لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 09/20/21 في كل الموقع
-
أحاول إنشاء قالب template لعرض قيم حقول نموذج المحدد ، إلى جانب أسماء الحقول. على سبيل المثال، لنفترض أن لدي النموذج التالي: class User(Model): name = CharField(max_length=150) email = EmailField(max_length=100, verbose_name="E-mail") أرغب في إخراج البيانات السابقة في قالب معين لتكون النتيجة كالتالي: name My Full Name E-mail mail@example.com لذلك أحاول أن أقوم بعمل القالب بالشكل التالي: <table> {% for field in fields %} <tr> <td>{{ field.name }}</td> <td>{{ field.value }}</td> </tr> {% endfor %} </table> بالطبع الكود السابق لن يعمل، ولكن هذا ما أحاول أن أقوم به، هل هناك طريقة يوفرها جانغو Django للقيام بذلك؟4 نقاط
-
كيف أحصل على اسم المجال/النطاق Domain لموقعي الحالي من داخل قالب في جانغو Django؟ لقد حاولت البحث في وسوم tags أوالمرشحات filters تقوم بهذا الأمر لكنني لم أتوصل إلى شيء. هل يجب أن أحصل على meta data من الطلب الذي يرسله المتصفح أم أن هناك طرق أخرى؟4 نقاط
-
كيف يمكننا نسخ الأوزان من طبقة إلى طبقة أخرى؟2 نقاط
-
السلام عليكم ورحمة الله وبركاته . أريد أن أتعلم أحد المهارات التي تساعدني في بناء مشاريع ديناميكية و قوية , ولا أدري ماذا أتعلم على وجه الخصوص : ajax أو websocket . فهلا تفضل أحدكم بشرح وإبراز لأهم الفروقات بينهما ؟ و ما هي ميزة وعيوب كل منهما ؟ سيسهل علي ذلك التحديد بينهما . و شكرا مسبقا .2 نقاط
-
ECMAScript هي المعايير(Standards) التي تتبعها لغات الإسكريبت مثل javascript, coffescript, actionscript, livescript وهي تُعد النواة التي بُنيت عليها الجافاسكريبت ,حيث يمكنك إعتبار أن لغات البرمجة مثل جافاسكريبت مثل السيارة , والECMAScript هي المحرك لتلك السيارة(أو النواة أو المعايير كما إتفقنا بالأعلى) حيث النحويات(syntax) في لغة الجافاسكريبت مثل المصفوفات والكائنات والبرمجة كائنية التوجه وكل تلك الأشياء الأساسية يتم إستمدادها من معايير الECMAScript , وكما ذكرنا بما أنها معايير فليست دائما مُتبعة من المتصفحات, فستجد بعض المتصفحات الحديثة تدعم المعايير الجديدة وبعض المتصفحات القديمة لا تدعمها بالنسبة للإختصار فهي مكونة من كلمتين ECMA وهي راجعة إلى منظمة ECMA وهي منظمة تقوم بوضع المعايير وكلمة Script والتي تعبر عن أن تلك المعايير للغات الscripting مثل الجافاسكريبت بالنسبة للإصدارات ستجدها موضحة بالجدول بالأدنى { 1 June 1997 2 June 1998 3 December 1999 4 Abandoned 5 December 2009 5.1 June 2011 6 June 2015[11] ECMAScript 2015 (ES2015) 7 June 2016[12] ECMAScript 2016 (ES2016) 8 June 2017[13] ECMAScript 2017 (ES2017) 9 June 2018[14] ECMAScript 2018 (ES2018) 10 June 2019[15] ECMAScript 2019 (ES2019) 11 June 2020[16] ECMAScript 2020 (ES2020) 12 June 2021[9] ECMAScript 2021 (ES2021) } بالنسبة لES next يُقصد به الإصدار القادم من الECMAScript و ECMA international هي تلك منظمة المعايير التي تكلمنا عنها بالأعلى2 نقاط
-
يأتيني رسالة الخطأ /garden.cpp:12:66: error: no match for 'operator+' (operand types are 'std::__cxx11::basic_string<char>' and 'int') عندما أحاول تنفيذ الكود string findTrees(int arr[],int n){ string position; int a; if(arr[0]==arr[2]){ a=abs(arr[3]-arr[1]); position=abs(arr[0]-a)+" " +to_string(arr[1])+' '+abs(arr[0]-a)+' '+ arr[3]; }2 نقاط
-
 سنتعرف في هذا المقال على مفهوم واجهة برمجية التطبيقات Application Programming Interface، هذا المصطلح السهل المعقد حيث سنحاول فهمه وكيفية بناء مواقع الويب والتطبيقات الحديثة في يومنا هذا بالاعتماد على الواجهات البرمجية ونجيب على سؤال مهم وهو كيف ترتبط الواجهة الأمامية مع الواجهة الخلفية لتطبيق الويب أو الموقع الإلكتروني. هذا المقال هو جزء من سلسلة مقالات حول الواجهة البرمجية API وكيفية الاستفادة منها في بناء تطبيق ويب: مدخل إلى الواجهات البرمجية API الاتصال بواجهة زد البرمجية وفهم عملية الاستيثاق والتصريح أمثلة عملية لاستخدام واجهة برمجة متاجر زد zid API تطوير تطبيق عملي يزيد من احتفاظ العملاء عبر واجهة زد البرمجية مفهوم الواجهة البرمجية للتطبيقات API قبل أن ندخل في أية تفاصيل تقنية عن موضوعنا اليوم، سأحكي لك يومًا في حياة علي. علي هو مبرمج تطبيقات ويب يعمل في إحدى الشركات التقنية العربية، علي يحب تجربة المأكوﻻت المختلفة، بحيث يجرب في كل يوم أكلة جديدة في المطاعم المحيطة وإن سمع بافتتاح مطعم جديد بالقرب من مكان عمله، فإنه ﻻ يتوانى في زيارته وتذوق مختلف اﻷطباق التي يقدمها. ذهب علي ﻷحد المطاعم التي فتحت أبوابها مؤخرا، واختار مكانا هادئًا ونادى النادل يسأله عن اﻷطباق التي يقدمونها من أجل أن يأخذ طلبيته إلى الطباخ لتحضير ما طلبه علي. دوَّن النادل ما يريد علي تناوله من مأكوﻻت وذهب بها إلى الطباخ من أجل تحضيرها، بعد مدة وجيزة، عاد النادل إلى علي وهو يحمل كل ما طلبه وقدمها متمنيا أنه يعجبه اﻷكل، تذوق علي المأكوﻻت وأبدى إعجابه اﻷولي بها، وبدأ في اﻷكل إلى أن أنهى كل ما في الصحون، دفع الحساب، وخرج من المطعم شاكرا النادل على حسن اﻷستقبال. هل تتساءل اﻵن، ما علاقة هذه القصة بالواجهات البرمجية؟ وهل تساءلت يومًا عن طريقة عمل تطبيقات الهواتف الذكية، وكيف تتصل بخوادم الشركات المطورة لها، هل استطعت الوصول إلى إجابات كافية عن ذلك؟ سأبين لك ما العلاقة بين المثال السابق والواجهات البرمجية وكيف أن الواجهات البرمجية ماهي إﻻ تطبيق لمثالنا باختلاف بسيط وهو مكان التطبيق فقط، فمثالنا هو من الواقع الذي نعيشه يوميًا ونراه دائمًا حتى تعودنا عليه حتى أصبحنا ﻻ ندركه، أما الواجهات البرمجية، فقد أصبحت جزءًا ﻻ يتجزأ من حياة مبرمج المواقع وتطبيقات الويب المهنية. كنت قد نوهتك ﻷن تسأل نفسك عن طريقة ربط تطبيقات الهواتف الذكية مع خوادم الشركات. هنالك طريقتين لربط تطبيقات الهواتف الذكية مع خوادم الشركات المطورة، الطريقة اﻷقدم تسمى SOAP وهي اختصار لجملة Simple Object Access Protocol، أما الطريقة اﻷحدث فهي الواجهة البرمجيةللتطبيقات API وهي اختصار لجملة Application Programming Interface، وهي التي سأركز عليها، ولكن باختصار، API هي طريقة لتواصل البرمجيات في ما بينها باستخدام صيغة JavaScript Object Notation والتي تعرف اختصارا بـ JSON. لن أدخل في التفاصيل التاريخية وسأبقى مركزا على الجانب التقني فقط، لهذا أتوقع منك أن تحاول البحث عن تاريخ ابتكار وتطوير تقنية API والتقنية المكملة لها REST والتي هي اختصار لجملة REpresentational State Transfer. مصطلحات وجب معرفتها سنسرد بعض المصطلحات باللغة الإنجليزية والعربية الضروري على كل مطور ويب أن يعرفها: Backend: الواجهة الخلفية، هي المسؤولة عن العمليات المنطقية للنظام، تتعامل مع الملفات أيضا ومع قواعد البيانات. Frontend: الواجهات الأمامية، كل ما يراه المستخدم ويتعامل معه بشكل مباشر، ويتم ربطها مع النظم الخلفية بما يعرف بالواجهة البرمجية للتطبيقات API. API: الواجهة البرمجية للتطبيقات، هي حلقة الوصل ما بين النظم أو الواجهة الخلفية والواجهات الأمامية. Request: الطلب الذي يرسله العميل (قد تكون الواجهة الأمامية) إلى الخادم Server الموجود في الواجهة الخلفية. Header: ترويسة الطلب Request المرسل والذي يحوي بعض البيانات الوصفية التي تصف الطلبية وحالها وأية معلومات إضافية مطلوبة. Body: جسم أو متن الطلب المرسل والذي يحوي غالبًا على البيانات المتبادلة في الطلبية. Response: استجابة أو رد الخادم وهي المعلومات الراجعة من الخادم إلى العميل مقدم الطلب ردًا على طلبه. تحوي المعلومات الراجعة من الخادم إلى العميل على ترويسة Header وأيضا على متن Body. Endpoint: نقطة الوصول، وهي نقطة اتصال الواجهات الأمامية مع موقع محدد في الواجهة الخلفية أي نقطة محددة تتصل عبرها الواجهة الأمامية مع الواجهة الخلفية لغرض محدَّد. HTTP Client Software: عميل خادم HTTP وهو برنامج يساعد على تسريع التعامل مع الواجهات البرمجية بتوفير آلية واضحة في عملية إرسال واستقبال الطلبيات والردود. هل تعرفت على أي من المصطلحات التي ذكرناها قبل قليل؟ لا بأس إن لم تفعل، فسنشرحها لك حتى تكون لديك معرفة مبدئية بموضوع الواجهات البرمجية. لماذا نستخدم الواجهات البرمجية للتطبيقات APIs وما هي فائدتها؟ تُعَد الواجهات البرمجية للتطبيقات طبقة الحماية الأولى First Security Layer للبرمجية الموجودة على خادم الويب، بسبب أنها تفصل ما بين النظم الخلفية والعمليات الجارية على قواعد البيانات عن الواجهات الأمامية سواءً كانت صفحات ويب عادية أو تطبيقات هواتف ذكية. أي أن أي تطبيق ويب أو موقع اليوم يتألف من واجهة خلفية وواجهة أمامية وواجهة برمجية تعد وصلة وصل بينهما. أما الواجهة الخلفية، فتحوي على كامل العمليات والإجراءات والخدمات التي يوفرها التطبيق أو الموقع مثل معالجة صورة أو بيانات أو حتى تقديم خدمة الطقس. أما الواجهة الأمامية فهي الواجهة التي يراها المستخدم والمسؤولة عن عرض البيانات القادمة من الواجهة الخلفية للمستخدم بصورة مناسبة ومتناسقة مع إرسال البيانات من المستخدم إلى الخادم بالشكل الذي يطلبها، فالبيانات المتبادلة تلك تكون بشكلها الخام (تستعمل غالبًا صيغة JSON أو حتى صيغة XML)، أما الواجهة البرمجية للتطبيقات API فهي صلة الوصل كما ذكرنا ووظيفتها استلام البيانات من الواجهة الأمامية وتسلميها للواجهة الخلفية وإرسال البيانات من الواجهة الخلفية إلى الأمامية بطريقة وأسلوب موحد أي هي التي تؤمن عملية التفاهم بين الواجهة الأمامية والخلفية لتأمين التخاطب فيما بينهما. كيف تعمل الواجهات البرمجية للتطبيقات API سأحاول قدر اﻹمكان تبسيط آلية عمل الواجهات البرمجية بمثال عملي من حياتنا اليومية، وليكن مثلا منصة فيسبوك. كما تعلم أنه بإمكانك الدخول إلى حسابك في فيسبوك من أي جهاز تريد، سواءً من هاتفك الذكي أو من جهازك اللوحي أو من جهاز الحاسوب بل بإمكانك الدخول منها مجتمعة وفي نفس الوقت، وهنا يجب أن تطرح سؤاﻻ مهمًا، كيف تتم مزامنة حسابك في كل تلك اﻷجهزة؟ هنا تأتي أهمية الواجهة البرمجية، بحيث أن كل تلك اﻷجهزة متصلة بنظام خلفي واحد وكلها تتصل بالواجهة البرمجية التي تكون حلقة الوصل ما بين كل اﻷجهزة المتصلة و النظام الخلفي. سنأخذ مثاﻻ من حياتنا اليومية وهو موقع فيسبوك، سنقوم بالدخول إلى حسابنا باستخدام الأجهزة التي بحوزتنا، إن لم تكن لديك أجهزة غير جهاز الحاسوب، افتح أكثر من متصفح، ليس نفس المتصفح، مثلا متصفح كروم Google Chrome ومتصفح فايرفوكس Mozilla Firefox، في هذه الحالة يمكنك فتح حسابك 4 مرات باستخدام التصفح الخفي، في متصفح كروم يسمى Incognito Mode أما في متصفح فايرفوكس فيسمى Private Mode. هل قمت بذلك؟ كيف تستطيع إرسال رسائل إلى أصدقائك من أي متصفح وتشاهدها في نفس الوقت من بقية المتصفحات؟ قم بالدخول إلى حسابك على فيسبوك من هاتفك الذكي، من التطبيق الرسمي أو من المتصفح، هل تستطيع أن ترى الرسائل التي قمت بإرسالها على هاتفك أيضا، كيف يحدث ذلك؟ كيف تستطيع الدخول إلى حسابك من أماكن مختلفة في نفس الوقت؟ سأشرح العملية بأكملها بشكل بسيط وبالمقارنة مع مثالنا في بداية المقال وبدون الدخول في التفاصيل الدقيقة في الوقت الحالي. عند دخول علي مطور الويب إلى المطعم، كان عليه أن يختار طاولة محددة برقم حتى يعلم النادل موقعه وأنه يريد تناول الطعام وبالتالي يستطيع تقديم مختلف الخدمات التي يعرضها المطعم. هنا الطاولة وتفاصيلها (من رقم وحجم وغيرهما) تعتبر المكان المتفق عليه من أجل اﻹستفادة من خدمات المطعم، ويمكن القول أنها نقطة الوصول إلى خدمات المطعم Endpoint. في حالة موقع فيسبوك، وعند قيامك فتح التطبيق مثلا، سيتصل تطبيقك بخادم الشركة، في نقطة متفق عليها ومحددة مسبقًا في التطبيق وفيها فقط يستطيع الخادم أن يقدم خدماته للتطبيق. جاء النادل إلى عليٍ والذي يسمى العميل client ليأخذ الطلبات منه، ودون أية ملاحظات أو أي خدمات أخرى، وبعدها ذهب إلى المطبخ ليخبر الطباخ بالطلبات من أجل تحضيرها. هنا نسمي العملية: إرسال طلب Send Request من العميل علي إلى الطباخ في المطعم مقدمة الخدمة. في حالة موقع فيسبوك، أقرب عملية لذلك المثال عملية تسجيل الدخول حيث تُدخل اسم المستخدم الخاص بك مع كلمة المرور، تأخذ الواجهة الأمامية منك هذه المعلومات وترسلها للواجهة الخلفية لموقع فيسبوك لتتحقق منها ومن الطلب الخاص بك، طلب تسجيل الدخول. يستلم الطباخ الطلبية ويتأكد من أنها طلبية صالحة ويمكنك تحضيرها (أي ليست طلبية شراء ملابس مثلًا) ثم يبدأ بتحضيرها وعندما ينتهي منها، يعطيها للنادل الذي يرتبها بدوره في صينية ويأخذها إلى علي ليضعها على طاولته حتى يتسنى له البدء في تذوقها. هذه العملية تسمى: اﻹستجابة Send Response أي استجاب الطباخ لطلبية علي وقدم له ما يريد. وفي حالة موقع فيسبوك، إن كانت المعلومات المقدمة صالحة، سيقوم خادم فيسبوك بالسماح لك بالدخول واستعراض مختلف الصفحات واﻷجزاء الخاصة به والاستفادة من خدمته التي يقدمها. هل اتضحت الصورة العامة اﻵن؟ ببساطة، الواجهة البرمجية تنفذ عمل النادل في المطعم، حيث أن النادل يقوم بأخذ طلبات الزبائن إلى الطباخ وفريقه لتحضيرها وبعد ذلك، يقوم بأخذ تلك استجابة الطباخ لتلك الطلبات إلى أصحابها، أي أن الواجهة البرمجية تأخذ الطلبات من المستخدمين (الواجهة الأمامية) إلى النظام الخلفي لتقوم بعمل محدد ومن ثم تعيد النتائج المتحصل عليها إلى طالبيها أي تعيدها للواجهة الأمامية مرةً أخرى. خاتمة تعرفنا على ماهية الواجهة البرمجية للتطبيقات وأهم المصطلحات فيها وكيف يستفيد منها المطورون في بناء تطبيقات الويب الحديثة واستثمارها في التواصل ما بين الواجهة الأمامية والخلفية لتطبيقات الويب والمواقع الحالية، فالتعامل مع الواجهة البرمجية للتطبيقات ضروري لأي مبرمج متخصص في تطوير الويب، وعليه أن يعي مفهوم الواجهة البرمجة تمامًا إذ أصبح هذا المفهوم هو المفهوم الحديث في التواصل ما بين الواجهة البرمجية الخلفية والأمامية للمواقع وتطبيقات الويب، أضف إلى ذلك أن الكثير من الخدمات والمواقع أصبحت تتيح واجهتها البرمجية (مثل الواجهة البرمجية للمطورين من فيسبوك وتويتر وغيرهما) للاستفادة منها أو حتى هنالك واجهة برمجية مخصصة فقط لتقديم خدمات محددة (مثل واجهة برمجية للحصول على معلومات الطقس) وتقدمها للمطورين للاستفادة من تلك الخدمات في مختلف المشاريع. اقرأ أيضًا المقال التالي: الاتصال بواجهة زد البرمجية وفهم عملية الاستيثاق والتصريح كيفية إنشاء متجر إلكتروني متكامل باستعمال منصة زد الواجهة البرمجية Fetch API في جافاسكريبت1 نقطة
سنتعرف في هذا المقال على مفهوم واجهة برمجية التطبيقات Application Programming Interface، هذا المصطلح السهل المعقد حيث سنحاول فهمه وكيفية بناء مواقع الويب والتطبيقات الحديثة في يومنا هذا بالاعتماد على الواجهات البرمجية ونجيب على سؤال مهم وهو كيف ترتبط الواجهة الأمامية مع الواجهة الخلفية لتطبيق الويب أو الموقع الإلكتروني. هذا المقال هو جزء من سلسلة مقالات حول الواجهة البرمجية API وكيفية الاستفادة منها في بناء تطبيق ويب: مدخل إلى الواجهات البرمجية API الاتصال بواجهة زد البرمجية وفهم عملية الاستيثاق والتصريح أمثلة عملية لاستخدام واجهة برمجة متاجر زد zid API تطوير تطبيق عملي يزيد من احتفاظ العملاء عبر واجهة زد البرمجية مفهوم الواجهة البرمجية للتطبيقات API قبل أن ندخل في أية تفاصيل تقنية عن موضوعنا اليوم، سأحكي لك يومًا في حياة علي. علي هو مبرمج تطبيقات ويب يعمل في إحدى الشركات التقنية العربية، علي يحب تجربة المأكوﻻت المختلفة، بحيث يجرب في كل يوم أكلة جديدة في المطاعم المحيطة وإن سمع بافتتاح مطعم جديد بالقرب من مكان عمله، فإنه ﻻ يتوانى في زيارته وتذوق مختلف اﻷطباق التي يقدمها. ذهب علي ﻷحد المطاعم التي فتحت أبوابها مؤخرا، واختار مكانا هادئًا ونادى النادل يسأله عن اﻷطباق التي يقدمونها من أجل أن يأخذ طلبيته إلى الطباخ لتحضير ما طلبه علي. دوَّن النادل ما يريد علي تناوله من مأكوﻻت وذهب بها إلى الطباخ من أجل تحضيرها، بعد مدة وجيزة، عاد النادل إلى علي وهو يحمل كل ما طلبه وقدمها متمنيا أنه يعجبه اﻷكل، تذوق علي المأكوﻻت وأبدى إعجابه اﻷولي بها، وبدأ في اﻷكل إلى أن أنهى كل ما في الصحون، دفع الحساب، وخرج من المطعم شاكرا النادل على حسن اﻷستقبال. هل تتساءل اﻵن، ما علاقة هذه القصة بالواجهات البرمجية؟ وهل تساءلت يومًا عن طريقة عمل تطبيقات الهواتف الذكية، وكيف تتصل بخوادم الشركات المطورة لها، هل استطعت الوصول إلى إجابات كافية عن ذلك؟ سأبين لك ما العلاقة بين المثال السابق والواجهات البرمجية وكيف أن الواجهات البرمجية ماهي إﻻ تطبيق لمثالنا باختلاف بسيط وهو مكان التطبيق فقط، فمثالنا هو من الواقع الذي نعيشه يوميًا ونراه دائمًا حتى تعودنا عليه حتى أصبحنا ﻻ ندركه، أما الواجهات البرمجية، فقد أصبحت جزءًا ﻻ يتجزأ من حياة مبرمج المواقع وتطبيقات الويب المهنية. كنت قد نوهتك ﻷن تسأل نفسك عن طريقة ربط تطبيقات الهواتف الذكية مع خوادم الشركات. هنالك طريقتين لربط تطبيقات الهواتف الذكية مع خوادم الشركات المطورة، الطريقة اﻷقدم تسمى SOAP وهي اختصار لجملة Simple Object Access Protocol، أما الطريقة اﻷحدث فهي الواجهة البرمجيةللتطبيقات API وهي اختصار لجملة Application Programming Interface، وهي التي سأركز عليها، ولكن باختصار، API هي طريقة لتواصل البرمجيات في ما بينها باستخدام صيغة JavaScript Object Notation والتي تعرف اختصارا بـ JSON. لن أدخل في التفاصيل التاريخية وسأبقى مركزا على الجانب التقني فقط، لهذا أتوقع منك أن تحاول البحث عن تاريخ ابتكار وتطوير تقنية API والتقنية المكملة لها REST والتي هي اختصار لجملة REpresentational State Transfer. مصطلحات وجب معرفتها سنسرد بعض المصطلحات باللغة الإنجليزية والعربية الضروري على كل مطور ويب أن يعرفها: Backend: الواجهة الخلفية، هي المسؤولة عن العمليات المنطقية للنظام، تتعامل مع الملفات أيضا ومع قواعد البيانات. Frontend: الواجهات الأمامية، كل ما يراه المستخدم ويتعامل معه بشكل مباشر، ويتم ربطها مع النظم الخلفية بما يعرف بالواجهة البرمجية للتطبيقات API. API: الواجهة البرمجية للتطبيقات، هي حلقة الوصل ما بين النظم أو الواجهة الخلفية والواجهات الأمامية. Request: الطلب الذي يرسله العميل (قد تكون الواجهة الأمامية) إلى الخادم Server الموجود في الواجهة الخلفية. Header: ترويسة الطلب Request المرسل والذي يحوي بعض البيانات الوصفية التي تصف الطلبية وحالها وأية معلومات إضافية مطلوبة. Body: جسم أو متن الطلب المرسل والذي يحوي غالبًا على البيانات المتبادلة في الطلبية. Response: استجابة أو رد الخادم وهي المعلومات الراجعة من الخادم إلى العميل مقدم الطلب ردًا على طلبه. تحوي المعلومات الراجعة من الخادم إلى العميل على ترويسة Header وأيضا على متن Body. Endpoint: نقطة الوصول، وهي نقطة اتصال الواجهات الأمامية مع موقع محدد في الواجهة الخلفية أي نقطة محددة تتصل عبرها الواجهة الأمامية مع الواجهة الخلفية لغرض محدَّد. HTTP Client Software: عميل خادم HTTP وهو برنامج يساعد على تسريع التعامل مع الواجهات البرمجية بتوفير آلية واضحة في عملية إرسال واستقبال الطلبيات والردود. هل تعرفت على أي من المصطلحات التي ذكرناها قبل قليل؟ لا بأس إن لم تفعل، فسنشرحها لك حتى تكون لديك معرفة مبدئية بموضوع الواجهات البرمجية. لماذا نستخدم الواجهات البرمجية للتطبيقات APIs وما هي فائدتها؟ تُعَد الواجهات البرمجية للتطبيقات طبقة الحماية الأولى First Security Layer للبرمجية الموجودة على خادم الويب، بسبب أنها تفصل ما بين النظم الخلفية والعمليات الجارية على قواعد البيانات عن الواجهات الأمامية سواءً كانت صفحات ويب عادية أو تطبيقات هواتف ذكية. أي أن أي تطبيق ويب أو موقع اليوم يتألف من واجهة خلفية وواجهة أمامية وواجهة برمجية تعد وصلة وصل بينهما. أما الواجهة الخلفية، فتحوي على كامل العمليات والإجراءات والخدمات التي يوفرها التطبيق أو الموقع مثل معالجة صورة أو بيانات أو حتى تقديم خدمة الطقس. أما الواجهة الأمامية فهي الواجهة التي يراها المستخدم والمسؤولة عن عرض البيانات القادمة من الواجهة الخلفية للمستخدم بصورة مناسبة ومتناسقة مع إرسال البيانات من المستخدم إلى الخادم بالشكل الذي يطلبها، فالبيانات المتبادلة تلك تكون بشكلها الخام (تستعمل غالبًا صيغة JSON أو حتى صيغة XML)، أما الواجهة البرمجية للتطبيقات API فهي صلة الوصل كما ذكرنا ووظيفتها استلام البيانات من الواجهة الأمامية وتسلميها للواجهة الخلفية وإرسال البيانات من الواجهة الخلفية إلى الأمامية بطريقة وأسلوب موحد أي هي التي تؤمن عملية التفاهم بين الواجهة الأمامية والخلفية لتأمين التخاطب فيما بينهما. كيف تعمل الواجهات البرمجية للتطبيقات API سأحاول قدر اﻹمكان تبسيط آلية عمل الواجهات البرمجية بمثال عملي من حياتنا اليومية، وليكن مثلا منصة فيسبوك. كما تعلم أنه بإمكانك الدخول إلى حسابك في فيسبوك من أي جهاز تريد، سواءً من هاتفك الذكي أو من جهازك اللوحي أو من جهاز الحاسوب بل بإمكانك الدخول منها مجتمعة وفي نفس الوقت، وهنا يجب أن تطرح سؤاﻻ مهمًا، كيف تتم مزامنة حسابك في كل تلك اﻷجهزة؟ هنا تأتي أهمية الواجهة البرمجية، بحيث أن كل تلك اﻷجهزة متصلة بنظام خلفي واحد وكلها تتصل بالواجهة البرمجية التي تكون حلقة الوصل ما بين كل اﻷجهزة المتصلة و النظام الخلفي. سنأخذ مثاﻻ من حياتنا اليومية وهو موقع فيسبوك، سنقوم بالدخول إلى حسابنا باستخدام الأجهزة التي بحوزتنا، إن لم تكن لديك أجهزة غير جهاز الحاسوب، افتح أكثر من متصفح، ليس نفس المتصفح، مثلا متصفح كروم Google Chrome ومتصفح فايرفوكس Mozilla Firefox، في هذه الحالة يمكنك فتح حسابك 4 مرات باستخدام التصفح الخفي، في متصفح كروم يسمى Incognito Mode أما في متصفح فايرفوكس فيسمى Private Mode. هل قمت بذلك؟ كيف تستطيع إرسال رسائل إلى أصدقائك من أي متصفح وتشاهدها في نفس الوقت من بقية المتصفحات؟ قم بالدخول إلى حسابك على فيسبوك من هاتفك الذكي، من التطبيق الرسمي أو من المتصفح، هل تستطيع أن ترى الرسائل التي قمت بإرسالها على هاتفك أيضا، كيف يحدث ذلك؟ كيف تستطيع الدخول إلى حسابك من أماكن مختلفة في نفس الوقت؟ سأشرح العملية بأكملها بشكل بسيط وبالمقارنة مع مثالنا في بداية المقال وبدون الدخول في التفاصيل الدقيقة في الوقت الحالي. عند دخول علي مطور الويب إلى المطعم، كان عليه أن يختار طاولة محددة برقم حتى يعلم النادل موقعه وأنه يريد تناول الطعام وبالتالي يستطيع تقديم مختلف الخدمات التي يعرضها المطعم. هنا الطاولة وتفاصيلها (من رقم وحجم وغيرهما) تعتبر المكان المتفق عليه من أجل اﻹستفادة من خدمات المطعم، ويمكن القول أنها نقطة الوصول إلى خدمات المطعم Endpoint. في حالة موقع فيسبوك، وعند قيامك فتح التطبيق مثلا، سيتصل تطبيقك بخادم الشركة، في نقطة متفق عليها ومحددة مسبقًا في التطبيق وفيها فقط يستطيع الخادم أن يقدم خدماته للتطبيق. جاء النادل إلى عليٍ والذي يسمى العميل client ليأخذ الطلبات منه، ودون أية ملاحظات أو أي خدمات أخرى، وبعدها ذهب إلى المطبخ ليخبر الطباخ بالطلبات من أجل تحضيرها. هنا نسمي العملية: إرسال طلب Send Request من العميل علي إلى الطباخ في المطعم مقدمة الخدمة. في حالة موقع فيسبوك، أقرب عملية لذلك المثال عملية تسجيل الدخول حيث تُدخل اسم المستخدم الخاص بك مع كلمة المرور، تأخذ الواجهة الأمامية منك هذه المعلومات وترسلها للواجهة الخلفية لموقع فيسبوك لتتحقق منها ومن الطلب الخاص بك، طلب تسجيل الدخول. يستلم الطباخ الطلبية ويتأكد من أنها طلبية صالحة ويمكنك تحضيرها (أي ليست طلبية شراء ملابس مثلًا) ثم يبدأ بتحضيرها وعندما ينتهي منها، يعطيها للنادل الذي يرتبها بدوره في صينية ويأخذها إلى علي ليضعها على طاولته حتى يتسنى له البدء في تذوقها. هذه العملية تسمى: اﻹستجابة Send Response أي استجاب الطباخ لطلبية علي وقدم له ما يريد. وفي حالة موقع فيسبوك، إن كانت المعلومات المقدمة صالحة، سيقوم خادم فيسبوك بالسماح لك بالدخول واستعراض مختلف الصفحات واﻷجزاء الخاصة به والاستفادة من خدمته التي يقدمها. هل اتضحت الصورة العامة اﻵن؟ ببساطة، الواجهة البرمجية تنفذ عمل النادل في المطعم، حيث أن النادل يقوم بأخذ طلبات الزبائن إلى الطباخ وفريقه لتحضيرها وبعد ذلك، يقوم بأخذ تلك استجابة الطباخ لتلك الطلبات إلى أصحابها، أي أن الواجهة البرمجية تأخذ الطلبات من المستخدمين (الواجهة الأمامية) إلى النظام الخلفي لتقوم بعمل محدد ومن ثم تعيد النتائج المتحصل عليها إلى طالبيها أي تعيدها للواجهة الأمامية مرةً أخرى. خاتمة تعرفنا على ماهية الواجهة البرمجية للتطبيقات وأهم المصطلحات فيها وكيف يستفيد منها المطورون في بناء تطبيقات الويب الحديثة واستثمارها في التواصل ما بين الواجهة الأمامية والخلفية لتطبيقات الويب والمواقع الحالية، فالتعامل مع الواجهة البرمجية للتطبيقات ضروري لأي مبرمج متخصص في تطوير الويب، وعليه أن يعي مفهوم الواجهة البرمجة تمامًا إذ أصبح هذا المفهوم هو المفهوم الحديث في التواصل ما بين الواجهة البرمجية الخلفية والأمامية للمواقع وتطبيقات الويب، أضف إلى ذلك أن الكثير من الخدمات والمواقع أصبحت تتيح واجهتها البرمجية (مثل الواجهة البرمجية للمطورين من فيسبوك وتويتر وغيرهما) للاستفادة منها أو حتى هنالك واجهة برمجية مخصصة فقط لتقديم خدمات محددة (مثل واجهة برمجية للحصول على معلومات الطقس) وتقدمها للمطورين للاستفادة من تلك الخدمات في مختلف المشاريع. اقرأ أيضًا المقال التالي: الاتصال بواجهة زد البرمجية وفهم عملية الاستيثاق والتصريح كيفية إنشاء متجر إلكتروني متكامل باستعمال منصة زد الواجهة البرمجية Fetch API في جافاسكريبت1 نقطة -
لماذا الjwt أفضل من الsessions1 نقطة
-
أحاول البحث عن كائنات من نموذج User من خلال قيمة الحقل DateTimeField. من خلال الكود التالي: User.objects.filter(datetime_registred=datetime.date(2021,9,12)) أحصل على كائن queryset فارغ، أعتقد لأنني لم أحدد وقت في عملية البحث، حيث وضعت تاريخ فقط، لكنني أريد أي وقت خلال اليوم المحدد. أي أني أريد تحديد كل المستخدمين الذين سجلوا خلال هذا اليوم هل هناك طريقة سهلة في Django للقيام بذلك؟1 نقطة
-
سلام عليكم ما هو ECMAScript وهى اختصار لاى وماذا تعنى ? وما هى اصداتها مع ذكر تواريخ ؟ ما المقصود ب ES Next ؟ وما هى Ecma International ؟1 نقطة
-
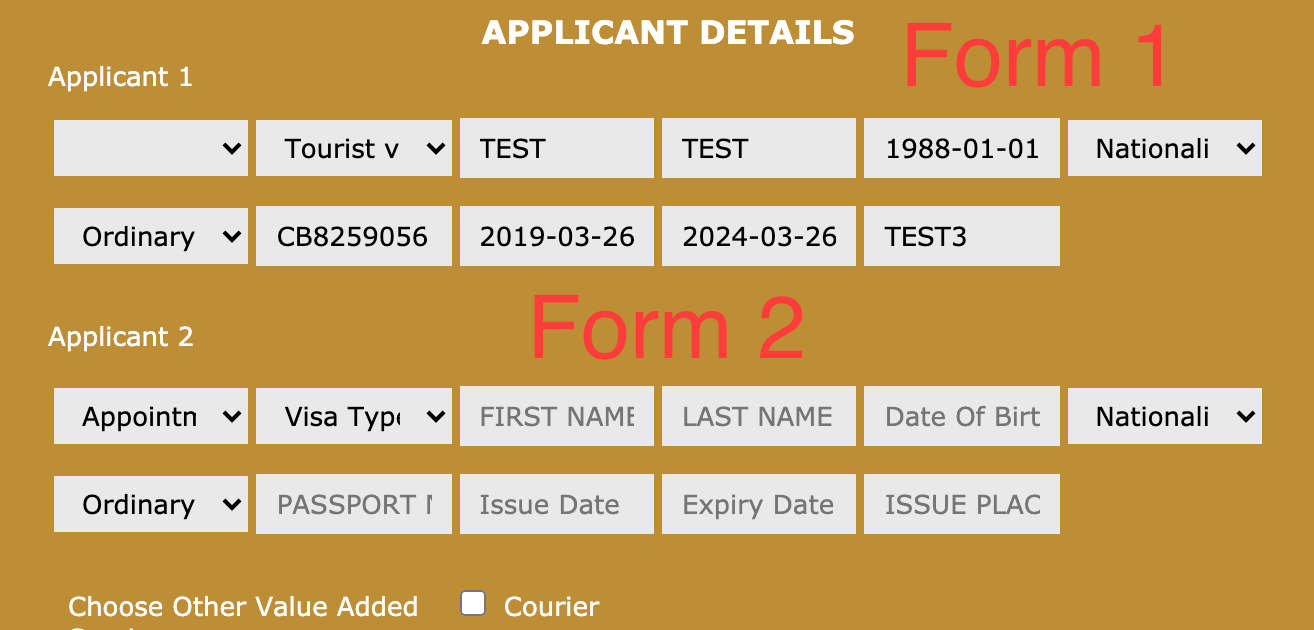
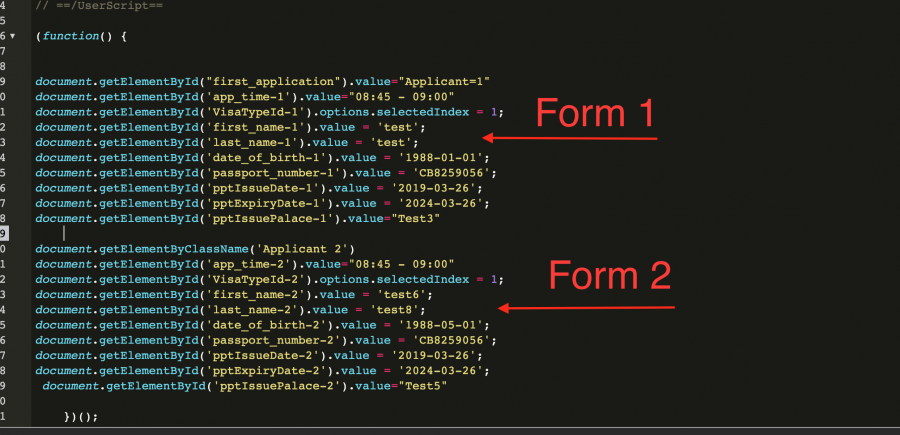
لدي كود جافا سكريبت على Tampermonkey , أحاول عمل auto fill لحقول معينة , و لكن عندما اقوم بتشغيل الكود يتم ملئ الخانات الاولى دون باقي الخانات، الكود كالتالي : مثال عن حقل : صورة توضيحية للهيكلية : المرجو المساعدة و شكرا

 1 نقطة
1 نقطة -
في الطبيعي يكون رد مصادقة simpleJWT من جانغو Django مشابه للتالي: { "refresh":"" "access": "" } كيف يمكنني أن أعدل على الرد السابق لكي أضيف خصائص آخرى مثل: { "username": "", "detail": "", "accessToken": "", "refreshToken": "" }1 نقطة
-
Schema::create('users', function (Blueprint $table) { $table->id(); $table->string('name'); $table->string('email')->unique(); $table->string('google_id')->nullable(); $table->string('facebook_id')->nullable(); $table->string('country_id')->nullable()->unsigned(); $table->integer('role_id')->default('2'); $table->string('avatar')->nullable(); $table->string('avatar_original')->nullable(); $table->boolean('Account_Verification')->default(false); $table->timestamp('email_verified_at')->nullable(); $table->string('password'); $table->rememberToken(); $table->timestamps(); });1 نقطة
-
المشكلة أنك تحاول اعطاء خاصية unsigned لعمود من نوع سلسلة نصية, وهذا غير منطقي, الخطأ بالتحديد في هذا السطر $table->string('country_id')->nullable()->unsigned(); الخاصية unsigned هو قيد على قيمة العمود بأنه لا يمكن أن تكون قيمة سالبة, ويجب ان يكون نوع العمود رقم, ولذلك يعطيك هذا الخطأ, حاول تعديل السطر ليكون كالتالي $table->string('country_id')->nullable(); أو يمكنك تحويل نوع العمود الى integer , بناء على اسم الحقل country_id فهو يجب أن يكون من نوع intger فيكون شكل الكود كالتالي $table->integer('country_id')->nullable()->unsigned(); ثم نفذ الامر مرة أخرى1 نقطة
-
