لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 10/20/21 in أجوبة
-
لدي استعلامين من جدولين بالشكل التالي: -- الجدول الأول Select col_1 col_2 -- الجدول الثاني Select col_1 col_3 -- إن قمت بعمل union col_1 col_2 -- ستكون النتيجة خطأ -- وأنا أريد col_1 col_2 col_3 -- عمود الدمج col_12 نقاط
-
كل حلقات الأنمي والأفلام والمسلسلات والمسرحيات .. إلخ لها حقوق ملكية وفكرية للأستوديوهات التي قامت بصنعها أو لقنوات التلفاز التي تقوم بعرضها، لذلك لن تجد API مجاني يوفر تحميل أو مشاهدة الحلقات بأي شكل من الأشكل وكل التطبيقات والمواقع التي تقوم بتوفير مشاهدة الحلقات أو تحميلها بشكل مجاني تقوم بسرقة هذه الحقوق وهذا الأمر مخالف للقانون بالطبع، لذلك لن تجد أيًا من هذه التطبيقات موجودة على متجر Play على سبيل المثال أو لن تجد إعلانات جوجل أدسنس على أحد هذه المواقع، وذلك لأن جوجل تقوم بمنع وحظر المحتوى المُقرصن pirated content. لكن يمكنك الحصول على API مجاني يعرض لك معلومات عن مسلسلات الأنمي والأفلام مثل Jikan أو MyAnimeList API ولكن لا يوفر أي من هذه المصادر مشاهدة الحلقات أو تحميلها بأي شكل من الأشكال، وذلك لأن هذا الأمر مخالف للقانون كما ذكرت سابقًا. ما يقوم به تطبيق مثل Anime Slayer هو تخزين روابط مشاهدة الحلقات عبر خوادم ok.ru أو 4shared أو غيرها وتكون هذه الروابط عبارة عن embedded URL بالطبع لكي يمكن لهذه الخوادم إضافة إعلانات عليها، وبعد ذلك يقوم التطبيق بمحاولة إستخراج روابط المشاهدة المباشرة من هذه الصفحات وتوفيرها للمستخدم وهذا يعرف بمجال سحب البيانات Web Scraping، بالتأكيد سيكون هناك الكثير من الروابط التي لا تعمل لأن هذه الخوادم تقوم بحذفهال بإستمرار وفقًا لسياستها التي تمنع المحتوى المقرصن أيضًا.2 نقاط
-
لا اعلم شيي عن البرمجة واريد ان اكون مبرمج full stack او علي الاقل backend الكل نصحني بهذا ويذكر انه اهم وافضل .. بحثت في دورات حسوب وجدت دورة مدخل الي عالم الكمبيوتر كبداية ثم تطوير واجهات المستخدم ولكن لم اري دورات back end ؟1 نقطة
-
كيف يمكنني حذف محور axis محدد من ال plot؟1 نقطة
-
هل هناك طريقة معينة في بايثون أو OpenCV لتدوير الصورة بدرجة معينة؟1 نقطة
-
كيف يمكننا تحويل الصورة من تنسيقOpenCV إلى تنسيق (Pillow )PIL والعكس؟1 نقطة
-
ما الفرق بين الاستعلامين: SELECT * FROM T1 WHERE T1.col IN (SELECT col FROM T2) وهذا: SELECT T1.* FROM T1 JOIN T2 ON T1.col = T2.col1 نقطة
-
احاول استخدام فايربيز مع react import firebase from '@firebase/app'; import '@firebase/storage'; const storage = firebase.storage(); const ref=storage.ref("images"); ولكن يعطيني خطأ TypeError: Cannot read properties of undefined (reading 'storage')1 نقطة
-
إن مشروعي يعتمد على حزمة npm خاصة قمت بعمل لها auth credentials على شكل authentication token وأريد تضمينها في مشروعي وهي مرفوعة على خدمة sinopia1 نقطة
-
تُستخدم الأسماء المستعارة لـ SQL لإعطاء اسم مؤقت لجدول أو عمود في جدول. غالبًا ما تستخدم الأسماء المستعارة لجعل أسماء الأعمدة أكثر قابلية للقراءة. الاسم المستعار موجود فقط لمدة هذا الاستعلام. يتم إنشاء اسم مستعار باستخدام الكلمة الأساسية AS. يوجد أكثر من جدول واحد متضمن في الاستعلام يتم استخدام functions في الاستعلام أسماء الأعمدة كبيرة أو غير مقروءة جيدًا يتم دمج عمودين أو أكثر معًا فنعطي اسم العمود الناتج عن الدمج اسم يعبر عنه يمكن استخدام column_alias في عبارة ORDER BY ، ولكن لا يمكن استخدامها في جملة WHERE أو GROUP BY أو HAVING. لا يسمح SQL القياسي بالإشارة إلى الأسماء المستعارة للأعمدة في جملة WHERE. يتم فرض هذا التقييد لأنه عند تقييم جملة WHERE ، يكون لم يتم تحديد قيمة العمود بعد، بسبب ترتيب تنفيذ أجزاء الاستعلامات. يمكن إعطاء اسم مستعار لنتيجة subquery أي استعلام جزئي يمكن إعطاء اسم مستعار لنتيجة دالة تجميع aggregation function مثل sum - man - avg أمثلة عامة: -- اسم مستعار لعمود Alias Column SELECT column_name_1 AS alias_name_1, column_name_2 AS alias_name_2, FROM