


Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 في الإصدارات الأحدث من جانغو تم إضافة الوسيط html_message للدالة send_mail لإرسال ملفات ال HTML مع البريد الالكتروني. قد تحتاج إلى نموذجين لبريدك الإلكتروني - نموذج نص عادي، مخزن في مجلد القوالب ضمن email.txt، وآخر لملف ال HTML. from django.template.loader import render_to_string from django.core.mail import send_mail as email # تحديد الرسائل #templates تحميل ال # تحميل قالب النص text = render_to_string('templates/email.txt', {'some_params': some_params}) #html تحميل قالب ملف ال Html = render_to_string('templates/email.html', {'some_params': some_params}) # إرسال الرسائل email( 'email title', # عنوان الايميل text, # النص 'some@sender.com', # المرسل ['some@receiver.com'], # المستقبل/المستقبلين html_message=msg_html, # ملف الاتش تي ام ال المرفق )
في الإصدارات الأحدث من جانغو تم إضافة الوسيط html_message للدالة send_mail لإرسال ملفات ال HTML مع البريد الالكتروني. قد تحتاج إلى نموذجين لبريدك الإلكتروني - نموذج نص عادي، مخزن في مجلد القوالب ضمن email.txt، وآخر لملف ال HTML. from django.template.loader import render_to_string from django.core.mail import send_mail as email # تحديد الرسائل #templates تحميل ال # تحميل قالب النص text = render_to_string('templates/email.txt', {'some_params': some_params}) #html تحميل قالب ملف ال Html = render_to_string('templates/email.html', {'some_params': some_params}) # إرسال الرسائل email( 'email title', # عنوان الايميل text, # النص 'some@sender.com', # المرسل ['some@receiver.com'], # المستقبل/المستقبلين html_message=msg_html, # ملف الاتش تي ام ال المرفق ) -
حسناً تابع في المثال التالي: import tensorflow as tf from tensorflow import keras mnist = tf.keras.datasets.mnist (x_train, y_train),(x_val, y_val) = mnist.load_data() x_train = x_train / 255.0 x_val = x_test / 255.0 # تعريف نموذج def model(): m = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(456, activation="relu"), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(128, activation="relu"), tf.keras.layers.Dropout(0.3), tf.keras.layers.Dense(10, activation="softmax") ]) return m model=model() model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy',metrics=['acc']) # تدريب النموذج model.fit(x_train, y_train, epochs = 10, validation_data = (x_test,y_test)) الآن بشكل عام model.save تقوم بحفظ كل المعلومات اللازمة لمواصلة التدريب، لكن المشكلة الوحيدة هي حالة ال Optimizer فقد لايتم تحميلها أو حفظها بشكل صحيح (يحدث فقدان للمعلومات). ولهذا السبب ينصح بحفظ نموذجك بتنسيق تنسرفلو أي tf بدلاً من حفظها بالامتداد الافتراضي (h5). # حفظ النموذج بتنسيق تنسرفلو model.save('./MyModel_tf',save_format='tf') الآن لو أردت إعادة تحميله ومواصلة التدريب: # تحميل النموذج model = tf.keras.models.load_model('./MyModel_tf') # التدريب model.fit(....)
-
إضافة لما ذكره سامح فإنه في في النسخ الأحدث (2.2) من جانغو يمكنك استخدام BlogPost كالتالي: # model من ال from posts.model import BlogPost as bp fields = bp._meta.fields #أو fields = bp._meta.get_fields() ############################################### # instance ومن ال import posts.model.BlogPost blogpost = BlogPost() fields = blogpost._meta.fields
- 3 اجابة
-
- 1
-

-
أعتقد أنك بحاجة لطريقة لأداة متطورة أكثر (تستخدم هذه الطريقة فقط عند البحث عن تكرارات كلمة وليس جمل)، وتعتمد هذه الطريقة على الأداة Tokenizer حيث تقوم هذه الأداة بمعالجة البيانات الممررة لها ليتثنى لنا الحصول على المعلومات التي نريدها مثل عدد مرات تكرار كلمة معينة: from keras.preprocessing.text import Tokenizer t = Tokenizer() x = "hello, world! Hi! hello!" t.fit_on_texts(x.split()) # الكلمات وتكرارها # النتيجة ستكون مخزنة في قاموس وبالتالي يمكنك الاستعلام عن عدد مرات تكرار أي كلمة من خلال اسمها dic=t.word_counts print(dic) dic["hello"] # 2 # OrderedDict([('hello', 2), ('world', 1), ('hi', 1)]) # عدد الكلمات print(t.document_count)# 4 # كل كلمة والرقم الذي يمثلها # أو الفهرس الذي يمثلها أو بمعنى أدق ترميزها print(t.word_index) # {'hello': 1, 'world': 2, 'hi': 3} لاحظ أنه أصبح بإمكانك الاستعلام عن عدد مرات ظهور أي كلمة فقط من خلال اسمها. وفي حالة أردت البحث عن جمل فهنا أنصح بالطريقة الأولى التي قدمها عبود.
