كل الأنشطة
- الساعة الماضية
-
 Tasneem Aboelfadl اشترك بالأكاديمية
Tasneem Aboelfadl اشترك بالأكاديمية -
انا درس فاهمه لكن عند انشاء موقع انسى كيف ينكتب او كيف ابدا وانا بدي طريقة فعالة بدون ملل
-
 منيرة الميتكنانى اشترك بالأكاديمية
منيرة الميتكنانى اشترك بالأكاديمية -
 صلاح محمد صلاح اشترك بالأكاديمية
صلاح محمد صلاح اشترك بالأكاديمية -
 Deyaa Aleryani اشترك بالأكاديمية
Deyaa Aleryani اشترك بالأكاديمية -
 عمر حسام4 اشترك بالأكاديمية
عمر حسام4 اشترك بالأكاديمية - اليوم
-
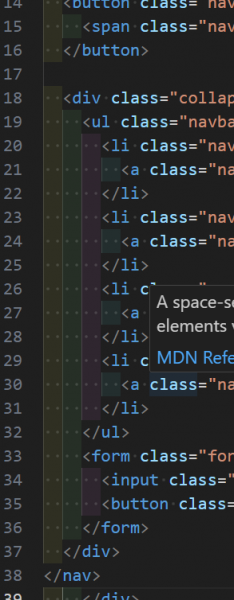
هل قمت بتثبيت إضافة "Prettier - Code formatter" ؟ يرجى التأكد من تثبيتها وهي تلك الإضافة : https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode من المفترض عند إستخدامها أن يتم تنسيقها بالشكل الصحيح حيث يتم وضع الأبناء بداخل الأباء وتنسيقها بشكل صحيح وواضح ولكن بالفعل لو كان السطر كبيرا سيتم تقسيمه إلى عدة أسطر وذلك منعا لجعل السطر طويل جدا . أيضا لاحظت أنه لديك إضافة Indent Rainbow وتلك الإضافة ممتازة حيث تقوم بتلوين كل عنصر بلون ما في الإزاحات : لاحظ كيف لكل عنصر اللون الخاص به والذي يوضح بدايته ونهايبته والعناصر الأبناء له .
-
 وفاء المشتولي اشترك بالأكاديمية
وفاء المشتولي اشترك بالأكاديمية -
 Ezzat Emad اشترك بالأكاديمية
Ezzat Emad اشترك بالأكاديمية -
 هديل فؤاد اشترك بالأكاديمية
هديل فؤاد اشترك بالأكاديمية -
 Mohamed Al Shora اشترك بالأكاديمية
Mohamed Al Shora اشترك بالأكاديمية -
وعليكم السلام ورحمة الله وبركاته. نعم بالتأكيد هذا الحاسوب ممتاز جدا للبرمجة ومواصفته جيدة حتى لو العمل على الذكاء الاصطناعي وهو يعتبر من الأجهزة القوية في هذا المجال. فهنا يوجد المعالج (M3 Pro) وهذا المعالج من أقوى معالجات آبل وسيمنحك أداء سريع جدا في كل مهام البرمجة مثل تشغيل الأكواد (compiling) والتعامل مع بيئات التطوير (IDEs) الكبيرة والتي تتطلب ذاكرة ومعالج قوي وأيضا يمكنك تشغيل عدة تطبيقات في نفس الوقت بسلاسة. والذاكرة العشوائية(Ram) هنا بحجم 18 جيجابايت ويعتبر ممتاز للبرمجة وسيمكنك من تشغيل المحاكيات (emulators) وقواعد البيانات ونماذج تعلم الآلة والعديد من الأدوات الأخرى في نفس الوقت دون أن تشعر بأي بطء في الجهاز. وهنا أيضا وحدة التخزين وهي من نوع SSD وتضمن سرعة فائقة في فتح البرامج والمشاريع وبحجم 512 جيجابايت يعتبر جيد في بداية تعلمك ولكن بعد ذلك قد تحتاج إلى إدارة المساحة أو استخدام وحدات تخزين خارجية إذا كانت مشاريعك أو البيانات التي تتعامل معها كبيرة الحجم. تلخيصا هذا الجهاز قادر على التعامل مع معظم مهام الذكاء الاصطناعي بكفاءة عالية وأيضا في البرمجة بشكل عام. ولكن أنصحك بمراجعة حالة الجهاز وأيضا التأكد من السعر بالنسبة للسوق لديك هل هو مناسب أم سعره مرتفع.
