لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 11/25/23 في كل الموقع
-
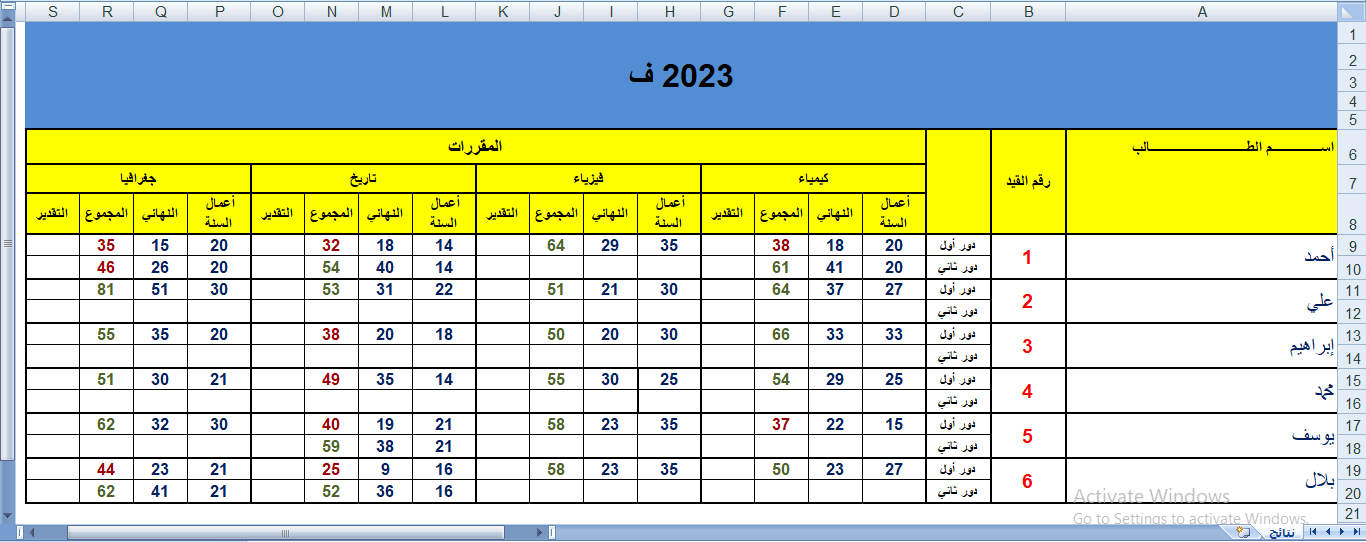
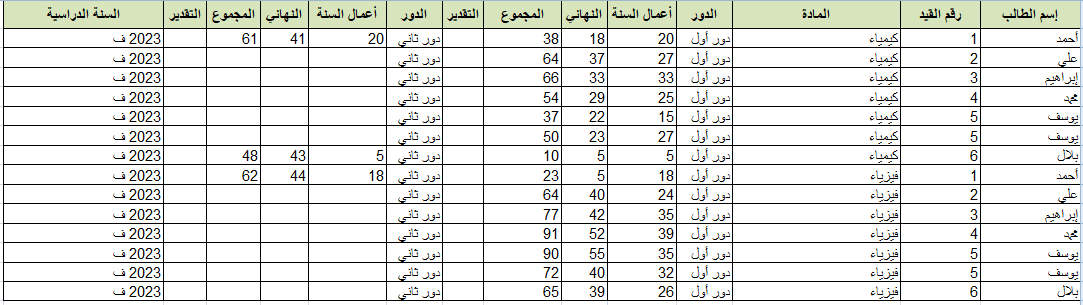
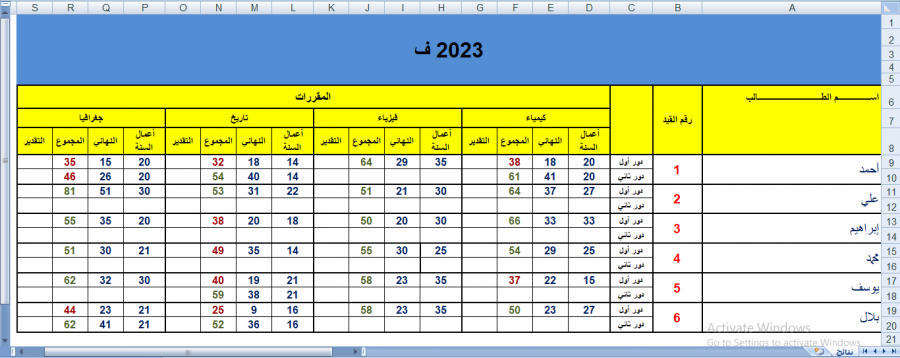
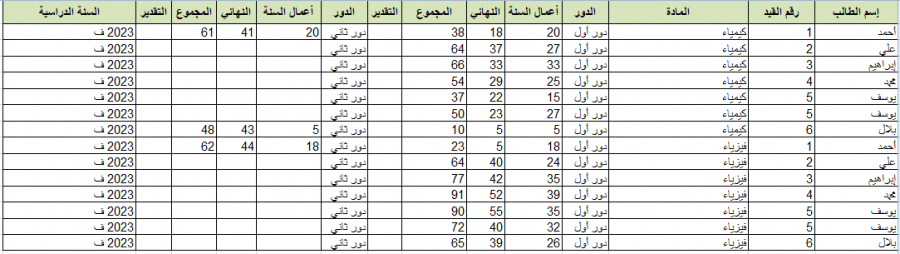
السلام عليكم إخوتي أحتاج مساعدة في كتابة كود Python بإستخدام مكتبة pandas لتحويل ونسخ البيانات من هذا الفورم أو هذا الشكل إلى هذا الفورم أو بهذه الكيفية بإستخدام الكود الرجاء التوضيح ولو بشيء من التفصيل وشاكر تعاونكم
 1 نقطة
1 نقطة -
السلام عليكم اي هي وظفيه dir() فيه python ?1 نقطة
-
السلام عليك احبتي اريد كود في بيثون لاستخراج النص المكتوب بخط اليد من الصوره ويعرض النتايج في عنصر نص او طباعته1 نقطة
-
وعليكم السلام، بالإضافة إلى ما تحدث عنه الأستاذ مصطفى، سوف تعلم الفرق الحقيقي بين production و developement عند الدخول في سوق العمل فمعظم الشركة تعتمدان على بيئتين أو ثلاث في حال وجود مرحلة الاختبار في حال developement هذه البيئة تكون مخصص للمطورين الموجودين في الشركة وتكون على سيرفر مستقل ومن الممكن أن تكون مشتركة مع بيئة الاختبار أو منفصلة عنها ولكن في الاغلب الاوقات تكون بيئة التطوير والاختبار على سيرفر واحد لتوفير التكاليف في حال production هذه البيئة يتم فيها إطلاق المنتج النهائي للخدمة وتكون على سيرفر مستقل وفي حال قمنا بتسمية سيرفر فمن الممكن أن تكون على اكثر من سيرفر وهذه السيرفرات مربوطة في نظام واحد في حال تعطل احدها يستطيع الاخر الرد على المستخدم ولكن يطلق عليها كمجموعة سيرفر وهنا تأتي فائدة node envirement حيث يوجد لكل بيئة متغيرات خاصة بها ونجد ذلك بشكل صريح في حال database، الاكيد أن database الخاصة ببيئة التطوير developement منفصلة عن بيئة الانتاج production من خلال اسم المستخدم كلمة السر وما إلى ذلك ولكن أنت لا تقوم بتعيين هذه القيم بشكل يدوي في كل مرة يتم وضع الكود فيها على بيئة التطوير والانتاج تقوم بوضع هذه القيم في ملفين مثلا الاول الخاص بالتطوير developement والاخر خاص بالانتاج production وتستطيع أن تضع في نفس الملف قيمة توضح على إي بيئة نعمل ثم عند وضع الكود في بيئة التطوير يقوم الكود بقراءة هذه القيم من الملف الخاص به باستخدام process.env وكذلك بالنسبة لبيئة الانتاج process.env وهذا يجعل مرحلة التطوير والانتاج اكثر عملية واقل تضيع للوقت1 نقطة
-
وعليكم السلام ورحمة الله كما تحدث الاستاذ عدنان بالإضافة ليس اسماء المتحولات والمتغيرات بل يشمل إيضا اسماء التوابع وكذلك الكائنات المأخوذه من الصفوف وكذلك اسماء المكتبات المستخدمة ضمن الكود الخاص بك import numpy def get(x): return x a = 5 b = "Hi" c = [1, 2, 3, 4] names = dir() #طباعة الخرج print(names) #الخرج ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b', 'c', 'get', 'numpy'] ما يهمنا الجزء الاخير حيث نلاحظ وجود المتحولات a,b,c وكذلك اسم التابع get وكذلك اسم المكتبة numpy مع ذلك نحن كمبرمجين لا نقوم باستخدام جميع ما هو متوافر باللغة البرمجية بل نستخدم حسب الحاجة وهنا ك dir من الممكن أن لا يكون لها اي استخدام على مستوى الكود لأنها لا تقدم إضافة كبيرة1 نقطة
-
وعليكم السلام ورحمة الله، يجب عليك توفير عينه بسيطة للملف الأول، إي قم برفع الملف إلى هنا لكي نستطيع مساعدتك في توفير كود لحل المشكلة1 نقطة
-
تستخدم حصرا للحصول على قائمة تحتوي على الأسماء (المتغيرات والوحدات) المتاحة في النطاق الحالي. مثال: # مثال بسيط x = 10 y = "Hello, World!" # استخدام dir() للحصول على قائمة الأسماء names = dir() # طباعة الأسماء print(names) سيعرض هذا الكود قائمة بجميع الأسماء المتاحة في النطاق الحالي، والتي هي x و y. يمكنك أيضًا استخدام dir(object) للحصول على قائمة بالأسماء المرتبطة بكائن معين. على سبيل المثال: # مثال على استخدام dir() مع كائن my_list = [1, 2, 3] # استخدام dir() للحصول على قائمة الأسماء المرتبطة بالقائمة list_names = dir(my_list) # طباعة الأسماء print(list_names) هاته هي فكرتها باختصار.1 نقطة
-
السلام عليكم هو فيه فرق بين الlist و arrry فيه الباثيون ؟1 نقطة
-
لا يوجد اختلاف بالنسبة للاساسيات في بايثون حيث أن list هي نفسها array ولكن في بايثون تمت تسميتها list اما الفرق بينها وبين اللغات الاخرى وعلى سبيل المثال جرب أن تقوم بتعبئة مصفوفة في لغة سي بلس أو جافا بعناصر مختلفة لا يمكنك ذلك حيث لا يمكن وضع سلسلة نصية مع عدد صحيح مع عدد حقيقي [1.5, 1, "111", 'c'] # هذا خاطئ في سي بلس أو جافا في حين تستطيع القيام بذلك بكل سهولة في بايثون حيث تقبل list عناصر مختلفة كالمثال السابق [1.5, 1, "111", 'c', [1, 2, 3]] # هذا صحيح في بايثون حيث تقبل عناصر مختلفة في النوع1 نقطة
-
نعم هناك فرق بين القائمة (list) والمصفوفة (array) في لغة برمجة Python. القائمة (list) هي ترتيب مرن من العناصر، حيث يمكن أن تحتوي على أي نوع من البيانات مثل الأعداد والسلاسل والقوائم الأخرى وحتى الكائنات. يمكن إضافة وحذف العناصر من القائمة وتعديلها بسهولة. على سبيل المثال: my_list = [1, 2, 3, "four", [5, 6]] أما بالنسبة ل المصفوفة (array) هي هيكل بيانات متجانس يحتوي على عناصر من نفس النوع. تستخدم المصفوفات عادة للعمليات الرياضية والعلمية ومعالجة البيانات الكبيرة. لإنشاء مصفوفة في Python ، يمكنك استخدام مكتبة NumPy التي توفر دعمًا قويًا للمصفوفات. على سبيل المثال: import numpy as np my_array = np.array([1, 2, 3, 4, 5]) المصفوفات في NumPy توفر عمليات فعالة للتعامل مع البيانات الرقمية وتنفيذ العمليات الرياضية بسرعة. كما توفر أيضًا وظائف مفيدة للتلاعب بالمصفوفات وتحويلها. لذا، إذا كنت تحتاج إلى هيكل بيانات مرن ومتنوع، فإن القائمة (list) هي الخيار المناسب. أما إذا كنت تعمل على العمليات الرياضية أو معالجة البيانات الكبيرة، فإن المصفوفة (array) في NumPy هي الخيار المناسب.1 نقطة
-
تستطيع ذلك بكل سهولة عبر نفس الكود السابق مع إضافة البداية 10 عبر وضع الاتي language_list = df['A'][10:].tolist() # حددنا اسم العمود ضمن المتحول الذي خذنا فيه البيانات print(language_list) # طباعة النتيجة لاحظ فقط وضعنا اسم العمود ضمن قوسين مصفوفة ثم قوسين مع وضع 10 ثم نقطتين إي نعني بذلك من السطر العاشر وحتى النهاية بالنسبة للعمود A1 نقطة
-
اقرا الرد السابق في اخره لقد شرحت ذلك عليك فقط تغيير اسم العمود إلى اسم العمود لديك1 نقطة
-
اختيار موفق في استعمال pandas للتعامل مع البيانات الموجودة في ملفات csv و excel حيث انها توفر اشكالا سهلة وبسيطة سواء للتعامل او لقراءة للبيانات وكذلك العمليات الرياضية البسيطة التي توضح معالجة للبيانات بشكل سهل وواضح. كذلك فإنها تعتمد على شكل dataframe والذي يجعل شكل البيانات سهلا وواضحا للقراءة، لذا فهي اكثر المكتبات استخداما في مجال تحليل البيانات يوجد ملف في الاسفل خاص بexecl تستطيع قراءة الملف باستخدام pandas كالاتي import pandas as pd df = pd.read_excel("test.xlsx", header=0) # قراءة الملف باستخدام المسار print(df.head()) # استعراض أول 5 اسطر من الملف تستطيع وضع عدد الاسطر التي سوف تقوم بعرضها ضمن التابع والنتيجة كالاتي Rank Language Percentageof worldpopulation(2018) 0 1 Mandarin Chinese 12.3% 1 2 Spanish 6.0% 2 3 English 5.1% 3 3 Arabic 5.1% 4 5 Hindi 3.5% لتحويل العمود langauge إلى list نستطيع كتابة الاتي language_list = df['Language'].tolist() # حددنا اسم العمود ضمن المتحول الذي خذنا فيه البيانات print(language_list) # طباعة النتيجة #الخرج الذي سيظهر ['Mandarin Chinese', 'Spanish', 'English', 'Arabic', 'Hindi', 'Bengali', 'Portuguese', 'Russian', 'Japanese', 'Western Punjabi', 'Javanese'] حيث الوظيفة tolist تحول العمود إلى قائمة list وهكذا تستطيع التعامل مع العمود عبر كتابة اسم المتحول الذي يخزن البيانات وهو هنا df ثم قوسين مع اسم العمود ضمن علامتي اقتباس test.xlsx1 نقطة
-
لايوجد اجابة صحيحة بالمطلق هنا، حيث أن القيمة الافتراضية لل state تعتمد كليا على نوع البيانات الخاص بك والسياق الذي تريده. سأعطيك بعض الأمثلة: بفرض لدينا form يحتوي على قائمة منسدلة للبلدان ليختار منها المستخدم، ففي هذه الحالة يجب اختيار أول خيار كقيمة افتراضية (اليمن) لأنه يمكن ان لايغير المستخدم القيمة الاولى الظاهرة لتبقى اليمن، فان كانت القيمة الافتراضية فارغة او null او undefinded، فانه لن يتم تخزين اليمن (القيمة الاولى الظاهرة) في حال لم يضغط المستخدم على الخيارات. const [country, setCountry] = useState("يمن") <select value={country} onChange={handleChange}> <option>اليمن</option> <option>سوريا</option> <option>مصر</option> </select> يمكن تعيين القيمة الافتراضية ل state معينة ك null او undefined لسهولة فحص ان كانت موجودة او لا، خصيصا عند التعامل مع API او مع بيانات قد يتم الحصول عليها او لا: const [data, setData] = useState(null) if (!data) { return <div>data is not fetched</div> } else { return <div>data is fetched</div> }1 نقطة
-
 لقد أوصلنا التطور السريع للتكنولوجيا إلى منعطف محوري، حيث أصبح الخيال العلمي حقيقة ملموسة. الذكاء الصناعي Artificial Intellegence، المجال الذي كان يقتصر في السابق على عالم الخيال، أصبح الآن قوة كبيرة تدعم الابتكار في مختلف الصناعات. بدءًا من السيارات ذاتية القيادة التي تتنقل في الشوارع المزدحمة إلى المساعدين الافتراضيين الذين يفهمون ويستجيبون لأوامرنا مثل سيري Siri وأليكسا Alexa، أصبح الذكاء الصناعي جزءًا لا يتجزأ من الحياة الحديثة. يكمن في قلب هذا التحوّل الفن المعقد لبرمجة الذكاء الصناعي، وهي عملية تتضمن صياغة خوارزميات ونماذج تُعالج وتحلّل كميات هائلة من البيانات، بغية إنشاء آلات ذكية يمكنها محاكاة الوظائف الإدراكية البشرية، مثل التعلم والاستدلال وحل المشكلات واتخاذ القرار. تتضمن برمجة الذكاء الصناعي تطوير البرامج التي تسمح للآلات بإظهار السلوك الذكي وحل المشكلات والتعلم من البيانات كما ذكرنا. إنه مجال متعدد التخصصات يجمع بين علوم الحاسب والرياضيات والعلوم المعرفية والهندسة. الهدف هو تزويد الآلات بالقدرة على تحليل البيانات المعقدة والتعلم من الأنماط والتكيّف مع الظروف المتغيرة، وحتى الانخراط في حل المشكلات التي تتطلّب حثًا إبداعيًّا. تتحدّث هذه المقالة عن برمجة الذكاء الصناعي وتستكشف مفاهيمها الأساسية وتقنياتها المتطورة وأساليب النشر والاعتبارات الأخلاقية والإمكانيات غير العادية التي تحملها لتشكيل المستقبل وأكثر. ما الفرق بين الذكاء الاصطناعي والبرمجة؟ الذكاء الصناعي والبرمجة هما مفهومان متمايزان ولكن مترابطان في مجال علوم الحاسب. تشير البرمجة إلى عملية إنشاء التعليمات البرمجية أو الشيفرة البرمجية التي تتبعها أجهزة الحاسب لأداء مهام محددة ومدروسة سابقًا ولا يمكن الخروج عنها أي لن يستجيب البرنامج إن حاولت استعماله في شيء ليس مبرمجًا عليه. يتضمن ذلك كتابة الخوارزميات والأوامر بلغات البرمجة المختلفة لتحقيق النتائج المرجوة. من الناحية الأخرى، يتجاوز الذكاء الصناعي البرمجة التقليدية من خلال تمكين الآلات من محاكاة الوظائف المعرفية بطريقة البشرية، مثل التعلم والاستدلال وحل المشكلات واتخاذ القرار. يمكن لأنظمة الذكاء الصناعي التكيف وتحسين أدائها بناءً على البيانات والخبرات، مما يسمح لها بالتعامل مع المواقف المعقدة وغير المؤكدة التي قد لا تكون مبرمجة بشكل واضح. من هنا نجد أن برمجة الذكاء الاصطناعي تختلف عن البرمجة التقليدية التي اعتدنا عليها. صحيح أن البرمجة تشكل الأساس لبناء أنظمة الذكاء الصناعي، إلا أن الذكاء الصناعي يتضمن تطوير خوارزميات ونماذج يمكنها التعلم من البيانات وتحسين أدائها بمرور الوقت، مما يمثل خروجًا كبيرًا عن نماذج البرمجة التقليدية. سأضرب مثالًا حديثًا يوضح الفرق بين الذكاء الاصطناعي والبرمجة، نشر إلون ماسك بتاريخ 26 أغسطس هذا العام فيديو على حسابه على تويتر وهو جالس في سيارة تسلا ذاتية القيادة متوجهًا من مكان إلى آخر دون أن يتدخل وقد علق قائلًا أثناء مرور السيارة بجانب دراجة أننا لم نكتب سطرًا من كود ولم نبرمج السيارة على التصرف في حال المرور بجانب شخص يقود دراجة هوائية، وقد مرت السيارة مرورًا سلسلًا بجانب الدراجة، ثم عند الوصول إلى تقاطع في إشارات مرورية علق قائلًا، نحن لم نبرمج السيارة على قراءة الإشارات المرورية ولم نكتب سطرًا برمجيًا يوضح كل اللافتات والإشارات المرورية بل الأمر متروك للسيارة باستنتاج معنى الإشارة وتطبيق ما يلزم، حيث مرت السيارة بجانب إشارة تطلب تخفيف السرعة فاستجابت لذلك، ويمكنك مشاهدة الفيديو كاملًا وهو بطول 45 دقيقة في سيارة تسلا ذاتية القيادة التي تقود مستعينة بالذكاء الاصطناعي. كان هذا أوضح مثال عن الفرق بين برمجة الذكاء الاصطناعي والبرمجة التقليدية. باختصار، تتضمن البرمجة كتابة تعليمات واضحة ليتبعها الحاسب، في حين تتضمن برمجة الذكاء الاصطناعي إنشاء أنظمة يمكنها التعلم من البيانات لإجراء تنبؤات أو قرارات دون أن تتم برمجتها بشكل صريح لكل موقف. مبرمج الذكاء الاصطناعي خلف كواليس تلك التطورات المذهلة التي يشهدها الذكاء الاصطناعي، يوجد محترفون ماهرون ينجزون هذا التطور، هم مبرمجي الذكاء الاصطناعي. يلعب هؤلاء الأفراد دورًا حاسمًا في تطوير الخوارزميات والنماذج والأنظمة التي تدعم تطبيقات الذكاء الاصطناعي. دور مبرمج الذكاء الاصطناعي مبرمج الذكاء الصناعي هو مطور برامج متخصص يركز على تصميم أنظمة الذكاء الصناعي وتنفيذها وتحسينها. هدفه الأساسي هو إنشاء خوارزميات ونماذج تمكن الآلات من أداء المهام التي تتطلب عادةً ذكاءًا بشريًّا. تتراوح هذه المهام من معالجة اللغة الطبيعية والتعرف على الصور إلى أنظمة التوصية والمركبات المستقلة. يقوم مبرمجي الذكاء الصناعي بسد الفجوة بين مفاهيم الذكاء الاصطناعي النظرية والتطبيقات العملية في العالم الحقيقي. تتضمن المهام الأساسية: تطوير الخوارزميات: يقوم مبرمجي الذكاء الاصطناعي بتصميم وتطوير خوارزميات تُمكّن الآلات من معالجة البيانات وتفسيرها وإنتاجها وإجراء التنبؤات وحتى توليد الأفكار. إنشاء النماذج: يقومون ببناء وتدريب نماذج التعلم الآلي والتعلم العميق باستخدام مجموعات بيانات ضخمة. تتعلم هذه النماذج الأنماط والعلاقات من البيانات لاتخاذ قرارات مستنيرة. المعالجة المسبقة للبيانات: يقوم مبرمجي الذكاء الاصطناعي بتنظيف البيانات ومعالجتها مسبقًا وتحويلها لجعلها مناسبة لتدريب نماذج الذكاء الاصطناعي. يتضمن ذلك مهام مثل تسوية البيانات واستخراج الميزات ومعالجة القيم المفقودة ..