لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 09/24/21 in أجوبة
-
أحاول الحصول على المستخدم الحالي (الذي قام بعمل الطلب request) في داخل نموذجserializers، لقد جربت الكود التالي، ولكنه لا يعمل. class PostSerializer(serializers.ModelSerializer): class Meta: model = Post def save(self): user = self.context['request.user'] كيف يمكنني الوصول إلى request.user من صنف Serializer الخاص بي؟3 نقاط
-
لدي وسم cache في القالب الرئيسي في مشروع جانغو Django: {% cache 5000 posts %} Content goes here {% endcache %} عندما أقوم بإضافة منشور جديد من خلال لوحة تحكم جانغو Django، أريد إبطال ذاكرة التخزين المؤقت هذه، وبالتالي يظهر المحتوى الأحدث: class PostsAdmin(admin.ModelAdmin): def save_model(self, request, obj, form, change): super(postsAdmin, self).save_model(request, obj, form, change) cache.delete('posts') لكن ذاكرة التخزين المؤقت تبقى صالحة! ويظهر المحتوى القديم أيضًا، ما الخطأ هنا؟ وما هي الطريقة الصحيحة لإبطال التخزين المؤقت في جوء معين؟2 نقاط
-
السلام عليكم. ما الذي يعنيه هذا الكود ؟ : [...Array(5).keys()] الجزء الذي به بعض الغموض حاليا لدي هي تلك النقاط الثلاث, فما فائدتها ؟2 نقاط
-
لدى جانغو Django العديد من الحقول الرقمية المتاحة للاستخدام في النماذج models. فهل هناك أي طريقة لتقييد حقل معين لتخزين الأرقام فقط ضمن نطاق معين ، على سبيل المثال يمكن للحقل تخزين الأرقام من 0.0 إلى 5.0 فقط؟ كيف يمكن عمل ذلك على حقل من نوع IntegerField في جانغو Django؟2 نقاط
-
لدي قائمة مكونة من قوائم بأحجام مختلفة (مجموعة بيانات) وأريد تحويلها tf.data.Dataset، كيف يمكنني القيام بذلك؟ على سبيل المثال القائمة التالية كيف نحولها إلى Dataset: li = [[1,11], [1,2,3]]1 نقطة
-
بشكل عام كيف يمكنني عمل لعبة تلوين على موقعي الخاص مثل المرفقة في الصورة ؟؟
 1 نقطة
1 نقطة -
عندما ارفع صوره على الموقع لا يتم تخزينها في الداتا و عند عرضها يعرض الصوره الافتراضيه لكن عند رفع الصوره من admin يتم رفعها بكل بساطة1 نقطة
-
عندي زرين radio كل واحد فيهم مسئول عن تعطيل و تمكين مربع النص الخاص به و يعمل ممتاز و كل ما سبق تحت مظلة بند النوع الاول مشكلتي في التكرار لما بجي بكرر ما سبق و اسميه النوع التاني و محتاج بيان تاني خالص بيانات النوع الاول بتتغير فيديو قصير توضيحي للمشكلة 2021-09-24_15-59-47.mp4 الكود يمكن تجربته مباشرة على السيرفر الشخصي test.php <HTML> <HEAD> <TITLE> Text Demo </TITLE> <!-- Latest compiled and minified CSS --> <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.4.1/css/bootstrap.min.css"> <link rel="stylesheet" href="http://gtms.areyada.com/main.css"> <!-- jQuery library --> <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script> <!-- Latest compiled JavaScript --> <script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.4.1/js/bootstrap.min.js"></script> </HEAD> <BODY> <div class="form-row threads-fields mt-4 mb-3 cl"> <!-- الصف الأول --> <div class="col-12 size30">النوع الاول</div> <div class="col-6"> <label >سعر المتر الطولي</label> <div class="input-group"> <label class="container mt-0"> <input type="radio" class="moth" checked value="one" name="moth"> <span class="checkmark"></span> </label> </div> </div> <div class="col-6 "> <label>سعر الكيلو</label> <div class="input-group"> <label class="container mt-0"> <input type="radio" class="moth" value="two" name="moth"> <span class="checkmark"></span> </label> </div> </div> <!-- سعر المتر الطولي --> <div class="col-6 one"> <label class="required m"> سعر المتر الطولي <i class="fa fa-question-circle text-info size15"></i></label> <div class="input-group"> <div class="input-group-prepend"> <span class="input-group-text" id="inputGroupPrepend"><i class="fa fa-th"></i></span> </div> <input id= "mPrice" type="number" class="form-control mPrice" required name="mPrice" value="0"> <div class="invalid-feedback"> يرجى تحديد </div> </div> </div> <!-- سعر الكيلو --> <div class="col-6 two"> <label class="required k"> سعر الكيلو <i class="fa fa-question-circle text-info size15"></i></label> <div class="input-group"> <div class="input-group-prepend"> <span class="input-group-text" id="inputGroupPrepend"><i class="fa fa-th"></i></span> </div> <input id= "mPrice" type="number" class="form-control kPrice" required name="mPrice" value="0" disabled> <div class="invalid-feedback"> يرجى تحديد </div> </div> </div> <div class="col-12 size30">النوع الثاني</div> <div class="col-6"> <label >سعر المتر الطولي</label> <div class="input-group"> <label class="container mt-0"> <input type="radio" class="moth" checked value="one" name="moth"> <span class="checkmark"></span> </label> </div> </div> <div class="col-6 "> <label>سعر الكيلو</label> <div class="input-group"> <label class="container mt-0"> <input type="radio" class="moth" value="two" name="moth"> <span class="checkmark"></span> </label> </div> </div> <div class="col-6 one"> <label class="required m"> سعر المتر الطولي <i class="fa fa-question-circle text-info size15"></i></label> <div class="input-group"> <div class="input-group-prepend"> <span class="input-group-text" id="inputGroupPrepend"><i class="fa fa-th"></i></span> </div> <input id= "mPrice" type="number" class="form-control mPrice" required name="mPrice" value="0"> <div class="invalid-feedback"> يرجى تحديد </div> </div> </div> <!