
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/30/21 في كل الموقع
-
أقوم بتمرير بعض المتغيرات في الطلب من النوع GET إلى خادم الويب node.js، وأعلم أنه يمكنني الحصول على قيم هذه المتغيرات ضمن express كالتالي: var param = req.query.param; ولكن لا أستخدم إطار express في مشروعي، فكيف يمكنني الحصول على هذه القيم ضمن node.js فقط؟2 نقاط
-
أحاول إيجاد طريقة لإنشاء والكتابة على ملف نصي من خلال node.js مباشرةً أي من ضمن الكود البرمجي. كيف يمكنني تنفيذ ذلك؟ وماهي الحزمة التي يجب أن أقوم باستخدامها؟1 نقطة
-
لا يمكنني معرفة كيفية استخدام array أو matrix بالطريقة التي أستخدم بها القائمة list عادةً. أريد إنشاء array فارغة ثم إضافة عمود (أو صف) إليها في المرة الواحدة مثلما نفعل عندما نستخدم التابع append على القوائم على سبيل المثال نقوم بالتالي في حالة إستخدام القوائم lists: lst = [] for item in data: lst.append(item) كيف يمكننا القيام بذلك في Numpy؟1 نقطة
-
ضمن main layout لنبطل التخزين المؤقت: @guest <meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate" /> <meta http-equiv="Pragma" content="no-cache" /> <meta http-equiv="Expires" content="0" /> <meta http-equiv="refresh" content="{{config('session.lifetime') * 60}}"> @endguest ربما سبب المشكلة في ملفات الكوكيز، لاحظت Apple Bug Reporter PID #13966978. حيث إن قمت بتثبيت عدة قيم كوكيز مباشرة فهذا لن يعمل، بل يجب وضع قيمة بسيطة كأول كوكيز يتم تخزينها: setcookie("hi","true"); ثم أكمل باقي الكوكيز. إن لم تعمل ربما يحل المشكلة التالي: Cross-domain cookies/sessions in Safari1 نقطة
-
لنحل مشكلة csrf سنقوم بوضع عنصر html وهو meta tag يخزن هذه القيمة: ضعه في الترويسة مثلا.. (صفحة HTML الرئيسية للموقع main Layout <meta name="csrf-token" content="{{ csrf_token() }}" /> كما يمكن يمكن عمل زر ومن ثم إخفاءه : type="hidden" ويمكن هكذا <input type="hidden" name="_token" value="{!! {{ 'csrf_token()' }} !!}"> ثم عندما تريد إرسال الطلبية نجلب قيمته meta: <script type="text/javascript"> $.ajaxSetup({ headers: { 'X-CSRF-TOKEN': $('meta[name="csrf-token"]').attr('content') } }); </script> ونمررها في الترويسة.. نضع هذه الشيفرة في المسارين التاليين حسب إصدار لارافل، وأرى أنك تستخدم إصدار قديم resources/js/bootstrap.js file for Laravel 5.7 and resources/assets/js/bootstrap.js for Laravel 5.6 هل تضع قيمة للجلسة session ؟ مثل Timeout ؟ يمكن زيادة مدة الجلسة: config/session.php 'lifetime' => 3601 نقطة
-
عند استخدامها لا يحدث اي مشاكل, بحثت عن بعض المواقع التي تحاكي اجهزة الأيفون وجدت هذا الموقع: http://www.responsinator.com/?url=voting-system-sadouki.herokuapp.com%2FVXgptEmRD عند الضغط على زر تصويت يظهر في console خطأ 419: message "CSRF token mismatch." الكود الذي استخدمه لارسال التصويت لقاعدة البيانات: $.ajax({ type: 'post', url: "{{ route('vote') }}", data: { '_token': "{{ csrf_token() }}", 'id': id, 'voted': voted, 'unique_url': unique_url }, success: function (data) { if(data.status == true) { // code } else { // code } }, error: function(reject) { }
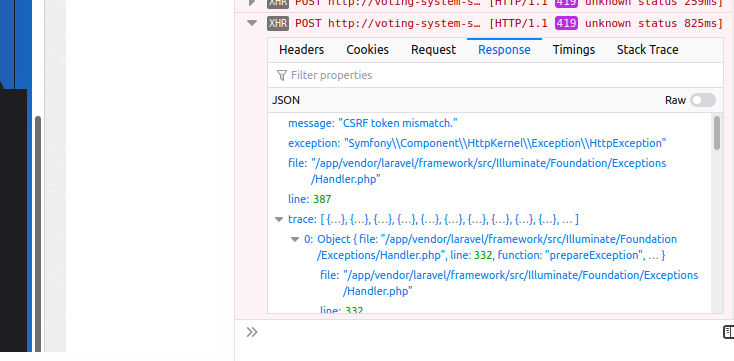 1 نقطة
1 نقطة -
كيف أقوم بتحويل مصفوفة NumPy إلى قائمة List في Python على سبيل المثال: import numpy lst = [[1,2,3], [4,5,6]] newArray = numpy.array(lst) print(newArray) """ Output: [[1 2 3] [4 5 6]] """ الآن كيف يمكنني تحويل newArray إلى قائمة List مرة أخرى؟ حاولت أن أستعمل الدالة list ولكن يبدو أنها تحول كل صف إلى مصفوفة Numpy array: >>> list(newArray) [array([1, 2, 3]), array([4, 5, 6])]1 نقطة
-
السلام عليكم ورحمة الله وبركاتهُ، كيف حالكم جميعاً ؟ بإذن الله تكونوا جميعاً بخير. هل يمكن أن نقوم بتصميم تطبيقات الجوال بدون برمجة يعني تصميمها من ناحية الـ Front-end فقط بدون Back-end ؟ حياكم الله، ويومكم مُبارك.1 نقطة
-
كون الدالتين تستعملان نفس الحدث فلن نحتاج إلا لوضعهما بالمكان الصحيح بدل تكرار الكود : أي بعد نجاح طلب الأجاكس , و المقصود هنا هو التابع success . نقوم في الكود الأول بإرسال طلب أجاكس لتخزين بيانات الرسالة بعد تقديم النموذج , لاحظ : $j('#messages_form') .on('submit', function(event) { event.preventDefault(); if ($j('#username') .val() != '' && $j('#message') .val() != '') { var form_data = $j(this) .serialize(); $j.ajax({ url: "send_messages_form.php", method: "POST", data: form_data, success: function(data) { $j('#messages_form')[0].reset(); load_unseen_notification(); } }); } else { alert(" رسالة فارغة رجاءا اكتب شىء "); } }); في حين أننا نقوم بعرض رسالة في قسم الرسائل في النجاح في الكود الثاني , لاحظ : success: function(response) { $j("#norec") .hide(); $j("#div_show_message") .append(response); $j('#messages_form') .trigger('reset'); }, error: function(xhr, ajaxOptions, thrownError) { alert(thrownError); } أي أن دمج الكودين لن يكون إلا في ما بعد نجاح طلب الأجاكس , و بالتالي : $j('#messages_form') .on('submit', function(event) { event.preventDefault(); if ($j('#username') .val() != '' && $j('#message') .val() != '') { var form_data = $j(this) .serialize(); $j.ajax({ url: "send_messages_form.php", method: "POST", data: form_data, success: function(data) { $j('#messages_form')[0].reset(); load_unseen_notification(); // عرض الرسالة $j("#norec") .hide(); $j("#div_show_message") .append(data); $j('#messages_form') .trigger('reset'); }, // إضافة حالة فشل الطلب error: function(xhr, ajaxOptions, thrownError) { alert(thrownError); } }); } else { alert(" رسالة فارغة رجاءا اكتب شىء "); } }); ثم كخطوة أخيرة لن تحتاج إلا تحريك الشريط الجانبي للأسفل , و بالطبع سيكون ذلك بعد نجاح طلب الأجاكس , أي أن العملية ستتبع منطقا واحد . وهو نفس المنطق المتبع في الكود المرفق . يمكنك المحاولة بقيام ذلك ثم سيمكن مساعدتك في حالة الاستعصاء .1 نقطة