إلخ. تحسين الأداء: بمجرد تطوير النموذج، يقوم مبرمجو الذكاء الاصطناعي بتحسين أدائه من خلال ضبط المعلمات الخاصة بتدريب النموذج بدقة وتقليل المتطلبات الحسابية وتعزيز الكفاءة العامة. التكامل: يقوم مبرمجي الذكاء الاصطناعي بدمج نماذج وأنظمة الذكاء الاصطناعي في تطبيقات أكبر، مما يجعلها تتفاعل بسلاسة مع مكونات البرامج الأخرى. المهارات المطلوبة: إتقان البرمجة: يعد إتقان إحدى لغات البرمجة على الأقل مثل لغة بايثون أو لغة R أو جافا أمرًا أساسيًا. تحتاج عملية برمجة الذكاء الاصطناعي إلى كتابة التعليمات البرمجية لتنفيذ الخوارزميات ومعالجة البيانات وتطوير نماذج الذكاء الصناعي. التعلم الآلي: يعد الفهم القوي لمفاهيم التعلم الآلي أو تعلم الآلة، بما في ذلك التعلم الخاضع للإشراف وغير الخاضع للإشراف والانحدار والتصنيف والتجميع والشبكات العصبية، أمرًا ضروريًا. الرياضيات والإحصاء: تتضمن برمجة الذكاء الاصطناعي التعامل مع مفاهيم رياضية، مثل الجبر الخطي وحساب التفاضل والتكامل والاحتمالات. المعرفة الإحصائية السليمة أمر بالغ الأهمية لتقييم النماذج واختبار الفرضيات. أطر التعلم العميق: يعد الإلمام بمكتبات التعلم العميق مثل تنسرفلو TensorFlow وباي تورش PyTorch وكيراس Keras أمرًا ضروريًا لبناء الشبكات العصبية وتدريبها. التعامل مع البيانات: تعد المهارة في معالجة البيانات والمعالجة المسبقة وأدوات التصور ضرورية لإعداد البيانات للتدريب على نماذج الذكاء الصناعي. حل المشكلات: يجب أن يكون مبرمجي الذكاء الاصطناعي ماهرين في تقسيم المشكلات المعقدة إلى مكونات يمكن التحكم فيها واستنباط حلول فعالة. المعرفة بالمجال: قد يحتاج مبرمجي الذكاء الاصطناعي إلى معرفة خاصة بالمجال الذي يتم بناء النموذج للعمل عليه. على سبيل المثال، يجب على مبرمجي تطبيقات الذكاء الاصطناعي الطبية فهم المصطلحات والممارسات الطبية. الوعي بالأخلاق والتحيز: مع تأثير أنظمة الذكاء الاصطناعي على القرارات الحاسمة، يعد فهم الاعتبارات الأخلاقية وتخفيف التحيز أمرًا بالغ الأهمية. مبرمجو الذكاء الاصطناعي هم مهندسو المستقبل القائم على الذكاء الاصطناعي. تعتبر خبرتهم في الخوارزميات والتعلم الآلي ومعالجة البيانات مفيدة في إنشاء أنظمة يمكنها تحليل كميات هائلة من البيانات واتخاذ قرارات مستنيرة والتعلم المستمر من التجربة. ومع استمرار الذكاء الاصطناعي في إحداث ثورة في الصناعات وإعادة تعريف الإمكانيات، يظل دور مبرمجي الذكاء الاصطناعي محوريًا في تشكيل هذا المشهد التحويلي. سواء كان الأمر يتعلق بتعزيز تجارب العملاء أو إحداث ثورة في تشخيص الرعاية الصحية أو تمكين السيارات ذاتية القيادة، فإن مبرمجي الذكاء الاصطناعي هم في الطليعة، حيث يحولون الأفكار المتطورة إلى واقع عملي. المفاهيم الأساسية للذكاء الاصطناعي يشمل الذكاء الاصطناعي مجموعة واسعة من المفاهيم والتقنيات التي تهدف إلى إنشاء أنظمة قادرة على أداء المهام المختلفة. فيما يلي بعض المفاهيم الأساسية للذكاء الاصطناعي: التعلم الآلي Machine Learning التعلم الآلي هو مجموعة فرعية من الذكاء الاصطناعي الذي يركز على تطوير الخوارزميات والنماذج التي تمكن أجهزة الحاسب من التعلم والتنبؤ أو اتخاذ القرارات بناءً على البيانات. ويمكن تصنيفها إلى: التعلم الخاضع للإشراف Supervised Learning: تتعلم الخوارزميات من بيانات التدريب المصنفة لإجراء تنبؤات أو تصنيفات. وتشمل الأمثلة مهام الانحدار والتصنيف. التعلم غير الخاضع للإشراف Unsupervised Learning: تتعلم الخوارزميات من البيانات غير المسماة لاكتشاف الأنماط والعلاقات. ومن الأمثلة على ذلك التجميع وتقليل الأبعاد. التعلم المعزز Reinforcement Learning: يتعلم الوكلاء Agents تنفيذ الإجراءات ضمن بيئة محددة لتحقيق أقصى قدر من المكافآت. شائع في مهام مثل اللعب والروبوتات. الشبكات العصبية Neural Networks الشبكات العصبية هي نماذج حسابية مستوحاة من بنية الدماغ البشري. وهي تتكون من عقد مترابطة (خلايا عصبية) منظمة في طبقات. كل اتصال له وزن يمكن تعديله أثناء التدريب لتحسين أداء النموذج. التعلم العميق Deep Learning التعلم العميق هو مجال فرعي من التعلم الآلي يتضمن شبكات عصبية ذات طبقات متعددة (شبكات عصبية عميقة). لقد أتاح التعلم العميق تحقيق إنجازات كبيرة في مهام مثل التعرف على الصور والكلام نظرًا لقدرته على تعلم الأنماط المعقدة تلقائيًا من البيانات. معالجة اللغات الطبيعية Natural Language Processing تتضمن البرمجة اللغوية العصبية تمكين أجهزة الحاسب من فهم اللغة البشرية وتفسيرها وتوليدها. يتم استخدامه في مهام مثل تحليل المشاعر وترجمة اللغات وروبوتات الدردشة وإنشاء النصوص. الرؤية الحاسوبية Computer Vision تركز رؤية الحاسب على منح الآلات القدرة على تفسير المعلومات المرئية من البيئة المحيطة. يُستخدم في تحليل الصور والفيديو واكتشاف الأشياء والتعرف على الوجه والمركبات ذاتية القيادة. الأنظمة الخبيرة Expert Systems الأنظمة الخبيرة هي برامج الذكاء الاصطناعي التي تحاكي قدرات اتخاذ القرار للخبير البشري في مجال معين. ويستخدمون تقنيات تمثيل المعرفة والتفكير لحل المشكلات المعقدة. تمثيل المعرفة والاستدلال Knowledge Representation and Reasoning تحتاج أنظمة الذكاء الاصطناعي إلى تمثيل المعرفة بتنسيق منظم يمكن لأجهزة الحاسب فهمه. يتضمن الاستدلال استخدام القواعد المنطقية لإجراء الاستدلالات واستخلاص النتائج من المعرفة الممثلة. الحوسبة المعرفية Cognitive Computing تهدف الحوسبة المعرفية إلى إنشاء أنظمة يمكنها محاكاة عمليات التفكير البشري، مثل التفكير وحل المشكلات والتعلم. غالبًا ما يجمع بين تقنيات الذكاء الاصطناعي ومعالجة اللغة الطبيعية وتحليل البيانات. الإدراك الآلي Machine Perception يتضمن ذلك منح الآلات القدرة على إدراك العالم وفهمه من خلال المدخلات الحسية مثل الصور والصوت واللمس. يتضمن مهام مثل التعرف على الصور والتعرف على الكلام والتعرف على الإيماءات. توفر هذه المفاهيم فهمًا أساسيًا للذكاء الاصطناعي. ومع استمرار تطور هذا المجال، ستظهر تقنيات وأساليب جديدة، مما يساهم في تقدمه السريع. تجدر الإشارة إلى أنك كمبرمج للذكاء الصناعي لست مضطرًا لتعلّم كل هذه المفاهيم، وإنما يكفي فهم عام لها (فهم سطحي)، والتخصص في واحدة أو اثنتين منها فقط، لأن التخصص في كل هذه المفاهيم أو في كل مجالات الذكاء الصناعي هو أمر شبه مستحيل. خوارزميات الذكاء الاصطناعي خوارزميات الذكاء الاصطناعي عبارة عن مجموعات من التعليمات خطوة بخطوة أو الإجراءات الحسابية المصممة لحل مشكلات أو مهام محددة تتطلب عادةً ذكاءً بشريًا. تقع هذه الخوارزميات في قلب أنظمة الذكاء الاصطناعي، مما يمكّن الآلات من التعلم والتفكير واتخاذ القرارات.عمومًا، هذه الخوارزميات هي مجرد أفكار ونظريات تحتاج إلى تحويل إلى صيغة يمكن للآلات استغلالها، وهنا يتجلى دور برمجة الذكاء الاصطناعي في تحويل هذه الأفكار إلى شيفرات برمجية، بالتالي تصبح الآلات قادرة على تحليل البيانات بشكل ذكي، مما يتيح لها اكتساب المعرفة وتحديث أساليبها تلقائيًا. هناك مجموعة واسعة من الخوارزميات ذات الصلة بالذكاء الصناعي منها خوارزميات البحث والخوارزميات الجينية والشبكات العصبية وأشجار القرار وخوارزميات التجميع وخوارزميات معالجة اللغات الطبيعية وخوارزميات التعلم المعزز. يعتمد اختيار الخوارزمية على المشكلة التي تحاول حلها والبيانات المتوفرة لديك ومهمة الذكاء الاصطناعي المحددة التي تعمل عليها. لن نخوض في هذه الخوارزميات الآن، فقد كان لنا محطة عندها في مقالة خوارزميات الذكاء الاصطناعي. البدء في برمجة الذكاء الاصطناعي عند وجود أساس جيد للمفاهيم الأساسية للذكاء الاصطناعي، يكون قد حان الوقت للشروع في رحلتك إلى عالم برمجة الذكاء الصناعي. نوجّهك في هذا القسم إلى الخطوات الأولية لبدء برمجة تطبيقات الذكاء الصناعي. لغات برمجة الذكاء الاصطناعي تُستخدم العديد من لغات برمجة الذكاء الاصطناعي والمكتبات بشكل شائع لتطوير الذكاء الصناعي نذكر منها ما يلي: لغة بايثون Python لغة R لغة جافا Java لغة جوليا Julia 1. لغة بايثون Python لغة بايثون هي لغة شائعة لبرمجة الذكاء الصناعي نظرًا لبساطتها ونظامها الإيكولوجي الشامل لمكتبات الذكاء الصناعي مثل تنسرفلو TensorFlow وباي تورش PyTorch وسكايت ليرن scikit-Learn. لغة R تُستخدم لغة R على نطاق واسع في التحليل الإحصائي وتصوّر البيانات، مما يجعلها الخيار المفضل لمشاريع الذكاء الصناعي التي تتضمن تحليل البيانات. لغة جافا Java القدرات القوية للبرمجة غرضية التوجّه OOP في لغة جافا تجعلها مناسبة لبناء تطبيقات الذكاء الصناعي. لغة جوليا Julia تكتسب لغة جوليا قوة دفع لقدراتها عالية الأداء في الحوسبة العلمية والتعلم الآلي. سنتحدث عن استخدامات هذه اللغات -ولغات أخرى- في سياق الذكاء الصناعي بشيءٍ من التفصيل لاحقًا. تجدر الإشارة إلى أنه يمكنك الاطلاع على سلاسل مقالات كاملة عن مكتبة بايثون، ولغة جافا، ولغة R. استكشاف مكتبات وأطر عمل الذكاء الاصطناعي تصبح برمجة الذكاء الصناعي أكثر سهولة وكفاءة بمساعدة المكتبات والأطر المتخصصة. توفر هذه الأدوات دوال وتجريدات مختلفة لجعل تطوير الذكاء الصناعي أكثر كفاءة. فيما يلي بعض مكتبات وأطر عمل الذكاء الصناعي الشائعة: تنسرفلو TensorFlow تم تطوير إطار العمل تنسرفلو TensorFlow بواسطة شركة جوجل، وهي واحدة من مكتبات الذكاء الصناعي مفتوحة المصدر الأكثر استخدامًا. توفر نظامًا بيئيًا شاملاً للتعلم الآلي والتعلم العميق، بما في ذلك دعم الشبكات العصبية ومعالجة اللغة الطبيعية NLP والرؤية الحاسوبية. باي تورش PyTorch طوّر باي تورش بواسطة مختبر أبحاث الذكاء الصناعي FAIR التابع لشركة ميتا، وهو يتبع أسلوبًا ديناميكيًا في تنفيذ الشبكات العصبية، مما يجعله أكثر مرونة للبحث والتجريب. يستخدم على نطاق واسع في الأوساط الأكاديمية والصناعية لتطوير نماذج التعلم العميق. كيراس Keras في الأصل هي مكتبة مستقلة، لكن أصبحت كيراس الآن جزءًا من تنسرفلو باعتبارها واجهة برمجة تطبيقات عالية المستوى. يوفر واجهة سهلة الاستخدام لبناء الشبكات العصبية وتدريبها، مما يجعلها رائعة للمبتدئين. سكايت-ليرن Scikit-Learn هذه مكتبة شهيرة للتعلم الآلي، ولكن ليس لها أي علاقة بالتعلم العميق والشبكات العصبية. توفر هذه المكتبة عددًا كبيرًا من خوارزميات التعلم الآلي التقليدية. توفر مجموعة أدوات بسيطة وفعالة للمعالجة المسبقة للبيانات وهندسة الميزات وتقييم النموذج. توفر هذه المكتبات والأطر بيئة مناسبة ومريحة وآمنة وموثوقة، لتسهيل عملية بناء وتطوير مشاريع الذكاء الصناعي. نتحدث عن هذه المكتبات والأطر في المقالة القادمة بشكل أكبر أيضًا. أدوات تطوير وبرمجة تطبيقات الذكاء الاصطناعي قبل البدء في الخوض في عالم برمجة الذكاء الاصطناعي، من الضروري إنشاء بيئة تطوير قوية توفر الأدوات والموارد اللازمة لكتابة الشيفرات وإنشاء الاختبارات بسلاسة: اختر نظام التشغيل الخاص بك أولاً وقبل كل شيء، حدد نظام التشغيل الذي يناسب تفضيلاتك ومتطلباتك. يمكن إجراء تطوير الذكاء الصناعي على منصات مختلفة، إلا أن العديد من مكتبات وأدوات الذكاء الصناعي مدعومة جيدًا على الأنظمة المستندة إلى لينكس Linux مثل أبونتو Ubuntu. تجدر الإشارة أيضًا إلى أن نظامي التشغيل ويندوز Windows وماك macOS هما أيضًا خيارات يمكن الاعتماد عليها. يعتمد اختيارك إلى حد كبير على معرفتك بالنظام وراحتك، وممكن استعمال لينكس ضمن ويندوز عبر طريقتين إما عبر بيئة وهمية أو عبر نظام لينكس الداخلي WSL، أو يمكن تثبيت لينكس مع ويندوز. تثبيت بايثون Python بايثون هي لغة البرمجة المفضلة لبرمجة الذكاء الاصطناعي نظرًا لبساطتها وبيئتها الواسعة التي تتضمن العديد من المكتبات الداعمة للذكاء الصنعي. ابدأ بتثبيت بايثون على نظامك. يمكنك مراجعة مقال تثبيت لغة بايثون الشامل الذي يشرح تنزيل بايثون على كل أنظمة التشغيل. بعد التثبيت، ستتمكن من الوصول إلى مجموعة المكتبات والأدوات الثريّة في بايثون. اختر بيئة تطوير متكاملة IDE إن استخدام بيئة تطوير متكاملة يؤدي إلى تحسين تجربة البرمجة الخاصة بك من خلال توفير ميزات مثل إكمال التعليمات البرمجية وتصحيح الأخطاء وإدارة المشروع. تشمل الخيارات الشائعة PyCharm و Jupyter Notebook المخصصين لبايثون وكذلك Visual Studio Code الذي يُعتبر بيئة تطوير عامة. تُقدم بيئات التطوير المتكاملة مكونات إضافية وإضافات متخصصة لتطوير الذكاء الاصطناعي، مما يبسط سير عملك. تثبيت أطر ومكتبات الذكاء الصناعي لتسخير قوة الذكاء الاصطناعي، ستحتاج إلى تثبيت مكتبات وأطر تسهل مهام التعلم الآلي والتعلم العميق. تعد تنسرفلو TensorFlow وباي تورش PyTorch وكيراس Keras وسكايت ليرن scikit-Learn بعض المكتبات الأساسية التي يجب أخذها بعين الاعتبار. يمكنك تثبيت هذه المكتبات باستخدام مدير حزم بايثون pip، عن طريق تنفيذ أوامر بسيطة. إعداد البيئات الافتراضية يعد إنشاء بيئات افتراضية أفضل ممارسة لعزل مشاريعك وتبعياتها. تضمن البيئات الافتراضية أن المكتبات والحزم المثبتة لمشروع واحد لا تتداخل مع المشاريع والحزم الأخرى. استخدم أدوات مثل venv أو conda أو pipenv لإنشاء وإدارة بيئات افتراضية، وتحسين تنظيم مشروعك وتجنب تعارضات الإصدار. إعداد التحكم في الإصدار Version Control يعد التحكم في الإصدار أمرًا بالغ الأهمية لإدارة التغييرات في قاعدة التعليمات البرمجية الخاصة بك والتعاون مع الآخرين. جيت Git هو أكثر أنظمة التحكم في الإصدارات شيوعًا. أنشئ مستودع جيت لمشاريع الذكاء الاصطناعي الخاصة بك لتتبع التغييرات والتعاون مع أعضاء الفريق والاحتفاظ بسجل لقاعدة التعليمات البرمجية الخاصة بك. يمكنك الاطلاع على سلاسل مقالات كاملة للتعرّف على كيفية التعامل مع جيت من قسم Git التعليمي. استكشاف المنصات السحابية Cloud Platforms نظرًا لأن مشاريع الذكاء الاصطناعي أصبحت أكثر تعقيدًا، فقد تحتاج إلى قوة حسابية إضافية. توفر المنصات السحابية مثل خدمات أمازون ويب Amazon Web Services وسحابة جوجل Google Cloud ومايكروسوفت أزور Microsoft Azure موارد لتطوير الذكاء الاصطناعي ونشره. تعرّف على هذه المنصات لتسخير قدراتها في بناء مشاريعك. إن إنشاء بيئة تطوير قوية يضع الأساس لبرمجة ناجحة للذكاء الصناعي. مع بايثون ومكتبات الذكاء الصناعي و بيئة التطوير المتكاملة المناسبة والتحكم في الإصدار، فأنت مجهز جيدًا لبدء رحلة الذكاء الصناعي الخاصة بك. تجدر الإشارة أيضًا، إلا أن المبدتئين يمكنهم تجاوز الخطوات 6 و 7 مبدأيًا، والخوض بهما لاحقًا عند الحاجة. مراحل برمجة نموذج ذكاء اصطناعي؟ تتضمن عملية تطوير نماذج الذكاء الصناعي مرحلتين أساسيتين هما: عملية التدريب وعملية التقييم. إنهما مرحلتين حاسمتين في برمجة الذكاء الصناعي. مرحلة التدريب هي المرحلة التي يتعلم فيها نموذجك من البيانات ويضبط معلماته Parameters (العناصر القابلة للتعديل داخل النموذج، والتي تؤثر بشكل كبير على أداء النموذج وسلوكه) لعمل تنبؤات دقيقة في العالم الحقيقي. يتمثل دورك كمبرمج للذكاء الصناعي في هذه المرحلة في بناء النموذج وإعداد البيانات اللازمة للتدريب والتأكد من أن نموذجك يتعلم من البيانات بشكل فعّال وينتج تنبؤات دقيقة (أي التدريب ومراقبة صحة عملية التدريب). أما مرحلة التقييم، فهي المرحلة التي تلي مرحلة التدريب، حيث تتضمن سلسلة من الاختبارات اللازمة للتأكد من مدى فعالية النموذج عند تعريضه لبيانات العالم الحقيقي. من خلال فهم الفروق الدقيقة في تدريب النموذج والتحقق من صحة التدريب والتقييم، ستتمكن من ضبط تطبيقات الذكاء الصناعي الخاصة بك للحصول على الأداء الأمثل. ستمهد هذه المعرفة الطريق لك لإنشاء نماذج ذكاء اصطناعي أكثر تطوراً ودقة في المستقبل. نشر نماذج الذكاء الاصطناعي تظهر القيمة الحقيقية لنموذج الذكاء الصناعي عند نشره واستخدامه في سيناريوهات العالم الحقيقي، إنه الخطوة المحورية التي تحول الخوارزميات المدربة من تجارب إلى حلول عملية. إنها المرحلة التي يتم فيها إتاحة نماذج الذكاء الصناعي الخاصة بك للتفاعل مع العالم الحقيقي وإجراء تنبؤات أو تصنيفات أو قرارات. نتحدث في هذا القسم عن تعقيدات نشر نماذج الذكاء الصناعي ونغطي الاعتبارات المختلفة للنشر الناجح. اختيار نهج النشر الصحيح عند نشر نماذج الذكاء الاصطناعي، لديك عدة خيارات، لكل منها مزاياها ومقايضاتها. سنناقش طريقتين أساسيتين للنشر: النشر المحلي والنشر المستند إلى مجموعة النظراء. النشر المحلي أو النشر في أماكن العمل On-Premises Deployment: يوفر نشر نماذج الذكاء الصناعي في أماكن العمل درجة عالية من التحكم والأمان وخصوصية البيانات. يتضمن نهج النشر هذا استضافة نماذج الذكاء الصناعي الخاصة بك على الخوادم المحلية أو الأجهزة المتطورة داخل البنية التحتية لمؤسستك. يعد النشر المحلي مفيدًا بشكل خاص عند التعامل مع البيانات الحساسة أو عندما تكون التفاعلات ذات زمن الوصول المنخفض ضرورية. النشر المستند إلى السحابة Cloud-Based Deployment: أحدث النشر المستند إلى السحابة ثورة في طريقة إتاحة نماذج الذكاء الاصطناعي للمستخدمين، مما يوفر قابلية التوسع وإمكانية الوصول والتكلفة المنخفضة. هنا تحتاج إلى تحديد مزود الخدمة السحابية المناسب الذي يناسب متطلبات مشروعك، وأشهرها خدمات أمازون ويب Amazon Web Services ومنصة جوجل السحابية Google Cloud Platform ومايكروسوفت آزور Microsoft Azure. تحسين النموذج المستمر يعد تحسين النموذج للنشر خطوة مهمة لضمان أن تكون نماذج الذكاء الصناعي فعّالة وسريعة وقادرة على تقديم تنبؤات دقيقة في سيناريوهات العالم الحقيقي. نظرًا لأن نماذج الذكاء الصناعي أصبحت أكثر تعقيدًا، فإن حجمها ومتطلباتها الحسابية يمكن أن تشكل تحديات عند نشرها على أجهزة مختلفة، من الأجهزة المتطورة إلى الخوادم السحابية. تلعب تقنيات تحسين النموذج دورًا مهمًا لمواجهة هذه التحديات. أهم هذه التقنيات هم التكميم والتقليم والضغط. يمكن لممارسي الذكاء الاصطناعي تحقيق توازن بين أداء النموذج وكفاءة النشر من خلال الخوض في استراتيجيات التحسين هذه، مما يضمن أن حلول الذكاء الصناعي الخاصة بهم تقدم النتائج بسرعة وفعاليّة. التكميم Quantization: التكميم هو تقنية مهمة في مجال نشر نماذج الذكاء الاصطناعي. يتضمن تقليل دقة القيم العددية في معلمات النموذج، عادةً من عرض بت أعلى (على سبيل المثال، 32 بت) إلى عرض بت أقل (على سبيل المثال، 8 بتات). ينتج عن هذه العملية تمثيل أفضل عمليًا للنموذج، مما يقلل بشكل كبير من استخدام الذاكرة ويحسن سرعة الاستدلال. إذًا يتيح التكميم نشر نماذج الذكاء الصناعي بكفاءة على الأجهزة محدودة الموارد مثل الأجهزة المتطورة والهواتف المحمولة وأجهزة إنترنت الأشياء، وذلك من خلال التضحية بالقليل من الدقة. إنه يحقق توازنًا بين الكفاءة الحسابية والحفاظ على الأداء المعقول، مما يجعله أداة لا غنى عنها في ترسانة مهندسي الذكاء الصناعي الذين يسعون جاهدين للحصول على حلول النشر المثلى. التقليم Pruning: التقليم هو أسلوب آخر في مجال تحسين نموذج الذكاء الصناعي للنشر، يهدف إلى تبسيط التعقيد وتحسين كفاءة النماذج المُدرّبة. تتضمن هذه العملية القضاء الانتقائي على الاتصالات الزائدة أو العقد أو المعلمات من الشبكة العصبية، وبالتالي تقليل حجمها الكلي مع السعي للحفاظ على أدائها في نفس الوقت. لا ينتج عن التقليم نماذج أخف وأسرع أثناء الاستدلال فحسب، بل يساهم أيضًا في معالجة مشكلات الضبط المُفرط Overfitting. إذًا يعمل التقليم على تحسين قدرات التعميم من خلال إزالة المكونات الأقل تأثيرًا في النموذج، وغالبًا ما يؤدي إلى تحسين الدقة عمومًا. تُقدّم هذه التقنية إمكانية التوازن بين تعقيد النموذج والأداء، وتوضح كيف يمكن أن يؤدي التبسيط الاستراتيجي إلى حلول ذكاء اصطناعي أكثر مرونة وفعالية. الضغط Compression: يعد الضغط تقنية أخرى في عالم نشر نماذج الذكاء الصناعي. يهدف أيضًا إلى تحقيق توازن بين دقة النموذج وكفاءة الموارد. تلعب تقنيات الضغط دورًا مهمًا في تقليل الذاكرة التي يستهلكها النموذج وتسريع الاستدلال دون التضحية الكبيرة في الأداء التنبئي، وذلك من خلال إزالة المعلومات الزائدة واستغلال الأنماط داخل معلمات النموذج. لا يؤدي الضغط إلى تحسين متطلبات التخزين فحسب، بل يُقلل أيضًا الزمن اللازم للتنبؤ. من تقليم الاتصالات غير المهمة إلى تحديد قيم المعلمات، يمكّن الضغط مطوري الذكاء الاصطناعي من نشر نماذج قوية وفعّالة عمليًا، مما يضمن السلاسة عبر الأجهزة وسيناريوهات الاستخدام المحتملة. الأمان والخصوصية تعتبر اعتبارات الأمان والخصوصية في عملية نشر نماذج الذكاء الاصطناعي ذات أهمية قصوى. نظرًا لأن نماذج الذكاء الاصطناعي تتفاعل مع البيانات الحساسة وتقوم بالتنبؤات التي تؤثر على القرارات الحاسمة، فإن الحماية من الوصول غير المصرح به وضمان الاستخدام الأخلاقي يصبح أمرًا ضروريًا. يعد تنفيذ إجراءات أمنية قوية أمرًا ضروريًا للحفاظ على ثقة المستخدم والامتثال للوائح. تلعب تقنيات مثل التشفير دورًا محوريًا في تأمين البيانات أثناء النقل والتخزين. تساعد المصادقة المستندة إلى الرمز المميز والتحكم في الوصول المُستند إلى الدور -في تنظيم من يمكنه الوصول إلى واجهات برمجة تطبيقات الذكاء الاصطناعي، مما يضمن أن المستخدمين المُصرّح لهم فقط هم من يمكنهم إجراء تنبؤات. إضافةً إلى ذلك ونظرًا لأن أنظمة الذكاء الصناعي غالبًا ما تتعامل مع المعلومات الشخصية والسرية، فمن الضروري اعتماد أساليب الحفاظ على الخصوصية، مثل إخفاء البيانات وحماية الهويات الشخصية. إذًا من خلال تضمين اعتبارات الأمان والخصوصية عند نشر نماذج الذكاء الاصطناعي، يؤمّن المطورون بيئة أكثر أمانًا ومسؤولية لمستخدمي الذكاء الصناعي. المراقبة والصيانة المراقبة والصيانة هما شريان الحياة لنماذج الذكاء الصناعي المنشورة، حيث تضمنان استمرار دقتها وموثوقيتها وأدائها. بعد نشر نموذج الذكاء الصناعي الخاص بك، من المهم إنشاء نهج منظّم لمراقبة سلوكه ومعالجة أي مشكلات قد تنشأ لاحقًا. تتضمن المراقبة تتبع مقاييس مختلفة، مثل دقة التنبؤ وأوقات الاستجابة واستخدام الموارد لاكتشاف الأخطاء أو الانحرافات عن السلوك المتوقع. يجري ذلك من خلال إعداد التنبيهات والفحوصات الآلية، وبالتالي إمكانية تحديد أي مشكلات ومعالجتها على الفور قبل أن تؤثر على المستخدمين أو العمليات التجارية. بالنسبة للصيانة فهي تتجاوز موضوع الكشف عن الخلل وإصلاحه؛ إنها تنطوي على إدارة نماذج الذكاء الصناعي الخاصة بك بمرور الوقت، فمع تغيّر البيانات وتطور متطلبات المستخدم، قد يحتاج نموذجك إلى تحديثات دورية ليظل فعّالاً. تتضمن الصيانة أيضًا تحديد إصدارات النماذج وواجهات برمجة التطبيقات، مما يتيح لك إجراء تحسينات دون الإخلال بتجربة المستخدم. يضمن الاختبار المنتظم والتحقق من صحة سير العمل وقياس الأداء مقابل البيانات الجديدة، استمرار نماذجك في تقديم نتائج دقيقة. من خلال ضبط نماذجك باستمرار وإبقائها مواكبة لأحدث التطورات، فإنك تضمن أن حلول الذكاء الاصطناعي المنشورة تظل أصولًا قيّمة لمؤسستك. مستقبل برمجة الذكاء الاصطناعي يتطور مجال برمجة الذكاء الصناعي بسرعة، ويحمل المستقبل إمكانيات مثيرة للاهتمام. من المرجح أن تصبح الحلول التي تعمل بالذكاء الصناعي أكثر سهولة، مع الأدوات التي تسمح للمطورين بمستويات مختلفة من الخبرة لإنشاء تطبيقات الذكاء الصناعي. نستكشف الآن الاتجاهات والتحديات والإمكانيات التي تنتظر مستقبل برمجة الذكاء الصناعي. من الخوارزميات إلى أنظمة التعلم تتضمّن برمجة الذكاء الاصطناعي تقليديًا، صياغة خوارزميات معقدة لحل مشاكل محددة. إن مستقبل برمجة الذكاء الصناعي يتميز بالتحول نحو بناء أنظمة التعلم التي يمكن أن تتكيف وتتطور. لقد دفع التعلم الآلي وتقنيات التعلم العميق هذا التطور، مما مكّن أجهزة الحاسب من التعلم من البيانات وتحسين أدائها بمرور الوقت. نظرًا لأن برمجة الذكاء الصناعي تصبح أكثر اعتمادًا على البيانات، سيركز المطورون بشكل متزايد على إنشاء خوارزميات تعلم قوية وقابلة للتكيف والتطور وفقًا للبيانات. التعاون مع التخصصات الأخرى لم تعد برمجة الذكاء الصناعي مجالًا لعلماء الحاسب فقط. سيشهد المستقبل تعاونًا متزايدًا بين مبرمجي الذكاء الصناعي وخبراء المجال وعلماء الأخلاق وعلماء النفس وغيرهم من المتخصصين. سيتطلب بناء أنظمة ذكاء اصطناعي ناجحة اتباع نهج متعدد التخصصات لضمان توافق التكنولوجيا مع احتياجات وقيم العالم الحقيقي. الذكاء الاصطناعي القابل للتفسير عندما تصبح أنظمة الذكاء الاصطناعي أكثر تعقيدًا، يمكن أن تظهر عمليات اتخاذ القرار الخاصة بها على أنها "صناديق سوداء". هذا النقص في الشفافية يعيق التبني الأوسع للذكاء الاصطناعي في التطبيقات الهامة (عدم الثقة بقرار لاتعرف كيف أُنتج). سيشهد المستقبل طفرة في جهود البحث والتطوير لإنشاء أنظمة ذكاء اصطناعي قابلة للتفسير. ستوفر هذه الأنظمة رؤى حول كيفية توصل نماذج الذكاء الصناعي إلى قراراتهم، وبالتالي تعزيز الثقة بقرارات هذه النماذج وإمكانية التفسير. التعلم الآلي التلقائي AutoML أصبحت برمجة الذكاء الاصطناعي نفسها أكثر ذكاءً. يشهد التعلم الآلي التلقائي اهتمامًا كبيرًا بين الباحثين والشركات. إنه مجال يُركز على أتمتة المراحل المختلفة من خط أنابيب التعلم الآلي. سيستخدم المطورون أدوات AutoML لاختيار الخوارزميات وعمليات المعالجة المسبقة وتحسين النماذج تلقائيًا، مما يجعل من عملية تطوير نماذج الذكاء الصناعي أكثر سهولة. واجهات اللغة الطبيعية تتضمن برمجة الذكاء الاصطناعي التقليدية كتابة التعليمات البرمجية بلغات البرمجة. قد يتضمن المستقبل برمجة أنظمة الذكاء الاصطناعي باستخدام لغة طبيعية، أي أن مفهوم برمجة الذكاء الاصطناعي من الممكن أن يصبح أكثر تطورًا وسهولة. سيؤدي ذلك إلى إضفاء الطابع الديمقراطي على تطوير وبرمجة الذكاء الاصطناعي، مما يسمح للأفراد الذين ليس لديهم خبرة في كتابة الشيفرت البرمجية، بإنشاء تطبيقات ذكية من خلال محادثات بسيطة مع واجهات الذكاء الاصطناعي. الحوسبة المتطورة والذكاء الاصطناعي تستعد حوسبة الحافة Edge Computing (نموذج حوسبة يهدف إلى تنفيذ المعالجة والحوسبة قرب مصادر البيانات "الحواف")، لتشكيل مستقبل برمجة الذكاء الاصطناعي. ستحتاج خوارزميات الذكاء الاصطناعي إلى التحسين للنشر على الأجهزة محدودة الموارد مثل الهواتف الذكية وأجهزة إنترنت الأشياء والأنظمة المدمجة. سيتطلب ذلك مستوى جديدًا من الكفاءة والقدرة على التكيف في برمجة الذكاء الاصطناعي. التعلم المستمر مدى الحياة والذكاء الاصطناعي غالبًا ما يتم تدريب أنظمة الذكاء الاصطناعي التقليدية على مجموعات البيانات الثابتة. سيشهد المستقبل صعود التعلم المستمر والذكاء الاصطناعي مدى الحياة، حيث يمكن للأنظمة التعلم من البيانات الجديدة وتكييف معارفها دون نسيان تجارب التعلم السابقة. سيتطلب ذلك تقنيات خاصة لبرمجة الذكاء الاصطناعي تسهل التكامل السلس للمعلومات الجديدة في النماذج الحالية. برمجة الذكاء الاصطناعي الكمومية سيؤدي ظهور الحوسبة الكمومية Quantum computing إلى إحداث نقلة نوعية في برمجة الذكاء الاصطناعي. تمتلك أجهزة الحاسب الكمومية القدرة على إحداث ثورة في خوارزميات التعلم الآلي والعميق ومشكلات التحسين. سيشهد المستقبل قيام مبرمجي الذكاء الاصطناعي بالتعمق في برمجة الذكاء الاصطناعي الكمومي لتسخير قوة الحوسبة الكمومية من أجل حلول ذكاء اصطناعي أسرع وأكثر كفاءة. الذكاء الاصطناعي المرتكز على الإنسان إن مستقبل برمجة الذكاء الاصطناعي لا يقتصر فقط على بناء آلات أكثر ذكاءً؛ يتعلق الأمر بإنشاء ذكاء اصطناعي يكمل القدرات البشرية ويزيدها. ستصبح أنظمة الذكاء الاصطناعي أكثر تخصيصًا، بحيث تتكيف مع تفضيلات واحتياجات المستخدمين الفرديين. يتطلب هذا التحول من مبرمجي الذكاء الاصطناعي التأكيد على مبادئ التصميم التي تتمحور حول الإنسان، وإنشاء أنظمة تعزز الخبرات البشرية والإنتاجية. التعلم الموحد مفهوم تحولي آخر يأتي مع انتشار الأجهزة المتصلة عبر الشبكات، حيث يُمكّن نماذج الذكاء الاصطناعي من التدريب بطريقة تعاونية عبر العديد من الأجهزة اللامركزية المتصلة بالشبكة، دون الحاجة إلى نقل البيانات الأولية إلى خادم مركزي. الذكاء الاصطناعي وإنترنت الأشياء IoT يمثل تكامل الذكاء الاصطناعي مع إنترنت الأشياء تقاربًا بين تقنيتين تحويليتين تمتلكان القدرة على إعادة تشكيل الصناعات والحياة اليومية. يشير إنترنت الأشياء IoT إلى شبكة من الأجهزة المادية المترابطة والمجهزة بأجهزة استشعار وبرامج واتصالات، مما يمكنها من جمع البيانات وتبادلها. من الناحية الأخرى، يُمكّن الذكاء الاصطناعي الآلات من محاكاة الوظائف الإدراكية البشرية مثل التعلم والاستدلال واتخاذ القرار. عندما تتضافر هاتان القوتان، تظهر أوجه تآزر ملحوظة. يضفي الذكاء الاصطناعي براعته التحليلية على الكم الهائل من البيانات التي تنتجها أجهزة إنترنت الأشياء. يمكن لهذه الأجهزة جمع البيانات من البيئة أو تفاعلات المستخدم أو حتى من الأجهزة الأخرى. يمكن لخوارزميات الذكاء الاصطناعي بعد ذلك معالجة هذه البيانات لاستخراج الأنماط والاتجاهات والحالات الشاذة التي يصعب على المحللين البشريين تمييزها في الزمن الحقيقي. تخيل مدينة ذكية حيث تتعاون الأجهزة المترابطة في إشارات المرور والكاميرات والمركبات لتحسين تدفق حركة المرور استجابةً لظروف الوقت الفعلي. تعالج خوارزميات الذكاء الاصطناعي البيانات من هذه الأجهزة وتتنبأ بالازدحام المروري وتضبط توقيت إشارات المرور ديناميكيًا للتخفيف من الاختناقات. التحديات والقيود في برمجة الذكاء الاصطناعي في حين أن مجال برمجة الذكاء الاصطناعي يوفر فرصًا هائلة، إلا أنه مصحوب أيضًا بمجموعة من التحديات والقيود التي يجب على المطورين التعامل معها. أبرزها: جودة البيانات وكميتها الموارد الحسابية القابلية للتفسير والشرح الأخلاق والتحيز الافتقار إلى الفطرة السليمة وفهم السياق التعميم والقدرة على التكيف الأمان والخصوصية استهلاك الطاقة التعاون بين الإنسان والذكاء الاصطناعي التعلم المستمر والتحديثات 1. جودة البيانات وكميتها تعتمد أنظمة الذكاء الاصطناعي بشكل كبير على البيانات للتعلم واتخاذ القرارات. يمكن أن تؤثر جودة وكمية البيانات المتاحة بشكل كبير على أداء نماذج الذكاء الاصطناعي. يمكن أن تؤدي البيانات غير الكاملة أو المتحيزة أو التي تتضمّن أخطاءً إلى تنبؤات غير دقيقة ونتائج غير موثوقة. 2. الموارد الحسابية تتطلب خوارزميات الذكاء الاصطناعي، وخاصة نماذج التعلم العميق، موارد حسابية كبيرة. تتطلب نماذج التدريب المعقدة أجهزة قوية، وعلى الرغم من أن الحوسبة السحابية جعلت هذه الموارد أكثر سهولة، إلا أن التكلفة والتوافر لا يزالان من القيود المفروضة على بعض المشاريع. 