لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 02/11/25 in أجوبة
-
السلام عليكم هو اي الفرق مابين الconfusion_matrix ويبن الConfusionMatrixDisplay ؟3 نقاط
-
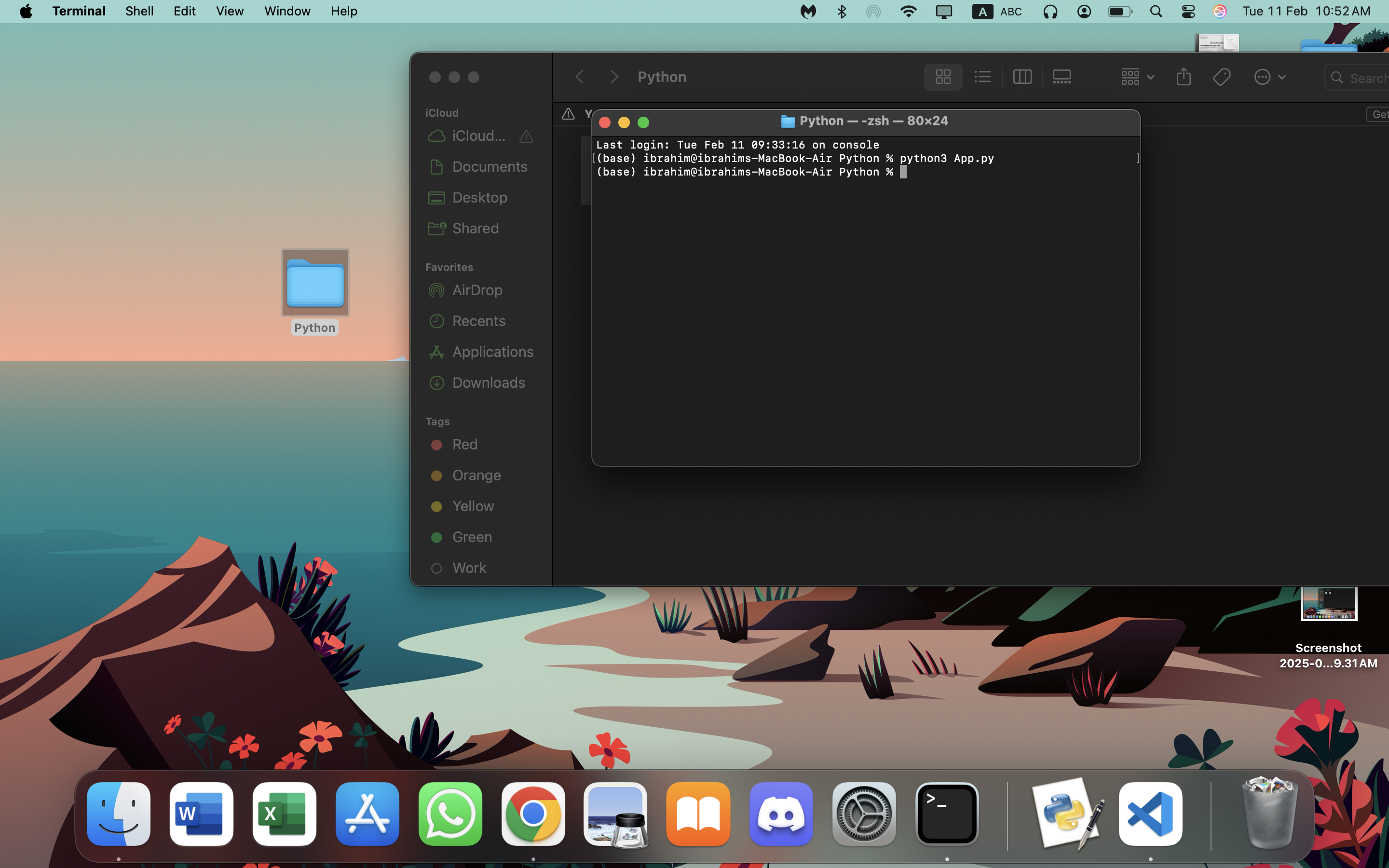
السلام عليكم.. هل يمكنني التسلسل في الدورات حسب ما هو ظاهر في الصورة ?
