عبد الوهاب بومعراف
-
المساهمات
2389 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
3
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو عبد الوهاب بومعراف
-
 يمكنك استخدام إضافة اسمها Live Server لعرض التغييرات تلقائيا في المتصفح بدون الحاجة لإعادة التحميل، في VS Code اضغط على رمز الإضافات على اليسار و اكتب في البحث: Live Server، و اختر أول نتيجة واضغط على Install. بعد تثبيت الإضافة، افتح ملف index.html واضغط كليك يمين داخل الملف، ثم اختر "Open with Live Server"، و سيتم فتح الملف في المتصفح، وكل مرة تحفظ فيها سيتم تحديث الصفحة تلقائيا.
يمكنك استخدام إضافة اسمها Live Server لعرض التغييرات تلقائيا في المتصفح بدون الحاجة لإعادة التحميل، في VS Code اضغط على رمز الإضافات على اليسار و اكتب في البحث: Live Server، و اختر أول نتيجة واضغط على Install. بعد تثبيت الإضافة، افتح ملف index.html واضغط كليك يمين داخل الملف، ثم اختر "Open with Live Server"، و سيتم فتح الملف في المتصفح، وكل مرة تحفظ فيها سيتم تحديث الصفحة تلقائيا. -
وعليكم السلام ورحمة الله، Code Golf هو تحد برمجي تكون فيه الغاية عكس المعتاد أي ليس كتابة كود منظم أو واضح بل تقليص عدد الأحرف في الحل إلى الحد الأدنى. أين يطلب من المبرمج أن ينجز مهمة أو يحل مشكلة باستخدام أقل عدد ممكن من الرموز، دون اعتبار للوضوح أو سهولة الفهم. وتستخدم في هذا النوع من التحديات لغات تدعم الاختصار الشديد أو تحتوي على بناء جملي مرن مثل Python أو لغات مخصصة لل Code Golf مثل Jelly وGolfScript. وهذا النوع من البرمجة يشبه التلاعب اللغوي، ويجمع بين التفكير التحليلي والقدرة على استغلال ثغرات اللغة لتحقيق الهدف بكود صغير جدا.
- 4 اجابة
-
- 1
-

-
بناء على اطلاعي على ملفك الشخصي على منصة مستقل انصحك باستبدال صورتك الشخصية بأخرى احترافية مع تجنب وضع النظارات. ويجب كتابة وصف موجز من 150-200 كلمة يبرز خبرتك في HTML، CSS، JavaScript، وأطر عمل مثل React مع الإشارة إلى قدرتك على إنشاء واجهات مستخدم متكاملة كما في عملك السابق على مكونات مثل About.js وProjects.js. يمكنك إضافة حتى 5 مشاريع متنوعة إلى معرض أعمالك ولو كانت تجريبية ورفعها على منصات مثل Netlify أو GitHub لعرضها عمليا سيكون جذابا. وعند التقديم على مشروع يمكنك أن تقدّم عرضا مخصصا يظهر فهمك لمتطلبات العميل وحلولك المبتكرة، مثل تحسين تجربة المستخدم. وأن تركز على المشاريع الصغيرة لتقليل المنافسة وتقدّم خدمة إضافية مجانية كتحسين سرعة التحميل لتمييز نفسك.
-
أنت لديك: points = [[-3, 1, 2], [1, 4, 0], [-1, -4, 5]] وهذه عبارة عن قائمة ثنائية الأبعاد أي قائمة من القوائم بحيث كل عنصر من عناصرها هو صف مكوّن من 3 أرقام وعند كتابة: points[1] في القائمة فإنك تطلب الوصول إلى العنصر الثاني في القائمة لأن الترقيم يبدأ من الصفر وبالتالي ترجع القيمة [1, 4, 0] وهي الصف الثاني بالكامل وليس عمودا. أما القيمة [1, 4, -4] التي أشرت إليها فهي تمثل العناصر ذات الفهرس 1 في كل صف أي أنها تشكل ما يعرف بالعمود الثاني في مصفوفة ثنائية الأبعاد، وللحصول عليها في بايثون يجب استخدام حلقة أو فهم قائمة مثل: [row[1] for row in points]
- 3 اجابة
-
- 1
-
-
توفر بايثون العديد من المكتبات والأدوات التي تتيح لك التفاعل مع أنظمة التشغيل والأجهزة المختلفة، حيث يمكنك استخدام مكتبة pyautogui لأتمتة المهام على الحاسوب، أو adb-shell للتحكم في أجهزة الأندرويد عبر واجهة ADB، أو حتى مكتبات مثل OpenCV لمعالجة الصور والفيديوهات من الكاميرا.
