لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 10/04/24 في كل الموقع
-
 يعد إطار عمل لارافيل Laravel واحدًا من أهم أطر عمل PHP وأكثرها شهرة وقوة، فقد تمكن لارافيل من إثبات جدارته واحتلال مواقع متصدرة بين نظم تطوير تطبيقات الويب لما يتمتع به من ميزات أبرزها توفير الكثير من الوظائف البرمجية الجاهزة التي تجعل تطوير الويب أسهل وأسرع، واهتمامه الخاص بأمن مواقع الويب وحمايتها من الثغرات الأمنية. فإذا كنت تتساءل ما هو لارافيل Laravel وما فوائد استخدامه، وترغب في التعرف على أبرز مميزاته وعيوبه، واكتشاف أفضل المصادر العربية التي تمكنك من تعلم لارافيل واستخدامه في إنشاء مواقع وتطبيقات ويب بميزات متقدمة فهذا المقال لك. ما هو لارافيل Laravel لارافيل Laravel هو إطار عمل مفتوح المصدر مبني على لغة PHP يستخدم لتطوير تطبيقات الويب، طوره تايلور أوتويل Taylor Otwell عام 2011 ليمكّن المطورين من إنشاء تطبيقات ويب متكاملة الميزات بسهولة وسرعة من خلال توفير أكثر المهام والوظائف الشائعة التي يحتاجونها في مشاريع الويب. وإطار العمل Framework هو باختصار بيئة توفر مجموعة من الوظائف والأدوات الجاهزة المكتوبة مسبقًا والتي يستخدمها المبرمجون والمطورون لتسهل عليه عملهم في التطوير وتمكنهم من أداء المطلوب باستخدام أقل قدر من التعليمات البرمجية، وللمزيد من المعلومات أنصح بالاطلاع على مقال تعرف على مفهوم إطار العمل Framework وأهميته في البرمجة لقد عزز إطار العمل لارافيل من قوة لغة PHP وساهم في استمراريتها وديمومتها، حيث أنه وفر للمبرمجين طريقة أكثر كفاءة في التعامل معها وبسّط كتابة تعليماتها المعقدة نوعًا ما وجعل تطوير تطبيقات الويب باستخدامها أسرع وأسهل. إصدارات لارافيل Laravel قبل إصدار لارافيل 9 كان فريق لارافيل يوفر إصدارًا رئيسيًا كل ستة أشهر بمعدل نسختين رئيسيتين سنويًا لتخفيف أعباء الصيانة، لكن تقرر بعد ذلك توفير الإصدارات الجديدة بشكل سنوي. يتطور لارافيل Laravel بسرعة فائقة مع مرور الوقت ويضيف تحسينات وميزات ووظائف جديدة تواكب اتجاهات السوق المتغيرة باستمرار أو يغير بعض الوظائف أو يلغيها لذلك من الضروري معرفة الإصدار الذي تستخدمه في تطوير مشاريعك. وإليك قائمة بأهم إصدارات لارافيل laravel وتاريخ صدورها: أطلق الإصدار الأول لارافيل 1.0 في 9 يونيو/حزيران 2011 توالت بعدها الإصدارات لغاية لارافيل 8 الذي تم إطلاقه في 8 سبتمبر/أيلول 2020 وهو الإصدار العشرين من Laravel ولم تعد كافة هذه الإصدارات تتلقى تحديثات أمنية لذا يفضل أن تتم ترقية التطبيقات المبنية بأحدها لإصدار أحدث لمنع الثغرات الأمنية والوصول إلى الميزات الجديدة. صدر لارافيل 9 بتاريخ 8 فبراير 2022 ويتطلب هذا الإصدار نسخة PHP 8.0 كحد أدنى. صدر لارافيل 10 بتاريخ 7 فبراير 2023 وتضمن العديد من الميزات الجديدة التي تعزز أداء تطبيقات الويب وأمانها ووظائفها ويتطلب هذا الإصدار نسخة 8.1 من لغة PHP كحد أدنى. ومن المتوقع أن يصدر لارافيل 11 في الربع الأول من عام 2024، وللمزيد من التفاصيل يمكنك مطالعة الصفحة التالية لكافة إصدارات لارافيل، والجدير بالذكر أن لارافيل قد أثبت كفاءته لأكثر من عقد من الزمن وتمكن من فرض نفسه كأحد أكثر أطر PHP شيوعًا وتفضيلًا من قبل مطوري الويب بفضل طريقة تنظيمه الأنيقة وميزاته القوية. أهمية إطار لارافيل في سوق العمل يعد لارافيل أحد أشهر أطر عمل PHP وأكثرها استخدامًا ويملك مجتمعًا كبيرًا من المطورين الذين يوفرون الكثير من المكتبات والحزم الجاهزة والمتاحة للاستخدام بسهولة. كما يعد لارافيل أحد المهارات المطلوبة بشدة في سوق العمل، ويبحث الكثير من أرباب العمل عن مطورين محترفين في استخدام إطار العمل لارافيل لتطوير تطبيقاتهم ومواقعهم الإلكترونية ولا عجب في ذلك فهو واحد من أسرع أطر عمل PHP نموًا وأكثرها غنىً بالميزات. وتستخدم العديد من المواقع الكبرى لارافيل في تطوير تطبيقاتها الخاصة،فبحسب موقع builtwith الذي يحدد التقنيات المستخدمة في إنشاء المواقع هناك 1,175,772 موقع ويب مبني باستخدام إطار عمل Laravel ولك أن تتخيل مدى شعبيته. كما يلبي لارافيل كافة متطلبات العمل لكونه يعتمد على لغة PHP العريقة التي تعد واحدة من أقوى لغات البرمجة من جانب الخادم والتي تستخدم في تطوير ملايين المواقع الإلكترونية من بينها مواقع شهيرة مثل فيسبوك وويكيبيديا. فإذا كنت مهتمًا بمجال تطوير الويب فتعلم إطار عمل لارافيل Laravel يوفر لك الكثير من الفرص المميزة في مجال تطوير تطبيقات الويب ويمكنك من إنشاء كافة أنواع التطبيقات والمواقع الإلكترونية سواء المواقع البسيطة للشركات الناشئة منها أو المواقع المتقدمة كمواقع التجارة الإلكترونية بسرعة واحترافية. ويتنافس إطار عمل لارافيل مع أطر عمل تطوير الويب الأخرى في سوق العمل مثل جانغو Django المبني باستخدام لغة البرمجة بايثون Python والتي تعتبر أسرع من لغة PHP وأكثر شعبية منها، وإطار عمل إكسبريس Express المبني باستخدام لغة جافا سكريبت أحد أكثر لغات البرمجة شهرة واستخدامًا بين أوساط المطورين، وإطار عمل ريلز Rails المبني باستخدام لغة البرمجة روبي Ruby المحببة للمبتدئين، تقدم معظم أطر العمل ميزات متشابهة وكي تتمكن من اختيار إطار العمل الأنسب لك عليك أن تأخذ عدة أمور بعين الاعتبار مثل لغة البرمجة التي تفضل تعلمها وطبيعة المشاريع التي تعمل عليها، ولمزيد من التفاصيل حول أشهر أطر عمل تطوير الويب أنصح بمطالعة مقال مقارنة بين Django و Laravel و Rails. مميزات لارافيل Laravel لاشك أن لارافيل Laravel ليس إطار العمل الوحيد المتاح اليوم بل هو واحد من بين عشرات أطر عمل تطوير الويب، وقد تتساءل لماذا أستخدم لارافيل دونًا عن غيره؟ وما الذي يميزه عن غيره من أطر عمل تطوير الويب؟ في الواقع نجد تحيز من قبل المبرمجين لاختيار لارافيل دون غيره نظرًا لما يتمتع به من ميزات، وإليك قائمة بأهم 10 مميزات لإطار لارافيل: سهولة التعلم والاستخدام. تسريع وقت التطوير. التوثيق الجيد. غني بالميزات وقابل للتوسيع. يهتم بأمان التطبيقات. يحسن أداء التطبيقات. يدعم تعدد اللغات. يسهل تصحيح أخطاء التطبيقات وصيانتها. يوفر نظام لتهجير البيانات Migration. يوفر نظام التوجيه Routing. لنناقش كل خاصية من هذه الخواص بمزيد من التفصيل ونكتشف أهميتها في تطوير الويب. 1. سهولة التعلم والاستخدام يتميز لارافيل بكود سهل التعلم والاستخدام، لكنه بالطبع يشترط امتلاك معرفة مسبقة بأساسيات PHP ومبادئ البرمجة كائنية التوجه OOP إلى جانب وجود معرفة جيدة حول HTML وأحد أنظمة إدارة قواعد البيانات مثل MySQL أو PostgreSQL بعدها سيكون تعلم لارافيل أمرًا في غاية البساطة. 2. تسريع وقت التطوير يتضمن لارافيل Laravel العديد من الوظائف التي تسهل على المطور تنفيذ المهام الشائعة مثل عمليات المصادقة authentication، والتوجيه routing، وتهجير قواعد البيانات migrating، والتخزين المؤقت cach، فكل هذه الوظائف مضمنة ومدمجة في نظام لارافيل وجاهزة لتستخدمها بكل سهولة. كما يتضمن واجهة سطر أوامر مدمجة تسمى آرتيزان Artisan توفر مجموعة من الأوامر المفيدة في بناء تطبيقات الويب، وبالجمع بين أوامر آرتيزان والوظائف المضمنة تصبح عملية تطوير تطبيقات الويب أسرع بكثير. 3. التوثيق الجيد يحتوي لارافيل Laravel على توثيق مميز عبر الإنترنت يساعد المطورين والمبرمجين في تعلم كل ما يحتاجونه والعثور على إجابات لكافة تساؤلاتهم حول التعامل مع هذا الإطار، كما تتوفر معلومات هائلة متاحة من مجتمع مطوري لارافيل. المشكلة الوحيدة التي توجد في هذه المصادر هو أنها متاحة باللغة الإنجليزية وشرحها جامد إلى حد ما، وفي فقرة تعلم لارافيل سأطلعك على مصادر عربية جيدة تساعدك في تعلم لارافيل. 4. غني بالميزات وقابل للتوسيع يعد لارافيل نظامًا قويًا وغنيًا بالكثير من الميزات المضمنة ويوفر مجموعة متنوعة من المكتبات المضمنة التي تساعدك على بناء تطبيقات متقدمة تعالج ملايين الطلبات بفضل دعمه للتخزين المؤقت السريع والتخزين الموزع، كما يوفر لارافيل منصات سحابية خفية الخوادم Serverless مثل Laravel Forge و Vapor تمكنك من نشر التطبيقات وتشغيلها دون الحاجة إلى إدارة الخوادم وهي منصات قابلة للتوسيع التلقائي بكل سهولة. أضف إلى ذلك يوفر مطوروا لارافيل الكثير من الحزم الخارجية لأي وظيفة أو ميزة تحتاجها، على سبيل المثال يمكنك باستخدام مكتبة Socialite تضمين ميزة تسجيل الدخول إلى موقعك باستخدام حسابات شبكات التواصل الاجتماعي على فيسبوك أو تويتر أو لينكدإن أو جيتهب أو جوجل بكل سهولة. 5. يهتم بأمان التطبيقات يمكنك لارافيل من تطوير مواقع وتطبيقات آمنة بفضل العديد من ميزات الأمان المدمجة مثل نظام المصادقة أو الاستيثاق المدمج authentication system ونظام المصادقة authorization والتحقق من صحة البيانات data validation وتشفير البيانات والتحقق من البريد الإلكتروني وإعادة تعيين كلمة المرور، كما يسهل عليك تكوين ميزات الأمان المتقدمة التي تحمي تطبيقاتك من الاختراق وتضمن أمان بيانات عملائك. 6. يحسن أداء التطبيقات يوفر لارافيل عدة طرق لتحسين سرعة التطبيقات وتحسين أدائها مثل دعم التخزين المؤقت لموقعك الإلكتروني على الخادم، كما أنه يسهل تنفيذ تقنيات أخرى لتحسين السرعة مثل تقليل استخدام الذاكرة وفهرسة قاعدة البيانات. فإذا كانت سرعة الموقع أولوية لديك فإن لارافيل خيارك الأنسب. 7. يدعم تعدد اللغات فمن خلال ميزة التوطين localization يمكنك لارافيل من إنشاء تطبيقات متعددة اللغات واسترداد السلاسل النصية بلغات مختلفة، وهو يدعم عدة لغات من بينها اللغة العربية. 8. يسهل تصحيح أخطاء التطبيقات وصيانتها يحتوي لارافيل على ميزات تختبر كل جزء من موقع الويب الخاص بك للبحث عن أي أخطاء ويعرض لك رسائل واضحة ومفصلة تبين كافة الأخطاء التي تحدث في موقعك ويسهل عليك تصحيحها، كما أنه يسهل صيانة التطبيقات بفضل ميزات الكود النظيف واعتماد مبادئ البرمجة كائنية التوجه OOP ومعمارية MVC التي تنظم الكود وتمكن أي مطور من متابعة العمل على مشروع سابق وتطويره وإضافة الميزات المطلوبة له. 9.يوفر نظام تهجير البيانات Migration يوفر لارافيل ميزة تهجير البيانات Migration التي توفر آليات لإنشاء وتعديل جداول قاعدة البيانات كما يوفر آلية شبيهة بنظام التحكم في الإصدارات لقاعدة البيانات الخاصة بك تتعقب كيفية تعديل قاعدة البيانات مع الوقت وتسمح لكافة أعضاء فريق التطوير بتعديل قاعدة بيانات المشروع ومشاركته فيما بينهم وتسهل حذف قاعدة البيانات وإعادة إنشائها عند الضرورة. وللمزيد من التفاصيل حول هذه الميزة يمكنك مطالعة مقال تهجير قواعد البيانات في لارافيل 5 10. يوفر نظام التوجيه Routing يوفر لارافيل نظام توجيه Routing قوي لمعالجة وإدارة مسارات تطبيق الويب ويُمكِّنك من الانتقال من مكان لآخر في تطبيقك وتبادل المعلومات بينها بسهولة، كما يمكّنك من استخدام أسماء بسيطة ترتبط بأجزاء مختلفة من تطبيقك بدلاً من الأسماء الطويلة والمربكة، ستجد كافة المسارات الخاصة بالتطبيق في الملف web.php ضمن المجلد routes لمشروعك وللمزيد من التفاصيل يمكنك الاطلاع على توثيق التوجيه Routing في لارافيل. عيوب لارافيل Laravel لا تخلو أي تقنية مهما كانت متقدمة من بعض العيوب ومن بينها لارافيل، فهو يملك بعض جوانب النقص وإليك قائمة بأبرز عيوب لارافيل: يعتبر إطار عمل لارافيل بطيئًا نسبيًا عند مقارنته ببعض أطر تطوير الويب الأخرى. رغم كونه آمنًا بشكل كبير إلا أنه لا يزال مهددًا باستهدافه بالثغرات الأمنية بسبب اعتماده على PHP التي وسمت بكثرة الثغرات الأمنية فيها تحديدًا في الإصدارات القديمة منها. تكلفته عالية فالمواقع المطورة بإطار لارافيل قد تكون أغلى نسبيًا من المواقع المطورة بغيرها من تقنيات الويب كأنظمة إدارة المحتوى أو أطر العمل الأخرى وهذا رغم كونه عامل قوة لك كمطور لكنه قد يجعل بعض العملاء يفضلون الخيارات الأرخص. وجود تحديثات متكررة قد يجعلك تواجه صعوبات في تعلم الجديد في كل إصدار وتعديل شيفرة تطبيقاتك المطورة بإصدارات قديمة لذا يجب أن تكون لديك رغبة مستمرة في التعلم كي تتلاءم مع كل إصدار جديد. كانت هذه قائمة بأبرز عيوب أو سلبيات لارافيل Laravel، وبموازنة السلبيات والإيجابيات يمكن أن تقرر فيما إذا كان إطار لارافيل سيلبي احتياجاتك أم لا. تنظيم الكود في لارافيل Laravel يتميز إطار لارافيل Laravel بكود منظم وسهل الصيانة يحافظ على تنظيم مشاريعك البرمجة من خلال استخدامه معمارية MVC وهي اختصار لثلاث كلمات هي: النموذج Model الذي يعني بيانات التطبيق فهو يتفاعل مباشرة مع قاعدة البيانات الخاصة بك ويسترد المعلومات منها. العرض View الذي يعني واجهة التطبيق فهو يعرض الصفحات التي يتفاعل معها المستخدم مباشرة. المتحكم Controller وهو صلة الوصل بين العرض والنموذج فهو يستقبل طلبات المستخدمين ويسترد البيانات المطلوبة من النموذج ويعالجها ويرسلها إلى صفحات العرض. وباستخدام هذا الأسلوب التنظيمي يستطيع لارافيل فصل كود التطبيق إلى ثلاث مجموعات لكل منها وظيفة محددة وهي الواجهة الخلفية والواجهة الأمامية ووحدة التحكم للربط بين الواجهتين وهذه الميزة تجعل من لارافيل أفضل إطار عمل PHP لتطبيقات الويب. بالإضافة إلى ذلك يستخدم لارافيل المسارات routes لتعيين عناوين URL الخاصة بإجراءات متحكم معين، فعندما يقوم المستخدم بإدخال عنوان URL خاص بالتطبيق يعين المسار المرتبط بهذا العنوان عنوان URL للمتحكم المسؤول عن استرداد البيانات المطلوبة من قاعدة البيانات أو النموذج ويمررها إلى صفحات العرض النهائية. كيف أتعلم لارافيل Laravel؟ بعد أن تعرفنا على إطار عمل لارافيل وأهم مميزاته واستخداماته، سنوضح لك في هذه الفقرة طريقة تعلم لارافيل وأهم الخطوات التي عليك اتباعها كي تحترفه. قبل أن تبدأ بتعلم لارافيل يجب أن تكون على دراية بأساسيات تطوير الويب والمفاهيم الأساسية في HTML و CSS. يجب أن تتعلم أساسيات البرمجة بلغة PHP وتتمكن من كتابة برامج PHP بسيطة وتعرف كذلك مبادئ البرمجة كائنية التوجه OOP. تعلم المكونات الأساسية لإطار عمل لارافيل ومعمارية MVC ومفاهيم النماذج وصفحات العرض والمتحكمات من خلال مصادر التعلم التي تفضلها سواء كانت مواقع الإنترنت أو الكتب أو الدورات التعليمية واحرص على تحديد خطة للتعلم والتزم بها كي تحقق أهدافك. طور مشاريع تطبق فيها ما تعلمته، فالتطبيق العملي طريقة رائعة لتعلم المفاهيم التي تعلمتها، ابدأ بمشروع بسيط ثم انتقل إلى مشاريع أكثر تقدمًا فهذا يساعدك على إنشاء معرض أعمال يعزز مسيرتك المهنية. لا تتوقف عن التعلم واطلع على كل جديد في مجال تطوير الويب عمومًا وإطار لارافيل على وجه الخصوص، فالتقنيات تتطور بسرعة والتعلم المستمر يساعدك على التكيف مع أي تطور جديد والبقاء في الصدارة. مصادر تعلم لارافيل Laravel إذا كنت تبحث عن مصدر عربي موثوق لتعلم لارافيل من الصفر للاحتراف بشهادة معتمدة تعزز فرصتك في سوق العمل ستجد في أكاديمية حسوب دورة تطوير تطبيقات الويب باستخدام لغة PHP وهي دورة تدريبية عالية الجودة تضم مسارات متعددة ولا تتطلب منك أي معرفة مسبقة وتعلمك كل ما يخص لغة PHP وإطار عملها لارافيل وتدمج بين الشرح النظري والتطبيق العملي، فمن خلالها ستتعلم تطوير العديد من تطبيقات الويب المتكاملة وتبني من خلالها معرض أعمال قوي، كما ستتمكن من خلال هذه الدورة من التواصل مع مدربين أكفاء وطرح أي سؤال أو مشكلة تواجهك عند تطبيق مشروعك البرمجي. كما ستجد في أكاديمية حسوب الكثير من مصادر التعلم المجانية مثل المقالات والدروس المتنوعة حول PHP وحول إطار عمل لارافيل Laravel، وبالإضافة لكل ما سبق فقد ترجمت موسوعة حسوب توثيق لارافيل الأجنبي إلى اللغة العربية ويمكنك من خلاله أن تتعرف على كل ما يخص هذا الإطار بتسلسل منظم وواضح. تنصيب لارافيل Laravel كي تتمكن من التعامل مع مشاريع لارافيل في حاسوبك المحلي عليك اتباع مجموعة من الخطوات وهي كالتالي: أول خطوة قبل البدء بتثبيت لارافيل Laravel على جهازك المحلي هي تحويل حاسوبك إلى خادم ويب محلي كي يتمكن من تشغيل PHP و نظام إدارة قواعد البيانات مثل MySQL أو PostgreSQL، يمكنك القيام بذلك باستخدام XAMPP المتوافق مع كافة أنظمة التشغيل. عليك كذلك تثبيت أي محرر أكواد أو بيئة تطوير متكاملة IDE ترغب بها لتحرير أكواد مشروعك مثل PhpStorm أو Visual Studio Code أو أي محرر آخر تتآلف معه. بعدها عليك تثبيت مدير الحزم كومبوزر Composer لتحميل إطار لارافيل من خلاله، وهو ضروري لتحديد المكتبات التي يحتاجها مشروعك بكل سهولة وإدارتها بالنيابة عنك. وللمزيد يمكنك مطالعة مقال ما هو Composer ولماذا يجب على كل مطور PHP استخدامه. الآن يمكنك تثبيت لارافيل على جهازك، وأبسط طريقة لتحميل لارافيل هي تشغيل محرر الأوامر في نظامك والانتقال للمسار الذي تريد إنشاء مشروع لارافيل الخاص بك فيه ثم كتابة الأمر التالي، هنا أنشأنا مشروع لارافيل باسم example-app composer create-project laravel/laravel example-app لتشغيل المشروع انتقل إلى مجلد مشروعك وهو في حالتنا D:\example-app ونفذ الأمر التالي: D:\cd example-app D:\example-app>php artisan serve هذا الأمر سيشغل تطبيق لارافيل على خادم تطوير PHP وينتج عن تنفيذه عرض رابط المشروع بالشكل التالي http://127.0.0.1:8000، كل ما عليك هو نسخ هذا الرابط ولصقه في المستعرض لتظهر لك الصفحة الرئيسية لموقع لارافيل الخاص بك كما هو موضح في الصورة التالية. ولإيقاف تشغيل خادم التطوير من خلال سطر الأوامر اضغط على مفتاحي Ctrl+C في لوحة المفاتيح. ولمزيد من المعلومات حول تثبيت لارافيل يمكنك مطالعة مقال تثبيت وإعداد لارافيل Laravel على دوكر كومبوز Docker Compose ومقال تثبيت Laravel 5 وإعداده على Windows وUbuntu. أخيرًا أنصحك أن تفتح مشروع في محرر الشيفرات الذي اخترته وتتعرف على بنية المجلدات في Laravel وتفهم دورها في المشروع ومساهمتها في نموذج MVC المستخدم في إطار العمل لارافيل. هذا كل شيء! أنت جاهز الآن لتبدأ رحلتك في اكتشاف لارافيل والبدء بتعلمه. الخلاصة اكتشفنا في مقال اليوم ما هو إطار عمل لارافيل Laravel وأهميته في سوق العمل، وتعرفنا على أهم المميزات التي يقدمها في مجال تطوير مواقع وتطبيقات الويب، كما تعرفنا على كيفية تنصيب لارافيل وبدء التعامل معه وأهم مصادر تعلمه. وسواء كنت مطورًا مبتدئًا أو خبيرًا في برمجة تطبيقات الويب فإن لارافيل Laravel خيار مناسب لك تمامًا فهو يوفر لك بيئة تطوير سهلة وقوية ويقدم لك الكثير من الميزات والوظائف المبرمجة مسبقًا التي تمكنك من بناء تطبيقات ويب احترافية وعالية الجودة بسرعة وسهولة. لا تتردد وابدأ من اليوم بتعلم لارافيل وإن اعترضك أي سؤال حوله شاركنا إياه في قسم التعليقات أسفل المقال. اقرأ أيضًا دليل مطوّري PHP للبدء في بناء تطبيقات Laravel - الجزء الأوّل دليل مطوّري PHP للبدء في بناء تطبيقات Laravel - الجزء الثاني رفع الملفّات وإدارتها في تطبيقات Laravel تجريد إعداد قواعد البيانات في لارافيل باستعمال عملية التهجير Migration والبذر Seeder لارافيل للمبتدئين-الجزء الأول: البدء في إنشاء مدونة بسيطة1 نقطة
يعد إطار عمل لارافيل Laravel واحدًا من أهم أطر عمل PHP وأكثرها شهرة وقوة، فقد تمكن لارافيل من إثبات جدارته واحتلال مواقع متصدرة بين نظم تطوير تطبيقات الويب لما يتمتع به من ميزات أبرزها توفير الكثير من الوظائف البرمجية الجاهزة التي تجعل تطوير الويب أسهل وأسرع، واهتمامه الخاص بأمن مواقع الويب وحمايتها من الثغرات الأمنية. فإذا كنت تتساءل ما هو لارافيل Laravel وما فوائد استخدامه، وترغب في التعرف على أبرز مميزاته وعيوبه، واكتشاف أفضل المصادر العربية التي تمكنك من تعلم لارافيل واستخدامه في إنشاء مواقع وتطبيقات ويب بميزات متقدمة فهذا المقال لك. ما هو لارافيل Laravel لارافيل Laravel هو إطار عمل مفتوح المصدر مبني على لغة PHP يستخدم لتطوير تطبيقات الويب، طوره تايلور أوتويل Taylor Otwell عام 2011 ليمكّن المطورين من إنشاء تطبيقات ويب متكاملة الميزات بسهولة وسرعة من خلال توفير أكثر المهام والوظائف الشائعة التي يحتاجونها في مشاريع الويب. وإطار العمل Framework هو باختصار بيئة توفر مجموعة من الوظائف والأدوات الجاهزة المكتوبة مسبقًا والتي يستخدمها المبرمجون والمطورون لتسهل عليه عملهم في التطوير وتمكنهم من أداء المطلوب باستخدام أقل قدر من التعليمات البرمجية، وللمزيد من المعلومات أنصح بالاطلاع على مقال تعرف على مفهوم إطار العمل Framework وأهميته في البرمجة لقد عزز إطار العمل لارافيل من قوة لغة PHP وساهم في استمراريتها وديمومتها، حيث أنه وفر للمبرمجين طريقة أكثر كفاءة في التعامل معها وبسّط كتابة تعليماتها المعقدة نوعًا ما وجعل تطوير تطبيقات الويب باستخدامها أسرع وأسهل. إصدارات لارافيل Laravel قبل إصدار لارافيل 9 كان فريق لارافيل يوفر إصدارًا رئيسيًا كل ستة أشهر بمعدل نسختين رئيسيتين سنويًا لتخفيف أعباء الصيانة، لكن تقرر بعد ذلك توفير الإصدارات الجديدة بشكل سنوي. يتطور لارافيل Laravel بسرعة فائقة مع مرور الوقت ويضيف تحسينات وميزات ووظائف جديدة تواكب اتجاهات السوق المتغيرة باستمرار أو يغير بعض الوظائف أو يلغيها لذلك من الضروري معرفة الإصدار الذي تستخدمه في تطوير مشاريعك. وإليك قائمة بأهم إصدارات لارافيل laravel وتاريخ صدورها: أطلق الإصدار الأول لارافيل 1.0 في 9 يونيو/حزيران 2011 توالت بعدها الإصدارات لغاية لارافيل 8 الذي تم إطلاقه في 8 سبتمبر/أيلول 2020 وهو الإصدار العشرين من Laravel ولم تعد كافة هذه الإصدارات تتلقى تحديثات أمنية لذا يفضل أن تتم ترقية التطبيقات المبنية بأحدها لإصدار أحدث لمنع الثغرات الأمنية والوصول إلى الميزات الجديدة. صدر لارافيل 9 بتاريخ 8 فبراير 2022 ويتطلب هذا الإصدار نسخة PHP 8.0 كحد أدنى. صدر لارافيل 10 بتاريخ 7 فبراير 2023 وتضمن العديد من الميزات الجديدة التي تعزز أداء تطبيقات الويب وأمانها ووظائفها ويتطلب هذا الإصدار نسخة 8.1 من لغة PHP كحد أدنى. ومن المتوقع أن يصدر لارافيل 11 في الربع الأول من عام 2024، وللمزيد من التفاصيل يمكنك مطالعة الصفحة التالية لكافة إصدارات لارافيل، والجدير بالذكر أن لارافيل قد أثبت كفاءته لأكثر من عقد من الزمن وتمكن من فرض نفسه كأحد أكثر أطر PHP شيوعًا وتفضيلًا من قبل مطوري الويب بفضل طريقة تنظيمه الأنيقة وميزاته القوية. أهمية إطار لارافيل في سوق العمل يعد لارافيل أحد أشهر أطر عمل PHP وأكثرها استخدامًا ويملك مجتمعًا كبيرًا من المطورين الذين يوفرون الكثير من المكتبات والحزم الجاهزة والمتاحة للاستخدام بسهولة. كما يعد لارافيل أحد المهارات المطلوبة بشدة في سوق العمل، ويبحث الكثير من أرباب العمل عن مطورين محترفين في استخدام إطار العمل لارافيل لتطوير تطبيقاتهم ومواقعهم الإلكترونية ولا عجب في ذلك فهو واحد من أسرع أطر عمل PHP نموًا وأكثرها غنىً بالميزات. وتستخدم العديد من المواقع الكبرى لارافيل في تطوير تطبيقاتها الخاصة،فبحسب موقع builtwith الذي يحدد التقنيات المستخدمة في إنشاء المواقع هناك 1,175,772 موقع ويب مبني باستخدام إطار عمل Laravel ولك أن تتخيل مدى شعبيته. كما يلبي لارافيل كافة متطلبات العمل لكونه يعتمد على لغة PHP العريقة التي تعد واحدة من أقوى لغات البرمجة من جانب الخادم والتي تستخدم في تطوير ملايين المواقع الإلكترونية من بينها مواقع شهيرة مثل فيسبوك وويكيبيديا. فإذا كنت مهتمًا بمجال تطوير الويب فتعلم إطار عمل لارافيل Laravel يوفر لك الكثير من الفرص المميزة في مجال تطوير تطبيقات الويب ويمكنك من إنشاء كافة أنواع التطبيقات والمواقع الإلكترونية سواء المواقع البسيطة للشركات الناشئة منها أو المواقع المتقدمة كمواقع التجارة الإلكترونية بسرعة واحترافية. ويتنافس إطار عمل لارافيل مع أطر عمل تطوير الويب الأخرى في سوق العمل مثل جانغو Django المبني باستخدام لغة البرمجة بايثون Python والتي تعتبر أسرع من لغة PHP وأكثر شعبية منها، وإطار عمل إكسبريس Express المبني باستخدام لغة جافا سكريبت أحد أكثر لغات البرمجة شهرة واستخدامًا بين أوساط المطورين، وإطار عمل ريلز Rails المبني باستخدام لغة البرمجة روبي Ruby المحببة للمبتدئين، تقدم معظم أطر العمل ميزات متشابهة وكي تتمكن من اختيار إطار العمل الأنسب لك عليك أن تأخذ عدة أمور بعين الاعتبار مثل لغة البرمجة التي تفضل تعلمها وطبيعة المشاريع التي تعمل عليها، ولمزيد من التفاصيل حول أشهر أطر عمل تطوير الويب أنصح بمطالعة مقال مقارنة بين Django و Laravel و Rails. مميزات لارافيل Laravel لاشك أن لارافيل Laravel ليس إطار العمل الوحيد المتاح اليوم بل هو واحد من بين عشرات أطر عمل تطوير الويب، وقد تتساءل لماذا أستخدم لارافيل دونًا عن غيره؟ وما الذي يميزه عن غيره من أطر عمل تطوير الويب؟ في الواقع نجد تحيز من قبل المبرمجين لاختيار لارافيل دون غيره نظرًا لما يتمتع به من ميزات، وإليك قائمة بأهم 10 مميزات لإطار لارافيل: سهولة التعلم والاستخدام. تسريع وقت التطوير. التوثيق الجيد. غني بالميزات وقابل للتوسيع. يهتم بأمان التطبيقات. يحسن أداء التطبيقات. يدعم تعدد اللغات. يسهل تصحيح أخطاء التطبيقات وصيانتها. يوفر نظام لتهجير البيانات Migration. يوفر نظام التوجيه Routing. لنناقش كل خاصية من هذه الخواص بمزيد من التفصيل ونكتشف أهميتها في تطوير الويب. 1. سهولة التعلم والاستخدام يتميز لارافيل بكود سهل التعلم والاستخدام، لكنه بالطبع يشترط امتلاك معرفة مسبقة بأساسيات PHP ومبادئ البرمجة كائنية التوجه OOP إلى جانب وجود معرفة جيدة حول HTML وأحد أنظمة إدارة قواعد البيانات مثل MySQL أو PostgreSQL بعدها سيكون تعلم لارافيل أمرًا في غاية البساطة. 2. تسريع وقت التطوير يتضمن لارافيل Laravel العديد من الوظائف التي تسهل على المطور تنفيذ المهام الشائعة مثل عمليات المصادقة authentication، والتوجيه routing، وتهجير قواعد البيانات migrating، والتخزين المؤقت cach، فكل هذه الوظائف مضمنة ومدمجة في نظام لارافيل وجاهزة لتستخدمها بكل سهولة. كما يتضمن واجهة سطر أوامر مدمجة تسمى آرتيزان Artisan توفر مجموعة من الأوامر المفيدة في بناء تطبيقات الويب، وبالجمع بين أوامر آرتيزان والوظائف المضمنة تصبح عملية تطوير تطبيقات الويب أسرع بكثير. 3. التوثيق الجيد يحتوي لارافيل Laravel على توثيق مميز عبر الإنترنت يساعد المطورين والمبرمجين في تعلم كل ما يحتاجونه والعثور على إجابات لكافة تساؤلاتهم حول التعامل مع هذا الإطار، كما تتوفر معلومات هائلة متاحة من مجتمع مطوري لارافيل. المشكلة الوحيدة التي توجد في هذه المصادر هو أنها متاحة باللغة الإنجليزية وشرحها جامد إلى حد ما، وفي فقرة تعلم لارافيل سأطلعك على مصادر عربية جيدة تساعدك في تعلم لارافيل. 4. غني بالميزات وقابل للتوسيع يعد لارافيل نظامًا قويًا وغنيًا بالكثير من الميزات المضمنة ويوفر مجموعة متنوعة من المكتبات المضمنة التي تساعدك على بناء تطبيقات متقدمة تعالج ملايين الطلبات بفضل دعمه للتخزين المؤقت السريع والتخزين الموزع، كما يوفر لارافيل منصات سحابية خفية الخوادم Serverless مثل Laravel Forge و Vapor تمكنك من نشر التطبيقات وتشغيلها دون الحاجة إلى إدارة الخوادم وهي منصات قابلة للتوسيع التلقائي بكل سهولة. أضف إلى ذلك يوفر مطوروا لارافيل الكثير من الحزم الخارجية لأي وظيفة أو ميزة تحتاجها، على سبيل المثال يمكنك باستخدام مكتبة Socialite تضمين ميزة تسجيل الدخول إلى موقعك باستخدام حسابات شبكات التواصل الاجتماعي على فيسبوك أو تويتر أو لينكدإن أو جيتهب أو جوجل بكل سهولة. 5. يهتم بأمان التطبيقات يمكنك لارافيل من تطوير مواقع وتطبيقات آمنة بفضل العديد من ميزات الأمان المدمجة مثل نظام المصادقة أو الاستيثاق المدمج authentication system ونظام المصادقة authorization والتحقق من صحة البيانات data validation وتشفير البيانات والتحقق من البريد الإلكتروني وإعادة تعيين كلمة المرور، كما يسهل عليك تكوين ميزات الأمان المتقدمة التي تحمي تطبيقاتك من الاختراق وتضمن أمان بيانات عملائك. 6. يحسن أداء التطبيقات يوفر لارافيل عدة طرق لتحسين سرعة التطبيقات وتحسين أدائها مثل دعم التخزين المؤقت لموقعك الإلكتروني على الخادم، كما أنه يسهل تنفيذ تقنيات أخرى لتحسين السرعة مثل تقليل استخدام الذاكرة وفهرسة قاعدة البيانات. فإذا كانت سرعة الموقع أولوية لديك فإن لارافيل خيارك الأنسب. 7. يدعم تعدد اللغات فمن خلال ميزة التوطين localization يمكنك لارافيل من إنشاء تطبيقات متعددة اللغات واسترداد السلاسل النصية بلغات مختلفة، وهو يدعم عدة لغات من بينها اللغة العربية. 8. يسهل تصحيح أخطاء التطبيقات وصيانتها يحتوي لارافيل على ميزات تختبر كل جزء من موقع الويب الخاص بك للبحث عن أي أخطاء ويعرض لك رسائل واضحة ومفصلة تبين كافة الأخطاء التي تحدث في موقعك ويسهل عليك تصحيحها، كما أنه يسهل صيانة التطبيقات بفضل ميزات الكود النظيف واعتماد مبادئ البرمجة كائنية التوجه OOP ومعمارية MVC التي تنظم الكود وتمكن أي مطور من متابعة العمل على مشروع سابق وتطويره وإضافة الميزات المطلوبة له. 9.