لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 02/17/25 في كل الموقع
-
السلام عليكم ورحمة الله وبركاته كيف يمكن التقديم على الاختبار النهائي بعد الانتهاء من الكورس؟ شكراً لكم2 نقاط
-
كيف سيكون الاختبار؟ أونلاين أم وجهاً لوجه؟ أم كيف؟2 نقاط
-
السلام عليكم هو الDeep Learning افضل بكثير من Machine Learning اي كان المكشله اي واي حجم البيانات اي وعديد الميزات اي والا الا ؟1 نقطة
-
السلام عليكم انا كنت احل احد المشاكل في البرمجة و الكود لم يعمل بلطريقة الصحيحة و عندما بحثت وجدت ان الغلط هو في ان الكائنات في جافاسكريبت عناصرها غير مرتبة ولاكنني لم افهم ما معنى هذا ارجو المساعة واما الكود الذي كنت اواجه فيه المشكلة فارفقته في الملف orderWeight.js1 نقطة
-
السلام عليكم ورحمة الله، أحيانا أجد في لابتوبي بطء وعمل المحرك بكثرة وتعليق واستهلاك الشحن بكثرة من غير سبب وأيضا إذا قمت بإغلاق الانترنت أجد قد هدأ مروحة المحرك قليلًا ، وإذا قمت بالفحص من خلال فاحص الفيروسات من ويندوز لا أجد شيئًا هل يعني ذلك وجود مشكلة ما ؟ وهل يوجد أدوات في power shell أو سطر الأوامر للفحص وعلاج مثل هذه المشكلات ؟1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. ال Deep Learning ليس دائما أفضل من ال Machine Learning بشكل عام بل يعتمد ذلك على المشكلة التي تعمل عليها وحجم البيانات والميزات المتاحة لديك. حجم البيانات (Data Size): Deep Learning: إن التعليم العميق يتطلب كميات ضخمة وكبيرة جدا من البيانات لتدريب النماذج بفعالية. فإذا كانت لديك بيانات ضخمة ومعقدة مثل الصور أو الصوت أو حتى النصوص فإن الشبكات العصبية العميقة مثل CNN أو RNN ستكون جيدة لك. Machine Learning: إن تعلم الآلة يمكن أن يعمل بشكل جيد مع مجموعات بيانات أصغر من التعلم العميق . تعقيد المشكلة (Problem Complexity): Deep Learning: إن التعليم العميق مناسب للمشاكل المعقدة التي تحتوي على علاقات غير خطية أو أنماط معقدة مثل التعرف على الصور و معالجة اللغة الطبيعية والتعرف على الصوت و الشبكات العصبية قادرة على تعلم العلاقات المعقدة من البيانات. Machine Learning: إن تعلم الآلة يعمل بشكل جيد مع المشاكل الأبسط أو عندما تكون العلاقات بين الميزات وواضحة قليلا و إذا كانت المشكلة يمكن حلها باستخدام خوارزميات أبسط إذا فليس هناك أى حاجة لإستخدام التعلم العميق . عدد الميزات (Number of Features): Deep Learning: إن التعليم العميق يمكنه التعامل مع عدد كبير جدا من الميزات بشكل تلقائي حيث يستطيع النموذج أن يتعلم الفرق بين المميزات وأي المميزات هي الأكثر أهمية. Machine Learning : إن تعلم الآلة قد يحتاج إلى اختيار الميزات يدويا أو إستخدام هندسة المميزات ال (Feature Engineering) لتحسين الأداء خاصة إذا كان عدد الميمزات كبير لديك. الوقت والحسابات (Computation and Time): Deep Learning: إن التعليم العميق يتطلب قوة حسابية كبيرة بإستخدام ال GPUs أو ال TPU ووقت التدريب كبير وبخاصة مع البيانات الكبيرة. Machine Learning: إن تعلم الآلة عادة ما يكون أسرع في التدريب ويتطلب موارد حسابية أقل من التعلم العميق. تلخيصا لما سبق يمكنك إستخدام التعلم العميق عندما يكون لديك كمية كبيرة جدا من البيانات و عندما تكون المشكلة معقدة بشكل كبير وتتطلب تعلم أنماط غير خطية ومعقدة وأيضا إذا كانت الموارد لديك تسمح بذلك . أما عندما تكون البيانات محدودة لديك وتكون المشكلة أبسط ويمكن حلها بخوارزميات أبسط والموارد التي لديك ليست كافية فالأفضل إستخدام تعلم الآلة. ويمكنك قراءة الإجابة التالية للتوضيح أكثر :1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. هل يظهر البطئ وإستهلاك البطارية الكثير دائما أم في بعض الأحيان . إذا لم يكن دائما هل يمكنك توضيح متى يتم ذلك ؟ هل عندما تستخدم برنامج ما ؟ أو تقوم بتنفيذ أمر معين في ال power shell أو ال cmd ؟ يمكنك دائما فتح مدير المهام task manager لرؤية السبب الذي يؤدي إلى هذا . يمكنك فتح ال task manager من خلال الضغط بالزر الأيمن على شريط المهام : يرجى الضغط على ال CPU لرؤية البرامج التي تستهلك موارد كثيرة ويمكنك رؤية النسب لكل برنامج : يمكنك محاولة تنزيل antivirus لفصح الجهاز لديك حيث مضاد الفايروسات الخاص بالويندوز ليس جيدا في إكتشاف جميع الفيروسات. وأنصح بتنزيل برنامج malwarebytes وسيعطيك فترة مجانية يمكنك منه فحص جهازك وهو جيد في إكتشاف الفايروسات وال malware التي تسرق بياناتك أو تعمل في الخلفية.
