لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/29/21 في كل الموقع
-
لقد قمت باستخدام المكتبة multer للتعامل مع الملفات والصور في مشروع node.js ونجحت بالفعل في رفع هذه الملفات إلى الخادم من خلال الكود التالي: app.post("/images/upload", [upload.single('upload')], controller.uploadImage); exports.uploadImage = async (req, res) => { ... //يتم هنا حفظ اسم الملف والمسار في قاعدة البيانات ... } ولكن سؤالي هو كيف يمكنني إظهار نسبة التحميل (نسبة مئوية مثلاً) إلى المستخدم؟ ففي حالة الملفات الكبيرة لم أعد أستطع تحديد الوقت المتبقي لاكتمال عملية رفع الملف.1 نقطة
-
يتم استخدام كل من sharding و replication مع قواعد بيانات mongodb بشكل مشابه وخاصةً عند التعامل مع المشاريع الكبيرة والموزعة. ولكن ماهو الاختلاف بين كل منهما؟ فعد استخدامي لأدوات التجزئة وجدتها أسهل وأقل تعقيداً من replication، فهل يمكنني استخدامها دوماً بدلاً من replication؟1 نقطة
-
لقد لاحظت في العديد من المشاريع كتابة الجملة "use strict" في أول ملفات الجافاسكريبت التابعة ل node.js ما الذي تقوم به هذه الجملة بالتحديد؟ وهل يمكن وضعها في أماكن أخرى غير السطر الأول من ملف الجافاسكريبت؟1 نقطة
-
لقد وجدت طريقتين في إرسال الرد response إلى الزبون من قبل خادم node.js وهما: res.send(); و res.end(); ما الفرق بين هذه الطريقتين ومتى يتم استخدام كل منها في node.js ؟1 نقطة
-
لقد تم إحداث هذه الخاصية في ECMAScript النسخة الخامسة. ويتم إهمالها من قبل النسخ القديمة من الجافاسكريبت. ومن إحدى أهم مزاياها هو أنك لا تستطيع استخدام المتغيّرات التي لم يتم التصريح عنها، ولعلّها تساعد المبرمجين بعدم ارتكاب بعض الأخطاء وتسهّل الوصول إلى الأخطاء عند حدوثها. مثال: "use strict"; x = 3.14; // سيسبب خطأ لأنه لم يتم التصريح مسبقاً عن المتغيّر يجب أن تكون بالشكل التالي: "use strict"; let x = 3.14; في الوضع غير المقيد (أي عند عدم وضع use strict) ، ستكون المتغيرات والتي يمكن الوصول إليها داخل أي دالة عبارة عن مصفوفة مثل الكائن Object على سبيل المثال والذي يحتوي على جميع المعاملات التي يتم تمريرها له عادةً، ستكون هذه المعاملات الموجودة داخلها مراجع إلى نفس القيم المخزنة في تعريف الوظيفة. مثلاً عند تعريف دالة ما تحوي بارامتر واحد وليكن اسمه myArg، سنتمكّن من الوصول إلى هذا المتغير إما من خلال اسمه muArg أو من خلال المصفوفة arguments[0] وعندما نقوم بتغيّر قيمته من خلال هذه المصفوفة ستقوم أيضاً بتغيير قيمته التابعة للاسم نفسه: function myFunc(myArg) { console.log(`${myArg} -- ${arguments[0]}`); arguments[0] = 20; // نقوم هنا بتغيير قيمته من خلال مصفوفة المتغيرات console.log(`${myArg} -- ${arguments[0]}`); } test(10); سنلاحظ هنا أن النتيجة نفسها لكل من مصفوفة المتغيّرات، وأيضاً اسم