- 5 اجابة
-
- 1
-
-
بداية يجب أن تنهي الدورة وتتقدم للامتحان الخاص بالدورة ,يمكنك التقدم إلى امتحان الدورة، من خلال التواصل مع مركز مساعدة أكاديمية حسوب, لكي تتقدم للامتحان يجب أن تتوفر بعض الشروط : يجب أن تكون قد أتممت أربعة مسارات تعليمية على الأقل من مسارات الدورة يجب أن تكون قد طبقت المشاريع التي يتم تطبيقها أثناء الدورة ، والاحتفاظ بالمشاريع العملية الناتجة لإرسالها للمراجعة أن تكون قد رفعت كافة المشاريع على حسابك على github ومشاركتها مع مركز المساعدة ثم يتم الامتحان على 4 مراحل مختلفة: بداية تتواصل مع مركز المساعدة وتخبرهم برغبتك في التقدم للامتحان محادثة صوتية مدتها 30 دقيقة يطرح عليك المدرب بعض الأسئلة المتعلقة بالدورة ويناقش ما تم تعلمه في الدورة سوف يحدد لك المدرب مشروع تخرج تقوم بتنفيذه خلال فترة بين أسبوع الى أسبوعين مراجعة المشروع ان تمت جميع الأمور بشكل صحيح تستطيع الحصول على الشهادة , يمكنك معرفة المزيد والتحدث معهم من صفحة الامتحان والحصول على الشهادة.
- 8 اجابة
-
- 1
-
-
البرمجة الإجرائية (Procedural Programming) هي نموذج برمجي يعتمد على تنظيم الكود في شكل إجراءات أو دوال منفصلة تستدعى بتسلسل محدد fpde يقوم هذا النموذج على مبدأ "فرµق تسد" حيث يتم تقسيم المشكلة الكبيرة إلى مشاكل أصغر يتم حلها بواسطة دوال منفصلة والبيانات والدوال تكون منفصلة عن بعضها البعض وتمرر البيانات كمعاملات للدوال التي تعالجها وترجع النتائج. التحكم في تدفق البرنامج يتم من خلال استدعاء الدوال بترتيب معين، مع استخدام هياكل التحكم مثل الحلقات والشروط. من أشهر لغات البرمجة الإجرائية: C و Pascal و COBOL و FORTRAN و أجزاء من JavaScript و Python. يمكنك التعرف عليها أكثر من هنا:
- 6 اجابة
-
- 1
-
-
أرجو مراجعة الإجابة التالية فهي تحلّ نفس المشكل الذي تواجهه: في حال استمرت المشكلة قم ب الضغط على Ctrl + shift + r لتحميل الصفحة مع حذف الكاش كما يمكنك تجربة استخدام متصفح آخر ثم التجربة مرة أخرى.
-
مع الأسف لا يوجد حاليا توثيق رسمي ل Pandas في موسوعة حسوب، لكن يمكنك أن تجد الكثير من المعلومات والمصادر داخل مقالات أكاديمية حسوب من هنا: وفي نهاية الصفحة ستجد عدة روابط أخرى يمكها أن تفيدك أكثر:

- 3 اجابة
-
- 1
-
-
رغم الأداء المتفوق الذي تقدمه Bun، خاصة في سرعة تنفيذ العمليات حيث بعد بحث قصير وجدت أن بعض الاختبارات التي تم إجراؤها أظهرت أنه أسرع من Node.js بثلاثة أضعاف في طلبات HTTP إلا أن الإحصائيات الرسمية لعام 2024 و2025 تؤكد أن Node.js لا يزال المسيطر في السوق. فبحسب استطلاع Stack Overflow 2024، يستخدم أكثر من 40.8% من المطورين Node.js، وتظهر تقارير مثل W3Techs أن أكثر من 4.6% من المواقع تستخدمه، مع أكثر من 1.4 مليار عملية تنزيل تاريخيا. كما أنّ Node.js يحظى بدعم واسع في المؤسسات الكبرى ولديه نظام بيئي ناضج يضم ملايين الحزم على npm. في المقابل لا تزال Bun حديثة نسبيا حيث أطلقت نسختها المستقرة الأولى في سبتمبر 2023 وتفتقر إلى الاستقرار الكامل والتبني المؤسسي على نطاق واسع.