 2 نقاط
2 نقاط -
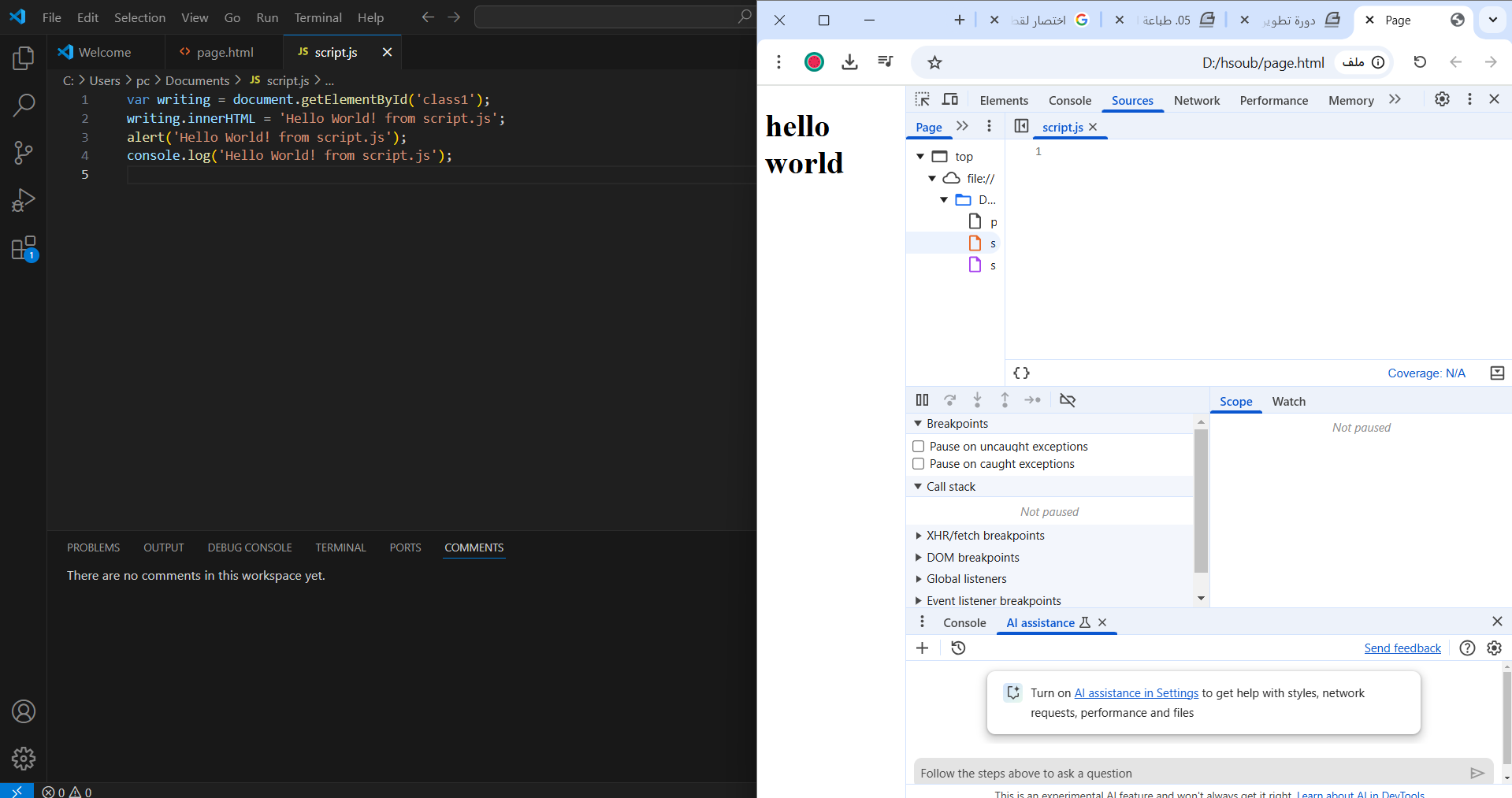
لا يوجد أي تاثير لجافاسكريبت على محتوى الصفحة سواء في الconsole أو في محتوى الصفحة وعند النظر إلى الsourses في chrome يظهر كود جافاسكريبت فارغا ما سبب المشكلة ؟hsoub.ziphsoub.zip
 2 نقاط
2 نقاط -
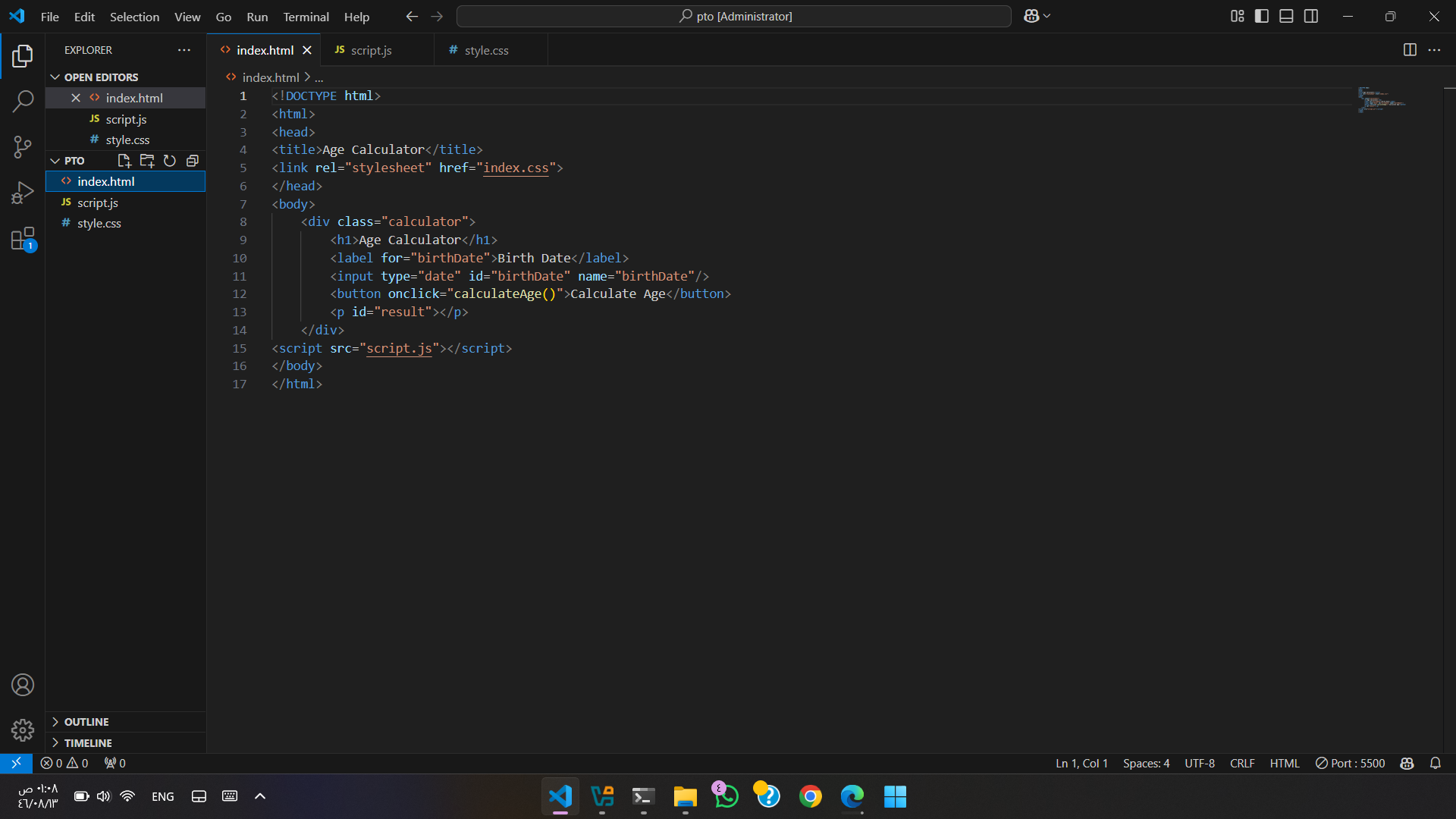
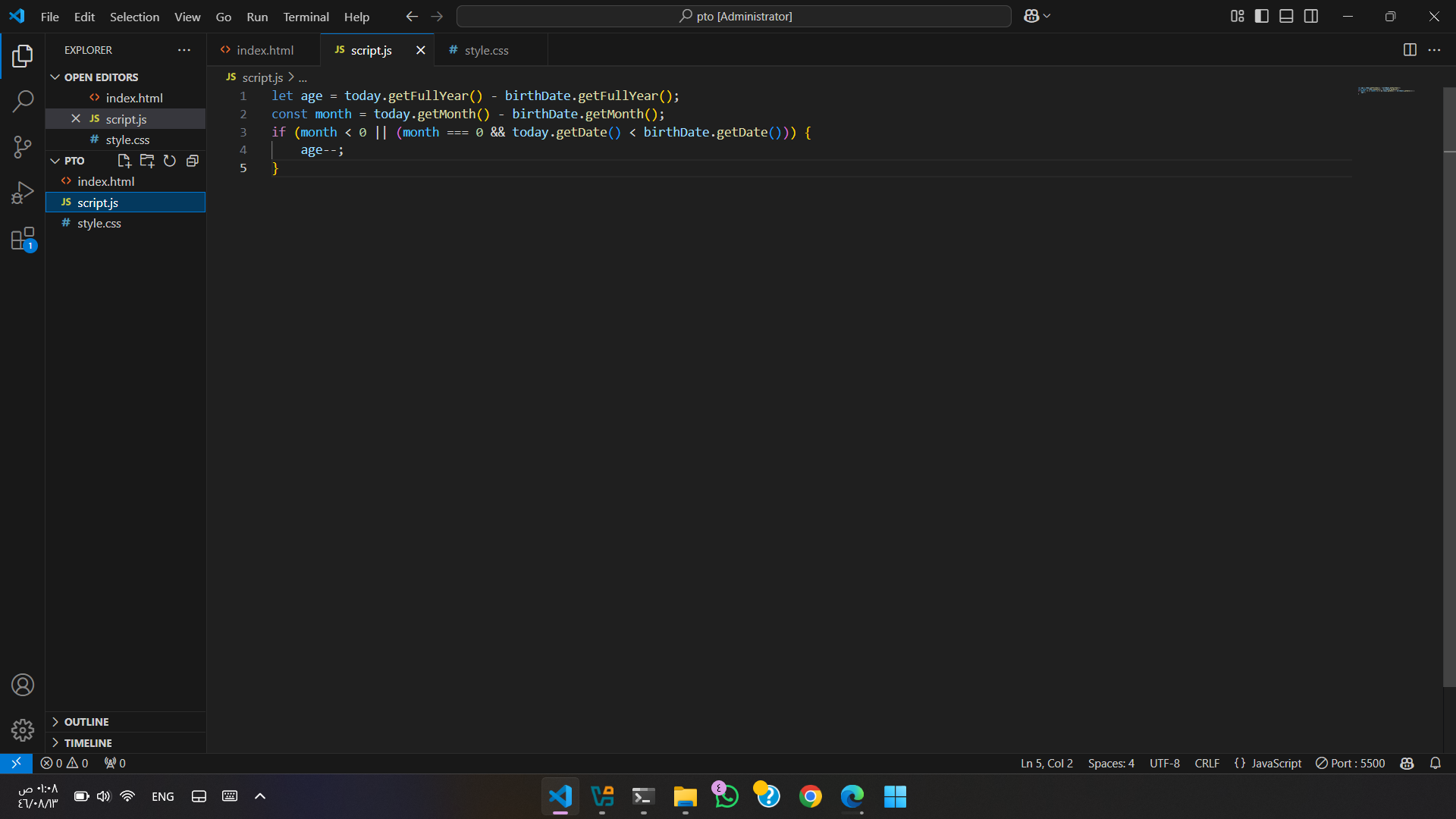
السلام عليكم عندي متغير في صفحه php &chance = "a > 0" عايز اطبع قيمه المتغير ده داخل قاعده if بمعني If($chance){ echo "ok"} يعني عايزه يستدعي قيمه المتغير داخل قاعده if يعني عايزه يكتب If(a>0){ echo "ok"}
 1 نقطة
1 نقطة -
السلام عليكم هي اي الداله دي predict_proba ؟1 نقطة
-
السلام عليكم هو اي الnumpy.where واي االفرق مابينها وبين الif ؟1 نقطة
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.1 نقطة
-
