
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 02/10/25 in أجوبة
-
ما هي قيمة المبلغ المدفوع بالجنيه المصري وما هي الطريقه التي يمكنني بها استرداد استثمار خلال 6 أشهر ما هي الطريفه5 نقاط
-
السلام عليكم مثال انا عندي عمود زي دي فيه قيمه زي دي اغلب القيمه عبار عن 0.0 فا ازي اخلي النموذج مايكونش منحيز لقيمه دي ؟ وكمان القيمه الزي دي اي الافضل الطبقه الاخير sigmoid والا linear ؟ efs_combined 0.0 13268 5.8 329 5.5 326 5.2 322 5.6 317 ... 27.7 1 24.1 1 37.6 1 21.8 1 17.2 12 نقاط
-
السلام عليكم هل يوجد علاقه مابين الepochs والbatch-size في الشبكه العصبيه ؟2 نقاط
-
السلام عليكم هو امتي استخدم mean-absolute-error , mean-squared-error , root-mean-squared-error ؟2 نقاط
-
السلام عليكم انا بحثت كتير عن حل هذه المشكله ولاكن ما وجدتها ولا عرف سببها فحتى انا وقت بنشء مشروع من الصفر بتظهر ممكن مساعدة وسوف ارفق الاصدارات التي استخدمها package.json
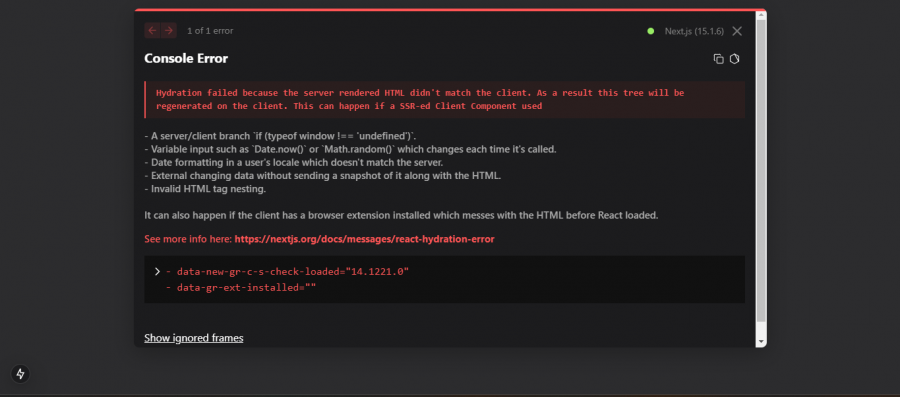 2 نقاط
2 نقاط -
نعم هذا السؤال غير متعلق بمشروع الدورة فهو مشروع جانبي لي2 نقاط
-
السلام عليكم ورحمة الله في الاسهم غالبا ما يعتمد على التحليل الفني طيب هذا عرفناه هل يوجد تخصصات في الاسهم او دراسات عليا وماهو ملخص عن الهندسة المالية وهل الخبراء في الاسهم يخسرون وما فائدة ما تعلموه اذا خسروا ياليت توضيح الفريق المتكامل في مستثمري الاسهم والمضاربين ارجوا اعطاء طريق يلم بجميع الخبرات في عالم الاسهم وشكرا . .1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. نعم بالفعل هناك علاقة بين عدد ال epochs و حجم ال batch size في تدريب الشبكات العصبية وهذه العلاقة تؤثر على أداء النموذج وتدريبه. إن ال epoch هو عندما يتم المرور مرة واحدة على كامل مجموعة البيانات (dataset) خلال عملية التدريب أى إذا وضعناه مثلا ب 2 سيتم تمرير البيانات بالكامل مرتين أثناء عملية التدريب. و كلما زاد عدد ال epochs، زادت فرصة النموذج في تعلم الأنماط في البيانات و لكن قد يؤدي ذلك إلى الإفراط في التخصيص (overfitting) إذا كان عدد الـ epochs كبيرا جدا. أما ال Batch Size فهو عدد العينات التي يتم معالجتها في كل خطوة (step) قبل تحديث أوزان النموذج. و كلما كان حجم ال batch size أكبر كانت عملية التدريب أسرع لأنه يتم تحديث الأوزان بعد معالجة عدد أكبر من العينات و لكن قد يتطلب ذلك ذاكرة أكبر. أما إذا كان حجم الـ batch size صغيرا فإن النموذج سيتم تحديثه بشكل متكرر مما قد ينتج عنه تقلبات كبيرة في عملية التدريب. مثال : إذا كان لديك batch size = 32 و عدد الـ epochs = 10 فإن النموذج سيتدرب 10 مرات على البيانات كاملة مع تحديث الأوزان بعد كل 32 عينة. و إذا قمت بزيادة batch size إلى 64 فإن عدد التحديثات في كل epoch سينخفض إلى النصف وقد تحتاج إلى زيادة عدد الـ epochs للحفاظ على نفس الأداء. إذا زيادة حجم ال batch size ستقلل من عدد التحديثات في كل epoch وقد تتطلب منك زيادة عدد ال epochs.وتقليل حجم ال batch size سيزيد من عدد التحديثات في كل epoch وقد يتطلب منك تقليل عدد ال epochs.1 نقطة
