لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/23/21 في كل الموقع
-
لدي DataFrame بإستخدام مكتبة Pandas كالتالي: DataFrame([ {'var1': 'a', 'var2': 1}, {'var1': 'b', 'var2': 1}, {'var1': 'c', 'var2': 1}, {'var1': 'd', 'var2': 2}, {'var1': 'e', 'var2': 2}, {'var1': 'f', 'var2': 2} ]) كيف يمكنني أن أحول إطار البيانات هذا إلى مصفوفة في مكتبة Numpy؟2 نقاط
-
رأيت اليوم كود يستخدم جملة with للتعامل مع الملفات لكن لم أفهم ما الذي تفعله هذه الجملة ولماذا تم استعمالها، لذلك لدي بعض الأسئلة حولها: ما هو إستخدام هذه الجملة؟ وما هي الصيغة syntax الصحيحة لاستعمالها؟ هل يوجد خطر في استخدام هذه الجملة؟ وهل يمكنني أن أستعمل جملة try … except بدلًا منها ما هي المكتبات / الأصناف / الدوال القياسية التي يمكنني استخدامها معها؟ (مثل دالة open على سبيل المثال)2 نقاط
-
الكلاس Imputer تم حذفه من الموديول preprocessing في النسخ الحديثة من Sklearn وتم تضمينه في الموديول impute، لذا يجب أن تقوم باستيراده بالشكل التالي : from sklearn.impute import SimpleImputer ويمكنك أيضاً استيراد الأنواع الأخرى بنفس الطريقة: from sklearn.impute import KNNImputer from sklearn.impute import MissingIndicator from sklearn.impute import IterativeImputer2 نقاط
-
 تقيِّد سياسة الأصل المشترك same origin أو سياسة الموقع المشترك same site من إمكانية وصول النوافذ أو الإطارات إلى بعضها إن لم تكن ضمن الموقع نفسه، فلو فتح مستخدم صفحتين، بحيث الأولى مصدرها الموقع academy.hsoub.com، والأخرى مصدرها الموقع gmail.com؛ فلا نريد هنا بالطبع لأية شيفرة من الصفحة academy.hsoub.com أن تقرأ بريده الإلكتروني الذي تعرضه الصفحة gmail.com، فالغاية إذًا من سياسة الأصل المشترك هي حماية المستخدم من لصوص المعلومات. الأصل المشترك نقول أنّ لعنواني URL أصلًا مشتركًا إن كان لهما نفس البروتوكول، والنطاق domain، والمنفذ. لذا يمكن القول أنّ للعناوين التالية أصلًا مشتركًا: http://site.com http://site.com/ http://site.com/my/page.html بينما لا تشترك العناوين التالية مع السابقة بالأصل: http://www.site.com (النطاق مختلف لوجود www هنا). http://site.org (النطاق مختلف لوجود org بدلًا من com). https://site.com (البروتوكول مختلف هنا https). http://site.com:8080 (المنفذ مختلف 8080). وتنص سياسة الأصل المشترك على مايلي: إذا وُجِد مرجع إلى نافذة أخرى، مثل: النوافذ المنبثقة المُنشأة باستخدام الأمر window.open، أو الموجودة داخل وسم النافذة الضمنية <iframe>، وكان للنافذتين الأصل نفسه، فسيمنحنا ذلك إمكانية الوصول الكامل إلى تلك النافذة. إذا لم يكن للنافذتين الأصل نفسه، فلا يمكن لإحداهما الوصول إلى محتوى الأخرى، بما في ذلك المتغيرات والمستندات، ويُستثنى من ذلك موضع النافذة location، إذ يمكننا تغييره (وبالتالي إعادة توجيه المستخدم)، دون القدرة على قراءة موضع النافذة (وبالتالي لا يمكننا معرفة مكان المستخدم الآن، وبالتالي لن تتسرب المعلومات). العمل مع النوافذ الضمنية iframe يستضيف الوسم iframe نافذةً ضمنيةً منفصلةً عن النافذة الأصلية، ولها كائنان، هما document وwindow مستقلان، ويمكن الوصول إليهما بالشكل التالي: iframe.contentWindow للحصول على الكائن window الموجودة ضمن الإطار iframe. iframe.contentDocument للحصول على الكائنdocument ضمن الإطار iframe، وهو اختصار للأمر iframe.contentWindow.document. سيتحقق المتصفح أنّ للإطار والنافذة الأصل نفسه عندما نَلِج إلى شيء ما داخل نافذة مضمّنة، وسيرفض الوصول إن لم يتحقق ذلك (تُستنثنى هنا عملية تغيير الخاصية location فلا تزال مسموحة). لنحاول مثلًا القراءة والكتابة إلى الإطار iframe من مورد لا يشترك معه بالأصل: <iframe src="https://example.com" id="iframe"></iframe> <script> iframe.onload = function() { // يمكننا الحصول على مرجع إلى النافذة الداخلية let iframeWindow = iframe.contentWindow; // صحيح try { // ...لكن ليس للمستند الموجود ضمنه let doc = iframe.contentDocument; // خطأ } catch(e) { alert(e); // (خطأ أمان (أصل مختلف } // لايمكننا أيضًا قراءة العنوان ضمن الإطار try { // Location لا يمكن قراءة عنوان الموقع من كائن الموضع let href = iframe.contentWindow.location.href; // خطأ } catch(e) { alert(e); // Security Error } // يمكن الكتابة ضمن خاصية الموضع وبالتالي تحميل شيء آخر ضمن الإطار iframe.contentWindow.location = '/'; // صحيح iframe.onload = null; //امسح معالج الحدث، لا تنفذه بعد تغيير الموضع }; </script> See the Pen JS-P3-01-cross-window-communications-ex1 by Hsoub (@Hsoub) on CodePen. ستعطي الشيفرة السابقة أخطاءً عند تنفيذها عدا حالتي: الحصول على مرجع إلى النافذة الداخلية iframe.contentWindow فهو أمر مسموح. تغيير الموضع location. وبالمقابل، إن كان للإطار iframe نفس أصل النافذة الداخلية، فيمكننا أن نفعل فيها ما نشاء: <!-- iframe from the same site --> <iframe src="/" id="iframe"></iframe> <script> iframe.onload = function() { // افعل ما تشاء iframe.contentDocument.body.prepend("Hello, world!"); }; </script> See the Pen JS-P3-01-cross-window-communications-ex2 by Hsoub (@Hsoub) on CodePen. الموازنة بين الحدثين iframe.onload وiframe.contentWindow.onload يؤدي الحدث iframe.onload على الوسم iframe مبدئيًا، نفس ما يؤديه الحدث iframe.contentWindow.onload على كائن النافذة المضمنة، إذ يقع الحدث عندما تُحمّل النافذة المضمنة بكل مواردها، لكن لا يمكن الوصول إلى الحدث iframe.contentWindow.onload لإطار من آخر ذي أصل مختلف، وبالتالي سنستخدم عندها iframe.onload. النوافذ ضمن النطاقات الفرعية والخاصية document.domain وجدنا من التعريف أنّ العناوين المختلفة تقود إلى موارد غير مشتركة بالأصل، لكن لو تشاركت النوافذ بالنطاق الفرعي أو النطاق من المستوى الثاني -مثل النطاقين الفرعيين التاليين: john.site.com وpeter.site.com (المشتركان بالنطاق الفرعي site.com)-، فيمكن حينها أن نطلب من المتصفح أن يتجاهل الفرق، وبالتالي سيعدهما من أصل مشترك، وذلك لأغراض التخاطب بين النوافذ. ولكي ننفذ ذلك لا بدّ من وجود الشيفرة التالية في كل نافذة: document.domain = 'site.com'; ستتخاطب النوافذ مع بعضها الآن دون معوقات، ولا بد أن نذكر أن هذا ممكن فقط في الصفحات التي تشترك بنطاق من المستوى الثاني. مشكلة كائن "document" خاطئ في النوافذ الضمنية عندما نتعامل مع نافذة ضمنية لها الأصل نفسه، يمكننا الوصول إلى الكائن document الخاص بها، وعندها ستواجهنا مشكلة لا تتعلق بالأصل المشترك -لكن لا بدّ من الإشارة إليها-، وهي أن النافذة الضمنية سيكون لها كائن document مباشرةً بعد إنشائها، لكنه سيختلف عن الكائن الذي سيُحمَّل ضمنها، وبالتالي قد يضيع الأمر الذي ننفِّذه على الكائن document مباشرةً. لنتأمل الشيفرة التالية: <iframe src="/" id="iframe"></iframe> <script> let oldDoc = iframe.contentDocument; iframe.onload = function() { let newDoc = iframe.contentDocument; // كائن المستند الذي حُمِّل مختلف عن الكائن الأساسي alert(oldDoc == newDoc); // false النتيجة }; </script> See the Pen JS-P3-01-cross-window-communications-ex3 by Hsoub (@Hsoub) on CodePen. لا ينبغي التعامل مع الكائن document لأي إطار قبل التحميل الكامل لمحتوياته لتجنب التعامل مع الكائن الخاطئ، إذ سيتجاهل المتصفح أية معالجات أحداث قد نستخدمها ضمن الكائن. لكن كيف نحدد اللحظة التي يجهز فيها الكائن document؟ سيظهر المستند بالتأكيد عند وقوع الحدث iframe.onload، والذي لا يطلق إلا عندما تُحمَّل موارد الإطار كلها. كما يمكن التقاط اللحظة المناسبة بالتحقق المستمر خلال فترات زمنية محددة عبر التعليمة setInterval: <iframe src="/" id="iframe"></iframe> <script> let oldDoc = iframe.contentDocument; // تحقق أن المستند الجديد جاهز كل 100 ميلي ثانية let timer = setInterval(() => { let newDoc = iframe.contentDocument; if (newDoc == oldDoc) return; alert("New document is here!"); clearInterval(timer); // فلن تحتاجها الآن setInterval ألغ }, 100); </script> See the Pen JS-P3-01-cross-window-communications-ex4 by Hsoub (@Hsoub) on CodePen. استخدام المجموعة window.frames يمكن استخدام طريقة بديلة للوصول إلى الكائن window الخاص بالنافذة الضمنية iframe عبر المجموعة window.frames: باستخدام الرقم: إذ سيعطي الأمر [window.frames[0 كائن window الخاص بأول إطار في المستند. باستخدام الاسم: إذ يعطي الأمر window.frames.iframeName كائن window الخاص بالإطار الذي يحمل الاسم "name="iframeName. مثلًا: <iframe src="/" style="height:80px" name="win" id="iframe"></iframe> <script> alert(iframe.contentWindow == frames[0]); // true alert(iframe.contentWindow == frames.win); // true </script> See the Pen JS-P3-01-cross-window-communications-ex5 by Hsoub (@Hsoub) on CodePen. قد تحوي نافذة ضمنية ما نوافذ ضمنيةً أخرى، وعندها ستكون الكائنات window الناتجة عن الانتقال الشجري بين الإطارات هي: window.frames: وتمثل مجموعة النوافذ الأبناء للإطارات المتداخلة nested. window.parent: المرجع إلى النافذة الأم المباشرة (الخارجية). window.top: المرجع إلى النافذة الأم الأعلى ترتيبًا. مثلًا: window.frames[0].parent === window; // محقق يمكن استخدام الخاصية top للتحقق من أنّ المستند الحالي مفتوح ضمن إطار أم لا: if (window == top) { // current window == window.top? alert('The script is in the topmost window, not in a frame'); } else { alert('The script runs in a frame!'); } See the Pen JS-P3-01-cross-window-communications-ex6 by Hsoub (@Hsoub) on CodePen. الخاصية sandbox المتعلقة بالنافذة الضمنية iframe تسمح الخاصية sandbox باستبعاد تنفيذ أفعال معينة داخل النافذة الضمنية <iframe>، وذلك لمنع تنفيذ الشيفرة غير الموثوقة، إذ تقيَّد الخاصية sandbox للإطار كونه آتيًا من أصل مختلف مع/أو بالإضافة إلى قيود أخرى. تتوفر عدة تقييدات افتراضية ضمن الأمر <"..."