كما تم التوضيح بالتعليق السابق فإن numpy.where هي دالة تستخدم مع مصفوفات NumPy وتعمل بشكل مختلف عن if العادية . ولذلك يفضل استخدم numpy.where مع مصفوفات NumPy الكبيرة وعندما تريد عمليات سريعة وبينما يفضل استخدم if للحالات البسيطة أو عندما تحتاج منطق معقد لا يمكن تنفيذه بـ where1 نقطة
-
لا الدالة predict_proba ليست موجودة بشكل مباشر في TensorFlow أو Keras هذه الدالة موجودة بمكتبة scikit-learn ولكنها موجودة في بعض النماذج وليس جميعها. في Keras يمكنك استخدام model.predict للحصول على احتمالات التنبؤ مثل الدالة predict_proba ولكن يجب أن تكون طبقة الإخراج sigmoid أو softmax.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. numpy.where هي دالة تُستخدم لاختيار العناصر بناء على شرط معين. ويمكن استخدامها بدلا من if في بعض العمليات التي كنت تستخدم if فيها.وإن الدالة where تعمل بطريقة أكثر كفاءة عندما تتعامل مع المصفوفات. وإليك طريقة إستخدامها : numpy.where(condition, x, y) حيث : condition: هو الشرط الذي يتم التحقق منه . x: القيمة التي سيتم اختيارها إذا