-- سعر الكيلو --> <div class="col-6 two"> <label class="required k"> سعر الكيلو <i class="fa fa-question-circle text-info size15"></i></label> <div class="input-group"> <div class="input-group-prepend"> <span class="input-group-text" id="inputGroupPrepend"><i class="fa fa-th"></i></span> </div> <input id= "mPrice" type="number" class="form-control kPrice" required name="mPrice" value="0" disabled> <div class="invalid-feedback"> يرجى تحديد </div> </div> </div> </div> </BODY> </HTML> <script> $(document).on('change', '.moth', function() { var moth = $(this).val(); var mainContEl = $(this).parents('div.threads-fields'); var mPrice = (mainContEl).children().find("input.mPrice"); //var mPrice = $(".mPrice"); // var kPrice = $(".kPrice"); var kPrice = (mainContEl).children().find("input.kPrice"); if (moth == "two") { // when select price for KG (mPrice).attr("disabled","disabled"); // disable meter price input (mPrice).removeAttr("required"); (kPrice).removeAttr("disabled"); // enable kg price checkbox //$(".height-thread").removeAttr("disabled"); } else { (kPrice).attr("disabled","disabled"); (kPrice).removeAttr("required"); (mPrice).removeAttr("disabled"); //$(".height-thread").attr("disabled","disabled"); } }); </script> انتظر ارائكم1 نقطة
-
السلام عليكم يتم عادة عرض المواضيع ذات الصلة في صفحة الموضوع , و هذا الذي كان يحدث عندي بشكل طبيعي . و لكن بعد أن قمت بتصغير رابط المواضيع بالموقع بإستخدام أكواد RewriteRule في ملف .htaccess . لم تعد تظهر هاته المواضيع ذات صلة . فإذا فتحت الموضوع من الرابط الاصلي تكون موجودة اما اذا فتحته من الرابط المعدل لا اجد هاته المواضيع . و للعلم فإني قد استخدمت $_GET لجلب المواضيع التي هي من نفس فئة الموضوع الحالي . قد حاولت البحث كثيرا عن حل لهذه المشكلة ولم اجد , ارجو المساعدة من اصحاب الخبرة و شكرا مسبقا لكم ..1 نقطة
-
لدي برنامج أحتاج فيه أن أقارن أعداد أُسية كبير مثلاً أحتاج مقارنة إن كان 100 ^100 أكبر أم 72 ^115 , والذي ﻻ يمكنني تحقيقه لأن تقريبا لا يوجد نوع بيانات في لغة ال++c يمكنا حمل رقم بهذا الحجم , فما الحل1 نقطة
-
يحتمل أن ذلك بسبب طريقة قراءة معرف المقالة و الفئة من الرابط من الواجهة الخلفية . خصوصا و أنك ذكرت أنك تقوم بإستعمال $_GET لجلب ذلك . و كأن الأمر على هاته الشاكلة : $targetCategory = $_GET['category']; # جلب الفئة المستهدفة من الرابط ثم كتابة إستعلام لجلب المقالات ذات نفس الفئة : $query = 'SELECT * FROM articles WHERE category_id=' . $targetCategory; ما الذي يحدث هنا ؟ في حالة غياب الفئة => لن يتم إعادة أي نتائج من الإستعلام => بالتالي فإنه في حالة عدم توفير معرف للمقالة في الرابط فإنه لن يتم إظهار أي مواضيع ذات صلة , و في الأغلب هذا الذي حدث معك. لا يقترح أي حل للمشكلة سوى إعادة طريقة عرض الروابط بالطريقة القديمة , فهذا هو السبيل الوحيد للتواصل بين الواجهة الأمامية و الواجهة الخلفية . و إلا فإنه لن يتم الوصول إلى ما تقدمه الواجهة الأمامية من طرف الواجهة الخلفية لذات التطبيق . إن لم تمتلك أي خبرة تقنية , يمكنك الإستعانة بمبرمج ما لتعديل طريقة القراءة وفق ما هو أنسب لك , وفق ما يلبي حاجتك .1 نقطة
-
الرابط يكون بهذا الشكل للموضوع "post.php?id=$1&&category=$2" واصبح بهذا الشكل "post/$1/$2" بعد استخدامي لاكواد RewriteRule في ملف .htaccess لكن عند استخدامي للرابط الجديد لا تظهر المواضيع ذات الصلة "المواضيع التي تكون من نفس الفئة" بنهاية الموضوع واعتذر على عدم توضيح المشكلة بشكل جيد.1 نقطة
-
و عليكم السلام , هلا قمت بالتفصيل أكثر فيما تقصده بـ "تصغير رابط المواضيع بالموقع بإستخدام ملف htaccess. " ؟ كما أن مشكلتك غير واضحة جيدا , يرجى التفصيل أكثر1 نقطة
-
كلام ممتاز في حال لو هما النوعين ( سطرين فقط ) اللي عندي لكن ممكن المستخدم يحدد اكتر من 5 او 6 سطور ( من خلال jquery ، بشكل متغير مش ثابت ، فالحل ده مش هايكون فعال معايا1 نقطة
-
السلام عليكم. ما سبب إستخدام transform-style: preserve-3d في هذه الحالة ؟1 نقطة
-
مرحبا عندما اقوم باستخدام suneditor مع next jsواحاول جلب الbutton list ياتيني هذا الخطاCannot use import statement outside a module الكود import {buttonList} from "suneditor-react"1 نقطة
-
براك الله فيك اخي زادك الله علما وجعلها في ميزان حسناتك ♥♥1 نقطة
-
يقوم التابع setFetchMode بضبط وضع جلب البيانات، فيمكنك التحكم بطريقة جلب هذه البيانات لاستخدامها لاحقاً في شيفرتك البرمجية من خلال أنماط عديدة ومنها: PDO::FETCH_ASSOC والتي تقوم بجلب البيانات وفهرستها اعتماداً على اسماء الأعمدة في قاعدة البيانات PDO::FETCH_BOTH الافتراضية والتي تقوم بجلب البيانات وفهرستها ضمن مصفوفة من اسماء الأعمدة والقيم. PDO::FETCH_BOUND تعيد القيمة true والتي تقوم باسناد قيم الأعمدة إلى النتيجة النهائية كما يوجد أيضاً FETCH_CLASS , PDO::FETCH_INTO , PDO::FETCH_LAZY وغيرها الكثير. يمكنك الاطلاع عليها من التوثيق الرسمي ل PHP لمعاينة بعض الأمثلة وطرق الاستخدام.1 نقطة
-
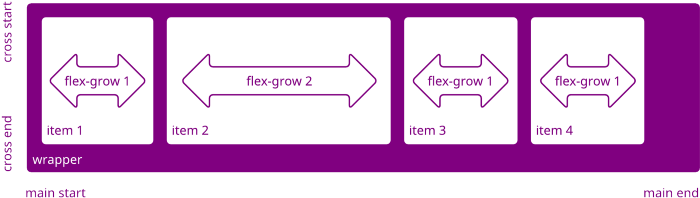
لنقم بإقتباس التعريفين التالين من ويكي حسوب كالتالي : و لنفترض أن حجم حاوية ما لدينا هو 1000 بكسل . هاته الحاوية تحوي 4 عناصر . قمنا بتحديد flex-basis أو أساس مرن لكل عنصر بـ 200 بكسل . سيجعل هذا العناصر تظهر كالتالي : كل من العناصر الأربع سيمتلك عرضا 200 بكسل .بالإضافة إلى مساحة إضافية متبقية 200 بكسل بعد توزيع العناصر . إذا قمنا الان بإعطاء العنصر الثاني flex-grow أو نمو مرن بمقدار 2 (أي تعويضا لعنصرين flex) ، فسيشغل هذا العنصر الثاني ضعف المساحة المتبقية عن العناصر الأخرى و سيأخذ 200 بكسل إضافية , و سيظهر و كأنه يتمدد على باقي العناصر . لاحظ نمذجة للعملية : و بالتالي ،فإنه من أجل استخدام flex-grow لعنصر ما ، يجب أولاً تعيين flex-basis لينطلق منه الـ flex-grow فيعتبره مرجعا و معيارا يحدد معدل التمدد من عليه , فإن حددنا أساسا بـ 100 بكسل و أعطينا قيمة نمو بـ 3 , فسيكون عنصر الـ flex هذا معوضا لـ 3 من قيمة الأساس أي 300 بكسل . و لتتذكر الأمر على هذا النحو : flex-basis : ترجمة لـ أساس مرن . flex-grow : ترجمة لـ نمو مرن . و لتحديد هذا النمو المرن لن نحتاج إلا لمعرفة ما هو المقدار الذي سينمو به عنصر عن باقي العناصر الأخرى , و عليه فإن : flex-grow تتطلب flex-basis . يمكنك الإطلاع على توثيق كل من الخاصيتين في ويكي حسوب كالتالي : flex-basis . flex-grow .