 1 نقطة
1 نقطة -
السلام عليكم هو ازي اقدر ان اقسم البيانات الي تدريب - تطواير - اختبار بس يكون نفس التوزيع ؟1 نقطة
-
الف شكراا جدا جدا لحضرتك جزاك الله كل خير1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. أولا قبل التقسيم يجب عليك التأكد من أن الفئات أو التصنيفات التي لديك في البيانات متوازنة أيضا. فإذا كانت البيانات نفسها غير متوازنة مثل وجود فئة أكثر من الأخرى فستحتاج إلى استخدام تقنيات مثل Stratified Sampling لتستطيع الحفاظ على نفس النسبة في كل مجموعة. حيث يمكنك من استخدام train_test_split مع stratify للحفاظ على نفس التوزيع في كل مجموعة : from sklearn.model_selection import train_test_split X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, stratify=y) X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, stratify=y_temp) هنا test_size=0.3 تعني أننا نريد 30% من البيانات أن تكون في مجموعة التطوير والاختبار. و stratify=y تضمن أن التوزيع في الفئات y سيكون متشابها في جميع المجموعات. حيث أن X هي البيانات و إن y هي الفئات. ويمكنك قراءة المزيد حول stratify في مكتبة scikit-learn من خلال الرابط : https://scikit-learn.org/stable/modules/cross_validation.html#stratification1 نقطة
-
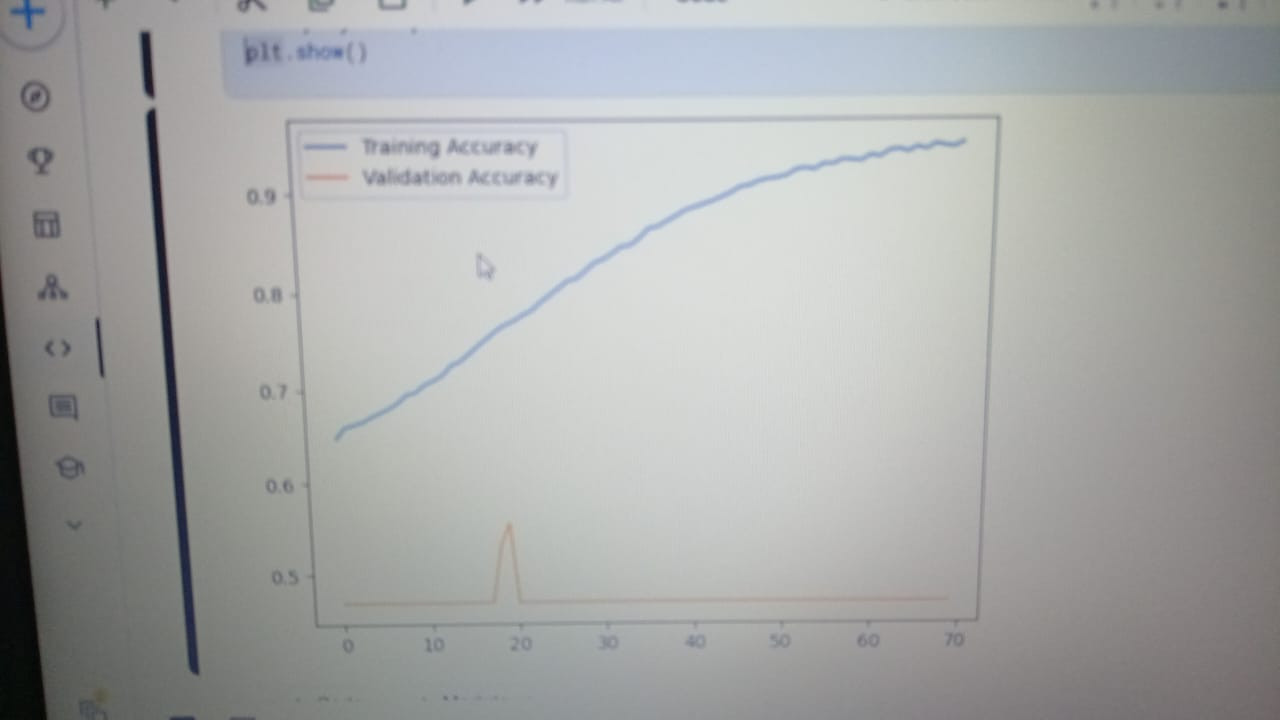
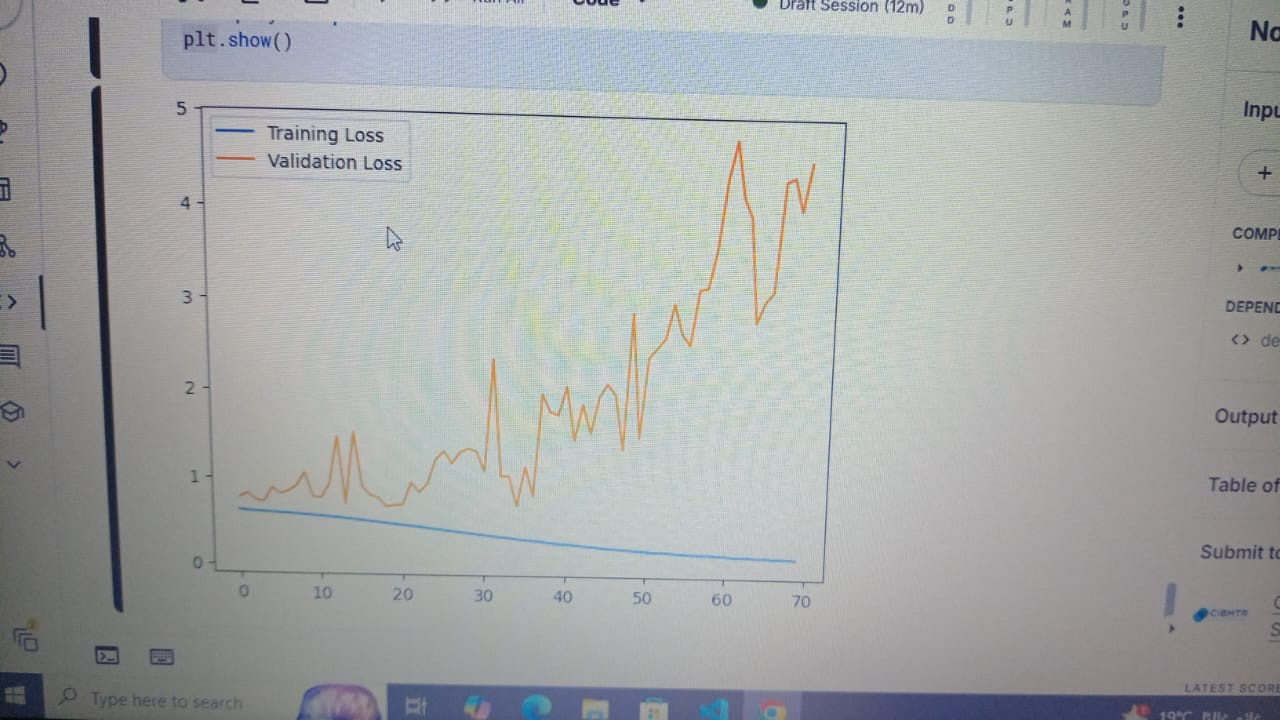
السلام عليكم انا هنا عمل نموذج التصنيف فا الval_accuracy زي ماهي مش عارف ليه
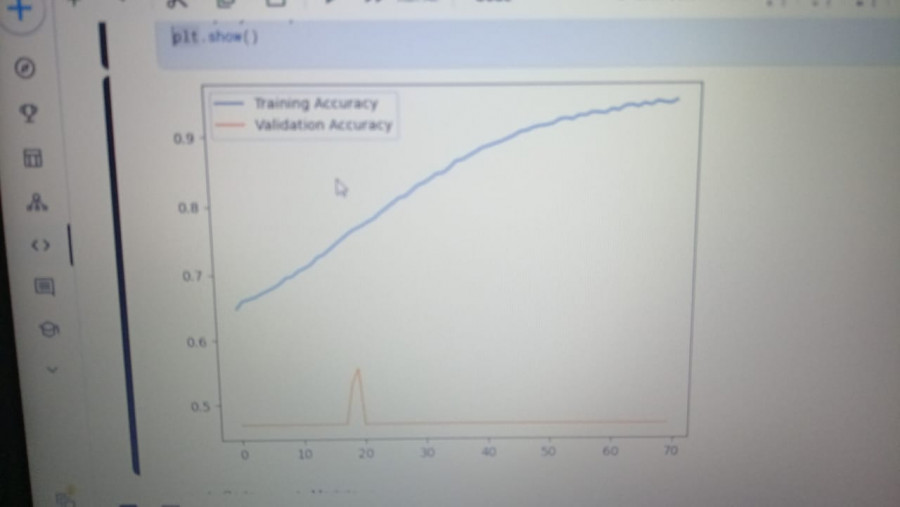
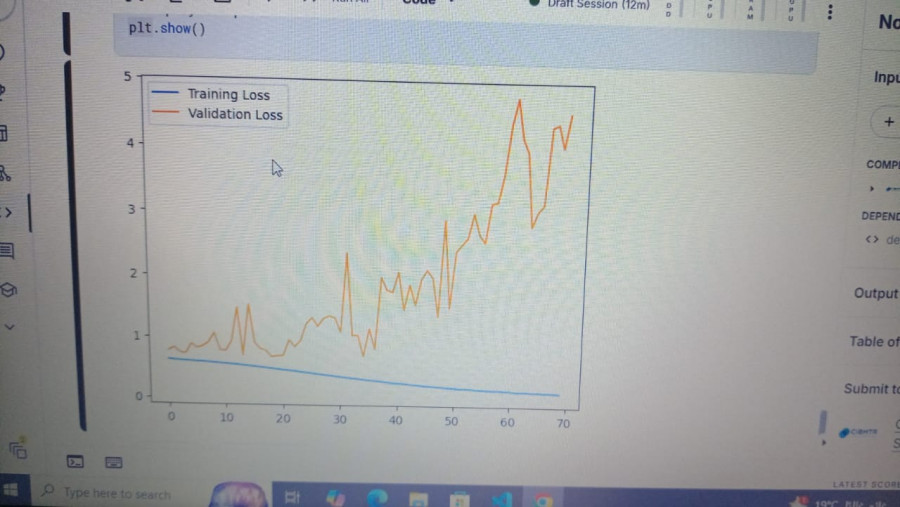 1 نقطة
1 نقطة -
السلام عيلكم هو في شبكه عصبيه لمهام التصنيف هل الازم ان الaccuracy و val_accuracy يزيدو عشان النموذج يكون كويس ؟1 نقطة
-
السلام عليكم في نموذج التصنيف هل اقدر احسن الTrue Negatives وكمان الTrue positives في نفس الوقت والا الا حاجه هتتحسن علي حساب حاجه التاني ؟1 نقطة
-
لا نستخدم ذلك بشكل مباشر هنا، لأن النموذج الحالي مبني باستخدام طبقات بسيطة Dense, BatchNormalization بدون ميزات skip connections في ResNet أو التوصيلات الكثيفة dense blocks في DenseNet. لو أردت دمج مفاهيم ResNet أو DenseNet في النموذج، يجب تعديل بنية الطبقات كالتالي، أولاً تُضاف Residual Connections بين الطبقات، حيث يُضاف إخراج طبقة سابقة إلى إخراج طبقة لاحقة. وستقوم بتعديل جزء من الكود باستخدام Functional API لأن Sequential لا يدعم التوصيلات المتفرعة Residual Connections. from tensorflow.keras.layers import Add input_layer = keras.layers.Input(shape=(input_shape,)) x = keras.layers.Dense(8)(input_layer) x = keras.layers.BatchNormalization()(x) x = keras.layers.Activation('tanh')(x) residual = x x = keras.layers.Dense(128)(x) x = keras.layers.BatchNormalization()(x) x = keras.layers.Activation('tanh')(x) x = Add()([x, residual]) # إضافة الوصلة المتبقية هنا from tensorflow.keras.layers import Add input_layer = keras.layers.Input(shape=(input_shape,)) x = keras.layers.Dense(8)(input_layer) x = keras.layers.BatchNormalization()(x) x = keras.layers.Activation('tanh')(x) residual = x x = keras.layers.Dense(128)(x) x = keras.layers.BatchNormalization()(x) x = keras.layers.Activation('tanh')(x) x = Add()([x, residual]) # إضافة الوصلة المتبقية هنا # باقي الطبقات ثم تُضاف Dense Connections حيث يُوصَل إخراج كل طبقة سابقة كمدخل لجميع الطبقات اللاحقة في الـblock. from tensorflow.keras.layers import Concatenate def dense_block(x): x1 = keras.layers.Dense(128)(x) x1 = keras.layers.BatchNormalization()(x1) x1 = keras.layers.Activation('tanh')(x1) x = Concatenate()([x, x1]) # دمج الإخراج مع المدخلات الأصلية x2 = keras.layers.Dense(64)(x) x2 = keras.layers.BatchNormalization()(x2) x2 = keras.layers.Activation('tanh')(x2) x = Concatenate()([x, x2]) return x input_layer = keras.layers.Input(shape=(input_shape,)) x = dense_block(input_layer) وللحفاظ على بنية Sequential، الأفضل استخدام حزم جاهزة مثل tensorflow.keras.applications.ResNet50، لكن ذلك غير عملي للشبكات الصغيرة.1 نقطة
-
