
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/08/21 في كل الموقع
-
أريد أن أقوم بطباعة الأرقام الكبيرة (أكبر من 999) بعلامة الفاصلة comma بين كل ثلاثة أرقام، على سبيل المثال الرقم 123456789 يصبح 123,456,789 مع العلم أن هذه أرقام وليست نصوص، حاولت تحويل الأرقام إلى نصوص ثم تقسيم هذا النص إلى أجزاء وإعادة دمجها ولكن أعتقد أن هناك طريقة أسهل وأسرع للقيام بهذا الأمر1 نقطة
-
الخطأ هو أن شكل الخرج Y في البيانات هو (,60000) يجب أن يكون شكل الخرج في البيانات مطابق لشكل الخرج في الموديل حيث شكل الخرج في الموديل الذي تقوم بتدريبه هو (32,2) وشكل المخرجات التي تظهر في خرج البيانات باعتبار انها 0 أو 1 هو (32,1) لذلك يجيب تغير الموديل لإخراج قيمة واحدة بدلاً من 2 واستخدام تابع التفعيل sigmoid مع تابع الخسارة binary_crossentropy أي يصبح الكود كالتالي: import numpy as np import pandas as pd from keras.models import Sequential from keras.layers import Dense , Activation, Dropout from keras.models import Sequential from keras.utils.np_utils import to_categorical from keras.datasets import mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() y_train[y_train<=5]=0 y_train[y_train>5]=1 y_train=y_train.astype('int64') print(x_train.shape, y_train.shape) image_size = x_train.shape[1] input_size = image_size * image_size x_train = np.reshape(x_train, [-1, input_size]) x_train = x_train.astype('float32') / 255 x_test = np.reshape(x_test, [-1, input_size]) x_test = x_test.astype('float32') / 255 batch_size = 32 hidden_units = 256 model = Sequential() model.add(Dense(hidden_units, input_shape=(input_size,))) model.add(Activation('relu')) model.add(Dropout(0.45)) model.add(Dense(hidden_units)) model.add(Activation('relu')) model.add(Dropout(0.45)) #إصلاح model.add(Dense(1)) #إصلاح model.add(Activation('sigmoid')) #إصلاح model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5, batch_size=batch_size)1 نقطة
-
أنت قمت بتعيين الطبقة الأولى بحيث تتوقع منك أبعاد الإدخال (،300) عن طريق ضبطك للوسيط input_shape على input_shape = (300،) ثم أعطيت النموذج لاحقاً أبعاداً مختلفة مساوية لأبعاد البيانات التي تريد التدريب عليه، وهذا خاطئ. الوسيط input_shape يحدد أبعاد المدخلات للطبقة، لذا يجب أن يكون مطابقاً لأبعاد بياناتك. لحل المشكلة استخدم train_data.shape[1] أي تصبح input_shape=(train_data.shape[1],) بدلاً من تحديد الأبعاد بشكل يدوي أي بدلاً من (,input_shape = (300: from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss="mse", metrics=['mae']) #بالشكل التالي compile هنا استخدمناها كدالة تكلفة وكمعيار عن طريق تمريره إلى الدالة #model.compile(optimizer='rmsprop', loss='mse', metrics=['mse']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64)1 نقطة
-
كيف يمكنني كتابة تعليمات وجمل بايثون على أكثر من سطر، لأن هذه التعليمات تأخذ مساحة كبيرة في سطر واحد ويصبح من الصعب تتبع الكود، على سبيل المثال: كيف يمكنني عمل شيء مثل هذا: x = 1 + 2 + 3 + 4 + 51 نقطة
-
الطريقة WaitAll(): هي طريقة ستاتيكية تستدعى لأجل الصف، دخلها مصفوفة عناصر من النمط Task، مهمتها إيقاف الأب، مثلاً لو استدعيناها في ال mian سيتم إيقافه (ينتظر) حتى تنفيذ كل التاسكات الموجودة ضمن هذه المصفوفة فقط . مثال : هنا مثال عن الطريقة فقط ، باعتبار الصف Test صف يحوي طريقتين وهما MethodA تقوم بطباعة A خمسين مرة، والطريقة MethodB تطبع B خمسين مرة: var TaskA = new Task.Factory.StartNew(Test.MethodA); var TaskB = new Task.Factory.StartNew(Test.MethodB); Task [] stopmain = { TaskA , TaskB }; Task.WaitAll(stopmain); هنا سيتوقف ال main حتى يتم تنفيذ جميع ال task في المصفوفة stopmain. For (int i=0 ; i<50;i++){ console.WriteLine("Main");} الخرج : طباعة A و B خمسين مرة بشكل متداخل(ترتيب غير معلوم) ومن ثم طباعة Main خمسين مرة. الطريقة WaitAny() : هي أيضا طريقة ستاتيكية و تقبل مصفوفة تاسكات كسابقتها اذاً هي شبيها بالطريقة السابقة ولكن لو استدعيناها في ال main مثلاً لن تنتظر انتهاء كل التاسكات، بل تنتظر انتهاء أول task وعند اكتمال تنفيذ هذا التاسك يستأنف ال main العمل بالتوازي مع التاسكات الأخرى مع الملاحظة أن هذه الطريقة ترد قيمة وهي index يمثل موقع التاسك الذي انتهى من المصفوفة. مثال : var TaskA = new Task.Factory.StartNew(Test.MethodA); var TaskB = new Task.Factory.StartNew(Test.MethodB); Task [] stopmain = new Task[] { TaskA , TaskB }; Int id = Task.WaitAny(stopmain); هنا سيتوقف ال main حتى يتم تنفيذ إحدى تاسكات المصفوفة لا على التعيين و ترد هذه الطريقة ال index للتاسك الذي اكتمل تنفيذه أولاً إلى المتحول id ، حيث أن المصفوفة هنا تحوي عنصرين فال index إما 0 أو 1. For (int i=0 ; i<50;i++){ console.WriteLine("Main");} الخرج : طباعة A خمسين مرة و طباعة B خمسين مرة بترتيب غير معلوم ولكن طباعة الكلمة main لا تبدأ إلا بعد انتهاء طباعة إحدى العبارات "ِA" أو "B".1 نقطة
-
