لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 10/31/21 في كل الموقع
-
مرحبا أحمد , في مسار أساسيات CSS في دورة تطوير واجهات المستخدم في الأكاديمية يتم التحدث عن أساسيات الـ css بمجملها و منطق تعاملها , ولا يتم تناول كل خاصية على حدة . و ذلك بهدف تسهيل إستذكارها للطلاب , و لجعل عملية ترتيبها و إستيعابها منطقية . فلا نجد مثلا دروسا كالتالي : الخاصية display الخاصية flex-wrap مجموعة الخواص background بل نجد دروسا ذات عناوين و محتويات دلالية , جامعة لمجموعة أفكار تضم مجموعة خواص تصب في ذات السياق , من مثل : التعامل مع الألوان . الروابط و الأصناف الزائفة . طرق العرض display modes . و هكذا .. أي أن ترتيب الدروس و تصنيفها كالتالي يجعل من إستيعابها أسهل و أكثر وضوحا . كما أن الأمور التي ذكرتها بعيدة بعض الشيء عن الأساسيات ذاتها , فهي من الأمور المتقدمة التي يتطلب التعامل معها معرفة مسبقة بـ css .. فلا يعقل مثلا أن نستوعب عمل transition أو transform دون أن نعرف الخواص التي يتخذها العنصر أثناء و بعد تحويله . في حين أن مسار أساسيات CSS يتعرض للأساسيات فقط . و لهذا فقد تم التطرق لهاته الأمور في المسارات اللاحقة لمسار أساسيات CSS في دورة تطوير واجهات المستخدم , و لذلك فقد تم تطبيقها عمليا و بشكل مكرر في كثير من المواضع اللاحقة , مثل مسار بناء صفحات هبوط أو مجموعة الفيديوهات في قسم تجاوبية الصفحة في مسار تطوير متجر إلكتروني .. و غيرها الكثير . كما يمكنك دوما الإستزادة بالإطلاع على موسوعة حسوب .2 نقاط
-
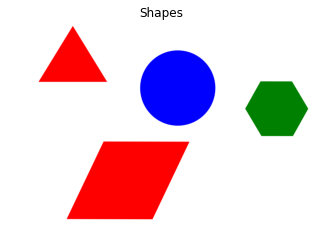
كيف يمكننا اكتشاف الأشكال الهندسية، مثلاً الموجودة في الصورة التالية:
 1 نقطة
1 نقطة -
 الخوارزمية الشرهة هي كل خوارزمية تسعى إلى حل مشكلةٍ عبر البحث عن أفضل خيار في كل مرحلة جزئية من أجل إيجاد الحل الشامل والمثالي، ولهذا تُسمّى شرهة، إذ تحاول أن تبحث عن أفضل الخيارات في كل مرحلة ممكنة، ولا تأخذ بالضرورة كل المراحل بالحسبان، ولذلك لا تعطي الحل المثالي دائمًا لكامل المشكلة، وإنّما تعطي حلًا مؤلفًا من حلول جزئية مثالية، والتي تكون عادةً قريبةً إلى حدّ ما من الحل الشامل المثالي في مدة زمنية معقولة. ترميز هوفمان Human Coding ترميز هوفمان هو نوع خاص من الترميز المُحسّن optimal prefix code الذي يُستخدم في الضغط المحافظ على البيانات lossless data compression، إذ تضغط هذه الخوارزمية البيانات بفعالية كبيرة، بحيث يمكن أن تختزل من 20٪ إلى 90٪ من مساحة الذاكرة تبعًا لخصائص البيانات المضغوطة. ونحن ننظر إلى البيانات التي سنعمل عليها على أنها سلاسل من الحروف، تبدأ خوارزمية هوفمان الشرهة Huffman's greedy algorithm بإنشاء جدول يحدّد عدد مرات ظهور كل حرف (أي تردّده)، وبناءً على ذلك تنشئ الترميز المثالي لتمثيل كل حرف على هيئة سلسلة من القيم الثنائية (0 و 1). وقد اقتُرِحت هذه الخوارزمية على يد ديفيد هوفمان في عام 1951. لنفترض أنّ لدينا ملفًّا يحتوي بيانات مؤلفة من 100000 محرف، ونود ضغطها في أقل مساحة ممكنة. سنفترض أنّ هناك 6 أحرف مختلفة فقط في الملف. وأنّ تردّد الأحرف هو كالتالي: +---------------------------------+-----+-----+-----+-----+-----+-----+ | Character | a | b | c | d | e | f | +---------------------------------+-----+-----+-----+-----+-----+-----+ |Frequency (in thousands) | 45 | 13 | 12 | 16 | 9 | 5 | +---------------------------------+-----+-----+-----+-----+-----+-----+ لدينا عدة خيارات لتمثيل هذه البيانات، وسنحاول فيما يلي تصميم ترميز ثنائي للمحارف Binary Character Code، بحيث نمثّل كلّ حرف بسلسلة ثنائية فريدة سنسميها codeword أو الكلمة الرمزية. هذان الترميزان مشتقّان من الشجرة أعلاه: +----------------------------------+-----+-----+-----+-----+------+------+ | Character | a | b | c | d | e | f | +----------------------------------+-----+-----+-----+-----+------+------+ | Fixed-length Codeword | 000 | 001 | 010 | 011 | 100 | 101 | +----------------------------------+-----+-----+-----+-----+------+------+ |Variable-length Codeword | 0 | 101 | 100 | 111 | 1101 | 1100 | +----------------------------------+-----+-----+-----+-----+------+------+ إذا أردنا استخدام ترميز ثابت الطول فسنحتاج إلى ثلاث بتّات bit لتمثيل الأحرف الستة. تتطلّب هذه الطريقة 300000 بتّة لتخزين الملف بأكمله. والسؤال الآن، هل هذا أفضل ترميز ممكن؟ هناك نوع آخر من الترميز، وهو ترميز متغيّر الطول، أي أنّ الشيفرات التي تمثّل الحروف قد تكون من أطوال مختلفة، قد يكون أفضل بكثير من الترميز ثابت الطول، إذ أنّه يُرشِّد المساحة المُستخدمة لتخزين البيانات عبر إعطاء الأحرف الكثيرة التكرار/التردد شيفرات قصيرة، فيما يترك الشيفرات الطويلة للأحرف قليلة التردّد. ويتطلب هذا الترميز الآتي: (45 X 1 + 13 X 3 + 12 X 3 + 16 X 3 + 9 X 4 + 5 X 4) X 1000 = 224000 بتّةً لتمثيل الملف، أي أنّه يقتص على حوالي 25% من مساحة الذاكرة موازنة بالتمثيل ثابت الطول. تبسّط ترميزات السوابق Prefix codes عمليّة فك الترميز decoding، فما دام من غير الممكن أن يكون أيّ ترميز كلميّ سابقة لترميز كلميّ آخر، فإنّ الترميز الكلميّ الذي يبدأ ترميز الملف لن يكون فيه أيّ لبس، لهذا يمكننا بسهولة تحديد الترميز الكلميّ الأولي، ثمّ ترجمته إلى الحرف الأصلي الذي يرمز له، ثمّ تكرار عملية فك الترميز على بقية الملف المُرمّز. على سبيل المثال، هناك طريقة واحدة فقط لفك ترميز 001011101، وهي 0.0.101.1101، لتي تُترجم إلى aabe. باختصار، ستكون جميع توليف التمثيلات الثنائية مختلفةً عن بعضها، فإذا رمزنا لحرف ما بالترميز الكلمي 110 مثلًا، فلا يمكن ترميز أيّ حرف آخر بترميز كلمي يبدأ بالترميز السابق، مثل 1101 أو 1100. وهذا لمنع اللبس أثناء فك الترميز، وتجنّب أيّ ارتباك حول ما إذا كان علينا اختيار 110 أو الاستمرار في تحليل التسلسل البتّي. تقنيات الضغط تعمل تقنية الضغط عبر إنشاء شجرة ثنائية من العقد، يمكن تخزينها في مصفوفة عادية حجمها (n) يساوي عدد الرموز، وكل عقدة يمكن أن تكون إما ورقة leaf أو عقدة داخلية internal node. وتكون جميع العقد في البداية عبارة عن أوراق، تحتوي كل ورقة الرمز المراد تمثيله إلى جانب تردّده، ورابطًا اختياريًا يشير إلى ابنيها child nodes. ونصطلح في العادة على تمثيل الابن الأيسر بالبتّة '0'، فيما تمثّل البتة '1' الابن الأيمن، وتُخزّن العقد في رتل أو طابور، وعند استخراج قيمة منه، يعيد العقدة ذات التردد الأقل. وهذه هي خطوات العملية: أنشئ ورقةً لكلّ رمز، ثمّ أضفه إلى رتل الأولويات. طالما يحتوي الطابور أكثر من عقدة واحدة: انزع العقدتين ذواتي أكبر أولوية من الطابور. أنشئ عقدةً داخليةً جديدة، مع جعل العُقدتين اللتان استخرجتَهما من الطابور أبناءً لها، بحيث يساوي التردّد مجموع تردّدي العقدتين. أضف العقدة الجديدة إلى الطابور. العقدة المتبقية هي العقدة الجذرية، وبهذا نكون قد أكملنا شجرة هوفمان. انظر إلى الأمثلة التالية: ستبدو الشيفرة التوضيحية pseudo-code كالتالي، حيث أن C هي مجموعة المحارف والمعلومات ذات الصلة: Procedure Huffman(C): n = C.size Q = priority_queue() for i = 1 to n n = node(C[i]) Q.push(n) end for while Q.size() is not equal to 1 Z = new node() Z.left = x = Q.pop Z.right = y = Q.pop Z.frequency = x.frequency + y.frequency Q.push(Z) end while Return Q يتطلب استخدام الخوارزمية في الحالات العامة إجراء عملية ترتيب مسبق للمصفوفة المُدخلة. ويمثّل n عدد الرموز في الأبجدية، ويكون عادةً صغيرًا جدًّا (موازنةً بطول الرسالة المراد ترميزها)، لذا فإنّ تعقيد الوقت ليس مهمًا جدًا في اختيار هذه الخوارزمية. تقنيات فك الضغط Decompression فك الضغط هو عملية ترجمة تدفق من ترميزات السوابق prefix codes إلى بايتات فردية، وعادةً عن طريق تسلّق الشجرة عقدة بعقدة مع قراءة كل بتّة من المدخلات. يؤدّي الوصول إلى ورقة إلى إنهاء البحث عن قيمة البايت المضغوط، حيث تمثل قيمة الورقة الحرفَ المطلوب. وعادةً ما تُنشأ شجرة هوفمان باستخدام بيانات معدّلة إحصائيًا في كل دورة ضغط، وعليه فإنّ إعادة البناء بسيطة إلى حدّ ما؛ أما خلاف ذلك، فيجب إرسال المعلومات اللازمة لإعادة بناء الشجرة بشكل منفصل. انظر الشيفرة التوضيحية التالية، تمثل root جذر شجرة هوفمان، بينما تمثل S تدفق البتات المراد ضغطه: Procedure HuffmanDecompression(root, S): n := S.length for i := 1 to n current = root while current.left != NULL and current.right != NULL if S[i] is equal to '0' current := current.left else current := current.right endif i := i+1 endwhile print current.symbol endfor يحسب ترميز هوفمان تردّد كل محرف ويخزّنه على هيئة سلسلة ثنائية، وتتمثل فكرة الخوارزمية هنا في تعيين ترميزات متغيرة الأطوال للمحارف المُدخلة، بحيث يستند طول الترميزات على تردّدات الأحرف المقابلة، وذلك عبر إنشاء شجرة ثنائية والعمل عليها تصاعديًا حتى يكون الحرفان الأقل ترددًا بعيدين قدر الإمكان عن الجذر. وبهذه الطريقة سيحصل الحرف الأكثر تردّدًا على أقصر ترميز، بينما يحصل الحرف الأقل تردّدًا على أطول ترميز. مشكلة اختيار الأنشطة Activity Selection Problem لنفترض أنّ لديك مجموعةً من المهام التي عليك إنجازها (أنشطة)، بحيث لكل نشاط وقت بداية ووقت نهاية. ولا يُسمح لك بأداء أكثر من نشاط واحد في كلّ مرّة. السؤال الآن هو كيف تعثر على طريقة لأداء أقصى عدد ممكن من الأنشطة. على سبيل المثال، لنفترض أنّ لديك مجموعةً من الأقسام الدراسية للاختيار من بينها. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } النشاط رقم وقت البداية وقت النهاية 1 10.20 صباحا 11.00 صباحا 2 10.30 صباحا 11.30 صباحا 3 11.00 صباحا 12.00 صباحا 4 10.00 صباحا 11.30 صباحا 5 9.00 صباحا 11.00 صباحا تذكّر أنه لا يمكنك أخذ فصلين دراسيين متداخلين، وهذا يعني أنه لا يمكنك أخذ الفصل 1 و2، لأنهما يتشاركان في الفترة من 10:30 صباحًا إلى 11.00 صباحًا. بالمقابل، يجوز لك أخذ الفصلين 1 و3، لأنهما لا يتشاركان أيّ وقت. عليك الآن أن تختار الفصول بطريقة تتيح لك أخذ أكبر عدد ممكن من الفصول دون أي تداخل، لكن كيف تفعل هذا؟ تحليل الجدول الزمني للفصول هذه بعض الطرق الممكنة لحل المشكلة: ترتيب الأنشطة بحسب وقت البداية: هذا يعني أنّنا سنأخذ النشاطات التي تبدأ أولًا، ثم نأخذ النشاطات من القائمة المُرتّبة من النشاط الأوّل إلى الأخير، ونتحقق ممّا إذا كان كل نشاط يتداخل مع النشاط الذي اخترناه سابقًا أم لا. إذا لم يكن هناك تداخل بين النشاطين، فسننفّذ النشاط، وإلا لن ننفّذه. تُعَد هذه الطريقة صالحةً لبعض الحالات، كما في المثال التالي: النشاط رقم وقت البداية وقت النهاية 1 11.00 صباحا 1.30 مساء 2 11.30 صباحا 12.00 ظهرًا 3 1.30 مساء 2.00 مساء 4 10.00 صباحا 11.00 صباحا سنحصل على هذا الترتيب 4 -> 1 -> 2 -> 3، وسننفّذ الأنشطة 4 -> 1 -> 3، ونتخطّى النشاط 2. وهذا يعني أننا سننفّذ 3 نشاطات، وهو الحد الأقصى الممكن. بهذا تكون طريقتنا قد نجحت إذًا في هذه الحالة، لكن هذا لا يعني أنّها ستنجح دائمًا، إذ هناك حالات يمكن أن تفشل فيها. كما يبيّن المثال التالي: النشاط رقم وقت البداية وقت النهاية 1 11.00 صباحا 1.30 مساء 2 11.30 صباحا 12.00 ظهرًا 3 1.30 مساء 2.00 مساء 4 10.00 صباحا 3.00 صباحا سنحصل على الترتيب التالي: 4 -> 1 -> 2 -> 3، ولن يُنفّذ إلا النشاط 4، أي نشاط واحد وحسب، لكنّنا نعلم أنّ الإجابة الأمثل هي 1 -> 3 أو 2- -> 3، وذلك لأنه في كلا الحالتين سنحضر فصلين دراسيين، وهذا يبيّن أنّ طريقتنا لم تنجح في الحالة المذكورة أعلاه، وذلك لنجرّب طريقةً أخرى. ترتيب الأنشطة بحسب مددها الزمنية: هذا يعني تنفيذ أقصر الأنشطة أولًا. ستحل هذه الطريقة المشكلة السابقة، لكنها ليست كاملةً أيضًا، فلا تزال هناك بعض الحالات التي لا يمكن أن تحلها. ولنطبق الطريقة على الحالة التالية: النشاط رقم وقت البداية وقت النهاية 1 6.00 صباحا 11.40 صباحا 2 11.30 صباحا 12.00 ظهرًا 3 11.40 صباحا 2.00 مساء إذا رتّبنا الأنشطة بحسب مددها الزمنية فسنحصل على الترتيب 2 -> 3 -> 1، لكن إن نفّذنا النشاط رقم 2 أولاً، فلن نستطيع تنفيذ أيّ نشاط آخر. الجواب المثالي هو تنفيذ النشاط 1 ثم 3، لذا لا يمكن أن يكون هذا حلًا لهذه المشكلة. لنجرّب طريقةً أخرى: ترتيب الأنشطة بحسب وقت الإنتهاء: هذا يعني أنّ الأنشطة التي تنتهي أولا توضع أولًا. انظر الخوارزمية: ترتيب الأنشطة بحسب أوقات نهايتها. إذا لم يتقاسم النشاط المراد تنفيذه وقتًا مشتركًا مع الأنشطة المُنفّذة سابقًا، فسننفّذه. لنحلّل المثال الأول: النشاط رقم وقت البداية وقت النهاية 1 10.20 صباحا 11.00 صباحا 2 10.30 صباحا 11.30 صباحا 3 11.00 صباحا 12.00 صباحا 4 10.00 صباحا 11.30 صباحا 5 9.00 صباحا 11.00 صباحا نرتب الأنشطة بحسب أوقات نهاياتها لنحصل على الترتيب 1 -> 5 -> 2 -> 4 -> 3، والجواب الصحيح هو 1 -> 3، أي أنّنا سننفّذ النشاطين 1 و3. وهو الجواب الصحيح: ترتيب الأنشطة. نفّذ أول نشاط في قائمة الأنشطة المرتبة. عيّن قيمة النشاط الأول إلى النشاط الحالي Current_activity := first activity. عين end_time := t، حيث t يمثل وقت إنهاء النشاط الحالي اذهب إلى النشاط الموالي