يوفر نظام تهجير البيانات Migration يوفر لارافيل ميزة تهجير البيانات Migration التي توفر آليات لإنشاء وتعديل جداول قاعدة البيانات كما يوفر آلية شبيهة بنظام التحكم في الإصدارات لقاعدة البيانات الخاصة بك تتعقب كيفية تعديل قاعدة البيانات مع الوقت وتسمح لكافة أعضاء فريق التطوير بتعديل قاعدة بيانات المشروع ومشاركته فيما بينهم وتسهل حذف قاعدة البيانات وإعادة إنشائها عند الضرورة. وللمزيد من التفاصيل حول هذه الميزة يمكنك مطالعة مقال تهجير قواعد البيانات في لارافيل 5 10. يوفر نظام التوجيه Routing يوفر لارافيل نظام توجيه Routing قوي لمعالجة وإدارة مسارات تطبيق الويب ويُمكِّنك من الانتقال من مكان لآخر في تطبيقك وتبادل المعلومات بينها بسهولة، كما يمكّنك من استخدام أسماء بسيطة ترتبط بأجزاء مختلفة من تطبيقك بدلاً من الأسماء الطويلة والمربكة، ستجد كافة المسارات الخاصة بالتطبيق في الملف web.php ضمن المجلد routes لمشروعك وللمزيد من التفاصيل يمكنك الاطلاع على توثيق التوجيه Routing في لارافيل. عيوب لارافيل Laravel لا تخلو أي تقنية مهما كانت متقدمة من بعض العيوب ومن بينها لارافيل، فهو يملك بعض جوانب النقص وإليك قائمة بأبرز عيوب لارافيل: يعتبر إطار عمل لارافيل بطيئًا نسبيًا عند مقارنته ببعض أطر تطوير الويب الأخرى. رغم كونه آمنًا بشكل كبير إلا أنه لا يزال مهددًا باستهدافه بالثغرات الأمنية بسبب اعتماده على PHP التي وسمت بكثرة الثغرات الأمنية فيها تحديدًا في الإصدارات القديمة منها. تكلفته عالية فالمواقع المطورة بإطار لارافيل قد تكون أغلى نسبيًا من المواقع المطورة بغيرها من تقنيات الويب كأنظمة إدارة المحتوى أو أطر العمل الأخرى وهذا رغم كونه عامل قوة لك كمطور لكنه قد يجعل بعض العملاء يفضلون الخيارات الأرخص. وجود تحديثات متكررة قد يجعلك تواجه صعوبات في تعلم الجديد في كل إصدار وتعديل شيفرة تطبيقاتك المطورة بإصدارات قديمة لذا يجب أن تكون لديك رغبة مستمرة في التعلم كي تتلاءم مع كل إصدار جديد. كانت هذه قائمة بأبرز عيوب أو سلبيات لارافيل Laravel، وبموازنة السلبيات والإيجابيات يمكن أن تقرر فيما إذا كان إطار لارافيل سيلبي احتياجاتك أم لا. تنظيم الكود في لارافيل Laravel يتميز إطار لارافيل Laravel بكود منظم وسهل الصيانة يحافظ على تنظيم مشاريعك البرمجة من خلال استخدامه معمارية MVC وهي اختصار لثلاث كلمات هي: النموذج Model الذي يعني بيانات التطبيق فهو يتفاعل مباشرة مع قاعدة البيانات الخاصة بك ويسترد المعلومات منها. العرض View الذي يعني واجهة التطبيق فهو يعرض الصفحات التي يتفاعل معها المستخدم مباشرة. المتحكم Controller وهو صلة الوصل بين العرض والنموذج فهو يستقبل طلبات المستخدمين ويسترد البيانات المطلوبة من النموذج ويعالجها ويرسلها إلى صفحات العرض. وباستخدام هذا الأسلوب التنظيمي يستطيع لارافيل فصل كود التطبيق إلى ثلاث مجموعات لكل منها وظيفة محددة وهي الواجهة الخلفية والواجهة الأمامية ووحدة التحكم للربط بين الواجهتين وهذه الميزة تجعل من لارافيل أفضل إطار عمل PHP لتطبيقات الويب. بالإضافة إلى ذلك يستخدم لارافيل المسارات routes لتعيين عناوين URL الخاصة بإجراءات متحكم معين، فعندما يقوم المستخدم بإدخال عنوان URL خاص بالتطبيق يعين المسار المرتبط بهذا العنوان عنوان URL للمتحكم المسؤول عن استرداد البيانات المطلوبة من قاعدة البيانات أو النموذج ويمررها إلى صفحات العرض النهائية. كيف أتعلم لارافيل Laravel؟ بعد أن تعرفنا على إطار عمل لارافيل وأهم مميزاته واستخداماته، سنوضح لك في هذه الفقرة طريقة تعلم لارافيل وأهم الخطوات التي عليك اتباعها كي تحترفه. قبل أن تبدأ بتعلم لارافيل يجب أن تكون على دراية بأساسيات تطوير الويب والمفاهيم الأساسية في HTML و CSS. يجب أن تتعلم أساسيات البرمجة بلغة PHP وتتمكن من كتابة برامج PHP بسيطة وتعرف كذلك مبادئ البرمجة كائنية التوجه OOP. تعلم المكونات الأساسية لإطار عمل لارافيل ومعمارية MVC ومفاهيم النماذج وصفحات العرض والمتحكمات من خلال مصادر التعلم التي تفضلها سواء كانت مواقع الإنترنت أو الكتب أو الدورات التعليمية واحرص على تحديد خطة للتعلم والتزم بها كي تحقق أهدافك. طور مشاريع تطبق فيها ما تعلمته، فالتطبيق العملي طريقة رائعة لتعلم المفاهيم التي تعلمتها، ابدأ بمشروع بسيط ثم انتقل إلى مشاريع أكثر تقدمًا فهذا يساعدك على إنشاء معرض أعمال يعزز مسيرتك المهنية. لا تتوقف عن التعلم واطلع على كل جديد في مجال تطوير الويب عمومًا وإطار لارافيل على وجه الخصوص، فالتقنيات تتطور بسرعة والتعلم المستمر يساعدك على التكيف مع أي تطور جديد والبقاء في الصدارة. مصادر تعلم لارافيل Laravel إذا كنت تبحث عن مصدر عربي موثوق لتعلم لارافيل من الصفر للاحتراف بشهادة معتمدة تعزز فرصتك في سوق العمل ستجد في أكاديمية حسوب دورة تطوير تطبيقات الويب باستخدام لغة PHP وهي دورة تدريبية عالية الجودة تضم مسارات متعددة ولا تتطلب منك أي معرفة مسبقة وتعلمك كل ما يخص لغة PHP وإطار عملها لارافيل وتدمج بين الشرح النظري والتطبيق العملي، فمن خلالها ستتعلم تطوير العديد من تطبيقات الويب المتكاملة وتبني من خلالها معرض أعمال قوي، كما ستتمكن من خلال هذه الدورة من التواصل مع مدربين أكفاء وطرح أي سؤال أو مشكلة تواجهك عند تطبيق مشروعك البرمجي. كما ستجد في أكاديمية حسوب الكثير من مصادر التعلم المجانية مثل المقالات والدروس المتنوعة حول PHP وحول إطار عمل لارافيل Laravel، وبالإضافة لكل ما سبق فقد ترجمت موسوعة حسوب توثيق لارافيل الأجنبي إلى اللغة العربية ويمكنك من خلاله أن تتعرف على كل ما يخص هذا الإطار بتسلسل منظم وواضح. تنصيب لارافيل Laravel كي تتمكن من التعامل مع مشاريع لارافيل في حاسوبك المحلي عليك اتباع مجموعة من الخطوات وهي كالتالي: أول خطوة قبل البدء بتثبيت لارافيل Laravel على جهازك المحلي هي تحويل حاسوبك إلى خادم ويب محلي كي يتمكن من تشغيل PHP و نظام إدارة قواعد البيانات مثل MySQL أو PostgreSQL، يمكنك القيام بذلك باستخدام XAMPP المتوافق مع كافة أنظمة التشغيل. عليك كذلك تثبيت أي محرر أكواد أو بيئة تطوير متكاملة IDE ترغب بها لتحرير أكواد مشروعك مثل PhpStorm أو Visual Studio Code أو أي محرر آخر تتآلف معه. بعدها عليك تثبيت مدير الحزم كومبوزر Composer لتحميل إطار لارافيل من خلاله، وهو ضروري لتحديد المكتبات التي يحتاجها مشروعك بكل سهولة وإدارتها بالنيابة عنك. وللمزيد يمكنك مطالعة مقال ما هو Composer ولماذا يجب على كل مطور PHP استخدامه. الآن يمكنك تثبيت لارافيل على جهازك، وأبسط طريقة لتحميل لارافيل هي تشغيل محرر الأوامر في نظامك والانتقال للمسار الذي تريد إنشاء مشروع لارافيل الخاص بك فيه ثم كتابة الأمر التالي، هنا أنشأنا مشروع لارافيل باسم example-app composer create-project laravel/laravel example-app لتشغيل المشروع انتقل إلى مجلد مشروعك وهو في حالتنا D:\example-app ونفذ الأمر التالي: D:\cd example-app D:\example-app>php artisan serve هذا الأمر سيشغل تطبيق لارافيل على خادم تطوير PHP وينتج عن تنفيذه عرض رابط المشروع بالشكل التالي http://127.0.0.1:8000، كل ما عليك هو نسخ هذا الرابط ولصقه في المستعرض لتظهر لك الصفحة الرئيسية لموقع لارافيل الخاص بك كما هو موضح في الصورة التالية. ولإيقاف تشغيل خادم التطوير من خلال سطر الأوامر اضغط على مفتاحي Ctrl+C في لوحة المفاتيح. ولمزيد من المعلومات حول تثبيت لارافيل يمكنك مطالعة مقال تثبيت وإعداد لارافيل Laravel على دوكر كومبوز Docker Compose ومقال تثبيت Laravel 5 وإعداده على Windows وUbuntu. أخيرًا أنصحك أن تفتح مشروع في محرر الشيفرات الذي اخترته وتتعرف على بنية المجلدات في Laravel وتفهم دورها في المشروع ومساهمتها في نموذج MVC المستخدم في إطار العمل لارافيل. هذا كل شيء! أنت جاهز الآن لتبدأ رحلتك في اكتشاف لارافيل والبدء بتعلمه. الخلاصة اكتشفنا في مقال اليوم ما هو إطار عمل لارافيل Laravel وأهميته في سوق العمل، وتعرفنا على أهم المميزات التي يقدمها في مجال تطوير مواقع وتطبيقات الويب، كما تعرفنا على كيفية تنصيب لارافيل وبدء التعامل معه وأهم مصادر تعلمه. وسواء كنت مطورًا مبتدئًا أو خبيرًا في برمجة تطبيقات الويب فإن لارافيل Laravel خيار مناسب لك تمامًا فهو يوفر لك بيئة تطوير سهلة وقوية ويقدم لك الكثير من الميزات والوظائف المبرمجة مسبقًا التي تمكنك من بناء تطبيقات ويب احترافية وعالية الجودة بسرعة وسهولة. لا تتردد وابدأ من اليوم بتعلم لارافيل وإن اعترضك أي سؤال حوله شاركنا إياه في قسم التعليقات أسفل المقال. اقرأ أيضًا دليل مطوّري PHP للبدء في بناء تطبيقات Laravel - الجزء الأوّل دليل مطوّري PHP للبدء في بناء تطبيقات Laravel - الجزء الثاني رفع الملفّات وإدارتها في تطبيقات Laravel تجريد إعداد قواعد البيانات في لارافيل باستعمال عملية التهجير Migration والبذر Seeder لارافيل للمبتدئين-الجزء الأول: البدء في إنشاء مدونة بسيطة1 نقطة -
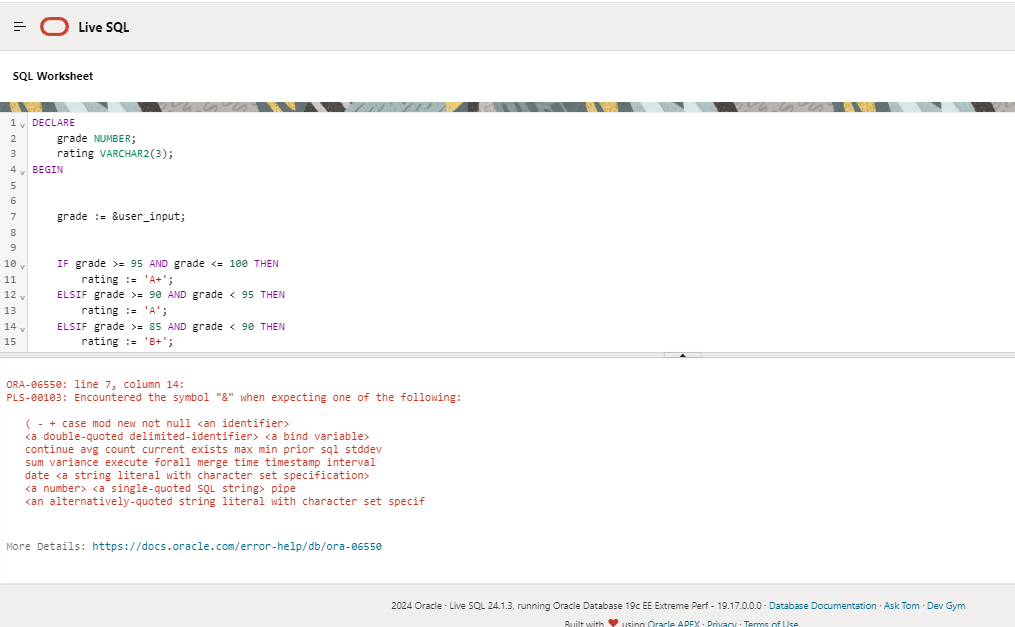
السلام عليكم ده مسائل من LeetCode Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target. You may assume that each input would have exactly one solution, and you may not use the same element twice. You can return the answer in any order. وده الحل بتاعي # Interview Google class Solution: def towSum(self,nums,target): for i in range(len(nums)): for j in range(i+1,len(nums)): if nums[i] + nums[j] == target: print(f"{nums[i]} + {nums[j]} = {target}") return 1 print("Not Found") return 0 num = Solution() num.towSum([2,7,11,15],9) الكود ده بيشتغل عادي علي Vscode ولكن علي LeetCode مش بيشتغل وبيظهار الخظاء ده SyntaxError: invalid syntax ^ print(f"{nums[i]} + {nums[j]} = {target}") Line 7 (Solution.py)1 نقطة
-
مشكلة في الكود الكود صحيح لماذا تخرج لي هذا وماهو الحل اريده فبي نفس الموقع هذا1 نقطة
-
كيف يمكن إنشاء عنصر تحكم مترابط في أكثر من موضع من ملف الوورد بحيث يمكن تعديل جميع المواضع مرة واحدة فمثلا أضع في موضعين مختلفين من الورد عبارة: (الله أكبر) فإذا قمت بتعديل الموضع الأول إلى (الله أعظم) تعدل الموضع الثاني تلقائيًا إلى نفس العبارة الجديدة. جزاكم الله خيرًا.1 نقطة
-
1 نقطة
-
السلام عليكم هو انا ازي اكبر او اضغير حجم VScode ؟ انا سالت السوال ده اقبل كده بس مش عارف وصل السوال ده1 نقطة
-
السلام عليكم واي هي شهادات CompTIA ؟1 نقطة
-
تلك مجموعة من الشهادات المهنية في مجال تكنولوجيا المعلومات، تُمنح من قبل معهد CompTIA (Computing Technology Industry Association)، ومعترف بها عالميًا وتُغطي مجموعة واسعة من المجالات، من أساسيات تكنولوجيا المعلومات إلى مجالات متخصصة مثل الأمن السيبراني. وتقدم شهادات للمبتدئين والمتوسطين والمتخصصين، ويتم تحديثها بانتظام لتتناسب مع التطورات في مجال تكنولوجيا المعلومات. ومن أشهرها: A+: شهادة أساسية تُغطي أساسيات دعم تكنولوجيا المعلومات، وهي نقطة انطلاق ممتازة للمهنة. Network+: شهادة تُغطي أساسيات الشبكات الحاسوبية. Security+: شهادة تُغطي أساسيات الأمن السيبراني. Cloud+: شهادة تُغطي أساسيات الحوسبة السحابية. Linux+: شهادة تُغطي أساسيات نظام التشغيل Linux. Project+: شهادة تُغطي إدارة المشاريع في مجال تكنولوجيا المعلومات. Cybersecurity Analyst (CySA+): شهادة متقدمة في مجال الأمن السيبراني. PenTest+: شهادة متقدمة في مجال اختبار الاختراق.1 نقطة
-
كنت استخدم لينوڤو Lenovo IdeaPad Flex 5 ،Intel i7-1255U, 16GB RAM, 512GB SSDولكن حالياً اريد ان اغير هل ينفع اخذ MacBook Air m1 للبرمجه ؟1 نقطة
-
السلام عليكم يعطيكن العافية لو سمحتوا انا لابتوبي اصدار 7 عم ادرس الوردبريس وقت عم نزل المكتبات عم يحدث مشاكل أرجوا حل هذه المشكلة @Mustafa Suleiman لو سمحتوا الأمر ضروري متعطلة عليه لو سمحتوا الأمر ضروري متعطلة عليه1 نقطة
-
خطأ غير مقصود، وأرجو طرح المشاكل التي تواجهك أسفل الدرس وسيتم المتابعة معك، شكرًا لتفهمك1 نقطة
-
هي مو اول مرة ما بيتم قبولها عم ابعث على الايميل محدا عم برد غير استاذ محمد رد علي وانا بحاجة حل للأسئلة
 1 نقطة
1 نقطة -
بالنسبة للتحكم بحاسبوك الشخصي عبر بايثون فيمكنك فقط اعتماد سطر الاوامر عبر احد المكاتب os او shutil1 نقطة
-
مختلفة تمامًا عما هي عليه اليوم، فلم تكن هناك لغات برمجة عالية المستوى مثل Python أو Java أو C++، بل كانت البرمجة تتم باستخدام لغات منخفضة المستوى جدًا، أو حتى مباشرة مع الأجهزة. في البداية، كان البرمجة تتم مباشرة باستخدام لغة الآلة، وهي عبارة عن سلسلة من الأرقام الثنائية (0 و 1) التي تفهمها المعالجات مباشرة، وكانت تلك العملية شاقة للغاية ومعرضة للخطأ، حيث كان على المبرمجين تذكر كل تعليمة وعنوانها في الذاكرة. حيث كانت وسيلة الإدخال الرئيسية للبرامج هي البطاقات المثقبة - Punch Cards، بمعنى كان المبرمجون يثقبون ثقوبًا في البطاقات وفقًا لتعليمات البرنامج، ثم يتم قراءة تلك البطاقات بواسطة قارئ خاص لإدخال الكود إلى الحاسوب، وتلك العملية بطيئة ومعرضة للخطأ، ويمكن أن يؤدي ثقب خاطئ إلى تعطل البرنامج بالكامل. وفي بعض الأحيان، كان المبرمجون يكتبون الكود يدويًا على ورق، ثم يقومون بترجمته إلى بطاقات مثقبة، وكانت مساحة الذاكرة في الحواسيب القديمة محدودة للغاية، مما أجبر المبرمجين على كتابة كود فعال للغاية ومضغوط. وعملية تصحيح الأخطاء debugging كانت صعبة للغاية، حيث لم تكن هناك أدوات متقدمة لمساعدة المبرمجين، وكان عليهم الاعتماد على تقنيات بدائية مثل طباعة قيم المتغيرات أو فحص محتوى الذاكرة يدويًا. ثم تطور الأمر، وأصبح هناك ما يسمى لغة التجميع Assembly Language لتسهيل عملية البرمجة، فبدلاً من الأرقام الثنائية Binary، استخدمت لغة التجميع رموزًا مختصرة mnemonics تمثل تعليمات المعالج. لكنها كانت لا تزال تعتمد على بنية المعالج بشكل كبير، مما يعني أن كود مكتوب بلغة تجميع لمعالج معين لا يعمل على معالج آخر، وكان يتم استخدام برامج تسمى المجمعات assemblers لتحويل كود التجميع إلى لغة الآلة.1 نقطة
-
ستحتاج مكتبة QPrinter من PyQt6 لطباعة محتوى QWidget، ولا يمكنك طباعة QWidget مباشرةً، بل عليك رسم محتوى QWidget على QPainter المرتبط بـ QPrinter. قم بالاستيراد كالتالي: from PyQt6.QtGui import QPixmap, QPainter, QPrinter وإنشاء دالة باسم paint_invoice: def paint_invoice(self, painter): header_rect = QRect(0, 0, painter.device().width(), 150) painter.drawRect(header_rect) painter.drawText(header_rect, Qt.AlignmentFlag.AlignCenter, "فاتورة مبيعات مبسطة") company_info_rect = QRect(10, 20, painter.device().width() - 20, 100) painter.drawText(company_info_rect, Qt.AlignmentFlag.AlignLeft | Qt.AlignmentFlag.AlignTop, "اسم الشركة: شركة مثال\nالعنوان: شارع 123، المدينة\nاسم العميل: العميل الافتراضي") table_rect = QRect(10, 170, painter.device().width() - 20, 200) painter.drawRect(table_rect) self.paint_table(painter, self.table_details, table_rect) totals_rect = QRect(10, 380, painter.device().width() - 20, 100) painter.drawRect(totals_rect) self.paint_totals(painter, totals_rect) barcode_rect = QRect(painter.device().width() - 170, 380, 150, 100) if self.barcode_label.pixmap(): painter.drawPixmap(barcode_rect, self.barcode_label.pixmap()) ثم إضافة الزر: def __init__(self): super().__init__() # ... (أضف التالي) ... self.print_button = QPushButton("طباعة الفاتورة") self.print_button.clicked.connect(self.print_invoice) main_layout.addWidget(self.print_button)1 نقطة
-
