Kais Hasan
-
المساهمات
2633 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
26
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Kais Hasan
-
مرحبًا، توجد مكتبات وأدوات مثل Kivy وBeeWare تتيح لك إنشاء تطبيقات باستخدام بايثون. على الرغم من ذلك، قد تكون هذه الأدوات أقل شيوعًا مقارنة بأطر أخرى مخصصة مثل Flutter أو React Native. أما إذا كنت تبحث عن لغة تشبه بايثون وسهلة التعلم، فإنني أوصي بلغة Dart مع إطار Flutter. Dart لديها هيكلية سهلة و بسيطة و قد تكون انتقالًا سلسًا لمتعلمي بايثون. باستخدام Flutter، يمكنك بناء تطبيقات جميلة وسريعة تعمل على أنظمة التشغيل Android وiOS. تحياتي.
-
مرحبًا، دورة تطوير التطبيقات باستخدام بايثون تركز على البايثون نفسه، و لذلك في حال نظرت إليها من ناحية المجالات (تحليل بيانات، ويب، الخ) ستجدها مشتتة، و لكنها تركز على بايثون و هناك الكثير من الأشخاص الذين يعملون في الكثير من المجالات بسبب خبرتهم في اللغة. يبدو أنك مهتم بمجال تحليل البيانات و الذكاء الصنعي، لذلك من الجيد بعد إنهاء المسارات التي ذكرتها أن تقوم بدراسة دورة الذكاء الصنعي، فهي شاملة أكثر و ستتعلم فيها كل ما تحتاجه في المجال. تحياتي.
-
في حال كان المقصود هو مجال تحليل البيانات، فإنهاء المسار المذكور غير كافٍ. عليك إنهاء المسار الذي يليه و الذي يوضح كيفية التعامل مع قواعد البيانات فهي مهمة في مجال تحليل البيانات. كما عليك أن تدرس قسم تحليل البيانات و قسم أساسيات تعلم الآلة فهي أمور أساسية و مهمة في مجال تحليل البيانات. بعد إنهاء هذه المسارات يفترض أن تصبح لديك معلومات كافية للعمل، و لكن عليك القيام بالعديد من المشاريع في هذا المجال فأغلب الشركات تطلب ذلك و عدد المشاريع الذي ستقوم بها في هذه الدورة غير كافٍ لأن الدورة مخصصة لتطوير التطبيقات بشكل عام و ليس فقط إلى مجال تحليل البيانات. من الجيد بعد إنهاء المسارات التي ذكرتها لك أن تقوم بمحاولة حل بعض المشاكل على مواقع مثل Kaggle فهي تساعدك على تحسين مهاراتك. لتجد فرص عمل في هذا المجال من الجيد أن تقوم بالإطلاع على موقع مستقل، فبشكل يومي يطلب مشاريع يمكن لمن لديه معلومات في تحليل البيانات القيام بها. كمان أن هذا سيكون خطوة على طريق أن تعمل في شركة. بالإضافة إلى موقع مستقل حاول دائمًا أن تبني حساب جيد على LinkedIn و أن تحاول التقديم على وظائف مثل Data Analyst فهي مناسبة لما تريده و عادة لا يتم طلب خبرة كبيرة في بعضها. تحياتي.
-
و عليكم السلام، كلاهما عبارة عن طريقة لتمثيل الكلمات بشكل رقمي. الطريقة الأولى فقط تقوم بتحويل الكلمات إلى أرقام بدون أي معنى، أي أنها تقوم باعتبار أن كل كلمة مستقلة عن غيرها بشكل كامل، لذلك يتم تمثيلها على شكل 1 في الدليل الخاص بالكلمة و 0 في كل مكان آخر. الطريقة الثانية تعتبر أن الكلمات لها معاني، و بالتالي يمكن تمثيلها حسب المعاني التي تحملها، لذلك تقوم بإنشاء فضاء أشعة كل بعد فيه يمثل معنى ما، و بذلك يتم تمثيل الكلمات كأشعة ضمن هذا الفضاء بحيث قيمة هذا الشعاع عند كل بعد هو مدى علاقة هذه الكلمة بذلك البعد. مثلًا لنفترض أن الفضاء يحوي على بعدين أحدهما يمثل الجنس (ذكر و أنثى، مثلًا الذكر بالاتجاه الموجب و الأنثى بالسالب)، بعد آخر يمثل العمر، بعد آخر يمثل المكانة المجتمعية (مثلًا مواطن عادي، أو رئيس) الخ.. بتلك الحالة يمكن تمثيل كلمة "ملك" على أن لها قيمة موجبة في بعد الجنس و قيمة موجبة كبيرة في بعد المكانة الاجتماعية، و قيمة موجبة كبيرة نوعًا ما في بعد العمر (فالملك غالبًا لا يكون عمره صغير). هذا مثال بسيط جدًا، بالطبع هذه الأبعاد يتم تعلمها بشكل تلقائي و لكن يمكن فهم ما تمثله عن طريق رؤية تمثيل العديد من الكلمات بعد القيام بتدريب النموذج. بالطبع عليك استعمال Embedding Layer، فهي الطريقة المعتمدة حاليًا. تحياتي.