المتغيّر أو reference: 10 -- 10 20 -- 20 أما إذا قمنا بكتابة use strict وأعدنا تنفيذ هذا التابع: 'use strict'; // قمنا هنا بإضافة use strict function myFunc(myArg) { console.log(`${myArg} -- ${arguments[0]}`); arguments[0] = 20; console.log(`${myArg} -- ${arguments[0]}`); } test(10); سنلاحظ أنه حتى لو غيّرنا قيمة المتغيّر من خلال المصفوفة، فإن ذلك لن يؤثر فعلياً على قيمة المتغيّر نفسه المحجوز في الذاكرة. وعندما نقوم باستدعائه من خلال اسم المتغيّر أو reference سنلاحظ أن قيمته لم تتغيّر واحتفظت بالقيمة نفسها، فيكون الناتج: 10 -- 10 10 -- 20 ^^1 نقطة
-
إن الزمن الافتراضي timeout هو 200 ميلي ثانية، ولكن بإمكانك تغيير timeout limit عند القيام بالاختبار من خلال الأمر نفسه بإضافة الخيار --timeout كالتالي: mocha --timeout 15000 مع تجربة الزمن المناسب لعملياتك. أو: يمكنك وضع التابع الزمني ضمن كل اختبار على حدى، بالشكل التالي: describe('your test here', function(){ this.timeout(15000); it('test', function(done){ this.timeout(15000); setTimeout(done, 15000); }); }); بشكل مماثل يمكنك التحكّم بتعديل timeouts على مستوى suit, hook, test وغيرها من الخصائص التي يمكنك الاطلاع عليها من خلال التوثيق الرسمي لـ mocha1 نقطة
-
السلام عليكم أريد شرح خاصية position في Css وخاصة القيمتين absolute و relative ؟. وشكرا مسبقا.1 نقطة
-
لدي مجموعة بيانات نصية (مقالات) و أريد أن أصنفها (X: words of the articles, y: class) لكن عدد المقالات غير متوازن أي صنف يحتوى على عدد كبير و الأخر على عدد بسيط. هل يوجد طريقة مثل SMOTE لموازنة البيانات في حال كانت النصية؟ شكراً1 نقطة
-
السلام عليكم , انا جديد على تايب سكريبت والاحظ انه فى الدورات يتم استخدام tsx احيانا واحيانا ts واحيانا اخرى يتم استخدام js مع ts انا حقا اريد ان اعرف ما الفرق بين tsx و ts وايهما افضل للستخدام مع react native CLI أنا شاهدت فى فيديو على اليوتيوب شخص يستخدم ملفات ts عادى .. اما انا فقت بتنصيب بعض ال libraries جعلت تطبيقى لا يقبل ال ts وانما يجب ان يكون الكمبوننت tsx فقط سؤال ثانى هل ال typescript سوف تفيدنى فى النود جى اس .. اعلم ان النود يمكننى استخدام typescript فيها .. لكن هل هناك توجه مثلا نحوها وانها ستكون اضافة قوية ل Node js ؟ ام انها سوف تفيدنى فقط فى رياكت ورياكت ناتيف ؟1 نقطة
-
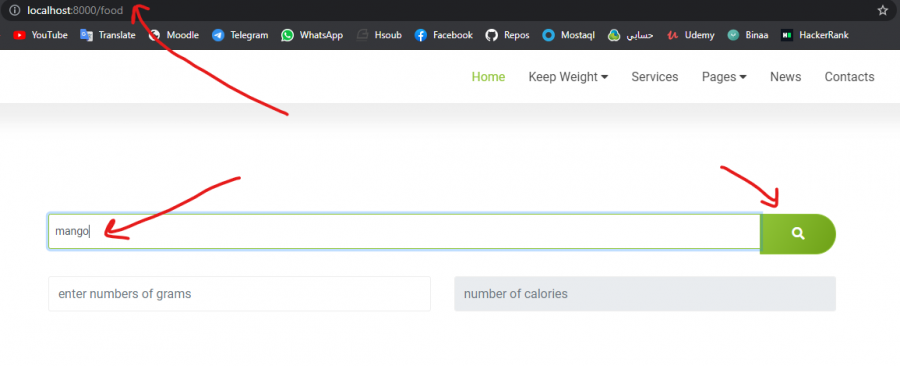
كيف أستطيع أن أرسل القيمة التي يكتبها المستخدم في ال search وعند الضغط على الزر، يتم إرسال ال path بهذه الطريقة ( علما أني أستخدم blade ) http://localhost:8000/search/mango
 1 نقطة
1 نقطة -
