


Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
توفر جافا متابعة التزامن على كل كائن من فئة Object، حتى أنه يمكن استخدامها بمثابة قفل lock للتزامن. بدلاً من السماح للمبرمجين بتصميم طرق الأقفال الخاصة وإدارة كتل التزامن وتطبيق قواعد التزامن. بما أن جميع الفئات classes ترث الصف Object، وبالتالي جميع الكائنات في جافا يمكن استخدامها في التزامن. وهناك 3 طرق لتعريف كتل متزامنة في جافا: أول طريقة هي Synchronized Class Method وهنا تصبح جميع التعليمات البرمجية في هذه الدالة كتلة متزامنة و الغرض (الكائن) الذي يتم إنشاؤه من هذا الصف هو القفل. class class_name { static synchronized type method_name() { statement block } } الطريقة الثانية Synchronized Instance Method وهنا تصبح جميع التعليمات البرمجية في هذه الدالة كتلة متزامنة و ال instance object هو القفل. class class_name { synchronized type method_name() { statement block } } الطريقة الثالثة Synchronized Statement وهنا جميع التعليمات البرمجية المحددة ما بين القوسين في Synchronized تصبح كتلة متزامنة ويكون الكائن المحدد (هنا object) هو القفل. class class_name { type method_name() { synchronized (object) { statement block } } } تطبق الجافا قواعد التزامن من خلال تحديد المالك للقفل لل Thread التي تستخدم الكتلة المتزامنة ، و هنا توضيح بسيط: عند الوصول الى كتلة متزامنة في الThread المنفذة أو الحالية فانها تحاول الحصول على امتلاك هذا الكائن و إذا وجدت Thread أخرى تستخدم هذا الكائن فانها تنتظر الاخرى حتى تنتهي منه. في حالة تحرير القفل فان الThread المنتظرة تصبح مالكة لهذا القفل و تبدأ بتنفيذ مهامها عليه. في حالة الانتهاء من تنفيذ الكتلة الكتزامنة فأن القفل يتحرر مرة اخرى. يمكن ان يحتوي البرنامج الواحد على عدة كتل متزامنة، و يمكن ربط نفس القفل بعدة كتل متزامنة. مثال: في هذا المثال تم تعرف كتلتين متزامنتين، و كلاهما ارتبط بنفس القفل The Instance Object. class class_name { type method_name() { synchronized (this) { statement block 1 } } synchronized type method_name() { statement block 2 } } الكتلة رقم 1 لا يمكن ان تنفذ بنفس الوقت مع الكتلة رقم 2. أما في المثال التالي تم تعريف كتلتين و كلاهما مرتبط بقفل مختلف الأول مع كائن الفئة نفسها و الآخر مع دالة لكائن من الفئة، و الكتلتين لا ينتظران بعذهما البعض أبدا أي يمكن تنفيذهما بنفس الوقت: class class_name { type method_name() { synchronized (this) { statement block 1 } } static synchronized type method_name() { statement block 2 } }
-
تابع معي: import numpy as np import pandas as pd np.random.seed(0) # بدايةً نقوم بتعريف الداتافريم بشكل صحيح لأنه كان يحتوي بعض الأخطاء df = pd.DataFrame({'city': ['Cairo', 'Dohha', 'Riyadh', 'Dubai'] * 3, 'office_id':[x*2 for x in range(1, 7)]*2 , 'sales': [np.random.randint(100000, 999999) for _ in range(12)]}) df """ city office_id sales 0 Cairo 2 405711 1 Dohha 4 535829 2 Riyadh 6 217952 3 Dubai 8 252315 4 Cairo 10 982371 5 Dohha 12 459783 6 Riyadh 2 404137 7 Dubai 4 222579 8 Cairo 6 710581 9 Dohha 8 548242 10 Riyadh 10 474564 11 Dubai 12 835831 """ #office_id و city نطبق عملية التجميع على أساس العمود # نحصل الآن على المدن مع كل المكاتب الموجودة فيها مع مبيعات كل مكتب city_office = df.groupby(['city', 'office_id']).agg({'sales': 'sum'}) city_office """ sales city office_id Cairo 2 405711 6 710581 10 982371 Dohha 4 535829 8 548242 12 459783 Dubai 4 222579 8 252315 12 835831 Riyadh 2 404137 6 217952 10 474564 """ # لكننا نريد حساب النسبة المئوية