=iframe sandbox src>، ويفضل أن نترك فراغًا بين عناصر قائمة القيود التي لا نريد تطبيقها كالتالي: <iframe sandbox="allow-forms allow-popups"> ستطبّق أكثر التقييدات صرامةً عندما تكون الخاصية sandbox فارغة "دون قائمة قيود" ، ويمكننا رفع ما نشاء منها بذكرها ضمن قائمة يفصل بين عناصرها فراغات. وإليك قائمة الخيارات المتعلقة بالتقييدات: allow-same-origin: تجبر الخاصية sandbox المتصفح على احتساب النافذة الضمنية من أصل مختلف تلقائيًا، حتى لو دلت الصفة src على الأصل نفسه، لكن هذا الخيار يزيل التطبيق الافتراضي لهذه الميزة. allow-top-navigation: يسمح هذا الخيار للنافذة الضمنية بتغيير قيمة parent.location. allow-forms: يسمح هذا الخيار بإرسال نماذج forms انطلاقًا من الإطار. allow-scripts: يسمح هذا الخيار بتشغيل سكربتات انطلاقًا من الإطار. allow-popups: يسمح بفتح نوافذ منبثقة باستخدام الأمر window.open انطلاقًا من الإطار. اطلع على تعليمات التنفيذ إن أردت التعرف على المزيد. يُظهر المثال التالي إطارًا مقيَّدًا بمجموعة القيود الافتراضية <"..."=iframe sandbox src>، ويتضمن المثال شيفرةً ونموذجًا وملفين، وستلاحظ أنّ الشيفرة لن تعمل نظرًا لصرامة القيود الافتراضية. الشيفرة الموجودة في الملف "index.html": <!doctype html> <html> <head> <meta charset="UTF-8"> </head> <body> <div>The iframe below has the <code>sandbox</code> attribute.</div> <iframe sandbox src="sandboxed.html" style="height:60px;width:90%"></iframe> </body> </html> وفي الملف "sandbox.html": <!doctype html> <html> <head> <meta charset="UTF-8"> </head> <body> <button onclick="alert(123)">Click to run a script (doesn't work)</button> <form action="http://google.com"> <input type="text"> <input type="submit" value="Submit (doesn't work)"> </form> </body> </html> وستكون النتيجة: ملاحظة: إنّ الغاية من وجود الصفة sandbox هي إضافة المزيد من القيود فقط، إذ لا يمكنها إزالة هذه القيود، لكنها تخفف بعض القيود المتعلقة بالأصل المشترك إن لم يكن للإطار الأصل نفسه. تبادل الرسائل بين النوافذ تسمح واجهة التخاطب postMessage للنوافذ بالتخاطب مع بعضها أيًا كان أصلها، فهي إذًا أسلوب للالتفاف على سياسة "الأصل المشترك"، إذ يمكن لنافذة من النطاق academy.hsoub.comأن تتخاطب مع النافذةgmail.com` وتتبادل المعلومات معها، لكن بعد موافقة كلتا النافذتين ووجود دوال JavaScript الملائمة فيهما، وهذا بالطبع أكثر أمانًا للمستخدم. تتكون الواجهة من قسمين رئيسيين: القسم المتعلق بالتابع postMessage تستدعي النافذة التي تريد إرسال رسالةٍ التابع postMessage العائد للنافذة الهدف، أي إن أردنا إرسال رسالة إلى win، فعلينا تنفيذ الأمر (win.postMessage(data, targetOrigin، وإليك توضيح وسطاء هذا التابع: data: وهي البيانات المراد إرسالها، والتي قد تكون أي كائن. حيث تُنسخ البيانات باستخدام خوارزمية التفكيك البنيوي "structured serialization". لا يدعم المتصفح Internet Explorer سوى النصوص، لذلك لا بدّ من استخدام التابع JSON.stringify مع الكائنات المركبة التي سنرسلها لدعم هذا المتصفح. targetOrigin: يُحدد أصل النافذة الهدف، وبالتالي ستصل الرسالة إلى نافذة من أصل محدد فقط، ويعَدّ هذا مقياسًا للأمان، فعندما تأتي النافذة الهدف من أصل مختلف، فلا يمكن للنافذة المرسِلة قراءة موقعها location، ولن نعرف بالتأكيد الموقع الذي سيُفتح حاليًا في النافذة المحددة، وقد ينجرف المستخدم بعيدًا دون علم النافذة المرسِلة. إذًا سيضمن تحديد الوسيط targetOrigin أن النافذة الهدف ستستقبل البيانات ما دامت في الموقع الصحيح، وهذا ضروري عندما تكون البيانات على درجة من الحساسية. في هذا المثال ستستقبل النافذة الرسالة إن كان مستندها (الكائن document الخاص بها) منتميًا إلى الموقع "http://example.com": <iframe src="http://example.com" name="example"> <script> let win = window.frames.example; win.postMessage("message", "http://example.com"); </script> يمكن إلغاء التحقق من الأصل بإسناد القيمة "*" إلى الوسيط targetOrigin: <iframe src="http://example.com" name="example"> <script> let win = window.frames.example; win.postMessage("message", "*"); </script> القسم المتعلق بالحدث onmessage ينبغي أن تمتلك النافذة التي ستستقبل الرسالة، معالجًا للحدث message، والذي يقع عند استدعاء التابع postMessage (ويجري التحقق بنجاح من قيمة الوسيط targetOrigin). لكائن الحدث خصائص مميزة، هي: data: وهي البيانات التي يحضرها التابع postMessage. origin: أصل المرسل، مثلًا: http://javascript.info. source: المرجع إلى النافذة المرسِلة، إذ يمكننا الرد مباشرة بالشكل التالي (...)source.postMessage إن أردنا. ولتحديد معالج الحدث السابق لا بدّ من استخدام addEventListener، إذ لن يعمل الأمر دونه، فمثلًا: window.addEventListener("message", function(event) { if (event.origin != 'http://javascript.info') { // كائن من نطاق مختلف، سنتجاهله return; } alert( "received: " + event.data ); // يمكن إعادة الإرسال باستخدام event.source.postMessage(...) }); يتكون المثال من الملف "iframe.html": <!doctype html> <html> <head> <meta charset="UTF-8"> </head> <body> Receiving iframe. <script> window.addEventListener('message', function(event) { alert(`Received ${event.data} from ${event.origin}`); }); </script> </body> </html> والملف "index.html": <!doctype html> <html> <head> <meta charset="UTF-8"> </head> <body> <form id="form"> <input type="text" placeholder="Enter message" name="message"> <input type="submit" value="Click to send"> </form> <iframe src="iframe.html" id="iframe" style="display:block;height:60px"></iframe> <script> form.onsubmit = function() { iframe.contentWindow.postMessage(this.message.value, '*'); return false; }; </script> </body> </html> وستكون النتيجة كالتالي: الخلاصة لاستدعاء التوابع التي تسمح بالوصول إلى نوافذ أخرى، لا بدّ من وجود مرجع إليها، حيث نحصل على هذا المرجع بالنسبة للنوافذ المنبثقة باستخدام: window.open: يُنفَّذ ضمن النافذة الأساسية، وسيفتح نافذة جديدة ويعيد مرجعًا إليها. window.opener: يُنفّذ ضمن النافذة المنبثقة، ويعطي مرجعًا إلى النافذة التي أنشأتها. يمكن الوصول إلى النوافذ الآباء والأبناء ضمن النوافذ الضمنية <iframe> بالشكل التالي: window.frames: تمثل مجموعة من الكائنات window المتداخلة. window.parent وwindow.top: يمثلان مرجعين إلى النافذة الأم المباشرة والنافذة الأم العليا. iframe.contentWindow: تمثل النافذة الموجودة داخل وسم النافذة الضمنية iframe. إذا كان لنافذتين الأصل نفسه (البرتوكول والمنفذ والنطاق)، فيمكنهما التحكم ببعضهما كليًا أما إن لم يكن لهما أصل مشترك، فيمكن إجراء مايلي: تغيير موقع location نافذة أخرى (سماحية للكتابة فقط). إرسال رسالة إليها. لكن توجد بعض الاستثناءات: إذا كان لنافذتين النطاق الفرعي (نطاق من المستوى الثاني) ذاته، مثلًا: a.site.com وb.site.com، فيمكن أن ندفع المتصفح لأن يعدّهما من الأصل ذاته بإضافة الأمر 'document.domain='site.com' في كلتيهما. إن امتلك الإطار الخاصية sandbox، فسيُعَدّ قسرًا من أصل مختلف، إلا في الحالة التي نستخدم فيها القيمة allow-same-origin لهذه الخاصية، ويستخدَم ذلك لتشغيل شيفرة غير موثوقة ضمن نافذة ضمنية على الموقع نفسه. تسمح الواجهة postMessage لنافذتين -ليس لهما بالضرورة الأصل ذاته- بالتخاطب مع بعضهما، حيث: تستدعي النافذة المرسِلة التابع (targetWin.postMessage(data, targetOrigin إن لم يكن للوسيط targetOrigin القيمة "*"، فسيتحقق المتصفح من أن للنافذة الهدف نفس الأصل المحدد كقيمة له. إن كان للنافذتين نفس الأصل أو لم يأخذ الوسيط targetOrigin القيمة "*"، فسيقع الحدث message الذي يمتلك الخصائص التالية: origin: نفس أصل النافذة المرسِلة مثل "http://my.site.com". source: وهو المرجع إلى النافذة المرسِلة. data: البيانات المرسَلة، ويمكن أن تكون كائنًا من أي نوع، عدا في المتصفح Internet Explorer الذي لا يقبل سوى الكائنات النصية. ولا بدّ لنا أيضًا من استخدام addEventListener لضبط معالج هذا الحدث داخل النافذة الهدف. ترجمة -وبتصرف- للفصل cross-window communication من سلسلة The Modern JavaScript Tutorial. اقرأ أيضًا الأحداث المتعلقة بدورة حياة صفحة HTML وكيفية التحكم بها عبر جافاسكربت أساسيات بناء تطبيقات الويب 10 أخطاء شائعة عند استخدام إطار العمل Bootstrap1 نقطة
