
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 09/23/21 in أجوبة
-
أريد أن أكتب اختبار وحدة Unit Test للأمر معين في manage.py والذي يقوم بعملية في جدول في قاعدة البيانات. كيف يمكنني استدعاء هذا الأمر مباشرة من داخل الكود؟ لا أرغب في تنفيذ الأمر على على shell الخاص بنظام التشغيل يدويًا لأنني حينها لن أستطيع استخدام بيئة الاختبار التي تم إعدادها باستخدام manage.py test. لذلك أريد أن أعرف كيف يمكنني استدعاء أمر manage.py مخصص مباشرةً من داخل ملف اختبار test؟3 نقاط
-
لدي نموذج يمثل المنشورات التي أقدمها على موقعي. وأود أن أعرض بعضًا من العشوائية. لكنني أواجهة مشكلة في الحصول على سجل record عشوائي من قاعدة البيانات. حاول أن أكتب الكود التالي: number_of_records = Post.objects.count() random_index = int( random.random() * number_of_records ) + 1 random_post = Post.get(pk = random_index) لا يبدو أن من الصحيح حساب عدد كل الصفوف للحصول على سجدل عشوائي. هل توجد أي خيارات أخرى كيف تمكنني من القيام بذلك؟2 نقاط
-
كيف يمكنني تغيير اسم أحد النماذج models من "Post" إلى "Posts" في لوحة التحكم Admin في إصدار 3.2 من جانغو Django؟ ومع ذلك حاولت أن أقوم بتغير إعدادات modeladmin إلا أن إعداد verbose_name_plural داخل النموذج modeladmin لا يفعل شيئًا. ولا أعرف سبب المشكلة؟2 نقاط
-
أنا أستخدم webpack 5 config لتشغيل مستودع react ويبدو أن كل شيء يعمل بشكل جيد باستثناء تحميل الصور ، لدي خطأ لا أفهمه: ERROR in ./src/assets/styles/main.scss Module build failed (from ./node_modules/mini-css-extract-plugin/dist/loader.js): ModuleNotFoundError: Module not found: Error: Can't resolve 'file-loader' in........... لقد حاولت إعادة تثبيت بعقب mini-css-extract-plugin الذي لم ينجح ، ولست متأكدًا مما يمكن أن يكون المشكلة هنا. rules: [ { test: /\.(js|jsx)$/, use: { loader: "babel-loader" } }, { test: /\.(png|jpg|gif|svg)$/, use: [ { loader: 'file-loader', options: { outputPath: "images", }, }, ], },2 نقاط
-
أنا جديد على Next.js وفي مشروعي ، قمت بتثبيت dotenv (https://www.npmjs.com/package/dotenv) وأنشأت ملف .env في جذر المشروع وكل شيء يعمل بشكل جيد. السابق. API_BASE_PATH = http: // localhost: 8000 / api بعد ذلك ، قمت بإنشاء ملف .env آخر أطلق عليه اسم .env.testing هناك ، ولدي قيم مختلفة لـ API_BASE_PATH. فكيف يمكنني التبديل بين تلك .env في local development؟ "scripts": { "dev": "next dev -p 3001", "build": "next build", "start": "next start", "export": "npm run build && next export" }, أريد إضافته إلى scripts1 نقطة
-
السلام عليكم. لما يستخدم بعض الناس flex-grow مع flex-basis في عنصر معين رغم أنهم لا يستخدمونها لغرض الـتجاوبية أو الـ responsiveness ؟1 نقطة
-
السلام عليكم . أواجه مشكلة في فهم خاصية transform-style: preserve-3d , فهلا تكرمتم في شرحها لي ؟1 نقطة
-
و عليكم السلام . قبل التعرض للقيم التي تأخذها الخاصية ينبغي أولا معرفة ما الذي تقوم به الخاصية , فالخاصية tranfrom-style أو نمط التحويل تحدد ما إذا كانت العناصر الفرعية أو الأبناء لعنصر ما موضوعة في مساحة ثلاثية الأبعاد أو إذا تم وضعها في مستوى العنصر الأب نفسه . أي أن الخاصية ممكن لها أن تأخذ أحد القيمتين : flat : يعني هذا أن العناصر الأبناء لعنصر ما يمتلك هاته الخاصية سيتم وضعها في نفس مستوى العنصر . preserve-3d : ترجمة للـحفاظ على البعد الثلاثي , و تجعل هاته القيمة الأبناء موضوعة في مساحة ثلاثية الأبعاد خاصة بها . و لإتضاح الفرق جيدا لاحظ الفرق بين الصورتين : الصورة رقم 1 : الصورة رقم 2 : لاحظ في كلتا الصورة أن العنصر الأب parent باللون البرتقالي يمتلك تحويلا معينا يعطيه الإنحناءة ثلاثية الأبعاد التي هو عليها , و مثل ما هو الحال مع محاور ذات العنصر , أي أن المحاور أيضا أعيد تعيينها بعد تطبيق التحويل الذي عليه . في الصورة الأولى : نلاحظ إنتماء العنصر الابن باللون الزهري إلى مستوى عنصر الأب , أي أن العنصر يظهر بشكل وكأنه مواز له , و لكنه في الحقيقة على ذات المستوى , كأن الأمر يجرد هكذا : في الصورة الثانية : نلاحظ تداخل العنصر الاابن باللون الزهري مع العنصر الأب , يظهر ذلك و كأن كل منهما مرسوم ومعبر عنه في مستوى خاص به , هذا المستوى هو مساحة ثلاثية الأبعاد خاصة به . و كأن الأمر هكذا : ففي الأولى : العناصر الأبناء للعنصر الحالي ستكون مسطحةً (flattened) في مستوى العنصر الأب . أي أن العنصر الأب يمتلك القيمة flat في خاصية نمط العنصر . و في الثانية : العناصر الأبناء للعنصر الحالي ستكون موجودةً في الفضاء ثلاثي الأبعاد الخاص بها . أي أن العنصر الأب يمتلك القيمة preserve-3d في خاصية نمط التحويل . و هو ما سؤالك حوله بالضبط . يمكن تلخيص قواعد الـ css لكل من المثالين كالتالي : صورة 1 : transform-style: flat; صورة 2 : transform-style: preserve-3d; تعرف أكثر على الخاصية transform-style من هنا . كما يمكنك الإطلاع على المثال الذي تم طرحه و التلاعب بقيم الخاصية من هنا .