لمبيعات كل مكتب ضمن مدينة معينة أي يجب أن نحسب النسبة مقارنةً بباقي مبيعات المكاتب ضمن المدينة # بذا يجب علينا إنشاء داتافريم آخر ليحسب لنا مجموع مبيعات كل المكاتب ضمن كل مدينة # الآن ننظم مبيعات كل مكتب City = df.groupby(['city']).agg({'sales': 'sum'}) City """ sales city Cairo 2098663 405711+710581+982371 Dohha 1543854 Dubai 1310725 Riyadh 1096653 """ #city على القيمة المقابلة له من جدول sales الآن نعود للداتافريم السابق ونقوم بقسمة كل قيمة في عمود ال # وبالتالي نحصل على النسبة المطلوبة # نحتاج فقط لاستخدام للقسمة والضرب ب100 في عمود المبيعات city_office.div(City, level='city') * 100 """ sales city office_id Cairo 2 19.331879 = (405711/2098663)*100 6 33.858747 10 46.809373 Dohha 4 34.707233 8 35.511259 12 29.781508 Dubai 4 16.981365 8 19.250033 12 63.768601 Riyadh 2 36.851857 6 19.874290 10 43.273852 """
- 3 اجابة
-
- 1
-

-
حاول استخدام هذه الحزمة من npm لإنشاء وكيل Node.js لـExpress: http-proxy-middleware، ثم يمكنك ضبط الخيار target لل proxy requests مثال: const proxy = require('http-proxy-middleware') app.use('/api', proxy({ target: 'http://localhost:5000', changeOrigin: true }));
-
أيضاً للحصول على حل بسيط للغاية لاستخدمه في النماذج الأولية يمكنك فقط استخدام طريقة عرض django المدمجة. هذا الحل ممتاز للنماذج الأولية أو العمل لمرة واحدة: from django.views.static import serve file = '/some/path/to/local/file.txt' return serve(request, os.path.basename(file), os.path.dirname(file)) لكن كما ذكرت يصلح للنماذج الأولية وليس للاستخدام العملي.
- 3 اجابة
-
- 1
-
-
size و count كل منهما يستخدم من أجل أغراض مختلفة. size هو attribute تقوم بحساب حجم (أو طول) الكائن الذي تم استدعاؤه عليه. وبطبيعة الحال يتضمن هذا أيضاً الصفوف / القيم التي هي NaN. أما count فهو تابع مهمته عد الخلايا التي ليست NaN لكل عمود أو صف. import pandas as pd import numpy as np df = pd.DataFrame({'col': ['x', np.nan, 'x']}) df """ col 0 x 1 NaN 2 x """ df.col.size # 3 df.col.count() # 2 nan لم يحسب ال أيضاً هناك اختلاف في بنية الناتج عند استدعاء GroupBy.size و GroupBy.count. حيث أن GroupBy.count تعيد DataFrame أما GroupBy.siz تعيد series: import pandas as pd import numpy as np df = pd.DataFrame({ 'gb': list('aaab'), 'col': ['x', np.nan, 'x',"x"]}) df """ gb col 0 a x 1 a NaN 2 a x 3 b x """ df.groupby('gb').size() """ gb a 3 b 1 dtype: int64 """ df.groupby('gb').count() """ col gb a 2 b 1 """ type(df.groupby('gb').count()) # pandas.core.frame.DataFrame type(df.groupby('gb').size()) # pandas.core.series.Series هناك اختلاف أخير عند استخدامنا ل pivot_table. لنفترض أننا نود حساب ال cross tabulation لـلداتافريم التالي: df """ A B 0 0 1 1 0 1 2 1 2 3 0 2 4 0 0 """ pd.crosstab(df.A, df.B) """ B 0 1 2 A 0 1 2 1 1 0 0 1 """ #يمكنك عرض الحجم pivot_table باستخدام df.pivot_table(index='A', columns='B', aggfunc='size', fill_value=0) """ B 0 1 2 A 0 1 2 1 1 0 0 1 """ #لايعمل هنا حيث يتم إرجاع داتافريم فارغ count لكن df.pivot_table(index='A', columns='B', aggfunc='count') """ Empty DataFrame Columns: [] Index: [0, 1] """
-
 كما أشار سامح. أويمكنك أيضاً تنفيذ الأمرين التاليين لحل المشكلة: sudo apt-get install libpq-dev python-dev # ثم pip install psycopg2 # pip3 install psycopg2 $ لبايثون 3 أيضاً قد يظهر الخطأ "No module named psycopg2.extensions" عندما لايكون هناك مترجم compiler مثبت، ونحن تحتاج إلى واحد لبناء حزمة psycopg2 لذا يكون الحل: # تثبيت الاعتماديات sudo apt-get build-dep python-psycopg2 sudo apt install python3-psycopg2 # Python 3 #virtualenv ثم ضمن ال pip install psycopg2-binary
