لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 02/22/25 in أجوبة
-
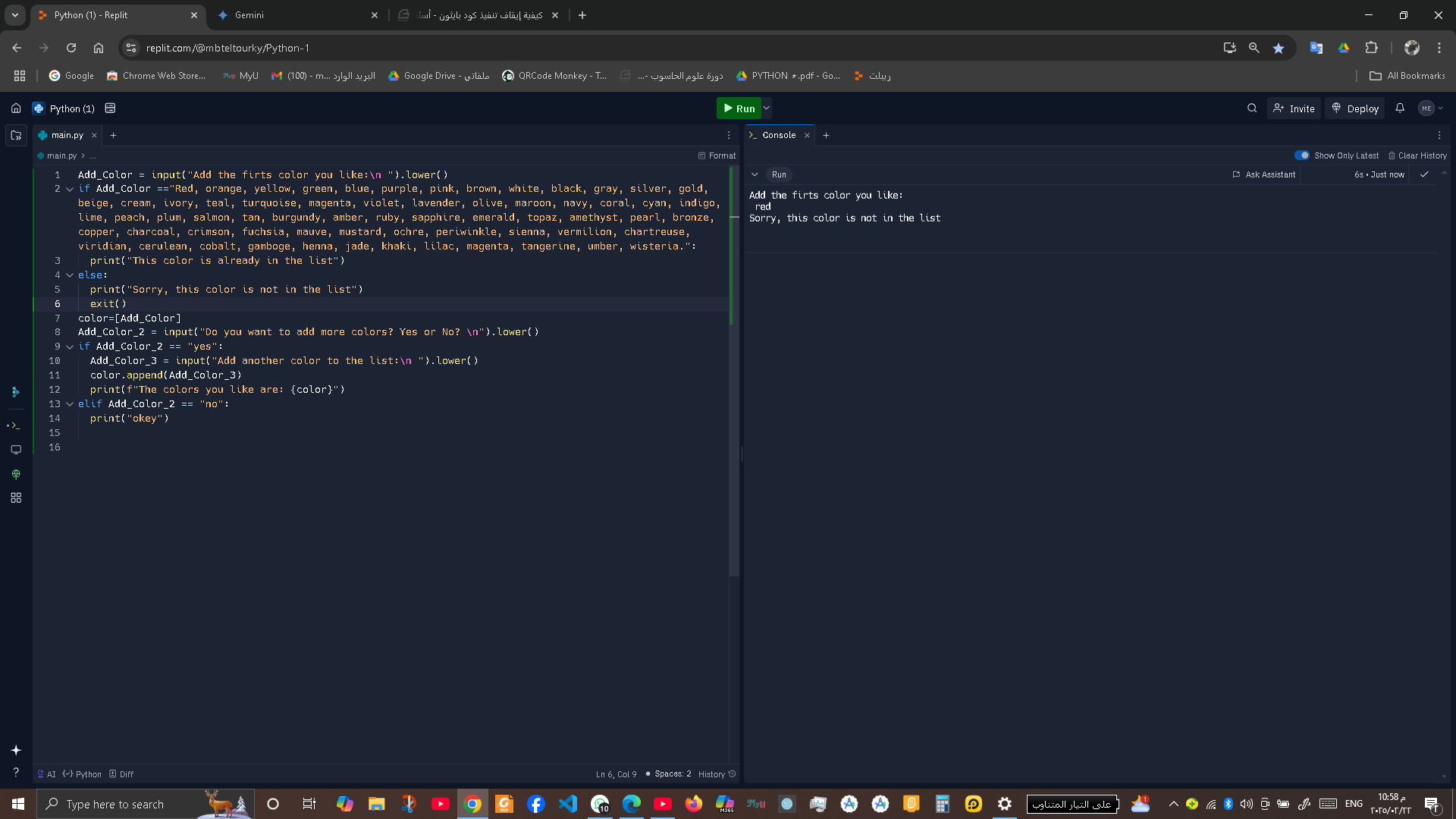
عندي صفحه php عايز اعملها اعاده تحميل اوتوماتيك بعد فتحها في المره الاولي لكي اجلب بعض البيانات من قاعده البيانات تم ادراجها في قاعده البيانات عند فتح الصفحه في المره الاولي عايز كود php لتنفيذ ذلك ولكم جزيل الشكر والاحترام2 نقاط
-
نمام هو عمل اعاده تحميل للصفحه ونفذ اللي انا عايزه لكنه قاعد بيعمل اعاده تحميل كل شويه انا عايزه يعمل لها اعاده تحميل لمره واحده2 نقاط
-
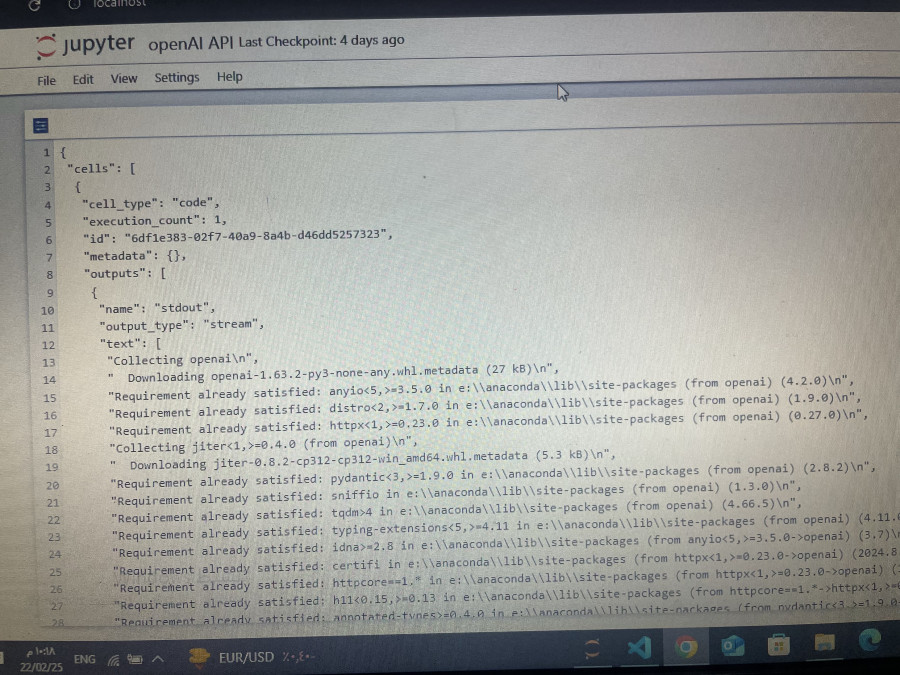
اعدت فتح ملف ب jupyter الذي انشأته واشتغلت عليه سابقا ولكنه ظهر بهذا الشكل ليس على شكل خلايا ما السبب؟
 2 نقاط
2 نقاط -
السلام عليكم. أريد بناء تطبيق محلي يوفر واجهة حقول تتيح البحث أو الإضافة أو التعديل .... (مثل التي يوفرها access أو excel VBA) سيستعمل هذا التطبيق هذا التطبيق مجموعة من الأفراد الذين ليست لهم أي صلة بالبرمجة. بماأني مطور ويب جافاسكريبت فأهدف لتوظيف مهاراتي في SQL لبناء هذا التطبيق. أبحث عن أفضل الحلول الممكنة لبناء هذا التطبيق. شكرا.2 نقاط
-
السلام هليكم هو ممكن ان استخدم الGridSearchCV مع الearly_stopping_rounds في خورزميات الXGBClassifier ؟1 نقطة
-
هو ممكن افتح اكثر من سيشن في الصفحه لاني فاتح اصلا في الصفحه سيشن1 نقطة
-
php نمام هو عمل اعاده تحميل للصفحه ونفذ اللي انا عايزه لكنه قاعد بيعمل اعاده تحميل كل شويه انا عايزه يعمل لها اعاده تحميل لمره واحده1 نقطة
-
ذلك غير عملي، أعتقد ما تريده جلب البيانات وتحديث واجهة المستخدم وذلك يتم من خلال استخدام جافاسكريبت، حيث سنقوم بتنفيذ طلب بواسطة دالة fetch إلى الـ API في الواجهة الخلفية لجلب البيانات، ثم تحديث واجهة المستخدم دونّ إعادة تحميل الصفحة. وإليك مثال: class DataFetcher { constructor(apiUrl) { this.apiUrl = apiUrl; this.container = document.getElementById('data-container'); } async fetchData() { try { const response = await fetch(this.apiUrl); const data = await response.json(); this.container.innerHTML = data.map(item => ` <div class="data-item"> <h3>${item.title}</h3> <p>${item.description}</p> </div> `).join(''); } catch (error) { console.error('Error:', error); } } init() { this.fetchData(); } } document.addEventListener('DOMContentLoaded', () => { const fetcher = new DataFetcher('https://api.test.com/data'); fetcher.init(); }); بالطبع تحتاج إلى استيعاب أساسيات جافاسكريبت على الأقل لتتمكن من استخدام الكود وتعديله.1 نقطة