-
لمعرفة فيما إذا كان هناك نتائج أم لا يمكنك أيضاً القيام بذلك من خلال محاولة الوصول إلى أول عنصر في نتيجة الاستعلام، فإذا لم يكن موجوداً سيعطي بايثون خطأ IndexError: try: Users[0] # موجود except IndexError: # غير موجود وهذه الطريقة مفيدة جداً (أسرع بكثير في بعض الأحيان) إذا كان لديك عدد كبير من العناصر. كما يمكنك استخدام فإذا كان هناك نتيجة يقوم بردها (وبالتالي تكافئ True إذا وضعناها ضمن عبارة شرطية) وإلا سيعطي None أي تكافئ (False): if Users.first(): # موجود كذلك يمكنك استخدام Users.count والفرق بين هذه الطرق هو الأداء.
- 3 اجابة
-
- 1
-
-
نستخدم CSVLogger callback للقيام بحفظ نتائج ال Epochs خلال عملية التدريب: tf.keras.callbacks.CSVLogger(filename, separator=",", append=False) حيث نمرر له مسار الملف الذي نريد أن يتم حفظ البيانات فيه. والفاصل الذي نريد أن يتم فصل العناصر فيه. أما الوسيط الأخير فنضبطه على True إذا كان الملف موجود مسبقاً ونريد الإضافة عليه (في حالة كان موجود ولم يتم ضبطه على True سيتم الكتابة فوق الملف). ويمكننا استخدامه أثناء تدريب النماذج بالشكل التالي: # نقوم بتعريف الكول باكس أولاً csv_logger = CSVLogger('training.log') #fit في الدالة callbacks ثم نمرره إلى الوسيطة model.fit(X_train, Y_train, callbacks=[csv_logger]) مثال: from tensorflow.keras.models import Sequential from sklearn.datasets import make_moons from tensorflow.keras.layers import Dense # تعريف بيانات عشوائية X, y = make_moons(n_samples=200, noise=0.2, random_state=4) # قسم البيانات إلى تدريب واختبار n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # تعريف نموذج model = Sequential() model.add(Dense(600, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # تعريف الكولباكس from tensorflow.keras.callbacks import CSVLogger csv_logger = CSVLogger('training.log') # تدريب النموذدج model.fit(trainX, trainy, validation_data=(testX, testy), epochs=5000, verbose=0, callbacks=[csv_logger])
- 2 اجابة
-
- 1
-
-
الاختلاف الرئيسي في أن مجال علوم الحاسوب Computer Science تركز على الجانب التقني بينما مجال تكنلوجيا المعلومات IT تركز أكثر على الأعمال ومايلي سيوضخ الأمر أكثر.. حسب تعريف إيان جورتون فإن علوم الحاسوب Computer Science أو علوم الكمبيوتر هي "فهم كل من النظريات والمفاهيم المجردة التي تستند إليها الحوسبة، وكذلك استخدام مهارات البرمجة العملية لبناء التعليمات البرمجية وتطوير الأنظمة المعقدة." إن من يقوم بدراسة هذا التخصص يتعلم الأدوات والممارسات (خوارزميات ومنهجيات علمية) المختلفة التي تدخل في عملية تطوير التكنولوجيا هذه، إلى جانب كيفية نشر أنظمتهم الخاصة وتحديث هذه الأنظمة وتحسينها باستمرار بمرور الوقت. وبشكل أدق يدرس الطلاب الذين يختارون هذا العلم الرياضيات فهي أساس الحوسبة ولاسيما الجبر الخطي والتفاضلات ونظرية الأعداد والجبر اللاخطي ويدرس بعض مواد الفيزياء مثل أنصاف النواقل والدارات الكهربائية والفيزياء الكهربائية إضافة إلى دراسة الخوارزميات وكيفية بناءها وحساب تعقيدها، ويدرس العديد من لغات البرمجة مثل C++ وجافا وبايثون، إضافة إلى العديد من المواضيع الأخرى. وتندرج تحتها الحوسبة والخوارزميات وهياكل البيانات ومنهجية البرمجة واللغات وعناصر الحاسوب وبنى البيانات و هندسة البرمجيات والذكاء الاصطناعي وشبكات الحاسوب والاتصالات وأنظمة قواعد البيانات والحساب المتوازي والنظم الموزعة والتفاعل بين الإنسان والحاسوب ورسوميات الحاسوب وأنظمة التشغيل والحساب الرقمي والرمزي.. إلخ. أما تكنلوجيا المعلومات Information Technology فحسب إيان جورتون هي على عكس علوم الكمبيوتر - التي تركز على المهارات اللازمة لبناء أنظمة معقدة من الألف إلى الياء - فإن المتخصصين في تكنولوجيا المعلومات "يقومون بتهيئة تلك الأنظمة لحل مشاكل الشركة" ، حسب وصفه. أي أنهم يقومون باستخدام هذه الأنظمة داخل الشركة أو المؤسسة وتكون مهمتهم دمجها بالشكل الصحيح الذي تحتاجه المؤسسة إضافةً إلى متابعتها والحفاظ على استمراريتها بالعمل بشكل صحيح. وهذه الانظمة تضم (قواعد البيانات- السيرفرات- البرمجيات- والشبكات-والعتاد Hardware..إلخ.). وإضافة إلى ذلك فإنه يقع على عاتقهم واجبات الدعم الفني، وتحليل العمليات، وتكوين الشبكات، وتدريب الموظفين الجدد... إلخ. ننصحك بالإطلاع على مقال المدخل الشامل لتعلم علوم الحاسوب ففيه معلومات واسعة حول هذا المجال.