الأمر يعتمد على طبيعة البيانات والخوارزمية المستخدمة، فالحالات التي يُمكن فيها تحسين TP وTN معًا هي عند تحسين عام في النموذج أي لو قمت بتحسين جودة النموذج بشكل عام مثل استخدام خوارزمية أكثر تعقيدًا، تحسين الميزات، أو معالجة البيانات بشكل أفضل، فقد يزيد كل من TP وTN معًا. بمعنى استخدام نموذج مثل Gradient Boosting بدلًا من Logistic Regression في حال البيانات غير خطية، ومعالجة البيانات المفقودة أو إزالة الضوضاء. الحالة الأخرى هي تحسين توازن الفئات في البيانات غير المتوازنة، باستخدام تقنيات مثل Oversampling كـ SMOTE للفئة الأقل، وClass weighting في الخوارزميات كزيادة وزن الفئة النادرة. او تحسين مساحة الميزات من خلال تقنيات مثل PCA أو Feature Engineering لفصل الفئتين بشكل أفضل. ستفاضل بينهم في حالات معينة، وهي عند تغيير عتبة التصنيف Threshold فسيتم زيادة TN أي تصنيف سلبي أكثر دقة، وانخفاض TP فبعض الإيجابيات الحقيقية تُصنف خطأً كسلبية، وتخفيض العتبة Threshold يؤدي إلى العكس أيضًا. وفي البيانات المتداخلة، فلو هناك تداخل كبير بين توزيعات الفئتين، فتحسين TP يتطلب تخفيض TN والعكس صحيح. ولتحسين كلاهما، تفقد الدقة Accuracy، فلو تحسنت سيتحسن TP و/أو TN مع تقليل الأخطاء FP وFN. أيضًا منحنى ROC-AUC، والذي يقيس الأداء العام بغض النظر عن العتبة، تحسنه يعني قدرة النموذج على التمييز بين الفئتين بشكل أفضل، وذلك يعزز كل من TP وTN معًا. وتأكد من أن النموذج لا ينحاز لفئة معينة، مع استخدام مقياس مثل F1-Score (يجمع بين Precision وRecall) أو G-Mean، بالإضافة إلى Grid Search أو Bayesian Optimization لتحسين معلمات النموذج.1 نقطة
-
نعم ولا في نفس الوقت. حيث ارتفاع كل من دقة التدريب والتحقق ليس بالضرورة مؤشراً على جودة النموذج، لعدة أسباب منها مشكلة Overfitting فقد يحقق النموذج دقة عالية جداً على بيانات التدريب (training accuracy) لكن أداءه يكون ضعيفاً على البيانات الجديدة التي لم يرها من قبل ولاحظ أنه في بعض المشاكل المعقدة يعتبر تحقيق دقة 80% إنجازاً كبيراً في بعض التطبيقات ولذك يجب مقارنة النتائج مع معايير المجال والتطبيق المحدد وبالطبع يجب التأكد من توازن النموذج وقدرته على التعميم من خلال مراقبة مؤشرات أخرى وعدم التركيز على الدقة وحدها.1 نقطة
-
هل يلزم تعريف نوع المتغير إن كان عددياً أو نصياً ، لاحظت أن المدرب أعطى اسماً للمتغير ولكن لم يتم تعريفه.1 نقطة
-
ربما بسبب الـ Overfitting، ويحدث التدريب الزائد أو فرط التخصص في حال تعلم النموذج بيانات التدريب بشكل جيد جدًا، لدرجة أنه يبدأ في حفظ الضوضاء أو التفاصيل غير المهمة في بيانات التدريب، بالتالي يصبح النموذج جيدًا جدًا في التنبؤ ببيانات التدريب، ولكنه لا يؤدي أداءً جيدًا على البيانات الجديدة التي لم يرها من قبل أي بيانات التحقق، وارتفاع دقة التدريب مع ثبات دقة التحقق يعني مشكلة تدريب زائد. أو ربما مشكلة في بيانات التحقق ففي حال صغيرة جدًا، لن تكون ممثلة بشكل جيد للبيانات الحقيقية، وذلك يجعل دقة التحقق غير مستقرة أو لا تعكس الأداء الحقيقي للنموذج، وأيضًا لو مختلفة بشكل كبير عن بيانات التدريب من حيث التوزيع أو الخصائص، فلن يكون النموذج قادرًا على التعميم بشكل جيد عليها. أو معدل التعلم غير المناسب Learning Rate فعند إرتفاعه بشكل كبير مرتفعًا فسيتجاوز النموذج الحد الأمثل ولا يتمكن من الاستقرار على حل جيد لبيانات التحقق، ولو منخفضًا جدًا، فسيستغرق النموذج وقتًا طويلاً للتعلم على بيانات التحقق، أو لا يتعلم بشكل فعال على الإطلاق.1 نقطة
-
ستجد في الرابط الخاص بشروط التقد للإختبار كل شئ ستريده . وإليك التالي وهو مقتبس من هذا الرابط : سنحدد لك موعد لاجراء محادثة صوتية لمدة 30 دقيقة يطرح المدرب فيها أسئلة متعلقة بالدورة ويناقش معك ما نفذته خلالها. سيحدد لك المدرب مشروعًا مرتبطًا بما تعلمته أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع الى أسبوعين. سيراجع المدرب المشروع الذي أنجزته، وإن سارت جميع الخطوات السابقة بشكل صحيح، ستتخرج وتحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.1 نقطة
-
آلية الإختبار هي كالتالي: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتُطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. بعد الإنتهاء من الدورة يمكنك محادثة مركز الدعم من خلال الرابط التالي : https://support.academy.hsoub.com/conversations ويمكنك إخبارهم برغبتك في التقدم للإمتحان . ويرجى التأكد أولا من أنك قد أنهيت على الأقل أربع مسارات من الدورة و رفع جميع التطبيقات التي قمت بها في الدروس مع المدرب على github . ويمكن قراءة الشروط للتقدم للإختبار من خلال الرابط التالي: https://support.academy.hsoub.com/exams1 نقطة
-
بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة.1 نقطة
-
السلام عليكم انا اعمل على مشروع منتجات بس اتبع دورة متجر الكتروني لبيع الكتب في الخطوات لما اجيب المنتجات بالصفحة تظهر لي بشكل عمودي وهذا الشكل الاساسي لصفحة المنتج لدينا مسار الصفحة "seniorProject\php\resources\views\gallery.blade.php" ومسار صفحة style "seniorProject\php\resources\css\stylePS.css" والصور ما تظهر معانا seniorProject.zipملف المشروع كامل

 1 نقطة