table_name_1; -- اسم مستعار لجدول Alias Table SELECT column_name_s, *.. FROM table_name AS alias_name_table; اسم مستعار لعمود مع دوال التجميع: SELECT SQRT(a*b) AS root_square FROM math_table GROUP BY root HAVING root_square > 0; SELECT id, COUNT(*) AS count FROM employees GROUP BY id HAVING count > 0; SELECT id AS 'Customer identity' -- اسم توضيحي FROM Customer; دمج جدول مع نفسه: SELECT o.OrderID, o.OrderDate, c.CustomerName -- استخدام الاسم المستعار في SELECT FROM Customers c, Orders o -- يمكن تجاهل زضع as WHERE c.CustomerName LIKE "wael%" AND c.CustomerID=o.CustomerID; إعادة تسمية ناتج دمج عدة أعمدة: SQL SERVER: SELECT Name, CONCAT(Address,', ',City,', ',Country) AS Address FROM Customers; MySQL: SELECT Name, Address + ', ' + City + ', ' + Country AS Address FROM Customers;1 نقطة
-
تعلمت أساسيات nginx وكيفية تنصيبه، ولكن هل يوجد ميزات أخرى يوفرها هذا الخادم؟1 نقطة
-
كيف نتحكم بعدد الصور؟ قم بتعريف متغير عام، يحوي قيمة ابتدائية 0. يتم تحديثه أولا بعدد الصور التي تأتي من قاعدة البيانات.. imagesCounter = 0 if (response.statusCode == 200) { final items = json.decode(response.body).cast<Map<String, dynamic>>(); List<DataImage> listOfFruits = items.map<DataImage>((json) { return DataImage.fromJson(json); }).toList(); imagesCounter = listOfFruits.length; // هنا return listOfFruits; } ثم نمرر للدالة التي تسمح للمستخدم بجلب الصور من الاستديو عدد الصور التي من الممكن إضافتها، وهي 4 ناقص التي تم تحميلها فعليا maxAssets: 4 - imagesCounter, هكذا يكون لنا متغير عام يضبط عدد الصور.1 نقطة
-
بالإضافة إلى إجابة أستاذ أحمد, يوجد مواقف تحتاج أن تستخدم فيها الأسماء المستعارة (aliases) حتى تتمكن من تنفيذ الجملة الإستعﻻمية المُراد تنفيذها, مثلاً إن كان لدينا الجدول employee وأردنا أن نجلب جميع الموظفين الذين لديهم نفس المدينة, وقتها نحتاج أن نقوم بما يُدعى بالself join حيث أنك تقوم بكتابة جملة join ولكن بدلاً من أن تكون بين جدولين تكون بين الجدول ونفسه, مثال: SELECT a.name AS name1, n.name AS name2, a.City FROM Customers a, Customers n WHERE a.id <>n.id AND a.City = n.City بدون إعطاء أسماء مستعارة لن نتمكن من تفنيذ جملة مثل السابقة1 نقطة
-
يمكن إعداد خادم Nginx كموزع حمل Load Balancer بإستخدام أحد الآليات مثل round-robin أو least-connected أو ip-hash وهنا شرح مبسط عن كل آلية منهم: round-robin: في هذه الطريقة يتم تحديد كل خادم بالتتالي وفقًا للترتيب الذي قمت بتعيينه في ملف الإعدادات، أي يتم إرسال الطلب الأول إلى الخادم الأول ثم الطلب الثاني إلى الخادم الثاني وهكذا. هذا يوازن عدد الطلبات بالتساوي للعمليات القصيرة. وهذه هي الطريقة الإفتراضية التي يعمل بها nginx. least-connected: يتم تعيين الطلب التالي للخادم الذي لديه أقل عدد من الاتصالات النشطة active connection. ip-hash: في هذه الطريقة يتم استخدام دالة التجزئة hash-function لتحديد الخادم الذي يجب أن يقوم بمعالجة الطلب (بناءً على عنوان IP الخاص بالعميل). في الأساس، كل ما عليك فعله هو إعداد nginx مع تعليمات حول نوع الاتصالات التي يجب الاستماع إليها ومكان إعادة توجيهها. وذلك من خلال إنشاء ملف configuration جديد باستخدام أي محرر نصوص. على سبيل المثال: sudo nano /etc/nginx/conf.d/load-balancer.conf الآن في هذا الملف يجب تعريف جزئين رئيسيين، وهما upstream و server، على النحو التالي: http { upstream backend { # نضع هنا عناوين الخوادم التي سيتم إستخدامها server 10.1.0.101; server 10.1.0.102; server 10.1.0.103; } # لاحظ أن اسم upstream و proxy_pass يجب أن يكونا متطابقين. # في هذه الحالة تم إستعمال كلمة backend كاسم لهما server { listen 80; location / { proxy_pass http://backend; } } } الآن يمكن حفظ الملف (عبر الضغط على Ctrl + O) والخروج من محرر النصوص (عبر الضغط على Ctrl + X). نحتاج الآن إلى إستبدال ملف الإعدادات السابق بملف الإعدادات