-
 Maram Edress اشترك بالأكاديمية
Maram Edress اشترك بالأكاديمية -
السلام عليكم. تعطل الحاسوب الذي كنت استخدمه ووجدت واحدا آخر ولكن لا أعلم إذا كانت خصائصه مناسبة للبرمجة وأود ان تنصحوني من فضلكم . وجدت MacBook بالخصائص التي في الصورة المرفقة .هل هو مناسب ام ان الذاكرة الحية يجب ان تكون أكثو من ذلك والستوراج أكثر؟ مادع العلم أني أعمل في الحاسوب كثيرا .

- 1 جواب
-
- 1
-

-
هل تريد المراجعة أم التطبيق ؟ الأفضل إذا كنت متذكر الأساسيات والدروس السابقة التي درستها فأنصحك بالتطبيق العملي وهذا الأمر الذي سيقوم بتثبيت المعلومة لديك وإعطاءك المزيد من الخبرة . وإليك المواقع التي تقدم لك إختبارات : أما إذا أردت المراجعة فيوجد لديك موسوعة حسوب كمرجع لك، وأيضًا مقالات البرمجة التي بالأكاديمية.
-
 نعم اقصد هذا بس لما عملتها بيقسم الاسطر وبيعملها بطريقه غريبه انا كنت عايز خاصيه مثلا تنظم الكود اللي هو الاب جواه الابناء بتاعته ويبان من الشكل ان دولة جو دا
نعم اقصد هذا بس لما عملتها بيقسم الاسطر وبيعملها بطريقه غريبه انا كنت عايز خاصيه مثلا تنظم الكود اللي هو الاب جواه الابناء بتاعته ويبان من الشكل ان دولة جو دا -
هل تقصد عمل format أى تنسيق للكود بأكمله أم ماذا ؟ إذا كان كذلك فالزر هو ALT + SHIFT + F ويمكنك إختيارها من القائمة هنا من خلال إما تحديد العناصر التي تريد تنسيقها أو الصفحة بأكلمها من خلال الضغط بالزر الأيمن للفأرة بداخل الملف :
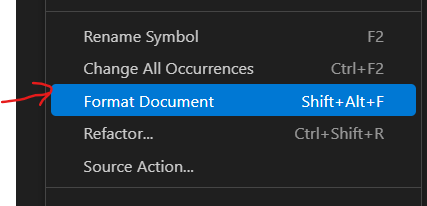
-
عارف دول في بقا زرار او خاصيه بتظبط شكل الاكواد في البرنامج عشان يكون منسق زي خاصية Prettier باين الخاصيه دي انا منزلها بس مش عارف شغاله ولا لا
-
هل تقصد محاذاة العناصر ؟ أى حذف المسافات لتعين ماكن بدأ العناصر ؟ إذا كان كذلك فالزر هو SHIFT + Tab وهذا الأمر سيقوم بحذف المسافات التي قبل العنصر أى يحذف إزاحة كاملة . أما زر ال Tab فإنه يضيف إزاحة زائدة.