1 نقطة -
يعطيك العافية ضبط الحمدلله , ومشكور جدا الله يرضى عليك1 نقطة
-
ليس بالضرورة، الأهم هو التوازن بين الدقتين، فارتفاع دقة التدريب مع ارتفاع دقة التحقق مع تقارب بينهما يعني أن النموذج يتعلم بشكل فعال ويُعمَّم جيدًا على البيانات الجديدة. ولو ارتفعت دقة التدريب كثيرًا بينما توقفت دقة التحقق أو انخفضت، فتدل على الإفراط في التخصيص حيث يحفظ النموذج بيانات التدريب بدلًا من تعلم الأنماط العامة. أيضًا استقرار دقة التحقق، فالهدف الرئيسي هو تحقيق دقة تحقق عالية ومستقرة، حتى لو توقفت دقة التدريب عن الزيادة، وأحيانًا تكون الزيادة المستمرة في دقة التدريب مع تراجع التحقق علامة سلبية على Overfitting. وعليك مراقبة الفرق بين الدقتين، الفرق الكبير بين دقة التدريب والتحقق مثل 98% تدريب مقابل 75% تحقق يشيران إلى مشكلة في التعميم، أما الفرق الصغير 90% تدريب مقابل 88% تحقق يُعتبر مؤشرًا جيدًا على توازن النموذج. وللعلم في مراحل التدريب أي في المراحل الأولى، من الطبيعي أن تزيد كلتا الدقتين معًا، ولاحقًا، ربما تستمر دقة التدريب في الزيادة بسبب تحسين النموذج لتفاصيل البيانات، لكن يجب ألا تتدهور دقة التحقق بشكل ملحوظ. ولا تعتمد فقط على الدقة، تتبع الخسارة Loss أثناء التدريب، فأحيانًا تتحسن الدقة مع زيادة الخسارة في بيانات التحقق، وذلك يعتبر مشكلة، واستخدم مقاييس أخرى مثل Precision، وRecall، أو منحنى ROC حسب طبيعة المهمة.1 نقطة
-
طيب هي بتكبت في اي جزاء في الكود ده # The 'deep_hit_model' is a Sequential model in Keras, meaning the layers are stacked in a linear fashion. deep_hit_model = keras.models.Sequential([ # - The first layer is a Dense layer with 8 units and 'tanh' activation function. This layer is responsible for transforming the input into a higher-dimensional space. keras.layers.Dense(8), keras.layers.BatchNormalization(), keras.layers.Activation('tanh'), keras.layers.Dropout(0.1), # - The second layer is a Dense layer with 128 units and 'tanh' activation function, allowing the model to learn more complex patterns. keras.layers.Dense(128), keras.layers.BatchNormalization(), keras.layers.Activation('tanh'), keras.layers.Dropout(0.3), # - The third layer is a Dense layer with 64 units and 'tanh' activation function, further processing the data with non-linearities. keras.layers.Dense(64), keras.layers.BatchNormalization(), keras.layers.Activation('tanh'), # - The fourth layer is a Dense layer with 32 units and 'tanh' activation function, continuing to refine the representation of the data. keras.layers.Dense(32), keras.layers.BatchNormalization(), keras.layers.Activation('tanh'), # - The final layer is a Dense layer with 1 unit and 'sigmoid' activation function, producing an output between 0 and 1, suitable for binary classification. keras.layers.Dense(1 , activation='sigmoid'), ])1 نقطة
-
 يعد روبوت الدردشة ChatGPT واحدًا من أشهر أدوات الذكاء الاصطناعي التوليدي Generative AI Tool، وقد طورته شركة OpenAI ليساعد للعاملين في مختلف المجالات، فهو يتيح طرح الأسئلة حول أي موضوع ويوفر إجابات تفصيلية. ولكن، بالرغم من فوائده الكثيرة إلا أنه ليس مفتوح المصدر open source، فهو يمنع المطورين من الوصول إلى أكواده المصدرية، وبناء بوتات مخصصة لاحتياجاتهم، وهو متاح للمطورين عبر واجهة برمجية API تسمح لهم بالتفاعل مع النموذج واستخدامه داخل تطبيقاتهم، فما هي أهم بدائل ChatGPT مفتوحة المصدر؟ هذا ما سنتعرف عليه في مقالنا حيث نستعرض لكم عدة بدائل مفتوحة المصدر لشات جي بي تي تمكنكم من بناء روبوت الدردشة الخاص بكم بمرونة كبيرة. أسباب البحث عن بدائل مفتوحة المصدر لشات جي بي تي فيما يلي قائمة بأبرز الأسباب التي تدفعنا لاستخدام بدائل لروبوت الدردشة ChatGPT: المعرفة الكاملة بطريقة تعامل روبوت الدردشة مع بيانات المستخدمين ومعالجتها إمكانية بناء روبوت دردشة خاص بنا شبيه بروبوت الدردشة مفتوح المصدر دون الحاجة لدفع تكاليف لاستخدامه سهولة تعديل روبوت الدردشة وتخصيصه حسب احتياجاتنا الخاصة المرونة في السياسات وعدم الحاجة للالتزام بسياسات الشركة المالكة لروبوت الدردشة التطور السريع والمستمر في روبوت الدردشة نظرًا لمشاركة عدد ضخم من المطورين في تحديث البوت وترقيته ملاحظة: لا يعني ذلك أنَّ بوت ChatGPT سيء بالطبع ولا ندعو لعدم استخدامه فقد وصل هذا البوت لدرجة عالية من الكفاءة قد تفوق البدائل مفتوحة المصدر، وإنما نقترح عليكم مطالعة هذه الحلول وتجربتها والنظر في إمكانية الاستفادة المثلى منها. دعونا نستعرض معًا عدد من