


Ahmed Nmer
-
المساهمات
8 -
تاريخ الانضمام
-
تاريخ آخر زيارة
إنجازات Ahmed Nmer
عضو مبتدئ (1/3)
6
السمعة بالموقع
-
 اولا احب اشكرك علي اهتمامك و توصياتك و انا لسه مبداء هتفديني كتير . في حاجات مش واضحه لي هل هي مش واضحه غير عندي بس زي ما موجود في الصوره بالنسبه لfinalize ده باكد لمستخدم علي الخطوات الي عمله (action log) وانا شاء الله همشي علي التوصيات دي و اعدل في الكود و شكرا
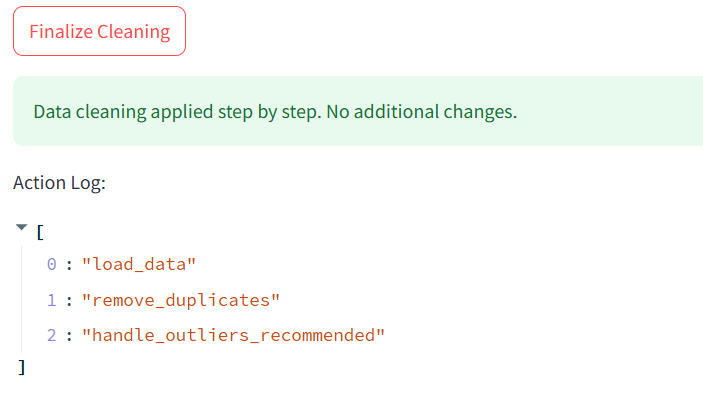
اولا احب اشكرك علي اهتمامك و توصياتك و انا لسه مبداء هتفديني كتير . في حاجات مش واضحه لي هل هي مش واضحه غير عندي بس زي ما موجود في الصوره بالنسبه لfinalize ده باكد لمستخدم علي الخطوات الي عمله (action log) وانا شاء الله همشي علي التوصيات دي و اعدل في الكود و شكرا
-
مرحبًا فريق أكاديمية حسوب، أنا من المتابعين لدوراتكم، وكنت حابب أشارك معاكم تطبيقي العملي اللي بنيته باستخدام Streamlit بعد ما أنهيت عدد من الدروس على المنصة، وطبّقت فيه كل اللي اتعلمته بالإضافة لبعض الاجتهادات الشخصية. رابط التطبيق على Streamlit Cloud: https://ml-app-010.streamlit.app/ عن التطبيق: ده تطبيق تفاعلي شامل بيغطي خطوات علم البيانات والتعلم الآلي من أول رفع البيانات وتنظيفها لحد تقييم النماذج وتفسير النتائج. الهدف منه يكون أداة تعليمية أو حتى وسيلة لتسريع تجربة النمذجة خاصة في المشاريع الصغيرة والمتوسطة. مميزات التطبيق باختصار: رفع ملفات CSV، Excel، أو JSON. تنظيف البيانات (duplicates، missing values، outliers) سواء يدويًا أو أوتوماتيكيًا باستخدام توصيات ذكية. اختيار نوع المشكلة (تصنيف أو انحدار). دعم لمجموعة من النماذج (Sklearn، XGBoost، LightGBM، CatBoost... إلخ). إمكانية التدريب باستخدام cross-validation أو AutoML. عرض تقييم شامل للنماذج المختارة. دعم أدوات شرح النماذج مثل SHAP وLIME. تصدير الخطوات المنفذة إلى Jupyter Notebook تلقائيًا. ملاحظات مهمة للمستخدمين: في جزئية الـ Missing Values وOutliers: التطبيق بيقدم طريقتين للتعامل، الأولى أوتوماتيكية بتوصيات، والتانية يدوية. يفضل المستخدم ياخد باله إنه لازم يختار واحدة منهم عشان ميتلخبطش. بعد خطوة الـ Split: بيظهر في الـ Sidebar اختيارات لScoring Metric زي Accuracy، F1، AUC لو كانت المهمة Classification، أو R²، MSE لو كانت Regression. فلازم المستخدم ينزل في الـ Sidebar بعد الـ Split عشان يظبط إعدادات التقييم. خيار Stratify: متاح فقط لو كانت المشكلة تصنيف (Classification)، فلو بتتعامل مع انحدار (Regression) من الأفضل تشيل التحديد من عليه. التطبيق غير مناسب لبيانات الـ Time Series في الوقت الحالي. استخداماته المحتملة: أداة تعليمية للمبتدئين. تسريع خطوات النمذجة للمشاريع الصغيرة و المتوسطه فهم خطوات ML بشكل تفاعلي بدل كتابة كود طويل. في النهاية: أنا حابب أسمع رأيكم في التطبيق، وإذا عندكم أي اقتراحات لتحسينه أو تطويره، هكون ممتن جدًا. كل ده جزء من رحلة التعلُّم اللي بدأتها معاكم، ولسه مكمل
- 2 اجابة
-
- 1
-

-
