لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 08/06/21 في كل الموقع
-
لدي مشروع مبني باستخدام الجافاسكريبت express و node.js، وهو جاهز للنشر ولكن بداخله العديد من تعليمات الطباعة على console ضمن العمليات التي تجري فيه مثل: console.log() console.error() والمشروع سيبقى قيد العمل دون توقّف، حيث سيتم طباعة رسائل الخطأ عند حدوثها لإمكانية الوصول إليها ومعالجتها. هل هنالك طريقة لإضافة التاريخ والوقت لهذه الأخطاء أو المعلومات التي سيتم طباعتها في console؟ لأستطيع الوصول إلى هذه المعلومات بشكل أسرع.1 نقطة
-
هل يُقبل دفع سعر دورة اكاديمية حسوب بالجنيه المصري؟1 نقطة
-

الإصدار 1.0.0
13018 تنزيل
التصميم هو مهنة العصر الحالية، هذا العصر الذي يولي أهميةً كبيرةً منقطعة النظير للعامل البصري، فيدخل مجال التصميم في كل مناحي حياتنا اليومية فكل شيء تراه حولك بدءًا من صور أغلفة المنتجات وحتى الإعلانات والملصقات والشعارات وأغلفة الكتب وكل شيء تقريبًا قد مرَّ على يدي مصمم وعولج داخل أحد تطبيقات الرسم والتصميم فسوق التصميم كبيرٌ يزداد فيه الطلب على المصممين يومًا بعد يوم. تمثلت رؤيتنا للكتاب في أن يكون المرجع الأول للمصمم العربي أو من يريد تعلم مجال التصميم الجرافيكي وذلك بجعله شاملًا لكل ما يحتاج إليه المتعلم في بداية رحلته التعليمية في هذا المجال وليتضمن العناصر الأساسية في هذا التخصص سواء كان ذلك في الأساسيات أو البرامج والتطبيقات أو أفكار التصميمات. يهدف الكتاب لإخراج أفراد متمكنين من أساسيات مجال التصميم الجرافيكي ولديهم المعلومات والخبرة الأساسية اللازمة لدخول سوق العمل وتحقيق دخل مادي عبر سوق الإنترنت الكبير وذلك من خلال تنفيذ أعمال التصميم الجرافيكي عبر منصات العمل الحر العربية مثل مستقل وخمسات. يتكون الكتاب من خمسة أقسام رئيسية: الأساسيات والمبادئ البرامج والتطبيقات مجالات التصميم الجرافيكي قواعد التصميم المسار المهني والتطوير الذاتي دخول سوق العمل هذه النقاط الخمس نعدها شاملة لما يحتاج إليه المصمم الجديد ليكون قادرًا على إنتاج تصميم وبيعه في السوق. يستهدف الكتاب جمهور المصممين المبتدئين أو من يريدون دخول هذا المجال، وعليه فإن الكتاب ليس موجهًا للمصممين المتقدمين أو المحترفين فهؤلاء في الغالب يتعلمون مباشرة من مصادر متقدمة سواءً عربية أو أجنبية ولكن قد يكون لدى البعض منهم نقص في معرفة أساسيات التصميم الفنية والأكاديمية، لذا يمكنهم آنذاك الرجوع إلى فصول بعينها من هذا الكتاب أي أنَّ فصول هذا الكتاب قد تفيد حتى من كان متقدمًا في مجال التصميم التطبيقي ولكن دون أساس أكاديمي سليم. هذا الكتاب مرخص بموجب رخصة المشاع الإبداعي Creative Commons «نسب المُصنَّف - غير تجاري - الترخيص بالمثل 4.0». يمكنك قراءة فصول الكتاب على شكل مقالات من هذه الصفحة، «أساسيات تصميم الرسوميات»، أو تجدها مسردة بالترتيب التالي: مقدمة إلى تصميم الرسوميات (التصميم الجرافيكي) عناصر تصميم الرسوميات مبادئ تصميم الرسوميات الألوان في تصميم الرسوميات ونظرية الألوان تعرف على أشهر برامج وتطبيقات تصميم الصور والرسوميات مقدمة إلى برنامج أدوبي فوتوشوب Adobe Photoshop مقدمة إلى برنامج أدوبي إليستريتور Adobe Illustrator والتعرف على واجهته مساحات وقياسات العمل التصميمي النص وأسلوب الطباعة Typography في تصميم الرسوميات قواعد التعامل مع الصور والرسوميات قواعد تصميم الأيقونات والشعارات قواعد تصميم المطبوعات والإعلانات قواعد تصميم الواجهات قواعد تصميم الرسوم البيانية قواعد تصميم الهوية البصرية دليل المسار المهني لمصمم الرسوميات مواقع العمل الحر والعمل عن بعد لتصميم الرسوميات1 نقطة -
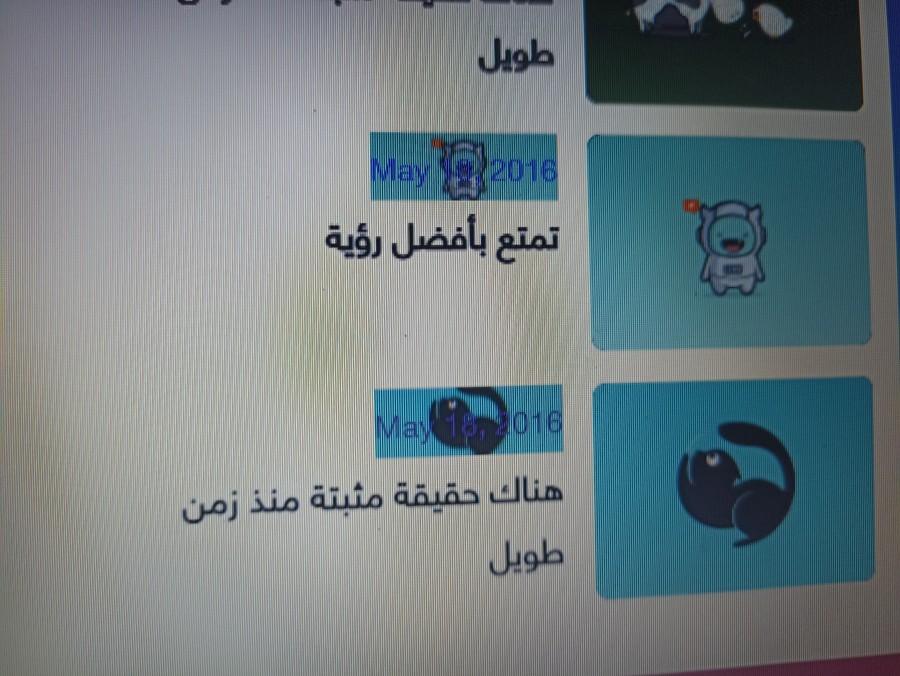
كيفية حذف Background الذي في التواريخ كما بالصورة التالية ارجو الرد للعلم ان هذا Background ليس من اكواد Css يعني مش موجود في اكواد Css.