إن كان موجودًا، خلاف ذلك أنهِ الخوارزمية. إن كان وقت البداية الخاص بالنشاط الحالي أكبر من end_time، نفّذ النشاط وعد إلى المرحلة 4. خلاف ذلك اذهب إلى المرحلة 5. مشكلة الصرف Change-making problem لنفترض أنّ لديك مبلغًا معينًا في نظام نقدي ما، هل يمكن إيجاد الحد الأدنى من القطع والأوراق النقدية المقابلة لذلك المبلغ. حسب الأنظمة المالية الأساسية، إذا افترضنا في بعض النظم المالية -مثل التي نستخدمها الآن- أنّ العملات النقدية الممكنة هي 1 و2 و5 و10، فالحل البديهي هو أن نبدأ بأعلى قطعة أو ورقة نقدية، ثمّ نكرّر هذا الإجراء إلى أن نستكمل المبلغ. فمثلا، إن كان المبلغ هو 28 درهمًا، فيمكننا تصريفه إلى 10 + 10 + 5 + 2 + 1 = 28، وهكذا سيكون الحدّ الأدنى هو 5، وهو الحل الصحيح. نستطيع فعل هذا بشكل تكراري في لغة OCaml كما يلي: (* نفترض أنّ النظام النقدي مُرتب ترتيبًا تنازليًا *) let change_make money_system amount = let rec loop given amount = if amount = 0 then given else (* القيمة الأولى أصغر أو تساوي باقي المبلغ *) let coin = List.find ((>=) amount) money_system in loop (coin::given) (amount - coin) in loop [] amount هذه الخوارزمية ليست صالحةً دائمًا، فلو كان المبلغ يساوي 99 وكانت القطع والأوراق النقدية الممكنة هي 10 و7 و5، فإنّ الحل السابق لن يعمل، إذ لو أخذنا أكبر القطع النقدية 10، وجمعناه إلى أن نصل إلى 90، فستبقى لنا 9، وهو مبلغ لا يمكن تكوينه من القطعتين 5 و7. ثم إنّه لا توجد ضمانة لوجود حلّ أصلًا، وهذه المشكلة في الواقع صعبة للغاية، لكن توجد بعض الحلول الصالحة التي تجمع بين الشره greediness والتذكر memoization، وتقوم على استكشاف جميع الإمكانات، واختيار تلك التي تتألف من أقل عدد من القطع النقدية. لنفترض أنّ لدينا مبلغًا X> 0، وقد اخترنا قطعة نقدية P من النظام المالي، سيكون المبلغ المتبقي إذن هو X-P. نحلّ الآن مشكلة تصريف المبلغ X-P إلى أقل عدد ممكن من القطع النقدية، ونجرّب هذا مع جميع القطع النقدية في النظام. لاحظ أنّه في كل مرة نختار قطعة نقدية P فإنّنا نجعل المشكلة أصغر (أي X-P). ويكون الحل النهائي -إذا كان موجودًا- هو أصغر مسار من المسارات التي اتبعناها وأدّت إلى المبلغ 0. انظر فيما يلي دالة OCaml تكرارية لحل هذه المشكلة، تعيد هذه الدالة None في حال لم يكن هناك حل: (* option utilities *) let optmin x y = match x,y with | None,a | a,None -> a | Some x, Some y-> Some (min x y) let optsucc = function | Some x -> Some (x+1) | None -> None (* مشكلة الصرف*) let change_make money_system amount = let rec loop n = let onepiece acc piece = match n - piece with | 0 -> (*problem solved with one coin*) Some 1 | x -> if x < 0 then (* نتجاهل هذا الحل إن لم نصل إلى 0*) None else (*من القطع النقدية الباقية None نبحث عن أقصر مسار يخالف*) optmin (optsucc (loop x)) acc in (*على جميع القطع النقدية onepiece نستدعي*) List.fold_left onepiece None money_system in loop amount خوارزمية كروسكال Kruskal's Algorithm خوارزمية كروسكال هي خوارزمية تهدف إلى إيجاد المسار الأقصر (الأقل كلفة)، وهي من الخوارزميات الشرهة Greedy Algorithm التي تُستخدَم بكثرة في نظرية المخططات. استخدام المجموعات التوزيعية هناك شيئان يمكننا القيام بهما لتحسين مجموعة الخوارزميات الفرعية للمجموعات التوزيعية المُحسّنة sub-optimal disjoint-set subalgorithms، وهما: مقاييس بحثية لضغط المسار Path compression heuristic: لن تحتاج الدالة findSet (انظر الشيفرة أدناه) إلى التكرار على شجرة ارتفاعها أطول من 2، وإلا فيمكنها ربط العقد السفلية مباشرة بالجذر، مما يحسّن عمليات العبور traversals المستقبلية: subalgo findSet(v: a node): if v.parent != v v.parent = findSet(v.parent) return v.parent المقاييس البحثية القائمة على الارتفاع Height-based merging heuristic: خزّن ارتفاع الشجيرة subtree الخاصة بكل عقدة، واجعل الشجرة الأطول أبًا parent للشجرة الأصغر عند الدمج، وذلك دون زيادة ارتفاع أيّ شجرة: subalgo unionSet(u, v: nodes): vRoot = findSet(v) uRoot = findSet(u) if vRoot == uRoot: return if vRoot.height < uRoot.height: vRoot.parent = uRoot else if vRoot.height > uRoot.height: uRoot.parent = vRoot else: uRoot.parent = vRoot uRoot.height = uRoot.height + 1 يستغرق هذا مدة O(alpha(n)) لكلّ عملية، حيث تمثّل alpha مقلوب inverse دالة أكرمان Ackermann المعروفة بسرعة نموها، وهذا يعني أنّ alpha ستكون بطيئة جدًا، ويمكن عدّ تعقيدها عمليًا ثابتًا (O(1))، ما يعني أنّ تعقيد خوارزمية Kruskal سيساوي O(m log m + m) = O(m log m) أخذًا بالحسبان الترتيبَ الأولي. ولتجنّب تعقيد تخزين وحساب ارتفاعات الأشجار، يمكن اختيار الشجرة الأب parent عشوائيًا: subalgo unionSet(u, v: nodes): vRoot = findSet(v) uRoot = findSet(u) if vRoot == uRoot: return if random() % 2 == 0: vRoot.parent = uRoot else: uRoot.parent = vRoot عمليًا، ينتج عن هذه الخوارزمية العشوائية مرفوقة بعملية ضغط المسار في الدالة findSet، تحسّن كبير في الأداء رغم أنّها أكثر بساطة. تطبيق مفصل implementation من أجل رصد الدورات cycle detection بفعالية، سنعُدّ كل عقدة جزءًا من شجرة، ونتحقّق عند إضافة ضلع ممّا إذا كانت عقدَتاه جزءًا من شجرتين منفصلتين. في البداية، تشكّل كلّ عقدة شجرةً مؤلفةً من عقدة واحدة وحسب: algorithm kruskalMST(G: a graph) sort Gs edges by their value // بحسب القيم G ترتيب MST = a forest of trees, initially each tree is a node in the graph // غابة من الأشجار، حيث تمثل كل شجرة عقدة من الشعبة for each edge e in G: if the root of the tree that e.first belongs to is not the same as the root of the tree that e.second belongs to: connect one of the roots to the other, thus merging two trees إذا كان جذر الشجرة التي ينتمي إليها e.first يساوي جذر الشجرة التي ينتمي إليها e.second، فاربط أحد الجذرين بالآخر، وهكذا تُدمَج الشجرتان. return MST, which now a single-tree forest // أصبحت الآن غابة من شجرة واحدة MST يقوم منظور الغابات forest -مجموعة من الأشجار غير المتصلة بالضرورة- المذكور أعلاه على استخدام المجموعات التوزيعية disjoint-set data structure، وينطوي على ثلاث عمليات رئيسية: subalgo makeSet(v: a node): v.parent = v <- make a new tree rooted at v subalgo findSet(v: a node): if v.parent == v: return v return findSet(v.parent) subalgo unionSet(v, u: nodes): vRoot = findSet(v) uRoot = findSet(u) uRoot.parent = vRoot algorithm kruskalMST(G: a graph): sort Gs edges by their value for each node n in G: makeSet(n) for each edge e in G: if findSet(e.first) != findSet(e.second): unionSet(e.first, e.second) يستغرق هذا التطبيق حوالي O(n log n) لإدارة المجموعات التوزيعية، وهكذا يصبح التعقيد الزمني الإجمالي لخوارزمية كروسكال O(m*n log n ). في الأخير، نستعرض تطبيقًا آخر عالي المستوى للخوارزمية، حيث نرتّب الأضلاع بحسب القيم، ثمّ نضيف كلّ واحد منها إلى شجرة الامتداد الأدنى MST بالترتيب ما لم ينجم عن ذلك دورة. algorithm kruskalMST(G: a graph) sort Gs edges by their value MST = an empty graph for each edge e in G: if adding e to MST does not create a cycle: add e to MST return MST ترجمة -بتصرّف- للفصلين 16 و17 من كتاب Algorithms Notes for Professionals. اقرأ أيضًا المقال السابق: البرمجة الديناميكية مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية1 نقطة
الخوارزمية الشرهة هي كل خوارزمية تسعى إلى حل مشكلةٍ عبر البحث عن أفضل خيار في كل مرحلة جزئية من أجل إيجاد الحل الشامل والمثالي، ولهذا تُسمّى شرهة، إذ تحاول أن تبحث عن أفضل الخيارات في كل مرحلة ممكنة، ولا تأخذ بالضرورة كل المراحل بالحسبان، ولذلك لا تعطي الحل المثالي دائمًا لكامل المشكلة، وإنّما تعطي حلًا مؤلفًا من حلول جزئية مثالية، والتي تكون عادةً قريبةً إلى حدّ ما من الحل الشامل المثالي في مدة زمنية معقولة. ترميز هوفمان Human Coding ترميز هوفمان هو نوع خاص من الترميز المُحسّن optimal prefix code الذي يُستخدم في الضغط المحافظ على البيانات lossless data compression، إذ تضغط هذه الخوارزمية البيانات بفعالية كبيرة، بحيث يمكن أن تختزل من 20٪ إلى 90٪ من مساحة الذاكرة تبعًا لخصائص البيانات المضغوطة. ونحن ننظر إلى البيانات التي سنعمل عليها على أنها سلاسل من الحروف، تبدأ خوارزمية هوفمان الشرهة Huffman's greedy algorithm بإنشاء جدول يحدّد عدد مرات ظهور كل حرف (أي تردّده)، وبناءً على ذلك تنشئ الترميز المثالي لتمثيل كل حرف على هيئة سلسلة من القيم الثنائية (0 و 1). وقد اقتُرِحت هذه الخوارزمية على يد ديفيد هوفمان في عام 1951. لنفترض أنّ لدينا ملفًّا يحتوي بيانات مؤلفة من 100000 محرف، ونود ضغطها في أقل مساحة ممكنة. سنفترض أنّ هناك 6 أحرف مختلفة فقط في الملف. وأنّ تردّد الأحرف هو كالتالي: +---------------------------------+-----+-----+-----+-----+-----+-----+ | Character | a | b | c | d | e | f | +---------------------------------+-----+-----+-----+-----+-----+-----+ |Frequency (in thousands) | 45 | 13 | 12 | 16 | 9 | 5 | +---------------------------------+-----+-----+-----+-----+-----+-----+ لدينا عدة خيارات لتمثيل هذه البيانات، وسنحاول فيما يلي تصميم ترميز ثنائي للمحارف Binary Character Code، بحيث نمثّل كلّ حرف بسلسلة ثنائية فريدة سنسميها codeword أو الكلمة الرمزية. هذان الترميزان مشتقّان من الشجرة أعلاه: +----------------------------------+-----+-----+-----+-----+------+------+ | Character | a | b | c | d | e | f | +----------------------------------+-----+-----+-----+-----+------+------+ | Fixed-length Codeword | 000 | 001 | 010 | 011 | 100 | 101 | +----------------------------------+-----+-----+-----+-----+------+------+ |Variable-length Codeword | 0 | 101 | 100 | 111 | 1101 | 1100 | +----------------------------------+-----+-----+-----+-----+------+------+ إذا أردنا استخدام ترميز ثابت الطول فسنحتاج إلى ثلاث بتّات bit لتمثيل الأحرف الستة. تتطلّب هذه الطريقة 300000 بتّة لتخزين الملف بأكمله. والسؤال الآن، هل هذا أفضل ترميز ممكن؟ هناك نوع آخر من الترميز، وهو ترميز متغيّر الطول، أي أنّ الشيفرات التي تمثّل الحروف قد تكون من أطوال مختلفة، قد يكون أفضل بكثير من الترميز ثابت الطول، إذ أنّه يُرشِّد المساحة المُستخدمة لتخزين البيانات عبر إعطاء الأحرف الكثيرة التكرار/التردد شيفرات قصيرة، فيما يترك الشيفرات الطويلة للأحرف قليلة التردّد. ويتطلب هذا الترميز الآتي: (45 X 1 + 13 X 3 + 12 X 3 + 16 X 3 + 9 X 4 + 5 X 4) X 1000 = 224000 بتّةً لتمثيل الملف، أي أنّه يقتص على حوالي 25% من مساحة الذاكرة موازنة بالتمثيل ثابت الطول. تبسّط ترميزات السوابق Prefix codes عمليّة فك الترميز decoding، فما دام من غير الممكن أن يكون أيّ ترميز كلميّ سابقة لترميز كلميّ آخر، فإنّ الترميز الكلميّ الذي يبدأ ترميز الملف لن يكون فيه أيّ لبس، لهذا يمكننا بسهولة تحديد الترميز الكلميّ الأولي، ثمّ ترجمته إلى الحرف الأصلي الذي يرمز له، ثمّ تكرار عملية فك الترميز على بقية الملف المُرمّز. على سبيل المثال، هناك طريقة واحدة فقط لفك ترميز 001011101، وهي 0.0.101.1101، لتي تُترجم إلى aabe. باختصار، ستكون جميع توليف التمثيلات الثنائية مختلفةً عن بعضها، فإذا رمزنا لحرف ما بالترميز الكلمي 110 مثلًا، فلا يمكن ترميز أيّ حرف آخر بترميز كلمي يبدأ بالترميز السابق، مثل 1101 أو 1100. وهذا لمنع اللبس أثناء فك الترميز، وتجنّب أيّ ارتباك حول ما إذا كان علينا اختيار 110 أو الاستمرار في تحليل التسلسل البتّي. تقنيات الضغط تعمل تقنية الضغط عبر إنشاء شجرة ثنائية من العقد، يمكن تخزينها في مصفوفة عادية حجمها (n) يساوي عدد الرموز، وكل عقدة يمكن أن تكون إما ورقة leaf أو عقدة داخلية internal node. وتكون جميع العقد في البداية عبارة عن أوراق، تحتوي كل ورقة الرمز المراد تمثيله إلى جانب تردّده، ورابطًا اختياريًا يشير إلى ابنيها child nodes. ونصطلح في العادة على تمثيل الابن الأيسر بالبتّة '0'، فيما تمثّل البتة '1' الابن الأيمن، وتُخزّن العقد في رتل أو طابور، وعند استخراج قيمة منه، يعيد العقدة ذات التردد الأقل. وهذه هي خطوات العملية: أنشئ ورقةً لكلّ رمز، ثمّ أضفه إلى رتل الأولويات. طالما يحتوي الطابور أكثر من عقدة واحدة: انزع العقدتين ذواتي أكبر أولوية من الطابور. أنشئ عقدةً داخليةً جديدة، مع جعل العُقدتين اللتان استخرجتَهما من الطابور أبناءً لها، بحيث يساوي التردّد مجموع تردّدي العقدتين. أضف العقدة الجديدة إلى الطابور. العقدة المتبقية هي العقدة الجذرية، وبهذا نكون قد أكملنا شجرة هوفمان. انظر إلى الأمثلة التالية: ستبدو الشيفرة التوضيحية pseudo-code كالتالي، حيث أن C هي مجموعة المحارف والمعلومات ذات الصلة: Procedure Huffman(C): n = C.size Q = priority_queue() for i = 1 to n n = node(C[i]) Q.push(n) end