Illuminate\Database\QueryException SQLSTATE[42000]: Syntax error or access violation: 1064 You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version fo r the right syntax to use near 'unsigned null, `role_id` int not null default '2', `avatar` varchar(255) null...' at line 1 (SQL: create table `users` (`id` bigint unsigned not null auto_increment primary key, `name` varchar(255) not null, `email` varchar(255) not null, `google_id` varchar(255) null, `facebook_id` varchar(25 5) null, `country_id` varchar(255) unsigned null, `role_id` int not null default '2', `avatar` varchar(255) null, `avatar_original` varchar(255) null, `Account_Ver ification` tinyint(1) not null default '0', `email_verified_at` timestamp null, `password` varchar(255) not null, `remember_token` varchar(100) null, `created_at` timestamp null, `updated_at` timestamp null) default character set utf8mb4 collate 'utf8mb4_unicode_ci') at C:\xampp\htdocs\joabk\vendor\laravel\framework\src\Illuminate\Database\Connection.php:692 688▕ // If an exception occurs when attempting to run a query, we'll format the error 689▕ // message to include the bindings with SQL, which will make this exception a 690▕ // lot more helpful to the developer instead of just the database's errors. 691▕ catch (Exception $e) { ➜ 692▕ throw new QueryException( 693▕ $query, $this->prepareBindings($bindings), $e 694▕ ); 695▕ } 696▕ } 1 C:\xampp\htdocs\joabk\vendor\laravel\framework\src\Illuminate\Database\Connection.php:479 PDOException::("SQLSTATE[42000]: Syntax error or access violation: 1064 You have an error in your SQL syntax; check the manual that corresponds to your Maria DB server version for the right syntax to use near 'unsigned null, `role_id` int not null default '2', `avatar` varchar(255) null...' at line 1") 2 C:\xampp\htdocs\joabk\vendor\laravel\framework\src\Illuminate\Database\Connection.php:479 PDO::prepare("create table `users` (`id` bigint unsigned not null auto_increment primary key, `name` varchar(255) not null, `email` varchar(255) not null, `g oogle_id` varchar(255) null, `facebook_id` varchar(255) null, `country_id` varchar(255) unsigned null, `role_id` int not null default '2', `avatar` varchar(255) nu ll, `avatar_original` varchar(255) null, `Account_Verification` tinyint(1) not null default '0', `email_verified_at` timestamp null, `password` varchar(255) not nu ll, `remember_token` varchar(100) null, `created_at` timestamp null, `updated_at` timestamp null) default character set utf8mb4 collate 'utf8mb4_unicode_ci'")1 نقطة
-
هل يمكنك تصوير الخطأ الذي يظهر لديك؟ أو نسخه ولصقه لكي نساعدك بشكل جيد, لأننا لا نستطيع معرفة الخطأ فقط من الكود1 نقطة
-
ajax: هي إختصار لAsynchronous JavaScript and XML وهي تقنية لإرسال طلبات الHTTP من خﻻل الجافاسكريبت إلى الخادم بشكل متزامن مع باقي الشفرة البرمجية, بمعنى أن الطلب يتم إرساله وإنتظار الرد حتى يصل , وفي الوقت بين ما يتم إرسال الطلب وإستﻻم الرد المتعلق به يتم تنفيذ الشفرات البرمجية للجافاسكريبت بشكل طبيعي دون أن تتوقف الajax يتم إستعمالها عادةً من أجل التعامل مع الخادم دون الحاجة إلى إعادة تحميل الصفحة (reload) وليكون موقع الويب متفاعل مع المستخدم بشكل أكبر فتظهر البيانات بشكل ديناميكي دون الحاجة إلى إعادة تحميل الصفحة كل مرة من أجل إظهار البيانات Websocket:هي تقنية مبنية على الHTTP2 , كما ذكرنا في السابق أن الajax تقوم بإرسال الطلب وإنتظار الخادم حتى يرسل الرد , وهنا ينتهي الطلب وﻻ يستطيع الخادم إرسال بيانات جديدة للعميل إﻻ بعد فتح طلب جديد, بينما في الwebsocket يقوم العميل بفتح الإتصال بينه وبين الخادم , ومن هنا يستطيع كلا من العميل والخادم إرسال بيانات إلى بعضهم البعض دون الحاجة لإرسال طلب جديد كل مرة يتم إستخدام تلك التقنية عادةً في التطبيقات التي تحتاج إلى سرعة عالية في توفر البيانات الحديثة دون تأخير أو كما يقال (real time) مثل تطبيقات الدردشة والألعاب هل يمكن للwebsocket أن تقوم بإستبدال الajax?? الإجابة ﻻ, فكما أوضحت بالأعلى فإن لكل منهما عمله, فﻻ يجب على الwebsocket أن تتعامل مع الAPI أو أن تتعامل مع البيانات التي تتعامل مع بيانات لن يحدث ضرر إن تأخرت بضع أجزاء من الثانية1 نقطة
-
و عليكم السلام و رحمة الله لا أظن أن يجب عليك تعلم إحداها فقط دون الأخرى , بل كلاهما . و هذا لأن لكل منها مجاله التخصصي و إستعمالاته و حاجته التي دعت إلى إنشاءه من الأساس , فالمقارنة بينهما غير منطقية . و لنأخذ كل منهما على حدة كالتالي : يستخدم Ajax بروتوكول HTTP ويمكنه إرسال طلبات باستخدام طرق POST و GET بين العميل والخادم. WebSocket هو بروتوكول اتصال بين العميل والخادم ، وهو يختلف عن HTTP . ففي Ajax ، عندما ترسل طلبًا ، يرسل الخادم استجابة لهذا الطلب ويتم إنهاء الاتصال , و هذا ما يجعله مناسبا لإستعمالات من مثل : التواصل مع واجهات تطبيق برمجية . أي أنه يسمح لتطبيق ما ,من جانب العميل, بطلب الوصول إلى مورد من جانب الخادم (مثلا : طلب صفحة أو صورة أو ملف أو بيانات) . في حين أن باستخدام WebSockets عند إنشاء اتصال بالخادم ، يمكنك التواصل بقدر ما تريد بين العميل والخادم والحفاظ على الاتصال نشطًا في كل لحظة , و هذا يجعله مناسبا للإستعمالات من مثل : تلقي إشعارات الوقت الفعلي أو الدردشة الحية , مثل الإشعار الذي تلقيته بشأن إجابة عن سؤالك هذا . يمكن تلخيص الأمر بشكل بسيط كالتالي : ما وراء الـ AJAX يعتمد إتصالا يتم إغلاقه مباشرة بعد الرد . ما وراء الـ WebSocket يعتمد إتصالا متواصلا . أمثلة توضيحية : يحتاج العميل " أحمد " تفحص صورة من على الخادم , فيقوم بإرسال طلب GET إلى الخادم . يستقبل الخادم الطلب و يقوم بإعادة رد برابط الصورة ليقوم أحمد برؤيتها , و ينتهي الإتصال و يتوقف الخادم عن تبادل أية بيانات بينه و بين أحمد , و سيحتاج أحمد اتصالا جديدا كل مرة يريد فيها طلب شيء من على الخادم . الان , العميل " أحمد " على موقع دردشة , ينتظر أي رسائل تصله . في مقابل أن العميل " عماد " يريد مراسلة " أحمد " . يقوم أحمد بإنشاء إتصال عن طريق بروتوكول ويب سوكيت بينه و بين الخادم , و ما إن وصلت أي رسائل جديدة لأحمد للخادم سيتم تنبيهه فورا . بعد أن يكتب عماد الرسالة و يرسلها , سيلتقط الخادم طلبه و يخزن الرسالة و يقوم فورا بتنبيه أحمد بذلك , فيكتب ردا و هكذا . أي أن من غير المعقول أن يشغل دور أحد الثاني , فلكل منهما منطقه الذي يتعامل به , فكل إستعمال لأحدهما في مجاله ميزة , و أي إستعمال له في غير تخصصه و مجاله عيب و هكذا . أما كاقتراح و تفضيل , فأفضل أن تتعلم Ajax أولا , كونه ما ستحتاج إليه طوال مسارك . ثم في وقت لاحق , قد تدعوك الحاجة إلى تعلم websocket لتحقيق أغراض أو حالات إستعمال معينة . و هو في الغالب ما كان مسار أي مطور . يمكنك تصفح إجابات مختلفة لتعاريف حول ما هو الـ websocket و لما قد نحتاجه هنا . كما قد تحتاج الإطلاع على كيفية التعامل مع ajax في الـ jQuery هنا .1 نقطة
-
لديك بعض الأخطاء في الكود، ويجب إصلاح هذه الأخطاء حتى يعمل الكود بشكل سليم. لاحظ أن لديك خطأ في دالة getElementsByClassName، حيث أن كلمة Elements جمع (تنتهي بحرف s)، وبالتالي يحدث خطأ في هذا السطر مما يؤدي إلى توقف السكريبت، وسترى أن هناك خطأ في الـ console يخبرك بذلك. أيضًا إن كنت تحاول أن تحدد النموذج الثاني من خلال الـ class فيجب أن تستخدم الصنف lineheightExtra وليس النص الموجود داخله كالتالي: document.getElementsByClassName('lineheightExtra');1 نقطة
-
لاحظ أنه لا يوجد لديك فواصل منقوطة في نهايات العديد من الأسطر : السطرين برقم 0 و 1 في بداية النموذج الثاني . السطر برقم 8 في نهاية النموذج الأول . الأسطر برقم 0 و 9 في بداية النموذج الأول . قد أدى هذا إلى تعطيل قراءة السكربت كاملا , و لو قمت بتفحص شاشة الـ console ستجد رسالة تخبرك بما يحدث كالتالي : SyntaxError: missing ; before statement أو : SyntaxError: Unexpected 'document' كما أنه قد يوجد لديك مشكل بتحديد العنصر بالصنف : Applicant في السطر 0 في بداية النموذج الثاني كالتالي : document.getElementByClassName('Applicant 2'); في حين أن العنصر يتوفر كالتالي : <div class="lineheightExtra"> Applicant 2 </div> فها أنت تحاول تحديد العنصر التالي دون توظيف إسم صنفه على نحو صحيح , فالمفترض أن يكون هو ما هو كالتالي : document.getElementByClassName('lineheightExtra'); و ذلك حتى يتم تحديده بشكل صحيح .1 نقطة
-
كلا، الأوامر هي عبارة عن كلمات نصية عادية، إن تمت كتابتها في cmd منفذ الأوامر يقوم هو بالبحث عن البرنامج التنفيذية المطلوبة المثبتة ومنها كوردوفا .. لتنفيذ الأمر المطلوب، وفي حال كان الأمر صحيح، يتم تنفيذه. بعض الأوامر يجب أن تتم ضمن مسار المشروع، أي يكون مسار التنفيذ هو اسم مجلد المشروع لفتح المجلد في cmd مباشرة اكتب cmd ضمن مسار المشروع ثم اضغط Enter ** أوامر تثبيت البيئات لن تحتاجها إلا في حال حذفك للبرمجيات أو عمل فورمات للحاسوب، عد لدرس الدورة وتابع درس التهيئة من جديد وأعد كتابة الأوامر ** ومن خلال المتابعة مع المدرب باقي الأوامر أغلبها نفسه خاص بتشغيل التطبيق اكتبه مراراً وتكرارا لتحفظه وتتعود عليه لا تتعود على النسخ واللصق.. طريقة فتح المجلد في cmd:
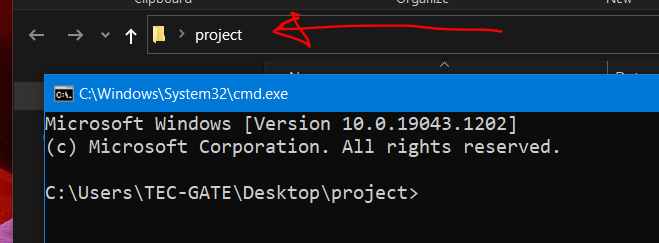 1 نقطة
1 نقطة -