 1 نقطة
1 نقطة -
ما الخطأ في هذا الكود عندما أفتح المتصفح لا يظهر شئ project (2).zip1 نقطة
-
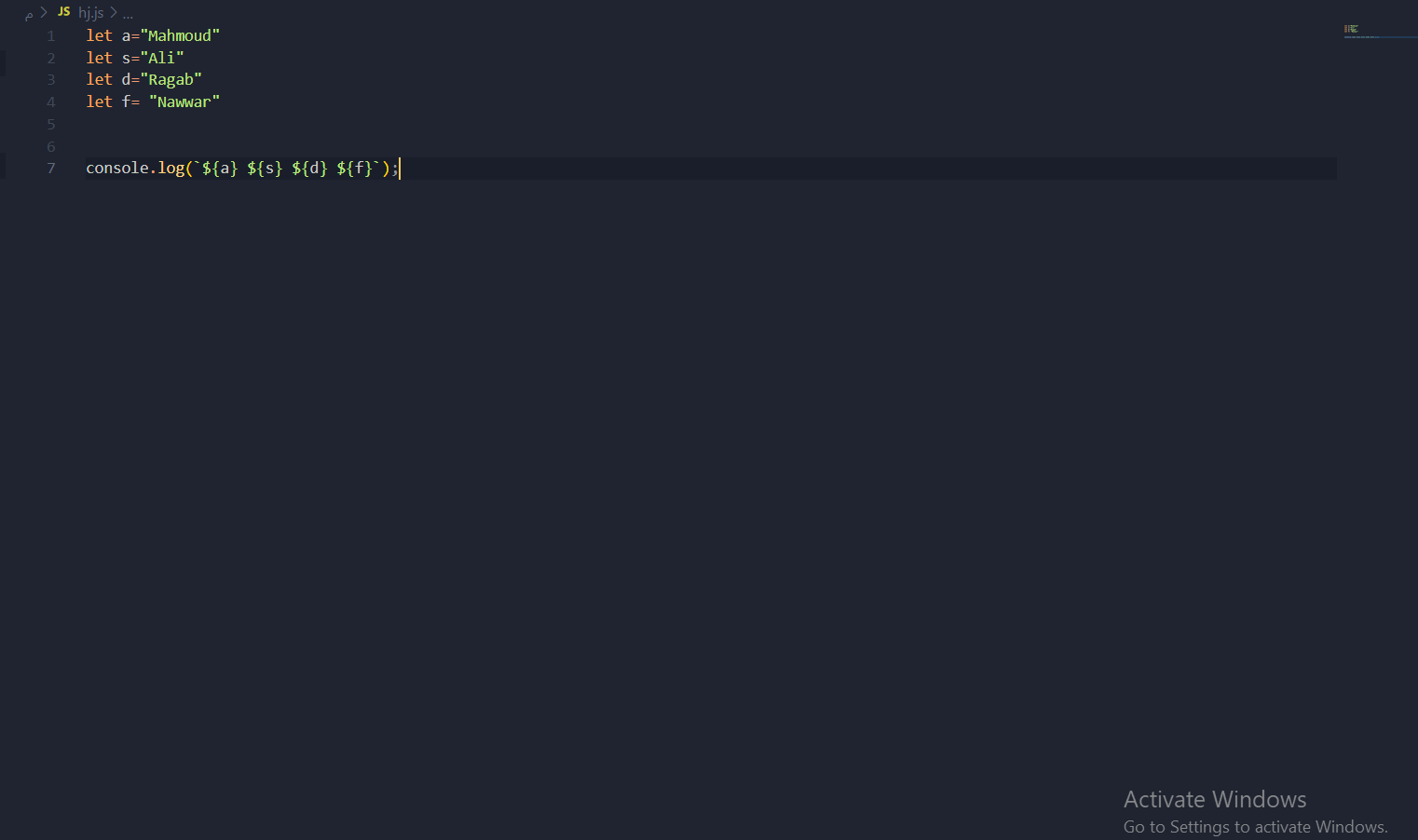
أنا اعمل على مشروع لمدرسة من خلال استعمال خادم wepack: المشكلة هي عندما اقوم بكتابة rules تحميل الصور و الfont file-loader not working ولكن عندما لا اكتبها يكون تحميل الصور بأمر جيد لكن تحمل الصفحة بشكل بطيء جدا مع ظهور شاشة بيضاء قبل تحميل عناصر الصفحة. لقد قمت بتجربة image-webpack-loader و url-loader و لم يتغير شيء
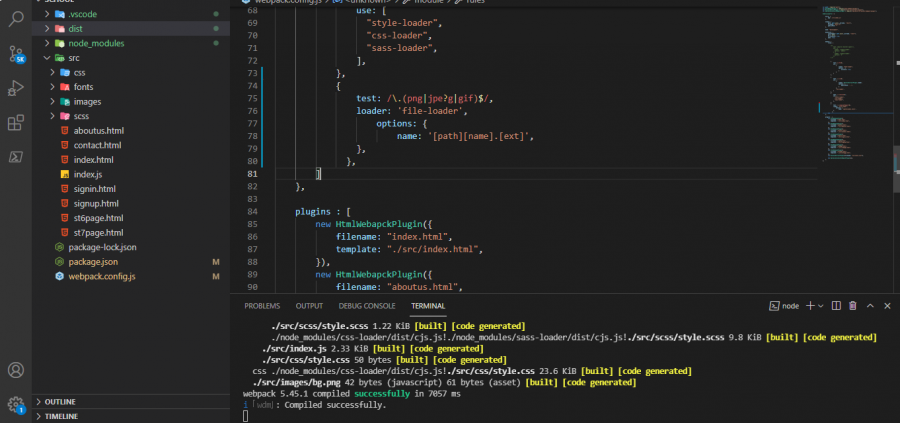 1 نقطة
1 نقطة -
إن كان حجم الصور كبيراً، عليك بضغطهم لتقليل حجمهم، استخدم أي ادوات من على الانترنت.. سبب عدم تحميل الصور مع file-loader هو أن html loader من الإصدار 2 أصبح يقوم بتحميل الصور بنفسه، و بتثبيت الإثنين معا، يحصل تضارب. الحل: إما تستعمل html loader الإصدار 1.3.2 حذف محدد امتداد الصور من file loader أو حذف القاعدة الخاصة بذلك نهائياً1 نقطة
-
لقد قمت بتضمين ملف الجافاسكريبت بالعنصر الخاص بتضمين CSS كالآتي <link rel="stylesheet" href="script/script.js"> وهذا خطأ هذا أنك تقوم بتضمين جافاسكريبت بإستخدام عنصر آخر يسمى script كالآتي <script src="script/script.js"></script> وكان يظهر خطأ أنك تقوم بإستدعاء ملف CSS ليست صيغته .css لأنك كنت تقوم بتضمين ملف جافاسكريبت الذي صيغته .js1 نقطة
-
في النسخ الحديثة تم استبدال الموديول visualize_util ب vis_utils وتم تغيير اسم التابع من plot إلى plot_mode وبالتالي يجب استيرادها بالشكل التالي: from keras.utils.vis_utils import plot_model أو من خلال وحدة كيراس المضمنة في تنسرفلو (بدءاً من نسخة تنسرفلو 2.0) كالتالي: from tensorflow.keras.utils import plot_model1 نقطة
-
السلام عليكم عندماأريد طباعة هذا الامر في الكونسول تظهر هذه الرسالة
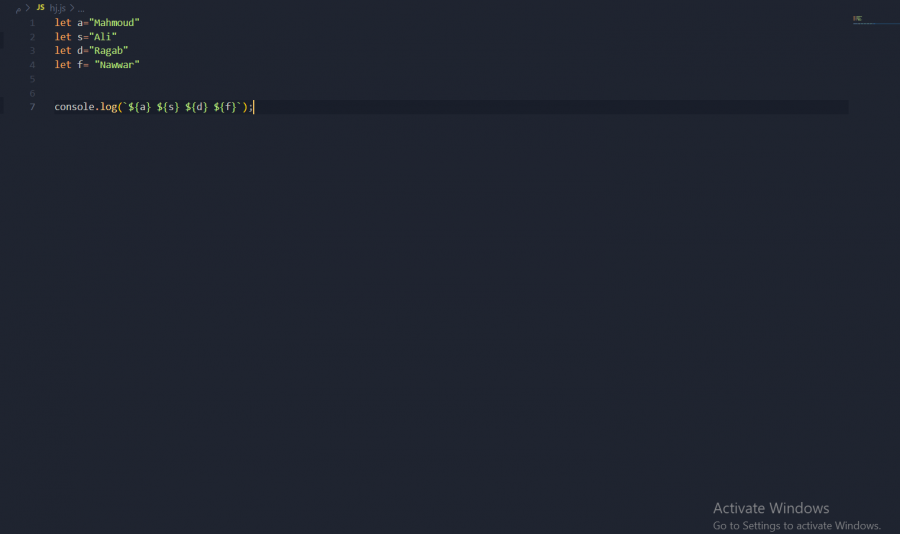
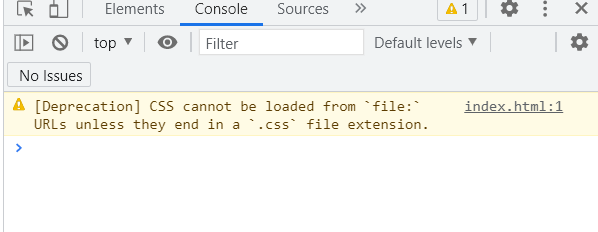 1 نقطة
1 نقطة -
شكرا لكي جدا1 نقطة
-
لديك خطأ بسيط في تضمين ملف ال JavaScript فكما ذكرت لك سابقًا، يتم تضمين ملفات JavaScript باستخدام الوسم script و يتم وضع المسار الخاص بملف ال JavaScript كقيمة لل src attribute كما يلي: <script src="script/script.js"></script> أمّا الوسم link فهو يستخدم لتضمين ملفات التنسيقات css الأكواد الخاصة بك بعد التعديل: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <link rel="stylesheet" href="css/style.css"> <script src="script/script.js"></script> <!-- السطر التالي هو السبب في الخطأ الذي ظهر لك حيث أنك تقوم بتضمين ملف جافاسكريبت هنا و لكن المتصفح كان يتوقع ملف تنسيقات --> <!-- <link rel="stylesheet" href="script/script.js"> --> </head> <body> </body> </html>1 نقطة
-
project.zip project.zip1 نقطة
-
لاحظت أن كلا الدالتين يقوم بإرجاع نفس القيمة بدون أي إختلاف: >>> import numpy as np >>> np.mean([1, 2, 3]) 2.0 >>> np.average([1, 2, 3]) 2.0 >>> ومع ذلك، أعتقد أنه يجب أن تكون هناك بعض الاختلافات، لأنهما في النهاية دالتين مختلفتين. ما هو الفرق بينهما؟1 نقطة
-
هل يمكنك إرفاق مجلد المشروع الخاص بك حتى نتمكن من المساعدة؟1 نقطة
-
لدي مصفوفة NumPy من نوع bool من النوع المنطقي. أريد حساب عدد العناصر التي تكون قيمها True. هل هناك دالة في Numpy أو Python مخصص لهذه المهمة؟ أو هل أحتاج إلى حلقة تكرار للعناصر الموجودة في المصفوفة الخاص بي؟1 نقطة
-
رسالة الخطأ التي تظهر لك تخبرك أن ملفات css التي يتم تضمينها باستخدام الوسم link يجب أن يكون لها اللاحقة css. لذلك تأكد أن قمت بكتابة اسم الملف كامل مع اللاحقة الخاصة به أثناء التضمين <link rel="stylesheet" href="./style.css" /> و تأكد أن الملفات تم تسميتها بشكل صحيح أيضًا. و لكن الخطأ السابق لا يوقف تنفيذ أكواد ال JavaScript لذلك أرجو منك التأكد من أنك قمت بتضمين ملف JavaScript في ملف ال html <html> <head></head> <body> <script src="./hj.js"> </script> <!-- " src يتم وضع مسار الملف داخل " --> </body> </html> و حفظ الملفات و تحديث المتصفح بعدها حتى تظهر التعديلات1 نقطة
-
