

بَعدَ أَن تَعرفنا في سِلسلة المقالات السابقة عَن نظام تَحليل المواقع Google Analytics، سنَشرح في هذا المَقال نظام أدوات إدارة المواقع Google webmaster Tools وكَيفية إنشاء ملف Robot.txt والاستهداف الدولي، وذلك بِخطوات مَشروحة مَع الصور التوضيحية بِطريقة مُبَسّطة.
ماهو Google Webmaster tools

تُقدم مُحركات البحث الرئيسية -بِما في ذلك مُحرك البحث Google- أدوات مجانية لِمُشرفي المواقع. وتُساعد أدوات مُشرفي المواقع (Google Webmaster Tools) مُشرفي المواقع على التحكم بِشكل أفضل في ما يَتعلق بِمدى تفاعل محرك البحث Google، كذلك الحصول على مَعلومات مُفيدة من Google عن مَواقِعهم، مع العِلم أنَّ استخدام أدوات مُشرفي المواقع لا يُساعد في الحصول على مُعاملة تَفضيلية من قِبل محرك البحث، بَل يُساعد في تحديد المشكلات التي يمكن أن تفيد موقعك إذا تَمت مُعالجتها في تَحسين الأداء بالنسبة إلى نَتائج البحث، فإن استخدام خدمة مشرفي المواقع Google Webmaster Tools ، يُتيح لك عمل الآتي :
- مَعرفة أجزاء الموقع التي واجه بِها برنامج Googlebot مُشكلات في الزحف إليها.
- إبلاغ Google عن أي ملف sitemap بتنسيق XML أو بِرابط خُلاصة RSS.
- تحليل ملفات robots.txt وإنشاؤها.
- حذف عناوين URL التي زحف إليها Googlebot.
- تَعيين النِطاق المُفضل لك.
- تَحديد المُشكلات المُتعلقة بالعنوان والعلامات الوَصفية التعريفية.
- فهم أهم طلبات البَحث المُستخدمة للوصول إلى موقع ما.
- أخذ فكرة عن كيفية رؤية Googlebot للصفحات.
- حذف روابط أقسام الموقع الغَير مرغوب فيها والتي قد يَستخدمها Google في نتائج البحث.
- تَلقي إشعار يَتعلق بانتهاكات إرشادات الجودة وطلب إعادة النظر في الموقع.
إضافة موقعك على Google Webmaster tools
سنبدأ العمل بفتح حساب Google Webmaster Tools وإضافة موقعك الالكتروني باتباع الخطوات التالية:
- سجّل الدخول إلى أدوات مُشرفي المواقع Google Webmaster tools باستخدام حِساب Google.
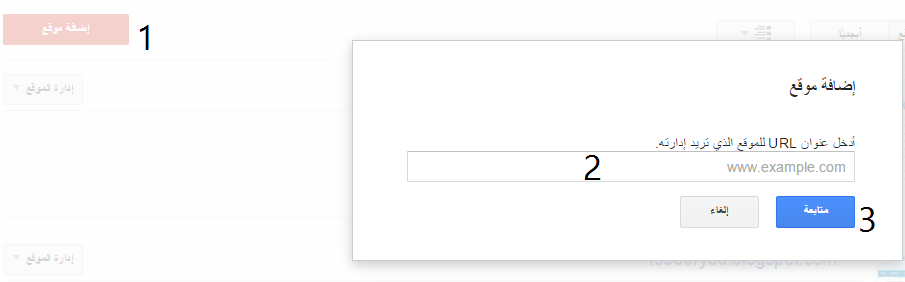
- أُنقر على الزر إضافة موقع Add Site ، واكتب عنوان URL للموقع الذي تُريد إضافته وتأكد من كتابة عنوان URL بالكامل، مثل: http://www.example.com.
- أنقر على مُتابعة وعندئذ، تَفتح صفحة التحقق من الموقع.
- في مربع الاسم، اكتب اسمًا لموقعك.
- حدد طريقة إثبات الملكية التي تريدها، واتبع الإرشادات.
