لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 08/19/21 في كل الموقع
-
لدي صورة RGB. أريد تحويله إلى مصفوفة Numpy. لذلك قمت بكتابة الكود التالي: img = cv.LoadImage("image.tiff") arr = np.asarray(img) لكن هذا الكود يقوم بصنع مصفوفة بلا شكل shape. وإعتقد أنه كائن من نوع iplimage. كيف يمكنني تحويل هذه الصورة إلى مصفوفة Numpy لكي أقوم بإجراء بعض العمليات عليها؟2 نقاط
-
اريد طريقة اضافة هذة الخاصية بجانب الصفحات في قوالب بلوجر . اريد الرد سريعاً
 1 نقطة
1 نقطة -
لقد وصلت في المرحلة الاخيرة من المشروع و هي ارسال ايملات عن طريق laravel jobs و كما نعلم انها لا توجد في الدورات قمت بالبحث و وجدت بعص الامور التي ساعدتني بعض الشئ ولكن اريد ان اتأكد من الاكواد و اريد طريقة لاتأكد من ارسال البريد الالكتروني غير mailtrap لان احتاج للاشتراك به عموما هذه هي الاكواد كود في المتحكم public function sendMails() { if (Auth::user()->role == 1) { $emails = Email::chunk(25, function ($email) { dispatch(new CompanyMail($email)); }); return 'emails will be sent in the background'; } else { abort(403); } } كود ال route Route::get('/send-mails', [EmailController::class, 'sendMails']); كود ال job <?php namespace App\Jobs; use Illuminate\Bus\Queueable; use Illuminate\Contracts\Queue\ShouldBeUnique; use Illuminate\Contracts\Queue\ShouldQueue; use Illuminate\Foundation\Bus\Dispatchable; use Illuminate\Queue\InteractsWithQueue; use Illuminate\Queue\SerializesModels; use Illuminate\Support\Facades\Mail; class CompanyMail implements ShouldQueue { use Dispatchable, InteractsWithQueue, Queueable, SerializesModels; /** * Create a new job instance. * * @return void */ public $email; public function __construct($email) { $this->email = $email; } /** * Execute the job. * * @return void */ public function handle() { foreach ($this->email as $email) { Mail::to($email->email)->send(new \App\Mail\CompanyMail()); } } } كود ال mail <?php namespace App\Mail; use Illuminate\Bus\Queueable; use Illuminate\Contracts\Queue\ShouldQueue; use Illuminate\Mail\Mailable; use Illuminate\Queue\SerializesModels; class CompanyMail extends Mailable { use Queueable, SerializesModels; /** * Create a new message instance. * * @return void */ public function __construct() { // } /** * Build the message. * * @return $this */ public function build() { return $this->subject('mail form Mohammad Kiblawi')->view('email.CompanyMail'); } } كود ملفات التهجير <?php use Illuminate\Database\Migrations\Migration; use Illuminate\Database\Schema\Blueprint; use Illuminate\Support\Facades\Schema; class CreateJobsTable extends Migration { /** * Run the migrations. * * @return void */ public function up() { Schema::create('jobs', function (Blueprint $table) { $table->bigIncrements('id'); $table->string('queue')->index(); $table->longText('payload'); $table->unsignedTinyInteger('attempts'); $table->unsignedInteger('reserved_at')->nullable(); $table->unsignedInteger('available_at'); $table->unsignedInteger('created_at'); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('jobs'); } }1 نقطة
-
طالما انك في مرحلة التطوير محليا يفضل أن لا تعتمد على خدمات خارجية فهي ستعيق عملك وتزيد من مدة التطوير يمكنك تخديم مشروعك باستخدام مخدم Laragon (أعتمده شخصيًا) يمكن تحميله من هنا يوجد دليل هجرة من WAMP و XAMPP يحتوي على ميزة Mail Catcher سيلتقط أي بريد الكتروني صادر من مشروعك محليا وينبهك ويقوم بحفظ النسخة المرسلة كما هي ضمن المجلد "laragon\bin\sendmail\output" لا يبدو هناك مشاكل في الشيفرة، لكن بعد القيام بتنصيب المخدم والتجربة تابع شرح المشكلة (إن حدث أي مشاكل)1 نقطة
-