كما أشار سامح. أويمكنك أيضاً تنفيذ الأمرين التاليين لحل المشكلة: sudo apt-get install libpq-dev python-dev # ثم pip install psycopg2 # pip3 install psycopg2 $ لبايثون 3 أيضاً قد يظهر الخطأ "No module named psycopg2.extensions" عندما لايكون هناك مترجم compiler مثبت، ونحن تحتاج إلى واحد لبناء حزمة psycopg2 لذا يكون الحل: # تثبيت الاعتماديات sudo apt-get build-dep python-psycopg2 sudo apt install python3-psycopg2 # Python 3 #virtualenv ثم ضمن ال pip install psycopg2-binary- 2 اجابة
-
- 1
-
-
إليك جميع الطرق مع مقارنة بزمن التنفيذ بينها: import numpy as np import pandas as pd df = pd.DataFrame(np.random.rand(100, 100)) %timeit df.iat[50,50]=50 # ✓ %timeit df.at[50,50]=50 # ✔ %timeit df.set_value(50,50,50) # سوف يتم إلغاءها في قادم النسخ %timeit df.iloc[50,50]=50 %timeit df.loc[50,50]=50 """ 7.06 µs ± 118 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) الأفضل 5.52 µs ± 64.2 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) الأفضل 3.68 µs ± 80.8 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 98.7 µs ± 1.07 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 109 µs ± 1.42 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) """ كما يمكنك تعديل القيم بالشكل التالي: import pandas as pd df = pd.DataFrame(index=['A','B','C'], columns=['D','E']) df.D["C"]=2
- 4 اجابة
-
- 1
-
-
إذا كنت بحاجة إلى استخدام شيء مشابه لسمة "tag" قالب عنوان url ضمن الكود الخاصة بك، فإن Django يوفر الدالة reverse: reverse(viewname, urlconf=None, args=None, kwargs=None, current_app=None)¶ يمكن أن يكون viewname اسم نمط URL أو كائن عرض قابل للاستدعاء. على سبيل المثال ، بالنظر إلى عنوان url التالي: from news import views path('archive/', views.archive, name='news-archive') يمكنك استخدام أي مما يلي لعكس عنوان URL: # URL باستخدام اسم عنوان reverse('news-archive') # تمرير كائن قابل للاستدعاء #بهذه الطريقة namespaced هذا غير محبذ لأنه لا يمكنك عكس طرق عرض from news import views reverse(views.archive) إذا كان عنوان URL يقبل الوسطاء، فيمكنك تمريرها في args. على سبيل المثال: from django.urls import reverse def myview(request): return HttpResponseRedirect(reverse('arch-summary', args=[1945])) يمكنك أيضاً تمرير kwargs بدلاً من args. على سبيل المثال: reverse('admin:app_list', kwargs={'app_label': 'auth'}) '/admin/auth/' لا يمكن تمرير args و kwargs إلى reve5rse في نفس الوقت. إذا تعذر إجراء أي تطابق ، فإن reverse يرمي استثناء NoReverseMatch. يمكن لوظيفة reverse عكس مجموعة كبيرة ومتنوعة من أنماط التعابير المنتظمة (regex) لعناوين URL ، ولكن ليس كل واحد ممكن.إن القيد الرئيسي في الوقت الحالي هو أن النمط لا يمكن أن يحتوي على خيارات بديلة عن طريق استخدام ("|"). إذاً يمكنك استخدام هذه الأنماط للمطابقة مع عناوين URL الواردة وإرسالها إلى طرق العرض، ولكن لا يمكنك عكس هذه الأنماط. تسمح لك الوسيطة current_app بتقديم تلميح "hint" إلى ال reslover يشير إلى التطبيق الذي تنتمي إليه طريقة العرض المنفذة حالياً. يتم استخدام وسيطة current_app كتلميح hint لتحليل فضاءات أسماء namespaces التطبيقات في عناوين URL، وفقاً ل namespaced URL resolution strategy. وسيطة urlconf هي وحدة URLconf التي تحتوي على أنماط عنوان URL المراد استخدامها للعكس.
