتضح الأمر أكثر انظر: import numpy as np a = np.array([[3, 22, 5], [12, 3, 0], [6, 8, 9]]) np.max(a) #22 np.max(a, axis=0) # سيجد لنا القيمة العظمى في كل عمود #array([12, 22, 9]) np.max(a, axis=1) # هنا في كل سطر #array([22, 12, 9]) السلوك الافتراضي لـ np.maximum هو أخذ مصفوفتين وحساب القيمة العظمى من المصفوفتين بشكل element-wise أي يقارن أول قيمة من المصفوفة الأولى بأول قيمة من الثانية والأكبر يضعه في المصفوفة الجديدة. هنا ، تعني كلمة "متوافق" أنه يمكن بث مصفوفة إلى الأخرى. فمثلا: a1 = np.array([8, 9, 1]) a2 = np.array([4, 10, 2]) np.maximum(a1, a2) array([8, 10, 2]) لكن np.maximum هي أيضاً وظيفة عامة مما يعني أن لها ميزات وطرق أخرى مفيدة عند العمل مع المصفوفات متعددة الأبعاد. على سبيل المثال ، يمكنك حساب القيمة العظمى التراكمية على مصفوفة (أو محور معين من المصفوفة) وهذا غير ممكن في np.max: a = np.array([3, 4, -1, 5, 8]) np.maximum.accumulate(a) #array([3, 4, 4, 5, 8]) كما ويمكنك جعلها تعمل مثل np.maax بالشكل التالي، حيث نستدعي np.maximum.reduce: import numpy as np a = np.array([[3, 22, 5], [12, 3, 0], [6, 8, 9]]) np.maximum.reduce(a,axis=None) #22 np.maximum.reduce(a,axis=0) #array([12, 22, 9]) ومن حيث الأداء فلا فرق ف np.max تستخدم ضمنياً np.maximum.reduce لحساب القيم العظمى، أي كلاهما متشابهان. أما الاختلاف فهو كما ذكرنا في الأعلى "حساب القيمة العظمى من المصفوفتين بشكل element-wise ". أما بالنسبة إلى np.amax و np.max فكلاهما يستدعي نفس التابع. np.max هو مجرد اسم مستعار لـ np.amax، ويحسبان القيمة العظمى لجميع العناصر في المصفوفة ، أو على طول محور المصفوفة المحدد.
- 1 جواب
-
- 1
-
-
حسناً: كيف نضيف أعمدة وأسطر لصفوفات نمباي، أول طريقة باستخدام التابع column_stack لإضافة عمود: # إضافة أعمدة import numpy as np arr = np.array([[3, 3, 2], [0, 8, 7]]) # طباعة المصفوفة الأصلية print("initial_array : \n", str(arr)); # العمود المراد إضافته col = np.array([0, 12]) # إضافة العمود a = np.column_stack((arr, col)) # نمرر المصفوفة ثم العمود # النتيجة print ("resultant array\n", str(a)) """ initial_array : [[3 3 2] [0 8 7]] resultant array [[ 3 3 2 0] [ 0 8 7 12]] """ ولإضافة عدة أعمدة دفعة واحدة: # إضافة أعمدة import numpy as np arr = np.array([[3, 3, 2], [0, 8, 7]]) # طباعة المصفوفة الأصلية print("initial_array : \n", str(arr)); # العمود المراد إضافته col = np.array([[0, 12],[5,6]]) # إضافة العمود a = np.column_stack((arr, col)) # نمرر المصفوفة ثم العمود # النتيجة print ("resultant array\n", str(a)) """ initial_array : [[3 3 2] [0 8 7]] resultant array [[ 3 3 2 0 12] [ 0 8 7 5 6]] """ أو استخدام التابع np.hstack لإضافة أعمدة أيضاً: # إضافة أعمدة import numpy as np arr = np.array([[3, 3, 2], [0, 8, 7]]) # طباعة المصفوفة الأصلية print("initial_array : \n", str(arr)); # العمود المراد إضافته col = np.array([[0, 12],[5,6]]) # إضافة العمود a = np.hstack((arr, np.atleast_2d(col).T))# نمرر المصفوفة ثم العمود # حيث أن np.atleast_2d(col) """ array([[ 0, 12], [ 5, 6]]) """ np.atleast_2d(col).T """ array([[ 0, 5], [12, 6]]) """ # النتيجة print ("resultant array\n", str(a)) """ initial_array : [[3 3 2] [0 8 7]] resultant array [[ 3 3 2 0 12] [ 0 8 7 5 6]] """ أو من خلال التابع np.vstack لإضافة أسطر: # إضافة أعمدة import numpy as np arr = np.array([[3, 3, 2], [0, 8, 7]]) # طباعة المصفوفة الأصلية print("initial_array : \n", str(arr)); # السطر المراد إضافته row = np.array([1, 2,5]) # السطر الذي نريد إضافته # إضافة السطر a = np.vstack ((arr, row) ) # نمررالمصفوفة والسطر # النتيجة print ("resultant array\n", str(a)) """ initial_array : [[3 3 2] [0 8 7]] resultant array [[3 3 2] [0 8 7] [1 2 5]] """ ولإضافة عدة أسطر دفعة واحدة: # إضافة أعمدة import numpy as np arr = np.array([[3, 3, 2], [0, 8, 7]]) # طباعة المصفوفة الأصلية print("initial_array : \n", str(arr)); # الأسطر المراد إضافتها row = np.array([[1, 2,5],[2,3,2]]) # السطر الذي نريد إضافته # إضافة السطر a = np.vstack ((arr, row) ) # نمررالمصفوفة والسطر # النتيجة print ("resultant array\n", str(a)) """ initial_array : [[3 3 2] [0 8 7]] resultant array [[3 3 2] [0 8 7] [1 2 5] [2 3 2]] """ في بعض الأحيانً يكون لدينا مصفوفة فارغة ونحتاج إلى إضافة صفوف لها. يوفر Numpy وظيفة لإضافة صف لمصفوفة Numpy فارغة باستخدام الدالة numpy.append . import numpy as np # إنشاء مصفوفة ثنائية فارغة arr = np.empty((0,2), int) # هنا حددنا عدد أعمدة ب2 لذا فأي صف نضيفه يجب أن يكون له عمودين print("Empty array:\n",arr) # إضافة أسطر جديدة arr = np.append(arr, np.array([[1,5]]), axis=0) arr = np.append(arr, np.array([[6,7]]), axis=0) print("array:\n") print(arr) """ Empty array: [] array: [[1 5] [6 7]] """
- 3 اجابة
-
- 1
-
-
من خلال Numpy يمكننا التحكم في شكل طباعة المصفوفات عن طريق التابع numpy.set_printoptions حيث أن الوسيط suppress يستطيع التحكم في ذلك، فضبطه على True سوف يلغي هذا الترميز: import numpy as np arr = np.array([[3.1415, 2.7182],[6.6260e-34, 6.6743e-11]]) #نتحكم بعدد الأرقام بعد الفاصلة precision من خلال الوسيط np.set_printoptions(precision=2) print(arr) """ [[3.14e+00 2.72e+00] [6.63e-34 6.67e-11]] """ np.set_printoptions(suppress=True) # إلغاء الترميز الأسي print(arr) """ [[3.14 2.72] [0. 0. ]] """ np.set_printoptions(suppress=False) print(arr) """ [[3.14e+00 2.72e+00] [6.63e-34 6.67e-11]] """ لكن هذا لاينفع مع الأعداد التي تحوي على أكثر من 8 أرقام، وأي محاولة لقمع الترميز الأسي في هذه الحالة لن يكون خياراً جيداً.