البدائل مفتوحة المصدر لبوت ChatGPT. ديب سيك DeepSeek تُعدّ DeepSeek منصة ذكاء صناعي مفتوحة المصدر مخصصة لإجراء عدة مهام باستخدام تقنيات معالجة اللغة الطبيعية وتعلم الآلة حيث توفر للمطورين نماذج متقدمة في الذكاء الاصطناعي صالحة لمختلف التطبيقات مثل نموذج DeepSeek-VL لفهم الوسائط المتعددة، ونموذج DeepSeek-Coder لتطوير البرمجيات، ونموذج DeepSeek-V2 الذي يركز على الكفاءة في الاستدلال، كما تقدم المنصة للمطورين إمكانية الوصول لواجهتها البرمجية API لمزيد من المرونة والتحكم. وتتضمن تطبيقًا مخصصًا للاستخدام على الهواتف المحمولة، بالإضافة إلى روبوت دردشة DeepSeek Chat للتفاعل المباشر مع الذكاء الصناعي والعديد من المميزات الأخرى. هاجينج شات HuggingChat توفر منصة Huggingface الشهيرة نماذج ذكاء اصطناعي مختلفة للمطورين، وتنشر باستمرار نسخًا تجريبية من بوتات الدردشة، ومن ضمنها روبوت HuggingChat المطوّر بواسطة المنصة ليكون بديلًا مفتوح المصدر لشات جي بي تي Chat GPT، فهو يستخدم مجموعة من أفضل نماذج الذكاء الاصطناعي الموجودة في المجتمع التقني، ويمكن تجربته عبر صفحة البوت على موقع Huggingface، كما يمكن الاطلاع على شيفرات البوت المصدرية، وكذلك يمكن استخدام الواجهة الأمامية للبوت الخاص بك، مع تعديل الواجهة الخلفية وتخصيصها بما يتناسب مع الخصائص أو الخدمات التي تريد دمجها، مثل إضافة وظائف جديدة أو تعديل طريقة معالجة البيانات. دولي Doly دولي Doly هو نموذج لغوي درَّبَته منصة تعلم الآلة المدفوعة داتا بريكس Databricks وهي منصة تقدم أدوات وتقنيات متقدمة لبناء وتشغيل تطبيقات الذكاء الاصطناعي وتحليل البيانات، ويمكن الاطلاع على الشيفرات المصدرية للنموذج عبر مستودع جيت هاب، كما يمكن تجربة النموذج ذاته عبر منصة Huggingface. كوالا Koala كوالا Koala بوت دردشة تابع إلى EasyLM وهو إطار عمل مفتوح المصدر يهدف إلى تبسيط وتسهيل استخدام النماذج اللغوية الكبيرة مثل GPT و BERT وغيرها. ويمكن استخدامه في العديد من التطبيقات مثل الترجمة الآلية وتحليل المشاعر والتلخيص والعديد من مهام معالجة اللغة الطبيعية. ويمكنك تشغيله محليًا عبر حاسوبك الخاص، وهو مبني على مجموعة بيانات LLaMA، ولمعرفة المزيد من التفاصيل يمكن مطالعة المدونة الرسمية للبوت. فيكونا Vicuna يعد فيكونا Vicuna بديلًا آخر مفتوح المصدر لشات جي بي تي، وقد تدرَّب على نموذج LLaMA الضخم الذي طورته Meta، وحسب مطوري البوت فإنَّ جودة نتائجه مقاربة لنتائج الإصدار الرابع من شات جي بي تي GPT-4، وللتحقق من هذا الادعاء يمكنكم تجربة البوت والتحقق من أدائه الفعلي عبر هذا الرابط، كما يمكنكم مطالعة المدونة الرسمية للبوت. أوبن شات كيت OpenChatKit يٌعدّ OpenChatKit بديلًا متكاملًا لبوت ChatGPT، وقد طورته شركة Together متعاونة مع منظمات بحثية مثل LAION لإنشاء مجموعة بيانات تدريبية تساعد البوت على التعلم والتطور، تعتمد شركة Together على نموذج الذكاء الاصطناعي RedPajama الذي يعد واحدًا من أهم وأشهر نماذج الذكاء الاصطناعي مفتوحة المصدر لتشغيل البوت OpenChatKit. ويمكن تجربة هذا البوت ومطالعة سائر تفاصيله التقنية عبر صفحة البوت على موقع جيت هاب. ChatRWKV يعد بوت ChatRWKV بديلًا مفتوح المصدر لشات جي بي تي، وهو يعتمد على النموذج اللغوي RNN، ويمكنكم إيجاد نسخة تجريبية منه عبر موقع Huggingface، كما يمكن معرفة سائر المعلومات التقنية ومتابعة الإصدارات عبر مستودع البوت على موقع جيت هاب، بالإضافة إلى ذلك، يمكن للمطورين وأصحاب الأعمال بناء روبوتات الدردشة الخاصة بهم باستخدام ChatRWKV. ColossalChat تشير Colossal AI إلى مبادرة تساعد المطورين على استخدام نماذج ذكاء اصطناعي مُدرَّبة مسبقًا لتطوير بوتات دردشة شبيهة بشات جي بي تي ChatGPT-Like، أما ColossalChat فهو شات بوت مبني باستخدام الأدوات التي توفرها مبادرة Colossal AI، ويمكنكم مطالعة مزيد من التفاصيل حوله عبر مستودع جيت هاب. GPT4ALL يختلف بوت GPT4ALL عن سائر بوتات الدردشة، ذلك بأنه بوت مفتوح المصدر يهدف لتزويدنا ببوتات دردشة قابلة للعمل في أي مكان، أي يمكننا أن نستخدم الشات بوت محليًا على أجهزتنا الخاصة ونعالج الأوامر عبر وحدة المعالجة المركزية دون الحاجة للاتصال بخوادم أو حتى الاتصال بالإنترنت، كما يدعم العمل على جميع وحدات المعالجة الرسومية تقريبًا، ولا نحتاج سوى تثبيت تطبيق سطح المكتب الخاص بالبوت ثم البدء باستخدامه، ولمعرفة طريقة عمل البوت يمكن الاطلاع على مستودعه على جيت هاب. Alpaca-LoRA يهدف نموذج ألباكا لوراAlpaca-LoRA إلى توفير نموذج لغوي باستخدام التكيُّف منخفض الرتبة Low-Rank Adaptation، أي يمكن تدريب النموذج وتحسين نتائجه باعتماد عدد قليل من البرامترات، وبالتالي يمكن أن يعمل النموذج بموارد قليلة وتكاليف منخفضة، ما يسمح لنا