لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 09/15/20 في كل الموقع
-
 اللغات المصرفة (Compiled) واللغات المفسرة (Interpreted) تندرج لغات البرمجة تحت صنفين اثنين: إما مُصرَّفة (compiled) أو مُفسَّرة (interpreted)، فيعني المصطلح لغة مُصرَّفة (compiled) ترجمة البرامج إلى لغة الآلة (machine language) لينفذها العتاد (hardware)، أما مصطلح لغة مُفسَّرة (interpreted) فيعني وجود برنامج يدعى «المفسِّر» (interpreter) يقرأ البرامج وينفذها مباشرةً وآنيًا . تُعَد لغة البرمجة C على سبيل المثال لغة مُصرَّفة (compiled) عادًة، بينما تُعَد لغة Python لغة مُفسَّرة (interpreted)، لكنّ التمييز بين المصطلحين غير واضح دائمًا حيث: أولًا يمكن للغات البرمجة المُفسَّرة أن تكون مُصرَّفة والعكس صحيح، فلغة C مثلًا هي لغة مصرَّفة ولكن يوجد مفسِرات لها تجعلها لغة مفسَّرةً أيضًا والأمر مماثل للغة Python المفسَّرة التي يمكن أن تكون مصرَّفة أيضًا. ثانيًا توجد لغات برمجة، جافا (Java) مثلًا، تستخدم نهجًا هجينًا (hybrid approach) يجمع بين التصريف والتفسير، حيث يبدأ هذا النهج بترجمة البرنامج إلى لغة وسيطة (intermediate language) عبر مصرِّف ثم تنفيذ البرنامج عبر مُفسِّر. تَستخدم لغة Java لغةً وسيطةً (intermediate language) تُدعى جافا بايتكود Java bytecode شبيهة بلغة الآلة، لكنها تُنفَّذ باستخدام مُفسِّر برمجيات يدعى بآلة جافا الافتراضية (Java virtual machine وتختصر إلى JVM). وسم لغة البرمجة بكونها لغة مفسَّرة أو مصرَّفة لا يكسبها خاصية جوهرية، على كل حال توجد اختلافات عامة بين اللغتين المُصرَّفة والمُفسَّرة. الأنواع الساكنة (Static Types) تدعم العديد من اللغات المُفسَّرة الأنواع الديناميكية (Dynamic Types)، وتقتصر اللغات المُصرَّفة على الأنواع الساكنة (Static Types). فيمكن في اللغات ساكنة النوع معرفة أنواع المتغيرات بمجرّد قراءة شيفرة البرنامج أي تكون أنواع المتغيرات محدَّدة قبل تنفيذ البرنامج، بينما تكون أنواع المتغيرات في اللغات التي توصف بأنها ديناميكية النوع غير معروفة قبل التنفيذ وتحدد وقت تنفيذ البرنامج. ويشير مصطلح ساكن (Static) إلى الأشياء التي تحدث في وقت التصريف (Compile time) (أي عند تصريف شيفرة البرنامج إلى شيفرة التنفيذ)، بينما يشير مصطلح Dynamic إلى الأشياء التي تحدث في وقت التشغيل (run time) (أي عندما يُشغَّل البرنامج). يمكن كتابة الدالة التالية في لغة Python على سبيل المثال: def add(x, y): return x + y لا يمكن معرفة نوع المتغيرين y وx بمجرد قراءة الشيفرة السابقة حيث لا يحدَّد نوعهما حتى وقت تنفيذ البرنامج، لذلك يمكن استدعاء هذه الدالة عدة مرات بتمرير قيمة بنوع مختلف إليها في كل مرة، وستعمل عملًا صحيحًا ما دام نوع القيمة المُمرَّرة إليها مناسبًا لتطبيق عملية الجمع عليها، وإلا سترمي الدالة اعتراضًا (exception) أو خطأً وقت التشغيل. يمكن كتابة نفس الدالة السابقة في لغة البرمجة C كما يلي: int add(int x, int y) { return x + y; } يتضمّن السطر الأول من الدالة تصريحًا واضحًا وصريحًا بنوعي القيمتين التي يجب تمريرهما إلى الدالة ونوع القيمة التي تعيدها الدالة أيضًا، حيث يُصرَّح عن y وx كأعداد صحيحة (integers)، وهذا يعني أنه يمكن التحقق في وقت التصريف (compiled time) فيما إذا كان مسموحًا استخدام عامل الجمع مع النوع integer أم لا (إنه مسموح حقًا)، ويُصرَّح عن القيمة المُعادة كعدد صحيح (integer) أيضًا. وعندما تُستدعى الدالة السابقة في مكان آخر من البرنامج يستطيع المصرِّف (compiler) باستخدام التصريحات أن يتحقق من صحة نوع الوسطاء (arguments) الممررة للدالة، ومن صحة نوع القيمة التي تعيدها الدالة أيضًا. يحدث التحقق في اللغات المصرَّفة قبل بدء تنفيذ البرنامج