- 3 اجابة
-
- 1
-
-
أولاً ال 2D-Heatmap هي خريطة التمثيل اللوني ثنائية الأبعاد هي أداة تصور البيانات التي تساعد على تمثيل حجم الظاهرة في شكل ألوان. في بايثون ، يمكننا رسم خرائط حرارية ثنائية الأبعاد باستخدام حزمة Matplotlib. هناك طرق مختلفة لرسم خرائط حرارية ثنائية الأبعاد ، ويمكنك تحقيق ذلك بعدة طرق. من خلال التابع imshow حيث أن cmap هي اسم خريطة الألوان colormap المستخدمة لربط البيانات العددية بالألوان بحيث كل عدد يقابل لون.: import matplotlib.pyplot as plt import numpy as np # تشكيل بيانات عشوائية a = np.random.random((20, 20)) #interpolation='nearest' و cmap='hot' نحدد للتابع الوسطاء plt.imshow(a, cmap='hot', interpolation='nearest') plt.show() هنا بنفس الطريقة لكن غيرنا خريطة الألوان: import numpy as np import matplotlib.pyplot as plt a = np.random.random(( 4 , 4 )) """ [[0.18622235 0.55756219 0.08281777 0.081955 ] [0.12048756 0.4210682 0.7152597 0.37106132] [0.29459933 0.49586024 0.09527473 0.00433101] [0.68683861 0.63551886 0.47319173 0.82563014]] """ plt.imshow( a , cmap = 'autumn' , interpolation = 'nearest' ) plt.title( "2-D Heat Map" ) plt.show() لاحظ كيف أن القيم الأكبر لونها أفتح والقيم الأصغر لونها أغمق. أو من خلال seaborn.heatmap: import seaborn as sns import matplotlib.pyplot as plt import numpy as np a = np.random.rand(10, 12) ax = sns.heatmap(a, linewidth=0.5) plt.show() وأخيراً من خلال التابع pcolormesh من الموديول matplotlib.pyplot: import matplotlib.pyplot as plt import numpy as np a = np.random.rand( 4 , 4 ) plt.pcolormesh( a , cmap = 'summer' ) plt.title( '2-D Heat Map' ) plt.show() # أو import matplotlib.pyplot as plt import numpy as np a = np.random.rand( 4 , 4 ) plt.pcolormesh( a , cmap = 'hot' ) # غيرنا الألوان plt.title( '2-D Heat Map' ) plt.show()
- 2 اجابة
-
- 1
-
-
لو قمت بعرض نوع البيانات لل history فستجد: type(history) # keras.callbacks.History وهو يعتبر مرجع ضعيف weakref أو weak rederence (المرجع الضعيف لكائن ما هو المرجع الذي لا يمنع الكائن من أن يتم استعادته بواسطة أداة تجميع البيانات المهملة garbage collector) وفي هذه الحالة لن تتمكن من حفظه بهذه الطريقة. لذا يظهر الخطأ والحل هو بتخزين القاموس الذي يحتويه هذا المرجع من خلال الواصفة history وهي كل مايهمنا حيث تحتوي على المعلومات المطلوبة. أي يصبح الحل: #history انظر كيف سنحصل على المعلومات المطلوبة من خلال الواصفة history.history """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ import pickle with open('/HistoryDict', 'wb') as f: pickle.dump(history.history, f) history = pickle.load(open('/HistoryDict', "rb")) history """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ كما يمكنك حفظ النتائج بعدة طرق أخرى تجدها في الرابط التالي:
-
بفرض لدينا النموذج التالي، الذي قمنا بتدريبه: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss="mae", metrics=['mae']) return model # تدريب النموذج model = build_model() # قمنا بتدريب النموذج hisyory=model.fit(train_data, train_targets,epochs=2, batch_size=64) --------------------------------------------------------------------------------------------- """ Epoch 1/2 7/7 [==============================] - 1s 2ms/step - loss: 21.4842 - mae: 21.4842 Epoch 2/2 7/7 [==============================] - 0s 3ms/step - loss: 20.2813 - mae: 20.2813 """ يمكنك حفظ النتائج في ملفات pickle بالشكل التالي: hisyory.history """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ import pickle with open('/HistoryDict', 'wb') as f: pickle.dump(hisyory.history, f) history = pickle.load(open('/HistoryDict', "rb")) history """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ أو كملفات json: import json with open('file.json', 'w') as f: json.dump(hisyory.history, f) history1 = json.load(open('file.json')) history1 """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ أو بالشكل التالي: # حفظها np.save('my_history.npy',hisyory.history) load=np.load('my_history.npy',allow_pickle='TRUE').item() load """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ أو يمكنك تحويلها لداتافريم Dataframe ثم يمكنك حفظها كملفات CSV: import pandas as pd df = pd.DataFrame(hisyory.history) print(df.head(n=1)) """ loss mae 0 21.153151 21.153151 """ with open('history.csv', mode='w') as f: df.to_csv(f) # إعادة تحميله data = pd.read_csv("history.csv") data.head() """ Unnamed: 0 loss mae 0 0 21.153151 21.153151 1 1 19.534307 19.534307 """
- 2 اجابة
-
- 1
-
-