الإفتراضي، وذلك عبر الأوامر التالية: # في Debian و Ubuntu sudo rm /etc/nginx/sites-enabled/default # في نظام CentOS sudo mv /etc/nginx/conf.d/default.conf /etc/nginx/conf.d/default.conf.disabled الآن يجب إعادة تشغيل خادم nginx مرة أخرى وذلك عبر الأمر: sudo systemctl restart nginx طريقة round-robin هي المستخدمة بشكل إفتراضي لذلك لا حاجة لتعديل الملف السابق مرة أخرى، بينما يُمكن تغير الآلية المستعملة في الخادم لموازنة الحمل عبر تعديل قسم upstream في ملف الإعدادات السابق، كالتالي: لإستخدام طريقة least-connected: upstream backend { least_conn; server 10.1.0.101; server 10.1.0.102; server 10.1.0.103; } لإستخدام طريقة ip-hash: upstream backend { ip_hash; server 10.1.0.101; server 10.1.0.102; server 10.1.0.103; }1 نقطة
-
علينا القيام بالخطوات التالية: ربط الجدولين حسب حقل الاسم سوف نستخدم LEFT JOIN للتاكد من ورود أسماء المهندسين تجميع النتائج حسب اسم المهندس نستخدم GROUP BY NAME عمل تجميع ضمن عبارة SELECT باستخدام GROUP_CONCATE التي تدمج السلاسل النصية في سلسة واحدة مع تحديد محرف الفصل بين القيم SELECT x.name, --جلب الاسم GROUP_CONCAT(y.LanguageName SEPARATOR ', ') -- دمج أسماء لغات البرمجة التي تعود لنفس المهندس FROM Engineers e LEFT JOIN ProgramingLanguages pl ON pl.name = e.name -- عمل ربط حسب اسم المهندس GROUP BY e.name -- تجميع حسب اسم المهندس والنتيجة: Ex: wael c++, java, php walid java, javascript wasim c#, asp.NET1 نقطة
-
الأفضل هو عمل جدول منفصل للحالة، يحوي حقلين، هما معرف الحالة والقيمة الاسمية للحالة، أي جدول يعمل ك lookup table ويأخذ الحقل status في جدول الطلبيات القيمة tiny int، يمكن عمل الربط عن طريق المفتاح الثانوي، ولكن الأفضل عدم عمل ربط أثناء الاستعلامات، بل جلب القيم واستبدالها لاحقاً في صفحة الويب أو التطبيق لكي نحسن من الأداء في قاعدة البيانات. tiny int لتوفير مساحة التخيزين، جدول الحالات ك lookup table يمكن استعمال مفهوم العرض view لتركيب استعلام معقد حسب الحالة لديك. status_table status_id | status name 0 pending 1 cooking 2 delevering 3 delevered1 نقطة
-
من أجل توفير المساحة وتحسين الأداء، يجب اختيار الشكل الأمثل للبيانات الذي يكون دقيقا على حجم البيانات التي تريد ادخالها. هنا في status توجد لديك عدة حالات منها استلام - قيد التوصيل - قيد الطهي - في الانتظار وغيرها..، وهنا يعتمد شكل البيانات على طريقة استخدامك لهذة الطرق وهناك طريقتين: اما ان تكون البيانات بداخلها نصا، مثلا "نعم" أو "لا" وهكذا، حينها يجب أن تكون البيانات من نوع Varchar. أما اذا قررت استخدامها ك 0 و 1، بحيث تعني 0 "لا" وتعني 1 "نعم" ، حنها يمكنك اما استخدام int أو tinyint .1 نقطة
-
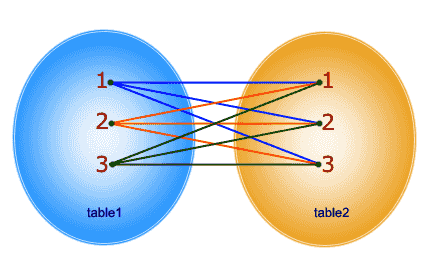
يمكنك استخدام cross join والتي تقوم بعمل مزيج بين كل العناصر في الجدول الأول عناصر الجدول الثاني كما توضح الرسمة التالية: ويتم كتابتها بالشكل التالي: SELECT * FROM table1 CROSS JOIN table2; للتوضيح كمثال، دعنا ننشئ الجدول التالي: Player Department_id Goals Ahmed 1 2 Mohamed 2 2 Eyad 3 5 والجدول الثاني هكذا: Department_id Department_name 1 IT 2 HR 3 Marketing اذا قمنا بكتابة الكود لتالي لعمل cross بين الجدولين: SELECT * FROM MatchScore CROSS JOIN Departments يظهر لنا الجدول التالي: Player Department_id Goals Depatment_id Department_name Ahmed 1 2 1 IT mohamed 2 2 1 IT Eyad 3 5 1 IT Ahmed 1 2 2 HR mohamed 2 2 2 HR Eyad 3 5 2 HR Ahmed 1 2 3 Marketing mohamed 2 2 3 Marketing Eyad 3 5 3 Marketing لاحظ أنه قام بدمج كل عنصر في الجدول الأول بكل عنصر في الجدول الثاني
 1 نقطة
1 نقطة -