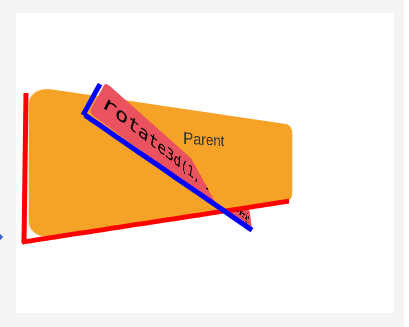
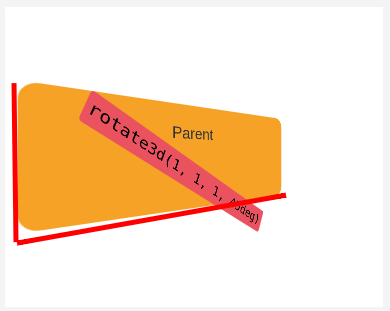 1 نقطة
1 نقطة -
أريد توضيح لكيفية استخدام الطبقة Conv2D؟1 نقطة
-
أريد إنشاء نموذج PostModel يحتوي على حقل من نوع ForeignKey يشير إلى المعرف الأساسي id لكائن آخر من نفس النموذج، أي شيء كالتالي على سبيل المثال: class PostModel(models.Model): parent = models.ForeignKey(PostModel) هل يمكن عمل ذلك في قواعد البيانات (أي أن يشير مفتاح أجنبي ForeignKey إلى كائن آخر من نفس النموذج (في نفس الجدول))؟ أم أن هناك طرق أخرى للوصول إلى نفس النتيجة؟ وكيف أقوم بهذا؟1 نقطة
-
هل يوجد كورسات عملية في هذا الموقع ل لغات Angular اوReact ؟1 نقطة
-
يجب عليك كتابة الشيفرة البرمجية التي تستخدم فيها fetch لنستطيع مساعدتك بشكل أفضل، فلا يمكن تحديد الخطأ الذي يحدث دون الاطلاع على الشيفرة البرمجية التي تقوم بكتابتها. أما بالنسبة للفرق بين fetch , fetchAll فهو بسيط جداً: يقوم التابع fetch بإعادة سطر واحد فقط (أول سطر) من قاعدة البيانات. مثال: <?php $sth = $dbh->prepare("SELECT name, colour FROM fruit"); $sth->execute(); print("استعادة أول نتيجة من جدول قاعدة البيانات"); $result = $sth->fetch(PDO::FETCH_ASSOC); print_r($result); وسيكون الناتج بشكل مصفوفة الحقل المفتاح فيها هو اسم العمود في قاعدة البيانات وقيمته هي قيمة العنصر نفسه: Array ( [name] => apple [colour] => red ) أما التابع fetchAll: يقوم بإعادة مصفوفة فيها جميع الأسطر (النتائج) الموجودة في قاعدة البيانات. مثال: <?php $sth = $dbh->prepare("SELECT name, colour FROM fruit"); $sth->execute(); print("استعادة اسم ولون جميع الفواكه الموجودة في جدول قاعدة البيانات"); $result = $sth->fetchAll(); print_r($result); ?> وسيكون الناتج ضمن مصفوفة بالشكل التالي: Array ( [0] => Array ( [name] => apple [0] => apple [colour] => red [1] => red ) [1] => Array ( [name] => pear [0] => pear [colour] => green [1] => green ) [2] => Array ( [name] => watermelon [0] => watermelon [colour] => pink [1] => pink ) ) أما بالنسبة للشرح، فيمكنك قراءة التوثيق لأي تابع أو خاصية في PHP مباشرةً من الموقع الرسمي وستحصل على جميع التفاصيل اللازمة لعمله وأمثلة عن استخداماته.1 نقطة
-
كيف يمكننا أن نستخدم نموذج VGG16 لتوقع فئة الصور.. على سبيل المثال لدي صورة ما وأريد تصنيفها من خلال هذا النموذج، كيف نقوم بذلك؟1 نقطة
-
السلام عليكم ورحمة الله .. انا مطور رياكت ناتيف واتعلم نود واعرف انه التعلم رحلة لا تنتهى لكن يمكننا تحديد المطلوب للوصول لمستوى معين وانا اريد ان اعرف مالدى مازلت احتاجه حتى اصل الى مستوى junior node developer ؟ هده هى مهاراتى js es6 express mongo db mogoose mustache js socket io type script unit test integration test heroku I can make [get, put, post, delete] requests, Upload images using multer, Hashing the Password, Login and Create a Token, Protect the Requests with the Token, Upload server on Heroku رجاء أريد ان اعرف ما ينقصنى ام ان هدا المستوى كافى ام ماذا احتاج ؟1 نقطة
-
لماذا تقوم قواعد البيانات باستخدام الb+ tree بدلاً من hashtable على الرغم ان الhash table أسرع1 نقطة
-
طيب ما الحل ؟1 نقطة
-
احاول استخدام دالة getline ولكن يعطيني هذا الخطأ error: no matching function for call to 'getline(std::string&)' string s; std::getline(s);1 نقطة
-
أنا أستخدم Webpack وأحاول استخدام صورة png لعرضها في متصفح Firefox الخاص بي. تكمن المشكلة في أن Webpack يقوم بإنشاء صورتين في مجلد dist webpack.config.js module: { rules: [{ test: /\.css$/, use: ['style-loader', 'css-loader'] }, { test: /\.(jpe?g|png|gif|svg)$/, use: ['file-loader'] } ] } .logo { background-image: url('../assets/foto.png'); background-size: cover; height: 200px; width: 200px; margin: 0 auto;} <div class="logo"></div> dist/ - h74g3ffgf3ff34h76.png - analytics.54t54gg4.js - ab0d12j489gh4igh8.png - index.html - main.h74rg34u73f.js src/ assets/ - foto.png styles/ - styles.css - analytics.js - index.html - script.js - package-lock.json - package.json - webpack.config.js1 نقطة
-
أخطط لإضافة مكتبة React-slick إلى مشروع nextjs الخاص لشريط تمرير الصور ولكن أواجه مشكلة ولكن بمجرد أن أقوم باستيراد css في ملف _app.tsx الخاص بي ، فإنه يعطي خطأ Module not found: Can't resolve '~slick-carousel/slick/slick-theme.css' _app.js import React from "react"; import { AppProps } from "next/app"; import Head from "next/head"; import "@styles/global.scss"; import { Provider } from "react-redux"; import store from "@redux/store"; import { MuiThemeProvider } from "@material-ui/core/styles"; import CssBaseline from "@material-ui/core/CssBaseline"; import theme from "src/createMiuitheme"; import "~slick-carousel/slick/slick.css"; import "~slick-carousel/slick/slick-theme.css"; function MyApp({ Component, pageProps }: AppProps): JSX.Element { // const theme = responsiveFontSizes(createTheme()); return ( <> <Head> <link rel="shortcut icon" href="#" /> <meta charSet="utf-8" /> <meta name="viewport" content="minimum-scale=1, initial-scale=1, width=device-width, shrink-to-fit=no" /> <meta name="theme-color" content={theme.palette.primary.main} /> </Head> <Provider store={store}> <MuiThemeProvider theme={theme}> <CssBaseline /> <Component {...pageProps} /> </MuiThemeProvider> </Provider> </> ); } export default MyApp;1 نقطة