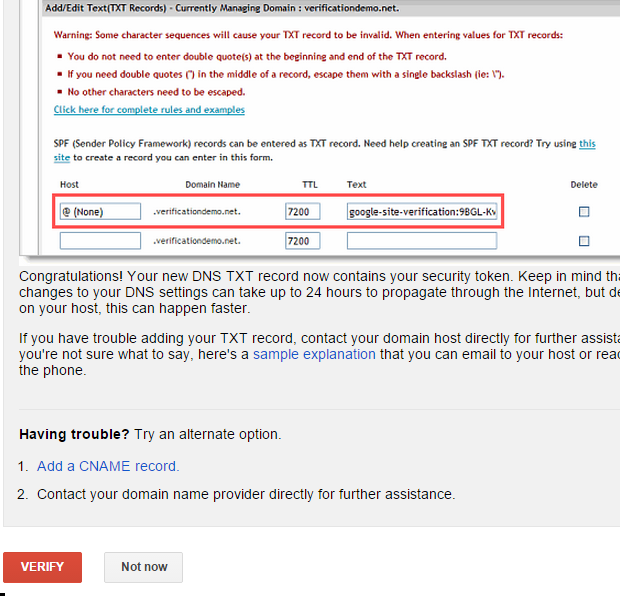
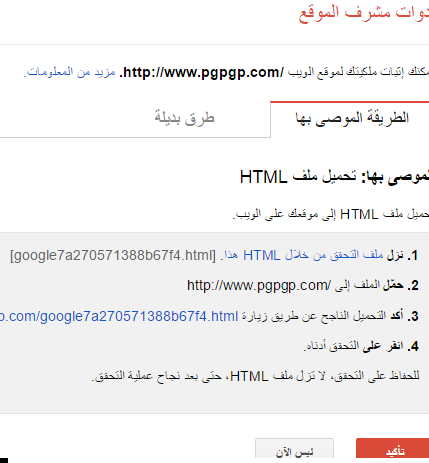

تَعمل بيانات أدوات مشرفي المواقع وميزة إعداد التقارير على أفضل ما يكون على مُستوى الموقع. فعلى سبيل المثال، إذا اشتمل موقعك http://www.example.com على أقسام منفصلة لبلدان مختلفة، فإننا نُوصي بإضافة كل من هذه المواقع الفرعية أو المجلدات الفرعية كموقع منفصل. فمثلاً، إذا كان لديك موقع سفر يشتمل على مجلدات فرعية خاصة تغطي لبنان ومصر والمغرب، فيمكنك إضافة المواقع التالية إلى حساب أدوات مشرفي المواقع:
- http://www.example.com
- http://www.example.com/lebanon
- http://www.example.com/egypt
- http://www.example.com/morocco
وبالمثل، إذا كان موقعك يحتوي على إصداري http:// وhttps://، فيجب إضافة كُل إصدار كموقع مُنفصل.
استهداف البلد على Google Webmaster tools
يعرض بحث Google المواقع الأكثر صلة وفائدة كاستجابة لِطلب البَحث الذي أجراه المُستخدم و لذلك يُمكن أن تَختلف النتائج التي نَعرِضها لِمُستخدم في الإمارات عن النتائج التي نَعرضها لِمستخدم في السعودية.
إذا كان مَوقعك ذا نِطاق عام على المستوى العلوي، مثل .com أو .org، ويَستهدف مُستخدمين في مَواقع جُغرافية مُحددة، يُمكنك تَزويدنا بالمعلومات التي تُساعد Google في تَحديد الشكل الذي يَظهر به مَوقعك على الويب في نَتائج البحث و هذا يُؤدي إلى تَحسين نتائج بحث Google في ما يَتعلق بِطلبات البَحث الجُغرافية و لن يُؤثر في ظهور مَوقعك في نتائج البحث ما لم يَحصر المُستخدم نطاق البحث على بلد مُعَيَّن.
إذا كان موقعك يَتضمن نِطاقًا يتضمن رمز البلد في المستوى العلوي (مثل: (.psفهذا يعني أنه مرتبط حاليًا بمنطقة جغرافية (مثل فلسطين في هذه الحالة). وفي هذه الحالة، لن تتمكن من تحديد موقع جغرافي.
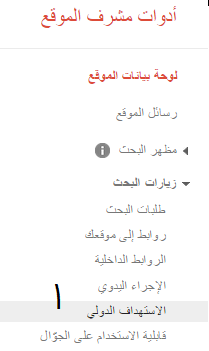
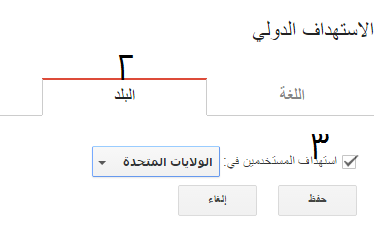
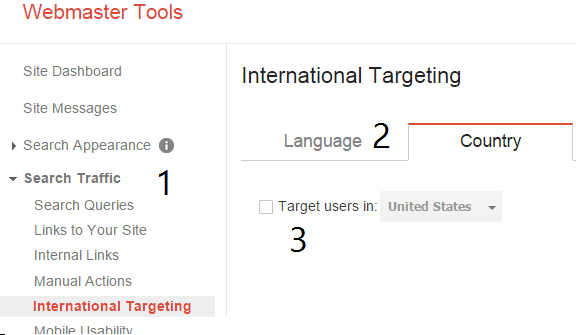
تعيين البلد المستهدف
- انتقل إلى قائمة زيارات البحث Search Traffic.