Hinge loss هي دالة تكلفة تستخدم لمصنفات التدريب مثل SVM تقوم هذه الدالة بحساب خسارة هاينغ بين القيم المتوقعة والقيم الحققية للنموذج. يتم استخدامها عبر الموديول: keras.losses loss = maximum(1 - y_true * y_pred, 0) مثال: y_true = [[1., 0.], [0., 0.]] y_pred = [[0.3, 0.5], [0.2, 0.6]] h = tf.keras.losses.Hinge() h(y_true, y_pred).numpy() لاستخدامها في تدريب نموذجك نقوم بتمريرها إلى الدالة compile كالتالي: model.compile( loss=keras.losses.hinge(), ... ) # أو model.compile( loss="hinge", ... ) سأعطي الآن مثال لاستخدمها في بناء نموذج في في كيراس يحاكي خوارزمية SVM: #SVM النموذج التالي يعمل بشكل مشابه لل #RandomFourierFeatures نقوم باستخدام طبقات SVM لتحقيق from tensorflow.keras.layers.experimental import RandomFourierFeatures from tensorflow import keras from keras.datasets import mnist from tensorflow.keras import layers (x_train, y_train), (x_test, y_test) =mnist.load_data() # معالجة البيانات x_train = x_train.reshape(-1, 784).astype("float32") / 255 x_test = x_test.reshape(-1, 784).astype("float32") / 255 y_train = keras.utils.to_categorical(y_train) y_test = keras.utils.to_categorical(y_test) # بناء النموذج model = keras.Sequential( [ keras.Input(shape=(784,)), RandomFourierFeatures( output_dim=4096, scale=10.0, kernel_initializer="gaussian" ), layers.Dense(units=10), ] ) model.compile( optimizer="rmsprop", loss=keras.losses.hinge(), metrics=["acc"], ) # تدريب النموذج model.fit(x_train, y_train, epochs=2, batch_size=64, validation_split=0.2)1 نقطة
-
الفكرة واضحة. أنا فقط أرى أن مصطلح `مرفقة` أو `محملة` أقرب للمعنى من `مغلفة` لأن `محملة` تعبير حقيقي بينما `مغلفة` تعبير مجازي. ولكن من نظرة سريعة على المقالات في حسوب يبدو أن مصطلح مغلفة أو تغليف أكثر شيوعًا وبالتالي سأعتمده في لغة الأسس لأن توحيد المصطلحات أهم من دقتها. وجدت أيضًا بعض المقالات التي تعتمد المصطلح منغلقة، وهو على ما يبدو ترجمة حرفية لم تُعِر اهتمامًا للمعنى. شكرًا على التوضيح، وطبعًا شكرا على جهودكم في الترجمة.1 نقطة
-
ايه الفرق بين flutter inspector و flutter Emulator ؟1 نقطة
-
flutter inspector: يعد فاحص أدوات flutter أداة قوية لتصوير و استكشاف أشجار عناصر واجهة flutter. يستخدم إطار عمل flutter عناصر واجهة المستخدم باعتبارها اللبنة الأساسية لأي شيء بدءاً من عناصر التحكم مثل النصوص و الأزرار و المفاتيح , إلى عناصر التخطيط و هي Center, Column, Padding, Rows , يساعدك المراقب ( flutter inspector ) على استكشاف هذه العناصر والعمل على فهم المخطط الخاص بواجهة المستخدم أو تشخيص المشكلات التي تكون في تخطيط الصفحة. يلجأ الكثير من المبرمجين إلى استخدام هذه الأداة لحل المشكلات التي قد تكون في الواجهة مما يوفر عليه عدم مراجعة كود تخطيط الصفحة من البداية وعدم اللجوء إلى تبديل عناصر قد تكون المشكلة بسبب عناصر أخرى غيرها. flutter Emulator: هو محاكي مثل أجهزة الموبايل android على نظام الكمبيوتر الخاص بك , بحيث يتيح لك تجربة تطبيقاتك عليه , ايضا يزود المحاكي المستخدم بعدة أجهزة ليتيح تجربة التطبيق على أكثر من جهاز موبايل بمختلف الإصدارات. يوفر هذا المحاكي عدة أمكانيات شبيهة بنظام الجوال, مثل محاكاة المكالمات الهاتفية و الرسائل الواردة و الصادرة , تحديد موقع الجهاز, أجهزة الاستشعار الأخرى, الوصول إلى متجر قوقل بلاي وغير ذلك الكثير, يعد أختبار تطبيقك على المحاكي اسرع و اسهل من أختباره على جهاز موبايل حقيقي.1 نقطة
-
هي إحدي الدوال التي تستخدم لقياس دقة النموذج و بالتالي حساب معدل الخسارة loss و ذلك عن طريق إيجاد متوسط الفروقات بين القيم الحقيقية و المتوقعة بإستخدام النموذج. كلما قلت القيمة الناتجة من الدالة كلما زادت دقة النموذج، و يكون إستخدامه مفيداَ في حالة قياس دقة النماذج المطبقة على البيانات التي تحتوي على قيم شاذة أو متطرفة. يمكننا إستدعاء دالة mean_absolute_error من sklearn.metrics مباشرة أو القيام ببرمجته مباشرة فهو من أسهل المقاييس: from sklearn.metrics import mean_absolute_error as MAE import pandas as pd y_true = pd.DataFrame({'values':[3,6,5,8,9,4,2]}) y_pred = [4,8,7,3,2,4,2] error = 0 for i in range(len(y_true)): error += abs(y_true.values[i] - y_pred[i]) print('manual MAE = ', error / len(y_true)) print('sklearn MAE = ', MAE(y_true, y_pred)) لاحظ لنتيجة كل من الدالتين والتي تكون متقاربة لحد كبير، ويمكننا إظهار كل الأرقام الكسرية في دالة MAE المحسوبة بالبرنامج بزيادة عدد الأرقام الظاهرة في الطباعة. manual MAE = [2.42857143] sklearn MAE = 2.4285714285714284 لاحظ من البرنامج أن دالة MAE قامت بإستقبال القيم الحقيقية y والقيم المتوقعة y_pred وقامت بالحسابات ضمنياً، ويمكن لنفس الدالة إستقبال multioutput والتي يمكن تعريفها في حال كنا نريد إرجاع MAE لكل feature على حدة، و يمكننا أيضاً تمرير sample_weight والتي تقوم بإسناد معاملات لمعدل الفقد. y_true = [[0., 1.], [0., 0.]] y_pred = [[1., 1.], [1., 0.]] #تطبيق sample weight MAE(y_true, y_pred, sample_weight=[0.7, 0.3]) #تطبيق multioutput MAE(y_true, y_pred, multioutput='raw_values') في حالة تطبيق multioutput بدلاً من تمرير معاملات لكل الخصائص في مجموعة البيانات قمنا بتمرير raw_values وهي ترجع كل قيم MAE لكل خاصية على حدا.1 نقطة