-
نعم يمكنك استخدام الأداة inspect_checkpoint.py حيث أنها توفر لنا الدالة print_tensors_in_checkpoint_file التي يمكننا من خلالها الحصول على مانريده، ولها الشكل التالي: print_tensors_in_checkpoint_file(file_name, tensor_name, all_tensors,all_tensor_names) الوسيط الأول هو مسار ملف ال checkpoint. أما بالنسبة للوسيط الثاني فهو اسم التنسر وهنا لدينا حالتان: حالة لم نمرر أي قيمة لل tensorname (أو مررنا " "): سيتم طباعة أسماء كل التنسر الموجودة مع أبعادها (ال shapes) في ملف ال ckp. حالة تم تمرير اسم للتنسر: سيتم طباعة محتوى هذه التنسر. الوسيط الثالث نضعه على True في حال أردنا طباعة كل التنسر (افتراضياً True). أما الوسيط الأخير نضعه على TRue في حال أردنا طباعة أسماء كل التنسر. مثال: from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file import os # تحميل مسار الملف ckp_path = os.path.join(dir, "model_10000.ckpt") # الحصول على أسماء كل التنسر الموجودة print_tensors_in_checkpoint_file(file_name=ckp_path, tensor_name='',all_tensor_names=True) # الخرج يكون بالشكل التالي: # v0/RMSprop (DT_FLOAT) [4,4,1,45] # الآن بفرض أريد الحصول على محتويات المتغير السابق print_tensors_in_checkpoint_file(file_name=checkpoint_path, tensor_name='v0') # tensor_name: v0 [[[[ 5.444958265e-02 2.00026209e-01 .... أو من خلال الطريقة البديلة التالية: from tensorflow.python import pywrap_tensorflow import os ckp = os.path.join(dir, "model_1000.ckpt") r = pywrap_tensorflow.NewCheckpointReader(ckp) x = r.get_variable_to_shape_map() for tensor in x: print("Tensor name: ", tensor) # الأسماء print(r.get_tensor(tensor)) # القيم
- 2 اجابة
-
- 1
-
-
يمكنك البحث عن العناصر ضمن المصفوفات باستخدام عدة طرق: أولاً من خلال خوارزمية ال Binary Search حيث يمكننا استخدام الدالة الجاهزة Arrays.binarySearch للقيام بعملية البحث عن عنصر ما داخل مصفوفة. الكود التالي هو تطبيق لكيفية استخدامها: import java.util.stream.IntStream; import java.util.Arrays; class check { // نعرف تابع لتغليف عملية البحث private static void checkit(int[] array, int value) { // نقوم بفرز المصفوفة Arrays.sort(array); // نستخدم خوارزمية البحث الثنائي لاختبار وجود العنصر ضمن المصفوفة int res = Arrays.binarySearch(arr, value); boolean bool = res > 0 ? true : false; //True في حالة كان موجود سيطبع System.out.println(bool); } // الآن سنستخدمه ضمن البرنامج الرئيسي public static void main(String[] args) { // نعرف مصفوفة int myarray[] = {1, 4, 9, 0}; // تحديد القيمة التي نريد البحث عنها int val = 4; // استخدام التابع checkit(arr, val); // True } } هذه الطريقة هي الأفضل والأكثر فعالية لأن تعقيدها هو الأقل. هناك طرق أخرى مثلاً استخدام List.contains أو خوارزمية البحث الخطي لكن هذه الطرق أقل كفاءة من هذه الطريقة، وبكافة الأحوال سأكتب لك التابعين التاليين إذا رغبت باستخدامهما. أولاً استخدام List.contains : private static void check(Integer[] arr, int val) { boolean bool = Arrays.asList(arr).contains(val); System.out.println(bool); } ثانياً البحث الخطي: private static void check(int[] arr, int val) { boolean b = false; for (int element : arr) { if (element == val) { test = true; break; } } System.out.println(b); }