مفهوم Redis: Redis هو عبارة عن مخزن مفتوح المصدر يُستعمل لتخزين البيانات على شكل أزواج من مفتاح-قيمة Key-Value في الذاكرة الرئيسية In-Memory، حيث Key-Value storage عبارة عن نظام تخزين يتم فيه تخزين البيانات على شكل أزواج من المفاتيح والقيم ، تخزّن هذه الأزواج في الذاكرة الرئيسية RAM وهذا ما نقصده بـ In-Memory وبهذا يمكننا القول أن تقنية Redis تخزن البيانات في الذاكرة الرئيسية على شكل أزواج من المفاتيح والقيم. يكون المفتاح في هذه التقنية عبارة عن سلسلة نصية String، أما القيمة فيمكن أن تكون سلسلة محارف String أو قائمة List أو مزيج منهما. يُمكن استخدام Redis إمّا كخادوم قاعدة بيانات لوحده أو مرتبطًا مع قاعدة بيانات أخرى مثل MySQL. خطوات تثبيت Redis على أوبنتو: إعداد بيئة ومتطلبات Redis نقوم في البداية بتحديث جميع حزم apt-get: sudo apt-get update بعد ذلك نقوم بتحميل مُترجم (compiler) باستخدام الحزمة build-essential، والّتي من شأنها المساعدة في تنصيب Redis من المصدر: sudo apt-get install build-essential سنقوم بعدها بتحميل الأداة tcl الّتي يَعتمد عليها Redis: sudo apt-get install tcl8.5 تنصيب Redis: بعد أنّ تمّ تنصيب المُتطلّبات الأساسيّة، فمن المُمكن الآن الشروع وتنصيب redis، ويُمكن تحديد الإصدار المطلوب أو تحميل الإصدار الأخير والذي سيحمل دائمًا الاسم redis-stable: wget http://download.redis.io/redis-stable.tar.gz يجب بعد ذلك فك ضغط الملفّ والانتقال إليه: tar xvzf redis-stable.tar.gz cd redis-stable ثم المتابعة بتنفيذ الامر: make make ولتنصيب Redis على كامل النّظام، فيُمكن إما نسخ ملفاته من المصدر: sudo cp src/redis-server /usr/local/bin/ sudo cp src/redis-cli /usr/local/bin/ أو تنفيذ الأمر التّالي: sudo make install بعد انتهاء عمليّة التنصيب، من المُستحسن تشغيل Redis كحارس (daemon) في خلفيّة النّظام، ولعمل ذلك يأتي Redis بملفّ برمجي (سكريبت) لهذه المُهمّة. يجب الانتقال إلى المسار utils للوصول إلى هذا الملفّ: cd utils ومن ثم تشغيل الملفّ الخاص بتوزيعات Ubuntu/Debian: sudo ./install_server.sh سيَعرض السكريبت بعض الأسئلة لإتمام عمليّة التهيئة، ولكن يُمكن الاعتماد على الإعداد الافتراضي والاكتفاء بالضغط على Enter، وبعد انتهاء عملية التهيئة سيكون خادم Redis يعمل في الخلفيّة (background). يُمكن تنفيذ الأمر التّالي للوصول إلى قاعدة البيانات Redis: redis-cli يُمكن اختبار Redis كالتّالي: λ redis-cli 127.0.0.1:6379> ping PONG 127.0.0.1:6379> set name hsoub OK 127.0.0.1:6379> get name "hsoub" 127.0.0.1:6379> بإمكانك المتابعة مع المقال التالي: الذي يشرح كيفية التثبيت بشكل مفصل و الإطلاع على بقية أوامر Redis.1 نقطة
-
Nginx عبارة عن مشروع مفتوح المصدر، له استخدامات مُختلفة قد يكون أهمها هو استخدامه كخادوم ويب. تنصيب NGINX بعد الدخول إلى السيرفر نفذ الأمريين التاليين لتثبيت وتشغيل برنامج Nginx على السيرفر: sudo apt-get update sudo apt-get install -y nginx بعد التثبيت يمكنك زيادة السيرفر من المتصفح عبر وضع عنوان السيرفر (Ip Address) في شريط العنوان في المتصفح، وسوف تظهر لك الصفحة الافتراضية لـNginx. تابع هذا الدرس لمعرفة كيفية التثبيت و ضبط خادم Nginx على توزيعة اوبنتو بالإضافة إلى مثال بسيط لتخديم صفحات html : و أيضا هناك عدة مقالات تم نشرها على الأكاديمية تشرح عن Nginx و كيفية التعامل معه بإمكانك الوصول لها من خلال: مقالات Nginx
 1 نقطة
1 نقطة -
لكي يُمكن تثبيت وإستخدام شهادة SSL على موقع معين، يجب أن يكون الموقع مستضاف على خادم خاص VPS أو dedicated server مع إمكانية التحكم به عبر سطر اللأوامر من خلال SSH أو أي طريقة أخرى، كما يجب أن يكون لديكِ صلاحيات لإستخدام الأمر sudo. بعد التأكد من وجود كل المتطلبات السابقة، يمكن البدء في الخطوات التالية: أولًا يجب تسجيل الدخول إلى الخادم عبر SSH بإستخدام حسساب مستخدم لديه صلاحيات إستخدام الأمر sudo ثانيًا يجب تثبيت Snapd والذي يأتي مثبيت مسبقًا على خوادم Ubuntu 16.04 وما بعد ذلك، لكن إن لم يكن مثبتًا مسبقًا لديكِ، فيمكن تنفيذ هذه الأوامر لتثبيته من جديد: sudo apt update sudo apt install snapd sudo snap install core حذف حزم Certbot: في كثير من الأحيان يحتوي النظام على حزم خاصة بــ Certbot مسبقًا، ويجب حذف هذه الحزم قبل عملية تثبيت Certbot snap الذي سيسمح لنا بتثبيت شهادة SSL، لإلغاء تثبيت Certbot يمكن