-
كان في حاجه بضغط عليها مع زرار Tab عشان اظبط الاكواد عشان ابقى عارف اول الكود فين واخره فين بس عشان فضلت فتره مش بعمل مشاريع نسيته ممكن حد يفكرني بيها كنت بضغط تاب مع حاجه عشان ينسق الاكواد
- 5 اجابة
-
- 1
-
-
لو انت مشترك في احدى الدورتين تواصل معايا انا بحاول اعمل مجتمع يكون لينا للي معاه الدورتين او واحده فيهم عشان نتشارك الافكار مع بعض ونذاكر ونشجع بعض
-
انا الان انهيت اساسيات html and css and java script واريد طريقة لمراجعتهما بطريقة ممتعة لأنني لم استطع ان اراجع بطريقة العادية مع انني حاولة لا اعرف مالذي يمنعني انا احب ان ادرس وادرس كثيرا ولكن في المراجعة انا سيء هل من حل
- 2 اجابة
-
- 1
-
-
انا بدرس في دورة الذكاء الاصطناعي بقالي حوالي ست شهور وحاليا في مسار machine learning وانا عندي 17 سنه وبلعب في كوره في نادي وفي نفس الوقت عندي دراستي اللي في المدرسه فا الوقت عندي بيبقي محدود اني اذاكر الذكاء الاصطناعي لان بصراحه عندي شغف بيه فانا كنت عايز طريقه او خطه اني اقدر استفيد من الدوره كامله اكبر استفاده وابقي متخرج كا جونير كويس في المجال حتي لو مش هشتغل بيه بحب اقعد اجرب التقنيات اللي اتعملتها فا ارجو الإفاده
-
يرجى إرفاق ملف الكود وليس نسخه هكذا ليتم الحفاظ على هيكل الكود ومساعدتك بشكل أفضل. إذا كان هذا السؤال خاص بإحدى الدورات يرجى وضع سؤالك أسفل الدرس مباشرة لنستطيع مساعدتك بشكل أفضل.
-
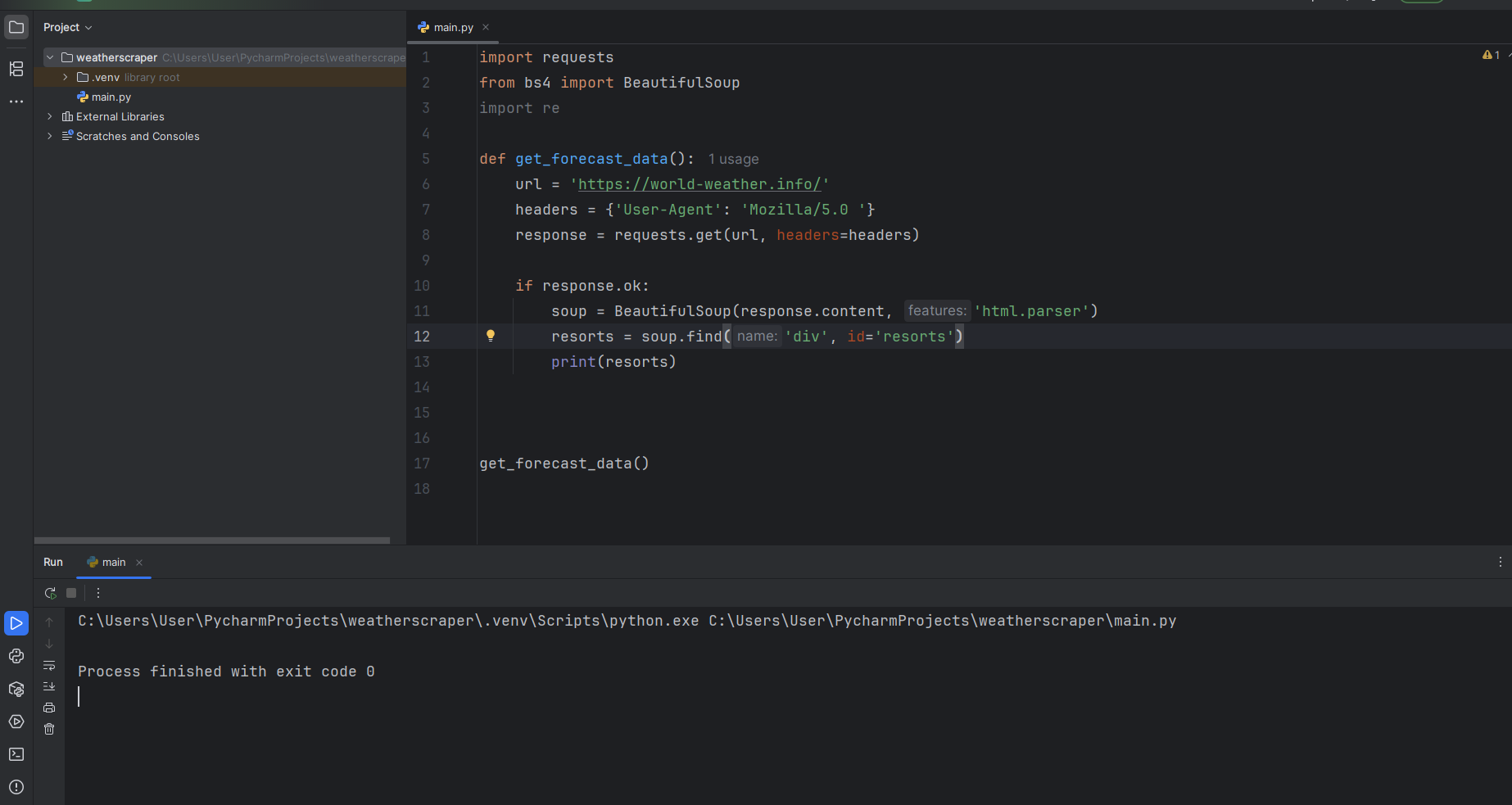