-
ال reflection هي عبارة عن API تُستخدم لفحص أو تعديل سلوك الدوال و الكلاسات والواجهات في وقت التشغيل (Runtime). حيث يمنحنا القدرة على الوصول لمعلومات الكلاس الذي ينتمي له الكائن %D ال reflection هي عبارة عن API تُستخدم لفحص أو تعديل سلوك الدوال و الكلاسات والواجهات في وقت التشغيل (Runtime). حيث يمنحنا القدرة على الوصول لمعلومات الكلاس الذي ينتمي له الكائن الذي قمنا بتعريفه والدوال التي يمكن تنفيذها واستدعاءها خلال وقت التشغيل كما يمنحنا إمكانية التعامل معها في حالة كانت private أو أيُاً كان محدد الوصول المستخدم. إليك المثال التالي لتوضيح استخدامه حيث سنستخدم فيه أهم التوابع وسنعرَف بها: الدالة getConstructors تستخدم هذه الدالة للحصول على معلومات البواني للكلاس الذي ينتمي له الكائن (البواني العامة public). الدالة getClass ترد هذه الطريقة اسم الكلاس الذي ينتمي له الكائن. الدالة getmethod تعطينا معلومات عن الدوال العامة الموجودة ضمن الكلاس الذي ينتمي له الكائن. يمكننا استدعاء طريقة من خلال الانعكاس عن طريق تمرير اسمها وأنواع الوسطاء إلى الدالة invoke. أو من خلال الدالة getDeclaredMethod كما في المثال التالي. يمكننا من خلال الدالة getDeclaredField الحصول على الحقول ال private في الكلاس الذي ينتمي له الكائن. وأخيراً الدالة setAccessible تسمح لنا بالوصول للحقل أو الدالة بغض النظر عن نوع محدد الوصول. import java.lang.reflect.Field; import java.lang.reflect.Constructor; import java.lang.reflect.Method; // تعريف كلاس class ref { private String str; // تعريف سلسلة // تعريف باني public Test() { str = "Hsoub"; } // تعريف دالة تقوم بطباعة السلسلة public void m1() { System.out.println("my string: " + str); } // دالة أخرى public void me2(int x) { System.out.println("my number: " + x); } } class myprogram { public static void main(String args[]) throws Exception { // إنشاء كائن ليتم التحقق من خصائصه ref o = new ref(); //getClass استخدام الدالة Class c = o.getClass(); System.out.println(c.getName()); //getConstructor استخدام الدالة Constructor const = c.getConstructor(); System.out.println(const.getName()); //getMethods استخدام Method[] methods = c.getMethods(); //getDeclaredMethod الدالة //ألتي ترغب بها method إنشاء كائن من ال Method call1 = c.getDeclaredMethod("m2", int.class); // نقوم بتمرير اسم الطريقة وفئة الوسيط // استدعاء الطريقة خلال وقت النشعيل methodcall1.invoke(o, 5); // 5 // getDeclaredField // مثل السابق لكن للحقول Field myfield = c.getDeclaredField("str"); myfield.setAccessible(true); // السماح للكائن بالوصول للحقل بغض النظر عن محدد الوصول // يأخذ الكائن والقيمة الجديدة المراد تعيينها للحقل كوسائط field.set(o, "HHH"); Method call2 = cls.getDeclaredMethod("m1"); call2.invoke(o); // HHH } } الانعكاس مفيد جداً في العديد من الحالات، ولاسيما عند بناء أدوات التصحيح والاختبار حيث أن المصححات تستخدم الانعكاس لفحص أو اختبار الأعضاء الخاصة private ضمن الكلاس. ,ولكن قد يكون استخدمه فكرة سيئة مع التطبيقات الحساسة للأداء لأنه يجعل الكود أبطأ.