أثناء قرائتي لأمثلة لمكتبة Numpy وجود الكود التالي: >>> a = np.zeros((9, 3)) # A transpose make the array non-contiguous >>> b = a.T # Taking a view makes it possible to modify the shape without modifying the # initial object. >>> c = b.view() >>> c.shape = (27) AttributeError: Incompatible shape for in-place modification. Use `.reshape()` to make a copy with the desired shape. لكني لم أفهم ما الذي تعنيه مصفوفة non-contiguous؟ وما الفرق بينها وبين المصفوفات من نوع contiguous؟ ولماذا لا يمكن إستخدام الخاصية shape مع مصفوفات non-contiguous ويظهر الخطأ السابق؟1 نقطة
-
انا اقوم بعمل كلون لريبو .. وقمت بتنصيب النود موديولز بنجاح ولكن عن عمل pod install تظهر هده المشكلة فى الكوونسول Ignoring unf_ext-0.0.7.6 because its extensions are not built. Try: gem pristine unf_ext --version 0.0.7.6 Auto-linking React Native modules for target `maltevinder`: RNCAsyncStorage, RNCMaskedView, RNDateTimePicker, RNFastImage, RNGestureHandler, RNReanimated, RNScreens, RNVectorIcons, lottie-ios, lottie-react-native, react-native-cookies, react-native-document-picker, react-native-restart, and react-native-safe-area-context Analyzing dependencies Fetching podspec for `DoubleConversion` from `../node_modules/react-native/third-party-podspecs/DoubleConversion.podspec` Fetching podspec for `Folly` from `../node_modules/react-native/third-party-podspecs/Folly.podspec` Fetching podspec for `glog` from `../node_modules/react-native/third-party-podspecs/glog.podspec` [!] No podspec found for `react-native-image-picker` in `../node_modules/react-native-image-picker` هدا هو ملف ال podfile الخاص بى require_relative '../node_modules/react-native/scripts/react_native_pods' require_relative '../node_modules/@react-native-community/cli-platform-ios/native_modules' platform :ios, '10.0' target 'maltevinder' do config = use_native_modules! use_react_native!(:path => config["reactNativePath"]) pod 'react-native-image-picker', :path => '../node_modules/react-native-image-picker' target 'maltevinderTests' do inherit! :complete # Pods for testing end # Enables Flipper. # # Note that if you have use_frameworks! enabled, Flipper will not work and # you should disable these next few lines. use_flipper! post_install do |installer| flipper_post_install(installer) end end target 'maltevinder-tvOS' do # Pods for maltevinder-tvOS target 'maltevinder-tvOSTests' do inherit! :search_paths # Pods for testing end end1 نقطة
-
انا قمت بحل المشكلة عن طريق تسطيب المكتبة لانها لم تكن فى package.json واشتغل المشروع بنجاح الحمد لله1 نقطة
-
حاول إضافة ios/ في نهاية مسار المكتبة.. node_modules/react-native-image-picker/ios1 نقطة
-
لا طلعت المشكلة من github copilot مو متوافق مع اعدادات vs code1 نقطة
-
لقد تبين الخطأ معي وشكرا جزيلا1 نقطة
-
سلام عليكم انا وجدت فى موقع الكترونى واثتاء تصفحى فى كود html كود يقوم باستداعاء ملف java script اسمه jnit وهذا هو الكود : <!-- Init JavaScript --> <script src="js/js-init.js"></script> فاريد ان اعرف ما هو اختصار init وماذا تعنى؟ وما وظيفة الملف init.js ? وهل محتويات الملف عبارة عن jquery? وهل الملف يتم قرأته قبل او بعد فتح الموقع على المتصفح ؟ وهل حقا كان الملف يستخدم مؤخرا ك command line فى الخمسة السنين الاخيرة واصبح غير ضرورى حيث صارو يعتمدو اكثر على package.json هذا هو رابط الملف : https://syberweb.sybertechnology.com/resources/js/init.js بانتظار اجابة كاملة وشكرا1 نقطة
-
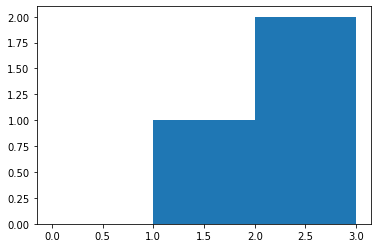
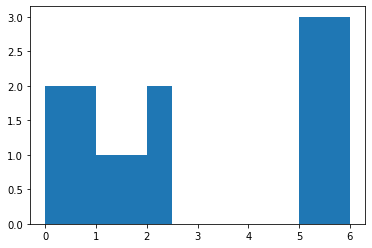
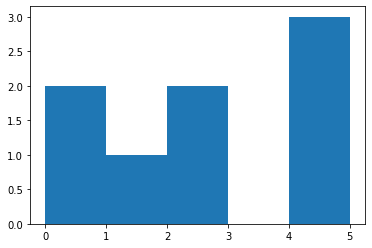