def get_forecast_data(): from selenium import webdriver from selenium.webdriver.chrome.options import Options from bs4 import BeautifulSoup options = Options() options.add_argument('--headless') # تشغيل بدون واجهة رسومية options.add_argument('--disable-gpu') options.add_argument('--no-sandbox') options.add_argument('--log-level=3') prefs = { "profile.default_content_setting_values": { "images": 2, "plugins": 2, "popups": 2, "notifications": 2, "media_stream": 2, } } options.add_experimental_option("prefs", prefs) driver = webdriver.Chrome(options=options) driver.get("https://world-weather.info/") html = driver.page_source # هنا كما بالدرسBeautifulSoup اكتب الكود الخاص بـ soup = BeautifulSoup(html, "html.parser") resorts = soup.find_all("div", id="resorts") print(resorts) driver.quit() get_forecast_data() import requests from bs4 import BeautifulSoup import re def get_forecast_data(): url = 'https://world-weather.info/' headers = {'User-Agent': 'Mozilla/5.0'} response = requests.get(url, headers=headers) if response.ok: soup = BeautifulSoup(response.content, 'html.parser') resorts = soup.find('div', class_='list') re_cities = r'">([\w\s]+)<\/a><span>' cities = re.findall(re_cities, str(resorts)) print(cities) get_forecast_data()
- 1 جواب
-
- 1
-
-
مرحبا هل يمكنني ان اعرض لكم سكريبت الخاص بي
-
وعليكم السلام ورحمة الله وبركاته. ستجد أسفل فيديو الدرس صندوق للتعليقات كما هنا يرجى طرح سؤالك أسفل الدرس وليس هنا حيث هنا قسم الأسئلة العامة ولا نقوم بإجابة الأسئلة الخاصة بمحتوى الدورة أو الدرس، وذلك لمعرفة الدرس الذي توجد به مشكلتك و لمساعدتك بشكل أفضل.
