لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 03/18/25 in أجوبة
-
السلام عليكم هو ازي اقدر احديد نطاق معين من الاعمد مثل من x_1 الي x_10 بستخدم loc ؟4 نقاط
-
السلام عليكم هو اي الفرق مابين pandas.drop() , pandas.dropna() ؟4 نقاط
-
السلام عليكم هو عادي ان يكون الtrain_labels 5 اعمده فقط ولكن الvalidation_labels بيتكون من 123 عمود ؟4 نقاط
-
السلام عليكم تضهر معي مشكلة عند رفع الملفات على منصة GitHup يضهر معي هذا الخطاء الخطاء يضهر ان الملفات تزيد عن 100ميجابايت بالرغم من استخدامي لملف .gitignore.txt ومحتوياته # Logs logs *.log npm-debug.log* yarn-debug.log* yarn-error.log* pnpm-debug.log* lerna-debug.log* node_modules/ node_modules dist dist/ dist-ssr *.local # Editor directories and files .vscode/* !.vscode/extensions.json .idea .DS_Store *.suo *.ntvs* *.njsproj *.sln *.sw?
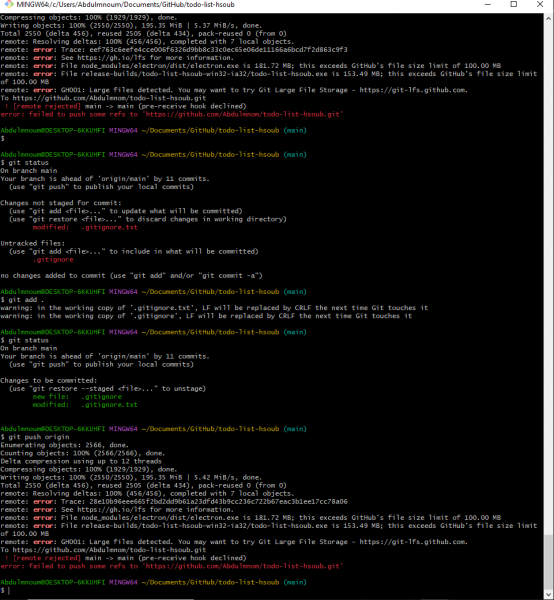 3 نقاط
3 نقاط -
السلام عليكم. بعد تصحيح الأخطاء ومراجعة التحذيرات تظهر الرسالة التالية . مرفق صور الجداول المذكورة SELECT * FROM _user_groups WHERE `ID` = ? ORDER BY ID ASC LIMIT 0, 1 SELECT * FROM _setting_admin WHERE `var` = ? LIMIT 0, 1
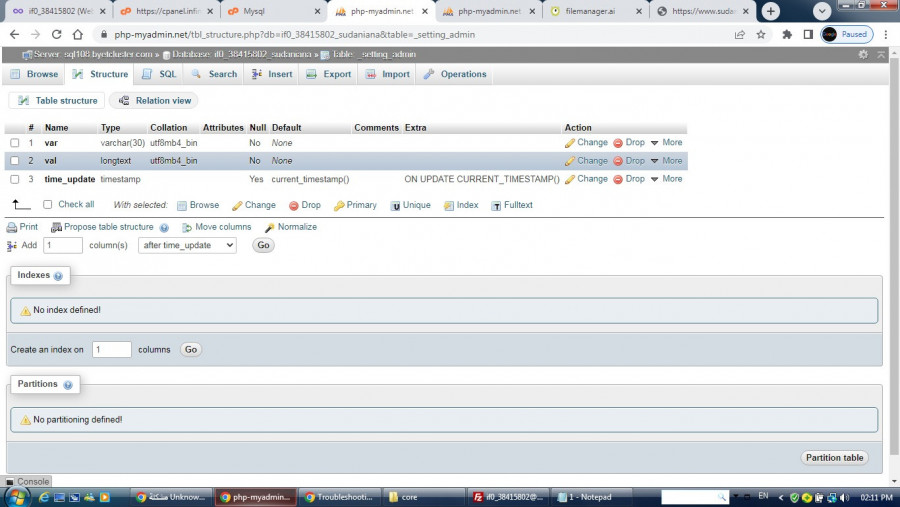
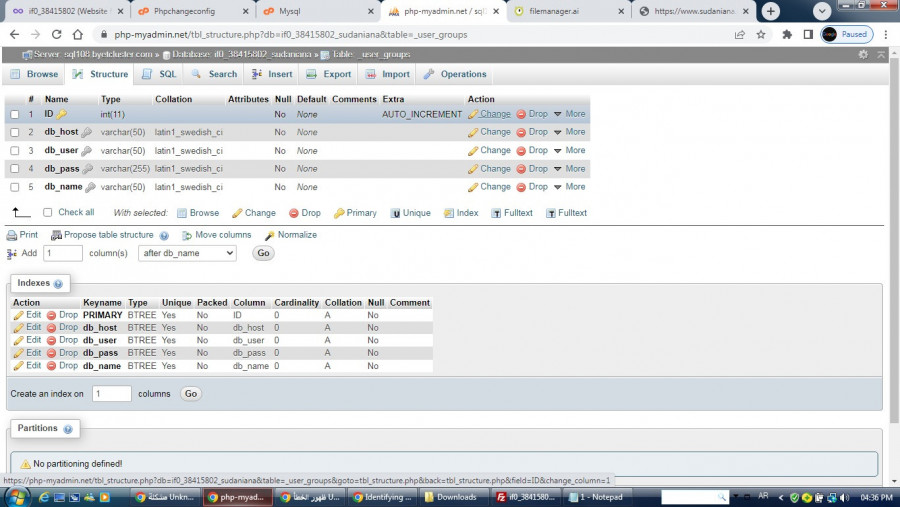 3 نقاط
3 نقاط -
with the rise of Deepseek and manus , it seems that it will replace every data scientist | AI including mine, sould I still keep going?3 نقاط
-
ليس هنالك خطأ. لكن الموقع لا يفتح وتظهر هذه الرسالة. الموضع الذي وجدت به ;echo $query في ملف class-db.php هو التالي، وعندما اقوم بحذفه يحذف الاستعلام ولكن تبقى الصفحة فارغة ولا تنتقل الى صفحة الموقع: public function prepare( $query, $generic = false ){ echo $query; $run = parent::prepare( $query ); $this->__log(array( "query" => $query, "__cf" => "prepare", "safe" => 1, "generic" => $generic ? 1 : 0, )); return $run; }2 نقاط
-
انا مستخدم Safari لم اجد في اعدادات المتصفح خيارات أخرى
 1 نقطة
1 نقطة -
وعليكم السلام ورحمة الله وبركاته. هل تقصد تحديد النطاق بطريقة ثابته أم مثلا نطاق متغير بناء على شرط ما ؟ إذا كنت تقصد نطاق ثابت من x_1 إلى x_10 يمكنك إستخدام الكود التالي : df.loc[:, 'x_1':'x_10']1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. لتحديد نطاق معين من الأعمدة باستخدام loc ، يمكنك استخدام الصيغة التالية: dataframe.loc[:, 'x_1':'x_10'] وإذا كانت الأعمدة غير موجودة بالترتيب الصحيح أو تحتوي على فجوات، فإن loc ستأخذ فقط الأعمدة الموجودة ضمن هذا النطاق.1 نقطة
-