بتشغيله على الحواسيب المصغرة محدودة الموارد، مثل حاسوب راسبيري باي Raspberry Pi، ومن المثير أنه يمكن تدريب النموذج كاملًا باستخدام معالج الرسوميات RTX 4090 GPU خلال ساعات قليلة، ويمكن مطالعة المزيد عنه عبر مستودع البوت على جيت هاب. H2oGPT يعد بوت H2oGPT مخصصًا لتلخيص المستندات النصية، وإن كان يمكنك محادثته واستفساره كسائر البوتات، فهو يسمح لنا برفع واستعراض المستندات وتلخيصها عبر واجهته الأمامية، كما تتوافر مثبتات Installers لبوت H2oGPT لنظامي تشغيل ويندوز Windows وماك أو إس MacOS، بينما نحتاج استخدام دوكر Docker لتنصيبه على نظام تشغيل لينكس Linux، ويمكن تجربته عبر المتصفح من موقع Huggingface، كما يمكن الاطلاع على شيفراته المصدرية عبر مستودع جيت هاب. Cerebras-GPT لا يعد Cerebras-GPT بوت دردشة في حد ذاته، ولكنه يوفر نماذج لغوية مفتوحة المصدر مُدرَّبة على بيانات بأحجام ضخمة وشبيهة بنموذج جي بي تي GPT-Like، يساعدنا استخدام هذه النماذج في تطوير البوت الخاص بنا على زيادة دقة البوت ورفع كفاءته الحسابية، ولمطالعة مزيد من المعلومات عن النموذج يمكن زيارة صفحته على Huggingface. KoboldAI يعد KoboldAI شات بوت يعمل مساعدًا شخصيًا للكُتَّاب، ولا سيما كتاب الروايات، ويُستخدم عبر المتصفح Browser-Based، ويمكن تشغيله مع برنامج Google Colab بسهولة، يتميز KoboldAI بقدرته على الكتابة بأساليب مختلفة، ليساعد الكتاب على إثراء نصوصهم ويساعدهم على توليد أفكار جديدة. ويمكن اختبار أداه والاطلاع على المزيد من التفاصيل حوله عبر مستودع جيت هاب. الخاتمة بهذا نكون وصلنا لنهاية مقالنا الذي عرفناكم فيه على مجموعة من البدائل مفتوحة المصدر لبوت ChatGPT، كل ما عليكم هو تجربتها واستخدامها في تطوير بوتات مخصصة تلائم احتياجات أعمالكم دون الحاجة إلى ميزانية مرتفعة والتحقق من مدى كفاءتها، ونرجب بمشاركة تجربتكم مع أي روبوت دردشة مفتوح المصدر في قسم التعليقات أسفل المقال. ترجمة -وبتصرف- لمقال Best Open Source ChatGPT Alternatives لكاتبه Ankush Das اقرأ أيضًا تدريب بوت المحادثة ChatGPT وتعليمه كيف يتحدث ويتعلم تعرف على 11 طريقة يساعدك فيها ChatGPT كمطور ووردبريس دليل استخدام ChatGPT API لتحسين خدماتك عبر الإنترنت بناء روبوت دردشة باستخدام بايثون و OpenAI API1 نقطة
يعد روبوت الدردشة ChatGPT واحدًا من أشهر أدوات الذكاء الاصطناعي التوليدي Generative AI Tool، وقد طورته شركة OpenAI ليساعد للعاملين في مختلف المجالات، فهو يتيح طرح الأسئلة حول أي موضوع ويوفر إجابات تفصيلية. ولكن، بالرغم من فوائده الكثيرة إلا أنه ليس مفتوح المصدر open source، فهو يمنع المطورين من الوصول إلى أكواده المصدرية، وبناء بوتات مخصصة لاحتياجاتهم، وهو متاح للمطورين عبر واجهة برمجية API تسمح لهم بالتفاعل مع النموذج واستخدامه داخل تطبيقاتهم، فما هي أهم بدائل ChatGPT مفتوحة المصدر؟ هذا ما سنتعرف عليه في مقالنا حيث نستعرض لكم عدة بدائل مفتوحة المصدر لشات جي بي تي تمكنكم من بناء روبوت الدردشة الخاص بكم بمرونة كبيرة. أسباب البحث عن بدائل مفتوحة المصدر لشات جي بي تي فيما يلي قائمة بأبرز الأسباب التي تدفعنا لاستخدام بدائل لروبوت الدردشة ChatGPT: المعرفة الكاملة بطريقة تعامل روبوت الدردشة مع بيانات المستخدمين ومعالجتها إمكانية بناء روبوت دردشة خاص بنا شبيه بروبوت الدردشة مفتوح المصدر دون الحاجة لدفع تكاليف لاستخدامه سهولة تعديل روبوت الدردشة وتخصيصه حسب احتياجاتنا الخاصة المرونة في السياسات وعدم الحاجة للالتزام بسياسات الشركة المالكة لروبوت الدردشة التطور السريع والمستمر في روبوت الدردشة نظرًا لمشاركة عدد ضخم من المطورين في تحديث البوت وترقيته ملاحظة: لا يعني ذلك أنَّ بوت ChatGPT سيء بالطبع ولا ندعو لعدم استخدامه فقد وصل هذا البوت لدرجة عالية من الكفاءة قد تفوق البدائل مفتوحة المصدر، وإنما نقترح عليكم مطالعة هذه الحلول وتجربتها والنظر في إمكانية الاستفادة المثلى منها. دعونا نستعرض معًا عدد من البدائل مفتوحة المصدر لبوت ChatGPT. ديب سيك DeepSeek تُعدّ DeepSeek منصة ذكاء صناعي مفتوحة المصدر مخصصة لإجراء عدة مهام باستخدام تقنيات معالجة اللغة الطبيعية وتعلم الآلة حيث توفر للمطورين نماذج متقدمة في الذكاء الاصطناعي صالحة لمختلف التطبيقات مثل نموذج DeepSeek-VL لفهم الوسائط المتعددة، ونموذج DeepSeek-Coder لتطوير البرمجيات، ونموذج DeepSeek-V2 الذي يركز على الكفاءة في الاستدلال، كما تقدم المنصة للمطورين إمكانية الوصول لواجهتها البرمجية API لمزيد من المرونة والتحكم. وتتضمن تطبيقًا مخصصًا للاستخدام على الهواتف المحمولة، بالإضافة إلى روبوت دردشة DeepSeek Chat للتفاعل المباشر مع الذكاء الصناعي والعديد من المميزات الأخرى. هاجينج شات HuggingChat توفر منصة Huggingface