 1 نقطة
1 نقطة -
الطبقة Conv2D هي الطبقة التي يمكننا من خلالها بناء شبكة CNN في كيراس وتنسرفلو.. وسأشرح كيف نستخدمها.. أولاً الشكل العام لها: tf.keras.layers.Conv2D( filters, kernel_size, strides=(1, 1), padding="valid", data_format=None, activation=None, use_bias=True, kernel_initializer="glorot_uniform", bias_initializer="zeros", kernel_regularizer=None, bias_regularizer=None, input_shape, **kwargs ) الوسيط الأول filters يمثل عدد المرشحات التي تريد أن يتم تطبيقها على مجموعة بياناتك (الصور). حيث يتم تطبيق كل فلتر على كل صورة لاستخراج السمات المميزة فيها (حواف زوايا نقاط..إلخ) عن طريق تنفيذ عملية "التفاف" convolution عليها. وعدد هذه الفلاتر سيمثل عدد القنوات التي سيتم إخراجها من هذه الطبقة (ستفهم أكثر في المثال بعد قليل). الوسيط الثاني kernel_size يمثل حجم النواة (حجم المرشحات التي سيتم تطبيقها) حيث نمرر tuble يحوي قيمتين تمثلان طول وعرض المرشح، على سبيل المثال إذا قمنا بتمرير (3,3) فهذا يعني أن المرشحات التي سيتم تطبيقها ستكون أبعادها 3*3. كما يمكننا أن نمرر قيمة واحدة بدلاً من ال tuble، على سبيل المثال يمكن أن نمرر 5 وبالتالي سيفهم تلقائياً أن حجم المرشح الذي تريده هو 5*5. كما يجب أن نعلم أن أبعاد هذا المرشح يجب أن تكون أعداداً فردية لأن الأرقام الزوجية تعطي أداء ضعيف لأنك ستعاني مما يسمى بال aliasing error وهي عبارة عن تشوهات غير مرغوبة. الوسيط الثالث هو strides أي عدد الخطوات، فكما نعلم إن عملية ال convolution هي عملية مرور مرشح على الصورة بدءاً من أعلى اليسار وصولاً لأسفل اليمين من الصورة. والوسيط strides يقوم بتحيد عدد الخطوات (عدد البكسلات). الوسيط الرابع padding لتحيد فيما إذا كنت تريد تنفيذ عملية حشو للصورة أو لا (حشو جوانب الصورة بأصفار). ويأخذ قيمتان same لتنفيذ عملية الحشو و valid لعدم تنفيذها. ويكون الحشو في يمين ويسار أو أسفل وأعلى الصورة حسبما تحتاجه الصورة وذلك للحفاظ على نفس الأبعاد للصورة. الوسيط الخامس data_format لتحديد شكل أبعاد الصور في بياناتك فمثلاً إذا كان عدد القنوات اللونية للصور في مجموعة بياناتك يتم تمثيلها في البعد الأخير (أي الثالث) فهنا نضع channels_last (وهي الحالة الافتراضية حيث أن أغلب الصور يتم تمثيل القنوات اللونية فيها كآخر بعد (batch_size, height, width, channels) ). أو channels_first في حال كان عدد القنوات اللونية ممثل في أول بعد (batch_size, channels, height, width). الوسيط السادس activation هو دالة التنشيط التي سيتم استخدامها (افتراضياُ لن يتم استخدام أي دالة تنشيط) حيث يتم تطبيقها على مخرجات الطبقة. أما الوسيط السابع use_bias ويأخذ إما True أو False لتحديد فيما إذا كنت تريد إضافة وزن يمثل ال bias بحيث يتم جمعه على ناتج تطبيق الفلتر. أما الوسيط الثامن فهو kernel_initializer وهو لتحديد نوع التهيئة التي سيتم فيها تهيئة الفلاتر (افتراضياً يكون "glorot_uniform") والوسيط التاسع bias_initializer وافتراضياً يكون التهيئة بأصفار"zeros". وأخيراً input_shape لتحديد حجم الصور التي سيتم تقديمها للطبقة حيث نحدد لها طول وعرض وعدد القنوات اللونية للصورة وهو يضيف تلقائياُ البعد الرابع الذي يمثل حجم الباتش أي: batch_shape + (channels, rows, cols) أو batch_shape + (rows, cols, channels) حسب موضع القناة اللونية. خرج هذه الطبقة هو: batch_shape + (filters, new_rows, new_cols) في حالة كانت القناة اللونية في البداية. أو batch_shape + (new_rows, new_cols, filters) في حالة كانت القناة اللونية في النهاية. ال new_rows و ال new_cols يتم حسابهم من المعادلة: new_col=(col-2*p+f)/strides + 1 new_row=(row-2*p+f)/strides + 1 {{{{{{{{{وعدد الخطوات هو 1 p=0 في حالة كان بدون حشو يكون }}}}}}}}}} new_col=(col-f) + 1 new_row=(row-f + 1 الأمثلة التالية ستوضح الأمر أكثر: # سنقوم بإنشاء 4 صور طولها 28 وعرضها 28 وملونة أي لها 3 قنوات لونية # سنقوم بتوليد هذه الصور بقيم عشوائية import tensorflow as tf x = tf.random.normal((4, 28, 28, 3)) #Conv2D الآن سنطبق عليها ال # سنستخدم مرشحين بحجم 3*3 #p=0 لن نستخدم حشو أي # وعدد الخطوات هو (1, 1) y = tf.keras.layers.Conv2D(2, 3,padding="valid",strides=(1, 1), activation='relu', input_shape=(28, 28, 3))(x) # الآن لنعرض أبعاد الخرج print(y.shape) (4, 26, 26, 2) # لاحظ أن الخرج ينتج من المعدلات السابقة كالتالي # new_col=new_row=28-3+1=26 # وعدد الفلاتر يصبح عدد القنوات في حالة كان ال padding=same: y = tf.keras.layers.Conv2D(2, 3, activation='relu', padding="same", input_shape=input_shape[1:])(x) print(y.shape) # (4, 28, 28, 2) # لاحظ أن الخرج لم يتغير حيث أنه يقوم هنا بعملية حشو بأصفار بحيث تحافظ الصورة على أبعادها مثال عملي، حيث سأقوم باستخدامها مع مجموعة البيانات التالية لتصنيف صور القطط والكلاب (يمكنك الحصول على مجموعة البيانات من هنا https://www.kaggle.com/c/dogs-vs-cats/data): from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense from keras import backend as K # نحدد مسارات البيانات train_data_dir = 'data/train' validation_data_dir = 'data/validation' nb_train_samples = 2000 # عدد عينات التدريب nb_validation_samples = 800 # التحقق epochs = 50 batch_size = 16 # عدد الباتشات # أبعاد الصور img_width, img_height = 150, 150 # نحدد طبقة الادخال input_shape = (img_width, img_height, 3) #DataAugmentation الآن سنقوم بعملية # إن لم يكن لديك معرفة بها فلقد تركت لك رابط في الأسفل train_datagen = ImageDataGenerator( rescale=1. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1. / 255) train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(img_width, img_height), batch_size=batch_size, class_mode='binary') validation_generator = test_datagen.flow_from_directory( validation_data_dir, target_size=(img_width, img_height), batch_size=batch_size, class_mode='binary') # نبدأ ببناء النموذج model = Sequential() # نعرف أول طبقة التفاف model.add(Conv2D(32, (3, 3),activation='relu', input_shape=input_shape)) #وذلك لتقليل أبعاد الصورة Conv2Dبعد كل طبقة MaxPooling2D غالباً مانستخدم طبقة تسمى # إن لم يكن لديك معرفة بها فلقد تركت لك رابطاً في الأسفل لتوضيها model.add(MaxPooling2D(pool_size=(2, 2))) # ثاني طبقة التفاف model.add(Conv2D(32, (3, 3),activation='relu', )) model.add(MaxPooling2D(pool_size=(2, 2))) # ثالث طبقة model.add(Conv2D(64, (3, 3),activation='relu', )) model.add(MaxPooling2D(pool_size=(2, 2))) # نقوم بتسطيح المخرجات model.add(Flatten()) # fully-connected نبني الكلاسيفير الآن وهنا سنستخدم الطبقات المتصلة بالكامل model.add(Dense(64)) model.add(Activation('relu')) model.add(Dropout(0.5)) #لمنع الأوفرفيت model.add(Dense(1)) # طبقة الخرج model.add(Activation('sigmoid')) # تجميع النموذج model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc']) # تدريب النموذج model.fit_generator( train_generator, steps_per_epoch=nb_train_samples // batch_size, epochs=epochs, validation_data=validation_generator, validation_steps=nb_validation_samples // batch_size)1 نقطة
-
لقد قمت بتجربة متصفح اخر واضفت كل المكتبات المصطلوبة هذا هو ملف ريكت هل يمكن تجربته مصمم الفرونت اند يرسل لي انه يعمل عنده ولم اجد الحل لماذا لا يعمل ارجوا المساعدة yourMaWebsite-new-components.zip1 نقطة
-
يمكنك استخدام هذا النموذج من خلال الموديول application.vgg16 في كيراس وتنسرفلو: tf.keras.applications.vgg16.VGG16 وبالتالي لإنشاء النموذج نقوم بمايلي: # نقوم أولاً بإنشاء المودل from tensorflow.keras.applications.vgg16 import VGG16 # استيراده model = VGG16() # تعريف كائن يمثل المودل print(model.summary()) # يمكنك استعراض شكل النموذج بالشكل التالي # كما يمكنك عرض رسم بياني يمثل النموذج from keras.utils.vis_utils import plot_model plot_model(model, to_file='vgg.png') الآن لتكن لدينا صورة ما ونريد تصنيفها من خلال هذا النموذج، فأول خطوة يجب القيام بها هي تحميل الصورة، ويمكننا القيام بذلك من خلال الدالة load image: # نقوم بتحميل الصورة from tensorflow.keras.preprocessing.image import load_img image = load_img('/car.jpg', target_size=(224, 224)) # تعديل حجم الصورة بشكل يتناسب مع الحجم الذي تتطلبه الشبكة الصورة التي استخدمناها هي صورة سيارة: الآن يجب أن نقوم بتحويل الصورة إلى شكلها الرياضي (مصفوفة بكسلات) من خلال الدالة img_to_array: # تحويل المصفوفة إلى مصفوفة from tensorflow.keras.preprocessing.image import img_to_array image = img_to_array(image) # أبعاد الصورة image.shape # (224, 224, 3) الآن الصورة ستكون ب 3 أبعاد (طول وعرض وقنوات لونية)، لكن النموذج vgg16 (وأي نموذج آخر يتعامل مع الصور) يتوقع منك أن تمرر الصور في batches (حزم أو مجموعة من الصور دفعة واحدة). لذا يجب أن نقوم بتوسيع أبعاد الصورة (جعلها رباعية الأبعاد) بحيث أن البعد الجديد سوف يمثل عدد العينات(عدد الصور): # نقوم بتوسيع أبعاد الصورة image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2])) # عرض حجمها الآن image.shape # (1, 224, 224, 3) # البعد الجديد يمثل عدد الصور وهنا لدينا صورة واحدة فقط الآن علينا القيام ببعض عمليات المعالجة على الصورة، بشكل يتطابق مع العمليات التي تمت على الصور أثناء تدريب النموذج، وحسب الورقة البحثية بهذا النموذج: فإن مانحتاجه هو عملية واحدة فقط وهي طرح متوسط قيم ال RGB من كل بكسل، والخبر الجميل أنك لن تضطر للقيام بذلك بشكل يدوي وإنما هناك دالة preprocess_input تقوم بمايلزم: # القيام بمعالجة الصورة بشكل يتطابق مع عمليات الممعالجة التي تمت على الصور التي تم تدريب النموذج عليها from keras.applications.vgg16 import preprocess_input image = preprocess_input(image) الآن الصورة (أو مجموعة الصور) جاهزة لأن يتم إنشاء توقعات لها من خلال النموذج: # إيجاد التوقعات yhat = model.predict(image) yhat.shape # (1, 1000) كما نعلم فإن هذا النموذج تم تدريبه على مجموعة بيانات ImageNet التي تحوي ألف فئة مختلفة وبالتالي الخرج سيكون 1000 قيمة احتمالية تمثل احتمال انتماء هذه الصورة لكل فئة. لذا نحتاج لطريقة نستطيع فيها أخذ أكبر احتمال وهذا مايقدمه لنا decode_predictions: from keras.applications.vgg16 import decode_predictions # تحويل الاحتمالات إلى تسميات فئة label = decode_predictions(yhat) label """ [[('n04037443', 'racer', 0.562338), # لاحظ أن أقوى احتمال هو أن الصورة تمثل صورة متسابق باحتمالية قدرها 56 بالمئة ('n04285008', 'sports_car', 0.28281146), # ثاني أكبر احتمال هو أنها صورة سيارة سباق باحتمالية قدرها 28 بالمئة ('n03100240', 'convertible', 0.08739577), ('n02974003', 'car_wheel', 0.037510887), ('n03930630', 'pickup', 0.010782746)]] """ الآن إذا كنت تريد استخلاص أكبر احتمال (التوقع الأساسي): # استرداد النتيجة الأكثر احتمالا ، على سبيل المثال أعلى احتمال label = label[0][0] # طباعة التصنيف print('%s (%.2f%%)' % (label[1], label[2]*100)) # racer (56.23%) هذا كل شيئ...