-
وعليكم السلام ورحمة الله وبركاته. إن ال (Test-Driven Development - TDD) هو أسلوب في تطوير البرمجيات يجعلك تكتب الاختبار (Test Case) الخاص بوظيفة معينة قبل أن تكتب الكود الفعلي لتلك الوظيفة فالفكرة الأساسية هي أن الاختبار هو الذي يقود عملية كتابة الكود وليس العكس. وهنا ثلاث خطوات للدورة الواحدة في ال TDD : أولا كتابة اختبار فاشل :حيث في تلك المرحلة تقوم بكتابة اختبار آلي (Automated Test) لجزء صغير من الوظيفة التي تريد إضافتها. ولأنك لم تكتب الكود الفعلي بعد فمن الطبيعي أن هذا الاختبار سيفشل عند تشغيله وهو أمر متوقع ومطلوب وهذا يضمن أن الاختبار نفسه يعمل بشكل صحيح. ثانيا كتابة الكود لتخطي الاختبار بنجاح: فهنا نكتب أقل كمية ممكنة من الكود التي تجعل الاختبار الذي قمنا بكتابته ينجح وفي هذه المرحلة لا نهتم بجودة الكود أو نظافته أو كفاءته بل الهدف الوحيد هو جعل الاختبار ينجح. ثالثا تحسين الكود : بعد أن ينجح الاختبار وأصبحت تعرف أن الوظيفة تعمل كما هو متوقع تبدأ الآن في تحسين الكود وتنظيفه. ثم بعد ذلك تكرر هذه الدورة لكل وظيفة صغيرة جديدة تريد إضافتها في برنامجك.
-
وعليكم السلام ورحمة الله، هو عبارة عن هو منهجية في تطوير البرمجيات تعتمد على كتابة اختبارات برمجية تلقائية قبل كتابة الشيفرة الفعلية حتى بحيث تبدأ العملية بكتابة اختبار فاشل يصف ميزة أو وظيفة جديدة يراد تطويرها، ثم يقوم المبرمج بكتابة أبسط كود ممكن لكي يجعل هذا الاختبار ينجح، وبعدها يتم تحسين الكود من خلال إعادة التصميم دون تغيير سلوكه لضمان جودته وقابليته للصيانة. وهذه الدورة تتكرر بشكل سريع ومنظم لتغطية كل الوظائف الجديدة مما يزيد من جودة الكود ويقوي الثقة بأن البرمجيات تعمل كما هو متوقع. أما وأسلوب TDD يشجع على التفكير المسبق في متطلبات البرنامج وتصميمه ويعتمد بشكل كبير على اختبار وحدات الكود الصغيرة بشكل مستقل مما يسهل اكتشاف الأخطاء وتصحيحها بشكل مبكر كما يقلل من حدوث مشاكل عند تطوير الوظائف الجديدة أو تعديل الكود القائم يمكنك الاطلاع أكثر من هنا:
-
السلام عليكم هو اي مفهوم الTest-Driven Development ؟
- 2 اجابة
-
- 2
-
-
الف شكراا جدا لحضرتك جزاك الله كل خير
-
وعليكم السلام ورحمة الله وبركاته. إن البيانات الضخمة (Big Data) هو مصطلح يصف الكميات الهائلة والمعقدة من البيانات التي لا يمكن معالجتها أو تحليلها باستخدام الطرق التقليدية العادية. وتتميز هذه البيانات بثلاث خصائص رئيسية تعرف بـ 3Vs: الحجم (Volume): وهنا كمية البيانات تكون كبيرة جدا . السرعة (Velocity): يتم إنتاج البيانات بسرعة عالية جدا وبشكل مستمر مثل بيانات وسائل التواصل الاجتماعي أو أجهزة الاستشعار وغيرها. التنوع (Variety): تأتي البيانات بأشكال مختلفة منها البيانات المنظمة مثل جداول قواعد البيانات وغير المنظمة