كيف يمكنك الحصول على مقدار (حجم) المتجه magnitude (مصفوفة أحادية البعد 1D) في Numpy؟ حاولت أن أقوم بالأمر بنفسي وكتبت الكود التالي: def magnitude(x): return math.sqrt(sum(i**2 for i in x)) الكود السابق يعمل بدون مشكلة، لكني أتسأل هل توجد دالة جاهزة في Numpy تقوم بهذا الأمر بدلًا من إستعمال مكتبات مثل math؟1 نقطة
-
ستحتاج لها بالتأكيد، و لكن يمكنك تعلمها. فالمحتوى الأكاديمي أصبح متوفر بكثرة هذه الأيام على الانترنت و بشكل مجاني. أي أن الأمر ليس مستحيلًا و يمكن لأي شخص دراسة ما يحب هذه الأيام دون أن تشكل له الجامعة أو المصادر أي عائق1 نقطة
-
وعليكم السلام ورحمة الله وبركاته المشكلة ليست في كود جافاسكريبت بل في ملف CSS حيث أن الخطأ يقول أن المتصفح يقوم بتحميل ملف CSS ولكن اسم الملف لا يتنهي بصيغة .css لهذا يظهر لك هذا الخطأ ، ولهذا يجب عليك تغيير صيغة ملف ال CSS الى .css على سبيل المثال إذا كان ملف ال CSS يسمى ب style فيجب أن يكون اسمه كالآتي style.css وتضمينه في ملف HTML كالآتي <link rel="stylesheet" href="style.css"> وايضاً تأكد من أنك قمت بتضمين ملف جافاسكريبت بشكلٍ صحيح ، على سبيل المثال <script src="hj.js"></script>1 نقطة
-
يمكن إنشاء دالة خسارة مخصصة عن طريق تعريف الدلة التي تريد استخدامها، بحيث يجب أن تأخذ هذه الدالة القيم الحقيقية والقيم المتوقعة ،وأن تعيد الدالة قيم الكلفة للبيانات الممررة. وأخيراً يكون بعد ذلك بإمكانك تمرير التابع الخاص بك في مرحلة الترجمة compile. ويجب أن تكون حريصاً في النقاط التالية: 1. تأخذ دالة الخسارة وسيطتين فقط ، وهما القيمة المستهدفة (y_true) والقيمة المتوقعة (y_pred). لأنه من أجل قياس الخطأ في التنبؤ (الخسارة) نحتاج إلى هاتين القيمتين. يتم تمرير هذه الوسائط من النموذج نفسه في وقت ملاءمة البيانات. 2. يجب أن تستفيد دالة الخسارة من قيمة y_pred أثناء حساب الخسارة ، إذا لم تقم بذلك ، فستحصل على خطأ ولن يتم حساب ال Gradients.ا 4. يكون البعد الأول للوسيطتين y_true و y_pred دائماً هو نفسه حجم الدفعة (حجم الباتش Batch_size). على سبيل المثال، إذا كنت تلائم البيانات بحجم دفعة 64، وكانت شبكتك العصبية تحتوي على 10خلايا إخراج، فستكون أبعاد y_pred هي (64,10) . لأنه سيكون هناك 64 قيمة كخرج للنموذج، ولكل منها 10 قيم. (64 حجم الباتش ولدينا 10 خلايا في طبقة الخرج، هذا يعني أنه سيكون لدينا في كل مرة 64 عينة نحسب لها 10 نواتج وكل ناتج نقارنه بالقيمة الحقيقية وفق دالة التكلفة). 5. يجب أن تقوم دالة الخسارة دائماً بإرجاع متجه بطول batch_size. لأنه يتعين عليك إرجاع خسارة لكل نقطة بيانات أي لكل عينة. يمكنك تعريفها بالشكل التالي: def loss(y_true, y_pred): # نكتب الدالة هنا ولاننسى أن تكون متعلقة بالقيم المتوقعة return loss # بعدها يمكننا تمريرها للنموذج بالشكل التالي model.compile( loss=custom_loss, ) بشكل عام يفضل استخدام keras.backend أثناء بناء دالتك لتحنب حدوث أخطاء (يمكنك استخدام نمباي لامشكلة، لكن يفضل استخدام backend ). في المثال التالي سأقوم ببناء دالة تكلفة وأعطي وزن أيضاً للإخراج. فرضاً لدينا مهمة توقع والخرج هو قيمتين [x1, x2] ونريد إعطاء x2 أهمية أكبر عند حساب التكلفة: from keras import backend def custom_mse(y_true, y_pred): # حساب مربع الفرق بين القيم الحقيقية والمتوقعة loss = backend.square(y_pred - y_true) # (batch_size, 2) # ضرب النواتج بقيم الأوزان التي نريدها حيث هنا أعطينا أهمية أكبر للمخرج الثاني loss = loss * [0.3, 0.7] # (batch_size, 2) # حساب مجموع الأخطاء loss = backend.sum(loss, axis=1) # (batch_size,) return loss1 نقطة
-
رفع مشروع على السيرفر من خلال git كيف ارفعه واربطه باي تغيير يصير فيه الملف يتعدل في السيرفر1 نقطة
-