-
هو اي الفرق مابين دي و دي eval_metric='logloss' ازي اعمل كده الان بيظهر ده في النتجيه /usr/local/lib/python3.10/dist-packages/joblib/externals/loky/process_executor.py:752: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak. warnings.warn(1 نقطة
-
ذلك ممكن، لكن يتطلب إعدادًا دقيقًا لتجنب تسريب البيانات، أولاً استيراد المكتبات الضرورية: from sklearn.model_selection import GridSearchCV, train_test_split from xgboost import XGBClassifier import numpy as np ثم تقسيم البيانات إلى تدريب واختبار: X, y = ... X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) حيث X, y هي البيانات لديك. ثم إعداد النموذج وشبكة المعلمات: model = XGBClassifier(objective='binary:logistic', n_estimators=1000) param_grid = { 'max_depth': [3, 5], 'learning_rate': [0.1, 0.01], 'subsample': [0.8, 1.0] } ولاحظ n_estimators كبير لتفادي التوقف المبكر وتمكين early_stopping_rounds من التوقف عند الاستقرار. ثم تحديد fit_params لـ Early Stopping: fit_params = { 'eval_set': [(X_test, y_test)], 'early_stopping_rounds': 50, 'verbose': False } 'eval_set': [(X_test, y_test)] يعمل كمجموعة تحقق. بعد ذلك تشغيل GridSearchCV: grid_search = GridSearchCV( estimator=model, param_grid=param_grid, cv=5, scoring='accuracy', n_jobs=-1 ) grid_search.fit(X_train, y_train, **fit_params) وطباعة النتائج: print( grid_search.best_params_) print(grid_search.best_score_) وللعلم من الأفضل إنشاء مجموعة تحقق validation set مستقلة داخل كل fold من folds الـ cross-validation لتجنب تسريب البيانات، من خلال PredefinedSplit أو StratifiedKFold مخصص، أو تقسيم البيانات يدويًا داخل كل fold مثلاً train_test_split في كود مخصص.1 نقطة
-
السلام عليكم كيف أربط ملفات الhtml مع بعضها لأنني أريد جعل الموقع متجاوب وفتحت ملف html جديد لأجل الهاتف لان عناصر الhtml مختلفة قليلا عن الحاسوب و اريد طريقة لكي اربط ملف الhtml للحاسوب مع ملف الhtml للهاتف والسلام عليكم1 نقطة