حسناً سأقترح لك عدة طرق، بدايةً سأقوم بإنشاء تابع لك، تمرر له رقم العمود أو الأعمدة التي تريدها أن تظهر في المصفوفة الجديدة ويعطيك الخرج المطلوب (تمررها على شكل قائمة): import numpy as np arr = np.random.randint(5, size=(5,3)) print(arr) """ [[4 1 2] [3 2 3] [0 1 4] [4 3 3] [2 3 0]] """ # التابع def make(index,a): a=a.T b=a[index] return b.T # الآن بفرض أنك تريد مصفوفة جديدة من المصفوفة الأصلية مكونة من ثاني و ثالث عمود make([1,2],arr) # الخرج """ array([[1, 2], [2, 3], [1, 4], [3, 3], [3, 0]]) """ # إذا أردنا ثاني عمود فقط make([1],arr) """ array([[1], [2], [1], [3], [3]]) """ حيث اعتمدت على فكرة أخذ منقول المصفوفة ثم اختيار الأعمدة التي أريدها (التي أصبحت تشكل أسطر) ثم بعدها نأخذ المنقول مرة أخرى لتعطي الخرج. وبشكل أكثر سهولة يمكنك استخدام مفهوم الفهرسة والتقطيع في بايثون، بالشكل التالي: # إذا أردت ثاني عمود arr[:,[1]] """ array([[1], [2], [1], [3], [3]]) """ # ثاني وثالث عمود arr[:,[1,2]] """ array([[1, 2], [2, 3], [1, 4], [3, 3], [3, 0]]) """ وأخيراً، إذا أردت أسطر وأعمدة محددين: # ثاني وثالث عمود مع أول سطرين فقط arr[:2,1:3] """ array([[1, 2], [2, 3]]) """
- 3 اجابة
-
- 2
-
-
متوسط النسبة المئوية للخطأ المطلق (MAPE)، هي دالة تستخدم لحساب متوسط النسبة المئوية للخطأ المطلق بين y_true و y_pred أي القيم الحقيقية والقيم المتوقعة من قبل النموذج. وتستخدم مع مهام التوقع، وهي تشابه لحد ما الدالة MAE: loss = 100 * abs(y_true - y_pred) / y_true ويعتبر هذا المقياس من المقاييس الأكثر شيوعاً المستخدمة مع مهام التنبؤ بالمناخ، ويعمل بشكل أفضل إذا لم تكن البيانات متطرفة (ولاتحوي أصفاراً). ويمكن استدعاؤها من الموديول التالي: tf.keras.losses.MeanAbsolutePercentageError مثال على استخدامها في كيراس: import tensorflow as tf y_true = [[2., 1.], [2., 3.]] y_pred = [[1., 1.], [1., 0.]] mape = tf.keras.losses.MeanAbsolutePercentageError() mape(y_true, y_pred).numpy() 50. لاستخدامها في نماذجك يمكنك تمريرها للدالة compile بالشكل التالي: model.compile( ... loss="MeanAbsolutePercentageError" ) # أو model.compile( ... loss=tf.keras.losses.MeanAbsolutePercentageError() ) مثال عليها أثناء تدريب نموذج لتوقع أسعار المنازل: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='adam', loss="MeanAbsolutePercentageError", metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=14, batch_size=32) ----------------------------------------------------------------------------------------------- Epoch 11/14 13/13 [==============================] - 0s 3ms/step - loss: 17.9825 - mae: 4.1283 Epoch 12/14 13/13 [==============================] - 0s 2ms/step - loss: 15.7485 - mae: 3.3775 Epoch 13/14 13/13 [==============================] - 0s 2ms/step - loss: 14.7182 - mae: 3.3004 Epoch 14/14 13/13 [==============================] - 0s 2ms/step - loss: 14.9168 - mae: 3.4608 <keras.callbacks.History at 0x7fe5c3a0f810>
- 2 اجابة
-
- 1
-
-
1. تحويل ال tuple إلى قوائم ثم تحويل القائمة إلى مصفوفة، ثم تنفيذ عملية Transpose عليها (المنقول): tuples = [('a', 2), ("b", 4), ("c", 6)] lists = [list(x) for x in tuples] print(lists) # [['a', 2], ['b', 4], ['c', 6]] arr=np.array(lists) arr.T """ array([['a', 'b', 'c'], ['2', '4', '6']], dtype='<U1') """ 2.بشكل مشابه للطريقة السابقة لكن هنا سوف نستبدل حلقة ال for بتعليمة ال map: tuples = [('a', 2), ("b", 4), ("c", 6)] lists = list(map(list, tuples)) print(lists) # [['a', 2], ['b', 4], ['c', 6]] arr=np.array(lists) arr.T """ array([['a', 'b', 'c'], ['2', '4', '6']], dtype='<U1') """ 3.تحويلها إلى قاموس، ثم تحويلها إلى مصفوفة، ثم تنفيذ عملية Transpose عليها (المنقول): tuples = [('a', 2), ("b", 4), ("c", 6)] dic=dict(tuples) print(dic) # {'a': 2, 'b': 4, 'c': 6} # [['a', 2], ['b', 4], ['c', 6]] arr=np.array(dic).T arr # array({'a': 2, 'b': 4, 'c': 6}, dtype=object) 4. أو بالشكل التالي، حيث نقوم بتحويل القائمة إلى قاموس، ثم نخزن قيمه (القيم وليس المفاتيح)، ثم نحول الخرج ليصبح قائمة ثم نحوله لمصفوفة، وأخيراً نحوله من البعد (,3) إلى البعد (3,1) أي أصبحت مصفوفة ثنائية ثم نقوم باستخراج المفاتيح و نضعهم في مصفوفة (كما في المرحلة السابقة لكن هنا نستخرج المفاتيح ونخزنها) والغاية من ذلك هي لربط النتائج ووضعها في مصفوقة واحدة، حيث أن المفاتيح للقاموس الذي تم إنتاجه هي ال a c أما القيم فهي القيم التي تقابلها: tuples = [('a', 2), ("b", 4), ("c", 6)] values=np.array(list(dict(tuples).values())).reshape(1,-1) # dict_values([2, 4, 6]) keys=np.array(list(dict(tuples).keys())).reshape(1,-1) # dict_keys(['a', 'b', 'c']) np.concatenate((keys, values), axis=0) """ array([['a', 'b', 'c'], ['2', '4', '6']], dtype='<U21') """
- 2 اجابة
-
- 2
-
-
يمكنك القيام بذلك بالشكل التالي في باندا: df = df.astype(object).where(pd.notnull(df),None) ويمكنك استبدال nan بـ None في مصفوفة numpy الخاصة بك من خلال استخدام التابع np.where حيث نمرر له كوسيط أول القيمة المعادة من تطبيق التابع np.isnan على المصفوفة الخاصة بك، ثم القيمة المراد الاستبدال بها، ثم المصفوفة: arr = np.array([4, np.nan]) arr = np.where(np.isnan(arr), None, arr) # [4.0 None] print type(arr[1]) #<type 'NoneType'> كما ويمكنك القيام بذلك بسهولة من خلال التابع replace في باندا: df = df.replace({np.nan: None}) وللتحويل من none ل nan: import numpy as np x = np.array([3,4,None,55]) x = np.array(x,dtype=float) x #array([ 3., 4., nan, 55.]) # أو x = np.array(x) x.astype(float) #array([ 3., 4., nan, 55.])