هناك عدة طرق منها , يمكنك إنشاء مسار Route::get('/search', 'GalleryController@search')->name('search'); بحيث يكون مسؤول عن عملية redirect , وتكون دالة search مهمتها جلب القيمة التي تم إرسالها بالفورم public function search(Request $request) { return redirect()->route('getData', $request->name); } طبعاً نعرف مسار آخر لعرض الرابط كما نريد http://127.0.0.1:8000/search/mobile وليكن المسار بهذا الشكل Route::get('/search/{name}', 'GalleryController@foundData')->name('getData'); وتكون دالة foundData هي دالة عرض بيانات عن طريق القيمة التي نبحث عنها public function foundData(Request $request, $name) { $books = Book::where('title', 'like', "%{$request->name}%")->paginate(12); $title = ' عرض نتائج البحث عن: ' . $request->name; return view('gallery', compact('books', 'title')); } ويكون form الإدخال بهذا الشكل <form class="form-inline col-md-6 justify-content-center" action="{{ route('search') }}" method="GET"> <input type="text" class="form-control mx-sm-3 mb-2" name="name"> <button type="submit" class="btn btn-secondary mb-2">ابحث</button> </form> بحيث يكون نوع الإرسال من نوع GET و رابط التوجيه هو {{ route('search') }} و حقل الإدخال يحمل خاصية name="name" <input type="text" class="form-control mx-sm-3 mb-2" name="name">1 نقطة
-
بما أن الموقع تم إنشاؤه لحماية حقوق كل من البائع والمشتري، من الطبيعي أخذ إجراءات لتجنب أي عملية احتيال أو خداع .. يوجد الكثير من المشترين الذين لا يمكلون أدنى فكرة عمّا يقومون بشرائه، فقط يعلمون أنهم بحاجة إلى هذه الخدمة ويضعون كامل ثقتهم في البائع. تخيل لو أنك مشتري طلبت من أحد البائعين إنشاء موقع الكتروني خاص بك .. ثم قمت بتفقده وأعجبك التصميم والموقع بشكل عام واستلمت المشروع .. لكن بعد عشرة أيام واستخدام الزوار المتكرر له، تتلقى شكوى بعدم عمل قسم كامل في الموقع، من الطبيعي أن تتكلم مع البائع لكي يقوم بإصلاح المشكلة، لكن الطامة الكبرى هي رفض البائع أن يقوم بإصلاح ما قصّر فيه! بالطبع حقوقك محمية تحت سياسة موقع حسوب، ستتواصل مع المنصة وسيقومون بتجميد أرباحه حتى يقوم بإصلاح المشكلة ورضاك عن الإصلاح .. هذا هو الهدف من الإبقاء على الأرباح 14 يوم .. ضمان حقوقك كمشتري عزيزي.1 نقطة
-
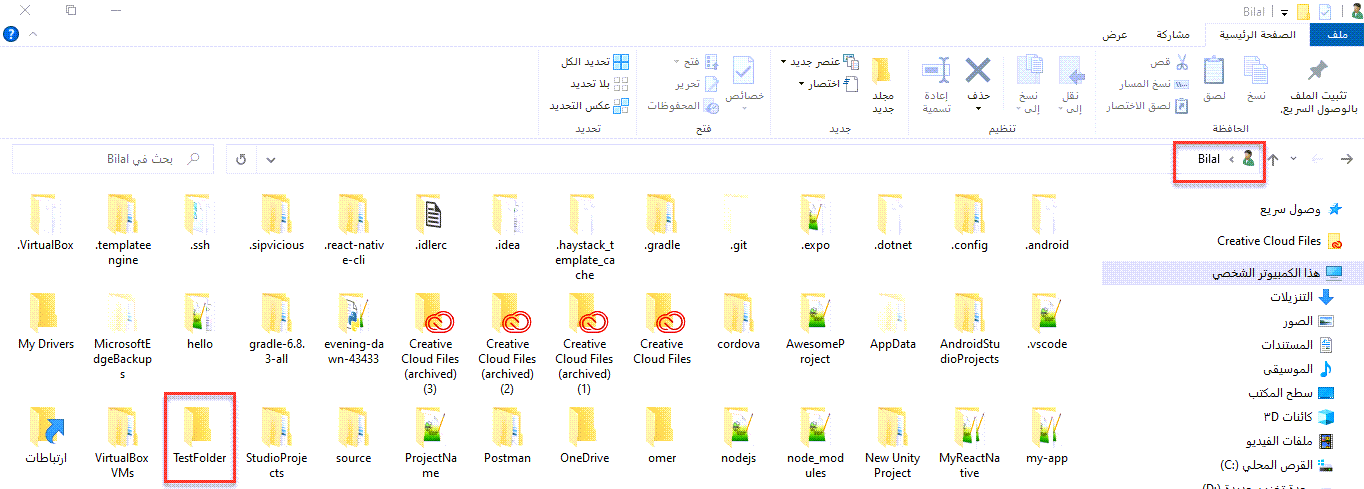
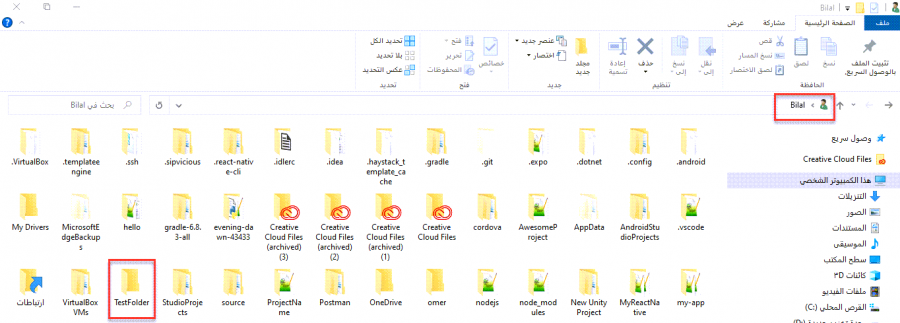
السلام عليكم , في موسوعة حسوب وجدت انه لإنشاء ملف عبر سطر الاوامر CMD نستخدم السطر التالي > mkdir %USERPROFILE%\projects > cd %USERPROFILE%\projects اما انا من قبل كنت استخدم : > mkdir projects > cd projects ما الفرق بينهما او ماذا يقصد ب %USERPROFILE%1 نقطة
-