for while Q.size() is not equal to 1 Z = new node() Z.left = x = Q.pop Z.right = y = Q.pop Z.frequency = x.frequency + y.frequency Q.push(Z) end while Return Q يتطلب استخدام الخوارزمية في الحالات العامة إجراء عملية ترتيب مسبق للمصفوفة المُدخلة. ويمثّل n عدد الرموز في الأبجدية، ويكون عادةً صغيرًا جدًّا (موازنةً بطول الرسالة المراد ترميزها)، لذا فإنّ تعقيد الوقت ليس مهمًا جدًا في اختيار هذه الخوارزمية. تقنيات فك الضغط Decompression فك الضغط هو عملية ترجمة تدفق من ترميزات السوابق prefix codes إلى بايتات فردية، وعادةً عن طريق تسلّق الشجرة عقدة بعقدة مع قراءة كل بتّة من المدخلات. يؤدّي الوصول إلى ورقة إلى إنهاء البحث عن قيمة البايت المضغوط، حيث تمثل قيمة الورقة الحرفَ المطلوب. وعادةً ما تُنشأ شجرة هوفمان باستخدام بيانات معدّلة إحصائيًا في كل دورة ضغط، وعليه فإنّ إعادة البناء بسيطة إلى حدّ ما؛ أما خلاف ذلك، فيجب إرسال المعلومات اللازمة لإعادة بناء الشجرة بشكل منفصل. انظر الشيفرة التوضيحية التالية، تمثل root جذر شجرة هوفمان، بينما تمثل S تدفق البتات المراد ضغطه: Procedure HuffmanDecompression(root, S): n := S.length for i := 1 to n current = root while current.left != NULL and current.right != NULL if S[i] is equal to '0' current := current.left else current := current.right endif i := i+1 endwhile print current.symbol endfor يحسب ترميز هوفمان تردّد كل محرف ويخزّنه على هيئة سلسلة ثنائية، وتتمثل فكرة الخوارزمية هنا في تعيين ترميزات متغيرة الأطوال للمحارف المُدخلة، بحيث يستند طول الترميزات على تردّدات الأحرف المقابلة، وذلك عبر إنشاء شجرة ثنائية والعمل عليها تصاعديًا حتى يكون الحرفان الأقل ترددًا بعيدين قدر الإمكان عن الجذر. وبهذه الطريقة سيحصل الحرف الأكثر تردّدًا على أقصر ترميز، بينما يحصل الحرف الأقل تردّدًا على أطول ترميز. مشكلة اختيار الأنشطة Activity Selection Problem لنفترض أنّ لديك مجموعةً من المهام التي عليك إنجازها (أنشطة)، بحيث لكل نشاط وقت بداية ووقت نهاية. ولا يُسمح لك بأداء أكثر من نشاط واحد في كلّ مرّة. السؤال الآن هو كيف تعثر على طريقة لأداء أقصى عدد ممكن من الأنشطة. على سبيل المثال، لنفترض أنّ لديك مجموعةً من الأقسام الدراسية للاختيار من بينها. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } النشاط رقم وقت البداية وقت النهاية 1 10.20 صباحا 11.00 صباحا 2 10.30 صباحا 11.30 صباحا 3 11.00 صباحا 12.00 صباحا 4 10.00 صباحا 11.30 صباحا 5 9.00 صباحا 11.00 صباحا تذكّر أنه لا يمكنك أخذ فصلين دراسيين متداخلين، وهذا يعني أنه لا يمكنك أخذ الفصل 1 و2، لأنهما يتشاركان في الفترة من 10:30 صباحًا إلى 11.00 صباحًا. بالمقابل، يجوز لك أخذ الفصلين 1 و3، لأنهما لا يتشاركان أيّ وقت. عليك الآن أن تختار الفصول بطريقة تتيح لك أخذ أكبر عدد ممكن من الفصول دون أي تداخل، لكن كيف تفعل هذا؟ تحليل الجدول الزمني للفصول هذه بعض الطرق الممكنة لحل المشكلة: ترتيب الأنشطة بحسب وقت البداية: هذا يعني أنّنا سنأخذ النشاطات التي تبدأ أولًا، ثم نأخذ النشاطات من القائمة المُرتّبة من النشاط الأوّل إلى الأخير، ونتحقق ممّا إذا كان كل نشاط يتداخل مع النشاط الذي اخترناه سابقًا أم لا. إذا لم يكن هناك تداخل بين النشاطين، فسننفّذ النشاط، وإلا لن ننفّذه. تُعَد هذه الطريقة صالحةً لبعض الحالات، كما في المثال التالي: النشاط رقم وقت البداية وقت النهاية 1 11.00 صباحا 1.30 مساء 2 11.30 صباحا 12.00 ظهرًا 3 1.30 مساء 2.00 مساء 4 10.00 صباحا 11.00 صباحا سنحصل على هذا الترتيب 4 -> 1 -> 2 -> 3، وسننفّذ الأنشطة 4 -> 1 -> 3، ونتخطّى النشاط 2. وهذا يعني أننا سننفّذ 3 نشاطات، وهو الحد الأقصى الممكن. بهذا تكون طريقتنا قد نجحت إذًا في هذه الحالة، لكن هذا لا يعني أنّها ستنجح دائمًا، إذ هناك حالات يمكن أن تفشل فيها. كما يبيّن المثال التالي: النشاط رقم وقت البداية وقت النهاية 1 11.00 صباحا 1.30 مساء 2 11.30 صباحا 12.00 ظهرًا 3 1.30 مساء 2.00 مساء 4 10.00 صباحا 3.00 صباحا سنحصل على الترتيب التالي: 4 -> 1 -> 2 -> 3، ولن يُنفّذ إلا النشاط 4، أي نشاط واحد وحسب، لكنّنا نعلم أنّ الإجابة الأمثل هي 1 -> 3 أو 2- -> 3، وذلك لأنه في كلا الحالتين سنحضر فصلين دراسيين، وهذا يبيّن أنّ طريقتنا لم تنجح في الحالة المذكورة أعلاه، وذلك لنجرّب طريقةً أخرى. ترتيب الأنشطة بحسب مددها الزمنية: هذا يعني تنفيذ أقصر الأنشطة أولًا. ستحل هذه الطريقة المشكلة السابقة، لكنها ليست كاملةً أيضًا، فلا تزال هناك بعض الحالات التي لا يمكن أن تحلها. ولنطبق الطريقة على الحالة التالية: النشاط رقم وقت البداية وقت النهاية 1 6.00 صباحا 11.40 صباحا 2 11.30 صباحا 12.00 ظهرًا 3 11.40 صباحا 2.00 مساء إذا رتّبنا الأنشطة بحسب مددها الزمنية فسنحصل على الترتيب 2 -> 3 -> 1، لكن إن نفّذنا النشاط رقم 2 أولاً، فلن نستطيع تنفيذ أيّ نشاط آخر. الجواب المثالي هو تنفيذ النشاط 1 ثم 3، لذا لا يمكن أن يكون هذا حلًا لهذه المشكلة. لنجرّب طريقةً أخرى: ترتيب الأنشطة بحسب وقت الإنتهاء: هذا يعني أنّ الأنشطة التي تنتهي أولا توضع أولًا. انظر الخوارزمية: ترتيب الأنشطة بحسب أوقات نهايتها. إذا لم يتقاسم النشاط المراد تنفيذه وقتًا مشتركًا مع الأنشطة المُنفّذة سابقًا، فسننفّذه. لنحلّل المثال الأول: النشاط رقم وقت البداية وقت النهاية 1 10.20 صباحا 11.00 صباحا 2 10.30 صباحا 11.30 صباحا 3 11.00 صباحا 12.00 صباحا 4 10.00 صباحا 11.30 صباحا 5 9.00 صباحا 11.00 صباحا نرتب الأنشطة بحسب أوقات نهاياتها لنحصل على الترتيب 1 -> 5 -> 2 -> 4 -> 3، والجواب الصحيح هو 1 -> 3، أي أنّنا سننفّذ النشاطين 1 و3. وهو الجواب الصحيح: ترتيب الأنشطة. نفّذ أول نشاط في قائمة الأنشطة المرتبة. عيّن قيمة النشاط الأول إلى النشاط الحالي Current_activity := first activity. عين end_time := t، حيث t يمثل وقت إنهاء النشاط الحالي اذهب إلى النشاط الموالي إن كان موجودًا، خلاف ذلك أنهِ الخوارزمية. إن كان وقت البداية الخاص بالنشاط الحالي أكبر من end_time، نفّذ النشاط وعد إلى المرحلة 4. خلاف ذلك اذهب إلى المرحلة 5. مشكلة الصرف Change-making problem لنفترض أنّ لديك مبلغًا معينًا في نظام نقدي ما، هل يمكن إيجاد الحد الأدنى من القطع والأوراق النقدية المقابلة لذلك المبلغ. حسب الأنظمة المالية الأساسية، إذا افترضنا في بعض النظم المالية -مثل التي نستخدمها الآن- أنّ العملات النقدية الممكنة هي 1 و2 و5 و10، فالحل البديهي هو أن نبدأ بأعلى قطعة أو ورقة نقدية، ثمّ نكرّر هذا الإجراء إلى أن نستكمل المبلغ. فمثلا، إن كان المبلغ هو 28 درهمًا، فيمكننا تصريفه إلى 10 + 10 + 5 + 2 + 1 = 28، وهكذا سيكون الحدّ الأدنى هو 5، وهو الحل الصحيح. نستطيع فعل هذا بشكل تكراري في لغة OCaml كما يلي: (* نفترض أنّ النظام النقدي مُرتب ترتيبًا تنازليًا *) let change_make money_system amount = let rec loop given amount = if amount = 0 then given else (* القيمة الأولى أصغر أو تساوي باقي المبلغ *) let coin = List.find ((>=) amount) money_system in loop (coin::given) (amount - coin) in loop [] amount هذه الخوارزمية ليست صالحةً دائمًا، فلو كان المبلغ يساوي 99 وكانت القطع والأوراق النقدية الممكنة هي 10 و7 و5، فإنّ الحل السابق لن يعمل، إذ لو أخذنا أكبر القطع النقدية 10، وجمعناه إلى أن نصل إلى 90، فستبقى لنا 9، وهو مبلغ لا يمكن تكوينه من القطعتين 5 و7. ثم إنّه لا توجد ضمانة لوجود حلّ أصلًا، وهذه المشكلة في الواقع صعبة للغاية، لكن توجد بعض الحلول الصالحة التي تجمع بين الشره greediness والتذكر memoization، وتقوم على استكشاف جميع الإمكانات، واختيار تلك التي تتألف من أقل عدد من القطع النقدية. لنفترض أنّ لدينا مبلغًا X> 0، وقد اخترنا قطعة نقدية P من النظام المالي، سيكون المبلغ المتبقي إذن هو X-P. نحلّ الآن مشكلة تصريف المبلغ X-P إلى أقل عدد ممكن من القطع النقدية، ونجرّب هذا مع جميع القطع النقدية في النظام. لاحظ أنّه في كل مرة نختار قطعة نقدية P فإنّنا نجعل المشكلة أصغر (أي X-P). ويكون الحل النهائي -إذا كان موجودًا- هو أصغر مسار من المسارات التي اتبعناها وأدّت إلى المبلغ 0. انظر فيما يلي دالة OCaml تكرارية لحل هذه المشكلة، تعيد هذه الدالة None في حال لم يكن هناك حل: (* option utilities *) let optmin x y = match x,y with | None,a | a,None -> a | Some x, Some y-> Some (min x y) let optsucc = function | Some x -> Some (x+1) | None -> None (* مشكلة الصرف*) let change_make money_system amount = let rec loop n = let onepiece acc piece = match n - piece with | 0 -> (*problem solved with one coin*) Some 1 | x -> if x < 0 then (* نتجاهل هذا الحل إن لم نصل إلى 0*) None else (*من القطع النقدية الباقية None نبحث عن أقصر مسار يخالف*) optmin (optsucc (loop x)) acc in (*على جميع القطع النقدية onepiece نستدعي*) List.fold_left onepiece None money_system in loop amount خوارزمية كروسكال Kruskal's Algorithm خوارزمية كروسكال هي خوارزمية تهدف إلى إيجاد المسار الأقصر (الأقل كلفة)، وهي من الخوارزميات الشرهة Greedy Algorithm التي تُستخدَم بكثرة في نظرية المخططات. استخدام المجموعات التوزيعية هناك شيئان يمكننا القيام بهما لتحسين مجموعة الخوارزميات الفرعية للمجموعات التوزيعية المُحسّنة sub-optimal disjoint-set subalgorithms، وهما: مقاييس بحثية لضغط المسار Path compression heuristic: لن تحتاج الدالة findSet (انظر الشيفرة أدناه) إلى التكرار على شجرة ارتفاعها أطول من 2، وإلا فيمكنها ربط العقد السفلية مباشرة بالجذر، مما يحسّن عمليات العبور traversals المستقبلية: subalgo findSet(v: a node): if v.parent != v v.parent = findSet(v.parent) return v.parent المقاييس البحثية القائمة على الارتفاع Height-based merging heuristic: خزّن ارتفاع الشجيرة subtree الخاصة بكل عقدة، واجعل الشجرة الأطول أبًا parent للشجرة الأصغر عند الدمج، وذلك دون زيادة ارتفاع أيّ شجرة: subalgo unionSet(u, v: nodes): vRoot = findSet(v) uRoot = findSet(u) if vRoot == uRoot: return if vRoot.height < uRoot.height: vRoot.parent = uRoot else if vRoot.height > uRoot.height: uRoot.parent = vRoot else: uRoot.parent = vRoot uRoot.height = uRoot.height + 1 يستغرق هذا مدة O(alpha(n)) لكلّ عملية، حيث تمثّل alpha مقلوب inverse دالة أكرمان Ackermann المعروفة بسرعة نموها، وهذا يعني أنّ alpha ستكون بطيئة جدًا، ويمكن عدّ تعقيدها عمليًا ثابتًا (O(1))، ما يعني أنّ تعقيد خوارزمية Kruskal سيساوي O(m log m + m) = O(m log m) أخذًا بالحسبان الترتيبَ الأولي. ولتجنّب تعقيد تخزين وحساب ارتفاعات الأشجار، يمكن اختيار الشجرة الأب parent عشوائيًا: subalgo unionSet(u, v: nodes): vRoot = findSet(v) uRoot = findSet(u) if vRoot == uRoot: return if random() % 2 == 0: vRoot.parent = uRoot else: uRoot.parent = vRoot عمليًا، ينتج عن هذه الخوارزمية العشوائية مرفوقة بعملية ضغط المسار في الدالة findSet، تحسّن كبير في الأداء رغم أنّها أكثر بساطة. تطبيق مفصل implementation من أجل رصد الدورات cycle detection بفعالية، سنعُدّ كل عقدة جزءًا من شجرة، ونتحقّق عند إضافة ضلع ممّا إذا كانت عقدَتاه جزءًا من شجرتين منفصلتين. في البداية، تشكّل كلّ عقدة شجرةً مؤلفةً من عقدة واحدة وحسب: algorithm kruskalMST(G: a graph) sort Gs edges by their value // بحسب القيم G ترتيب MST = a forest of trees, initially each tree is a node in the graph // غابة من الأشجار، حيث تمثل كل شجرة عقدة من الشعبة for each edge e in G: if the root of the tree that e.first belongs to is not the same as the root of the tree that e.second belongs to: connect one of the roots to the other, thus merging two trees إذا كان جذر الشجرة التي ينتمي إليها e.first يساوي جذر الشجرة التي ينتمي إليها e.second، فاربط أحد الجذرين بالآخر، وهكذا تُدمَج الشجرتان. return MST, which now a single-tree forest // أصبحت الآن غابة من شجرة واحدة MST يقوم منظور الغابات forest -مجموعة من الأشجار غير المتصلة بالضرورة- المذكور أعلاه على استخدام المجموعات التوزيعية disjoint-set data structure، وينطوي على ثلاث عمليات رئيسية: subalgo makeSet(v: a node): v.parent = v <- make a new tree rooted at v subalgo findSet(v: a node): if v.parent == v: return v return findSet(v.parent) subalgo unionSet(v, u: nodes): vRoot = findSet(v) uRoot = findSet(u) uRoot.parent = vRoot algorithm kruskalMST(G: a graph): sort Gs edges by their value for each node n in G: makeSet(n) for each edge e in G: if findSet(e.first) != findSet(e.second): unionSet(e.first, e.second) يستغرق هذا التطبيق حوالي O(n log n) لإدارة المجموعات التوزيعية، وهكذا يصبح التعقيد الزمني الإجمالي لخوارزمية كروسكال O(m*n log n ). في الأخير، نستعرض تطبيقًا آخر عالي المستوى للخوارزمية، حيث نرتّب الأضلاع بحسب القيم، ثمّ نضيف كلّ واحد منها إلى شجرة الامتداد الأدنى MST بالترتيب ما لم ينجم عن ذلك دورة. algorithm kruskalMST(G: a graph) sort Gs edges by their value MST = an empty graph for each edge e in G: if adding e to MST does not create a cycle: add e to MST return MST ترجمة -بتصرّف- للفصلين 16 و17 من كتاب Algorithms Notes for Professionals. اقرأ أيضًا المقال السابق: البرمجة الديناميكية مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية1 نقطة -