-
Log-cosh هي دالة أخرى من دوال التكلفة المستخدمة مع مهام التوقع وهي أكثر سلاسة من MSE، وهي لوغاريتم جيب التمام الزائدي لخطأ التنبؤ "hyperbolic cosine of the prediction error". log(cosh(x)) تساوي تقريباً: (x ** 2) / 2 #صغيرة x عندما تكون abs(x) - log(2) # عندما تكون كبيرة هذا يعني أنها تعمل في الغالب مثل MSE، ولكنها لا تتأثر بالتنبؤ غير الصحيح إلى حد كبير. ولديها كل مزايا دالة هوبر، إضافة إلى إمكانية تفاضلها مرتين، على عكس دالة هوبر. وهذا مهم مع العديد من الخوارزميات التحسين مثل Newton’s. في كيراس يمكن استخدامها من الموديول: keras.losses الصيغة الرياضية: # logcosh = log((exp(x) + exp(-x))/2); x= y_pred - y_true مثال: import keras y_true = [[0., 1.], [0., 0.]] y_pred = [[1., 1.], [0., 0.]] l = keras.losses.LogCosh() l(y_true, y_pred).numpy() # 0.1084452 ولاستخدامها في نموذجك نمررها إلى الدالة compile كالتالي: model.compile( loss='LogCosh' ... ) # أو model.compile( loss=keras.losses.LogCosh() ... ) مثال عملي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss='LogCosh', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64) -----------------------------------------------------------------------Epoch 1/8 7/7 [==============================] - 1s 5ms/step - loss: 21.0908 - mae: 21.7840 Epoch 2/8 7/7 [==============================] - 0s 6ms/step - loss: 20.3744 - mae: 21.0669 Epoch 3/8 7/7 [==============================] - 0s 4ms/step - loss: 18.8925 - mae: 19.5840 Epoch 4/8 7/7 [==============================] - 0s 2ms/step - loss: 17.1608 - mae: 17.8454 Epoch 5/8 7/7 [==============================] - 0s 3ms/step - loss: 16.1519 - mae: 16.8398 Epoch 6/8 7/7 [==============================] - 0s 3ms/step - loss: 14.0706 - mae: 14.7509 Epoch 7/8 7/7 [==============================] - 0s 3ms/step - loss: 13.2366 - mae: 13.9173 Epoch 8/8 7/7 [==============================] - 0s 3ms/step - loss: 11.4787 - mae: 12.15371 نقطة
-
حسناً اعتدنا على تمرير وسيطين إلى طبقة التضمين، الأول هو عدد ال tokens (المفردات) الموجودة في بياناتك أي (1 + maximum word index) والثاني هو dimensionality of the embeddings أي أبعاد التضمين. وكان ذلك كافياً عندما تكون الطبقة التالية هي طبقة تكرارية (أحد أنواع RNN). لكنك هنا تستخدم طبقة Flatten بعدها، لذا في هذه الحالة يجب أن نقوم بتمرير وسيط إضافي إلى طبقة التضمين وهو input_length أي طول سلاسل الإدخال لديك: from keras.datasets import imdb from keras.layers import Embedding, SimpleRNN,Flatten,Dense from keras.models import Sequential (input_train, y_train), (input_test, y_test) = imdb.load_data( num_words=10000) print(len(input_train), 'train sequences') print(len(input_test), 'test sequences') ################ نضيف################### from keras.preprocessing import sequence maxlen = 20 print('Pad sequences (samples x time)') input_train = sequence.pad_sequences(input_train, maxlen=maxlen) input_test = sequence.pad_sequences(input_test, maxlen=maxlen) ############# انتهى#################### print('input_train shape:', input_train.shape) print('input_test shape:', input_test.shape) from keras.layers import Dense model = Sequential() model.add(Embedding(10000, 16, input_length=maxlen)) model.add(Flatten()) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(input_train, y_train, epochs=2, batch_size=32, validation_split=0.2) --------------------------------------------------------------------------------------------- 25000 train sequences 25000 test sequences Pad sequences (samples x time) input_train shape: (25000, 20) input_test shape: (25000, 20) Epoch 1/2 625/625 [==============================] - 2s 3ms/step - loss: 0.6506 - acc: 0.5996 - val_loss: 0.5080 - val_acc: 0.7414 Epoch 2/2 625/625 [==============================] - 2s 3ms/step - loss: 0.4356 - acc: 0.7957 - val_loss: 0.4968 - val_acc: 0.75341 نقطة
-
الصف object هو جذر كل الصفوف في بايثون أو الأب لكل الصفوف base-class. في بايثون 3 لافرق في كتابة: class hi: pass hi.__bases__ #(<type 'object'>,) أو: class hi(object): pass hi.__bases__ # الخرج #(<type 'object'>,) فكلاهما يؤدي إلى إنشاء صف جديد مع تحديد الصف object كأب له كما تلاحظ من الخرج. أما في بايثون 2 (تحديداً من بعد 2.2) فإن تعريف الكلاس بالشكل: class hi(object): pass يؤدي إلى إنشاء صف جديد مع تحديد الصف object كأب له، ويسمى التعريف بهذا الشكل "new style class"، أي كما في بايثون 3. أما تعريفه بهذا الشكل: class hi: pass # انظر hi.__bases__ # الخرج () فهنا لايكون لدينا object كصف رئيسي. وتسمى بالطريقة الكلاسيكية."old style class". وطبعاً أنت ستهتم بالطريقة الجديدة فكلنا نتبع الطرق الأحدث. طبعاً في كل كم النمط القديم والحديث فإن ال staticmethod و classmethod تعملان بشكل طبيعي، property تعمل مع القراءة في النمط القديم لكنها تفشل مع ال intercept writes وأما __slots__ فتم تحسينها من حيث سرعة الوصول إلى ال attribute وأيضاً توفيرها للذاكرة.1 نقطة
