لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 08/26/21 في كل الموقع
-
لدي البيانات التالية على شكل dataframe A B C 0 foo 0 A 1 foo 1 A 2 foo 1 B 3 bar 1 A أريد إزالة الصفوف التي تتشابة فيها قيم عمودين، على سبيل المثال أريد إزالة الصفوف التي تتشابه فيها قيم العمود A والعمود C لذا في المثال السابق سنقوم بحذف الصفين 0 و 1. أعرف أن الدالة drop_duplicates تحذف الصفوف التي تتشابه جميع قيمها، لكن هنا أريد تحديد أعمدة بعينها، كيف يمكنني فعل هذا؟2 نقاط
-
لدي نموذج يحتوي على الاسم الأول fName والاسم الأخير lName والاسم المستعار nickName (اختياري nullable) وكنت أريد استعلام عن جميع الأشخاص الذين يملكون اسم مستعار. وقد حاولت أن أستخدم الكود التالي: User.objects.filter(nickName!="") لكن يبدو أن الأمر لم ينجح، كيف أقوم بإستبعاد المستخدمين الذين لا يملكون اسم مستعار؟2 نقاط
-
لدي عدة ملفات على شكل csv وأريد تحميلهم في pandas على هيئة dataframes بحيث يتم دمجهم سويا في dataframe واحدة كبيرة، حاولت إستخدام الكود التالي لكنه لم يفلح: import glob import pandas as pd # تحميل الملفات path =r'C:\DRO\DCL_rawdata_files' filenames = glob.glob(path + "/*.csv") dfs = [] for filename in filenames: dfs.append(pd.read_csv(filename)) # جمع الملفات في ملف واحد big_frame = pd.concat(dfs, ignore_index=True) كيف يمكنني فعل هذا؟2 نقاط
-
أستخدم virtualenv وأريد تحديث حزمة جانغو Django وبعض الحزم الأخرى ولكن يظهر لدي خطأ التالي: Source in <virtualenv>/build/Django has version 3.1.23 that conflicts with Django==3.2.6 (from -r requirements.txt (line 3)) أنا أستخدم هذا الأمر لإجراء الترقية بالفعل: pip --install --upgrade -E build/Django/ --requirement requirements.txt لا يمكنني معرفة كيفية إعادة تنزيل حزمة جانغو Django . حتى أنني حاولت تشغيل أمر إلغاء التثبيت أولاً ، ثم تثبيت جانغو Django مرة أخرى، لكن بدون فائدة. كيف يمكنني تحديث جانغو Django بشكل صحيح؟2 نقاط
-
السؤال الأول: كيف اقوم برسم خطوط شبه شفافه مثال: شخص يريد أن يرسم خط أحمر و خط ازرق و في تقاطعهما ينشأ اللون البنفسجي السؤال الثاني: هل يمكن عمل تطبيق اندرويد بمكتبة Pygame؟ السؤال الثالث: هل هناك مكتبة تساعد في كتابة اللغه العربيه في مكتبة Pygame1 نقطة
-
.png.2d6d55ae046aa1e7d58ea9e2acee7e2b.png) إن كنت مطور ويب أو أحد المهتمين بتطوير الأنظمة المعلوماتية المختلفة في بيئة الويب، فإنك تعلم حجم التنوع الكبير للغات البرمجة المستخدمة في تطوير مواقع الويب وخدماته، ولربما كنت أحد مطوري هذه الخدمات وترغب بأن تكون خدماتك سريعة الانتشار وسهلة الاستخدام من قبل التطبيقات المختلفة ، وكما تعلم فإن كثرة لغات البرمجة المستخدمة في تطوير خدمات الويب تجعل من الصعب التواصل والتكامل بين هذه التطبيقات. إن المصطلح REST وهو اختصار لـ Representational state transfer يعبر عن المعمارية المستخدمة في تطوير خدمات الويب، التي تهدف إلى وضع معايير تضبط إدارة موارد الأنظمة resources وتحدد كيفية عنونتها ونقلها عبر بروتوكل HTTP إلى طيف واسع من التطبيقات المختلفة بغض النظر عن لغات البرمجة التي طورت بها تلك التطبيقات، وتعد معمارية REST أكثر معماريات تصميم الويب هيمنة خلال السنوات الماضية وذلك لسهولة استخدامها والتعامل معها. بعد التعرف على RESTful ستكون قادر على الانطلاق لتصميم الخدمة الخاصة بك دون القلق بشأن من سيستخدم الخدمة الخاصة بك.1 نقطة
إن كنت مطور ويب أو أحد المهتمين بتطوير الأنظمة المعلوماتية المختلفة في بيئة الويب، فإنك تعلم حجم التنوع الكبير للغات البرمجة المستخدمة في تطوير مواقع الويب وخدماته، ولربما كنت أحد مطوري هذه الخدمات وترغب بأن تكون خدماتك سريعة الانتشار وسهلة الاستخدام من قبل التطبيقات المختلفة ، وكما تعلم فإن كثرة لغات البرمجة المستخدمة في تطوير خدمات الويب تجعل من الصعب التواصل والتكامل بين هذه التطبيقات. إن المصطلح REST وهو اختصار لـ Representational state transfer يعبر عن المعمارية المستخدمة في تطوير خدمات الويب، التي تهدف إلى وضع معايير تضبط إدارة موارد الأنظمة resources وتحدد كيفية عنونتها ونقلها عبر بروتوكل HTTP إلى طيف واسع من التطبيقات المختلفة بغض النظر عن لغات البرمجة التي طورت بها تلك التطبيقات، وتعد معمارية REST أكثر معماريات تصميم الويب هيمنة خلال السنوات الماضية وذلك لسهولة استخدامها والتعامل معها. بعد التعرف على RESTful ستكون قادر على الانطلاق لتصميم الخدمة الخاصة بك دون القلق بشأن من سيستخدم الخدمة الخاصة بك.1 نقطة -
مرحبا , لقد تعلمت useCallback, and useMemo hooks واعلم كيف استخدمهم ولكن لا افهم ما الفرق بينهما1 نقطة