-
السلام عليكم ما المشكلة عند رفع مشروع react & node على منصة هيروكو , يعمل المشروع كاملا و لكن قاعدة البيانات mongodb لا تعمل مع انني اضع نتغيرات البيئة بالطريقة الصحيحة و شكرا 2021-09-22T20:30:30.990879+00:00 heroku[router]: at=info method=GET path="/static/css/2.8a85707e.chunk.css" host=node-apps-heroku.herokuapp.com request_id=4e264311-4620-4014-a177-c50f9aab3bc1 fwd="80.79.145.135" dyno=web.1 connect=0ms service=1ms status=304 bytes=400 protocol=https و يظهر هذا الفي ال log1 نقطة
-
لاحظ أن لديك خطأ في كتابة كود JavaScript في عملية تحديد العنصر من خلال الصنف open، حيث أن الكود يجب أن يكون كالتالي: <script> let ahref = document.querySelectorAll('.open'); console.log(ahref[1].classList) </script> لاحظ إستخدام التابع querySelectorAll وليس quer أيضًا يجب إضافة نقطة . قبل كلمة open حيث أننا نقوم بتحديد العناصر من خلال الصنف class ولذلك يجب إضافة . قبل اسم الصنف. ملاحظة: يتم إضافة العلامة # قبل المعرف في حالة إستخدام المعرفات IDs بدلًا من الأصناف. أيضًا كما وضح وائل أن كود جافاسكريبت يتم تنفيذه قبل تحميل عناصر HTML، لذا حتى في حالة كان كود جافاسكريبت يعمل بشكل سليم، فلن يتم إيجاد العنصر .open وذلك لأنه لم يتم تحميله بعد (في وقت تنفيذ كود جافاسكريبت)، ولحل هذه المشكلة يجب نقل الكود إلى أسفل المستند (قبل نهاية جسم الصفحة body)، على النحو التالي: <html> <head> <meta charset="UTF-8" /> <title>Learn JavaScript</title> </head> <body> <a class="open" href="https://google.com">Google</a> <a class="open" href="https://wikipedia.org">wikipedia</a> <a class="not" href="https://facebook.com">Facebook</a> <a class="linked" href="https://wikipedia.org">wikipedia</a> <script> let ahref = document.querySelectorAll('.open'); console.log(ahref[1].classList) </script> </body> </html> أو يمكنك أن تستخدم الحدث onload ليتم تنفيذ الكود عندما يكتمل تحميل الصفحة فقط، كالتالي: <html> <head> <meta charset="UTF-8" /> <title>Learn JavaScript</title> <script> document.onload = function(e){ let ahref = document.querySelectorAll('.open'); console.log(ahref[1].classList) } </script> </head> <body> <a class="open" href="https://google.com">Google</a> <a class="open" href="https://wikipedia.org">wikipedia</a> <a class="not" href="https://facebook.com">Facebook</a> <a class="linked" href="https://wikipedia.org">wikipedia</a> </body> </html> ويمكنك أن تستعين بهذه المقالة لفهم المزيد عن الأحداث وكيف تعمل (فهم الأحداث في جافاسكربت - أكاديمية حسوب)1 نقطة
-
إن جافاسكربت تعمل مباشرة حال وصول قراءة شيفرة HTML للأسطر الخاصة بها، لذلك علينا تأجيل تنفيذ شيفرة جافاسكربت حتى اكتمال تحميل body، أي انقل جزء script من عنصر head إلى آخر جزء ضمن body قبل وسم الإغلاق، ليصبح آخر عنصر ضمنه. وباستعمال window.onload هنا نقوم بتعريف مستم أحداث خاص باكتمال تحميل الصفحة، لذلك نضمن وجود عناصر HTML على شكل DOM وجاهزيتها لتنفيذ شيفرات جافاسكربت عليها. الطريقة الأولى مستعملة أكثر لأنها أبسط. بعد نقل الشيفرة للأسفل، أصلح أخطائها..1 نقطة
-
المعلمات غير القابلة للتدريب " non-trainable parameter " هي عدد الأوزان التي لن يتم تحديثها أثناء التدريب باستخدام خوارزمية ال Gradient descent الانتشار العكسي backpropagation. وهناك نوعان رئيسيان للأوزان / المعلمات غير القابلة للتدريب: أوزان wights نريد جعلها ثابتة لاتتغير قيمتها خلال عملية التدريب. هذا يعني أن keras لن تقوم بتحديث هذه الأوزان من خلال خواررزمية GD أثناء التدريب على الإطلاق (على سبيل المثال عندما نقوم باستخدام نماذج نقل التعلم مثل VGG أو Inception أو Res .. إلخ) فإننا نقوم بعملية تجميد لهذه الأوزان المدربة (فتغييرها من خلال خواررزمية GD يلغي فكرة نقل التعلم كلها فنحن نريد هذه الأوزان المدربة لذا نحتاج إلى تجميدها freez لكي لاتتغير). أو مثلاً عندما نستخدم شبكات تلاففية CNN فكما نعلم فإن هذه الشبكات تعتمد على تطبيق مرشحات لكشف سمات الصورة مثل الحواف من خلال مرشح سوبل مثلاُ الذي يعتمد على مشتقات الدرجة الأولى. وكما نعلم فإن قيم المرشح ستتغير من خلال عملية الانتشار الخلفي. لكن لو قمنا بتثبيت قيمها (قمنا بتثبيت قيم مرشح سوبل -قيم المرشحات تعتبر أوزان-) فقد يؤدي ذلك إلى أداء أفضل. النوع الثاني ليس أوزان وإنما معلمات كتلك التي نستفيد منها للقيام بعمليات أشبه بالعمليات الإحصائية عندما نستخدم فكرة ال BatchNormalization في نماذجنا. وبالرغم من أنه قد يتم تحديث بعضها خلال التدريب إلى أنه لايتم تعديلهم من خلال ال backpropagation. لاحظ عندما نستخدم ال BatchNormalization: model.add(BatchNormalization()) model.summary() """_________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 