لماذا يستخدم OpenCV فضاء الألوان BGR بدلاً من RGB علماً أن جميع الصور تقريباً تكون RGB؟ وهل هناك فرق بينهما أساساً؟1 نقطة
-
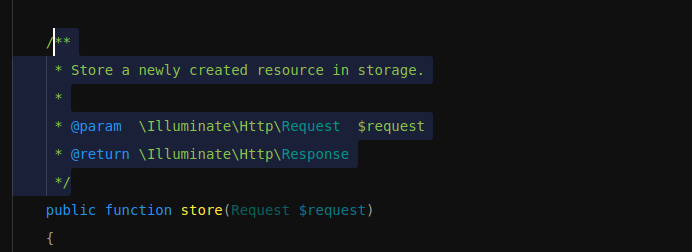
مرحبا, ممكن احد يشرحلي ما سبب كتابة التعليقات بهذا الشكل و ماذا تعني؟ و هل تؤثر على function ؟
 1 نقطة
1 نقطة -
أين media query وأين css grid وأين transition و transform1 نقطة
-
هنا أجبت إجابة مفصلة عن سؤالك. وبطريقتين مختلفين. وكونك مبتدئ اقترح عليك الطريقة الأولى كونها أسهل.1 نقطة
-
هل ساتعلم كل شئ فى مسار front-end لانى أرى عناوين اساسيات فقط ولا أرى تعمق أكثر ف css و JavaScript1 نقطة
-
السلام عليكم ورحمة الله وبركاته اخواني الأعزاء عند تجربة اسكربت الموقع على السيرفر المحلي يتم ارسال البيانات الى القاعدة وتخزينها بدون أي مشاكل لكن عند تجربة استضافات مجانية لا يتم تخزين البيانات في جداول معينة وهناك جداول اخرى يتم تخزين البيانات فيها في الوقت نفسه عند تجربة استضافات مجانية اخرى يتغير الحال فبعض الجداول التي كانت لا تستقبل البيانات هنا تستقبلها والاخرى التى كانت تخزن لا تخزن هنا جربت الكثير منها والمشكلة مازالت رغم انها تعمل بشكل جيد على السيرفر المحلي ما المشكلة في ذلك هل متعلقة ببرمجة الاكواد المسئولة عن الارسال ام انها متعلقة بالقاعدة نفسها وهل الاستضافات المدفوعة تظهر بها مثل هذه المشاكل1 نقطة
-
صحيح , لا تحدث لأنه تستخدم ما تدفع ثمنه , أما الاستضافات المجانية يتم تعطيل ميزات كثيرة فيها غير المشاكل التي تحدث بدون توقع.1 نقطة
-
هل هذه المشكلة لا تحدث في الاستضافة المدفوعة.1 نقطة
-
المشكلة هذه خاصة بالاستضافات المجانية , فأغلبها تحدث بها هذه المشكلة , الأفضل اللجوء إلى استضافة مدفوعة.1 نقطة
-
ما المقصود بsubnet mask وكيفية استخدامه1 نقطة
-
subnet mask هي عملية لتجزئة الشبكة ما المقصود بتجزئة الشبكة؟ يجب أولاً أن نعلم أن عنوان الشبكة يكون به جزأ خاص بالشبكات وجزأ خاص بالأجهزة ويختلف هذا الجزأ حسب تصنيف الشبكة, فيوجد للشبكة تصنيفات : التصنيف A: ويكون من 1.0.0.1 إلى 126.255.255.254 التصنيف B: يكون من 128.1.0.1 إلى 191.255.255.254 التصنيف C: يكون من 192.0.1.1 إلى 223.255.254.254 التصنيف D: يكون من 224.0.0.0 إلى 239.255.255.255 سنأخذ مثال على الip الذي رقمه 192.168.0.0 والذي هو من التصنيف C كما تﻻحظ فإن العنوان ينقسم إلى أربع خانات, في هذا التصنيف يكون أول ثﻻث خانات محجوزين للشبكات بينما أخر خانة محجوزة للأجهزة كل خانة من تلك الخانات تُمثل 8 بيتات أي أن أقصى رقم في كل خانة هو 255 أي 256 جهاز (لأننا نأخذ رقم 0 في الحسبان) فمثلاً الشبكة التي عنوانها 192.168.1.0 تستطيع إضافة 256 جهاز من 192.168.1.0 إلى 192.168.1.255 كيف يتم كتابة الsubnet mask؟ يتم كتابة الأجزاء الخاصة بالشبكات على هيئة 8 بيتات ممتلئة (255) والأجزاء الخاصة بالأجهزة يتم كتابتها على هيئة أصفار إذا الشبكة 192.168.1.0 يكون الsubnet mask الخاص بها 255.255.255.0 الأن ماذ لو كاانت تلك الشبكة تريد فقط إضافة 8 أجهزة, هل سنترك باقي الخانات فارغة وغير مستغلة؟ هذا يُعد تضيع للموارد إذا يجب أن نعيد تجزئة تلك الشبكة لنجعل خانات الأجهزة أقل وخانات الشبكات أكثر كيف يتم التجزئة دعنا نعلم أولاً أن 255.255.255.0 هي في الأصل 1111 1111. 1111 1111. 1111 1111. 0000 0000 ولكن لتسهيل التعامل نقوم بكتابتها على الصورة الثمانية بدلاً من الصورة الثنائية, لنزيد عدد الشبكات نقوم بزيادة الخانات التي قيمتها 1 وتقليل الخانات التي قيمتها 0, فمثلاً إن كنا نريد أن نجعل عدد الأجهزة المتاحة 6 أجهزة نقوم بحساب أقرب أس للعدد 2 يعطينا 6 سنجد أن 3 يعطينا 8 ,ويوجد ععنوانين ﻻ يمكننا إستخدامهم لانهم دوماً محجوزين فإذا يعطينا 6, فهنا نترك فقط ثﻻث بيتات من أجل الأجهزة والباقي للشبكات 1111 1111. 1111 1111. 1111 1111. 1111 1000 ويتم ترجمته إلى 255.255.255.248 مما يعني توفر 8 عناوين للإستخدام والباقي من أجل الشبكات , فبهذا نقوم زدنا من عدد الشبكات وقللنا من عدد الأجهزة1 نقطة
-
لقد قمت بتجربته شخصيا ولا أسميه ترقية ضرورية للغاية حتى الآن على الأقل ليس للجميع يعد التحديث المرئي رائعًا حقًا كما أن المهام الأساسية مثل إسكات الإشعارات وضبط الإعدادات بسرعة أصبحت أسهل بفضل بعض التعديلات على الواجهة الذكية ولكن في كل مرة أعود فيها إلى جهاز الكمبيوتر القديم الذي يعمل بنظام Windows 10 لا أشعر حقًا أنني أفتقد الكثير ف windows 11 لم يقدم لي الكثير. في الوقت الحالي يجب عليك الترقية لسبب من سببين أنت تقوم بمهام متعددة ثقيلة أو تريد ببساطة Windows أفضل المظهر من المرجح أن يقدّر أولئك الذين يوفقون بين الكثير من المشاريع والتطبيقات في وقت واحد القدرة على إنشاء العديد من أجهزة سطح المكتب الافتراضية بالإضافة إلى التعديلات المفيدة التي أجرتها Microsoft لالتقاط النوافذ معًا عندما تجمع ذلك مع سهولة الوصول إلى الأشياء يمكن أن يتألق Windows 11 حقًا للأشخاص الذين يتطلعون إلى إنجاز عمل جاد.1 نقطة
-
سيتم وضع ذات الشكل ولكن مع مراعاة التالي: يتم وضع العﻻقة بين الكائنان على هيئة معين مكتوب بداخله ما هي العﻻقة مثلاً في المثال بالأعلى العﻻقة بين الطالب والدورة أن الطالب يدرس الدورة إذات نكتب في المعين study يتم وضع الattributes خارج المستطيل الخاص بالكائن وبدلاً من ذلك يتم وضعهم على هيئة دوار مُرتبطة بالكائنات ولكن مع مراعاة أن يتم وضع خط أسفل الخاصية التي تعبر عن المفتاح الرئيسي primary key1 نقطة
-
ويندوز 11 جديد نسبيًا مقارنة بالإصدارات السابقة منه مثل Windows 10 أو Windows 8.1، لذلك قد يكون هناك الكثير من المشاكل -حتى ولو كانت صغيرة- التي لم يتم حلها بعد (أو لم يتم إكتشافها من الأساس)، وعلى سبيل المثال إن كان حاسوبك يعمل بمعالج من نوع AMD Ryzen فقد تواجهة مشكلة في تشغيل بعض الألعاب أو بطء عام في الجهاز بنسبة تصل إلى 15% من أداء الجهاز العادي، مع العلم أن Microsoft قد أعلنت أنها أصلحت هذه المشكلة في التحديث الأخير (تحديث رقم Build 22000.282)، وقد قامت شركة AMD بطرح تعريف Driver جديد لإصلاح المشكلة من جانبها أيضًا (الإصدار 3.10.08.506). هذا وقد تجد عدد من المشاكل الأخرى مثل الإتصال بالطابعات، أو طلب صلاحييات المدير في كل مرة يتم فيها إستخدام الطابعة، أو مشاكل عند إنشاء أو إستخدام نظام إفتراضي Virtual machines (VMs)، وغيرها من المشاكل الأخرى يمكنك الإطلاع على آخر المشكلات الموجودة حاليًا في النظام ومعرفة كيفية إصلاح المشكلة (إن كان لها حل في الوقت الحالي) من خلال Windows 11 known issues and notifications الرسمية. لذلك لا يُنصح بتجربة Windows 11 على حاسوب الشخصي وخصوصًا إن كان لديك ملفات مهمة أو تستخدمه بكثرة في الأعمال، لأنك قد تواجهة مشكلة من المشكلات السابقة أو حتى مشكلة جديدة لم يتم إصلاحها بعد، مما سيؤثر بالسلب على عملك أو وقتك، ويُفضل أن تنتظر عدة أسابيع أخرى قبل تجربة النظام لضمان أن أغلب المشكلات قد تم حلها بالفعل. كما أنك في الغالب لا تحتاج إلى تثبيت Windows 11 من الأساس، فإن كان حاسوبك على ما يرام بـ Windows 10 وكل البرامج التي لديك تعمل عليه، فلست بحاجة إلى المخاطرة وتجربة نظام جديد خصوصًا إن كنت تستعمل حاسوبك في أمور مهمة كالعمل أو الدراسة كما ذكرت سابقًا، أما إن كان ينتابك الفضول فقط وتريد تجربة النظام فمن الأفضل أن تقوم بتجربة على حاسوب آخر أو حتى كنظام وهمي Virtual machine مع العلم أن هذا الأمر قد يكون معقدًا قليلًا في الوقت الحالي بسبب متطلبات تشغيل windows 11.1 نقطة
-
يمكن التأكد من أن المتغير ليس فارغ لتنجب وضع %% وراء بعضهم se_var_val = "_" if str(self.se_var.get()) != "" se_var_val = str(self.se_var.get()) str(self.se_by.get())+" LIKE " + '%' + se_var_val + '%')1 نقطة
-
يمكن حل المشكلة مؤقتاً باستعمال أحد أدوات VPN بهذا يتم تجنب حظر IP حسب الدولة التي تتصل منها. لمعرفة نوع الخطأ المتعلق بالمصادقة يمكنك الاطلاع على السؤال: الأخطاء من نوع 4xx هي أخطاء من طرف المستخدم إما لم يرسل بيانات مصادقة، أو بياناته خاطئة أو ممنوع من الوصول بالأساس من الخدمة1 نقطة
-
الخطأ 403 يعني أنك ﻻ تمتلك صﻻحية الوصول إلى الresources المطلوبة ع الرغم من إثبات هويتك, فلو كنت لم تثبت هويتك بعد لكان الخطأ المُفترض أن تحصل عليه هو 401 authorization error حسب المعايير القياسية لتصميم الapis فإن ذلك الخطأ بشكلٍ غالب يعني أنك قمت بطلب بيانات ﻻ يمكنك رؤيتها, كمثال إن كنت تطلب بيانات ينقصر رؤيتها على المدير(admin) أو مثلاً تطلب بيانات لمستخدم أخر وليس لك الحق في طلبها. كما من الممكن أن يكون الحساب الخاص بك ليس مُفعل بعد1 نقطة
-
يوجد معماريتين لأنظمة التشغيل الخاصة بالحواسيب والهواتف وهي 32 بت و 64 بت. إن كان ipad حاصتك حديث وله نظام تشغيل أحدث من 10.3 فعليك تعديل إعدادات مشروعك لدعم تشغيله على 64 بت. هنا يجب تحديد targets an iOS حديث. نحتاج دعم 64-bit architecture تعديل Architectures build setting إلى Standard Architectures support the 64-bit runtime environment وإلا فالمشكلة بسبب توقف دعم أنظمة ios لتطبيقات 32 بت، تأكد أن ipad خاصتك من ضمن قائمة 64 بت: iOS devices are 64-bit: iPhone 5s/SE/6/6s/7 iPad Air and iPad Air 2 iPad mini 2, iPad mini 3 and iPad mini 4 Sixth-generation iPod touch 12.9-inch iPad Pro and 9.7-inch iPad Pro 9.7-inch iPad (2017) كان نظام iOS 10.3 آخر من يدعم تطبيقات 32 بت. حاول عمل التوافقية لدعم الإصدارات الأقدم: minimum iOS version as 10.0 or 10.2 or 10.3.1 نقطة
-
401 Unauthenticated غير موثق أنا لا أعلم من أنت وأحتاج أن تثبت هويتك، قد يكون الخطأ له علاقة بعدم إرفاق token مع الطلب، أو لم يقم المستخدم بتسجيل الدخول 403 Unauthorized غير مخوّل أنا أعلم من أنت ولكن غير مسموح لك بالقيام بهذا الفعل، الخطأ يكون له علاقة بقصور صلاحيات المستخدم على أمر معين، كأن يحاول الوصول إلى مورد لا يملكه ولا يملك صلاحية الاطلاع عليه (بيانات شخصية لمستخدم آخر - صور لمستخدمين آخرين)، أو منع بسبب تقني كأن يتجاوز عدد الطلبات المسموح بها في مدة زمنية محدودة1 نقطة
-
يمكنك أن تستخدم سطر الأوامر Command Line لإستخراج وإستدعاء قواعد البيانات خصوصًا إن كانت كبيرة الحجم للغاية، ولكي لا تنتظر تحميل الصفحة في phpMyadmin أو خطأ timeout عندما يتم إستخراج قاعدة البيانات يفضل أن تستخدم سطر الأوامر للقيام بهذه المهمة. أيضًا في كثير من الأحيان لا يكون هنا دعم لـ phpMyadmin على الخادم لذلك لا يتوفر سوى إستخدام سطر الأوامر بشكل إفتراضي. تتوفر MySQL على أداة mysqldump التي تسمح لك بإستخراج وإستيراد قواعد البيانات بشكل سهل وسريع، وذلك من خلال تنفيذ الأمر التالي: mysqldump -u YourUser -p YourDatabaseName > wantedsqlfile.sql سوف يتم طلب إدخال كلمة السر الخاصة بسمتخدم قاعدة البيانات YourUser. ثم لإستيراد قاعدة البيانات على خادم آخر، يمكنك أن تقوم بتنفيذ الأمر التالي: mysql -u YourUser -ptmppassword AnotherDatabaseName < wantedsqlfile.sql قم بتغير اسم المستخدم وكلمة السر واسم قاعدة البيانات وسيبدأ عملية إستيراد قاعدة البيانات.1 نقطة
-
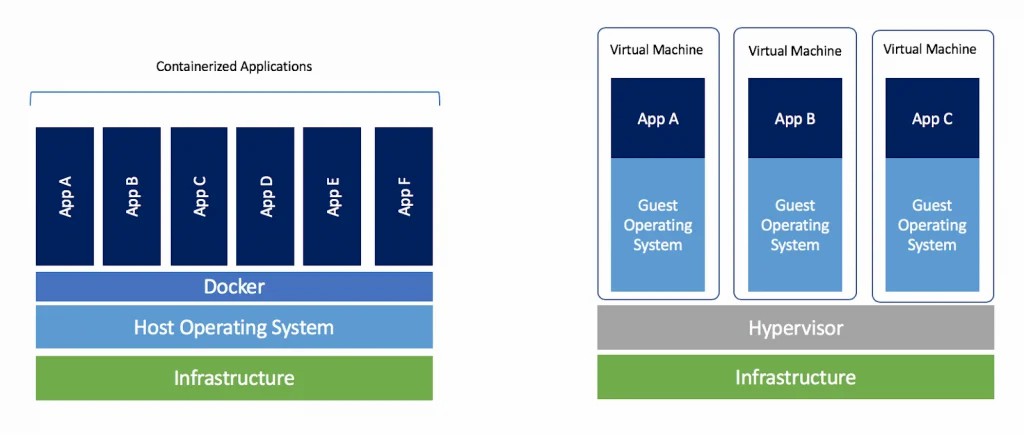
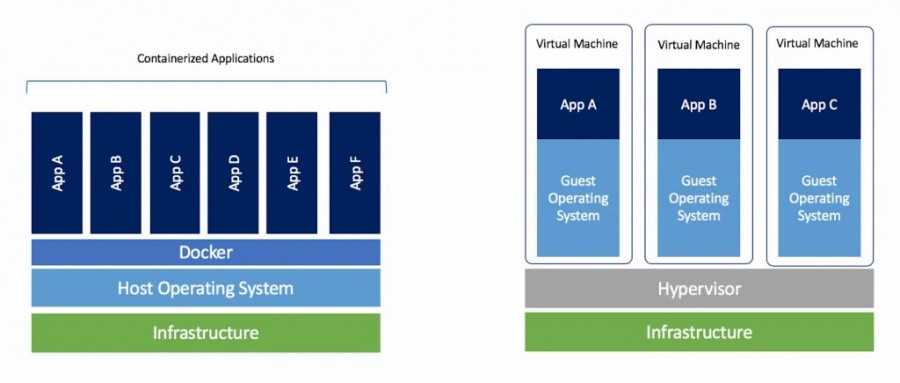
أداة Docker عبارة عن أداة تستخدم المحاكاة الافتراضية virtualization على مستوى نظام التشغيل لتقديم البرامج في حزم تسمى الحاويات. أي أنه يقدم كل حاوية وكأنها نظام تشغيل منفصل عن غيره من الحاويات. يتم عزل الحاويات عن بعضها البعض وتقوم بتجميع البرامج والمكتبات وملفات التكوين configuration files الخاصة بها؛ يمكن للحاويات التواصل مع بعضهم البعض من خلال قنوات محددة جيدًا. والسبب في إستخدام هذه التقنية بدلًا من الأنظمة الإفتراضية Virtual Systems هو أن جميع الحاويات تشترك في خدمات services نواة نظام تشغيل واحدة، وبالتالي يتم إستخدام موارد أقل بكثير من الأنظمة الإفتراضية Virtual Systems. لاحظ كيف أن الحاويات تتشارك نفس النواة الخاصة بنظام التشغيل، مما يسمح بتشغيل عدد أكبر من التطبيقات المعزولة عن بعضها البعض، بينما في الأنظمة الإفتراضية تكون معزولة عن بعضها البعض، ولكنها تستهلك الموارد أكثر. كما أن Docker توفر مجموعة مختلفة من الأدوات مثل Docker Hub والتي يمكن رفع الحاويات عليها لتشاركها مع أشخاص محددين او بشكل مفتوح المصدر و Docker Compose التي تسمح بتعريف وتشغيل تطبيقات دوكر متعددة الحاويات. وتستخدم ملفات خاصة مكتوبة بصيغة YAML (مشابهة إلى حدٍ ما من JSON ولكن بدون أقواس). تستعمل أداة Docker في الوقت الحالي لنشر تطبيقات الويب، حيث يتم إستخدام نفس الحاوية المستخدمه في عملية التطوير على الخادم Server وبالتالي تقليل المشاكل والإختلافات بين بيئة التطوير على الجهاز المحلي وبيئة الإنتاج Production على الخادم Server.