نستخدم drop لحذف صفوف أو أعمدة محددة بناء على أسمائها أو مواقعها، مما يمنحك تحكما دقيقا في البيانات التي تريد إزالتها، فمثلا يمكنك حذف عمود معين بتحديد اسمه وتعيين axis=1: import pandas as pd data = {'Name': ['Ali', 'Sara', 'Omar'], 'Age': [25, 30, 22], 'City': ['Cairo', 'Alex', 'Giza']} df = pd.DataFrame(data) df = df.drop('City', axis=1) # حذف عمود "City" print(df) أما dropna يعمل على حذف أي صفوف أو أعمدة تحتوي على قيم مفقودة NaN دون الحاجة إلى تحديدها يدويا، حيث يمكنه حذف الصفوف التي تحتوي على أي قيمة مفقودة أو التي تكون جميع قيمها مفقودة: import pandas as pd import numpy as np data = {'Name': ['Ali', 'Sara', np.nan], 'Age': [25, np.nan, 22], 'City': ['Cairo', 'Alex', 'Giza']} df = pd.DataFrame(data) df = df.dropna() # حذف الصفوف التي تحتوي على أي قيمة مفقودة print(df) الناتج سيكون: Name Age City 0 Ali 25.0 Cairo1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. أولا إن pandas.drop() نستخدمها لنستطيع حذف صفوف أو أعمدة في إطار البيانات لدينا من خلال إستخدام أسماء الفهارس (index) أو الأعمدة (columns) أو إستخدام ترتيبهم . df = pd.DataFrame(np.arange(12).reshape(3, 4),columns=['A', 'B', 'C', 'D']) print(df) # A B C D # 0 0 1 2 3 # 1 4 5 6 7 # 2 8 9 10 11 df.drop(['B', 'C'],axis=1) # هنا سيتم حذف الأعمدة b و c # A D # 0 0 3 # 1 4 7 # 2 8 11 df.drop([0, 1]) # هنا سيتم خذف الصف الأول والثاني # A B C D # 2 8 9 10 11 لاحظ أنه يمكنك استخدام الخيار axis=0 لحذف صفوف و axis=1 لحذف أعمدة. ويمكنك الإطلاع على التوثيق الرسمي لها: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop.html أما pandas.dropna() فهي نستخدمها لحذف الصفوف أو الأعمدة التي تحتوي على قيم مفقودة (NaN) حيث تمكننا من حذف الصفوف أو الأعمدة التي تحتوي على قيم مفقودة . df = pd.DataFrame({ "name": ['Alfred', 'Batman', 'Catwoman'], "toy": [np.nan, 'Batmobile', 'Bullwhip'], "born": [pd.NaT, pd.Timestamp("1940-04-25"),pd.NaT] }) print(df) # name toy born # 0 Alfred NaN NaT # 1 Batman Batmobile 1940-04-25 # 2 Catwoman Bullwhip NaT df.dropna() # name toy born # 1 Batman Batmobile 1940-04-25 وإليك التوثيق الرسمي لها : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html1 نقطة
-