-
كنت أقرأ أحد الأكواد على غيتهاب، وظهر لي هذا المفهوم لكنني لم أفهم ماهو، هل يمكن لأحد أن يوضحه لي؟ وأيضاً في المقطع التالي لماذا ضبطنا قيمة global_step على 0 : def training(loss,learning_rate): tf.summary.scalar('loss',loss) t_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=tf.Variable(0, name='global_step',trainable=False)) return t_op1 نقطة
-
يمكن لكلاس abstract ان يورث اكثر من كلاس؟1 نقطة
-
شركة فيها ٤اقسام فكل قسم موظفين وعمال ومدراءولكل واحدمنهم صفات تخصه ولايمكن للموظف العمل في اكثر من قسم ،ولكل قسم موظفين وعمال تخصه ويمكن لاكثر من قسم الاشتراك في نفس العمال. اريد شرح الفكرة هل القسم كلاس اب نرث منه اوكلاس ابن يرث من كلاس يحتوي على كلاسات فرعية1 نقطة
-
السلام عليكم... اخوتي في الله انا مبرمج مبتدئ و قمت ببرمجة سكربت يقوم بالبحث في 100 موقع عن اسم اقوم بأعطاءه للكمبيوتر مسبقاً... سوالي هو : هذا السكربت يعمل حسب سرعة الانترنت لدي لكني أريدها أن يقوم بعملية البحث بسرعة كبيرة كيف يمكن لي فعل ذلك؟1 نقطة
-
يجب توضيح تفاصيل أكثر عن الطريقة التي تقوم بها حاليا، يمكنك إتباع احدى الطرق: اذا كنت تبحث في نفس ال 100 صفحة كل مرة يمكن لبرنامجك المرور عليها مرة واحدة وتخزينها محليا ومن ثم عند طلب البحث عن اسم البحث في الصفحات المخزنة محليا، بهذه الطريقة لن تعتمد على سرعة الاتصال لديك سوى أول مرة يمكن تخزين نتائج البحث السابقة محليا، وعند تكرار طلب لنفس الاسم ترجع النتيجة جاهزة مسبقا يمكن إرسال الطلبات على التوازي، بدل من البحث في صفحة واحدة كل مرة يمكن البحث عدة صفحات معا دفعة واحدة سرعة الانترنت لديك هي عنق الزجاجة في النظام الذي تبنيه، يمكن الاستفادة من التخزين المؤقت و الطلبات المتوازية لتحقيق أقصى سرعة ممكنة للتعويض1 نقطة
-
هل يمكنك إضافة تفاصيل أكثر عن البرنامج؟1 نقطة
-
قمت ببناء شبكة عصبية لتصنيف الصور باستخدام إطار العمل Caffe والآن أقوم بنقله إلى TensorFlow ولكن لا يبدو أنه يوجد في تنسرفلو تهيئة xavier. أنا أستخدم truncated_normal ولكن يبدو أن هذا يجعل التدريب أكثر صعوبة.1 نقطة
-
عند مشاركة اي تطبيق ويب باستخدام flask على شبكة خارجيه تحول عنوان الايبي الى 0000 . هل تفعل شي اخر؟1 نقطة
-
كلاس ليس abstractيمكن ان يرث من كلاس abstract؟ وهل العكس ممكن؟1 نقطة
-
1 نقطة
-
يمكنك حساب كل المعاملاتا الاحصائية بالطريقة التالية: import numpy as np keys = np.array([ ['A', 'B'], ['A', 'B'], ['A', 'B'], ['A', 'B'], ['C', 'D'], ['C', 'D'], ['C', 'D'], ['E', 'F'], ['E', 'F'], ['G', 'H'] ]) df = pd.DataFrame( np.hstack([keys,np.random.randn(10,4).round(2)]), columns = ['col1', 'col2', 'col3', 'col4', 'col5', 'col6'] ) df[['col3', 'col4', 'col5', 'col6']] = df[['col3', 'col4', 'col5', 'col6']].astype(float) # الآن لحساب ماتريده df[['col1', 'col2', 'col3', 'col4']].groupby(['col1', 'col2']).agg(['mean',"median", 'count',"std","min","max"]) """ col3 col4 mean median count std min max mean median count std min max col1 col2 A B 0.567500 0.685 4 1.280088 -0.96 1.86 0.205 0.10 4 1.391534 -1.34 1.96 C D -0.086667 -0.040 3 0.641275 -0.75 0.53 0.160 0.58 3 1.187097 -1.18 1.08 E F 0.310000 0.310 2 1.173797 -0.52 1.14 -1.140 -1.14 2 0.098995 -1.21 -1.07 G H 0.640000 0.640 1 NaN 0.64 0.64 0.410 0.41 1 NaN 0.41 0.41 """ كما يمكنك استخدام الدالة describe: df[['col1', 'col2', 'col3', 'col4']].groupby(['col1', 'col2']).describe() كما بمكنك استخدام الدالةvalue_counts لمعرفة عدد عناصر كل مجموعة : df[['col1', 'col2']].value_counts() """ col1 col2 A B 4 C D 3 E F 2 G H 1 dtype: int64 """1 نقطة
-
لا هذا غير مسموح به في جافا , لن يكون من المنطقي السماح بالوراثة المتعددة, ولكن يمكنك فعل ذلك بطريقة ما كالتالي public abstract class Y {...} public abstract class Z extends Y{...} public class X extends Z {...} كما تلاحظي قمت بانشاء كلاس مجرد اسمه Y ثم انشأت كلاس مجرد اسمه Z يرث من الكلاس المجرد Y , ثم أنشأت كلاس X يرث من الكلاس المجرد Z , تحصيل حاصل يرث من Y, يمكنك فعل ذلك من خلال هذه الطريقة1 نقطة
-