3. القابلية للتفسير والشرح مع ازدياد تعقيد أنظمة الذكاء الاصطناعي، يصبح فهم كيفية التوصل إلى قرارات معينة تحديًا متزايدًا. يمكن أن يؤدي هذا الافتقار إلى الشفافية إلى إعاقة الثقة والتبني، خاصة في التطبيقات المهمة مثل الرعاية الصحية والتمويل. 4. الأخلاق والتحيز يمكن لنماذج الذكاء الاصطناعي أن تديم التحيزات الموجودة في بيانات التدريب دون قصد، مما يؤدي إلى نتائج غير عادلة أو تمييزية. يمثل تحقيق التوازن بين قدرات اتخاذ القرار في الذكاء الاصطناعي والاعتبارات الأخلاقية تحديًا مستمرًا. 5. الافتقار إلى الفطرة السليمة وفهم السياق تكافح أنظمة الذكاء الاصطناعي مع التفكير المنطقي وفهم السياق بنفس الطريقة التي يعمل بها البشر. قد يتفوقون في مهام محددة لكنهم يفتقرون إلى الفهم الأوسع الذي يمتلكه البشر. 6. التعميم والقدرة على التكيف بينما يمكن تدريب نماذج الذكاء الاصطناعي على أداء مهام محددة، قد يكون نقل تلك المعرفة إلى سيناريوهات أو مجالات جديدة أمرًا صعبًا. لا يزال تحقيق القدرة الحقيقية على التكيّف عبر مختلف السياقات يمثل تحديًا مستمرًا. 7. الأمان والخصوصية أنظمة الذكاء الاصطناعي التي تتعامل مع البيانات الحساسة عرضة للانتهاكات الأمنية. بالإضافة إلى ذلك، يشكل ضمان الخصوصية عند التعامل مع بيانات المستخدم تحديات أخلاقية وقانونية تتطلب دراسة متأنية. 8. استهلاك الطاقة يمكن أن يكون تدريب نماذج التعلم العميق مُستهلكًا كبيرًا للطاقة، مما يساهم في إثارة المخاوف بشأن التأثير البيئي لتطوير الذكاء الاصطناعي. 9. التعاون بين الإنسان والذكاء الاصطناعي إن دمج الذكاء الاصطناعي بسلاسة في سير العمل البشري يعتبر تحديًا، ويتطلب التأكد من أن الذكاء الاصطناعي يُكمل المهارات البشرية ويساعد بشكل فعال، وهذا يتطلب فهماً عميقاً لكلا المجالين. 10. التعلم المستمر والتحديثات تحتاج نماذج الذكاء الاصطناعي إلى التطور بمرور الوقت لتبقى ملائمة ودقيقة. يتطلب تحديث النماذج والتحسين المستمر لأدائها جهدًا مستمرًا. التعرف على هذه القيود أمر بالغ الأهمية لإنشاء أنظمة ذكاء اصطناعي مسؤولة وفعالة. تتطلب مواجهة هذه التحديات التعاون بين الباحثين والمطورين وواضعي السياسات والمجتمع ككل. بينما ندفع حدود برمجة الذكاء الاصطناعي، من المهم الحفاظ على منظور متوازن والعمل على التغلب على هذه العقبات من أجل تحسين مستقبلنا الذي يحركه الذكاء الاصطناعي. مصادر تعلم برمجة الذكاء الاصطناعي يعد التعرف على الذكاء الاصطناعي رحلة مثيرة تتطلب الوصول إلى مجموعة متنوعة من الموارد لتعميق فهمك ومهاراتك. فيما يلي بعض موارد تعلم الذكاء الاصطناعي القيمة لمساعدتك على البدء والتقدم في هذا المجال: الدورات التدريبية هناك العديد من الموارد المتاحة عبر الإنترنت لتعلم برمجة الذكاء الاصطناعي. تقدم أكاديمية حسوب دورة شاملة لتعلم برمجة الذكاء الاصطناعي باستخدام لغة بايثون، التي تعد كما ذكرنا اللغة الأساسية لكتابة تطبيقات ونماذج الذكاء الصناعي، حيث يمكنك تعلمها من خلال دورة الذكاء الاصطناعي التي تعد دورة شاملة لاحتراف برمجة الذكاء الاصطناعي وتحليل البيانات وتعلم كافة المعلومات المطلوبة لبناء نماذج ذكاء اصطناعي متخصصة مع مُدربين مُميزين يُرافقونك طوال الدورة للإجابة عن استفساراتك. تبقى الدورة مفتوحة لك مدى الحياة، كما أنها تطور باستمرار لمواكبة أحدث التطورات في المجال. الكتب يُمثل كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة نقطة بدءٍ مناسبةٍ للمبتدئين الذين يرغبون الخوض في هذا المجال ويرغبون في فهم المفاهيم الأساسية للتعلم العميق والشبكات العصبية وتعلم الآلة، حيث يبدأ الكتاب معك من الأساسيات ليمهد الطريق أمامك لتعلم هذا العلم. يمكنك أيضًا الاطلاع على كتاب عشرة مشاريع عملية عن الذكاء الاصطناعي إما بعد الكتاب السابق أو يمكنك البدء به مباشرة إن كانت لديك خبرة أساسية. مؤتمرات وورش عمل الذكاء الاصطناعي يُعتبر مؤتمر NeurIPS أحد أكبر مؤتمرات الذكاء الاصطناعي مع العروض التقديمية وورش العمل. هناك أيضًا مؤتمر CVPR الذي يُركز على رؤية الحاسب والتعلم العميق و ICML يُغطي أبحاث وتطبيقات التعلم الآلي. المقالات والمدونات يمكنك أيضًا الاطلاع على عشرات المقالات المتعلقة بالذكاء الصناعي، والتي توفرها أكاديمية حسوب في قسم الذكاء الاصطناعي. المجتمعات عبر الإنترنت يوفر قسم أسئلة وأجوبة في أكاديمية حسوب إمكانية طرح أسئلة للإجابة عليها من قبل مختصين في كافة المجالات ومنها مجال برمجة الذكاء الاصطناعي. البرمجة والممارسة يُقدّم موقع كاغل Kaggle مسابقات في الذكاء الاصطناعي ومجموعات بيانات وموارد سحابية لتدريب النماذج. يمكنك أيضًا الذهاب إلى غيت هاب GitHub لاستكشف مشاريع ومستودعات الذكاء الاصطناعي مفتوحة المصدر. تُمكّنك أكاديمية حسوب أيضًا من البدء بإنشاء مشاريعك من خلال الاطلاع على مشاريع مرجعية مشروحة ومنظمة جيدًا. مثل كتاب عشرة مشاريع عملية عن الذكاء الاصطناعي. الوثائق الرسمية لأطر عمل الذكاء الاصطناعي اطلع على الوثائق الرسمية والبرامج التعليمية مثل توثيق باي تورش PyTorch وتوثيق تنسرفلو TensorFlow عبر موقعهم الرسمي. فهم يقدمون شروحات موجزة وأمثلة وحالات استخدام مختلفة إضافة إلى التوثيق الرسمي لكافة الأدوات المستخدمة في بناء وبرمجة الذكاء الاصطناعي. تذكر أن الذكاء الاصطناعي هو مجال سريع التطور، لذا فإن البقاء على اطلاع بأحدث الأوراق البحثية والتطورات أمر هام، كما أن البقاء على اطلاع على أحدث الأدوات المستخدمة في برمجة الذكاء الاصطناعي هو أمر هام أيضًا. استخدم مجموعة من هذه الموارد لبناء أساس قوي ومواصلة التفاعل مع مجتمع الذكاء الاصطناعي. خاتمة برز عالم الذكاء الاصطناعي كثورة ضمن المشهد التكنولوجي سريع التطور الذي ظهر في العقود القليلة الماضية، يقدم فرصًا وتحديات لا حدود لها على حد سواء. بينما كنا نتعمق في عالم برمجة الذكاء الاصطناعي، شرعنا في رحلة بدأت من التحدث عن لغات وأدوات برمجة الذكاء الاصطناعي إلى المكتبات والأطر المتطورة وإنشاء نماذج الذكاء الاصطناعي ونشر هذه النماذج. بالنظر إلى الأُفق، اكتشفنا المستقبل الذي ينتظر برمجة الذكاء الاصطناعي. إن مفاهيم مثل الذكاء الاصطناعي القابل للتفسير والتعلم الموحد ودمج الذكاء الاصطناعي مع إنترنت الأشياء هي المفتاح لفتح أبعاد جديدة للابتكار. بينما نرتقي إلى مستويات أعلى، يجب أن نعترف بالقيود والاعتبارات الأخلاقية التي تقدمها برمجة الذكاء الاصطناعي ونعالجها. أخيرًا، كان لابد لنا من ذكر بعض من المصادر الهامة لتعلّم الذكاء الصناعي. في الختام، مجال برمجة الذكاء الاصطناعي هو نسيج معقد منسوج بخيوط من الابتكار والأخلاق وإمكانات لا حدود لها. بينما نتنقل في هذا المشهد المعقد، فإننا لسنا مجرد مبرمجي آلات؛ نحن نشكل مستقبل الأنظمة الذكية التي لديها القدرة على إحداث ثورة في الصناعات وتعزيز حياة البشر وإعادة تعريف نسيج وجودنا التكنولوجي. إن سمفونية جهودنا في برمجة الذكاء الاصطناعي تتماشى مع الوعد بمستقبل حيث تشرع الآلات، مسترشدةً ببراعتنا، في رحلة من الذكاء والفهم. انظر أيضًا تعلم الذكاء الاصطناعي تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال1 نقطة
لقد أوصلنا التطور السريع للتكنولوجيا إلى منعطف محوري، حيث أصبح الخيال العلمي حقيقة ملموسة. الذكاء الصناعي Artificial Intellegence، المجال الذي كان يقتصر في السابق على عالم الخيال، أصبح الآن قوة كبيرة تدعم الابتكار في مختلف الصناعات. بدءًا من السيارات ذاتية القيادة التي تتنقل في الشوارع المزدحمة إلى المساعدين الافتراضيين الذين يفهمون ويستجيبون لأوامرنا مثل سيري Siri وأليكسا Alexa، أصبح الذكاء الصناعي جزءًا لا يتجزأ من الحياة الحديثة. يكمن في قلب هذا التحوّل الفن المعقد لبرمجة الذكاء الصناعي، وهي عملية تتضمن صياغة خوارزميات ونماذج تُعالج وتحلّل كميات هائلة من البيانات، بغية إنشاء آلات ذكية يمكنها محاكاة الوظائف الإدراكية البشرية، مثل التعلم والاستدلال وحل المشكلات واتخاذ القرار. تتضمن برمجة الذكاء الصناعي تطوير البرامج التي تسمح للآلات بإظهار السلوك الذكي وحل المشكلات والتعلم من البيانات كما ذكرنا. إنه مجال متعدد التخصصات يجمع بين علوم الحاسب والرياضيات والعلوم المعرفية والهندسة. الهدف هو تزويد الآلات بالقدرة على تحليل البيانات المعقدة والتعلم من الأنماط والتكيّف مع الظروف المتغيرة، وحتى الانخراط في حل المشكلات التي تتطلّب حثًا إبداعيًّا. تتحدّث هذه المقالة عن برمجة الذكاء الصناعي وتستكشف مفاهيمها الأساسية وتقنياتها المتطورة وأساليب النشر والاعتبارات الأخلاقية والإمكانيات غير العادية التي تحملها لتشكيل المستقبل وأكثر. ما الفرق بين الذكاء الاصطناعي والبرمجة؟ الذكاء الصناعي والبرمجة هما مفهومان متمايزان ولكن مترابطان في مجال علوم الحاسب. تشير البرمجة إلى عملية إنشاء التعليمات البرمجية أو الشيفرة البرمجية التي تتبعها أجهزة الحاسب لأداء مهام محددة ومدروسة سابقًا ولا يمكن الخروج عنها أي لن يستجيب البرنامج إن حاولت استعماله في شيء ليس مبرمجًا عليه. يتضمن ذلك كتابة الخوارزميات والأوامر بلغات البرمجة المختلفة لتحقيق النتائج المرجوة. من الناحية الأخرى، يتجاوز الذكاء الصناعي البرمجة التقليدية من خلال تمكين الآلات من محاكاة الوظائف المعرفية بطريقة البشرية، مثل التعلم والاستدلال وحل المشكلات واتخاذ القرار. يمكن لأنظمة الذكاء الصناعي التكيف وتحسين أدائها بناءً على البيانات والخبرات، مما يسمح لها بالتعامل مع المواقف المعقدة وغير المؤكدة التي قد لا تكون مبرمجة بشكل واضح. من هنا نجد أن برمجة الذكاء الاصطناعي تختلف عن البرمجة التقليدية التي اعتدنا عليها. صحيح أن البرمجة تشكل الأساس لبناء أنظمة الذكاء الصناعي، إلا أن الذكاء الصناعي يتضمن تطوير خوارزميات ونماذج يمكنها التعلم من البيانات وتحسين أدائها بمرور الوقت، مما يمثل خروجًا كبيرًا عن نماذج البرمجة التقليدية. سأضرب مثالًا حديثًا يوضح الفرق بين الذكاء الاصطناعي والبرمجة، نشر إلون ماسك بتاريخ 26 أغسطس هذا العام فيديو على حسابه على تويتر وهو جالس في سيارة تسلا ذاتية القيادة متوجهًا من مكان إلى آخر دون أن يتدخل وقد علق قائلًا أثناء مرور السيارة بجانب دراجة أننا لم نكتب سطرًا من كود ولم نبرمج السيارة على التصرف في حال المرور بجانب شخص يقود دراجة هوائية، وقد مرت السيارة مرورًا سلسلًا بجانب الدراجة، ثم عند الوصول إلى تقاطع في إشارات مرورية علق قائلًا، نحن لم نبرمج السيارة على قراءة الإشارات المرورية ولم نكتب سطرًا برمجيًا يوضح كل اللافتات والإشارات المرورية بل الأمر متروك للسيارة باستنتاج معنى الإشارة وتطبيق ما يلزم، حيث مرت السيارة بجانب إشارة تطلب تخفيف السرعة فاستجابت لذلك، ويمكنك مشاهدة الفيديو كاملًا وهو بطول 45 دقيقة في سيارة تسلا ذاتية القيادة التي تقود مستعينة بالذكاء الاصطناعي. كان هذا أوضح مثال عن الفرق بين برمجة الذكاء الاصطناعي والبرمجة التقليدية. باختصار، تتضمن البرمجة كتابة تعليمات واضحة ليتبعها الحاسب، في حين تتضمن برمجة الذكاء الاصطناعي إنشاء أنظمة يمكنها التعلم من البيانات لإجراء تنبؤات أو قرارات دون أن تتم برمجتها بشكل صريح لكل موقف. مبرمج الذكاء الاصطناعي خلف كواليس تلك التطورات المذهلة التي يشهدها الذكاء الاصطناعي، يوجد محترفون ماهرون ينجزون هذا التطور، هم مبرمجي الذكاء الاصطناعي. يلعب هؤلاء الأفراد دورًا حاسمًا في تطوير الخوارزميات والنماذج والأنظمة التي تدعم تطبيقات الذكاء الاصطناعي. دور مبرمج الذكاء الاصطناعي مبرمج الذكاء الصناعي هو مطور برامج متخصص يركز على تصميم أنظمة الذكاء الصناعي وتنفيذها وتحسينها. هدفه الأساسي هو إنشاء خوارزميات ونماذج تمكن الآلات من أداء المهام التي تتطلب عادةً ذكاءًا بشريًّا. تتراوح هذه المهام من معالجة اللغة الطبيعية والتعرف على الصور إلى أنظمة التوصية والمركبات المستقلة. يقوم مبرمجي الذكاء الصناعي بسد الفجوة بين مفاهيم الذكاء الاصطناعي النظرية والتطبيقات العملية في العالم الحقيقي. تتضمن المهام الأساسية: تطوير الخوارزميات: يقوم مبرمجي الذكاء الاصطناعي بتصميم وتطوير خوارزميات تُمكّن الآلات من معالجة البيانات وتفسيرها وإنتاجها وإجراء التنبؤات وحتى توليد الأفكار. إنشاء النماذج: يقومون ببناء وتدريب نماذج التعلم الآلي والتعلم العميق باستخدام مجموعات بيانات ضخمة. تتعلم هذه النماذج الأنماط والعلاقات من البيانات لاتخاذ قرارات مستنيرة. المعالجة المسبقة للبيانات: يقوم مبرمجي الذكاء الاصطناعي بتنظيف البيانات ومعالجتها مسبقًا وتحويلها لجعلها مناسبة لتدريب نماذج الذكاء الاصطناعي. يتضمن ذلك مهام مثل تسوية البيانات واستخراج الميزات ومعالجة القيم المفقودة ..إلخ. تحسين الأداء: بمجرد تطوير النموذج، يقوم مبرمجو الذكاء الاصطناعي بتحسين أدائه من خلال ضبط المعلمات الخاصة بتدريب النموذج بدقة وتقليل المتطلبات الحسابية وتعزيز الكفاءة العامة. التكامل: يقوم مبرمجي الذكاء الاصطناعي بدمج نماذج وأنظمة الذكاء الاصطناعي في تطبيقات أكبر، مما يجعلها تتفاعل بسلاسة مع مكونات البرامج الأخرى. المهارات المطلوبة: إتقان البرمجة: يعد إتقان إحدى لغات البرمجة على الأقل مثل لغة بايثون أو لغة R أو جافا أمرًا أساسيًا. تحتاج عملية برمجة الذكاء الاصطناعي إلى كتابة التعليمات البرمجية لتنفيذ الخوارزميات ومعالجة البيانات وتطوير نماذج الذكاء الصناعي. التعلم الآلي: يعد الفهم القوي لمفاهيم التعلم الآلي أو تعلم الآلة، بما في ذلك التعلم الخاضع للإشراف وغير الخاضع للإشراف والانحدار والتصنيف والتجميع والشبكات العصبية، أمرًا ضروريًا. الرياضيات والإحصاء: تتضمن برمجة الذكاء الاصطناعي التعامل مع مفاهيم رياضية، مثل الجبر الخطي وحساب التفاضل والتكامل والاحتمالات. المعرفة الإحصائية السليمة أمر بالغ الأهمية لتقييم النماذج واختبار الفرضيات. أطر التعلم العميق: يعد الإلمام بمكتبات التعلم العميق مثل تنسرفلو TensorFlow وباي تورش PyTorch وكيراس Keras أمرًا ضروريًا لبناء الشبكات العصبية وتدريبها. التعامل مع البيانات: تعد المهارة في معالجة البيانات والمعالجة المسبقة وأدوات التصور ضرورية لإعداد البيانات للتدريب على نماذج الذكاء الصناعي. حل المشكلات: يجب أن يكون مبرمجي الذكاء الاصطناعي ماهرين في تقسيم المشكلات المعقدة إلى مكونات يمكن التحكم فيها واستنباط حلول فعالة. المعرفة بالمجال: قد يحتاج مبرمجي الذكاء الاصطناعي إلى معرفة خاصة بالمجال الذي يتم بناء النموذج للعمل عليه. على سبيل المثال، يجب على مبرمجي تطبيقات الذكاء الاصطناعي الطبية فهم المصطلحات والممارسات الطبية. الوعي بالأخلاق والتحيز: مع تأثير أنظمة الذكاء الاصطناعي على القرارات الحاسمة، يعد فهم الاعتبارات الأخلاقية وتخفيف التحيز أمرًا بالغ الأهمية. مبرمجو الذكاء الاصطناعي هم مهندسو المستقبل القائم على الذكاء الاصطناعي. تعتبر خبرتهم في الخوارزميات والتعلم الآلي ومعالجة البيانات مفيدة في إنشاء أنظمة يمكنها تحليل كميات هائلة من البيانات واتخاذ قرارات مستنيرة والتعلم المستمر من التجربة. ومع