ألصورة التالية توضح مفهوم ال Tokenaization: توفر لك كيراس القيام بذلك بسهولة عن طريق الأداة Tokenizer من الموديول tf.keras.preprocessing.text.Tokenizer حيث تمكنك هذه الأداة من ترميز النص الخاص بك ليصبح عبارة عن سلسلة من الأعداد الصحيحة، بحيث نقوم بتمرير كامل مجموعة البيانات الخاصة بنا له، ثم يقوم بملائمتها fitting ، وتتضمن عملية الملائمة هذه بعض عمليات الفلترة على البيانات النصية ثم تقسيم كل نص (عينة) إلى الكلمات المكون منها ثم إنشاء قاموس يحوي كل الكلمات الفريدة التي وجدها مع عدد صحيح يمثلها (كل كلمة يعبر عنها بعدد صحيح)، وتسمى "Tokens". ثم بعد ذلك يمكننا تحول كل عينة من بياناتنا إلى الترميز العددي من خلال التابع texts_to_sequences. لكن أولاً دعنا نستعرض شكل هذه الأداة: tf.keras.preprocessing.text.Tokenizer( num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=" ", char_level=False, oov_token=None, document_count=0, **kwargs) الوسيط الأول يعبر عن العدد الأعظمي للكلمات المرغوب بحفظها في القاموس، حيث كما ذكرنا فإن هذه الأداة تقوم بإنشاء قاموس يحوي كامل الكلمات التي وجدها مع عدد صحيح يمثل كل كلمة، وبالتالي قد يحتوي هذا القاموس على مئات الآلاف من الكلمات الفريدة لكن لاتبقى كلها حيث يتم اختيار أهم 10 آلاف كلمة كحد أقصى من القاموس حسب أهميتها (الأهمية تعتمد على عدد مرات ظهور الكلمة في البيانات) ويتم الاختفاظ بها أما باقي الكلمات يتم تجاهلها. لكن يمكننا تغيير هذا الرقم من خلال الوسيط num_words فافتراضياً يأخذ القيمة 10 آلاف، لكن يمكننا وضع قيمة أخرى، مثلاً 75000 أي الاحتفاظ بأهم 75 ألف كلمة. أما الوسيط الثاني فهو الفلتر الذي سيتم تطبيقه على البيانات ويتضمن حذف علامات الترقيم والمسافات الفارغة والرموز (يمكنك تحديد ماتريد، لكن إذا تركت علامات الترقيم مثلاً، فسيتم ترميزها أي إسناد عدد صحيح يمثلها)، أما الوسيط الثالث فهو يحدد فيما إذا أردت تغيير حالة أحرف النصوص إلى أحرف صغيرة أم لا (يفضل القيام بذلك لأنه مثلاً إذا وجد كلمة Good و good سيتم اعتبارهما كلمتين مختلفتين وبالتالي يعطيهما ترميز مختلف)، أما الوسيط split فهو يمثل الرمز الذي سيتم تقسيم كل نص على أساسه إلى كلمات منفصلة. والوسيط الخامس لتحديد مستوى التقسيم وفي حالتنا نضعه على False (عند وضعه على True ستتم عملية التقسيم على مستوى الأحرف وليس الكلمات أي مثلاً سيتم تقسيم الكلمة Win إلى W و i و n وهنا لانحتاجه)، أما الوسيط السادس فنحتاجه عند القيام بعملية texts_to_sequences وذلك لوضع عدد صحيح يمثل الكلمات التي لم يجدها في القاموس (غير موجودة لديه، حيث كما ذكرنا فهو يحتفظ بعدد محدد من الكلمات وبالتالي قد يستقبل كلمة غير معرَفة لديه وغالباً نضعه على None أي الحالة الافتراضية) . أما التوابع التي نحتاجها فهي التابع fit_on_texts للقيام بعملية ال fitting حيث نمرر له كامل مجموعة البيانات، والتابع texts_to_sequences للقيام بعملية التحويل حيث نمرر له العينة أو مجموعة العينات (البيانات) المراد تطبيق التحويل عليها دفعة واحدة كما سنعرض في المثال التالي، وأيضاً هناك بعض الواصفات التي يمكننا أن نستعرض من خلالها محتويات القاموس مثل word_counts الذي يعرض لك قاموس ال Tokens مع عدد مرات ظهور كل Tokens، والواصفة document_count يرد لك عدد العينات (المستندات النصية) التي قام بترميزها. و word_index الذي يرد ال Tokens والعدد الصحيح الذي يمثلها يحيث يكون عبارة عن قاموس المفاتيح فيه هي الكلمات والقيم فيه هي العدد الصحيح الذي يمثلها. word_docs يرد كل ال Tokens وتردد كل منها. مثال: from keras.preprocessing.text import Tokenizer #إنشاء غرض t = Tokenizer() text = ['assign integers to characters', 'Machine Learning', 'assign', 'Machine Learning'] # الملاءمة t.fit_on_texts(text) # عرض المعلومات print("Count of characters:",t.word_counts) print("Length of text:",t.document_count) print("Character index",t.word_index) print("Frequency of characters:",t.word_docs) # التحويل s = t.texts_to_sequences(text) print(s) """ Count of characters: OrderedDict([('assign', 2), ('integers', 1), ('to', 1), ('characters', 1), ('machine', 2), ('learning', 2)]) Length of text: 4 Character index {'assign': 1, 'machine': 2, 'learning': 3, 'integers': 4, 'to': 5, 'characters': 6} Frequency of characters: defaultdict(<class 'int'>, {'assign': 2, 'integers': 1, 'to': 1, 'characters': 1, 'machine': 2, 'learning': 2}) [[1, 4, 5, 6], [2, 3], [1], [2, 3]] """ وإليك المثال العملي لاستخدامها أثناء تحضير البيانات قبل بناء نموذج لتصنيف المشاعر حيث تكون البيانات نصية ونريد إدخالها في الشبكة العصبية للتدريب وبالتالي يجب أولاً القيام