إياد أحمد
-
المساهمات
92 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو إياد أحمد
-
لدي الكود التالي الذي يولد تمثيلاً بيانياً لمعدلات النمو في بعض الولايات: import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt State = ["NewMexico", "NewYork", "Albany","Gorgenia"] growth = [860280, 994163, 308245, 266684] df = pd.DataFrame({"State": State, "Growth": growth}) sns.barplot(x='State', y="Growth", data=df,palette="hsv_r") والخرج: ما أحتاجه هو ترتيب أعمدة البيانات هذه ضمن المخطط؟
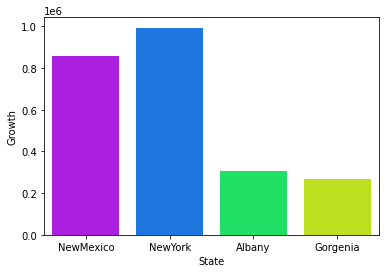
- 1 جواب
-
- 1
-

-
لدي ال Heatmap التالية: import seaborn as sns import matplotlib.pyplot as plt import numpy as np data = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]) text = np.array([['A', 'B', 'C', 'D', 'E'], ['F', 'G', 'H', 'I', 'J'], ['K', 'L', 'M', 'N', 'O']]) # نقوم بدمجهم يدوياً formatted_text = (np.asarray(["{0}\n{1:.2f}".format( text, data) for text, data in zip(text.flatten(), data.flatten())])).reshape(3, 5) fig, ax = plt.subplots() ax = sns.heatmap(data, annot=formatted_text, fmt="") وأحتاج إلى طريقة لزيادة حجم ال annotations، كيف نفعل ذلك؟
- 1 جواب
-
- 1
-
-
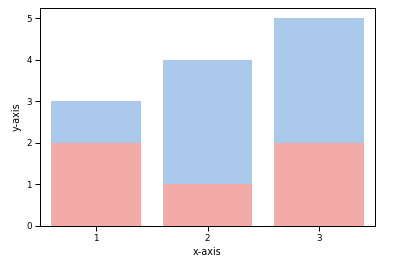
لدي البيانات التالية: df = pd.DataFrame({ 'A': [10, 32, 14], 'B': [60, 22, 34], 'C': [21, 50, 5] }) وأريد استخدام barplot لرسم كل من: x=df["A"] && y=df["B"] و x=df["A"] && y=df["C"] بحيث تكون المخططات متداخلة أي مثلاً كما في الصورة:
- 1 جواب
-
- 1
-
-
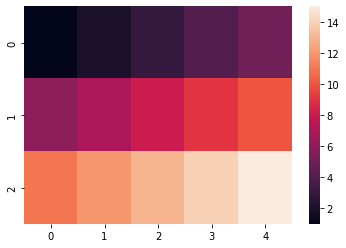
لدي الكود التالي الذي يمثل Heatmap: import numpy as np import seaborn as sns import matplotlib.pyplot as plt data = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]) fig, ax = plt.subplots() ax = sns.heatmap(data, fmt="") الخرج: ما أحتاجه هو أن تتم إضافة عبارات توضيحية لكل خلية، على سبيل المثال أريد أن تكون عناصر القائمة التالية موضوعة ضمن كل خلية بالترتيب: text = np.array([['A', 'B', 'C', 'D', 'E'], ['F', 'G', 'H', 'I', 'J'], ['K', 'L', 'M', 'N', 'O']]) أيضاً كيف يمكنني أن أجعل العبارات التوضيحية مُشكلةً من القيم data ومن ال text. أي مثلاً أريد أن يكون النص التوضيحي للخلية الأولى هو: A 1.00 والخلية الثانية: B 2.00 وهكذا..