-
التقنية المناسبة هي إطار Electron.js بما أنك تهدف إلى تطوير تطبيق سطح مكتب، وقاعدة البيانات ستكون SQLite فهي خفيفة الوزن، ملف واحد ولا يتطلب خادم، بالطبع الأمر عائد لك وما تريد تنفيذه فمن الممكن استخدام قاعدة بيانات مختلفة لكن طالما التطبيق سيعمل بدون إنترنت على ما أعتقد فقاعدة SQLite مناسبة وتستطيع توفير خيار للنسخ الإحتياطي. بخصوص واجهة المستخدم ستكون React مع مكتبة Grid تفاعلية مثل AG-Grid أو TanStack Table لكن AG-Grid هي الأسهل بسبب أنها توفر واجهة مستخدم جاهزة مع ميزات مختلفة مثل: AG-Grid Community نسخة مجانية ومفتوحة المصدر تقدم مجموعة واسعة من الميزات الأساسية والقوية. Sorting فرز البيانات بسهولة تصاعديًا أو تنازليًا بناءً على أي عمود. Filtering تصفية البيانات بناءًا على معايير مختلفة نص، رقم، تاريخ، إلخ باستخدام أنواع تصفية متعددة نصية، نطاقية، قائمة، وخلافه. Grouping تجميع البيانات بناءًا على عمود واحد أو أكثر، وعرض ملخصات للمجموعات. Pivoting تحويل البيانات لتلخيصها وعرضها بطريقة محورية صفوف وأعمدة ديناميكية. Editing السماح للمستخدمين بتحرير البيانات مباشرة داخل الجدول. Resizing تغيير حجم الأعمدة والصفوف يدويًا. Column Reordering سحب وإفلات الأعمدة لتغيير ترتيبها. Column Pinning تثبيت أعمدة معينة لتظل مرئية أثناء التمرير الأفقي. Virtual Scrolling التعامل بكفاءة مع مجموعات البيانات الكبيرة جدًا عن طريق تحميل وعرض البيانات المرئية فقط. Exporting تصدير البيانات إلى تنسيقات مختلفة مثل CSV، Excel، JSON، PDF. Theming تخصيص مظهر الجدول بشكل كامل باستخدام CSS أو مظاهر جاهزة. وستقوم بتهيئة المشروع من خلال الأمر التالي: npx create-electron-app my-app --template=react1 نقطة
-
السلام عليكم هو اي الافضل لتنفيذ خورزميات الBinary Search هل الarray والا data structure Tree ؟1 نقطة
-
تمام جدا الف شكراا جدا لحضرتك جزاك الله كل خير1 نقطة
-