-
يوجد فرق واضح بينهما رغم أن المفهومين مرتبطان ببعضهما فنمذجة الكائنات هي مرحلة تحليل وتصميم تسبق كتابة الكود، وتركز على تمثيل النظام من خلال كائنات (Objects) تحاكي مكونات العالم الحقيقي. في هذه المرحلة نستخدم أدوات مثل الرسومات التخطيطية ك UML لتحديد الكائنات، خصائصها (السمات)، وسلوكها (الوظائف أو الدوال)، وكيفية تفاعلها معا والهدف منها هو الفهم العميق للنظام المطلوب بناءه وتنظيمه بطريقة منطقية قبل الدخول في عملية البرمجة. أما البرمجة كائنية التوجه، فهي أسلوب لكتابة الكود بلغة تدعم هذا النمط مثل Java و بايثون C++. في هذا الأسلوب نقوم بتحويل التصميم أو النموذج الذي أنشأناه في مرحلة النمذجة إلى كود حقيقي من خلال إنشاء "Classes" و"Objects"، واستخدام مفاهيم مثل الوراثة (Inheritance)، التغليف (Encapsulation)، والتعددية الشكلية (Polymorphism).
- 4 اجابة
-
- 1
-
-
لا داعلي للقلق ففي HTML بعض الوسوم مثل <link> لا تحتاج أن تكتب في آخرها /، لأنها وسوم ذاتية الإغلاق ففي HTML5 كتابة الوسم بدون / صحيحة تماما وليس فيها أي مشكلة فالشرطة المائلة / كانت ضرورية في نسخ قديمة مثل XHTML فقط.
- 3 اجابة
-
- 1
-
-
هندسة البرومبت هي فن وعلم صياغة التعليمات أو الأسئلة الموجهة لنماذج الذكاء الاصطناعي، وخاصة النماذج اللغوية الكبيرة لتحقيق أفضل النتائج الممكنة، و تعتمد على فهم كيفية تفاعل النموذج مع المدخلات، واستخدام تقنيات مثل التوضيح، التدرج في الأسئلة، أو تضمين أمثلة في البرومبت لتحسين دقة ومصداقية الإجابة، لتعلمها ابدأ بدراسة أساسيات الذكاء الاصطناعي واللغويات التطبيقية، ثم تدرب على صياغة أسئلة متنوعة وتحليل استجابات النموذج، و بالتأكيد الممارسة المستمرة والتجريب هما المفتاح لإتقان هذا المجال سريع التطور.
- 5 اجابة
-
- 1
-
-
بالنسبة لأدوات التصميم، فإن Canva يعتبر بسيط جدا لمشاريع الويب المحترفة، وبدلا منه يمكنك تجربة Figma أو Adobe XD لإنشاء نماذج أولية وتصاميم تفصيلية قبل التنفيذ، و أيضا لا تنسَ استخدام أطر عمل مثل Bootstrap أو Tailwind CSS لتسريع عملية التطوير، و المفتاح هو البدء بالأساسيات ثم التدرج نحو الأدوات الاحترافية مع تطور مهاراتك.
-
للتقدم للإختبار يجب إنهاء على الأقل أربع مسارات من الدورة، في نهاية كل مسار ستجد مشروع خاص بذلك المسار، و بعدها قم برفع هذه المشاريع على github، ثم بعدها يمكنك مراسلة مركز الدعم من أجل مراجعة المشاريع و تحديد موعد الإختبار الخاص بك.
-
في React نستخدم map بدلا من الحلقات التقليدية مثل for وwhile لأن map ستعيد لنا مصفوفة جديدة تحتوي على عناصر JSX جاهزة للعرض مباشرة داخل دالة render أو داخل return للدوال المركبة وهو ما يتماشى مع التصميم الدالي (Functional) لرياكت. بعكس for وwhile التي تستخدم لأغراض تكرار عام وتحتاج إلى إنشاء مصفوفة خارجية ثم دفع العناصر إليها يدويا فإن map تبقي الكود أكثر نظافة وتسمح بتعيين key لكل عنصر بسهولة وتجنب التعديلات الجانبية. وهذه ميزة في React بحيث تسهل تتبّع العناصر وإعادة رسمها بكفاءة عند التحديث ونستخدمها بكثرة لأنها متوافقة تماما مع نمط JSX الذي يتطلب إرجاع عناصر قابلة للعرض مباشرة ضمن البنية الشجرية للمكوّن.