هناك العديد من الطرق وإليك إياها: ############# JSON format حفظه ك ############# # حفظ النموذج model_json = model.to_json() with open("model.json", "w") as json_file: json_file.write(model_json) # HDF حفظ الأوزان كملف model.save_weights("model.h5") print("Saved model to disk") ############### لتحميله لاحقاً ############# json_file = open('model.json', 'r') loaded_model_json = json_file.read() json_file.close() loaded_model = model_from_json(loaded_model_json) # تحميل الأوزان إلى النموذج loaded_model.load_weights("model.h5") أو: ############ YAML Format ############## # pip install PyYAML model_yaml = model.to_yaml() with open("model.yaml", "w") as yaml_file: yaml_file.write(model_yaml) # weights to HDF5 model.save_weights("model.h5") # تحميله لاحقاً yaml_file = open('model.yaml', 'r') loaded_model_yaml = yaml_file.read() yaml_file.close() loaded_model = model_from_yaml(loaded_model_yaml) # تحميل الأوزان إلى النموذج loaded_model.load_weights("model.h5") أو بشكل مباشر من خلال إطار العمل يمكنك حفظ النموذج مع الأوزان وبالنسبة لي هذه هي الطريقة الأفضل والأكثر راحة: model.save("model.h5") # ولتحميله from tensorflow.keras.models import load_model model = load_model('model.h5')1 نقطة
-
دورات الأكاديمية مقسمة لمسارات و كل مسار مقسم إلى مسارات فرعية أو دروس لذلك عندما تشترك بدورة ما ستجد أن جميع مسارات تلك الدورة قابلة للوصول من طرف حسابك، لكن يُنصح بمتابعة الدورة بالترتيب حتى تستفيد بشكل أكبر، إلى جانب الدورة الأساسية التي اشتركت بها ستجد أن الأكاديمية قد فتحت لك المسارات الأولى من بقية الدورات و ذلك بغرض تعريف الطلاب ببقية المجالات الخاصة ببقية الدورات و تقوية أنفسهم ببعض النقائص و المتطلبات. فمثلاً لنفترض أنك اشتركت بدورة php فمن المستحسن أن يكون لديك خلفية في أساسيات لغات الويب (html، css، js) و في هذه الحالة سيُساعدك المسار الأول من دورة تطوير واجهات المستخدم، فموضوع فتح المسارات الأولى للمشتركين مفيد جداً للطلاب. يُمكنك الإطلاع على صفحة الدورة التي لديك اهتمام بها للحصول على معلومات أكثر حول تلك الدورة كما يوجد لديك مركز المساعدة للتحدث و الإستفسار عن أي شيء تريد او الإطلاع على المواضيع الشائعة حول الدورات و الإمتحان.1 نقطة
-
إليك كل ما قد تحتاجه من معلومات مع المثال التالي: import tensorflow as tf with tf.compat.v1.Session() as sess: hello = tf.constant('hello world') print(sess.run(hello)) ######################################### # للحصول على كل العقد [n for n in tf.compat.v1.get_default_graph().as_graph_def().node] """ [name: "Const" op: "Const" attr { key: "dtype" value { type: DT_STRING } } attr { key: "value" value { tensor { dtype: DT_STRING tensor_shape { } string_val: "hello world" } } }] """ # oprations للحصول على كل العمليات tf.compat.v1.get_default_graph().get_operations() # [<tf.Operation 'Const' type=Const>] # للحصول على كل المتغيرات tf.compat.v1.global_variables() #Tensors للحصول على كل ال [tensor for op in tf.compat.v1.get_default_graph().get_operations() for tensor in op.values()] # [<tf.Tensor 'Const:0' shape=() dtype=string>] # placeholders الحصول على ال [placeholder for op in tf.compat.v1.get_default_graph().get_operations() if op.type=='Placeholder' for placeholder in op.values()]1 نقطة
-
كونك لم ترفق لنا شكل بياناتك سأتعامل مع مشكلتك بحالة عامة، وسأقدم المثال التالي، مع أول طريقة وهي استخدام itertuples، ومن خلال الكود التالي ستحصل أيضاً على موقع الأسطر أيضاً import pandas as pd df = pd.DataFrame({'country': ['US blabla', 'US adfv fda', 'Germany adce', 'China']}) print("Given Dataframe is :\n",df) """ Given Dataframe is : country 0 US blabla 1 US adfv fda 2 Germany adce 3 China """ for x in df.itertuples(): if x[1].find('US') != -1: print(x) """ Pandas(Index=0, country='US blabla') Pandas(Index=1, country='US adfv fda') """ حيث أن itertuples يقوم بإنشاء مكرر على الداتا فرام ثم نقوم بالمرور على الأسطر في الداتا من خلاله واستخراج المطلوب بالاعتماد على الدالة find، كما يمكنك استخدام الدالة iterrows أيضاً: for index, row in df.iterrows(): if 'US' in row['country']: print(index, row['country']) """ 0 US blabla 1 US adfv fda """ كما يمكننا استخدام الدالة Search من مكتبة ال regular expressions كالتالي: # regular expressions from re import search for ind in df.index: if search('US', df['country'][ind]): print(ind,df['country'][ind]) """ 0 US blabla 1 US adfv fda """ كما يمكننا تطبيق الطريقة التي قدمها أحمد على الفريم السابق: df[df['country'].str.contains('US', regex=False, case=False, na=False)] """ country 0 US blabla 1 US adfv fda """ أو بالشكل التالي: df[df.country.str.contains('[US]')] """ country 0 US blabla 1 US adfv fda """1 نقطة