 1 نقطة
1 نقطة -
 تختلف الأنواع الكائنية (object types) بلغة الجافا عن الأنواع البسيطة (primitive type)، فمثلًا، لا تُنشِئ تَعْليمَة التّصْريح (declare) عن مُتْغيِّر، نوعه عبارة عن صَنْف (class)، كائنًا (object) من ذلك الصنف، بل ينبغي أن تقوم بذلك صراحةً. وفقًا للحاسوب، تَتَكوَّن عملية إنشاء كائن من محاولة العثور على مساحة غَيْر مُستخدَمة بقسم الكومة (heap) من الذاكرة وبحيث تَكُون كبيرة بما فيه الكفاية لحَمْل الكائن المطلوب إنشائه، ومن ثَمَّ مَلْئ مُتْغيِّرات نُسخ (instance variables) ذلك الكائن. كمبرمج، أنت لا تهتم عادةً بالمكان الذي يُخزَّن فيه الكائن بالذاكرة، ولكن ستَرغَب غالبًا بالتَحكُّم بالقيم المبدئية المُخزَّنة بمُتْغيِّرات نُسخ ذلك الكائن، كما قد تحتاج في بعض الأحيان إلى إجراء تهيئة (initialization) أكثر تعقيدًا مع كل كائن جديد يُنشَئ. تهيئة متغيرات النسخ (initialization) تستطيع عمومًا إِسْناد قيمة مبدئية إلى أيّ مُتْغيِّر نسخة (instance variable) أثناء التَّصْريح (declaration) عنه، وذلك كأيّ مُتْغيِّر عادي آخر. على سبيل المثال، لنَفْترِض مثلًا أن لدينا الصَنْف PairOfDice المُعرَّف بالأسفل. سيُمثِل أيّ كائن من هذا الصَنْف حجري نَّرد، وسيَحتوِي على مُتْغيِّري نسخة لتمثيل الأعداد الظاهرة على حجري النَّرد، بالإضافة إلى تابع نُسخة (instance method) مسئول عن مُهِمّة رمِي حجرى النَّرد. public class PairOfDice { public int die1 = 3; // العدد الظاهر على الحجر الأول public int die2 = 4; // العدد الظاهر على الحجر الثاني public void roll() { // حاكي تجربة رمي حجري النرد die1 = (int)(Math.random()*6) + 1; die2 = (int)(Math.random()*6) + 1; } } // نهاية الصنف PairOfDice وفقًا لتعريف الصَنْف بالأعلى، سيُهيَئ (initialize) مُتْغيِّري النُسخة die1 و die2 إلى القيم ٣ و ٤ على الترتيب أينما بَنينا كائنًا من الصنف PairOfDice. ينبغي أن تفهم كيفية حُدوث ذلك: لمّا كان من المُمكن إِنشاء عدة كائنات من الصَنْف PairOfDice، فإنه، وبكل مرة يُنشَئ فيها واحد منها، فإن الكائن المُنشَىء سيَحصُل على مُتْغيِّري نُسخة (instance variables) خاصين به، ثم ستُنفَّذ تَعْليمتَي الإِسْناد die1 = 3 و die2 = 4 لمَلئ قيم مُتْغيِّراته. اُنظر النسخة التالية من الصَنْف PairOfDice لمزيد من الإيضاح: public class PairOfDice { public int die1 = (int)(Math.random()*6) + 1; public int die2 = (int)(Math.random()*6) + 1; public void roll() { die1 = (int)(Math.random()*6) + 1; die2 = (int)(Math.random()*6) + 1; } } // نهاية الصنف PairOfDice وفقًا للتعريف بالأعلى، فإنه، وبكل مرة يُنشَئ فيها كائن (object) من الصَنْف PairOfDice، ستُهيَئ مُتْغيِّرات النُسخ إلى قيم عشوائية كما لو كنا نَرمِي حجري نَّرد على طاولة اللعب. لمّا كانت تلك التهيئة (initialization) تُنفَّذ لكل كائن على حدى، فستُحسَب تلك القيم لكل حجري نَّرد، وسيَحصُل كل حجري نَّرد مختلفين على قيم مبدئية مختلفة. سيَكُون الوضع مختلفًا بالتأكيد في حالة تهيئة المُتْغيِّرات الأعضاء الساكنة (static member variables)؛ وذلك لوجود نُسخة وحيدة فقط من أيّ مُتْغيِّر ساكن (static)، والتي تُهيَئ (initialization) مرة واحدة فقط عند تحميل الصَنْف (class) لأول مرة. تُهيَئ مُتْغيِّرات النُسخ (instance variable) بقيم مبدئية افتراضية تلقائيًا إذا لَمْ يُوفِّر لها المبرمج قيمة مبدئية. فمثلًا، تُهيَئ مُتْغيِّرات النسخ من الأنواع العددية مثل int و double تلقائيًا إلى الصفر إذا لم يُوفِّر لها المبرمج قيم آخرى، أما المُتْغيِّرات من النوع boolean فتُهيئ إلى القيمة false، بينما المُتْغيِّرات من النوع char تُهيَئ للمحرف المقابل لقيمة ترميز اليونيكود (Unicode code) رقم صفر \u0000. وأخيرًا، بالنسبة لمُتْغيِّرات النُسخ كائنية النوع (object type)، فإن قيمها المبدئية الافتراضية هي القيمة الفارغة null. على سبيل المثال، لمّا كانت السَلاسِل النصية من النوع String عبارة عن كائنات (objects)، فإن القيمة المبدئية الافتراضية للمُتْغيِّرات من النوع String تُساوِي null. بواني الكائنات (constructors) يُستخدَم العَامِل new لإنشاء الكائنات (objects)، فمثلًا، يُمكِننا كتابة الشيفرة التالية لإنشاء كائن من الصَنْف PairOfDice: PairOfDice dice; // صرح عن متغير من النوع PairOfDice // أنشئ كائنا جديدا من الصنف واسنده مرجعه الى المتغير dice = new PairOfDice(); يُخصِّص التعبير new PairOfDice() مساحة بالذاكرة للكائن، ويُهيِئ مُتْغيِّرات النسخ (instance variables) الخاصة به، وأخيرًا، يُعيد مَرجِعًا (reference) إليه كقيمة للتعبير، والتي تُخزِّنها تَعْليمَة الإِسْناد (assignment statement) بالمُتْغيِّر dice، أي سيُشير dice إلى الكائن الجديد المُنشَئ للتو بعد تَّنْفيذ تَعْليمَة الإِسْناد. يبدو الجزء PairOfDice() وكأنه عملية استدعاء لبرنامج فرعي (subroutine call). ليس هذا في الواقع مجرد مصادفة؛ فهو بالفعل يُمثِل عملية استدعاء، ولكن لنوع خاص من البرامج الفرعية تُعرَف باسم "البَانِي أو بَانِي الكائن (constructor)". قد يُربكك ذلك خاصة وأن تعريف الصَنْف PairOfDice لا يَحتوِي على أي برنامج فرعي بنفس تلك البصمة. في الحقيقة، لابُدّ لأيّ صَنْف من أن يَحتوِي على بَانِي كائن (constructor) واحد على الأقل، لذا يُوفِّر النظام بَانِي كائن افتراضي (default constructor) لأي صَنْف لم يُعرِّف له المبرمج بَانِي كائن (constructor). يَقْتصِر دور البواني الافتراضية على تَخْصِيص مساحة بالذاكرة للكائن، وتهيئة مُتْغيِّرات النُسخ (instance variables)، أما إذا أردت تَّنْفيذ أشياء آخرى عند إنشاء كائن من صَنْف معين، فستحتاج إلى تعريف باني كائن (constructor) واحد أو ربما أكثر ضِمْن تعريف ذلك الصَنْف. تُشبه تعريفات البَوانِي (constructors) في العموم تعريف أيّ برنامج فرعي (subroutine) آخر مع ثلاثة استثناءات. أولًا، لا يُمكِن تَخْصيص النوع المُعاد (return type) من البَانِي بما في ذلك المُبدِّل void. ثانيًا، ينبغي أن يَكُون اسم الباني هو نفسه اسم الصَنْف المُعرَّف بداخله. أخيرًا، تَقْتصِر المُبدِّلات (modifiers) التي يُمكِن اِستخدَامها بتعريف أيّ باني على مُبدِّلات الوصول (access modifiers)، أي public و private و protected، ولا يُمكِن اِستخدَام المُبدِّل static بالتحديد أثناء التَّصْريح عنها. في المقابل، يُمكِنك كتابة مَتْن البَانِي ككُتلَة من التَعْليمَات (statements) كأيّ مَتْن برنامج فرعي (subroutine body) تقليدي آخر؛ فلا يوجد أي قيود على التَعْليمَات التي يُمكِن اِستخدَامها ضِمْن المَتْن، كما يُمكِن للبَانِي أن يَستقبِل قائمة من المُعامِلات الصُّوريّة (formal parameters)، بل إن قدرته على اِستقبَال تلك المُعامِلات هي السبب الرئيسي من اِستخدَامه أساسًا، حيث تُوفِّر تلك المُعامِلات البيانات الضرورية لإِنشاء الكائن (object)، فمثلًا، يُمكِن لأحد بواني الصَنْف PairOfDice أن يُوفِّر قيم الأعداد المبدئية لحجري النَّرد. تَعرَض الشيفرة التالية تعريف الصَنْف في تلك الحالة: public class PairOfDice { public int die1; // العدد الظاهر بالحجر الأول public int die2; // العدد الظاهر بالحجر الثاني public PairOfDice(int val1, int val2) { // يُنشئ الباني حجري نرد ويُهيئهما مبدئيًا بالقيم الممررة die1 = val1; die2 = val2; } public void roll() { // حاكي تجربة الرمي die1 = (int)(Math.random()*6) + 1; die2 = (int)(Math.random()*6) + 1; } } // نهاية الصنف PairOfDice صَرَّحت الشيفرة بالأعلى عن بَانِي كائن (constructor) على الصورة public PairOfDice(int val1, int val2) .... ستُلاحِظ أننا لَمْ نُخصِّص النُوع المُعاد (return type) من البَانِي، كما أننا أعطيناه نفس اسم الصَنْف، وهذه هي الكيفية التي تُمكِّن مُصرِّف الجافا (Java compiler) من تَمييز بَوانِي الكائن. نُلاحِظ أيضًا أن البَانِي يَستقبِل مُعامِلين (parameters)، ينبغي لقيمهما أن تُمرَّر عند استدعاء البَانِي. على سبيل المثال، سيُنشِئ التعبير new PairOfDice(3,4) كائنًا (object) من الصَنْف PairOfDice، ويُهيِئ مُتْغيِّرات نُسخه die1 و die2 مبدئيًا إلى القيم ٣ و ٤ على الترتيب. أخيرًا، ينبغي أن تُستخدَم القيمة المُعادة (return value) من البَانِي بطريقة ما، كالتالي: // صرح عن متغير من الصنف PairOfDice PairOfDice dice; // سيشير dice إلى كائن جديد من الصنف PairOfDice مُهيَأ مبدئيًا بالقيم 1 و 1 dice = new PairOfDice(1,1); الآن، وبعد أن أَضفنا بَانِي كائن إلى الصَنْف PairOfDice، لَمْ يَعُدْ بمقدورنا اِستخدَام التعبير new PairOfDice() لإنشاء كائن؛ حيث تَحتوِي النسخة الجديدة من الصَنْف PairOfDice -بالأعلى- على بَانِي وحيد، والذي يَتَطلَّب مُعامِلين فعليين (actual parameter)، بينما نحن نحاول استدعاء بَانِي بدون أيّ مُعامِلات، ولأن النظام لا يُوفِّر البَانِي الافتراضي (default constructor) سوى للأصناف التي لا يَتَضمَّن تعريفها (class definition) أي بَانِي على الإطلاق، فسنحتاج إلى إضافة بَانِي آخر لا يَستقبِل أي مُعامِلات للصنف، وهو في الواقع أمر بسيط. تستطيع عمومًا إضافة أيّ عدد من البَوانِي (constructors) طالما كانت بَصْمتهم (signatures) مختلفة، أيّ طالما كان لديهم أعداد مختلفة أو أنواع مختلفة من المُعامِلات الصُّوريّة (formal parameters). بالشيفرة التالية، أَضفنا بَانِي بدون أي مُعامِلات إلى الصَنْف PairOfDice سيُهيِئ حجري النَّرد بقيم مبدئية عشوائية، كالتالي: public class PairOfDice { public int die1; // العدد الظاهر بالحجر الأول public int die2; // العدد الظاهر بالحجر الثاني public PairOfDice() { // يرمي الباني حجري النرد ليحصل على قيم عشوائية مبدئية roll(); } public PairOfDice(int val1, int val2) { // يُنشئ الباني حجري نرد ويُهيئهما مبدئيًا بالقيم الممررة die1 = val1; die2 = val2; } public void roll() { // حاكي تجربة الرمي die1 = (int)(Math.random()*6) + 1; die2 = (int)(Math.random()*6) + 1; } } // end class PairOfDice الآن، تستطيع إنشاء كائن من الصَنْف PairOfDice بطريقتين، إِما باِستخدَام التعبير new PairOfDice() أو باِستخدَام التعبير new PairOfDice(x,y)، حيث x و y هي تعبيرات من النوع العَدَدَي الصحيح. تستطيع أيضًا اِستخدَام نفس الصَنْف -بالأعلى- بأي برنامج آخر يَتَعامَل مع حجري نَّرد، وبذلك لن تَضَطرّ إلى اِستخدَام التعبير الغامض نوعًا ما (int)(Math.random()*6)+1 مرة آخرى؛ لأنه مُضمَّن بالفعل داخل الصَنْف PairOfDice، أيّ ستحتاج للتَعامُل مع مسألة رمِي حجري النَّرد مرة واحدة ضِمْن الصَنْف، ثم لا حاجة للقلق بشأنها مُجددًا. بالمثال التالي، يَستخدِم البرنامج main الصَنْف PairOfDice؛ لعدّ عدد مرات رمِي زوجين من حجري النَّرد حتى يَتساوَى حاصل مجموع كِلا الزوجين، وهو ما يُوضِح إِمكانية إنشاء عدة نُسخ (instances) من نفس الصَنْف: public class RollTwoPairs { public static void main(String[] args) { PairOfDice firstDice; // يشير إلى الزوج الأول من حجري النرد firstDice = new PairOfDice(); PairOfDice secondDice; // يشير إلى الزوج الثاني من حجري النرد secondDice = new PairOfDice(); int countRolls; // عدد مرات الرمي int total1; // حاصل مجموع الزوج الأول int total2; // حاصل مجموع الزوج الثاني countRolls = 0; do { // إرم زوجي حجري النرد حتى يتساوى حاصل مجموع كلا منهما firstDice.roll(); // إرم الزوج الأول total1 = firstDice.die1 + firstDice.die2; // Get total. System.out.println("First pair comes up " + total1); secondDice.roll(); // إرم الزوج الثاني total2 = secondDice.die1 + secondDice.die2; // Get total. System.out.println("Second pair comes up " + total2); countRolls++; // أزد عدد الرميات System.out.println(); // Blank line. } while (total1 != total2); System.out.println("It took " + countRolls + " rolls until the totals were the same."); } // نهاية main() } // نهاية الصنف RollTwoPairs البَوانِي في العموم عبارة عن برامج فرعية (subroutines)، ولكن من نوع خاص. هي بلا شك ليست توابع نُسخ (instance methods)؛ لأنها لا تنتمي إلى الكائنات (objects). لكونها مسئولة عن إِنشاء الكائنات، أي لابُدّ من وُجودها قَبْل وُجود أيّ كائن من الصَنْف، فإنها قد تَكُون أكثر شبهًا بالبرامج الفرعية الأعضاء الساكنة (static) مع أنه لا يُسمَح باِستخدَام المُبدِّل