تقيِّد سياسة الأصل المشترك same origin أو سياسة الموقع المشترك same site من إمكانية وصول النوافذ أو الإطارات إلى بعضها إن لم تكن ضمن الموقع نفسه، فلو فتح مستخدم صفحتين، بحيث الأولى مصدرها الموقع academy.hsoub.com، والأخرى مصدرها الموقع gmail.com؛ فلا نريد هنا بالطبع لأية شيفرة من الصفحة academy.hsoub.com أن تقرأ بريده الإلكتروني الذي تعرضه الصفحة gmail.com، فالغاية إذًا من سياسة الأصل المشترك هي حماية المستخدم من لصوص المعلومات. الأصل المشترك نقول أنّ لعنواني URL أصلًا مشتركًا إن كان لهما نفس البروتوكول، والنطاق domain، والمنفذ. لذا يمكن القول أنّ للعناوين التالية أصلًا مشتركًا: http://site.com http://site.com/ http://site.com/my/page.html بينما لا تشترك العناوين التالية مع السابقة بالأصل: http://www.site.com (النطاق مختلف لوجود www هنا). http://site.org (النطاق مختلف لوجود org بدلًا من com). https://site.com (البروتوكول مختلف هنا https). http://site.com:8080 (المنفذ مختلف 8080). وتنص سياسة الأصل المشترك على مايلي: إذا وُجِد مرجع إلى نافذة أخرى، مثل: النوافذ المنبثقة المُنشأة باستخدام الأمر window.open، أو الموجودة داخل وسم النافذة الضمنية <iframe>، وكان للنافذتين الأصل نفسه، فسيمنحنا ذلك إمكانية الوصول الكامل إلى تلك النافذة. إذا لم يكن للنافذتين الأصل نفسه، فلا يمكن لإحداهما الوصول إلى محتوى الأخرى، بما في ذلك المتغيرات والمستندات، ويُستثنى من ذلك موضع النافذة location، إذ يمكننا تغييره (وبالتالي إعادة توجيه المستخدم)، دون القدرة على قراءة موضع النافذة (وبالتالي لا يمكننا معرفة مكان المستخدم الآن، وبالتالي لن تتسرب المعلومات). العمل مع النوافذ الضمنية iframe يستضيف الوسم iframe نافذةً ضمنيةً منفصلةً عن النافذة الأصلية، ولها كائنان، هما document وwindow مستقلان، ويمكن الوصول إليهما بالشكل التالي: iframe.contentWindow للحصول على الكائن window الموجودة ضمن الإطار iframe. iframe.contentDocument للحصول على الكائنdocument ضمن الإطار iframe، وهو اختصار للأمر iframe.contentWindow.document. سيتحقق المتصفح أنّ للإطار والنافذة الأصل نفسه عندما نَلِج إلى شيء ما داخل نافذة مضمّنة، وسيرفض الوصول إن لم يتحقق ذلك (تُستنثنى هنا عملية تغيير الخاصية location فلا تزال مسموحة). لنحاول مثلًا القراءة والكتابة إلى الإطار iframe من مورد لا يشترك معه بالأصل: <iframe src="https://example.com" id="iframe"></iframe> <script> iframe.onload = function() { // يمكننا الحصول على مرجع إلى النافذة الداخلية let iframeWindow = iframe.contentWindow; // صحيح try { // ...لكن ليس للمستند الموجود ضمنه let doc = iframe.contentDocument; // خطأ } catch(e) { alert(e); // (خطأ أمان (أصل مختلف } // لايمكننا أيضًا قراءة العنوان ضمن الإطار try { // Location لا يمكن قراءة عنوان الموقع من كائن الموضع let href = iframe.contentWindow.location.href; // خطأ } catch(e) { alert(e); // Security Error } // يمكن الكتابة ضمن خاصية الموضع وبالتالي تحميل شيء آخر ضمن الإطار iframe.contentWindow.location = '/'; // صحيح iframe.onload = null; //امسح معالج الحدث، لا تنفذه بعد تغيير الموضع }; </script> See the Pen JS-P3-01-cross-window-communications-ex1 by Hsoub (@Hsoub) on CodePen. ستعطي الشيفرة السابقة أخطاءً عند تنفيذها عدا حالتي: الحصول على مرجع إلى النافذة الداخلية iframe.contentWindow فهو أمر مسموح. تغيير الموضع location. وبالمقابل، إن كان للإطار iframe نفس أصل النافذة الداخلية، فيمكننا أن نفعل فيها ما نشاء: <!-- iframe from the same site --> <iframe src="/" id="iframe"></iframe> <script> iframe.onload = function() { // افعل ما تشاء iframe.contentDocument.body.prepend("Hello, world!"); }; </script> See the Pen JS-P3-01-cross-window-communications-ex2 by Hsoub (@Hsoub) on CodePen. الموازنة بين الحدثين iframe.onload وiframe.contentWindow.onload يؤدي الحدث iframe.onload على الوسم iframe مبدئيًا، نفس ما يؤديه الحدث iframe.contentWindow.onload على كائن النافذة المضمنة، إذ يقع الحدث عندما تُحمّل النافذة المضمنة بكل مواردها، لكن لا يمكن الوصول إلى الحدث iframe.contentWindow.onload لإطار من آخر ذي أصل مختلف، وبالتالي سنستخدم عندها iframe.onload. النوافذ ضمن النطاقات الفرعية والخاصية document.domain وجدنا من التعريف أنّ العناوين المختلفة تقود إلى موارد غير مشتركة بالأصل، لكن لو تشاركت النوافذ بالنطاق الفرعي أو النطاق من المستوى الثاني -مثل النطاقين الفرعيين التاليين: john.site.com وpeter.site.com (المشتركان بالنطاق الفرعي site.com)-، فيمكن حينها أن نطلب من المتصفح أن يتجاهل الفرق، وبالتالي سيعدهما من أصل مشترك، وذلك لأغراض التخاطب بين النوافذ. ولكي ننفذ ذلك لا بدّ من وجود الشيفرة التالية في كل نافذة: document.domain = 'site.com'; ستتخاطب النوافذ مع بعضها الآن دون معوقات، ولا بد أن نذكر أن هذا ممكن فقط في الصفحات التي تشترك بنطاق من المستوى الثاني. مشكلة كائن "document" خاطئ في النوافذ الضمنية عندما نتعامل مع نافذة ضمنية لها الأصل نفسه، يمكننا الوصول إلى الكائن document الخاص بها، وعندها ستواجهنا مشكلة لا تتعلق بالأصل المشترك -لكن لا بدّ من الإشارة إليها-، وهي أن النافذة الضمنية سيكون لها كائن document مباشرةً بعد إنشائها، لكنه سيختلف عن الكائن الذي سيُحمَّل ضمنها، وبالتالي قد يضيع الأمر الذي ننفِّذه على الكائن document مباشرةً. لنتأمل الشيفرة التالية: <iframe src="/" id="iframe"></iframe> <script> let oldDoc = iframe.contentDocument; iframe.onload = function() { let newDoc = iframe.contentDocument; // كائن المستند الذي حُمِّل مختلف عن الكائن الأساسي alert(oldDoc == newDoc); // false النتيجة }; </script> See the Pen JS-P3-01-cross-window-communications-ex3 by Hsoub (@Hsoub) on CodePen. لا ينبغي التعامل مع الكائن document لأي إطار قبل التحميل الكامل لمحتوياته لتجنب التعامل مع الكائن الخاطئ، إذ سيتجاهل المتصفح أية معالجات أحداث قد نستخدمها ضمن الكائن. لكن كيف نحدد اللحظة التي يجهز فيها الكائن document؟ سيظهر المستند بالتأكيد عند وقوع الحدث iframe.onload، والذي لا يطلق إلا عندما تُحمَّل موارد الإطار كلها. كما يمكن التقاط اللحظة المناسبة بالتحقق المستمر خلال فترات زمنية محددة عبر التعليمة setInterval: <iframe src="/" id="iframe"></iframe> <script> let oldDoc = iframe.contentDocument; // تحقق أن المستند الجديد جاهز كل 100 ميلي ثانية let timer = setInterval(() => { let newDoc = iframe.contentDocument; if (newDoc == oldDoc) return; alert("New document is here!"); clearInterval(timer); // فلن تحتاجها الآن setInterval ألغ }, 100); </script> See the Pen JS-P3-01-cross-window-communications-ex4 by Hsoub (@Hsoub) on CodePen. استخدام المجموعة window.frames يمكن استخدام طريقة بديلة للوصول إلى الكائن window الخاص بالنافذة الضمنية iframe عبر المجموعة window.frames: باستخدام الرقم: إذ سيعطي الأمر [window.frames[0 كائن window الخاص بأول إطار في المستند. باستخدام الاسم: إذ يعطي الأمر window.frames.iframeName كائن window الخاص بالإطار الذي يحمل الاسم "name="iframeName. مثلًا: <iframe src="/" style="height:80px" name="win" id="iframe"></iframe> <script> alert(iframe.contentWindow == frames[0]); // true alert(iframe.contentWindow == frames.win); // true </script> See the Pen JS-P3-01-cross-window-communications-ex5 by Hsoub (@Hsoub) on CodePen. قد تحوي نافذة ضمنية ما نوافذ ضمنيةً أخرى، وعندها ستكون الكائنات window الناتجة عن الانتقال الشجري بين الإطارات هي: window.frames: وتمثل مجموعة النوافذ الأبناء للإطارات المتداخلة nested. window.parent: المرجع إلى النافذة الأم المباشرة (الخارجية). window.top: المرجع إلى النافذة الأم الأعلى ترتيبًا. مثلًا: window.frames[0].parent === window; // محقق يمكن استخدام الخاصية top للتحقق من أنّ المستند الحالي مفتوح ضمن إطار أم لا: if (window == top) { // current window == window.top? alert('The script is in the topmost window, not in a frame'); } else { alert('The script runs in a frame!'); } See the Pen JS-P3-01-cross-window-communications-ex6 by Hsoub (@Hsoub) on CodePen. الخاصية sandbox المتعلقة بالنافذة الضمنية iframe تسمح الخاصية sandbox باستبعاد تنفيذ أفعال معينة داخل النافذة الضمنية <iframe>، وذلك لمنع تنفيذ الشيفرة غير الموثوقة، إذ تقيَّد الخاصية sandbox للإطار كونه آتيًا من أصل مختلف مع/أو بالإضافة إلى قيود أخرى. تتوفر عدة تقييدات افتراضية ضمن الأمر <"..."=iframe sandbox src>، ويفضل أن نترك فراغًا بين عناصر قائمة القيود التي لا نريد تطبيقها كالتالي: <iframe sandbox="allow-forms allow-popups"> ستطبّق أكثر التقييدات صرامةً عندما تكون الخاصية sandbox فارغة "دون قائمة قيود" ، ويمكننا رفع ما نشاء منها بذكرها ضمن قائمة يفصل بين عناصرها فراغات. وإليك قائمة الخيارات المتعلقة بالتقييدات: allow-same-origin: تجبر الخاصية sandbox المتصفح على احتساب النافذة الضمنية من أصل مختلف تلقائيًا، حتى لو دلت الصفة src على الأصل نفسه، لكن هذا الخيار يزيل التطبيق الافتراضي لهذه الميزة. allow-top-navigation: يسمح هذا الخيار للنافذة الضمنية بتغيير قيمة parent.location. allow-forms: يسمح هذا الخيار بإرسال نماذج forms انطلاقًا من الإطار. allow-scripts: يسمح هذا الخيار بتشغيل سكربتات انطلاقًا من الإطار. allow-popups: يسمح بفتح نوافذ منبثقة باستخدام الأمر window.open انطلاقًا من الإطار. اطلع على تعليمات التنفيذ إن أردت التعرف على المزيد. يُظهر المثال التالي إطارًا مقيَّدًا بمجموعة القيود الافتراضية <"..."=iframe sandbox src>، ويتضمن المثال شيفرةً ونموذجًا وملفين، وستلاحظ أنّ الشيفرة لن تعمل نظرًا لصرامة القيود الافتراضية. الشيفرة الموجودة في الملف "index.html": <!doctype html> <html> <head> <meta charset="UTF-8"> </head> <body> <div>The iframe below has the <code>sandbox</code> attribute.