 1 نقطة
1 نقطة -
الخبرة اهم حاجة في اي مشروع وحسب معلوماتي البسيطة الخبرة لاتاتي من قراءة الكتب القراءة فقط تزيد من مداركك في ادارة المشروع مثل الادخار و إدارة المشروع بطرق جيدة فقط 2- حدد هدفك بالمشروع القريب لنفسك كهواية مثلا اذا تحب السيارات بامكانك العمل مبدئيا بفكرة محل بيع قطع غيار طبعا يلزمك البحث العميق قبل البداية 3 بعد ماتحدد هدفك من موهبتك حدد موزعي الجملة وتواصل معهم 4- اكيد خصوصا ان اصحاب المتاجر ينتظرون الزبون القادم لشراء سلعهم بصافي الفائدة بدون اي تكلفة اضافية1 نقطة
-
تستطيع تعيين فئة Meta افتراضيا إلى "managed = false". على سبيل المثال: class Rssemailsubscription(models.Model): id = models.CharField(primary_key=True, max_length=36) ... area = models.FloatField('Area (Sq. KM)', null=True) class Meta: managed = False db_table = 'RSSEmailSubscription' من خلال التغيير managed إلى True، سوف تبدأ ملفات التهجير في التقاط التغييرات.1 نقطة
-
يوفر جانغو Django طريقة سهلة للحصول على سجل عشوائي بسطر واحد فقط، كالتالي: Post.objects.order_by('?').first() لكن هذه الطريقة تستهلك الكثير من موارد الخادم وتسبب بطئ في التشغيل، لذلك يمكنك أن تستخدم طريقة أخرى وهي إستخدام التابع choice من الحزمة random، كالتالي: random.choice(Post.objects.all()) هذه الطريقة جيدة في قواعد البيانات الصغير (التي تحتوي على أقل من 100,000 من الصفوف في الجدول). أيضًا يمكنك أن تقوم بعمل نفس الأمر لكن من خلال حساب عدد الكائنات في قاعدة البيانات، على النحو التالي: from random import randint count = Post.objects.all().count() random_index = randint(0, count - 1) random_post = Post.objects.all()[random_index]1 نقطة
-
بالاضافة للحلول السابقة، قد تكون المشكلة في Meta subclass of models.. قد يكون لديك تعريف كالتالي سواء في apps.py أو models.py أو views.py : label = <app name> اذا كان هناك أي إحتمال بحيث أن meta class لا يحمل نفس العنوان label الخاص بالتطبيق خاصتك app ، قد لا يتم رصد أي تغيرات تحدث، ببساطة لانه لا يجد توافق بين ما تقوم بتغييره وما هو معرف عنده. لذا قد تحتاج الى تعديلها كالتالي: class ModelClassName(models.Model): class Meta: app_label = '<app name>' # <-- هذا ما يجب ضبطه باسم تطبيقك. field_name = models.FloatField() ...1 نقطة
-
هناك العديد من الأسباب المحتملة لعدم اكتشاف django لما سيتم ترحيله أثناء أمر makemigrations: يجب أنت تكون حزمة الترحيل في تطبيقك. أيضاً في INSTALLED_APPS، يوصى بتحديد مسار ال module app config كاملاً "application.apps.MyAppConfig" أيضاً يجب أن تتأكد من أنك قمت بتعيين ملف ال settings الصحيح manage.py makemigrations --settings mysite.settings ، ويفضل أن تقوم أيضاً بوضع اسم التطبيق بشكل صريح في manager.py makemigrations myapp - فهذا يساعدك على عزل المشكلة. أيضاً تأكد من أن لديك ال app_label الصحيح في model meta. أيضاً يمكنك تنفيذ الأمر makemigrations -v 3 الذي قد يساعدك في تحديد المشكلة. أيضاً يجب أن تتأكد من أن اسم التطبيق الخاص بك موجود في settings.py ا INSTALLED_APPS وإلا فلن يتم تشغيل عمليات الترحيل بغض النظر عن ما تفعله: INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'blog', ] ثم قم بتنفيذ: ./manage.py makemigrations blog1 نقطة
-
لإنشاء عمليات ترحيل أولية لأحد التطبيقات بما في ذلك المجلد migrations، قم بتشغيل الأمر "makemigrations" وحدد اسم التطبيق. سيتم إنشاء مجلد migrations بشكل تلقائي. ./manage.py makemigrations <myapp> كما يجب تضمين تطبيقك في INSTALLED_APPS أولاً داخل الملف settings.py وإلا سوف يؤدي إلى ظهور خطأ بعدم وجود التطبيق من الأساس. تحتاج إلى تحديد اسم التطبيق إذا كان التطبيق لا يحتوي على مجلد migrations. وقد يحدث هذا إذا قمت بإنشاء التطبيق يدويًا، أو قمت بالترقية من إصدار قديم من جانغو Django لا يحتوي على أي ملفات تهجير migrations. إيضًا إذا لم تكن تستخدم الملف models.py وتستخدم مجلد models مخصص للنماذج فيجب أن تقوم بإنشاء الملف init، فعلى سبيل المثال، إن كنت تستخدم الملف my_model.py في المجلد models، فيجب أن تقوم بإنشاء الملف التالي: my_app/models/__init__.py أيضًا يجب أن تستدعي في داخله الملف my_model.py، على النحو التالي: from .my_model import MyModel1 نقطة
-
تتبع الخطوات التالية لإعادة تسمية التطبيق في جانغو: أولاً: قم بإعادة تسمية مجلد التطبيق، على سبيل المثال ليكن اسم التطبيق القديم هو "app1" و "app2" هو اسم التطبيق الجديد. mv ./app1 ./app2 ثم قم بتحديث كافة عمليات الاستيراد التي تشير إلى المجلد القديم وقم بجعلها تشير إلى الجديد. مثال: from myproject.app1 import models ----> from myproject.app2 import models ثم قم بتحديث مراجع اسم التطبيق القديم داخل عمليات ترحيل Django. أمثلة على التغييرات التي قد تضطر إلى القيام بها: # قبل dependencies = [ ('app1', '...'), ] # بعد dependencies = [ ('app2', '...'), ] # قبل field = models.ForeignKey( default=None, on_delete=django.db.models.deletion.CASCADE, to='old_app.Experiment' ) # بعد field = models.ForeignKey( default=None, on_delete=django.db.models.deletion.CASCADE, to='new_app.Experiment' ) ثم قم بعمل commit في هذه المرحلة. بعد ذلك، يمكنك تشغيل عمليات ترحيل التطبيق في بيئة منشورة، قم بتشغيل django_rename_app قبل تشغيل عمليات الترحيل في هذه العملية. على سبيل المثال ، قبل "python manager.pyigration --noinput" ، كما يوضح المثال التالي: # قبل python manage.py collectstatic --noinput python manage.py migrate --noinput gunicorn my_project.wsgi:application # بعد python manage.py collectstatic --noinput python manage.py rename_app old_app new_app python manage.py migrate --noinput gunicorn my_project.wsgi:application سيؤدي هذا إلى تحديث اسم التطبيق في جداول قاعدة بيانات Django الداخلية التالية: django_content_type django_migrat2ions وإعادة تسمية بادئة "prefix" جميع جداولك لتبدأ باسم التطبيق الجديد، بدلاً من الاسم القديم.1 نقطة
-
