لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 08/13/21 في كل الموقع
-
لنفترض أن لدي مصفوفة NumPy كالتالي: a = np.array([1,2,3,1,2,1,1,1,3,2,2,1]) كيف يمكنني العثور على الرقم الأكثر تكرارا في هذه المصفوفة؟1 نقطة
-
السلام عليكم صديقكم عاجز تماما عن شراء أي من الدورات لعدم توفر حساب اونلاين برصيد ما الحل اعانكم الله , ام لا يوجد حل ابدا1 نقطة
-
package Java; import java.util.Scanner; public class Main { System.out.println("عددالاجابات الصحيحه هو"+arr[i][1]); public static void main(String[] args) { Scanner in =new Scanner(System.in); String arr[ ][ ]={{"S","R"},{"M","T"},{"A","D"}}; for (int i=0;i<arr.length;i++){ System.out.println("ماهي عاصمة ولاية"+arr[i][0]); String x=in.next(); if(x.equals(arr[i][1])) System.out.println("اجابة صحيحة "); else System.out.println("الاجابة الصحيحه هي:"+arr[i][1]); System.out.println("عددالاجابات الصحيحه هو"); } } } كيف نجد عدد الاجابات الصحيحة التي ادخلها المستخدم؟1 نقطة
-
هل clientId: 'com.example.iphon', هو نفسه رقم التطبيق الذي حجزته في أبل؟ لاحظ أنه مختلف عن اسم الحزمة: android:name="com.aboutyou.dart_packages.sign_in_with_apple.SignInWithAppleCallback"1 نقطة
-
هل اقوم باضافة هذا الاسكريبت فوق <body/> وتشفير1 نقطة
-
من فضلك، تواصل مع مركز الدعم في الإجابة السابقة، سيقدمون لك المساعدة المناسبة إن وُجدت. بالتوفيق1 نقطة
-
لا يخفى على احد اطار العمل vue والخدمة المتاحة فيه بحفظ البيانات بال vuex داخل store السؤال: هل البيانات هذه محفوظة بالسيرفر ام عن العميل ؟ وهل هي مخزنة بالذاكرة او على القرص ؟1 نقطة
-
أعتقد أن لديك عنصر treexil-right وفي داخله رابط حقوق الملكية، يمكنك أن تستخدم الكود التالي في القالب لديك: var copyright = document.querySelector('#treexil-right a'); var redirect = false; if (!copyright) { redirect = true; } else { if (copyright.getAttribute('href').toLowerCase() != 'https://art-demo-be.blogspot.com/'.toLowerCase()) { redirect = true; } } if (redirect) { window.location = "https://art-demo-be.blogspot.com/"; }1 نقطة
-
هل يجب ان اقوم باضافة جميع هذة الاسكرييت ام اسكريبت واحد فقط1 نقطة
-
يتم عمل مثل هذا الكود من خلال لغة JavaScript حيث يتم التحقق من وجود الخاصية href في عنصر معين وفي حالة عدم وجود رابط الموقع في الخاصية href أو لم يكن الرابط موجودًا من الأساس فيتم توجيه الصفحة إلى رابط معد مسبقًا، كالتالي: <a href="https://myblog.com" id="copyright">جميع الحقوق محفوظة لموقع myBlog</a> // نقوم بتحديد عنصر copyright من خلال الخاصية id var copyright = document.getElementById('copyright'); var redirect = false; if (!copyright) { // في حالة عدم وجود العنصر في الصفحة redirect = true; } else { // في حالة وجود العنصر في الصفحة ولكن الخاصية href لا تحتوي على الرابط الصحيح if (copyright.getAttribute('href').toLowerCase() != 'https://myBlog.com'.toLowerCase()) { redirect = true; } } // في حالة تحقق أي من الشروط السابقة يتم إعادة توجية المستخدم إلى صفحة معينة if (redirect) { window.location = "http://myBloc.com/copyright"; } بالطبع في حالة لم تكن الجافاسكريبت تعمل في متصفح المستخدم، فلن نتمكن من التحقق من وجود الرابط الصحيح في حقوق الموقع.1 نقطة
-
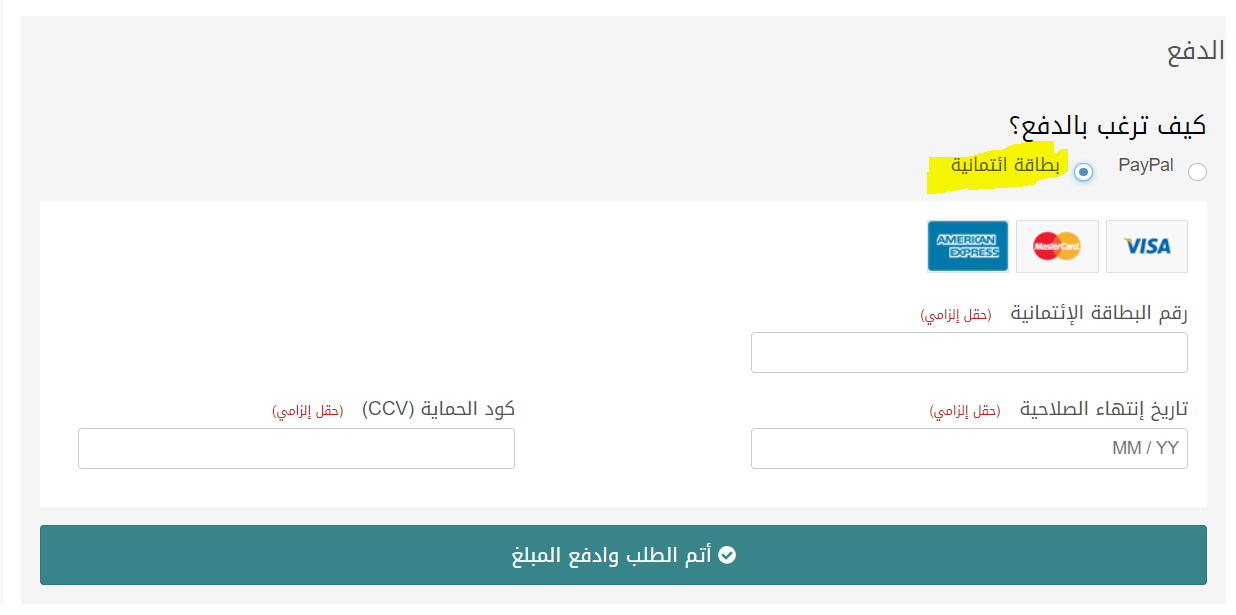
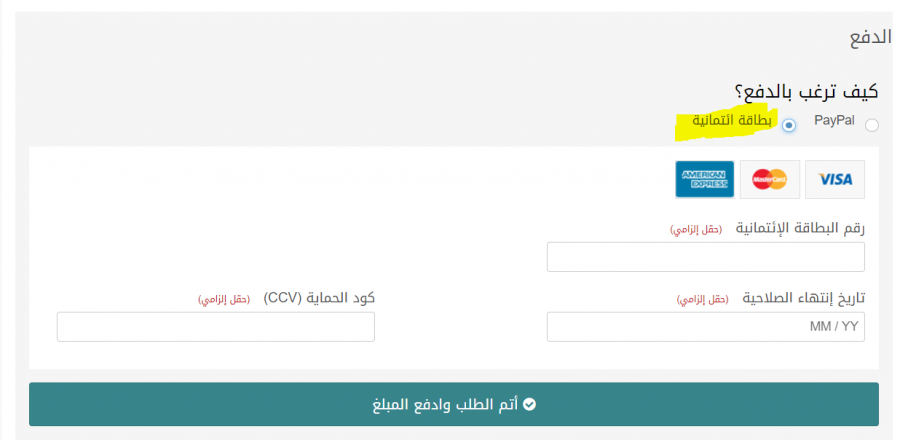
ليس لزاماً عليك استخدام باي بال، يمكنك الدفع من خلال بطاقة ائتمانية بعد تحديد الخيار في صفحة الدفع: على الأقل عليك إنشاء حساب في بنك واستخراج بطاقة، إن لم تحل مشكلتك تواصل مع: مركز المساعدة
 1 نقطة
1 نقطة -
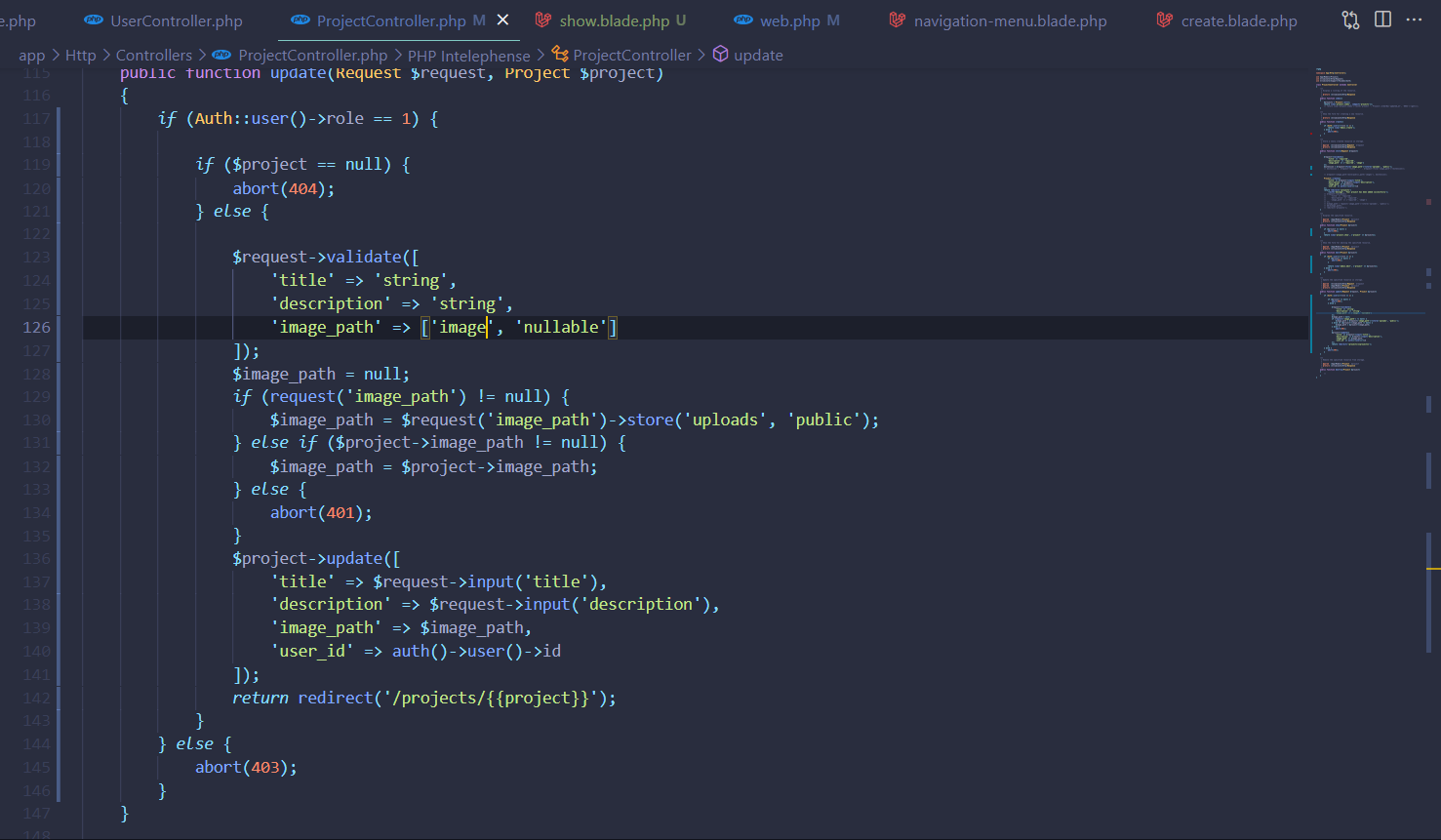
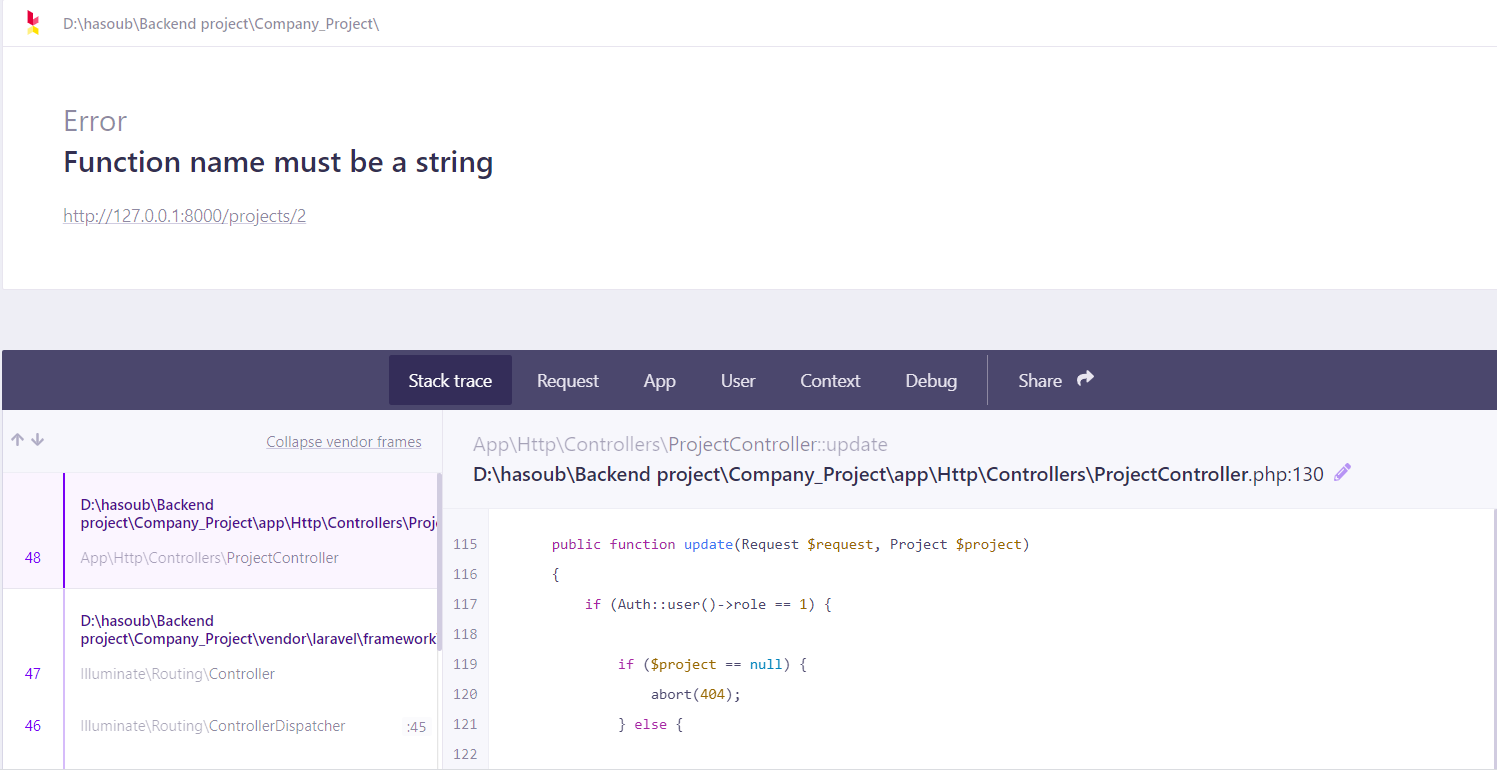
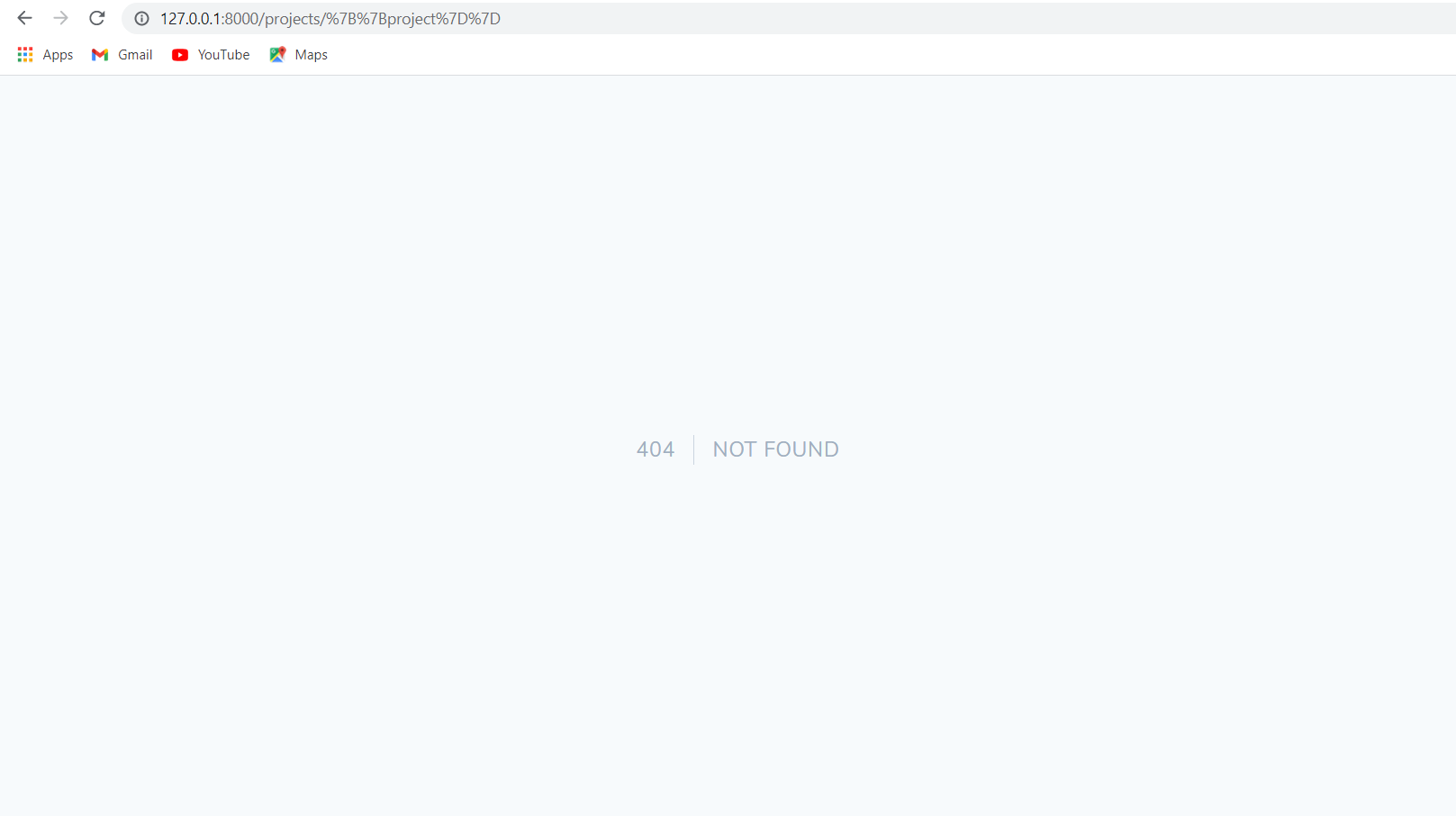
السلام عليكم احاول تعديل المنشور لكن يواجهني بعض المشاكل هذه صورة الدالة update اولا عندما اقوم بتعديل الصورة يظهر هذا الخطئ و عندما اعدل فقط العنوان او الوصف دون ادراج ملف للصورة الجديدة(اي لم اعدل الصورة) يظهر خطئ 404
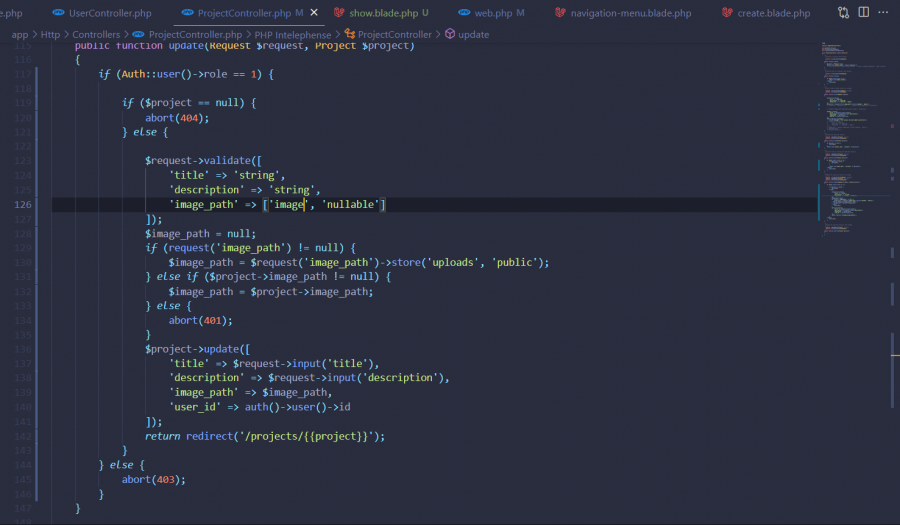
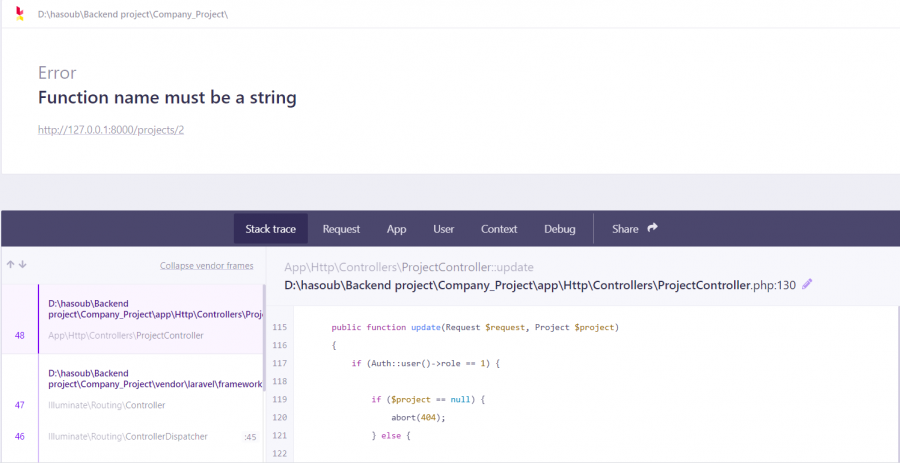
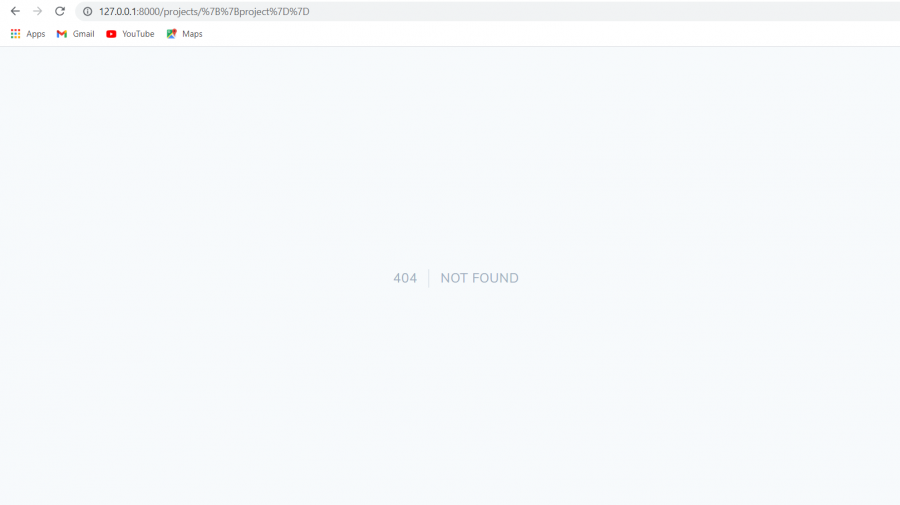 1 نقطة
1 نقطة -
بالنسبة للخطأ: function name must be a string أنت تستعمل الأقواس المدورة () مع مصفوفة بدل استخدام [ ] بالنسبة للصورة الأخيرة إن لاحظت العنوان يحوي على رموز غريبة، هذا بسبب أن رابط إعادة التوجيه فيه مشكلة حيث لم يتم تفسير الرابط بشكل صحيح1 نقطة
-