-
توجه لمتصفح chrome ثم Developer Tools/Settings/Overrides ثم User agent واختر نوع المستخدم iPhone/iPad أو Safari يفترض أن يعمل المتصفح مثل Safari بكل خصائص front-end ضمنه. السبب على الأغلب:: هل تستخدم أي مكتبات أو خاصيات غير مدعومة على Safari أو ios web بشكل عام؟ تأكد من إصدار المكتبات، ويمكنك مشاركة هذه المعلومات لنعمل على حل المشكلة.1 نقطة
-
المشكلة موجودة، زر التصويت لا يعمل، لا يتم تحديث العداد.1 نقطة
-
الكود كالتالي : <div class="dropdown"> <a class="dropdown-toggle" data-toggle="dropdown"> <div class="label count"></div> <div class="glyphicon" title="الرسائل"></div> </a> <div class="dropdown-menu"></div> </div> <script> var $j = jQuery.noConflict(); $j(document) .ready(function() { function load_unseen_notification(view = '') { $j.ajax({ url: "show_messages_menu.php", method: "POST", data: { view: view }, dataType: "json", success: function(data) { $j('.dropdown-menu') .html(data.notification); if (data.unseen_notification > 0) { $j('.count') .html(data.unseen_notification); } } }); } load_unseen_notification(); $j('#messages_form') .on('submit', function(event) { event.preventDefault(); if ($j('#username') .val() != '' && $j('#message') .val() != '') { var form_data = $j(this) .serialize(); $j.ajax({ url: "send_messages_form.php", method: "POST", data: form_data, success: function(data) { $j('#messages_form')[0].reset(); load_unseen_notification(); } }); } else { alert(" رسالة فارغة رجاءا اكتب شىء "); } }); $j(document) .on('click', '.dropdown-toggle', function() { $j('.count') .html(''); load_unseen_notification('yes'); }); setInterval(function() { load_unseen_notification();; }, 5000); }); </script> لكن كيف يمكن ان نضمن الكود التالي فيه : success: function(response) { $j("#norec") .hide(); $j("#div_show_message") .append(response); $j('#messages_form') .trigger('reset'); }, error: function(xhr, ajaxOptions, thrownError) { alert(thrownError); } كذلك كيف نضمن كود التحريك التلقائي للشريط الجانبي @Adnane Kadri قمت بتعديل الكود لكن مشكلتي هي التحريك التلقائي للشريط الجانبي مالطريقة <script> var $j = jQuery.noConflict(); $j(document).ready(function(){ function load_unseen_notification(view = '') { $j.ajax({ url:"show_messages_menu.php", method:"POST", data:{view:view}, dataType:"json", success:function(data) { $j('.dropdown-menu').html(data.notification); if(data.unseen_notification > 0) { $j('.count').html(data.unseen_notification); } } }); } load_unseen_notification(); $j('#messages_form').on('submit', function(event){ event.preventDefault(); if($j('#username').val() != ''&& $j('#message').val() != '') { var form_data = $j(this).serialize(); $j.ajax({ url:"send_messages_form.php", method:"POST", data:form_data, success:function(response){ $j("#norec").hide(); $j("#div_show_message").append(response); $j('#messages_form').trigger('reset'); load_unseen_notification(); }, error: function(xhr, ajaxOptions, thrownError) { alert(thrownError); } }); } else { alert(" رسالة فارغة رجاءا اكتب شىء "); } }); $j(document).on('click', '.dropdown-toggle', function(){ $j('.count').html(''); load_unseen_notification('yes'); }); setInterval(function(){ load_unseen_notification();; }, 5000); }); </script>1 نقطة
-
يمكنك القيام بذلك عن طريق File System API و هو عبارة عن module جاهز في node/js: لاحظ المثال التلي: const fs = require('fs'); fs.writeFile("/tmp/test", "Hey there!", function(err) { if(err) { return console.log(err); } console.log("The file was saved!"); }); أو const fs = require('fs'); fs.writeFileSync('/tmp/test-sync', 'Hey there!');1 نقطة
-
من الطبيعي جدا أن تجد بعض الصعوبة في عمل أي تطبيق عملي , ولكنه سيجب عليك تخطي هاته الصعوبة بالمحاولة و التكرار . و لذلك فإنه لن يكون لتقديم الكود أي منفعة . عوضا عن ذلك يمكنك الإنطلاق بالفعل في صياغة الكود الخاص بك , و سنساعدك في ذلك .1 نقطة
-
عذرا اخي انا مبتديء في البرمجة خاصة الجافاسكربت هل تتفضل اخي الكريم - المشروع في المرفقات هل تتكرم وتعدل الاكواد .1 نقطة
-
مرحبا, ممكن احد يشرحلي طريقة اضافة بوابة الدفع paysera checkout او اذا كان فيه مشروع مفتوح المصدر يكفي ذلك هذا التوثيق الخاص بهم و لم استطع فهم طريقة الاضافة https://www.paysera.com/v2/en/payment-gateway-checkout استعمل لارافيل1 نقطة
-