استمرار الذكاء الاصطناعي في إحداث ثورة في الصناعات وإعادة تعريف الإمكانيات، يظل دور مبرمجي الذكاء الاصطناعي محوريًا في تشكيل هذا المشهد التحويلي. سواء كان الأمر يتعلق بتعزيز تجارب العملاء أو إحداث ثورة في تشخيص الرعاية الصحية أو تمكين السيارات ذاتية القيادة، فإن مبرمجي الذكاء الاصطناعي هم في الطليعة، حيث يحولون الأفكار المتطورة إلى واقع عملي. المفاهيم الأساسية للذكاء الاصطناعي يشمل الذكاء الاصطناعي مجموعة واسعة من المفاهيم والتقنيات التي تهدف إلى إنشاء أنظمة قادرة على أداء المهام المختلفة. فيما يلي بعض المفاهيم الأساسية للذكاء الاصطناعي: التعلم الآلي Machine Learning التعلم الآلي هو مجموعة فرعية من الذكاء الاصطناعي الذي يركز على تطوير الخوارزميات والنماذج التي تمكن أجهزة الحاسب من التعلم والتنبؤ أو اتخاذ القرارات بناءً على البيانات. ويمكن تصنيفها إلى: التعلم الخاضع للإشراف Supervised Learning: تتعلم الخوارزميات من بيانات التدريب المصنفة لإجراء تنبؤات أو تصنيفات. وتشمل الأمثلة مهام الانحدار والتصنيف. التعلم غير الخاضع للإشراف Unsupervised Learning: تتعلم الخوارزميات من البيانات غير المسماة لاكتشاف الأنماط والعلاقات. ومن الأمثلة على ذلك التجميع وتقليل الأبعاد. التعلم المعزز Reinforcement Learning: يتعلم الوكلاء Agents تنفيذ الإجراءات ضمن بيئة محددة لتحقيق أقصى قدر من المكافآت. شائع في مهام مثل اللعب والروبوتات. الشبكات العصبية Neural Networks الشبكات العصبية هي نماذج حسابية مستوحاة من بنية الدماغ البشري. وهي تتكون من عقد مترابطة (خلايا عصبية) منظمة في طبقات. كل اتصال له وزن يمكن تعديله أثناء التدريب لتحسين أداء النموذج. التعلم العميق Deep Learning التعلم العميق هو مجال فرعي من التعلم الآلي يتضمن شبكات عصبية ذات طبقات متعددة (شبكات عصبية عميقة). لقد أتاح التعلم العميق تحقيق إنجازات كبيرة في مهام مثل التعرف على الصور والكلام نظرًا لقدرته على تعلم الأنماط المعقدة تلقائيًا من البيانات. معالجة اللغات الطبيعية Natural Language Processing تتضمن البرمجة اللغوية العصبية تمكين أجهزة الحاسب من فهم اللغة البشرية وتفسيرها وتوليدها. يتم استخدامه في مهام مثل تحليل المشاعر وترجمة اللغات وروبوتات الدردشة وإنشاء النصوص. الرؤية الحاسوبية Computer Vision تركز رؤية الحاسب على منح الآلات القدرة على تفسير المعلومات المرئية من البيئة المحيطة. يُستخدم في تحليل الصور والفيديو واكتشاف الأشياء والتعرف على الوجه والمركبات ذاتية القيادة. الأنظمة الخبيرة Expert Systems الأنظمة الخبيرة هي برامج الذكاء الاصطناعي التي تحاكي قدرات اتخاذ القرار للخبير البشري في مجال معين. ويستخدمون تقنيات تمثيل المعرفة والتفكير لحل المشكلات المعقدة. تمثيل المعرفة والاستدلال Knowledge Representation and Reasoning تحتاج أنظمة الذكاء الاصطناعي إلى تمثيل المعرفة بتنسيق منظم يمكن لأجهزة الحاسب فهمه. يتضمن الاستدلال استخدام القواعد المنطقية لإجراء الاستدلالات واستخلاص النتائج من المعرفة الممثلة. الحوسبة المعرفية Cognitive Computing تهدف الحوسبة المعرفية إلى إنشاء أنظمة يمكنها محاكاة عمليات التفكير البشري، مثل التفكير وحل المشكلات والتعلم. غالبًا ما يجمع بين تقنيات الذكاء الاصطناعي ومعالجة اللغة الطبيعية وتحليل البيانات. الإدراك الآلي Machine Perception يتضمن ذلك منح الآلات القدرة على إدراك العالم وفهمه من خلال المدخلات الحسية مثل الصور والصوت واللمس. يتضمن مهام مثل التعرف على الصور والتعرف على الكلام والتعرف على الإيماءات. توفر هذه المفاهيم فهمًا أساسيًا للذكاء الاصطناعي. ومع استمرار تطور هذا المجال، ستظهر تقنيات وأساليب جديدة، مما يساهم في تقدمه السريع. تجدر الإشارة إلى أنك كمبرمج للذكاء الصناعي لست مضطرًا لتعلّم كل هذه المفاهيم، وإنما يكفي فهم عام لها (فهم سطحي)، والتخصص في واحدة أو اثنتين منها فقط، لأن التخصص في كل هذه المفاهيم أو في كل مجالات الذكاء الصناعي هو أمر شبه مستحيل. خوارزميات الذكاء الاصطناعي خوارزميات الذكاء الاصطناعي عبارة عن مجموعات من التعليمات خطوة بخطوة أو الإجراءات الحسابية المصممة لحل مشكلات أو مهام محددة تتطلب عادةً ذكاءً بشريًا. تقع هذه الخوارزميات في قلب أنظمة الذكاء الاصطناعي، مما يمكّن الآلات من التعلم والتفكير واتخاذ القرارات.عمومًا، هذه الخوارزميات هي مجرد أفكار ونظريات تحتاج إلى تحويل إلى صيغة يمكن للآلات استغلالها، وهنا يتجلى دور برمجة الذكاء الاصطناعي في تحويل هذه الأفكار إلى شيفرات برمجية، بالتالي تصبح الآلات قادرة على تحليل البيانات بشكل ذكي، مما يتيح لها اكتساب المعرفة وتحديث أساليبها تلقائيًا. هناك مجموعة واسعة من الخوارزميات ذات الصلة بالذكاء الصناعي منها خوارزميات البحث والخوارزميات الجينية والشبكات العصبية وأشجار القرار وخوارزميات التجميع وخوارزميات معالجة اللغات الطبيعية وخوارزميات التعلم المعزز. يعتمد اختيار الخوارزمية على المشكلة التي تحاول حلها والبيانات المتوفرة لديك ومهمة الذكاء الاصطناعي المحددة التي تعمل عليها. لن نخوض في هذه الخوارزميات الآن، فقد كان لنا محطة عندها في مقالة خوارزميات الذكاء الاصطناعي. البدء في برمجة الذكاء الاصطناعي عند وجود أساس جيد للمفاهيم الأساسية للذكاء الاصطناعي، يكون قد حان الوقت للشروع في رحلتك إلى عالم برمجة الذكاء الصناعي. نوجّهك في هذا القسم إلى الخطوات الأولية لبدء برمجة تطبيقات الذكاء الصناعي. لغات برمجة الذكاء الاصطناعي تُستخدم العديد من لغات برمجة الذكاء الاصطناعي والمكتبات بشكل شائع لتطوير الذكاء الصناعي نذكر منها ما يلي: لغة بايثون Python لغة R لغة جافا Java لغة جوليا Julia 1. لغة بايثون Python لغة بايثون هي لغة شائعة لبرمجة الذكاء الصناعي نظرًا لبساطتها ونظامها الإيكولوجي الشامل لمكتبات الذكاء الصناعي مثل تنسرفلو TensorFlow وباي تورش PyTorch وسكايت ليرن scikit-Learn. لغة R تُستخدم لغة R على نطاق واسع في التحليل الإحصائي وتصوّر البيانات، مما يجعلها الخيار المفضل لمشاريع الذكاء الصناعي التي تتضمن تحليل البيانات. لغة جافا Java القدرات القوية للبرمجة غرضية التوجّه OOP في لغة جافا تجعلها مناسبة لبناء تطبيقات الذكاء الصناعي. لغة جوليا Julia تكتسب لغة جوليا قوة دفع لقدراتها عالية الأداء في الحوسبة العلمية والتعلم الآلي. سنتحدث عن استخدامات هذه اللغات -ولغات أخرى- في سياق الذكاء الصناعي بشيءٍ من التفصيل لاحقًا. تجدر الإشارة إلى أنه يمكنك الاطلاع على سلاسل مقالات كاملة عن مكتبة بايثون، ولغة جافا، ولغة R. استكشاف مكتبات وأطر عمل الذكاء الاصطناعي تصبح برمجة الذكاء الصناعي أكثر سهولة وكفاءة بمساعدة المكتبات والأطر المتخصصة. توفر هذه الأدوات دوال وتجريدات مختلفة لجعل تطوير الذكاء الصناعي أكثر كفاءة. فيما يلي بعض مكتبات وأطر عمل الذكاء الصناعي الشائعة: تنسرفلو TensorFlow تم تطوير إطار العمل تنسرفلو TensorFlow بواسطة شركة جوجل، وهي واحدة من مكتبات الذكاء الصناعي مفتوحة المصدر الأكثر استخدامًا. توفر نظامًا بيئيًا شاملاً للتعلم الآلي والتعلم العميق، بما في ذلك دعم الشبكات العصبية ومعالجة اللغة الطبيعية NLP والرؤية الحاسوبية. باي تورش PyTorch طوّر باي تورش بواسطة مختبر أبحاث الذكاء الصناعي FAIR التابع لشركة ميتا، وهو يتبع أسلوبًا ديناميكيًا في تنفيذ الشبكات العصبية، مما يجعله أكثر مرونة للبحث والتجريب. يستخدم على نطاق واسع في الأوساط الأكاديمية والصناعية لتطوير نماذج التعلم العميق. كيراس Keras في الأصل هي مكتبة مستقلة، لكن أصبحت كيراس الآن جزءًا من تنسرفلو باعتبارها واجهة برمجة تطبيقات عالية المستوى. يوفر واجهة سهلة الاستخدام لبناء الشبكات العصبية وتدريبها، مما يجعلها رائعة للمبتدئين. سكايت-ليرن Scikit-Learn هذه مكتبة شهيرة للتعلم الآلي، ولكن ليس لها أي علاقة بالتعلم العميق والشبكات العصبية. توفر هذه المكتبة عددًا كبيرًا من خوارزميات التعلم الآلي التقليدية. توفر مجموعة أدوات بسيطة وفعالة للمعالجة المسبقة للبيانات وهندسة الميزات وتقييم النموذج. توفر هذه المكتبات والأطر بيئة مناسبة ومريحة وآمنة وموثوقة، لتسهيل عملية بناء وتطوير مشاريع الذكاء الصناعي. نتحدث عن هذه المكتبات والأطر في المقالة القادمة بشكل أكبر أيضًا. أدوات تطوير وبرمجة تطبيقات الذكاء الاصطناعي قبل البدء في الخوض في عالم برمجة الذكاء الاصطناعي، من الضروري إنشاء بيئة تطوير قوية توفر الأدوات والموارد اللازمة لكتابة الشيفرات وإنشاء الاختبارات بسلاسة: اختر نظام التشغيل الخاص بك أولاً وقبل كل شيء، حدد نظام التشغيل الذي يناسب تفضيلاتك ومتطلباتك. يمكن إجراء تطوير الذكاء الصناعي على منصات مختلفة، إلا أن العديد من مكتبات وأدوات الذكاء الصناعي مدعومة جيدًا على الأنظمة المستندة إلى لينكس Linux مثل أبونتو Ubuntu. تجدر الإشارة أيضًا إلى أن نظامي التشغيل ويندوز Windows وماك macOS هما أيضًا خيارات يمكن الاعتماد عليها. يعتمد اختيارك إلى حد كبير على معرفتك بالنظام وراحتك، وممكن استعمال لينكس ضمن ويندوز عبر طريقتين إما عبر بيئة وهمية أو عبر نظام لينكس الداخلي WSL، أو يمكن تثبيت لينكس مع ويندوز. تثبيت بايثون Python بايثون هي لغة البرمجة المفضلة لبرمجة الذكاء الاصطناعي نظرًا لبساطتها وبيئتها الواسعة التي تتضمن العديد من المكتبات الداعمة للذكاء الصنعي. ابدأ بتثبيت بايثون على نظامك. يمكنك مراجعة مقال تثبيت لغة بايثون الشامل الذي يشرح تنزيل بايثون على كل أنظمة التشغيل. بعد التثبيت، ستتمكن من الوصول إلى مجموعة المكتبات والأدوات الثريّة في بايثون. اختر بيئة تطوير متكاملة IDE إن استخدام بيئة تطوير متكاملة يؤدي إلى تحسين تجربة البرمجة الخاصة بك من خلال توفير ميزات مثل إكمال التعليمات البرمجية وتصحيح الأخطاء وإدارة المشروع. تشمل الخيارات الشائعة PyCharm و Jupyter Notebook المخصصين لبايثون وكذلك Visual Studio Code الذي يُعتبر بيئة تطوير عامة. تُقدم بيئات التطوير المتكاملة مكونات إضافية وإضافات متخصصة لتطوير الذكاء الاصطناعي، مما يبسط سير عملك. تثبيت أطر ومكتبات الذكاء الصناعي لتسخير قوة الذكاء الاصطناعي، ستحتاج إلى تثبيت مكتبات وأطر تسهل مهام التعلم الآلي والتعلم العميق. تعد تنسرفلو TensorFlow وباي تورش PyTorch وكيراس Keras وسكايت ليرن scikit-Learn بعض المكتبات الأساسية التي يجب أخذها بعين الاعتبار. يمكنك تثبيت هذه المكتبات باستخدام مدير حزم بايثون pip، عن طريق تنفيذ أوامر بسيطة. إعداد البيئات الافتراضية يعد إنشاء بيئات افتراضية أفضل ممارسة لعزل مشاريعك وتبعياتها. تضمن البيئات الافتراضية أن المكتبات والحزم المثبتة لمشروع واحد لا تتداخل مع المشاريع والحزم الأخرى. استخدم أدوات مثل venv أو conda أو pipenv لإنشاء وإدارة بيئات افتراضية، وتحسين تنظيم مشروعك وتجنب تعارضات الإصدار. إعداد التحكم في الإصدار Version Control يعد التحكم في الإصدار أمرًا بالغ الأهمية لإدارة التغييرات في قاعدة التعليمات البرمجية الخاصة بك والتعاون مع الآخرين. جيت Git هو أكثر أنظمة التحكم في الإصدارات شيوعًا. أنشئ مستودع جيت لمشاريع الذكاء الاصطناعي الخاصة بك لتتبع التغييرات والتعاون مع أعضاء الفريق والاحتفاظ بسجل لقاعدة التعليمات البرمجية الخاصة بك. يمكنك الاطلاع على سلاسل مقالات كاملة للتعرّف على كيفية التعامل مع جيت من قسم Git التعليمي. استكشاف المنصات السحابية Cloud Platforms نظرًا لأن مشاريع الذكاء الاصطناعي أصبحت أكثر تعقيدًا، فقد تحتاج إلى قوة حسابية إضافية. توفر المنصات السحابية مثل خدمات أمازون ويب Amazon Web Services وسحابة جوجل Google Cloud ومايكروسوفت أزور Microsoft Azure موارد لتطوير الذكاء الاصطناعي ونشره. تعرّف على هذه المنصات لتسخير قدراتها في بناء مشاريعك. إن إنشاء بيئة تطوير قوية يضع الأساس لبرمجة ناجحة للذكاء الصناعي. مع بايثون ومكتبات الذكاء الصناعي و بيئة التطوير المتكاملة المناسبة والتحكم في الإصدار، فأنت مجهز جيدًا لبدء رحلة الذكاء الصناعي الخاصة بك. تجدر الإشارة أيضًا، إلا أن المبدتئين يمكنهم تجاوز الخطوات 6 و 7 مبدأيًا، والخوض بهما لاحقًا عند الحاجة. مراحل برمجة نموذج ذكاء اصطناعي؟ تتضمن عملية تطوير نماذج الذكاء الصناعي مرحلتين أساسيتين هما: عملية التدريب وعملية التقييم. إنهما مرحلتين حاسمتين في برمجة الذكاء الصناعي. مرحلة التدريب هي المرحلة التي يتعلم فيها نموذجك من البيانات ويضبط معلماته Parameters (العناصر القابلة للتعديل داخل النموذج، والتي تؤثر بشكل كبير على أداء النموذج وسلوكه) لعمل تنبؤات دقيقة في العالم الحقيقي. يتمثل دورك كمبرمج للذكاء الصناعي في هذه المرحلة في بناء النموذج وإعداد البيانات اللازمة للتدريب والتأكد من أن نموذجك يتعلم من البيانات بشكل فعّال وينتج تنبؤات دقيقة (أي التدريب ومراقبة صحة عملية التدريب). أما مرحلة التقييم، فهي المرحلة التي تلي مرحلة التدريب، حيث تتضمن سلسلة من الاختبارات اللازمة للتأكد من مدى فعالية النموذج عند تعريضه لبيانات العالم الحقيقي. من خلال فهم الفروق الدقيقة في تدريب النموذج والتحقق من صحة التدريب والتقييم، ستتمكن من ضبط تطبيقات الذكاء الصناعي الخاصة بك للحصول على الأداء الأمثل. ستمهد هذه المعرفة الطريق لك لإنشاء نماذج ذكاء اصطناعي أكثر تطوراً ودقة في المستقبل. نشر نماذج الذكاء الاصطناعي تظهر القيمة الحقيقية لنموذج الذكاء الصناعي عند نشره واستخدامه في سيناريوهات العالم الحقيقي، إنه الخطوة المحورية التي تحول الخوارزميات المدربة من تجارب إلى حلول عملية. إنها المرحلة التي يتم فيها إتاحة نماذج الذكاء الصناعي الخاصة بك للتفاعل مع العالم الحقيقي وإجراء تنبؤات أو تصنيفات أو قرارات. نتحدث في هذا القسم عن تعقيدات نشر نماذج الذكاء الصناعي ونغطي الاعتبارات المختلفة للنشر الناجح. اختيار نهج النشر الصحيح عند نشر نماذج الذكاء الاصطناعي، لديك عدة خيارات، لكل منها مزاياها ومقايضاتها. سنناقش طريقتين أساسيتين للنشر: النشر المحلي والنشر المستند إلى مجموعة النظراء. النشر المحلي أو النشر في أماكن العمل On-Premises Deployment: يوفر نشر نماذج الذكاء الصناعي في أماكن العمل درجة عالية من التحكم والأمان وخصوصية البيانات. يتضمن نهج النشر هذا استضافة نماذج الذكاء الصناعي الخاصة بك على الخوادم المحلية أو الأجهزة المتطورة داخل البنية التحتية لمؤسستك. يعد النشر المحلي مفيدًا بشكل خاص عند التعامل مع البيانات الحساسة أو عندما تكون التفاعلات ذات زمن الوصول المنخفض ضرورية. النشر المستند إلى السحابة Cloud-Based Deployment: أحدث النشر المستند إلى السحابة ثورة في طريقة إتاحة نماذج الذكاء الاصطناعي للمستخدمين، مما يوفر قابلية التوسع وإمكانية الوصول والتكلفة المنخفضة. هنا تحتاج إلى تحديد مزود الخدمة السحابية المناسب الذي يناسب متطلبات مشروعك، وأشهرها خدمات أمازون ويب Amazon Web Services ومنصة جوجل السحابية Google Cloud Platform ومايكروسوفت آزور Microsoft Azure. تحسين النموذج المستمر يعد تحسين النموذج للنشر خطوة مهمة لضمان أن تكون نماذج الذكاء