-
نقوم بتحقيق السمات (attributes) index_title و site_header و index_title على AdminSite مخصص لتغيير عنوان صفحة موقع ال Admin ونص العنوان بسهولة. سنقوم بإنشاء AdminSite subclass وربط instance منها بـال URLconf: # admin.py ضمن ملف from django.contrib.admin import AdminSite from django.utils.translation import ugettext_lazy as ul class admin(AdminSite): site_title = ul('...') #(page's <title>) كل صفحة <title> نص تريد وضعه في نهاية site_header = ul('...') #(page's <h1>)+ وفوق نموذج تسجيل الدخول index_title = ul('...') #admin في أعلى صفحة فهرس ال #instance إنشاء admin_ = admin() #urls.py ضمن ملف from django.conf.urls import patterns, include from myproject.admin import admin_ # نقوم بتمريره هنا urlpatterns = patterns('',(r'^myadmin/', include(admin_.urls)),)
- 3 اجابة
-
- 1
-
-
أولاً سأبدأ بالشكل العام لهذه الطبقة: tf.compat.v1.keras.layers.CuDNNLSTM( units, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, return_sequences=False, return_state=False, go_backwards=False, **kwargs ) حيث أن units هي عدد الخلايا أو الوحدات في الشبكة وتمثل عدد المخرجات (output space)، أما الوسيط الثاني فيستخدم من أجل التحويل الخطي للمدخلات وهو عبارة عن مُهيئ لمصفوفة أوزان النواة (افتراضياً نستخدم عادةً glorot_uniform لأغلب المهام)، أما الثالث فهو مُهيئ لمصفوفة أوزان recurrent_kernel ، وتُستخدم للتحويل الخطي للحالة المتكررة "recurrent state" والقيمة الافتراضية التي نستخدمها غالباً "orthogonal". أما الوسيط الرابع فهو مُهيئ لمصفوفة الانحراف bias (افتراضياً 0 وأيضاً نستخدم هذه القيمة غالباً أي لاتشغل نفسك بتغييرها). الوسيط الخامس فيحدد فيما إذا كنت تريد إضافة 1 إلى الانحراف bias الخاص ببوابة النسيان (يستحسن استخدامه حسب ماذكره Jozefowicz et al.). الوسيط السادس فيستخدم لتطبيق penalties على أوزان الطبقة (أي على ال Kernal_weights). السابع أيضاً مثل السادس لكن هنا يتم تطبيقها على ال recurrent_kernel. الثامن كذلك الأمر لكنه يطبق على أوزان ال bias أي على ال (bias vector). الوسيط التاسع return_sequences لتحديد شكل الإخراج ففي حال قمت بضبطه على True سوف يكون الخرج 3D حيث يقوم بإعادة كامل التسلسل أما في الحالة الافتراضية أي False يقوم بإعادة الخرج الأخير من تسلسل الخرج. طبعاً لكي لاتقع في الأخطاء يجب أن نضع True إذا كانت الطبقة التالية هي طبقة تكرارية و False إذا كانت طبقة Dense فالطبقات التكرارية دخلها يجب أن يكون 3D بينما طبقات Dense دخلها يكون 2D. والدخل لهذه الطبقة يكون: [batch, timesteps, feature] والخرج: يكون إما 2D أو 3D كما أشرنا. أما الوسيط العاشر فهو لتحديد فيما إذا كنت ترد إرجاع الحالة "state" الأخيرة أم لا إلى جانب الخرج. الحادي عشر في حالة ضبطه على True فسيتم معالجة تسلسل الدخال بشكل عكسي وسيرجع التسلسل المعكوس. الآن هذا كان تعريف بالطبقة في حالة أردت استخدامه، ونستخدمه مع النماذج بشكل مشابه للطبقة LSTM (سأرفق رابط تم فيه شرح هذه الطبقة مع مثال). حيث أن هذه الطبقة هي نفسها الطبقة LSTM ولكن مع بعض التحديثات+أسرع. فالطبقة CuDNNLSTM نسميها "Fast LSTM" ولايمكنك تشغيلها إلا على ال GPU ومع TensorFlow (لايمكنك استخدامها من إطار العمل keras فهي غير معرفة هناك) هذه الطبقة أسرع بحوالي 10 مرات من طبقة LSTM العادية. وسميت بهذا الاسم لأنه تم بناءها للاستفادة من النواة cuDNN وهي اختصار ل CUDA Deep Neural Network (cuDNN).