- 5 اجابة
-
- 1
-

-
 و عليكم السلام علي، عادة ما يكون هناك تقاطع بين المجالات، فأهداف بعض المجالات قد تكون مشتركة. مثلًا مجال معالجة الصورة يهتم بكافة الأمور المتعلقة بالعمليات التي نقوم بتطبيقها على الصور، من فلاتر و تحسينات و غيرها. أما مجال علم البيانات فهو يهتم بالعمليات التي يمكن عن طريقها استخراج الأنماط من البيانات و استعمالها في اتخاذ القرارات. بالتالي في حال كانت البيانات التي تريد استخلاص أنماط منها هي صور، فغالبًا ستقوم بتطبيق بعض الأمور التي تتبع لمجال معالجة الصور. تحياتي.
و عليكم السلام علي، عادة ما يكون هناك تقاطع بين المجالات، فأهداف بعض المجالات قد تكون مشتركة. مثلًا مجال معالجة الصورة يهتم بكافة الأمور المتعلقة بالعمليات التي نقوم بتطبيقها على الصور، من فلاتر و تحسينات و غيرها. أما مجال علم البيانات فهو يهتم بالعمليات التي يمكن عن طريقها استخراج الأنماط من البيانات و استعمالها في اتخاذ القرارات. بالتالي في حال كانت البيانات التي تريد استخلاص أنماط منها هي صور، فغالبًا ستقوم بتطبيق بعض الأمور التي تتبع لمجال معالجة الصور. تحياتي.- 4 اجابة
-
- 1
-
-
يمكنك استعمالها في ال console الخاص بالمتصفح، فقط اضغط على ctrl+shift+c يفترض أن يظهر لك. هناك يمكنك كتابة بعض أكواد جافا سكربت و رؤية ما تقوم به على الصفحة. أيضًا في حال قمت بكتابة موقع و فيه كود js يمكنك وضع بعض تعليمات الطباعة للتحقق مما يحدث و فتح ال console لرؤية الخرج و فهم كيف يسير العمل. بشكل عام هذه طرق عملية للقيام بذلك، و لكن الصحيح هو أن تفهم آلية عمل اللغة، فعندها يمكنك تخيل كيف سيسير عمل البرنامج و هذا ضروري. تحياتي.
-
مرحبًا علي، خوارزميات ال binary search تحتاج إلى شروط أكثر، فيجب أن تكون العناصر قابلة للترتيب بناء على ما تريد البحث عنه، مثلًا في حال كنت تريد البحث عن رقم ما ضمن مصفوفة أرقام يجب أن تكون الأرقام مرتبة. أما ال tree فلا تفترض ترتيب كهذا فعملية البحث تتم عن طريق جداول hashing لا تفترض أن البيانات مرتبة بشكل تلقائي. كما أن ال tree تسمح لك بإضافة و حذف عناصر بسهولة على عكس المصفوفة. أي بشكل عام لا يوجد خيار مفضل بشكل مطلق، دائمًا قم بالتفكير بما تريده بشكل دقيق و على أساس ذلك يتم تحديد أي الخيارات أفضل. تحياتي.