- 3 اجابة
-
- 2
-
-
يمكنك القيام بذلك بالشكل التالي، حيث قمنا بتعريف التابع random.randint الذي يقوم بإنشاء مصفوفة عشوائية من القيم الصحيحة ب 10 أسطر و 3 أعمدة، بحيث أعلى قيمة فيها هي 5. بعد ذلك قمنا باستخدام نفس التابع لكي يقوم بتوليد أعداد صحيحة أعلى قيمة فيها يساوي 10، وبحجم 3 أي سكون الخرج مصفوفة أحادية البعد، قيم هذه المصفوفة ستمثل فهارس الأسطر التي ستم اختيارها من المصفوفة الجديدة لتشكيل المصفوفة. وأخيراً نقوم باستخدام التعليمة arr[index,:] لعرض المطلوب. حيث في مثالنا يمكنك أن تلاحظ أن المصفوفة index التي شكلناها تحوي القيم 9 9 4 وبالتالي سنختار الأسطر 9 9 4 من المصفوفة الأصلية لتشكيل المصفوفة الجديدة. كما يجب أن تلاحظ أننا حددنا أكبر قيمة في المصفوفة index بالعدد 10 أي ستكون القيم المولدة أقل من 10 أي من 0 ل 9 وذلك لأن عدد أسطر المصفوفة الأصلية هو 10 أي الفهارس من 0 ل 9 وهذا مهم لكي لانخرج عن حدود المصفوفة وبالتالي لتجنب ظهور أي خطأ. import numpy as np arr = np.random.randint(5, size=(10,3)) print(arr) """ [[4 1 1] [2 3 2] [1 4 1] [2 2 0] [1 3 3] [3 2 0] [2 0 3] [2 1 2] [4 0 4] [0 2 3]] """ index = np.random.randint(10, size=3) print(index) # [9 9 4] arr[index,:] أو من خلال استخدام التابع np.random.choice ليختار لنا الفهارس بطريقة عشوائية: indices = np.random.choice(arr.shape[0],3, replace=False) arr[indices] """ array([[3, 2, 0], [2, 3, 2], [2, 2, 0]]) """ arr[np.random.choice(arr.shape[0], 4, replace=False)] """ array([[3, 2, 0], [0, 2, 3], [2, 2, 0], [1, 3, 3]]) """
- 2 اجابة
-
- 2
-
-
يؤدي تكرار مصفوفة كصف باستخدام NumPy إلى ظهور مصفوفة ثنائية الأبعاد جديدة بحيث يكون كل صف هو المصفوفة الأصلية. ينتج عن تكرار مصفوفة كعمود مصفوفة ثنائية الأبعاد جديدة بحيث يكون كل عمود هو المصفوفة الأصلية. أول طريقة لتنفيذ ماتطلبه هي استخدام دالة np.repeat بالشكل التالي، حيث نمرر لها المصفوفة والمحور الذي نريد التكرار عليه وعدد التكرارات: import numpy as np array_2d = np.array([[1,2,3]]) # سيتم تكرار عناصر المصفوفة على طول الصفوف أي إلى أسفل. np.repeat(array_2d,repeats=3,axis=0) """ array([[1, 2, 3], [1, 2, 3], [1, 2, 3]]) """ arr = np.array([[1],[2],[3]]) # ًفي هذه الحالة، إذا كنت ستستخدم المحور = 1 ، فسيتم تكرار العناصر مع الأعمدة أي أفقيا np.repeat(arr,repeats=3,axis=1) """ array([[1, 1, 1], [2, 2, 2], [3, 3, 3]]) """ يمكنك أيضاً استخدام الدالة numpy.tile حيث نمرر لها المصفوفة وعدد مرات التكرار ك tuple أي بالشكل (n, 1) حيث تمثل n عدد مرات التكرار. والنتيجة ستكون تكرار المصفوفة أحادية الأبعاد الممررة للدالة tile على المحور العمودي. (أي التكرار كأسطر). an_array = np.array([1,2,3]) # عدد مرات التكرار repeat = 3 np.tile(an_array, (repeat, 1)) """ array([[1, 1, 1], [2, 2, 2], [3, 3, 3]]) """ أما لو أردت التكرار كأعمدة كما في الحالة الثانية يمكنك استخدام numpy.transpose بالشكل التالي: an_array = np.array([[1],[2],[3]]) # عدد مرات التكرار repeat = 3 np.transpose([an_array] * repeat) """ array([[[1, 1, 1], [2, 2, 2], [3, 3, 3]]]) """ وأخيراً يمكنك استخدام التابع np.broadcast_to بحيث نمرر له المصفوفة والأبعاد الجديدة وهو سيتكفل بالتكرار كما في المثال التالي : an_array = np.array([[1],[2],[3]]) np.broadcast_to(an_array, (3, 3)) """ array([[1, 1, 1], [2, 2, 2], [3, 3, 3]]) """ an_array = np.array([1,2,3]) np.broadcast_to(an_array, (3, 3)) """ array([[1, 2, 3], [1, 2, 3], [1, 2, 3]]) """
- 2 اجابة
-
- 2
-
-
pandas: إنها مكتبة مفتوحة المصدر ومرخصة من BSD مكتوبة بلغة Python. توفر Pandas هياكل بيانات وأدوات تحليل بيانات عالية الأداء وسريعة وسهلة الاستخدام لمعالجة البيانات الرقمية والسلاسل الزمنية. تم إنشاء Pandas على مكتبة numpy ومكتوبة بلغات مثل Python و Cython و C. في الباندا ، يمكننا استيراد البيانات من تنسيقات ملفات مختلفة مثل JSON و SQL و Microsoft Excel وما إلى ذلك. مثال: # استيراد المكتبة import pandas as pd # تهيئة وإنشاء قائمة متداخلة age = [['Aman', 95.5, "Male"], ['Sunny', 65.7, "Female"], ['Monty', 85.1, "Male"], ['toni', 75.4, "Male"]] #DataFrame إنشاء df = pd.DataFrame(age, columns=['Name', 'Marks', 'Gender']) Numpy: إنها المكتبة الأساسية للبايثون، وتستخدم لتنفيذ عمليات الحوسبة العلمية. يوفر مصفوفات وأدوات متعددة الأبعاد عالية الأداء للتعامل معها. المصفوفة الرقمية هي شبكة من القيم (من نفس النوع) مفهرسة بواسطة مجموعة من الأعداد الصحيحة الموجبة، والمصفوفات غير المتقاربة سريعة وسهلة الفهم ، وتمنح المستخدمين الصلاحية في إجراء العمليات الحسابية عبر المصفوفات. ويعتمد عليها كثيرٌ من العلماء والباحثين في إجراء العمليات الحسابية الكبيرة والمعقدة على بياناتهم وفي اختباراتهم العلمية. مثال: # استيراد المكتبة import numpy as np # 3-D numpy array using np.array() org_array = np.array([[10, 1, 77], [5, 0, 4]]) عندما يتعين علينا العمل على البيانات الجدولية ، فإننا نفضل وحدة الباندا. عندما يتعين علينا العمل على البيانات العددية ، فإننا نفضل الوحدة النمطية numpy. أدوات الباندا القوية هي Dataframe و Series. في حين أن الأداة القوية لـ numpy هي Arrays. تستهلك الباندا المزيد من الذاكرة. نمباي أكثر فعالية في التعامل مع الذاكرة. تتمتع Pandas بأداء أفضل عندما يكون عدد الصفوف 500 ألف أو أكثر. يتمتع Numpy بأداء أفضل عندما يكون عدد الصفوف 50 ألفًا أو أقل. تعد فهرسة سلاسل الباندا بطيئة جداً مقارنةً بمصفوفات نمباي. تعد الفهرسة في مصفوفات نمباي سريعة جداً. تقدم Pandas كائنات تمثل جدول ثنائي الأبعاد يسمى DataFrame. Numpy قادر على توفير مصفوفات متعددة الأبعاد. نمباي تقدم لك عمليات سريعة وبكفاءة عالية عند التعامل مع المصفوفات، وإستخدام أمثل للمصادر عند المعالجة. وتعتمد عليها كثير من المكتبات الأخرى مثل Pandas و theanets وغيرهما. يوفر باندا وظائف كثيرة مثل: data alignment و NA-friendly statistics و groupby و merge و join والعديد من الأدوات الأخرى المريحة، التي أصبحت شائعة جداً في السنوات الأخيرة في التطبيقات المالية. وأيضاً في تعلم الآلة. وتقدم المكتبة ما يسمى ب إطار البيانات (Data Frame) والذي يسهل من إستيراد البيانات والتعامل معها بسهولة. و تسهل المكتبة عمليات (Data Preprocessing ) مثل تنظيف البيانات، ومعالجة القيم الفارغة فيها، وإجراء العمليات الإستكشافية على البيانات. وتسهل دمج البيانات ببعضها أو تجزيئها إلى إطارات متعددة. أما بالنسبة لمكتبة SciPy فبشكل مختصر مكتبة (SciPy) هي نفس مكتبة (NumPy) تقريباً وهي أيضاً من بين المكتبات الاساسية للحسابات العلمية وخوارزميات الرياضيات والدوال المعقدة. ولكنها مبنية كأمتداد لمكتبة (NumPy) مما يعني أنهما يستخدمان سوية في أغلب الاحيان. تأتي هذه المكتبة على رأس هرم مكتبات علم البيانات بالبايثون ، وتخدم جانب تحليل البيانات و تعليم الالة بشكل قوي، ولا تقتصر على ذلك، حيث تقدم إمكانات هائلة في مجال معالجة الإشارات ومعالجة الصور والعمليات الحسابية المعقدة. تتكون وتعتمد مكتبة Scipy على خليط من المكتبات المشهورة مثل Numpy, Pandas, Matplotlib, Sympy, IPython وغيرها. تُقدم المكتبة مجموعة واسعة من الخوارزميات والحزم العلمية التي لها علاقة بالأخص بالعمليات الرياضية، الدوال الإحصائية وتعليم الألة. ومن ميزاتها أنها تقدم دوال واسعة في مجال الاحتمالات والإحصاء عبر موديول stats. وتدعم عمليات الجبر الخطي و Fourier transform. وتقدم المكتبة مجموعة من الدوال الخاصة بمعالجة المصفوفات متعددة الأبعاد لمعالجة الصور. وإجراء التحليل المكاني (Spatial Analysis) عبر مجموعة من الخوارزميات المتخصصة الموجودة في موديول spatial.