-
بالطبع وتؤثر بشكل مباشر على أداء النموذج ووقت التدريب، للتوضيح Epoch دورة واحدة تمر خلالها الشبكة على كامل بيانات التدريب مرة واحدة، بينما Batch Size هي عدد العينات التي تُعالَج معًا قبل تحديث أوزان النموذج مثلاً 32، 64، 128 عينة في كل خطوة. بالتالي لو لديك 1000 عينة وbatch size = 100، فسيكون لديك 10 خطوات لكل epoch أي يتم القسمة /. زيادة batch size يؤدي إلى تقليل عدد الخطوات في كل epoch لأنك تُعالج عينات أكثر في كل خطوة، وتحتاج إلى تقليل عدد الـ epochs لأن التحديثات تكون أقل تكرارًا ولكن أكثر استقرارًا. ولكن يؤدي إلى تعميم أسوأ Generalization بسبب تقليل الضجيج المفيد في التدرج، أيضًأ الحاجة إلى ذاكرة أكبر. أما تقليل batch size فأحيانًا تحتاج إلى زيادة عدد الـ epochs لأن التحديثات تصبح أكثر تكرارًا ولكنها أكثر ضجيجًا noisy، وسيصبح التدريب أبطأ بسبب التحديثات المتكررة.1 نقطة
-
MAE أو متوسط الخطأ المطلق تستخدمه لو تريد قياس سهل التفسير بنفس وحدة البيانات الأصلية، وفي وجود قيم متطرفة Outliers، حيث أن MAE أقل حساسية لها مقارنةً بـ MSE/RMSE لأنه لا يعاقب الأخطاء الكبيرة بشكل مبالغ فيه. أيضًا في حال جميع الأخطاء متساوية في الأهمية، بغض النظر عن حجمها مثل تكاليف ثابتة لكل خطأ. كالتنبؤ بأسعار المنازل في سوق مستقر، حيث الأخطاء الصغيرة والكبيرة لها تأثير مماثل على القرار. MSE أو متوسط مربع الخطأ مناسب لمعاقبة الأخطاء الكبيرة بشدة، بمعنى الأخطاء الكبيرة مُكلفة بشكل غير خطي كحوادث السيارات في التنبؤ بالسلامة. وعند استخدام خوارزميات تعتمد على التفاضل كالانحدار الخطي، حيث إن MSE قابل للتفاضل بسلاسة، وذلك يسهل عملية التحسين. لاحظ وحدة القياس هنا مربع الوحدة الأصلية مثل دولار²، وذلك يعقد التفسير المباشر. أما RMSE وهو جذر متوسط مربع الخطأ فمناسب لو تريد مقياسًا بنفس وحدة البيانات الأصلية مثل MAE لكن مع إعطاء وزن أكبر للأخطاء الكبيرة مثل MSE. وعند المقارنة بين نماذج مختلفة، حيث يُفضل RMSE عند الاهتمام بالحد من الأخطاء الكبيرة تحديدًا، كالتنبؤ بدرجات الحرارة في أنظمة الطقس، حيث الأخطاء الكبيرة كـ 10°C أكثر خطرًا من الصغيرة.1 نقطة
-