- 1 جواب
-
- 1
-
-
لتكن لدينا البيانات التالية: import pandas as pd df1 = pd.DataFrame({'id': ['1', '2'], 'Name': ['ali', 'Eyad']}) df1 """ id Name 0 1 ali 1 2 Eyad """ df2 = pd.DataFrame({'id': ['3', '4'], 'Name': ['asdc', 'gbf']}) df2 """ id Name 0 3 asdc 1 4 gbf """ pd.concat: dataframes = [df1, df2] pd.concat(dataframes) """ id Name 0 1 ali 1 2 Eyad 0 3 asdc 1 4 gbf """ # لاحظ أن الفهرس أصبح غير مرتب وبالتالي لضبطه نقوم بالتالي pd.concat(dataframes, ignore_index=True) """ id Name 0 1 ali 1 2 Eyad 2 3 asdc 3 4 gbf """ df.append: df1.append([df2]) """ id Name 0 1 ali 1 2 Eyad 0 3 asdc 1 4 gbf """ # كذلك لإصلاح الفهرس نضيف الوسيط التالي df1.append([df2],ignore_index=True) الحلول الأسرع مع البيانات الكبيرة تكون من خلال الاتجاه إلى نمباي وهناك العديد من الطرق للقيام بذلك وسأذكر اثنين منها (هما الأفضل لأداء المهمة): # vstack import numpy as np pd.DataFrame(np.vstack((df1.to_numpy(),df2.to_numpy())),columns=["id","name"]) """ id name 0 1 ali 1 2 Eyad 2 3 asdc 3 4 gbf """ # column_stack pd.DataFrame(np.column_stack((df1.to_numpy().T,df2.to_numpy().T)).T,columns=["id","name"]) """ id name 0 1 ali 1 2 Eyad 2 3 asdc 3 4 gbf """ وللمقارنة بين المناهج السابقة: %timeit pd.DataFrame(np.vstack((df1.to_numpy(),df2.to_numpy())),columns=["id","name"]) # 1000 loops, best of 5: 398 µs per loop %timeit df1.append([df2]) # 1000 loops, best of 5: 473 µs per loop %timeit pd.concat([df1, df2]) # 1000 loops, best of 5: 434 µs per loop %timeit pd.DataFrame(np.column_stack((df1.to_numpy().T,df2.to_numpy().T)).T,columns=["id","name"]) # 1000 loops, best of 5: 407 µs per loop vstack هو الأفضل. ويظهر الفرق أكبر عندما نتعامل مع عدد كبير من الداتافريم أو الأحجام الكبيرة.
-
ليكن لدينا الفريم التالي: import pandas as pd #Map df = pd.DataFrame({'time':['09:00','10:00','11:00','12:00','13:00'], 'result':['+52A','+62B','+44a','+30b','-110a']}) df """ time result 0 09:00 +52A 1 10:00 +62B 2 11:00 +44a 3 12:00 +30b 4 13:00 -110a """ استخدام التعابير المنطقية والدالة re.sub و re.compile من مكتبة regex: import re df['result'] = [re.compile(r'\D').sub('', x) for x in df['result']] df """ time result 0 09:00 52 1 10:00 62 2 11:00 44 3 12:00 30 4 13:00 110 """ # يفضل كتابة التعبير المنتظم مسبقاُ لتجنب الحسابات المكررة reg=re.compile(r'\D') df['result'] = [reg.sub('', x) for x in df['result']] كما ويمكنك استخدام الدالة re.search بدلاً من re.sub: reg = re.compile(r'\d+') df['result'] = [reg.search(x)[0] for x in df['result']] استخدام الدالة lstrip: df['result'] = [x.lstrip('+-').rstrip('aAbBcC') for x in df['result']] df """ time result 0 09:00 52 1 10:00 62 2 11:00 44 3 12:00 30 4 13:00 110 """ وإذا كنت تريد حلاً بايثونياً (أقصد بدون توابع مساعدة): df['result'] = [x[1:-1] for x in df['result']]
-
يمكنك أيضاً استخدام مفهوم ال array slicing: Entry.objects.all()[:1].get() والتي من الممكن استخادمها مع filter: Entry.objects.filter()[:1].get() من الضروري أن تضع get لكي تحصل على object، وإلا ستحصل على QuerySet.
- 3 اجابة
-
- 2
-
-
يجب أن يحتوي التطبيق على مجلد Templatetags على نفس المستوى مثل Models.py و views.py .. إلخ. وإذا لم يكن هذا موجود فعليَاً، قم بإنشائه ولا تنس ملف __init__.py لضمان معاملة المجلد على أنه حزمة بايثون. أولاً قم بإنشاء ملف باسم event.py داخل المجلد Templatetags مع الكود التالي(بعد إضافة وحدة Templatetags، ستحتاج إلى إعادة تشغيل الخادم قبل أن تتمكن من استخدام ال tags أو filters في القوالب) : from django import template as tem reg = tem.Library() @reg.simple_tag def define(val=None): return val ثم في القالب الخاص بك يمكنك تعيين قيم إلى ال context كالتالي: {% load event %} {% if item %} {% define "Edit" as action %} {% else %} {% define "Create" as action %} {% endif %} Would you like to {{action}} this item?
- 3 اجابة
-
- 2
-
-
أيضاً قد يكون الحل التالي أفضل لل SEO: <Link href="/timer" passHref> <Tab component="a" label="Timer" /> </Link> حيث أن Link لايضيف href لل child. يقوم passHref بفرض هذا، لكن preventDefault لايمكن وضعه onClick لأنه لن يغير عنوان URL.