الصناعي فعّالة وسريعة وقادرة على تقديم تنبؤات دقيقة في سيناريوهات العالم الحقيقي. نظرًا لأن نماذج الذكاء الصناعي أصبحت أكثر تعقيدًا، فإن حجمها ومتطلباتها الحسابية يمكن أن تشكل تحديات عند نشرها على أجهزة مختلفة، من الأجهزة المتطورة إلى الخوادم السحابية. تلعب تقنيات تحسين النموذج دورًا مهمًا لمواجهة هذه التحديات. أهم هذه التقنيات هم التكميم والتقليم والضغط. يمكن لممارسي الذكاء الاصطناعي تحقيق توازن بين أداء النموذج وكفاءة النشر من خلال الخوض في استراتيجيات التحسين هذه، مما يضمن أن حلول الذكاء الصناعي الخاصة بهم تقدم النتائج بسرعة وفعاليّة. التكميم Quantization: التكميم هو تقنية مهمة في مجال نشر نماذج الذكاء الاصطناعي. يتضمن تقليل دقة القيم العددية في معلمات النموذج، عادةً من عرض بت أعلى (على سبيل المثال، 32 بت) إلى عرض بت أقل (على سبيل المثال، 8 بتات). ينتج عن هذه العملية تمثيل أفضل عمليًا للنموذج، مما يقلل بشكل كبير من استخدام الذاكرة ويحسن سرعة الاستدلال. إذًا يتيح التكميم نشر نماذج الذكاء الصناعي بكفاءة على الأجهزة محدودة الموارد مثل الأجهزة المتطورة والهواتف المحمولة وأجهزة إنترنت الأشياء، وذلك من خلال التضحية بالقليل من الدقة. إنه يحقق توازنًا بين الكفاءة الحسابية والحفاظ على الأداء المعقول، مما يجعله أداة لا غنى عنها في ترسانة مهندسي الذكاء الصناعي الذين يسعون جاهدين للحصول على حلول النشر المثلى. التقليم Pruning: التقليم هو أسلوب آخر في مجال تحسين نموذج الذكاء الصناعي للنشر، يهدف إلى تبسيط التعقيد وتحسين كفاءة النماذج المُدرّبة. تتضمن هذه العملية القضاء الانتقائي على الاتصالات الزائدة أو العقد أو المعلمات من الشبكة العصبية، وبالتالي تقليل حجمها الكلي مع السعي للحفاظ على أدائها في نفس الوقت. لا ينتج عن التقليم نماذج أخف وأسرع أثناء الاستدلال فحسب، بل يساهم أيضًا في معالجة مشكلات الضبط المُفرط Overfitting. إذًا يعمل التقليم على تحسين قدرات التعميم من خلال إزالة المكونات الأقل تأثيرًا في النموذج، وغالبًا ما يؤدي إلى تحسين الدقة عمومًا. تُقدّم هذه التقنية إمكانية التوازن بين تعقيد النموذج والأداء، وتوضح كيف يمكن أن يؤدي التبسيط الاستراتيجي إلى حلول ذكاء اصطناعي أكثر مرونة وفعالية. الضغط Compression: يعد الضغط تقنية أخرى في عالم نشر نماذج الذكاء الصناعي. يهدف أيضًا إلى تحقيق توازن بين دقة النموذج وكفاءة الموارد. تلعب تقنيات الضغط دورًا مهمًا في تقليل الذاكرة التي يستهلكها النموذج وتسريع الاستدلال دون التضحية الكبيرة في الأداء التنبئي، وذلك من خلال إزالة المعلومات الزائدة واستغلال الأنماط داخل معلمات النموذج. لا يؤدي الضغط إلى تحسين متطلبات التخزين فحسب، بل يُقلل أيضًا الزمن اللازم للتنبؤ. من تقليم الاتصالات غير المهمة إلى تحديد قيم المعلمات، يمكّن الضغط مطوري الذكاء الاصطناعي من نشر نماذج قوية وفعّالة عمليًا، مما يضمن السلاسة عبر الأجهزة وسيناريوهات الاستخدام المحتملة. الأمان والخصوصية تعتبر اعتبارات الأمان والخصوصية في عملية نشر نماذج الذكاء الاصطناعي ذات أهمية قصوى. نظرًا لأن نماذج الذكاء الاصطناعي تتفاعل مع البيانات الحساسة وتقوم بالتنبؤات التي تؤثر على القرارات الحاسمة، فإن الحماية من الوصول غير المصرح به وضمان الاستخدام الأخلاقي يصبح أمرًا ضروريًا. يعد تنفيذ إجراءات أمنية قوية أمرًا ضروريًا للحفاظ على ثقة المستخدم والامتثال للوائح. تلعب تقنيات مثل التشفير دورًا محوريًا في تأمين البيانات أثناء النقل والتخزين. تساعد المصادقة المستندة إلى الرمز المميز والتحكم في الوصول المُستند إلى الدور -في تنظيم من يمكنه الوصول إلى واجهات برمجة تطبيقات الذكاء الاصطناعي، مما يضمن أن المستخدمين المُصرّح لهم فقط هم من يمكنهم إجراء تنبؤات. إضافةً إلى ذلك ونظرًا لأن أنظمة الذكاء الصناعي غالبًا ما تتعامل مع المعلومات الشخصية والسرية، فمن الضروري اعتماد أساليب الحفاظ على الخصوصية، مثل إخفاء البيانات وحماية الهويات الشخصية. إذًا من خلال تضمين اعتبارات الأمان والخصوصية عند نشر نماذج الذكاء الاصطناعي، يؤمّن المطورون بيئة أكثر أمانًا ومسؤولية لمستخدمي الذكاء الصناعي. المراقبة والصيانة المراقبة والصيانة هما شريان الحياة لنماذج الذكاء الصناعي المنشورة، حيث تضمنان استمرار دقتها وموثوقيتها وأدائها. بعد نشر نموذج الذكاء الصناعي الخاص بك، من المهم إنشاء نهج منظّم لمراقبة سلوكه ومعالجة أي مشكلات قد تنشأ لاحقًا. تتضمن المراقبة تتبع مقاييس مختلفة، مثل دقة التنبؤ وأوقات الاستجابة واستخدام الموارد لاكتشاف الأخطاء أو الانحرافات عن السلوك المتوقع. يجري ذلك من خلال إعداد التنبيهات والفحوصات الآلية، وبالتالي إمكانية تحديد أي مشكلات ومعالجتها على الفور قبل أن تؤثر على المستخدمين أو العمليات التجارية. بالنسبة للصيانة فهي تتجاوز موضوع الكشف عن الخلل وإصلاحه؛ إنها تنطوي على إدارة نماذج الذكاء الصناعي الخاصة بك بمرور الوقت، فمع تغيّر البيانات وتطور متطلبات المستخدم، قد يحتاج نموذجك إلى تحديثات دورية ليظل فعّالاً. تتضمن الصيانة أيضًا تحديد إصدارات النماذج وواجهات برمجة التطبيقات، مما يتيح لك إجراء تحسينات دون الإخلال بتجربة المستخدم. يضمن الاختبار المنتظم والتحقق من صحة سير العمل وقياس الأداء مقابل البيانات الجديدة، استمرار نماذجك في تقديم نتائج دقيقة. من خلال ضبط نماذجك باستمرار وإبقائها مواكبة لأحدث التطورات، فإنك تضمن أن حلول الذكاء الاصطناعي المنشورة تظل أصولًا قيّمة لمؤسستك. مستقبل برمجة الذكاء الاصطناعي يتطور مجال برمجة الذكاء الصناعي بسرعة، ويحمل المستقبل إمكانيات مثيرة للاهتمام. من المرجح أن تصبح الحلول التي تعمل بالذكاء الصناعي أكثر سهولة، مع الأدوات التي تسمح للمطورين بمستويات مختلفة من الخبرة لإنشاء تطبيقات الذكاء الصناعي. نستكشف الآن الاتجاهات والتحديات والإمكانيات التي تنتظر مستقبل برمجة الذكاء الصناعي. من الخوارزميات إلى أنظمة التعلم تتضمّن برمجة الذكاء الاصطناعي تقليديًا، صياغة خوارزميات معقدة لحل مشاكل محددة. إن مستقبل برمجة الذكاء الصناعي يتميز بالتحول نحو بناء أنظمة التعلم التي يمكن أن تتكيف وتتطور. لقد دفع التعلم الآلي وتقنيات التعلم العميق هذا التطور، مما مكّن أجهزة الحاسب من التعلم من البيانات وتحسين أدائها بمرور الوقت. نظرًا لأن برمجة الذكاء الصناعي تصبح أكثر اعتمادًا على البيانات، سيركز المطورون بشكل متزايد على إنشاء خوارزميات تعلم قوية وقابلة للتكيف والتطور وفقًا للبيانات. التعاون مع التخصصات الأخرى لم تعد برمجة الذكاء الصناعي مجالًا لعلماء الحاسب فقط. سيشهد المستقبل تعاونًا متزايدًا بين مبرمجي الذكاء الصناعي وخبراء المجال وعلماء الأخلاق وعلماء النفس وغيرهم من المتخصصين. سيتطلب بناء أنظمة ذكاء اصطناعي ناجحة اتباع نهج متعدد التخصصات لضمان توافق التكنولوجيا مع احتياجات وقيم العالم الحقيقي. الذكاء الاصطناعي القابل للتفسير عندما تصبح أنظمة الذكاء الاصطناعي أكثر تعقيدًا، يمكن أن تظهر عمليات اتخاذ القرار الخاصة بها على أنها "صناديق سوداء". هذا النقص في الشفافية يعيق التبني الأوسع للذكاء الاصطناعي في التطبيقات الهامة (عدم الثقة بقرار لاتعرف كيف أُنتج). سيشهد المستقبل طفرة في جهود البحث والتطوير لإنشاء أنظمة ذكاء اصطناعي قابلة للتفسير. ستوفر هذه الأنظمة رؤى حول كيفية توصل نماذج الذكاء الصناعي إلى قراراتهم، وبالتالي تعزيز الثقة بقرارات هذه النماذج وإمكانية التفسير. التعلم الآلي التلقائي AutoML أصبحت برمجة الذكاء الاصطناعي نفسها أكثر ذكاءً. يشهد التعلم الآلي التلقائي اهتمامًا كبيرًا بين الباحثين والشركات. إنه مجال يُركز على أتمتة المراحل المختلفة من خط أنابيب التعلم الآلي. سيستخدم المطورون أدوات AutoML لاختيار الخوارزميات وعمليات المعالجة المسبقة وتحسين النماذج تلقائيًا، مما يجعل من عملية تطوير نماذج الذكاء الصناعي أكثر سهولة. واجهات اللغة الطبيعية تتضمن برمجة الذكاء الاصطناعي التقليدية كتابة التعليمات البرمجية بلغات البرمجة. قد يتضمن المستقبل برمجة أنظمة الذكاء الاصطناعي باستخدام لغة طبيعية، أي أن مفهوم برمجة الذكاء الاصطناعي من الممكن أن يصبح أكثر تطورًا وسهولة. سيؤدي ذلك إلى إضفاء الطابع الديمقراطي على تطوير وبرمجة الذكاء الاصطناعي، مما يسمح للأفراد الذين ليس لديهم خبرة في كتابة الشيفرت البرمجية، بإنشاء تطبيقات ذكية من خلال محادثات بسيطة مع واجهات الذكاء الاصطناعي. الحوسبة المتطورة والذكاء الاصطناعي تستعد حوسبة الحافة Edge Computing (نموذج حوسبة يهدف إلى تنفيذ المعالجة والحوسبة قرب مصادر البيانات "الحواف")، لتشكيل مستقبل برمجة الذكاء الاصطناعي. ستحتاج خوارزميات الذكاء الاصطناعي إلى التحسين للنشر على الأجهزة محدودة الموارد مثل الهواتف الذكية وأجهزة إنترنت الأشياء والأنظمة المدمجة. سيتطلب ذلك مستوى جديدًا من الكفاءة والقدرة على التكيف في برمجة الذكاء الاصطناعي. التعلم المستمر مدى الحياة والذكاء الاصطناعي غالبًا ما يتم تدريب أنظمة الذكاء الاصطناعي التقليدية على مجموعات البيانات الثابتة. سيشهد المستقبل صعود التعلم المستمر والذكاء الاصطناعي مدى الحياة، حيث يمكن للأنظمة التعلم من البيانات الجديدة وتكييف معارفها دون نسيان تجارب التعلم السابقة. سيتطلب ذلك تقنيات خاصة لبرمجة الذكاء الاصطناعي تسهل التكامل السلس للمعلومات الجديدة في النماذج الحالية. برمجة الذكاء الاصطناعي الكمومية سيؤدي ظهور الحوسبة الكمومية Quantum computing إلى إحداث نقلة نوعية في برمجة الذكاء الاصطناعي. تمتلك أجهزة الحاسب الكمومية القدرة على إحداث ثورة في خوارزميات التعلم الآلي والعميق ومشكلات التحسين. سيشهد المستقبل قيام مبرمجي الذكاء الاصطناعي بالتعمق في برمجة الذكاء الاصطناعي الكمومي لتسخير قوة الحوسبة الكمومية من أجل حلول ذكاء اصطناعي أسرع وأكثر كفاءة. الذكاء الاصطناعي المرتكز على الإنسان إن مستقبل برمجة الذكاء الاصطناعي لا يقتصر فقط على بناء آلات أكثر ذكاءً؛ يتعلق الأمر بإنشاء ذكاء اصطناعي يكمل القدرات البشرية ويزيدها. ستصبح أنظمة الذكاء الاصطناعي أكثر تخصيصًا، بحيث تتكيف مع تفضيلات واحتياجات المستخدمين الفرديين. يتطلب هذا التحول من مبرمجي الذكاء الاصطناعي التأكيد على مبادئ التصميم التي تتمحور حول الإنسان، وإنشاء أنظمة تعزز الخبرات البشرية والإنتاجية. التعلم الموحد مفهوم تحولي آخر يأتي مع انتشار الأجهزة المتصلة عبر الشبكات، حيث يُمكّن نماذج الذكاء الاصطناعي من التدريب بطريقة تعاونية عبر العديد من الأجهزة اللامركزية المتصلة بالشبكة، دون الحاجة إلى نقل البيانات الأولية إلى خادم مركزي. الذكاء الاصطناعي وإنترنت الأشياء IoT يمثل تكامل الذكاء الاصطناعي مع إنترنت الأشياء تقاربًا بين تقنيتين تحويليتين تمتلكان القدرة على إعادة تشكيل الصناعات والحياة اليومية. يشير إنترنت الأشياء IoT إلى شبكة من الأجهزة المادية المترابطة والمجهزة بأجهزة استشعار وبرامج واتصالات، مما يمكنها من جمع البيانات وتبادلها. من الناحية الأخرى، يُمكّن الذكاء الاصطناعي الآلات من محاكاة الوظائف الإدراكية البشرية مثل التعلم والاستدلال واتخاذ القرار. عندما تتضافر هاتان القوتان، تظهر أوجه تآزر ملحوظة. يضفي الذكاء الاصطناعي براعته التحليلية على الكم الهائل من البيانات التي تنتجها أجهزة إنترنت الأشياء. يمكن لهذه الأجهزة جمع البيانات من البيئة أو تفاعلات المستخدم أو حتى من الأجهزة الأخرى. يمكن لخوارزميات الذكاء الاصطناعي بعد ذلك معالجة هذه البيانات لاستخراج الأنماط والاتجاهات والحالات الشاذة التي يصعب على المحللين البشريين تمييزها في الزمن الحقيقي. تخيل مدينة ذكية حيث تتعاون الأجهزة المترابطة في إشارات المرور والكاميرات والمركبات لتحسين تدفق حركة المرور استجابةً لظروف الوقت الفعلي. تعالج خوارزميات الذكاء الاصطناعي البيانات من هذه الأجهزة وتتنبأ بالازدحام المروري وتضبط توقيت إشارات المرور ديناميكيًا للتخفيف من الاختناقات. التحديات والقيود في برمجة الذكاء الاصطناعي في حين أن مجال برمجة الذكاء الاصطناعي يوفر فرصًا هائلة، إلا أنه مصحوب أيضًا بمجموعة من التحديات والقيود التي يجب على المطورين التعامل معها. أبرزها: جودة البيانات وكميتها الموارد الحسابية القابلية للتفسير والشرح الأخلاق والتحيز الافتقار إلى الفطرة السليمة وفهم السياق التعميم والقدرة على التكيف الأمان والخصوصية استهلاك الطاقة التعاون بين الإنسان والذكاء الاصطناعي التعلم المستمر والتحديثات 1. جودة البيانات وكميتها تعتمد أنظمة الذكاء الاصطناعي بشكل كبير على البيانات للتعلم واتخاذ القرارات. يمكن أن تؤثر جودة وكمية البيانات المتاحة بشكل كبير على أداء نماذج الذكاء الاصطناعي. يمكن أن تؤدي البيانات غير الكاملة أو المتحيزة أو التي تتضمّن أخطاءً إلى تنبؤات غير دقيقة ونتائج غير موثوقة. 2. الموارد الحسابية تتطلب خوارزميات الذكاء الاصطناعي، وخاصة نماذج التعلم العميق، موارد حسابية كبيرة. تتطلب نماذج التدريب المعقدة أجهزة قوية، وعلى الرغم من أن الحوسبة السحابية جعلت هذه الموارد أكثر سهولة، إلا أن التكلفة والتوافر لا يزالان من القيود المفروضة على بعض المشاريع. 3. القابلية للتفسير والشرح مع ازدياد تعقيد أنظمة الذكاء الاصطناعي، يصبح فهم كيفية التوصل إلى قرارات معينة تحديًا متزايدًا. يمكن أن يؤدي هذا الافتقار إلى الشفافية إلى إعاقة الثقة والتبني، خاصة في التطبيقات المهمة مثل الرعاية الصحية والتمويل. 4. الأخلاق والتحيز يمكن لنماذج الذكاء الاصطناعي أن تديم التحيزات الموجودة في بيانات التدريب دون قصد، مما يؤدي إلى نتائج غير عادلة أو تمييزية. يمثل تحقيق التوازن بين قدرات اتخاذ القرار في الذكاء الاصطناعي والاعتبارات الأخلاقية تحديًا مستمرًا. 5. الافتقار إلى الفطرة السليمة وفهم السياق تكافح أنظمة الذكاء الاصطناعي مع التفكير المنطقي وفهم السياق بنفس الطريقة التي يعمل بها البشر. قد يتفوقون في مهام محددة لكنهم يفتقرون إلى الفهم الأوسع الذي يمتلكه البشر. 6. التعميم والقدرة على التكيف بينما يمكن تدريب نماذج الذكاء الاصطناعي على أداء مهام محددة، قد يكون نقل تلك المعرفة إلى سيناريوهات أو مجالات جديدة أمرًا صعبًا. لا يزال تحقيق القدرة الحقيقية على التكيّف عبر مختلف السياقات يمثل تحديًا مستمرًا. 7. الأمان والخصوصية أنظمة الذكاء الاصطناعي التي تتعامل مع البيانات الحساسة عرضة للانتهاكات الأمنية. بالإضافة إلى ذلك، يشكل ضمان الخصوصية عند التعامل مع بيانات المستخدم تحديات أخلاقية وقانونية تتطلب دراسة متأنية. 8. استهلاك الطاقة يمكن أن يكون تدريب نماذج التعلم العميق مُستهلكًا كبيرًا للطاقة، مما يساهم في إثارة المخاوف بشأن التأثير البيئي لتطوير الذكاء الاصطناعي. 9. التعاون بين الإنسان والذكاء الاصطناعي إن دمج الذكاء الاصطناعي بسلاسة في سير العمل البشري يعتبر تحديًا، ويتطلب التأكد من أن الذكاء الاصطناعي يُكمل المهارات البشرية ويساعد بشكل فعال، وهذا يتطلب فهماً عميقاً لكلا المجالين. 