- 2 اجابة
-
- 2
-
-
في النسخ الحديثة تم استبدال الموديول visualize_util ب vis_utils وتم تغيير اسم التابع من plot إلى plot_mode وبالتالي يجب استيرادها بالشكل التالي: from keras.utils.vis_utils import plot_model أو من خلال وحدة كيراس المضمنة في تنسرفلو (بدءاً من نسخة تنسرفلو 2.0) كالتالي: from tensorflow.keras.utils import plot_model
- 2 اجابة
-
- 1
-
-
أولاً np.mean يحسب دائماً متوسطاً حسابياً، ولديه بعض الخيارات الإضافية للإدخال والإخراج (على سبيل المثال ، أنواع البيانات التي يجب استخدامها ، ومكان وضع النتيجة. numpy.mean(a, axis=None, dtype=None, out=None) أمثلة: a = np.array([[1, 2], [3, 4]]) np.mean(a) #2.5 np.mean(a, axis=0) #array([2., 3.]) np.mean(a, axis=1) #array([1.5, 3.5]) حيث أن الوسيط الأول هو المصفوفة، والثاني هي المحاور أو المحور الذي سيتم حساب المتوسط عليه.و الافتراضي none يعني حساب متوسط المصفوفة المسطحة أي كامل المصفوفة. أما الوسيط الثالث فهو النمط المستخدم في حساب المتوسط. بالنسبة لمدخلات الأعداد الصحيحة ، الافتراضي هو ؛ float64 ولمدخلات الفاصلة العائمة، وهو نفس نوع الإدخال dtype. أما الوسيط التالي فهو مصفوفة إخراج بديلة لوضع النتيجة فيها. ثانياً np.average يمكن حساب المتوسط الموزون إذا قمنا بتزويده بأوزان المعلمات. numpy.average(a, axis=None, weights=None) أول وثاني وسيط كما في التابع السابق لكن الوسيط الثالث هو مصفوفة الأوزان المرتبطة بالقيم الموجودة في المصفوفة. كل قيمة في a تساهم في المتوسط وفقاً للوزن المرتبط بها. يمكن أن تكون مصفوفة الأوزان إما 1-D (وفي هذه الحالة يجب أن يكون طولها بحجم a على طول المحور المحدد) أو من نفس الشكل مثل a. إذا كانت الأوزان = None، فسيتم افتراض أن جميع البيانات الموجودة في a لها نفس الوزن. أمثلة: data = np.arange(1, 5) np.average(data) #2.5 np.average(np.arange(1, 11), weights=np.arange(10, 0, -1)) #4.0 data = np.arange(6).reshape((3,2)) """ array([[0, 1], [2, 3], [4, 5]]) """ np.average(data, axis=1, weights=[1./4, 3./4]) #array([0.75, 2.75, 4.75]) np.average(data, weights=[1./4, 3./4]) # TypeError: Axis must be specified when shapes of a and weights differ.
- 2 اجابة
-
- 1
-
-
ببساة يمكنك استخدام التابع sum فكما نعلم أن هذا التابع يقوم بحساب مجموع قيم مصفوفة ما، لكن إذا طبقته على مصفوفة بوليانية سيقوم بعد عدد مرات ظهور القيمة True : a=np.array([True,True,True,False,False]) sum(a) # 3 # أما في حالة كانت المصفوفة متعددة الأبعاد a=np.array([[True,True,True,False,False],[True,True,True,False,False]]) sum(a.ravel()) # 6 # أي يجب تسطيح المصفوفة إذا كانت بأكثر من بعد أو ببساطة متناهية: a=np.array([[True,True,True,False,False],[True,True,True,False,False]]) a[a].size حيث أن ناتج a[a] هو: array([ True, True, True, True, True, True]) أي فقط القيم التي تعطي True من a. أو من خلال التابع np.count_nonzero(array) : np.count_nonzero(a) # 6 أو من خلال التابع sum في نمباي: a.sum() أو من خلال استخدام التابع bicount من نمباي: arr=np.array([False, True, True, True, False, True, False, True, True]) #false وعدد ال true سيقوم بحساب عدد ال bin_arr = np.bincount(arr) bin_arr # array([3, 6]) #True لاستخلاص عدد ال bin_arr[1] # 6 للمقارنة: a=np.array([[True,True,True,False,False]*100]) %timeit a[a].size %timeit sum(a.ravel()) %timeit np.count_nonzero(a) %timeit a.sum() %timeit np.bincount(a.ravel()) """ The slowest run took 23.84 times longer than the fastest. This could mean that an intermediate result is being cached. 1000000 loops, best of 5: 1.82 µs per loop 1000 loops, best of 5: 1.14 ms per loop The slowest run took 19.70 times longer than the fastest. This could mean that an intermediate result is being cached. 1000000 loops, best of 5: 975 ns per loop The slowest run took 27.08 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 2.98 µs per loop The slowest run took 67.31 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 2.62 µs per loop """
- 2 اجابة
-
- 1
-
-
يمكنك القيام بحساب طويلة متجه بعدة طرق. أولها من خلال التابع numpy.linalg.norm بالشكل التالي: import numpy as np x = np.array([1,2,3,4]) np.linalg.norm(x) # 5.477225575051661 حيث أن التابع np.linalg.norm(x) يقوم بحساب الطويلة للشعاع. أو يمكنك تحقيق ذلك بشكل يدوي من خلال استخدم التابع dot و sqrt كالتالي حيث أن عملية إيجاد الطويلة لمتجه هو تربيع القيم ثم حساب الجذر التربيعي وبالتالي نستخدم عملية الضرب x.dot(x) لتقوم بعملية ضرب عناصر الشعاع x ببعضها ثم حساب جذر المجموع الناتج: m = np.sqrt(x.dot(x)) # 5.477225575051661 # بحيث: # x.dot(x)=30 # 1*1+2*2+3*3+4*4=30 # 30^1/2=5.477 أو يمكنك الاعتماد على مكتبة einsum لتنفيذ الجداء : np.sqrt(np.einsum('...i,...i', x, x)) # 5.477225575051661 أو: from numpy.core.umath_tests import inner1d np.sqrt(inner1d(x,x)) أو من خلال مكتبة vg استخدم التابع : import vg vg.magnitude(x) #5.477225575051661 لكن عليك أولاً أن تقوم بتحميلها: pip install vg للمقارنة: %timeit vg.magnitude(x) %timeit np.sqrt(inner1d(x,x)) %timeit np.sqrt(np.einsum('...i,...i', x, x)) %timeit np.sqrt(x.dot(x)) %timeit np.linalg.norm(x) """ The slowest run took 142.37 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 8.71 µs per loop The slowest run took 8.71 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 5.11 µs per loop The slowest run took 6.30 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 8.37 µs per loop The slowest run took 10.48 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 4.6 µs per loop The slowest run took 17.93 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 8.51 µs per loop """