-
كلامك صحيح ولهذا Python يستخدم Event Loop من مكتبة asyncio لتنظيم المهام غير المتزامنة. فعندما يواجه كلمة await سيتوقف عن تنفيذ هذه المهمة مؤقتا وينتقل لتنفيذ مهام أخرى، ثم يعود إليها عندما تصبح جاهزة. وكل هذا يحدث في نفس الخيط الرئيسي، ولكن بطريقة تعاونية بحيث كل مهمة تعطي الفرصة للمهام الأخرى عند الانتظار. لاحظ الكود التالي: import asyncio async def task1(): await asyncio.sleep(2) async def task2(): await asyncio.sleep(1) asyncio.run(asyncio.gather(task1(), task2())) في البداية قمنا باستيراد المكتبة asyncio ثم عندما يبدأ تنفيذ task1 ويصل ل: await asyncio.sleep(2) يتركها فورا وينتقل ل task2 وعندما يصل ل: await asyncio.sleep(1) يتركها أيضا ويعود للأولى أو ينتظر وهكذا يدور بينهما لأن task2 تحتاج ثانية واحدة فقط بينما task1 تحتاج ثانيتين أي ستنتهي task2 أولا رغم أن task1 بدأت قبلها، وهذا يثبت أن Event Loop يشغلهما بالتوازي وليس واحدة تلو الأخرى.
-
للأسف لا يمكنك تحميل دروس الدورة في الوقت الحالي وتم منع ذلك تفاديا لإعادة نشر الدروس خارج منصة الأكاديمية وهذا لتحقيق العدل بين مشتركي الأكاديمية فلا يعقل أن يشترك البعض لكي يستفيدوا من الدروس بينما آخرون يأخذونها على طبق من ذهب. لذا بدلا من تحميل الفيديو يمكنك خفض جودته إلى 540 وهي جودة مناسبة لمتابعة الدروس بسلاسة.
-
يجب عليك إنشاء ملف حتى يظهر لديك زر run، أرجوا الضغط على File و من ثم إختر new file من هناك، أو يمكنك فتح ملف بايثون مباشرة إذا كان متوفر لديك و بعدها يمكنك الضغط على run.
-
وعليكم السلام. بداية في حال كان سؤالك متعلقا بإحدى دروس الدورة التي قمت بالاشتراك فيها فأرجو طرح أسئلتك هناك أسفل الدرس فهنا نجيب فقط على الأسئلة العامة، على العموم فلو أخذنا فرضا أنك تقصد العمل ب Vue Js فلتفعيل النموذج عند حدث submit في <form> يمكننا استخدام التوجيه كالتالي: @submit.prevent="methodName" حيث يقوم @submit بالاستماع إلى الحدث و.prevent تمنع إعادة تحميل الصفحة الافتراضية عند الإرسال وأما methodName هو اسم الدالة التي تنفّذ عند الإرسال لماذا ذلك؟ لأنه في إطار Vue.js تعد إدارة النماذج سهلة وفعالة بفضل نظام التوجيه (directives) وعند التعامل مع نموذج، مثل تسجيل الدخول أو إنشاء حساب ستحتاج إلى التقاط الحدث الذي يحدث عند الضغط على زر "إرسال". وللقيام بذلك نستخدم عنصر <form> ونربطه بحدث submit عبر التوجيه @submit وتفاديا السلوك الافتراضي الذي يتمثل في إعادة تحميل الصفحة نضيف .prevent، فيصبح @submit.prevent. داخل هذا النموذج ويرتبط كل حقل ب v-model ليتم ربط بيانات النموذج بحالة (state) المكون ثم تعرّف دالة في قسم methods للتعامل مع البيانات عند إرسال النموذج كالتالي: بمجرد أن يضغط المستخدم على زر "Send"، يتم تنفيذ دالة handleSubmit دون إعادة تحميل الصفحة. تُستخدم هذه الطريقة بشكل واسع في التعامل مع النماذج، خاصة عند إرسال بيانات إلى API أو التحقق من صحة المدخلات. استخدام v-model يجعل البيانات متزامنة بين الواجهة والنموذج، مما يسهل إدارتها. كما يمكن توسيع هذه التقنية لتشمل التحقق من المدخلات، أو إظهار رسائل خطأ، أو إرسال البيانات إلى الخادم باستخدام مكتبات مثل Axios. خلاصة القول، Vue.js توفر أدوات بسيطة وفعالة لتفعيل النماذج والاستجابة لحدث الإرسال بطريقة منظمة وتفاعلية. <template> <form @submit.prevent="handleSubmit"> <input v-model="name" type="text" placeholder="Your name" /> <button type="submit">Send</button> </form> </template> <script> export default { data() { return { name: "" }; }, methods: { handleSubmit() { alert(`Hello, ${this.name}`); } } }; </script> فهنا بمجرد أن يضغط المستخدم على زر "Send" سيتم تنفيذ دالة handleSubmit دون إعادة تحميل الصفحة. وفي حال كنت تعمل على شيء آخر أرجو التوضيح لمساعدتك بشكل دقيق.