-
يمكنك استخدام POST كالتالي: request.POST["id"] # فقط نمرر له الوسيط الذي نريده أو من خلال GET: # في حالة كان المفتاح إلزامي request.GET["id"] وهنا سيرد قيمة المفتاح، وإذا لم يجد قيمة له سيرمي استثناء. أما في حالة كان المفتاح اختيارياً: # في حالة كان المفتاح اختياري request.GET.get('id') وفي الحالات التي يكون لديك فيها كائن request فقط يمكنك استخدام: request.parser_context['kwargs']['your_param']1 نقطة
-
تستطيع استخدام filter لتحديد الأعمدة التي تحتوي على كلمة hello كالتالي df.filter(like='hello') ولتحديد الصفوف عن طريق المطابقة الجزئية للسلسلة تحتاج لتمرير المتغير axis واسناد القيمة صفر اليه كالتالي df.filter(like='hello', axis=0) سوف يتم تحديد الصفوف التي تحتوي على كلمة hello1 نقطة
-
يمكنك الحصول على أي Query Parameter من خلال التابع get كالتالي: // URL: localhost:8000/posts?id=123 request.GET.get('id', '1') # Output: 123 يتم تمرير اسم الـ Parameter إلى التابع get والقيمة الثانية هي القيمة الإفتراضية التي سوف يتم إستخدامها في حالة لم يتم إيجاد اي parameter باسم id. على العموم إن كنت تريد إستخدام regex، فيمكنك أن تستخدم re_path كالتالي: from django.urls import path, re_path from . import views urlpatterns = [ path('posts/2003/', views.special_case_2003), re_path(r'^posts/(?P<year>[0-9]{4})/$', views.year_archive), ] وعليك أن تقوم بتجهيز views.py كالتالي: def post_page(request, year): # Rest of the method1 نقطة
-
يمكنك ببساطة أستخدام الدالة to_list والتي ستقوم بعمل ما تريد تماما، حيث انها تفصل الصف الى عناصر مختلفة ومنها يمكنك جعلك تلك العناصر في شكل أعمدة. أنظر الكود التالي للتوضيح: df2[['Fruit1','Fruit2']] = pd.DataFrame(df2.Fruits.tolist(), index= df2.index) print (df2) Fruit1 Fruit2 0 Apple Orange 1 Apple Orange 2 Apple Orange 3 Apple Orange 4 Apple Orange 5 Apple Orange 6 Apple Orange كذلك إذا أردت فصل مجوعة من العناصر لكنها ليست في شكل list، كأن تكون العلامة "," هي الفاصل بين العناصر مثلا، يمكنك استخدام الكود التالي: pd.DataFrame(df["Fruits"].str.split('<delim>', expand=True).values, columns=['Fruit1', 'Fruit2'])1 نقطة
-
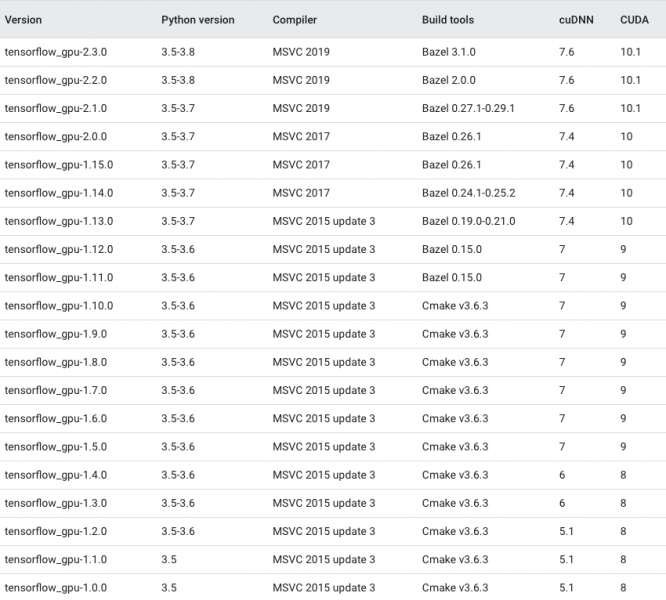
قم بفحص الإصدار الذي لديك من CUDA ومن cuDNN: # cuDNN grep CUDNN_MAJOR -A 2 /usr/local/cuda/include/cudnn.h # CUDA cat /usr/local/cuda/version.txt ثم قم بتنزيل النسخة التي تتطابق معهم من خلال الرابط التالي الذي يحوي جداول كاملة توفر نظرة عامة على المجموعات المدعومة و المختبرة رسمياً من CUDA و TensorFlow على Linux و macOS و Windows: https://www.tensorflow.org/install/source#tested_build_configurations ملاحظة : هذه الجداول يتم تحديثها باستمرار. إليك عينة من هذه الجداول للتركيبات المتوافقة على ال GPU في ويندوز 10:
 1 نقطة
1 نقطة -
بعض لغات البرمجة كـ C تمر بمرحلة تحويل من الشيفرة المصدرية إلى لغة الآلة وينتج ملفات مكتوبة بلغة الآلة يمكن تنفيذها مباشرة، من يريد تنفيذ البرنامج فقط يحتاج للوصول الى البرنامج التنفيذي المكتوب بلغة الآلة وتنفيذه مباشرة ويمكنك ابقاء الشيفرة المصدر لديك دون مشاركتها هذه اللغات تسمى Compiled Languages يقابلها لغات أخرى مثل PHP, Python, Javascript لا تترجم وانما يقوم المفسر الخاص باللغة (Interpreter) عند التنفيذ بالمرور على الشيفرة المصدرية سطر سطر وتنفيذها، أي من يحتاج لتنفيذ البرنامج (في حالتك العميل) سيحتاج للوصول للشيفرة المصدرية حتى يتمكن من تنفيذها هذه اللغات تسمى Interpreted Languages الحلول المقترحة في حالتك: الحماية القانونية إن أمكن بكتابة عقد مع العميل بمنع البيع او النسخ أو الإفصاح عن الشيفرة المصدرية للنظام (حماية ممتازة إن توفرت) قم بتمويه الشيفرة المصدرية قبل تسليمها للعميل ما أمكن أي جعلها غير قابلة للقراءة بالاستعانة بمموه (حماية متوسطة) استئجار استضافة على حسابك الشخصي وتنصيب النظام عليها وتوفير الوصول للعميل فقط الى الواجهة الأمامية للموقع أو أي خدمات يستفيد منها (حماية ممتازة)1 نقطة
-
يجب أن تضيف إلى الأمر الذي تريد تنفيذه سماحية المستخدم "user permission" وهذا مايخبرك به الخطأ أي أضف --user كالتالي: pip3 install --upgrade tensorflow-gpu --user1 نقطة
-