بعملية Tokenizaton كالتالي: from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences import numpy as np maxlen = 100 training_samples = 200 validation_samples = 10000 max_words = 10000 tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(texts) sequences = tokenizer.texts_to_sequences(texts) word_index = tokenizer.word_index print('Found %s unique tokens.' % len(word_index)) data = pad_sequences(sequences, maxlen=maxlen) labels = np.asarray(labels) print('Shape of data tensor:', data.shape) print('Shape of label tensor:', labels.shape) indices = np.arange(data.shape[0]) np.random.shuffle(indices) data = data[indices] labels = labels[indices] x_train = data[:training_samples] y_train = labels[:training_samples] x_val = data[training_samples: training_samples + validation_samples] y_val = labels[training_samples: training_samples + validation_samples] glove_dir = '/Users/fchollet/Downloads/glove.6B' embeddings_index = {} f = open(os.path.join(glove_dir, 'glove.6B.100d.txt')) for line in f: values = line.split() word = values[0] coefs = np.asarray(values[1:], dtype='float32') embeddings_index[word] = coefs f.close() print('Found %s word vectors.' % len(embeddings_index)) embedding_dim = 100 embedding_matrix = np.zeros((max_words, embedding_dim)) for word, i in word_index.items(): if i < max_words: embedding_vector = embeddings_index.get(word) if embedding_vector is not None: embedding_matrix[i] = embedding_vector from keras.models import Sequential from keras.layers import Embedding, Flatten, Dense model = Sequential() model.add(Embedding(max_words, embedding_dim, input_length=maxlen)) model.add(Flatten()) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.layers[0].set_weights([embedding_matrix]) model.layers[0].trainable = False model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
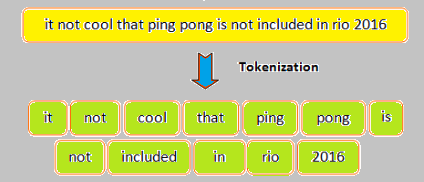 1 نقطة
1 نقطة -
السلام عليكم كيف يمكن جلب البيانات من قاعدة البيانات بدون تحميل الصفحة الكود التالي يظهر الأعضاء المتواجدون الان في الموقع لكن اذا خرج او دخل عضو لابد من اعادة تحميل الصفحة كيف يمكن حل هذه المشكلة <div class="div_online_memper"> <div id="content_online_memper"> <?php include('show_pages/display_online_memper.php'); ?> </div> </div> display_online_memper.php <?php include('connect_file.php'); $stmt1 = $db->prepare("SELECT * FROM accounts"); $stmt1->execute(); $result1 = $stmt1->get_result(); ?> <?php while ($row1 = $result1->fetch_assoc()) :?> <?php $stmt2 = $db->prepare("SELECT * FROM online_users where session=? "); $stmt2->bind_param('s', $row1['id']); $stmt2->execute(); $result2 = $stmt2->get_result(); ?> <?php while ($row2 = $result2->fetch_assoc()) :?> <a class="a_memper_name" href="index.php?users=<?=$row1['id'] ?>"> <table class="table_online_users"><tr><td class="td_online_users_picture"> <?php if (($row1['image_profile_path']) == NULL ):?> <img class="image_online_users" src="uploads/profile/user_logo.png"/> <?php else :?> <img class="image_online_users" src="uploads/profile/<?=$row1['image_profile_path'] ?>"/> <?php endif ;?> </td><td><?=$row1['thename'] ?></td></tr></table></a> <?php endwhile ;?> <?php endwhile ;?>1 نقطة
-
السلام عليكم @Hamada Ahmed يوجد عدة طرق لذلك لكن سأعطي مثال لكيفية عمل ذلك من خلال Ajax نقوم بعمل طلب لإرجاع البيانات من السيرفر كل مدة معينة مثلا كل 3 ثواني بدون الحاجة إلى تحديث الصفحة هكذا <script type="text/javascript" src="https://ajax.googleapis.com/ajax/libs/jquery/1.8.3/ jquery.min.js"></script> <script> (function worker() { $.ajax({ url: 'https://mywebsite.com/display_online_memper.php', success: function(data) { $('#content_online_memper').html(data); }, complete: function() { // Isuue The Second request when the current one's complete setTimeout(worker, 3000); } }); })(); </script> بعد ذلك سيتم إرسال طلب للسيرفر لجلب البيانات الجديدة كل 3 ثواني أو يمكنك وضع التوقيت الذي يناسبك (لكن لاحظ الثانية = 1000) بدون اعادة تحميل الصفحة1 نقطة