10) 1010 _________________________________________________________________ batch_normalization_1 (Batch (None, 10) 40 ================================================================= Total params: 1,050 # العدد الكلي للمعلمات والأوزان Trainable params: 1,030 # قابلة للتدريب Non-trainable params: 20 # معلمات غير قابلة للتدريب _________________________________________________________________ """ ويمكنك مثلاً جعل أوزان طبقة ما ثابتة باستخدام الواصفة trainable حيث نقوم بضبطها على False: model.get_layer(layerName).trainable = False كما يمكن التحكم بها من خلال الوسيط trainable لكن فقط أثناء بناء النموذج. مثال: model.add(Dense(32, trainable=False,..)) # هنا جعلنا كل الخلايا غير قابلة للتدريب في هذه الطبقة أما ال trainable parameter فهي الأوزان وال bias التي يتم تحديث قيمهم خلال عملية التدريب من خلال خوارزمية ال GD أي أنها الأوزان الموجودة داخل الشبكة والتي يتم تعديلها للحصول على ما نريد (حل مشكلة معينة).حيث يتم تعديل قيمهم من خلال خوارزمية الانتشار العكسي بحيث يتم تقليل قيمة ال loss إلى أقل مايمكن. وبشكل افتراضي ، يمكن تدريب جميع الأوزان في نموذج keras مالم تحدد عكس ذلك (مالم تقوم بتجميد بعضها -الحالة الأولى في الأعلى-). هذا كل شيئ.1 نقطة
-
الدالة compile هي الدالة المسؤولة عن تكوين النموذج بعد أن تكون قد قمت بتحديد هيكليته (طبقاته وبارمتراته). حيث تقوم بترجمة هذه الهيكلية وتحديد المعلومات الأخرى اللازمة لتكوين النموذج وتجهيزه لبدء عملية التدريب. ولها الشكل التالي: Model.compile( optimizer="rmsprop", loss=None, metrics=None, weighted_metrics=None, steps_per_execution=None, **kwargs ) حيث أن الوسيط الأول هو المحسَن المستخدم (وفي الرابط في الأسفل هناك شرح لأشهر نوعين من المحسنات وهما Rmsprop و Adam). أما الوسيط الثاني فهو دالة التكلفة المراد تطبيقها (غالباً نستخدم Binary_cross_Entropy مع مسائل التصنيف الثنائي و Categorical Crossentropy مع مسائل التصنيف المتعدد أو Spare Categorical Crossentropy) وأيضاً تجدهما في الروابط وكذلك يمكنك القيام بتعريف دالة التكلفة الخاصة بك واستخدامها كما تم شرح ذلك في الرابط في الأسفل. أما الوسيط الثالث فهو معيار قياس أداء النموذج خلال التدريب وغالباً نستخدم المعيار Accuracy عندما تكون البيانات متوازنة أو F1-Score عندما تكون البيانات غير متوازنة. أما الوسيط الخامس فهو لتوزين الفئات حيث نمرر لها قائمة المقاييس التي سيتم تقييمها ووزنها حسب وزن العينة sample_weight أو وزن الفئة class_weight أثناء التدريب والاختبار. أما الوسيط الأخير steps_per_execution فهذا يتعلق بسرعة التنفيذ و الافتراضي هو 1. ويمث عدد الدُفعات batches التي سيتم تنفيذها أثناء كل استدعاء tf.function. والفائدة منه تكمن في أن تشغيل دفعات متعددة داخل استدعاء tf.function واحد إلى تحسين الأداء بشكل كبير في حال كنت تستخدم وحدات TPU(على كولاب مثلاً). وما يلي هو مثال بسيط لها: model.compile(optimizer=tf.keras.optimizer.Adam(learning_rate=1e-3), # هنا مررنا المحسن loss=tf.keras.losses.BinaryCrossentropy(), # دالة التكلفة metrics=[tf.keras.metrics.BinaryAccuracy(), # ومقياسين للأداء tf.keras.metrics.FalseNegatives()]) كما يمكنك أن تجد مثال عنها في كل رابط من الروابط المذكورة في الأسفل مع نماذج بسيطة وواضحة.1 نقطة
-
يمكنك أن تتبع الخطوات التالية لتغيير اسم التطبيق في مشروع جانغو Django: أعد تسمية المجلد الموجود في جذر مشروعك (مجلد المشروع الرئيسي) غيّر أي مراجع لتطبيقك وكل تبعياتها dependencies، على سبيل المثال، الملفات views.py و urls.py و management.py و settings.py قم بتعديل جدول قاعدة البيانات django_content_type باستخدام الأمر التالي: UPDATE django_content_type SET app_label='<NewAppName>' WHERE app_label='<OldAppName>' إذا كانت لديك نماذج، فسيتعين عليك إعادة تسمية جداول النماذج. بالنسبة إلى postgreSQL و mysql، استخدم الأمر التالي: ALTER TABLE <oldAppName>_modelName RENAME TO <newAppName>_modelName إن كنت تستخدم الإصدار 1.7 أو أعلى من جانغو Django، فيجب أن تقوم بتحديث جدول django_migrations لتجنب إعادة تشغيل عمليات الترحيل السابقة: UPDATE django_migrations SET app='<NewAppName>' WHERE app='<OldAppName>' إذا كانت Meta Class الموجود في الملف models.py يحتوي على app_name، فتأكد من إعادة تسمية ذلك أيضًا. إذا قمت بوضع مجلدات ثابتة static أو قوالب templates داخل تطبيقك، فستحتاج أيضًا إلى إعادة تسميتها. على سبيل المثال، أعد تسمية OldAppName /static/OldAppName إلى NewAppName/static/NewAppName. لإعادة تسمية نماذج جانغو Django، ستحتاج إلى تغيير django_content_type.name في قاعدة البيانات. بالنسبة لـ postgreSQL و mysql، استخدم الأمر التالي: UPDATE django_content_type SET name='<newModelName>' where name='<oldModelName>' AND app_label='<OldAppName>' يجب إزالة المجلد __pycache __ الموجود داخل التطبيق، وإلا ستحصل على خطأ من نوع EOFError: EOFError: marshal data too short when trying to run the server بعد ذلك يمكنك إعادة تشغيل المشروع بدون مشكلة وستجد أن اسم المشروع قد تغير في كل الإماكن.1 نقطة