- اختر علامة التبويب "البلد" "Country" من قسم الاستهداف الدولي International Targeting.
- حدد مربع الاختيار الهدف الجغرافي Target User in واختر البلد المستهدف.
إذا كنت تريد التأكد من عدم اقتران موقعك بأي بلد أو منطقة، فحدد غير مدرج Unlisted في القائمة المنسدلة.
إذا لَم يَتِم إدخال أية مَعلومات في أدوات مشرفي المواقع سَيعتمد Google بِشكل كَبير على نِطاق البلد لهذا الموقع (مِثل .ps و(.eg. وإذا كُنت تَستخدم نِطاقًا دوليًا.com أو .org أو .eu سَيعتمد Google على إشارات مُتعددة تَتَضمن عِنوان IP ومَعلومات الموقع في الصفحة والروابط المُؤدية إلى الصفحة وأية مَعلومات ذات صِلة مِن أماكن Google وإذا تَم تَغيير المُستضيف لِنطاق البلد فيجب ألا يَحدث أي تأثير، وإذا تَم تَغيير المُستضيف لِنطاق دَولي إلى مُوفِر في بلد آخر، فإننا ننصح باستخدام أدوات مشرفي المواقع لإعلام Google بالبلد الذي يَجب أن يَقترن به مَوقعك.
هذا الإعداد مُخَصص للبيانات الجُغرافية فقط إذا كُنت تَستهدف المُستخدمين في مَواقع مُختلفة فمثلاً إذا كان لَديك مَوقع بالفَرنسية تُريد أن يَقرأه المُستخدمون في فرنسا وكندا ومالي فلا تستخدم هذه الأداة لتعيين فرنسا كمنطقة جغرافية، بل يكون تَحديد فرنسا كهدف جغرافي مفيدًا لموقع ويب خاص بأحد المطاعم مثلاً: فإذا كان المطعم في كندا، فمن المرجح ألا يكون ذا أهمية لأشخاص في فَرنسا. أما إذا كان المحتوى باللغة الفرنسية ويمثل أهمية لأشخاص في بلدان/أقاليم مُتعددة، فَسيكون الأفضل على الأرجح ألا يتم حصره على منطقة جغرافية مُعينة.
كيفية إنشاء ملف Robot.txt
ملف robots.txt عبارة عن ملف في جَذر مَوقعك الإلكتروني يُبين أجزاء الموقع التي لا تَرغب في وصول زواحف مُحركات البحث إليها.
يستخدم الملف Robots Exclusion Standard وهو بُرتوكول يَتَضمن مَجموعة صغيرة مِن الأوامر التي يُمكنك استخدامها لِتوضيح إمكانية الوصول إلى مَوقِعك الإلكتروني حَسب القسم وحَسب أنواع مُحددة مِن زواحف الويب (مثل زواحف الجوال مُقابل زواحف سطح المكتب).
مُلاحظة: لا تَحتاج إلى ملف robots.txt إلا إذا كان مَوقعك يَتَضمن مُحتوى لا تُريد أن يُفهرسه مُحرك بحث Google أو مُحركات البحث الأخرى .
و لإختبار عناوين URL التي يستطيع مُحرك البحث Google الدخول إليها وتِلك التي لا يستطيع الدخول إليها على موقعك الإلكتروني، جرب استخدام أداة اختبار Tester robots.txt.
قبل إنشاء ملف robots.txt، يَجب مَعرفة مَخاطر هذه طَريقة لحَظر عناوين URL، ففي بَعض الأحيان قَد تَحتاج إلى استخدام آليات أُخرى لِضمان عَدم إمكانية العثور على عناوين URL لِمَوقعك على الوِب.
إرشادات ملف Robots.txt عُبارة عن تَوجيهات فقط
لا يُمكن لإرشادات ملفات robots.txt فرض سُلوك مُعَين على الزاحف إلى موقعك الإلكتروني بل إنها تَعمل بِمثابة تَوجيهات للزواحف أثناء وصولها إلى موقعك، فإذا أردت الحفاظ على المعلومات آمنة مِن زواحف الويب، فَمِن الأفضل استخدام طُرق حظر أخرى مِثل حماية الملفات الخاصة على الخادم بكلمة مرور .