- 2 اجابة
-
- 1
-
-
مرحبًا علي، رغم أنه يجب أن يكون هناك توافق بين الاثنين، إلا أن ال loss قد يعطيك فكرة عن بعض المشاكل التي قد لا توضحها ال accuracy. أحد أهم هذه المشاكل هو التوقع بدون مقدار ثقة عالية من النموذج، مثلًا في حال كنا نقوم بمهمة تصنيف ثنائي لنفترض حالة متطرفة بأن النموذج توقع كل الأصناف التي هي 1 عن طريق وضع احتمال 0.51 و كل الأصناف التي هي 0 عن طريق وضع احتمال 0.49. في هذه الحالة ستكون الدقة 100% و لكن الخطأ مرتفع جدًا بسبب أن النموذج غير واثق من نتائجه و أي تغيير طفيف في الدخل قد يؤدي إلى تغير الخرج بين الصنفين. لذلك دائمًا أبقي نظرك على كليهما. تحياتي.
- 2 اجابة
-
- 1
-
-
مرحبًا علي، نعم كلما كانت أقل كلما كانت أفضل. و لكن عليك النظر إلى كل من نتيجة الخطأ على بيانات التدريب و بيانات الاختبار، فإذا كان الخطأ كبير في بيانات التدريب هذا يعني أن النموذج لم يتعلم الأنماط الموجودة في البيانات و عليك زيادة تعقيده. أما في حال كان الخطأ صغير على بيانات التدريب، فهنا يكون هناك مشكلة over-fitting و عليك البدء بحلول بسيطة مثل تقليل تعقيد النموذج و إضافة regularization و غيرها من الطرق البسيطةـ في حال لم ينجح الأمر حاول استعمل transfer learning عن طريق استعمال نموذج مدرب مسبقًا على بيانات كثيرة في مهمة تشبه المهمة التي تحاول القيام بها، عندها يمكنك الاستفادة من الأنماط التي اكتشفها و تدريب جزء صغير منه فقط ليناسب المهمة الخاصة بك. في حال لم ينجح أي مما سبق قد تضطر إلى جمع بيانات أكثر. تحياتي.
- 3 اجابة
-
- 1
-
-
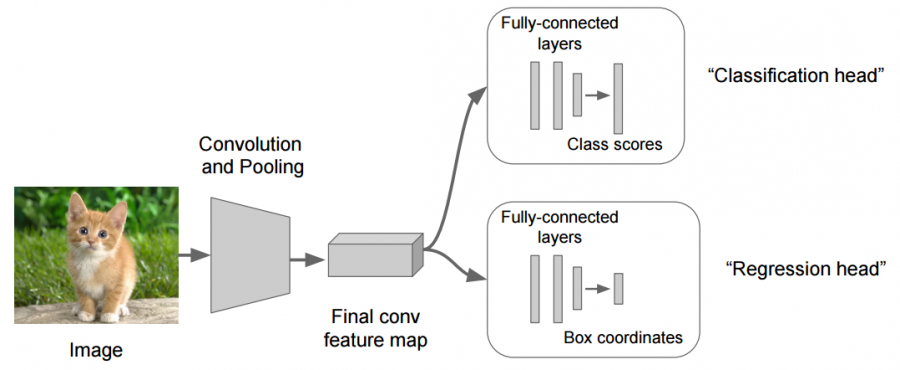
و عليكم السلام، يمكنك استعمال ما تشاء من قيم الخرج، لا وجود لحد نظري يخبرك أنه لا يمكن استعمال أكثر من خرج. أي أن هناك الكثير من الشبكات تقوم بتوقع العديد من الأمور في نفس الوقت، مثلًا ال YOLO تقوم بتوقع موقع الغرض (عن طريق صندوق يحيط به)، الصنف الذي يتبع له هذا الغرض، و مقدار الثقة في التوقع. لذلك عندما تريد توقع أكثر من قيمة ببساطة يجب أن يكون هناك أكثر من label، بحيث تقارن توقع النموذج به. بالطبع قد تحتاج إلى بعض التغييرات في هيكلية الشبكة، حيث يتم قسمها إلى قسم مختص باستخراج الميزات، و عدد من الرؤوس كل منها مبني على قسم الاستخراج و يقوم بتوقع قيمة ما. هذه صورة توضح أحد الأمثلة على استعمال رأسين للشبكة: تحياتي.