مثل النصوص والصور ومقاطع الفيديو. أما إدارة البيانات الضخمة (Big Data Management) فهي عملية جمع وتخزين ومعالجة وتحليل كميات كبيرة من البيانات لضمان جودتها وأمانها وإتاحتها لاتخاذ قرارات أفضل وتتضمن هذه العملية عدة خطوات وتقنيات منها: تكامل البيانات (Data Integration) حيث يتم جمع البيانات من مصادر متعددة. تخزين البيانات (Data Storage) وهنا يتم إستخدام أنظمة تخزين تستطيع على التعامل مع الحجم الهائل والكبير للبيانات مثل أنظمة الملفات الموزعة . معالجة البيانات (Data Processing) عن طريق استخدام أدوات قوية لمعالجة هذه البيانات بسرعة وهنا يأتي دور PySpark. حوكمة البيانات (Data Governance) وهي وضع سياسات ومعايير لضمان جودة البيانات وأمانها والامتثال للقوانين. وPySpark هو واجهة برمجية (API) بلغة بايثون لمحرك Apache Spark وإطار عمل قوي ومفتوح المصدر لمعالجة البيانات الضخمة بشكل موزع وعلى نطاق واسع. فببساطة PySpark يسمح للمطورين وعلماء البيانات باستخدام لغة بايثون لكتابة أكواد يمكنها تحليل ومعالجة كميات هائلة من البيانات بسرعة فائقة عن طريق توزيع المهام على مجموعة من الأجهزة . وأهم استخداماته: تحليل البيانات الضخمة. تعلم الآلة (Machine Learning) على مجموعات بيانات كبيرة. معالجة البيانات (Streaming Data) في الوقت الفعلي. أما مستودع البيانات (Data Warehouse) هو نظام مركزي لتخزين كميات كبيرة من البيانات من مصادر متنوعة داخل المؤسسة والهدف الأساسي منه ليس إدارة العمليات اليومية بل دعم عمليات التحليل الذكي للأعمال (Business Intelligence - BI) واتخاذ القرارات الاستراتيجية ويتم تنظيم البيانات فيه بشكل يسهل عمل الاستعلامات التحليلية وإنشاء التقارير. وETL هي عملية أساسية لبناء مستودع البيانات وتتكون من ثلاث مراحل: الاستخراج (Extract): سحب البيانات من مصادر مختلفة. التحويل (Transform): تنظيف البيانات وتنسيقها وتحويلها لتكون متوافقة مع هيكل مستودع البيانات وقد تتضمن هذه المرحلة دمج البيانات وإزالة التكرار وتغيير التنسيقات. التحميل (Load): تحميل البيانات المحولة إلى مستودع البيانات (DWH) لتكون جاهزة للتحليل. أما DI (Data Integration) تكامل البيانات فهو مصطلح أشمل من ETL. وإنه يشير إلى جميع العمليات والتقنيات المستخدمة لدمج البيانات من مصادر مختلفة لتقديم رؤية موحدة وشاملة ويمكن أن يتم تكامل البيانات بعدة طرق، ويعتبر ETL أحد أشهر هذه الطرق. و أخيرا PL/SQL (Procedural Language/Structured Query Language) هي لغة برمجة إجرائية تم تطويرها بواسطة شركة أوراكل كإمتداد للغة SQL وبينما تستخدم SQL للتعامل مع البيانات تضيف PL/SQL إمكانيات برمجية مثل: المتغيرات (Variables). الحلقات التكرارية (Loops). الجمل الشرطية (IF-THEN-ELSE). معالجة الأخطاء (Exception Handling).