</div> <iframe sandbox src="sandboxed.html" style="height:60px;width:90%"></iframe> </body> </html> وفي الملف "sandbox.html": <!doctype html> <html> <head> <meta charset="UTF-8"> </head> <body> <button onclick="alert(123)">Click to run a script (doesn't work)</button> <form action="http://google.com"> <input type="text"> <input type="submit" value="Submit (doesn't work)"> </form> </body> </html> وستكون النتيجة: ملاحظة: إنّ الغاية من وجود الصفة sandbox هي إضافة المزيد من القيود فقط، إذ لا يمكنها إزالة هذه القيود، لكنها تخفف بعض القيود المتعلقة بالأصل المشترك إن لم يكن للإطار الأصل نفسه. تبادل الرسائل بين النوافذ تسمح واجهة التخاطب postMessage للنوافذ بالتخاطب مع بعضها أيًا كان أصلها، فهي إذًا أسلوب للالتفاف على سياسة "الأصل المشترك"، إذ يمكن لنافذة من النطاق academy.hsoub.comأن تتخاطب مع النافذةgmail.com` وتتبادل المعلومات معها، لكن بعد موافقة كلتا النافذتين ووجود دوال JavaScript الملائمة فيهما، وهذا بالطبع أكثر أمانًا للمستخدم. تتكون الواجهة من قسمين رئيسيين: القسم المتعلق بالتابع postMessage تستدعي النافذة التي تريد إرسال رسالةٍ التابع postMessage العائد للنافذة الهدف، أي إن أردنا إرسال رسالة إلى win، فعلينا تنفيذ الأمر (win.postMessage(data, targetOrigin، وإليك توضيح وسطاء هذا التابع: data: وهي البيانات المراد إرسالها، والتي قد تكون أي كائن. حيث تُنسخ البيانات باستخدام خوارزمية التفكيك البنيوي "structured serialization". لا يدعم المتصفح Internet Explorer سوى النصوص، لذلك لا بدّ من استخدام التابع JSON.stringify مع الكائنات المركبة التي سنرسلها لدعم هذا المتصفح. targetOrigin: يُحدد أصل النافذة الهدف، وبالتالي ستصل الرسالة إلى نافذة من أصل محدد فقط، ويعَدّ هذا مقياسًا للأمان، فعندما تأتي النافذة الهدف من أصل مختلف، فلا يمكن للنافذة المرسِلة قراءة موقعها location، ولن نعرف بالتأكيد الموقع الذي سيُفتح حاليًا في النافذة المحددة، وقد ينجرف المستخدم بعيدًا دون علم النافذة المرسِلة. إذًا سيضمن تحديد الوسيط targetOrigin أن النافذة الهدف ستستقبل البيانات ما دامت في الموقع الصحيح، وهذا ضروري عندما تكون البيانات على درجة من الحساسية. في هذا المثال ستستقبل النافذة الرسالة إن كان مستندها (الكائن document الخاص بها) منتميًا إلى الموقع "http://example.com": <iframe src="http://example.com" name="example"> <script> let win = window.frames.example; win.postMessage("message", "http://example.com"); </script> يمكن إلغاء التحقق من الأصل بإسناد القيمة "*" إلى الوسيط targetOrigin: <iframe src="http://example.com" name="example"> <script> let win = window.frames.example; win.postMessage("message", "*"); </script> القسم المتعلق بالحدث onmessage ينبغي أن تمتلك النافذة التي ستستقبل الرسالة، معالجًا للحدث message، والذي يقع عند استدعاء التابع postMessage (ويجري التحقق بنجاح من قيمة الوسيط targetOrigin). لكائن الحدث خصائص مميزة، هي: data: وهي البيانات التي يحضرها التابع postMessage. origin: أصل المرسل، مثلًا: http://javascript.info. source: المرجع إلى النافذة المرسِلة، إذ يمكننا الرد مباشرة بالشكل التالي (...)source.postMessage إن أردنا. ولتحديد معالج الحدث السابق لا بدّ من استخدام addEventListener، إذ لن يعمل الأمر دونه، فمثلًا: window.addEventListener("message", function(event) { if (event.origin != 'http://javascript.info') { // كائن من نطاق مختلف، سنتجاهله return; } alert( "received: " + event.data ); // يمكن إعادة الإرسال باستخدام event.source.postMessage(...) }); يتكون المثال من الملف "iframe.html": <!doctype html> <html> <head> <meta charset="UTF-8"> </head> <body> Receiving iframe. <script> window.addEventListener('message', function(event) { alert(`Received ${event.data} from ${event.origin}`); }); </script> </body> </html> والملف "index.html": <!doctype html> <html> <head> <meta charset="UTF-8"> </head> <body> <form id="form"> <input type="text" placeholder="Enter message" name="message"> <input type="submit" value="Click to send"> </form> <iframe src="iframe.html" id="iframe" style="display:block;height:60px"></iframe> <script> form.onsubmit = function() { iframe.contentWindow.postMessage(this.message.value, '*'); return false; }; </script> </body> </html> وستكون النتيجة كالتالي: الخلاصة لاستدعاء التوابع التي تسمح بالوصول إلى نوافذ أخرى، لا بدّ من وجود مرجع إليها، حيث نحصل على هذا المرجع بالنسبة للنوافذ المنبثقة باستخدام: window.open: يُنفَّذ ضمن النافذة الأساسية، وسيفتح نافذة جديدة ويعيد مرجعًا إليها. window.opener: يُنفّذ ضمن النافذة المنبثقة، ويعطي مرجعًا إلى النافذة التي أنشأتها. يمكن الوصول إلى النوافذ الآباء والأبناء ضمن النوافذ الضمنية <iframe> بالشكل التالي: window.frames: تمثل مجموعة من الكائنات window المتداخلة. window.parent وwindow.top: يمثلان مرجعين إلى النافذة الأم المباشرة والنافذة الأم العليا. iframe.contentWindow: تمثل النافذة الموجودة داخل وسم النافذة الضمنية iframe. إذا كان لنافذتين الأصل نفسه (البرتوكول والمنفذ والنطاق)، فيمكنهما التحكم ببعضهما كليًا أما إن لم يكن لهما أصل مشترك، فيمكن إجراء مايلي: تغيير موقع location نافذة أخرى (سماحية للكتابة فقط). إرسال رسالة إليها. لكن توجد بعض الاستثناءات: إذا كان لنافذتين النطاق الفرعي (نطاق من المستوى الثاني) ذاته، مثلًا: a.site.com وb.site.com، فيمكن أن ندفع المتصفح لأن يعدّهما من الأصل ذاته بإضافة الأمر 'document.domain='site.com' في كلتيهما. إن امتلك الإطار الخاصية sandbox، فسيُعَدّ قسرًا من أصل مختلف، إلا في الحالة التي نستخدم فيها القيمة allow-same-origin لهذه الخاصية، ويستخدَم ذلك لتشغيل شيفرة غير موثوقة ضمن نافذة ضمنية على الموقع نفسه. تسمح الواجهة postMessage لنافذتين -ليس لهما بالضرورة الأصل ذاته- بالتخاطب مع بعضهما، حيث: تستدعي النافذة المرسِلة التابع (targetWin.postMessage(data, targetOrigin إن لم يكن للوسيط targetOrigin القيمة "*"، فسيتحقق المتصفح من أن للنافذة الهدف نفس الأصل المحدد كقيمة له. إن كان للنافذتين نفس الأصل أو لم يأخذ الوسيط targetOrigin القيمة "*"، فسيقع الحدث message الذي يمتلك الخصائص التالية: origin: نفس أصل النافذة المرسِلة مثل "http://my.site.com". source: وهو المرجع إلى النافذة المرسِلة. data: البيانات المرسَلة، ويمكن أن تكون كائنًا من أي نوع، عدا في المتصفح Internet Explorer الذي لا يقبل سوى الكائنات النصية. ولا بدّ لنا أيضًا من استخدام addEventListener لضبط معالج هذا الحدث داخل النافذة الهدف. ترجمة -وبتصرف- للفصل cross-window communication من سلسلة The Modern JavaScript Tutorial. اقرأ أيضًا الأحداث المتعلقة بدورة حياة صفحة HTML وكيفية التحكم بها عبر جافاسكربت أساسيات بناء تطبيقات الويب 10 أخطاء شائعة عند استخدام إطار العمل Bootstrap1 نقطة -
كيف يمكنني إنشاء دالة تكرارية (أو كائن مكرر) في لغة بايثون؟ بحيث يمكن إستخدامه في حلقات التكرار مثل حلقة for ، على سبيل المثال عمل صنف Counter يمكن إستخدامه بالشكل التالي: for i in Counter(3, 9): print(i)1 نقطة
-
السلام عليكم ورحمة الله وبركاته لدي هذا الكود فقط يقبل الأحرف الإنجليزية ولا يقبل الاحرف العربية ، كيف أقوم بجعله يقبل الأحرف العربيه والإنجليزية معاً this.filter = new Filter({ regex: /[^a-zA-z0-9:alnum:|\$|\@]|^/gi, list: [ "تجربه", "test",1 نقطة
-
استخدم المكتبة file-uploader في node.js للتعامل مع الملفات. وعندما أقوم برفع الملف إلى الخادم، يتم إيقاف الخادم ويظهر الخطأ التالي: Error: ENOSPC. وحالة الخادم كالتالي: Filesystem Size Used Avail Use% Mounted on /dev/xvda1 7.9G 4.1G 3.5G 55% / udev 288M 8.0K 288M 1% /dev tmpfs 119M 168K 118M 1% /run none 5.0M 0 5.0M 0% /run/lock none 296M 0 296M 0% /run/shm /dev/xvdf 9.9G 3.0G 6.5G 32% /vol overflow 1.0M 1.0M 0 100% /tmp ماهو هذا الخطأ ENOSPC. ؟1 نقطة
-
لدي إطار بيانات dataframe يحتوي على بعض فصائل الدم وبعض المجموعات كالتالي: Type Set 1 A A 2 B B 3 O B 4 B A أريد أن يتم إضافة عمود جديد (بنفس عدد الصفوف في باقي الأعمدة) بناء على قيم العمود Set، فعلى سبيل المثال يتم إضافة القيمة "Group 1" في حالة كانت القيم A، وقيمة "Group 2" في حالة B كيف يمكنني القيام بذلك؟1 نقطة
-
لدي مصفوفتين كالتالي: a = numpy.array([0,1, 2]) b = numpy.array([3, 4, 5]) كيف يمكنني الحصول على الناتج الديكارتي cartesian product من هذه المصفوفات، لتكون النتيجة كالتالي: result = array([0, 3], [0, 4], [0, 5], [1, 3], [1, 4], [1, 5], [2, 3], [2, 4], [2, 5]) حاولت أن استخدم itertools.product ثم أقوم بتحويل القائمة الناتجة من العملية إلى مصفوفة numpy لكن يبدو أن هذه العملية بطيئة بعض الشيء خصوصًا عند تنفيذها داخل حلقة for كيف يمكن تنفيذ هذا الأمر بإستخدام مكتبة Numpy؟1 نقطة
-
يظهر لدي الخطأ التالي دائمًأ عندما أحاول أن أستخدم مكتبة Numpy: حاولت أن أستخدم بايثون الإصدار 3.7 و 3.8 ولكن يبدو أن هذا الأمر لم يحل المشكلة، كما حاولت أن أعيد تثبيت كل من pandas و numpy من خلال الأمر pip install -r requirements.txt وهذه محتويات ملف requirements.txt numpy==1.19.4 pandas==1.1.2 beautifulsoup4==4.8.4 requests==2.25.01 نقطة
-
لدي مصفوفة تحتوي على عدد من الأعمدة والصفوف كالتالي: array([ [1, 1, 1, 0, 0, 0], [0, 0, 1, 1, 0, 0], [0, 0, 1, 1, 0, 0], [1, 1, 1, 0, 0, 0], [0, 0, 1, 1,0, 0] ]) لاحظ أن أول صفين فقط يتم تكرارهما أكثر من مرة كيف يمكنني الحصول على الصفوف الفريدة بدون هاته الصفوف المكررة، لتكون النتيجة كالتالي: array([ [1, 1, 1, 0, 0, 0], [0, 0, 1, 1, 0, 0] ]) أريد أن أقوم بهذه العملية في مكتبة numpy لتكون سريعة بما فيه الكفاية1 نقطة
-
يمكن إيجاد الصفوف الفريدة بأكثر من طريقة، منها بإستخدام unique كما هو موضح في الإجابة أعلاه، أو بإستخدام الدالة vstack كما في المثال التالي: import numpy as np a = np.array([ [1, 1, 1, 0, 0, 0], [0, 0, 1, 1, 0, 0], [0, 0, 1, 1, 0, 0], [1, 1, 1, 0, 0, 0], [0, 0, 1, 1, 0, 0]]) print(np.vstack({tuple(row) for row in a})) print(np.vstack(set(map(tuple, a)))) بعد إستدعاء الدالة numpy تم تعريف المصفوفة، و من بعدها الدالة vstack من numpy (التي تحول المدخل إلى مكدس رأسي) و بإستخدام خاصية المجموعة التي تقوم بإختيار القيم غير المكررة فقط من الصفوف الموجودة في المصفوفة a. أما في السطر الأخير فقد تم عمل نفس الشئ بتحويل الصفوف إلى مدخلات للمجموعة بإستخدام دالة map والتي تحول أي صف إلى tuple أولا و من ثم تنفذ عملية التحويل إلى مجموعة و في الأخير تحويل الناتج إلى مكدس رأسي. طريقة أخرى لإستخراج الصفوف الفريدة بإستخدام طريقة إقصاء الصفوف المكررة عن طريق الدالة drop_duplicates() والتي تستخدم مع dataframe، راجع البرنامج التالي: import pandas as pd pd.DataFrame(a).drop_duplicates().values والتي نحول فيها المصفوفة إلى dataframe لنتمكن من إستخدام الدالة الخاصة بالإقصاء و من ثم لتحويل الناتج إلى مصفوفة نستدعى الدالة values. لكن عزيزي @Fahmy Mostafa إن كنت تريد الحصول على أسرع طريقة، يمكنك التأكد بإستخدام العبارة timeit والتي تعطيك الزمن المتوسط (لأسرع 5 نتائج) من تنفيذ الدالة 1000 مرة، و حسب التنفيذ و الشرح الموضح في الموقع بأخر الإجابة vstack تعتبر أسرع طريقة: timeit np.vstack(set(map(tuple, a))) #10000 loops, best of 5: 25.1 µs per loop timeit np.vstack({tuple(row) for row in a}) #10000 loops, best of 5: 24.3 µs per loop timeit np.unique(a, axis=0) #10000 loops, best of 5: 107 µs per loop timeit pd.DataFrame(a).drop_duplicates().values #1000 loops, best of 5: 1.39 ms per loop يمكنك مراجعة الصورة التالية أيضاً: والتي توضح إختلاف سرعات التنفيذ للدوال المستخدمة في إيجاد الصفوف الفريدة، يمكنك مراجعة موقع GitHub لتتعرف على المزيد من التفاصيل.1 نقطة