-
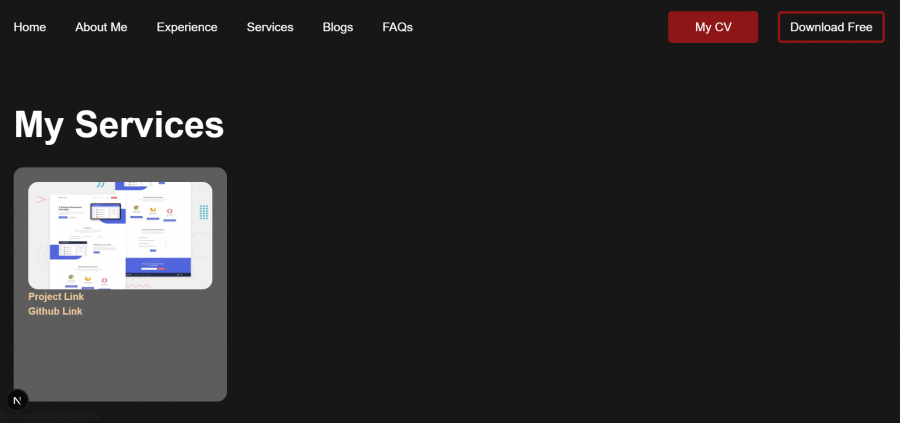
وعليكم السلام. لديك عدة مشاكل في مشروعك عند فتح المشروع على: http://localhost:3000 يظهر الخطأ التالي: SyntaxError: Unexpected token '<', "<!DOCTYPE "... is not valid JSON وهذا لأنه ليس لديك هذا المسار /api/languages فهو غير موجود في مشروع Next.js لذا انتقل إلى app ثم أنشئ المجلدات التالية: app/api/languages/route.js ثم داخل ملف route.js ضع التالي: export async function GET() { const data = [ { name: "JavaScript", proficiency: "Advanced" }, { name: "Python", proficiency: "Intermediate" }, { name: "C++", proficiency: "Basic" }, ]; return Response.json(data); } يمكنك التأكد من أن الخطأ زال إذا ظهرت لك بيانات JSON عند التوجه إلى: http://localhost:3000/api/languages ومنه سيعمل الكود في <About /> بدون خطأ. أيضا في ملف components/MyServices.jsx بعض كلاسـات Tailwind مثل: cursor-pointer hover:underline hover:text-main-color هي لا تعمل، والسبب هو أنّه في مشروع Next.js الذي يستخدم App Router أي مجلد app/ بدل pages/ ومنه فجميع المكونات بدون "use client" تعتبر Server Components وكما نعلم فإنّ Server Components لا تدعم التفاعلات مع المستخدم مباشرة، لذلك كلاسـات مثل hover: أو cursor-pointer لا تطبق ومنه في أعلى الملف يجب إضافة: "use client" ليصبح الكود كالتالي: 'use client'; import React from "react"; import Image from "next/image"; import Link from "next/link"; function MyServices() { return ( <div className="p-8"> <h1 className="text-6xl font-bold my-10">My Services</h1> <div className="flex items-center flex-col md:flex-row justify-between gap-10"> <div className="bg-white/30 -z-10 h-96 max-w-[350px] rounded-2xl p-6"> <Image src="/front-end-project.webp" alt="Service 1" className="h-44 rounded-2xl" width={500} height={500} /> <p className="user-select-none text-main-secondary-color font-bold cursor-pointer hover:underline hover:text-main-color"> Project Link </p> <Link href="/" className="text-main-secondary-color font-bold cursor-pointer hover:underline hover:text-main-color" > Github Link </Link> </div> </div> </div> ); } export default MyServices; ولكي يتم استخدام هذا المكون يجب تعديل ملف app/services/page.js لاستعمال المكون كالتالي: 'use client'; import MyServices from "../components/MyServices"; export default function Services() { return <MyServices />; } وعند فتح الرابط على: http://localhost:3000/services ستجد أنه يعمل:
-