- 2 اجابة
-
- 1
-
-
لقد حللت مشكلتك. كان هناك مشكلة في ترك فراغ حتى يمكن رسم ال legends فيه باستعمال الطريقة السابقة. لكن إبقاء المخططين بجانب بعضهما سيجعل المخططات متداخلة، لذلك قمت ببعض التنسيق بحيث تظهر المخططات بشكل أفضل: import matplotlib.pyplot as plt import seaborn as sns import pandas as pd from matplotlib.patches import Patch data_train = pd.read_csv('train.csv') # Create figure with 2 vertical subplots (2 rows, 1 column) fig, axes = plt.subplots(2, 1, figsize=(12, 14)) # Increased height for vertical spacing # ----------------------------------------------------------------- # Plot 1: Top plot (age_at_hct vs gvhd_proph) # ----------------------------------------------------------------- hue_categories_1 = data_train['gvhd_proph'].unique() palette_1 = sns.color_palette("Blues", n_colors=len(hue_categories_1)) sns.histplot( data=data_train, x='age_at_hct', hue='gvhd_proph', multiple='stack', palette=palette_1, ax=axes[0], legend=False ) axes[0].set_title("Stacked Histogram of Age at HCT and GVHD Prophylaxis", pad=20) axes[0].set_xlabel("Age at HCT") axes[0].set_ylabel("Count") # Legend for top plot (right side) legend_patches_1 = [Patch(color=color, label=label) for color, label in zip(palette_1, hue_categories_1)] axes[0].legend( handles=legend_patches_1, bbox_to_anchor=(1.05, 1), # Right side loc='upper left', title='GVHD Prophylaxis' ) # ----------------------------------------------------------------- # Plot 2: Bottom plot (age_at_hct vs tbi_status) # ----------------------------------------------------------------- hue_categories_2 = data_train['tbi_status'].unique() palette_2 = sns.color_palette("Blues", n_colors=len(hue_categories_2)) sns.histplot( data=data_train, x='age_at_hct', hue='tbi_status', multiple='stack', palette=palette_2, ax=axes[1], legend=False ) axes[1].set_title("Stacked Histogram of Age at HCT and Tbi-Status", pad=20) axes[1].set_xlabel("Age at HCT") axes[1].set_ylabel("Count") # Legend for bottom plot (right side) legend_patches_2 = [Patch(color=color, label=label) for color, label in zip(palette_2, hue_categories_2)] axes[1].legend( handles=legend_patches_2, bbox_to_anchor=(1.05, 1), # Right side loc='upper left', title='TBI Status' ) # ----------------------------------------------------------------- # Final layout adjustments # ----------------------------------------------------------------- plt.tight_layout() plt.subplots_adjust( hspace=0.3, # Space between subplots right=0.85 # Make space for legends on the right ) plt.show() تحياتي.
- 6 اجابة
-
- 1
-
-
بشكل عام تكون مفيدة في حال كان هناك ترتيب للبيانات، مثلًا لنفترض أنه لديك بيانات توضح درجات الحرارة من تاريخ محدد لتاريخ محدد. في حال كان هناك أحد التواريخ فيه خطأ و لم يتم تسجيل درجة الحرارة فيه، يمكنك استعمال هذه التقنية فبشكل عام أنت تريد أن تعطي وزن أكبر للأيام القريبة، فدرجات الحرارة نادرًا ما تتغير بشكل كبير بين يوم و آخر، و لكن بنفس الوقت تريد إبقاء تأثير الأيام البعيدة و لكن بدرجة أخف (لإلغاء تأثير تقلب حدث بشكل استثنائي في درجات الحرارة). تحياتي.
- 5 اجابة
-
- 1
-
-
مرحبًا، يجب أن يكون استعمال bbox_to_anchor مناسب لحل مشكلتك، يمكننا وضعه في أول الرسم البياني بحيث يكون فوق الرسم. جرب استعمال الكود التالي و أخبرني بالنتيجة: import matplotlib.pyplot as plt import seaborn as sns # Assuming 'data_train' is your DataFrame # Set the overall figure size plt.figure(figsize=(12, 11)) # Plot 1: age_at_hct vs gvhd_proph plt.subplot(2, 2, 1) sns.histplot(data=data_train, x='age_at_hct', hue='gvhd_proph', multiple='stack', palette='Blues') plt.title("Stacked Histogram of Age at HCT and GVHD Prophylaxis") plt.xlabel("Age at HCT") plt.ylabel("Count") plt.legend(bbox_to_anchor=(1, 1), loc='upper left') # Move legend outside # Plot 1: age_at_hct vs tbi_status plt.subplot(2, 2, 2) sns.histplot(data=data_train, x='age_at_hct', hue='tbi_status', multiple='stack', palette='Blues') plt.title("Stacked Histogram of Age at HCT and Tbi-Status") plt.xlabel("Age at HCT") plt.ylabel("Count") plt.legend(bbox_to_anchor=(1, 1), loc='upper left') # Move legend outside plt.tight_layout() plt.show() تحياتي.