بدءاً من نسخة تنسرفلو Tensorflow2.0 أصبح التنفيذ الافتراضي في تنسرفلو "Eager Execution" وهو مصطلح يشير إلى عملية تقييم العمليات على الفور، دون الانتظار لتشكيل ال Graph. أي يمكنك معرفة قيمة أي متغير أو ناتج أي عملية على الفور أما في النسخ السابقة لهذه النسخة كان التنفيذ الافتراضي للعمليات في تنسرفلو هو "Graph Execution" أي أن العمليات لايتم تقييمها حتى يتم إنشاء الجلسة بواسطة: tf.Session().run() أي لانكون قادرين على معرفة قيم المتغيرات حتى يتم تنفيذ ال Graph من أول عقدة فيه لآخر عقدة من خلال هذا الكود. الآن أنت لديك نسخة 2.4 وتحاول استخدام Session التي لم يعد هناك حاجة لها فهي غير موجودة بعد الآن في تنسرفلو (بدءاً من 2.0). لذا لاداعي لاستخدام session ويمكنك عرض ناتج أي عملية مباشرةً كالتالي: import tensorflow as tf msg = tf.constant('Hello, TensorFlow!') tf.print(msg) # Hello, TensorFlow! أما إذا كنت تريد أن تستخدم Session واعتماد ال Graph Execution فيمكنك تعطيل Eager Execution من خلال السطر التالي: tf.compat.v1.disable_eager_execution() وبالتالي يصبح الكود: import tensorflow as tf tf.compat.v1.disable_eager_execution() hello = tf.constant('Hello, TensorFlow!') sess = tf.compat.v1.Session() print(sess.run(hello)) أو من خلال with: import tensorflow as tf with tf.compat.v1.Session() as sess: hello = tf.constant('hello world') print(sess.run(hello))1 نقطة
-
في حال كنت تستخدم tensorflow2.x: print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU'))) في tensorflow1: sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) أو بالشكل التالي حيث يعرض لك قائمة بالأجهزة المتاحة له: from tensorflow.python.client import device_lib print(device_lib.list_local_devices()) """ [name: "/cpu:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 4402277519343584096, name: "/gpu:0" device_type: "GPU" memory_limit: 6772842168 locality { bus_id: 1 } incarnation: 7471795903849088328 physical_device_desc: "device: 0, name: GeForce GTX 1070, pci bus id: 0000:05:00.0" ] """ أو: tf.test.is_gpu_available( cuda_only=False, min_cuda_compute_capability=None) حيث يرد True إذا كانت تنسرفلو تستخدم ال GPU.1 نقطة
-
يمكنك معرفة ماحدث لل object عند وصوله لل template كالتالي: @register.filter def pdb(element): import pdb; pdb.set_trace() return element الآن ، داخل القالب يمكنك القيام ب {{template_var | pdb}} والدخول إلى جلسة pdb حيث يمكنك فحص عنصرك. كما يمكنك استخدام PyCharm فهو يجعلك قادراً بصرياً على المرور عبر الكود الخاص بك ومعرفة ما يحدث (يشير لك لأماكن وجود أخطاء في الكود أثناء كتابته). أيضاً هناك epdb وهو إضافة أو توسيع ل Python Debugge : import epdb; epdb.serve() بمجرد تنفيذ هذا الكود، أفتح "Python interpreter" وأتصل ب serving instance. يمكنك تحليل جميع القيم والخطوات من خلال الكود باستخدام أوامر pdb مثل n ، s ، إلخ. import epdb; epdb.connect() (Epdb) request <WSGIRequest path:/foo, GET:<QueryDict: {}>, POST:<QuestDict: {}>, ... > (Epdb) request.session.session_key 'i31kq7lljj3up5v7hbw9cff0rga2vlq5' (Epdb) list 85 raise some_error.CustomError() 86 87 # Example login view 88 def login(request, username, password): 89 import epdb; epdb.serve() 90 -> return my_login_method(username, password) 91 92 # Example view to show session key 93 def get_session_key(request): 94 return request.session.session_key 951 نقطة
-
إليك كل الطرق، من خلال التيرمينال Terminal Commands أو من خلال واجهة أوامر جانغو Django Shell :Commands ################## Django Shell Commands ############# import pkg_resources pkg_resources.get_distribution('django').version # أو import django django.get_version() أو django.VERSION # أو from django.utils import version version.get_version() أو version.get_complete_version() ############### Terminal Commands ###################3 ./manage.py --version أو python manage.py --version # أو django-admin --version أو django-admin.py version # أو python -m django --version # أو pip freeze | grep Django أو pip3 show django pip show django # أو python -c "import django; print(django.get_version())" # أو python manage.py runserver --version1 نقطة
-