bin هو مجال يمثل عرض bar (شريط) واحد من الهستوغرام على طول المحور الأفقي X. كما يمكن أن نسميه بالفاصل الزمني. يقوم هذا التابع بحساب عدد مرات ظهور عناصر من مصفوفة الدخل ضمن مجال معين "bar"، ستفهم أكثر من خلال المثال التالي، لكن سأعطيك مثال من خلال دالة تكافئ هذه الدالة لأن هذه الدالة لاتقوم بالرسم: import matplotlib.pyplot as plt plt.hist([1, 2, 2], bins=[0, 1, 2, 3]) plt.show() # bins=[0, 1, 2, 3] تعني أنه سيتم تقسيم المحور الأفقي إلى أريع مجالات تبعاً لهذه القيم # [1, 2, 2] هي الثائمة التي نريد حساب هستوغرامها # وبالتالي هذا التابع يحسب لنا عدد مرات ظهور عناصر من بيانات الدخل ضمن مجال معين # لاحظ أنه ضمن المجال من 0 إلى 1 لايوجد أي عناصر في بيانات الدخل ولهذا لم يظهر لنا البار # ضمن المجال من 1 ل 2 يوجد قيمة وحيدة وهي 1 # لاحظ أن 2 لاتحتسب ضمن المجال وإنما الأصغر تماماً من 2 # الآن ضمن المجال من 2 ل 3 يوجد قيمتين في بيانات الدخل وهما 2 و 2 لذا كانت قمة البار تقابل القيمة 2 على المحور الأفقي مثال آخر: plt.hist([0,0,1, 2, 2,5,5,5], bins=[0, 1, 2, 3,4,5]) plt.show() # لاحظ أنه ضمن المجال من 3 ل4 لاتوجد أي قيمة في بيانات الدخل لذا كان طول البار يساوي 0 ضمن هذا المجال # كما نلاحظ أن طول البار يساوي 3 ضمن المجال من 4 ل 5 لوجود 3 قيم في بيانات الدخل ضمن هذا المجال # لاحظ أيضاً أنه بالرغم من أن 5 ليست أصغر تماماً لكنها احتسبت ضمن المجال وهذه حالة خاصة لأنها آخر مجال لاحظ هنا عند إضافة مجال آخر ستحتسب القيمة 5 ضمن المجال الجديد: # هنا سنعبث بالمجالات plt.hist([0,0,1, 2, 2,5,5,5], bins=[0, 1, 2,2.5,5,6]) plt.show() # أو مجال من 0 ل1 والثاني من 1 ل2والثالث من 2 ل 2.5 ويوجد ضمنه قيمتين وهكذا دالة np.histogram تعمل بشكل مكافئ تماماً، لكنها لاتقوم بالرسم. # أمثلة np.histogram([1, 2, 1], bins=[0, 1, 2, 3]) #(array([0, 2, 1]), array([0, 1, 2, 3])) np.histogram(np.arange(4), bins=np.arange(5), density=True) #(array([0.25, 0.25, 0.25, 0.25]), array([0, 1, 2, 3, 4])) np.histogram([[1, 2, 1], [1, 0, 1]], bins=[0,1,2,3]) #(array([1, 4, 1]), array([0, 1, 2, 3])) ونستخدمها في الأمور الإحصائية أو في مهام معالجة الصور حيث أن حساب هستوغرام صورة يخبرنا بالعديد من المعلومات عن الصورة.
 1 نقطة
1 نقطة -
يجب إضافة ORDER BY DESC و تحديد كم صف يجلب عن طريق LIMIT 1 , ولاحظ ان رقم 1 هو عدد الصفوف الذي نود جلبها عند تنفيذ الأستعلام, يمكنك تجربة تنفيذ ذلك و أخباري بالنتيجة.1 نقطة
-
هناك استعلام يتم إنشاء حدث من خلال كل وقت معين في قاعدة البيانات و هذا الاستعلام هو CREATE EVENT و يمكنك إنشاء حدث كل وقت معين , كل ساعة أو كل دقيقة أو كل ثانية فيمكنك فعل التالي CREATE EVENT `eventName` ON SCHEDULE EVERY 12 HOUR ON COMPLETION NOT PRESERVE ENABLE DO UPDATE users SET tasks_pro = 0 فلاحظ أنه قمنا بإنشاء حدث يتكرر كل 12 ساعة و اسم هذا الحدث هو eventName , ويقوم بعمل reset لحل tasks_pro و يرجع قيمته 0 , ويمكنك تحويل الحدث إلى العمل بالدقائق فيمكنك تغيير كلمة Hour إلى MINUTE فيصبح الحدث CREATE EVENT `eventName` ON SCHEDULE EVERY 12 MINUTE ON COMPLETION NOT PRESERVE ENABLE DO UPDATE users SET tasks_pro = 01 نقطة
-
الطريقتين السابقتين تعتمدان على إنشاء مايسمى view لكن ماهو هذا ال view وكيف ينتج.. دعنا نفهم ذلك؟ ال view أو المشهد هو عرض جديد للمصفوفة مع نفس البيانات. أو بمعنى أوضح فكما يقول اسمها، إنها ببساطة طريقة أخرى لعرض بيانات المصفوفة. من الناحية الفنية ، هذا يعني أنه تتم مشاركة بيانات كلا الكائنين. هذا العرض الجديد للمصفوفة ينتج في حالتين الأولى عند قيامك بتطبيق مفهوم ال slicing (مثلاً عرض جزء من المصفوفة أو كاملها)، أو تغيير نمط البيانات (أو كليهما). وفيما يلي توضيح أكبر. وله الشكل التالي في بايثون: ndarray.view([dtype][, type]) # الوسيط الأول هو نمط البيانات الذي تريده # الوسيط الثاني نوع العرض الذي سيتم إرجاعه أمثلة، أولاُ سنعطي مثال لكيفية إنتاج مشهد للمصفوفة من خلال مفهوم التشريح أو slicing: # Slice views أخذ شرائح من المصفوفة أو أقسام محددة منها # المصفوفة الناتجة تكون عبارة عن مشهد من المصفوفة الأصلية بحيث تتم مشاركة البيانات import numpy as np arr = np.arange(8) arr # array([0, 1, 2, 3, 4, 5, 6, 7]) # الآن سنطبق مفهوم الشرائح ve = arr[1:2] ve # array([1]) # سنعدل