


Arabic Language
-
المساهمات
32 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Arabic Language
-
مرحبا أعمل على بيانات لغوية باستعمال LSTM و عند تجربة الكود تظهر لي الدقة 99% أما المخرج فمخيب للآمال ولا أعرف ما السبب النظام عبارة عن إسناد نوع الكلمة للكلمة مثلا: ذهب V يعني فعل البيانات في عمودين الأول الكلمة والثاني نوع الكلمة وعندي 30 ألف كلمة تدريب واختبار فهل المشكلة في تنسيق البيانات! أم في القيم ! أم في عدد الكلمات! لأن الأكواد تعمل بشكل جيد فضلا هل لديكم توجيه معين حيال هذه المشكلة؟
-
ضبطططططط معقول يصير المشكل من عدد أحرف اسم الملف!!!! سميته T فقط واشتغل !! ما زلت أجهل السبب!! قد جربته ويقول الملف غير موجود خلاص الحمد لله ضبط نفسي اعرف السبب !
-
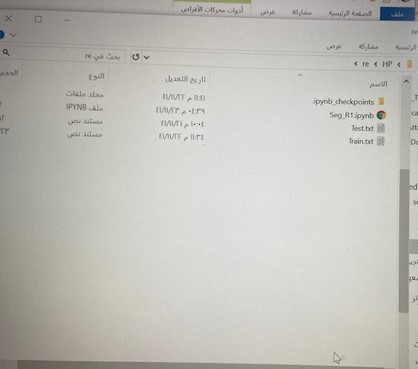
جربت ولم يحل المشكلة بل إني غيرت محتوى ملف الترين ليكون نفس ملف التست ولم يعمل ! ووضعت كل ملف بمكان ولم يعمل ! تفضل الصور

-
يمنى شكرا لك شكرا لك يمنى أنا قلت إنه يقرأ ملف التست ولا يقرأ الترين لأني عطلت السطر المتعلق بملف الترين وعمل الكود!!!!!!!!!!! وقرأ الملف كالتالي: import os from lazyme import per_section import nltk #training_sentences = [[tuple(token.split('\t')) for token in sent] for sent in per_section(open('C:\\Users\\HP\\re\\Train.txt'))] test_sentences = [[tuple(token.split('\t')) for token in sent] for sent in per_section(open('C:\\Users\\HP\\re\\Test.txt'))] #print(training_sentences[1]) print(test_sentences[1]) out: [('__SPACE__', '0'), ('ث', '0'), ('م', '0'), ('__SPACE__', '0'), ('ق', '0'), ('ا', '0'), ('ل', '0'), ('و', '0'), ('ا', '0'), ('__SPACE__', '0'), ('ف', '0'), ('ي', '0'), ('__SPACE__', '0'), ('م', '0'), ('س', '0'), ('ا', '0'), ('و', '0'), ('ئ', '0')] وجربت حذف txt نفس المشكلة
-
شكرا لجوابك أولا. طبقت هذه الطريقة ونفس نوع الخطأ ظهر لي ما زلت أستغرب من قراءته لملف التست وعدم قراءته لملف الترين لدرجة حذفت بيانات ملف الترين ووضعت فيها نفس بيانات التست ومازال الخطأ يظهر ! import os print(os.getcwd()) المخرج C:\Users\HP\re ورسالة الخطأ كالتالي: FileNotFoundError Traceback (most recent call last) <ipython-input-1-0383278864ef> in <module> 2 import nltk 3 ----> 4 training_sentences = [[tuple(token.split('\t')) for token in sent] for sent in per_section(open('Train.txt'))] 5 test_sentences = [[tuple(token.split('\t')) for token in sent] for sent in per_section(open('Test.txt'))] 6 print(training_sentences[1]) FileNotFoundError: [Errno 2] No such file or directory: 'Train.txt' شكرا جزيلا لك مقدما أدخلت هذا الكود "os.path.join("C:", "Users", "HP", "re" , "Train.txt") المخرج 'C:\\Users\\HP\\re\\Train.txt' أدخلته كما هو نفس الرسالة الملف غير موجود!!! حيرتي لماذا يجد الملف الموجود معه بنفس الصيغة ونفس المحتوى أقصد ملف التست ولا يجد ملف الترين !!!!!
-
مرحبا وأرجو أن تكونوا بخير حاولت البحث عن حل لهذه المشكلة وجربت كل الطرائق المقترحة ولم أفلح استدعيت ملفين ملف تدريب واختبار المكان واحد والمحتوى واحد لدرجة أني حاولت أن أجعل الملفين بمحتوى واحد لأتتبع المشكلة from lazyme import per_section import nltk training_sentences = [[tuple(token.split('\t')) for token in sent] for sent in per_section(open('C:\\Users\\HP\\re\\Train.txt'))] test_sentences = [[tuple(token.split('\t')) for token in sent] for sent in per_section(open('C:\\Users\\HP\\re\\Test.txt'))] print(training_sentences[1]) print(test_sentences[1]) أيضا حملت وحذفت الاناكوندا اكثر من مرة والمكتبات ايضا ومازالت المشكلة لاحظ في الكود أن ملف train لا يعثر عليه فما المشكلة؟ النتيجة التي يظهر فيها هذا الخطأ FileNotFoundError Traceback (most recent call last) <ipython-input-2-8159264d756d> in <module> 2 import nltk 3 ----> 4 training_sentences = [[tuple(token.split('\t')) for token in sent] for sent in per_section(open('C:\\Users\\HP\\re\\Train.txt'))] 5 test_sentences = [[tuple(token.split('\t')) for token in sent] for sent in per_section(open('C:\\Users\\HP\\re\\Test.txt'))] 6 print(training_sentences[1]) FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\HP\\re\\Train.txt' فما سبب المشكلة وما الحل ؟ مع شكري الجزيل لكم