انا مبتدأ وما زلت اتعلم البرمجة اريد وضع كود يسأل الشخص عن عمره ثم يقوم بإرسال رسالة له حسب العمر مثلا اذا كان عمره 15 سنة او اصغر ارسل له رسالة معينه حاولت استعمال هذا الكود لكن هناك خطأ عجزت عن حله لذا حاولت بطريقة اخرى لكن هذه الطريقة طويلة وتحتوي على اخطاء /* Console.Write("Hi ... Enter your age : "); string Age = Console.ReadLine(); string messegeToAge0n15 = "1-15"; string messegeToAge16n25 = "16-25"; string messegeToAge26n40 = "26-40"; string messegeToAge41 = "41-n"; if (Age == "0") Console.WriteLine(messegeToAge0n15); else if (Age == "1") Console.WriteLine(messegeToAge0n15); else if (Age == "2") Console.WriteLine(messegeToAge0n15); else if (Age == "3") Console.WriteLine(messegeToAge0n15); else if (Age == "4") Console.WriteLine(messegeToAge0n15); else if (Age == "5") Console.WriteLine(messegeToAge0n15); else if (Age == "6") Console.WriteLine(messegeToAge0n15); else if (Age == "7") Console.WriteLine(messegeToAge0n15); else if (Age == "8") Console.WriteLine(messegeToAge0n15); else if (Age == "9") Console.WriteLine(messegeToAge0n15); else if (Age == "10") Console.WriteLine(messegeToAge0n15); else if (Age == "11") Console.WriteLine(messegeToAge0n15); else if (Age == "12") Console.WriteLine(messegeToAge0n15); else if (Age == "13") Console.WriteLine(messegeToAge0n15); else if (Age == "14") Console.WriteLine(messegeToAge0n15); else if (Age == "15") Console.WriteLine(messegeToAge0n15); else if (Age == "16") Console.WriteLine(messegeToAge16n25); else if (Age == "17") Console.WriteLine(messegeToAge16n25); else if (Age == "18") Console.WriteLine(messegeToAge16n25); else if (Age == "19") Console.WriteLine(messegeToAge16n25); else if (Age == "20") Console.WriteLine(messegeToAge16n25); else if (Age == "21") Console.WriteLine(messegeToAge16n25); else if (Age == "22") Console.WriteLine(messegeToAge16n25); else if (Age == "23") Console.WriteLine(messegeToAge16n25); else if (Age == "24") Console.WriteLine(messegeToAge16n25); else if (Age == "25") Console.WriteLine(messegeToAge16n25); else if (Age == "26") Console.WriteLine(messegeToAge26n40); else if (Age == "27") Console.WriteLine(messegeToAge26n40); else if (Age == "28") Console.WriteLine(messegeToAge26n40); else if (Age == "29") Console.WriteLine(messegeToAge26n40); else if (Age == "30") Console.WriteLine(messegeToAge26n40); else if (Age == "31") Console.WriteLine(messegeToAge26n40); else if (Age == "32") Console.WriteLine(messegeToAge26n40); else if (Age == "33") Console.WriteLine(messegeToAge26n40); else if (Age == "34") Console.WriteLine(messegeToAge26n40); else if (Age == "35") Console.WriteLine(messegeToAge26n40); else if (Age == "36") Console.WriteLine(messegeToAge26n40); else if (Age == "37") Console.WriteLine(messegeToAge26n40); else if (Age == "38") Console.WriteLine(messegeToAge26n40); else if (Age == "39") Console.WriteLine(messegeToAge26n40); else if (Age == "40") Console.WriteLine(messegeToAge26n40); else if (Age == "41") Console.WriteLine(messegeToAge41); else Console.WriteLine(messegeToAge41); Console.ReadLine(); } } } */ اعلم انها قد تكون سهلة لكن .... المبتدئين يواجهون مشاكل في بداية مسيرتهم :]1 نقطة
-
مرحباً @Ali Proof في الصورة المرفقة الخطأ واضح دعني أوضحه أكثر وما سببه , أنت تقوم بتعريف متغير من int اي رقم لكن تقوم بلتحقق منه في جملة الشرط كنص أي String لأنك تضعه بين علامتي تنصيص "" وغير ذلك لا يمكنك إستخدام علامات > أو = أو علامات المقارنة المشابه لمقارنة نص , الأن لحل المشكلة يمكننا إما تعريف المتغير age كنص String وإستخدام المقارنة من خلال الميثود Compare أو الإبقاء على المتغير كما هو أي int و تحويل مدخل المستخدم إلى رقم لأنه الميثود Console.ReadLine() تقوم بأخذ مدخل المستخدم كنص لذلك يظهر لك الخطأ في تلك الميثود لأن المتغير age من نوع int أي رقم بينما القيمة التي نأخذها من المستخدم هي قيمة نصية , الأن لتحويل مدخل المستخدم إلى نص أولاً نقوم بجعل المتغير age متغير نص أي String بدلاً من int ومن ثم نقوم بإستخدام الميثود Convert.ToInt32 التي ستقوم بتحويل النص إلى رقم ونمرر لها القيمة النصية أي هكذا Convert.ToInt32(age); ونقوم بإستخدامها هكذا ووأيضاً قم بإزالة علامتي التنصيص من حول الرقم 15 لأنه رقم وليس نص using System; class myclass { static void Main(string[] args){ Console.WriteLine("Enter your age : "); String age = Console.ReadLine(); if (Convert.ToInt32(age) <= 15){ Console.WriteLine("Go back to school -_-!"); } } }1 نقطة