-
مرحبًا أخي @واثق الشويطر، نشكرك على اهتمامك بما يُنشر بالأكاديمية، كما نشكرك على التنبيه إلى المشكلة التي صادفتك. لقد كان ثمة خلل على مستوى الرابط، وقد صُحِّح للتو. نتمنى لك تجربة قراءة جيدة، والحصول على الفائدة المرجوة من المقال.1 نقطة
-
يمكنك أن تقوم بإستيراد sklearn أولاً ثم التأكد من الإصدارة و عمل ترفيع لأخر إصدارة بإستخدام البرنامج التالي: import sklearn sklearn.__version__ !pip install -U scikit-learn # or using conda هذه الخطوة مهمة لتفادي أي أخطاء قد تنتج من إستخدام دوال في إصدارات قديمة. و القيام بعملية إستدعاء مودل SimpleImputer من الموديول sklearn.impute كما هو موضح في الإجابة أعلاه. راجع المثال التالي و الذي يقوم بإستخدام SimpleImputer لملء ثلاث خانات في مصفوفة: import numpy as np from sklearn.impute import SimpleImputer imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean') X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]] imp_mean.fit_transform(X) في أول سطرين تم إستدعاء الدوال numpy و SimpleImputer ومن ثم تعريف الدالة SimpleImputer و التي تحتوي على إستراتيجية التعبئة للقيم المفقودة في المصفوفة و في هذه الحالة هي القيمة المتوسطة لكل feature أو عمود في البيانات، بالإضافة لتحديد القيم المفقودة معرفة بnp.nan . في السطر الرابع قمنا بتعريف مصفوفة البيانات التي نريد تعبئتها، و أخيراً نقوم بإستخدام fit_transform للمصفوفة، والناتج يكون المصفوفة معبأة بالقيم المولدة بإستخدام SimpleImputer. array([[ 7., 2., 3.], [ 4., 2., 6.], [10., 2., 9.]])1 نقطة
-
يمكنك استبدال الإشارات في حال وجودها ضمن اسم المستخدم أو كلمة المرور بالترميز الذي يدل عليها. على سبيل المثال، يمكنك كتابة الرمز (%40) بدلاً من @ ضمن كلمة المرور فيصبح الاتصال على الشكل التالي: //بفرض كلمة المرور هي my@password mongoClient.connect("mongodb://username:my%40pssword@host:port/dbname?authSource=admin", { useNewUrlParser: true }, function(err, db) { } ); وفي حال كنت تستخدم node.js يجب عليك أيضاً تمرير التالي ضمن تابع الاتصال: {uri_decode_auth: true} أما الاتصال عن طريق mongoose فمكن أن يتم بالشكل التالي: mongoose.connect('mongodb://localhost/mydatabase', {user: 'usr', pass: 'any@password@'}, callback);1 نقطة
-
لقد تمّت إزالة الأوامر المباشرة المتعلّقة ب mongodb من homebrew-core, لذلك يجب عليك إزالة النسخة الحالية من خلال تنفيذ الأوامر التالية: brew services stop mongodb brew uninstall mongodb ثم التحميل من خلال tap لنستطيع إضافة mongodb: brew tap mongodb/brew وبعدها: brew install mongodb-community brew services start mongodb-community1 نقطة
-
بما أن محرر الأوامر في mongodb تفاعلي يمكنك إجراء الأوامر التالية: mongo dbname << EOF > output.json db.collection.find().pretty() EOF أو بإمكانك الاستفادة من جافاسكريبت لأخذ نتيجة find وتحويلها إلى JSON: mongo dbname mongoCommands.js > output.json بعد أن يتم وضع الأمر ضمن الملف mongoCommands.js كالتالي: printjson( db.collection.find().toArray() )1 نقطة
-
يمكن الاعتماد على المؤشر iterator: حيث نقوم ببناء الصنف بطريقة مشابهة للتالي: class Counter(object): # تهيئة العنصر def __init__(self, start, stop): self.start = start self.stop = stop # تعريف المؤشر def __iter__(self): return self # الدالة لجلب العنصر التالي def __next__(self): # next in Python 2 # اختبار الشرط if self.start >= self.stop: raise StopIteration current = self.start * self.start self.start += 1 return current iterator = Counter(a, b) ولجلب العنصر الحالي يمكن إضافة الدالة current التي تعيد start ألمعدلة: def current(self): return self.start وبطريقة أخرى: كما يمكن الاستفادة من مفهوم المولد generator والكلمة المفتاحية yield: def counter(start, stop): for i in range(start, stop): yield i Counter = counter(3, 9)1 نقطة
-
الخطأ ENOSPC يظهر عندما لا تتوفر مساحة على القرص. حاول التنفيذعن طريق هذا الأمر: echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p ثم: // في حال Arch Linux أضف السطر التالي to /etc/sysctl.d/99-sysctl.conf: fs.inotify.max_user_watches=524288 // التنفيذ sysctl --system حاول حذف الملفات المؤقتة مثل temp كما يمكن حذف كاش npm: npm cache clear1 نقطة
-
أرغب بتنفيذ أوامر معينة مثل الطباعة عندما يحدث إنهاء أو إيقاف تشغيل لخادم الويب node.js، وقمت باستخدام الدالة process كالتالي: process.on('exit', function (){ console.log('the server will shut down..'); }); ولكن عندما أقوم بالضغط على crtl-c في لوحة المفاتيح لإيقاف الخادم، أو حتى عندما يحدث أي خطأ Exception يوقف عمله، لا تظهر هذه الرسالة.1 نقطة
-
في بايثون الكلمة المحجوزة with تستخدم عند التعامل مع الموارد غير المُدارة مثل file streams إنه يسمح لك بالتأكد من أن المَورد تم تنظيفه عندما يكون الكود الذي استخدمه انتهى من عمله حتى إذا ظهرت إستثناءات exceptions فيمكنك إستخدام try/finally لمعالجة الإستثناء وايضاً with تتأكد من أن عملية file stream لا تقوم بحظر العمليات الأخرى إذا ظهر إستثناء إذا أردت فتح وقراءة ملف ستستخدم الكود التالي file = open('file-path', 'w') try: file.write('Lorem ipsum') finally: file.close() لكن مع with ستحصل على كود أكثر نظافة كالآتي with open('file-path', 'w') as file: file.write('Lorem ipsum') كما في الكود السابق ، مع with تم تبسيط الكود الى سطرين فقط يمكنك إستخدام with مع عمليات الطلب من قواعد البيانات ايضاً كما يلي def get_all_users(): with sqlite3.connect('db/users.db') as connection: cursor = connection.cursor() cursor.execute("SELECT * FROM users ORDER BY id desc") all_users = cursor.fetchall() return all_users1 نقطة
-
عندما أقوم بطباعة أي صنف في بايثون أحصل على نتيجة مشابهة للتالي: <__main__.Foo instance at 0x7fa2b29d> هل توجد طريقة لعمل مثل هذه النتيجة عند طباعة صنف قمت بإنشائه بنفسي، بحيث يتم طباعة هذه النتيجة عند إستخدام دالة print لطباعة instance من الصنف1 نقطة
-
يمكنك استخدام with في ال error handling و ال management resources غالباً في بث الملفات حيث تستخدم في عدة عمليات مرتبطة ومترتبة على بعضها ويمكنك استخدامها كالتالي with open('file.txt', 'w') as f: f.write('hello') في هذه الحالة لا تحتاج لاستخدام f.close فهي تقوم بذلك بدلاً عنك بالطبع لا مشكلة في استخدام with بل اعد الأفضل في بعض الإستخدامات يمكنك بالطبع استخدام try except بدلاً منها ولكن with توفر عليك بعض المهام وإختصار للكود حتى تستطيع استخدام with يجب توفير الدعم لها من خلال إنشاء Context Manager على هيئة كائن حتى يتواجد الدوال __enter__ و __exit__ لتستطيع العمل ب with هناك العديد من الدوال والمكتبات التي بدأت توفير الدعم للعمل ب with1 نقطة
-
مرحبا اذا كان لدي رابط بهذا الشكل http://localhost:3000/post?id=1 كيف يمكنني الحصول على ال query id من الرابط ؟1 نقطة
-
عند استخدام window في مكون الكلاس يحدث معي خطأ import React, { Component } from 'react' export default class index extends Component { componentWillMount() { console.log('window.innerHeight', window.innerHeight); } render() { return ( <div> ..... </div> ) } } Unhandled Rejection (ReferenceError): window is not defined ما المشكلة ؟1 نقطة
-
هذه المشكلة قد تظهر معك في حالة استخدمت أي خوارزمية أخرى في Sklearn. المشكلة تظهر عندما يصل التنفيذ للتابع fit. السبب في أن بيانات y_train من النمط object لذلك فإن Sklearn لم تستطع التعرف على نوعها. ولحل المشكلة قم بتحويل بيانات ال y_train إلى النمط integer كالتالي: y_train =y_train .astype('int')1 نقطة
-