- 6 اجابة
-
- 1
-
-
يبدو أن هذا السؤال متعلق بوظيفة. في أكاديمية حسوب لا نقوم بحل الوظائف، فهذا لا يعود عليك بأي فائدة. من الافضل أن تحاول حل الوظيفة لوحدك و يمكننا مساعدتك في حال كان لديك سؤال محدد عن آلية عمل تابع معين أو عن خطأ لم تستطع معرفة سببه. تحياتي.
-
مرحبًا، أعتقد أن ما تقصده هو تقسيم البيانات إلى 3 أقسام هي train, dev, test. الهدف من هذا التقسيم هو عدم الوقوع في مشكلة overfitting على ال test. أي عندما تقوم بالتدريب و تعديل النموذج بناء على نتائج الاختبار على ال test فأنت فعليًا ستقع في مشكلة حيث أن نموذج تم تدريبه بحيث يعطي أفضل نتيجة على ال test و بالتالي قد يكون هناك overfitting. تظهر هذه المشكلة عندما تريد المقارنة بين النماذج، فالمقارنة العادلة يجب أن تختبر كيف تقوم النماذج بتعميم بيانات التدريب على بيانات الاختبار و لهذا السبب يجب ألا يتم اختيار بارامترات النماذج بحيث تعطي أفضل نتائج، و إلا يكون الاختبار بلا فائدة. في نفس الوقت يجب أن تختبر النموذج خلال التدريب حتى تختار قيم بارامترات جيدة تعطي نتائج لا بأس بها على بيانات لم تراها. لحل هذا التعارض تم إنشاء التقسيم الثالث و هو ال dev حتى تقوم باستعمالها كبيانات اختبار خلال عملية تطوير النموذج، و تكون ال test فقط لاختبار النموذج مرة واحدة بعد الانتهاء من تطويره و مقارنته بنماذج أخرى قد تكون طورتها لمعرفة أيها أفضل. تحياتي.
- 4 اجابة
-
- 1
-
-
مهمتها هي إضافة إزاحة لأول سطر في محتوى نصي، أي في حال كان لديك فقرات نصية ضمن الموقع الخاص بك، فإن أحد طرق التنسيق هي أن تقوم بإزاحة أول سطر من الفقرة قليلًا. هذا الأسلوب متبع بكثرة في الكتب مثلًا و يمكن أن تجده في بعض المواقع. هذه هي النتيجة عند تطبيقها، لاحظ كيف تمت إزاحة أول سطر: تحياتي.

- 3 اجابة
-
- 1
-
-
مرحبًا شريف، في حالتك هذه ينصح باستعمال الخدمات السحابية بدلًا من بناء الأمر بنفسك، فهي تقدم لك حلًا لمشاكل انقطاع الكهرباء و إمكانية إنشاء نسخ احتياطية، كما تعالج مشاكل الأمان لوحدها. يمكنك الإطلاع على الخدمات التي تقدمها شركات مثل Amazon و Google و غيرها. تحياتي.
-
و عليكم السلام علي، يبدو أن بعض الأعمدة تحمل قيم نصية، يبدو أن هذه نفس البيانات التي قمت بسؤالنا عنها منذ فترة، مثلًا العمود cyto_score يحمل قيمة نصية و ليس عددية، و لا يمكنك تطبيق عملية المتوسط الحسابي عليه. تحياتي.
- 2 اجابة
-
- 1
-
-
مرحبًا علي، بعد الإطلاع على المسابقة يبدو أن هذا ما يظهر لك فقط، أي تم إظهار أول 3 أسطر حتى تعرف ما هو شكل بيانات الاختبار و لكن البيانات مخفية. عادة ما يتم القيام بذلك لضمان أنك لم ترى بيانات الاختبار بنفسك و لم تصمم النموذج بحيث يتوافق معها. لقد تم ذكر هذا الأمر هنا: https://www.kaggle.com/competitions/equity-post-HCT-survival-predictions/discussion/549958#3079219 تحياتي.
- 4 اجابة
-
- 1
-
-
من الصعب الإجابة بدون معرفة عن أي بيانات تتحدث. فقد يكون هناك سبب منطقي. أو قد تكون البيانات غير جيدة. فليس كل شيء على كاغل ذو جودة عالية. حيث أنه يمكن لأي شخص رفع بيانات. تحياتي.