لاحظ أن %USERPROFILE%\ معناها هو مجلد user profile على الجهاز و هو يقصد به مجلد تعريف المستخدم الخاص بك في مجلد المستخدمين على محرك نظام windows الخاص بك , والذي يكون على معظم أجهزة الكمبيوتر على القرص C فلاحظ عندما قمت بتنفيذ هذا الأمر في cmd cd %USERPROFILE%\ سيقوم بفتح المسار التالي C:\Users\Bilal> ماذا لو أردنا إنشاء مجلد في هذا المسار نقوم باستخدام الأمر التالي mkdir %USERPROFILE%\\TestFolder فسيقوم بإنشاء مجلد باسم TestFolder في المسار التالي على الحاسوب C:\Users\Bilal> عندما كنت تستخدم الأمرين mkdir projects > cd projects لاحظ انه عندما تقوم بفتح cmd تلقائياً يكون المسار الموضوع هو مسار مجلد تعريف المستخدم
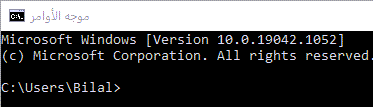 1 نقطة
1 نقطة -
يمكنك استخدامها عبر الموديول: keras.utils.np_utils يقوم التابع to_categorical بتحويل البيانات العددية إلى بيانات فئوية ممثلة بأصفار و واحدات ، حيث يقوم بترميز كل قيمة عددية مميزة (ال class) في شعاع طوله بعدد الفئات Classes المختلفة الموجودة في بياناتنا. وبشكل أكثر وضوح: بعد أن يتم إعطاء كل class في مجموعة البيانات رقمً تعريف فريد Classid يتراوح بين 1 و | Classes | . حيث Classes هي مجموعة الفئات (الأصناف) الموجودة لدينا . ثم يتم تمثيل كل فئة عبر متجه بأبعاد مقدارها | Classes | مملوء كلها بـ صفر باستثناء الفهرس ، حيث index = Classid. حيث نضع في هذا الفهرس ببساطة 1. ونستخدمه عادة عندما يكون لدينا مهمة تصنيف متعدد (عندما يكون لدينا عدة فئات). في المثال التالي لدي شعاع y فيه 3 كلاسات مختلفة وبالتالي كل كلاس سوف يتم تمثيله بشعاع له 3 أبعاد. # استيراد التابع from keras.utils.np_utils import to_categorical # خرج مزيف y=[0,1,0,2,1,0,1,2,0,1,2] # استخدام المحول الفئوي y=to_categorical(y) #طباعة النتائج print(y) ''' array([[1., 0., 0.], [0., 1., 0.], [1., 0., 0.], [0., 0., 1.], [0., 1., 0.], [1., 0., 0.], [0., 1., 0.], [0., 0., 1.], [1., 0., 0.], [0., 1., 0.], [0., 0., 1.]], dtype=float32) ''' سأقوم بتطبيق هذا التابع لترميز مجموعة بيانات routers، حيث أن هذه البيانات لديها 46 فئة (صنف) مختلف: # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=100) # ترميز الفئات المختلفة للبيانات from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) # قمنا بعرض فئة أول عينة من بيانات التدريب print('one_hot_train_labels[0]:\n',one_hot_train_labels[0]) ''' one_hot_train_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' # قمنا بعرض فئة أول عينة من بيانات الاختبار print('one_hot_test_labels[0]:\n',one_hot_test_labels[0]) ''' one_hot_test_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' ملاحظة: هذا الترميز هو نفسه ال One-Hot-Encoding1 نقطة
-
يوجد مكتبة تدعى ordered-set يمكن تثبيتها: pip install ordered-set ثم استخدامها بشكل طبيعي .. مثال من التوثيق: #تضمين المكتبة from ordered_set import OrderedSet # بناء غرض letters = OrderedSet('abracadabra') # عرض العناصر letters OrderedSet(['a', 'b', 'r', 'c', 'd']) # فحص وجود عنصر >>> 'r' in letters True التوثيق: pypi/ordered-set حلول أخرى: setlist - sortedcontainers1 نقطة