توجد العديد من النماذج التي تسطيع تطبيقها هنا وهذا يعتمد على المبلغ الذي ستوفره و مدى تفرغك للمشروع . أولا لا يمكن لشريكك أن يأخذ راتب وأرباح معا فهو يأخذ أى منهما بناء على الإتفاق الخاص بكما . حيث من المفترض أنك شريك مالي وهو شريك إدارى والشريك الإدارى لا يأخذ راتب بل يأخذ نسبة من الأرباح نصيب تفرغة الكامل للمشروع وإدارته و أنت نسبتك في الأرباح نابعة من أنك صاحب رأس المال . فإذا كنت أنت لن تكون متفرغا للمشروع فقط تعطيه رأس المال وهو يقوم بإدارته فالنموذج السابق هو الأمثل . حيث تقوم بتحديد نسبة ربح له ولتكن 40% و 60% لك وتكون أن شريك برأس المال وهو شريك بالإدارة والمجهود ويمكنكما تحديد النسبة أيضا بناء على مدي حجم رأس المال ومدي حجم المشروع الذي سيديره هو . ثانيا في حالة الخسارة هنا يجب أن تتفقا في حال الخسارة التوجه إلى أصحاب الخبره لمعرفة هل الخسارة نابعة من سوء إدارة وإهمال من شريكك أم خسارة طبيعية حيث لا يوجد مشروع لا يخسر ولكن أسباب الخسارة تختلف, فهنا إن كان تقصير من شريكك وإهمال فيفترض هو من يتحمل نسبة الخساره بأكملها حيث أنه مؤتمن على هذا المال والمشروع أو يمكنك تحديد نسبة أكبر له للخسارة مثلا 80 له و 20 لك . أما إذا كانت الخسارة طبيعية فهنا أنت ستخسر من رأس مالك وهو سيخسر وقته الذي أمضاه في إدارة هذا المشروع وهذا هو العدل حيث أنكما شركيان معا في الخسارة والأرباح. أما إذا أعطيته نسبة من الأرباح و مرتب شهرى فهذه ليست شراكه فهكذا هو موظف وليس شريك فكيف يأخذ الإثنان معا. ويجب عليك وضع جيمع البنود والشروط قبل العقد حتي لا تحدث لك مشاكل فيما بعد.1 نقطة
-
الراتب ذلك أمر تحدده أنت، وكمثال ليس أكثر حدد مبلغًا ثابتًا، لنقل 5000 جنيه مصري (أو أي مبلغ آخر تتفقان عليه)، وسيكون الراتب ضمانًا لشريكك، بغض النظر عن أداء العمل، وهناك عوامل لتحديد الراتب: خبرة الشريك في المجال. حجم العمل وعدد ساعات العمل المتوقعة منه. متوسط الرواتب في سوق العمل لمثل تلك الوظائف. هل سيزيد الراتب مع مرور الوقت وزيادة المبيعات؟ وكيف سيتم احتساب هذه الزيادة؟ وهل سيكون هناك حوافز إضافية للشريك بناءً على أدائه وزيادة المبيعات؟ بالإضافة إلى الراتب، قم بتقديم نظام مشاركة في الأرباح، حيث يحصل شريكك على نسبة مئوية من صافي الربح، أي تقديم 20٪ من صافي الربح الأمر الذي سيشجعه على العمل الجاد لزيادة المبيعات والأرباح. وفي حالة تكبد العمل خسارة فذلك أمر وار جدًا ولا يوجد مشروع بدون خسارة، عليك الاتفاق على تقاسم الخسارة مع شريكك، مثلاً تقسيم الخسارة بنسبة 50/50، أو 60/40، أو أي نسبة أخرى تتفقان عليها، وسيضمن ذلك أن يكون هو مسؤولاً أيضًا عن أداء العمل. وكمثال على كيفية عمل هيكل الشراكة: أنت تقدم 100000 جنيه مصري كرأس مال لبدء العمل. يحصل هو على راتب شهري قدره 5000 جنيه مصري. يحقق العمل صافي ربح قدره 20000 جنيه مصري في شهر واحد. يحصل على 20٪ من صافي الربح، أي 4000 جنيه مصري (بالإضافة إلى راتبه). إن تكبد العمل خسارة قدرها 10000 جنيه مصري في شهر واحد، فستقسم أنت وهو الخسارة بنسبة 50/50، وبالتالي سيكون مسؤولاً عن 5000 جنيه مصري من الخسارة.1 نقطة
-
حاليا يوجد في دورة الجافاسكريبت مسار خاص تطوير تطبيقات الأندرويد باستخدام React Native، و لكن نقدر اقتراحك بشأن دورة تطوير تطبيقات الأندرويد بلغة كوتلن، وسنقوم بإيصال طلبك إلى الإدارة، فإذا كان الطلب عليها كبير ستراجع الإدارة هذه النقطة و ربما ستتوفر في القريب العاجل.1 نقطة
-
 نناقش في مقال اليوم النماذج اللغوية الكبيرة LLMs وهي صاحبة الدور الرئيسي في توليد النصوص، فهي تتكون من نماذج ذكاء اصطناعي كبيرة من نوع المحولات transformer، ومُدَرَّبة مُسبقًا على مهمة التنبؤ بالكلمة التالية أو token التالي من أي مُوجه يعطى لها، فهي إذًا تتنبأ بكلمات فردية بمقدار كلمة واحدة في كل مرة، لذا فإن توليد الجمل الكاملة سيحتاج تقنيةً أوسع تسمى توليد الانحدار الذاتي autoregressive generation. ويُعرَّف توليد الانحدار الذاتي بأنه إجراءٌ استدلالي متكرر مع الزمن، يستدعي نموذج LLM مراتٍ متكررة وفي كل مرة يُمرر له المخرجات التي وَلَّدها في المرة السابقة كمدخلات وهكذا، وبطبيعة الحالة يحتاح إلى مدخلات ابتدائية نقدمها له ليستخدمها في الاستدعاء الأول للنموذج، وتوفر مكتبة المحولات Transformers تابعًا خاصًا لهذا الغرض هو generate()، يعمل جميع النماذج ذات الإمكانات التوليدية generative. نسعى في هذا المقال لتحقيق ثلاثة أهداف رئيسية: شرح كيفية توليد نص باستخدام نموذج لغوي كبير LLM الإضاءة على بعض المخاطر الشائعة لتتجنبها اقتراح بعض المصادر التي ستساعدك على تحقيق أقصى استفادة ممكنة من نماذج LLMs تأكد في البداية من تثبيت المكتبات الضرورية للعمل قبل أن نبدأ بالتفاصيل، وذلك وفق التالي: pip install transformers bitsandbytes>=0.39.0 -q توليد النص يأخذ النموذج اللغوي المُدَرَّب على النمذجة اللغوية السببية سلسلة من الرموز النصية كمدخلات inputs ويرجع بناءً عليها التوزع الاحتمالي للرمز التالي المتوقع، ألقِ نظرة على الصورة التوضيحية التالية: أما عن كيفية اختيار الرمز التالي من هذا التوزع الاحتمالي الناتج، فهي تختلف حسب الحالة، فقد تكون بسيطةً تتمثل بانتقاء الرمز الأكثر احتمالية من ضمن رموز التوزع الاحتمالي، أو معقدة لدرجة نحتاج معها لتطبيق عشرات التحويلات قبل الاختيار، وبصرف النظر عن طريقة الاختيار فإننا سنحصل بعد هذه المرحلة على رمز جديد نستخدمه في التكرار التالي أو الاستدعاء التالي للنموذج كما هو موضح في الصورة التالية لتوليد الانحدار الذاتي: تستمر عملية توليد الكلمات حتى نصل إلى أحد شروط التوقف التي يُحددها النموذج، ويتعلم النموذج متى ينبغي أن يرجع رمز نهاية السلسلة (EOS) الذي يُعدّ الإنهاء المثالي لعملية توليد النص، وفي حال لم يرجع النموذج هذا الرمز فسيظل العمل مستمرًا لحين الوصول إلى الحد الأقصى المسموح به من الرموز. إذًا فلديك أمرين مهمين ينبغي أن تهتم بهما ليعمل نموذجك التوليدي بالطريقة المرجوة، الأمر الأول هو كيفية اختيار الرمز التالي من بين رموز التوزع الاحتمالي، والأمر الثاني هو تحديد شرط إنهاء التوليد، تُضبط هذه الإعدادات في ملف إعدادات التوليد GenerationConfig الخاص بكل نموذج توليدي، يُحَمَّل هذا الملف مع النموذج وهو يتضنت معاملاتٍ افتراضية مناسبة له. لنبدأ الآن بالتطبيق العملي، حَمِّل أولًا النموذج كما يلي: >>> from transformers import AutoModelForCausalLM >>> model = AutoModelForCausalLM.from_pretrained( "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True ) استخدمنا في الاستدعاء from_pretrained السابق معاملين device_map و load_in_4bit: يضمن المعامل device_map أن حمل النموذج سيتوزع تلقائيًا على وحدات GPU المتاحة. يساعد المعامل load_in_4bit على تقليل استخدام الموارد الحاسوبية إلى أقصى حد ممكن عبر تطبيق التكميم الديناميكي 4 بت. توجد طرق أخرى عديدة لتهيئة نموذج LLM عند تحميله، عرضنا إحداها في الأمر السابق، وهي أساسية وبسيطة. نحتاج الآن لمعالجة النص معالجةً مسبقة قبل إدخاله للنموذج وذلك باستخدام المُرَمِّز Tokenizer وهو نوع المعالجة المناسب للنصوص كما تعلمنا في مقال المعالجة المُسبقة للبيانات قبل تمريرها لنماذج الذكاء الاصطناعي: >>> from transformers import AutoTokenizer >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left") >>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda") سيُخَزَّن خرج المُرَمِّز (وهو عبارة عن النص المُرَمَّز وقناع الانتباه attention mask) في المتغير model_inputs، ويوصى عادةً بتمرير بيانات قناع الانتباه ما أمكن ذلك للحصول على أفضل النتائج، رغم أن التابع generate() سيسعى لتخمين قيمة قناع الانتباه عند عدم تمريره. ملاحظة: قناع الانتباه attention mask هو أداة تساعد النموذج اللغوي على معرفة الأجزاء المهمة في النص الذي يعالجه وتجاهل الأجزاء غير المهمة كرموز الحشو التي تُضاف لجعل طول النصوص موحدًا. يوجه هذا القناع النموذج ليركز فقط على الكلمات الفعلية في النص ويهمل الرموز لا تعني شيئًا للحصول على نتائج دقيقة. بعد انتهاء الترميز يُستدعى التابع generate() الذي سيُرجع الرموز tokens المتنبأ بها، والتي ستتحول إلى نص قبل إظهارها في خرج النموذج. >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A list of colors: red, blue, green, yellow, orange, purple, pink,' ننوه أخيرًا إلى أنك لست مضطرًا لتمرير مدخلاتك إلى النموذج على شكل جمل مفردة، جملة واحدة في كل مرة، إذ يمكنك تجميع أكثر من جملة وتمريرها بهيئة دفعات batches مع استخدام الحشو padding لجعلها متساوية الطول، كما في المثال التالي، يزيد هذا الأسلوب من إنتاجية النموذج ويقلل الزمن والذاكرة المستهلكين: >>> tokenizer.pad_token = tokenizer.eos_token # لا تملك معظم النماذج اللغوية الكبيرة رمزًا للحشو افتراضيًا >>> model_inputs = tokenizer( ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True) ['A list of colors: red, blue, green, yellow, orange, purple, pink,', 'Portugal is a country in southwestern Europe, on the Iber'] إذًا ببضع أسطر برمجية فقط استفدنا من أحد النماذج اللغوية الكبيرة LLM واستطعنا توليد نصوص مكلمة للجمل التي أعطيناها للنموذج. بعض المشكلات المحتمل وقوعها لا تناسب القيم الافتراضية لمعاملات النماذج التوليدية جميع المهام فلكل مشروع خصوصيته، والاعتماد عليها قد لا يعطينا نتائج مرضية في العديد من حالات الاستخدام، سنعرض لك أشهرها مع طرق تجنبها: لنبدأ أولًا بتحميل النموذج والمُرَمِّز ثم نتابع بقية أجزاء الشيفرة ضمن الأمثلة تباعًا: >>> from transformers import AutoModelForCausalLM, AutoTokenizer >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1") >>> tokenizer.pad_token = tokenizer.eos_token # لا تمتلك معظم النماذج اللغوية الكبيرة رمزًا للحشو افتراضيًا >>> model = AutoModelForCausalLM.from_pretrained( "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True ) توليد خرج أطول أو أقصر من اللازم يُرجع التابع generate عشرين tokens كحد أقصى افتراضيًا، طالما أننا لم نحدد ما يخالف ذلك في ملف إعدادات التوليد Generation-config، ولكن ما ينبغي الانتباه له أن نماذج LLMs وخاصة النماذج من نوع decoder models مثل GPT و CTRL تُرجع مُوجَّه الدخل input prompt أيضًا مع كل خرج تعطيه، لذا ننصحك بتحديد الحد الأقصى لعدد الـ tokens الناتجة يدويًا، وعدم الاعتماد على الحد الافتراضي، وذلك ضمن المتغير max_new_tokens المرافق لاستدعاء generate، ألقِ نظرة على المثال التالي ولاحظ الفرق في الخرج بين الحالتين، الحالة الافتراضية، وحالة تحديد العدد الأقصى للرموز الناتجة: >>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], >>> return_tensors="pt").to("cuda") # الحالة الافتراضية الحد الأقصى لعدد الرموز الناتجة هو 20 رمز >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A sequence of numbers: 1, 2, 3, 4, 5' # عند ضبط قيمة المتغير الذي سيحدد العدد الأقصى للرموز الناتجة >>> generated_ids = model.generate(**model_inputs, max_new_tokens=50) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,' نمط توليد غير مناسب افتراضيًا يختار التابع generate الرمز الأكثر احتمالية من بين الرموز الناتجة في كل تكرار ما لم نحدد طريقة مغايرة للاختيار في ملف إعدادات التوليد GenerationConfig، يسمى هذا الأسلوب الافتراضي فك التشفير الشره greedy decoding، وهو لا يناسب المهام الإبداعية التي تستفيد من بعض العينات، مثل: بناء روبوت دردشة لمحادثة العملاء أو كتابة مقال متخصص، لكنه من ناحية أخرى يعمل جيدًا مع المهام المستندة إلى المدخلات، نحو: التفريغ الصوتي والترجمة وغيره، لذا اضبط المتغير على القيمة do_sample=True في المهام الإبداعية، كما يبين المثال التالي الذي يتضمن ثلاث حالات: >>> # استخدم هذا السطر إذا رغبت بالتكرار الكامل >>> from transformers import set_seed >>> set_seed(42) >>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda") >>> # LLM + فك التشفير الشره = مخرجات متكررة ومملة >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'I am a cat. I am a cat. I am a cat. I am a cat' >>> # مع تفعيل أخذ العينات، تصبح المخرجات أكثر إبداعًا >>> generated_ids = model.generate(**model_inputs, do_sample=True) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'I am a cat. Specifically, I am an indoor-only cat. I' الحشو في الجانب الخاطئ ذكرنا سابقًا أنك عندما تقوم بإدخال جمل أو نصوص ذات أطوال مختلفة للنموذج، فقد تحتاج إلى جعل هذه المدخلات بطول موحد ليتمكن النموذج من معالجتها بشكل صحيح من خلال إضافة رموز الحشو (padding tokens) التي تجعل جميع المدخلات بطول متساوٍ. لكن النماذج اللغوية الكبيرة LLMs هي بنى لفك التشفير فقط decoder-only فهي تكرر الإجراءات نفسها على مدخلاتك، لكنها غير مُدَرَّبة على الاستمرار بالتكرار على رموز الحشو، لذا عندما تكون مدخلاتك مختلفة الأطوال وتحتاج للحشو لتصبح بطول موحد، فاحرص على إضافة رموز الحشو على الجانب الأيسر left-padded (أي قبل بداية النص الحقيقي) ليعمل التوليد بطريقة سليمة، وتأكد من تمرير قناع الانتباه attention mask للتابع generate حتى لا تترك الأمر للتخمين: >>> # المُرَمِّز المستخدم هنا يحشو الرموز على الجانب الأيمن افتراضيًا، والسلسلة النصية الأولى هي >>> # السلسلة الأقصر والتي تحتاج لحشو، وعند حشوها على الجانب الأيمن سيفشل النموذج التوليدي في التنبؤ بمنطقية >>> model_inputs = tokenizer( ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt" ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] '1, 2, 33333333333' >>> # لاحظ الفرق عند تعديل الحشو ليصبح على الجانب الأيسر >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left") >>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default >>> model_inputs = tokenizer( ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt" ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] '1, 2, 3, 4, 5, 6,' مُوجَّهات خاطئة يتراجع أداء بعض النماذج عندما لا نمرر لها مُوجَّهات input prompt بالتنسيق الصحيح الذي يناسبها، يمكنك الحصول على مزيد من المعلومات عن طبيعة الدخل المتوقع للنماذج مع كل مهمة بالاطلاع على دليل المُوجَّهات في نماذج LLMs على منصة Hugging Face، ألقِ نظرة على المثال التالي الذي عن استخدام نموذج LLM للدردشة باستخدام قوالب الدردشة: >>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha") >>> model = AutoModelForCausalLM.from_pretrained( "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True ) >>> set_seed(0) >>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug.""" >>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda") >>> input_length = model_inputs.input_ids.shape[1] >>> generated_ids = model.generate(**model_inputs, max_new_tokens=20) >>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0]) "I'm not a thug, but i can tell you that a human cannot eat" >>> # لم يتبع النموذج تعليماتنا هنا فهو لم يرد على السؤال كما ينبغي أن يرد أي شخص عنيف >>> # سنقدم الآن دخلًا أفضل يناسب النموذج باستخدام قوالب الدردشة، ونرى الفرق النتيجة >>> set_seed(0) >>> messages = [ { "role": "system", "content": "You are a friendly chatbot who always responds in the style of a thug", }, {"role": "user", "content": "How many helicopters can a human eat in one sitting?"