- 2 اجابة
-
- 1
-
-
لدي ال heatmap التالية: import seaborn as sns import matplotlib.pyplot as plt example = sns.load_dataset("flights") example = example.pivot("month", "year", "passengers") res = sns.heatmap(example) plt.show() والخرج: أريد الآن طريقة لإضافة إطار إلى ال Axes؟
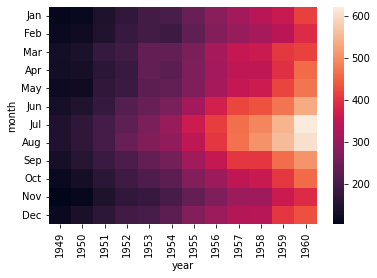
- 2 اجابة
-
- 1
-
-
لدي الكود التالي الذي يقوم بتمثيل البيانات من خلال boxplot: import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt df = pd.DataFrame({ 'Corn': np.random.normal(40, 15, 100), 'Rice': np.random.normal(60, 10,100), 'Wheat': np.random.normal(80, 5, 100), 'Peas': np.random.normal(30, 13, 100), }) data_df = df.melt(var_name='Pulses', value_name='Tons Consumed') sns.boxplot(x="Pulses", y="Tons Consumed", data=data_df) الخرج: ما أحتاجه هو تغيير الألوان المرسومة، أعرف أن seaborn تحتوي العديد من لوحات التلوين لكن كيف يمكن أن نستخدمها؟
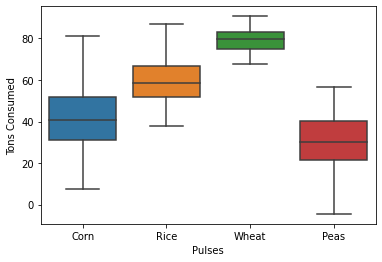
- 2 اجابة
-
- 1
-
-
لدي الكود التالي الذي يقوم برسم heatmap: import numpy as np; np.random.seed(0) import seaborn as sns; sns.set_theme() uniform_data = np.random.rand(10, 12) ax = sns.heatmap(uniform_data) والخرج: الآن أريد تغيير حجم ال colorbar، كيف يمكننا القيام بذلك؟
.png.211f80e17f8c48ba9a9ac402d97284a2.png)
- 2 اجابة
-
- 1
-
-
لدي الكود التالي الذي يعبر عن مخطط بياني: import seaborn as sns import matplotlib.pyplot as plt # loading dataset data = sns.load_dataset("iris") # draw lineplot sns.lineplot(x="sepal_length", y="sepal_width", data=data) plt.show() لكن خلفية الشكل تكون بيضاء، وأريد أن يتم تغييرها، لذا كيف نقوم بذلك؟
- 2 اجابة
-
- 1
-
-
لدي المخطط التالي: from matplotlib import pyplot as plt import seaborn as sns plt.rcParams["figure.figsize"] = [7.50, 3.50] plt.rcParams["figure.autolayout"] = True sns.set_style("whitegrid") tips = sns.load_dataset("tips") ax = sns.boxplot(x="day", y="total_bill", data=tips) plt.show() وخرجه: ما أحتاجه هو ضبط حدود أو مجال قيم المحاور الأفقية و العمودية؟ على سبيل المثال أريد جعل مجال قيم المحور العمودي من 5 إلى 50؟
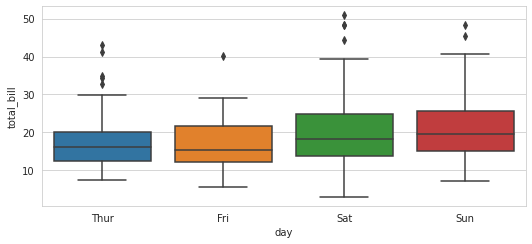
- 2 اجابة
-
- 1
-
-
لدي ال heatmap التالية: import pandas as pd import seaborn as sns df = pd.DataFrame({'A':(10,20,30,40), 'B':(10,20,30,40), 'C':(90,110,130,200)}) sns.heatmap(df.pivot_table(index='B', columns='A', values='C')) والخرج: ما أحتاجه هو إضافة label إلى جانب ال colour bar؟
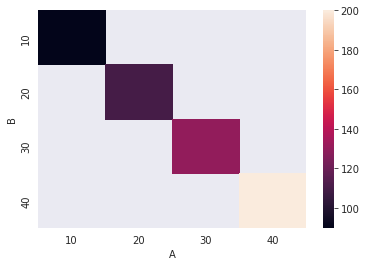
- 2 اجابة
-
- 1
-
-
قمت بإنشاء مخططين من خلال الكود التالي: import seaborn as sns data = sns.load_dataset('iris') plot1 = sns.barplot(x='sepal_length', y='species', data=data).get_figure() plot1.savefig('plot1.pdf') plot2 = sns.barplot(x='sepal_width', y='species', data=data).get_figure() plot2.savefig('plot2.pdf') لكن المشكلة أنه يقوم بحفظ المخطط الثاني فوق المخطط الأول، لذا كيف يمكن حل هذه المشكلة؟
- 2 اجابة
-
- 1
-
-
لدي إطار بيانات dataframe يمكنني أن أقوم برسمه من خلال boxplot بشكل طبيعي كما يلي: import pandas as pd import seaborn as sns %pylab inline df = pd.DataFrame({'Alpha' :['one','one','two','two','one','two','one','one','one','two'], 'Beta': [1,2,1,2,1,2,1,2,1,1], 'Gama': [1,2,3,4,6,1,2,3,4,6]}) sns.boxplot( data=df,y="Beta", x="Alpha") لكن لا أعرف كيف يمكن أن أرسم subplot لكل المتغيرات؟ أي أريد رسم أكثر من مخطط وأريد وضع كل منها ضمن subplot..