-
الدالة range في بايثون تستخدم مع الأعداد الصحيحة فقط integers وليس مع الأعداد العشرية decimals أو float فإذا أردت عدم استدعاء دالة من numpy أو أي دالة خارجية فيمكنك بناء دالة للقيام بالمطلوب # المُدخل الأول هو عدد البداية # المُدخل الثاني هو عدد النهاية # المُدخل الثالث هو درجة الفرق def drange(start, stop, step): r = start while r < stop: yield r r += step dec =drange(0.0, 1.0, 0.1) print(["%g" % x for x in dec])1 نقطة
-
يمكن اعتبارها كتحسين لل MSE أو كتطوير لها للتعامل مع حالات معينة، وهي مزيج من ال MSE و MSA. إن ال (MSE) يركز على القيم المتطرفة في مجموعة البيانات، بينما متوسط الخطأ المطلق (MAE) جيد لتجاهل القيم المتطرفة. لكن في بعض الحالات فإن البيانات التي تبدو وكأنها قيم متطرفة، قد لا تشكل مشكلة بالنسبة لك، وأيضاً تلك النقاط من البيانات لا ينبغي أن تحظى بأولوية عالية. وهنا حيث يأتي هوبر لوس. الصيغة الرياضية: كما قلنا فهي مزيج من MSE و MAE مما يعني أنها تربيعية (MSE) عندما يكون الخطأ صغيرًا وإلا فهي MAE. دلتا هنا تعتبر من المعاملات العليا hyperparameter لتحديد نطاق MAE و MSE. من المعادلة نجد أنه عندما يكون الخطأ أقل من دلتا ، يكون الخطأ تربيعيًا وإلا يكون مطلقًا. يمن استخدامها في كيراس بسهولة كالتالي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) #model.compile(optimizer='rmsprop', loss='Huber', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64) """ Epoch 1/8 7/7 [==============================] - 7s 2ms/step - loss: 21.8385 - mae: 22.3385 Epoch 2/8 7/7 [==============================] - 0s 3ms/step - loss: 20.6043 - mae: 21.1043 Epoch 3/8 7/7 [==============================] - 0s 3ms/step - loss: 19.8923 - mae: 20.3920 Epoch 4/8 7/7 [==============================] - 0s 3ms/step - loss: 18.4374 - mae: 18.9368 Epoch 5/8 7/7 [==============================] - 0s 4ms/step - loss: 17.2154 - mae: 17.7146 Epoch 6/8 7/7 [==============================] - 0s 3ms/step - loss: 15.7804 - mae: 16.2756 Epoch 7/8 7/7 [==============================] - 0s 2ms/step - loss: 14.0492 - mae: 14.5466 Epoch 8/8 7/7 [==============================] - 0s 3ms/step - loss: 12.3948 - mae: 12.8905 """
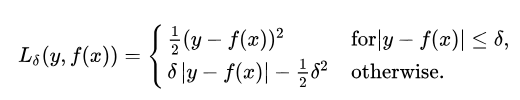 1 نقطة
1 نقطة -
أشهر دالة تكلفة والأفضل مع مسائل التوقع ويمكن استخدامها أيضاً كمعيار لكن من غير الشائع القيام بذلك، وهي تقوم على حساب متوسط الفرق التربيعي بين القيم المتوقعة من النموذج والقيمة الفعلية. ال MSE قوي في التعامل مع القيم المتطرفة في البيانات. الصيغة الرياضية: ال MSE من أجل عينة ما : # من أجل عينة واحدة loss = square(y_true - y_pred) لاستخدامها نقوم بتمررها إلى الدالة compile في نوذجنا كما في المثال: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss=keras.losses., metrics=['mae']) #بالشكل التالي compile هنا استخدمناها كدالة تكلفة وكمعيار عن طريق تمريره إلى الدالة #model.compile(optimizer='rmsprop', loss='mse', metrics=['mse']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64) """ Epoch 1/8 7/7 [==============================] - 1s 2ms/step - loss: 583.3815 - mse: 583.3815 Epoch 2/8 7/7 [==============================] - 0s 2ms/step - loss: 531.9802 - mse: 531.9802 Epoch 3/8 7/7 [==============================] - 0s 3ms/step - loss: 503.3803 - mse: 503.3803 Epoch 4/8 7/7 [==============================] - 0s 3ms/step - loss: 409.2950 - mse: 409.2950 Epoch 5/8 7/7 [==============================] - 0s 2ms/step - loss: 387.9506 - mse: 387.9506 Epoch 6/8 7/7 [==============================] - 0s 3ms/step - loss: 303.1605 - mse: 303.1605 Epoch 7/8 7/7 [==============================] - 0s 2ms/step - loss: 253.2450 - mse: 253.2450 Epoch 8/8 7/7 [==============================] - 0s 3ms/step - loss: 190.7695 - mse: 190.7695 """
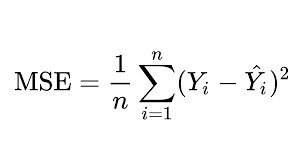 1 نقطة
1 نقطة -
بالاعتماد على Numpy يمكن استخدام الدالة linspace كالتالي: # تضمين import numpy as np # بناء مصفوفة مع القفزة العشرية # بداية - قفزة - نهاية # يتم اعتبار القفزة بمقلوب القيمة الصحيحية الممررة np.linspace(0,1,11) # الناتج array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]) في حال لم ترد وجود نقطة النهائبة نضع endpoint = false : مثل (0,1,10,endpoint=False) كما يمكن استعمال arange بقيم عشرية: np.arange(0.0, 1.0, 0.1) array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) وبطريقة عادية نستخدم حلقة و نعيد كل عنصر منها مضروبا بنسبة تصغير معينة: #1 [x * 0.1 for x in range(0, 10)] #2 for i in range(0, 11, 1): print i / 10.0 #3 for i * 100 in range(0, 100, 10): print i / 100.0 يمكن الإطلاع على مرجع أكاديمية حسوب لتعلم بايثون :1 نقطة
-