لذلك يمكن إيجاد الأخطاء باكرًا، ويمكن إيجاد الأخطاء أيضًا في أجزاء البرنامج التي لم تُشغَّل على الإطلاق وهو الشيء الأهم. علاوًة على ذلك لا يتوجب على هذا التحقق أن يحدث في وقت التشغيل (runtime)، وهذا هو أحد الأسباب التي تجعل تنفيذ اللغات المُصرَّفة أسرع من اللغات المُفسَّرة عمومًا. يحافظ التصريح عن الأنواع في وقت التصريف (compile time) على مساحة الذاكرة في اللغات ساكنة النوع أيضًا، بينما تُخزَّن أسماء المتغيرات في الذاكرة عند تنفيذ البرنامج في اللغات ديناميكية النوع التي لا تحوي تصريحات واضحة لأنواعها وتكون أسماء هذه المتغيرات قابلة للوصول من قبل البرنامج. توجد دالة مبنيّة مسبقًا في لغة Python هي locals، تعيد هذه الدالة قاموسًا (dictionary) يتضمن أسماء المتغيرات وقيمها. ستجد تاليًا مثالًا عن مفسِّر Python: >>> x = 5 >>> print locals() {'x': 5, '__builtins__': <module '__builtin__' (built-in)>, '__name__': '__main__', '__doc__': None, '__package__': None} يبيّن المثال السابق أنه يُخزَّن اسم المتغير في الذاكرة عند تنفيذ البرنامج (مع بعض القيم الأخرى التي تُعَد جزءًا من بيئة وقت التشغيل الافتراضية). بينما تتواجد أسماء المتغيرات في اللغات المُصرَّفة في الذاكرة في وقت التصريف (compile time) ولا تتواجد في وقت التشغيل (runtime). حيث يختار المصرّف موقعًا في الذاكرة لكل متغير ويسجل هذه المواقع كجزء من البرنامج المُصرَّف (سنتطرّق إلى مزيد من التفاصيل عن ذلك لاحقًا). يدعى موقع المتغير في الذاكرة عنوانًا (address) حيث تُخزَّن قيمة كل متغير في عنوانه، ولا تُخزَّن أسماء المتغيرات في الذاكرة على الإطلاق في وقت التشغيل (ولكن هذا شيء اختياري للمصرف فيمكن أن يضيف المصرِّف (compiler) أسماء المتغيرات إلى الذاكرة في وقت التشغيل بهدف تنقيح الأخطاء (debugging)، أي لمعرفة أماكن تواجد الأخطاء في البرنامج). عملية التصريف (The compilation process) يجب أن يفهم المبرمج فهمًا تامًا ما يحدث خلال عملية التصريف (compilation)، فإذا فُهِمت هذه العملية جيدًا سيساعد ذلك في تفسير رسائل الخطأ وتنقيح الأخطاء في الشيفرة وأيضًا في تجنُّب الزلات الشائعة. للتصريف خطوات هي: المعالجة المسبقة (Preprocessing): تتضمن لغة البرمجة C موجِّهات معالجة مسبقة (preprocessing directives) والتي تدخل حيز التنفيذ قبل تصريف البرنامج، فمثلًا يسبّب الموجِّه #include إدراج شيفرة مصدرية (source code) خارجية موضع استعماله. التحليل (Parsing): يقرأ المُصرِّف (compiler) أثناء هذه الخطوة الشيفرة المصدرية (source code) ويبني تمثيلًا داخليًّا internal) (representation للبرنامج يُدعى بشجرة الصيغة المجردة (abstract syntax tree). تُسمى عادًة الأخطاء المكتشفة خلال هذه الخطوة بأخطاء صياغية (syntax errors). التحقق الساكن (Static checking): يتحقق المصرِّف من صحة نوع المتغيرات والقيم وفيما إذا اُستدعيت الدوال بعدد ونوع وسطاء صحيحين وغير ذلك من التحققات. يُدعى اكتشاف الأخطاء في هذه الخطوة أحيانًا بالأخطاء الدلالية الساكنة (static semantic errors). توليد الشيفرة (Code generation): يقرأ المصرِّف التمثيل الداخلي (internal representation) للبرنامج ويولّد شيفرة الآلة (machine code) أو الشيفرة التنفيذية (byte code) للبرنامج. الربط (Linking): إذا استخدم البرنامج قيمًا ودوالًا مُعرَّفة في مكتبة، فيجب أن يجد المُصرِّف المكتبة المناسبة وأن يُضمِّن (include) الشيفرة المطلوبة المتعلقة بتلك المكتبة. التحسين (Optimization): يحسّن المصرف دومًا خلال عملية التصريف من الشيفرة ليصبح تنفيذها أسرع أو لجعلها تستهلك مساحةً أقل من الذاكرة. معظم هذه التحسينات هي تغييرات بسيطة توفر من الوقت والمساحة، ولكن تطبِّق بعض المُصرِّفات (compilers) تحسيناتٍ أعقد. ينفذ المصرف كل خطوات التصريف ويولّد ملفًا تنفيذيًا (executable file) عند تشغيل الأداة gcc. المثال التالي هو شيفرة بلغة C: #include <stdio.h> int main() { printf("Hello World\n"); } إذا حُفِظت الشيفرة السابقة في ملف اسمه hello.c فيمكن تصريفها ثم تشغيلها كما يلي: $ gcc hello.c $ ./a.out تخزّن الأداة gcc الشيفرة القابلة للتنفيذ (executable code) في ملف يدعى افتراضيًا a.out (والذي يعني في الأصل خرج مُجمَّع (assembler output)). ينفذ السطر الثاني الملف التنفيذي، حيث تخبر البادئة ./ الصدفة (shell) لتبحث عن الملف التنفيذي في المجلّد (directory) الحالي. من الأفضل استخدام الراية -o لتوفير اسم أفضل للملف التنفيذي، حيث يُعطى الملف التنفيذي الناتج بعد عملية التصريف اسمًا افتراضيًا (a.out) بدون استخدام الراية -o، ولكن يُعطى اسمًا محددًا باستخدام الراية -o كما يلي: $ gcc hello.c -o hello $ ./hello التعليمات المُصرَّفة (Object code) تخبر الراية -c الأداة gcc بأن تصرِّف البرنامج وتولّد شيفرة الآلة (machine code) فقط، بدون أن تربط (link) البرنامج أو تولّد الملف التنفيذي. $ gcc hello.c -c النتيجة هي توليد ملف يُدعى hello.o، حيث يرمز حرف o إلى object code وهو البرنامج المُصرّف. والتعليمات المُصرَّفة (object code) غير قابلة للتنفيذ لكن يمكن ربطها بملف تنفيذي. يقرأ الأمر nm في UNIX ملف التعليمات المُصرَّفة (object file) ويولّد معلومات عن الأسماء التي يُعرِّفها ويستخدمها الملف، فمثلًا: $ nm hello.o 0000000000000000 T main U puts يشير الخرج السابق إلى أن hello.o يحدد اسم التابع الرئيسي main ويستخدم دالة تدعى puts، والتي تشير إلى (put string). وتطّبق gcc تحسينًا (optimization) عن طريق استبدال printf (وهي دالة كبيرة ومعقدة) بالدالة puts البسيطة نسبيًا. يمكن التحكم بمقدار التحسين الذي تقوم به gcc مع الراية -O، حيث تقوم gcc بإجراء تحسينات قليلة جدًا افتراضيًا مما يجعل تنقيح الأخطاء (debugging) أسهل. بينما يفعّل الخيار -O1 التحسينات الأكثر شيوعًا وأمانًا، وإذا استخدمنا مستويات أعلى (أي O2 وما بعده) فستفعِّل تحسينات إضافية، ولكنها تستغرق وقت تصريف أكبر. لا ينبغي أن يغير التحسين من سلوك البرنامج من الناحية النظرية بخلاف تسريعه، ولكن إذا كان البرنامج يحتوي خللًا دقيقًا (subtle bug) فيمكن أن تحمي عملية التحسين أثره أو تزيل عملية التحسين هذا الخلل. إيقاف التحسين فكرة جيدة أثناء مرحلة التطوير عادةً، وبمجرد أن يعمل البرنامج ويجتاز الاختبارات المناسبة يمكن تفعيل التحسين والتأكد من أن الاختبارات ما زالت ناجحة. الشيفرة التجميعية (Assembly code) تتشابه الرايتان -S و-c، حيث أن الراية -S تخبر الأداة gcc بأن تصرف البرنامج وتولد الشيفرة التجميعية (assembly code), والتي هي بالأساس نموذج قابل للقراءة تستطيع شيفرة الآلة (machine code) قراءته. $ gcc hello.c -S ينتج ملف يدعى hello.s والذي يبدو كالتالي .file "hello.c" .section .rodata .LC0: .string "Hello World" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $.LC0, %edi call puts movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Ubuntu/Linaro 4.7.3-1ubuntu1) 4.7.3" .section .note.GNU-stack,"",@progbits تُضبَط gcc عادةً لتولد الشيفرة للآلة التي تعمل عليها، ففي حالتي، يقول المؤلف، وُلِّدت شيفرة لغة آلة لمعمارية x86 للمعالجات والتي يمكن تنفيذها على شريحة واسعة من معالجات Intel ومعالجات AMD وغيرهما وفي حال استهداف معمارية مختلفة، فستولد شيفرة أخرى مختلفة عن تلك التي تراها الآن. المعالجة المسبقة (Preprocessing) يمكن استخدام الراية -E لتشغيل المعالج المُسبق (preprocessor) فقط بدون الخطوات