- 2 اجابة
-
- 1
-
-
طريقة أخرى إضافةً لما قاله سامح وذلك من خلال Library. كما يلي: # coding=utf-8 from django.template.base import Library register = Library() @register.filter def get_item(dictionary, key): return dictionary.get(key) واستخدامه كالتالي: {{ mydict|get_item:item.NAME }} وإذا
- 2 اجابة
-
- 1
-
-
اعتقد أنك تحتاج إلى حل أكثر أناقة ونظافة وراحة للعين: # نعرف تابع يأخذ 3 وسطاء ويرد محموعهم def func(arguments): ali, eyad, Thyme = arguments[0] , arguments[1] , arguments[2] return ali+eyad+Thyme # نعرف الدالة الرئيسية if __name__ == "__main__": import multiprocessing pool = multiprocessing.Pool(4) # تمرير 3 وسطاء out = pool.map(func, [ [1,2,3] ]) print(out) # الخرج # [6]
-
الكلام التالي ينطبق على عدد الوحدات في بقية أنواع الطبقات أيضاً مثل Dense وغيرها في كيراس وتنسرفلو.. num_units هو عدد يشير إلى ال "Learning capacity" أي قدرة الشبكة على التعلم وهي تعكس عدد ال "learned parameters" ضمن الطبقة أي عدد المعلمات التي سيتم تدريبها لمعالجة بياناتك. إن num_units يندرج تحت مفهوم ال Hyperparameters أي المعاملات العليا للنموذج، أي يجب أن تقوم بضبطها من خلال التجريب، أي ليس هناك قاعدة ثابتة لاختيار قيمتها لكن هناك نقاط يجب وضعها بعين الاعتبار عند تحديد قيمتها وهي: زيادة عددها يعطي الشبكة قدرة أكبر على التعلم من نماذج بيانات أكبر و أكثر تعقيداً (تعطي النموذج قدرة أكبر على التعلم من البيانات-يمكنك تخيل الأمر على أنه حجم ذاكرتها فكلما زاد حجمها زادت قدرتها على التعلم-). لكن زيادة عددها قد يجعل النموذج يتجه إلى حالة ال Oveffitting لذا يجب أن تكون حذراً وأن لتجعل حجمها يتناسب مع حجم المشكلة (عدد ال features للعينات وعدد العينات أي حجم الداتاسيت بشكل عام ومدى تعقيدها). تقليل عددها يجعل الشبكة أضعف وأقل قدرة على التعلم من البيانات. وبالتالي قد يتجه النموذج إلى حالة Underfitting. لذا يجب الموازنة بين الأمرين السابقين أي عملية Trade-off بينهما. أما بالنسبة للعدد 128 فهذا ليس رقماً ثابتاً كما أوضحت لك هو Hyperparameter لكن في كثير من الأحيان يكون ملائم. كما تجدر الإشارة إلى أن عدد ال num_units يفضل دوماً أن يتم أخذه من العلاقة 2 أس n أي: 16- 32-64-128-256-512.... لأن هذه الأرقام تسرع عمليات الحساب لأن المعالج يفضلها.
- 2 اجابة
-
- 1
-
-
يمكن تحقيق ذلك عن طريق إنشاء محسِّنَيْن "GradientDescentOptimizer". لنفرض أن لديك شبكة مسبقة التدريب من 5 طبقات ونريد ضبط معدل التعلم لأول لهم على 0.00001 ونريد طبقة إضافية بمعدل 0.0001 . في هذه الحالة يمكنك استخدام tf.trainable_variables للحصول على جميع متغيرات التدريب وتقرر الاختيار من بينها. كالتالي: var_list1 = [variables from first 5 layers] var_list2 = [the rest of variables] opt1 = tf.train.GradientDescentOptimizer(0.00001) opt2 = tf.train.GradientDescentOptimizer(0.0001) grads = tf.gradients(loss, var_list1 + var_list2) grads1 = grads[:len(var_list1)] grads2 = grads[len(var_list1):] tran_op1 = opt1.apply_gradients(zip(grads1, var_list1)) train_op2 = opt2.apply_gradients(zip(grads2, var_list2)) train_op = tf.group(train_op1, train_op2)
- 1 جواب
-
- 2
-
-
طالما أنك لم تعطنا مصدر البيانات فلايمكننا تحديد المشكلة، لكن هناك احتمالين الأول هو أنه هناك مسافات فارغة (وحلها كما أشار أيضاً)، أو أن هناك separator مختلف فافتراضياً يكون الفاصل هو "," لكن ليس بالضرورة دوماً لذا يجب عليك: إذا كنت تعرف نوع ال separator فقم بتعيينه مباشرة للوسيط. أو إذا لم تكن تعرفه قم بفتح ملف ال csv وتحقق من نوع ال separator. على سبيل المثال إذا كان ; نقوم بقراءة البيانات بالشكل: pd.read_csv("D:\\data.csv", sep=';')
- 3 اجابة
-
- 2
-
-
يمكنك القيام بذلك من خلال التابع التالي: //importAll تعريف تابع function importAll(r) { let images = {}; r.keys().map((item, index) => { images[item.replace('./', '')] = r(item); }); return images; } // استخدامه const images = importAll(require.context('./images', false, /\.(png|jpe?g|svg)$/)); <img src={images['doggy.png']} />
- 3 اجابة
-
- 1
-
-
ألكود التالي هو كل ماتحتاج إليه وذلك من أجل كل الأنظمة : const process = require('process'); //platform من خلال الواصفة var platform = process.platform; switch(platform) { case 'aix': // هنا تقوم بماتريد console.log("IBM AIX platform"); break; case 'darwin': // هنا تقوم بماتريد console.log("Darwin platform(MacOS, IOS etc)"); break; case 'freebsd': // هنا تقوم بماتريد console.log("FreeBSD Platform"); break; case 'linux': // هنا تقوم بماتريد console.log("Linux Platform"); break; case 'openbsd': // هنا تقوم بماتريد console.log("OpenBSD platform"); break; case 'sunos': // هنا تقوم بماتريد console.log("SunOS platform"); break; case 'win32': // هنا تقوم بماتريد console.log("windows platform"); break; default: const os = require('os'); var type = os.type(); switch(type) { //Windows_NT حالة النظام كان case 'Windows_NT': // هنا تقوم بماتريد console.log("windows operating system"); break; }
- 4 اجابة
-
- 1
-
-
من خلال emitter.setMaxListeners(n) بحيث n هي عدد صحيح ويعيد <EventEmitter> وبشكل افتراضي ، سيقوم EventEmitters بطباعة تحذير إذا تمت إضافة أكثر من 10 مستمعين "listeners" لحدث معين. لكن تسمح الدالة emitter.setMaxListeners بتعديل ذلك حيث يمكنك ضبطه على Infinity (أو 0) للإشارة إلى عدد غير محدود من المستمعين. مثال: const emitter = new EventEmitter() emitter.setMaxListeners(100) //limit أو 0 لإيقاف ال emitter.setMaxListeners(0) يتم ضبطه على 10 بشكل افتراضي لأن هذا يساعد في تجنب الوصول إلى حالة Memory leak" تسرب الذاكرة" (الاستهلاك غير المتعمد للذاكرة المؤقتة "ram" في الحاسوب، بواسطة برنامج حاسوب، حيث يفشل البرنامج في إفراغ الذاكرة بعد الانتهاء من استخدامه).