}, ] >>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda") >>> input_length = model_inputs.shape[1] >>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20) >>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0]) 'None, you thug. How bout you try to focus on more useful questions?' >>> # كما تلاحظ فقد تغير أسلوب الرد واتبع تعليماتنا بطريقة أفضل فكان رده أقرب للأسلوب المطلوب مصادر مفيدة للاستفادة من نماذج LLMs ستحتاج لتعميق معرفتك بالنماذج اللغوية الكبيرة (LLMs) إذا رغبت بتحقيق أقصى استفادة منها، وإليك بعض الأدلة المفيدة من منصة Hugging Face المتخصصة في المجال: أدلة الاستخدام المتقدم للتوليد Generating دليل استراتيجيات توليد النصوص باستخدام الذكاء الاصطناعي الذي يساعدك في تعلم كيفية التحكم بتوابع توليد مختلفة، وضبط مخرجاتها، وملفات الإعدادات الخاصة بها. دليل لاستخدام قوالب الدردشة مع نماذج LLMs. دليل LLM prompting يتضمن الأساسيات وأفضل الممارسات في كتابة المُوجَّهات. توثيقات واجهة برمجة التطبيقات API لكل من ملف إعدادات التوليد GenerationConfig و التابع ()generate و الأصناف clasess المرتبطة مع المعالجة المسبقة والعديد من الأمثلة التوضيحية. أشهر نماذج LLMs النماذج مفتوحة المصدر التي تُركِّز على الجودة Open LLM Leaderboard. النماذج التي تهتم بالإنتاجية Open LLM-Perf Leaderboard. أدلة حول تحسين السرعة والإنتاجية وتقليل استخدام الذاكرة دليل تحسين السرعة والذاكرة في نماذج LLMs. دليل التكميم Quantization باستخدام تقنيات مثل bitsandbytes و autogptq، لتخفيض متطلبات استخدام الذواكر. مكتبات مرتبطة بالنماذج اللغوية الكبيرة المكتبة text-generation-inference، وهي بمثابة خادم إنتاج جاهز للعمل مع نماذج LLMs. المكتبة optimum، وهي امتداد لمكتبة المحوّلات Transformers تساعدك في تحسين استخدام مكونات الحاسوب وموارده. كما تساعدك دورة الذكاء الاصطناعي من أكاديمية حسوب في فهم طريقة التعامل مع النماذج اللغوية الكبيرة LLMs وربط الذكاء الاصطناعي مع تطبيقاتك المختلفة، كما يمكنك الحصول على معلومات مفيدة من دروس ومقالات قسم الذكاء الاصطناعي على أكاديمية حسوب. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن الخلاصة وصلنا إلى ختام المقال وقد عرضنا فيه طريقة استخدام النماذج اللغوية الكبيرة LLMs لتوليد النصوص الطويلة تلقائيًا من نص بسيط مُدخل، مع بيان بعض المخاطر الشائعة التي تعترض مستخدميها وكيفية تجنبها، بالإضافة لتعداد أشهر نماذج LLM، وبعض المصادر الموثوقة لمن يريد تعلمها بتعمقٍ أكبر. ترجمة -وبتصرف- لقسم Generation with LLMs من توثيقات Hugging Face. اقرأ أيضًا المقال السابق: استخدام وكلاء مكتبة المحولات Transformers Agents في الذكاء الاصطناعي التوليدي تدريب المًكيَّفات PEFT Adapters بدل تدريب نماذج الذكاء الاصطناعي بالكامل بناء تطبيق بايثون يجيب على أسئلة ملف PDF باستخدام الذكاء الاصطناعي تطوير تطبيق 'اختبرني' باستخدام ChatGPT ولغة جافاسكربت مع Node.js مصطلحات الذكاء الاصطناعي للمبتدئين1 نقطة
نناقش في مقال اليوم النماذج اللغوية الكبيرة LLMs وهي صاحبة الدور الرئيسي في توليد النصوص، فهي تتكون من نماذج ذكاء اصطناعي كبيرة من نوع المحولات transformer، ومُدَرَّبة مُسبقًا على مهمة التنبؤ بالكلمة التالية أو token التالي من أي مُوجه يعطى لها، فهي إذًا تتنبأ بكلمات فردية بمقدار كلمة واحدة في كل مرة، لذا فإن توليد الجمل الكاملة سيحتاج تقنيةً أوسع تسمى توليد الانحدار الذاتي autoregressive generation. ويُعرَّف توليد الانحدار الذاتي بأنه إجراءٌ استدلالي متكرر مع الزمن، يستدعي نموذج LLM مراتٍ متكررة وفي كل مرة يُمرر له المخرجات التي وَلَّدها في المرة السابقة كمدخلات وهكذا، وبطبيعة الحالة يحتاح إلى مدخلات ابتدائية نقدمها له ليستخدمها في الاستدعاء الأول للنموذج، وتوفر مكتبة المحولات Transformers تابعًا خاصًا لهذا الغرض هو generate()، يعمل جميع النماذج ذات الإمكانات التوليدية generative. نسعى في هذا المقال لتحقيق ثلاثة أهداف رئيسية: شرح كيفية توليد نص باستخدام نموذج لغوي كبير LLM الإضاءة على بعض المخاطر الشائعة لتتجنبها اقتراح بعض المصادر التي ستساعدك على تحقيق أقصى استفادة ممكنة من نماذج LLMs تأكد في البداية من تثبيت المكتبات الضرورية للعمل قبل أن نبدأ بالتفاصيل، وذلك وفق التالي: pip install transformers bitsandbytes>=0.39.0 -q توليد النص يأخذ النموذج اللغوي المُدَرَّب على النمذجة اللغوية السببية سلسلة من الرموز النصية كمدخلات inputs ويرجع بناءً عليها التوزع الاحتمالي للرمز التالي المتوقع، ألقِ نظرة على الصورة التوضيحية التالية: أما عن كيفية اختيار الرمز التالي من هذا التوزع الاحتمالي الناتج، فهي تختلف حسب الحالة، فقد تكون بسيطةً تتمثل بانتقاء الرمز الأكثر احتمالية من ضمن رموز التوزع الاحتمالي، أو معقدة لدرجة نحتاج معها لتطبيق عشرات التحويلات قبل الاختيار، وبصرف النظر عن طريقة الاختيار فإننا سنحصل بعد هذه المرحلة على رمز جديد نستخدمه في التكرار التالي أو الاستدعاء التالي للنموذج كما هو موضح في الصورة التالية لتوليد الانحدار الذاتي: تستمر عملية توليد الكلمات حتى نصل إلى أحد شروط التوقف التي يُحددها النموذج، ويتعلم النموذج متى ينبغي أن يرجع رمز نهاية السلسلة (EOS) الذي يُعدّ الإنهاء المثالي لعملية توليد النص، وفي حال لم يرجع النموذج هذا الرمز فسيظل العمل مستمرًا لحين الوصول إلى الحد الأقصى المسموح به من الرموز. إذًا فلديك أمرين مهمين ينبغي أن تهتم بهما ليعمل نموذجك التوليدي بالطريقة المرجوة، الأمر الأول هو كيفية اختيار الرمز التالي من بين رموز التوزع الاحتمالي، والأمر الثاني هو تحديد شرط إنهاء التوليد، تُضبط هذه الإعدادات في ملف إعدادات التوليد GenerationConfig الخاص بكل نموذج توليدي، يُحَمَّل هذا الملف مع النموذج وهو يتضنت معاملاتٍ افتراضية مناسبة له. لنبدأ الآن بالتطبيق العملي، حَمِّل أولًا النموذج كما يلي: >>> from transformers import AutoModelForCausalLM >>> model = AutoModelForCausalLM.from_pretrained( "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True ) استخدمنا في الاستدعاء from_pretrained السابق معاملين device_map و load_in_4bit: يضمن المعامل device_map أن حمل النموذج سيتوزع تلقائيًا على وحدات GPU المتاحة. يساعد المعامل load_in_4bit على تقليل استخدام الموارد الحاسوبية إلى أقصى حد ممكن عبر تطبيق التكميم الديناميكي 4 بت. توجد طرق أخرى عديدة لتهيئة نموذج LLM عند تحميله، عرضنا إحداها في الأمر السابق، وهي أساسية وبسيطة. نحتاج الآن لمعالجة النص معالجةً مسبقة قبل إدخاله للنموذج وذلك باستخدام المُرَمِّز Tokenizer وهو نوع المعالجة المناسب للنصوص كما تعلمنا في مقال المعالجة المُسبقة للبيانات قبل تمريرها لنماذج الذكاء الاصطناعي: >>> from transformers import AutoTokenizer >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left") >>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda") سيُخَزَّن خرج المُرَمِّز (وهو عبارة عن النص المُرَمَّز وقناع الانتباه attention mask) في المتغير model_inputs، ويوصى عادةً بتمرير بيانات قناع الانتباه ما أمكن ذلك للحصول على أفضل النتائج، رغم أن التابع generate() سيسعى لتخمين قيمة قناع الانتباه عند عدم تمريره. ملاحظة: قناع الانتباه attention mask هو أداة تساعد النموذج اللغوي على معرفة الأجزاء المهمة في النص الذي يعالجه وتجاهل الأجزاء غير المهمة كرموز الحشو التي تُضاف لجعل طول النصوص موحدًا. يوجه هذا القناع النموذج ليركز فقط على الكلمات الفعلية في النص ويهمل الرموز لا تعني شيئًا للحصول على نتائج دقيقة. بعد انتهاء الترميز يُستدعى التابع generate() الذي سيُرجع الرموز tokens المتنبأ بها، والتي ستتحول إلى نص قبل إظهارها في خرج النموذج. >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A list of colors: red, blue, green, yellow, orange, purple, pink,' ننوه أخيرًا إلى أنك لست مضطرًا لتمرير مدخلاتك إلى النموذج على شكل جمل مفردة، جملة واحدة في كل مرة، إذ يمكنك تجميع أكثر من جملة وتمريرها بهيئة دفعات batches مع استخدام الحشو padding لجعلها متساوية الطول، كما في المثال التالي، يزيد هذا الأسلوب من إنتاجية النموذج ويقلل الزمن والذاكرة المستهلكين: >>> tokenizer.pad_token = tokenizer.eos_token # لا تملك معظم النماذج اللغوية الكبيرة رمزًا للحشو افتراضيًا >>> model_inputs = tokenizer( ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True) ['A list of colors: red, blue, green, yellow, orange, purple, pink,', 'Portugal is a country in southwestern Europe, on the Iber'] إذًا ببضع أسطر برمجية فقط استفدنا من أحد النماذج اللغوية الكبيرة LLM واستطعنا توليد نصوص مكلمة للجمل التي أعطيناها للنموذج. بعض المشكلات المحتمل وقوعها لا تناسب القيم الافتراضية لمعاملات النماذج التوليدية جميع المهام فلكل مشروع خصوصيته، والاعتماد عليها قد لا يعطينا نتائج مرضية في العديد من حالات الاستخدام، سنعرض لك أشهرها مع طرق تجنبها: لنبدأ أولًا بتحميل النموذج والمُرَمِّز ثم نتابع بقية أجزاء الشيفرة ضمن الأمثلة تباعًا: >>> from transformers import AutoModelForCausalLM, AutoTokenizer >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1") >>> tokenizer.pad_token = tokenizer.eos_token # لا تمتلك معظم النماذج اللغوية الكبيرة رمزًا للحشو افتراضيًا >>> model = AutoModelForCausalLM.from_pretrained( "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True ) توليد خرج أطول أو أقصر من اللازم يُرجع التابع generate عشرين tokens كحد أقصى افتراضيًا، طالما أننا لم نحدد ما يخالف ذلك في ملف إعدادات التوليد Generation-config، ولكن ما ينبغي الانتباه له أن نماذج LLMs وخاصة النماذج من نوع decoder models مثل GPT و CTRL تُرجع مُوجَّه الدخل input prompt أيضًا مع كل خرج تعطيه، لذا ننصحك بتحديد الحد الأقصى لعدد الـ tokens الناتجة يدويًا، وعدم الاعتماد على الحد الافتراضي، وذلك ضمن المتغير max_new_tokens المرافق لاستدعاء generate، ألقِ نظرة على المثال التالي ولاحظ الفرق في الخرج بين الحالتين، الحالة الافتراضية، وحالة تحديد العدد الأقصى للرموز الناتجة: >>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], >>> return_tensors="pt").to("cuda") # الحالة الافتراضية الحد الأقصى لعدد الرموز الناتجة هو 20 رمز >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A sequence of numbers: 1, 2, 3, 4, 5' # عند ضبط قيمة المتغير الذي سيحدد العدد الأقصى للرموز الناتجة >>> generated_ids = model.generate(**model_inputs, max_new_tokens=50) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,' نمط توليد غير مناسب افتراضيًا يختار التابع generate الرمز الأكثر احتمالية من بين الرموز الناتجة في كل تكرار ما لم نحدد طريقة مغايرة للاختيار في ملف إعدادات التوليد GenerationConfig، يسمى هذا الأسلوب الافتراضي فك التشفير الشره greedy decoding، وهو لا يناسب المهام الإبداعية التي تستفيد من بعض العينات، مثل: بناء روبوت دردشة لمحادثة العملاء أو كتابة مقال متخصص، لكنه من ناحية أخرى يعمل جيدًا مع المهام المستندة إلى المدخلات، نحو: التفريغ الصوتي والترجمة وغيره، لذا اضبط المتغير على القيمة do_sample=True في المهام الإبداعية، كما يبين المثال التالي الذي يتضمن ثلاث حالات: >>> # استخدم هذا السطر إذا رغبت بالتكرار الكامل >>> from transformers import set_seed >>> set_seed(42) >>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda") >>> # LLM + فك التشفير الشره = مخرجات متكررة ومملة >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'I am a cat. I am a cat. I am a cat. I am a cat' >>> # مع تفعيل أخذ العينات، تصبح المخرجات أكثر إبداعًا >>> generated_ids = model.generate(**model_inputs, do_sample=True) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'I am a cat. Specifically, I am an indoor-only cat. I' الحشو في الجانب الخاطئ ذكرنا سابقًا أنك عندما تقوم بإدخال جمل أو نصوص ذات أطوال مختلفة للنموذج، فقد تحتاج إلى جعل هذه المدخلات بطول موحد ليتمكن النموذج من معالجتها بشكل صحيح من خلال إضافة رموز الحشو (padding tokens) التي تجعل جميع المدخلات بطول متساوٍ. لكن النماذج اللغوية الكبيرة LLMs هي بنى لفك التشفير فقط decoder-only فهي تكرر الإجراءات نفسها على مدخلاتك، لكنها غير مُدَرَّبة على الاستمرار بالتكرار على رموز الحشو، لذا عندما تكون مدخلاتك مختلفة الأطوال وتحتاج للحشو لتصبح بطول موحد، فاحرص على إضافة رموز الحشو على الجانب الأيسر left-padded (أي قبل بداية النص الحقيقي) ليعمل التوليد بطريقة سليمة، وتأكد من تمرير قناع الانتباه attention mask للتابع generate حتى لا تترك الأمر للتخمين: >>> # المُرَمِّز المستخدم هنا يحشو الرموز على الجانب الأيمن افتراضيًا، والسلسلة النصية الأولى هي >>> # السلسلة الأقصر والتي تحتاج لحشو، وعند حشوها على الجانب الأيمن سيفشل النموذج التوليدي في التنبؤ بمنطقية >>> model_inputs = tokenizer( ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt" ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] '1, 2, 33333333333' >>> # لاحظ الفرق عند تعديل الحشو ليصبح على الجانب الأيسر >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left") >>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default >>> model_inputs = tokenizer( ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt" ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] '1, 2, 3, 4, 5, 6,' مُوجَّهات خاطئة يتراجع أداء بعض النماذج عندما لا نمرر لها مُوجَّهات input prompt بالتنسيق الصحيح الذي يناسبها، يمكنك الحصول على مزيد من المعلومات عن طبيعة الدخل المتوقع للنماذج مع كل مهمة بالاطلاع على دليل المُوجَّهات في نماذج LLMs على منصة Hugging Face، ألقِ نظرة على المثال التالي الذي عن استخدام نموذج LLM للدردشة باستخدام قوالب الدردشة: >>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha") >>> model = AutoModelForCausalLM.from_pretrained( "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True ) >>> set_seed(0) >>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug.""" >>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda") >>> input_length = model_inputs.input_ids.shape[1] >>> generated_ids = model.generate(**model_inputs, max_new_tokens=20) >>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0]) "I'm not a thug, but i can tell you that a human cannot eat" >>> # لم يتبع النموذج تعليماتنا هنا فهو لم يرد على السؤال كما ينبغي أن يرد أي شخص عنيف >>> # سنقدم الآن دخلًا أفضل يناسب النموذج باستخدام قوالب الدردشة، ونرى الفرق النتيجة >>> set_seed(0) >>> messages = [ { "role": "system", "content": "You are a friendly chatbot who always responds in the style of a thug", }, {"role": "user", "content": "How many helicopters can a human eat in one sitting?"