لما لا تقوم فقط بإستعمال واحدة من الحزم التي تستعمل طريقة omnipay لتوحيد عمل بوابات الدفع لإضافة بوابة دفع بايسيرا كونك تطبيقك لارافيل ؟ يقترح : semyonchetvertnyh/omnipay-paysera . povils/omnipay-paysera . و لن يكون ذلك مشكلة إن قمت بالتعامل مع أي من حزمها من قبل . كما يمكنك أيضا إستعمال حزمة adumskis/laravel-paysera (لا تنتمي لمجموعة حزم omnipay) و عموما ستكون ملزما بإتباع الخطوات : فتح حساب بايسيرا , خاص أو تجاري (سيكون هذا ضروريا في عمليات توثيق التعاملات). ستحتاج طلب خدمة بوابة الدفع : يمكنك القيام بذلك مجانًا عن طريق تسجيل الدخول إلى حسابك والانتقال إلى الإعدادات > إعدادات الملف الشخصي > إدارة الخدمة . قم بإنشاء مشروع , يمكنك اتباع الخطوات الموضحة في الفيديو التالي . قم بربط بوابة الدفع , إما عن طريق الإضافة التي توفرها بايسيرا , أو عن طريق الواجهة البرمجية . يمكن الإستعانة بواحدة من الحزم السابقة أو إستعمال الواجهة بشكل مباشر .1 نقطة
-
بعد مراجعة التوثيق، تبين أن عليك (صاحب المشروع) عمل حساب في المنصة، ثم من خلال الحساب الشخصي سوف يقوم بعمل مشروع (مشروع جزئي ضمن حساب بوابة الدفع خاص بالدفع للمشروع البرمجي)، بعد هذه الخطوات يمكنك تضمين المكتبات البرمجية الخاصة ببوابة الدفع، وتحديد الإعادادات الموافقة لحسابك الشخصي فيها، إن ذكرت في أي مرحلة وصلت هذا يساعدنا في إرشادك للخطوة التالية، شكرا لك1 نقطة
-
الحمد لله لقيت الحل عن طريق برنامج ظريف اسمه mysql compare1 نقطة
-
package Java; import java.util.Scanner; public class Main { public static void main(String[] args) { System.out.println(" ENTER size:"); Scanner input=new Scanner(System.in); int rows=input.nextInt(); int colums=input.nextInt(); System.out.println(" ENTER Elemnt:"); int arr[][]=new int[rows][colums]; for(int i=0;i<rows;i++){ for (int j=0;j<colums;j++){ arr[i][j]=input.nextInt(); } } printArray(arr); System.out.println(); int max; max=arr[0][0]; if(arr[i][j]>max) max=arr[i][j]; for(int i=0;i<rows;i++){ for (int j=0;j<colums;j++){ System.out.println(max); } } int R,C,SR,SC; R=arr.length; C=arr[0].length; for(int i=0;i<R;i++){ SR=0; for(int j=0;j<C;j++){ SR+=arr[i][j]; } System.out.println("sum of row :"+(i+1)+":="+SR); } for(int i=0;i<C;i++){ SC=0; for(int j=0;j<R;j++){ SC+=arr[j][i]; } System.out.println("sum of colum :"+(i+1)+":="+SC); } } static void printArray(int a [] []){ System.out.println(" Data "); for(int []x:a){ for(int y:x){ System.out.print(y+" "); } System.out.println(); } } } ١/ايجاد اكبر عنصر في المصفوفة ٢/ايجاد اكبر مجموع صفوف1 نقطة
-
قمت بإضافة بعض ملفات SCSS ضمن مشروع node.js وأرغب بإجراء تحديث تلقائي للملفات أثناء إجراء التغييرات على التنسيقات. كيف يمكنني جعل هذه الملفات تقوم بالتحديث تلقائياً باستخدام node.js و node-sass ؟1 نقطة
-
لقد تم تعديل الحزمة node-sass إلى node-sass-middleware وأصبح من الممكن استخدامها مباشرةً بالكود لديك كالتالي: var fs = require('fs'), path = require('path'), express = require('express'), sassMiddleware = require('node-sass-middleware') var app = module.exports = express(); app.use( sassMiddleware({ src: __dirname + '/sass', dest: __dirname + '/src/css', debug: true, }) ); app.use(express.static(path.join(__dirname, 'public'))); بحيث تضع المسارات حسب وجود ملفات النسيقات في مشروعك بدلاً من sass و src/css. مع الانتباه لضرورة تضمين الوسيط قبل إضافة كود express.static حتى يتم التحديث على الملفات قبل إعادتها إلى المتصفح.1 نقطة
-
لقد قمت بإضافة الترويسة التالية إلى الطلبات في خادم node.js للوصول إلى طول البيانات خلال الطلب: res.set({'Content-Type':'text/plain;charset=utf-8', 'Content-Length': Buffer.byteLength(data, 'utf-8')}); وعندما أقوم بطباعة المحتوى أحصل على حجم البيانات كما هو، لكن إذا قمت باستعراضها ضمن المتصفح في الكونسول أرى جميع الخصائص عدى الخاصية content-length: Connection:keep-alive Content-Encoding:gzip Content-Type:text/plain;charset=utf-8 Date:Sat, 17 Aug 2021 08:21:59 GMT Transfer-Encoding:chunked Vary:Accept-Encoding X-Powered-By:Express لماذا تختفي هنا content-length؟ وكيف يمكنني ضمان وجودها مع جميع الطلبات التي سيتم إرسالها؟1 نقطة
-
بالإطلاع على محتوى الرد نجد الخاصية Transfer-Encoding: chunked، وهنا لا يمكن تضمين content-length لأن البيانات يتم تقسيمها إلى جزء أو عدة أجزاء (ما يدعى ب chunks) ضمن محتوى الرد (response body) مع وجود علامات ضمن كل جزء تدل على حجم بيانات هذا الجزء فقط. وإن node.js بشكل افتراضي يقوم بإضافة Transfer-Encoding: chunked ضمن ترويسة الطلب، ولكن عند إضافة Content-Length يتم تعطيلها. أما وجود الخاصية Content-Encoding:gzip ضمن الترويسة فتدل على أنه تم تفعيل الوسيط connect.compress والذي يقوم أيضاً بإيقاف Content-Length. ولكن بجميع الأحوال السابقة في حال لم تقم بإنشاء محتوى مضغوط بنفسك بشكل يدوي، فإن الترويسة Content-Length التي قمت بإنشائها بشكل يدوي ستكون غير ملائمة للمحتوى الأخير الذي يتم إرسالة من طرف الخادم وبالتالي يجب عليك الاعتماد على الوسيط connect بدلاً من إجرائها بشكل يدوي لتجنب بعض المشاكل. وفي النهاية يجب الأخذ بعين الاعتبار أن البيانات التي يتم إرسالها من الخادم إلى المستخدم النهائي من الممكن أن تخضع للعديد من الإضافات أو التعديلات بحسب الوسطاء التي يتم استخدامها والتي تقوم بدورها بالتعديل مرات عديدة على ترويسة الطلب.1 نقطة
-
يقوم إطار العمل express تلقائياً بوضع قيمة الخيار httpOnly إلى true، وبالتالي تصبح ملفات تعريف الارتباط هذه غير قابلة للوصول من طرف الزبون (الجافاسكريبت من خلال المتصفح). لجعل ملفات تعريف الارتباط قابلة للوصول من قبل كود الجافاسكريبت من طرف الزبون يجب تعديل الكود لديك ليصبح بالشكل التالي: res.cookie('testcookie', 'hello', { maxAge: 900000, httpOnly: false}); ويجب أيضاً الانتباه إلى نوع الاتصال لديك في حال كان http أو https والقيام بالتعديل المطلوب على الكود بإضافة القيمة secure إما true لـ https أو false ل: http بالشكل الموافق: res.cookie("testcookie", "hello", { secure:true, maxAge:120000, httpOnly: true });1 نقطة