10. التعلم المستمر والتحديثات تحتاج نماذج الذكاء الاصطناعي إلى التطور بمرور الوقت لتبقى ملائمة ودقيقة. يتطلب تحديث النماذج والتحسين المستمر لأدائها جهدًا مستمرًا. التعرف على هذه القيود أمر بالغ الأهمية لإنشاء أنظمة ذكاء اصطناعي مسؤولة وفعالة. تتطلب مواجهة هذه التحديات التعاون بين الباحثين والمطورين وواضعي السياسات والمجتمع ككل. بينما ندفع حدود برمجة الذكاء الاصطناعي، من المهم الحفاظ على منظور متوازن والعمل على التغلب على هذه العقبات من أجل تحسين مستقبلنا الذي يحركه الذكاء الاصطناعي. مصادر تعلم برمجة الذكاء الاصطناعي يعد التعرف على الذكاء الاصطناعي رحلة مثيرة تتطلب الوصول إلى مجموعة متنوعة من الموارد لتعميق فهمك ومهاراتك. فيما يلي بعض موارد تعلم الذكاء الاصطناعي القيمة لمساعدتك على البدء والتقدم في هذا المجال: الدورات التدريبية هناك العديد من الموارد المتاحة عبر الإنترنت لتعلم برمجة الذكاء الاصطناعي. تقدم أكاديمية حسوب دورة شاملة لتعلم برمجة الذكاء الاصطناعي باستخدام لغة بايثون، التي تعد كما ذكرنا اللغة الأساسية لكتابة تطبيقات ونماذج الذكاء الصناعي، حيث يمكنك تعلمها من خلال دورة الذكاء الاصطناعي التي تعد دورة شاملة لاحتراف برمجة الذكاء الاصطناعي وتحليل البيانات وتعلم كافة المعلومات المطلوبة لبناء نماذج ذكاء اصطناعي متخصصة مع مُدربين مُميزين يُرافقونك طوال الدورة للإجابة عن استفساراتك. تبقى الدورة مفتوحة لك مدى الحياة، كما أنها تطور باستمرار لمواكبة أحدث التطورات في المجال. الكتب يُمثل كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة نقطة بدءٍ مناسبةٍ للمبتدئين الذين يرغبون الخوض في هذا المجال ويرغبون في فهم المفاهيم الأساسية للتعلم العميق والشبكات العصبية وتعلم الآلة، حيث يبدأ الكتاب معك من الأساسيات ليمهد الطريق أمامك لتعلم هذا العلم. يمكنك أيضًا الاطلاع على كتاب عشرة مشاريع عملية عن الذكاء الاصطناعي إما بعد الكتاب السابق أو يمكنك البدء به مباشرة إن كانت لديك خبرة أساسية. مؤتمرات وورش عمل الذكاء الاصطناعي يُعتبر مؤتمر NeurIPS أحد أكبر مؤتمرات الذكاء الاصطناعي مع العروض التقديمية وورش العمل. هناك أيضًا مؤتمر CVPR الذي يُركز على رؤية الحاسب والتعلم العميق و ICML يُغطي أبحاث وتطبيقات التعلم الآلي. المقالات والمدونات يمكنك أيضًا الاطلاع على عشرات المقالات المتعلقة بالذكاء الصناعي، والتي توفرها أكاديمية حسوب في قسم الذكاء الاصطناعي. المجتمعات عبر الإنترنت يوفر قسم أسئلة وأجوبة في أكاديمية حسوب إمكانية طرح أسئلة للإجابة عليها من قبل مختصين في كافة المجالات ومنها مجال برمجة الذكاء الاصطناعي. البرمجة والممارسة يُقدّم موقع كاغل Kaggle مسابقات في الذكاء الاصطناعي ومجموعات بيانات وموارد سحابية لتدريب النماذج. يمكنك أيضًا الذهاب إلى غيت هاب GitHub لاستكشف مشاريع ومستودعات الذكاء الاصطناعي مفتوحة المصدر. تُمكّنك أكاديمية حسوب أيضًا من البدء بإنشاء مشاريعك من خلال الاطلاع على مشاريع مرجعية مشروحة ومنظمة جيدًا. مثل كتاب عشرة مشاريع عملية عن الذكاء الاصطناعي. الوثائق الرسمية لأطر عمل الذكاء الاصطناعي اطلع على الوثائق الرسمية والبرامج التعليمية مثل توثيق باي تورش PyTorch وتوثيق تنسرفلو TensorFlow عبر موقعهم الرسمي. فهم يقدمون شروحات موجزة وأمثلة وحالات استخدام مختلفة إضافة إلى التوثيق الرسمي لكافة الأدوات المستخدمة في بناء وبرمجة الذكاء الاصطناعي. تذكر أن الذكاء الاصطناعي هو مجال سريع التطور، لذا فإن البقاء على اطلاع بأحدث الأوراق البحثية والتطورات أمر هام، كما أن البقاء على اطلاع على أحدث الأدوات المستخدمة في برمجة الذكاء الاصطناعي هو أمر هام أيضًا. استخدم مجموعة من هذه الموارد لبناء أساس قوي ومواصلة التفاعل مع مجتمع الذكاء الاصطناعي. خاتمة برز عالم الذكاء الاصطناعي كثورة ضمن المشهد التكنولوجي سريع التطور الذي ظهر في العقود القليلة الماضية، يقدم فرصًا وتحديات لا حدود لها على حد سواء. بينما كنا نتعمق في عالم برمجة الذكاء الاصطناعي، شرعنا في رحلة بدأت من التحدث عن لغات وأدوات برمجة الذكاء الاصطناعي إلى المكتبات والأطر المتطورة وإنشاء نماذج الذكاء الاصطناعي ونشر هذه النماذج. بالنظر إلى الأُفق، اكتشفنا المستقبل الذي ينتظر برمجة الذكاء الاصطناعي. إن مفاهيم مثل الذكاء الاصطناعي القابل للتفسير والتعلم الموحد ودمج الذكاء الاصطناعي مع إنترنت الأشياء هي المفتاح لفتح أبعاد جديدة للابتكار. بينما نرتقي إلى مستويات أعلى، يجب أن نعترف بالقيود والاعتبارات الأخلاقية التي تقدمها برمجة الذكاء الاصطناعي ونعالجها. أخيرًا، كان لابد لنا من ذكر بعض من المصادر الهامة لتعلّم الذكاء الصناعي. في الختام، مجال برمجة الذكاء الاصطناعي هو نسيج معقد منسوج بخيوط من الابتكار والأخلاق وإمكانات لا حدود لها. بينما نتنقل في هذا المشهد المعقد، فإننا لسنا مجرد مبرمجي آلات؛ نحن نشكل مستقبل الأنظمة الذكية التي لديها القدرة على إحداث ثورة في الصناعات وتعزيز حياة البشر وإعادة تعريف نسيج وجودنا التكنولوجي. إن سمفونية جهودنا في برمجة الذكاء الاصطناعي تتماشى مع الوعد بمستقبل حيث تشرع الآلات، مسترشدةً ببراعتنا، في رحلة من الذكاء والفهم. انظر أيضًا تعلم الذكاء الاصطناعي تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال1 نقطة -
 سنتحدث في هذا المقال عن أشهر علماء الحاسب أولئك الذين تغير علم الحاسوب بعدهم وتركوا بصمة فيه لنسلط الضوء على إنجازاتهم ونفتخر بهم وبأن قسم كبير منهم كانوا من العلماء العرب، فهل أنت جاهز للتعرف عليهم؟ لنبدأ! من هو عالم الحاسب؟ لم يصل علم الحاسوب إلى ما وصل عليه الآن ولم يبلغ التطور الرقمي مبلغه الآن إلا بفضل علماء ساهموا به وقدموا له الإنجازات وبذلوا فيه التضحيات لتتراكم تلك الإنجازات فوق بعضها ويصل العالم اليوم إلى تطور رقمي لم يصله من قبل حتى بات الشخص يسافر أبعد المسافات، ويتحدث أحدهم من أقصى الشرق مع آخر من أقصى الغرب، ويرسل آخر حوالة مالية من أقصى الشمال لتصل إلى أقصى الجنوب بمدة زمن خيالية وغير ذلك ما لو كان أجدادنا الأولون هنا لتعجبوا أشد العجب، وربما تعجبنا مثله نحن مستقبلًا على تطورات لم نكن نتخيلها الآن أو ربما جرى تأليف فلم خيال علمي عنها. وعمومًا، عالم الحاسب هو من أفنى عمره في مجال علوم الحاسوب وما يتصل به ولم يعمل به فقط، بل ساهم فيه وقدم إنجازات معتبرة بها يدرج ضمن الخط الزمني التاريخي حيث التاريخ ما قبله ليس كما بعده، وستجد اسمه مدرجًا في المراجع والمقالات التاريخية أو يُذكر في أروقة الجامعات مقرونًا بإنجازه في المجال. أهم علماء الحاسب نتعرف الآن على مجموعة من أشهر علماء الحاسب الذين تركوا علامات فارقة وإنجازات تركت أثرًا على حياتنا الآن إما بنظريات جديدة أو بمنتجات وخدمات تقوم هي أيضًا على نظريات أحدثوها أو طوروها. تيم بيرنرز-لي Tim Berners-Lee الصورة بواسطة Paul Clarke، منشورة برخصة CC BY-SA 4.0 أحد أشهر علماء الحاسب البريطانيين، أنشأ أول نسخة من الشبكة العالمية WWW (شبكة الإنترنت) عام 1989. عمل كمهندس في شركة اتصالات ثم انضم إلى المنظمة الأوروبية للبحث النووي CERN في عام 1980 ثم مرة أخرى في 1984 وقرر اختبار نموذج الربط التشعبي فيه إذ كان أكبر شبكة إنترنت في أوروبا وقتها، وهو ما شكل الأساس فيما بعد لشبكة الويب التي تقوم على الروابط المتشعبة Hyper Links باستخدام بروتوكول نقل النصوص الفائقة Hyper Text Transfer Protocol أو HTTP. فينتون سيرف Venton Cerf الصورة بواسطة Duncan.Hull منشورة برخصة CC BY-SA 4.0 أحد علماء الحاسب الأمريكيين، يُعد أحد آباء الإنترنت الذين أنشأوه حيث كتب أول بروتوكول TCP بالاشتراك مع يوجين دلال Yogen Dalal وكارل صنشاين Carl Sunshine. عمل كذلك كأستاذ مساعد في جامعة ستانفورد في عام 1972 لأربعة سنوات أجرى فيها أبحاثًا حول بروتوكولات الاتصالات الشبكية، وصمم حزمة DoD TCP/IP بالاشتراك مع بوب خان Bob Kahn. آلان تيورنج Alan Turing رياضي بريطاني وأحد أهم علماء الحاسب البريطانيين الذين عملوا أثناء الحرب العالمية الثانية في المدرسة الحكومية البريطانية للتشفير والتعمية Government Code and Cypher School على فك تشفير آلة إنيجما الألمانية التي استُخدمت في تشفير الرسائل الألمانية العسكرية، وكتب ورقتين حول استخدام التحليل الرياضي لتحديد الإعدادات الأقرب التي يمكن استخدامها بسرعة لفك الشيفرة المستخدمة، ولم تُنشر هاتان الورقتان للعلن إلا في عام 2012. يُعزى إليه الفضل مع جوردون ويلشمَن Gordon Welchman في إنشاء أول آلة كهروميكانيكية استُخدمت في فك تشفير آلة إنيجما، ثم عمل بعد الحرب على تصميم محرك حوسبة آلي نشر ورقته في 1946، يصف فيه برنامج مخزَّن على الحاسب، ثم عمل بعده على كتابة برامج لأحد أوائل الحواسيب ذات الذاكرة، وهو حاسب مانشيستر مارك1. كذلك اقترح في عام 1950 ما عُرف بعدها باختبار تيورنج الذي يعرِّف فيه الآلة على أنها ذكية إذا لم يدرك الإنسان الذي يتعامل معها أنها آلة آنذاك. طاهر الجمل الصورة بواسطة Alexander Klink منشورة برخصة CC BY 3.0 أحد أشهر علماء الحاسب العرب من الحاصلين على الجنسية الأمريكية إذ هو مصري الأصل، يُعزى إليه الفضل في إنشاء بروتوكول SSL أثناء عمله في شركة Netscape، إضافة إلى نظام تعمية عُرف باسمه ElGamal encryption system عبارة عن خوارزمية تعمية باستخدام المفتاح العام، حيث يكون للمستخدم مفتاحان واحد عام يمكن نشره للعامة وآخر سري، ويرتبطان معًا بعملية حسابية تختلف وفقًا للخوارزمية المستخدمة، ورغم ارتباطهما فلا يمكن الوصول إلى أحد المفتاحين عن طريق الآخر. تُستخدم هذه التقنية بكثرة في تعمية الرسائل وتستخدمها البنوك لضمان سرية معاملاتها المالية. عباس الجمل أحد علماء الحاسب العرب من الحاصلين على الجنسية الأمريكية إذ هو مصري الأصل كذلك، وهو أخو الدكتور طاهر الجمل الذي ذكرناه أعلاه. شغل عدة مناصب أكاديمية في جامعة ستانفورد، وطور نوعًا من الدوائر الإلكترونية يمكن برمجته بعد مرحلة التصنيع ليوافق احتياجات المستخدم، وله عدة براءات اختراعات وأوراق علمية في هذا المجال. وقد عمل أيضًا على تطوير مستشعرات CMOS المستخدمة حاليًا في الكاميرات الرقمية والهواتف المحمولة، ثم أنشأ العديد من الشركات مثل Actel التي تعمل على تصنيع الدوائر الإلكترونية التي طورها، وشركة Pixim لتطوير رقاقات في كاميرات المراقبة تستخدم تقنية حساس البكسل الرقمي Digital Pixel Sensor التي طورتها مجموعته في ستانفورد. لينوس تورفالدز Linus Torvalds الصورة بواسطة kuvaaja - Linuxmag.com منشورة برخصة CC BY-SA 3.0 أحد أشهر علماء الحاسب في مجال هندسة البرمجيات، وهو أمريكي فنلندي، حيث يُنسب إليه اختراع نواة نظام التشغيل لينكس في 1991، وقد تطور نظام لينكس وتوسع انتشاره ليصبح من أهم نظم التشغيل حاليًا، إذ تعمل به جميع الحواسيب الخارقة في العالم، ويُبنى عليه نظام أندرويد الذي تعمل به أكثر الهواتف. يتميز نظام لينكس والتوزيعات المبنية عليه بمستويات الأمان المتقدم ونظام الصلاحيات الذي لا يسمح للمستخدمين ولا الملفات بإحداث ضرر غير مقصود أو تلقائي في النظام، كما يتميز أيضًا بمجانيته وأنه مفتوح المصدر في نفس الوقت، مما يقلل من تكلفة استخدام الحواسيب إلى حد كبير، خاصة في حالة المؤسسات الكبرى التي لديها أعداد كبيرة من الأجهزة، إلا أن بعض التوزيعات المبنية عليه تقدم خدمة الدعم الفني للشركات الكبيرة التي تحتاج إلى ذلك بمقابل مادي. ثم طور في 2005 نظام Git للتحكم في إصدارات البرمجيات، وهو النظام الأشهر الأكثر استخدامًا الآن من قبل المطورين والمبرمجين في العالم. ريتشارد ستولمان Richard Stallman أحد أهم علماء الحاسب الأمريكيين، اشتهر في الثمانينات من القرن الماضي حين بدأ في تطوير نظام تشغيل مفتوح المصدر من الصفر على إثر إغلاق نظام يونكس الذي كان منتشرًا وقتها، إضافة إلى بعض البرامج الأساسية للنظام مثل محرر النصوص Emacs والمصرِّف الخاص بنظام جنو Gnu Compiler Collection GCC، وغيرهما، وسُمي هذا النظام باسم جنو GNU، وأصدر له رخصة حرة خاصة به وأدوات تطوير تنشر مبدأ حرية البرمجيات وتعديلها بشرط أن يُعاد نشرها بنفس الرخصة. وقد بُني على هذا النظام أول نواة لينكس التي طورها لينوس تورفالدز الذي ذكرناه قبل قليل. دينيس ريتشي Dennis Ritchie الصورة بواسطة Denise Panyik-Dale - منشورة برخصة CC BY 2.0 أحد أهم علماء الحاسب الأمريكيين، ساهم في إنشاء نظام يونكس UNIX الذي كان يعمل على تطويره مع كين ثومبسون Ken Thompson، وهو أول نظام تشغيل للحواسيب متعدد المهام، وقد استُخدم بكثرة منذ إصداره في 1971، ثم صار الاسم يُطلق على أي نظام تشغيل يحقق عدة معايير مجموعة في واجهة POSIX التي أُصدرت في الثمانينات. كذلك يُنسب إليه الفضل في إنشاء لغة البرمجة C، مع بريان كيرنيهان Brian Kernighan، وهي اللغة الأشهر منذ إصدارها في السبعينات إلى الآن، وتُستخدم في برمجة أنظمة التشغيل وتعريفات العتاد والبرامج والتطبيقات، رغم تراجع استخدامها في التطبيقات مؤخرًا، ولا يزال كتابهما الذي أصدر كدليل للغة في 1972 صالحًا للتطبيق حتى الآن، مما يشهد بمدى تقدم تلك اللغة وقت إصدارها والنقلة النوعية التي أحدثتها في الوسط التقني. كين تومبسون Ken Thompson الصورة بواسطة National Inventors Hall of Fame منشورة برخصة CC BY-SA 3.0 أحد علماء الحاسب الأمريكيين الأوائل، عمل في مختبرات بل Bell Labs حقبة من الزمن وقد ساهم في تصميم نظام التشغيل يونكس UNIX وتشييده وقد ساهم في اختراع لغة B مع دينيس ريتشي اللغة التي تسبق مباشرةً لغة سي C، وقد ساهم أيضًا في اختراع نظام التشغيل Plan 9 وتطويره. انتقل كين للعمل في شركة غوغل Google منذ عام 2006 حيث أضاف إلى سجل إنجازاته المساهمة في تطوير لغة جو Go، ونذكر أيضًا من تلك الإنجازات العمل على التعابير النمطية RegEx وتعريف الترميز UTF-8. حصد كين تسعة جوائز معتبرة منها جائزة تيورنج Turing Award مع شريكه دينيس ريتشي عام 1983 وآخرها جاهزة Japan Prize عام 2011 تقديرًا لإنجازاته وجهوده المبذولة. جيمس غوسلينغ James Gosling الصورة بواسطة Eugene Zelenko منشورة برخصة CC BY-SA 4.0 عالم حاسوب كندي الأصل اشتهر شهرة كبيرة في تأسيسه للغة جافا Java الشهيرة وتصميمه لها ولمعماريتها المتمثلة في آلة جافا الافتراضية Java VM، كما له مساهمات معتبرة في اختراع النوافذ windows ضمن أنظمة التشغيل، إذ كان من أوائل من اخترع نظام النافذة في نظام التشغيل يونيكس تحت مظلة شركة Sun Microsystems. محمد عطا الله فيزيائي ومهندس أمريكي مصري وأحد علماء الحاسب الذين لهم أثر كبير في مجال أشباه الموصلات حيث اخترع أحد أشكال الترانزستور المسمى MOSFET في عام 1959، وهو ترانزستور به قناة نقل من أشباه الموصلات، يُستخدم في الدوائر المتكاملة -مثل المعالجات الدقيقة- ومحولات الطاقة في السيارات الكهربائية وأنظمة الاتصالات. حاتم زغلول أحد أشهر علماء الحاسب العرب حيث نستخدم اختراعه كل يوم، وهو كندي مصري، سجل براءة اختراع لتقنية هي أساس تقنيات الواي فاي الحديثة التي نستخدمها اليوم، مع ميشيل فتوش، أحد زملائه من علماء الحاسب المصريين أيضًا، وقد أنشأ معه عدة شركات لتسويق اختراعاتهما، حيث بُنيت عليها تقنيات الاتصالات