-
عندما أقوم برسم المخططات البيانية في seaborn من خلال Factplot تواجهنني مشكلتين، الأولى هي حجم النص المكتوب ضمن ال Legend، فعندما تكون هناك الكثير من النصوص ضمنها تظهر بحجم صغير جداً يصعب قراءته، وأيضاً بالنسبة لحجم ال Labels. لذا كيف يمكننا تغيير هذا الأمر؟
- 2 اجابة
-
- 1
-
-
لدي المخطط التالي: import seaborn as sns import matplotlib.pyplot as plt sns.set(style="whitegrid") titanic = sns.load_dataset("titanic") g = sns.factorplot("class", "survived", "sex", data=titanic, kind="bar", size=6, palette="muted") g.despine(left=True) g.set_ylabels("survival probability") والخرج: ما أحتاج إليه هو تغيير موضع ال legend، على سبيل المثال أريد وضعه في أعلى اليسار؟
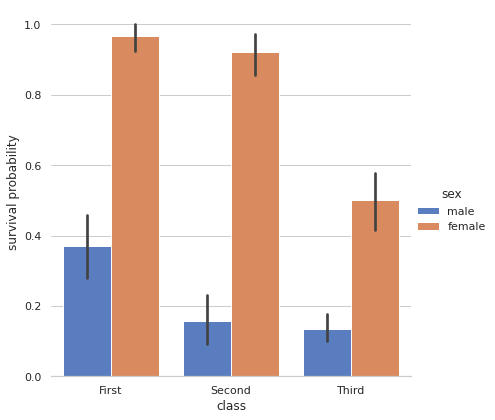
- 2 اجابة
-
- 1
-
-
لدي المخطط التالي: import seaborn as sns tips = sns.load_dataset('tips') rp = sns.relplot(data=tips, x='total_bill', y='tip',col='sex', row='smoker', kind='scatter') rp.fig.subplots_adjust(top=0.9) والشكل الناتج: ما أريده هو وضع عنوان عام للمخططات البيانية؟
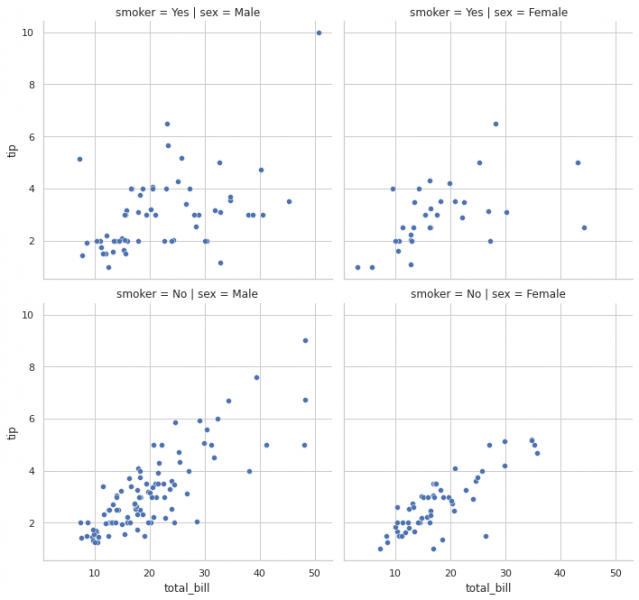
- 3 اجابة
-
- 1
-
-
لدي مخطط بياني يحتوي العديد من التسميات (لكل نقطة بيانات هناك اسم) ولهذا السبب تتداخل التسميات مع بعضها البعض، لذا أريد أن يتم تدوير هذه التسميات بزاوية 90 درجة بحيث تصبح عمودية، لذا كيف يمكننا القيام بذلك؟
- 2 اجابة
-
- 1
-
-
تغيير لون المحاور axis و ال ticks و الملصقات labels للرسم البياني في لدي الكود التالي وأحاول وضع أسماء للمحاور بالشكل التالي: import seaborn as sns import pandas as pd df = pd.DataFrame({'color': ['black', 'blue', 'brown'], 'num': [1, 2, 3]}) figObj = sns.barplot(x = 'num', y = 'color', data = df, color = 'red') figObj.set_axis_labels('Colors', 'Values') لكنه يعطيني الخطأ التالي: --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-9-5708b6ef67e6> in <module>() 5 data = df, 6 color = 'red') ----> 7 fig.set_axis_labels('Colors', 'Values') AttributeError: 'AxesSubplot' object has no attribute 'set_axis_labels'