مرحبا عبد العلي، الأوامر التنفيذية تبقى نتيجتها محفوظة، مثل تثبيت أو تحميل أو تعديل إعدادات، لاتقلق لن يحذف شيئ. أما الأوامر نفسها - المستخدمة بكثرة - ستحفظها مع الوقت والتمرين. أوامر تثبيت المكتبات و الاعتماديات لديك تم تنفيذها وكل شيئ على مايرام. أرجو كتابة التعليقات المرتبطة بالدروس في قسم التعليقات أسفل الدرس، وسرعة الاستجابة من المدربين جيدة جداً وتلقى متابعة أفضل من الأسئلة العامة، وطلبك بسرعة لن يفيدك بشئ.. المدرب الذي يعرفل الإجابة لمشكلتك سيكتبها مباشرة. ملاحظة: لحفظ الأوامر يمكنك فتح ملف نصي بسيط وكتابتهم فيه وحفظه.. وهكذا يمكنك العودة إليهم وقتما تشاء1 نقطة
-
الJWT(JSON web Token) ليست أفضل من الsessions في المطلق, وإنما تقوم بحل بعض المشكلات التي تنتج من إستخدامنا للsessions أو بالأدق المشاكل التي تنتج من إعتمادنا على المصادفة من خﻻل الخادم (server-side authentication) من تلك المشاكل: تخزين الsessions, حيث يكون لنا خيارين , إما تخزينها في قواعد البيانات والذي يؤدي إلى زيادة التكلفة وضعف في الأداء نسبياً الخيار الثاني هو تخزينها في الذاكرة , وذلك ليس حل فعال إن كان التطبيق يتم خدمته من خﻻل أكثر من خادم على أكثر من حاسوب , لأن الذاكرة ليست مشتركة مما قد يسبب مشاكل وأخطاء في عملية المصادقة أما بالنسبة للjwt فيكون الtoken مُخزن على حاسوب العميل فﻻ يحتاج الخادم إلى تخزينه وﻻ تقابلنا المشاكل السابقة , إذا للjwt المميزات الأتية أقل في التكلفة حيث لا يحتاج إلى قاعدة بيانات في الأغلب للتخزين ﻻمركزي, بمعنى أن الرموز(tokens) ليست موجودة في مكان واحد (الخادم) وإنما كل عميل يحمل الرمز الخاص به ولكن على الجانب الأخر نجد تحديات عند إستخدام الرموز(tokens) تأمين عملية تخزين الرموز, بما أنها مُخزنة على حاسوب العميل فهذا يجعلها أقل أماناً ويصنع تحدي في عملية الحفاظ عليها تأمين عملية نقلها عبر الشبكة, حيث أنها تُرسل من قِبل العميل فيُمثل أمر إنتقالها بدون أن يتم التجسس عليها تحدياً بالنسبة للمطورين عملية تحديد الرموز كغير صالحةinvalid يُعد من الأمور الشاقة نسبياً بالنسبة للمصادقة عبر الجلسات sessions authentication1 نقطة
-
عندما احاول تثبيت المكتبة ياتيني ذلك الخطا npm ERR! code ERESOLVE npm ERR! ERESOLVE unable to resolve dependency tree npm ERR! npm ERR! While resolving: blog@0.1.0 npm ERR! Found: react@17.0.2 npm ERR! node_modules/react npm ERR! react@"17.0.2" from the root project npm ERR! npm ERR! Could not resolve dependency: npm ERR! peer react@"^16.0.0" from react-facebook-login@4.1.1 npm ERR! node_modules/react-facebook-login npm ERR! react-facebook-login@"*" from the root project npm ERR! npm ERR! Fix the upstream dependency conflict, or retry npm ERR! this command with --force, or --legacy-peer-deps npm ERR! to accept an incorrect (and potentially broken) dependency resolution. npm ERR! npm ERR! See /root/.npm/eresolve-report.txt for a full report. npm ERR! A complete log of this run can be found in: npm ERR! /root/.npm/_logs/2021-09-20T06_30_40_111Z-debug.log1 نقطة
-
طيب منكن تكتب لى نفس الكود بالطريقة العادية1 نقطة
-
Z=x2+y3nm1 نقطة
-
يمكنك إنشاء متغير لكل عنصر في المعادلة , وحساب الأُسُس عن طريق الدالة pow المستدعاة من المكتبةcmath ويمكن التعبير عن ماسبق عن طريق الشفرة البرمجية التالية #include <iostream> #include <cmath> using namespace std; int findValueOfZ(int x, int y, int n, int m){ return pow(x,2)+pow(y,3)*n*m //Z=x2+y3nm } int main(){ int x, y, n, m; cin>>x>>y>>n>>m cout<<findValueOfZ(x,y,n,m); }1 نقطة
-
سبب الخطأ أن الدالة abs تقوم بأخذ قيمة عددية وترجع القيمة المطلقة لها, والتي بدورها أيضا قيمة عددية كما أن المتغير في المصفوفة arr[3] يُعد أيضاً قيمة عددية, وال" " عبارة عن سلسلة نصية, ﻻ يمكنك جمع سلسلة نصية وقيمة عددية في الوقت ذاته, الحل أن تقوم بتحويل القيم العددية إلى سلسلة نصية عن طريق الدالة to_string كما عملت في عﻻمة الجمع رقم إثنين فتصبح الشفرة البرمجية خاصتك على الصيغة التالية string findTrees(int arr[],int n){ string position; int a; if(arr[0]==arr[2]){ a=abs(arr[3]-arr[1]); position=to_string(abs(arr[0]-a))+" " +to_string(arr[1])+' '+to_string(abs(arr[0]-a))+' '+ to_string(arr[3]); }1 نقطة
-
في c++ علامة الاقتباس المفردة" ' " تدل على النوع محرف char، وعلامة الاقتباس المزدوجة " " " تدل على نص الخطأ في المثال السابق هو عند محاولة جمع محرف و عدد int، بدل علامات الاقتباس للفراغات بعلامة مزدوجة كالتالي string findTrees(int arr[],int n){ string position; int a; if(arr[0]==arr[2]){ a=abs(arr[3]-arr[1]); position=abs(arr[0]-a) + " " + to_string(arr[1]) + " " + abs(arr[0]-a) + " " + arr[3]; }1 نقطة
-
يأتي جانغو Django مع إطار عمل "sites" اختياري. وهي عبارة عن وسيلة ربط الكائنات والوظائف بمواقع ويب معينة، ويمكن من خلاله أن تقوم بإستخراج نطاق الموقع Domain كالتالي: from django.contrib.sites.models import Site site = Site.objects.get_current() site.domain كما يوفر جانغو Django طرق أخرى لكي يتم إحضارت نطاق الموقع، مثل التابع get_host في الكائن HttpRequest والذي يقوم بإستخراج النطاق من رأس الطلب request headers، وبالتحديد من الترويسة HTTP_X_FORWARDED_HOST (يجب أن يكون USE_X_FORWARDED_HOST مفعلًا True في ملف الإعدادات settings.py) أو من خلال HTTP_HOST (على الترتيب). ملاحظة: يمكن إستخدام الترويسة HTTP_HOST بشكل مباشر من خلال الكائن request كما في الكود التالي: request.META['HTTP_HOST'] لكن لا يجب الإعتماد على هذه الطريقة لأنها تعتمد في الأساس على الطلب الذي يرسله العميل، والذي يمكنه التلاعب به بعدة طرق، وبالتالي يستطيع تغير قيمة الترويسة HTTP_HOST بأي شيء يريده. أما إن كان نطاق الموقع ثابت وتريد إستخدامه في أكثر من مكان فيمكنك أن تقوم بتخزينه في ملف settings.py وتستدعيه في أي مكان كما ترغب، على النحو التالي: # settings.py SITE_URL = 'http://example.com' ثم يمكنك إستعمال هذا المتغير كالتالي: from django.conf import settings def site(request): return {'SITE_URL': settings.SITE_URL} طريقة أخيرة يوفرها جانغو Django وهي إستخدام التابع build_absolute_uri والذي يعيد عنوان URI بالكامل (متضمنًا على نطاق الموقع): domain = request.build_absolute_uri('/')[:-1] # https://example.com1 نقطة
-
بداية من الإصدار 2.2 من جانغو Django أصبح بإمكانك تعديل مجموعة من الكائنات دفة واحدة من خلال التابع bulk_update، كالتالي: >>> objs = [ ... Entry.objects.create(name='old name 1'), ... Entry.objects.create(name='old name 2'), ... ] >>> objs[0].name = 'new name 1' >>> objs[1].name = 'new name 2' >>> Entry.objects.bulk_update(objs, ['name']) تقوم هذه الطريقة بتحديث الحقول المحددة بكفاءة في كائنات النموذج المتوفرة، بشكل عام باستخدام استعلام واحد فقط. أما بالنسبة للإصدارات الأقدم (تعمل الطريقة مع كل إصدارات جانغو Django) فيمكنك أن تقوم بعمل التالي: Entry.objects.filter(name='old name').update(name="new name") يعيد الكود السابق عدد الكائنات التي تم تحديثها في قاعدة البيانات كرقم صحيح Integer ملاحظة: إن كان لديك كود في التابع save فلن يتم تنفيذه، حيث أن التابع save لا يتم إستدعائه من البداية.1 نقطة
-
يمكنك أن تقوم بالتأكد من أن الكائن يتم إنشائه وليس تحديثه في قاعدة البيانات بأكثر من طريقة: الطريقة الأولى هي إستخدام self.pk على النحو التالي: self.pk is None: الشرط السابق يتم تنفيذه فقط في حالة كان الكائن يتم إنشائه في قاعدة البيانات لأول مرة، أي أنها عملية insert وليست Update. ملاحظة يجب أن يتم إضافة السطر السابق قبل إستدعاء التابع save من الصنف الأب super، أي قبل super(...).save يوفر جانغو Django خاصية فريدة لمعرفة نوع العملية، هل هي عملية حفظ كائن جديد Create أو عملية تحديث كائن موجود مسبقًا، وذلك من خلال الخاصية _state.adding: self._state.adding is True إن تحقق الشرط فهي عملية insert وإن لم يتحقق فهي عملية تحديث Update1 نقطة
-
يمكنك أيضاً وضع الكود التالي في __init__.py وسيستورد جميع فئات الاختبار في الحزمة والحزم الفرعية. وسيسمح لك هذا بإجراء اختبارات محددة دون استيراد كل ملف يدويا: import pkgutil import unittest for loader, module_name, is_pkg in pkgutil.walk_packages(__path__): module = loader.find_module(module_name).load_module(module_name) for name in dir(module): obj = getattr(module, name) if isinstance(obj, type) and issubclass(obj, unittest.case.TestCase): exec ('%s = obj' % obj.__name__) وبشكل مشابه، بالنسبة لمجموعة الاختبار الخاصة بك، يمكنك ببساطة استخدام:. def suite(): return unittest.TestLoader().discover("appname.tests", pattern="*.py")1 نقطة
-