قم أولاً بإنشاء حساب SendGrid (إرسال بريد إلكتروني باستخدام SendGrid هو مجاني ويصل إلى 12 ألف بريد إلكتروني كل شهر) من الرابط التالي (https://signup.sendgrid.com/). ثم أضف المعلومات التالية إلى ملف settings.py: EMAIL_HOST = 'smtp.sendgrid.net' EMAIL_HOST_USER = '<your sendgrid username>' EMAIL_HOST_PASSWORD = '<your sendgrid password>' EMAIL_PORT = 587 EMAIL_USE_TLS = True والآن يمكنك إرسال الإيميل: from django.core.mail import send_mail send_mail('<Your subject>', '<Your message>', 'from@example.com', ['to@example.com']) وإذا كنت تريد من Django أن يرسل إليك بريداً إلكترونياً عندما يكون هناك خطأ 500 داخلي في الخادم ، فأضف ما يلي إلى settings. py: DEFAULT_FROM_EMAIL = 'your.email@example.com' ADMINS = [('<Your name>', 'your.email@example.com')] كما يمكنك استخدام "Test Mail Server Tool" لاختبار إرسال البريد الإلكتروني على جهازك أو المضيف المحلي. قم بتنزيل "Test Mail Server Tool" وقم بإعدادها، ثم في ملف settings. py : EMAIL_BACKEND= 'django.core.mail.backends.smtp.EmailBackend' EMAIL_HOST = 'localhost' EMAIL_PORT = 25 ثم استخدم send_mail للإرسال: from django.core.mail import send_mail send_mail('subject','message','sender email', ['receipient email'],fail_silently=False )1 نقطة
-
يتم تصنيف الآلات التي تستخدم الذاكرة المشتركة إلى ( Uniform Memory Access) UMA و(Non Uniform Memory Access) NUMA وذلك بالاعتماد على زمن الوصول للذاكرة "memory access time" حيث أن UMA يكون فيها الوصول للذاكرة متساوٍ، أما NUMA يكون الوصول غير متساوي. هنا إليك ملخص عن كل منهم: تعرف باسم اكثر شهرة وهو SMP المعالجات المتعددة المتناظرة "Symmetric Multiprocessor" (متناظرة=أي المعالجات المتكافئة في العمل،كل معالج هو رئيس وند للآخر) + المعالجات متماثلة (أي نفس الصلاحيات ونفس العمل) Identical Processor + متساوية في السماحية بالوصول للذاكرة ووقت الوصول للذاكرة access time + تحقق مبدأ ترابط الكاش cache coherency، حيث تسمى أحيانا بcc_uma. يكون لدينا ذاكرة واحدة مشتركة مع كل المعالجات موجودة في نفس المكان (كتلة واحدة) + هي عبارة عن SMP واحدة + يوجد لدينا متحكم واحد في الذاكرة ( single memory controller ) + يمكننا إضافة عدد محدود من المعالجات. + كل المعالجات لها نفس زمن الوصول latency إلى الذاكرة + يوجد نوع واحد منها هو cc_uma. يتم تحقيقها عادة بشكل فيزيائي عن طريق ربط جهازي SMP أو أكثر + كل جهاز SMP يمكنه أن يصل مباشرة إلى ذاكرة جهاز SMP آخر حيث أن المعالجات تتصل ببعضها عن طريق ناقل bus الموجود ضمن الحاسب نفسه + الوصول للذاكرة عبر الناقل أبطأ من الوصول المباشر للذاكرة ضمن نفس الSMP + ليس كل المعالجات لها وصول متساوٍ إلى كل الذواكر + كل معالج له ذاكرته المحلية الخاصة والتي تكون مشتركة مع كل المعالجات الأخرى، أي أن الذاكرة موزعة في أكثر من موقع (كتل) + كل معالج له زمن وصول محدد إلى ذاكرة المعالجات الأخرى ويختلف ذلك بحسب مكانه + يمكننا إضافة العدد الذي نريده من المعالجات + هي عبارة عن مجموعة من الSMP + يوجد لدينا عدة متحكمات في الذاكرة ( multiple memort controller) + يوجد نوعين منها هما :numa ,cc_numa.1 نقطة
-
هذا لأن القائمة لم تأخذ إرتفاع الصفحة بالكامل, إنما فقط أخذت الإرتفاع الكافي لنشر عناصرها, لجعلها تأخذ الإرتفاع بالكامل قم بتعديل الstyleالخاص بالقائمة والعناصر التي تقوم بإحتواء القائمة عبر إضافة class الخاص بالإرتفاع h-100 <div class="container h-100"> <div class="row h-100"> <!-- Start right menu --> <div class="col-md-2 col-xs-2 h-100"> <div class="menu-outer h-100"> <div class="menu-icon"> <div class="bar"></div> <div class="bar"></div> <div class="bar"></div> </div> <nav> <ul> <li><a href="#">الرئيسية</a></li> <li><a href="#">المدونة</a></li> <li><a href="#">من نحن</a></li> <li><a href="#">إتصل بنا</a></li> </ul> </nav> وقتها ستجد القائمة أخذت إرتفاع الصفحة بأكملها1 نقطة
-
بفرض لدينا النموذج التالي، الذي قمنا بتدريبه: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss="mae", metrics=['mae']) return model # تدريب النموذج model = build_model() # قمنا بتدريب النموذج hisyory=model.fit(train_data, train_targets,epochs=2, batch_size=64) --------------------------------------------------------------------------------------------- """ Epoch 1/2 7/7 [==============================] - 1s 2ms/step - loss: 21.4842 - mae: 21.4842 Epoch 2/2 7/7 [==============================] - 0s 3ms/step - loss: 20.2813 - mae: 20.2813 """ يمكنك حفظ النتائج في ملفات pickle بالشكل التالي: hisyory.history """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ import pickle with open('/HistoryDict', 'wb') as f: pickle.dump(hisyory.history, f) history = pickle.load(open('/HistoryDict', "rb")) history """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ أو كملفات json: import json with open('file.json', 'w') as f: json.dump(hisyory.history, f) history1 = json.load(open('file.json')) history1 """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ أو بالشكل التالي: # حفظها np.save('my_history.npy',hisyory.history) load=np.load('my_history.npy',allow_pickle='TRUE').item() load """ {'loss': [21.15315055847168, 19.5343074798584], 'mae': [21.15315055847168, 19.5343074798584]} """ أو يمكنك تحويلها لداتافريم Dataframe ثم يمكنك حفظها كملفات CSV: import pandas as pd df = pd.DataFrame(hisyory.history) print(df.head(n=1)) """ loss mae 0 21.153151 21.153151 """ with open('history.csv', mode='w') as f: df.to_csv(f) # إعادة تحميله data = pd.read_csv("history.csv") data.head() """ Unnamed: 0 loss mae 0 0 21.153151 21.153151 1 1 19.534307 19.534307 """1 نقطة
-
حسناً سأقترح لك عدة طرق، بدايةً سأقوم بإنشاء تابع لك، تمرر له رقم العمود أو الأعمدة التي تريدها أن تظهر في المصفوفة الجديدة ويعطيك الخرج المطلوب (تمررها على شكل قائمة): import numpy as np arr = np.random.randint(5, size=(5,3)) print(arr) """ [[4 1 2] [3 2 3] [0 1 4] [4 3 3] [2 3 0]] """ # التابع def make(index,a): a=a.T b=a[index] return b.T # الآن بفرض أنك تريد مصفوفة جديدة من المصفوفة الأصلية مكونة من ثاني و ثالث عمود make([1,2],arr) # الخرج """ array([[1, 2], [2, 3], [1, 4], [3, 3], [3, 0]]) """ # إذا أردنا ثاني عمود فقط make([1],arr) """ array([[1], [2], [1], [3], [3]]) """ حيث اعتمدت على فكرة أخذ منقول المصفوفة ثم اختيار الأعمدة التي أريدها (التي أصبحت تشكل أسطر) ثم بعدها نأخذ المنقول مرة أخرى لتعطي الخرج. وبشكل أكثر سهولة يمكنك استخدام مفهوم الفهرسة والتقطيع في بايثون، بالشكل التالي: # إذا أردت ثاني عمود arr[:,[1]] """ array([[1], [2], [1], [3], [3]]) """ # ثاني وثالث عمود arr[:,[1,2]] """ array([[1, 2], [2, 3], [1, 4], [3, 3], [3, 0]]) """ وأخيراً، إذا أردت أسطر وأعمدة محددين: # ثاني وثالث عمود مع أول سطرين فقط arr[:2,1:3] """ array([[1, 2], [2, 3]]) """1 نقطة