يمكنك القيام بذلك بعدة طرق، أولها استخدام الوسيط device_count عند إنشاء الجلسة كالتالي: sess = tf.Session( config=tf.ConfigProto( device_count = {'GPU': 0}) # عنه GPU إخفاء ال ) أو من خلال ضبط قيمة متغير البيئة "environment variable" على 1- أو " ": import os os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ['CUDA_VISIBLE_DEVICES'] = '-1' أو: import tensorflow as tf tf.config.set_visible_devices([], 'GPU') حيث أن كل هذه الطرق تعتمد على إخفاء ال GPU عن المترجم وبالتالي يذهب إلى ال CPU. أو من خلال tf.device مع جملة with حيث نضع كل الكود الذي نريد تنفيذه على ال cpu ضمن البلوك نفسه (أقصد الكتلة نفسها) أي: with tf.device('/CPU:0'): # ضع الكود هنا ضمن الكتلة1 نقطة
-
بالإضافة للطرق المقترحة في التعليق السابق يمكنك أيضاً من خلال pip ( إذا كان لديك pip ) بواسطة الأمر التالي pip freeze سيظهر لك قائمة لإصدارات الحزم المستخدمة ولكن إذا أردت Django فقط يمكنك استخدام الأمر pip freeze | grep Django1 نقطة
-
هناك العديد من الطرق للقيام بذلك ، ولكن الأكثر وضوحا هو ببساطة استخدام Python debugger فقط أضف السطر التالي إلى دالة view import pdb; pdb.set_trace() #or breakpoint() #from Python3.7 وأيضاً إذا كنت تستخدم IDE مثل PyCharm سيوفر لك سهولة في تتبع الأخطاء في الكود1 نقطة
-
Django 1.5 يدعم Python 2.6.5 والإصدارات الأحدث. إذا كنت تعمل بنظام Linux وتريد التحقق من إصدار Python الذي تستخدمه ، فقم بتشغيله python -V من سطر الأوامر. إذا كنت تريد التحقق من إصدار Django ، فافتح وحدة تحكم Python واكتب >>> import django >>> django.VERSION (2, 0, 0, 'final', 0) أو يمكنك ببساطة استخدم أمر قابل للتنفيذ من خلال سطر الأوامر كالآتي $ python -c "import django; print(django.get_version())" 2.0 اما إذا قمت بتثبيت التطبيق فيمكنك العثور على الإصدرا بهذا الأمر $ django-admin --version 2.0 أو يمكنك الذهاب الى مسار مشروع Django وتنفيذ الآتي ./manage.py --version1 نقطة
-
يمكنك أيضاً استخدام الدالة df.agg: dataframe = pd.DataFrame({'col_1' : ['a','b','c','d'], 'col_2' : ['name_a','name_b','name_c','name_d'], 'col_3' : ['age_a','age_b','age_c','age_d']}) dataframe['features'] = dataframe.agg( lambda s: r' <{}> '.join(s).format(*range(s.size)), axis=1) """ col_1 col_2 col_3 features 0 a name_a age_a a <0> name_a <1> age_a 1 b name_b age_b b <0> name_b <1> age_b 2 c name_c age_c c <0> name_c <1> age_c 3 d name_d age_d d <0> name_d <1> age_d """ أو بشكل يدوي معقد قليلاً: dataframe = pd.DataFrame({'col_1' : ['a','b','c','d'], 'col_2' : ['name_a','name_b','name_c','name_d'], 'col_3' : ['age_a','age_b','age_c','age_d']}) dataframe['features'] = [" ".join(F"{entry}<{num}>" if ent[-1] != entry else entry for num, entry in enumerate(ent) ) for ent in dataframe.to_numpy()]1 نقطة
-
يمكنك إلغاؤها كلها من خلال os.environ: import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' بحيث: نقوم بإسناد القيمة 3 لمنع طباعة المعلومات INFO والتنبيهات WARNING و رسائل الأخطاء ERROR messages أما 2 لمنع ال INFO و ال WARNING messages بينما 1 لمنع المعلومات INFO messages بينما 0 ستؤدي لتسجيل كل الرسائل.1 نقطة
-
كلاهما يستخدم لتخزين حالة المتغيرات ضمن ال graph في تنسرفلو (نستخدمهما لتعريف متغيرات ضمن جلسة تنسرفلو) لكن الفرق بينهما هو أن tf.Variable يحتاج إلى تهيئته بقيم أولية بشكل فوري أي بلحظة تعريفه مثلاً: w = tf.Variable([[1.], [2.]]) هنا عرفنا متغير ضمن ال graph نسميها عقدة ضمن الغراف (البيان) واسمينها w، لاحظ أننا قمنا بإعطائه قيم مباشرةً. أما بالنسبة ل tf.placeholder فنعَرف أيضاً من خلاله متغيرات لكن هنا لانحتاج لتهيئة المتغيرات بقيم أولية كما في tf.Variable وهذا مهم جداً جداً. لماذا؟ عند بناء نماذج التعلم (الشبكات العصبية مثلاً) فنحن لدينا نوعين من المتغيرات: بيانات الدخل X التي نجلبها من الDataset + الأوزان التدريبية أي w و b. وكما نعلم فإن الأوزان نحتاج لتهيئتها بقيم ابتدائية (عادةً قيم عشوائية) وهذه المتغيرات نسميها trainable variables أي متغيرات قابلة للتدريب (للتحديث) ونستخدم معها tf.Variable . أما بيانات الدخل X و Y فلايتم تهيئتها بقيم ابتدائية حيث أننا نضطر لتعريفها داخل النموذج (بدون تعيين قيم لها) وننتظر أن يتم إعطاءها قيم عندما يتم تغذية الشبكة بال Dataset. ولهذا السبب نحتاج لتعريفهم ك placeholder. مثال: ##################### Variable ################## weights = tf.Variable(tf.truncated_normal([IMAGE_PIXELS, hidden1_units], stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))), name='weights') biases = tf.Variable(tf.zeros([hidden1_units]), name='biases') ##################### placeholder ############### images_placeholder = tf.placeholder(tf.float32, shape=(batch_size, IMAGE_PIXELS)) labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size)) #################### تغذية الشبكة بالبيانات #### for step in xrange(FLAGS.max_steps): feed_dict = { images_placeholder: images_feed, labels_placeholder: labels_feed, } _, loss_value = sess.run([train_op, loss], feed_dict=feed_dict)1 نقطة