الأخرى من عملية التصريف: $ gcc hello.c -E سينتج خرج من المعالج المسبق فقط. يحتوي المثال السابق تلقائيًا على الشيفرة المُضمَّنة (included code) المبنية مسبقًا والمتعلقة بالمكتبة stdio.h المذكورة في بداية البرنامج، وبالتالي يتضمن كل الملفات المُضمَّنة المتعلقة بتلك المكتبة، وكل الملفات الفرعية التابعة للملفات السابقة والملفات الموجودة في الملفات الفرعية أيضًا وهكذا. فعلى حاسوبي، يقول المؤلف، وصل العدد الإجمالي للشيفرة الإجمالية المضمنة إلى 800 سطر، ونظرًا أن كل برنامج C يتضمّن ملف الترويسات stdio.h تقريبًا، لذلك تُضمَّن تلك الأسطر في كل برنامج مكتوب بلغة C. وتتضمّن العديد من برامج C المكتبة stdlib.h أيضًا، وبالتالي ينتج أكثر من 1800 سطر إضافي من الشيفرة يجب تصريفها جميعًا. فهم الأخطاء (Understanding errors) أصبح فهم رسائل الخطأ أسهل بعد معرفة خطوات عملية التصريف، فمثلًا عند وجود خطأ في الموجّه #include ستصل رسالة من المعالج المسبق هي: hello.c:1:20: fatal error: stdioo.h: No such file or directory compilation terminated. أما عند وجود خطأ صياغي (syntax error) متعلق بلغة البرمجة، ستصل رسالة من المُصرِّف (compiler) هي: hello.c: In function 'main': hello.c:6:1: error: expected ';' before '}' token عند استخدام دالة غير معرَّفة في المكتبات القياسية ستصل رسالة من الرابط (linker) هي: /tmp/cc7iAUbN.o: In function `main': hello.c:(.text+0xf): undefined reference to `printff' collect2: error: ld returned 1 exit status ld هو اسم رابط UNIX ويشير إلى تحميل (loading)، حيث أن التحميل هو خطوة أخرى من عملية التصريف ترتبط ارتباطًا وثيقًا بخطوة الربط (linking). تجري لغة C تحققًا سريعًا جدًا ضمن وقت التشغيل بمجرد بدء البرنامج، لذلك من المحتمل أن ترى بعضًا من أخطاء وقت التشغيل (runtime errors) فقط وليس جميعها، مثل خطأ القسمة على صفر (divide by zero)، أو تطبيق عملية عدد عشري غير مسموحة وبالتالي الحصول على اعتراض عدد عشري (Floating point exception)، أو الحصول على خطأ تجزئة (Segmentation fault) عند محاولة قراءة أو كتابة موقع غير صحيح في الذاكرة. ترجمة -وبتصرّف- للفصل Compilation من كتاب Think OS A Brief Introduction to Operating Systems1 نقطة
اللغات المصرفة (Compiled) واللغات المفسرة (Interpreted) تندرج لغات البرمجة تحت صنفين اثنين: إما مُصرَّفة (compiled) أو مُفسَّرة (interpreted)، فيعني المصطلح لغة مُصرَّفة (compiled) ترجمة البرامج إلى لغة الآلة (machine language) لينفذها العتاد (hardware)، أما مصطلح لغة مُفسَّرة (interpreted) فيعني وجود برنامج يدعى «المفسِّر» (interpreter) يقرأ البرامج وينفذها مباشرةً وآنيًا . تُعَد لغة البرمجة C على سبيل المثال لغة مُصرَّفة (compiled) عادًة، بينما تُعَد لغة Python لغة مُفسَّرة (interpreted)، لكنّ التمييز بين المصطلحين غير واضح دائمًا حيث: أولًا يمكن للغات البرمجة المُفسَّرة أن تكون مُصرَّفة والعكس صحيح، فلغة C مثلًا هي لغة مصرَّفة ولكن يوجد مفسِرات لها تجعلها لغة مفسَّرةً أيضًا والأمر مماثل للغة Python المفسَّرة التي يمكن أن تكون مصرَّفة أيضًا. ثانيًا توجد لغات برمجة، جافا (Java) مثلًا، تستخدم نهجًا هجينًا (hybrid approach) يجمع بين التصريف والتفسير، حيث يبدأ هذا النهج بترجمة البرنامج إلى لغة وسيطة (intermediate language) عبر مصرِّف ثم تنفيذ البرنامج عبر مُفسِّر. تَستخدم لغة Java لغةً وسيطةً (intermediate language) تُدعى جافا بايتكود Java bytecode شبيهة بلغة الآلة، لكنها تُنفَّذ باستخدام مُفسِّر برمجيات يدعى بآلة جافا الافتراضية (Java virtual machine وتختصر إلى JVM). وسم لغة البرمجة بكونها لغة مفسَّرة أو مصرَّفة