static أثناء تعريفها. تقنيًا، البَوانِي ليست أعضاء (members) ضِمْن الصَنْف على الإطلاق، ولا يُشار إليها على أساس كَوْنها توابع (methods) بالصَنْف. بخلاف البرامج الفرعية (subroutines) الآخرى، تستطيع استدعاء البَوانِي فقط من خلال العَامِل new، ويُكْتَب على الصيغة التالية: new <class-name> ( <parameter-list> ) قد تَكُون قائمة المُعامِلات فارغة. تُعدّ الشيفرة بالأعلى تعبيرًا (expression)؛ لأنها بالنهاية تَحسِب قيمة وتُعيدها، حيث تُعيد مَرجِعًا (reference) إلى الكائن المنُشَئ، والذي يُفترَض عادةً تَخْزِينه بمُتْغيِّر. تستطيع أيضًا اِستدعاء البَوانِي (constructor call) بطرائق شتى آخرى، مثلًا، كمُعامِل (parameter) ضِمْن تَعْليمَة اِستدعاء برنامج فرعي (subroutine call)، أو كجُزء من تعبير (expression) أكثر تعقيدًا. لاحِظ أنه في حالة عَدْم الاحتفاظ بالمَرجِع (reference) المُعاد داخل مُتْغيِّر، فلن تَتَمكَّن من الإشارة إلى الكائن المُنشَئ مرة آخرى. يُعدّ استدعاء البَانِي (constructor call) عمومًا أكثر تعقيدًا من أيّ استدعاء عادي لبرنامج فرعي (subroutine) أو لدالة (function)، لذا من المهم أن تَفهَم الخطوات التي يُنفِّذها الحاسوب أثناء استدعاء البَوانِي: يَعثُر الحاسوب على كُتلَة غَيْر مُستخدَمة بقسم الكَوْمة (heap) من الذاكرة، بشَّرْط أن تَكُون كبيرة بما فيه الكفاية لتَحمِل كائن من النوع المُخصَّص. يُهيِئ الحاسوب مُتْغيِّرات النُسخ (instance variables) للكائن، فإذا كان التَّصْريح عنها يَتَضمَّن قيمة مبدئية، فإنه يَحسِب تلك القيمة ويُخزِّنها بمُتْغيِّر النُسخة. أما إن لَمْ تَكُن مُضمَّنة، فإنه يَستخدِم القيمة المبدئية الافتراضية. تُحسَب قيم المُعامِلات الفعليّة (actual parameters) بالبَانِي -إن وُجدت-، ثم تُسنَد إلى المُعامِلات الصُّوريّة (formal parameters). تُنفَّذ التَعْليمَات الموجودة بمَتْن البَانِي (constructor body) إن وُجدت. يُعاد مَرجِع (reference) إلى الكائن المُنشَئ كقيمة لتعبير استدعاء البَانِي (constructor call) تَكُون النتيجة النهائية هي حُصولك على مَرجِع (reference) يُشير إلى الكائن المُنشَئ حديثًا. كمثال آخر، سنُضيف بَانِي كائن (constructor) إلى الصَنْف Student المُستخدَم بالقسم الأول، كذلك أَضفنا مُتْغيِّر نُسخة (instance variable) خاص اسمه هو name. اُنظر الشيفرة: public class Student { private String name; // اسم الطالب public double test1, test2, test3; // درجات الطالب public Student(String theName) { // يستقبل باني الكائن اسم الطالب if ( theName == null ) throw new IllegalArgumentException("name can't be null"); name = theName; } public String getName() { // تابع جلب لقراءة قيمة متغير النسخة return name; } public double getAverage() { // احسب متوسط درجات الطالب return (test1 + test2 + test3) / 3; } } // نهاية الصنف Student عَرَّفنا بَانِي كائن (constructor) يَستقبِل مُعامِلًا (parameter) من النوع String ليُمثِل اسم الطالب. يَحتوِي أي كائن من النوع Student على بيانات طالب معين، ويُمكِننا عمومًا إِنشاء كائنات من ذلك الصَنْف باِستخدَام التَعْليمَات التالية مثلًا: std = new Student("John Smith"); std1 = new Student("Mary Jones"); بالنسخة الأصلية من ذلك الصَنْف، كان المُبرمج يَضطرّ لإِسْناد قيمة مُتْغيِّر النُسخة name بعد إنشاء الكائن، مما يَعنِي عدم وجود ضمانة لأن يَتَذكَّر المُبرمج ضَبْط قيمة ذلك المُتْغيِّر بصورة سليمة. في المقابل، بالنسخة الجديدة من الصَنْف، لا يُمكِن إنشاء كائن من الصَنْف Student إلا عن طريق استدعاء البَانِي (constructor)، والذي يَضبُط قيمة مُتْغيِّر النُسخة name تلقائيًا، كما أنه يَضمَن ألا تَكُون تلك القيمة فارغة. يُسهِل ذلك عمومًا من عَمَل المبرمج، ويُجنِّبه عددًا كبيرًا من الأخطاء البرمجية (bugs). لاحِظ أننا قد اِستخدَمنا المُبدِّل private ضِمْن تَعْليمَة التَّصْريح عن مُتْغيِّر النُسخة name، وهو ما يُوفِّر نوعًا آخر من الضمانة؛ فبذلك لن يَتَمكَّن أي مكان بالشيفرة خارج الصنف Student من الوصول مباشرة إلى مُتْغيِّر النُسخة name، فمثلًا، تُضبَط قيمته بشكل غَيْر مباشر عند استدعاء البَانِي (constructor). في حين يَتَضمَّن الصَنْف دالة جَلْب (getter function) هي getName()، والتي يُمكِن من خلالها مَعرِفة قيمة مُتْغيِّر النُسخة name لطالب معين من مكان خارج الصَنْف، فإن الصَنْف لا يَحتوِي على أيّ تابع ضَبْط (setter method) أو على أي طريقة آخرى لتَعْدِيل قيمة المُتْغيِّر name، أيّ بمُجرَّد إنشاء كائن من ذلك الصَنْف، فإنه سيَظلّ مُحتفِظًا بنفس قيمة المُتْغيِّر name المَبدئية طوال فترة وجوده بالبرنامج. في تلك الحالة، رُبما من الأفضل التَّصْريح عن مُتْغيِّر النُسخة name باِستخدَام المُبدِّل final. يُمكِنك التَّصْريح عن أيّ مُتْغيِّر نُسخة (instance variable) عمومًا باِستخدَام المُبدل final بشَّرْط إِسْناد قيمة إليه إما بتَعْليمَة التَّصْريح (declaration) أو بكل البواني (constructor) المُعرَّفة بذلك الصَنْف. في العموم، لا يُمكِن إِسْناد قيمة إلى مُتْغيِّر نُسخة (instance variable) قد صُرِّح عنه باِستخدَام المُبدِّل final، ولكن يُستَثنَى من ذلك مَتْن البواني (constructor). حسنًا، ماذا سيَحدُث عندما تَستخدِم أعضاء ساكنة (static) وآخرى غَيْر ساكنة (non-static) ضِمْن نفس الصَنْف؟ يَعرِف أيّ كائن عمومًا الصَنْف الذي يَنتمِي إليه، ويُمكِنه الإشارة إلى أعضاء صَنْفه الساكنة (static members). لذا يُمكِن لأيّ تابع نُسخة (instance method) بالصَنْف أن يُشير إلى المُتْغيِّرات الأعضاء (member variables) الساكنة أو أن يَستدعِي البرامج الفرعية الأعضاء (member subroutines) الساكنة. لكن، لاحِظ أن هناك دائمًا نُسخة وحيدة فقط من أيّ عضو ساكن، والتي تَنتمِي للصَنْف ذاته، مما يَعنِي أن جميع كائنات صَنْف معين تَتَشارك نُسخة وحيدة من أيّ عضو ساكن مُعرَّف بالصَنْف. كمثال، اُنظر النسخة التالية من الصَنْف Student، والتي أُضيف إليها مُتْغيِّر نُسخة ID لكل طالب، بالإضافة إلى عضو ساكن (static member) هو nextUniqueID. على الرغم من وجود مُتْغيِّر ID بكل كائن من النوع Student، فهناك مُتْغيِّر nextUniqueID واحد فقط: public class Student { private String name; // اسم الطالب public double test1, test2, test3; // درجات الطالب private int ID; // رقم معرف لهوية الطالب private static int nextUniqueID = 0; // للاحتفاظ برقم الهوية المتاح التالي Student(String theName) { // باني كائن يستقبل اسم الطالب ويسند رقم هوية فريد إليه name = theName; nextUniqueID++; ID = nextUniqueID; } public String getName() { // تابع جلب لقراءة قيمة متغير النسخة name return name; } public int getID() { // تابع جلب لقراءة قيمة رقم الهوية return ID; } public double getAverage() { // احسب متوسط درجات الطالب return (test1 + test2 + test3) / 3; } } // نهاية الصنف Student لمّا كان المُتْغيِّر nextUniqueID ساكنًا (static)، فإنه يُهيَئ مبدئيًا باِستخدَام التعبير nextUniqueID = 0 مرة واحدة فقط عند تحميل الصَنْف لأول مرة. بعد ذلك، عندما نُحاوِل إنشاء كائن من الصَنْف Student، سيُنفِّذ الباني (constructor) التَعْليمَة nextUniqueID++;، والتي تُزِيد دائمًا قيمة نفس المُتْغيِّر العضو الساكن (static member variable) بمقدار الواحد، فتُصبِح قيمة المُتْغيِّر nextUniqueID مُساوِية للعدد ١ بَعْد إنشاء أول كائن من الصَنْف Student، ثم تُصبِح مُساوِية للعدد ٢ بَعْد إنشاء الكائن الثاني، وتُصبِح مُساوِية للعدد ٣ بَعْد الكائن الثالث، ويستمر المُتْغيِّر بالزيادة مع كل كائن جديد يُنشَىء من ذلك الصَنْف. في المقابل، لمّا كان المُتْغيِّر ID عبارة عن مُتْغيِّر نُسخة (instance variable)، فإن كل كائن لديه نُسخته الخاصة من ذلك المُتْغيِّر، والتي يُخْزِّن فيها البَانِي القيمة الجديدة من المُتْغيِّر nextUniqueID بَعْد إِنشائه للكائن. صُمّم الصَنْف Student عمومًا بحيث يَحصُل كل طالب على قيمة مختلفة لنُسخته من المُتْغيِّر ID تلقائيًا. ولأننا قد صَرَّحنا عن المُتْغيِّر ID بكَوْنه خاصًا (private)، فيَستحِيل أيضًا التَلاعُب بقيمة ذلك المُتْغيِّر بأيّ طريقة بَعْد إنشاء الكائن، وهو ما يَضمَن تَخْصِيص رقم هوية فريد ودائم لكل كائن من الصَنْف Student، وهو أمر رائع إذا فكرت بالأمر! لو أعدت التفكير بالأمر، ستَجِدْ أن تلك الضمانة ليست مُطلقة تمامًا، وإنما هي مُقْتصِرة فقط على البرامج التي تَستخدِم خيطًا (thread) واحدًا، أما البرامج مُتعددة الخيوط (multi-thread)، أي التي يُمكِن خلالها تَّنْفيذ عدة أشياء بنفس ذات الوقت، فإن الأشياء تُصبِح غريبة قليلًا، فقد يُنشِئ خيطان كائنين من الصَنْف Student بنفس ذات الوقت، ولهذا قد يَحصُل كِلا الكائنين في تلك الحالة على نفس رقم الهوية. سنعود إلى هذا الموضوع بالقسم الفرعي ١٢.١.٣، حيث ستَتَعلَّم كيفية حلّ تلك المشكلة. كانس المهملات (garbage collection) حتى الآن، كان حديثنا خلال هذا القسم مُقْتصِرًا على إنشاء الكائنات، فماذا عن هَدْمِها؟ تُحذَف الكائنات بلغة الجافا أتوماتيكيًا. يَقع أيّ كائن عمومًا بقسم الكَوْمة (heap) من الذاكرة، ويُمكِن الوصول إلى كائن معين فقط عَبْر المُتْغيِّرات التي تَحمِل مَراجِع (references) تُشير إليه. والآن، ماذا سيَحدُث لو لم يَعُدْ هناك أيّ مُتْغيِّرات تُشير إلى كائن معين؟ اُنظر مثلًا للشيفرة التالية (لاحِظ أنها لأغراض تعليمية فقط؛ فليس من المُحتمل على الإطلاق كتابة تَعْليمَتين على هذا النحو ببرنامج فعليّ): Student std = new Student("John Smith"); std = null; بالسطر الأول، اُنشِئ كائن من الصَنْف Student، ثم خُزِّن مَرجِع (reference) يُشير إليه بالمُتْغيِّر std، ثم بالسطر التالي، تَغيَّرت قيمة std، ولم يَعُدْ مَرجِع الكائن المُنشَئ للتو موجودًا، بل لم يَعُدْ هناك أي مَراجِع (references) تُشير إليه بأي مُتْغيِّر آخر، وبالتالي، لن يَتَمكَّن البرنامج من اِستخدَام ذلك الكائن مُجددًا، ولهذا يَنبغي استعادة مساحة الذاكرة المُخصَّصة للكائن لكي تُصبِح مُتاحة للاِستخدَام لأغراض آخرى. تَستخدِم الجافا إجراءً (procedure) يُعرَف باسم "كَنْس المُهملات (garbage collection)"؛ لاستعادة أجزاء الذاكرة التي كانت قد خُصِّصت للكائنات (objects)، والتي لَمْ يَعُدْ بإِمكان البرنامج الوصول إليها. يَتولَّى النظام -لا المبرمج- مسئولية تَعقُّب تلك الكائنات التي أَصبحت ضِمْن "المُهملات (garbage)". بالمثال السابق، تستطيع بسهولة أن تَرى أن الكائن قد أَصبح ضِمْن المُهملات، ولكن تَكُون الأمور في العادة أكثر تعقيدًا خاصة بَعْد اِستخدَام الكائن لفترة، فيُحتمَل عندها وجود عدة مَراجِع (references) تُشير إليه مُخزَّنة بعدة مُتْغيِّرات. لاحِظ أن الكائن لا يُعدّ جزءًا من المُهملات إلا بعد أن تُصبِح جميع مَراجِعه غَيْر مُتوفرة. تَقَع مسئولية حَذْف المُهملات على عاتق المبرمج بالكثير من اللغات البرمجية الأخرى. ولمّا كان تَعقُّب اِستخدَام الذاكرة يَنطوِي على الكثير من التعقيدات، فإنه عادةً ما يَتسبَّب بحُدوث الكثير من الأخطاء البرمجية (bugs) الخطيرة. أحد تلك الأخطاء هو خطأ المُؤشر المُعلّق (dangling pointer)، والذي يَحدُث عندما يَحذِف المبرمج عن طريق الخطأ كائنًا من الذاكرة ما يزال البرنامج يَملُك مَرجِعًا (references) إليه، مما يَتسبَّب بحُدوث مشاكل إذا حَاول البرنامج الوصول إلى كائن لم يَعُدْ موجودًا. نوع آخر من الأخطاء هو تَسريب الذاكرة (memory leak)، والذي يَحدُث عندما لا يهتم المبرمج بحَذْف الكائنات التي لم تَعُدْ مُستخدَمة، مما يُؤدي إلى مَلئ الذاكرة بكائنات غَيْر قابلة للوصول، ومِن ثَمَّّ قد يُعاني البرنامج من مشكلة نفاد الذاكرة مع أنها فقط مُهدرة في الواقع. يَستحِيل حُدوث مثل تلك الأخطاء بالجافا؛ لأنها تَعتمِد على إجراء كَنْس المُهملات (garbage collection)، وهو عمومًا فكرة قديمة اِستخدَمتها بعض اللغات البرمجية بدايةً من ستينيات القرن الماضي. لماذا إذًا لا تَستخدِمها جميع اللغات؟ لأنها في الماضي كانت بطيئة جدًا، ولكنها أَصبحت عملية بفضل العديد من الدراسات العلمية التي تناولت موضوع كَنْس المهملات عن كثب، بالإضافة إلى السرعة الفائقة للحواسيب الحديثة. ترجمة -بتصرّف- للقسم Section 2: Constructors and Object Initialization من فصل Chapter 5: Programming in the Large II: Objects and Classes من كتاب Introduction to Programming Using Java.1 نقطة