-
يمكنك فعل ذلك من خلال استخدام itertools كالتالي from itertools import chain dataframe['features'] = dataframe.apply(lambda x: ''.join([*chain.from_iterable((v, f' <{i}> ') for i, v in enumerate(x))][:-1]), axis=1) print(dataframe) سوف يكون الناتج كالتالي col_1 col_2 col_3 features 0 a name_a job_a a <0> name_a <1> job_a 1 b name_b job_b b <0> name_b <1> job_b 2 c name_c job_c c <0> name_c <1> job_c 3 d name_d job_d d <0> name_d <1> job_d1 نقطة
-
يأتي مصطلح "slug" من المقالات والصحف وهو الاسم الغير رسمي الذي يُطلق على قصة أو مقالة أثناء عملية الإنتاج. أما في جانغو يتم استخدام حقل slug لتخزين وإنشاء عناوين URL صالحة لصفحات الويب التي تم إنشاؤها ديناميكياً. بشكل عام باستخدام البيانات التي تم الحصول عليها بالفعل. على سبيل المثال ، يستخدم slug عنوان المقالة لإنشاء عنوان URL. <title> damn cat </title> <content> Wonderful movie </content> <slug> Wonderful-movie </slug> يمكنك إنشاء slug من خلال SlugField: slug = models.SlugField(max_length=90) وينصح بإنشاء الرابط الثابت عن طريق تابع، بالنظر إلى العنوان أو جزء آخر من البيانات، بدلاً من تعيينه يدوياً. مثال: # الآن لنفرض لدينا النموذج التالي class art(models.Model): title = models.CharField(max_length=59) content = models.TextField(max_length=1900) slug = models.SlugField(max_length=50) #وباسم ذو معنى URL يمكنك الإشارة إلى هذا الكائن بعنوان # :بالشكل URL بحيث يكون عنوان Article.id على سبيل المثال استخدام www.slu.com/art/23 # أو www.slu.com/art/damn cat #20% لذا يجب استبدالها ب URL وبما أن المسافات غير مسموحة في عناوين www.example.com/art/damn%20cat #slugأما باستخدام # - يمكننا استبال الفراغات ب www.example.com/article/damn-cat كما يمكنك استخدام التابع slugify لاستخدام ال slug كعنوان: from django.template.defaultfilters import slugify class art(models.Model): title = models.CharField(max_length=90) def slug(self): return slugify(self.title) كما يمكنك استخدام الوسيط unique=True إذا أردت جعله فريداً: slug = models.SlugField(max_length=90, unique=True)1 نقطة
-
ال slug هو طريقة لانشاء url له معنى وصالح فى نفس الوقت, كمثال اذا كان لدينا صفحة html تعبر عن مقالة كالشكل التالى <title> The 46 Year Old Virgin </title> <content> A silly comedy movie </content> <slug> the-46-year-old-virgin </slug> وانشأنا لها django model بالشكل الاتى: class Article(models.Model): title = models.CharField(max_length=100) content = models.TextField(max_length=1000) slug = models.SlugField(max_length=40) ماهى افضل طريقة لانشاء url يشير لهذا الموديل؟ اولا من الممكن ان نصل له عن طريق الid فيصبح الurl كالشكل التالى www.example.com/article/23 او من الممكن ان نصل له عن طريق attribute الslug كما بالشكل التالى www.example.com/article/The 46 Year Old Virgin ولكن تلك الطريقة فيها مشكلة لان المسافات غير مسموح بها فى الurl فبالتالى يتغير شكل الurl ليصبح كالاتى: www.example.com/article/The%2046%20Year%20Old%20Virgin ومن الواضح اخى الفاضل ان كلا الطريقتين اعلى ليسو جيدين , فاول طريقة ستجد ان الurl لا يعطى وصفا عما يتضمنه فانت لا تستطيع ان تعرف عما تتكلم المقالة بمجرد معرفة الid اللذى هو 23 والطريقة الثانية ليست جيدة ايضا لانها صعبة القراءة وتؤذى العين,وهنا يأتى دور الslug فنجعل عنوان الurl مثل حقل الslug فيكون كالتالى www.example.com/article/the-46-year-old-virgin1 نقطة
-
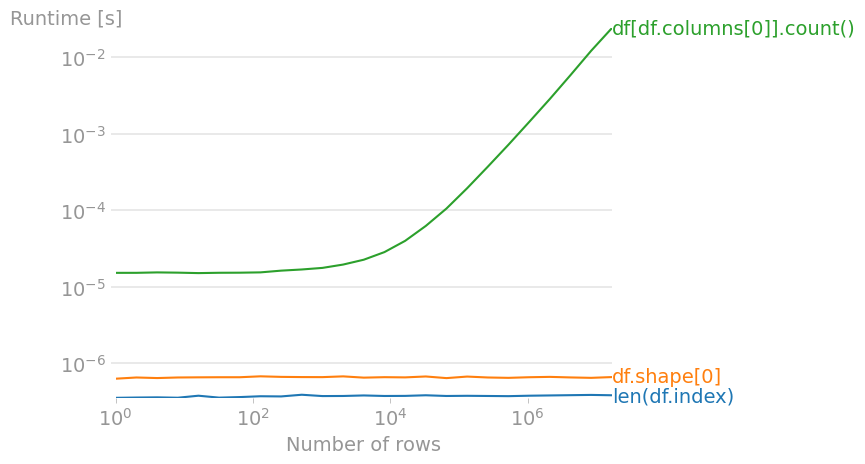
هناك ثلاث طرق داخل pandas يمكن بها إيجاد عدد الصفوف بداخل dataframe وهم: len(df.index) df.shape[0] df[df.columns[0]].count() وعلى الرغم من أن الثلاث طرق يمكنهم تنفيذ المهمة، الا انهم ليسوا بنفس الكفاءه، أنظر الرسم البياني التالي: الشكل يوضح الوقت الذي تأخذه كل طريقة في عد الصفوف، نجد أن df[df.columns[0]].count() هي أسوأ طريقة لانه كلما زاد حجم ال dataframe زاد الوقت الذي تأخذه الدالة للعد بشكل كبير. بينما تعد أفضل طريقة هي len(df.index) وذلك لانها تأخذ أقل وقت أثناء العمل.