المستخدم في مشروع Bluebook for Bulldozers على GitHub، لاحظت أنه تم استخدام الطريقة اليدوية لتشفير البيانات وملء القيم المفقودة على مجموعة بيانات كبيرة. هذا ما جعلني مشوشًا. كيف يمكن تفسير استخدام الطريقة اليدوية هنا مع العلم أن scikit-learn يعتبر أكثر كفاءة خاصة مع البيانات الكبيرة؟ ولماذا لم يتم تقسيم البيانات إلى مجموعة تدريب واختبار قبل القيام بالمعالجة المسبقة في هذا الكود، كما ذكرت أن تقسيم البيانات قبل المعالجة أفضل لتجنب تسريب البيانات؟ رابط المثال على Kaggle: Bluebook for Bulldozers
-
في الكود التالي، قام بتشفير القيم التصنيفية وملء القيم المفقودة بشكل يدوي دون استخدام مكتبة scikit-learn: def preprocess_data(df): """ Performs transformations on df and returns transformed df. """ df["saleYear"] = df.saledate.dt.year df["saleMonth"] = df.saledate.dt.month df["saleDay"] = df.saledate.dt.day df["saleDayOfWeek"] = df.saledate.dt.dayofweek df["saleDayOfYear"] = df.saledate.dt.dayofyear df.drop("saledate", axis=1, inplace=True) # Fill the numeric rows with median for label, content in df.items(): if pd.api.types.is_numeric_dtype(content): if pd.isnull(content).sum(): # Add a binary column which tells us if the data was missing or not df[label+"_is_missing"] = pd.isnull(content) # Fill missing numeric values with median df[label] = content.fillna(content.median()) # Fill categorical missing data and turn categories into numbers if not pd.api.types.is_numeric_dtype(content): df[label+"_is_missing"] = pd.isnull(content) # Add +1 to category codes to avoid -1 for missing categories df[label] = pd.Categorical(content).codes+1 return df متى يجب عليّ استخدام هذه الطريقة اليدوية لتشفير القيم وملء القيم المفقودة؟ ومتى يكون من الأفضل استخدام مكتبة scikit-learn، مثل استخدام دالة SimpleImputer لملء القيم المفقودة و OneHotEncoder لتشفير القيم التصنيفية؟ أيضًا، متى يجب تقسيم البيانات قبل القيام بعمليات المعالجة المسبقة (مثل التشفير وملء القيم المفقودة)؟ ومتى يكون من المناسب معالجة البيانات كاملة كما في المثال أعلاه؟ مثال باستخدام scikit-learn: from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline # Split data X_train, X_test, y_train, y_test = train_test_split(df.drop("target", axis=1), df["target"], test_size=0.2) # Define preprocessing pipeline numeric_features = ['age', 'income'] categorical_features = ['gender'] numeric_transformer = SimpleImputer(strategy='median') categorical_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='most_frequent')), ('onehot', OneHotEncoder(handle_unknown='ignore')) ]) # Combine both transformers preprocessor = ColumnTransformer( transformers=[ ('num', numeric_transformer, numeric_features), ('cat', categorical_transformer, categorical_features) ]) # Apply the transformations on training and testing sets X_train_transformed = preprocessor.fit_transform(X_train) X_test_transformed = preprocessor.transform(X_test)
- 2 اجابة
-
- 1
-