يُمكن للدالة range التعامل مع الأعداد الصحيحة فقط أي لا يُمكن تمرير معاملات بقيم بفاصلة عشرية و إنما يُمكن الوصول لما تريد بعدة طرق من بينها: إستخدام list comprehension: print([x/10 for x in range(0, 10)]) # [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] إستخدام دالة linspace من مكتبة numpy: import numpy as np print(np.linspace(0,1,10,endpoint=False)) # [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9] إستخدام الدالة arange من مكتبة numpy تتيح لك تحديد الخطوة بالفاصلة العشرية: import numpy as np print(np.arange(0.0, 1.0, 0.1)) # [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9] يُمكن إنطلاقاً من الطريقة الأولى إنشاء دالة لتوليد قائمة مع تمرير المعاملات: def seq(start, stop, step=1): n = int(round((stop - start)/float(step))) if n > 1: return([start + i / pow(step, -1) for i in range(n+1)]) elif n == 1: return([start]) else: return([]) print(seq(1, 2)) # [1] print(seq(10, 0, -2)) # [10, 8, 6, 4, 2, 0] print(seq(0, 5, -1)) # [] print(seq(0, 1, 0.1)) # [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]1 نقطة
-
نعم يمكننا ذلك، ففي كيراس تم تعريف ال CosineSimilarity كدالة تكلفة لمهام التوقع. المعادلة الرياضية: loss = -sum(l2_norm(y_true) * l2_norm(y_pred)) يكون الخرج بين ال 1 و -1، بحيث كلما اقتربت القيم من ال -1 يكون التشابه أعظم وكلما اقترب من 1 يكون أقل تشابه وتشير ال 0 إلى حالة التعامد. وهذا مايجعلها قابلة للاستخدام كدالة تكلفة. يمكن استيرادها من الموديول: keras.losses لاستخدامها مع نموذج نمررها للدالة compile كما في المثال التالي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss=keras.losses.CosineSimilarity(axis=1), metrics=['mae']) #model.compile(optimizer='rmsprop', loss='CosineSimilarity', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64)1 نقطة
-
نعم هناك فرق في استخدام الكود كما في الطريقة السابقة حيث أن ال "classic" style classes كالتالي class ClassicSpam: pass ال "new" style classes كالتالي class MyClass(object): pass الطريقة الثانية تم إضافتها في الإصدار 2.2 وتتميز بدعمها ل يمكنك استخدام ال property لإدارة الخصائص ال slots لتحديد الخصائص المطلوبة الدالة __new__ لتحديد كيفية إنشاء الكائنات من الاصناف الدالة super() يمكنك القراءة عن هذه الإضافات بتعمق أما في الإصدار الثالث فإنه سواء استخدمت الطريقة السابقة أم لا فإنه يتم استخدام ال"new" style classes مما يعني أن الكود التالي class MyClass(object): pass مكافئ تماماً ل class MyClass(): pass1 نقطة
-
يمكنك فعل ذلك كالتالي step = .1 print([ x / pow(step, -1) for x in range(0, 10) ]) حيث نقوم بتحديد المقدار الذي سوف نقوم بزيادته في كل حلقة, ثم نقوم بعمل حلقة تكرار لإنتاج أرقام متتالية, سوف تكون النتيجة كالتالي [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]1 نقطة
-
إضافة للإجابات في الأعلى. سأتحدث عن مكتبة psutil كونها تعمل على مختلف أنظمة التشغيل، حيث توفر واجهة لاسترداد المعلومات حول العمليات الجارية واستخدام النظام (وحدة المعالجة المركزية والذاكرة). import psutil # استخدام المعالج print(psutil.cpu_percent()) # 15.3 # عرض نسبة استخدام الذاكرة print(psutil.virtual_memory().percent) # 71.1 # حساب المساحة المتوفرة من الذاكرة psutil.virtual_memory().available * 100 / psutil.virtual_memory().total # 28.76908537555775 # يمكنك عرض معلومات كاملة psutil.virtual_memory() # svmem(total=4169424896, available=1228451840, percent=70.5, used=2940973056, free=1228451840) ولمستخدمي لينوكس يمكنهم أيضاً استخدام مكتبة os: import os # استخدام المعالج cpu=str(round(float(os.popen('''grep 'cpu ' /proc/stat | awk '{usage=($2+$4)*100/($2+$4+$5)} END {print usage }' ''').readline()),2)) #print results print("usage :" + cpu) # استخدام الذاكرة # os.popen() # الحصول على كل معلومات الذاكرة total_memory, used_memory, free_memory = map( int, os.popen('free -t -m').readlines()[-1].split()[1:]) # استخدام الذاكرة print("RAM memory % used:", round((used_memory/total_memory) * 100, 2)) ويمكنك الحصول على معلومات مفصلة للتحليل ولعرض استخدام الذاكرة لكل سطر باستخدام وحدتي profile line_profiler وmemory_profiler بالطريقة التالية: اكتب برنامج python المراد اختباره ، والوظيفة المراد اختبارها وأضف أعلاها @ profile ، ثم احفظها كملف py. ثم ضع في سطر الأوامر commandline أو في محرر الأكواد: kernprof -l -v *.py ستتم طباعة تحليل الأداء وطباعة نتائج البرنامج. مثال، سنكتب تابع صغير ثم سنحفظه باسم ali.py @profile def com(): for i in range(10): print(i**4) if __name__=='__main__': com() ثم ضع في سطر الأوامر Command Line أو في محرر الأكواد. kernprof -l -v ali.py ''' Wrote profile results to test.py.lprof Timer unit: 1e-06 s Total time: 0.012405 s File: test.py Function: compute at line 1 Line # Hits Time Per Hit % Time Line Contents ============================================================== 1 @profile 2 def compute(): 3 101 74.0 0.7 0.6 for i in range(10): 4 100 12331.0 123.3 99.4 print(i**4) ''' Timer unit : وحدة الموقت ، ميكروثانية Total time :إجمالي وقت تشغيل الكود Time : زمن تشغيل السطر Hits: Number of runs % Time: النسبة المئوية لزمن تشغيل السطر ويمكنك استخدام بنفس الطريقة لكن نضع: python -m memory_profiler ali.py ''' Line # Mem usage Increment Line Contents ================================================ 2 39.08 MiB 39.08 MiB @profile(precision=2) 3 def compute(): 4 39.08 MiB 0.00 MiB for i in range(100): 5 39.08 MiB 0.00 MiB print(i**3) ''' Increment: زيادة الذاكرة أو نقصانها بعد تشغيل كل سطر من التعليمات البرمجية Mem usage: استخدام الذاكؤة لكل سطر يمكنك تثبيت المكتبات كالتالي: pip install line_profiler pip install memory_profiler1 نقطة