لا يكسبها خاصية جوهرية، على كل حال توجد اختلافات عامة بين اللغتين المُصرَّفة والمُفسَّرة. الأنواع الساكنة (Static Types) تدعم العديد من اللغات المُفسَّرة الأنواع الديناميكية (Dynamic Types)، وتقتصر اللغات المُصرَّفة على الأنواع الساكنة (Static Types). فيمكن في اللغات ساكنة النوع معرفة أنواع المتغيرات بمجرّد قراءة شيفرة البرنامج أي تكون أنواع المتغيرات محدَّدة قبل تنفيذ البرنامج، بينما تكون أنواع المتغيرات في اللغات التي توصف بأنها ديناميكية النوع غير معروفة قبل التنفيذ وتحدد وقت تنفيذ البرنامج. ويشير مصطلح ساكن (Static) إلى الأشياء التي تحدث في وقت التصريف (Compile time) (أي عند تصريف شيفرة البرنامج إلى شيفرة التنفيذ)، بينما يشير مصطلح Dynamic إلى الأشياء التي تحدث في وقت التشغيل (run time) (أي عندما يُشغَّل البرنامج). يمكن كتابة الدالة التالية في لغة Python على سبيل المثال: def add(x, y): return x + y لا يمكن معرفة نوع المتغيرين y وx بمجرد قراءة الشيفرة السابقة حيث لا يحدَّد نوعهما حتى وقت تنفيذ البرنامج، لذلك يمكن استدعاء هذه الدالة عدة مرات بتمرير قيمة بنوع مختلف إليها في كل مرة، وستعمل عملًا صحيحًا ما دام نوع القيمة المُمرَّرة إليها مناسبًا لتطبيق عملية الجمع عليها، وإلا سترمي الدالة اعتراضًا (exception) أو خطأً وقت التشغيل. يمكن كتابة نفس الدالة السابقة في لغة البرمجة C كما يلي: int add(int x, int y) { return x + y; } يتضمّن السطر الأول من الدالة تصريحًا واضحًا وصريحًا بنوعي القيمتين التي يجب تمريرهما إلى الدالة ونوع القيمة التي تعيدها الدالة أيضًا، حيث يُصرَّح عن y وx كأعداد صحيحة (integers)، وهذا يعني أنه يمكن التحقق في وقت التصريف (compiled time) فيما إذا كان مسموحًا استخدام عامل الجمع مع النوع integer أم لا (إنه مسموح حقًا)، ويُصرَّح عن القيمة المُعادة كعدد صحيح (integer) أيضًا. وعندما تُستدعى الدالة السابقة في مكان آخر من البرنامج يستطيع المصرِّف (compiler) باستخدام التصريحات أن يتحقق من صحة نوع الوسطاء (arguments) الممررة للدالة، ومن صحة نوع القيمة التي تعيدها الدالة أيضًا. يحدث التحقق في اللغات المصرَّفة قبل بدء تنفيذ البرنامج لذلك يمكن إيجاد الأخطاء باكرًا، ويمكن إيجاد الأخطاء أيضًا في أجزاء البرنامج التي لم تُشغَّل على الإطلاق وهو الشيء الأهم. علاوًة على ذلك لا يتوجب على هذا التحقق أن يحدث في وقت التشغيل (runtime)، وهذا هو أحد الأسباب التي تجعل تنفيذ اللغات المُصرَّفة أسرع من اللغات المُفسَّرة عمومًا. يحافظ التصريح عن الأنواع في وقت التصريف (compile time) على مساحة الذاكرة في اللغات ساكنة النوع أيضًا، بينما تُخزَّن أسماء المتغيرات في الذاكرة عند تنفيذ البرنامج في اللغات ديناميكية النوع التي لا تحوي تصريحات واضحة لأنواعها وتكون أسماء هذه المتغيرات قابلة للوصول من قبل البرنامج. توجد دالة مبنيّة مسبقًا في لغة Python هي locals، تعيد هذه الدالة قاموسًا (dictionary) يتضمن أسماء المتغيرات وقيمها. ستجد تاليًا مثالًا عن مفسِّر Python: >>> x = 5 >>> print locals() {'x': 5, '__builtins__': <module '__builtin__' (built-in)>, '__name__': '__main__', '__doc__': None, '__package__': None} يبيّن المثال السابق أنه يُخزَّن اسم المتغير في الذاكرة عند تنفيذ البرنامج (مع بعض القيم الأخرى التي تُعَد جزءًا من بيئة وقت التشغيل الافتراضية). بينما تتواجد أسماء المتغيرات في اللغات المُصرَّفة في الذاكرة في وقت التصريف (compile time) ولا تتواجد في وقت التشغيل (runtime). حيث يختار المصرّف موقعًا في الذاكرة لكل متغير ويسجل هذه المواقع كجزء من البرنامج المُصرَّف (سنتطرّق إلى مزيد من التفاصيل عن ذلك لاحقًا). يدعى موقع المتغير في الذاكرة