}, ] >>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda") >>> input_length = model_inputs.shape[1] >>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20) >>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0]) 'None, you thug. How bout you try to focus on more useful questions?' >>> # كما تلاحظ فقد تغير أسلوب الرد واتبع تعليماتنا بطريقة أفضل فكان رده أقرب للأسلوب المطلوب مصادر مفيدة للاستفادة من نماذج LLMs ستحتاج لتعميق معرفتك بالنماذج اللغوية الكبيرة (LLMs) إذا رغبت بتحقيق أقصى استفادة منها، وإليك بعض الأدلة المفيدة من منصة Hugging Face المتخصصة في المجال: أدلة الاستخدام المتقدم للتوليد Generating دليل استراتيجيات توليد النصوص باستخدام الذكاء الاصطناعي الذي يساعدك في تعلم كيفية التحكم بتوابع توليد مختلفة، وضبط مخرجاتها، وملفات الإعدادات الخاصة بها. دليل لاستخدام قوالب الدردشة مع نماذج LLMs. دليل LLM prompting يتضمن الأساسيات وأفضل الممارسات في كتابة المُوجَّهات. توثيقات واجهة برمجة التطبيقات API لكل من ملف إعدادات التوليد GenerationConfig و التابع ()generate و الأصناف clasess المرتبطة مع المعالجة المسبقة والعديد من الأمثلة التوضيحية. أشهر نماذج LLMs النماذج مفتوحة المصدر التي تُركِّز على الجودة Open LLM Leaderboard. النماذج التي تهتم بالإنتاجية Open LLM-Perf Leaderboard. أدلة حول تحسين السرعة والإنتاجية وتقليل استخدام الذاكرة دليل تحسين السرعة والذاكرة في نماذج LLMs. دليل التكميم Quantization باستخدام تقنيات مثل bitsandbytes و autogptq، لتخفيض متطلبات استخدام الذواكر. مكتبات مرتبطة بالنماذج اللغوية الكبيرة المكتبة text-generation-inference، وهي بمثابة خادم إنتاج جاهز للعمل مع نماذج LLMs. المكتبة optimum، وهي امتداد لمكتبة المحوّلات Transformers تساعدك في تحسين استخدام مكونات الحاسوب وموارده. كما تساعدك دورة الذكاء الاصطناعي من أكاديمية حسوب في فهم طريقة التعامل مع النماذج اللغوية الكبيرة LLMs وربط الذكاء الاصطناعي مع تطبيقاتك المختلفة، كما يمكنك الحصول على معلومات مفيدة من دروس ومقالات قسم الذكاء الاصطناعي على أكاديمية حسوب. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن الخلاصة وصلنا إلى ختام المقال وقد عرضنا فيه طريقة استخدام النماذج اللغوية الكبيرة LLMs لتوليد النصوص الطويلة تلقائيًا من نص بسيط مُدخل، مع بيان بعض المخاطر الشائعة التي تعترض مستخدميها وكيفية تجنبها، بالإضافة لتعداد أشهر نماذج LLM، وبعض المصادر الموثوقة لمن يريد تعلمها بتعمقٍ أكبر. ترجمة -وبتصرف- لقسم Generation with LLMs من توثيقات Hugging Face. اقرأ أيضًا المقال السابق: استخدام وكلاء مكتبة المحولات Transformers Agents في الذكاء الاصطناعي التوليدي تدريب المًكيَّفات PEFT Adapters بدل تدريب نماذج الذكاء الاصطناعي بالكامل بناء تطبيق بايثون يجيب على أسئلة ملف PDF باستخدام الذكاء الاصطناعي تطوير تطبيق 'اختبرني' باستخدام ChatGPT ولغة جافاسكربت مع Node.js مصطلحات الذكاء الاصطناعي للمبتدئين1 نقطة -
.png.c1af3fe12a171a203e8715d9e0d954c6.png) لقد أحدثت النماذج اللغوية الكبيرة LLMs وأشهرها روبوت المحادثة ChatGPT الذي طورته شركة OpenAI ثورة في الكثير من المجالات وأثبتت قدرتها على توليد نصوص تشبه النصوص البشرية، كما سهلت أداء العديد من المهام في مختلف المجالات ومن أبرزها مجال تطوير البرمجيات، فقد وفرت للمطورين والمبرمجين واجهات برمجية APIs تساعدهم في إنشاء تطبيقات ذكاء اصطناعي بسهولة كبيرة. سنتعلم في مقال اليوم كيفية تطوير تطبيق بايثون قادر على فهم نصوص ملف PDF والإجابة على أي أسئلة نطرحها حول محتوى هذا الملف بالاستفادة من ميزات نماذج الذكاء الاصطناعي التي توفرها واجهة برمجة تطبيقات OpenAI API وإطار عمل LangChain، وهو إطار عمل للغة البرمجة بايثون يمكن دمجه في تطبيقاتك لتعزز إمكانيات النماذج اللغوية الكبيرة. نظرة عامة على التطبيق المطلوب ومتطلباته نريد تطوير تطبيق بايثون باسم "اسأل PDF" يتيح هذا التطبيق للمستخدم تحميل ملف PDF من جهاز الحاسوب الخاص به، ويسمح له بطرح أي سؤال، ويستخدم تقنيات معالجة اللغة الطبيعية NLP للبحث عن إجابة مناسبة على هذا السؤال بناءً على محتوى الملف ويعرض له الإجابة. يحتاج تنفيذ التطبيق إلى المتطلبات التالية: معرفة بأساسيات لغة بايثون وتثبيت بيئة بايثون على الحاسوب المحلي. تثبيت أداة pip لتثبيت وإدارة حزم البرمجيات المساندة لبايثون. إنشاء حساب على على منصة OpenAI والحصول على مفتاح الواجهة البرمجية OpenAI API key خاص بك. معرفة بأساسيات نماذج وأطر عمل الذكاء الاصطناعي واختيار النماذج المناسبة لعمل التطبيق. معرفة بطريقة معالجة النصوص باستخدام التضمينات الرقمية ومخازن المتجهات. ما أهمية التضمينات الرقمية في تطبيقات البحث كي نتمكن من إنجاز عملية البحث في ملف pdf نحتاج لإنشاء تضمينات رقمية "Embedding" لكل جزء من أجزاء الملف، فبما أننا سنبحث في ملفات تتضمن الكثير من النصوص، فسنحتاج للاعتماد على تقنية التضمين وهي تقنية تستخدم في معالجة اللغة الطبيعية NLP وتقوم بتمثيل النصوص بشكل أعداد عشرية لتساعدنا على اكتشاف المعنى الدلالي للكلمات والعبارات والجمل بسرعة وفعالية، وتحولها لتنسيق يسهل الوصول إليه والبحث فيه عن المعلومات بدقة وكفاءة، بعدها سنقسم الملف إلى أجزاء صغيرة chunks حجم كل منها مثلًا 1000 حرف، ونفهرس هذه الأجزاء في قاعدة بيانات أو مخزن متجهات vectors حتى نتمكن من استرجاعها بسهولة عندما نريد الإجابة على الأسئلة الموجودة فيه. بهذه الطريقة ستملك النصوص ذات المحتوى المتشابه لغويًا متجهات متشابهة وبهذا يمكن مقارنة المتجهات والعثور على النصوص المتشابهة بسهولة وسرعة، وعندما نريد الحصول على إجابة لسؤال معين فسوف ننشئ كذلك تضمين رقمي لنص السؤال، ثم نقارن تضمين السؤال مع جميع المتجهات التي خزناها في مخزن المتجهات، ونختار الأكثر تشابهًا بناءً على حسابات رياضية على المتجهات، ثم نمرر تضمين السؤال مع التضمينات الأكثر تشابهًا معه إلى روبوت المحادثة ليولّد لنا الإجابة المناسبة بناءً على هذه المعطيات. خطوات التطبيق العملي لننشئ تطبيق واجهة رسومية GUI بلغة بايثون باستخدام المكتبة المدمجة Tkinter يمكننا من خلالها تحميل ملف PDF الذي نريده ثم نبدأ بمعالجة محتواه واستخراج كافة النصوص منه، فبعد تحميل الملف المطلوب سنحول نصوصه إلى تضمينات كما شرحنا سابقًا، ثم سنبدأ بعملية طرح سؤال متعلق بمحتوى الملف. سنحول السؤال كذلك لتضمين أو تمثيل رقمي ونبحث عن كافة المحتوى المشابه له وسنرسل بعد ذلك للواجهة البرمجية ChatGPT API سلسلة تتضمن السؤال وكل المحتوى المرتبط به الذي وجدناه ضمن الملف كمدخلات، ثم سنولّد بناءً على ذلك الإجابة المناسبة بالاستفادة من إمكانيات النماذج اللغوية الكبيرة LLMs. وإليك خطوات القيام بذلك بالتفصيل: خطوة 1: الحصول على مفتاح API الخاص بك من OpenAI للحصول على مفتاح API الخاص بك من OpenAI عليك اتباع الخطوات التالية: انتقل إلى الصفحة الرسمية لمنصة openai وأنشئ حسابًا جديدًا إذا لم تكن قد أنشأته من قبل ثم سجل الدخول لحسابك. انقر على القسم اAP للدخول لحسابك في صفحة مطوري OpenAI. انقر على أيقونة ChatGPT أعلى يمين الصفحة واختر البند API Keys. انقر على Create new secret key لإنشاء مفتاح API الخاص بك. أدخل اسمًا اختياريًا لمفتاح API للرجوع إليه لاحقًا. هذا كل ما يلزم لإنشاء مفتاح API الخاص بك من OpenAI. سيبدأ المفتاح بـ sk- انسخه واحفظه في مكان آمن واحرص على عدم مشاركته مع أحد أو كتابته في كود عام، فقد يقوم الآخرون باستخدام مفتاح API الخاص بك ويستهلكون رصيدك المتاح. ملاحظة: عليك الاشتراك بخطة مدفوعة للاستفادة من واجهة برمجة التطبيقات OpenAI API في تطبيقاتك، وسيكون المبلغ المقتطع بحسب الاستهلاك والنموذج المستخدم، فلكل نموذج تكلفة مختلفة وكلما زادت طلباتك أو عدد الرموز tokens المرسلة والمستقبلة من النموذج كلما زادت فاتورتك، لكن يمكنك في البداية الحصول على رصيد مجاني بقيمة 5 دولار عند الاشتراك حديثًا في المنصة للتجربة. خطوة 2: إنشاء ملفات تطبيق بايثون اسأل PDF للقيام بهذه الخطوة يجب أن تكون بيئة بايثون مثبتة على جهازك، ولإنشاء مشروع بايثون جديد، افتح سطر الأوامر (أو الطرفية) في نظام التشغيل وانتقل للمسار المطلوب، وأنشئ مجلدًا جديدًا للمشروع وليكن باسم askpdf، ثم أنشئ ضمنه ملفين الأول ask_pdf.py لإضافة كود الواجهة الرسومية للتطبيق، والثاني ملف .env لإضافة مفتاح الواجهة الرسومية OpenAI API Key اللازمة لعمل التطبيق من خلال كتابة التعليمات التالية تباعًا في سطر الأوامر: C:\Users\PC>d: D:\>md askpdf D:\>cd askpdf D:\askpdf>touch ask_pdf.py Touching ask_pdf.py D:\askpdf>touch .env Touching .env D:\askpdf> تثبيت المكتبات اللازمة لعمل التطبيق يحتاج التطبيق إلى تثبيت العديد من مكتبات ووحدات بايثون الخارجية باستخدام مدير الحزم pip وهي كالتالي: pip install python-dotenv PyPDF2 langchain langchain-openai langchain-community faiss-cpu إليك وصفًا موجزًا لكل مكتبة ولماذا استخدمناها في التطبيق: المكتبة python-dotenv لقراءة قيمة المفتاح الذي سأخزنه في الملف env. المكتبة PyPDF2 ضرورية للتعامل مع ملف PDF وقراءته محتوياته. إطار عمل LangChain ليسهل التعامل مع نموذج text-embedding-ada-002 لتقسيم النصوص، وإنشاء تضمينات وفهارس لها، كما أنه يدعم نموذج GPT-3.5 Turbo Instruct لتوليد إجابات على الأسئلة المطروحة. سنستدعي مكتبات langchain و langchain-openai و langchain-community من هذا الإطار وهي مكتبات مفيدة تتكامل مع نماذج OpenAI وتوسع إمكانياتها. وأخيرًا سنستخدم مكتبة Faiss وهي مكتبة بايثون يوفرها إطار LangChain تسرع عملية البحث عن التشابه في البيانات النصية دون الحاجة لاستهلاك الكثير من الموارد. كتابة الكود البرمجي للتطبيق الخطوة التالية هي إضافة الكود الخاص بالتطبيق، سأفتح الآن مجلد المشروع بمحرر الأكواد VSCode وأكتب بدايةً في ملف إعدادات التطبيق .env قيمة مفتاح الواجهة البرمجية على النحو الآتي: OPENAI_API_KEY= Your_KEY وعليك بالطبع استبدال Your_KEY في الكود السابق بالقيمة الفعلية لمفتاحك ليعمل التطبيق بشكل صحيح. الآن سننتقل للملف الأساسي للتطبيق ask_pdf.py ونستورد بدايةً كافة المكتبات والوظائف اللازمة لعمل التطبيق. ويوضح التعليق ضمن الكود دور كل منها على النحو الآتي: import os from dotenv import load_dotenv # مكتبات إنشاء الواجهة الرسومية import tkinter as tk from tkinter import filedialog, scrolledtext, ttk from tkinter import font from PIL import Image, ImageTk # قراءة ومعالجة ملفات PDF from PyPDF2 import PdfReader # الواجهة البرمجية OpenAI from langchain_openai import OpenAI from langchain_community.vectorstores import FAISS from langchain_community.callbacks import get_openai_callback from langchain.text_splitter import CharacterTextSplitter from langchain.chains.question_answering import load_qa_chain from langchain_openai import OpenAIEmbeddings بعدها سننشئ الصنف الأساسي للتطبيق باسم askpdfgui ونعرّف بداخله التابع __init__ لإضافة وتهيئة عناصر الواجهة الرسومية Widgets للتطبيق، ستتضمن الواجهة عناصر متعددة مثل حاويات العناوين Labels وشريط تقدم Progressbar وزِرَّين Buttons الأول لتحميل ملف PDF من الجهاز لذاكرة التطبيق ومعالجته، والثاني للبحث عن إجابة السؤال الذي يكتبه المستخدم ولا يكون هذا الزر مُفعّلًًا إلا بعد اكتمال تحميل ومعالجة الملف. class askpdfgui: def __init__(self, root): self.root = root self.root.title("اسأل PDF") self.root.geometry("800x700") custom_font = font.Font(family="Verdana", size=24, weight="bold") self.label = tk.Label(root, text="? PDF اسأل", font=custom_font) self.label.pack(pady=10) # عرض تقدم حالة تحميل الملف self.progress_label = ttk.Label(root, text="", foreground="green") self.progress_label.pack(pady=5) self.progress_bar = ttk.Progressbar(root, orient="horizontal") self.progress_bar.pack(pady=5) script_dir = os.path.dirname(os.path.abspath(__file__)) image_path = os.path.join(script_dir, "robopdf.png") image = Image.open(image_path) tk_image = ImageTk.PhotoImage(image) self.image_label = tk.Label(root, image=tk_image) self.image_label.image = tk_image self.image_label.pack(pady=10) # إضافة زر تحميل الملف self.upload_button = tk.Button( root, text="حمل ملفك هنا", command=self.upload_pdf ) self.upload_button.pack(pady=10) # حقل نصي لكتابة السؤال self.question_entry = tk.Entry(root, width=60, justify="center") self.question_entry.pack(pady=10) # زر طرح السؤال وإلغاء تفعيله لحين اكتمال معالجة الملف self.ask_button = tk.Button( root, text="اطرح السؤال", command=self.ask_question, state=tk.DISABLED ) self.ask_button.pack(pady=10) # عرض نتيجة السؤال self.result_text = tk.Text(root, wrap=tk.WORD, width=60, height=10) self.result_text.configure(font=("TkDefaultFont", 12)) self.result_text.pack(pady=10, anchor=tk.CENTER) سيكون شكل التطبيق على النحو التالي: الآن وبعد أن انتيهنا من تصميم واجهة التطبيق وتهيئة خصائص عناصر واجهة المستخدم سنبرمج وظائفه، بداية نحقق كود الدالة upload_pdf التي ستمكن المستخدم من فتح نافذة لتحميل ملف PDF الخاص به لداخل التطبيق كما يلي: def upload_pdf(self): file_path = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")]) if file_path: self.process_pdf(file_path) بعد أن يختار المستخدم ملف PDF يستدعى التابع process_pdf الذي يأخذ كوسيط مسار هذا الملف لبدء عملية المعالجة ويستخرج النصوص منه باستخدام الدالة extract_text، ويقسمه إلى أجزاء أو مقاطع أو نصوص بطول 1000 حرف مع تداخل بقيمة 200 حرف بين الأجزاء كي لا يفقد السياق، بمعنى سيكون الجزء الأول من البداية إلى الحرف 1000 أما الجزء الثاني فسيبدأ من الحرف 801 لضمان استمرارية المعنى وعدم فقدان معلومات مهمة بين النصوص المتجاورة. هناك