و بالرغم مِن اتباع زواحف الويب طيبة السمعة للتوجهات الواردة في ملف robots.txt، فَقد يُفسر كُل زاحف التوجهات بِشكل مُختلف، لِذا عَليك مَعرفة البُنية الصحيحة للتعامل مَع زواحف الويب المُختلفة، نظرًا لأن بعض هذه البرامج قد لا يَتَمكن مِن فَهم إرشادات مُعَينة.
لا يُمكن لِتَوجهات robots.txt مَنع الإحالة إلى عناوين URL لِمَوقعك مِن المواقع الإلكترونية الأُخرى، بَينما لا يزحف مُحرك البحث Google إلى المُحتوى المَحظور بِملف robots.txt أو يُفهرسه، قَد يَعثر على عنوان URL غير مَسموح بالوصول إليه وَارد مِن أماكن أخرى على الويب ويَعمل المحرك على فهرسته ونَتيجة لِذلك يُمكن أن يَستمر ظهور عِنوان URL ورُبما المَعلومات الأُخرى المُتاحة بِشكل عام مِثل نَص الرَابط في الروابط المُؤدية إلى الموقع وذلك في نتائج بحث Google، يُمكنك إيقاف ظهور عنوان URL في نَتائج بَحث Google تمامًا باستخدام ملف robots.txt بالاشتراك مع طُرق أُخرى لِحظر عناوين URL مثل حماية الملفات على الخادم بكلمة مرور أو إدراج علامات وصفية لتوجيه الفهرسة في HTML.
مُلاحظة: قَد يُؤدي الجمع بَين تَوجيهات مُتعددة للزحف والفَهرسة إلى تَعطيل بَعض التوجيهات للأخرى، لِذا تَعرف على كَيفية التهيئة الصحيحة للتَوجيهات بقراءة الجمع بين الزحف والفهرسة / قسم توجيهات العرض في مستندات Google Developers.
إنشاء ملف Robot.txt
لِتتمكن من إنشاء ملف robots.txt عليك الدخول إلى جذر نطاقك ويُمكنك إنشاء ملف robots.txt أو تَعديل ملف حالي باستخدام أداة اختبار robots.txt ويُتيح لَك هذا اختبار التَغييرات التي أدخلتها عِند ضَبط ملفrobots.txt.
التعرف على بنية robots.txt
يَستخدم ملف robots.txt كلمتين رئيسيتين، وهُما User-agent و Disallow. تمثل كلمة User-agent "وكلاء المستخدم" برامج روبوت لمحركات البحث (أو برامج زحف الويب)، و يَتِم عرض مُعظم وكلاء المستخدم في قاعدة بيانات برامج روبوت الويب. و كلمة Disallow (عدم السماح) تُمثل أمرًا يَتم تَوجيهُه إلى وَكيل المُستخدم بِحَيث لا يَتم الدخول إلى عنوان URL مُعَين و لِمنح مُحرك بحث Google إمكانية الدخول إلى عنوان URL مُعين يُمثل دَليلاً فَرعيًا يَندرج ضِمن دَليل رَئيسي غير مسموح بالدخول إليه، يُمكنك استخدام كلمة رئيسية ثالثة، ألا وهي Allow.
يستخدم محرك بحث Google العديد من وكلاء المستخدم، مثل Googlebot للجوّال لِبحث Google على هاتفك وGooglebotImage لبحث صور Google وسَيَتبِع مُعظم وكلاء المُستخدم لِمُحرك البحث Google القواعد التي تعدها لبرنامج Googlebot، ولكن يُمكنك تَجاوز هذا الخيار وإنشاء قواعد خاصة لِوكلاء مستخدم مُعَينين لِمُحرك البحث Google أيضًا.