الشهيرة نماذج ذكاء اصطناعي مختلفة للمطورين، وتنشر باستمرار نسخًا تجريبية من بوتات الدردشة، ومن ضمنها روبوت HuggingChat المطوّر بواسطة المنصة ليكون بديلًا مفتوح المصدر لشات جي بي تي Chat GPT، فهو يستخدم مجموعة من أفضل نماذج الذكاء الاصطناعي الموجودة في المجتمع التقني، ويمكن تجربته عبر صفحة البوت على موقع Huggingface، كما يمكن الاطلاع على شيفرات البوت المصدرية، وكذلك يمكن استخدام الواجهة الأمامية للبوت الخاص بك، مع تعديل الواجهة الخلفية وتخصيصها بما يتناسب مع الخصائص أو الخدمات التي تريد دمجها، مثل إضافة وظائف جديدة أو تعديل طريقة معالجة البيانات. دولي Doly دولي Doly هو نموذج لغوي درَّبَته منصة تعلم الآلة المدفوعة داتا بريكس Databricks وهي منصة تقدم أدوات وتقنيات متقدمة لبناء وتشغيل تطبيقات الذكاء الاصطناعي وتحليل البيانات، ويمكن الاطلاع على الشيفرات المصدرية للنموذج عبر مستودع جيت هاب، كما يمكن تجربة النموذج ذاته عبر منصة Huggingface. كوالا Koala كوالا Koala بوت دردشة تابع إلى EasyLM وهو إطار عمل مفتوح المصدر يهدف إلى تبسيط وتسهيل استخدام النماذج اللغوية الكبيرة مثل GPT و BERT وغيرها. ويمكن استخدامه في العديد من التطبيقات مثل الترجمة الآلية وتحليل المشاعر والتلخيص والعديد من مهام معالجة اللغة الطبيعية. ويمكنك تشغيله محليًا عبر حاسوبك الخاص، وهو مبني على مجموعة بيانات LLaMA، ولمعرفة المزيد من التفاصيل يمكن مطالعة المدونة الرسمية للبوت. فيكونا Vicuna يعد فيكونا Vicuna بديلًا آخر مفتوح المصدر لشات جي بي تي، وقد تدرَّب على نموذج LLaMA الضخم الذي طورته Meta، وحسب مطوري البوت فإنَّ جودة نتائجه مقاربة لنتائج الإصدار الرابع من شات جي بي تي GPT-4، وللتحقق من هذا الادعاء يمكنكم تجربة البوت والتحقق من أدائه الفعلي عبر هذا الرابط، كما يمكنكم مطالعة المدونة الرسمية للبوت. أوبن شات كيت OpenChatKit يٌعدّ OpenChatKit بديلًا متكاملًا لبوت ChatGPT، وقد طورته شركة Together متعاونة مع منظمات بحثية مثل LAION لإنشاء مجموعة بيانات تدريبية تساعد البوت على التعلم والتطور، تعتمد شركة Together على نموذج الذكاء الاصطناعي RedPajama الذي يعد واحدًا من أهم وأشهر نماذج الذكاء الاصطناعي مفتوحة المصدر لتشغيل البوت OpenChatKit. ويمكن تجربة هذا البوت ومطالعة سائر تفاصيله التقنية عبر صفحة البوت على موقع جيت هاب. ChatRWKV يعد بوت ChatRWKV بديلًا مفتوح المصدر لشات جي بي تي، وهو يعتمد على النموذج اللغوي RNN، ويمكنكم إيجاد نسخة تجريبية منه عبر موقع Huggingface، كما يمكن معرفة سائر المعلومات التقنية ومتابعة الإصدارات عبر مستودع البوت على موقع جيت هاب، بالإضافة إلى ذلك، يمكن للمطورين وأصحاب الأعمال بناء روبوتات الدردشة الخاصة بهم باستخدام ChatRWKV. ColossalChat تشير Colossal AI إلى مبادرة تساعد المطورين على استخدام نماذج ذكاء اصطناعي مُدرَّبة مسبقًا لتطوير بوتات دردشة شبيهة بشات جي بي تي ChatGPT-Like، أما ColossalChat فهو شات بوت مبني باستخدام الأدوات التي توفرها مبادرة Colossal AI، ويمكنكم مطالعة مزيد من التفاصيل حوله عبر مستودع جيت هاب. GPT4ALL يختلف بوت GPT4ALL عن سائر بوتات الدردشة، ذلك بأنه بوت مفتوح المصدر يهدف لتزويدنا ببوتات دردشة قابلة للعمل في أي مكان، أي يمكننا أن نستخدم الشات بوت محليًا على أجهزتنا الخاصة ونعالج الأوامر عبر وحدة المعالجة المركزية دون الحاجة للاتصال بخوادم أو حتى الاتصال بالإنترنت، كما يدعم العمل على جميع وحدات المعالجة الرسومية تقريبًا، ولا نحتاج سوى تثبيت تطبيق سطح المكتب الخاص بالبوت ثم البدء باستخدامه، ولمعرفة طريقة عمل البوت يمكن الاطلاع على مستودعه على جيت هاب. Alpaca-LoRA يهدف نموذج ألباكا لوراAlpaca-LoRA إلى توفير نموذج لغوي باستخدام التكيُّف منخفض الرتبة Low-Rank Adaptation، أي يمكن تدريب النموذج وتحسين نتائجه باعتماد عدد قليل من البرامترات، وبالتالي يمكن أن يعمل النموذج بموارد قليلة وتكاليف منخفضة، ما يسمح لنا بتشغيله على الحواسيب المصغرة محدودة الموارد، مثل حاسوب راسبيري باي Raspberry Pi، ومن المثير أنه يمكن تدريب النموذج كاملًا باستخدام معالج الرسوميات RTX 4090 GPU خلال ساعات قليلة، ويمكن مطالعة المزيد عنه عبر مستودع البوت على جيت هاب. H2oGPT يعد بوت H2oGPT مخصصًا لتلخيص المستندات النصية، وإن كان يمكنك محادثته واستفساره كسائر البوتات، فهو يسمح لنا برفع واستعراض المستندات وتلخيصها عبر واجهته الأمامية، كما تتوافر مثبتات Installers لبوت H2oGPT لنظامي تشغيل ويندوز Windows وماك أو إس MacOS، بينما نحتاج استخدام دوكر Docker لتنصيبه على نظام تشغيل لينكس Linux، ويمكن تجربته عبر المتصفح من موقع Huggingface، كما يمكن الاطلاع على شيفراته المصدرية عبر مستودع جيت هاب. Cerebras-GPT