-
متوسط النسبة المئوية للخطأ المطلق (MAPE)، هي دالة تستخدم لحساب متوسط النسبة المئوية للخطأ المطلق بين y_true و y_pred أي القيم الحقيقية والقيم المتوقعة من قبل النموذج. وتستخدم مع مهام التوقع، وهي تشابه لحد ما الدالة MAE: loss = 100 * abs(y_true - y_pred) / y_true ويعتبر هذا المقياس من المقاييس الأكثر شيوعاً المستخدمة مع مهام التنبؤ بالمناخ، ويعمل بشكل أفضل إذا لم تكن البيانات متطرفة (ولاتحوي أصفاراً). ويمكن استدعاؤها من الموديول التالي: tf.keras.losses.MeanAbsolutePercentageError مثال على استخدامها في كيراس: import tensorflow as tf y_true = [[2., 1.], [2., 3.]] y_pred = [[1., 1.], [1., 0.]] mape = tf.keras.losses.MeanAbsolutePercentageError() mape(y_true, y_pred).numpy() 50. لاستخدامها في نماذجك يمكنك تمريرها للدالة compile بالشكل التالي: model.compile( ... loss="MeanAbsolutePercentageError" ) # أو model.compile( ... loss=tf.keras.losses.MeanAbsolutePercentageError() ) مثال عليها أثناء تدريب نموذج لتوقع أسعار المنازل: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='adam', loss="MeanAbsolutePercentageError", metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=14, batch_size=32) ----------------------------------------------------------------------------------------------- Epoch 11/14 13/13 [==============================] - 0s 3ms/step - loss: 17.9825 - mae: 4.1283 Epoch 12/14 13/13 [==============================] - 0s 2ms/step - loss: 15.7485 - mae: 3.3775 Epoch 13/14 13/13 [==============================] - 0s 2ms/step - loss: 14.7182 - mae: 3.3004 Epoch 14/14 13/13 [==============================] - 0s 2ms/step - loss: 14.9168 - mae: 3.4608 <keras.callbacks.History at 0x7fe5c3a0f810>1 نقطة
-
1. تحويل ال tuple إلى قوائم ثم تحويل القائمة إلى مصفوفة، ثم تنفيذ عملية Transpose عليها (المنقول): tuples = [('a', 2), ("b", 4), ("c", 6)] lists = [list(x) for x in tuples] print(lists) # [['a', 2], ['b', 4], ['c', 6]] arr=np.array(lists) arr.T """ array([['a', 'b', 'c'], ['2', '4', '6']], dtype='<U1') """ 2.بشكل مشابه للطريقة السابقة لكن هنا سوف نستبدل حلقة ال for بتعليمة ال map: tuples = [('a', 2), ("b", 4), ("c", 6)] lists = list(map(list, tuples)) print(lists) # [['a', 2], ['b', 4], ['c', 6]] arr=np.array(lists) arr.T """ array([['a', 'b', 'c'], ['2', '4', '6']], dtype='<U1') """ 3.تحويلها إلى قاموس، ثم تحويلها إلى مصفوفة، ثم تنفيذ عملية Transpose عليها (المنقول): tuples = [('a', 2), ("b", 4), ("c", 6)] dic=dict(tuples) print(dic) # {'a': 2, 'b': 4, 'c': 6} # [['a', 2], ['b', 4], ['c', 6]] arr=np.array(dic).T arr # array({'a': 2, 'b': 4, 'c': 6}, dtype=object) 4. أو بالشكل التالي، حيث نقوم بتحويل القائمة إلى قاموس، ثم نخزن قيمه (القيم وليس المفاتيح)، ثم نحول الخرج ليصبح قائمة ثم نحوله لمصفوفة، وأخيراً نحوله من البعد (,3) إلى البعد (3,1) أي أصبحت مصفوفة ثنائية ثم نقوم باستخراج المفاتيح و نضعهم في مصفوفة (كما في المرحلة السابقة لكن هنا نستخرج المفاتيح ونخزنها) والغاية من ذلك هي لربط النتائج ووضعها في مصفوقة واحدة، حيث أن المفاتيح للقاموس الذي تم إنتاجه هي ال a c أما القيم فهي القيم التي تقابلها: tuples = [('a', 2), ("b", 4), ("c", 6)] values=np.array(list(dict(tuples).values())).reshape(1,-1) # dict_values([2, 4, 6]) keys=np.array(list(dict(tuples).keys())).reshape(1,-1) # dict_keys(['a', 'b', 'c']) np.concatenate((keys, values), axis=0) """ array([['a', 'b', 'c'], ['2', '4', '6']], dtype='<U21') """1 نقطة
-
يمكنك القيام بذلك بالشكل التالي في باندا: df = df.astype(object).where(pd.notnull(df),None) ويمكنك استبدال nan بـ None في مصفوفة numpy الخاصة بك من خلال استخدام التابع np.where حيث نمرر له كوسيط أول القيمة المعادة من تطبيق التابع np.isnan على المصفوفة الخاصة بك، ثم القيمة المراد الاستبدال بها، ثم المصفوفة: arr = np.array([4, np.nan]) arr = np.where(np.isnan(arr), None, arr) # [4.0 None] print type(arr[1]) #<type 'NoneType'> كما ويمكنك القيام بذلك بسهولة من خلال التابع replace في باندا: df = df.replace({np.nan: None}) وللتحويل من none ل nan: import numpy as np x = np.array([3,4,None,55]) x = np.array(x,dtype=float) x #array([ 3., 4., nan, 55.]) # أو x = np.array(x) x.astype(float) #array([ 3., 4., nan, 55.])1 نقطة
-
يمكنك القيام بذلك بالشكل التالي، حيث قمنا بتعريف التابع random.randint الذي يقوم بإنشاء مصفوفة عشوائية من القيم الصحيحة ب 10 أسطر و 3 أعمدة، بحيث أعلى قيمة فيها هي 5. بعد ذلك قمنا باستخدام نفس التابع لكي يقوم بتوليد أعداد صحيحة أعلى قيمة فيها يساوي 10، وبحجم 3 أي سكون الخرج مصفوفة أحادية البعد، قيم هذه المصفوفة ستمثل فهارس الأسطر التي ستم اختيارها من المصفوفة الجديدة لتشكيل المصفوفة. وأخيراً نقوم باستخدام التعليمة arr[index,:] لعرض المطلوب. حيث في مثالنا يمكنك أن تلاحظ أن المصفوفة index التي شكلناها تحوي القيم 9 9 4 وبالتالي سنختار الأسطر 9 9 4 من المصفوفة الأصلية لتشكيل المصفوفة الجديدة. كما يجب أن تلاحظ أننا حددنا أكبر قيمة في المصفوفة index بالعدد 10 أي ستكون القيم المولدة أقل من 10 أي من 0 ل 9 وذلك لأن عدد أسطر المصفوفة الأصلية هو 10 أي الفهارس من 0 ل 9 وهذا مهم لكي لانخرج عن حدود المصفوفة وبالتالي لتجنب ظهور أي خطأ. import numpy as np arr = np.random.randint(5, size=(10,3)) print(arr) """ [[4 1 1] [2 3 2] [1 4 1] [2 2 0] [1 3 3] [3 2 0] [2 0 3] [2 1 2] [4 0 4] [0 2 3]] """ index = np.random.randint(10, size=3) print(index) # [9 9 4] arr[index,:] أو من خلال استخدام التابع np.random.choice ليختار لنا الفهارس بطريقة عشوائية: indices = np.random.choice(arr.shape[0],3, replace=False) arr[indices] """ array([[3, 2, 0], [2, 3, 2], [2, 2, 0]]) """ arr[np.random.choice(arr.shape[0], 4, replace=False)] """ array([[3, 2, 0], [0, 2, 3], [2, 2, 0], [1, 3, 3]]) """1 نقطة