منذ الإصدار 1.6 من جانغو Django يمكنك تشغيل حالة اختبار كاملة، أو اختبار فردي. سيتم اكتشاف الاختبارات تلقائيًا الموجودة في أي ملف يبدأ بكلمة test ضمن المسار الحالي Current Working Directory (CWD). لذلك إذا كنت في نفس المجلد الذي يحتوي على الملف manager.py وتريد تشغيل test_a داخل الصنف الفرعي A داخل الملف test.py ضمن التطبيقapp / الوحدة module باسم example، فيجب أن تنفذ الأمر التالي: ./manage.py test example.tests.A.test_a ويمكننا أن نضع صيغة الأمر كالتالي: ./manage.py test app_name.tests.SubClass.test_name كما يمكنك أن تستخدم الحزمة django-nose التي تتيح لك تحديد الاختبارات لتشغيلها على النحو التالي: ./manage.py test another.test:TestCase.test_method أو كما هو مذكور في التعليقات ، استخدم بناء الجملة: ./manage.py test another.test.TestCase.test_method لاحظ أن الأمر الأخير لا يحتوي على علامة نقتطين : عكس الأمر الذي يسبقه. لتثبيت حزمة django-nose يمكنك تنفيذ أحد الأمر التاليين: pip install django-nose pip install -e git://github.com/jazzband/django-nose.git#egg=django-nose ثم يجب إضافة الحزمة ضمن التطبيقات المثبته installed apps في ملف settings.py، كالتالي: INSTALLED_APPS = ( # ... 'django_nose', # ... ) وفي النهاية يجب إضافة TEST_RUNNER إلى نفس الملف لكي تتمكن الحزمة من تشغيل الإختبارات: TEST_RUNNER = 'django_nose.NoseTestSuiteRunner'1 نقطة
-
تجدر الإشارة أيضاً إلى أنه لم تكن هناك أخطاء في طلبات AJAX POST في Django 1.2.4 وماقبلها (لم تكن AJAX محمية بأي شكل من الأشكال، لكنها كانت تعمل بشكل جيد). لحل المشكلة استخدام معالج ajaxSetup بدلاً من معالج ajaxSend: $.ajaxSetup({ beforeSend: function(xhr, settings) { function getCookie(name) { var cookieValue = null; if (document.cookie && document.cookie != '') { var cookies = document.cookie.split(';'); for (var i = 0; i < cookies.length; i++) { var cookie = jQuery.trim(cookies[i]); // هل تبدأ سلسلة ملفات تعريف الارتباط هذه بالاسم الذي نريده؟ if (cookie.substring(0, name.length + 1) == (name + '=')) { cookieValue = decodeURIComponent(cookie.substring(name.length + 1)); break; } } } return cookieValue; } if (!(/^http:.*/.test(settings.url) || /^https:.*/.test(settings.url))) { //ذات الصلة، أي محليًا URL فقط إلى عناوين Token أرسل ال xhr.setRequestHeader("X-CSRFToken", getCookie('csrftoken')); } } }); قم باستخدام هذا الكود كما هو وستكون قادر على النشر بدون خطأ 403.1 نقطة
-
يحدث هذا الأمر لأنك لا ترسل رمز CSRF Token مع الطلب، وبالتالي لا يتعرف جانغو Django على مُرسل الطلب، وهذا الأمر لحماية الموقع من بعض الهجمات الإحتيالية التي قد تؤدي إلى إرسال طلبات عشوائية من مواقع مختلفة على أساس أنها مستخدمين، أو حتى سرقة بيانات المستخدمين وكلمات المرور والبطاقات البنكية .. إلخ. ولحل المشكلة كل ما عليك فعله هو إرسال رمز CSRF من خلال الخاصية csrfmiddlewaretoken في بيانات الطلب data، على النحو التالي: $.ajax({ data: { somedata: 'somedata', csrfmiddlewaretoken: '{{ csrf_token }}' }, إن لم يكن كود JavaScript يتم توليد في ملف عرض view (أي إن كنت تستخدم CDN أو حتى تخزن ملفات JS منفصلة)، فيمكنك أن تقوم بإضافة رمز CSRF إلى الصفحة في شكل حقل مخفي أو حتى كود JavaScript منفصل، ومن خلال JavaScript يتم إحضار هذا الرمز وإدراجه في الطلب، كالتالي: <!-- حقل إدخال مخفي --> <input type='hidden' name='csrfmiddlewaretoken' value='{{ csrf_token }}' /> <!-- أو من خلال كود جافاسكريبت منفصل --> <script type="text/javascript"> window.CSRF_TOKEN = "{{ csrf_token }}"; </script> بعد ذلك من خلال جافاسكريبت تستطيع إحضار هذه القيمة وإستخدامها في الطلب.1 نقطة
-
يمكنك بشكل اختياري توفير نموذج مخصص باسم "403.html" للتحكم في عرض أخطاء HTTP 403. أيضاً يجب أن تعلم أنه لا يمكن استخدام النموذج 403 إلا إذا قمت برفع PermissionDenied. يعرض الكود التالي نموذج عرض مستخدم لاختبار القوالب المخصصة "403.html" و "404.html" و "500.html": def index(request): h = """ <!DOCTYPE html> <html lang="en"> <body> <ul> <li><a href="/">home</a></li> <li><a href="?action=raise403">Raise Error 403</a></li> <li><a href="?action=raise404">Raise Error 404</a></li> <li><a href="?action=raise500">Raise Error 500</a></li> </ul> </body> </html> """ event = request.GET.get('action', '') from django.http import Http404 if event == 'raise404': raise Http404 from django.core.exceptions import PermissionDenied as PD if event == 'raise403': raise PD if event == 'raise500': raise Exception('Server error') return HttpResponse(h) أيضاً يجب تعيين DEBUG = False في settings المشروع أو سيعرض لك إطار العمل traceback بدلاً من ذلك لـ 404 و 500.1 نقطة
-
قم بإرجاعه كما تفعل مع أي رد آخر كالتالي from django.http import HttpResponseForbidden return HttpResponseForbidden()1 نقطة
-
يمكنك إعادة رد بكود 403 في جانغو من خلال الكود التالي: from django.core.exceptions import PermissionDenied def my_view(request, ...): if not request.user.is_admin: raise PermissionDenied بالطبع يمكنك تغير الشرط في الكود السابق كما تريد. على عكس الخطأ HttpResponseForbidden، يؤدي إعادة PermissionDenied إلى عرض رسالة الخطأ باستخدام القالب 403.html ، أو يمكنك استخدام middleware لإظهار ملف عرض مخصصة. كما يمكنك عرض رسالة خطأ مخصصة، على النحو التالي: from django.core.exceptions import PermissionDenied def my_view(request, ...): if not request.user.is_admin: raise PermissionDenied("You do not have permission to visit this page")1 نقطة
-
نعم يمكنك تخصيص نسبة من حجم ال GPU أثناء إنشاء الجلسة tf.session، ليتم استخدامها فقط. ويتم ذلك عن طريق تمرير tf.GPUOptions كجزء من وسيطة config، كالتالي: gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.25) sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) حيث افترضنا أن لديك gpu ب 8 جيجابايت، وخصصنا 2 جيجا فقط منها لتكون متاحة خلال الجلسة.1 نقطة
-
ال epoch هو عملية مرور على كامل بيانات التدريب التي لديك، فمثلاً إذا كان لديك 5000 عينة تدريبية، مقسمة إلى 100 باتش-حزمة- (مفهوم ال Mini-Batches) وبالتالي سيكون لدينا حجم كل باتش batch-size يساوي 50 عينة. هذا يعني أنه عند المرور على كامل البيانات (ال 5000 عينة) سنكون قد قمنا ب 100 iteration أي 100 عملية forward و backward على البيانات (مرور على البيانات ثم تحديث قيم الأوزان في الشبكة). وهذا هو الفرق، ولهذا السبب نستخدم مفهوم ال epoch بدلاً من ال iteration فهو أعم، ونحتاجه في حالة التعامل مع ال Mini-Batches.1 نقطة
-
أولاً logits في الرياضيات هي دالة تقوم بتعيين الاحتمالات [0 ، 1] إلى [-inf ، + inf]. ثانياً لاترتبك من الاسم، ال logits في تنسرفلو هي فقط مخرجات الطبقة الأخيرة من نموذجك وتمت تسميتها بهذا الاسم كون مخرجات الطبقة الأخيرة من النموذج لاتكون قيم احتمالية وإنما تكون قيم من [-inf, +inf] أي أن مجموعها لايساوي 1. وعند تمرير هذه ال logits (مخرجات الطبقة الأخيرة من نموذجك) إلى دالة التنشيط Softmax تصبح قيم هذه ال logits احتمالية أي قيمها بين 0 و 1 ومجموعها كلها يساوي 1. هذا كل شيئ. وفي التوثيق الرسمي لتنسرفلو هذا ماتم شرحه عنها: "هي Tensor غير فارغة " non-empty Tensor " ويجب أن تكون من أحد الأنماط التالية half, float32, float64." الآن بالنسبة ل tf.nn.softmax فهي دالة ال softmax التي نعرفها جميعاً (وفي حال لن تكن على دراية بها يمكنك الذهاب إللى الرابط في الأسفل) : import tensorflow as tf import numpy as np logits = tf.constant(np.array([[.1, .3, .5, .9]])) # الدخل هو قيم غير محدودة print((tf.nn.softmax(logits))) # لاحظ أن الخرج أصبح قيم احتمالية بين 0 و1 # tf.Tensor([[0.16838508 0.205666 0.25120102 0.37474789]], shape=(1, 4), dtype=float64) أما بالنسبة ل tf.nn.softmax_cross_entropy_with_logits فهي تطبق الدالة السابقة على ال logits ثم تطبق cross_entropy على خرجه، أي: <<< افترض أن لديك فهم للانتروبيا المتقطعة في نظرية المعلومات>>> sm = tf.nn.softmax(x) ce = cross_entropy(sm) # وفي تنسرفلو يتم دمج هاتين العمليتين كالتالي tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None) وتستخدم كدالة تكلفة cost حيث يقيس الخطأ الاحتمالي في مهام التصنيف المنفصلة أي التي تكون فيها الفئات متنافية (كل إدخال في فئة واحدة بالضبط). على سبيل المثال ، يتم تصنيف كل صورة على أنها كلب أو قطة وليس كلاهما. وطبعاً كون الفئات متنافية فهذا لايعني بالضرورة أن تكون احتمالاتها متنافية. وكل مايهمنا هو أن يكون التوزيع الاحتمالي لاحتمالاتها صالحاً (أي مجموع ال label يساوي 1) على سبيل المثال: logits = [[4.0, 2.0, 1.0], [0.0, 5.0, 1.0]] labels = [[1.0, 0.0, 0.0], [0.0, 0.8, 0.2]] tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits) # <tf.Tensor: shape=(2,), dtype=float32, numpy=array([0.16984604, 0.82474494], dtype=float32)> ويجب أن تكون كل من label و logits من نفس الأبعاد أي [batch_size, num_classes]. افرض المثال التالي، لدينا مصفوفتي tensor الأولى هي قيم y_hat ولتكن تساوي y = W*x +b أي الأوزان التدريبية مضروبة بالدخل مجموعة على الانحراف (أي القيم المتوقعة من دون إدخالها في دالة تنشيط أي logits)، وو y_true هي القيم الحقيقية. y_hat = ... # Predicted label, e.g. y = tf.matmul(X, W) + b y_true = ... # True label, one-hot encoded وبالتالي يكون مقدار الخطأ الكلي للانتروبيا المتقطعة يساوي إلى : y_hat_softmax = tf.nn.softmax(y_hat) total_loss = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), [1])) وهو مايكافئ الدالة التالية في تنسرفلو: total_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true))1 نقطة
-