كانت condition صحيحة (True). y: القيمة التي سيتم اختيارها إذا كانت condition خاطئة (False). مثال : import numpy as np a = np.array([1, 2, 3, 4, 5]) result = np.where(a > 3, 'bigger', 'lower') print(result) #['lower' 'lower' 'lower' 'bigger' 'bigger'] هنا لاحظ أنه سيتم تنفيذ الدالة على جميع العناصر في المصفوفة وسيتم إستبدال العنصر بكلمة bigger إذا كان أكبر من 3 و lower إذا كان أقل منها أو يساوي 3. في المثال السابق كان يمكنك إستخدام if كالتالي : for num in a: if num > 3: print('bigger') else: print('lower') إذا نستخدم numpy.where للتحقق من شرط معين على جميع العناصر مرة واحدة في مصفوفة وتحديد قيمة معينة بناء على هذا الشرط. أما if نستخدمها للتحقق من شرط واحد في كل مرة. وإليك التوثيق الرسمي ل where : https://numpy.org/doc/2.2/reference/generated/numpy.where.html1 نقطة
-
الـ L2 Regularization يُضاف إلى الطبقات للحد من مشكلة Overfitting عن طريق معاقبة الأوزان الكبيرة في النموذج. model.add(Dense(64, kernel_regularizer='l2'))1 نقطة
-
طيب الداله دي موجود في TensorFlow و keras ؟1 نقطة
-
السلام عليكم هو مش التصنيف يعتبر بردو تنبواء ؟ يعني النموذج بيتنباء ان الشخص دي مريض لكن دي مش مريض1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. التصنيف (Classification) هو التنبؤ بمتغير تصنيفي، أي تحديد فئة أو تصنيف معين (من مجموعة محددة مسبقًا) بناءً على أمثلة تدريبية. ولذلك تعتبر عملية التصنيف تُعد نوعًا من عمليات التنبؤ أو هو نوع من التنبؤ يختص بتحديد الفئات. وللتوضيح أكثر يعتبر التنبؤ هو مصطلح عام يشمل جميع أنواع تقدير النتائج سواء كانت تصنيفية أو عددية.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. الدالة predict_proba تستخدم في العديد من نماذج للحصول على احتمالات التنبؤ بدلا من الحصول فقط على التصنيف النهائي. حيث تقوم الدالة بإعادة الاحتمالات التي من الممكن حدوثها لكل عينة