تختلف الأنواع الكائنية (object types) بلغة الجافا عن الأنواع البسيطة (primitive type)، فمثلًا، لا تُنشِئ تَعْليمَة التّصْريح (declare) عن مُتْغيِّر، نوعه عبارة عن صَنْف (class)، كائنًا (object) من ذلك الصنف، بل ينبغي أن تقوم بذلك صراحةً. وفقًا للحاسوب، تَتَكوَّن عملية إنشاء كائن من محاولة العثور على مساحة غَيْر مُستخدَمة بقسم الكومة (heap) من الذاكرة وبحيث تَكُون كبيرة بما فيه الكفاية لحَمْل الكائن المطلوب إنشائه، ومن ثَمَّ مَلْئ مُتْغيِّرات نُسخ (instance variables) ذلك الكائن. كمبرمج، أنت لا تهتم عادةً بالمكان الذي يُخزَّن فيه الكائن بالذاكرة، ولكن ستَرغَب غالبًا بالتَحكُّم بالقيم المبدئية المُخزَّنة بمُتْغيِّرات نُسخ ذلك الكائن، كما قد تحتاج في بعض الأحيان إلى إجراء تهيئة (initialization) أكثر تعقيدًا مع كل كائن جديد يُنشَئ. تهيئة متغيرات النسخ (initialization) تستطيع عمومًا إِسْناد قيمة مبدئية إلى أيّ مُتْغيِّر نسخة (instance variable) أثناء التَّصْريح (declaration) عنه، وذلك كأيّ مُتْغيِّر عادي آخر. على سبيل المثال، لنَفْترِض مثلًا أن لدينا الصَنْف PairOfDice المُعرَّف بالأسفل. سيُمثِل أيّ كائن من هذا الصَنْف حجري نَّرد، وسيَحتوِي على مُتْغيِّري نسخة لتمثيل الأعداد الظاهرة على حجري النَّرد، بالإضافة إلى تابع نُسخة (instance method) مسئول عن مُهِمّة رمِي حجرى النَّرد. public class PairOfDice { public int die1 = 3; // العدد الظاهر على الحجر الأول public int die2 = 4; // العدد الظاهر على الحجر الثاني public void roll() { // حاكي تجربة رمي حجري النرد die1 = (int)(Math.random()*6) + 1; die2 = (int)(Math.random()*6) + 1; } } // نهاية الصنف PairOfDice وفقًا لتعريف الصَنْف بالأعلى، سيُهيَئ (initialize) مُتْغيِّري النُسخة die1 و die2 إلى القيم ٣ و ٤ على الترتيب أينما بَنينا كائنًا من الصنف PairOfDice. ينبغي أن تفهم كيفية حُدوث ذلك: لمّا كان من المُمكن إِنشاء عدة كائنات من الصَنْف PairOfDice، فإنه، وبكل مرة يُنشَئ فيها واحد منها، فإن الكائن المُنشَىء سيَحصُل على مُتْغيِّري نُسخة (instance variables) خاصين به، ثم ستُنفَّذ تَعْليمتَي الإِسْناد die1 = 3 و die2 = 4 لمَلئ قيم مُتْغيِّراته. اُنظر النسخة التالية من الصَنْف PairOfDice لمزيد من الإيضاح: public class PairOfDice { public int die1 = (int)(Math.random()*6) + 1; public int die2 = (int)(Math.random()*6) + 1; public void roll() { die1 = (int)(Math.random()*6) + 1; die2 = (int)(Math.random()*6) + 1; } } // نهاية الصنف PairOfDice وفقًا للتعريف بالأعلى، فإنه، وبكل مرة يُنشَئ فيها كائن (object) من الصَنْف PairOfDice، ستُهيَئ مُتْغيِّرات النُسخ إلى قيم عشوائية كما لو كنا نَرمِي حجري نَّرد على طاولة اللعب. لمّا كانت تلك التهيئة (initialization) تُنفَّذ لكل كائن على حدى، فستُحسَب تلك القيم لكل حجري نَّرد، وسيَحصُل كل حجري نَّرد مختلفين على قيم مبدئية مختلفة. سيَكُون الوضع مختلفًا بالتأكيد في حالة تهيئة المُتْغيِّرات الأعضاء الساكنة (static member variables)؛ وذلك لوجود نُسخة وحيدة فقط من أيّ مُتْغيِّر ساكن (static)، والتي تُهيَئ (initialization) مرة واحدة فقط عند تحميل الصَنْف (class) لأول مرة. تُهيَئ مُتْغيِّرات النُسخ (instance variable) بقيم مبدئية افتراضية تلقائيًا إذا لَمْ يُوفِّر لها المبرمج قيمة مبدئية. فمثلًا، تُهيَئ مُتْغيِّرات النسخ من الأنواع العددية مثل int و double تلقائيًا إلى الصفر إذا لم يُوفِّر لها المبرمج قيم آخرى، أما المُتْغيِّرات من النوع boolean فتُهيئ إلى القيمة false، بينما المُتْغيِّرات من النوع char تُهيَئ للمحرف المقابل لقيمة ترميز اليونيكود (Unicode code) رقم صفر \u0000. وأخيرًا، بالنسبة لمُتْغيِّرات النُسخ كائنية النوع (object type)، فإن قيمها المبدئية الافتراضية هي القيمة الفارغة null. على سبيل المثال، لمّا كانت السَلاسِل النصية من النوع String عبارة عن كائنات (objects)، فإن القيمة المبدئية الافتراضية للمُتْغيِّرات من النوع String تُساوِي null. بواني الكائنات (constructors) يُستخدَم العَامِل new لإنشاء الكائنات (objects)، فمثلًا، يُمكِننا كتابة الشيفرة التالية لإنشاء كائن من الصَنْف PairOfDice: PairOfDice dice; // صرح عن متغير من النوع PairOfDice // أنشئ كائنا جديدا من الصنف واسنده مرجعه الى المتغير dice = new PairOfDice(); يُخصِّص التعبير new PairOfDice() مساحة بالذاكرة للكائن، ويُهيِئ مُتْغيِّرات النسخ (instance variables) الخاصة به، وأخيرًا، يُعيد مَرجِعًا (reference) إليه كقيمة للتعبير، والتي تُخزِّنها تَعْليمَة الإِسْناد (assignment statement) بالمُتْغيِّر dice، أي سيُشير dice إلى الكائن الجديد المُنشَئ للتو بعد تَّنْفيذ تَعْليمَة الإِسْناد. يبدو الجزء PairOfDice() وكأنه عملية استدعاء لبرنامج فرعي (subroutine call). ليس هذا في الواقع مجرد مصادفة؛ فهو بالفعل يُمثِل عملية استدعاء، ولكن لنوع خاص من البرامج الفرعية تُعرَف باسم "البَانِي أو بَانِي الكائن (constructor)". قد يُربكك ذلك خاصة وأن تعريف الصَنْف PairOfDice لا يَحتوِي على أي برنامج فرعي بنفس تلك البصمة. في الحقيقة، لابُدّ لأيّ صَنْف من أن يَحتوِي على بَانِي كائن (constructor) واحد على الأقل، لذا يُوفِّر النظام بَانِي كائن افتراضي (default constructor) لأي صَنْف لم يُعرِّف له المبرمج بَانِي كائن (constructor). يَقْتصِر دور البواني الافتراضية على تَخْصِيص مساحة بالذاكرة للكائن، وتهيئة مُتْغيِّرات النُسخ (instance variables)، أما إذا أردت تَّنْفيذ أشياء آخرى عند إنشاء كائن من صَنْف معين، فستحتاج إلى تعريف باني كائن (constructor) واحد أو ربما أكثر ضِمْن تعريف ذلك الصَنْف. تُشبه تعريفات البَوانِي (constructors) في العموم تعريف أيّ برنامج فرعي (subroutine) آخر مع ثلاثة استثناءات. أولًا، لا يُمكِن تَخْصيص النوع المُعاد (return type) من البَانِي بما في ذلك المُبدِّل void. ثانيًا، ينبغي أن يَكُون اسم الباني هو نفسه اسم الصَنْف المُعرَّف بداخله. أخيرًا، تَقْتصِر المُبدِّلات (modifiers) التي يُمكِن اِستخدَامها بتعريف أيّ باني على مُبدِّلات الوصول (access modifiers)، أي public و private و protected، ولا يُمكِن اِستخدَام المُبدِّل static بالتحديد أثناء التَّصْريح عنها. في المقابل، يُمكِنك كتابة مَتْن البَانِي ككُتلَة من التَعْليمَات (statements) كأيّ مَتْن برنامج فرعي (subroutine body) تقليدي آخر؛ فلا يوجد أي قيود على التَعْليمَات التي يُمكِن اِستخدَامها ضِمْن المَتْن، كما يُمكِن للبَانِي أن يَستقبِل قائمة من المُعامِلات الصُّوريّة (formal parameters)، بل إن قدرته على اِستقبَال تلك المُعامِلات هي السبب الرئيسي من اِستخدَامه أساسًا، حيث تُوفِّر تلك المُعامِلات البيانات الضرورية لإِنشاء الكائن (object)، فمثلًا، يُمكِن لأحد بواني الصَنْف PairOfDice أن يُوفِّر قيم الأعداد المبدئية لحجري النَّرد. تَعرَض الشيفرة التالية تعريف الصَنْف في تلك الحالة: public class PairOfDice { public int die1; // العدد الظاهر بالحجر الأول public int die2; // العدد الظاهر بالحجر الثاني public PairOfDice(int val1, int val2) { // يُنشئ الباني حجري نرد ويُهيئهما مبدئيًا بالقيم الممررة die1 = val1; die2 = val2; } public void roll() { // حاكي تجربة الرمي die1 = (int)(Math.random()*6) + 1; die2 = (int)(Math.random()*6) + 1; } } // نهاية الصنف PairOfDice صَرَّحت الشيفرة بالأعلى عن بَانِي كائن (constructor) على الصورة public PairOfDice(int val1, int val2) .... ستُلاحِظ أننا لَمْ نُخصِّص النُوع المُعاد (return type) من البَانِي، كما أننا أعطيناه نفس اسم الصَنْف، وهذه هي الكيفية التي تُمكِّن مُصرِّف الجافا (Java compiler) من تَمييز بَوانِي الكائن. نُلاحِظ أيضًا أن البَانِي يَستقبِل مُعامِلين (parameters)، ينبغي لقيمهما أن تُمرَّر عند استدعاء البَانِي. على سبيل المثال، سيُنشِئ التعبير new PairOfDice(3,4) كائنًا (object) من الصَنْف PairOfDice، ويُهيِئ مُتْغيِّرات نُسخه die1 و die2 مبدئيًا إلى القيم ٣ و ٤ على الترتيب. أخيرًا، ينبغي أن تُستخدَم القيمة المُعادة (return value) من البَانِي بطريقة ما، كالتالي: // صرح عن متغير من الصنف PairOfDice PairOfDice dice; // سيشير dice إلى كائن جديد من الصنف PairOfDice مُهيَأ مبدئيًا بالقيم 1 و 1 dice = new PairOfDice(1,1); الآن، وبعد أن أَضفنا بَانِي كائن إلى الصَنْف PairOfDice، لَمْ يَعُدْ بمقدورنا اِستخدَام التعبير new PairOfDice() لإنشاء كائن؛ حيث تَحتوِي النسخة الجديدة من الصَنْف PairOfDice -بالأعلى- على بَانِي وحيد، والذي يَتَطلَّب مُعامِلين فعليين (actual parameter)، بينما نحن نحاول استدعاء بَانِي بدون أيّ مُعامِلات، ولأن النظام لا يُوفِّر البَانِي الافتراضي (default constructor) سوى للأصناف التي لا يَتَضمَّن تعريفها (class definition) أي بَانِي على الإطلاق، فسنحتاج إلى إضافة بَانِي آخر لا يَستقبِل أي مُعامِلات للصنف، وهو في الواقع أمر بسيط. تستطيع عمومًا إضافة أيّ عدد من البَوانِي (constructors) طالما كانت بَصْمتهم (signatures) مختلفة، أيّ طالما كان لديهم أعداد مختلفة أو أنواع مختلفة من المُعامِلات الصُّوريّة (formal parameters). بالشيفرة التالية، أَضفنا بَانِي بدون أي مُعامِلات إلى الصَنْف PairOfDice سيُهيِئ حجري النَّرد بقيم مبدئية عشوائية، كالتالي: public class PairOfDice { public int die1; // العدد الظاهر بالحجر الأول public int die2; // العدد الظاهر بالحجر الثاني public PairOfDice() { // يرمي الباني حجري النرد ليحصل على قيم عشوائية مبدئية roll(); } public PairOfDice(int val1, int val2) { // يُنشئ الباني حجري نرد ويُهيئهما مبدئيًا بالقيم الممررة die1 = val1; die2 = val2; } public void roll() { // حاكي تجربة الرمي die1 = (int)(Math.random()*6) + 1; die2 = (int)(Math.random()*6) + 1; } } // end class PairOfDice الآن، تستطيع إنشاء كائن من الصَنْف PairOfDice بطريقتين، إِما باِستخدَام التعبير new PairOfDice() أو باِستخدَام التعبير new PairOfDice(x,y)، حيث x و y هي تعبيرات من النوع العَدَدَي الصحيح. تستطيع أيضًا اِستخدَام نفس الصَنْف -بالأعلى- بأي برنامج آخر يَتَعامَل مع حجري نَّرد، وبذلك لن تَضَطرّ إلى اِستخدَام التعبير الغامض نوعًا ما (int)(Math.random()*6)+1 مرة آخرى؛ لأنه مُضمَّن بالفعل داخل الصَنْف PairOfDice، أيّ ستحتاج للتَعامُل مع مسألة رمِي حجري النَّرد مرة واحدة ضِمْن الصَنْف، ثم لا حاجة للقلق بشأنها مُجددًا. بالمثال التالي، يَستخدِم البرنامج main الصَنْف PairOfDice؛ لعدّ عدد مرات رمِي زوجين من حجري النَّرد حتى يَتساوَى حاصل مجموع كِلا الزوجين، وهو ما يُوضِح إِمكانية إنشاء عدة نُسخ (instances) من نفس الصَنْف: public class RollTwoPairs { public static void main(String[] args) { PairOfDice firstDice; // يشير إلى الزوج الأول من حجري النرد firstDice = new PairOfDice(); PairOfDice secondDice; // يشير إلى الزوج الثاني من حجري النرد secondDice = new PairOfDice(); int countRolls; // عدد مرات الرمي int total1; // حاصل مجموع الزوج الأول int total2; // حاصل مجموع الزوج الثاني countRolls = 0; do { // إرم زوجي حجري النرد حتى يتساوى حاصل مجموع كلا منهما firstDice.roll(); // إرم الزوج الأول total1 = firstDice.die1 + firstDice.die2; // Get total. System.out.println("First pair comes up " + total1); secondDice.roll(); // إرم الزوج الثاني total2 = secondDice.die1 + secondDice.die2; // Get total. System.out.println("Second pair comes up " + total2); countRolls++; // أزد عدد الرميات System.out.println(); // Blank line. } while (total1 != total2); System.out.println("It took " + countRolls + " rolls until the totals were the same."); } // نهاية main() } // نهاية الصنف RollTwoPairs البَوانِي في العموم عبارة عن برامج فرعية (subroutines)، ولكن من نوع خاص. هي بلا شك ليست توابع نُسخ (instance methods)؛ لأنها لا تنتمي إلى الكائنات (objects). لكونها مسئولة عن إِنشاء الكائنات، أي لابُدّ من وُجودها قَبْل وُجود أيّ كائن من الصَنْف، فإنها قد تَكُون أكثر شبهًا بالبرامج الفرعية الأعضاء الساكنة (static) مع أنه لا يُسمَح باِستخدَام المُبدِّل static