هذه الطريقة تقوم على تقييم النموذج على كامل العينات، بحيث في كل مرة تقوم بتدريب النموذج على كل العينات ماعدا عينة واحدة تخرجها لكي تقوم باستخدامها للاختبار. المثاليين يوضحان كل شيء: import numpy as np from sklearn.model_selection import LeaveOneOut X = np.array([[1,4],[2,1],[3,4],[7,8]]) y = np.array([2,1,3,9]) loo = LeaveOneOut() # لمعرفة عدد التقسيمات الممكنة print(loo.get_n_splits(X)) # تقسيم البيانات for train_index, test_index in loo.split(X): # للتقسيمة index عرض ال print("TRAIN:"+str(train_index)+'\n'+"TEST:"+str(test_index),end='\n\n') # تقسيم البيانات X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] # عرض البيانات المقسمة print('X_train:\n '+str(X_train),end='\n\n') print('X_test:\n '+str(X_test),end='\n\n') print('y_train:\n '+str(y_train),end='\n\n') print('y_test:\n' +str(y_test),end='\n\n') #--------------------------------------------------------------------------------------------------# 4 TRAIN:[1 2 3] TEST:[0] X_train: [[2 1] [3 4] [7 8]] X_test: [[1 4]] y_train: [1 3 9] y_test: [2] TRAIN:[0 2 3] TEST:[1] X_train: [[1 4] [3 4] [7 8]] X_test: [[2 1]] y_train: [2 3 9] y_test: [1] TRAIN:[0 1 3] TEST:[2] X_train: [[1 4] [2 1] [7 8]] X_test: [[3 4]] y_train: [2 1 9] y_test: [3] TRAIN:[0 1 2] TEST:[3] X_train: [[1 4] [2 1] [3 4]] X_test: [[7 8]] y_train: [2 1 3] y_test: [9] لاحظ كيف أنه في كل تكرار يتم أخذ عينة واحدة للاختبار وباقي العينات للتدريب. في المثال التالي سوف أستخدم هذا النهج في تدريب نموذج واختباره: from sklearn.model_selection import LeaveOneOut from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score from sklearn.datasets import make_blobs # إنشاء داتاسيت مزيفة ب10 عينات و3 فئات X, y = make_blobs(n_samples=10, random_state=2021) # y=array([1, 1, 2, 0, 1, 2, 0, 2, 0, 0]) # LeaveOneOut إنشاء كائن من الكلاس cv = LeaveOneOut() # لتخزين النتائج من كل تقسيمة y_true, y_pred = list(), list() # عملية التقسيم for train_ix, test_ix in cv.split(X): print("TRAIN:"+str(train_ix)+'\n'+"TEST:"+str(test_ix),end='\n\n') # تقسيم البيانات X_train, X_test = X[train_ix, :], X[test_ix, :] y_train, y_test = y[train_ix], y[test_ix] # تدريب النموذج model = RandomForestClassifier(random_state=44) model.fit(X_train, y_train) # تقييم النموذج yhat = model.predict(X_test) # تخزين النتيجة y_true.append(y_test[0]) y_pred.append(yhat[0]) # حساب الدقة acc = accuracy_score(y_true, y_pred) print('Accuracy: %.3f' % acc) لاحظ كيف أنه في كل مرة أقوم بأخذ عينة واحدة للاختبار والباقي للتدريب ثم أدرب النموذج عليها وأقوم بحساب القيمة المتوقعة على عينة الاختبار وأضعها في y_pred وأضع القيمة الحقيقية في y_true, وهكذا بالنسبة لبقية التقسيمات حتى ننتهي وبعدها أقوم بحساب دقة النموذج.1 نقطة
-
هذا المنهج هو نهج من مناهج ال Feature Selection ويعمل على حذف ال Feature التي يكون تباينها أقل من عتبة محددة.حيث يزيل بشكل افتراضي كل ال Features التي يكون تباينها صفري (نفس القيم في كل العينات). المثال التالي سيجعل الأمر واضح: قمت بإنشاء مجموعة بيانات صغيرة وقمت بجعل ال feature الأولى منها ذات تباين قليل (أغلب قيمها أصفار)، ثم قمت بتطبيق عتبة threshold وقمت بتمريرها للكلاس VarianceThreshold بحيث أن شكل العتبة سأجعله من الشكل: p(1-p) في حالة وضعنا p=8 كما في مثالنا، فسيتم حذف ال Features التي تحوي قيم مكررة بنسبة أكبر أو تساوي 80%. p=10 فسيتم حذف ال Features التي تحوي قيم مكررة بنسبة تساوي 100%. from sklearn.feature_selection import VarianceThreshold X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]] print(X) # هنا سنحذف الفيتشرز التي تتكرر قيمها بنسبة أكثر من ثمانون بالمئة sel = VarianceThreshold(threshold=(.8 * (1 - .8))) X=sel.fit_transform(X) print(X) ''' [[0 1] [1 0] [0 0] [1 1] [1 0] [1 1]] ''' لاحظ كيف تم حذف أول feature. مثال آخر: from sklearn.feature_selection import VarianceThreshold X = [[0, 0, 1,3], [0, 1, 0,3], [1, 0, 0,3], [0, 1, 1,3], [0, 1, 0,3], [0, 1, 1,3]] print(X) # هنا سنحذف الفيتشرز التي تتكرر قيمها بنسبة مئة بالمئة sel = VarianceThreshold(threshold=(.10 * (1 - .10))) X=sel.fit_transform(X) print(X) ''' [[0 0 1] [0 1 0] [1 0 0] [0 1 1] [0 1 0] [0 1 1]] '''1 نقطة
-
يمكنك استخدام الكلاس QuantileTransformer من الموديول: sklearn.preprocessing.QuantileTransformer في المثال التالي سأوضح لك الأمر: قمت بإنشاء مجموعة بيانات صغيرة موزعة توزيعاً غاوصياً، ثم قمت بجعل قيم هذه البيانات متطرفة عن طريق إدخالها بتابع أسي، ثم بعد ذلك سنطبق التحويل QuantileTransformer لكي نعيد نوحيد البيانات وجعلها موزعة توزيعاً موحداً uniform. from numpy.random import randn from sklearn.preprocessing import QuantileTransformer from numpy import exp from matplotlib import pyplot # توليد بيانات غاوصية data = randn(2000) # نغير القيم في بياناتنا بحيث نجعل قيمها متطرفة data = exp(data) # نرسك شكل البيانات بعد جعلها متطرفة pyplot.hist(data, bins=50) pyplot.show() # عمل إعادة تعيين لأبعاد البيانات للحصول على أسطر وأعمدة data = data.reshape((len(data),1)) #quantile transform تطبيق تحويل quantile = QuantileTransformer(n_quantiles=2000,output_distribution='uniform',copy=True) data = quantile.fit_transform(data) # عرض شكل البيانات بعد تطبيق التحويل pyplot.hist(data, bins=50) pyplot.show() الوسيط الأول: عدد الكميات المطلوب حسابها. إنه يتوافق مع عدد المعالم المستخدمة لتحديد دالة التوزيع التراكمي. إذا كانت n_quantiles أكبر من عدد العينات ، فسيتم تعيين n_quantiles على عدد العينات نظرًا لأن عددًا أكبر من الكميات لا يعطي تقديرًا تقريبيًا أفضل لمقدر دالة التوزيع التراكمي. افتراضياً 1000. الوسيط الثاني: لتحديد نظام توحيد البيانات المطلوب (إما توزيع طبيعي-غاوصي- أو توزيع موحد كما في مثالنا) أي إما normal أو uniform. الثالث: لكل لايتم تطبيق التغييرات على البيانات الأساسية.
 1 نقطة
1 نقطة -
نعم هذا هو الأمر، لكن توضيح أخير فقط اول اوبشن تستخدم لتنبيه المستخدم و يرفق معها نص كالرجاء الإختيار او اي شيء توضيحي نضع لها الخاصية disabled حتى لا يتم اختيارها و لا نضع لها قيمة في الخاصية value و من باقي الخيارات نحدد التي نريد جعلها selected و ستجد انني وضعت شرط بداخل الحلقة في حالة ما إذا كان الخيار الحالي هو الموجود في قاعدة البيانات قم بتحديده. بالتوفيق1 نقطة
-
الامر كله كان في اني مدي لاوبشن العرض قيمة و ده خطأ ، القيمة المفروض في اوبشن الاختيار لو حبيت احدث و ده انا عامله فعلا تعطيل ال option الخاص بالعرض مع وجود value خلى المتغير مش عارف يقرا value ده عشان يدخله جوا الداتابيز فبالتالي بيعتبر ان القيمة صفر او فاضية لانه مش عارف يقراها لما اتفتحت له سكة يقرا ال value و خصوصا ان زي حضرتك ما تفضلت و سألتني انا ليه عامل العرض selected و ده غلط هو شايف فيه اوبشن معمول سيليكت و محطوط له قيمة قام حاططها في الداتابيز لكن لما شلت ال disabled و ال selected و كمان ال value ما لاقاش قيمة يدخلها و لا حتى صفر فبالتالي ساب الداتابيز في حالها و الحمد لله اخيرا اشكر لك معروفك و صنيعك و طول بالك و جزاكم الله خيرا اخي الفاضل1 نقطة
-
هذا ما فهمته من المشكلة وهذا الحل حسب فهمي بفرض ان القيمة قبل التعديل تكون مخزنة في user['fibersID']$ <select class="form-control fiber-thread" name="fiber-thread"> <option disabled value="">Choose here</option> <?php $result = $conn->query("SELECT * FROM fibers"); while ($row = $result->fetch_assoc()) { if($row['id'] == $user['fibersID']) { echo '<option selected value="' . $row['id'] . '">' . $row['name'] . '</option>'; } else { echo '<option value="' . $row['id'] . '">' . $row['name'] . '</option>'; } } ?> </select> و في ملف ال php تقوم بنفس الفكرة: $id = $_POST['id']; $name = $_POST['name']; $fiber = $_POST['fiber']; $num = $_POST['num']; $color = $_POST['color']; $pantone = $_POST['pantone']; $height = $_POST['height']; $weight = $_POST['weight']; $factory = $_POST['factory']; $tprice = $_POST['tprice']; $mprice = $_POST['mprice']; $q = "UPDATE `thread` SET `name`='$name',`num`='$num',`color`='$color',`pantone`='$pantone',`height`='$height',`weight`='$weight',`factory`='$factory',`tPrice`='$tprice',`mPrice`='$mprice'"; if (isset($fiber) && !empty($fiber)) { $q .= ",`fiber`='$fiber'"; } if (isset($_FILES['image']['name'])) { // rename and upload image $q .= ",`image`='$image'"; } $q .= " WHERE thread.id =".$id.";"; $result = $conn->query($q); if ($result) { echo "done"; }1 نقطة
-
طيب لأن القيمة 0 ليست null لذلك الشرط يتحقق في كل الأحوال if (isset($fiber) && !empty($fiber)) {1 نقطة
-
قيمة المتغير fiber ماذا تكون في حالة لم تُعدل على القائمة؟1 نقطة
-
نستخدم هذه الأداة لقياس ال score لنموذج أو عدة نماذج في كل Folds. يمكنك استخدامها عبر الموديول: sklearn.model_selection.cross_val_score الصيغة المبسطة: sklearn.model_selection.cross_val_score(estimator, X, y, cv=None) الوسيط cv لتحديد عدد ال Folds التي نريد تطبيقها. ال estimator هو الخوارزمية المطلوب تطبيقها. مثال للتوضيح (استخدام مودل واحد): from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestRegressor # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=2021) CVTrain = cross_val_score(RandomForestRegressor(), X_train, y_train, cv=5) CVTest = cross_val_score(RandomForestRegressor(), X_test, y_test, cv=5) # عرض النتائج print('Cross Validate Score for Training Set: ', CVTrain) print('Cross Validate Score for Testing Set: ', CVTest) # Cross Validate Score for Training Set: [0.88749657 0.885243 0.90868134 0.89021845 0.81435844] # Cross Validate Score for Testing Set: [0.68090613 0.84052288 0.7597606 0.49063984 0.66992151] استخدام عدة نماذج: from sklearn.datasets import load_boston from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor from sklearn.svm import SVR from sklearn.model_selection import cross_val_score # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تعريف النماذج التي سنطبقها model1 = SVR() model2 = DecisionTreeRegressor() model3 = RandomForestRegressor() model = [model1 , model2 , model3] j=1 for m in model: print('result of model number : ' , j ,' for cv value ',n,' is ' , cross_val_score(m, X, y, cv=3)) print('-------------------------------------------------------------------------------------------') j+=1 #result of model number : 1 for cv value 10 is [0.51272653 0.75456596 0.69387067] #------------------------------------------------------------------------------------------- #result of model number : 2 for cv value 10 is [0.41026494 0.64218456 0.54842306] #------------------------------------------------------------------------------------------- #result of model number : 3 for cv value 10 is [0.65818535 0.8420133 0.80363026] #-------------------------------------------------------------------------------------------1 نقطة