الحديثة من الجيل الرابع، مثل CDMA، كما أسس عدة شركات في مجال التكنولوجيا والاتصالات. محمد بن موسى الخوارزمي الصورة بواسطة ميشيل بكني مشتقة من 1983 CPA 5426.jpg و CC BY-SA 4.0 وهو أحد علماء المسلمين الأغنياء عن التعريف لما اشتهر به من كتب ومؤلفات في الرياضيات والجبر والمثلثات والفلك، حيث اعتمد العلماء المسلمون في زمانه -القرن الثاني الهجري- على ترجمة أعمال الأمم التي سبقت بالعلوم والمعرفة وتعلمها ثم البناء عليها. وقد بنى علماء الحاسب في العصر الحديث أغلب تقنياتهم الحوسبية على المفاهيم التي أسسها الخوارزمي في الجبر وحساب المثلثات والمعادلات الخطية والتربيعية، وكذلك الخوارزميات التي سميت باسمه. يعقوب بن إسحاق الكِندي هو أحد العلماء المسلمين في القرن الثاني الهجري، برع في الفلسفة والرياضة والفلك والطب، لكننا سنركز على أعماله في التشفير والتعمية cryptography هنا، حيث كان له الفضل في تطوير أسلوب في التعمية لتحليل الاختلاف في وتيرة حدوث الحروف في الرسائل بالتحليل الإحصائي، ومن ثم فك الشفرات التي كُتبت بها، وقد فصّل ذلك في مخطوطة وُجدت في الأرشيف العثماني في اسطنبول بعنوان "مخطوط في فك رسائل التشفير". الخليل بن أحمد الفراهيدي أحد علماء المسلمين في القرن الثاني الهجري كذلك، وله إسهاماته في اللغة والأدب والعروض، وقد أثرت دراسته تلك في أعماله في علم التعمية إذ كان أول عالم لغوي يضع كتابًا في التعمية والتشفير، ذكر فيه استخدام التراكيب اللغوية والتباديل التي تسرد الكلمات العربية الممكنة بحروف العلة ومن غيرها، وأثرت أعماله في علم التعمية على الكِندي الذي ذكرناه قبل قليل. ويُنسب إليه كذلك علامات التشكيل العربية التي نستخدمها الآن والتي حلت محل النظام النقطي الذي كان قبلها، وقد كان ينوي استخدامها في الشعر فقط بادئ الأمر، إلا أنها صارت تُستخدم في كل مكان أيضًا. خاتمة تعرفنا في هذا المقال على أهم علماء الحاسب الذين كانت لهم بصمات مؤثرة في التقنيات التي نستخدمها اليوم، إما مباشرة أو بطريق غير مباشر، ونرجو بذكرنا للعلماء العرب أن نقدم قدوة للشباب ولأولادهم من بعدهم يحتذوا بها ويزيدوا عليها أيضًا، فمن كان يظن أن من اخترع الواي فاي وتقنيات الجيل الرابع وتقنيات التشفير والتعمية وبعض أشهر أنواع الرقائق الإلكترونية هم عرب تعلموا في مدارسنا وبيننا؟! ويبقى هنالك من علماء حاسوب لم نذكرهم في المقالة ليس لصغر إنجازاتهم ولكن لأن القائمة لن تنتهي وستتعرف عليهم تباعًا إن دخلت إلى مجال علوم الحاسوب. اقرأ أيضًا المدخل الشامل إلى علوم الحاسوب تعلم البرمجة دليلك إلى لغات البرمجة1 نقطة
سنتحدث في هذا المقال عن أشهر علماء الحاسب أولئك الذين تغير علم الحاسوب بعدهم وتركوا بصمة فيه لنسلط الضوء على إنجازاتهم ونفتخر بهم وبأن قسم كبير منهم كانوا من العلماء العرب، فهل أنت جاهز للتعرف عليهم؟ لنبدأ! من هو عالم الحاسب؟ لم يصل علم الحاسوب إلى ما وصل عليه الآن ولم يبلغ التطور الرقمي مبلغه الآن إلا بفضل علماء ساهموا به وقدموا له الإنجازات وبذلوا فيه التضحيات لتتراكم تلك الإنجازات فوق بعضها ويصل العالم اليوم إلى تطور رقمي لم يصله من قبل حتى بات الشخص يسافر أبعد المسافات، ويتحدث أحدهم من أقصى الشرق مع آخر من أقصى الغرب، ويرسل آخر حوالة مالية من أقصى الشمال لتصل إلى أقصى الجنوب بمدة زمن خيالية وغير ذلك ما لو كان أجدادنا الأولون هنا لتعجبوا أشد العجب، وربما تعجبنا مثله نحن مستقبلًا على تطورات لم نكن نتخيلها الآن أو ربما جرى تأليف فلم خيال علمي عنها. وعمومًا، عالم الحاسب هو من أفنى عمره في مجال علوم الحاسوب وما يتصل به ولم يعمل به فقط، بل ساهم فيه وقدم إنجازات معتبرة بها يدرج ضمن الخط الزمني التاريخي حيث التاريخ ما قبله ليس كما بعده، وستجد اسمه مدرجًا في المراجع والمقالات التاريخية أو يُذكر في أروقة الجامعات مقرونًا بإنجازه في المجال. أهم علماء الحاسب نتعرف الآن على مجموعة من أشهر علماء الحاسب الذين تركوا علامات فارقة وإنجازات تركت أثرًا على حياتنا الآن إما بنظريات جديدة أو بمنتجات وخدمات تقوم هي أيضًا على نظريات أحدثوها أو طوروها. تيم بيرنرز-لي Tim Berners-Lee الصورة بواسطة Paul Clarke، منشورة برخصة CC BY-SA 4.0 أحد أشهر علماء الحاسب البريطانيين، أنشأ أول نسخة من الشبكة العالمية WWW (شبكة الإنترنت) عام 1989. عمل كمهندس في شركة اتصالات ثم انضم إلى المنظمة الأوروبية للبحث النووي CERN في عام 1980 ثم مرة أخرى في 1984 وقرر اختبار نموذج الربط التشعبي فيه إذ كان أكبر شبكة إنترنت في أوروبا وقتها، وهو ما شكل الأساس فيما بعد لشبكة الويب التي تقوم على الروابط المتشعبة Hyper Links باستخدام بروتوكول نقل النصوص الفائقة Hyper Text Transfer Protocol أو HTTP. فينتون سيرف Venton Cerf الصورة بواسطة Duncan.Hull منشورة برخصة CC BY-SA 4.0 أحد علماء الحاسب الأمريكيين، يُعد أحد آباء الإنترنت الذين أنشأوه حيث كتب أول بروتوكول TCP بالاشتراك مع يوجين دلال Yogen Dalal وكارل صنشاين Carl Sunshine. عمل كذلك كأستاذ مساعد في جامعة ستانفورد في عام 1972 لأربعة سنوات أجرى فيها أبحاثًا حول بروتوكولات الاتصالات الشبكية، وصمم حزمة DoD TCP/IP بالاشتراك مع بوب خان Bob Kahn. آلان تيورنج Alan Turing رياضي بريطاني وأحد أهم علماء الحاسب البريطانيين الذين عملوا أثناء الحرب العالمية الثانية في المدرسة الحكومية البريطانية للتشفير والتعمية Government Code and Cypher School على فك تشفير آلة إنيجما الألمانية التي استُخدمت في تشفير الرسائل الألمانية العسكرية، وكتب ورقتين حول استخدام التحليل الرياضي لتحديد الإعدادات الأقرب التي يمكن استخدامها بسرعة لفك الشيفرة المستخدمة، ولم تُنشر هاتان الورقتان للعلن إلا في عام 2012. يُعزى إليه الفضل مع جوردون ويلشمَن Gordon Welchman في إنشاء أول آلة كهروميكانيكية استُخدمت في فك تشفير آلة إنيجما، ثم عمل بعد الحرب على تصميم محرك حوسبة آلي نشر ورقته في 1946، يصف فيه برنامج مخزَّن على الحاسب، ثم عمل بعده على كتابة برامج لأحد أوائل الحواسيب ذات الذاكرة، وهو حاسب مانشيستر مارك1. كذلك اقترح في عام 1950 ما عُرف بعدها باختبار تيورنج الذي يعرِّف فيه الآلة على أنها ذكية إذا لم يدرك الإنسان الذي يتعامل معها أنها آلة آنذاك. طاهر الجمل الصورة بواسطة Alexander Klink منشورة برخصة CC BY 3.0 أحد أشهر علماء الحاسب العرب من الحاصلين على الجنسية الأمريكية إذ هو مصري الأصل، يُعزى إليه الفضل في إنشاء بروتوكول SSL أثناء عمله في شركة Netscape، إضافة إلى نظام تعمية عُرف باسمه ElGamal encryption system عبارة عن خوارزمية تعمية باستخدام المفتاح العام، حيث يكون للمستخدم مفتاحان واحد عام يمكن نشره للعامة وآخر سري، ويرتبطان معًا بعملية حسابية تختلف وفقًا للخوارزمية المستخدمة، ورغم ارتباطهما فلا يمكن الوصول إلى أحد المفتاحين عن طريق الآخر. تُستخدم هذه التقنية بكثرة في تعمية الرسائل وتستخدمها البنوك لضمان سرية معاملاتها المالية. عباس الجمل أحد علماء الحاسب العرب من الحاصلين على الجنسية الأمريكية إذ هو مصري الأصل كذلك، وهو أخو الدكتور طاهر الجمل الذي ذكرناه أعلاه. شغل عدة مناصب أكاديمية في جامعة ستانفورد، وطور نوعًا من الدوائر الإلكترونية يمكن برمجته بعد مرحلة التصنيع ليوافق احتياجات المستخدم، وله عدة براءات اختراعات وأوراق علمية في هذا المجال. وقد عمل أيضًا على تطوير مستشعرات CMOS المستخدمة حاليًا في الكاميرات الرقمية والهواتف المحمولة، ثم أنشأ العديد من الشركات مثل Actel التي تعمل على تصنيع الدوائر الإلكترونية التي طورها، وشركة Pixim لتطوير رقاقات في كاميرات المراقبة تستخدم تقنية حساس البكسل الرقمي Digital Pixel Sensor التي طورتها مجموعته في ستانفورد. لينوس تورفالدز Linus Torvalds الصورة بواسطة kuvaaja - Linuxmag.com منشورة برخصة CC BY-SA 3.0 أحد أشهر علماء الحاسب في مجال هندسة البرمجيات، وهو أمريكي فنلندي، حيث يُنسب إليه اختراع نواة نظام التشغيل لينكس في 1991، وقد تطور نظام لينكس وتوسع انتشاره ليصبح من أهم نظم التشغيل حاليًا، إذ تعمل به جميع الحواسيب الخارقة في العالم، ويُبنى عليه نظام أندرويد الذي تعمل به أكثر الهواتف. يتميز نظام لينكس والتوزيعات المبنية عليه بمستويات الأمان المتقدم ونظام الصلاحيات الذي لا يسمح للمستخدمين ولا الملفات بإحداث ضرر غير مقصود أو تلقائي في النظام، كما يتميز أيضًا بمجانيته وأنه مفتوح المصدر في نفس الوقت، مما يقلل من تكلفة استخدام الحواسيب إلى حد كبير، خاصة في حالة المؤسسات الكبرى التي لديها أعداد كبيرة من الأجهزة، إلا أن بعض التوزيعات المبنية عليه تقدم خدمة الدعم الفني للشركات الكبيرة التي تحتاج إلى ذلك بمقابل مادي. ثم طور في 2005 نظام Git للتحكم في إصدارات البرمجيات، وهو النظام الأشهر الأكثر استخدامًا الآن من قبل المطورين والمبرمجين في العالم. ريتشارد ستولمان Richard Stallman أحد أهم علماء الحاسب الأمريكيين، اشتهر في الثمانينات من القرن الماضي حين بدأ في تطوير نظام تشغيل مفتوح المصدر من الصفر على إثر إغلاق نظام يونكس الذي كان منتشرًا وقتها، إضافة إلى بعض البرامج الأساسية للنظام مثل محرر النصوص Emacs والمصرِّف الخاص بنظام جنو Gnu Compiler Collection GCC، وغيرهما، وسُمي هذا النظام باسم جنو GNU، وأصدر له رخصة حرة خاصة به وأدوات تطوير تنشر مبدأ حرية البرمجيات وتعديلها بشرط أن يُعاد نشرها بنفس الرخصة. وقد بُني على هذا النظام أول نواة لينكس التي طورها لينوس تورفالدز الذي ذكرناه قبل قليل. دينيس ريتشي Dennis Ritchie الصورة بواسطة Denise Panyik-Dale - منشورة برخصة CC BY 2.0 أحد أهم علماء الحاسب الأمريكيين، ساهم في إنشاء نظام يونكس UNIX الذي كان يعمل على تطويره مع كين ثومبسون Ken Thompson، وهو أول نظام تشغيل للحواسيب متعدد المهام، وقد استُخدم بكثرة منذ إصداره في 1971، ثم صار الاسم يُطلق على أي نظام تشغيل يحقق عدة معايير مجموعة في واجهة POSIX التي أُصدرت في الثمانينات. كذلك يُنسب إليه الفضل في إنشاء لغة البرمجة C، مع بريان كيرنيهان Brian Kernighan، وهي اللغة الأشهر منذ إصدارها في السبعينات إلى الآن، وتُستخدم في برمجة أنظمة التشغيل وتعريفات العتاد والبرامج والتطبيقات، رغم تراجع استخدامها في التطبيقات مؤخرًا، ولا يزال كتابهما الذي أصدر كدليل للغة في 1972 صالحًا للتطبيق حتى الآن، مما يشهد بمدى تقدم تلك اللغة وقت إصدارها والنقلة النوعية التي أحدثتها في الوسط التقني. كين تومبسون Ken Thompson الصورة بواسطة National Inventors Hall of Fame منشورة برخصة CC BY-SA 3.0 أحد علماء الحاسب الأمريكيين الأوائل، عمل في مختبرات بل Bell Labs حقبة من الزمن وقد ساهم في تصميم نظام التشغيل يونكس UNIX وتشييده وقد ساهم في اختراع لغة B مع دينيس ريتشي اللغة التي تسبق مباشرةً لغة سي C، وقد ساهم أيضًا في اختراع نظام التشغيل Plan 9 وتطويره. انتقل كين للعمل في شركة غوغل Google منذ عام 2006 حيث أضاف إلى سجل إنجازاته المساهمة في تطوير لغة جو Go، ونذكر أيضًا من تلك الإنجازات العمل على التعابير النمطية RegEx وتعريف الترميز UTF-8. حصد كين تسعة جوائز معتبرة منها جائزة تيورنج Turing Award مع شريكه دينيس ريتشي عام 1983 وآخرها جاهزة Japan Prize عام 2011 تقديرًا لإنجازاته وجهوده المبذولة. جيمس غوسلينغ James Gosling الصورة بواسطة Eugene Zelenko منشورة برخصة CC BY-SA 4.0 عالم حاسوب كندي الأصل اشتهر شهرة كبيرة في تأسيسه للغة جافا Java الشهيرة وتصميمه لها ولمعماريتها المتمثلة في آلة جافا الافتراضية Java VM، كما له مساهمات معتبرة في اختراع النوافذ windows ضمن أنظمة التشغيل، إذ كان من أوائل من اخترع نظام النافذة في نظام التشغيل يونيكس تحت مظلة شركة Sun Microsystems. محمد عطا الله فيزيائي ومهندس أمريكي مصري وأحد علماء الحاسب الذين لهم أثر كبير في مجال أشباه الموصلات حيث اخترع أحد أشكال الترانزستور المسمى MOSFET في عام 1959، وهو ترانزستور به قناة نقل من أشباه الموصلات، يُستخدم في الدوائر المتكاملة -مثل المعالجات الدقيقة- ومحولات الطاقة في السيارات الكهربائية وأنظمة الاتصالات. حاتم زغلول أحد أشهر علماء الحاسب العرب حيث نستخدم اختراعه كل يوم، وهو كندي مصري، سجل براءة اختراع لتقنية هي أساس تقنيات الواي فاي الحديثة التي نستخدمها اليوم، مع ميشيل فتوش، أحد زملائه من علماء الحاسب المصريين أيضًا، وقد أنشأ معه عدة شركات لتسويق اختراعاتهما، حيث بُنيت عليها تقنيات الاتصالات الحديثة من الجيل الرابع، مثل CDMA، كما أسس عدة شركات في مجال التكنولوجيا والاتصالات. محمد بن موسى الخوارزمي الصورة بواسطة ميشيل بكني مشتقة من 1983 CPA 5426.jpg و CC BY-SA 4.0 وهو أحد علماء المسلمين الأغنياء عن التعريف لما اشتهر به من كتب ومؤلفات في الرياضيات والجبر والمثلثات والفلك، حيث اعتمد العلماء المسلمون في زمانه -القرن الثاني الهجري- على ترجمة أعمال الأمم التي سبقت بالعلوم والمعرفة وتعلمها ثم البناء عليها. وقد بنى علماء الحاسب في العصر الحديث أغلب تقنياتهم الحوسبية على المفاهيم التي أسسها الخوارزمي في الجبر وحساب المثلثات والمعادلات الخطية والتربيعية، وكذلك الخوارزميات التي سميت باسمه. يعقوب بن إسحاق الكِندي هو أحد العلماء المسلمين في القرن الثاني الهجري، برع في الفلسفة والرياضة والفلك والطب، لكننا سنركز على أعماله في التشفير والتعمية cryptography هنا، حيث كان له الفضل في تطوير أسلوب في التعمية لتحليل الاختلاف في وتيرة حدوث الحروف في الرسائل بالتحليل الإحصائي، ومن ثم فك الشفرات التي كُتبت بها، وقد فصّل ذلك في مخطوطة وُجدت في الأرشيف العثماني في اسطنبول بعنوان "مخطوط في فك رسائل التشفير". الخليل بن أحمد الفراهيدي أحد علماء المسلمين في القرن الثاني الهجري كذلك، وله إسهاماته في اللغة والأدب والعروض، وقد أثرت دراسته تلك في أعماله في علم التعمية إذ كان أول عالم لغوي يضع كتابًا في التعمية والتشفير، ذكر فيه استخدام التراكيب اللغوية والتباديل التي تسرد الكلمات العربية الممكنة بحروف العلة ومن غيرها، وأثرت أعماله في علم التعمية على الكِندي الذي ذكرناه قبل قليل. ويُنسب إليه كذلك علامات التشكيل العربية التي نستخدمها الآن والتي حلت محل النظام النقطي الذي كان قبلها، وقد كان ينوي استخدامها في الشعر فقط بادئ الأمر، إلا أنها صارت تُستخدم في كل مكان أيضًا. خاتمة تعرفنا في هذا المقال على أهم علماء الحاسب الذين كانت لهم بصمات مؤثرة في التقنيات التي نستخدمها اليوم، إما مباشرة أو بطريق غير مباشر، ونرجو بذكرنا للعلماء العرب أن نقدم قدوة للشباب ولأولادهم من بعدهم يحتذوا بها ويزيدوا عليها أيضًا، فمن كان يظن أن من اخترع الواي فاي وتقنيات الجيل الرابع وتقنيات التشفير والتعمية وبعض أشهر أنواع الرقائق الإلكترونية هم عرب تعلموا في مدارسنا وبيننا؟! ويبقى هنالك من علماء حاسوب لم نذكرهم في المقالة ليس لصغر إنجازاتهم ولكن لأن القائمة لن تنتهي وستتعرف عليهم تباعًا إن دخلت إلى مجال علوم الحاسوب. اقرأ أيضًا المدخل الشامل إلى علوم الحاسوب تعلم البرمجة دليلك إلى لغات البرمجة1 نقطة