-
في إصدار 3.4 من بايثون يوجد وحدة جديدة تسمى tracemalloc ، حيث تقوم بتوفير إحصاءات مفصلة عن أي جزء من الكود يقوم بإستخدام أكبر قدر من الذاكرة ، وهذا مثال لكيفية إستخدمها import tracemalloc tracemalloc.start() # ... قم بتشغيل تطبيقك ... snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') print("[ أكبر 10 مستهلكين للذاكرة]") for stat in top_stats[:10]: print(stat)1 نقطة
-
يمكنك استخدام guppy3 لذلك وهي سهلة الاستخدام, ولكن يجب أن يكون لديك Python 3.6 أو 3.7 أو 3.8 أو 3.9, ثثم تحتاج الى تثبيتها من خلال الأمر الآتي باستخدام pip pip install guppy3 أو باستخدام conda conda install -c conda-forge guppy3 ثم تحتاج الى استدعاءها كالتالي from guppy import hpy; h=hpy() ثم استخدامها بالشكل الآتي h.heap() سوف يكون شكل المخرجات كالتالي Partition of a set of 132527 objects. Total size = 8301532 bytes. Index Count % Size % Cumulative % Kind (class / dict of class) 0 35144 27 2140412 26 2140412 26 str 1 38397 29 1309020 16 3449432 42 tuple 2 530 0 739856 9 4189288 50 dict (no owner) يمكنك أيضا معرفة المكان الذي تتم فيه الإشارة إلى الكائنات والحصول على إحصائيات عنها1 نقطة
-
 تُستخدم النماذج لعمل الاستطلاعات، الإحصائيات، تجميع البيانات أو غيرها من الأغراض. ومن السهل إنشاء النماذج القابلة للتعبئة باستخدام الأدوات التي يوفّرها ميكروسوفت وورد، سواء كنت تريد توزيع نسخ إلكترونية منها أو طباعتها. سنستعرض في هذا الدرس كيفية إنشاء النماذج من مستند فارغ وتخصيصها، بالإضافة إلى كيفية استخدام القوالب الجاهزة. إنشاء نموذج جديد من مستند فارغ يتكون النموذج من مجموعة عناصر نائبة (أو ماسكات مكان Placeholders) لأنّواع مختلفة من المعلومات، وتسمّى في ميكروسوفت وورد "حقول التحكّم بالمحتوى" Content Control Fields والتي تتضّمن مربعات النصوص text box، مربعات الخيار checkbox، القوائم المنسدلة drop-down list، وغيرها. يمكن الوصول إلى أدوات إنشاء النموذج من تبويب المطور Developer. وبما أنّ هذا التبويب غير مفعّل بشكل افتراضي، يجب اولًا أن نقوم بتفعيله بالذهاب إلى ملف File> خيارات Options: من قسم Customize Ribbon، بالتحديد من مجموعة Customize the Ribbon، نؤشر الخيار Developer ثم ننقر على OK: ستتم إضافته مع مجموعة التبويبات القياسية، ويمكننا أن نبدأ الآن بتصميم النموذج. كمثال بسيط، سنقوم بإنشاء نموذج استطلاع لآراء العملاء حول منتج ما، والعناصر التي سيحتويها موضّحة في الصورة أدناه: سنقوم أولًا بإنشاء جدول لاحتواء عناصر النموذج بشكل منظم، ثم ندخل عناوين حقول التحكّم بالمحتوى التي نريد إضافتها (الاسم، اللقب، العمر...): لإدراج أي عنصر تحكّم بالمحتوى، نضع مؤشر الكتابة في المكان المرغوب، ثم نختار العنصر المناسب من مجموعة Controls في تبويب Developer: في هذا المثال سنقوم بإدراج مربّع نص أمام حقل الاسم، لذا سنضع المؤشر في الحقل الفارغ أمامه ثم نختار أحد خياري مربعات النصوص: Rich Text: نص قابل للتنسيق. Plain Text: نص اعتيادي غير قابل للتنسيق. سنختار Plain Text لأنّنا لا نريد من المستخدمين الذين سيملؤون النموذج بتنسيق النص. بشكل افتراضي، سيحتوي مربّع النص على نص إرشادي لكي يعرف المستخدم ما الذي يجب إدخاله في الحقل: لتحرير النص الإرشادي وتخصيصه، ننقر على زر وضع التصميم Design Mode من مجموعة Controls: بعد ذلك نحذف النص الافتراضي وندخل النص المرغوب وننسّقه من أدوات التنسيق في تبويب الصفحة الرئيسية Home: يمكننا أيضًا أن نتحكّم بخصائص مربّع النص، أو أي حقل آخر للتحكّم بالمحتوى، عن طريق مربّع الحوار Content Control Properties. للقيام بذلك، نحدد مربّع النص ثم ننقر على زر Properties من مجموعة Controls: تختلف الخصائص باختلاف الحقل الذي قمنا بتحديده، فلمربع النص مثلا، يمكننا إضافة عنوان Title يظهر عند النقر على المربع عليه من قبل المستخدم، اختيار مظهر المربع من قائمة Show As، تغيير لون حدود المربع من قائمة Color، أو تقييد تحرير/حذف مربع النص من قسم Locking. سنقوم بتغيير لون إطار المربع إلى الأزرق ونؤشر الخيار Content control cannot be deleted لمنع المستخدمين من حذف هذا الحقل: وللمحافظة على الاتساق في التنسيق والخصائص، سنقوم بنسخ مربع النص ولصقه أمام عناصر النموذج المتبقية التي تحتاج إلى مربع نص ("اللقب"، "المدينة"، "الدولة"، و"اذكر السبب")، مع مراعاة تخصيص النص الإرشادي لكل عنصر: الخطوة التالية هي إنشاء مربعات الخيار لعنصر "الجنس". نضع مؤشر الكتابة أمام حقل "الجنس" ثم ننقر على زر مربع الخيار Check Box من مجموعة Controls: بعد ذلك نكتب نص مربّع الخيار، وهنا يجب ملاحظة أنّه لا يمكن كتابة النص داخل حدود حقل التحكم بالمحتوى، بل يجب