- 3 اجابة
-
- 1
-
-
نسخة قديمة من npm: بما أن إصدار npm المستخدم قديم. فقد يكون هذا هو السبب فعلى سبيل المثال فإن الإصدار Node v0.6.10 و npm v1.1.0-3. يحوي بعض المشاكل مع Ubuntu 12.04، لذا فإنه قبل كل شيء يجب أن تجرب تحديث Node (و npm معها) إلى الإصدار الأحدث: # linux $ sudo npm update npm -g إذا كنت تريد إعادة التثبيت بالكامل ، فستحتاج أولاً إلى إزالة الملفات التنفيذية Node / npm الحالية بالكامل: $ sudo apt-get purge nodejs npm ثم أعد التثبيت باستخدام إصدار أكثر تحديثًا ، مثل من Nodesource: $ curl -sL https://deb.nodesource.com/setup | sudo bash - $ sudo apt-get install -y nodejs لا يمكن التنزيل عبر HTTPS :لسبب أو لآخر ، لا يمكن لبعض الأشخاص الاتصال بالسجل عبر HTTPS. ويمكن إصلاح ذلك عن طريق تعيين السجل لاستخدام HTTP (هذا حل بديل): $ npm config set registry http://registry.npmjs.org/ $ npm config set strict-ssl false ومع ذلك ، لا يُنصح بذلك ، حيث سيتم تنزيل الحزم الخاصة بك بعد ذلك بشكل غير آمن. سيكون من الأفضل العثور على السبب الجذري الفعلي بدلاً من استخدام حل بديل مثل هذا. الوكيل Proxy: بالنسبة للعديد من الأشخاص ، يرجع السبب الأساسي في الواقع إلى استخدام وكيل على شبكتهم. إذا كانت هذه هي الحالة ، يمكنك استخدام الأوامر التالية لتعيين وكلاء HTTP و HTTPS:: $ npm config set proxy http://user:password@proxy.example.com:8181 $ npm config set https-proxy http://user:password@proxy.example.com:8181 سيؤدي هذا إلى حفظ التكوينات الجديدة وسيسمح لك بالوصول إلى الإنترنت مع npm.
-
يمكنك تحويل إطار البيانات بالكامل إلى سلسلة ثم عرضه من خلال الدالة display: import numpy as np from sklearn.datasets import load_iris import pandas as pd data = load_iris() df = pd.DataFrame(data.data, columns = data.feature_names) display(df.to_string()) أو من خلال pd.option_context: import numpy as np from sklearn.datasets import load_iris import pandas as pd data = load_iris() df = pd.DataFrame(data.data, columns = data.feature_names) with pd.option_context('display.max_rows', None, 'display.max_columns', None, 'display.precision', 3, ): print(df) كذلك يمكنك استخدام pd.set_option، ثم عرضها من خلال display: import numpy as np from sklearn.datasets import load_iris import pandas as pd data = load_iris() df = pd.DataFrame(data.data, columns = data.feature_names) # لعرض أكبر عدد من الأسطر و الأعمدة نقوم بعمليات الضبط التالية pd.set_option('display.max_rows', None) pd.set_option('display.max_columns', None) pd.set_option('display.width', None) pd.set_option('display.max_colwidth', -1) # قبل display(df) print('**RESET_OPTIONS**') # تطبيق المحددات السابقة pd.reset_option('all') # الآن سيتم عرضها بالكامل display(df)
- 3 اجابة
-
- 2
-
-
سأقوم بإنشاء قالب للقيام بذلك: import numpy as np import tensorflow.train.string_input_producer as qu import tensorflow.train.start_queue_runners as sqr import tensorflow as tf # قائمة بالملفات التي سنقرأها queue = qu(['tf.png']) # قراءة الملفات _, v = tf.WholeFileReader().read(queue) #حسب نوع الصور التي لديك decode_jpeg أو decode_png استخدم image = tf.image.decode_png(v) initialize = tf.initialize_all_variables() with tf.Session() as sess: sess.run(initialize) # ملء قائمة انتظار اسم الملف c = tf.train.Coordinator() threads = sqr(coord=c) for i in range(1): # طول القائمة التي لدينا image = image.eval() # الصورة ك تنسر # طباعة أبعادها image.shape # عرضها Image.show(Image.fromarray(np.asarray(image))) coord.request_stop() coord.join(threads) الكود السابق يقوم فقط بتحميل الصورة كتنسر والآن لحفظها ضمن ملف TFRecords: def _int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) def _bytes_feature(value): return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) # مجموعة الصور والتسميات كمدخلات def convert_to(images, labels, name): num_examples = labels.shape[0] if images.shape[0] != num_examples: raise ValueError("Images size %d does not match label size %d." % (images.shape[0], num_examples)) rows = images.shape[1] cols = images.shape[2] depth = images.shape[3] filename = os.path.join(FLAGS.directory, name + '.tfrecords') print('Writing', filename) writer = tf.python_io.TFRecordWriter(filename) for index in range(num_examples): image_raw = images[index].tostring() example = tf.train.Example(features=tf.train.Features(feature={ 'height': _int64_feature(rows), 'width': _int64_feature(cols), 'depth': _int64_feature(depth), 'label': _int64_feature(int(labels[index])), 'image_raw': _bytes_feature(image_raw)})) writer.write(example.SerializeToString()) ثم لقراءتها لاحقاً: #"train.TFRecord" لاتنسى إنشاء قائمة انتظار لاسم الملف لمسار ملف # القيمة المعادة لهذا التابع هو بياناتك بعد قراءتها #label أي الصورة وال def read_and_decode(filename_queue): reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, dense_keys=['image_raw', 'label'], # لم يتم تحديد الإعدادات الافتراضية لأن كلا المفتاحين مطلوبان dense_types=[tf.string, tf.int64]) image = tf.decode_raw(features['image_raw'], tf.uint8) image = tf.reshape(image, [my_cifar.n_input]) image.set_shape([my_cifar.n_input]) # إذا أردت يمكنك هنا أن تقوم بإعادة تعيين أبعاد الصور لديك أو تطبيق بعض العمليات على الصورة # الآن سنقوم بتحويل الصورة لفكتور # Convert from [0, 255] -> [-0.5, 0.5] floats. image = tf.cast(image, tf.float32) image = tf.cast(image, tf.float32) * (1. / 255) - 0.5 #int32 إلى uint8 التحويل من label = tf.cast(features['label'], tf.int32) return image, label
- 2 اجابة
-
- 2
-
-
إليك نسخة مبسطة من إجابة سامح باستخدام نموذج فارغ كقالب: <h3>My Services</h3> {{ serviceFormset.management_form }} <div id="form_set"> {% for form in serviceFormset.forms %} <table class='no_error'> {{ form.as_table }} </table> {% endfor %} </div> <input type="button" value="Add More" id="add_more"> <div id="empty_form" style="display:none"> <table class='no_error'> {{ serviceFormset.empty_form.as_table }} </table> </div> <script> $('#add_more').click(function() { var form_idx = $('#id_form-TOTAL_FORMS').val(); $('#form_set').append($('#empty_form').html().replace(/__prefix__/g, form_idx)); $('#id_form-TOTAL_FORMS').val(parseInt(form_idx) + 1); }); </script>
- 2 اجابة
-
- 2
-
-
يمكنك إزالة node_modules ثم إعادة تثبيت التبعيات من package.json. rm -rf node_modules/ npm install سيؤدي ذلك إلى مسح جميع الحزم المثبتة في المجلد الحالي وتثبيت التبعيات من package.json فقط. وفي حال تم تثبيت التبعيات مسبقاً، فسيحاول npm استخدام الإصدار المخزَن مؤقتاً ، وتجنب تنزيل التبعية مرة ثانية. كذلك يمكننا استخدام : npm prune [[<@scope>/]<pkg>...] [--production] [--dry-run] [--json] يزيل هذا الأمر حزم ال "extraneous" (أي الحزم الموجودة في مجلد node_modules التي لم يتم إدراجها ضمن قائمة تبعية لأي حزمة.). إذا تم توفير اسم حزمة ، فلن تتم إزالة سوى الحزم المطابقة لأحد الأسماء المقدمة. وإذا تم تحديد production-- أو تم تعيين متغير البيئة NODE_ENV على production، فسيؤدي هذا الأمر إلى إزالة الحزم المحددة في devDependencies. أما no-production-- فهو نفي تعيين NODE_ENV على production. وإذا تم استخدام --dry-run فلن يتم إجراء أي تغييرات فعليَاً. إذا تم استخدام --json ، فستتم طباعة التغييرات npm prune (أو التي تم إجراؤها باستخدام --dry-run) ككائن JSON.