-
يؤدي تكرار مصفوفة كصف باستخدام NumPy إلى ظهور مصفوفة ثنائية الأبعاد جديدة بحيث يكون كل صف هو المصفوفة الأصلية. ينتج عن تكرار مصفوفة كعمود مصفوفة ثنائية الأبعاد جديدة بحيث يكون كل عمود هو المصفوفة الأصلية. أول طريقة لتنفيذ ماتطلبه هي استخدام دالة np.repeat بالشكل التالي، حيث نمرر لها المصفوفة والمحور الذي نريد التكرار عليه وعدد التكرارات: import numpy as np array_2d = np.array([[1,2,3]]) # سيتم تكرار عناصر المصفوفة على طول الصفوف أي إلى أسفل. np.repeat(array_2d,repeats=3,axis=0) """ array([[1, 2, 3], [1, 2, 3], [1, 2, 3]]) """ arr = np.array([[1],[2],[3]]) # ًفي هذه الحالة، إذا كنت ستستخدم المحور = 1 ، فسيتم تكرار العناصر مع الأعمدة أي أفقيا np.repeat(arr,repeats=3,axis=1) """ array([[1, 1, 1], [2, 2, 2], [3, 3, 3]]) """ يمكنك أيضاً استخدام الدالة numpy.tile حيث نمرر لها المصفوفة وعدد مرات التكرار ك tuple أي بالشكل (n, 1) حيث تمثل n عدد مرات التكرار. والنتيجة ستكون تكرار المصفوفة أحادية الأبعاد الممررة للدالة tile على المحور العمودي. (أي التكرار كأسطر). an_array = np.array([1,2,3]) # عدد مرات التكرار repeat = 3 np.tile(an_array, (repeat, 1)) """ array([[1, 1, 1], [2, 2, 2], [3, 3, 3]]) """ أما لو أردت التكرار كأعمدة كما في الحالة الثانية يمكنك استخدام numpy.transpose بالشكل التالي: an_array = np.array([[1],[2],[3]]) # عدد مرات التكرار repeat = 3 np.transpose([an_array] * repeat) """ array([[[1, 1, 1], [2, 2, 2], [3, 3, 3]]]) """ وأخيراً يمكنك استخدام التابع np.broadcast_to بحيث نمرر له المصفوفة والأبعاد الجديدة وهو سيتكفل بالتكرار كما في المثال التالي : an_array = np.array([[1],[2],[3]]) np.broadcast_to(an_array, (3, 3)) """ array([[1, 1, 1], [2, 2, 2], [3, 3, 3]]) """ an_array = np.array([1,2,3]) np.broadcast_to(an_array, (3, 3)) """ array([[1, 2, 3], [1, 2, 3], [1, 2, 3]]) """1 نقطة
-
pandas: إنها مكتبة مفتوحة المصدر ومرخصة من BSD مكتوبة بلغة Python. توفر Pandas هياكل بيانات وأدوات تحليل بيانات عالية الأداء وسريعة وسهلة الاستخدام لمعالجة البيانات الرقمية والسلاسل الزمنية. تم إنشاء Pandas على مكتبة numpy ومكتوبة بلغات مثل Python و Cython و C. في الباندا ، يمكننا استيراد البيانات من تنسيقات ملفات مختلفة مثل JSON و SQL و Microsoft Excel وما إلى ذلك. مثال: # استيراد المكتبة import pandas as pd # تهيئة وإنشاء قائمة متداخلة age = [['Aman', 95.5, "Male"], ['Sunny', 65.7, "Female"], ['Monty', 85.1, "Male"], ['toni', 75.4, "Male"]] #DataFrame إنشاء df = pd.DataFrame(age, columns=['Name', 'Marks', 'Gender']) Numpy: إنها المكتبة الأساسية للبايثون، وتستخدم لتنفيذ عمليات الحوسبة العلمية. يوفر مصفوفات وأدوات متعددة الأبعاد عالية الأداء للتعامل معها. المصفوفة الرقمية هي شبكة من القيم (من نفس النوع) مفهرسة بواسطة مجموعة من الأعداد الصحيحة الموجبة، والمصفوفات غير المتقاربة سريعة وسهلة الفهم ، وتمنح المستخدمين الصلاحية في إجراء العمليات الحسابية عبر المصفوفات. ويعتمد عليها كثيرٌ من العلماء والباحثين في إجراء العمليات الحسابية الكبيرة والمعقدة على بياناتهم وفي اختباراتهم العلمية. مثال: # استيراد المكتبة import numpy as np # 3-D numpy array using np.array() org_array = np.array([[10, 1, 77], [5, 0, 4]]) عندما يتعين علينا العمل على البيانات الجدولية ، فإننا نفضل وحدة الباندا. عندما يتعين علينا العمل على البيانات العددية ، فإننا نفضل الوحدة النمطية numpy. أدوات الباندا القوية هي Dataframe و Series. في حين أن الأداة القوية لـ numpy هي Arrays. تستهلك الباندا المزيد من الذاكرة. نمباي أكثر فعالية في التعامل مع الذاكرة. تتمتع Pandas بأداء أفضل عندما يكون عدد الصفوف 500 ألف أو أكثر. يتمتع Numpy بأداء أفضل عندما يكون عدد الصفوف 50 ألفًا أو أقل. تعد فهرسة سلاسل الباندا بطيئة جداً مقارنةً بمصفوفات نمباي. تعد الفهرسة في مصفوفات نمباي سريعة جداً. تقدم Pandas كائنات تمثل جدول ثنائي الأبعاد يسمى DataFrame. Numpy قادر على توفير مصفوفات متعددة الأبعاد. نمباي تقدم لك عمليات سريعة وبكفاءة عالية عند التعامل مع المصفوفات، وإستخدام أمثل للمصادر عند المعالجة. وتعتمد عليها كثير من المكتبات الأخرى مثل Pandas و theanets وغيرهما. يوفر باندا وظائف كثيرة مثل: data alignment و NA-friendly statistics و groupby و merge و join والعديد من الأدوات الأخرى المريحة، التي أصبحت شائعة جداً في السنوات الأخيرة في التطبيقات المالية. وأيضاً في تعلم الآلة. وتقدم المكتبة ما يسمى ب إطار البيانات (Data Frame) والذي يسهل من إستيراد البيانات والتعامل معها بسهولة. و تسهل المكتبة عمليات (Data Preprocessing ) مثل تنظيف البيانات، ومعالجة القيم الفارغة فيها، وإجراء العمليات الإستكشافية على البيانات. وتسهل دمج البيانات ببعضها أو تجزيئها إلى إطارات متعددة. أما بالنسبة لمكتبة SciPy فبشكل مختصر مكتبة (SciPy) هي نفس مكتبة (NumPy) تقريباً وهي أيضاً من بين المكتبات الاساسية للحسابات العلمية وخوارزميات الرياضيات والدوال المعقدة. ولكنها مبنية كأمتداد لمكتبة (NumPy) مما يعني أنهما يستخدمان سوية في أغلب الاحيان. تأتي هذه المكتبة على رأس هرم مكتبات علم البيانات بالبايثون ، وتخدم جانب تحليل البيانات و تعليم الالة بشكل قوي، ولا تقتصر على ذلك، حيث تقدم إمكانات هائلة في مجال معالجة الإشارات ومعالجة الصور والعمليات الحسابية المعقدة. تتكون وتعتمد مكتبة Scipy على خليط من المكتبات المشهورة مثل Numpy, Pandas, Matplotlib, Sympy, IPython وغيرها. تُقدم المكتبة مجموعة واسعة من الخوارزميات والحزم العلمية التي لها علاقة بالأخص بالعمليات الرياضية، الدوال الإحصائية وتعليم الألة. ومن ميزاتها أنها تقدم دوال واسعة في مجال الاحتمالات والإحصاء عبر موديول stats. وتدعم عمليات الجبر الخطي و Fourier transform. وتقدم المكتبة مجموعة من الدوال الخاصة بمعالجة المصفوفات متعددة الأبعاد لمعالجة الصور. وإجراء التحليل المكاني (Spatial Analysis) عبر مجموعة من الخوارزميات المتخصصة الموجودة في موديول spatial.1 نقطة