اختبار. فبدلا من إعطائك الفئة النهائية التي تم التنبؤ بها مثل 0 أو 1 أو مريض وغير مريض في التصنيف الثنائي تقوم بإعطاءك احتمال وجود العينة في كل فئة. مثلا مريض : 65% وغير مريض : 35%. from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(X_train, y_train) probabilities = model.predict_proba(X_test) print(probabilities) ففي الكود السابق ستجد أن المخرجات ستكون عبارة عن نسبة إحتمال حدوث كل فئة : [[0.85, 0.15], [0.30, 0.70], [0.10, 0.90], [0.60, 0.40]] وهكذا ستجد أن العينة الأولى لها نسبة 85% لحدوث الصنف الأول ونسبة 15% لحدوث الصنف الثاني.1 نقطة
-
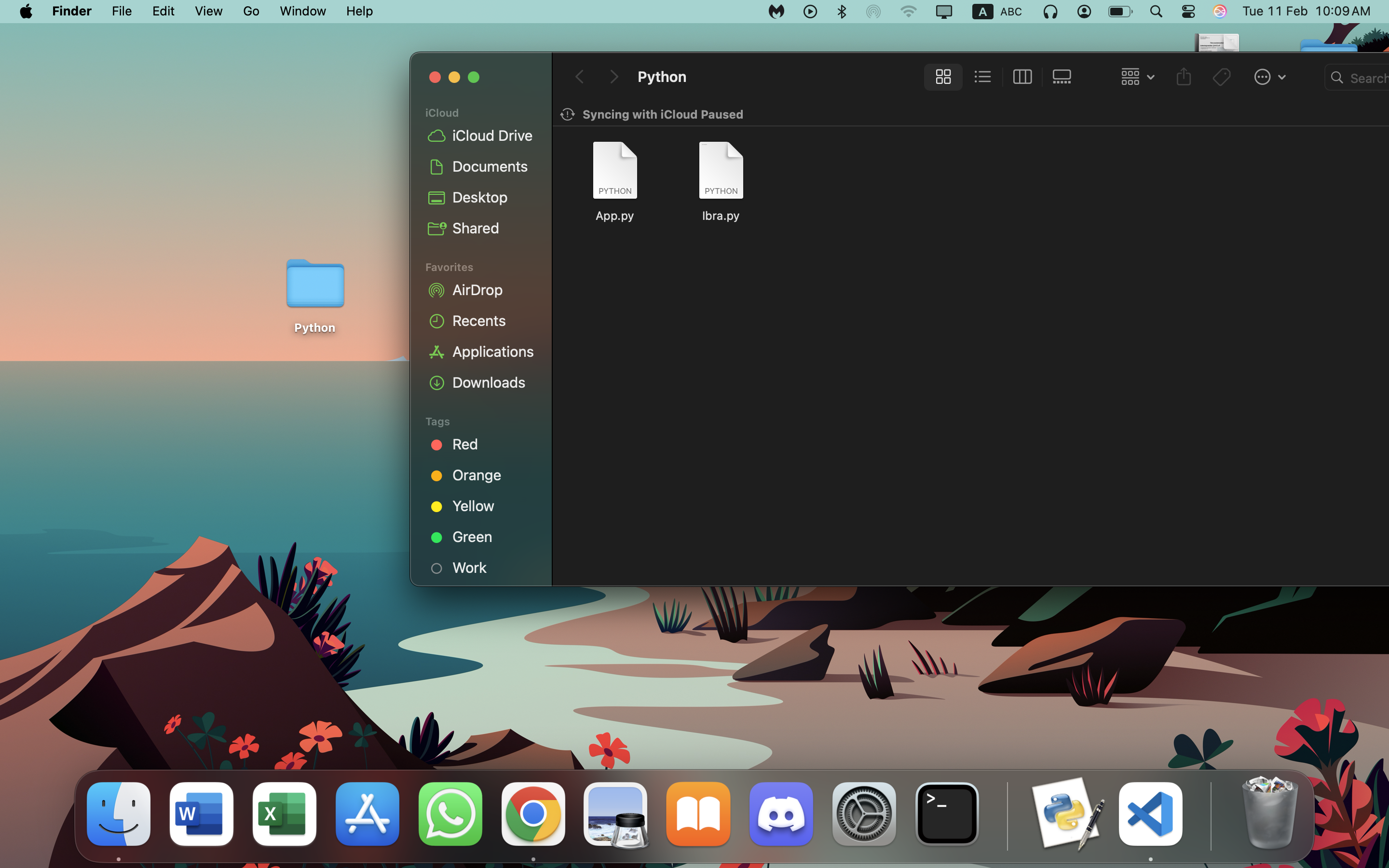
السلام عليكم ورحمة الله كيف يمكنني استعداء ملف بايثون App.py علما انه يوجد داخل ملف اخر اسمه Python محفوظ على ال Desktop وشكرا جزيلا لكم
 1 نقطة
1 نقطة -