قيمة في المصفوفة الأصلية لنرى فيما إذا كان حقاً قد تم تشارك البيانات arr[1] = 2 # لاحظ كيف تغيرت هي أيضاً ve # array([2]) # مثال آخر ve1 = arr[1::3] ve1 # array([1, 4, 10]) arr[7] = 10 ve1 #array([1, 4, 7]) الآن الطريقة الأخرى لإنتاج مشهد وهي تغيير نمط البيانات (حل مشكلتك): # Dtype views import numpy as np arr = np.arange(8, dtype='int32') arr # array([0, 1, 2, 3, 4, 5, 6, 7], dtype=int32) v = arr.view('float32') v """ array([0.e+00, 1.e-45, 3.e-45, 4.e-45, 6.e-45, 7.e-45, 8.e-45, 1.e-44], dtype=float32) """ # حسناً هنا صحيح أنهما تشاركا البيانات لكن حصل تشويه وهذ منطقي جداً لاختلاف حجم البايت بين النمطين (أنت تحاول تغيير النمط في نفس المكان) للقيم لذا يمكننا أن نعود بعد ذلك لفكرة التشريح # نقوم بإسناد قيم المصفوفة الأصلية ذات النمط الصحيح إلى المشهد ذو القيم الحقيقية v[:]=arr v[:] # array([0., 1., 2., 3., 4., 5., 6., 7.], dtype=float32) #وبالتالي هنا نكون حصلنا على مانريده # الآن لو نظرنا لقيم المصفوفة الأصلية arr """ array([ 0, 1065353216, 1073741824, 1077936128, 1082130432, 1084227584, 1086324736, 1088421888], dtype=int32) """ # ولو قمنا بتعديل أي قيمة فيها arr[2]=0 v # array([0., 1., 0., 3., 4., 5., 6., 7.], dtype=float32) # نلاحظ أن التعديل أنتقل إلى المصفوفة هذا يعني أنهما يتشاركان البيانات ########################################################################### #false مع تحديد النسخ على Astype بالنسبة لاستخدام #view فلا أظنها ترجع # كما أنني لم ارى ذلك في التوثيق # انظر للمثال التالي import numpy as np arr = np.arange(8, dtype='int32') arr # array([0, 1, 2, 3, 4, 5, 6, 7], dtype=int32) vv = arr.astype(np.float32, copy=False) vv # array([0., 1., 2., 3., 4., 5., 6., 7.], dtype=float32) arr[0]=5 arr # array([5, 1, 2, 3, 4, 5, 6, 7], dtype=int32) vv # array([0., 1., 2., 3., 4., 5., 6., 7.], dtype=float32) # لاحظ أنه لم يحدث أي تغيير لذا لاأظنها حلاً لمشكلتك1 نقطة
-
يمكنك استخدام astype مع المعامل copy بالقيمة false a = a.astype(numpy.float32, copy=False) لكن لاحظ أن استخدام المعامل copy بالقيمة false أنه دائماً يقوم بعمل view وليس copy حيث أن هذه الدالة تقوم بتفادي النسخ إذا كانت تقدر على ذلك فهناك حالات لا تستطيع تنفيذ ذلك1 نقطة
-
يمكنك إنشاء view بنوع مختلف ثم نسخه كالتالي import numpy as np x = np.arange(10, dtype='int32') y = x.view('float32') y[:] = x print(y) سوف تحصل على الآتي array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.], dtype=float32) لإظهار أن التحويل كان في مكانه ، لاحظ أن النسخ من x إلى y تم تغيير x: print(x) سوف يكون الناتج كالآتي array([0, 1065353216, 1073741824, 1077936128, 1082130432, 1084227584, 1086324736, 1088421888, 1090519040, 1091567616]) اذا تم التحويل في نفس المكان1 نقطة
-
يمكنك استخدام np.isnan كما في التعليق السابق مع استخدام sum أو min ولكن أيضاً يمكنك استخدام Dot numpy.isnan(numpy.dot(a, a)) كما يمكنك استخدام any numpy.any(numpy.isnan(a)) يعتبر استخدام dot الأسرع من بين الدوال السابقة1 نقطة
-
عليك في هذه الحالة استخدام المؤثرات إما في css transform أو عن طريق جيكويري نفسها لاحظ الرقم 3000 اي 3 ثواني، يمكنك زيادتها. جيكويري: التأثيرات والحركات في jQuery التابع animate التابع fadeToggle1 نقطة
-
من خلال np.isnan يمكنك معرفة ذلك، كل شيئ موضح في الكود التالي: import numpy as np a=np.array([[ 1. , 2.],[ 3. ,np.nan]]) a """ array([[ 1., 2.], [ 3., nan]]) """ # isnan #nan في مكان تواجد قيمة true هذا التابع يرد مصفوفة بوليانية بحيث تضع np.isnan(a) """ array([[False, False], [False, True]]) """ #وبالتالي nan أصغر قيمة هي دوماً np.min(a) #nan ترد np.isnan(np.min(a)) # True #لجمع عناصر مصفوفة تحوي قيم غير معرفة سيعطي نتيجة غير معرفة sum استخدام np.sum(a) # nan # وبالتالي np.isnan(np.sum(a)) # True ومن ناحية الأداء فاستخدام sum أفضل: a = np.random.rand(100000) %timeit