pip list | grep tensorflow أبسط طريقة من خلال ال IDE التي تعمل عليها (جوبيتر أو سبايدر أو باي شارم..) أو من محرر الأكواد الذي تتعامل معه: import tensorflow as tf print(tf.__version__) أو في النسخ الحديثة من تنسرفلو 2x: import tensorflow as tf print(tf.version.VERSION) أما بالنسبة للنسخ الأقدم: import tensorflow as tf print(tf.VERSION) أو من خلال CLI: # ضع الكود التالي فقط python -c 'import tensorflow as tf; print(tf.__version__)' وإذا كانت هناك نسخ متعددة من Python على النظام ، فاستخدم: python<version> -c 'import tensorflow as tf; print(tf.__version__)' أيضاً يمكنك من خلال pip: pip show tensorflow أو يمكنك استخدام pip list التي تعرض لك كل ماتم تنزيله باستخدام pip install + grep لفلترة النتائج وعرض تنسرفلو فقط (في حالة كنت تستخدم لينوكس) pip list | grep tensorflow في حالة ويندوز فيمكنك قلترة النتائج بالشكل: pip list | findstr "tensorflow" أما إذا كنت قد ثبت تنسرفلو على بيئة افتراضية Virtual Environment: قم أولاً بتفعيل البيئة الافتراضية: virtualenv <environment name> # Linux <environment name>\Scripts\activate # Windows # الآن pip show tensorflow أو من خلال أناكوندا، إذا كنت تعمل عليها: conda list | grep tensorflow conda list | findstr "tensorflow"1 نقطة
-
أنت بحاجة إلى إصدار 64 بت من Python وفي حالتك تستخدم إصدار 32 بت. اعتباراً من الآن ، يدعم Tensorflow إصدارات 64 بت من Python 3.5.x و 3.8.x على Windows. لحل مشكلتك: في حال كنت تستخدم Windows (8, 8.1, 10) قم بتثبيتها كالتالي: python3 -m pip install --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.12.0-py3-none-any.whl بالنسبة ل mac ولينوكس قم بتبديل python3 إلى python حسب التكوين الخاص بك، وقم بتغيير py3 إلى py2 في عنوان url إذا كنت تستخدم Python 2.x.1 نقطة
-
الأمر كله يتعلق بال CPU، أولاُ يجب أن تعلم أن لكل معالج مجموعة تعليمات منخفضة المستوى Low-Level هذه التعليمات نسميها ISA، مجموعة التعليمات هذه هي قائمة بجميع الأوامر المتاحة بمختلف أشكالها التي يمكن لمعالج ما تنفيذها، وتتضمن هذه التعليمات: تعليمات حسابية ومنطقية مثل الجمع المنطقي والضرب المنطقي والنفي المنطقي ووووو.. طريقة تعريف هذه التعليمات وتحقيقها يلعب دوراً كبيراً جداً في سرعة المعالج وأدائه. هناك مجموعات تعليمات أساسية تدعمها كل المعالجات الحديثة وهناك توسعات كثيرة لها "Instruction Set Extensions" مثل SSE2, SSE4, AVX 2,AVX ..إلخ هذه التوسعات أو الإضافات أو الامتدادات تعطي الحاسب سرعة وأداء إضافي كبيرة. إن هذه الرسالة التي تظهر لك مفادها أن معالجك يدعم مجموعة تعليمات AVX لكن تنسرفلو لاتستفيد منها، هذه التعليمات تنفذ عمليات تسمى fused multiply-accumulate (FMA) وفائدتها في أنها تسرع من تنفيذ عمليات الجبر الخطي وضرب المصفوفات والجداء النقطي "dot-product" وعمليات الالتفاف على المصفوفات "convolution"، وكما نعرف جميعنا فإن هذه العمليات هي 90% من العمليات الداخلية التي تنفذ في التعلم الآلي. وبالتالي فإن تسريع حسابها يزيد سرعة الأداء بشكل كبير جداً بنسبة تصل ل 300٪. حسناً لماذا لاتستفيد منها وتستخدمها؟ السبب هو أن التوزيع الافتراضي لـ tensorflow تم إنشاؤه بدون امتدادات وحدة المعالجة المركزية ، مثل SSE4.1 و SSE4.2 و AVX و AVX2 و FMA وما إلى ذلك ، حيث أن التصميمات الافتراضية تهدف إلى أن تكون متوافقة مع أكبر عدد ممكن من وحدات المعالجة المركزية. سبب آخر هو أنه حتى مع هذه الإضافات ، تعد وحدة المعالجة المركزية أبطأ بكثير من وحدة معالجة الرسومات GPU ، ومن المتوقع أن يتم تنفيذ تدريب التعلم الآلي على نطاق متوسط وكبير على وحدة معالجة الرسومات GPU. إذاً ما الحل؟ إذا كان لديك GPU ، فلا يجب أن تهتم بدعم AVX ، وبالتالي يمكنك ببساطة تجاهل هذا التحذير عن طريق (منعه من الظهور): import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' أو إذا أردت استخدام تعليمات AVX فهناك تحديثات خاصة لتنسرفلو لكي تدعم هذه التعليمات بأنواعها المختلفة SSE4.1 و SSE4.2 و AVX و AVX2 و FMA إلخ.، وهي موجودة على gitHub في الرابط التالي: https://reposhub.com/python/deep-learning/lakshayg-tensorflow-build.html بعد أن تقوم بتحميل النسخة التي تريدها فقط ادخل لل cmd: pip install --ignore-installed --upgrade /path/to/binary.whl --user حيث تمرر له المسار الذي يتواجد فيه الملف الذي تم تنزيلها، أو يمكنك تحميلها مباشرة من gitHub: pip install --ignore-installed --upgrade "Download URL" --user حيث فقط تمرر له رابط النسخة التي نريدها (هناك عشرين نسخة أو أكثر وكل منها لنظام مختلف وتوسعات مختلفة). هذا كل شيئ..1 نقطة
-
input_shape يمثل شكل البيانات التي ستدخل إلى طبقة معينة من نموذجك وبالتالي يجب أن تكون متوافقة مع حجم بياناتك، حيث أن كل طبقة من طبقات النموذج ستتلقى دخلأ بأبعاد معينة، لكننا لانحتاج لتحديد ذلك سوى لأول طبقة (لأن الطبقات التالية يتم استنتاج الأبعاد فيها لأنها تنتج من اختزال أبعاد الدخل على حجم الخلايا في الطبقة). وبما أن أول طبقة هي Dense فهي تتوقع منك مصفوفة (أو بمعنى أدق tensor) ثنائية الأبعاد تمثل حجم الباتش وعدد الفيتشرز features: model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(keras.layers.LayerNormalization()) input_shape=(10000,) تعني أن الدخل سيكون لديه 10 آلاف features (ال axis=0 لانحدده وبالتالي سيتم قبول أي قيمة لحجم الباتش).1 نقطة
-
يظهر هذا الخطأ عندما تكون بيانات التدريب والاختبار غير متوافقة، أقصد بذلك عندما تكون الأبعاد غير متوافقة، أي بمعنى أوضح إذا كانت:: # في حالة كانت بياناتك هي بيانات تصنيف ثنائي # x أبعاد الدخل shape : (samples,features) #سمها كما شئت y أو label أو ال target فيجب أن تكون أبعاد بيانات الهدف Shape: (samples,) # أي مثلاً X_Shape:(1000,521) --> يجب أن يكون --> y_shape:(1000,) #label أي بمعنى آخر يجب أن يكون لكل عينة من بياناتك قيمة تمثل الهدف أو # في حالة كانت بياناتك بيانات تصنيف متعدد X_Shape : (samples,features) y_shape: (samples,عدد الفئات) # أي في مثالك فإن أبعاد الدخل هي X_Shape : 7982, 10000) # ولدينا 46 فئة وبالتالي أبعاد الهدف تكون (7982, 46) وهنا يخبرك كيراس أن عدد ال samples في بياناتك هو 7982 بينما ال label هو 8982 لذا يظهر خطأ. الحل: x_val = x_train[:1000] partial_x_train = x_train[1000:] # هنا y_val = one_hot_train_labels[:1000] partial_y_train = one_hot_train_labels[1000:] # الآن: partial_x_train.shape # (7982, 10000) partial_y_train.shape # (7982, 46) ... ... . . #fit تدريب النموذج من خلال الدالة history = model.fit(tf.convert_to_tensor(partial_x_train, np.float32), partial_y_train, epochs=6, batch_size=512, validation_data=(x_val, y_val),max_queue_size=10) حيث أنك قمت باقتطاع جزء من بيانات التدريب لديك لتكون بيانات validation لكنك نسيت أن تقوم باقتطاع بيانات الهدف أيضاً.1 نقطة
-
تقوم هذه الدالة يتدريب نموذجك (تدريب الأوزان على المشكلة المعطاة)، ولها الشكل التالي: Model.fit( x=None, y=None, batch_size=None, epochs=1, verbose="auto", callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_batch_size=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, ) 1. أول وسيط يشير إلى بيانات الدخل، ويجب أن يكون مصفوفة نمباي (أو نوع آخر يشابهها)، أو قائمة من المصفوفات "list of arrays" (في حالة كان نموذجك متعدد الدخل multiple inputs). أو يمكن أن تكون مصفوفة تنسر "TensorFlow tensor" أو قائمة من التنسر "list of tensors" (في حالة كان نموذجك متعدد الدخل multiple inputs). أو قاموس يربط اسم بمصفوفة أو تنسر في حال كان لمصفوفات الدخل أسماء. أو tf.data مجموعة بيانات مكونة من خلال تنسرفلو، بحيث تكون من الشكل (inputs, targets) أو (inputs, targets, sample_weights).أو مولد generator أو تسلسل keras.utils.Sequence بحيث يعيد (inputs, targets) أو (inputs, targets, sample_weights). 2. ثاني وسيطة هي بيانات الهدف أو ال Target أو ال label، وبشكل مشابه لبيانات الدخل x يجب أن تكون Numpy array(s) أو TensorFlow tensor(s)، ويجب أن تكوم متسقة مع x، أي بمعنى إذا كانت x تحوي 400 عينة فهذا يعني أنه يجب أن يكون لدينا 400 target، و لايجب أن يكون x نمباي و y تنسر أو العكس. وفي حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence فلا تقم بتمرير قيم ال y لأنهم يحصلون علبها بشكل تلقائي من خلال x. 3. الوسيط الثالث هو ال batch_size وهو يمثل حجم دفعة البيانات، وهو عدد صحيح يشير إلى عدد العيانات التي سيتم تطبيق خوارزمية الانتشار الأمامي والخلفي عليها في المرة الواحدة. أي مثلاً لو كان لديل 100 عينة وكان حجم الباتش 10 هذا يعني أن هسيكون لديك 10 باتشات وكل باتش يحوي 10 عينات وبالتالي سيتم تطبيق خوارزمية الانتشار الأمامي ثم الخلفي (تحديث الأوزان) على أول باتش ثم ينتقل للباتش الثاني وهكذا.. أيضاً في حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence فلاتقم بتحديد هذا الوسيط لأنهم في الأساس يقومون بتوليد باتشات. وأيضاً في حالة لم تقوم بتعيين قيمة للباتش "None" فسأخذ القيمة الافتراضية 32. 4. الوسيط الرابع epochs عدد الحقب التي تريدها لتدريب النموذج، كل حقبة تقابل مرور على كامل مجموعة البيانات. 