pandas.drop() هي لإزالة صفوف أو أعمدة محددة من DataFrame حسب التسميات labels أو المواقع index وعليك أنت تحديد ذلك. import pandas as pd df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) df.drop('A', axis=1) لاحظ يجب تحديد ما تريد حذفه وهي أسماء الأعمدة أو أرقام الصفوف باستخدام المعاملات labels وaxis، بالتالي تستطيع اختيار العناصر التي تريد إزالتها، سواء كانت تحتوي على قيم مفقودة أم لا. أما pandas.dropna() هي لإزالة الصفوف أو الأعمدة التي تحتوي على قيم مفقودة NaN تلقائيًا، أي تعتمد على وجود القيم المفقودة ولا تتطلب منك تحديد ما تريد حذفه يدويًا، فهي تبحث عن NaN وتزيل الصفوف أو الأعمدة بناءًا على معايير معينة. وتسمح لك بتحديد شروط مثل حذف الصفوف التي تحتوي على أي قيمة مفقودة، أو فقط تلك التي كل قيمها مفقودة. import pandas as pd df = pd.DataFrame({'A': [1, None, 3], 'B': [4, 5, None]}) df.dropna() وسيتم حذف أي صف به قيمة واحدة على الأقل مفقودة. أما لو تريد حذف الصفوف التي كل قيمها مفقودة فقط ستكتب التالي: df.dropna(how='all')1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. في البداية يجب عليك ألا تنظر إلى المشكلات التي تواجهك كعائق يمنعك من التقدم، اعتبرها جزءًا أساسيًا من التعلم. حل المشاكل هو ما يجعلك مبرمجًا جيدًا. كل مشكلة تحلها هي خطوة للأمام، حتى لو استغرقت وقتًا. وثانياً طريقتك في تخصيص 30 دقيقة لحل المشكلة رائعة! هذا يمنعك من الوقوع في دوامة التفكير اللا نهائي. إذا لم تجد الحل خلال الوقت المحدد، ابحث عن إجابة وحل لمشكلتك ولاحظ أن البحث عن سبب المشكلة وحلها مهارة لا تقل أهمية عن محاولة حلك للمشكلة بنفسك. ومع الوقت ستجد أنك تستطيع الوصول لحل المشكلات الت وتواجهك بشكل أسرع مع البحث بشكل فعال وهذ هي المهارة الأساسية للمبرمج.1 نقطة
-
في سياق تعلم الآلة من غير الطبيعي أن يكون لديك تباين كبير في عدد الأعمدة بين train_labels و validation_labels، حيث عادة ما يكون لكل من بيانات التدريب والتحقق نفس البنية، حيث يجب أن يكون عدد الأعمدة متسقا بينهما، إذا كان لديك 5 أعمدة في train_labels و 123 عمودا في validation_labels، فهذا يشير إلى وجود خطأ في عملية تحضير البيانات أو تقسيمها. من المهم التحقق من الخطوات التي تم اتباعها لتقسيم البيانات وتكوين التسميات فقد يكون السبب في هذا التباين هو خطأ في الترميز أو في عملية التقسيم، إذا كنت تستخدم ترميز one-hot encoding للتسميات، فتأكد من أنه تم تطبيقه بشكل صحيح على كل من بيانات التدريب والتحقق. و أيضا تأكد من أن البيانات تم تقسيمها بشكل صحيح قبل تطبيق أي تحويلات عليها، و إذا كانت المشكلة مستمرة قد تحتاج إلى مراجعة الكود الخاص بتحضير البيانات وإعادة فحص الخطوات التي تم اتباعها لتجنب أي أخطاء في المستقبل.1 نقطة
-