-
تقدم لك كيراس Keras و tensorflow.keras الكلاس ExponentialDecay لتطبيق تقنية Exponential Learning Rate Decay ولها الشكل التالي: tf.keras.optimizers.schedules.ExponentialDecay( initial_learning_rate, decay_steps, decay_rate, staircase=False ) حيث أن الوسيط الأول هو قيمة معدل التعلم الابتدائي، أما الوسيط الثاني فهو عدد خطوات ال decay،والوسيط الثالث هو مقدار ال decay ( معامل التغير في قيمة معدل التعلم ويفضل أن تكون قيمته 0.95 ولايجب أن تتجاوز ال 1)، الوسيط الأخير لجعل ناتج القسمة step/decaysteps قيمة صحيحة وبالتالي ستتبع تغيرات قيم معدل التعلم نهجاً سلميَاً. أما المعادلة التي يتم تطبيقها لحساب ال lr في كل epoch هي: def decayed_learning_rate(step): return initial_learning_rate * decay_rate ^ (step / decay_steps) ولاستخدامه نقوم بتعريف object من هذا الكلاس ثم تمريره إلى وسيطة learning Rate في أي Optimaizer معرف في إطار العمل. مثال(decay كل 100000 خطوة بأساس 0.96: # نحدد القيمة الأولية initial_learning_rate = 0.1 # نعرَف غرض lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay( initial_learning_rate, decay_steps=100000, decay_rate=0.96, staircase=True) # نقوم بتمريره للأوبتيمايزر model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=lr_schedule), loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(data, labels, epochs=5)
- 1 جواب
-
- 1
-
-
Webpack عبارة عن أداة تجميع "bundler". إن ما يفعله webpack بشكل أساسي هو أنه يجمع كل ال assets والملفات الخاصة بك في حزم packages. حسناً لماذا نحتاج عملية التجميع هذه، لماذا لانترك السكريبت كما هو؟! الإجابة هي أنك تستطيع الاستغناء عنها لكن ذلك سيؤدي لمشكلة أو عدة مشاكل في المستقبل. افترض أن لديك سكريبت لصفحتك مكون من 20 ألف سطر من JS هنا تبدأ المشاكل بالظهور... لأن إدارة كل هذه التعليمات البرمجية في ملف واحد سيكون متعباً ومزعجاً للغاية ويزداد الأمر سوءاً عندما يكون هناك عدة أشخاص يعملون على نفس الملف في وقت واحد. لذلك لابد من قسيم الكود إلى أجزاء مختلفة، مثلاً قسم ملفنا الضخم إلى 20 ملف أصغر ، وأدخلنا 20 سمة <script> في الصفحة. ومع ذلك ما زلنا بحاجة إلى ضمان الترتيب الصحيح للملفات المراد ربطها، وسنحتاج إلى مراقبة تحديثات الكود في الملفات الموجودة، أو في حالة الحاجة إلى إضافة أي ملفات إضافية ، ثم ترتيبها….. لذا نحن بحاجة لطريقة أقوى للتعامل مع هذه القضايا من أجل الربط بينها والتعامل معها.. تتمثل الطريقة الأفضل في أن يخبرنا كل ملف بطريقة ما بالملفات الأخرى التي يتطلبها (التبعيات) ومن ثم يمكننا الاستفادة من ذلك للربط بين هذه الملفات. وهنا تدخل حزمة الويب webpack. توجد آليات لتحديد التبعيات والواردات في ES6 و nodeJS. يستخدم Webpack هذه الآليات لإنشاء غراف (بيان) لجميع الملفات وتبعياتها، وتجميع جميع الملفات في حزم.