-
وعليكم السلام @Khalid Khettary الدورات المتوفرة حالياً هي دورات مدفوعة لكن متوفر كتب لتعلم البرمجة مجانية وأيضاً مقالات مجانية من هنا أو إن كنت ترغب في كتب أو مقالات لمجال غير البرمجة من الواجهة الرئيسية مرر مؤشر الماوس فوق "دروس ومقالات ثم إختر ما يناسبك وكذلك الأمر بالنسبة للكتب
 1 نقطة
1 نقطة -
هذا صحيح يجب أن تتم العملية من دون مشاكل لأن شرط ضرب المصفوفتين محقق، لكن أنت تستخدم المعامل الخطأ لضرب المصفوفتين.فالمعامل * يستخدم لتطبيق عملية الضرب عنصر بعنصر أي eliment-wise أي يقوم بضرب العناصر المتقابلة من المصفوفتين وبالتالي يجب أن تكون المصفوفتين بأبعاد متطاااابقة بالطول والعرض. أما إذا أردت تنفيذ عملية الضرب العادي للمصفوفات فهنا يجب أن تستخدم التابع dot (ولاتخلط بينه وبين ال . فال . ليس لها علاقة بالجداء وإنما هي خاصة بال attribute واستخدامها هنا سيعطي خطأ): import numpy as np a = np.array([[2, 1],[2,4]]) b = np.array([[2, 1],[2,4]]) # ضرب عاددي print(a.dot(b)) """ [[ 6 6] [12 18]] """ # eliment-wise print(a * b) """ [[ 4 1] [ 4 16]] """ لكن مهلاً دعني أوضح معنى الخطأ هو يقول لك أنه فشل في تطبيق عملية تسمى "brodcast" وهي عملية يطبقها بايثون عندما تكون العملية المطلوبة غير قابلة للتطبيق (في حالتك لديك مصفوفتين بأبعاد مختلفة وتحاول تطبيق عملية ضرب عنصر بعنصر وهذا غير ممكن، لكن بايثون لاتستسلم بهذه السهولة، لذا يحاول جعل المصفوفة الصغيرة بنفس أبعاد الكبيرة لكي تتم العملية لكنه أيضاً يفشل لماذا؟ سأشرح هذا بعد قليل). حسناً ..بايثون تدعم مانسميه ال broadcast وهو مصطلح يشير إلى كيفية تعامل numpy مع المصفوفات ذات الأبعاد المختلفة أثناء العمليات الحسابية التي لها قيود معينة، يتم تطبيق broadcast للمصفوفة الأصغر لتتطابق مع المصفوفة الأكبر بحيث يكون لها شكل متوافق لتنفيذ العملية. وهذا أمر مفيد جداً في علوم تعلم الآلة. وبشكل أوضح أو أكثر دقة عندما تحاول تطبيق عملية (eliment-wise) ضرب أو طرح أو تطبيق أي عملية رياضية على مصفوفتين غير متوافقتين بالأبعاد فإن بايثون سيحاول جعل المصفوفتين متوافقتين لكي تتم العملية، حيث يقوم بنسخ وتكرار وتوسيع للمصفوفة الصغيرة بحيث تحقق شرط تطبيق العملية المطلوبة، وبشكل أدق ركز معي: لو كان لديك مصفوفة ابعادها (m,n) وقمت بجمعها او طرحها او ضربها او قسمتها على مصفوفة من الحجم (1 عمود و n سطر) سيتم نسخ المصفوفة الثانية m مرة ليصبح حجمها مثل حجم المصفوفة الأولى. وبشكل مشابه لو كان لديك مصفوفة بحجم m سطر و 1 عمود، سيتم نسخ هذه المصفوفة n مرة لتصبح بحجم الأولى أي (m,n) ومن ثم تطبيق العملية المرادة. ، مثال: import numpy as np a1 = np.array([2, 4, 3]) a1.shape # (3,) a2 = np.array([50, 2, 10]) a2.shape # (3,) # هنا مصفوفتين متوافقتين بالحجم لكن لايمكن ضربهما ضرب مصفوفات عادي لكن هنا يتم ضربهما عنصر بعنصر c = a1 * a2 print (c) #[350 4 180] مثال آخر: import numpy as np a1 = np.array([2, 4, 3]) a1.shape # (3,) a2 = 3 #brodcast هنا غير متطابقين ولا يتحقق شرط الجمع لكن يتم تنفيذ عملية c = a1 + a2 print(c) #[5 7 6] مثال: import numpy as np a1 = np.array([[1, 2, 3], [10, 2, 30]]) a2 = 4 C = a1 + a2 print(C) """ [[ 5 6 7] [14 6 34]] """ لكن لل brodcast شروط وهي أن المصفوفتين يجب أن تتطابق إحدى أبعادهما وإلا يفشل وهذا ماحدث معك. a = np.random.randn(97,2) b = np.random.randn(2,1) a*b #ValueError: operands could not be broadcast together with shapes (97,2) (2,1)1 نقطة
-
كما نعلم فأن مجال الثقة هو مجال عددي يُتوقع أن يحتوي على القيمة الحقيقية لمَعلَمة (كمية عددية تميّز و"تلخص" التوزع الاحتمالي لمجموعة من الأحداث المتشابهة) إحصائية يراد معرفتها لمجموعة من العناصر أو الأحداث المتشابهة (تسمى في عالم الإحصاء مجتمع إحصائي) التي تكون (بجميع عناصرها) موضوعا لدراسة علمية ما.