يجب أن يكون عدد الأعمدة في train_labels و validation_labels متساويا، حيث يمثل كل عمود فئة أو سمة متعلقة بالبيانات التي يتم استخدامها في النموذج، و إذا كان train_labels يحتوي على 5 أعمدة بينما validation_labels يحتوي على 123 عمود، فهذا يشير إلى وجود خلل في معالجة البيانات، و أحد الأسباب المحتملة هو عدم تناسق في تحويل التصنيفات إلى تنسيق One-Hot Encoding، حيث قد تكون بعض الفئات موجودة في بيانات التحقق ولكنها غير ممثلة في بيانات التدريب، كما قد يكون هناك خطأ في تقسيم البيانات أدى إلى فقدان بعض الأعمدة، أو اختلاف في مراحل المعالجة المسبقة مثل إزالة الأعمدة أو استبدال القيم المفقودة بطريقة غير متسقة بين المجموعتين، للتحق من ذلك يمكن طباعة أبعاد المصفوفات ومقارنة أسماء الأعمدة في كل من train_labels و validation_labels. في حال وجود اختلافات، يمكن استخدام align من pandas لتوحيد الأعمدة وإعادة ضبط القيم المفقودة إلى الصفر.1 نقطة
-
على حسب نوع المشكلة، ففي حالة التصنيف متعدد الفئات Multi-Class Classification، لو لديك عدد مختلف من الفئاتبين مجموعة التدريب ومجموعة التحقق، فيعني مشكلة في تقسيم البيانات، فيجب أن تكون الفئات متسقة بين المجموعتين، لكن لو مجموعة التحقق تحتوي على فئات إضافية مثل 123 فئة مقابل 5 فقط في التدريب، فيعني أن بيانات التحقق أكثر تنوعًا أوهناك خطأ في المعالجة المسبقة. وبالنسبة للتصنيف متعدد العلامات Multi-Label Classification، فمن الطبيعي أن يحتوي كل مثال على أكثر من علامة label، أي يتوافر عدد مختلف من الأعمدة بسبب أنّ مجموعة التحقق تحتوي على علامات إضافية لم تظهر في مجموعة التدريب، لكن ذلك سيؤدي إلى صعوبة في تقييم النموذج بشكل صحيح. أو ربما الفرق ناتجًا بسبب طريقة تحويل البيانات أي One-Hot Encoding أو Label Encoding، حيث إن تم تطبيق التحويل بشكل مختلف بين المجموعتين، فسينتج عن ذلك عدد أعمدة مختلف. بالتالي من الأفضل أن تتأكد من اتساق البيانات بين مجموعتي التدريب والتحقق، حيث عدد الأعمدة في train_labels وvalidation_labels متساويًا، ما لم يكن هناك سبب محدد كإضافة بيانات جديدة للتحقق فقط، ثم تفقد خطوات المعالجة للبيانات من المفترض أن تكون موحدة.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. لا ليس من العادي أن يكون لديك عدد أعمدة مختلف بين بيانات الو validation_labels. وغالبا يجب أن يكون لديك نفس عدد الأعمدة في كل من train_labels و validation_labels لأنها تمثل نفس النوع من البيانات . حيث إذا كان لديك 5 أعمدة في train_labels و 123 عمودًا في validation_labels فهنا توجود مشكلة إما في طريقة تحضير البيانات أو في تقسيم البيانات إلى مجموعات التدريب والتحقق. لذلك يجب يكون لديك نفس عدد الأعمدة في كل من train_labels و validation_labels لضمان أن النموذج يمكنه التعلم والتحقق بشكل صحيح.