- 2 اجابة
-
- 1
-
-
 على الأغلب فإنّ استمرارك في رفع التطبيقات على حساب الشركة من نفس الجهاز أو نفس عنوان ال IP الذي تم حظر حسابك الشخصي عليه سيشكل خطورة كبيرة جدا على حساب الشركة. حتى لو كان الحساب باسم شركة ومن بلد آخر فالسبب هو أن Google تربط الحسابات بالأجهزة والشبكات وأي تكرار لهذه العناصر بين حساب محظور وأي حساب آخر مهما كانت هوية الحساب الجديد يعرّض الحساب الجديد للحظر التلقائي أو المراجعة حتى لو مر وقت طويل أو تغيرت البيانات. لأنّ Google تستخدم تقنيات "البصمة الرقمية" أو Device Fingerprinting & IP Tracking حيث تتابع الجهاز نفسه حتى لو تم تغيير المستخدم وعنوان IP حتى مع تغيير الحساب أو الدولة وتتابع ملفات النظام المرتبطة بالحسابات المحظورة أيضا. لذا من الأفضل ألا تتستخدم نفس الجهاز أو نفس شبكة الإنترنت التي تم عبرها حظر حسابك الشخصي في أي عمل على حساب الشركة أي استخدام جهاز جديد كليا لم يسبق أن دخل عليه أي حساب Google Play محظور. واستخدام اتصال إنترنت جديد كليا ويفضّل أن يكون من بلد الشركة وليس أي اتصال كان مربوطا بالحساب المحظور. أما إذا اضطررت لاستخدام جهازك القديم فعليك إعادة تهيئة ضبط المصنع (Factory Reset) للجهاز ومسح كل بيانات الحسابات القديمة مع ذلك فهذا الحل قد لا يكون مضمونا لأنّه بالرغم من ذلك قد تكون الحسابات مربوطة برقم الجهاز نفسه (IMEI/MAC address)
على الأغلب فإنّ استمرارك في رفع التطبيقات على حساب الشركة من نفس الجهاز أو نفس عنوان ال IP الذي تم حظر حسابك الشخصي عليه سيشكل خطورة كبيرة جدا على حساب الشركة. حتى لو كان الحساب باسم شركة ومن بلد آخر فالسبب هو أن Google تربط الحسابات بالأجهزة والشبكات وأي تكرار لهذه العناصر بين حساب محظور وأي حساب آخر مهما كانت هوية الحساب الجديد يعرّض الحساب الجديد للحظر التلقائي أو المراجعة حتى لو مر وقت طويل أو تغيرت البيانات. لأنّ Google تستخدم تقنيات "البصمة الرقمية" أو Device Fingerprinting & IP Tracking حيث تتابع الجهاز نفسه حتى لو تم تغيير المستخدم وعنوان IP حتى مع تغيير الحساب أو الدولة وتتابع ملفات النظام المرتبطة بالحسابات المحظورة أيضا. لذا من الأفضل ألا تتستخدم نفس الجهاز أو نفس شبكة الإنترنت التي تم عبرها حظر حسابك الشخصي في أي عمل على حساب الشركة أي استخدام جهاز جديد كليا لم يسبق أن دخل عليه أي حساب Google Play محظور. واستخدام اتصال إنترنت جديد كليا ويفضّل أن يكون من بلد الشركة وليس أي اتصال كان مربوطا بالحساب المحظور. أما إذا اضطررت لاستخدام جهازك القديم فعليك إعادة تهيئة ضبط المصنع (Factory Reset) للجهاز ومسح كل بيانات الحسابات القديمة مع ذلك فهذا الحل قد لا يكون مضمونا لأنّه بالرغم من ذلك قد تكون الحسابات مربوطة برقم الجهاز نفسه (IMEI/MAC address)- 1 جواب
-
- 1
-
-
وعليكم السلام ورحمة الله، في دورة الذكاء الاصطناعي مسار تحليل البيانات لا يتناول موضوع البيانات الضخمة (Big Data) أو تقنياتها لأنّ هذا المجال واسع بحدّ ذاته وقد يحتاج إلى مسار أو اثنين منفصلين وفي بعض الحالات إلى دورة كاملة لشرحه وقد يتم إضافته مستقبلا في التحديثات القادمة، فالبيانات الضخمة هي كميات هائلة من البيانات التي تتطلب تقنيات خاصة لمعالجتها وتخزينها بسبب حجمها وسرعتها وتنوعها، ويتم إدارتها عبر بنى تحتية موزعة وبرمجيات متخصصة ضمن مفهوم يعرف ب Big Data management. أما PySpark فهو إطار عمل بلغة بايثون يتيح معالجة البيانات الضخمة باستخدام محرك Apache Spark بينما PLSQL فهي لغة برمجة خاصة بقواعد بيانات Oracle تمكن من كتابة إجراءات وبرامج داخل قاعدة البيانات. يمكنك الاطلاع أكثر من هنا:
- 2 اجابة
-
- 1
-