مرحبًا علي، خوارزميات ال binary search تحتاج إلى شروط أكثر، فيجب أن تكون العناصر قابلة للترتيب بناء على ما تريد البحث عنه، مثلًا في حال كنت تريد البحث عن رقم ما ضمن مصفوفة أرقام يجب أن تكون الأرقام مرتبة. أما ال tree فلا تفترض ترتيب كهذا فعملية البحث تتم عن طريق جداول hashing لا تفترض أن البيانات مرتبة بشكل تلقائي. كما أن ال tree تسمح لك بإضافة و حذف عناصر بسهولة على عكس المصفوفة. أي بشكل عام لا يوجد خيار مفضل بشكل مطلق، دائمًا قم بالتفكير بما تريده بشكل دقيق و على أساس ذلك يتم تحديد أي الخيارات أفضل. تحياتي.1 نقطة
-
الف شكراا جدا لحضرتك جزاك الله كل خير1 نقطة
-
أول شيء تحتاجه هو تصميم قاعدة بيانات مركزية تربط جميع الفروع وتتيح للفرع الرئيسي الإشراف على البيانات، بمعنى نموذج الفرع Branch يمثل كل فرع، مع حقل يحدد هل الفرع رئيسيًا أم فرعيًا. ثم نموذج المستخدم User، لربط المستخدمين بالفروع باستخدام نموذج المستخدم المدمج في Django، ثم نماذج البيانات المشتركة التي ستتشاركها الفروع، مثل الفواتير والدخل، مع ربطها بالفروع. بحيث كل فرع يُسجل في نموذج Branch، والفرع الرئيسي يتم تمييزه بـ is_main=True، والمستخدمون أي الموظفون مرتبطون بفروع محددة عبر نموذج Employee، والفواتير مرتبطة بالفروع، وذلك يسمح للفرع الرئيسي بمراجعة بيانات جميع الفروع. ثم عليك إدارة الصلاحيات، بتحديد من يمكنه الوصول إلى البيانات ومن يمكنه إضافتها أو تعديلها، مع إعطاء الفرع الرئيسي السيطرة الكاملة، وذلك بإنشاء مجموعات للمستخدمين، الأولى مجموعة الفرع الرئيسي لها صلاحيات كاملة مثل إضافة فروع جديدة والإشراف على الفواتير والدخل. ومجموعة الفروع الفرعية لها صلاحيات محدودة لإدخال وتعديل بيانات فرعها فقط. أي استخدم ديكوراتور @permission_required لتقييد الوصول، مثلاً للسماح للفرع الرئيسي فقط بإضافة فروع، وعند عرض الفواتير أو الدخل، تأكد أن كل فرع يرى بياناته فقط، بينما الفرع الرئيسي يرى كل شيء. ثم عليك ربط الفروع من خلال قاعدة بيانات مركزية يمكن لجميع الفروع الوصول إليها عبر تطبيق الويب، وكل فرع يدخل بياناته في نفس قاعدة البيانات، للسماح للفرع الرئيسي بالإشراف بسهولة. وأنشئ صفحة أو واجهة تسمح للفرع الرئيسي بإضافة فروع جديدة أو تعديل بياناتها، وذلك من خلال Django admin أو بناء واجهة مخصصة.1 نقطة
-