تَتَمثل بُنية استخدام الكلمات الرئيسية في ما يلي:
User-agent: [the name of the robot the following rule applies to] Disallow: [the URL path you want to block] Allow: [the URL path in of a subdirectory, within a blocked parent directory, that you want to unblock]
يَتِم اعتبار هذين السطرين معًا إدخالاً واحدًا في الملف حَيث تنطبق قاعدة Disallow على وكلاء المُستخدم المُحددين أعلاها فقط و يُمكنك تَضمين ما تَشاء مِن إدخالات ، كما يُمكن أن تَنطبق أسطر Disallow مُتعددة على العديد مِن وكلاء المستخدم وكل ذلك عبر إدخال واحد ويُمكنك ضبط الأمر User-agent لِينطبق على كُل برامج زحف الويب عَن طريق إدراج علامة (*) نِجمة كما هو موضح في المثال أدناه:
User-agent: *
منع الدخول إلى... | النموذج |
الموقع بأكمله باستخدام الشرطة المائلة للأمام (/) : | Disallow: / |
دليل ومحتوياته عن طريق إتباع اسم الدليل بشرطة مائلة للأمام: | Disallow: /sample-directory/ |
صقحة ويب عن طريق إدراج الصفحة بعد الشرطة المائلة : | Disallow: /private_file.html |
صورة مُعينة مِن صور Google: | User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
كُل الصور على موقعك من صور Google: | User-agent: Googlebot-Image Disallow: / |
ملفات من نوع معين على سبيل المثال، ملفات .gif : | User-agent: Googlebot Disallow: /*.gif$ |
الصفحات على موقعك، ولكن مع عرض إعلانات AdSense على تلك الصفحات، وعدم السماح بدخول كل برامج التَتَبُع الأُخرى بِخلاف بَرنامج تَتَبُع Mediapartners-Google. ويؤدي هذا إلى إخفاء الصفحات من نتائج البحث ، ولكن يظل بإمكان زاحف الويب Mediapartners-Google تحليل الصفحات لِتحديد الإعلانات التي سيعرضها. | User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / |
مُلاحظة: الأوامر تتأثر بحالة الأحرف على مَثال يؤدي استخدام Disallow: /file.asp إلى منع الدخول إلى http://www.example.com/file.asp، بينما يتيح الدخول إلى http://www.example.com/File.asp. كما يتجاهل Googlebot أيضًا المسافة البيضاء والأوامر غير المعروفة في ملف robots.txt.
قاعدة مطابقة الأنماط | النموذج |
لمنع الدخول إلى أي تسلسل من الأحرف، استخدم علامة النجمة (*)على سبيل المثال، يؤدي نموذج الشفرة إلى منع الدخول إلى كل الأدلة الفرعية التي تبدأ بكلمة "private": | User-agent: Googlebot Disallow: /private*/ |
لمنع الدخول إلى كل عناوين URL التي تتضمن علامات استفهام (?) على سبيل المثال، يؤدي نموذج الشفرة إلى منع الدخول إلى عناوين URL التي تبدأ باسم النطاق، متبوعًا بأية سلسلة، تتبعها علامة استفهام ثم تنتهي العناوين بأية سلسلة: | User-agent: Googlebot Disallow: /*? |
لمنع الدخول إلى أي عناوين URL تنتهي بطريقة محددة، استخدم $. على سبيل المثال، يؤدي نموذج الشفرة إلى منع الدخول إلى أي عناوين URL تنتهي بالامتدادxls.: | User-agent: Googlebot Disallow: /*.xls$ |
لمنع الدخول إلى أنماط باستخدام أمري Allow وDisallow، راجع النموذج على اليسار. في هذا المثال، تشير علامة الاستفهام ? إلى معرّف جلسة. ويجب عادة منع دخول محرك البحث Google إلى عناوين URL التي تحتوي على هذه المعرّفات، وذلك لمنع الزحف إلى صفحات مكررة. وفي الوقت ذاته، إذا كانت هناك بعض عناوين URL تنتهي بعلامة الاستفهام ? وتمثل نسخًا من الصفحة تريد تضمينها، يمكنك استخدام الطريقة المنهجية التالية للجمع بين استخدام أمر Allow وأمر Disallow:
| User-agent: * Allow: /*?$ Disallow: /*? |
يجب تطبيق قواعد الحفظ التالية حتى يتسنى لبرنامج الزحف Googlebot وبرامج زحف الويب الأخرى العثور على ملف robots.txt:
- يجب حفظ شفرة robots.txt كملف نصي من نوع TXT،
- يجب وضع الملف في الدليل الموجود على أعلى مستوى للموقع أو جذر النطاق،
- يجب تسمية ملف robots.txt بكلمة robots.txt.
على سبيل المثال، ملف robots.txt المحفوظ في جذر النطاق example.com، على عنوان URL http://www.example.com/robots.txt، سيتم اكتشافه عن طريق برامج زحف الويب، بينما لن يتم العثور على ملف robots.txt على http://www.example.com/not_root/robots.txt عن طريق أي زاحف ويب.
وبذلك نَكون قَد وَصلنا إلى نِهاية هذا المقال لشرح مدخل عن ِنظام Google Webmaster Toola بَعدما شَرحنا كيفية إضافة الموقع والاستهداف الدولي وإنشاء ملف Robot.txt، نسأل الله العلى القدير أن نَكون قَد قَدمنا لَكم الاستفادة.









أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.