np.isnan(np.min(a)) """ 10000 loops, best of 3: 153 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.9 us per loop """ # سأضع قيمة نان لإحدى الخلايا a[2000] = np.nan %timeit np.isnan(np.min(a)) """ 1000 loops, best of 3: 239 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.8 us per loop """ a[0] = np.nan %timeit np.isnan(np.min(a)) """ 1000 loops, best of 3: 326 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.9 us per loop """ نلاحظ أن min يكون أبطأ في وجود NaN أما في غيابها أسرع. أيضا يصبح أبطأ مع اقتراب NaN من بداية المصفوفة. من ناحية أخرى ، sum تبدو ثابتة بغض النظر عما إذا كانت هناك NaNs أو لا.1 نقطة
-
يمكن استخدام الدالة numpy.multiply كالتلي: import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) np.multiply(a,b) """ array([[ 5, 12], [21, 32]]) """ كما ويمكنك استخدام المعامل *: import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) a*b """ array([[ 5, 12], [21, 32]]) """1 نقطة
-
حسناً أنت لديك قائمة من المصفوفات، لذا للقيام بذلك هناك عدة طرق، أولها استخدام الدالة stack حيث تقوم هذه الدالة بتكديس المصفوفات على المحور المحدد لها (طبعاً يجب أن تكون المصفوفات متجانسة في الأبعاد بالنسبة للمحور المحدد لكي يتم التكديس): import numpy li = [numpy.array([ 3, 5]),numpy.array([ 3, 5])] # [array([3, 5]), array([3, 5])] numpy.stack( li, axis=0 ) # التكديس على المحور العمودي """ array([[3, 5], [3, 5]]) """ numpy.stack( li, axis=1 ) ألأفقي """ array([[3, 3], [5, 5]]) """ أما بالنسبة للدالة concatenate فلايمكنك استخدامها في حالتك مباشرةً، حيث أن هذه الدالة تتطلب أن تكون المصفوفات متجانسة الأبعاد أي يجب أن تكون كل المصفوفات ثنائية البعد حتى تعمل، في الرابط التالي كل شيئ تحتاجه لمعرفة كيفية عملها: أما إذا أردت تطبيقها على مثالك فلن ينجح ذلك لأن np.array([1, 2, 3]) تمثل شعاع أي ببعد واحد أما np.array([[4, 5, 6],[7, 8, 9]]) تمثل مصفوفة ثنائية وبالتالي لايمكن استخدام هذه الدالة لربطهما بالشكل الذي تريده. وسيعطي خطأ انظر: import numpy as np lst = [np.array([1, 2, 3]), np.array([[4, 5, 6],[7, 8, 9]])] np.concatenate(lst, axis=0 ) """ ValueError: all the input arrays must have same number of dimensions... لذا يجب عليك توسيع أبعاد المصفوفة الأولى قبل أن تستخدمها ولكن هذا سيكون مكلف، لذا فإن أفضل حل هو استخدام Stack. أو vstack : import numpy as np lst = [np.array([1, 2, 3]), np.array([[4, 5, 6],[7, 8, 9]])] np.vstack( lst ) """ array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) """ كما يمكنك استخدام row_stack: import numpy as np lst = [np.array([1, 2, 3]), np.array([[4, 5, 6],[7, 8, 9]])] np.row_stack( lst ) """ array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) """1 نقطة
-
لرفع المشروع على Github يلزم تحقيق عدة خطوات، ولكن بالمجمل هي شيئ ليس صعب أبداً.. إنشاء حساب على GitHub من هنا: github.com تثبيت الطرفية (البرمجية) git وهي source version control تسمح بإرسال البيانات و التحكم بالمشروع البرمجي وتثبيت التعديلات المرحلية وتبادل التحديثات بين المطورين و مستودع المشروع، يمكن تحميلها و تنصيبها: git في موقع github عليك القيام بإنشاء مستودع repository بإسم المشروع (مستودع خاص لكل مشروع) ثم في مجلد المشروع نقوم بتئيهة المستودع المحلي بتنفيذ عدة أوامر باستخدام cmd مثل تهيئة init والربط عن طريق url الخاص بالمستودع ثم دفع التحديثات ببساطة1 نقطة
-
نعم هناك العديد من الدوال التي تمكنك من تنفيذ المطلوب مثل استخدام concatenate a = np.array([[1, 2], [3, 4]]) b = np.array([[5, 6]]) np.concatenate((a, b), axis=0) array([[1, 2], [3, 4], [5, 6]]) np.concatenate((a, b.T), axis=1) array([[1, 2, 5], [3, 4, 6]]) np.concatenate((a, b), axis=None) array([1, 2, 3, 4, 5, 6]) لاحظ استخدام المعامل axis كما يمكنك استخدام stack a = np.array([1, 2, 3]) b = np.array([4, 5, 6]) np.stack((a, b)) array([[1, 2, 3], [4, 5, 6]]) ويمكنك أيضاً استخدام الدالة array كالتالي numpy.array( LIST )1 نقطة