- 2 اجابة
-
- 1
-
-
كيف يمكنني التحكم بحجم الشكل figure size أثناء عرض البيانات في seaborn، على سبيل المثال أحتاج إلى جعل حجمها مناسب لورق الطباعة A5 أو A4.
- 2 اجابة
-
- 1
-
-
قمت بتثبيت مكتبة NLTK وبعدها أتبعت أحد المسارات التعليمية من إحدى المواقع لتثبيت NLTK Data لكن يظهر لي خطأ: import nltk nltk.download() """ AttributeError: 'module' object has no attribute 'download' """ لذا كيف يمكنني تثبيت نماذج وبيانات nltk؟
- 1 جواب
-
- 1
-
-
أعمل على استخراج العلاقات الدلالية بين الكلمات، لذا أحتاج إلى طريقة لتحديد ال Entailments و Meronyms و Holonyms لكلمة ما؟
- 1 جواب
-
- 1
-
-
أعمل على استخراج بعض العلاقات الدلالية بين الكلمات Lexical relations من خلال nltk وأحتاج إلى استخراج ال Hypernyms و ال Hyponyms لكلمة محددة.. لذا كيف يمكننا القيام بذلك؟
- 1 جواب
-
- 1
-
-
هل يمكننا القيام بعملية Text Summarization من خلال NLTK؟ أو أي طريقة أخرى؟ مع توضيح الطريقة..
-
أعمل على نظام استراجاع معلومات Information Retrieval، وأحتاج إلى طريقة لتحديد نسبة التشابه بين الكلمات، وأعتقد أن أفضل طريقة للقيام بذلك ستكون من خلال استخدام نماذج Word2Vec لميلكوف (نموذج Skip Gram أو CBOW ). أعتقد أن NLTK تعرّف هذين النموذجين، لذا هل يمكن لأحد ما أن يقدم مثال لكيفية القيام بذلك؟ علماً أنه لدي مستند نصي يحوي البيانات النصية التي أريد تدريب النموذج عليها.
- 1 جواب
-
- 1
-
-
كيف بإمكاننا حذف الكلمات المكررة من النص مثلاً: Hiiiiiiiiiiiii --> Hi
- 1 جواب
-
- 1
-
-
أريد استخدام word_tokenize مع إطار بيانات df، وذلك للحصول على جميع الكلمات المستخدمة في صف معين من إطار البيانات ومعرفة طول كل نص. مثال: # شكل البيانات {'sentences': ['This is a very good site. I will recommend it to others.', 'Can you please give me a call at 9983938428. have issues with the listings.', 'good work! keep it up']} # والخرج المتوقع على سبيل المثال للصف الثاني 'Can','you','please','give','me','a','call','at','9983938428','.','have','issues','with','the','listings'
- 1 جواب
-
- 1
-