المشكلة كما هو موضح في الصورة تحدث لأنك تستخدم معرف وكلمة مرور خاطئة في connection string لذلك يظهر: "Access denied for user 'USER'@'localhost'" بالرجوع إلى ملف app.py في السطر التالي: SQLALCHEMY_DATABASE_URI='mysql+pymysql://USER:PASS@localhost/dashboard' USER و PASS هما placeholders وليسا بيانات حقيقية ومن المفترض أن تستخدم بدلا من ذلك: SQLALCHEMY_DATABASE_URI='mysql+pymysql://root:@localhost/dashboard' وهذا لأنك في ملف docker-compose.yml أنت تستخدم: USER_mysql: 'root' و أما كلمة السر PASSWORD_mysql فهي فارغة في حال استمر المشكل تأكد من أنّ MySQL يعمل وفي حال لم تنشئ قاعدة البيانات قم بإنشائها ثم أعد المحاولة مرة أخرى: CREATE DATABASE dashboard;
-
أنصحك بشدة بتعلم TypeScript بعد إتقان React فهو يضيف نظام الأنواع الثابتة الذي يكتشف الأخطاء أثناء الكتابة، مما يوفر وقت التصحيح. أيضا خاصية الإكمال التلقائي ستصبح أدق وأسرع في محرر النصوص مما يحسن جودة الكود في المشاريع الكبيرة ويسهل العمل الجماعي لأن الأنواع تعمل كتوثيق. كما أنّ معظم الشركات تستخدمه كمعيار أساسي، وهو مطلوب في الوظائف المتقدمة. ولا تقلق بشأن تعلمه فهو سهل لأنك تعرف React مسبقا فقط ستتعلم كتابة الأنواع للمكونات وال props وال state وهذا يساعد في تجنب الأخطاء الشائعة ويجعل إعادة التشكيل أكثر أمانا. بخصوص المكتبات الحديثة فهي توفر دعما ممتازا له كما أنّ الموارد التعليمية كثيرة أنصحك بويكي حسوب فلديها توثيق رسمي له: https://wiki.hsoub.com/TypeScript
-
يمكنك استخدام الصورة من مجلد assets: <link rel="icon" type="image/png" href="/src/assets/your-icon.png" /> أو إذا كانت الصورة في مجلد public: <link rel="icon" type="image/png" href="/your-icon.png" /> أما إذا كنت تستخدم Vite يمكنك وضع الأيقونة في مجلد public وليس assets ليكون بهذه التركيبة: public/ favicon.ico icon.png src/ assets/ ثم في HTML: <link rel="icon" type="image/x-icon" href="/favicon.ico" /> أو: <link rel="icon" type="image/png" href="/icon.png" /> أما إذا كنت تريد استخدام صورة من assets يمكنك نسخ الصورة إلى مجلد public ثم: <link rel="icon" type="image/png" href="/icon.png" /> ولدعم أحجام متعددة استعمل التالي: <link rel="icon" type="image/png" sizes="32x32" href="/icon-32x32.png" /> <link rel="icon" type="image/png" sizes="16x16" href="/icon-16x16.png" /> <link rel="apple-touch-icon" sizes="180x180" href="/apple-touch-icon.png" />
-
نقاط السمعة هي نقاط تدل على كمية تفاعلك داخل الأكاديمية، و تجعلك تعرف العضو النشيط و غير النشيط، هذه هي فائدتها الرئيسية، و الأمر نفسه مع الصاروخ الذي تحدثت عنه حيث يعتبر كمستويات تتعداها عند التفاعل بشكل أكثر و يحتوي حاليا على ثلاث مستويات فقط.
- 3 اجابة
-
- 1
-