-
توجد دالة في لغة بايثون تقوم بالفكرة التي تريد تنفيذها وهي wrap من textwrap ويمكنك استخدامها كالتالي from textwrap import wrap #لاتنسى استدعائها أولاً s = '1234567890' wrap(s, 2) # نمرر أولاً النص ثم نمرر العرض أو عدد الحروف التي تريدها #الناتج # ['12', '34', '56', '78', '90']1 نقطة
-
اذا قمت باستخدام javascript مسبقا فستعرف انه هناك شئ يطلق عليه typscript والذي يعطي قوة ال typed language ل javascript وذلك يوجد ايضا في python بحكم أن python مشابهة ل javascript فكلاهما ديناميكي حسنا لنرجع لtype hints ولنشرحها بمثال def ceaser(text, key): result = "" for char in text: c = ord(char) enc_char = chr(c + key) result += enc_char return result فوق لدينا دالة تشفير ceaser وهي دالة مشهورة تاخذ string و number للتشفير وترجع string يمكننا تعريف اولا المعطيات بنوعها def ceaser(text:str, key:int): result = "" for char in text: c = ord(char) enc_char = chr(c + key) result += enc_char return result يمكننا تعريف صنف نتيجة الدالة def ceaser(text, key) -> str : result = "" for char in text: c = ord(char) enc_char = chr(c + key) result += enc_char return result كما يمكننا تعريف نوع المتغيرات def ceaser(text, key) -> str : result:str = "" for char in text: c:int = ord(char) enc_char:str = chr(c + key) result += enc_char return result1 نقطة
-
type hints هي طريقة لأعطاء البايثون دلالة للقيمة الراجعة أو حتى الأصناق على القيمة المحتملة التيى تقوم ببناءها و هي طرdقة جيدة لمساعدة ال type checkers للبايثون بحيث أنه بهذه الطريقة يقوم بمعرفة ماذا يجب أن تمرر أو أن ترجع و من هنا يستطيع ال type checkers بسهولة أن يخمن إن كنت تقوم بإرسال صنف غير متوقع و مثال على هذا الموضوع التالي : def headline(text, align=True): if align: return f"{text.title()}\n{'-' * len(text)}" else: return f" {text.title()} ".center(50, "o") print(headline("python type checking")) print(headline("python type checking", align=False)) #--------------- أضف الآن تلميحات الكتابة عن طريق التعليق على الوسيطات وقيمة الإرجاع على النحو التالي: def headline(text: str, align: bool = True) -> str:# هنا نقوم بتحديد الصنف للقيمة الراجعة لتسهيل عملية التحمين if align: return f"{text.title()}\n{'-' * len(text)}" else: return f" {text.title()} ".center(50, "o") print(headline("python type checking", align="left")) print(headline("python type checking", align="center"))1 نقطة
-
كما يمكن استخدام التعابير المنتظمة regular expression : import re num_str = '123456' chunks = re.findall('\d{2}',num_str) # بحث عن أي سلسلة جزئية من أرقام طول رقمين print(chunks) حيث d تعبر عن digit أي رقم 0-91 نقطة
-
يمكننا فعل ذلك من خلال تعريف قائمة فارغة, ثم المرور على جميع عناصر السلسلة من خلال استخدام حلقة التكرار for وبداخل الحلقة نستخدم الدالة append, فيكون شكل الكود كالتالي str1 = '123456789'#السلسلة التي نريد تقسيمها myList = []#قمنا بتعريف قائمة فارغة for i in range(0, len(str1), 2):#حلقة للمرور على جميع عناصر السلسلة myList.append(str1[i : i + 2])# نقوم باضافة العناصر التي مررنا عليهاالى القائمة print(myList)#طباعة القائمة1 نقطة
-
يمكن استخدام المكتبة request وعمل قناة اتصال منها، وتحديد أجزاء صغير من الملف chunks ومن ثم تحميلها وتجميعها في ملف ثم كتابته على القرص المحلي: حيث أن هذه الطريقة المستخدمة لتحميل الملفات الكبيرة عن طريق تقسيمها.. def download_file(url): # جلب اسم الملف من الرابط local_filename = url.split('/')[-1] # تفعيل عمل قناة الاتصال stream=True with requests.get(url, stream=True) as r: r.raise_for_status() # رفع استثناء إن حصل أي مشكلة في الاتصال # تجهيز ملف محلي لتخزين البيانات with open(local_filename, 'wb') as f: # تحديد حجم جزء الملف for chunk in r.iter_content(chunk_size=8192): if chunk: # تحقق من تحميل الجزء # كابة الجزء المحمل من خلال قناة الاتصال f.write(chunk) return local_filename ولعمل مسار تقدم التحميل يمكن استخدام مكتبة "تقدم" tqdm وهي الأصل في التسمية لعمل progress bar: from tqdm import * import requests url = "https://path/to/file.mp4" name = "video" with requests.get(url, stream=True) as r: r.raise_for_status() # رفع استثناء إن حصل أي مشكلة في الاتصال with open(name, 'wb') as f: pbar = tqdm(total=int(r.headers['Content-Length']))#تهيئة عمودالتحميل بطول البيانات = حجم الملف for chunk in r.iter_content(chunk_size=8192): if chunk: # تحقق من تحميل الجزء f.write(chunk) pbar.update(len(chunk)) # تحديث التقدم في عمود التحميل كلما تم تحميل جزء من الملف، يتم حساب طول هذه الجزء من طول الملف الأصلي وتحرك المؤشر في عمود التقدم ليملأ فراغ بنفس الحجم.1 نقطة
-
كما تشير وثيقة Sklearn فإن ال estimator الخاص بهذه الخوارزمية مازال تجريبي (experimental) ولاستخادمها تحتاج إلى تمكين الميزات التجريبية أولاً (experimental features) ويتم ذلك عن طريق الاستدعاء التالي: from sklearn.experimental import enable_hist_gradient_boosting أي يصبح الكود: from sklearn.model_selection import train_test_split from sklearn.experimental import enable_hist_gradient_boosting from sklearn.ensemble import HistGradientBoostingClassifier Data = load_breast_cancer() X = Data.data y = Data.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=44, shuffle =True) clf = BaggingClassifier(n_estimators=150, random_state=444) clf.fit(X_train, y_train)1 نقطة
-
يمكن تمرير أكثر من وسيط للدالة map ونضع بينهم فاصلة كالتالي: pool.map(test, x, y) في حالات أخرى، يمكن تمرير قائمة تحوي على tuple وبالمرور على القائمة يتم استدعاء دالة الجمع لكل عنصر tuple منها كالتالي: def multi_run_wrapper(args): return add(*args) # تمرير عناصر الوسيط كمتغيرات منفصلة def add(x,y): return x+y if __name__ == "__main__": from multiprocessing import Pool pool = Pool(4) # استدعاء دالة تقوم باستخلاص العناصر من القائمة results = pool.map(multi_run_wrapper,[(1,2),(2,3),(3,4)]) print results output:: [3, 5, 7]1 نقطة
-
يمكن استخدام المكتبة: chardet التي تسمح لنا بمعرفة ماهو نمط الترميز الذي كتب فيه ملف ما. التثبيت: pip install chardet الاستخدام: # تضمين المكتبة import chardet # قراءة البيانات الخام بدون تحديد ترميز rawdata = open(file, "r").read() # معرفة الترميز من خلال استخدام المكتبة و الدالة detect result = chardet.detect(rawdata) # تخزين التركميز في متغير لاستخدامه لاحقا charenc = result['encoding'] ثم نقوم بتمرير نوع الترميز كوسيط لدالة قراءة الملف open: myfile = open('results.txt', 'r', encoding=charenc) ^^^^^^^^^^^^^^^^ بالعلم تدعم هذه المكتيبة العديد من أنواع الترميز: ASCII, UTF-8, UTF-16 (2 variants), UTF-32 (4 variants) Big5, GB2312, EUC-TW, HZ-GB-2312, ISO-2022-CN (Traditional and Simplified Chinese) EUC-JP, SHIFT_JIS, CP932, ISO-2022-JP (Japanese) EUC-KR, ISO-2022-KR (Korean) KOI8-R, MacCyrillic, IBM855, IBM866, ISO-8859-5, windows-1251 (Cyrillic) ISO-8859-2, windows-1250 (Hungarian) ISO-8859-5, windows-1251 (Bulgarian) windows-1252 (English) ISO-8859-7, windows-1253 (Greek) ISO-8859-8, windows-1255 (Visual and Logical Hebrew) TIS-620 (Thai)1 نقطة
-
يمكننا عمل ذلك عن طريق إستخدام دالة combinations المتوفرة في مكتبة itertools والتي تقوم بإسترجاع كافة التوافيق المحتملة بكل الأطوال الممكنة للمتغير string، لاحظ المثال أدناه: from itertools import combinations string = "01234567890123456789" res = [string[x:y] for x, y in combinations( range(len(string) + 1), r = 2)] print(list(set([i for i in res if len(i)==10]))) بعد إستيراد الدالة، قمنا بتعريف المتغير string ومن ثم إيجاد كل التوافيق اللازمة عن طريق تقسيم النص إلى أجزاء بإستخدام x,y في كل مرة يأخذان قيمتين مختلفتين إبتداء من 0 للمتغير x و 1 للمتغير y، بذلك يمكننا تقسيم string و الحصول على القيم من موقع x و حتى الوصول إلى موقع y (موضح بعملية التقسيم او slicing للمتغير string بقيم [x:y]. أخيراً عملية الإختبار الشرطية لإستخراج النصوص التي يبلغ طولها 10 حروف، و من ثم تحويلها لمجموعة بإستخدام set للحصول على القيم بدون تكرار، و القيم المطبوعة تكون في شكل قائمة بإستخدام دالة list لتقوم بعملية التحويل (إختياري حسب ما يتطلب البرنامج). و بذلك يمكننا الحصول على كل الإحتمالات الممكنة و إستخراج 10 قيم مختلفة بدون تكرار أو إخفاء لقيمة 0 في بداية النص.1 نقطة
-
يمكن أيضًا أن تستعمل regular expression للحصول على قائمة الأرقام كالتالي: >>> import re >>> string = "01234567890123456789" >>> matches = re.finditer(r'(?=(\d{10}))', string) >>> results = [int(match.group(1)) for match in matches] >>> results [123456789, 1234567890, 2345678901, 3456789012, 4567890123, 5678901234, 6789012345, 7890123456, 8901234567, 9012345678, 123456789] لاحظ أن رقم 10 في السطر الثالث يعبر عن طول سلسلة الأرقام1 نقطة
-
يمكن استخدام الترتاتيب permetions لتوليد جميع السلاسل الممكنة من مجموعة من العناصر حيث تتوفر بايثون على المكتبة المساعدة itertools على المولد للتراتيب permutations ويمكن تمرير له قائمة بالعناصر مع طول القوائم الجزئية منها: from itertools import permutations string = "01234567890123456789" for i in permutations(string, 10): print (i) يمكن تمرير سلسلة نصية* لن يتم الحفاظ على ترتيب العناصر ضمن المصفوفة إنما تشكيل جميع الاحتمالات الممكنة1 نقطة
-
الأمر بسيط أخي ...