-
الكود خاصتك غير منظم جيدا و لذلك هو غير واضح أو غير قابل للقراءة بشكل عادي . و لكن لتنفيذ الفكرة التي تصفها يمكنك عمل تحديث للصفحة و التحريك التلقائي لشريط التمرير بعد نجاح اظهار الرسائل . و لنتأكد من إتباع مبدأ فصل الاهتمامات لتنظيم العملية أكثر , سيتبع الكود المنطق الموصوف سابقا على نحو مشابه : function adjustScroll() {} function loadUnseenNotifications() { // بعد ارسال طلب الاجاكس لتحميل اشعار بالرسائل الغير مقروءة if (data.unseen_notification > 0) { $j('.count').html(data.unseen_notification); // تحميل الرسائل و عرضها ضمن الشاشة ان كانت الرسائل أكثر من 1 loadMessages(); } } function loadMessages() { // بعد تحميل الرسائل نحتاج تحديث الصفحة و عمل الاسكرول التلقايئ adjustScroll(); } setInterval(function() { loadUnseenNotifications(); }, 1000); أي : يتم التحقق كل ثانية إن كان هنالك إشعارات رسائل غير مقروءة . ان كان نعم سيتم تحديث عد الاشعارات غير المقروءة + تحميل رسائل جديدة . سيقوم تحميل رسائل جديدة تلقائيا بعد انتهاء طلب الأجاكس بتحديث الصفحة و عمل اسكرول تلقائي للأسفل لاخر رسالة تم تحميلها . و رغم أن تطبيقات الدردشة تستعمل تقنيات أحدث إلا أنه يعتبر تطبيقا عمليا جيدا . بالطبع فإن العملية وصفية , لكن يمكنك صياغة الكود الخاص بك وفق الخطوات السابقة .1 نقطة
-
ال dropout أو "التسرب " هو إحدى تقنيات محاربة ال Overfitting (الضبط الزائد). مبدأ هذه التقنية هو تجاهل أو تعطيل بعض الخلايا (العصبونات) بشكل عشوائي في طبقات (أو طبقة) الشبكة العصبية. . تأمل الصورة التالية: وبالتالي سنقوم بمنع المودل من التركيز على خاصية "feature" معينة و نجبره على التعلم من كل الخصائص الموجودة لا أن يأخذ خاصية واحدة كقاعدة في التعلم ويعتمد عليها بشكل دائم. وبهذه الطريقة نتجنب حالة الـ overfitting ونتعلم من كل الخصائص الموجودة. أي أن الفكرة خلف هذه التقنية هي أنه في كل تكرار نقوم بتعطيل خلايا (نجعلها لاتشترك في التدريب والتوقع) بينما الخلايا المتبقية تشارك في عملية التدريب والتوقع، أي يستخدم مجموعة جزئية من العصبونات في كل تكرار (التكرار الواحد هو عملية انتشار أمامي (للتوقع) ثم انتشار خلفي(لتحديث قيم الأوزان)). أي أن تأثير هذه التقنية هو أن الشبكة تصبح أقل حساسية للأوزان المحددة للخلايا العصبية. ينتج عن هذا بدوره شبكة قادرة على التعميم "generalization " بشكل أفضل ومن غير المرجح أن تقع في ال OF على بيانات التدريب. ويمكننا أن نقول أيضاً أن الشبكة لن تقوم بحفظ مسار أو سلوك معين في عملية التوقع. انظر للصورة التالية: وفي كيراس يمكنك استخدامها بالشكل التالي: from tensorflow.keras.layers import Dropout Dropout(rate) حيث أن ال rate هو معدل الحذف ويأخذ قيمة بين 0 و 1. فمثلاً عند وضع 0.5 أي سيتم تعطيل 50% من العصبونات، وتعتبر هذه القيمة من الـ hyper parameters أيضاً التي يجب ضبطها في نموذجك بشكل دقيق. فاختيار قيم كبيرة لل rate (فوق 0.5) قد يؤدي إلى مشكلة جديدة وهي ال Underfitting. يجب أن تعلم أيضاً أنه يتم استخدام التسرب فقط أثناء تدريب النموذج ولا يتم استخدامه عند التقييم النهائي للنموذج (مرحلة التدريب مثلاً أو الاستخدام العملي) أي بمعنى آخر يستخدم فقط في مرحلة التدريب أما في مرحلة الاختبار أو الاستخدام فإنه تلقائياً لايتم إشراكها في عملية التوقع. الآن سأعطيك مثال عملي عليه أثناء بناء نموذج لتصنيف الأرقام المكتوبة بخط اليد: from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Conv2D, Dropout, Flatten, MaxPooling2D # تحميل البيانات import tensorflow as tf (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() x_train.shape # (60000, 28, 28) # 4-dims تحويل المصفوفة إلى شكل رباعي الأبعاد x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) input_shape = (28, 28, 1) # لنتمكن من الحصول على الفواصل العشرية بعد القسمة x_train = x_train.astype('float32') x_test = x_test.astype('float32') # Normalizing x_train /= 255 x_test /= 255 print('x_train shape:', x_train.shape) print('Number of images in x_train', x_train.shape[0]) print('Number of images in x_test', x_test.shape[0]) # بناء النموذج model = Sequential() model.add(Conv2D(32, kernel_size=(3,3), input_shape=input_shape)) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(128, activation=tf.nn.relu)) model.add(Dropout(0.2)) # هنا أضفنا طبقة model.add(Dense(10,activation=tf.nn.softmax)) # تجميع النموذج model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['acc']) model.fit(x_train,y_train, epochs=9) model.evaluate(x_test, y_test) # 98.5% حيث نضيفها بعد الطبقة التي نريد تطبيق التسرب عليها، وهنا قمنا بإضاففتها بعد الطبقة dense(128) أي أن هذه الطبقة سيتم تطبيق التسرب عليها خلال عملية التدريب وبالتالي في كل كل تكرار سيتم تعطيل (أو تجاهل) 20% من الخلايا فيها بشكل عشوائي، أي في كل تكرار ستشترك 102 خلية في التدريب والتوقع وسيتم تجاهل باقي الخلايا. وطبعاً يمكنك إضافتها بعد كل طبقة من طبقات نموذجك (هذا يرجع لك حسب تقديرك للمشكلة وماتتطلبه). لكن لاتستخدمها في بداية النموذج أي بعد التعليمة sequential لأنه في هذه الحالة تكون قد طبقتها على طبقة الدخل وبالتالي سيتم تجاهل قسم من ال features الخاصة بعيناتك وهذا أمر غير محبذ أبداً.