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. لا داعي للقلق فهذا الأمر طبيعي جدا والجميع قد مر بتلك التجارب أثناء تعلمه البرمجة فبالطبع في بداية تعلمك أى شئ ستواجه صعوبة في التطبيق في البداية وأيضا المشاكل البسيطة ستأخذ معك وقتا طويلا ولكن بعد ذلك ستجد أن الأمور أبسط مما تتخيل ولكن بالمثابرة والمذاكرة والتدريب . أولا يجب عليك أن تكون على دراية جيدة جدا بالأساسيات قبل البدأ في خوض أو حل أى مشاكل . فإذا لم تكن على علم بالأساسيات فإن حلولك لن تكون جيدة لأنه من الممكن أن المشكلة التي تعمل عليها حلها في طريقة أو جزء لم تقم بمذاكرته حتى الآن أو لم تفهمه جيدا ولم تعرف فيما يطبق . حاول في بداية تعلمك عدم النظر إلى الوقت كثيرا فكل شخص يختلف عن الأخر في سرعة إستياعبه أو في طريقة تفكيره في البداية ولكن مع التدريب والتكرار ستجد أن كل شئ يسيير بشكل جيد . ولكن يجب عليك الإنتباه والتركيز على مهارة حل المشكلات لديك وجودة حلك وأيضا حاول أن تتحدى نفسك فسابقا حينما بدأت في تعلم البرمجة إذا كان هناك شئ صعب على كنت أحاول تحدي نفسي وألا أبحث عن الأمر إلا حينما أيئس تماما وكانت بعض المشاكل من الممكن أن تأخذ معي أكثر من يوم للوصول إلى حلها. وأيضا أمر جيد أنك لا تقوم مباشرة بالبحث عن الحل أو سؤال أى شخص فهذا هو الامر الجيد وهذا الذي يجعلك تتطور سريعا فيجب عليك المحاولة بنفسك ومحاولة إكتشاف إمكانياتك وبعد ذلك يمكنك البحث عن الحل وإذا لم تستطع الوصول إليه يمكنك حينها سؤال الأشخاص الأخرين حول هذا الأمر. أنصحك بعد مذاكرة الأساسيات أن تحاول تنمية مهارات حل المشكلات لديك حيث هي مهارة أساسية يجب أن تتوافر في أى مبرمج وهي التي تميز المبرمج الجيد من غيره . و تمكنك من التفكير المنطقي في حل المشكلات والبحث عن أفضل الحلول . وأيضا بالطبع يفضل دراسة هياكل البيانات Data Structure و ال Algorithmes . ويمكنك قراءة الإجابة التالية لمزيد من التفاصيل حولها : بخصوص هذا الأمر توجد إستراتيجية تسمي (divide and conquer) وفي هذه الإستراتيجية يتم تقسيم المشكلة الكبيرة التي لديك إلى عدة أجزاء صغيرة . وحل كل جزء صغير على حدى بشكل منفصل ومن ثم تجميع تلك الأجزاء الصغيرة معا لحل المشكلة الكبيرة التي تواجهك . ويمكنك قراءة الإجابات التالية لمزيد من التفاصيل حولها وحول كيفية حل المسائل البرمجية:1 نقطة
-
استخدام cv2.imwrite() هو المفضل عادة عندما تحتاج إلى الحفاظ على القيم الدقيقة للبكسل وجودة الصورة الأصلية، لأنه يكتب بيانات الصورة الخام مباشرة إلى الملف دون أي معالجة إضافية أو تنسيق، بينما plt.savefig() مصمّم لحفظ الأشكال الكاملة غالبا مع المحاور والعناوين وعناصر الرسم الأخرى وقد يدخل تعديلات مثل تغيير مقياس DPI، وإضافة الهوامش، أو حتى ظهور آثار ضغط خفيفة يمكن أن تؤثر على الجودة والدقة.1 نقطة