في أغلب الأبحاث أن يتم استخدام مجالات ثقة بمستوى ثقة قدره 95% ولكن يمكن أن يتم أيضا حسابها بمستويات ثقة أخرى مثل 99% و90%. في بايثون يمكنك استخدام scipy.stats.t.interval للحصول على مجال الثقة لعينة إحصائية ما. في بايثون يمكنك حسابه كالتالي: import scipy import scipy.stats as s import numpy as np sample=np.array([1,2,3,4,5,6]) confidence_level = 0.95 degrees_freedom = sample.size - 1 mean = np.mean(sample) standard_error = scipy.stats.sem(sample) confidenceinterval = s.t.interval(confidence_level, degrees_freedom, mean, standard_error) confidenceinterval # (1.5366856922723917, 5.463314307727608) استخدم numpy.ndarray.size - 1 مع numpy.array كمصفوفة من بيانات العينة للعثور على درجة الحرية. ثم استدعي numpy.mean(arr) لحساب المتوسط الحسابي لبيانات العينة arr، ثم استدعي scipy.stats.sem(arr) لحساب الخطأ المعياري لها "standard error" (طريقة قياس أو تقدير الانحراف المعياري) ثم استدعي scipy.stats.t.interval(confidence_level, degrees_freedom, mean, std) لحساب مجال الثقة. يمكنك أيضاً حسابها بالشكل التالي من خلال استخدام الدالة NormalDist : from statistics import NormalDist import scipy import numpy as np sample=np.array([1,2,3,4,5,6]) def confidenceinterval(s, confidence=0.95): #NormalDist.stdev& NormalDist.mean ترجع لنا كائن يحتوي معلومات أهمها المتوسط والانحراف المعياري من خلال استدعاء الواصفتين dist = NormalDist.from_samples(s) z = NormalDist().inv_cdf((1 + confidence) / 2.) h = dist.stdev * z / ((len(s) - 1) ** .5) return dist.mean - h, dist.mean + h1 نقطة
-
هذه المشكلة تحدث بسبب شكل المصفوفات التي تريد ضربهما، دعنا نفهم كيف تتم ضرب المصفوفات. لضرب مصفوفتين يجب ان يكون عدد الاعمدة في المصفوفة الاولى يساوى عدد صفوف المصفوفة الثانية، حيث ان ترتيب الضرب يهم، كمثال لضرب مصفوفة ذات ابعاد (5,3) * (4,5) تنتج مصفوفة ذات ابعاد (4,3) حيث تمثل اول قيمه عدد الصفوف وهي هنا =4 والقيمة الثانية عدد الاعمدة وهي هنا 3. اما بالنسبة للمشكلة هنا تحديدا فهي بسبب استخدام الشكل * ، وهي تقوم بعملية ضرب المصفوفات فقط في حالة انها علي شكل numpy.matrix وبشكل عام تقوم العلامة * بعمل ضرب القيم سويا او ما يسمي element wise multiplication وهذا يجعل عملية الضرب المطلوبة غير ملاءمة لانة يجب ان تكون كلتا المصفوفتين من نفس الشكل تماما. لكن المطورين ابتعدوا عن هذا الشكل وعوضا عنها استخدموا العلامة . والتي تمثل dot product . فيمكنك هنا اما تحويل المصفوفتين الي Numpy.matrix وضربهما او استخدام x.y للضرب مباشرة. يمكنك كذلك استخدام numpy.dot، والتي تقوم بعملية الضرب المعتادة للمصفوفات، انظر المثال التالي: In [1]: import numpy In [2]: numpy.dot(numpy.ones([97, 2]), numpy.ones([2, 1])).shape Out[2]: (97, 1)1 نقطة
-
يمكنك حلها بالدالة التالية ببساطة: import numpy as np import scipy.stats def mean_confidence_interval(data, confidence=0.95): a = 1.0 * np.array(data) n = len(a) m, se = np.mean(a), scipy.stats.sem(a) h = se * scipy.stats.t.ppf((1 + confidence) / 2., n-1) return m, m-h, m+h كذلك هناك دالة داخلية يمكنك استعمالها كالتالي: import numpy as np, scipy.stats as st st.t.interval(0.95, len(a)-1, loc=np.mean(a), scale=st.sem(a)) حيث ان 0.95 تمثل نسبة ال Confidence Interval التى تريدها. هنا بعض الامثلة التي قد توضح تبين الفكرة: In [9]: a = range(10,14) In [10]: mean_confidence_interval(a) Out[10]: (11.5, 9.4457397432391215, 13.554260256760879) In [11]: st.t.interval(0.95, len(a)-1, loc=np.mean(a), scale=st.sem(a)) Out[11]: (9.4457397432391215, 13.554260256760879) لاحظ ان قيم ال Confidence Interval في كلتا الطريقتين واحدة1 نقطة
-
تعلم البرمجة أمر سهل ولكن يتطلب بذل الكثير من المجهود والوقت خصوصًا في بداية التعلم حيث يكون الأمر أكثر صعوبة بسبب تعلم مصطلحات وتقنيات جديد كليًا، ومن الطبيعي للغاية أن أي درس مدته ساعتين على سبيل المثال يستغرق منك أكثر من ساعتين لإتمامه، وذلك لأن التطبيق العملي يأخذ الكثير من الوقت أيضًا. عليك أيضًا أن تحاول التعلم والمتابعة بشكل متواصل لأن التعلم المتقطع لن يفيدك كثيرًا ويعد مضيعة للوقت، لأنك ستتعلم تقنية معينة ولغة برمجة معينة ولكن عدم إستخدامك لها لفترة طويلة سيؤدي إلى نسيانك لما تعملته وبالتالي سيكون الوقت الذي استغرفته في تعلم هذه التقنية في البداية مضيعة للوقت لأنك ستعيد تعلمها من البداية. والحل هو التطبيق العملي كل فترة لكي لا تنسى ما كنت تتعلمه وتبدأ من الصفر في كل مرة. بالنسبة إلى الكلية أو الجامعة التي تدرس فيها، فهي ليس ذات أهمية، في الواقع يمكن لأي شخص لجيه إتصال بالإنترنت وحسوب أن يتعلم البرمجة بدون مشكلة، وأريد أن أشير إلى أن دورة CS50 والتي يقوم بشرحها ديفيد مالان، تعد بداية جيدة لبدأ التعلم، كما أن ديفيد مالان نفسه لم يكن يدرس في كلية تكنولوجية في البداية، بل كان يدرس في كلية الحقوق، لذلك لا تطعي بالًا لأمر إختلاف الكلية التي تخرجت منها. أنصحك أيضًا أن تقرأ هذه المقالة "دليلك الشامل لتعلم البرمجة" والتي سوف تساعدك كثيرًا في تحديد مسار معين لتتبعه وتسهل عليك الكثير من الأمر.1 نقطة
-