- 4 اجابة
-
- 1
-
-
و عليكم السلام، في المشاريع الحقيقية يفضل استعمال الأدوات الجاهزة، فهي توفر الوقت و قد تم اختبارها بشكل كبير لذلك يمكن الوثوق بها. أما في حال كتابة الكود من الصفر فقد يأخذ ذلك وقت طويل و قد يكون هناك أخطاء كثيرة من الصعب إيجادها. في حال كنت تعمل في قسم البحث العلمي الخاص بالشركة فقد تحتاج حينها إلى كتابة بعض الأمور غير المدعومة من قبل اللغات بعد، و عندها ستقوم بكتابة الكود بالاعتماد على نفسك. و لكن هذا لا يعني من الصفر تمامًا حيث ستعتمد على أدوات من المكاتب و لكن هيكلية الشبكة و تفاصيلها قد تكتبها بنفسك. أو كيفية عمل بعض المكونات فيها. أي في النهاية الأمر يعتمد على العمل الذي تقوم به، طالما يمكنك استعمال أدوات جاهزة قم بذلك. تحياتي.
- 2 اجابة
-
- 1
-
-
كما سبق و أخبرتك، هناك طرق يمكنك استعمالها في حال كان العمود مهمًا في نظرك و ليس من المفيد حذفه. في النهاية هنا تأتي مهمتك في أن تجد أهم الأعمدة، فعملية معالجة البيانات مهمة جدًا مثل عملية تطوير النموذج.
- 5 اجابة
-
- 1
-
-
مرحبًا علي، بالطبع يجب مسحه، عدم مسحه يفترض أن يعطيك خطأ. فمثلًا لو أنك قمت بتدريب النموذج على 10 أعمدة فهذا يعني أنه لديك أوزان مخصصة لهذه الأعمدة فقط، و في حال حاولت اختبار النموذج على 11 عمود يفترض أن يعطيك خطأ. من الطبيعي مسح الأعمدة، فهي جزء من عملية اختيار الميزات المهمة و حذف غير المهمة، و وجود بيانات ناقصة بشكل كبير في عمود قد يدل أن العمود غير مهم. في حال كان العمود رقمي، يمكنك تعويض مسح العمود بتعويض البيانات الناقصة ب 0 .. في تلك الحالة لن تؤثر على الوزن الخاص بذلك العمود، أي أن النموذج سيتعامل و كأن هذه العينة لا تحوي على هذه الميزة. تحياتي,
- 5 اجابة
-
- 1
-
-
مرحبًا علي، الكود ليس مهمًا فما يهم هو جودة النموذج الذي قمت بتطويره. قد يتم التحقق من الكود لضمان عدم وجود غش فقط و لكن عدا ذلك هو ليس معيار. أيضا الكود الخاص بك سيصبح مرئي للآخرين في حال الفوز و جودة الكود قد تكون في صالحك من ناحية أن من سيرى الكود سيعرف أنك منظم و تجيد كتابة كود جيد. تحياتي.
- 3 اجابة
-
- 1
-
-
و عليكم السلام، من الجيد أنه لديك معرفة مسبقة بال html, css. و لكن دورة تطوير واجهات المستخدم ليست فقط عنهما، فهما يمثلان المقدمة فقط و هذا ما ستتعلمه في تلك الدورة: مفهوم الواجهة الأماميّة للموقع front-end وكيفية عملها. أساسيات لغات تطوير واجهات المستخدم: HTML, CSS, JavaScript. استخدام أحدث أدوات التطوير: Bootstrap, jQuery, Sass, Gulp. التعامل مع خدمة استضافة المشاريع GitHub. إعداد هيكل الموقع ووضع خطة العمل. تطوير واجهة استخدام حقيقة لمتجر الكتروني كامل من الصفر. تطوير موقع لشركة مع مدونة خاصة خطوة بخطوة. بناء 5 صفحات هبوط مختلفة بناء واجهة لموقع يشبه YouTube بناء لوحة تحكم لتطبيق ويب في حال كنت تميل إلى تطوير واجهات المستخدم فهذا أفضل كورس. في حال كنت تريد تعلم كيفية بناء ال backend و كيفية بناء تطبيقات موبايل فالأفضل هو دورة تطوير التطبيقات باستعمال javascript. تحياتي.