-
المعامل @ يقوم باستدعاء الدالة ()matmul و ليس ()dot. >>> a = np.random.rand(2,3,3) >>> b = np.random.rand(2,3,3) >>> np.matmul(a, b).shape (2, 3, 3) >>> np.dot(a, b).shape (2, 3, 3) matmul تختلف عن dot في أمرين: الضرب في scalar غير مسموح به. يتم عمل broadcasting للمصفوفات معًا كما لو كانت المصفوفات عناصر. بالنسبة للجزء الثاني من السؤال, لا يمكنك الحصول على هذه النتيجة باستعمال ()dot. يجب استعمال اما ()matmul او @.1 نقطة
-
وعليكم السلام @نصرالدين صالح عطيفة بالتأكيد يمكنك لكن يعتمد على نوع قواعد البيانات المبني عليها الموقع مثلاً إن كان SQL يمكنكم ذلك وهذا مثال بسيط لكيفية عمل ذلك CREATE PROCEDURE SelectAllProducts AS SELECT * FROM Products GO; ثم نقوم بتنفيذ الprocedure (الإجراء) الذي قمنا بعمله اعلاه هكذا EXEC SelectAllProducts;1 نقطة
-
مرحبا عبد الله، انا إسماعيل متخرج من الأكادمية من دورة تطوير تطبيقات الويب بلغة php، الدورة مشروحة بلغة عربية فصحى و مفهومة كما يمكنك تسريع سرعة الصوت او تخفيضه إن لم تستوعب جزء ما. تبدأ الدورة بشرح الأساسيات في لغة php و إطار العمل لارافيل، ثم يوجد عدة مسارات في كل مسار يتم بناء مشروع و ما أعجبني أنه في كل مسار يتم الشرح مِن قبل أستاذ آخر فإذا لم تفهم أو لم تستوعب طريقة الشرح في مسار ما ستفهم في آخر. بالإضافة الى انه يوجد مدربين ذو خبرة و يمكنك سؤالهم عن أي شيئ سواء اسفل الدرس او القسم الخاص بالأسئلة. بالنسبة لسؤالك الثاني قد تختلف المدة من شخص لآخر و حسب قدرة كل شخص في الفهم، لكن ما أنصحك به أن لا تركز على الوقت بل ركز على فهم الأساسيات جيدا و البحث عن الحلول للمشاكل التي تواجهك بنفسك قبل سؤال المدربين مباشرة. ارجو لك التوفيق.1 نقطة
-
يجب عليك تخزين numpy.ndarray بتنسيق JSON أو أي تركيب من ال nested-list: import json import numpy as np class NumpyEncoder(json.JSONEncoder): # مشفر جيسون خاص للنوع نمباي def default(self, obj): if isinstance(obj, np.integer): return int(obj) elif isinstance(obj, np.floating): return float(obj) elif isinstance(obj, np.ndarray): return obj.tolist() return json.JSONEncoder.default(self, obj) dumped = json.dumps(data, cls=NumpyEncoder) with open(path, 'w') as f: json.dump(dumped, f) حيث أن JSON هو "Javascript Object Notation" وبالتالي يمكنه فقط تمثيل التركيبات الأساسية من لغة جافا سكريبت: كائنات (مماثلة لل dict ببايثون) ، ومصفوفات (مماثلة لقوائم بيثون) ، وأرقام ، وبيانات بوليانية، وسلاسل ، و nulls. أما المصفوفات Numpy ليست أياً من هذه الأشياء، وبالتالي لا يمكن تحويلها إلى تسلسل "serialised" في JSON. لذلك نلجأ للطريقة السابقة1 نقطة
-
المشكلة في التعليمات البرمجية الخاصة بك هي أنك تريد تطبيق العملية على كل صف. الطريقة التي كتبتها بها تأخذ عمودي "bar" و "foo" بالكامل ، وتحولها إلى سلاسل وتعطيك سلسلة واحدة . لذا يمكنك حل المشكلة بالشكل التالي: from pandas import * import numpy df = DataFrame({'foo':['a','b','c'], 'bar':[1, 2, 3]}) df.apply(lambda x:'%s is %s' % (x['bar'],x['foo']),axis=1) ومن خلال نمباي يمكنك القيام بذلك باستخدام الكلاس numpy.chararray حيث نقوم بتحويل الأعمدة إلى تسلسل على هيئة chararrays، ثم نقوم بدمجهم معاً كالتالي: from pandas import * import numpy d = DataFrame({'foo':['a','b','c'], 'bar':[1, 2, 3]}) def join(d): a = numpy.char.array(d['bar'].values) b = numpy.char.array(d['foo'].values) bar=(a + b' is ' + b).astype(str) return DataFrame({'bar':bar}) join(d) """ bar 0 1 is a 1 2 is b 2 3 is c """1 نقطة
-