بالإضافة للشرح الوافي ل reshape كما في التعليق السابق ولكن إذا كانت هناك العديد من الأبعاد وتحتاج عمل flat للكل عدا البعد الأخير يمكنك استخدام الحل التالي arr = numpy.zeros((50,100,25)) new_arr = arr.reshape(-1, arr.shape[-1]) new_arr.shape # (5000, 25) أو مثلاً عدا آخر بعدين arr = numpy.zeros((3, 4, 5, 6)) new_arr = arr.reshape(-1, *arr.shape[-2:]) new_arr.shape # (12, 5, 6) لاحظ مثال آخر arr = numpy.zeros((3, 4, 5, 6, 7, 8)) new_arr = arr.reshape(*arr.shape[:2], -1, *arr.shape[-2:]) new_arr.shape # (3, 4, 30, 7, 8)1 نقطة
-
يمكنك استخدام ravel أو flatten أو flat ولكن لكل دالة هدف حيث أن ravel تقوم بإرجاع view من المصفوفة أي أنه عند التغيير في المصفوفة الجديدة تطبق التغييرات على المصفوفة القديمة a = np.array([[1,2,3], [4,5,6]]) b = a.ravel() b array([1, 2, 3, 4, 5, 6]) بينما flatten تقوم بإرجاع نسخة أو copy من المصفوفة القديمة c = a.flatten() إنما flat تقوم بإرجاع iterator وليس مصفوفة d = a.flat1 نقطة
-
يمكنك القيام بذلك من خلال الدالة reshape هذه الدالة تمكنك من تعديل أبعاد المصفوفة بالشكل الذي تريده، والشرط الوحيد هو أن كون عدد العناصر في المصفوفة الجديدة التي تريد إعادة تشكيلها = عدد العناصر في المصفوفة الأصلية. أي إذا كانت المصفوفة الأصلية مصفوفة أحادية البعد ب 12 عنصر وأردنا تحويلها لمصفوفة ثنائية ببعدين وبالتالي يجب أن يكون ناتج جداء البعد الأول بالثاني =12 وبالتالي يمكن أن نستنتج أن أبعاد المصفوفة الناتجة إحدى الخيارات التالية: a=np.arange(12) a.reshape(3,4) """ array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) """ a.reshape(4,3) """ array([[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]]) """ a.reshape(6,2) """ array([[ 0, 1], [ 2, 3], [ 4, 5], [ 6, 7], [ 8, 9], [10, 11]]) """ a.reshape(2,6) a.reshape(4,4) # ValueError: cannot reshape array of size 12 into shape (4,4) كما أننا يمكننا أن نمرر له بعد واحد والبعد الآخر نضع مكانه -1 و هو سيستنتجه تلقائياً وفقاُ لمعادلة الجداء: a=np.arange(12) a.reshape(-1,4) # سيستنتج أنه3 """ array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) """ الآن بالتأكيد أصبحت تستطيع معالجة مشكلتك، حيث يمكنك التلاعب بشكل الإخراج بالشكل الذي تريده: arr = np.ones((50,100,25)) arr.shape # (50, 100, 25) arr1=arr.reshape(-1,50) # 100*25 arr1.shape #(2500, 50) arr2=arr.reshape(-1,25) # 100*50 arr2.shape #(5000, 25) arr3=arr.reshape(50,-1) # 100*25 arr3.shape #(50, 2500) arr4=arr.reshape(100,-1) arr4.shape # (100, 1250) arr5=arr.reshape(-1,100) arr5.shape #(1250, 100) أو مثلاً لو لدينا مصفوفة ب 4 أبعاد: arr = np.ones((50,100,25,4)) arr.shape #(50, 100, 25, 4) arr1=arr.reshape(-1,50) # 100*25*4 arr1.shape # (10000, 50) arr2=arr.reshape(50,100,-1) # 25*4 arr2.shape #(50, 100, 100) وهكذا..1 نقطة
-
هناك الكثير من الطرق وأولها الدالة flatten وهذه الدالة تعيد نسخة من المصفوفة الأصلية: import numpy as np a = np.array([[1, 2, 3], [45, 4, 7], [9, 6, 10]]) a.flatten() #array([ 1, 2, 3, 45, 4, 7, 9, 6, 10]) إذا كنت تتعامل مع ndarray كبيرة الحجم ، فقد يتسبب استخدام flatten في حدوث مشكلة في الأداء. يوصى بعدم استخدامه في هكذا حالات (كما أنه أبطأ كثيراً). ما لم تكن بحاجة إلى نسخة من البيانات للقيام بشيء آخر.... أيضاً يمكن استخدام الدالة ravel: import numpy as np a = np.array([[1, 2, 3], [45, 4, 7], [9, 6, 10]]) a.ravel() #array([ 1, 2, 3, 45, 4, 7, 9, 6, 10]) أو من خلال الدالة reshape: import numpy as np a = np.array([[1, 2, 3], [45, 4, 7], [9, 6, 10]]) a.reshape(-1) # فقط نمرر لها -1 #array([ 1, 2, 3, 45, 4, 7, 9, 6, 10]) ينصح باستخدام reshape فهي توفر المرونة في إعادة تشكيل الحجم إضافةً إلى أنها هي و ravel سريعتين (بنفس الأداء تقريباً). ويمكنك أيضاً استخدام flat لكن هنا لايعيد لك مصفوفة جديدة وإنما iterator (مكرر) على مصفوفتك (ربما يفيدك): import numpy as np a = np.array([[1, 2, 3], [45, 4, 7], [9, 6, 10]]) arr=a.flat for i in a.flat: print(i,end=" ") #1 2 3 45 4 7 9 6 101 نقطة
-