تنفيذ أحد الأوامر التالية حسب نظام التشغيل الذي لديكِ: sudo apt-get remove certbot sudo dnf remove certbot sudo yum remove certbot الآن سنقوم بتثبيت Certbot Snap من خلال تنفيذ الأمر التالي: sudo snap install --classic certbot وللتأكد من أن عملية التثبيت تمت بنجاح وأنه يمكن تشغيل وإستخدام Certbot، يُمكن تنفيذ الأمر التالي: sudo ln -s /snap/bin/certbot /usr/bin/certbot الآن يمكن الإختيار بين أن يقوم certbot بتعديل إعدادات خادم Apache وتثبيت شهادة SSL تلقائيًا أو تحميل الشهادة فقط، وذلك عبر أحد الأوامر التالية: السماح لـ Certbot بتعديل إعدادات Apache: sudo certbot --apache تحميل الشهادة فقط: sudo certbot certonly --apache ملاحظة: إن كان الخادم يعمل بـ Nginx، فيمكن تبديل apache بـ nginx في الأوامر السابقة، وسيعمل كل شيء على ما يرام. الآن تم تثبيت الشهادة بنجاح، ويمكن تحديث الشهادة كل فترة عبر الأمر التالي: sudo certbot renew --dry-run sudo certbot renew الأمر الأول للتحقق فقط من أن عملية تحديث الشهادة تتم بنجاح، أما الأمر الثاني فهو ما يقوم بتحديث الشهادات بالفعل. يمكن التأكد من أن شهادة SSL تعمل بنجاح من خلال زيارة رابط الموقع عبر بروتوكول HTTPS وليس HTTP مثل https://www.example.com. ملاحظة: عند إستخدام certbot والسماح له بتعديل إعدادات الخادم، يقوم بتوجيه الزيارات التي تتم من خلال HTTP إلى HTTPS تلقائيًا.1 نقطة
-
يستعمل الـ CROSS JOIN عادة لإنشاء ,إنطلاقا من جدولين, توليفة مزدوجة من كل صف من الجدول الأول مع كل صف من الجدول الثاني . أي إن كان الجدول الأول يحوي المعلومات : +++++++++++ |STUDENTS | |---------| |AHMED | |OMAR | |YOUNESS | +++++++++++ و الجدول الثاني المعلومات : +++++++++++ |CARS | |---------| |BMW | |MERCEDES | |HONDA | +++++++++++ فإن إستعمال الـ CROSS JOIN الذي سيقوم بتشكيل : سطر لأحمد بمحاذاة سطر BMW . // // // // MERCEDES . // // // // HONDA . و أيضا : سطر لعمر بمحاذاة سطر BMW . // // // // MERCEDES . // // // // HONDA . و أيضا : سطر ليونس بمحاذاة سطر BMW . // // // // MERCEDES . // // // // HONDA . بمعنى أنه سيتبع منطقا كالتالي : / BMW / |OMAR ---- MERCEDES \ \ HONDA / BMW / |AHMED --- MERCEDES \ \ HONDA / BMW / |YOUNESS --- MERCEDES \ \ HONDA لينتج لنا مجموعة النتائج التالية : ++++++++++++++++++++++ |STUDENTS | CARS | |---------|----------| |AHMED |BMW | |AHMED |MERCEDES | |AHMED |HONDA | | | | |OMAR |BMW | |OMAR |MERCEDES | |OMAR |HONDA | | | | |YOUNESS |BMW | |YOUNESS |MERCEDES | |YOUNESS |HONDA | ++++++++++++++++++++++ يشبه هذا جداء مجموع في الجبر , إذ يتم إستعمال النشر المزدوج كطريقة لتحليل عبارة جبرية تتضمن جداء مجموع , مثال : (a + c )( b + d ) = ab + ad + cb + cd سوى أن النتائج في الـ CROSS JOIN يتم نشرها كصفوف بنتيجة الإستعلام . السياق العام لها هو ما كالتالي : SELECT ColumnName_1, ColumnName_2, ColumnName_N FROM [Table_1] CROSS JOIN [Table_2] أو يكفي : SELECT ColumnName_1, ColumnName_2, ColumnName_N FROM [Table_1],[Table_2] و يتم استخدامه بغرض إنشاء مجموعة من كافة مجموعات العناصر بجدول ما بقاعدة البيانات ، مثل تشكيل مجموعات منازل ذات ألوان و أحجام معينة , هذا مع إمكانية التحكم في عناصر هاته المجموعات لونا أو حجما : select size, color from sizes CROSS JOIN colors ++++++++++++++++++++++ |SIZE | COLOR | |---------|----------| |XS |RED | |XS |BLUE | |XS |GREY | | | | |XM |RED | |XM |BLUE | |XM |GREY | | | | |XL |RED | |XL |GREY | |XL |BLUE | ++++++++++++++++++++++ فلو أردنا مثلا إستثناء المنازل الحمراء , فسنتثني اللون الأحمر فقط ليتم إستثناء كل التوليفات المشكلة من حجم X و لون أحمر .. : و هكذا . أو ربما تريد جدولاً يحتوي على صف لكل دقيقة في اليوم ، وتريد استخدامه للتحقق من تنفيذ إجراء ما كل دقيقة ، لذلك يمكنك تجاوز ثلاثة جداول : select hour, minute from hours CROSS JOIN minutes ++++++++++++++++++++++ |HOUR | MINUTE | |---------|----------| |13:00 |00 | |13:00 |01 | |13:00 |02 | |13:00 |03 | . . . . . . |21:00 |55 | |21:00 |56 | |21:00 |57 | |21:00 |58 | . . . . . . ++++++++++++++++++++++ فهو يخلق مجموعة إحتمالات غير مكررة ,بإعتبار أن الأعمدة تحمل قيما فريدة, إبتداءا من مجموعات محدودة من العناصر . يمكن أن يكون هذا عمليا جدا في عمليات مثل إختبار التطبيق أو بذر قواعد البيانات ببيانات تجريبية .1 نقطة