عدة تقنيات مختلفة متاحة لتنفيذ مهمة التضمين والفهرسة في تطبيقنا، وقد اعتمدنا في هذا هذا التطبيق على الصنف OpenAIEmbeddings من مكتبة langchain_openai ومررنا قيمة مفتاح الواجهة البرمجية openai_api_key لباني الصنف لأنه سيستخدم هنا النموذج Embading الذي توفره هذه الواجهة لتكوين التضمينات الرقمية وإنشاء المتجهات الخاصة بها بالاستعانة بمكتبة FAISS على النحو التالي: def process_pdf(self, file_path): self.progress_label.config(text="انتظر اكتمال تحميل ملف PDF...") self.progress_bar.start() self.root.update_idletasks() pdf_reader = PdfReader(file_path) text = "" for page in pdf_reader.pages: text += page.extract_text() # تقسيم نص الملف إلى أجزاء text_splitter = CharacterTextSplitter( separator="\n", chunk_size=1000, chunk_overlap=200, length_function=len ) chunks = text_splitter.split_text(text) # إنشاء تضمينات النصوص embeddings = OpenAIEmbeddings(api_key=openai_api_key) knowledge_base = FAISS.from_texts(chunks, embeddings) self.docs = knowledge_base.similarity_search("") بالنسبة للسطر الأخير في الكود: self.docs = knowledge_base.similarity_search("") سينفذ هذا السطر عملية بحث عن التشابه ويجد أقرب الجمل لسؤالك الذي ستطرحه باستخدام قاعدة بيانات المتجهات knowledge_base ويخزن النتيجة في متغير docs فهذا المتغير يخزن معلومات حول النصوص المتشابهة ودرجة التشابه بين النص أو السؤال الذي تبحث عنه والنص المخزن في قاعدة البيانات، لكن هنا لم نكتب السؤال بعد لذا نخزن نتائج البحث باعتبار السؤال فارغ، لاحقًا عندما ستتم عملية البحث الفعلية سيحدد النصوص المشابهة بشكل أفضل ويحسن عملية البحث. إليك مثالًا بسيطًا لبنية هذا المتغير، إذا كان السؤال الذي كتبه المستخدم هو "ما فائدة تعلم الذكاء الاصطناعي في تحسين مهارات التطوير" فسوف يحتوي المتغير عندها على قائمة من النصوص التي حصل عليها من الملف مع درجة التشابه مع السؤال المطروح على نحو مشابه للبنية التالية: self.docs = [ {"text": "تعلم لغات البرمجة يساعد في تطوير مهارات البرمجة", "similarity_score": 0.85}, {"text": "تعلم الذكاء الاصطناعي يحسن من تجربة المستخدم", "similarity_score": 0.92}, # ... وهكذا تأخذ هذه العملية بعض الوقت لقراءة الملف بالكامل ومعالجته بالاعتماد على حجم الملف وبعد اكتمال تحميل الملف وتحويله لتضمينات وفهرسته بالشكل المطلوب، سيُفعّل زر طرح السؤال إذ يمكن للمستخدم الآن كتابة أي سؤال في الحقل النصي question_entry للإجابة عليه بناءً على المحتوى الذي أنشأه البرنامج. self.progress_label.config(text="اكتملت عملية التحميل يمكنك طرح السؤال الآن") self.progress_bar.stop() self.progress_bar["value"] = 100 # تمكين زر طرح السؤال self.ask_button["state"] = tk.NORMAL الخطوة التالية والأخيرة هي تعريف التابع ask_question وهو أهم تابع في تطبيقنا وسنستدعيه بعد كتابة السؤال والنقر على زر طرح السؤال، ليبدأ بالبحث عن إجابة مناسبة على السؤال من محتوى المتغير doc ويرسل الطلب لواجهة OpenAI لتقديم إجابة مناسبة. def ask_question(self): user_question = self.question_entry.get() if user_question: llm = OpenAI(model="gpt-3.5-turbo-instruct", api_key=openai_api_key, temperature=0.0) chain = load_qa_chain(llm, chain_type="stuff") with get_openai_callback(): response = chain.run(input_documents=self.docs, question=user_question) print(response) # عرض الإجابة على السؤال self.result_text.tag_configure("center", justify="center") # مسح أي نص قديم إن وجد self.result_text.delete("1.0", tk.END) self.result_text.insert(tk.END, response, "center") كما هو موضح في الكود أعلاه سيحصل التابع على نص السؤال الذي أدخله المستخدم في الحقل النصي question_entry ثم يخزنه في المتغير user_question ويمرر مدخلات المستخدم إلى النموذج gpt-3.5-turbo-instruct لتوليد الإجابة، وهنا نحتاج كذلك لإدخال قيمة المفتاح openai_api_key لإنشاء اتصال مع واجهة برمجة تطبيقات OpenAI ولتخصيص أي وسطاء نحتاجها لتخصيص إجابة النموذج وأهم هذه الوسطاء temperature الذي يحدد درجة دقة السؤال. ويفضل في حالة تطبيقنا أن تبقى قيمته صفر للحصول على إجابات منطقية وحتمية تلتزم بمحتوى الملف، وعدم ترك النموذج يبدع ويؤلف إجابات لا صلة لها بالسياق وسنوضح المزيد عنه لاحقًا عن تجربة تنفيذ التطبيق. بعدها نستدعي الدالة load_qa_chain التي تنشئ سلسلةً نصيةً من نوع stuff لترسلها كمطالبة إلى الواجهة البرمجية OpenAI التي تفهم بدورها الطلب الذي أرسلناه وتعيد لنا الإجابة المناسبة response. ملاحظة: يحدد نوع السلسلة chain_type طريقة تمرير المستندات إلى النموذج اللغوي الكبير LLM وهنا مررنا القيمة ليكون stuff التي ترسل جميع المستندات في طلب واحد للواجهة البرمجية وهي تناسب حالة التعامل مع مستند واحد أو عدة مستندات صغيرة الحجم وتتضمن نفس طبيعة المحتوى، وهناك طرق أخرى هي Map-reduce تفيد في حال التعامل مع مستندات كبيرة هي تلخص كل مستند على حدا ثم تجمع التلخيصات في ملخص نهائي. أخيرًا نكتب كود تشغيل التطبيق كبرنامج رئيسي من خلال تحميل بيانات مفتاح OpenAI API من ملف .env وفحص فيما إذا كان المفتاح قد تم تعيينه أم لا، والبدء بإنشاء واجهة المستخدم الرسومية وتشغيل التطبيق حتى يتم إغلاق النافذة. if __name__ == "__main__": load_dotenv() openai_api_key = os.getenv("OPENAI_API_KEY") if openai_api_key is None: print( "OpenAI API تأكد من تعيين قيمة مفتاح" ) else: root = tk.Tk() app = askpdfgui(root) root.mainloop() تجربة عمل التطبيق لننفذ الآن كود التطبيق ونختبر آلية عمله: انتقل لمسار وجود التطبيق واكتب الأمر python ask_pdf.py في سطر الأوامر أو الطرفية لتشغيله، ستظهر لك الواجهة الأولية ولتجربة التطبيق سأنقر على زر "حمل ملفك هنا" يمكن تحميل أي ملف pdf خاص بك في التطبيق، وفي حالتي سأختار ملف يتحدث عن لغات برمجة الذكاء الاصطناعي كما يلي: بعد اكتمال عملية التحميل سأطرح السؤال التالي: "ما هي لغات برمجة الذكاء الاصطناعي؟" وسأحصل على الإجابة كما هو موضح في الصورة التالية: كما يمكن طرح أي أسئلة أخرى حول الملف مثل اسم الكاتب أو تاريخ نشره وسيتمكن من الإجابة كما توضح الصورة أدناه: الآن لو طرحت سؤالًا لا علاقة له بمحتوى هذا الملف مثل "من اخترع المصباح الكهربائي" ستكون النتيجة كما يلي: تأثير الوسيط Temperature على دقة نتائج التطبيق يستخدم المعامل أو الوسيط temperature كما وضحت سابقًا للتحكم في دقة أو عشوائية النتائج التي تعيدها نماذج واجهة برمجة تطبيقات OpenAI وتتراوح قيمة هذا الوسيط بين 0 و 2، فعند ضبط درجة الدقة على قيم قريبة من الصفر ستحصل على نتائج واقعية وذات صلة بالطلب وحين تضبطه على قيم قريبة من 2 ستحصل على نتائج أكثر إبداعًا لكنها قد تكون غير دقيقة ولا صلة لها بالسؤال. لذا عليك تعديل قيمة هذا المعامل بما يتناسب مع طبيعة تطبيقك، وهل يحتاج للدقة كما في حال تطبيقنا الذي يبحث عن النتائج الموافقة للسؤال، أم يسمح فيه الإبداع والابتكار كتطبيقات تأليف القصص والروايات. سأجرب على سبيل المثال تغير درجة الحرارة في الكود السابق وجعلها مثلًا 1.5 وأحمّل الملف نفسه واطرح سؤال "من هو أديسون؟" مثلًا ستكون النتيجة غير منطقية كما يلي! أما عند إعادة ضبطه بالقيمة 0 فسيجيب التطبيق بأنه لا يملك معلومات عن أديسون وفق الملف الذي وفرته له. قيود على عدد الرموز Tokens في التطبيق يمكنك تجربة التطبيق على أي ملف pdf خاص بك، لكن تملك نماذج من OpenAI API حدًا أقصى لعدد الرموز Token Limits التي تمثل إجمالي طول المدخلات التي تستقبلها والنتائج التي تولدها وفي حالة النموذج gpt-3.5-turbo-instruct المستخدم في الكود فالعدد الأقصى هو 4096 رمزًا، وبالتالي قد تحصل على الخطأ التالي عند تحميل ملفات كبيرة وتجاوز إجمالي الرموز في دخل وخرج النموذج هذا العدد، ومن الإجراءات الممكنة لتجاوز هذه القيود، تحديد قيمة المعامل max_tokens للنموذج كي تحدد له طول الرد الذي سينتج وتمنعه من إنشاء محتوى طويل جدًا أو تقصير نص الطلب أو السؤال قدر المستطاع. كما تحدد بعض النماذج سرعة معالجة الرموز في الدقيقة الواحدة، فالحد الأقصى المسموح به للتضمينات في نموذج text-embedding-ada-002 هو 15000 رمز في الدقيقة، وبالتالي إذا استخدمت ملفات pdf كبيرة تتجاوز هذه الحدود فسوف تحصل على كذلك أخطاء في التنفيذ بسبب القيود التي تفرضها الواجهة البرمجية ولحلها عليك رفع خطة الاشتراك في الواجهة البرمجية. الخلاصة بهذا نكون قد وصلنا لنهاية مقالنا، الذي شرحنا فيه خطوات إنشاء تطبيق بايثون يستفيد من واجهة برمجة تطبيقات OpenAI لتحميل ملف PDF وطرح أسئلة حوله وتوليد إجابات عليها من محتوى الملف، وهناك بالطبع الكثير من الأفكار الأخرى التي يمكنك الاستفادة منها من النماذج اللغوية الكبيرة LLMs في تطوير تطبيقات متقدمة في مجال الذكاء الاصطناعي، أطلق العنان لإبداعك واستفد من قوة هذه النماذج وإمكانياتها الهائلة. اقرأ أيضًا تطوير تطبيق "وصفة" لاقتراح الوجبات باستخدام ChatGPT و DALL-E في PHP تطوير تطبيق "اختبرني" باستخدام ChatGPT ولغة جافاسكربت مع Node.js إعداد بيئة العمل للمشاريع مع بايثون اكتشاف دلالات الأخطاء في شيفرات لغة بايثون كود التطبيق ask_pdf.zip1 نقطة
لقد أحدثت النماذج اللغوية الكبيرة LLMs وأشهرها روبوت المحادثة ChatGPT الذي طورته شركة OpenAI ثورة في الكثير من المجالات وأثبتت قدرتها على توليد نصوص تشبه النصوص البشرية، كما سهلت أداء العديد من المهام في مختلف المجالات ومن أبرزها مجال تطوير البرمجيات، فقد وفرت للمطورين والمبرمجين واجهات برمجية APIs تساعدهم في إنشاء تطبيقات ذكاء اصطناعي بسهولة كبيرة. سنتعلم في مقال اليوم كيفية تطوير تطبيق بايثون قادر على فهم نصوص ملف PDF والإجابة على أي أسئلة نطرحها حول محتوى هذا الملف بالاستفادة من ميزات نماذج الذكاء الاصطناعي التي توفرها واجهة برمجة تطبيقات OpenAI API وإطار عمل LangChain، وهو إطار عمل للغة البرمجة بايثون يمكن دمجه في تطبيقاتك لتعزز إمكانيات النماذج اللغوية الكبيرة. نظرة عامة على التطبيق المطلوب ومتطلباته نريد تطوير تطبيق بايثون باسم "اسأل PDF" يتيح هذا التطبيق للمستخدم تحميل ملف PDF من جهاز الحاسوب الخاص به، ويسمح له بطرح أي سؤال، ويستخدم تقنيات معالجة اللغة الطبيعية NLP للبحث عن إجابة مناسبة على هذا السؤال بناءً على محتوى الملف ويعرض له الإجابة. يحتاج تنفيذ التطبيق إلى المتطلبات التالية: معرفة بأساسيات لغة بايثون وتثبيت بيئة بايثون على الحاسوب المحلي. تثبيت أداة pip لتثبيت وإدارة حزم البرمجيات المساندة لبايثون. إنشاء حساب على على منصة OpenAI والحصول على مفتاح الواجهة البرمجية OpenAI API key خاص بك. معرفة بأساسيات نماذج وأطر عمل الذكاء الاصطناعي واختيار النماذج المناسبة لعمل التطبيق. معرفة بطريقة معالجة النصوص باستخدام التضمينات الرقمية ومخازن المتجهات. ما أهمية التضمينات الرقمية في تطبيقات البحث كي نتمكن من إنجاز عملية البحث في ملف pdf نحتاج لإنشاء تضمينات رقمية "Embedding" لكل جزء من أجزاء الملف، فبما أننا سنبحث في ملفات تتضمن الكثير من النصوص، فسنحتاج للاعتماد على تقنية التضمين وهي تقنية تستخدم في معالجة اللغة الطبيعية NLP وتقوم بتمثيل النصوص بشكل أعداد عشرية لتساعدنا على اكتشاف المعنى الدلالي للكلمات والعبارات والجمل بسرعة وفعالية، وتحولها لتنسيق يسهل الوصول إليه والبحث فيه عن المعلومات بدقة وكفاءة، بعدها سنقسم الملف إلى أجزاء صغيرة chunks حجم كل منها مثلًا 1000 حرف، ونفهرس هذه الأجزاء في قاعدة بيانات أو مخزن متجهات vectors حتى نتمكن من استرجاعها بسهولة عندما نريد الإجابة على الأسئلة الموجودة فيه. بهذه الطريقة ستملك النصوص ذات المحتوى المتشابه لغويًا متجهات متشابهة وبهذا يمكن مقارنة المتجهات والعثور على النصوص المتشابهة بسهولة وسرعة، وعندما نريد الحصول على إجابة لسؤال معين فسوف ننشئ كذلك تضمين رقمي لنص السؤال، ثم نقارن تضمين السؤال مع جميع المتجهات التي خزناها في مخزن المتجهات، ونختار الأكثر تشابهًا بناءً على حسابات رياضية على المتجهات، ثم نمرر تضمين السؤال مع التضمينات الأكثر تشابهًا معه إلى روبوت المحادثة ليولّد لنا الإجابة المناسبة بناءً على هذه المعطيات. خطوات التطبيق العملي لننشئ تطبيق واجهة رسومية GUI بلغة بايثون باستخدام المكتبة المدمجة Tkinter يمكننا من خلالها تحميل ملف PDF الذي نريده ثم نبدأ بمعالجة محتواه واستخراج كافة النصوص منه، فبعد تحميل الملف المطلوب سنحول نصوصه إلى تضمينات كما شرحنا سابقًا، ثم سنبدأ بعملية طرح سؤال متعلق بمحتوى الملف. سنحول السؤال كذلك لتضمين أو تمثيل رقمي ونبحث عن كافة المحتوى المشابه له وسنرسل بعد ذلك للواجهة البرمجية ChatGPT API سلسلة تتضمن السؤال وكل المحتوى المرتبط به الذي وجدناه ضمن الملف كمدخلات، ثم سنولّد بناءً على ذلك الإجابة المناسبة بالاستفادة من إمكانيات النماذج اللغوية الكبيرة LLMs. وإليك خطوات القيام بذلك بالتفصيل: خطوة 1: الحصول على مفتاح API الخاص بك من OpenAI للحصول على مفتاح API الخاص بك من OpenAI عليك اتباع الخطوات التالية: انتقل إلى الصفحة الرسمية لمنصة openai وأنشئ حسابًا جديدًا إذا لم تكن قد أنشأته من قبل ثم سجل الدخول لحسابك. انقر على القسم اAP للدخول لحسابك في صفحة مطوري OpenAI. انقر على أيقونة ChatGPT أعلى يمين الصفحة واختر البند API Keys. انقر على Create new secret key لإنشاء مفتاح API الخاص بك. أدخل اسمًا اختياريًا لمفتاح API للرجوع إليه لاحقًا. هذا كل ما يلزم لإنشاء مفتاح API الخاص بك من OpenAI. سيبدأ المفتاح بـ sk- انسخه واحفظه في مكان آمن واحرص على عدم مشاركته مع أحد أو كتابته في كود عام، فقد يقوم الآخرون باستخدام مفتاح API الخاص بك ويستهلكون رصيدك المتاح. ملاحظة: عليك الاشتراك بخطة مدفوعة للاستفادة من واجهة برمجة التطبيقات OpenAI API في تطبيقاتك، وسيكون المبلغ المقتطع بحسب الاستهلاك والنموذج المستخدم، فلكل نموذج تكلفة مختلفة وكلما زادت طلباتك أو عدد الرموز tokens المرسلة والمستقبلة من النموذج كلما زادت فاتورتك، لكن يمكنك في البداية الحصول على رصيد مجاني بقيمة 5 دولار عند الاشتراك حديثًا في المنصة للتجربة. خطوة 2: إنشاء ملفات تطبيق بايثون اسأل PDF للقيام بهذه الخطوة يجب أن تكون بيئة بايثون مثبتة على جهازك، ولإنشاء مشروع بايثون جديد، افتح سطر الأوامر (أو الطرفية) في نظام التشغيل وانتقل للمسار المطلوب، وأنشئ مجلدًا جديدًا للمشروع وليكن باسم askpdf، ثم أنشئ ضمنه ملفين الأول ask_pdf.py لإضافة كود الواجهة الرسومية للتطبيق، والثاني ملف .env لإضافة مفتاح الواجهة الرسومية OpenAI API Key اللازمة لعمل التطبيق من خلال كتابة التعليمات التالية تباعًا في سطر الأوامر: C:\Users\PC>d: D:\>md askpdf D:\>cd askpdf D:\askpdf>touch ask_pdf.py Touching ask_pdf.py D:\askpdf>touch .env Touching .env D:\askpdf> تثبيت المكتبات اللازمة لعمل التطبيق يحتاج التطبيق إلى تثبيت العديد من مكتبات ووحدات بايثون الخارجية باستخدام مدير الحزم pip وهي كالتالي: pip install python-dotenv PyPDF2 langchain langchain-openai langchain-community faiss-cpu إليك وصفًا موجزًا لكل مكتبة ولماذا استخدمناها في التطبيق: المكتبة python-dotenv لقراءة قيمة المفتاح الذي سأخزنه في الملف env. المكتبة PyPDF2 ضرورية للتعامل مع ملف PDF وقراءته محتوياته. إطار عمل LangChain ليسهل التعامل مع نموذج text-embedding-ada-002 لتقسيم النصوص، وإنشاء تضمينات وفهارس لها، كما أنه يدعم نموذج GPT-3.5 Turbo Instruct لتوليد إجابات على الأسئلة المطروحة. سنستدعي مكتبات langchain و langchain-openai و langchain-community من هذا الإطار وهي مكتبات مفيدة تتكامل مع نماذج OpenAI وتوسع إمكانياتها. وأخيرًا سنستخدم مكتبة Faiss وهي مكتبة بايثون يوفرها إطار LangChain تسرع عملية البحث عن التشابه في البيانات النصية دون الحاجة لاستهلاك الكثير من الموارد. كتابة الكود البرمجي للتطبيق الخطوة التالية هي إضافة الكود الخاص بالتطبيق، سأفتح الآن مجلد المشروع بمحرر الأكواد VSCode وأكتب بدايةً في ملف إعدادات التطبيق .env قيمة مفتاح الواجهة البرمجية على النحو الآتي: OPENAI_API_KEY= Your_KEY وعليك بالطبع استبدال Your_KEY في الكود السابق بالقيمة الفعلية لمفتاحك ليعمل التطبيق بشكل صحيح. الآن سننتقل للملف الأساسي للتطبيق ask_pdf.py ونستورد بدايةً كافة المكتبات والوظائف اللازمة لعمل التطبيق. ويوضح التعليق ضمن الكود دور كل منها على النحو الآتي: import os from dotenv import load_dotenv # مكتبات إنشاء الواجهة الرسومية import tkinter as tk from tkinter import filedialog, scrolledtext, ttk from tkinter import font from PIL import Image, ImageTk # قراءة ومعالجة ملفات PDF from PyPDF2 import PdfReader # الواجهة البرمجية OpenAI from langchain_openai import OpenAI from langchain_community.vectorstores import FAISS from langchain_community.callbacks import get_openai_callback from langchain.text_splitter import CharacterTextSplitter from langchain.chains.question_answering import load_qa_chain from langchain_openai import OpenAIEmbeddings بعدها سننشئ الصنف الأساسي للتطبيق باسم askpdfgui ونعرّف بداخله التابع __init__ لإضافة وتهيئة عناصر الواجهة الرسومية Widgets للتطبيق، ستتضمن الواجهة عناصر متعددة مثل حاويات العناوين Labels وشريط تقدم Progressbar وزِرَّين Buttons الأول لتحميل ملف PDF من الجهاز لذاكرة التطبيق ومعالجته، والثاني للبحث عن إجابة السؤال الذي يكتبه المستخدم ولا يكون هذا الزر مُفعّلًًا إلا بعد اكتمال تحميل ومعالجة الملف. class askpdfgui: def __init__(self, root): self.root = root self.root.title("اسأل PDF") self.root.geometry("800x700") custom_font = font.Font(family="Verdana", size=24, weight="bold") self.label = tk.Label(root, text="? PDF اسأل", font=custom_font) self.label.pack(pady=10) # عرض تقدم حالة تحميل الملف self.progress_label = ttk.Label(root, text="", foreground="green") self.progress_label.pack(pady=5) self.progress_bar = ttk.Progressbar(root, orient="horizontal") self.progress_bar.pack(pady=5) script_dir = os.path.dirname(os.path.abspath(__file__)) image_path = os.path.join(script_dir, "robopdf.png") image = Image.open(image_path) tk_image = ImageTk.PhotoImage(image) self.image_label = tk.Label(root, image=tk_image) self.image_label.image = tk_image self.image_label.pack(pady=10) # إضافة زر تحميل الملف self.upload_button = tk.Button( root, text="حمل ملفك هنا", command=self.upload_pdf ) self.upload_button.pack(pady=10) # حقل نصي لكتابة السؤال self.question_entry = tk.Entry(root, width=60, justify="center") self.question_entry.pack(pady=10) # زر طرح السؤال وإلغاء تفعيله لحين اكتمال معالجة الملف self.ask_button = tk.Button( root, text="اطرح السؤال", command=self.ask_question, state=tk.DISABLED ) self.ask_button.pack(pady=10) # عرض نتيجة السؤال self.result_text = tk.Text(root, wrap=tk.WORD, width=60, height=10) self.result_text.configure(font=("TkDefaultFont", 12)) self.result_text.pack(pady=10, anchor=tk.CENTER) سيكون شكل التطبيق على النحو التالي: الآن وبعد أن انتيهنا من تصميم واجهة التطبيق وتهيئة خصائص عناصر واجهة المستخدم سنبرمج وظائفه، بداية نحقق كود الدالة upload_pdf التي ستمكن المستخدم من فتح نافذة لتحميل ملف PDF الخاص به لداخل التطبيق كما يلي: def upload_pdf(self): file_path = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")]) if file_path: self.process_pdf(file_path) بعد أن يختار المستخدم ملف PDF يستدعى التابع process_pdf الذي يأخذ كوسيط مسار هذا الملف لبدء عملية المعالجة ويستخرج النصوص منه باستخدام الدالة extract_text، ويقسمه إلى أجزاء أو مقاطع أو نصوص بطول 1000 حرف مع تداخل بقيمة 200 حرف بين الأجزاء كي لا يفقد السياق، بمعنى سيكون الجزء الأول من البداية إلى الحرف 1000 أما الجزء الثاني فسيبدأ من الحرف 801 لضمان استمرارية المعنى وعدم فقدان معلومات مهمة بين النصوص المتجاورة. هناك عدة تقنيات مختلفة متاحة لتنفيذ مهمة التضمين والفهرسة في تطبيقنا، وقد اعتمدنا في هذا هذا التطبيق على الصنف OpenAIEmbeddings من مكتبة langchain_openai ومررنا قيمة مفتاح الواجهة البرمجية openai_api_key لباني الصنف لأنه سيستخدم هنا النموذج Embading الذي توفره هذه الواجهة لتكوين التضمينات الرقمية وإنشاء المتجهات الخاصة بها بالاستعانة بمكتبة FAISS على النحو التالي: def process_pdf(self, file_path): self.progress_label.config(text="انتظر اكتمال تحميل ملف PDF...") self.progress_bar.start() self.root.update_idletasks() pdf_reader = PdfReader(file_path) text = "" for page in pdf_reader.pages: text += page.extract_text() # تقسيم نص الملف إلى أجزاء text_splitter = CharacterTextSplitter( separator="\n", chunk_size=1000, chunk_overlap=200, length_function=len ) chunks = text_splitter.split_text(text) # إنشاء تضمينات النصوص embeddings = OpenAIEmbeddings(api_key=openai_api_key) knowledge_base = FAISS.from_texts(chunks, embeddings) self.docs = knowledge_base.similarity_search("") بالنسبة للسطر الأخير في الكود: self.docs = knowledge_base.similarity_search("") سينفذ هذا السطر عملية بحث عن التشابه ويجد أقرب الجمل لسؤالك الذي ستطرحه باستخدام قاعدة بيانات المتجهات knowledge_base ويخزن النتيجة في متغير docs فهذا المتغير يخزن معلومات حول النصوص المتشابهة ودرجة التشابه بين النص أو السؤال الذي تبحث عنه والنص المخزن في قاعدة البيانات، لكن هنا لم نكتب السؤال بعد لذا نخزن نتائج البحث باعتبار السؤال فارغ، لاحقًا عندما ستتم عملية البحث الفعلية سيحدد النصوص المشابهة بشكل أفضل ويحسن عملية البحث. إليك مثالًا بسيطًا لبنية هذا المتغير، إذا كان السؤال الذي كتبه المستخدم هو "ما فائدة تعلم الذكاء الاصطناعي في تحسين مهارات التطوير" فسوف يحتوي المتغير عندها على قائمة من النصوص التي حصل عليها من الملف مع درجة التشابه مع السؤال المطروح على نحو مشابه للبنية التالية: self.docs = [ {"text": "تعلم لغات البرمجة يساعد في تطوير مهارات البرمجة", "similarity_score": 0.85}, {"text": "تعلم الذكاء الاصطناعي يحسن من تجربة المستخدم", "similarity_score": 0.92}, # ... وهكذا تأخذ هذه العملية بعض الوقت لقراءة الملف بالكامل ومعالجته بالاعتماد على حجم الملف وبعد اكتمال تحميل الملف وتحويله لتضمينات وفهرسته بالشكل المطلوب، سيُفعّل زر طرح السؤال إذ يمكن للمستخدم الآن كتابة أي سؤال في الحقل النصي question_entry للإجابة عليه بناءً على المحتوى الذي أنشأه البرنامج. self.progress_label.config(text="اكتملت عملية التحميل يمكنك طرح السؤال الآن") self.progress_bar.stop() self.progress_bar["value"] = 100 # تمكين زر طرح السؤال self.ask_button["state"] = tk.NORMAL الخطوة التالية والأخيرة هي تعريف التابع ask_question وهو أهم تابع في تطبيقنا وسنستدعيه بعد كتابة السؤال والنقر على زر طرح السؤال، ليبدأ بالبحث عن إجابة مناسبة على السؤال من محتوى المتغير doc ويرسل الطلب لواجهة OpenAI لتقديم إجابة مناسبة. def ask_question(self): user_question = self.question_entry.get() if user_question: llm = OpenAI(model="gpt-3.5-turbo-instruct", api_key=openai_api_key, temperature=0.0) chain = load_qa_chain(llm, chain_type="stuff") with get_openai_callback(): response = chain.run(input_documents=self.docs, question=user_question) print(response) # عرض الإجابة على السؤال self.result_text.tag_configure("center", justify="center") # مسح أي نص قديم إن وجد self.result_text.delete("1.0", tk.END) self.result_text.insert(tk.END, response, "center") كما هو موضح في الكود أعلاه سيحصل التابع على نص السؤال الذي أدخله المستخدم في الحقل النصي question_entry ثم يخزنه في المتغير user_question ويمرر مدخلات المستخدم إلى النموذج gpt-3.5-turbo-instruct لتوليد الإجابة، وهنا نحتاج كذلك لإدخال قيمة المفتاح openai_api_key لإنشاء اتصال مع واجهة برمجة تطبيقات OpenAI ولتخصيص أي وسطاء نحتاجها لتخصيص إجابة النموذج وأهم هذه الوسطاء temperature الذي يحدد درجة دقة السؤال. ويفضل في حالة تطبيقنا أن تبقى قيمته صفر للحصول على إجابات منطقية وحتمية تلتزم بمحتوى الملف، وعدم ترك النموذج يبدع ويؤلف إجابات لا صلة لها بالسياق وسنوضح المزيد عنه لاحقًا عن تجربة تنفيذ التطبيق. بعدها نستدعي الدالة load_qa_chain التي تنشئ سلسلةً نصيةً من نوع stuff لترسلها كمطالبة إلى الواجهة البرمجية OpenAI التي تفهم بدورها الطلب الذي أرسلناه وتعيد لنا الإجابة المناسبة response. ملاحظة: يحدد نوع السلسلة chain_type طريقة تمرير المستندات إلى النموذج اللغوي الكبير LLM وهنا مررنا القيمة ليكون stuff التي ترسل جميع المستندات في طلب واحد للواجهة البرمجية وهي تناسب حالة التعامل مع مستند واحد أو عدة مستندات صغيرة الحجم وتتضمن نفس طبيعة المحتوى، وهناك طرق أخرى هي Map-reduce تفيد في حال التعامل مع مستندات كبيرة هي تلخص كل مستند على حدا ثم تجمع التلخيصات في ملخص نهائي. أخيرًا نكتب كود تشغيل التطبيق كبرنامج رئيسي من خلال تحميل بيانات مفتاح OpenAI API من ملف .env وفحص فيما إذا كان المفتاح قد تم تعيينه أم لا، والبدء بإنشاء واجهة المستخدم الرسومية وتشغيل التطبيق حتى يتم إغلاق النافذة. if __name__ == "__main__": load_dotenv() openai_api_key = os.getenv("OPENAI_API_KEY") if openai_api_key is None: print( "OpenAI API تأكد من تعيين قيمة مفتاح" ) else: root = tk.Tk() app = askpdfgui(root) root.mainloop() تجربة عمل التطبيق لننفذ الآن كود التطبيق ونختبر آلية عمله: انتقل لمسار وجود التطبيق واكتب الأمر python ask_pdf.py في سطر الأوامر أو الطرفية لتشغيله، ستظهر لك الواجهة الأولية ولتجربة التطبيق سأنقر على زر "حمل ملفك هنا" يمكن تحميل أي ملف pdf خاص بك في التطبيق، وفي حالتي سأختار ملف يتحدث عن لغات برمجة الذكاء الاصطناعي كما يلي: بعد اكتمال عملية التحميل سأطرح السؤال التالي: "ما هي لغات برمجة الذكاء الاصطناعي؟" وسأحصل على الإجابة كما هو موضح في الصورة التالية: كما يمكن طرح أي أسئلة أخرى حول الملف مثل اسم الكاتب أو تاريخ نشره وسيتمكن من الإجابة كما توضح الصورة أدناه: الآن لو طرحت سؤالًا لا علاقة له بمحتوى هذا الملف مثل "من اخترع المصباح الكهربائي" ستكون النتيجة كما يلي: تأثير الوسيط Temperature على دقة نتائج التطبيق يستخدم المعامل أو الوسيط temperature كما وضحت سابقًا للتحكم في دقة أو عشوائية النتائج التي تعيدها نماذج واجهة برمجة تطبيقات OpenAI وتتراوح قيمة هذا الوسيط بين 0 و 2، فعند ضبط درجة الدقة على قيم قريبة من الصفر ستحصل على نتائج واقعية وذات صلة بالطلب وحين تضبطه على قيم قريبة من 2 ستحصل على نتائج أكثر إبداعًا لكنها قد تكون غير دقيقة ولا صلة لها بالسؤال. لذا عليك تعديل قيمة هذا المعامل بما يتناسب مع طبيعة تطبيقك، وهل يحتاج للدقة كما في حال تطبيقنا الذي يبحث عن النتائج الموافقة للسؤال، أم يسمح فيه الإبداع والابتكار كتطبيقات تأليف القصص والروايات. سأجرب على سبيل المثال تغير درجة الحرارة في الكود السابق وجعلها مثلًا 1.5 وأحمّل الملف نفسه واطرح سؤال "من هو أديسون؟" مثلًا ستكون النتيجة غير منطقية كما يلي! أما عند إعادة ضبطه بالقيمة 0 فسيجيب التطبيق بأنه لا يملك معلومات عن أديسون وفق الملف الذي وفرته له. قيود على عدد الرموز Tokens في التطبيق يمكنك تجربة التطبيق على أي ملف pdf خاص بك، لكن تملك نماذج من OpenAI API حدًا أقصى لعدد الرموز Token Limits التي تمثل إجمالي طول المدخلات التي تستقبلها والنتائج التي تولدها وفي حالة النموذج gpt-3.5-turbo-instruct المستخدم في الكود فالعدد الأقصى هو 4096 رمزًا، وبالتالي قد تحصل على الخطأ التالي عند تحميل ملفات كبيرة وتجاوز إجمالي الرموز في دخل وخرج النموذج هذا العدد، ومن الإجراءات الممكنة لتجاوز هذه القيود، تحديد قيمة المعامل max_tokens للنموذج كي تحدد له طول الرد الذي سينتج وتمنعه من إنشاء محتوى طويل جدًا أو تقصير نص الطلب أو السؤال قدر المستطاع. كما تحدد بعض النماذج سرعة معالجة الرموز في الدقيقة الواحدة، فالحد الأقصى المسموح به للتضمينات في نموذج text-embedding-ada-002 هو 15000 رمز في الدقيقة، وبالتالي إذا استخدمت ملفات pdf كبيرة تتجاوز هذه الحدود فسوف تحصل على كذلك أخطاء في التنفيذ بسبب القيود التي تفرضها الواجهة البرمجية ولحلها عليك رفع خطة الاشتراك في الواجهة البرمجية. الخلاصة بهذا نكون قد وصلنا لنهاية مقالنا، الذي شرحنا فيه خطوات إنشاء تطبيق بايثون يستفيد من واجهة برمجة تطبيقات OpenAI لتحميل ملف PDF وطرح أسئلة حوله وتوليد إجابات عليها من محتوى الملف، وهناك بالطبع الكثير من الأفكار الأخرى التي يمكنك الاستفادة منها من النماذج اللغوية الكبيرة LLMs في تطوير تطبيقات متقدمة في مجال الذكاء الاصطناعي، أطلق العنان لإبداعك واستفد من قوة هذه النماذج وإمكانياتها الهائلة. اقرأ أيضًا تطوير تطبيق "وصفة" لاقتراح الوجبات باستخدام ChatGPT و DALL-E في PHP تطوير تطبيق "اختبرني" باستخدام ChatGPT ولغة جافاسكربت مع Node.js إعداد بيئة العمل للمشاريع مع بايثون اكتشاف دلالات الأخطاء في شيفرات لغة بايثون كود التطبيق ask_pdf.zip1 نقطة -
اريد صنع روبوت لاتحدث معه بالاردوينو اريد المكونات والكود من فضلكم ساعدوني1 نقطة