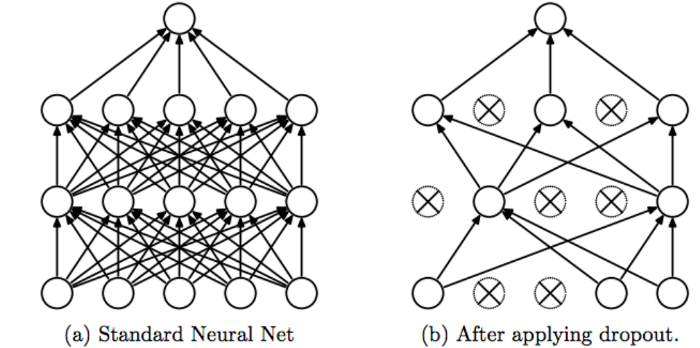 1 نقطة
1 نقطة -
يُمكنك إستخدام هذه الطريقة لتحويل عدد إلى محرف: public class Main { public static void main(String []args){ System.out.println(String.valueOf((char)(1 + 'A' - 1))); // A System.out.println(String.valueOf((char)(2 + 'A' - 1))); // B System.out.println(String.valueOf((char)(3 + 'A' - 1))); // C System.out.println(String.valueOf((char)(26 + 'A' - 1))); // Z } } حيث نستخدم ترميز ASCII ف: 1 + 'A' - 1 = 65 لأن الرمز الموافق للمحرف A هو 65 و المحرف B هو 66 و هكذا. و لتحويل العدد من رمز ASCI إلى محرف نستخدم cast إلى char: (char)65 = 'A' (char)66 = 'B' (char)67 = 'C' يُمكننا إنطلاقاً من هذه الطريقة إنشاء دالة تستقبل عدد و تقوم بالتحقق من أن العدد محصور بين 1 و 26 و عليه تُعيد المحرف الموافق له: public class Main { public static void main(String []args){ System.out.println(getCharForNumber(1)); // A System.out.println(getCharForNumber(2)); // B System.out.println(getCharForNumber(26)); // Z System.out.println(getCharForNumber(27)); // null } public static String getCharForNumber(int i) { return i > 0 && i < 27 ? String.valueOf((char)(i + 'A' - 1)) : null; } } يُمكنك إضافة الدالة إلى البرنامج الخاص بك و إستعمالها في التحويل.1 نقطة
-
عادة ماينتج هذا الخطأ عندما يكون حجم البيانات قليل، وبالتالي ينشأ هذا الخطأ بسبب حجم ال batch_size الذي اخترته حيث لايجب أن يكون حجمه أقل من حجم بيانات التدريب لديك، حيث أنه في معظم الحالات ، يكون سبب هذا الخطأ هو أن حجم بيانات التدريب أقل من حجم الدُفعة، لذا تأكد أولاً من أن with_noise يحتوي على 140 عينة على الأقل أو قم بتقليل حجم الدفعة (batch_size ). أي مثلاً اجعل حجمه 64 أو 32 أو اجعله Batch GD أي 1. float validation_split = 2f; Sequential model = new Sequential(); no_noise = no_noise.astype(np.float32); with_noise = with_noise.astype(np.float32); no_noise /= 255; with_noise /= 255; # بناء النموذج model.Add(new Conv2D(128, kernel_size: new Tuple<int, int>(5, 5), activation: "tanh", input_shape: new Shape(45, 45,1))); model.Add(new Conv2D(64, kernel_size: new Tuple<int, int>(3, 3), activation: "tanh")); model.Add(new Conv2DTranspose(64, kernel_size : new Tuple<int,int> (3, 3), kernel_constraint : max_norm, activation: "tanh")); model.Add(new Conv2DTranspose(32, kernel_size : new Tuple<int,int> (3, 3), activation: "relu")); model.Add(new Conv2D(1, kernel_size : new Tuple<int,int>(3, 3), activation: "sigmoid", padding: "same")); model.Compile(optimizer: "rmsprop", loss: "binary_crossentropy"); model.Fit(with_noise, no_noise,epochs: 10,batch_size: 64,steps_per_epoch:2,validation_split: validation_split);1 نقطة
-
هي طريقة أسرع وأكثر كفاءة ولاسيما في توفير الذاكرة للتعامل مع المصفوفات. ولاستخدام numpy.einsum، كل ما عليك فعله هو تمرير "subscript string" أو ما يسمى بالسلسلة المنخفضة كوسيطة أولى، حيث أن ال subscripts تشير إلى أبعاد المصفوفة بحيث كل بعد سيقابل label (مثلاً i أو j)، ثم مصفوفات الإدخال الخاصة بك كوسيط ثاني. لنفترض أن لديك مصفوفتان ثنائيتا الأبعاد ، A و B ، وتريد القيام بضرب المصفوفة. وبالتالي يكون الحل: np.einsum("ij, jk -> ik", A, B) ال subscripts (السلسلة المنخفضة) ij تتوافق مع المصفوفة A بينما تتوافق jk مع المصفوفة B. أيضاً، أهم شيء يجب ملاحظته هنا هو أن عدد الأحرف في كل subscript يجب أن يتطابق مع أبعاد المصفوفة. (على سبيل المثال ، حرفان للمصفوفات ثنائية الأبعاد ، وثلاثة أحرف للمصفوفات ثلاثية الأبعاد ، وهكذا..) وإذا كررت الأحرف بين السلاسل المنخفضة (j في حالتنا) ، فهذا يعني أنك تريد أن يحدث einsum على طول تلك الأبعاد. وبالتالي ، سيتم تخفيضها. (أي أن هذا البعد سوف يختفي). ستكون السلسلة الموجودة بعد -> هي المصفوفة الناتجة. إذا تركتها فارغة، فسيتم جمع كل شيء وإرجاع قيمة عددية كنتيجة لذلك. عدا ذلك ، سيكون للمصفوفة الناتجة أبعاداً وفقاً للسلسلة المنخفضة. في مثالنا ، سيكون ik. هذا أمر بديهي لأننا نعلم أنه بالنسبة لضرب المصفوفة، يجب أن يتطابق عدد الأعمدة في المصفوفة A مع عدد الصفوف في المصفوفة B وهو ما يحدث هنا (على سبيل المثال ، نقوم بترميز هذه المعرفة عن طريق تكرار الحرف j في السلسلة المنخفضة). فيما يلي بعض الأمثلة الأخرى التي توضح استخدام np.einsum وقوتها في تنفيذ بعض عمليات الموتر "tensor array" أو المصفوفات متعددة الأبعاد: # شعاع vec #array([0, 1, 2, 3]) # مصفوفة A """ array([[11, 12, 13, 14], [21, 22, 23, 24], [31, 32, 33, 34], [41, 42, 43, 44]]) """ # مصفوفة أخرى B """ array([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3], [4, 4, 4, 4]]) """ 1. ضرب المصفوفات: np.einsum("ij, jk -> ik", A, B) """ array([[130, 130, 130, 130], [230, 230, 230, 230], [330, 330, 330, 330], [430, 430, 430, 430]]) """ 2. استخراج العناصر على طول القطر الرئيسي: np.einsum("ii -> i", A) #array([11, 22, 33, 44]) 3. ضرب العناصر المتقابلة في مصفوفين: np.einsum("ij, ij -> ij", A, B) """ array([[ 11, 12, 13, 14], [ 42, 44, 46, 48], [ 93, 96, 99, 102], [164, 168, 172, 176]]) """ 4.