-
السلام عليكم ورحمة الله وبركاته اريد أن أنظم معكم لدورة علوم الحاسب. وارغب في تحسين مستواي في الرياضيات. احتاج من يدلني على المواضيع الرياضية التي سنحتاجها في علوم الحاسب. خصوصا في الخوارزميات. واذا فيه كتب دلوني عليها وجزاكم الله خيرا1 نقطة
-
إذا كنت تستخدم واجهة Keras المنفصلة، يجب عليك تحميل الحزمة التالية وذلك في حال كانت النسخة الخاصة بك أقل من 2.3: pip install keras-metrics ثم بعد ذلك يمكنك استخدام هذه المعايير من هذه الحزمة كالتالي: import keras_metrics model.compile( ... metrics=[keras_metrics.precision(), keras_metrics.recall()]) إذا كنت تستخدم نسخة كيراس الأحدث فيمكنك القيام بذلك من خلال الموديول keras.metrics: model.compile( ... metrics=[keras.metrics.Precision(), keras.metrics.Recall()]) أما إذا كنت تستخدم النسخة المدمجة مع تنسرفلو، فيمكنك القيام بذلك بشكل مباشر من خلال الموديول tf.keras.metrics: import tensorflow as tf model.compile( ... metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()]) أمثلة: m = tf.keras.metrics.Precision() m.update_state([0, 1, 1, 1], [1, 0, 1, 1]) m.result().numpy() #0.6667 m.reset_state() m.update_state([0, 1, 1, 1], [0, 1, 1, 1]) m.result().numpy() #1.0 m = tf.keras.metrics.Recall() m.reset_state() m.update_state([0, 1, 1, 1], [0, 1, 1, 1]) m.result().numpy() #1.0 التطبيق على نموذج: from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) from keras.datasets import mnist import keras import tensorflow as tf from tensorflow.keras.utils import to_categorical (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28, 28, 1)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) model.compile(optimizer='rmsprop', loss="CategoricalCrossentropy", metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()]) model.fit(train_images, train_labels, epochs=2, batch_size=512) ---------------------------------------------------------------------------------------- Epoch 1/2 118/118 [==============================] - 46s 374ms/step - loss: 0.9313 - precision_5: 0.7849 - recall_4: 0.3362 Epoch 2/2 118/118 [==============================] - 44s 375ms/step - loss: 0.1283 - precision_5: 0.9423 - recall_4: 0.8137 <keras.callbacks.History at 0x7f5e17641950> ولحسابهم على بيانات الاختبار: from keras import backend as K def recall(y_true, y_pred): tp = K.sum(K.round(K.clip(y_true * y_pred, 0, 1))) p = K.sum(K.round(K.clip(y_true, 0, 1))) result = tp / (p + K.epsilon()) return result.numpy() def precision(y_true, y_pred): tp = K.sum(K.round(K.clip(y_true * y_pred, 0, 1))) p = K.sum(K.round(K.clip(y_pred, 0, 1))) result = tp / (p + K.epsilon()) return result.numpy() e=precision_m(train_labels,model.predict(train_images))1 نقطة
-
شكرا هلى اهتمامك. انا كلما بدأت التعلم اتوقف بسبب الرياضيلت في مجال الخوارزميات1 نقطة
-
الكود يتغير عن طريق كود أخذته من مكتبة عن طريق حساب الصلاوات بمعنى كل فترة وفترة يتغير وقت صلاة الفجر لدقيقه زيادة مثلا او لدقيقة نقصان. لكن بأذن الله راح اجرب اجابتك وراح ارد لك خبر ان شاء الله1 نقطة
-
السلام عليكم @Aisha Zaki تفقد ال Github Repo الخاص بالمشروع وإختبرت المشروع لكن لا يوجد المشاكل التي ذكرتيها , عند محاولة إرسال الطلب بحقول فارغة لا يرسل يظهر رسالة بأن الحقل فارغ وكذلك بالنسبة للشاشات الصغيرة لم أواجه مشكلة حذف المنتج تلقائي عند تحديد الكمية أتوقع المشكلة لديك هي فقط من كاش المتصفح (الذاكرة المؤقتة) خاص ملفات ال .js تحفظ لمدة في المتصفحات عموماً لحل المشكلة جربي متصفح آخر وأتوقع ستعمل معك بدون مشاكل1 نقطة
-
هكذا ...