 1 نقطة
1 نقطة -
الحشو padding هو الآلية التي ستتبعها الخوارزمية أثناء عملية ال convolution (الالتفاف) على المصفوفة للتعامل مع حدود المصفوفة. ففي حالة قمت بضبطها على Valid فهذا يعني أن الخوارزمية قد تتجاهل حدود المصفوفة، مثلاً إذا كان حجم الخطوة strides هو2 وأبعاد المصفوفة 3*2 سيتم تجاهل العمود الثالث من المصفوفة ولن يدخل في الخوارزمية (فقدان معلومات). لأن حجم الخطوة هو بكسلين وبالتالي لن تستطيع معالجة هذا العمود لوحده لذا تتجاهله ، وطبعاً تكون أبعاد المصفوفة الناتجة أقل دوماً. أما في حالة وضعته على SAME فستقوم الخوارزمية بإضافة عمود جديد إلى اليمين وستضبط قيمه بأصفار (حشو padding) وبالتالي ستصبح المصفوفة 4*2 وبالتالي سيتم أخذ كل الأعمدة بعين الاعتبار وفي هذه الحالة ستكون أبعاد المصفوفة الناتجة هي نفس أبعاد المصفوفة الأصلية (عندما يكون حجم الخطوة 1 ينتج نفس الأبعاد) أو أقل. المعادلة التالية تحدد الأبعاد الناتجة في حالة استخدام VALID: output_shape = math.floor((input_shape - ksize) / strides) + 1 (when input_shape >= ksize) أما في حالة استخدمت same فسوف يقوم بعملية الحشو. والمصفوفة الناتجة في هذه الحالة: output_shape = math.floor((input_shape - 1) / strides) + 1 إليك بعض الأمثلة: import tensorflow as tf # تعريف تنسر matrix = tf.constant([ [0, 0, 1, 7], [0, 2, 0, 0], [5, 2, 0, 0], [0, 0, 9, 8], ]) #max_pool ضبط حجمها بالشكل الذي تتوقعه دالة reshaped = tf.reshape(matrix, (1, 4, 4, 1)) ########################## SAME ######################### #على المصفوفة max_pool تطبيق a1=tf.nn.max_pool(reshaped, ksize=2, strides=2, padding="SAME") a1 """ <tf.Tensor: shape=(1, 2, 2, 1), dtype=int32, numpy= array([[[[2], [7]], [[5], [9]]]], dtype=int32)> """ a1.shape # TensorShape([1, 2, 2, 1]) ########################## VAILD ######################### matrix = tf.constant([ [0, 0, 1, 7], [0, 2, 0, 0], [5, 2, 0, 0], [0, 0, 9, 8], ]) matrix = tf.constant([ [0, 0, 1, 7], [0, 2, 0, 0], [5, 2, 0, 0], [0, 0, 9, 8], ]) reshaped = tf.reshape(matrix, (1, 4, 4, 1)) #على المصفوفة max_pool تطبيق a2=tf.nn.max_pool(reshaped, ksize=2, strides=2, padding="VALID") a2 """ <tf.Tensor: shape=(1, 2, 2, 1), dtype=int32, numpy= array([[[[2], [7]], [[5], [9]]]], dtype=int32)> """ a2.shape # TensorShape([1, 2, 2, 1]) مثال آخر، هنا ستبقى المصفوفة بنفس الأبعاد عند استخدام SAME: ########################## SAME ######################### #على المصفوفة max_pool تطبيق a1=tf.nn.max_pool(reshaped, ksize=2, strides=1, padding="SAME") a1 """ <tf.Tensor: shape=(1, 4, 4, 1), dtype=int32, numpy= array([[[[2], [2], [7], [7]], [[5], [2], [0], [0]], [[5], [9], [9], [8]], [[0], [9], [9], [8]]]], dtype=int32)> """ import tensorflow as tf # تعريف تنسر matrix = tf.constant([ [ 0, 1], [ 2, 0] ]) #max_pool ضبط حجمها بالشكل الذي تتوقعه دالة reshaped = tf.reshape(matrix, (1, 2, 2, 1)) ########################## SAME ######################### import tensorflow as tf # تعريف تنسر matrix = tf.constant([ [ 0, 1], [ 2, 0] ]) #max_pool ضبط حجمها بالشكل الذي تتوقعه دالة reshaped = tf.reshape(matrix, (1, 2, 2, 1)) #على المصفوفة max_pool تطبيق a1=tf.nn.max_pool(reshaped, ksize=2, strides=1, padding="SAME") a1 """ <tf.Tensor: shape=(1, 2, 2, 1), dtype=int32, numpy= array([[[[2], [1]], [[2], [0]]]], dtype=int32)> """1 نقطة