-
لدينا 3 طرق. الأولى استخدام الدالة encodeURI لترميز ال URL: var uri = "my test.asp?name=ståle&car=saab"; // مثال var res = encodeURI(uri); لكن هذه الدالة لاتقوم بترميز المحارف التالية: A-Z a-z 0-9 ; , / ? : @ & = + $ - _ . ! ~ * ' ( ) # الطريقة الثانية هي استخدام الدالة encodeURIComponent : var uri = "https://example.com/my test.asp?name=ståle&car=saab"; //مثال var res = encodeURIComponent(uri); هذه الطريقة تقوم أيضاً بترميز المحارف / ? : @ & = + $ # التي لاترمزها الطريقة السابقة. لكنها لاتقوم بترميز المحارف التالية: A-Z a-z 0-9 - _ . ! ~ * ' ( ) مثال آخر: // encodes characters such as ?,=,/,&,: console.log(`?x=${encodeURIComponent('test2!?')}`); // expected output: "?x=test%3F" console.log(`?x=${encodeURIComponent('шеллы')}`); // expected output: "?x=%D1%88%D0%B5%D0%BB%D0%BB%D1%8B" كما يمكنك استخدام escape لكن تم إلغاؤها بدءاً من النسخة 1.5.
-
بفرض لدي التنسر التالية: ten = tf.constant([[0.0, 0.0], [0.0, 0.0]]) #[0,0] ونريد تعديل الخلية idx = [[0, 0]] # قائمة بالمواقع المراد تحديث قيمها # القيمة المراد إضافتها val = [3.0] # أبعاد المصفوفة dim = [2, 2] k = tf.SparseTensor(idx, val, dim) ثم نستخدم العملية tf.sparse_tensor_to_dense لإنشاء dense tenso من k ثم إضافتها ل ten: out = ten + tf.sparse_tensor_to_dense(k) sess = tf.Session() sess.run(out) # ==> array([[ 3., 0.], # [ 0., 0.]], dtype=float32)
- 1 جواب
-
- 1
-
-
حسناً لنبدأ بتوضيح تنسيق TFRecord : هو تنسيق بسيط لتخزين سلسلة من السجلات الثنائية. مخازن البروتوكول هي مكتبة عبر الأنظمة الأساسية ومتعددة اللغات لتسلسل فعال للبيانات المنظمة. يتم تعريف رسائل البروتوكول بواسطة ملفات .proto ، وهي غالباً أسهل طريقة لفهم نوع الرسالة. الرسالة tf.train.Example (أو protobuf) هي نوع رسالة مرن يمثل تعيين {"string": value} . إنه مصمم للاستخدام مع TensorFlow ويتم استخدامه في جميع واجهات برمجة التطبيقات عالية المستوى مثل TFX . بشكل عام ، يجب أن تقوم بتقسيم بياناتك عبر ملفات متعددة حتى تتمكن من موازنة الإدخال / الإخراج (داخل مضيف واحد أو عبر مضيفين متعددين). القاعدة الأساسية هي أن يكون لديك ما لا يقل عن 10 أضعاف عدد الملفات التي سيكون هناك مضيفون يقرؤون البيانات. وفي الوقت نفسه ، يجب أن يكون كل ملف كبيراً بدرجة كافية (10 ميجا بايت على الأقل و 100 ميجا بايت على الأقل) حتى تتمكن من الاستفادة من الجلب المسبق للإدخال / الإخراج. على سبيل المثال ، لنفترض أن لديك X جيجابايت من البيانات وأنك تخطط للتدريب على ما يصل إلى N مضيفين. من الناحية المثالية ، يجب أن تقوم بتقسيم البيانات إلى ~ 10*N الملفات ، طالما أن ~ X/(10*N) هي 10 ميجا بايت + (وبشكل مثالي 100 ميجا بايت +). إذا كان أقل من ذلك ، فقد تحتاج إلى إنشاء عدد أقل من الأجزاء لمقايضة مزايا التوازي ومزايا الجلب المسبق للإدخال / الإخراج. الآن لقراءة ملف TFRecord : يمكن تحليل الموترات التي تمت سلسلتها "serialized tensors" باستخدام tf.train.Example.ParseFromString: filenames = [filename] raw_dataset = tf.data.TFRecordDataset(filenames) raw_dataset # <TFRecordDatasetV2 shapes: (), types: tf.string> for raw_record in raw_dataset.take(1): example = tf.train.Example() example.ParseFromString(raw_record.numpy()) print(example) """ features { feature { key: "feature0" value { int64_list { value: 1 } } } feature { key: "feature1" value { int64_list { value: 1 } } } feature { key: "feature2" value { bytes_list { value: "dog" } } } feature { key: "feature3" value { float_list { value: -0.9885607957839966 } } } } """ كما يمكنك قراءتها من خلال tf_record_iterator مثلاً: import tensorflow.python_io.tf_record_iterator as record import tensorflow as tf for sample in record("file.tfrecord"): output = tf.train.SequenceExample.FromString(sample) break # أزلها لعرض كل العينات output #وإلا سيُظهر لك محتوى العينة الأولى # لفحص الميزات "الفيتشرز" الفردية باستخدام مفاتيحها output.context.feature["key"] #feature_lists من أجل output.feature_lists.feature_list["key"]