السلام عليكم، ان أردت بناء تطبيق كبير نسبيا وقابل للتوسع هل استخدام django api framwork وأبني API ورأبطه بالواجهة الأمامية؟ أم استخدام django كما في دورة بايثون سيكون أفضل؟1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. يعتمد كلا الخيارين على إحتياجات التطبيق فمثلاً عند استخدام Django REST framework (API) مع واجهة أمامية منفصلة يكون أفضل في الحالات التالية: عندما تحتاج لمرونة في تطوير الواجهة الأمامية باستخدام إطار عمل حديث مثل React أو Vue وإذا كنت تخطط لبناء تطبيقات موبايل تستخدم نفس API كما أنه عندما يعمل فريق مختلف على الواجهة الأمامية والخلفية للمشاريع التي تحتاج قابلية توسع عالية وفصل واضح بين الخدمات بينما استخدام Django التقليدي يكون أفضل عندما تريد سرعة في التطوير فهذه الطريقة تعتبر أبسط نسبياً تعمل بمفردك أو مع فريق صغير وتعتبر هذه النقطة مهمة حيث أنه عند العمل بمفردك واستخدام ال spa يكون مجهوداً مضاعفاً لا تحتاج لدعم تطبيقات موبايل أو واجهات متعددة1 نقطة
-
ماذا افعل بعد ذالك؟
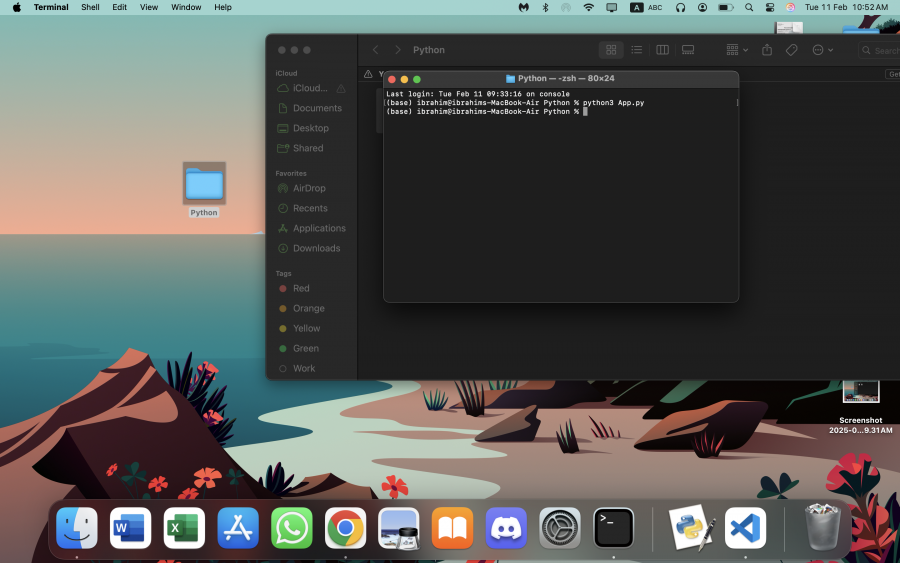 1 نقطة
1 نقطة