np.max هو فقط اسم مختصر أو مستعار لـ np.amax . نمرر لهذا التابع المصفوفة التي نريدها ويرد لنا القيمة العظمى فيها. أو يمكننا أن نحدد المحور الذي نريد حساب القيمة العظمى على أساسه وسيجد لنا القيمة العظمى على طول محور مصفوفة الإدخال (يرد مصفوفة جديدة بالقيم العظمى على طول الأسطر أو الأعمدة). ليتضح الأمر أكثر انظر: import numpy as np a = np.array([[3, 22, 5], [12, 3, 0], [6, 8, 9]]) np.max(a) #22 np.max(a, axis=0) # سيجد لنا القيمة العظمى في كل عمود #array([12, 22, 9]) np.max(a, axis=1) # هنا في كل سطر #array([22, 12, 9]) السلوك الافتراضي لـ np.maximum هو أخذ مصفوفتين وحساب القيمة العظمى من المصفوفتين بشكل element-wise أي يقارن أول قيمة من المصفوفة الأولى بأول قيمة من الثانية والأكبر يضعه في المصفوفة الجديدة. هنا ، تعني كلمة "متوافق" أنه يمكن بث مصفوفة إلى الأخرى. فمثلا: a1 = np.array([8, 9, 1]) a2 = np.array([4, 10, 2]) np.maximum(a1, a2) array([8, 10, 2]) لكن np.maximum هي أيضاً وظيفة عامة مما يعني أن لها ميزات وطرق أخرى مفيدة عند العمل مع المصفوفات متعددة الأبعاد. على سبيل المثال ، يمكنك حساب القيمة العظمى التراكمية على مصفوفة (أو محور معين من المصفوفة) وهذا غير ممكن في np.max: a = np.array([3, 4, -1, 5, 8]) np.maximum.accumulate(a) #array([3, 4, 4, 5, 8]) كما ويمكنك جعلها تعمل مثل np.maax بالشكل التالي، حيث نستدعي np.maximum.reduce: import numpy as np a = np.array([[3, 22, 5], [12, 3, 0], [6, 8, 9]]) np.maximum.reduce(a,axis=None) #22 np.maximum.reduce(a,axis=0) #array([12, 22, 9]) ومن حيث الأداء فلا فرق ف np.max تستخدم ضمنياً np.maximum.reduce لحساب القيم العظمى، أي كلاهما متشابهان. أما الاختلاف فهو كما ذكرنا في الأعلى "حساب القيمة العظمى من المصفوفتين بشكل element-wise ". أما بالنسبة إلى np.amax و np.max فكلاهما يستدعي نفس التابع. np.max هو مجرد اسم مستعار لـ np.amax، ويحسبان القيمة العظمى لجميع العناصر في المصفوفة ، أو على طول محور المصفوفة المحدد.1 نقطة
-
بعد مراجعة التوثيق، تبين أن عليك (صاحب المشروع) عمل حساب في المنصة، ثم من خلال الحساب الشخصي سوف يقوم بعمل مشروع (مشروع جزئي ضمن حساب بوابة الدفع خاص بالدفع للمشروع البرمجي)، بعد هذه الخطوات يمكنك تضمين المكتبات البرمجية الخاصة ببوابة الدفع، وتحديد الإعادادات الموافقة لحسابك الشخصي فيها، إن ذكرت في أي مرحلة وصلت هذا يساعدنا في إرشادك للخطوة التالية، شكرا لك1 نقطة
-
def count(text): tokens = [] # لتخزين الكلمات في النص بدون تكرار text = text.split() # لتقسيم النص إلى كلمات for word in text: # نمر على كل كلمة بالنص if word not in tokens: # إذا لم تكن الكلمة موجودة مسبقاً نضيفها tokens.append(word) for word in range(0, len(tokens)): #count نمر على كل كلمة فريدة بالنص ونحسب تكرارها باستخدام التابع print(tokens[word], ': ', text.count(tokens[word])) s ='Ali Messi Ali Messi Real Messi FCB FCB' count(s) # استدعاءالتابع1 نقطة
-
import re # regex استيراد المكتبة txt = input() # إدخال النص result = re.findall("\d*\.*\d* [E|e]uros", txt) # عرض النتائج if result: for word in result: print(word) else: print("No Euros!") يجب أن تكون الآن قادر على كتابة باقي الأكواد وحدك!1 نقطة
-
import re # regex استيراد المكتبة txt = input() # إدخال النص result = re.findall("056\d{7}", txt) # أي أول 3 محارف يجب أن يكونوا056 وبعدها 7 أرقام # عرض النتائج if result: for word in result: print(word) else: print("No ID!") الرمز d\ يدل على وجود رقم الرمز {7} يدل على أن المحرف الموجود قبلها يجب أن يتكرر 7 مرات وفي حالتنا (d\ أي يجب أن يتواجد 7 أرقام) الدالة (pattern,string)findall تبحث في النص الذي نمرره له مكان الباراميتر string لترى ما إذا كان يتطابق أو فيه جزء يتطابق مع التعبير النمطي الذي نمرره لها مكان الباراميتر pattern. في حال تم إيجاد جزء أو أكثر في النص يتطابق مع التعبير النمطي, ترجع list كل عنصر فيه يمثل الجزء الذي يتطابق مع التعبير النمطي. في حال لم يتم إيجاد أي تطابق, ترجع list فارغ. # تعدييييييل: الرمز ^ يختبر فقط بداية النص أي سيختبر مطابقة ال pattern مع أول كلمة في ال string لذلك لايصلح لاستخدامه في هذه المهمة وبشكل مشابه أيضاً المحرف $.1 نقطة
-
import re # regex استيراد المكتبة txt = input() # إدخال النص # $إيجاد كل مايبدأ بالرمز # وبعده رقم واحد على الأقل result = re.findall("\$\d+", txt) # عرض النتائج if result: for word in result: print(word) else: print("No dollars!")1 نقطة
-
import java.util.Vector; //vector استيراد الصف public class ourvector { public static void main(String[] args) { Vector vec = new Vector(); // تعريف غرض /* له عدة بواني vector الصف Vector() الباني الافتراضي، في هذه الحالة كلما امتلأ الشعاع يتم زيادة حجمه بمقدار واحد Vector(int size) باني بوسيط واحد يعبر عن حجم الشعاع وأيضاً يقوم بنفس العمل عندما يمتلئ Vector(int size,int inc) (الخانات التي ستحجو في الذاكرة)باني بوسيطين بحيث الباني الثاني يعبر عن عدد العناصر التي ستضاف كلما امتلأ */ vec.add(12); // لإضافة عنصر إلى الشعاع vec.add(82); vec.add(9);// يمكنك أيضاًإنشاء شعاع وتمريره لهذه الدالة وبالتالي سيضيف كل قيم الشعاع الممرر إلى الشعاع الأساسي System.out.println(vec.size()); // لطباعة عدد عناصر الشعاع for(int i=0; i<vec.size(); j++) { // لطباعة عناصر الشعاع System.out.println("vec[" +j+ "]= " +vec.get(j)); } vec.remove(1); // لحذف عنصر محدد حيث نقوم بتمرير موقعه vec.clear(); // لحذف عناصر الشعاع } } // استعرضت لك التوابع الأساسية، وهناك الكثير الكثير من التوابع الأخرى1 نقطة