-
نعم منذ Py2.6: قم بتثبيتها أولاً: pip install ordered-set from ordered_set import OrderedSet l = OrderedSet('abraca') print(l) # OrderedSet(['a', 'b', 'r', 'c'])1 نقطة
-
يمكن تعديل الصلاحيات للمجلد بالأمر التالي: sudo chown -R $USER /absolute/path/to/directory # # # # # /usr/local/lib/python3.7/dist-packages/ ثم التثبيت بشكل عادي..1 نقطة
-
إن بنية المعطيات الأساسية (data structure) في Keras هي "Model" هذا المودل يسمح لنا بتعريف و تصميم وتنظيم طبقات الشبكة العصبية المطلوب بناءها. في كيراس فإن أحد أشكال بنية المعطيات هذه (model) هو الهيكلية التي تسمى Sequential. وهو أبسط أشكال النماذج (طبقات مكدسة فوق بعضها بشكل خطي) وأشهرها وأكثرها استخداماً (مستخدم في أكثر من 95% من النماذج والمهام). إن دخل كل طبقة في هذه البنية هو tensor (مصفوفة) واحدة بالضبط وخرجها tensor واحدة بالضبط (exactly one input tensor and one output tensor). لتعريف بنية المعطيات Sequential واستخدامها لتصميم وتنظيم شبكة عصبية يجب علينا أولاً أن نقوم باستيرادها، ويتم ذلك من خلال الموديول التالي: keras.models هناك طريقتان لإضافة وتنظيم الطبقات إلى هذه البنية الأولى بباستخدام التابع add كما في المثال التالي والأخرى عن طريق تمرير قائمة بالطبقات التي نريدها إلى باني الصف Sequential كما سنرى: #add باستخدام model.add(layers.Dense(64)) model.add(layers.Dense(32)) model.add(layers.Dense(1)) # Sequential طريقة أخرى حيث نمرر قائمة من الطبقات إلى باني الصف model =Sequential( [ layers.Dense(64), layers.Dense(32), layers.Dense(1), ] ) المثال1: هنا سأقوم بتعريف نموذج باستخدام هذه المعمارية وقمت بترجمته وتدريبه (التدريب وكل شيء قمت به هو عشوائي، غايتي هي فقط أن أبين لك شكل المعمارية كيف يتم الأمر). # تحميل الدتا from keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data( num_words=100) # تحضير الداتا import numpy as np def vectorize_sequences(sequences, dimension=100): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) y_train = np.asarray(train_labels).astype('float32') y_test = np.asarray(test_labels).astype('float32') #----------------------------------------------------------------- # استيراد المكتبات from keras import layers # Sequential استيراد المعمارية from keras.models import Sequential # Sequential إنشاء كائن يمثل نموذج من النوع model = Sequential() # سنضيف الآن عدد من الطبقات بشكل عشوائي #إلى هذا النموذج Fully Conected قمنا بإضافة 3 طبقات من نوع model.add(layers.Dense(64, activation='relu', input_shape=(100,))) # features 