-
عند الاستعلام من جدول ما عادة نذكر أسماء الأعمدة فقط، ضمنيا تجاهلنا إسباق اسم الجدول الذي ينتمي له العمود ضمنيا أيضا تجاهلنا إسباق اسم قاعدة البيانات الذي ينتمي له الجدول بفرض لدينا جدول المستخدمين users داخل قاعدة البيانات بالاسم company، الثلاث استعلامات التالية متساوية: SELECT * FROM users; # يساوي SELECT users.* FROM users; # يساوي SELECT company.users.* FROM users; تنفيذ الاستعلام من عدة قواعد بيانات بالذكر الصريح لمكان تواجد البيانات يمكن الاستعلام من عدة جداول في قواعد بيانات مختلفة بفرض لدينا الجدول users في قاعدتي بيانات لشركتين بالاسم company1 و company2، نستعلم عن مستخدمي الشركتين معًا كالتالي: SELECT company1.users.*, company2.users.* FROM company1.users, company2.users; لدمج النتائج معا وإظهارها كما لو كنا نستعلم من جدول واحد نقوم بعمل دمج بين الجدولين لمطابقة الأعمدة SELECT * FROM company1.users; JOIN company2.users on company1.users.Id = company2.users.Id1 نقطة
-
بفرض لدينا جدول المستخدمين users التالي: +----+-------+ | Id | Name | +----+-------+ | 1 | أحمد | | 2 | عبدالله | | 3 | يوسف | | 4 | جمال | | 5 | محمد | | 6 | سعيد | +----+-------+ ونريد تصفح النتائج على صفحات كل صفحة فيها ثلاث أسطر، سيكون الجدول السابق عبارة عن صفحتين كل منها تحتوي ثلاث نتائج بالشكل التالي: # الصفحة الأولى +----+-------+ | Id | Name | +----+-------+ | 1 | أحمد | | 2 | عبدالله | | 3 | يوسف | +----+-------+ # الصفحة الثانية +----+-------+ | Id | Name | +----+-------+ | 4 | جمال | | 5 | محمد | | 6 | سعيد | +----+-------+ MYSQL نستخدم الكلمتين: LIMIT لتحديد عدد النتائج في الصفحة الواحدة (3 في حالتنا) OFFSET لتحديد رقم الصفحة يمكن تجاهلها للصفحة الأولى (1 أو 2 في حالتنا) تكون الاستعلامات كالتالي: # الصفحة الأولى SELECT * FROM users LIMIT 3 OFFSET 1; # أو SELECT * FROM users LIMIT 3; # الصفحة الثانية SELECT * FROM users LIMIT 3 OFFSET 2; SQL Server نستخدم الجملتين FETCH NEXT x ROWS ONLY لتحديد عدد النتائج في الصفحة الواحدة حيث x هو عدد النتائج (3 في حالتنا) OFFSET x ROWS لتحديد بداية الصفحة، حيث x يشير إلى ترتيب أول نتيجة نريدها في الصفحة، يمكن حسابها بدليل الصفحة كالتالي (حجم الصفحة × (رقم الصفحة - 1))، يمكن تجاهلها لأول صفحة (0 و 3 في حالتنا) تكون الاستعلامات كالتالي: # الصفحة الأولى SELECT * FROM users OFFSET 0 ROWS FETCH NEXT 3 ROWS ONLY; # أو SELECT * FROM users NEXT 3 ROWS ONLY; # الصفحة الثانية SELECT * FROM users OFFSET 3 ROWS FETCH NEXT 3 ROWS ONLY;1 نقطة
-
أداة Puppet هي أداة لإدارة البرامج تتضمن لغتها التعريفية لوصف إعدادات النظام. توفر Puppet حل يعتمد على لأتمتة العمليات بأقل قدر من المعرفة البرمجية لاستخدامه. يتم إستخدام برنامج الأتمتة Puppet لغة Puppet التعريفية لإدارة مراحل مختلفة من دورة حياة البنية التحتية لتكنولوجيا المعلومات IT، بما في ذلك التصحيح patching، والإعداد configuration، وإدارة نظام التشغيل والتطبيقات عبر مراكز بيانات المؤسسة Data Centers والبنى التحتية السحابية Cloud Structure. يتم إستخدام برنامج Puppet كبرنامج مفتوح المصدر تحت رخصة GPL حتى الإصدار 2.7.0، وتحت رخصة Apache في الإصدارات اللاحقة، كما توجد نسخة مدفوعة للمؤسسات باسم Puppet Enterprise وتحمل ترخيصًا خاصًا. يتبع Puppet عادةً بنية الخادم - العميل Client - Server. يُعرف العميل باسم الوكيل Agent ويُعرف الخادم باسم الرئيس Master. يمكن أيضًا استخدامه كتطبيق مستقل يتم تشغيله من سطر الأوامر للاختبار والإعدادات