5. الوسيط الخامس هو ال verbose لعرض تفاصيل عملية التدريب في حال ضبطه على 0 لن يظهر لك تفاصيل عملية التدريب "أي الوضع الصامت"، أما في حالة ضبطه على 1 فهذا يعني أنك تريد أن تظهر لك تفاصيل التديب (الكل يريد هذا طبعاً). 6. الوسيط السادس callbacks قائمة من keras.callbacks.Callback وهي قائمة الاسترجاعات المطلوب تقديمها أثناء التدريب. 7. الوسيط السابع validation_split هو عدد حقيقي بين 0 و ال 1، يحدد نسبة يتم اقتطاعها من بيانات التدريب ليتم استخدامها كعينات تطوير Validaton set، وهذه الخاصية غير مدعومة في حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence. 8. الوسيط الثامن validation_data هو البيانات التي تريد استخدامها كعينات تطوير Validaton set أي لن يستخدمها في عملية التدريب وإنما سيختبر عليها دقة النموذج بعد كل حقبة (تماماً كما في الوسيط السابق)، ويجب أن تكون tuble من الشكل (x_val, y_val) كما يجب أن تكون من نمط البيانات tensors أو مصفوفات نمباي، أو tf.data.Dataset أو generator أو keras.utils.Sequence تعيد (inputs, targets) أو (inputs, targets, sample_weights). 9. الوسيط التاسع shuffle يأخذ قيمة بوليانية لتحديد فيما إذا كنت تريد القيام بعملية خلط للبيانات قبل كل حقبة أو يأخذ str في حالة كنت تريد الخلط قبل كل باتش ونمرر له في هذه الحالة "batch". وفي حالة كانت بياناتك هي مولدات أو tf.data.Dataset سيتم تجاهل هذا الوسيط. ملاحظة: "batch" هي خيار خاص للتعامل مع قيود بيانات HDF5، يخلط في أجزاء chunks بحجم الدُفعة batch-sized chunks. ويكون له تأثير عندما تكون None= steps_per_epoch . أما الوسيط العاشر 10. فهو ال class_weight وهي عبارة عن قاموس (اختياري) يربط فهارس الفئة (أعداد صحيحة) بوزن (قيمة float) لتوزين دالة التكلفة (خلال فترة التدريب فقط) ويكون استخدامه مفيداً لإخبار النموذج "بإيلاء المزيد من الاهتمام" لفئات الأقلية في حال كانت البيانات غير متوازنة (مثلاً عدد صور القطط 1000 وعدد صور الكلب 4000). 11. الوسيط sample_weight هو مصفوفة أوزان (اختياري) لعينات التدريب وتستخدم أيضاً لتوزين دالة التكلفة.ويمكنك إما تمرير مصفوفة Numpy مسطحة (1D) بنفس طول عينات الإدخال (ربط 1: 1 بين الأوزان والعينات). أو في حالة البيانات الزمنية ، يمكنك تمرير مصفوفة ثنائية الأبعاد ذات شكل (عينات ، طول التسلسل) ، لتطبيق وزن مختلف لكل خطوة زمنية لكل عينة. وهذه الخاصية غير مدعومة في حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence.. الوسيط 12. هو initial_epoch عدد صحيح. الحقبة التي تبدأ فيها التدريب (مفيدة لاستئناف دورة تدريبية سابقة). 13. steps_per_epoch عدد صحيح أو None إجمالي عدد الخطوات (مجموعات العينات) قبل الإعلان عن انتهاء حقبة واحدة وبدء المرحلة التالية. عند التدريب باستخدام موترات الإدخال مثل TensorFlow data tensors ، فإن القيمة الافتراضيةNone تساوي عدد العينات في مجموعة البيانات الخاصة بك مقسوماً على حجم الباتش، أو 1 إذا تعذر تحديد ذلك. إذا كانت x عبارة عن tf.data ، وكانت "steps_per_epoch=" None ، فسيتم تشغيل الحقبة حتى يتم استنفاد مجموعة بيانات الإدخال. وهذه الوسيطة غير مدعومة عندما تكون مدخلاتك هي مصفوفات. 14. validation_steps: تعمل فقط إذا تم توفير validation_data وكانت عبارة عن tf.data. وهي إجمالي عدد الخطوات (باتش من العينات batches of samples) المطلوب سحبها قبل التوقف عند إجراء ال validation في نهاية كل حقبة. إذا كانت "validation_steps" هي None ، فسيتم تشغيل ال validation حتى يتم استنفاد مجموعة بيانات validation_data. أما إذا تم تحديد "Validation_steps" فسيتم استخدام جزء فقط من مجموعة البيانات ، وسيبدأ التقييم من بداية مجموعة البيانات في كل حقبة. وهذا يعني استخدام نفس عينات التحقق في كل مرة. 15. validation_batch_size: عدد العينات لكل دفعة validation. إذا لم يتم تحديدها ، فسيتم تعيينها افتراضياً إلى batch_size. لا تحدد validation_batch_size إذا كانت بياناتك في شكل dataset, generator, أو keras.utils.Sequence.. (لأنها تولد باتشات). 16. validation_freq: تعمل فقط إذا تم توفير validation_data وهي عبارة عن عدد صحيح أو collections.abc.Container (مثل list ، tuple ، إلخ). إذا كان عدداً صحيحاً ، فإنه يحدد عدد حقب التدريب التي سيتم تشغيلها قبل إجراء عملية تحقق جديدة، على سبيل المثال validation_freq = 2 يتم تشغيل ال validation كل حقبتين. إذا كانت Container ، فإنها تحدد الحفب التي سيتم فيها تشغيل ال validation ، على سبيل المثال Validation_freq = [1 ، 2 ، 10] أي تشغيل ال validation في نهاية الحقبة الأولى والثانية والعاشرة. 17. max_queue_size: عدد صحيح ، و يستخدم للمولد generator أو keras.utils.Sequence فقط. ويمثل الحجم الأقصى لرتل المولد. إذا لم يتم تحديدها ، فسيتم تعيين max_queue_size افتراضياً على 10. 18. use_multiprocessing: قيمة بوليانية لتحديد فيما إذا كنت تريد استخدام المعالجة المتعددة أم لا وهو مدعوم فقط في حالة generator أو keras.utils.Sequence. الآن سأعطيك مثال لاستخدامه في تدريب نموذج: from keras.datasets import reuters import keras import tensorflow as tf (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=10000) import numpy as np def vectorize_sequences(sequences, dimension=10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) from keras.utils.np_utils import to_categorical one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) x_val = x_train[:1000] partial_x_train = x_train[1000:] y_val = one_hot_train_labels[:1000] partial_y_train = one_hot_train_labels[1000:] from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(keras.layers.LayerNormalization()) model.add(layers.Dense(64, activation='relu')) model.add(keras.layers.LayerNormalization()) model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['CategoricalAccuracy']) #fit تدريب النموذج من خلال الدالة history = model.fit(tf.convert_to_tensor(partial_x_train, np.float32), partial_y_train, epochs=6, batch_size=512, validation_data=(x_val, y_val)) """ Epoch 1/6 16/16 [==============================] - 2s 75ms/step - loss: 1.7822 - categorical_accuracy: 0.6134 - val_loss: 1.1558 - val_categorical_accuracy: 0.7510 ... ... Epoch 6/6 16/16 [==============================] - 1s 56ms/step - loss: 0.1659 - categorical_accuracy: 0.9535 - val_loss: 0.9125 - val_categorical_accuracy: 0.8080 """ كما وترد هذه الدالة كائن History يحوي قيم ال loss وال accuracy لنموذجك في كل حقبة "epoch". حيث يمكننا الوصول إليهم من خلال الواصفة history من هذا الكائن أي كالتالي History.history: history.history """ {'categorical_accuracy': [0.6207717657089233, 0.8475319743156433, 0.9155600070953369, 0.9433726072311401, 0.9516412019729614, 0.9551491141319275], 'loss': [1.70294189453125, 0.7281545996665955, 0.43800199031829834, 0.2743467688560486, 0.2031983882188797, 0.1586201786994934], 'val_categorical_accuracy': [0.753000020980835, 0.7839999794960022, 0.7940000295639038, 0.796999990940094, 0.7900000214576721, 0.7860000133514404], 'val_loss': [1.115304946899414, 0.9754453897476196, 0.9541780948638916, 0.9103594422340393, 0.9673216342926025, 0.9509721994400024]} """1 نقطة
-
لفهم الفرق بين أنواع الـwidgets علينا أولاً فهم ماهيتها ومكوناتها. كل عنصر يظهر للمستخدم هو عبارة عن widget مثل نص، صورة، حقل إدخال...الخ. حيث يصف الـwidget سلوك وشكل العنصر في الشاشة، على سبيل المثال عند إضافة نص ومحاذاته في المنتصف نستخدم الـtext widget و الـcenter widget كالتالي: Center(// widget1 child: Text('hello',style:TextStyle(color:Colors.black)), // widget2 ) لاحظ أن الـ widget هو object يصف ويحدد شكل العنصر في الشاشة. بعد فهم ماهية الـwidget سنفرق بين الـstateless widget والـstateful widget. stateful widget: هو عبارة عن عنصر يحتوي على حالة أي يمكن حفظ بيانات فيه ويمكنه تغييرها وإعادة بناء/رسم نفسه أثناء التشغيل عن طريق الدالة setState. مثال عليه: class FavoriteWidget extends StatefulWidget { //القسم الأول الخاص بالعنصر @override _FavoriteWidgetState createState() => _FavoriteWidgetState(); } class _FavoriteWidgetState extends State<FavoriteWidget> { // القسم الثاني الخاص بحالة العنصر String msg = “hello”; // يمكن تعريف متغيرات وتغيير قيمتها أثناء تشغيل التطبيق @override Widget build(BuildContext context) { // الدالة الخاصة ببناء شكل العنصر return Text(‘$msg’); // نرجع نصاً يحمل قيمة المتغير المعرف مسبقاً } } stateless widget: هو عنصر ليس لديه حالة ولا يمكن تغيير بياناته أثناء تشغيل التطبيق إلا عن طريق إعادة تعريفه مرة أُخرى ببيانات مختلفة. مثال عليه: class MyWidget extends StatelessWidget { // يتكون من قسم واحد فقط خاص بالعنصر وليس له حالة final String msg = “hello”; // لاحظ تعريف المتغير يجب أن يكون نهائي ولا يمكن تغييره أثناء التشغيل @override Widget build(BuildContext context) { // دالة بناء شكل العنصر return Text(‘$msg’); } } إذاً نستخدم stateful مع العناصر التي تعتمد على بيانات متغيرة وتحتاج لإعادة رسم نفسها على الشاشة أثناء التشغيل. ونستخدم stateless في العناصر الثابتة التي لا نحتاج لتغييرها أو التعديل عليها أثناء التشغيل.1 نقطة