 1 نقطة
1 نقطة -
هذا هو الجواب الدقيق لماتطلبه أخي..
 1 نقطة
1 نقطة -
السلام عليكم صديقي .. عمرك ممتاز جداً .. اتبع مايلي ولن تندم: 1-اهتم بالرياضيات جداً جداً جداً وضع تركيزك فيها قبل البرمجة حالياً وركز فيها على (الجبر + الاشتقاق+نظرية الأعداد+الجيوميتري) 2-أبدأ بتعلم أي لغة برمجة وأنصحك بأن تبدأ في بايثون وهناك مئات الكورسات على الانترنت تعلمك أساسيات بايثون (لاتتعمق فيها فقط تعلم الأساسيات ولاداعي لدراسة الكائنات والبرمجة غرضية التوجه في هذه المرحلة) وبعدها أبدأ بكتابة أكواد بسيطة (حتى تصل ل 100 كود مثلاً). 3-اجعل 1 و 2 هما جل اهتمامك وانسى شيء اسمه برمجة تطبيقات الآن وكل هذه القصص لأنك الآن تحتاج إلى بناء عقل برمجي. 4-أبدأ بعدها بحل مسائل على موقع codeforces وهو موقع عالمي للبرمجة التنافسية وهي المنصة التي بدأت أتدرب عليها عندما كنت في عمرك تقريباً وقمت بحل أكثر من 400 كود عليها. 5-بعد أن تصل ل 400 كود على الأقل أبدأ بتعلم برمجة التطبيقات والأمور الأخرى . # 1 ستستمر فيها طيلة ال 8 أعوام القادمة. 2# ستسمر فيها حتى تصل ل 100 كود وقد تحتاج سنتين. #4 حتى تصل ل 400 وقد تحتاج سنة أو 2 أو 3 أو 4 وبعد أن تصل ل200. #5 ستكون مثل أكل المقبلات وأؤكد لك انسى انسى انسى برمجة التطقبيقات والأمور الأخرى .... لايمكنك بناء سقف بدون أعمدة أفعل ما أقوله وستكون خارقاً.1 نقطة
-
الأمر بسيط أخي ...
 1 نقطة
1 نقطة -
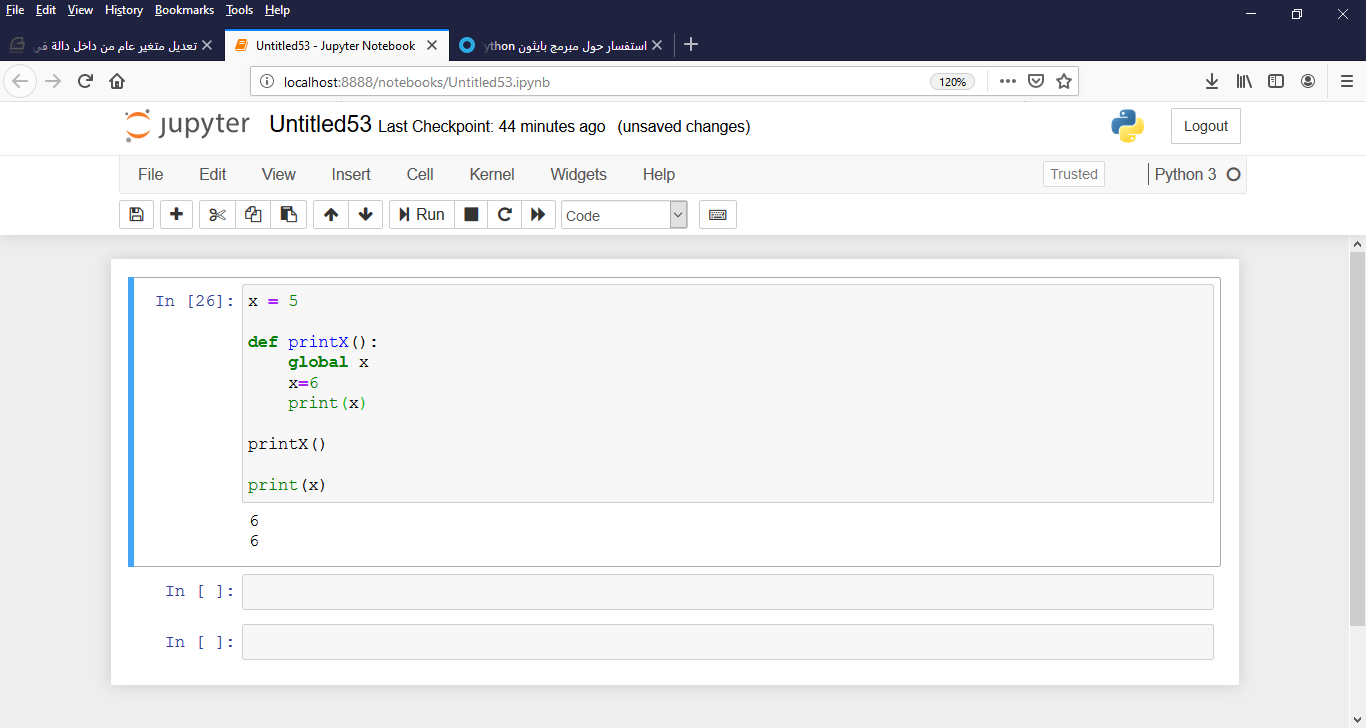
المتغيرات التي يتم تعريفها بداخل الدوال, يقال لها Local Variables أو متحولات محلية و هذه التسمية تعني أنه لا يمكن الوصول لها من خارج الدالة بشكل مباشر. المتغيرات التي يتم تعريفها خارج الدوال, يقال لها Global Variables أو متحولات عامة و هذه التسمية تعني أنه يمكن الوصول لها من أي مكان في الكود حتى من داخل التوابع functions، لكن في حال قمتي بتعديل قيمة المتغير العام من داخل تابع أو كلاس فإن التغيير يكون محصور ضمن التابع أو الكلاس الذي حدث فيه التعديل( لأنه تم إنشاء نسخة من المتحول داخل الدالة أو الكلاس)، لذا إذا أردت جعل التعديل يؤثر في المتحول الأساسي يجب أن تضعي global كما في الصورة...