-
لأرسل رسائل البريد الإلكتروني تحتاج إلى خادم SMTP حقيقي. إذا لم ترغب في تثبيت خادم SMTP خاص بك، فيمكنك العثور على الشركات التي توفر خادم SMTP بمقابل مادي أو تستخدم بديل مجاني مثل Google نفسها. أستخدام Gmail كخادم SMTP لـ Django أسهل بكثير من التعامل أي خادم آخر. ولعمل ذلك تحتاج إلى تعديل إعدادات المشروع. في ملف settings.py: EMAIL_USE_TLS = True EMAIL_HOST = 'smtp.gmail.com' EMAIL_PORT = 587 EMAIL_HOST_USER = 'me@gmail.com' EMAIL_HOST_PASSWORD = 'password' قم بإضافة البريد الإكتروني الخاص بك وإستخدم كلمة سر مؤقتة من خلال ما يسمى بـ less secure apps في جوجل (لا تستخدم كلمة المرور الخاصة بك في أي مكان ظاهر مثل ملف settings.py أو غيره من الملفات لأنك لا تعلم من سيمكنه قراءة هذا الملف في المستقبل). ملاحظة: بداية من 2016 لم تعد جوجل تقبل إستخدام كلمة المرور بالشكل السابق، بدلًا من ذلك أصبحت جوجل توفر ما يسمى بالتطبيقات الأقل أمانًا من خلال الذهاب Security > Account permissions > Access for less secure apps، حيث سوف تقوم بالحصول على كلمة سر مخصصة لإستخدامها في هذا التطبيق/المشروع بالتحديد ولا يمكن إستخدام كلمة السر هذه للدخول إلى حسابك بالكامل، بل فقط تستخدم لإرسال رسائل البريد الإلكتروني (أو حسب إعدادات التطبيق في جوجل). من الأفضل أيضًا أن تضع البريد الإلكتروني وكلمة المرور في متغيرات بيئة environment variable وإستخدام هذه المتغيرات في ملف settings.py بعد إتمام الإعدادات السابقة سيمكنك أن ترسل الرسائل من خلال الكود التالي: from django.core.mail import EmailMessage emails = ['another@email.com'] email = EmailMessage('Subject', 'Body', to=emails) email.send()1 نقطة
-
يمكن أن يظهر هذا الخطأ نتيجة تمريرك ال token كالتالي: token = RefreshToken(access_token) بينما يجب عليك أن تقوم بتمريره في refresh token.. يمكنك كذلك تجربة عل blacklist لل tokens كالتالي: #urls.py path('/api/logout', views.BlacklistRefreshView.as_view(), name="logout"), #view.py from rest_framework_simplejwt.tokens import RefreshToken class BlacklistRefreshView(APIView): def post(self, request) token = RefreshToken(request.data.get('refresh')) token.blacklist() return Response("Success")1 نقطة
-
يمكن استخدام JWT للمصادقة بدون قاعدة بيانات أو ما يسمى بـ database-less authentication. لأنه يشفر البيانات اللازمة للمصادقة في رموز tokens. حيث سيكون تطبيقك قادرًا على مصادقة المستخدمين بعد فك الرموز tokens بالبيانات المضمنة فيه. ولكن إذا كنت تريد تخزين رموز tokens في simplejwt ، فيمكنك استخدام نموذج OutstandingingToken لتخزين الرموز في قاعدة البيانات. لكن قبل استخدام OutstandingToken، تأكد من وضع rest_framework_simplejwt.token_blacklist في قائمة INSTALLED_APPS في ملف settings.py.، كالتالي: # Django project settings.py # ... INSTALLED_APPS = ( # ... 'rest_framework_simplejwt.token_blacklist', # ... ) ثم تشغيل الأمر التالي لتعديل قاعدة البيانات: python manage.py migrate عندما يتم اكتشاف تطبيق token_blacklist في قائمة التطبيقات المثبتة INSTALLED_APPS ، فسيضيف Simple JWT أي رموز refresh token أو access token تم إنشاؤها إلى قائمة من الرموز outstanding tokens.1 نقطة
-
أفضل حل تم نشره لـ Django الاصدارين 1.7 ، 1.9 هو تسجيل تحويل (register a transform) كالتالي from django.db import models class MySQLDatetimeDate(models.Transform): lookup_name = 'date' def as_sql(self, compiler, connection): lhs, params = compiler.compile(self.lhs) return 'DATE({})'.format(lhs), params @property def output_field(self): return models.DateField() يؤدي هذا إلى تنفيذ بحث SQL مخصص عند استخدام "__date" مع datetimes. لتمكين التصفية على التواريخ التي تقع في تاريخ معين ، قم باستيراد هذا التحويل وتسجيله في DateTimeField, ثم يمكنك استخدامه في عوامل التصفية الخاصة بك كالتالي Foo.objects.filter(created_on__date=date)1 نقطة
-
في البداية عليك أن تتأكد من أن كل البيانات على شكل datetime لان غير ذلك قد يسبب أخطاءا عن البحث: import datetime date_from = datetime.datetime.strptime(request.GET['q1'], '%Y-%m-%d') date_to = datetime.datetime.strptime(request.GET['q2'], '%Y-%m-%d') بعد ذلك تقوم بالبحث عن التواريخ التى تريد الحصول عليها ببساطة باستخدام الكود التالي: datetime = User.objects.filter(created__range=(date_from, date_to))1 نقطة
-