البسيطة. حيث يتم تثبيت Puppet Server على خادم واحد أو أكثر، ويتم تثبيت Puppet Agent على جميع الأجهزة التي يريد المستخدم إدارتها. يتواصل Puppet Agents مع الخادم Master ويقومون بإحضار تعليمات التكوين configuration. يقوم كل Agent بعد ذلك بتطبيق هذه التعليمات على النظام ويرسل تقرير الحالة status report إلى الخادم Master مرة أخرى. يمكن للأجهزة تشغيل Puppet Agent كبرنامج خفي daemon، يمكن تشغيله بشكل دوري كوظيفة cron أو يمكن تشغيله يدويًا عند الحاجة. هذه التعليمات تكتب بإستخدام لغة Puppet التعريفية Puppet declarative language على الصيغة التالية: type { 'title': attribute => value }1 نقطة
-
يمكنك أن تستخدم سطر الأوامر Command Line لإستخراج وإستدعاء قواعد البيانات خصوصًا إن كانت كبيرة الحجم للغاية، ولكي لا تنتظر تحميل الصفحة في phpMyadmin أو خطأ timeout عندما يتم إستخراج قاعدة البيانات يفضل أن تستخدم سطر الأوامر للقيام بهذه المهمة. أيضًا في كثير من الأحيان لا يكون هنا دعم لـ phpMyadmin على الخادم لذلك لا يتوفر سوى إستخدام سطر الأوامر بشكل إفتراضي. تتوفر MySQL على أداة mysqldump التي تسمح لك بإستخراج وإستيراد قواعد البيانات بشكل سهل وسريع، وذلك من خلال تنفيذ الأمر التالي: mysqldump -u YourUser -p YourDatabaseName > wantedsqlfile.sql سوف يتم طلب إدخال كلمة السر الخاصة بسمتخدم قاعدة البيانات YourUser. ثم لإستيراد قاعدة البيانات على خادم آخر، يمكنك أن تقوم بتنفيذ الأمر التالي: mysql -u YourUser -ptmppassword AnotherDatabaseName < wantedsqlfile.sql قم بتغير اسم المستخدم وكلمة السر واسم قاعدة البيانات وسيبدأ عملية إستيراد قاعدة البيانات.1 نقطة
-
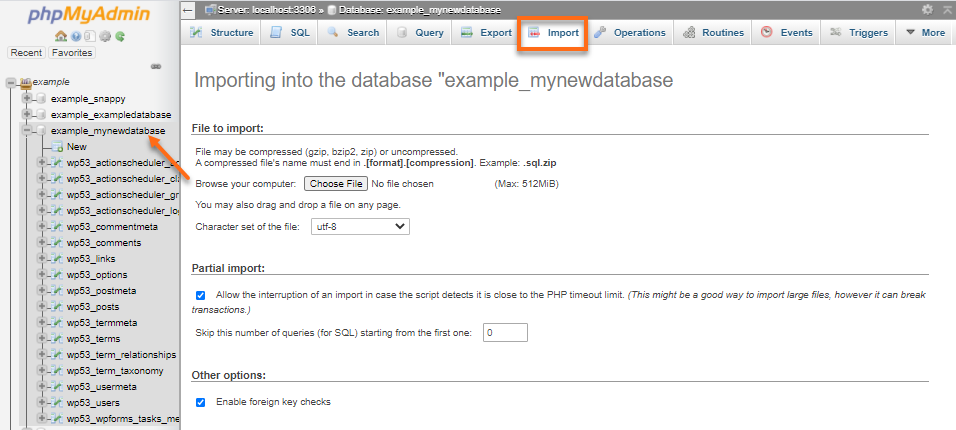
شائع عادة إستعمال مدير قواعد البيانات phpMyadmin لذلك . سواء في المستضيف المحلي أو على الإستضافة المشتركة . لنقم بتلخيص الأمر وفق الخطوات التالية : تصدير قواعد البيانات من المستضيف المحلي بصيغة SQL . يمكنك ذلك عن طريق الدخول إلى phpmyadmin من localhost و التوجه إلى export من قائمة التصفح العلوية التي تظهر بعد الضغط على اسم قواعد البيانات الخاصة بك , ثم اختيار صيغة التصدير و التصدير . (يمكنك تجاهل هاته الخطوة ان كنت تمتلك بالفعل ملف بلاحقة sql خاص بقاعدة البيانات التي لديك ) . الدخول إلى لوحة التحكم الخاصة بإستضافتك . الذهاب إلى phpMyadmin في الجزء الخاص بقواعد البيانات . (المثال من لوحة cPanel) قد تحتاج في بعض لوحات التحكم التي تعطي وصولا محدودا في phpMyadmin إلى إنشاء قاعدة بيانات ومستخدم كامل الصلاحيات . بعد الدخول إلى phpMyadmin تأكد أن تقوم بتحديد قاعدة البيانات المنشأة حديثا , أو أن تقوم بإنشاء واحدة جديدة , ان توفرت صلاحية ذلك , عن طريق الضغط على New أعلى القائمة الجانبية أسفل شعار phpmyAdmin . من قائمة التصفح العلوية نقوم بإختيار تضمين أو Import . قم بالتصفح إلى ملف الـ sql. الذي قمت بتصديره و قم بتحديده و تضمينه بعد الضغط على browse files . ربط موقعك بقواعد البيانات المضافة . يكون هذا عادة بملف إعداد للموقع على شاكلة env. أو init.php_ أو غيرها . قد تحتاج كخطوة إضافية في بعض الأحيان محو الملفات المؤقتة الخاصة بإعداد موقعك , و هذا في حالة إستعماله للملفات المؤقتة بالطبع (مثال : تطبيقات اللارافيل تستعمل ذلك) .

 1 نقطة
1 نقطة -
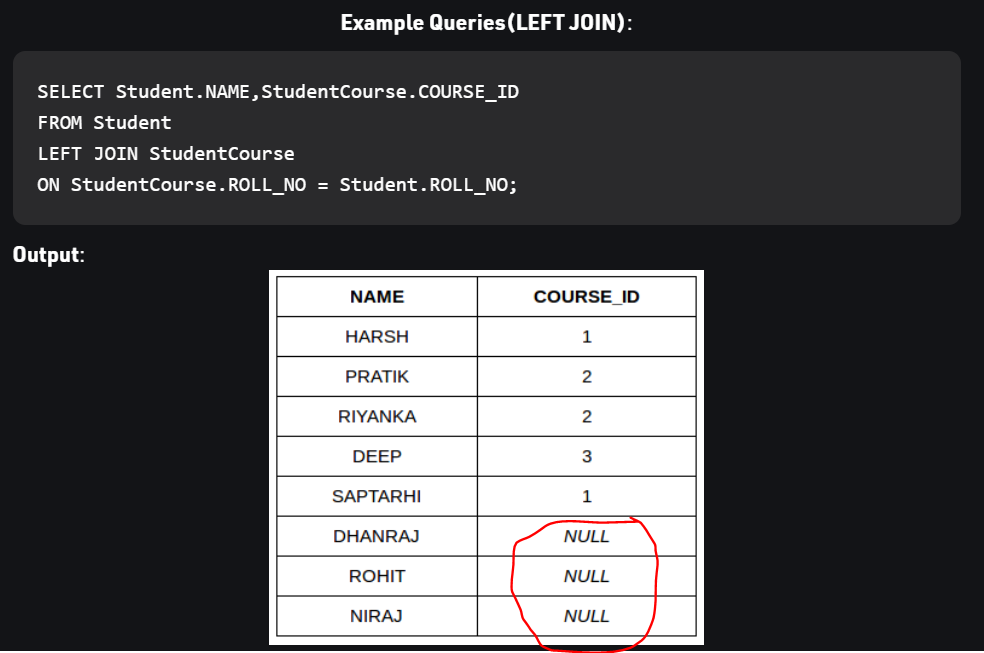
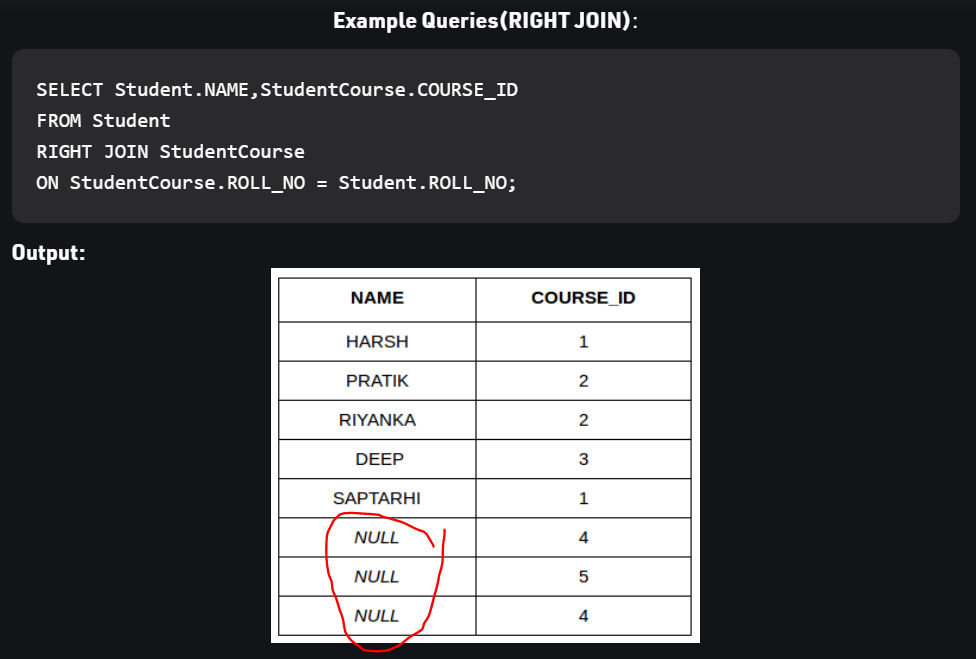
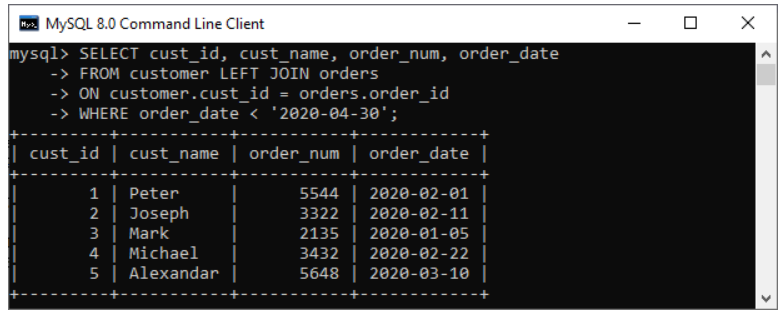
تبديل تررتيب الجداول يؤثر على نتيجة استعلام LEFT - RIGHT _ FULL حيث أن فيهم الربط يعتمد على عرض جميع بيانات أحد الجدولين (حسب جهة العرض) ثم البحث عن عنصر مقابل في الجدول الآخر، لذلك البيانات تختلف. أما في الربط الداخلي INNER JOIN نحصل على نفس النتيجة لكن ترتريب الأعمدة يختلف باختلاف ترتيب الدمج Table col1 col2 A a1 a2 B b1 b2 select * from A, B => a1, a2, b1, b2 select * from B, A => b1, b2, a1, a2 ولتثبيت ترتريب الأعمدة علينا تحديدهم في عبارة SELECT select a1, b1, b2, a2 from B, A => a1, b1, b2, a2 بالنسبة للدمج اليساري: سوف نثبت جدول