الف شكراا جدا حضرتك جزاك الله كل خير1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. Mean Absolute Error (MAE) : نستخدمه عندما نريد قياس الخطأ بشكل مباشر .وعندما يكون لديك بيانات تحتوي على قيم شاذة (Outliers) وتريد تقليل تأثيرها لأن MAE لا يضخم الأخطاء الكبيرة كما يفعل MSE. Mean Squared Error (MSE) : نستخدمه عندما نريد تضخيم نسبة الأخطاء الكبيرة بشدة لأنه يتم فيه تربيع الفروقات والذي يجعل الأخطاء الكبيرة تؤثر بشكل أكبر على النتيجة.وهو جيد عندما تكون القيم الشاذة غير مهمة لك أو تريد تضخيم تأثيرها وأيضا عندما يكون لديك نموذج تعلم آلة وتريد إعطاء أهمية أكبر للأخطاء الكبيرة مثل النماذج التي تحتاج إلى دقة عالية جدا مثل النماذج الطبية أو التي تحتاج إلى حسابات دقيقة مثل الإقتصاد وغيرها و التي يجب أن يكون نسبة الأخطاء بها صغيرة جدا والدقة عالية. Root Mean Squared Error (RMSE) : نستخدمه عندما نريد قياس الخطأ بنفس وحدات القياس الأصلية ولكننا في نفس الوقت نريد تضخيم الأخطاء الكبيرة بشكل أكبر كما في (MSE) وأيضا عندما يكون لديك تطبيقات تتطلب خطأ صغير جدا مثل تطبيقات التنبؤ بالأحوال الجوية أو الأنظمة الحساسة التي تتطلب دقة كبيرة. تلخيصا لم سبق : نستخدم MAE عندما نحتاج إلى مقياس خطأ بسيط لا يتأثر كثيرا بالقيم الشاذة. و نستخدم MSE عندما نريد تضخيم الأخطاء الكبيرة وإعطائها وزنا أكبر. و RMSE عندما نريد تفسير الخطأ بوحدة البيانات الأصلية ولكن مع تأثير للأخطاء الكبيرة. وإليك الإجابات التالية لكيفية إستخدامهم و المعادلة الخاصة لكل منهم :1 نقطة
-
لكتابة شفرات بايتون لم لانستعمل برنامج visual strudio , visuak studio code ?1 نقطة
-
هل الأصفار تمثل قيمًا صحيحة كغياب النشاط أو قيمًا مفقودة missing data؟ في حال مفقودة استخدم تقنيات مثل KNNImputer أو تعويضها بالمتوسط/المنوال، ولو صحيحة تعامل معها كجزء من التوزيع الطبيعي للبيانات. ولو المشكلة تصنيف Classification، فاستخدم تقنيات مثل SMOTE لإنشاء عينات جديدة للفئات النادرة، وحدد أوزانًا للفئات كالتالي TensorFlow: class_weight={0: 0.1, 1: 0.9}. أما لو المشكلة انحدار Regression جرب تحويل الـ Target باستخدام log(1 + y) لتقليل تأثير القيم الكبيرة، وحول المشكلة إلى تصنيف بتقسيم الـ Target إلى فئات (0، 5-10، 10-15، إلخ). أو أضف ميزة ثنائية binary feature تشير هل القيمة تساوي صفرًا أم لا. df['is_zero'] = df['efs_combined'].apply(lambda x: 1 if x == 0 else 0) أو استخدم نماذج مع Regularization ومنها L1/L2 في الانحدار الخطي لتجنب التركيز المفرط على الأصفار، كالتالي في Keras: model.add(Dense(64, kernel_regularizer='l2')) بخصوص اختيار الطبقة الأخيرة، ففي Binary Classification في حال تريد احتمالًا بين 0 و1 (وجود/عدم وجود حدث)، استخدم Sigmoid. model.add(Dense(1, activation='sigmoid')) في الإنحدار Regression لو تتنبأ بقيمة رقمية مستمرة كأسعار