تستطيع انشاء الشكل الخاص بك view دون الحاجة لاي اشكال مصنوعة مسبقا، الكود التالي يوضح كيفية انشاء token: from rest_framework import serializers, viewsets, status class SignInSerializer(serializers.Serializer): username = serializers.CharField(max_length=255, required=True) password = serializers.CharField(max_length=255, required=True, write_only=True) هناك حل أخر أطول قليلا هو أن تستدعي userview set ثم بتقوم بالكتابة على create method، بعدها تقوم بالحصول على المستخدم user ثم انشاء JWT tokens، الكود التالي يوضح تلك العملية: from rest_framework import status from djoser.views import UserViewSet from djoser import signals from djoser.compat import get_user_email from rest_framework_simplejwt.tokens import RefreshToken class CustomRegistrationView(UserViewSet): def perform_create(self, serializer): user = serializer.save() signals.user_registered.send( sender=self.__class__, user=user, request=self.request ) context = {"user": user} to = [get_user_email(user)] if settings.SEND_ACTIVATION_EMAIL: settings.EMAIL.activation(self.request, context).send(to) elif settings.SEND_CONFIRMATION_EMAIL: settings.EMAIL.confirmation(self.request, context).send(to) def create(self, request, *args, **kwargs): serializer = self.get_serializer(data=request.data) serializer.is_valid(raise_exception=True) self.perform_create(serializer) headers = self.get_success_headers(serializer.data) response_data = serializer.data user = User.objects.get(username = response_data['username']) refresh = RefreshToken.for_user(user) response_data['refresh'] = str(refresh) response_data['access'] = str(refresh.access_token) return Response(response_data, status=status.HTTP_201_CREATED, headers=headers)1 نقطة
-
يتم تنفيذ عمليات البحث هذه في django.views.generic.date_based على النحو التالي: {'date_time_field__range': (datetime.datetime.combine(date, datetime.time.min), datetime.datetime.combine(date, datetime.time.max))} كما يمكنك استخدام الخاصية startswith كالتالي: from datetime import date today = date.today() Model.objects.filter(date_created__startswith=today) أو من خلال الخاصية gte: Model.objects.filter(date_created__gte=today) وبشكل عام فإن الخاصية contain التي ذكرها سامح والخاصية startswith تعتبران الأسرع1 نقطة
-
يمكننا استخدام الدالة set_weights التي لها الشكل التالي: Model.set_weights(weights) حيث نمرر لهذه الدالة الأوزان (مصفوفة نمباي) المراد استخدامها كأوزان للطبقة المستدعية (عمليى نسخ). كما نعلم فإن أوزان الطبقة تعبر عن حالة الطبقة(سلوكها والتدريب الذي تلقته). إن هذه الدالة تقوم بنسخ الأوزان من طبقة لأخرى. حيث يجب تمرير قيم الوزن بالترتيب الذي تم إنشاؤه بواسطة الطبقة. على سبيل المثال ، تُرجع الطبقة Dense قائمة من قيمتين: مصفوفة النواة (مصفوفة الأوزان) ومتجه التحيز (قيم الانحراف bias). هذه القيم يمكن استخدامها لتعيين أوزان طبقة Dense أخرى: import tensorflow as tf #وتهيئة قيم أوزانها Dense إنشاء طبقة # تهيئة الانحراف بقيمة 0 والأوزان بقيمة 1 layer1 = tf.keras.layers.Dense(1,kernel_initializer=tf.constant_initializer(1.)) out1 = layer1(tf.convert_to_tensor([[1., 2., 3.]])) # طباعة الأوزان (يتضمن ذلك قيمة الانحراف) layer1.get_weights() """ [array([[1.], [1.], [1.]], dtype=float32), array([0.], dtype=float32)] """ # تعريف طبقة أخرى layer2 = tf.keras.layers.Dense(1,kernel_initializer=tf.constant_initializer(2.)) out2 = layer_b(tf.convert_to_tensor([[10., 20., 30.]])) layer2.get_weights() """ [array([[2.], [2.], [2.]], dtype=float32), array([0.], dtype=float32)] """ # نسخ أوزان الطبقة الأولى للثانية layer_2.set_weights(layer_1.get_weights()) # عرض أوزانها الآن للتأكد layer_2.get_weights() """ [array([[1.], [1.], [1.]], dtype=float32), array([0.], dtype=float32)] """1 نقطة
-
إليك طريقة أخرى باستخدام طريقة النموذج (model method). يمكنك باستخدام هذه الطريقة أن تتخطى الحقول الفارغة ويتيح لك استبعاد حقول محددة. def get_all_fields(self): """Returns a list of all field names on the instance.""" fields = [] for f in self._meta.fields: fname = f.name get_choice = 'get_'+fname+'_display' if hasattr(self, get_choice): value = getattr(self, get_choice)() else: try: value = getattr(self, fname) except AttributeError: value = None # اعرض فقط الحقول ذات القيم وتخطي بعض الحقول if f.editable and value and f.name not in ('id', 'status', 'workshop', 'user', 'complete') : fields.append( { 'label':f.verbose_name, 'name':f.name, 'value':value, } ) return fields ثم في القالب الخاص بك: {% for f in app.get_all_fields %} <dt>{{f.label|capfirst}}</dt> <dd> {{f.value|escape|urlize|linebreaks}} </dd> {% endfor %}1 نقطة
-
إضافة إلى الحلول التي ذكرها سامح يمكنك استخدام model_to_dict للحصول على أسماء الحقول وقيمها بالشكل التالي: from django.forms.models import model_to_dict def show(request, object_id): object = FooForm(data=model_to_dict(Foo.objects.get(pk=object_id))) return render_to_response('foo/foo_detail.html', {'object': object}) ثم في القالب: {% for field in object %} <li><b>{{ field.label }}:</b> {{ field.data }}</li> {% endfor %}1 نقطة
-
هذا الخطأ يظهر أحياناً بسبب وجود مشاكل في نسخة Pillow 8.3.0 الجديدة (صحيح أنك لاتستخدم import PIL بشكل صريح لكن الدالة ()tf.keras.preprocessing.image.load_img تستخدم PIL ضمنياً). لذا قم بتخفيض نسخة PIL إلى 8.2.0 وسينجح الأمر: !pip install pillow==8.2.0 وبشكل عام لمعرفة الإصدار الحالي من PIL: import PIL print(PIL.__version__)1 نقطة