الزبائن، ولكل زبون نبحث عن الطلبية التي تعود له LEFT JOIN Example SELECT cust_id, cust_name, order_num, order_date FROM customer LEFT JOIN orders ON customer.cust_id = orders.order_id WHERE order_date < '2020-04-30'; بالنسبة للدمج اليميني: سوف نثبت جدول الطلبيات، ولكل طلبية نبحث عن الزبون صاحبها الذي يعود إليها RIGHT JOIN Example SELECT cust_id, cust_name, occupation, order_num, order_date FROM customer RIGHT JOIN orders ON cust_id = order_id ORDER BY order_date; عندما لانجد بيانات من الجدول الثانوي سيعيد NULL وفي حال عمل FULL JOIN سنلحظ ربما وجود قيم فارغة في كلا الحقلين لأنه ليس شرطا تقابل القيم من كلا الجدولين

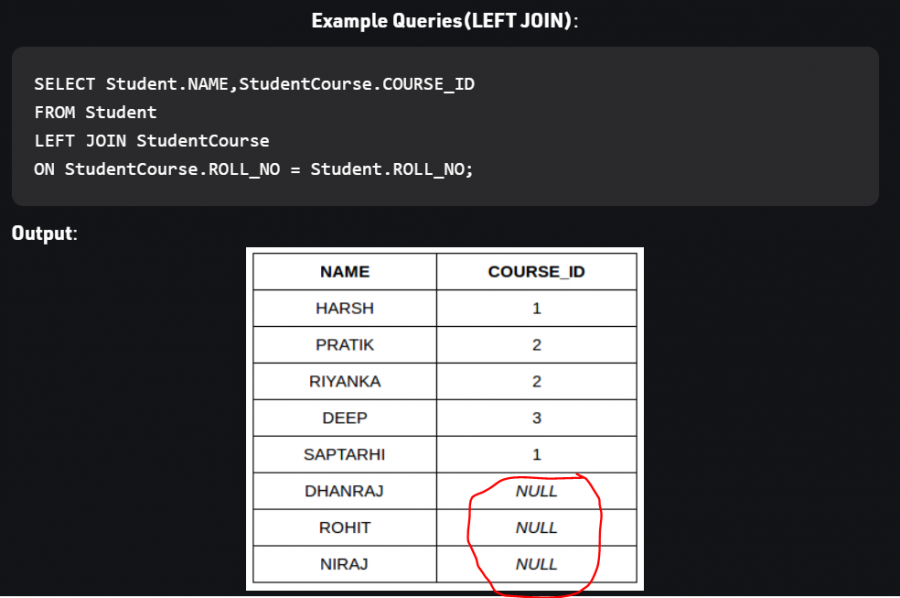
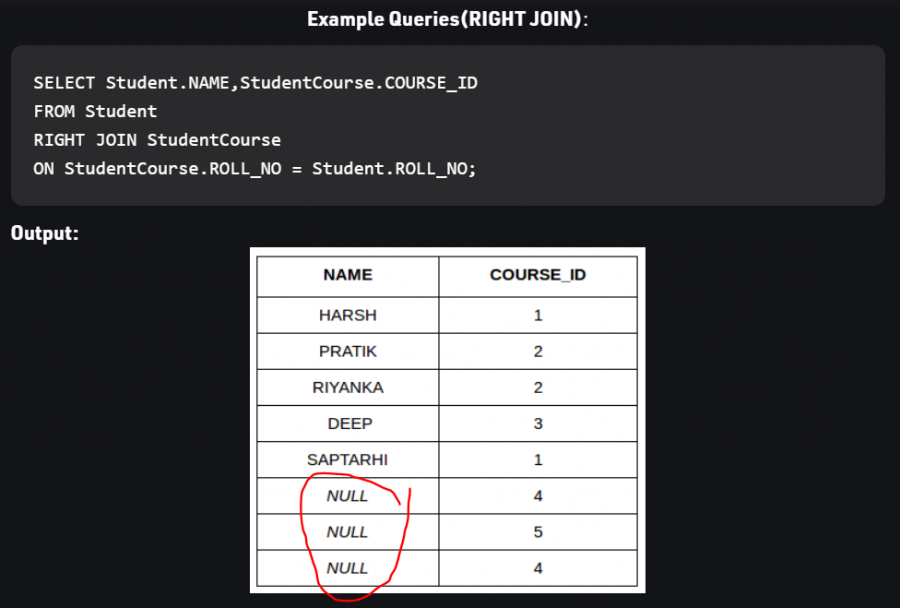 1 نقطة
1 نقطة -
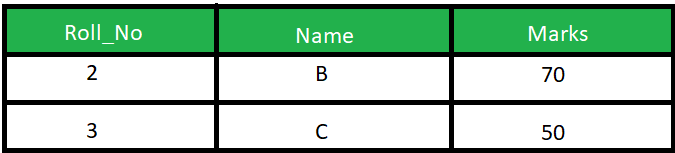
هناك فروق كثيرة بين الطريقتين، لكن بشكل أساسي، فان الفرق يتمثل فيه كيفية عمل كل منهما: Natural Join : تقوم باختيار الأعمدة بناء على التطابق في محتوى عمود مشترك بين الجداول التي يتم الاختيار بينها، بمعني انه يبحث عن عمود مشترك ويقوم باظهار كل الخصائص بدمج الأعمدة المراد دمجها بناء على تطابق هذا العمود المشترك، أنظر المثال التالي: تخيل أن هناك جدول للطلاب كالتالي: وجدول أخر للدرجات كالتالي: لاحظ وجود عمود مشترك Roll_No وبه أشخاص متطابقون في كلا الجدولين (2 و 3)، اذا قمنا بتشغيل هذا الأمر: SELECT * FROM Student NATURAL JOIN Marks; فسيقوم باختيار الأشخاص المشتركون في كلا الجدولين بناء على العمود Roll_No كالتالي: Inner Join : يقوم باختيار العناصر المتشابهة تمام مثلا Natural Join لكن يقوم بارجاع العمود المشترك مرة عن كل جدول، بمعني أخر أنه يقوم بوضع كل جدول بجانب الأخر بعد بحث التطابق بين الجدولين، في المثال السابق ، لو قمنا بتشغيل الأمر: SELECT * FROM student S INNER JOIN Marks M ON S.Roll_No = M.Roll_No; يكون الخرج على الشكل التالي:
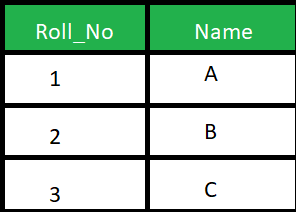
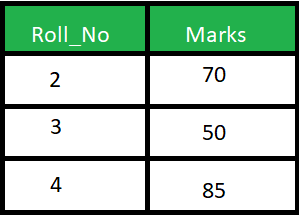
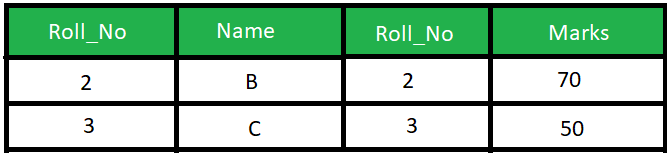 1 نقطة
1 نقطة -
أحد الاختلافات المهمة بين INNER JOIN و NATURAL JOIN هو عدد الأعمدة التي يتم إرجاعها, افترض لدينا الجدولين الآتيين TableA TableB Column1 Column2 Column1 Column3 1 2 1 3 لو حاولنا استخدام INNER JOIN كالتالي SELECT * FROM TableA AS a INNER JOIN TableB AS b USING (Column1); SELECT * FROM TableA AS a INNER JOIN TableB AS b ON a.Column1 = b.Column1; سوف تكون النتيجة كالتالي a.Column1 a.Column2 b.Column1 b.Column3 1 2 1 3 أما لو حاولنا استخدام NATURAL JOIN فسوف تكون النتيحة كالتالي SELECT * FROM TableA NATURAL JOIN TableB Column1 Column2 Column3 1 2 3 يتم تجنب العمدان المكررة1 نقطة
-
الصيغة العامة لاستخدام SELECT هي كالتالي بتحديد الأعمدة التي نريدها في النتيجة SELECT عمود_أول, عمود_ثان FROM جدول إذا أردنا كل الأعمدة يمكننا وضع نجمة "*" لنعبر عن جميع الأعمدة SELECT * FROM جدول إذا كنا نستعلم من عدة جداول معًا يجب وضع إسم أحد الجدولين قبل اسم العمود وبينهما نقطة "." SELECT جدول_أول.عمود, جدول_ثان.عمود FROM جدول_أول, جدول_ثان إذا أردت جلب كل الأعمدة من أحد الجداول نضع نجمة "*" SELECT جدول_أول.* , جدول_ثان.عمود FROM جدول_أول, جدول_ثان ملاحظة: في أول مثالين يمكن وضع اسم الجدول قبل اسم العمود، لكن اختصارا يمكن عدم كتابته في حال كنت تستعلم من جدول واحد1 نقطة
-
اصطلاحات الربط الربط بشكل عام يستخدم للربط بين البيانات (بغض النظر عن مكان وجودها)، أي نوع من أنواع الربط هو اصطلاح وتسمية لمكان وجود البيانات في كلا طرفي الربط الربط الذاتي Self Join عندما تكون البيانات في كلا الطرفين موجودة في نفس الجدول نصطلح أن نوع الربط هذا هو Self Join أي أننا نربط بيانات الجدول ببيانات أخرى من الجدول نفسه، أمثلة: جدول أشخاص، قد يكون هناك علاقة بين الأشخاص (أب - أبن، زوج - زوجة، صديق - صديق) جدول موظفين، قد يكون هناك علاقات بين الموظفين (موظف - مدير، موظف - زملاء)
 1 نقطة
1 نقطة