100 والدخل لهذه الطبقة هو relu طبقة ب32 خلية وتابع تنشيط model.add(layers.Dense(32, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) # طبقة الخرج حددناها بمخرج واحد فقط #---------------------------------------------------------------- # ثم سنرسم شكل المعمارية باستخدام واجهة برمجة التطبيقات من كيراس لتتضح لك # واجهة برمجة تطبيقات Keras الوظيفية أن تفعل ذلك لنا. from tensorflow.keras.utils import plot_model # قم بتشغيل الكود لترى هيكل النموذج إذا أحببت # هيكل النموذج هو الصورة في الأسفل plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True) #----------------------------------------------------------------- # ثم نقوم بترجمة النموذج وتمرير المعلومات التي يحتاجها model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) # وأخيراً تدريب النموذج history = model.fit(x_train, y_train, epochs=4) #---------------------------------------------------------------- # لتقييم النموذج model.evaluate(x_test,y_test) إذا هذا النموذج غير جيد في حال كان لديك أكثر من input أوأكثر من output في أي طبقة من طبقاتك، أو إذا كنت بحاجة إلى تشارك الطبقات أو إذا كنت لاتريد أن تكون طبولوجيا الشبكة خطية. # Writen by: Ali_H_Ahmad
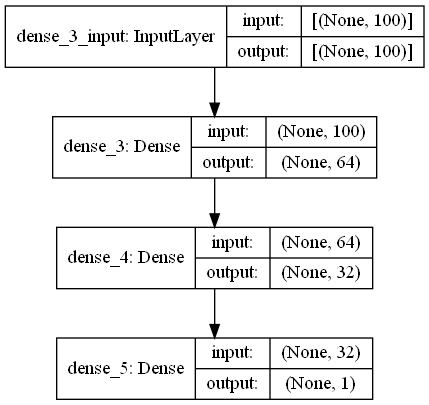 1 نقطة
1 نقطة -
الإجابة هي لا ,ولكن يمكنك استخدام المجموعات OrderedDict من مكتبة Python القياسية ويمكنك استخدامها كما في التعليق السابق للمدرب عبد المجيد, اعتبارا من بايثون Python 3.7 تم استخدام dict وهو اكثر أداء من OrderedDict ويمكن استخدامه كالتالي myList = ['foo', 'bar', 'bar', 'foo', 'baz', 'foo'] list(dict.fromkeys(myList)) #output ['foo', 'bar', 'baz']1 نقطة
-
يوجد أكثر من حل لهذه المشكلة، وهم كالتالي: تميرير --user عند تنفيذ أمر التثبيت كالتالي: pip install --user -r requirements.txt عمل بيئة عمل إفتراضية من خلال إستخدام أداة مثل virtualenv كالتالي: virtualenv .venv source .venv/bin/activate pip install -r requirements.txt إستخدام sudo عند تنفيذ أمر التثبيت كالتالي: sudo pip install -r requirements.txt لكن هذا الأمر الأخير خطير ولا ينصح بإستخدامه في أي حال من الأحوال، وذلك لوجود إحتمال بإحتواء بعض المكتبات على أكواد ضارة، وإذا قمت بتثبيت هذه المكتبات من خلال sudo قد تتمكن هذه الأكواد الضارة من الحصول على أذونات المستخدم الجذر root وسيكون بإمكانها فعل ما تشاء في الحسوب.1 نقطة
-
لديك خيارين لحل هذه المشكلة الخيار الأول عبر إنشاء بيئة وهمية وتفعيلها ومن ثم التثبيت كالآتي virtualenv .venv source .venv/bin/activate pip install -r requirements.txt الخيار الثاني يمكنك التثبيت في مسار home كالآتي pip install --user -r requirements.txt توصيتي باستخدام الخيار الآمن أي الخيار الأول ، بحيث لا تتداخل متطلبات هذا المشروع مع متطلبات المشاريع الأخرى.1 نقطة