-
tensorboard_callback هي أداة تسمح لك بمراقبة أداء النموذج من خلال رسم بياني يوضح حالة التدريب. ويمكنك استخدامها مع نموذجك أو أي نموذج آخر بنفس الطريقة كالتالي: %load_ext tensorboard # tensorboard نقوم بتحميل الإضافة # الآن سنعرف نموذج import tensorflow as tf import datetime mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 def create_model(): return tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) model = create_model() # ترجمة النموذج model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # مسار المجلد الذي سيتم فيه حفظ المعلومات التي سيقوم التنسربورد بتحليلها وعرضها log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") # تعريف الكولباكس tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir) # نقوم بتمرير الكولباكس إلى دالة التدريب model.fit(x=x_train, y=y_train, epochs=2, validation_data=(x_test, y_test), callbacks=[tensorboard_callback]) الآن لعرض الرسم البياني نقوم بتنفيذ الأمر التالي ضمن ال nootebook: # لعرض الغراف %tensorboard --logdir logs/fit # حيث نضع مسار المجلد السابق أو من خلال ال commandline استخدم نفس الأمر السابق لكن من دون استخدام المعامل % أي: tensorboard --logdir logs/fit وبهذه الطريقة يمكنك عرض معلومات الدقة والتكلفة loss ضمن نموذجك خلال عملية تدريب نموذجك.1 نقطة
-
في تنسرفلو يمكنك حسابهم بالشكل التالي اعتماداً على الصيغة العامة لهم: بعد حساب القيم المتوقعة y_pred نقوم بحساب ال TP و TN و FP و FN ونستخدم الدالة count_nonzero للقيام بذلك: TP = tf.count_nonzero(y_pred * y_true) TN = tf.count_nonzero((y_pred - 1) * (y_true - 1)) FP = tf.count_nonzero(y_pred * (y_true - 1)) FN = tf.count_nonzero((y_pred - 1) * y_true) ثم نقوم بتطبيق القوانين السابقة مباشرةً: precision = TP / (TP + FP) recall = TP / (TP + FN) f1 = 2 * precision * recall / (precision + recall) عموماً إذا لم تكن تستخدم graph فيمكنك أيضاً استخدام التوابع الجاهزة في sklearn لذا سأترك لك روابط لهم: في الرابط هنا تجد شرح لل TP و ال TN إلخ..
 1 نقطة
1 نقطة -
يمكنك القيام بعملية التحويل من خلال الكود التالي: import tensorflow as tf with tf.Session() as mysess: # تحميل الغراف saver = tf.train.import_meta_graph('model.ckpt-22480.meta') # meta نمرر مسار تواجد ملف # تحويل الأوزان saver.restore(mysess,tf.train.latest_checkpoint('path/of/your/.meta/file')) # تجميد الغراف output_nodes = ['output:0'] # نحدد أسماء عقد الإخراج frozen_graph_def = tf.graph_util.convert_variables_to_constants( mysess,mysess.graph_def, output_nodes) # حفظه with open('graph.pb', 'wb') as file: file.write(frozen_graph_def.SerializeToString()) وفي حال لم تكن تعرف أسماء عقد الخرج، يمكنك استخدام الكود التالي لاستخلاصها: output_nodes = [n.name for n in tf.get_default_graph().as_graph_def().node]1 نقطة
-
نعم يمكن، لكنها فكرة سيئة وقد تؤدي بك إلى العديد من المشاكل. لكن إليك بعض الطرق: قتل النيسب "Thread" من خلال تعريف flag بحيث عند رفعه يتم إيقافه: في الكود التالي، سنعرف علم (flag) وبمجرد أن نقوم برفعه ينتهي تنفيذ الدالة run ويمكن قتل النيسبth1 باستخدام th1.join. import time import threading as th def myfunc (): while True: print('The thread is still working') # نجعل العلم متحول عام لكي تكون التغيرات عليه عامة أي مرئية global flag #يتم إيقاف النيسب True إذا تم رفع العلم أي إذا كان if flag: break # في البداية نجعل العلم غير مرفوع flag = False # نعرف أول نيسب # النيسب يقوم بتنفيذ الدالة السابقة th1 = th.Thread(target = myfunc ) # تشغيل النيسب th1.start() time.sleep(1) # هنا مثلاً نقوم برفع العلم ليتم إيقافه stop_threads = True th1.join() print('thread killed') الطريقة الثانية هي إثارة استثناء في النيسب، من خلال استخدام الدالة PyThreadState_SetAsyncExc: في الكود التالي بمجرد استدعاء الدالة myexception سيتم إنهاء الدالة myfunc لأنه عندما يظهر الاستثناء سينتقل التحكم في البرنامج خارج كتلة try ويتم إنهاء الدالة. بعد ذلك نقوم باستخدام join لقتل النيسب. وفي حالة لم نقوم باستدعاء دالة رفع الاستثناء سيتم تنفيذ myfunc بدون توقف ولن يتم استدعاء Join لقتل النيسب. import threading from ctypes.pythonapi import PyThreadState_SetAsyncExc import time import ctypes # نيسب مع استثناء class exception(threading.Thread): def __init__(self, name): threading.Thread.__init__(self) self.name = name # التابع الهدف def myfunc(self): try: while True: print('is running ' + self.name) finally: print('is over') # دالة لإرجاع رقم الثريد def ID_(self): if hasattr(self, '_thread_id'): return self._thread_id for id, thread in threading._active.items(): if thread is self: return id # دالة لرفع استثناء def myexception(self): id = self.ID_() e = PyThreadState_SetAsyncExc(id, ctypes.py_object(SystemExit)) if e > 1: PyThreadState_SetAsyncExc(id, 0) # طباعة رسالة تعبر عن أنه تمت إثارة الاستقناء print('failure') th = exception('thr') # نمرر اسم النيسب # تشغيله th.start() time.sleep(1) # استدعاء دالة رفع الاستثناء ليتم إيقافه th.myexception() th.join()1 نقطة