-
import pandas as pd dic = {'column1':[17, 3, 4], 'column2':[66, 77, 66], 'column3':[66, 77, 5]} df = pd.DataFrame(dic) # لإعادة تسمية الأعمدة df1=df.rename(columns={"c1": "A", "c2": "B"}) print(df1,end='\n\n') # لإعادة تسمية الأسطر df2=df.rename(index={0: "x", 1: "y", 2: "z"}) print(df2)1 نقطة
-
import pandas as pd # لنفرض لدينا البيانات التالية dic = {'c1':[17, 3, 4], 'c2':[66, 77, 66], 'c3':[66, 77, 5]} # DataFrame نحولها ل df = pd.DataFrame(dic) print(df,end='\n\n') # عرض البيانات ################################ للاستعلام ######################################## # select * from table where column_name = some_value < تكافئ > table[table.column_name == some_value] # :مثال values=df[df.c2 == 66] # c2 أي سنختار الأسطر التي تتضمن القيمة 66 في العمود print(values,end='\n\n') # عرض نتيجة الاستعلام values=df.query('c2 == 66') # طريقة أخرى print(values,end='\n\n') # :أما في حالة كان لديك عدة شروط نستخدم # table.query('column_name1 == value1 | column_name2 == value2') # :أو # table[(table.column_name1 == some_value1) | (table.column_name2 == some_value2)] values=df[(df.c3 == 77) | (df.c1 == 3)] print(values) # وكان بإمكانك تجربة الشكل الثاني أيضاً1 نقطة
-
(object)append تضيف كائن في نهاية ال list كما هو: li = ['adam', 'messi',44] li.append([5,5]) # الخرج : ['adam', 'messi', 44, [5, 5]] (iterable)extend تقوم بإضافة عناصر إلى ال list من iterable (أي list أخرى أو tuble أو set أو dict): li2 = ['adam', 'messi',44] li2.extend([5,5]) # الخرج : ['adam', 'messi', 44, 5, 5] # لاحظ كيف اختلفت عملية الإضافة (index,value)insert: تستخدم لإضافة عنصر جديد في مكان محدد في الـlist الذي قام باستدعائها. li3 = ['adam', 'messi',44] li3.insert(0,[5,5]) # الخرج : [[5, 5], 'adam', 'messi', 44]1 نقطة
-
# iterrows باستخدام الدالة for i, row in df.iterrows(): for j, column in row.iteritems(): print(column) # أو بالشكل التالي for index, row in df.iterrows(): print(row['column1'], row['column2']) # iloc أو باستخدام التابع for i in range(0, len(data)): print df.iloc[i]['column1'], df.iloc[i]['ccolumn2'] حيث أن الدالة iterrows هو مولد ينتج كلاً من الفهرس والسطر (كسلسلة).1 نقطة
-
إن الـصف الابن يرث كل شيء موجود في الـصف الأب إلا الخصائص التي تم تعريفها كوسطاء بداخل الدالة __init__ و السبب في هذا أن الدالة __init__ تولد الخصائص لل object و تربطها بالكلاس لحظة إنشاء ال object. أي إذا لم تنشئ كائن من الكلاس لن يتم إستدعاء هذه الدالة أصلاً أي يمكنك القول أن المتحولات المعرفة ضمنها لن تكون موجودة، لذا لايمكن وراثتها بشكل مباشر. وحل هذه المشكلة يكون كما في المثال التالي، حيث نقوم باستدعاء الدالة __init__ للصف الأب داخل دالة __init__ للصف الابن: class myname: def __init__(self,name="Esraa"): self.name=name # نقوم بوراثته class emp(myname): def __init__(self): myname.__init__(self) # نقوم باستدعاء باني الصف الاب داخل باني الصف الاب p = emp() # أخذ غرض من الصف الابن print(p.name) # Esraa1 نقطة
-
 مراجعتي مجروحة... كمؤلف الكتاب... وليست هذه مراجعة حتّى لكنني أريد أن أتقدم هنا بالشكر الجزيل إلى فريق أكاديمية حسوب على إخراج وتنسيق الكتاب ورعايته. كان جهدًا طويلًا على مدار عدة أشهر لتنسيق الكتاب وإخراجه بشكل الحالي، خصوصًا أنه يحتوي الكثير من الصور والأوامر وغير ذلك من عناصر التنسيق المختلفة. أريد أن أنوه كذلك إلى أن هذا الكتاب يغطي معظم الأساسيات وأهم المواضيع، لكنه لا يغطي كل شيء في مجال الأمان الرقمي، ومايزال هناك الكثير من الأشياء الأخرى للحديث عنها. ويمكن للقارئ الكريم أن يتبحر على الشبكة بالبحث عن المزيد من المصادر حول المواضيع التي ذكرناها إن كان يريد المزيد، وهناك قائمة سريعة ببعض المواقع المفيدة في مجال الأمان الرقمي على الشبكة. أتوجه بالشكر هنا كذلك إلى كل القرّاء الذين حملوا الكتاب وساهموا بنشره للآخرين، ورغم أنه كتاب مجاني إلا أن أملي أن يستفيد منه أقصى عدد ممكن من الناس، ليحموا أنفسهم من مخاطر الخصوصية والأمان في هذا الوقت المتقلب. أنا جاهز لأي أسئلة أو استفسارات تحت هذا التعليق كذلك.1 نقطة