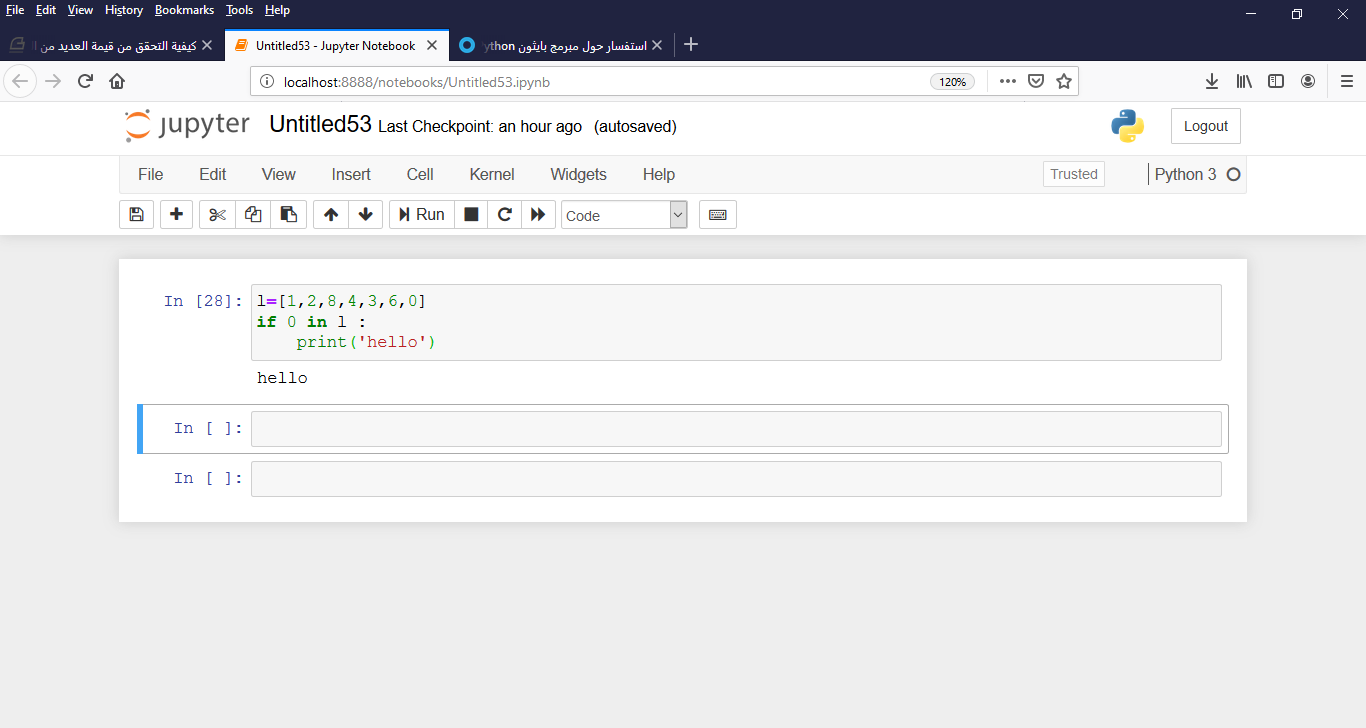
 1 نقطة
1 نقطة -
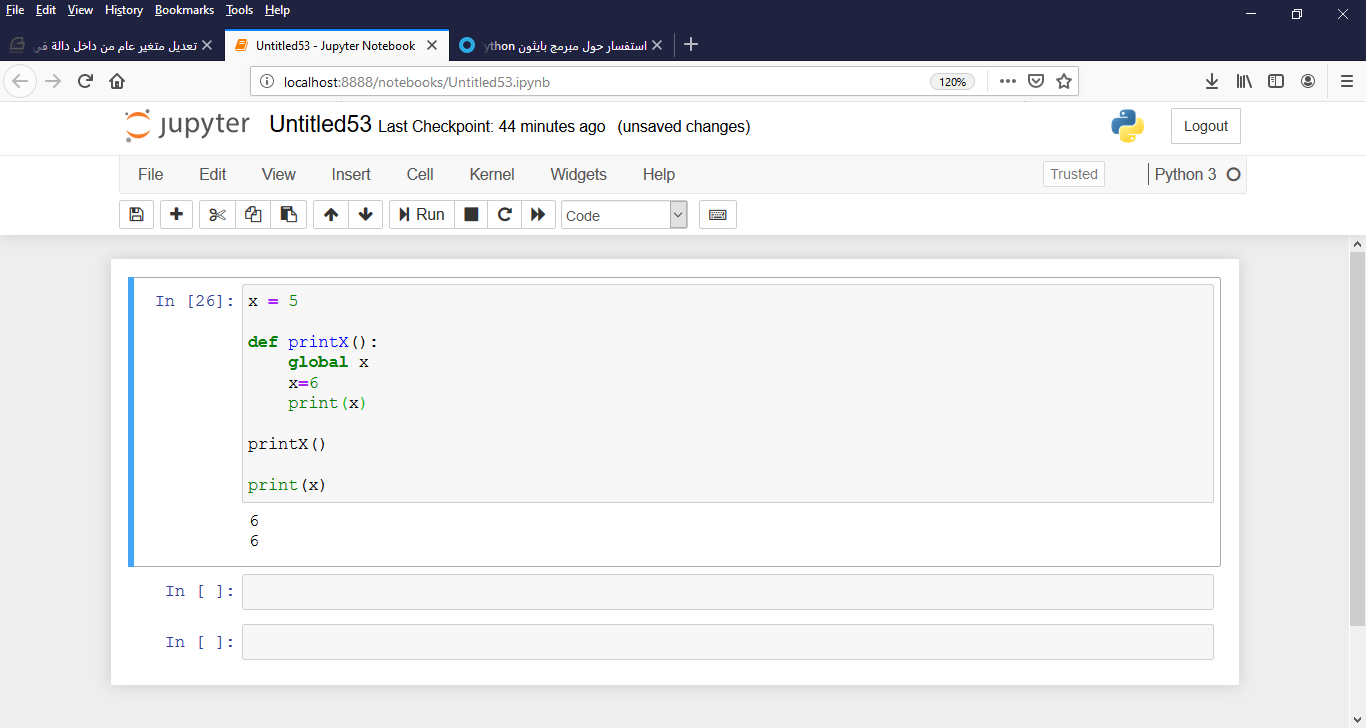
المتغيرات التي يتم تعريفها بداخل الدوال, يقال لها Local Variables أو متحولات محلية و هذه التسمية تعني أنه لا يمكن الوصول لها من خارج الدالة بشكل مباشر. المتغيرات التي يتم تعريفها خارج الدوال, يقال لها Global Variables أو متحولات عامة و هذه التسمية تعني أنه يمكن الوصول لها من أي مكان في الكود حتى من داخل التوابع functions، لكن في حال قمتي بتعديل قيمة المتغير العام من داخل تابع أو كلاس فإن التغيير يكون محصور ضمن التابع أو الكلاس الذي حدث فيه التعديل( لأنه تم إنشاء نسخة من المتحول داخل الدالة أو الكلاس)، لذا إذا أردت جعل التعديل يؤثر في المتحول الأساسي يجب أن تضعي global كما في الصورة...
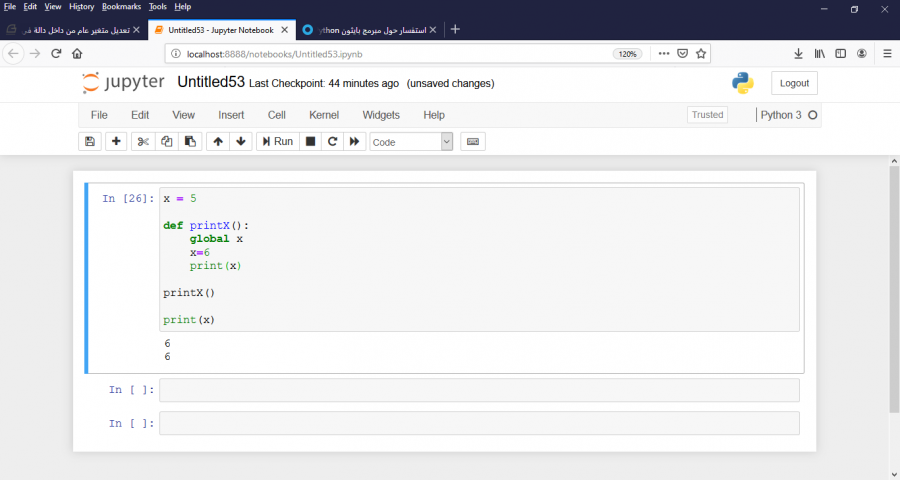 1 نقطة
1 نقطة -
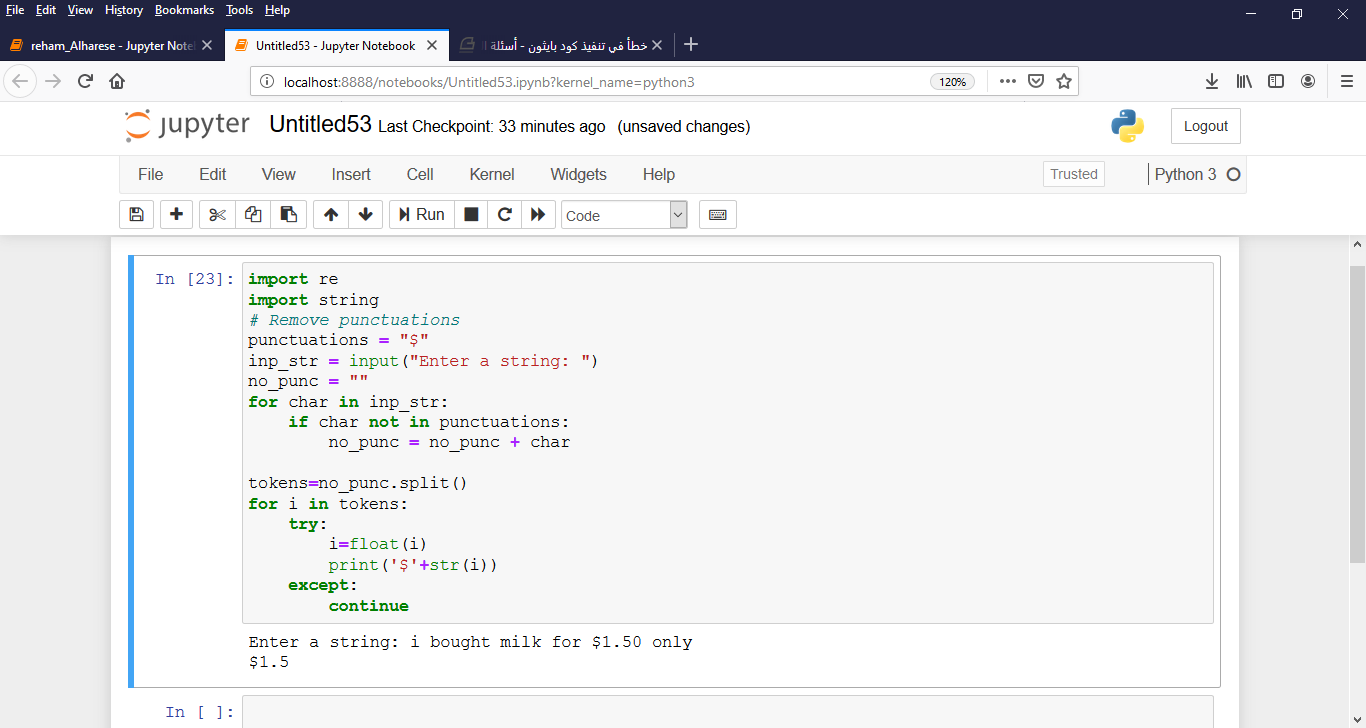
السلام عليكم أختي.. الكود الذي كتبته لايوجد به خطأ قواعدي ولكنه لايحقق المطلوب "برنامج لإدخال النص واستخراج الأسعار بالدولار" ... يمكنك أن تجربي الكود التالي وسيعمل :
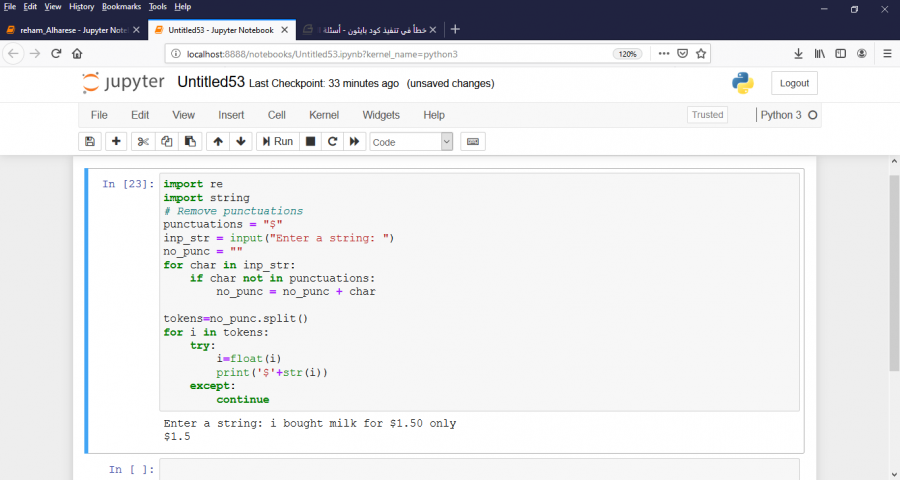 1 نقطة
1 نقطة