عنوانًا (address) حيث تُخزَّن قيمة كل متغير في عنوانه، ولا تُخزَّن أسماء المتغيرات في الذاكرة على الإطلاق في وقت التشغيل (ولكن هذا شيء اختياري للمصرف فيمكن أن يضيف المصرِّف (compiler) أسماء المتغيرات إلى الذاكرة في وقت التشغيل بهدف تنقيح الأخطاء (debugging)، أي لمعرفة أماكن تواجد الأخطاء في البرنامج). عملية التصريف (The compilation process) يجب أن يفهم المبرمج فهمًا تامًا ما يحدث خلال عملية التصريف (compilation)، فإذا فُهِمت هذه العملية جيدًا سيساعد ذلك في تفسير رسائل الخطأ وتنقيح الأخطاء في الشيفرة وأيضًا في تجنُّب الزلات الشائعة. للتصريف خطوات هي: المعالجة المسبقة (Preprocessing): تتضمن لغة البرمجة C موجِّهات معالجة مسبقة (preprocessing directives) والتي تدخل حيز التنفيذ قبل تصريف البرنامج، فمثلًا يسبّب الموجِّه #include إدراج شيفرة مصدرية (source code) خارجية موضع استعماله. التحليل (Parsing): يقرأ المُصرِّف (compiler) أثناء هذه الخطوة الشيفرة المصدرية (source code) ويبني تمثيلًا داخليًّا internal) (representation للبرنامج يُدعى بشجرة الصيغة المجردة (abstract syntax tree). تُسمى عادًة الأخطاء المكتشفة خلال هذه الخطوة بأخطاء صياغية (syntax errors). التحقق الساكن (Static checking): يتحقق المصرِّف من صحة نوع المتغيرات والقيم وفيما إذا اُستدعيت الدوال بعدد ونوع وسطاء صحيحين وغير ذلك من التحققات. يُدعى اكتشاف الأخطاء في هذه الخطوة أحيانًا بالأخطاء الدلالية الساكنة (static semantic errors). توليد الشيفرة (Code generation): يقرأ المصرِّف التمثيل الداخلي (internal representation) للبرنامج ويولّد شيفرة الآلة (machine code) أو الشيفرة التنفيذية (byte code) للبرنامج. الربط (Linking): إذا استخدم البرنامج قيمًا ودوالًا مُعرَّفة في مكتبة، فيجب أن يجد المُصرِّف المكتبة المناسبة وأن يُضمِّن (include) الشيفرة المطلوبة المتعلقة بتلك المكتبة. التحسين (Optimization): يحسّن المصرف دومًا خلال عملية التصريف من الشيفرة ليصبح تنفيذها أسرع أو لجعلها تستهلك مساحةً أقل من الذاكرة. معظم هذه التحسينات هي تغييرات بسيطة توفر من الوقت والمساحة، ولكن تطبِّق بعض المُصرِّفات (compilers) تحسيناتٍ أعقد. ينفذ المصرف كل خطوات التصريف ويولّد ملفًا تنفيذيًا (executable file) عند تشغيل الأداة gcc. المثال التالي هو شيفرة بلغة C: #include <stdio.h> int main() { printf("Hello World\n"); } إذا حُفِظت الشيفرة السابقة في ملف اسمه hello.c فيمكن تصريفها ثم تشغيلها كما يلي: $ gcc hello.c $ ./a.out تخزّن الأداة gcc الشيفرة القابلة للتنفيذ (executable code) في ملف يدعى افتراضيًا a.out (والذي يعني في الأصل خرج مُجمَّع (assembler output)). ينفذ السطر الثاني الملف التنفيذي، حيث تخبر البادئة ./ الصدفة (shell) لتبحث عن الملف التنفيذي في المجلّد (directory) الحالي. من الأفضل استخدام الراية -o لتوفير اسم أفضل للملف التنفيذي، حيث يُعطى الملف التنفيذي الناتج بعد عملية التصريف اسمًا افتراضيًا (a.out) بدون استخدام الراية -o، ولكن يُعطى اسمًا محددًا باستخدام الراية -o كما يلي: $ gcc hello.c -o hello $ ./hello التعليمات المُصرَّفة (Object code) تخبر الراية -c الأداة gcc بأن تصرِّف البرنامج وتولّد شيفرة الآلة (machine code) فقط، بدون أن تربط (link) البرنامج أو تولّد الملف التنفيذي. $ gcc hello.c -c النتيجة هي توليد ملف يُدعى hello.o، حيث يرمز حرف o إلى object code وهو البرنامج المُصرّف. والتعليمات المُصرَّفة (object code) غير قابلة للتنفيذ لكن يمكن ربطها بملف تنفيذي. يقرأ الأمر nm في UNIX ملف التعليمات المُصرَّفة (object file) ويولّد معلومات عن الأسماء التي يُعرِّفها ويستخدمها الملف، فمثلًا: $ nm hello.o 0000000000000000 T main U puts يشير الخرج السابق إلى أن hello.o يحدد اسم التابع الرئيسي main ويستخدم دالة تدعى puts، والتي تشير إلى (put string). وتطّبق gcc تحسينًا (optimization) عن طريق استبدال printf (وهي دالة كبيرة ومعقدة) بالدالة puts البسيطة نسبيًا. يمكن التحكم بمقدار التحسين الذي تقوم به gcc مع الراية -O، حيث تقوم gcc بإجراء تحسينات قليلة جدًا افتراضيًا مما يجعل تنقيح الأخطاء (debugging) أسهل. بينما يفعّل الخيار -O1 التحسينات الأكثر شيوعًا وأمانًا، وإذا استخدمنا مستويات أعلى (أي O2 وما بعده) فستفعِّل تحسينات إضافية، ولكنها تستغرق وقت تصريف أكبر. لا ينبغي أن يغير التحسين من سلوك البرنامج من الناحية النظرية بخلاف تسريعه، ولكن إذا كان البرنامج يحتوي خللًا دقيقًا (subtle bug) فيمكن أن تحمي عملية التحسين أثره أو تزيل عملية التحسين هذا الخلل. إيقاف التحسين فكرة جيدة أثناء مرحلة التطوير عادةً، وبمجرد أن يعمل البرنامج ويجتاز الاختبارات المناسبة يمكن تفعيل التحسين والتأكد من أن الاختبارات ما زالت ناجحة. الشيفرة التجميعية (Assembly code) تتشابه الرايتان -S و-c، حيث أن الراية -S تخبر الأداة gcc بأن تصرف البرنامج وتولد الشيفرة التجميعية (assembly code), والتي هي بالأساس نموذج قابل للقراءة تستطيع شيفرة الآلة (machine code) قراءته. $ gcc hello.c -S ينتج ملف يدعى hello.s والذي يبدو كالتالي .file "hello.c" .section .rodata .LC0: .string "Hello World" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $.LC0, %edi call puts movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Ubuntu/Linaro 4.7.3-1ubuntu1) 4.7.3" .section .note.GNU-stack,"",@progbits تُضبَط gcc عادةً لتولد الشيفرة للآلة التي تعمل عليها، ففي حالتي، يقول المؤلف، وُلِّدت شيفرة لغة آلة لمعمارية x86 للمعالجات والتي يمكن تنفيذها على شريحة واسعة من معالجات Intel ومعالجات AMD وغيرهما وفي حال استهداف معمارية مختلفة، فستولد شيفرة أخرى مختلفة عن تلك التي تراها الآن. المعالجة المسبقة (Preprocessing) يمكن استخدام الراية -E لتشغيل المعالج المُسبق (preprocessor) فقط بدون الخطوات الأخرى من عملية التصريف: $ gcc hello.c -E سينتج خرج من المعالج المسبق فقط. يحتوي المثال السابق تلقائيًا على الشيفرة المُضمَّنة (included code) المبنية مسبقًا والمتعلقة بالمكتبة stdio.h المذكورة في بداية البرنامج، وبالتالي يتضمن كل الملفات المُضمَّنة المتعلقة بتلك المكتبة، وكل الملفات الفرعية التابعة للملفات السابقة والملفات الموجودة في الملفات الفرعية أيضًا وهكذا. فعلى حاسوبي، يقول المؤلف، وصل العدد الإجمالي للشيفرة الإجمالية المضمنة إلى 800 سطر، ونظرًا أن كل برنامج C يتضمّن ملف الترويسات stdio.h تقريبًا، لذلك تُضمَّن تلك الأسطر في كل برنامج مكتوب بلغة C. وتتضمّن العديد من برامج C المكتبة stdlib.h أيضًا، وبالتالي ينتج أكثر من 1800 سطر إضافي من الشيفرة يجب تصريفها جميعًا. فهم الأخطاء (Understanding errors) أصبح فهم رسائل الخطأ أسهل بعد معرفة خطوات عملية التصريف، فمثلًا عند وجود خطأ في الموجّه #include ستصل رسالة من المعالج المسبق هي: hello.c:1:20: fatal error: stdioo.h: No such file or directory compilation terminated. أما عند وجود خطأ صياغي (syntax error) متعلق بلغة البرمجة، ستصل رسالة من المُصرِّف (compiler) هي: hello.c: In function 'main': hello.c:6:1: error: expected ';' before '}' token عند استخدام دالة غير معرَّفة في المكتبات القياسية ستصل رسالة من الرابط (linker) هي: /tmp/cc7iAUbN.o: In function `main': hello.c:(.text+0xf): undefined reference to `printff' collect2: error: ld returned 