مراجعتي مجروحة... كمؤلف الكتاب... وليست هذه مراجعة حتّى لكنني أريد أن أتقدم هنا بالشكر الجزيل إلى فريق أكاديمية حسوب على إخراج وتنسيق الكتاب ورعايته. كان جهدًا طويلًا على مدار عدة أشهر لتنسيق الكتاب وإخراجه بشكل الحالي، خصوصًا أنه يحتوي الكثير من الصور والأوامر وغير ذلك من عناصر التنسيق المختلفة. أريد أن أنوه كذلك إلى أن هذا الكتاب يغطي معظم الأساسيات وأهم المواضيع، لكنه لا يغطي كل شيء في مجال الأمان الرقمي، ومايزال هناك الكثير من الأشياء الأخرى للحديث عنها. ويمكن للقارئ الكريم أن يتبحر على الشبكة بالبحث عن المزيد من المصادر حول المواضيع التي ذكرناها إن كان يريد المزيد، وهناك قائمة سريعة ببعض المواقع المفيدة في مجال الأمان الرقمي على الشبكة. أتوجه بالشكر هنا كذلك إلى كل القرّاء الذين حملوا الكتاب وساهموا بنشره للآخرين، ورغم أنه كتاب مجاني إلا أن أملي أن يستفيد منه أقصى عدد ممكن من الناس، ليحموا أنفسهم من مخاطر الخصوصية والأمان في هذا الوقت المتقلب. أنا جاهز لأي أسئلة أو استفسارات تحت هذا التعليق كذلك.1 نقطة -
كرت الشاشة المدمج هو الكرت الذي يكون مدموجاً مع ال CPU أو المعالج فكل معالج يحتوي بداخله بعض الوحدات الخاصة بمعالجة الصور ,أما المنفصل فهو قطعه منفصلة عن المعالج تقوم بمعالجة الصور. فعندما يتم ذكر كرت شاشة غالباً يكون القصد به كرت الشاشة الخارجي والذي يقدم من شركتين AMD و Nvidia ,هذا لأن كرت الشاشة الداخلي يكون ضعيفاً ولا يعتمد عليه في المهام التي تحتاج بعض من التحليل للصور.1 نقطة
-
جميل انك تريد ان تعرف كيف ستبدأ مشوارك مع عالم البرمجة الواسع اللانهائي من وجهة نظري. لذلك لابُد من بداية صحيحة. البرمجه في وقتنا هذا تعتبر تخصص ذو قيمة كبيرة. البرمجة تنقسم الي اقسام مثل برمجة تطبيقات "الويب - الهواتف - سطح المكتب" 1- تطبيقات الويب اي برمجة مواقع تعمل على المتصفحات مثل Chrome , firefox , Safari , Opera , Internet Explorer - هذة التطبيقات يتم بناؤها وبرمجتها بلغات خاصة للويب مثل PHP , Ruby , Python , ASP ولغات اُخرى كثيرة. - وانصحك أن يكون لديك معرفة جيدة بما يكفي بهذه اللغات HTML , CSS , JavaScript عند أنتقالك الي جزئية البرمجه. وهذا ما ستسمعة من الجميع (المتخصصين) عندما تأخذ هذة الخطوة. 2- تطبيقات الهواتف - اي برمجة تطبيقات تعمل على الجوال او الهواتف الذكية مثل iPad , iPhone , Note , Tablet ألخ.. - هذه التطبيقات يتم برمجتها بلغات متخصصه مثل Java ME وهذة اللغة تستطيع برمجة تطبيقات تعمل على اجهزة بنظام Android مثل Samsong Galagy , Nexus , Sony Expria الخ.. - لغة Objective-C التي تقوم ببرمجة تطبيقات تعمل على اجهزة الـ iPhone , iPad 3- تطبيقات سطح المكتب اي برمجة تطبيقات تعمل على الحاسوب مثل اي برنامج تقوم بتثبيتة علي جهازك الشخصى او الجهاز المكتبى ومن هذه اللغات Java SE , VB او Visual Basic , C# , C++ , C , Objective C الخ.. - وانصحك ان يكون لديك معرفة بأنواع انظمة التشغيل فهناك أكثر من نظام تشغيل اشهرُها Window , MAC , Linux حتى يتوافع برنامجك الذي قمت ببرمجتة مع مثل هذه الانظمة. عندما تجد نفسك جيد في اللغة التي ستبدأ بها وتريد الإنتقال لسوق العمل فلابد ان يعرف الناس ما هي مميزات أعمالك. على سبيل المثال: - قم بعمل مشروع صغير من برمجتك الشخصيه وأجعلة قوي ومميز يوحى لمن يقوم بتجربتة أنك بذلت مجهود وإنك مبرمج جيد. - إهتم بالإنتقاد واجتهد في تحسين مستواك وافتخر بالاعجاب واستعين بالمتخصصين لسؤالهم ولا تكن خجولاً في طلب المساعدة. - لا تتوقف عن اعمالك ومساهماتك المجانيه كي يتعرف الاشخاص على اعمالك وكذلك الشركات. هناك الكثير من المنصات التي تستطيع ان تضع عليها اعمالك ليراها الاخرون واشهر هذه المنصات هو موقع GitHub من خلال هذه الاعمال المجانيه مع الوقت ستتلقى رسأل بطلب اعمال مدفوعة الاجر وبذلك انت الان على الطريق الصحيح ولك مكان في سوق عمل البرمجه. انصحك بعدم اخذ قفذّات سابقة للأوان. بمعنى اخر لا تذهب الي لغة البرمجه PHP وانت لا تملك اي خلفيه عن لغة HTML. اتمنى لك بداية صحيحة.1 نقطة
-
من وجهة نظري أن الفكرة الغير تقليدية هي التي تقدم إفادة حقيقية لشريحة معينة ، وبإمكانك الوصول إلى الأفكار التي تخدم الناس بالتعرف على مشاكلهم ثم تقدم لهذه المشاكل حلول ، أو تقدم ميزة إضافية تجعلك سابق بخطوة عن المنافس. ومن ضمن الأفكار التي أود أن أجد لها شركة عربية هي خدمة النشرة البريدية (موقع مثل getresponse أو aweber أو Mailchimp ولكن باللغة العربية ويكون بأسعار أقل ، كنت أتمنى أن يكون معي المال لتنفيذ هذه الفكرة ولكن إن كان بإمكانك أنت تنفيذها فأنت لها.1 نقطة