أن نضع مؤشر الكتابة خارجًا ثم ندخل النص: نحدّد مربع الخيار ثم ننقر على Properties لتعديل خصائصه. تتوفر لمربعات الخيار نفس خصائص مربعات النص آنفة الذكر، بالإضافة إلى خصائص أخرى مثل رمز المربع المؤشر Checked Symbol ورمز المربع غير المؤشر Unchecked Symbol. سننقر على زر Change لتغيير رمز المربع المؤشر إلى علامة صح بدلا من الرمز الافتراضي علامة ×، ونغيّر لون حدود مربع الخيار ثم ننقر على OK: ننسخ مربع الخيار الذي قمنا بإنشائه ونلصقه أمام حقل "هل توصي الآخرين بشرائه؟" مع مراعات تخصيص نص المربع: الخطوة التالية هي إنشاء القوائم المنسدلة لحقلي "العمر" و"تقييم المنتج". نضع مؤشر الكتابة أمام حقل "العمر" ثم ننقر على زر Drop-Down List من مجموعة Controls: بعد ذلك نحدد حقل التحكم بالمحتوى للقائمة المنسدلة وننقر على Properties لتعديل خصائصه وإضافة عناصر القائمة: سنقوم أولا بتعديل العنصر الأول الافتراضي بتحديده والنقر على زر Modify: بعد ذلك ندخل النص المرغوب في حقل Display name: ثم ننقر على زر Add لإضافة عنصر جديد للقائمة: وندخل اسم العنصر في Display name: نكرر الخطوتين السابقتين حتى ننتهي من إضافة جميع عناصر القائمة المنسدلة، ثم ننقر على OK لإنشاء القائمة المنسدلة: نكرر نفس خطوات إنشاء القائمة المنسدلة لحقل "تقييم المنتج" مع إضافة العناصر المناسبة إلى القائمة. بقي لنا حقل "تاريخ المنتج"، والخيار المناسب له هو إضافة تقويم لمساعدة مستخدم النموذج على اختيار التاريخ. نضع مؤشر الكتابة أمام حقل "تاريخ المنتج" ثم ننقر على زر Date Picker من مجموعة Controls: نفعّل وضع التصميم Design Mode لتغيير النص الإرشادي، ثم ننقر على زر Properties لتعديل خصائص التقويم: يتوفر لحقل التاريخ نفس خصائص الحقول التي ذكرناها سابقًا (العنوان، اللون، المظهر...)، بالإضافة إلى خصائص أخرى كتنسيق التاريخ، نوع التقويم، أو غيرها. نجري التعديلات المرغوبة ثم ننقر على OK لتطبيقها: أصبح نموذجنا الآن جاهزًا للحفظ والإرسال: حماية النموذج يعمل أمر الحماية على منع المستخدمين من إجراء أي تعديل على المستند الذي يحتوي النموذج، ويسمح لهم فقط بإدخال المحتويات في حقول النموذج. لحماية النموذج، ننقر على زر Restrict Editing من تبويب Developer: سيُفتح جزء Restrict Editing، ومنه نؤشر الخيارAllow only this type of editing in the document ، نختار Filling in Forms من القائمة المنسدلة، ثم ننقر على Yes, Start Enforcing Protection: وأخيرًا نقو بإدخال كلمة المرور للحماية مرتين، ثم ننقر على OK. بتطبيق هذه الخطوة ستصبح كل محتويات المستند محمية وغير قابلة للتعديل ما عدا حقول التحكم بالمحتوى للنموذج: لمعرفة المزيد حول حماية المستندات راجع هذا الدرس. استخدام قوالب النماذج الجاهزة إذا لم تكن ترغب في إنشاء النموذج من مستند فارغ، يمكنك استخدام أحد القوالب الجاهزة والتعديل عليها. لاستعراض قوالب النماذج المتوفرة، نذهب إلى File> New، ثم ندخل الكلمة المفتاحية "form" في حقل البحث ونضغط Enter: نتصفح نتائج البحث وننقر على القوالب لمعاينتها، وعند العثور على القالب المناسب ننقر على زر Create: سيتم إنشاء القالب في مستند جديد، ومنه يمكننا أن نبدأ بتعديل حقول التحكّم بالمحتوى الموجودة، أو إضافة حقول جديدة: خاتمة يوفّر وورد خيارات متنوّعة لإنشاء النماذج الإلكترونية القابلة للتعبئة، فبالإضافة إلى حقول التحكم بالمحتوى التي استخدمناها لإنشاء النموذج في المثال المذكور، تتوفر خيارات أخرى كأشرطة التمرير Scroll Bar، أزرار الخيار Option Button، عناصر نائبة للصور، وغيرها. ويمكنك أن تستكشف هذه الخيارات وخصائصها من مجموعة Controls في تبويب Developer.1 نقطة
تُستخدم النماذج لعمل الاستطلاعات، الإحصائيات، تجميع البيانات أو غيرها من الأغراض. ومن السهل إنشاء النماذج القابلة للتعبئة باستخدام الأدوات التي يوفّرها ميكروسوفت وورد، سواء كنت تريد توزيع نسخ إلكترونية منها أو طباعتها. سنستعرض في هذا الدرس كيفية إنشاء النماذج من مستند فارغ وتخصيصها، بالإضافة إلى كيفية استخدام القوالب الجاهزة. إنشاء نموذج جديد من مستند فارغ يتكون النموذج من مجموعة عناصر نائبة (أو ماسكات مكان Placeholders) لأنّواع مختلفة من المعلومات، وتسمّى في ميكروسوفت وورد "حقول التحكّم بالمحتوى" Content Control Fields والتي تتضّمن مربعات النصوص text box، مربعات الخيار checkbox، القوائم المنسدلة drop-down list، وغيرها. يمكن الوصول إلى أدوات إنشاء النموذج من تبويب المطور Developer. وبما أنّ هذا التبويب غير مفعّل بشكل افتراضي، يجب اولًا أن نقوم بتفعيله بالذهاب إلى ملف File> خيارات Options: من قسم Customize Ribbon، بالتحديد من مجموعة Customize the Ribbon، نؤشر الخيار Developer ثم ننقر على OK: ستتم إضافته مع مجموعة التبويبات القياسية، ويمكننا أن نبدأ الآن بتصميم النموذج. كمثال بسيط، سنقوم بإنشاء نموذج استطلاع لآراء العملاء حول منتج ما، والعناصر التي سيحتويها موضّحة في الصورة أدناه: سنقوم أولًا بإنشاء جدول لاحتواء عناصر النموذج بشكل منظم، ثم ندخل عناوين حقول التحكّم بالمحتوى التي نريد إضافتها (الاسم، اللقب، العمر...): لإدراج أي عنصر تحكّم بالمحتوى، نضع مؤشر الكتابة في المكان المرغوب، ثم نختار العنصر المناسب من مجموعة Controls في تبويب Developer: في هذا المثال سنقوم بإدراج مربّع نص أمام حقل الاسم، لذا سنضع المؤشر في الحقل الفارغ أمامه ثم نختار أحد خياري مربعات