التربيع: np.einsum("ij, ij -> ij", B, B) """ array([[ 1, 1, 1, 1], [ 4, 4, 4, 4], [ 9, 9, 9, 9], [16, 16, 16, 16]]) """ 5.مجموع العناصر القطرية الرئيسية: np.einsum("ii -> ", A) # 110 6. منقول مصفوفة: np.einsum("ij -> ji", A) """ array([[11, 21, 31, 41], [12, 22, 32, 42], [13, 23, 33, 43], [14, 24, 34, 44]]) """ 7. الضرب الخارجي للأشعة Outer Product : np.einsum("i, j -> ij", vec, vec) """ array([[0, 0, 0, 0], [0, 1, 2, 3], [0, 2, 4, 6], [0, 3, 6, 9]]) """ 8. الضرب الداخلي inner: np.einsum("i, i -> ", vec, vec) #14 9. الجمع على طول المحور 0 أو 1 أي الأسطر أو الأعمدة: # المحور 0 np.einsum("ij -> j", B) #array([10, 10, 10, 10]) # المحور 1 np.einsum("ij -> j", B) #array([10, 10, 10, 10]) 10. مجموع كل العناصر في مصفوفة: np.einsum("ijk -> ", BM) # 4801 نقطة
-
GitLab هي خدمة شبيهة بـ GitHub توفر الإدارة الداخلية لـ DevOps المستندة إلى الويب لمستودعات Git. يقدم GitLab خيارين: إصدار مجتمع مجاني وإصدار مؤسسة مدفوع. ولاتوجد اختلافات كبيرة بينهم فكلاهما يستخدمان لإدارة وعرض المشاريع. إضافةً إلى ماذكره @محمد أبو عواد هذا ملخص للفروقات: Open source.1: غيت لاب مفتوحة الممصدر، أما غيتهب ليست كذلك. 2. Private Repository: غيت لاب يسمح للمستخدمين بلإنشاء مستودع خاص مجاني، وغيتهب يسمح بذلك أيضاً لكن بحد أقصى 3 متعاونين. 3.Navigation: لاب يوفر ميزة التنقل في المستودع، وهب كذلك. 4.Project Analysis: يوفر للمستخدم رؤية مخططات تطوير المشروع، أما في هب فهي غير متوفرة. 5.Advantages: لاب هو تطبيق سحابي آمن جداً ومفتوح المصدر، هب يتم استخدامه لمشاركة العمل أمام الجمهور، ويساعدنا في إنشاء توثيق منظم للمشروع. 6.Disadvantages: لديه العديد من الأخطاء، هب لديه مستودع محدود ويدعم فقط git. وبشكل أساسي يتمثل الاختلاف الرئيسي بين GitHub و GitLab في النظام الذي تقدمه كل فلسفة. حيث يتمتع GitHub بانتشار أكبر ويركز بشكل أكبر على أداء البنية التحتية، بينما يركز GitLab بشكل أكبر على تقديم نظام قائم على الميزات مع نظام أساسي مركزي ومتكامل لمطوري الويب.1 نقطة
-
أولاً أحب أن ألفت الانتباه إلى أن الأمر غير مرتبط ب pandas فحتى مع المصفوفات العادية سيسلك نفس السلوك، صحيح أن الأمر قد يربك قليلاً كون أي شخص سيتوقع للمرة الأولى أن axis=1 يجب أن تحسب المتوسط للعمود وليس للسطر كما يحدث، لكن الأمر هنا مختلف ف axis= 0 تشير إلى التجميع على طول الصفوف أما 1 تشير إلى التجميع على طول الأعمدة بشكل أبسط يمكنك القول: axis:يحدد المحور الذي يتم من خلاله حساب المتوسط. المحور 0: سيعمل على جميع الصفوف في كل عمود. أما المحور 1: يعمل على جميع الأعمدة في كل صف. وبشكل افتراضي يحسب المتوسط على كل المصفوفة (عند ضبطه على NONE أي الحالة الافتراضية). كما في المثال: import numpy as np v = [[1,5], [1, 2],[1, 2]] v=np.array(v) """ array([[1, 5], [1, 2], [1, 2]]) """ v.mean(axis=None) # 2.0 v.mean(axis=1) # array([3. , 1.5, 1.5]) v.mean(axis=0) # array([1., 3.])1 نقطة
-
حسب اعتقادي فإن مصفوفات نمباي تتعامل مع بيانات المصفوفات الغير متجانسة ك "object" ولايمكنها التعامل معها ك int أو أي نمط آخر، لذا فالحل الوحيد هو حشر قيم في مصفوفتك (أصفار مثلاً)، ويمكنك القيام بذلك من خلال التابع pad_sequences كالتالي: import numpy as np v = [[1], [1, 2]] from keras import preprocessing maxlen=2 v=preprocessing.sequence.pad_sequences(v, maxlen=maxlen) print(v.dtype) # int32 v """ array([[0, 1], [1, 2]]) """1 نقطة
-
لنفهم ال struct دعنا نتابع المثال التالي. لنفرض أنه طلب منك أن تكتب برنامج تسجل فيه سجلات طلاب والذي يحوي بيانات ((( مختلفة )))). مثل (رقم الطالب (int) ، الاسم الأول (string)، الكنية (string)، المعدل (float)) وقد يكون هناك بيانات أخرى.. الآن بالحالة الاعتيادية لكي يتم ذلك، نعرف لكل طالب نعرف متغيرات يعبر كل منها عن نوع من البيانات المذكورة .. مثلاً لو كان لدي طالبين فأنا بحاجة 4 متحولات لكل طالب = 8 متحولات. وبالتالي السؤال الذي يفرض نفسه هنا هو ماذا لو كان لدي 20 طالب مثلاً ؟ سنحتاج 20 ×4 = 80 متحول !! وهذا كما نعلم أمر مقبول أو محبب ! ما الحل إذاً؟ الحل هو struct، إذاً : struct هي بنية معطيات تستخدم لتعريف نوع جديد يحوي مجموعة محددة من القيم مختلفة النوع، ويتم الوصول لهذه العناصر أو القيم عن طريق اسمها. مثال لتعريف struct: struct struct_name //struct_name : اسم نختاره { //هنا نكتب العناصر أو المتحولات وقيمها int id; string f_name; string l_name; float avg; } S1 ; الآن أصبح لدينا نمط جديد هو struct ويمكن أخذ غرض منه .. إما بذكر اسم الغرض بعد قوس النهاية مباشرة ( الغرض S1 ) ، أو بالشكل الاعتيادي: struct struct_name S1; مثال : للتعامل مع ال struct (الوصول إلى عناصره) و سنقوم بالتصريح عن طريقة تقبل بارمترين من نوع struct وتقوم بحساب مجموع رواتب موظفين اثنين (يمكن نسخ الكود التالي وتنفيذه لملاحظة النتائج): #include<bits/stdc++.h> using namespace std; struct employee { int id; string name; string last_name ; float salary ; float bonus ; } ; //تعريف الطريقة التي تقبل بارمترين لها من النمط ستراكت employee add_salary (employee emp1 , employee emp2) { employee result ; result.salary = emp1.salary + emp2.salary ; return result ; } int main() { employee e1,e2 ; // أخذنا غرضين من النمط السابق // مباشرة الوصول الى المتحولات واعطائها قيم e1.id = 10 ; e1.name = " ali "; e1.last_name = "haidar" ; e1.salary = 100000; e1.bonus = e1.salary * 0.2 ; // ادخال قيم متحولات الموظف الثاني من الكيبورد cout << " Enter the value of second employee's parameter is : "; cin>>e2.id>>e2.name>>e2.last_name>>e2.bonus; cout<< " the salary of first employee = "<<e1.salary<<endl; cout<<" the salary of second employee = " ; cin>>e2.salary ; employee z = add_salary(e1,e2); cout<<"the salary of two employees = "<< z.salary ; }1 نقطة
-
بالنسبة للحجم نعم هناك قيود على gmail حيث لا يمكن أن تكون المرفقات أكبر من 25 ميجابايت. يمكنك القيام بماتطلبه من خلال الكود التالي باستخدام مكتبة django: #لمرفقات البريد الإلكتروني from django.core.mail import EmailMessage def attachment_email(request): email = EmailMessage( 'Hello', #subject: موضوع البريد الإلكتروني 'Body goes here', #body: النص الأساسي 'MyEmail@MyEmail.com', #from: عنوان المرسل ['SendTo@SendTo.com'], #to: قائمة أو مجموعة من عناوين المستلمين ['bcc@example.com'], #bcc: قائمة أو مجموعة من العناوين المستخدمة في عنوان "Bcc" عند إرسال البريد الإلكتروني reply_to=['other@example.com'], headers={'Message-ID': 'foo'}, ) email.attach_file('/my/path/file') email.send() تتم تهيئة الصف EmailMessage بالمعلمات التالية subject و body و from_email و to و bcc و connection و attachments و headers و cc و reply_to . جميع المعلمات اختيارية ويمكن ضبطها في أي وقت قبل استدعاء التابع send(). headers: قاموس من الرؤوس الإضافية لوضعها على الرسالة. المفاتيح هي اسم الرأس ، والقيم هي قيم الرأس. الأمر متروك للمتصل للتأكد من أن أسماء الرأس والقيم بالتنسيق الصحيح لرسالة بريد إلكتروني. السمة المقابلة هي extra_headers. أما reply_to: قائمة أو مجموعة من عناوين المستلمين المستخدمة في عنوان "اreply-to" عند إرسال البريد الإلكتروني. أيضاُ يمكنك أن تمرر له الوسيط attachments وهو قائمة المرفقات المراد وضعها مع الرسالة. هذا الكلاس لديه التابع attach_file() الذي ينشئ مرفقًا جديدًا باستخدام ملف من نظام الملفات الخاص بك. استدعها بمسار الملف المراد إرفاقه ، واختيارياً ، نوع MIME المراد استخدامه للمرفق. إذا تم حذف نوع MIME ، فسيتم تخمينه من اسم الملف. وأيضاً التابع send لإرسال الرسالة. وتدعم هذه المكتبة العديد من العمليات الأخرى أيضاً لذا يمكنك الذهاب إلى توثيق المكتبة والإطلاع عليها، سيكون ذلك مفيداً لك. يمكنك أيضاً القيام بذلك كالتالي: import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart from email.mime.application import MIMEApplication from os.path import basename def send_mail(send_from: str, subject: str, text: str, send_to: list, files= None): send_to= default_address if not send_to else send_to msg = MIMEMultipart() msg['From'] = send_from msg['To'] = ', '.join(send_to) msg['Subject'] = subject msg.attach(MIMEText(text)) for f in files or []: with open(f, "rb") as fil: ext = f.split('.')[-1:] attachedfile = MIMEApplication(fil.read(), _subtype = ext) attachedfile.add_header( 'content-disposition', 'attachment', filename=basename(f) ) msg.attach(attachedfile) smtp = smtplib.SMTP(host="smtp.gmail.com", port= 587) smtp.starttls() smtp.login(username,password) smtp.sendmail(send_from, send_to, msg.as_string()) smtp.close() ولاستخدامه: username = 'my-address@gmail.com' # اسم المستخدم password = 'top-secret' # كلمة المرور default_address = ['my-address2@gmail.com'] # العنوان الافتراضي # إرسال الإيميل send_mail(send_from= username, subject="test", text="text", send_to= None, # المرسل إليه files=Path # مسار ملفاتك ) للاستخدام مع أي مزود بريد إلكتروني آخر ، ما عليك سوى تغيير تكوينات SMTP.1 نقطة
-