-
WebSocket هو بروتوكول الاتصال الذي يوفر اتصالاً ثنائي الاتجاه بين العميل والخادم عبر TCP. يظل WebSocket مفتوحاً طوال الوقت، لذا فهو يسمح بنقل البيانات في الوقت الفعلي (real time). عندما يقوم العملاء بإرسال الطلب إلى الخادم، فإنه لا يغلق الاتصال عند تلقي الاستجابة، بل يستمر وينتظر العميل أو الخادم لإنهاء الطلب. ميزاته: يساعد WebSocket في الاتصال في الوقت الفعلي بين العميل وخادم الويب. يساعد هذا البروتوكول في التحول إلى cross-platform في عالم ال real-time بين الخادم والعميل. يتيح أيضاً للأعمال التجارية في جميع أنحاء العالم الحصول على تطبيق ويب في الوقت الفعلي لتعزيز وزيادة الجدوى. الميزة الرئيسية أنه يعتمد على اتصال HTTP حيث أنه يوفر اتصال مزدوج الاتجاه. إليك مخطط له: لماذا نحتاجه: يوفر اتصالًا ثنائي الاتجاه ، مما يساعد في استمرار الاتصال الذي تم إنشاؤه بين العميل وخادم الويب. كما أنه يفي بالمعايير ويوفر الدقة والكفاءة في أحداث التدفق (من وإلى) مع زمن انتقال ضئيل negligible latency. WebSocket يزيل الحمل ويقلل من التعقيد. يجعل الاتصال في الوقت الفعلي سهل وفعال. Socket.IO هي مكتبة تتيح الاتصال في الوقت الفعلي مع نمط اتصال full-duplex بين العميل وخوادم الويب. ويستخدم بروتوكول WebSocket لتوفير الواجهة. وكلاً من WebSocket vs Socket.io هما مكتبات تعتمد على الأحداث (مقادة بال event). من جانب العميل: هي المكتبة التي تعمل داخل المتصفح. من جانب الخادم: مكتبة Node.js. ميزاته: يساعد في البث إلى مآخذ متعددة في وقت واحد ويتعامل مع الاتصال بشفافية. يعمل على جميع المنصات أو الخادم أو الجهاز ، مما يضمن المساواة والموثوقية والسرعة. يقوم تلقائياً بترقية المتطلبات إلى WebSocket إذا لزم الأمر. هو بروتوكول نقل مخصص في الوقت الفعلي. تنفيذه يكون فوق البروتوكولات الأخرى يتطلب استخدام كلا المكتبتين من جانب العميل بالإضافة إلى مكتبة من جانب الخادم. يعمل IO على الأحداث القائمة على العمل "work-based events". هناك بعض الأحداث المحجوزة التي يمكن الوصول إليها باستخدام Socket على جانب الخادم مثل Connect و message و Disconnect و Ping و Reconnect. هناك بعض الأحداث المحجوزة القائمة على العميل مثل الاتصال وخطأ الاتصال ومهلة الاتصال وإعادة الاتصال وما إلى ذلك. لماذا نحتاجه: يتعامل مع مستوى الدعم المتنوع "various support level" والتناقضات "inconsistencies" من المتصفح. تتعامل مع التدهورات الناتجة من استخدام البدائل التقنية لتوفر اتصال full-duplex في الوقت الفعلي. بعض المقارنة بينهم: WebSocket هو البروتوكول الذي تم إنشاؤه عبر اتصال TCP. بينما Socket هي مكتبة تعمل مع WebSocket. WebSocket يوفر الاتصال عبر TCP ، بينما Socket.io هي مكتبة لتجريد اتصالات WebSocket. لا يحتوي WebSocket على خيارات fallback، بينما يدعمها Socket.io. WebSocket هي التقنية ، بينما Socket.io هي مكتبة لـ WebSocket. WebSocket لايدعم ال broadcasting بينما Socket يدعمها. Proxy و load balancer غير مدعومين في WebSocket. بينما مدعومين في socket. Socket يوفر الاتصال القائم على الحدث بين المتصفح والخادم. بينما WebSocket يوفر اتصال مزدوج الاتجاه لاتصالات TCP.
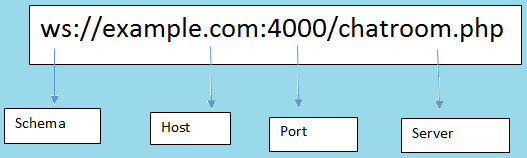
- 4 اجابة
-
- 2
-
-