نعم يمكنك ذلك، حيث يمكن للفرع الرئيسي الإشراف على الدخل والفواتير وإدارة الفروع الجديدة عبر واجهة تحكم مركزية، و من حيث الأمان فإن Django يوفر ميزات قوية مثل التصدي لهجمات SQL Injection، وإدارة الجلسات، ونظام المصادقة القوي، ولكن يجب عليك اتباع أفضل ممارسات الأمان مثل استخدام HTTPS، وتحديد صلاحيات المستخدمين بدقة، وتطبيق جدران حماية على قاعدة البيانات. بالنسبة للاستضافة يفضل استخدام خوادم سحابية قوية مثل AWS، أو DigitalOcean لضمان تحمل الضغط العالي وتدفق البيانات بين الفروع، أما عن تحويل المشروع إلى تطبيق يمكن تنزيله على الجوال والكمبيوتر، فيمكنك ذلك من خلال تحويل الواجهة إلى تطبيق ويب تفاعلي PWA أو استخدام تقنيات مثل React Native أو Flutter لتطوير تطبيقات مخصصة تتصل بالـ API الخاصة بالمشروع.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. يجب عليكي أولا معرفة الفرق بين مطور الواجهة الأمامية Front-End ومطور الواجهة الخلفية Back-end . حيث الواجهة الأمامية هو الجزء من موقع الويب أو التطبيق الذي يراه المستخدم، ويتضمن HTML وCSS وJavaScript، والتي يتم استخدامها لإنشاء الواجهة الرسومية للموقع أو التطبيق. أى شكل التطبيق الخارجي . أما الواجهة الخلفية أو Back-End تعني الجزء من موقع الويب أو التطبيق الذي لا يراه المستخدم، ويشمل ذلك الخوادم والبيانات والبرامج التي تعالج الطلبات وترسل ردودًا للمستخدمين. وإليكي الإجابات التالية لتتعرفي أكثر على الفرق بينهما : وبما أنكي تريدين دمج نماذج الذكاء الإصطناعي مع المواقع فهنا أنتي يجب عليكي أن تتخصي أكثر في الواجهات الخلفية والخوادم وليس الأمامية . وحيث أن دورة "تطوير واجهات المستخدم" هي مخصصة للأشخاص الذين يريدون أن يصبحوا مطورين واجهات أمامية لمواقع ثابته . فهنا لن تفيدكِ كثيرا لأنكِ فقط ستتعلمين كيفية إنشاء مواقع ثابته أى فقط هيكل الموقع وتنسيقاته ولن تستطيعين دمج تقنيات الذكاء الإصطناعي فيها. والأفضل لكي هو "دورة تطوير التطبيقات باستخدام لغة Python" حيث ستتعلمين بايثون والذي يتم إستخدامها في الذكاء الإصطناعي وهي دورة تعتبر back-end ويوجد بها مسار لكيفية دمج تقنيات الذكاء الإصطناعي مع تطبيقات ومواقع بايثون التي أنشاتيها . وستتعلمين كيفية إنشاء Chat bot وغيرها . لهذا أنصحكي بالبحث عن دورة back end وليس front end . وإذا لم تريدي تعلم بايثون لتطوير الواجهات الخلفية توجد عدة دورات أخرى هنا في الأكاديمية تؤهلكِ لذلك بعدة لغات ويمكنكِ قراءة الإجابة التالية لشرح تفاصيل الدورات هنا في الأكاديمية :1 نقطة