النصوص: Rich Text: نص قابل للتنسيق. Plain Text: نص اعتيادي غير قابل للتنسيق. سنختار Plain Text لأنّنا لا نريد من المستخدمين الذين سيملؤون النموذج بتنسيق النص. بشكل افتراضي، سيحتوي مربّع النص على نص إرشادي لكي يعرف المستخدم ما الذي يجب إدخاله في الحقل: لتحرير النص الإرشادي وتخصيصه، ننقر على زر وضع التصميم Design Mode من مجموعة Controls: بعد ذلك نحذف النص الافتراضي وندخل النص المرغوب وننسّقه من أدوات التنسيق في تبويب الصفحة الرئيسية Home: يمكننا أيضًا أن نتحكّم بخصائص مربّع النص، أو أي حقل آخر للتحكّم بالمحتوى، عن طريق مربّع الحوار Content Control Properties. للقيام بذلك، نحدد مربّع النص ثم ننقر على زر Properties من مجموعة Controls: تختلف الخصائص باختلاف الحقل الذي قمنا بتحديده، فلمربع النص مثلا، يمكننا إضافة عنوان Title يظهر عند النقر على المربع عليه من قبل المستخدم، اختيار مظهر المربع من قائمة Show As، تغيير لون حدود المربع من قائمة Color، أو تقييد تحرير/حذف مربع النص من قسم Locking. سنقوم بتغيير لون إطار المربع إلى الأزرق ونؤشر الخيار Content control cannot be deleted لمنع المستخدمين من حذف هذا الحقل: وللمحافظة على الاتساق في التنسيق والخصائص، سنقوم بنسخ مربع النص ولصقه أمام عناصر النموذج المتبقية التي تحتاج إلى مربع نص ("اللقب"، "المدينة"، "الدولة"، و"اذكر السبب")، مع مراعاة تخصيص النص الإرشادي لكل عنصر: الخطوة التالية هي إنشاء مربعات الخيار لعنصر "الجنس". نضع مؤشر الكتابة أمام حقل "الجنس" ثم ننقر على زر مربع الخيار Check Box من مجموعة Controls: بعد ذلك نكتب نص مربّع الخيار، وهنا يجب ملاحظة أنّه لا يمكن كتابة النص داخل حدود حقل التحكم بالمحتوى، بل يجب أن نضع مؤشر الكتابة خارجًا ثم ندخل النص: نحدّد مربع الخيار ثم ننقر على Properties لتعديل خصائصه. تتوفر لمربعات الخيار نفس خصائص مربعات النص آنفة الذكر، بالإضافة إلى خصائص أخرى مثل رمز المربع المؤشر Checked Symbol ورمز المربع غير المؤشر Unchecked Symbol. سننقر على زر Change لتغيير رمز المربع المؤشر إلى علامة صح بدلا من الرمز الافتراضي علامة ×، ونغيّر لون حدود مربع الخيار ثم ننقر على OK: ننسخ مربع الخيار الذي قمنا بإنشائه ونلصقه أمام حقل "هل توصي الآخرين بشرائه؟" مع مراعات تخصيص نص المربع: الخطوة التالية هي إنشاء القوائم المنسدلة لحقلي "العمر" و"تقييم المنتج". نضع مؤشر الكتابة أمام حقل "العمر" ثم ننقر على زر Drop-Down List من مجموعة Controls: بعد ذلك نحدد حقل التحكم بالمحتوى للقائمة المنسدلة وننقر على Properties لتعديل خصائصه وإضافة عناصر القائمة: سنقوم أولا بتعديل العنصر الأول الافتراضي بتحديده والنقر على زر Modify: بعد ذلك ندخل النص المرغوب في حقل Display name: ثم ننقر على زر Add لإضافة عنصر جديد للقائمة: وندخل اسم العنصر في Display name: نكرر الخطوتين السابقتين حتى ننتهي من إضافة جميع عناصر القائمة المنسدلة، ثم ننقر على OK لإنشاء القائمة المنسدلة: نكرر نفس خطوات إنشاء القائمة المنسدلة لحقل "تقييم المنتج" مع إضافة العناصر المناسبة إلى القائمة. بقي لنا حقل "تاريخ المنتج"، والخيار المناسب له هو إضافة تقويم لمساعدة مستخدم النموذج على اختيار التاريخ. نضع مؤشر الكتابة أمام حقل "تاريخ المنتج" ثم ننقر على زر Date Picker من مجموعة Controls: نفعّل وضع التصميم Design Mode لتغيير النص الإرشادي، ثم ننقر على زر Properties لتعديل خصائص التقويم: يتوفر لحقل التاريخ نفس خصائص الحقول التي ذكرناها سابقًا (العنوان، اللون، المظهر...)، بالإضافة إلى خصائص أخرى كتنسيق التاريخ، نوع التقويم، أو غيرها. نجري التعديلات المرغوبة ثم ننقر على OK لتطبيقها: أصبح نموذجنا الآن جاهزًا للحفظ والإرسال: حماية النموذج يعمل أمر الحماية على منع المستخدمين من إجراء أي تعديل على المستند الذي يحتوي النموذج، ويسمح لهم فقط بإدخال المحتويات في حقول النموذج. لحماية النموذج، ننقر على زر Restrict Editing من تبويب Developer: سيُفتح جزء Restrict Editing، ومنه نؤشر الخيارAllow only this type of editing in the document ، نختار Filling in Forms من القائمة المنسدلة، ثم ننقر على Yes, Start Enforcing Protection: وأخيرًا نقو بإدخال كلمة المرور للحماية مرتين، ثم ننقر على OK. بتطبيق هذه الخطوة ستصبح كل محتويات المستند محمية وغير قابلة للتعديل ما عدا حقول التحكم بالمحتوى للنموذج: لمعرفة المزيد حول حماية المستندات راجع هذا الدرس. استخدام قوالب النماذج الجاهزة إذا لم تكن ترغب في إنشاء النموذج من مستند فارغ، يمكنك استخدام أحد القوالب الجاهزة والتعديل عليها. لاستعراض قوالب النماذج المتوفرة، نذهب إلى File> New، ثم ندخل الكلمة المفتاحية "form" في حقل البحث ونضغط Enter: نتصفح نتائج البحث وننقر على القوالب لمعاينتها، وعند العثور على القالب المناسب ننقر على زر Create: سيتم إنشاء القالب في مستند جديد، ومنه يمكننا أن نبدأ بتعديل حقول التحكّم بالمحتوى الموجودة، أو إضافة حقول جديدة: خاتمة يوفّر وورد خيارات متنوّعة لإنشاء النماذج الإلكترونية القابلة للتعبئة، فبالإضافة إلى حقول التحكم بالمحتوى التي استخدمناها لإنشاء النموذج في المثال المذكور، تتوفر خيارات أخرى كأشرطة التمرير Scroll Bar، أزرار الخيار Option Button، عناصر نائبة للصور، وغيرها. ويمكنك أن تستكشف هذه الخيارات وخصائصها من مجموعة Controls في تبويب Developer.1 نقطة