- 2 اجابة
-
- 1
-
-
يمكن إنشاء دالة خسارة مخصصة عن طريق تعريف الدلة التي تريد استخدامها، بحيث يجب أن تأخذ هذه الدالة القيم الحقيقية والقيم المتوقعة ،وأن تعيد الدالة قيم الكلفة للبيانات الممررة. وأخيراً يكون بعد ذلك بإمكانك تمرير التابع الخاص بك في مرحلة الترجمة compile. ويجب أن تكون حريصاً في النقاط التالية: 1. تأخذ دالة الخسارة وسيطتين فقط ، وهما القيمة المستهدفة (y_true) والقيمة المتوقعة (y_pred). لأنه من أجل قياس الخطأ في التنبؤ (الخسارة) نحتاج إلى هاتين القيمتين. يتم تمرير هذه الوسائط من النموذج نفسه في وقت ملاءمة البيانات. 2. يجب أن تستفيد دالة الخسارة من قيمة y_pred أثناء حساب الخسارة ، إذا لم تقم بذلك ، فستحصل على خطأ ولن يتم حساب ال Gradients.ا 4. يكون البعد الأول للوسيطتين y_true و y_pred دائماً هو نفسه حجم الدفعة (حجم الباتش Batch_size). على سبيل المثال، إذا كنت تلائم البيانات بحجم دفعة 64، وكانت شبكتك العصبية تحتوي على 10خلايا إخراج، فستكون أبعاد y_pred هي (64,10) . لأنه سيكون هناك 64 قيمة كخرج للنموذج، ولكل منها 10 قيم. (64 حجم الباتش ولدينا 10 خلايا في طبقة الخرج، هذا يعني أنه سيكون لدينا في كل مرة 64 عينة نحسب لها 10 نواتج وكل ناتج نقارنه بالقيمة الحقيقية وفق دالة التكلفة). 5. يجب أن تقوم دالة الخسارة دائماً بإرجاع متجه بطول batch_size. لأنه يتعين عليك إرجاع خسارة لكل نقطة بيانات أي لكل عينة. يمكنك تعريفها بالشكل التالي: def loss(y_true, y_pred): # نكتب الدالة هنا ولاننسى أن تكون متعلقة بالقيم المتوقعة return loss # بعدها يمكننا تمريرها للنموذج بالشكل التالي model.compile( loss=custom_loss, ) بشكل عام يفضل استخدام keras.backend أثناء بناء دالتك لتحنب حدوث أخطاء (يمكنك استخدام نمباي لامشكلة، لكن يفضل استخدام backend ). في المثال التالي سأقوم ببناء دالة تكلفة وأعطي وزن أيضاً للإخراج. فرضاً لدينا مهمة توقع والخرج هو قيمتين [x1, x2] ونريد إعطاء x2 أهمية أكبر عند حساب التكلفة: from keras import backend def custom_mse(y_true, y_pred): # حساب مربع الفرق بين القيم الحقيقية والمتوقعة loss = backend.square(y_pred - y_true) # (batch_size, 2) # ضرب النواتج بقيم الأوزان التي نريدها حيث هنا أعطينا أهمية أكبر للمخرج الثاني loss = loss * [0.3, 0.7] # (batch_size, 2) # حساب مجموع الأخطاء loss = backend.sum(loss, axis=1) # (batch_size,) return loss
- 2 اجابة
-
- 1
-
-
ألصورة التالية توضح مفهوم ال Tokenaization: توفر لك كيراس القيام بذلك بسهولة عن طريق الأداة Tokenizer من الموديول tf.keras.preprocessing.text.Tokenizer حيث تمكنك هذه الأداة من ترميز النص الخاص بك ليصبح عبارة عن سلسلة من الأعداد الصحيحة، بحيث نقوم بتمرير كامل مجموعة البيانات الخاصة بنا له، ثم يقوم بملائمتها fitting ، وتتضمن عملية الملائمة هذه بعض عمليات الفلترة على البيانات النصية ثم تقسيم كل نص (عينة) إلى الكلمات المكون منها ثم إنشاء قاموس يحوي كل الكلمات الفريدة التي وجدها مع عدد صحيح يمثلها (كل كلمة يعبر عنها بعدد صحيح)، وتسمى "Tokens". ثم بعد ذلك يمكننا تحول كل عينة من بياناتنا إلى الترميز العددي من خلال التابع texts_to_sequences. لكن أولاً دعنا نستعرض شكل هذه الأداة: tf.keras.preprocessing.text.Tokenizer( num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=" ", char_level=False, oov_token=None, document_count=0, **kwargs) الوسيط الأول يعبر عن العدد الأعظمي للكلمات المرغوب بحفظها في القاموس، حيث كما ذكرنا فإن هذه الأداة تقوم بإنشاء قاموس يحوي كامل الكلمات التي وجدها مع عدد صحيح يمثل كل كلمة، وبالتالي قد يحتوي هذا القاموس على مئات الآلاف من الكلمات الفريدة لكن لاتبقى كلها حيث يتم اختيار أهم 10 آلاف كلمة كحد أقصى من القاموس حسب أهميتها (الأهمية تعتمد على عدد مرات ظهور الكلمة في البيانات) ويتم الاختفاظ بها أما باقي الكلمات يتم تجاهلها. لكن يمكننا تغيير هذا الرقم من خلال الوسيط num_words فافتراضياً يأخذ القيمة 10 آلاف، لكن يمكننا وضع قيمة أخرى، مثلاً 75000 أي الاحتفاظ بأهم 75 ألف كلمة. أما الوسيط الثاني فهو الفلتر الذي سيتم تطبيقه على البيانات ويتضمن حذف علامات الترقيم والمسافات الفارغة والرموز (يمكنك تحديد ماتريد، لكن إذا تركت علامات الترقيم مثلاً، فسيتم ترميزها أي إسناد عدد صحيح يمثلها)، أما الوسيط الثالث فهو يحدد فيما إذا أردت تغيير حالة أحرف النصوص إلى أحرف صغيرة أم لا (يفضل القيام بذلك لأنه مثلاً إذا وجد كلمة Good و good سيتم اعتبارهما كلمتين مختلفتين وبالتالي يعطيهما ترميز مختلف)، أما الوسيط split فهو يمثل الرمز الذي سيتم تقسيم كل نص على أساسه إلى كلمات منفصلة. والوسيط الخامس لتحديد مستوى التقسيم وفي حالتنا نضعه على False (عند وضعه على True ستتم عملية التقسيم على مستوى الأحرف وليس الكلمات أي مثلاً سيتم تقسيم الكلمة Win إلى W و i و n وهنا لانحتاجه)، أما الوسيط السادس فنحتاجه عند القيام بعملية texts_to_sequences وذلك لوضع عدد صحيح يمثل الكلمات التي لم يجدها في القاموس (غير موجودة لديه، حيث كما ذكرنا فهو يحتفظ بعدد محدد من الكلمات وبالتالي قد يستقبل كلمة غير معرَفة لديه وغالباً نضعه على None أي الحالة الافتراضية) . أما التوابع التي نحتاجها فهي التابع fit_on_texts للقيام بعملية ال fitting حيث نمرر له كامل مجموعة البيانات، والتابع texts_to_sequences للقيام بعملية التحويل حيث نمرر له العينة أو مجموعة العينات (البيانات) المراد تطبيق التحويل عليها دفعة واحدة كما سنعرض في المثال التالي، وأيضاً هناك بعض الواصفات التي يمكننا أن نستعرض من خلالها محتويات القاموس مثل word_counts الذي يعرض لك قاموس ال Tokens مع عدد مرات ظهور كل Tokens، والواصفة document_count يرد لك عدد العينات (المستندات النصية) التي قام بترميزها. و word_index الذي يرد ال Tokens والعدد الصحيح الذي يمثلها يحيث يكون عبارة عن قاموس المفاتيح فيه هي الكلمات والقيم فيه هي العدد الصحيح الذي يمثلها. word_docs يرد كل ال Tokens وتردد كل منها. مثال: from keras.preprocessing.text import Tokenizer #إنشاء غرض t = Tokenizer() text = ['assign integers to characters', 'Machine Learning', 'assign', 'Machine Learning'] # الملاءمة t.fit_on_texts(text) # عرض المعلومات print("Count of characters:",t.word_counts) print("Length of text:",t.document_count) print("Character index",t.word_index) print("Frequency of characters:",t.word_docs) # التحويل s = t.texts_to_sequences(text) print(s) """ Count of characters: OrderedDict([('assign', 2), ('integers', 1), ('to', 1), ('characters', 1), ('machine', 2), ('learning', 2)]) Length of text: 4 Character index {'assign': 1, 'machine': 2, 'learning': 3, 'integers': 4, 'to': 5, 'characters': 6} Frequency of characters: defaultdict(<class 'int'>, {'assign': 2, 'integers': 1, 'to': 1, 'characters': 1, 'machine': 2, 'learning': 2}) [[1, 4, 5, 6], [2, 3], [1], [2, 3]] """ وإليك المثال العملي لاستخدامها أثناء تحضير البيانات قبل بناء نموذج لتصنيف المشاعر حيث تكون البيانات نصية ونريد إدخالها في الشبكة العصبية للتدريب وبالتالي يجب أولاً القيام بعملية Tokenizaton كالتالي: from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences import numpy as np maxlen = 100 training_samples = 200 validation_samples = 10000 max_words = 10000 tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(texts) sequences = tokenizer.texts_to_sequences(texts) word_index = tokenizer.word_index print('Found %s unique tokens.' % len(word_index)) data = pad_sequences(sequences, maxlen=maxlen) labels = np.asarray(labels) print('Shape of data tensor:', data.shape) print('Shape of label tensor:', labels.shape) indices = np.arange(data.shape[0]) np.random.shuffle(indices) data = data[indices] labels = labels[indices] x_train = data[:training_samples] y_train = labels[:training_samples] x_val = data[training_samples: training_samples + validation_samples] y_val = labels[training_samples: training_samples + validation_samples] glove_dir = '/Users/fchollet/Downloads/glove.6B' embeddings_index = {} f = open(os.path.join(glove_dir, 'glove.6B.100d.txt')) for line in f: values = line.split() word = values[0] coefs = np.asarray(values[1:], dtype='float32') embeddings_index[word] = coefs f.close() print('Found %s word vectors.' % len(embeddings_index)) embedding_dim = 100 embedding_matrix = np.zeros((max_words, embedding_dim)) for word, i in word_index.items(): if i < max_words: embedding_vector = embeddings_index.get(word) if embedding_vector is not None: embedding_matrix[i] = embedding_vector from keras.models import Sequential from keras.layers import Embedding, Flatten, Dense model = Sequential() model.add(Embedding(max_words, embedding_dim, input_length=maxlen)) model.add(Flatten()) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.layers[0].set_weights([embedding_matrix]) model.layers[0].trainable = False model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
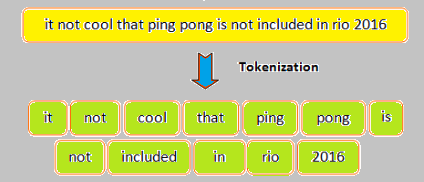
- 1 جواب
-
- 1
-
-
إذا كنت تستخدم واجهة Keras المنفصلة، يجب عليك تحميل الحزمة التالية وذلك في حال كانت النسخة الخاصة بك أقل من 2.3: pip install keras-metrics ثم بعد ذلك يمكنك استخدام هذه المعايير من هذه الحزمة كالتالي: import keras_metrics model.compile( ... metrics=[keras_metrics.precision(), keras_metrics.recall()]) إذا كنت تستخدم نسخة كيراس الأحدث فيمكنك القيام بذلك من خلال الموديول keras.metrics: model.compile( ... metrics=[keras.metrics.Precision(), keras.metrics.Recall()]) أما إذا كنت تستخدم النسخة المدمجة مع تنسرفلو، فيمكنك القيام بذلك بشكل مباشر من خلال الموديول tf.keras.metrics: import tensorflow as tf model.compile( ... metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()]) أمثلة: m = tf.keras.metrics.Precision() m.update_state([0, 1, 1, 1], [1, 0, 1, 1]) m.result().numpy() #0.6667 m.reset_state() m.update_state([0, 1, 1, 1], [0, 1, 1, 1]) m.result().numpy() #1.0 m = tf.keras.metrics.Recall() m.reset_state() m.update_state([0, 1, 1, 1], [0, 1, 1, 1]) m.result().numpy() #1.0 التطبيق على نموذج: from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) from keras.datasets import mnist import keras import tensorflow as tf from tensorflow.keras.utils import to_categorical (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28, 28, 1)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) model.compile(optimizer='rmsprop', loss="CategoricalCrossentropy", metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()]) model.fit(train_images, train_labels, epochs=2, batch_size=512) ---------------------------------------------------------------------------------------- Epoch 1/2 118/118 [==============================] - 46s 374ms/step - loss: 0.9313 - precision_5: 0.7849 - recall_4: 0.3362 Epoch 2/2 118/118 [==============================] - 44s 375ms/step - loss: 0.1283 - precision_5: 0.9423 - recall_4: 0.8137 <keras.callbacks.History at 0x7f5e17641950> ولحسابهم على بيانات الاختبار: from keras import backend as K def recall(y_true, y_pred): tp = K.sum(K.round(K.clip(y_true * y_pred, 0, 1))) p = K.sum(K.round(K.clip(y_true, 0, 1))) result = tp / (p + K.epsilon()) return result.numpy() def precision(y_true, y_pred): tp = K.sum(K.round(K.clip(y_true * y_pred, 0, 1))) p = K.sum(K.round(K.clip(y_pred, 0, 1))) result = tp / (p + K.epsilon()) return result.numpy() e=precision_m(train_labels,model.predict(train_images))
- 2 اجابة