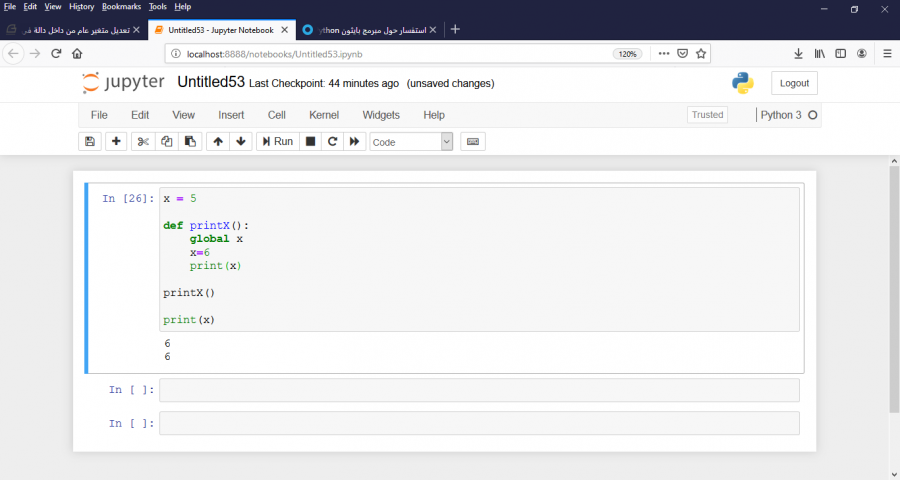 1 نقطة
1 نقطة -
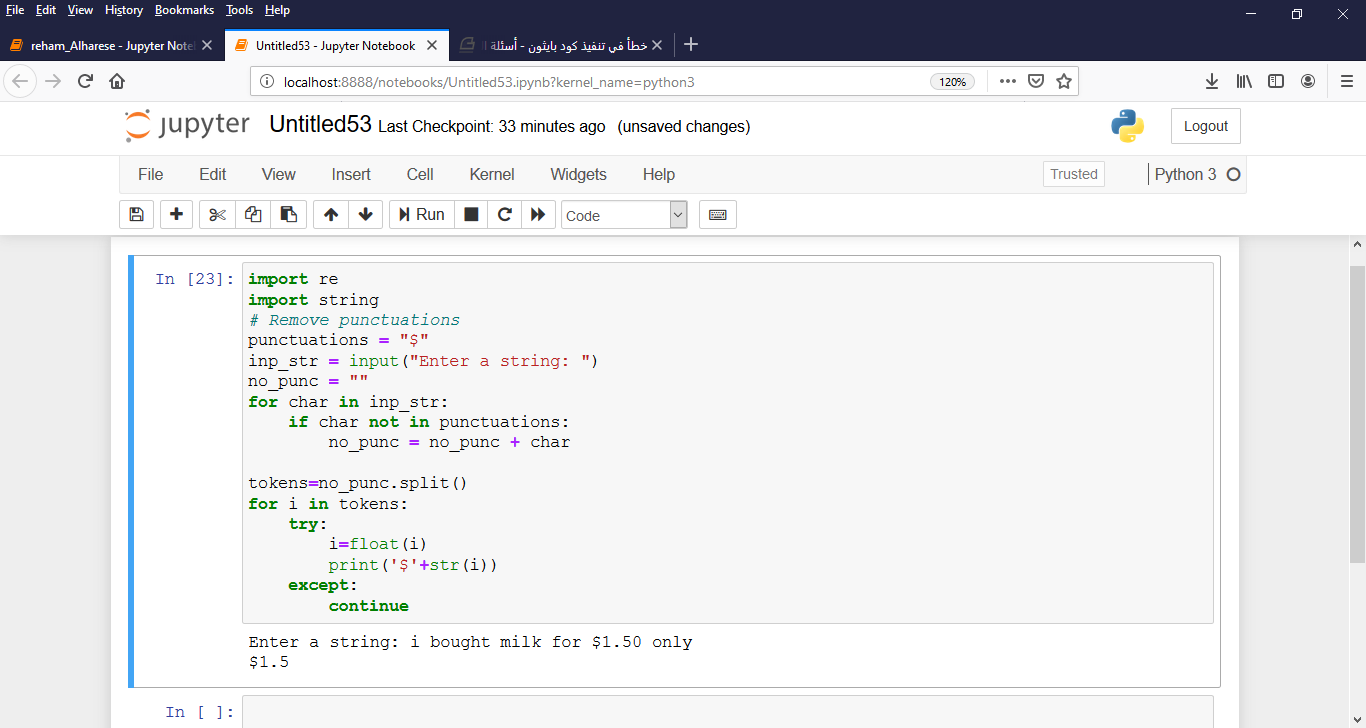
السلام عليكم أختي.. الكود الذي كتبته لايوجد به خطأ قواعدي ولكنه لايحقق المطلوب "برنامج لإدخال النص واستخراج الأسعار بالدولار" ... يمكنك أن تجربي الكود التالي وسيعمل :
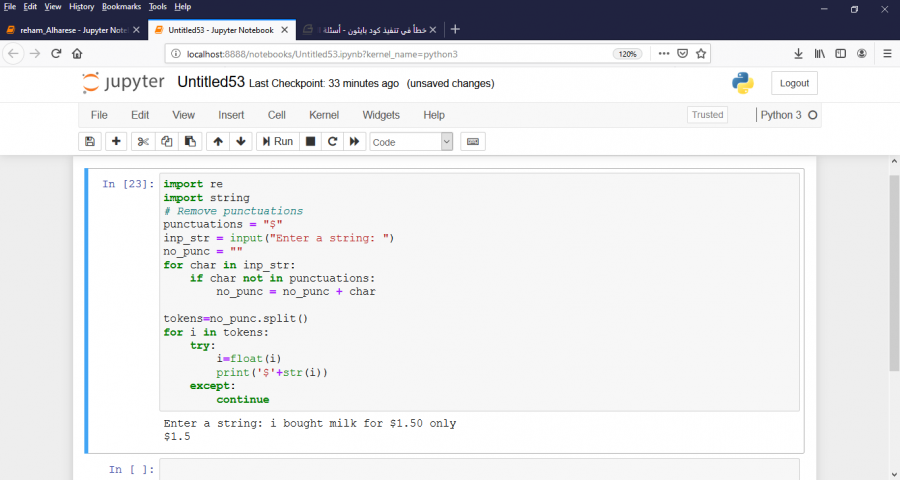 1 نقطة
1 نقطة