1 exit status ld هو اسم رابط UNIX ويشير إلى تحميل (loading)، حيث أن التحميل هو خطوة أخرى من عملية التصريف ترتبط ارتباطًا وثيقًا بخطوة الربط (linking). تجري لغة C تحققًا سريعًا جدًا ضمن وقت التشغيل بمجرد بدء البرنامج، لذلك من المحتمل أن ترى بعضًا من أخطاء وقت التشغيل (runtime errors) فقط وليس جميعها، مثل خطأ القسمة على صفر (divide by zero)، أو تطبيق عملية عدد عشري غير مسموحة وبالتالي الحصول على اعتراض عدد عشري (Floating point exception)، أو الحصول على خطأ تجزئة (Segmentation fault) عند محاولة قراءة أو كتابة موقع غير صحيح في الذاكرة. ترجمة -وبتصرّف- للفصل Compilation من كتاب Think OS A Brief Introduction to Operating Systems1 نقطة -
أهلا بك هناك أكثر من طريقة لعمل هذا ، على إعتبار أنك تستخدم ال firestore database فيمكنك استخدام الكود التالي لجلب قيمة معينة منها // تعريف المستند الذي تريد جلب البيانات منه var document = await Firestore.instance.collection('COLLECTION_NAME').document('TESTID1'); // جلب هذا المستند و طباعة العنصر المسمى ب name document.get() => then(function(document) { // جملة الطباعة print(document("name")); }); و لطباعة ال name على سبيل المثال داخل Text Widget قم بما يلي // تعريف متغير String _name ; var document = await Firestore.instance.collection('COLLECTION_NAME').document('TESTID1'); document.get() => then(function(document) { setState(){ // وضع القيمة من قاعدة البيانات داخل المتغير _name = document("name"); } }); . . . // عرض المتغير على شاشة التطبيق Text(_name), شكراً لك1 نقطة
-
اخي العزيز اشكرك لك توضيح اكثر ولكن الاختيارات لتي في مقطع لا تظهر لي اقصد هذا اختيار ووضح مشكله في صور سابقه ارجو مساعده
 1 نقطة
1 نقطة -
يمكنك تجربة بدأ atom بالأمر الآتي: atom --clear-window-state إن لم تحل المشكلة يمكنك تجربة إستخدام محرر آخر مثل vscode.1 نقطة
-
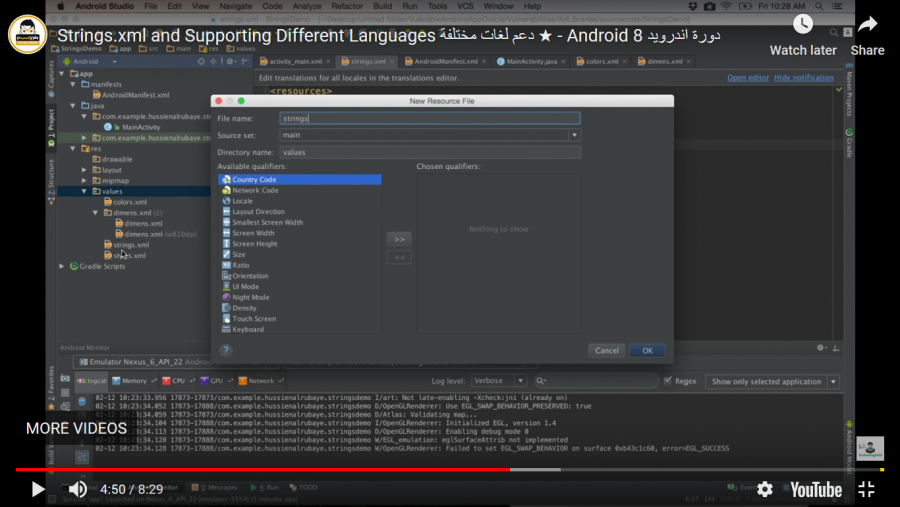
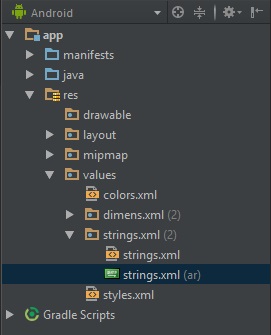
يمكنك حل المشكلة عن طريق عمل ملف strings.xml خاص باللغة العربية و ربطها بلغة الجهاز. يمكنك متابعة هذا الشرح وهو مشروح بالتفصيل لكيفية إضافة نصوص عربية و انكليزية و التبديل بينها. مميزات ملف الـ strings.xml: 1- تخزين جميع النصوص المستخدمة داخل التطبيق واستخدام الملف كمكتبة يتم استيراد النصوص منها بشكل مباشر (فصل النصوص بملفات خارجية أي خارج ال text Views). 2- تغيير النص داخل ملف الـ strings كفيل بتغيير كافة الـ text Views التي تستخدم هذا النص على سبيل المثال(ربطها عن طريق متحولات). 3- تخزين جميع اللغات التي ترغب أن يدعمها التطبيق الخاص بك. حيث سيتم عرض النصوص بحسب اللغة المستخدمة داخل الجهاز. لنتعرف معاً كيف يتم التعامل مع هذا الملف.
 1 نقطة
1 نقطة -
لا يوجد خطأ أخي يطلق عليها الإسمين array of objects أو أوبجيكت لأنها تحتوي الإثنان معنا يعني متعددة يوجد فيها اوبجيكتس والاوبجكتس تحتوي بداخلها مصفوفة1 نقطة
-
أهلاً بك . بالتأكيد الموضوع طبيعي نسبياً ، فهو يعتمد على الخبرة و الممارسة و المتابعة و التجربة ، و لن تكون محترف في تحليل و دراسة الخورزميات من البداية . لذلك لا داعي للقلق فهو طبيعي و يحصل مع معظم الناس، تابع الدروس و جرب مراراً و تكراراً و ستشعر بالتحسن في مهاراتك بشكل عام . ولكن لا بد من ذكر هذه المعلومة المهمة ، أن ليس كل الأشخاص بنفس المستوى من الذكاء و المبرمج الناجح بالتأكيد يجب أن يكون شخص ذكي . و البرمجة لا تصلح كمهنة أو دراسة لكل الأشخاص ـ لذلك على كل من يرى أنه لا يوجد توافق بينه و بين تعلم البرمجة أن يترك هذه المجال و يبحث عن شيء آخر و يختصر عليه الوقت و الجهد .1 نقطة