-
- 1
-
-
يمكنك استخدام الدالة numpy.flip عن طريق تمرير الدالة argsort لها حيث سترد لك ال indexes للقيم مرتبة بترتيب تنازلي بعد أن يتم فرزها تصاعدياً باستخدام argsort حيث تقوم هذه الدالة بعكس ترتيب العناصر : import numpy as np a = np.array([2, 9, 7, 10, 5, 3]) n=3 ids = np.flip(np.argsort(a)) print(ids[0:n]) #[3 1 2] نفس الفكرة باستخدام np.flipud: import numpy as np a = np.array([2, 9, 7, 10, 5, 3]) n=3 ids = np.flipud(np.argsort(a)) print(ids[0:n]) #[3 1 2] أو يمكنك القيام بعكسها بإحدى الأشكال التالية: # نضرب المصفوفة بسالب وبالتالي يصبح الأصغر أكبر وبالتالي نحصل على الفهرس المطلوب np.argsort(-1*a)[:3] #- كما ويمكن استخدام المعامل # أي بشكل مشابه للطريقة السابقة (-a).argsort()[:3] # أو بالطريقة التقليدية عن طريق أخذ آخر 3 عناصر a.argsort()[::-1][:3] وكمقارنة: %timeit np.flipud(np.argsort(a))[0:3] %timeit np.flip(np.argsort(a))[0:3] %timeit np.argsort(-1*a)[:3] %timeit (-a).argsort()[:3] %timeit a.argsort()[::-1][:3] 5.14 µs ± 211 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 5.29 µs ± 337 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 4.57 µs ± 127 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 1.97 µs ± 288 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 1.86 µs ± 251 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) # الطريقة الأخيرة أفضل
- 3 اجابة
-
- 2
-
-
يمكنك القيام بذلك بشكل يدوي: import numpy as np A = np.random.randint(low=0,high=255, size=(2, 4)).astype(float) A """ array([[166., 246., 37., 195.], [ 63., 33., 189., 200.]]) """ th=127 A[A > th] = 255.0 A """ array([[255., 255., 37., 255.], [ 63., 33., 255., 255.]]) """ كما ويمكنك استخدام التابع np.putmask حيث نمرر له المصفوفة والعتبة والقيمة المراد الاستبدال بها: A = np.random.randint(low=0,high=255, size=(2, 4)).astype(float) """ array([[ 62., 23., 218., 205.], [197., 254., 149., 32.]]) """ # تحديد العتبة T=127 np.putmask(A, A>=T, 255.0) """ array([[ 62., 23., 255., 255.], [255., 255., 255., 32.]]) """ أو من خلال np.place حيث نمرر له المصفوفة، ثم العتبة كما في المثال، ثم القيمة المراد التحويل لها : A=np.array([[ 62., 23., 218., 205.], [197., 254., 149., 32.]]) np.place(A, A >=127, 255) """ array([[ 62., 23., 255., 255.], [255., 255., 255., 32.]]) """ أو من خلال np.where: A=np.array([[ 62., 23., 218., 205.], [197., 254., 149., 32.]]) np.where(A > 127, 255,A) """ array([[ 62., 23., 255., 255.], [255., 255., 255., 32.]]) """ كمقارنة: %timeit np.place(A, A >=127, 255) %timeit np.putmask(A, A>127, 255) %timeit np.where(A > 127, 255,A) 3.44 µs ± 197 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 3.03 µs ± 162 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 4.84 µs ± 1.15 µs per loop (mean ± std. dev. of 7 runs, 100000 loops each) # قريبتان من بعضهما لكن الأولى أفضل
- 3 اجابة
-
- 2
-
-
يمكنك استخدام numpy.ndarray.size. فعن طريق الوصول إلى عدد العناصر في numpy.ndarray باستخدام numpy.ndarray.size. يمكنك تحديد فيما إذا كانت المصفوفة فارغة أم لا حيث، إذا كان عدد العناصر في المصفوفة يساوي 0 ، فإن المصفوفة فارغة: import numpy as np empty_array = np.array([]) is_empty = empty_array.size == 0 is_empty # True ################################ empty_array = np.array([1,2]) is_empty = empty_array.size == 0 is_empty # False حسناً قد تظهر لنا مشكلة عندما يتم تعريف المصفوفة الفارغة بالشكل np.array(None) حيث أن ناتج تطبيق size سيكون 1، لذا لحل المشكلة: import numpy as np empty_array = np.array(None) is_empty = False if empty_array.size and empty_array.ndim else True is_empty # True ########################## import numpy as np empty_array = np.array([]) is_empty = False if empty_array.size and empty_array.ndim else True is_empty # True ######################### import numpy as np empty_array = np.array([1]) is_empty = False if empty_array.size and empty_array.ndim else True is_empty # False ويمكنك كتابة التابع التالي الذي يشمل كل ماسبق: def elements(array): return False if array.ndim and array.size else True elements(np.array([1])) #False elements(np.array([])) # True elements(np.array(None)) # True كما ويمكنك استخدام الدالة np.any، لكن القيد على هذه الوظيفة هو أنها لا تعمل إذا كانت المصفوفة تحتوي على القيمة 0 فيها. import numpy as np arr = np.array([]) flag = not np.any(arr) if flag: print('empty') else: print('not empty') # empty ############################# arr = np.array(None) flag = not np.any(arr) if flag: print('empty') else: print('not empty') # empty ############################ arr = np.array([1]) flag = not np.any(arr) if flag: print('empty') else: print('not empty') # not empty أو من خلال تحويلها لقائمة: import numpy as np arr = np.array([1]) if len(arr.tolist()) == 0: print("Empty") else: print("Not") قمنا أولاً بتحويل المصفوفة إلى قائمة باستخدام طريقة tolist (). ثم تحققنا من حجم القائمة باستخدام طريقة len () للتحقق مما إذا كانت المصفوفة فارغة.، لكن في حال تم تعريف المصفوفة من خلال None فسيظهر خطأ لذا لحل المشكلة قمت بتعريف التابع التالي: def test(a): try: if len(a.tolist()) == 0: return "Empty" else: return "Not" except: return "Empty" test(np.array([1])) # 'Not' test(np.array([])) # 'Empty' test(np.array(None)) # 'Empty' وأخيراً من خلال التبع shape: import numpy as np a = np.array([]) if a.shape[0] == 0: print("Empty") وذلك من خلال التحقق مما إذا كان عدد العناصر في المحور 0 ، أي الصف ، صفراً أم لا.
- 3 اجابة
-
- 2
-