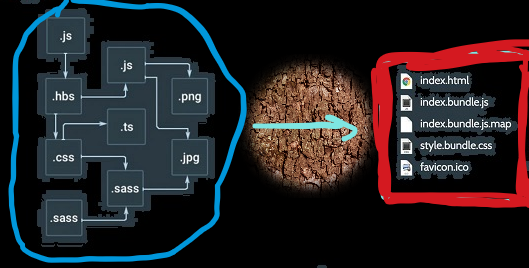
-
تشير المستندات الحديثة إلى إمكانية استخدام: {{ mydata|json_script:"mydata" }} لمنع البرمجة بالحقن "Code Injection" (أغراض تخريبية). {{ mydata|json_script:"mydata" }} <script> const mydata = JSON.parse(document.getElementById('mydata').textContent); </script> كما يمكنك استخدام كلاً من escapejs و JSON.parse كالتالي: var CropOpts = JSON.parse("{{ profile.last_crop_coords|escapejs }}");
- 3 اجابة
-
- 1
-
-
ليكن لدينا المثال التالي: df """ col1 col2 col3 col4 b ali 33 Up wq c ali 23 we qw a dac 23 we we e gsg 12 we ew f cds 66 ew ds g sdac 95 sdac dc i cd 55 adsc r j das 35 cda r k ads 12 cd vc d ad 88 cda Bhgu """ 1. فرز صفوف داتافريم بناءً على عمود معين: df.sort_values(by = 'col1') """ col1 col2 col3 col4 d ad 88 cda Bhgu k ads 12 cd vc b ali 33 Up wq c ali 23 we qw i cd 55 adsc r f cds 66 ew ds a dac 23 we we j das 35 cda r e gsg 12 we ew g sdac 95 sdac dc """ 2. اعتماداً على عدة أعمدة: df.sort_values(by = ['Name', 'Age']) 3. فرز الصفوف بناءً على عمود معين وترتيب تنازلي: df.sort_values(by = 'col', ascending = False) 4. لجعل عملية الفرز تتم على البيانات الأصلية نستخدم inplace: df.sort_values(by = 'Name', inplace = True) ليكن لدينا مثال آخر: Arabic Math Science English Ankit 75 50 60 70 Rahul 75 55 65 75 Aishwarya 75 35 45 25 Shivangi 75 90 60 70 Priya 76 90 70 60 Swapnil 90 80 70 60 Shaurya 65 10 30 20 1. فرز الأعمدة بناءً على سطر محدد: df.sort_values(by = 'Priya', axis = 1) """ English Science Arabic Math Ankit 70 60 75 50 Rahul 75 65 75 55 Aishwarya 25 45 75 35 Shivangi 70 60 75 90 Priya 60 70 76 90 Swapnil 60 70 90 80 Shaurya 20 30 65 10 """ وأخيراً يمكنك اختيار خوارزمية البحث التي تريدها من خلال الوسيط kind وهذه هي الخيارات المتوفرة: {‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’}, default ‘quicksort’ لاستخدامها: DataFrame.sort_values(... ... kind='quicksort' .. . . ) ,ولتطبيق عملية ما قبل أن يطبق الفرز يمكن استخدام الوسيط key وتمرير الدالة المناسبة له.
- 3 اجابة
-
- 1
-
-
يبدو أنه ليس لديك حزمة python mysql مثبتة، لذا جرب: pip install mysql-python وإذا لم تكن تستخدم بيئة افتراضية: sudo pip install mysql-python أو لأنه لم يعثر على مكتبة mysqldb: sudo apt-get install python-mysqldb أو أنك بحاجة لتثبيت mysqlclient: pip install mysqlclient
-
حل آخر: t1 = pd.to_datetime('1/1/2015 01:00') t2 = pd.to_datetime('1/1/2015 03:30') # إذا كنت تريد الساعات h=pd.Timedelta(t2 - t1).seconds / 3600.0 # إذا كنت تريد الدقائق m=pd.Timedelta(t2 - t1).seconds / 60.0
-
إضافةً إلى استخدام مكتبة التعابير المنتظمة كما أشار سامح يمكنك القيام بالتالي: # - توضع ضمن قائمة ثم نعيد تجميعها كلسلسلة بحيث يفصل بينهم tokens للتخلص من الفراغات نقوم بتقسيم السلسلة إلى url="How can this be achieved" "-".join( url.split() ) # How-can-this-be-achieved # حتى في حالة وجود فراغات متتالية url="How can this be achieved" "-".join( url.split() ) # How-can-this-be-achieved
-
من خلال resample يمكننا القيام بماتطلبه: import pandas as pd df = pd.DataFrame({ 'date': pd.to_datetime( ['2016-11-15','2016-11-16','2016-11-18']), 'values':['a','b','c']}) df """ date values 0 2016-11-15 a 1 2016-11-16 b 2 2016-11-18 c """ #resample استخدام df.set_index(df.date, inplace=True) df.resample('D').sum().fillna(0) """ values date 2016-11-15 a 2016-11-16 b 2016-11-17 0 2016-11-18 c """ ولتسهيل العملية يمكنك استخدام التابع التالي. حيث نمرر له ال dataframe والعمود الخاص بالتاريخ والطريقة التي نريد فرز العمود على أساسها والقيمة المراد وضعها للتواريخ المفقودة وهي تعتمد على دالة ال reindex التي سبق ذكرها في الإجابات السابقة: def fill_in_missing_dates(df, date_col_name = 'date',date_order = 'asc', fill_value = 0, days_back = 30): df.set_index(date_col_name,drop=True,inplace=True) df.index = pd.DatetimeIndex(df.index) d = datetime.now().date() d2 = d - timedelta(days = days_back) idx = pd.date_range(d2, d, freq = "D") df = df.reindex(idx,fill_value=fill_value) df[date_col_name] = pd.DatetimeIndex(df.index) return df
- 4 اجابة
-
- 1
-