أثناء تعريفها. تقنيًا، البَوانِي ليست أعضاء (members) ضِمْن الصَنْف على الإطلاق، ولا يُشار إليها على أساس كَوْنها توابع (methods) بالصَنْف. بخلاف البرامج الفرعية (subroutines) الآخرى، تستطيع استدعاء البَوانِي فقط من خلال العَامِل new، ويُكْتَب على الصيغة التالية: new <class-name> ( <parameter-list> ) قد تَكُون قائمة المُعامِلات فارغة. تُعدّ الشيفرة بالأعلى تعبيرًا (expression)؛ لأنها بالنهاية تَحسِب قيمة وتُعيدها، حيث تُعيد مَرجِعًا (reference) إلى الكائن المنُشَئ، والذي يُفترَض عادةً تَخْزِينه بمُتْغيِّر. تستطيع أيضًا اِستدعاء البَوانِي (constructor call) بطرائق شتى آخرى، مثلًا، كمُعامِل (parameter) ضِمْن تَعْليمَة اِستدعاء برنامج فرعي (subroutine call)، أو كجُزء من تعبير (expression) أكثر تعقيدًا. لاحِظ أنه في حالة عَدْم الاحتفاظ بالمَرجِع (reference) المُعاد داخل مُتْغيِّر، فلن تَتَمكَّن من الإشارة إلى الكائن المُنشَئ مرة آخرى. يُعدّ استدعاء البَانِي (constructor call) عمومًا أكثر تعقيدًا من أيّ استدعاء عادي لبرنامج فرعي (subroutine) أو لدالة (function)، لذا من المهم أن تَفهَم الخطوات التي يُنفِّذها الحاسوب أثناء استدعاء البَوانِي: يَعثُر الحاسوب على كُتلَة غَيْر مُستخدَمة بقسم الكَوْمة (heap) من الذاكرة، بشَّرْط أن تَكُون كبيرة بما فيه الكفاية لتَحمِل كائن من النوع المُخصَّص. يُهيِئ الحاسوب مُتْغيِّرات النُسخ (instance variables) للكائن، فإذا كان التَّصْريح عنها يَتَضمَّن قيمة مبدئية، فإنه يَحسِب تلك القيمة ويُخزِّنها بمُتْغيِّر النُسخة. أما إن لَمْ تَكُن مُضمَّنة، فإنه يَستخدِم القيمة المبدئية الافتراضية. تُحسَب قيم المُعامِلات الفعليّة (actual parameters) بالبَانِي -إن وُجدت-، ثم تُسنَد إلى المُعامِلات الصُّوريّة (formal parameters). تُنفَّذ التَعْليمَات الموجودة بمَتْن البَانِي (constructor body) إن وُجدت. يُعاد مَرجِع (reference) إلى الكائن المُنشَئ كقيمة لتعبير استدعاء البَانِي (constructor call) تَكُون النتيجة النهائية هي حُصولك على مَرجِع (reference) يُشير إلى الكائن المُنشَئ حديثًا. كمثال آخر، سنُضيف بَانِي كائن (constructor) إلى الصَنْف Student المُستخدَم بالقسم الأول، كذلك أَضفنا مُتْغيِّر نُسخة (instance variable) خاص اسمه هو name. اُنظر الشيفرة: public class Student { private String name; // اسم الطالب public double test1, test2, test3; // درجات الطالب public Student(String theName) { // يستقبل باني الكائن اسم الطالب if ( theName == null ) throw new IllegalArgumentException("name can't be null"); name = theName; } public String getName() { // تابع جلب لقراءة قيمة متغير النسخة return name; } public double getAverage() { // احسب متوسط درجات الطالب return (test1 + test2 + test3) / 3; } } // نهاية الصنف Student عَرَّفنا بَانِي كائن (constructor) يَستقبِل مُعامِلًا (parameter) من النوع String ليُمثِل اسم الطالب. يَحتوِي أي كائن من النوع Student على بيانات طالب معين، ويُمكِننا عمومًا إِنشاء كائنات من ذلك الصَنْف باِستخدَام التَعْليمَات التالية مثلًا: std = new Student("John Smith"); std1 = new Student("Mary Jones"); بالنسخة الأصلية من ذلك الصَنْف، كان المُبرمج يَضطرّ لإِسْناد قيمة مُتْغيِّر النُسخة name بعد إنشاء الكائن، مما يَعنِي عدم وجود ضمانة لأن يَتَذكَّر المُبرمج ضَبْط قيمة ذلك المُتْغيِّر بصورة سليمة. في المقابل، بالنسخة الجديدة من الصَنْف، لا يُمكِن إنشاء كائن من الصَنْف Student إلا عن طريق استدعاء البَانِي (constructor)، والذي يَضبُط قيمة مُتْغيِّر النُسخة name تلقائيًا، كما أنه يَضمَن ألا تَكُون تلك القيمة فارغة. يُسهِل ذلك عمومًا من عَمَل المبرمج، ويُجنِّبه عددًا كبيرًا من الأخطاء البرمجية (bugs). لاحِظ أننا قد اِستخدَمنا المُبدِّل private ضِمْن تَعْليمَة التَّصْريح عن مُتْغيِّر النُسخة name، وهو ما يُوفِّر نوعًا آخر من الضمانة؛ فبذلك لن يَتَمكَّن أي مكان بالشيفرة خارج الصنف Student من الوصول مباشرة إلى مُتْغيِّر النُسخة name، فمثلًا، تُضبَط قيمته بشكل غَيْر مباشر عند استدعاء البَانِي (constructor). في حين يَتَضمَّن الصَنْف دالة جَلْب (getter function) هي getName()، والتي يُمكِن من خلالها مَعرِفة قيمة مُتْغيِّر النُسخة name لطالب معين من مكان خارج الصَنْف، فإن الصَنْف لا يَحتوِي على أيّ تابع ضَبْط (setter method) أو على أي طريقة آخرى لتَعْدِيل قيمة المُتْغيِّر name، أيّ بمُجرَّد إنشاء كائن من ذلك الصَنْف، فإنه سيَظلّ مُحتفِظًا بنفس قيمة المُتْغيِّر name المَبدئية طوال فترة وجوده بالبرنامج. في تلك الحالة، رُبما من الأفضل التَّصْريح عن مُتْغيِّر النُسخة name باِستخدَام المُبدِّل final. يُمكِنك التَّصْريح عن أيّ مُتْغيِّر نُسخة (instance variable) عمومًا باِستخدَام المُبدل final بشَّرْط إِسْناد قيمة إليه إما بتَعْليمَة التَّصْريح (declaration) أو بكل البواني (constructor) المُعرَّفة بذلك الصَنْف. في العموم، لا يُمكِن إِسْناد قيمة إلى مُتْغيِّر نُسخة (instance variable) قد صُرِّح عنه باِستخدَام المُبدِّل final، ولكن يُستَثنَى من ذلك مَتْن البواني (constructor). حسنًا، ماذا سيَحدُث عندما تَستخدِم أعضاء ساكنة (static) وآخرى غَيْر ساكنة (non-static) ضِمْن نفس الصَنْف؟ يَعرِف أيّ كائن عمومًا الصَنْف الذي يَنتمِي إليه، ويُمكِنه الإشارة إلى أعضاء صَنْفه الساكنة (static members). لذا يُمكِن لأيّ تابع نُسخة (instance method) بالصَنْف أن يُشير إلى المُتْغيِّرات الأعضاء (member variables) الساكنة أو أن يَستدعِي البرامج الفرعية الأعضاء (member subroutines) الساكنة. لكن، لاحِظ أن هناك دائمًا نُسخة وحيدة فقط من أيّ عضو ساكن، والتي تَنتمِي للصَنْف ذاته، مما يَعنِي أن جميع كائنات صَنْف معين تَتَشارك نُسخة وحيدة من أيّ عضو ساكن مُعرَّف بالصَنْف. كمثال، اُنظر النسخة التالية من الصَنْف Student، والتي أُضيف إليها مُتْغيِّر نُسخة ID لكل طالب، بالإضافة إلى عضو ساكن (static member) هو nextUniqueID. على الرغم من وجود مُتْغيِّر ID بكل كائن من النوع Student، فهناك مُتْغيِّر nextUniqueID واحد فقط: public class Student { private String name; // اسم الطالب public double test1, test2, test3; // درجات الطالب private int ID; // رقم معرف لهوية الطالب private static int nextUniqueID = 0; // للاحتفاظ برقم الهوية المتاح التالي Student(String theName) { // باني كائن يستقبل اسم الطالب ويسند رقم هوية فريد إليه name = theName; nextUniqueID++; ID = nextUniqueID; } public String getName() { // تابع جلب لقراءة قيمة متغير النسخة name return name; } public int getID() { // تابع جلب لقراءة قيمة رقم الهوية return ID; } public double getAverage() { // احسب متوسط درجات الطالب return (test1 + test2 + test3) / 3; } } // نهاية الصنف Student لمّا كان المُتْغيِّر nextUniqueID ساكنًا (static)، فإنه يُهيَئ مبدئيًا باِستخدَام التعبير nextUniqueID = 0 مرة واحدة فقط عند تحميل الصَنْف لأول مرة. بعد ذلك، عندما نُحاوِل إنشاء كائن من الصَنْف Student، سيُنفِّذ الباني (constructor) التَعْليمَة nextUniqueID++;، والتي تُزِيد دائمًا قيمة نفس المُتْغيِّر العضو الساكن (static member variable) بمقدار الواحد، فتُصبِح قيمة المُتْغيِّر nextUniqueID مُساوِية للعدد ١ بَعْد إنشاء أول كائن من الصَنْف Student، ثم تُصبِح مُساوِية للعدد ٢ بَعْد إنشاء الكائن الثاني، وتُصبِح مُساوِية للعدد ٣ بَعْد الكائن الثالث، ويستمر المُتْغيِّر بالزيادة مع كل كائن جديد يُنشَىء من ذلك الصَنْف. في المقابل، لمّا كان المُتْغيِّر ID عبارة عن مُتْغيِّر نُسخة (instance variable)، فإن كل كائن لديه نُسخته الخاصة من ذلك المُتْغيِّر، والتي يُخْزِّن فيها البَانِي القيمة الجديدة من المُتْغيِّر nextUniqueID بَعْد إِنشائه للكائن. صُمّم الصَنْف Student عمومًا بحيث يَحصُل كل طالب على قيمة مختلفة لنُسخته من المُتْغيِّر ID تلقائيًا. ولأننا قد صَرَّحنا عن المُتْغيِّر ID بكَوْنه خاصًا (private)، فيَستحِيل أيضًا التَلاعُب بقيمة ذلك المُتْغيِّر بأيّ طريقة بَعْد إنشاء الكائن، وهو ما يَضمَن تَخْصِيص رقم هوية فريد ودائم لكل كائن من الصَنْف Student، وهو أمر رائع إذا فكرت بالأمر! لو أعدت التفكير بالأمر، ستَجِدْ أن تلك الضمانة ليست مُطلقة تمامًا، وإنما هي مُقْتصِرة فقط على البرامج التي تَستخدِم خيطًا (thread) واحدًا، أما البرامج مُتعددة الخيوط (multi-thread)، أي التي يُمكِن خلالها تَّنْفيذ عدة أشياء بنفس ذات الوقت، فإن الأشياء تُصبِح غريبة قليلًا، فقد يُنشِئ خيطان كائنين من الصَنْف Student بنفس ذات الوقت، ولهذا قد يَحصُل كِلا الكائنين في تلك الحالة على نفس رقم الهوية. سنعود إلى هذا الموضوع بالقسم الفرعي ١٢.١.٣، حيث ستَتَعلَّم كيفية حلّ تلك المشكلة. كانس المهملات (garbage collection) حتى الآن، كان حديثنا خلال هذا القسم مُقْتصِرًا على إنشاء الكائنات، فماذا عن هَدْمِها؟ تُحذَف الكائنات بلغة الجافا أتوماتيكيًا. يَقع أيّ كائن عمومًا بقسم الكَوْمة (heap) من الذاكرة، ويُمكِن الوصول إلى كائن معين فقط عَبْر المُتْغيِّرات التي تَحمِل مَراجِع (references) تُشير إليه. والآن، ماذا سيَحدُث لو لم يَعُدْ هناك أيّ مُتْغيِّرات تُشير إلى كائن معين؟ اُنظر مثلًا للشيفرة التالية (لاحِظ أنها لأغراض تعليمية فقط؛ فليس من المُحتمل على الإطلاق كتابة تَعْليمَتين على هذا النحو ببرنامج فعليّ): Student std = new Student("John Smith"); std = null; بالسطر الأول، اُنشِئ كائن من الصَنْف Student، ثم خُزِّن مَرجِع (reference) يُشير إليه بالمُتْغيِّر std، ثم بالسطر التالي، تَغيَّرت قيمة std، ولم يَعُدْ مَرجِع الكائن المُنشَئ للتو موجودًا، بل لم يَعُدْ هناك أي مَراجِع (references) تُشير إليه بأي مُتْغيِّر آخر، وبالتالي، لن يَتَمكَّن البرنامج من اِستخدَام ذلك الكائن مُجددًا، ولهذا يَنبغي استعادة مساحة الذاكرة المُخصَّصة للكائن لكي تُصبِح مُتاحة للاِستخدَام لأغراض آخرى. تَستخدِم الجافا إجراءً (procedure) يُعرَف باسم "كَنْس المُهملات (garbage collection)"؛ لاستعادة أجزاء الذاكرة التي كانت قد خُصِّصت للكائنات (objects)، والتي لَمْ يَعُدْ بإِمكان البرنامج الوصول إليها. يَتولَّى النظام -لا المبرمج- مسئولية تَعقُّب تلك الكائنات التي أَصبحت ضِمْن "المُهملات (garbage)". بالمثال السابق، تستطيع بسهولة أن تَرى أن الكائن قد أَصبح ضِمْن المُهملات، ولكن تَكُون الأمور في العادة أكثر تعقيدًا خاصة بَعْد اِستخدَام الكائن لفترة، فيُحتمَل عندها وجود عدة مَراجِع (references) تُشير إليه مُخزَّنة بعدة مُتْغيِّرات. لاحِظ أن الكائن لا يُعدّ جزءًا من المُهملات إلا بعد أن تُصبِح جميع مَراجِعه غَيْر مُتوفرة. تَقَع مسئولية حَذْف المُهملات على عاتق المبرمج بالكثير من اللغات البرمجية الأخرى. ولمّا كان تَعقُّب اِستخدَام الذاكرة يَنطوِي على الكثير من التعقيدات، فإنه عادةً ما يَتسبَّب بحُدوث الكثير من الأخطاء البرمجية (bugs) الخطيرة. أحد تلك الأخطاء هو خطأ المُؤشر المُعلّق (dangling pointer)، والذي يَحدُث عندما يَحذِف المبرمج عن طريق الخطأ كائنًا من الذاكرة ما يزال البرنامج يَملُك مَرجِعًا (references) إليه، مما يَتسبَّب بحُدوث مشاكل إذا حَاول البرنامج الوصول إلى كائن لم يَعُدْ موجودًا. نوع آخر من الأخطاء هو تَسريب الذاكرة (memory leak)، والذي يَحدُث عندما لا يهتم المبرمج بحَذْف الكائنات التي لم تَعُدْ مُستخدَمة، مما يُؤدي إلى مَلئ الذاكرة بكائنات غَيْر قابلة للوصول، ومِن ثَمَّّ قد يُعاني البرنامج من مشكلة نفاد الذاكرة مع أنها فقط مُهدرة في الواقع. يَستحِيل حُدوث مثل تلك الأخطاء بالجافا؛ لأنها تَعتمِد على إجراء كَنْس المُهملات (garbage collection)، وهو عمومًا فكرة قديمة اِستخدَمتها بعض اللغات البرمجية بدايةً من ستينيات القرن الماضي. لماذا إذًا لا تَستخدِمها جميع اللغات؟ لأنها في الماضي كانت بطيئة جدًا، ولكنها أَصبحت عملية بفضل العديد من الدراسات العلمية التي تناولت موضوع كَنْس المهملات عن كثب، بالإضافة إلى السرعة الفائقة للحواسيب الحديثة. ترجمة -بتصرّف- للقسم Section 2: Constructors and Object Initialization من فصل Chapter 5: Programming in the Large II: Objects and Classes من كتاب Introduction to Programming Using Java.1 نقطة