الخوارزمية الجشعة هي الخوارزمية التي تبني الحل خطوة خطوة أو قطعة قطعة وتعتمد على اختيار الخيار الأمثل (يعظم الربح) عند كل نقطة اختيار, أي أنها تخلق خيار مثالي محلي على أمل أن هذا السلوك سيقودنا الى حل مثالي شامل (أي حل مثالي لكامل المسألة). كما أنه لا يمكننا اثبات صحة حل مسألة تعتمد على الخوارزمية الجشعة ولكن يكفي إعطاء مثال لإثبات أن الخوارزمية خاطئة. لنأخذ المثال التالي ولنحاول حلها بطريقة الخوارزمية الجشعة: لنفرض لدينا قاعة وعدد من المقررات التي نريد اعطاء محاضرة منها في هذه القاعة مع توقيت بداية و نهاية كل من هذه المحاضرات والمطلوب ما هو أكبر عدد من الأنشطة او المحاضرات التي نستيطع القيام بها في هذه القاعة؟ تذكر أن يكفي إعطاء مثال لاثبات ان الخوارزمية خاطئة. 1_سنحاول حل هذه المسألة بختيار الأنشطة ذات الامتداد الزمني(توقيت النهاية-توقيت البداية) الأقصر,ولكن هذه الفكرة خاطئة ويمكن اعطاء هذا المثال لاثبات ذلك: النشاط الاول من 8 الى 11. النشاط الثاني من 10:30 الى 12. النشاط الثالث من 11:30 الى 3. بناءان على الفكرة السابقة سيتم اختيار النشاط الثاني فقط بينما من الأفضل اختيار النشاطين الأول و الثالث. 2_سنحاول هذه المرة باختيار الأنشطة ذات الزمن البداية الأصغر,ولكن هذه الفكرة خاطئة ايضا ويمكن اعطاء هذا المثال لأثبات ذلك: النشاط الأول من 8 الى 1. النشاط الثاني من 9 الى 10. النشاط الثالث من 10 الى 11. النشاط الرابع من 11:30 الى 12:30 بناءان على الفكرة السابقة سيتم اختيار النشاط الأول فقط بينما من الأفضل اختيار النشاط الثاني و الثالث و الرابع. إذاً ما هي فكرة حل هذه المسألة؟ يتم حل هذه المسألة بأخذ الأحداث التي تنتهي أولا مع مراعاة عدم تداخل تواقيتها، أي أقوم بترتيب الأنشطة حسب زمن انتهائها (من النشاط الذي ينتهي أولا الى النشاط الذي ينتهي اخيرا) ثم أقوم بأخذ النشاط الذي ينتهي أولا و من ثم أبحث عن اول نشاط يبدأ بعد انتهائه(كي لا يحدث تداخل في تواقيت الأنشطة) ومن ثم أبحث عن أول نشاط يبدأ بعد انتهاء أخر نشاط أخذناه وهكذا... ويكون pseudocode الخاص بالمسألة كالتالي: input: n activities output: a max size subset of compatible activities sort activities by increasing finish time A1,A2,A3 where F1<F2<F3<..<Fn E<-{1} T<-F1 for i=2 to n do { if(Si>=T)then { add i to E T<-Fi } } output E1 نقطة
-
هذا المفهوم هو مفهوم عام وغير محصور بلغة برمجية محددة، أي من الممكن أن تراه في لغات أخرى. في البداية تعددية الأشكال تعني قدرة الغرض أن يأخذ عدة أشكال، حيث أن الاستخدام الشائع لهذا المفهوم في البرمجة غرضية التوجه يحدث عندما يكون لدينا مرجع من صف أب (نسميه مقبض)يشير إلى كائن من صف ابن.. لاشك أنك تعرف الوراثة في جافا !! العكس لا يصح .. أي أن الغرض من الصف الأب و يشير إلى كائن من نفس الصف أو من الصف الابن حصراً ، مثلاً: class Human { ….. } class Student extends Human { ……. } //العبارات التالية صحيحة Human H ; //مقبض من الصف الأب H = new Human() ; // المقبض يشير إلى كائن من نفس الصف H = new Student () ; // المقبض يشير إلى كائن من الصف الابن // العبارات التالية خاطئة Student st = new Human ; // مقبض من الصف الابن يشير الى كائن من الصف الأب (لايجوز) الآن لفهم الكلام السابق سنعطي مثال ، نشرحه ثم نكتب كود برمجي يعبرعنه .. لنفرض مثلاً لدينا شاحنة ونريد نقل مجموعة سيارات بحيث كل شاحنة تتسع ل 10 سيارات ، وتنقل نوع واحد من السيارات .. ( يمكن تشبيه الشاحنة بمصفوفة تضم عناصر من نمط واحد ) .. لنفرض لدينا نوعين من السيارات نريد أن ننقلهم 4:BMW و 4:AUDI حسب الشروط المفروضة سنحتاج شاحنتين في كل واحدة سنضع 4 من نفس النوع .. الفكرة أن الشاحنة الواحدة (مصفوفة ) لا تحمل نوعين لكنها تتسع للعدد الكلي ، أي أننا قمنا بعملية نقل صحيحة لكنها مكلفة ( حجزنا شاحنة ويوجد أماكن فارغة بالأولى + ماذا لو كان لدينا أكثر من نوعين .. ) الحل : يجب أن نبحث عن شاحنة ( مصفوفة) تحمل النوعين .. ونعلم أن المصفوفة لا تحمل الا نوع واحد .. ما العمل هنا تأتي " تعددية الأشكال" بأن نعرف صف أب للصفين السابقين وليكن Carونرث منه الصفين BMW و AUDI ونأخذ مصفوفة مقابض من Car ( نمط واحد ) وكل عنصر (مقبض) نجعله يشير الى الكائن المطلوب .. BMW أو AUDI .. وهكذا نكون قد حللنا المشكلة و خزنا كائنات من صفوف مختلفة بمصفوفة واحدة مثال : (يمكن نسخ الكود وتنفيذه لملاحظة النتائج): package javaapplication29; class Car { void type () { System.out.println("car");} } class BMW extends Car { @Override void type () { System.out.println("BMW");} } class AUDI extends Car { @Override void type () { System.out.println("AUDI");} } public class JavaApplication29 { public static void main(String[]args ){ Car[]c =new Car[8]; //نعبئ أربع سيارات BMW for( int i=0; i<4 ; ++i ) c[i] = new BMW(); //نعبئ أربع سيارات AUDI for( int i=4; i<8 ; ++i ) c[i] = new AUDI(); //تعليمة طباعة للتأكد من أنه تم تعبئة النوعين for( int i=0; i<8 ; ++i ) c[i].type(); } }1 نقطة
-
 لكل من مرّ على صفحتي ولكل من قام بتحميل نسخته من الكتاب جزيل شكري وامتناني، واسأل الله أن يوفقكم وييسر لكم الخير1 نقطة
لكل من مرّ على صفحتي ولكل من قام بتحميل نسخته من الكتاب جزيل شكري وامتناني، واسأل الله أن يوفقكم وييسر لكم الخير1 نقطة