وقياسات، استخدم Linear. model.add(Dense(1, activation='linear'))1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. توجد عدة حلول لتلك المشكلة : إعادة توزيع البيانات بشكل متوازن : Oversampling: يمكنك زيادة عدد العينات للفئات الأقل مثل القيم الأخرى غير ال 0 عن طريق تكرارها. Undersampling: هنا يمكنك تقليل عدد العينات للفئة الأكثر وهي ال 0 عن طريق حذف بعض البيانات منها. SMOTE (Synthetic Minority Over-sampling Technique): هنا يمكنك إستخدام تلك التقنية والتي تقوم بإنشاء عينات جديدة للفئات الأقل عن طريق توليد بيانات وعينات أخرى. استخدام الأوزان (Class Weights) : عند استخدام نماذج معينة مثل الشبكات العصبية يمكنك تخصيص وزن أكبر للعينات الأقل تكرارا في بيانات التدريب مثل القيم التي تكون 5.8 أو 37.6 في المثال الخاص بك. وذلك لكي يتعلم النموذج تمثيلها بشكل أفضل. ويمكنك تعيين أوزان للفئات أثناء تدريب النموذج فمثلا في scikit-learn يمكنك استخدام class_weight='balanced' في العديد من النماذج. وفي TensorFlow أو PyTorch، يمكنك تعيين أوزان الفئات يدويا. مثال : from sklearn.linear_model import LogisticRegression class_weights = {0: 1, 1: 10} model = LogisticRegression(class_weight=class_weights) model.fit(X_train, y_train) تعديل دالة الخسارة (Loss Function) : يمكنك استخدام دالة خسارة Focal Loss والتي يتم إستخدامها عندما لا يكون هنا توزيع متوازن للبيانات والتي تقوم بإعطاء وزن أكبر للعينات الأقل .مثال : import tensorflow as tf def focal_loss(gamma=2., alpha=.25): def focal_loss_fixed(y_true, y_pred): pt = tf.where(tf.equal(y_true, 1), y_pred, 1 - y_pred) return -tf.reduce_sum(alpha * tf.pow(1. - pt, gamma) * tf.math.log(pt)) return focal_loss_fixed model.compile(optimizer='adam', loss=focal_loss(), metrics=['accuracy']) أما بخصوص الطبقة الأخيرة فإن Sigmoid يستخدم غالبا في المشاكل الثنائية (Binary Classification) حيث يكون المخرج بين 0 و 1. بينما Linear: يستخدم في مشاكل الانحدار (Regression) حيث يكون المخرج قيمة حقيقية.وهنا إذا كنت تحاول التنبؤ بقيمة مستمرة مثل efs_combined فمن الأفضل أن تكون الطبقة الأخيرة خطية (Linear) . أما إذا كنت تقوم بتصنيف ثنائي مثل هل القيمة أكبر من صفر أم لا أى تتوقع الناتج قيمة 0 أو 1 فيفضل إستخدام Sigmoid.1 نقطة
-
شكرا كتير كتير انحلت الحمد لله1 نقطة
-
لم اجد الا هذه النافذة بعد تحميل python وبعض الاوامر فيها تختلف عن IDLE لم اجد ال IDLE
.thumb.png.28309ae4a745e9c7d95afe8d075f2160.png) 1 نقطة
1 نقطة
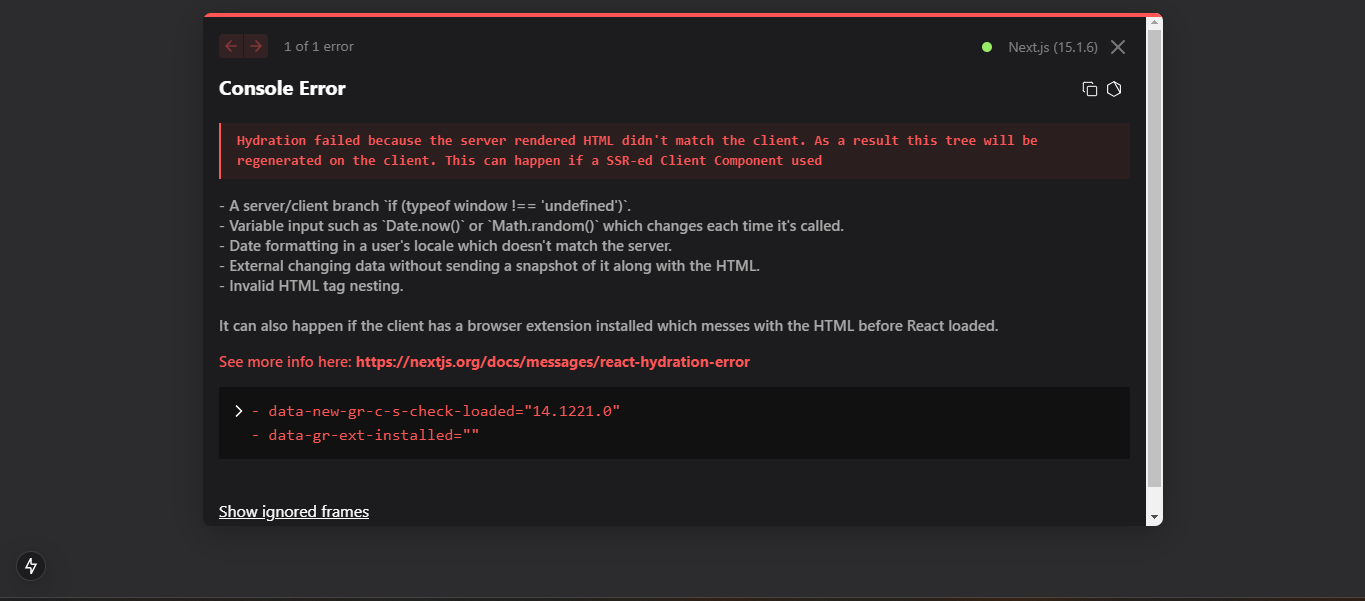




.png.fe2546d49c4000fb772d7b75fdf2c482.png)