-
يمكنك الحصول على قائمة بالتعليمات التي هي قيد التشغيل غلى جهازك من خلال تنفيذ الأمر التالي: sudo lsof -iTCP -sTCP:LISTEN -n -P وبعدها من القائمة يمكنك البحث عن الأمر mongod وأخذ ال PID التابع له، ثم تنفيذ الأمر التالي: sudo kill <pid here> ثم يمكنك إعادة التشغيل من خلال الأمر mongod من جديد. يتم إتباع هذه الطريقة لمعرفة أي تعليمات أو أوامر تشغل منافذ معيّنة في النظام حتى نستطيع تحرير هذه المنافذ واستخدامها.1 نقطة
-
يمكنك إستيراد OrderedDict من وحدة collections وإستخدام دالة ()fromkeys كما هو موضح في الكود للحصول على Ordered set أو قائمة مرتبة بدون قيم مكررة from collections import OrderedDict list(OrderedDict.fromkeys('abracadabra')) # ['a', 'b', 'r', 'c', 'd']1 نقطة
-
يبدو أنك تستخدم Mongodb بالفعل على المنفذ 27017 ، لديك حلين للتخلص من هذه المشكلة: إيقاف mongodb التي تعمل بالفعل من خلال الأمر التالي: sudo killall mongod يقوم الأمر السابق بإيقاف كل عمليات mongodb التي تعمل في الخلفية تغير منفذ التشغيل port من خلال الأمر التالي: mongod --port 270181 نقطة
-
يمكنك إنشاء دالة بسيطة لإيجاد النص المكرر في نص معين بكل سهولة بدون الحاجة الى التعابير الإعتيادية regular expression أو إستيراد دالة خارجية ، وهذا كود الدالة ، حيث ستحصل على فهرس أماكن الكلمة الذي تبحث عنها def find_all(a_str, sub): start = 0 while True: start = a_str.find(sub, start) if start == -1: return yield start start += len(sub) list(find_all("hello, world! Hi! hello!", "hello")) # [0, 18] أويمكنك استخدام دالة finditer من وحدة re لإيجاد النص المكرر import re [m.start() for m in re.finditer('test', 'test test test test')]1 نقطة
-
هناك عدة طرق للقيام بالأمر: إستخدام التعابير النمطية: import re x = "hello, world! Hi! hello!" count = len(re.findall("hello", x)) print(count) # 2 طريقة أخرى بإستخدام التعابير النمطية: import re x = "hello, world! Hi! hello!" word = "hello" count = sum(1 for _ in re.finditer(r'\b%s\b' % re.escape(word), x)) print(count) # 2 إستخدام split لتحويل النص إلى قائمة كلمات ثم إستخدام التابع count للقوائم: import re x = "hello, world! Hi! hello!" word = "hello" count = re.split(r'\W', x).count(word) print(count) # 21 نقطة
-
يمكنك استخدام format() كالتالي age= 18 print("I have {} years old".format(age)) أيضا يمكنك استخدام % كالتالي age= 18 print("I have %d years old"% age) كما يمكنك استخدام التكوين ""f كالتالي age= 18 print(f"I have {age} years old") كما يمكنك استخدام الفواصل كالتالي age= 18 print("I have ",age," years old")1 نقطة