لا يعد Cerebras-GPT بوت دردشة في حد ذاته، ولكنه يوفر نماذج لغوية مفتوحة المصدر مُدرَّبة على بيانات بأحجام ضخمة وشبيهة بنموذج جي بي تي GPT-Like، يساعدنا استخدام هذه النماذج في تطوير البوت الخاص بنا على زيادة دقة البوت ورفع كفاءته الحسابية، ولمطالعة مزيد من المعلومات عن النموذج يمكن زيارة صفحته على Huggingface. KoboldAI يعد KoboldAI شات بوت يعمل مساعدًا شخصيًا للكُتَّاب، ولا سيما كتاب الروايات، ويُستخدم عبر المتصفح Browser-Based، ويمكن تشغيله مع برنامج Google Colab بسهولة، يتميز KoboldAI بقدرته على الكتابة بأساليب مختلفة، ليساعد الكتاب على إثراء نصوصهم ويساعدهم على توليد أفكار جديدة. ويمكن اختبار أداه والاطلاع على المزيد من التفاصيل حوله عبر مستودع جيت هاب. الخاتمة بهذا نكون وصلنا لنهاية مقالنا الذي عرفناكم فيه على مجموعة من البدائل مفتوحة المصدر لبوت ChatGPT، كل ما عليكم هو تجربتها واستخدامها في تطوير بوتات مخصصة تلائم احتياجات أعمالكم دون الحاجة إلى ميزانية مرتفعة والتحقق من مدى كفاءتها، ونرجب بمشاركة تجربتكم مع أي روبوت دردشة مفتوح المصدر في قسم التعليقات أسفل المقال. ترجمة -وبتصرف- لمقال Best Open Source ChatGPT Alternatives لكاتبه Ankush Das اقرأ أيضًا تدريب بوت المحادثة ChatGPT وتعليمه كيف يتحدث ويتعلم تعرف على 11 طريقة يساعدك فيها ChatGPT كمطور ووردبريس دليل استخدام ChatGPT API لتحسين خدماتك عبر الإنترنت بناء روبوت دردشة باستخدام بايثون و OpenAI API1 نقطة -
كلاهما صالحان ولكل مميزات وعيوب، فتعلم الآلة أكثر قابلية للتفسير من نماذج التعلم العميق، الأمر الذي يسهل فهم سبب تقديم توصية معينة، وتستطيع تكييف نماذج تعلم الآلة بسهولة مع أنواع مختلفة من البيانات وصيغ المسائل، وأقل تكلفة من الناحية الحسابية للتدريب والنشر من نماذج التعلم العميق. لكن لا تتمكن نماذج تعلم الآلة من التقاط الأنماط والعلاقات المعقدة في مجموعات البيانات الكبيرة، وتتطلب نماذج تعلم الآلة هندسة دقيقة للميزات، والتي تستغرق وقتًا طويلاً وتتطلب خبرة في المجال. وكأمثلة: الترشيح التعاوني (CF) تحليل المصفوفة (MF) الترشيح القائم على المحتوى (CBF) الأنظمة القائمة على المعرفة (KBS) أما التعلم العميق DL لديها القدرة على تعلم الأنماط والعلاقات المعقدة في مجموعات البيانات الكبيرة، بالتالي هي مناسبة تمامًا لأنظمة التوصيات التي تضم قواعد مستخدمين وفهارس عناصر كبيرة. ويمكنها تعلم الميزات تلقائيًا من البيانات الأولية، مما يقلل من الحاجة إلى هندسة الميزات يدويًا، وباستطاعتك معالجة نماذج التعلم العميق بشكل متوازي وموزع، مما يجعلها مناسبة لأنظمة التوصيات واسعة النطاق. لكن يعيبها أنها أقل قابلية للتفسير من نماذج تعلم الآلة، ومن الصعب فهم سبب تقديم توصية معينة، وتتطلب نماذج التعلم العميق موارد حسابية كبيرة وتكون مكلفة من الناحية الحسابية للتدريب والنشر. ومنها: الترشيح التعاوني العصبي (NCF) التعلم الواسع والعميق تحليل المصفوفة العميقة (DMF) شبكات الالتفاف البياني (GCNs)1 نقطة
-
إن هناك فرق كبير بين تعلم الآلة (Machine Learning) و بين التعلم العميق (Deep Learning) والإختيار بين كلم منهما من حيث تقديم التوصيات يعتمد على عدة عوامل، منها حجم البيانات، تعقيد المشكلة، والموارد المتاحة. التعلم الآلي (Machine Learning): السهولة: غالبًا ما يستخدم نماذج بسيطة مثل الانحدار الخطي أو شجرة القرار أو ال SVM هذه النماذج تكون فعالة وسهلة التفسير. قلة البيانات: التعلم الآلي العادي يمكن أن يعمل جيدًا مع مجموعات بيانات أصغر مقارنة بالتعلم العميق حيث لا يتطلب كميات كبيرة من البيانات. التخصيص: مناسب لحالات تكون فيها العلاقات بين البيانات واضحة أو يمكن الاستفادة من ميزات معينة مباشرةً. التعلم العميق (Deep Learning): ضخامة وتعقيد البيانات: التعلم العميق مناسب جدًا عندما يكون لديك كميات كبيرة من البيانات أو بيانات غير منظمة (مثل النصوص، الصور، أو الفيديو). التوصيات المعقدة: يمكن أن يكتشف التعلم العميق أنماط معقدة في البيانات وليست مباشرة بفضل استخدام الشبكات العصبية، مما يجعله مفيدًا في أنظمة التوصيات التي تعتمد على فهم العلاقات الدقيقة بين المستخدمين والمحتوى. الحاجة إلى موارد كبيرة: يتطلب موارد حسابية كبيرة مثل وحدات معالجة الرسومات (GPU) ووقت تدريب أطول. تلخيصا لما سبق إذا كانت البيانات بسيطة ومحدودة الحجم فإن التعلم الآلي سيكون الخيار الأفضل بسبب السرعة والبساطة وأيضا بسبب قلة البيانات. أما إذا كانت البيانات كبيرة أو معقدة مثل التوصيات المعتمدة على تحليل تاريخ المستخدم بالتفصيل أو التعامل مع بيانات غير منظمة ولا تربطهم علاقات مباشرة فإن التعلم العميق يوفر نتائج أكثر دقة وتفصيلاً. ويمكنك قراءة الإجابة التالية لشرح أفضل للفرق بينهما :1 نقطة