-
أول طريقة من خلال استخدام النهج التكراري (الحلقات التكرارية): # باستخدام الحلقات التكرارية def cartesian_iterative(list): result = [[]] for l in list: result = [x+[y] for x in result for y in l] return result # الآن يمكننا استخدام التابع السابق لتنفيذ الجداء الديكارتي على القوائم sections = [ [1, 2, 3], [4, 5], [6, 7] ] cartesian_iterative(sections) من خلال استخدام lambda و reduce: # تعريف التابع def prod(pools): import functools from itertools import product return list(functools.reduce(lambda x,y: product(x,y) , pools)) # استخدامه prod(sections) أو من خلال العودية: # تعريف التابع def product(ar_list): if not ar_list: yield () else: for a in ar_list[0]: for prod in product(ar_list[1:]): yield (a,)+prod # لاستخدامه list(product(sections))1 نقطة
-
يمكنك استخدام الكلاس LambdaCallback التي تسمح لك بتعريفَ callback خاص بك وبالطريقة التي تريدها. باني هذا الكلاس يأخذ الوسطاء التالية التي تسمح لك بالتحكم في توقيت تنفيذ ال callback: tf.keras.callbacks.LambdaCallback( on_epoch_begin=None, on_epoch_end=None, on_batch_begin=None, on_batch_end=None, on_train_begin=None, on_train_end=None, **kwargs ) on_epoch_begin أي الاستدعاء يتم في بداية كل epoch. و on_epoch_end أي في نهايته. on_batch_begin أي في بداية الباتش... وهكذا بالنسبة لللبقية. بالنسبة ل on_epoch_begin و on_epoch_end فهما يتوقعان منك أن تتستخدم معهما وسيطين موضعيين هما ال epoch, logs. بالنسبة ل on_batch_begin و on_batch_end يتوقعان وسيطين أيضاً هما batch, logs. وأخيراً on_train_begin و on_train_end يتوقعان فقط وسيط واحد وهو logs. الآن لجعل الأمور أوضح سنأخذ المثال التالي: # بناء نموذج # compile ترجمته من خلال الدالة # fit الآن عندما نريد تعريف الكولباك يجب أن يتم ذلك قبل تنفيذ الدالة # تعريف الكولباك الذي طلبته mycallback= LambdaCallback(on_epoch_end=lambda epoch, logs:model.save_weights(myfile.hdf5) if logs["val_accuracy"]>0.7 else None) #لكن لاتنسى أن تقوم بتمرير الكولباك الذي عرفناه للدالة أي fit الآن تقوم بتدريب النموذج من خلال الدالة model.fit(..., callbacks=[mycallback]) وبالتالي سيتم حفظ أوزان النموذج كلما كانت قيمة ال val_acc أكبر من 70 في المئة. مثال آخر حيث سنقوم بتعريف كولباك يقوم بطباعة رقم الحزمة في بداية كل باتش: callback1 = LambdaCallback( on_batch_begin=lambda batch,logs: print(batch)) تعريف كول باك آخر يقوم بحفظ ال loss في نهاية كل epoch في ملف JSON (الملف سيكون عبارة عن كائن json في كل سطر): import json json_log = open('loss_log.json', mode='wt', buffering=1) #json إنشاء ملف callback2 = LambdaCallback( on_epoch_end=lambda epoch, logs: json_log.write( json.dumps({'epoch': epoch, 'loss': logs['loss']}) + '\n'), on_train_end=lambda logs: json_log.close() ) الآن نقوم بتمريرهم للدالة fit عندما نريد بدأ التدريب: model.fit(..., callbacks=[callback1, callback2])1 نقطة
-
يمكن عمل موقع بلغة JavaScript فقط (backend + frontend) لكن ستحتاج إلى إستخدام إطارات عمل مثل React.js لواجهة الموقع و express.js للـ backend بالإضافة إلى إستعمال SQL للتعامل مع قواعد البيانات (لاحظ أن SQL ليست لغة برمجة وإنما لغة تستعمل لكتابة جمل تتعامل مع قواعد البيانات لعمل عمليات الإضافة والتعديل والحذف .. إلخ). وهذا المسار من التقنيات يعرف بـ MERN (MongoDB Express.js React.js Node.js)1 نقطة
-
بالطبع يبدو الأمر صعبًا في البداية بسبب المنافسة بين المستقلين خصوصًا إن لم يكن لديك أي أعمال سابقة لتعرضها في معرض أعمالك، وسيكون حسابك بلا أي تقييمات سابقة بالطبع، بينما المستقلين الآخرين لديهم العديد من الأعمال والتقييمات المرتفعة، إذا لماذا سيقوم العميل بإختيارك أنت بدلًا من المستقلين الآخرين؟ وللإجابة على هذا السؤال يجب أن تقدم للعميل شيء يوضح له خبرتك في المجال، عليك أن تقوم بعمل بعض المشاريع الخاصة بنفسك تظهر فيها أقصى ما تستطيع الوصول إليه من إبداع ومجهود، ولا يجب أن تقوم بعمل العشرات من الأعمال يكفي 5 أعمال بسيطة وليست معقدة للغاية، يمكنك تصفح المشاريع المطلوبة على مستقل أو خمسات وقم تنفيذها بنفسك (بدون التقديم على العمل)، ثم قم بإضافة المشروع إلى معرض أعمالك، وبالتالي تكون قمت بعمل معرض أعمال والتدرب على مشاريع حقيقية. بعد ذلك دع معرض أعمالك يتحدث عنك، عندما تقوم بالتقديم على عمل جديد لا ترفع من تكلفة المشروع، وقم بكتابة عرض عمل منسق وإحترافي، أعرض على العميل أن تقوم بعمل بعض الأمور الأضافية التي قد تفيده، فقط أمور بسيطة مثل تصميم صفحة بسيطة إضافية، أو إختيار ألوان متناسقة أكثر .. إلخ، وتذكر أن الهدف في البداية هو الحصول على تقييم عالي وليس أن تتحصل على مبلغ مالي أكبر، ومع الوقت سيمكنك أن تقوم بتكبير معرض أعمال يحتوي على أعمال إحترافية وسيكون لديك تقييمات عالية، وسيمكنك المنافسة على المشاريع. عليك أيضًا أن تتابع مدونة خمسات ومستقل حيث يتم نشر تدوينات ستساعدك كثيرًا في العمل الحر، وإختيار العملاء وكيفية التعامل معهم بشكل سليم.1 نقطة