هذه تصنيفات تتبع لتصنيف فلين الكلاسيكي Flynn's Classical Taxonomy وهو تصنيف يميز بين الحواسيب متعددة المعالجات ويتم التصنيف على أساس بعدين مستقلين: الأول: مجرى التعليمات Instruction Stream والثاني Data Strem مجرى البيانات، حيق أن كل بعد من هذه الأبعاد يمكنه فقط أن يأخذ إحدى الحالتين : (مفرد) single أو Multiple (متعدد). إذاً لدينا بعدين وحالتين وبالتالي يكون لدينا 2*2=4 وبالتالي نحصل على الأصناف الأربعة التالية: 1.SISD: Single Instruction strem Single Data stream 2.SIMD: Single Instruction strem Multiple Data stream 3.MISD: Multiple Instruction strem Single Data stream 4.MIMD: Multiple Instruction strem Multiple Data stream 1.تعليمة مفردة،بيانات مفردة: تمثل حالة حاسب تسلسلي(وليس تفرعي أبداً).بحيث تعليمة مفردة تعني أن مجرى واحد للتعليمات يتم استخدامه من قبل المعالج في كل نبضة ساعة. وبيانات مفردة تعني أن مجرى واحد للبيانات يتم استخدامه كدخل للمعالج في كل نبضة ساعة. وهذا النمط يمثل الحواسيب الأقدم. 2. تعليمة مفردة، بيانات متعددة: عبارة عن حاسب تفرعي (التفرعية هنا من وجهة نظر البيانات)، وفي هذا النمط يظهر تعدد المعالجات. بحيث تعليمة مفردة تعني أن كل وحدات المعالجة تنفذ نفس التعليمة في كل نبضة ساعة. وبيانات متعددة تعني أن كل وحدة معالجة تستطيع التعامل مع عنصر بيانات مختلف (لها ممر خاص بها) مثال: في عملية جمع عناصر مصفوفة يمكن أن يتم تقسيم المصفوفة إلى عدة أقسام 4 أقسام مثلاً وكل معالج يأخذ قسم وينفذ عليه عملية الجمع+، ثم في النهاية تجمع نواتج الأقسام الأربعة. 3. تعليمات متعددة، بيانات مفردة: تمثل حالة حاسب تفرعي أيضاً (التفرعية هنا من وجهة نظر التعليمات )، وبصراحة لايوجد الكثير من الأمثلة لهذا النمط لكن ينطبق على الحالات التي يكون فيها من الممكن تطبيق أكثر من عملية (جمع وضرب مثلاً) بنفس الوقت على نفس البيانات لكن أشهر أمثلتها هو خوارزميات التشفير المتعددة التي تحاول فك شيفرة رسالة مشفرة مثلاً إذا كان لدينا رسالة نود تشفيرها ولدينا مرحلتين الأولى جعل الأحرف كبيرة والثانية إضافة 35 حسب جدول الآسكي، هنا نلاحظ أنه لدينا نوعين من التشفير (نوعين من التعليمات) والبيانات نفسها (الرسالة) إذاً MISD فهنا الرسالة تتألف من عدة أحرف --> كل حرف يمر أولاً على p1 ويشفر، ثم هو نفسه يمر على p2 ويشفر (لكن بعد فاصل زمني قصير لكي يتم التشفير بشكل صحيح). وطبعاً تعليمات متعددة تعني أن كل حاسب يعمل على البيانات بشكل مستقل عن الوحدات الأخرى عبر مجاري تعليمات مستقلة "Separate instruction streams". وبيانات مفردة تعني أن مجرى بيانات وحيد يستخدم لتغذية كل وحدات المعالجة. 4. تعليمات متعددة، بيانات متعددة: حاسب تفرعي (التفرعية هنا من جانب التعليمات والبيانات). بحيث كل معالج ينفذ تعليماته الخاصة على مجرى تعليمات مختلف. وكل معالج يعمل على مجرى بيانات مختلف. والتنفيذ هنا يكون متزامن أو غير متزامن، وحالياً الأجهزة الشائعة من الحاسبات تستخدم هذا النمط.1 نقطة
-
هذا خطأ شائع يقع فيه المبتدئين، وهو استخدام توابع التنشيط في آخر طبقة من طبقات نماذج التوقع، يجب أن تتذكر دوماً أن مسائل التوقع Regression تكون فيها قيم الخرج قيم مستمرة أي قيم غير محدودة بمجال معين أي ليست كما في ال classifications حيث يكون فيها الخرج قيم متقطعة أي قيم معينة. لذلك لايجب استخدام أحد توابع التنشيط معها ولاسيما توابع التنشيط اللوجستية مثل التابع السيني sigmoid أو حتى tanh. لأن هذين التابعين خرجهما يكون بين ال 0 وال 1 (بالنسبة للسيني) و من 1 لل -1 (بالنسبة لل tanh). وبالتالي إذا استخدمت أحدهما في آخر طبقة سيكون خرج نموذجك قيماً محصورة بمجال محدد وهذا خاطئ لأنه في أي مهمة توقع ولتكن مهمة توقع أسعار المنازل مثلاً، يجب أن يكون الخرج قيماً تنتمي إلى مجال غير محدود (قيم مستمرة) أما إذا استخدمت التابع السيني مثلاً سيكون خرج النموذج من أجل أي عينة قيمة محصورة بالمجال من 0 ل 1 والقيمة الحقيقية قد تكون 100 أو 50 أو 77 أو أو.. وبالتالي سيكون مقدار الخطأ في التوقع كبير جداً. لذا يجب ضبط تابع التنشيط في آخر طبقة على None دوماً. حسناً أنت تتساءل لماذا تابع ال relu يعطيك نتائج جيدة، وهذا صحيح فبالفعل قد يعطيك نتائج جيدة وفي بعض الأحيان قد يعطيك نتائج أفضل من عدم استخدام تابع تنشيط أي None كالمثال التالي، حيث سنستخدم relu والخطأ المطلق mae=2.2152: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) =boston_housing.load_data() mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1, activation='relu')) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) history = model.fit(train_data, train_targets,epochs=7, batch_size=1, verbose=1) ------------------------------------------------- Epoch 1/7 404/404 [==============================] - 1s 967us/step - loss: 338.1444 - mae: 15.1877 Epoch 2/7 404/404 [==============================] - 0s 1ms/step - loss: 21.6941 - mae: 3.1332 Epoch 3/7 404/404 [==============================] - 0s 1ms/step - loss: 17.6999 - mae: 2.8479 Epoch 4/7 404/404 [==============================] - 0s 947us/step - loss: 13.1258 - mae: 2.4018 Epoch 5/7 404/404 [==============================] - 0s 970us/step - loss: 15.7603 - mae: 2.6360 Epoch 6/7 404/404 [==============================] - 0s 1ms/step - loss: 12.1877 - mae: 2.3640 Epoch 7/7 404/404 [==============================] - 0s 965us/step - loss: 9.7259 - mae: 2.2152 أما بدونه mae: 2.3221: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) =boston_housing.load_data() mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1, activation=None)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) history = model.fit(train_data, train_targets,epochs=7, batch_size=1, verbose=1) ----------------------------------------------- Epoch 1/7 404/404 [==============================] - 1s 1ms/step - loss: 280.0789 - mae: 13.5154 Epoch 2/7 404/404 [==============================] - 0s 1ms/step - loss: 19.4468 - mae: 3.0621 Epoch 3/7 404/404 [==============================] - 0s 1ms/step - loss: 17.4921 - mae: 2.9243 Epoch 4/7 404/404 [==============================] - 0s 1ms/step - loss: 14.3356 - mae: 2.6068 Epoch 5/7 404/404 [==============================] - 0s 1ms/step - loss: 12.1125 - mae: 2.4581 Epoch 6/7 404/404 [==============================] - 0s 952us/step - loss: 16.5646 - mae: 2.5852 Epoch 7/7 404/404 [==============================] - 0s 1ms/step - loss: 12.4237 - mae: 2.3221 حسناً كما تلاحظ فإن النتيجة أفضل مع relu، والسبب في أن التابع relu هو تابع خطي خرجه من الشكل: max(x, 0) بحيث من أجل دخل x>0 سيكون خرجه هو x نفسها (أي لاتغيير أي كأننا لم نستخدم تابع تنشيط أي None ) ومن أجل دخل أصغر من الصفر يكون الخرج 0، هذا يعني أنه يسلك سلوك None من أجل الجزء الموجب وكما نعلم فإن أسعار المنازل هي دوماً موجبة وبالتالي استخدام relu سيكون مكافئاً ل None ولكن أفضل لأنه في حالة توقع النموذج قيمة سالبة للنموذج سوف يقصرها على 0 أي إذا توقع -5 سوف يجعلها 0 بسبب تابع ال relu ولهذا السبب كان استخدامه يعطي نتيجة أفضل، لكن هذا لايعني أن استخدامه صحيح وخصوصاً إذا كانت القيم السالبة ضمن مجال التوقع، وأيضاً استخدامه قد يضلل نموذجك قليلاً في الوصول للقيم الصغرى الشاملة لذا أنا أفضل عدم استخدامه.1 نقطة
-
أنت تحاول الوصول إلى ال history من دون أن تقوم بتخزينها، لذا قم بتخزين ال history حيث أن التابع model.fit يعيد History object وهذا الكائن لديه العضو history من النمط dict لذا: ########################## في جزء التدريب###################### # بدلاً من model1.fit(data, label, validation_split=0.2, epochs=13) model2.fit(data, label, validation_split=0.2, epochs=13) model3.fit(data, label, validation_split=0.2, epochs=13) # اكتب history1=model1.fit(data, label, validation_split=0.2, epochs=13) history2=model2.fit(data, label, validation_split=0.2, epochs=13) history3=model3.fit(data, label, validation_split=0.2, epochs=13) ######################### في جزء الرسم ######################### plt.plot(history1.history['val_loss'], 'r', history2.history['val_loss'], 'b', history3.history['val_loss'], 'g')1 نقطة
-
قد تواجهك نفس المشكلة على Windows10 . لذلك أيضاً إذا واجه شخص ما هذه المشكلة في Windows، فيمكن حله من خلال زيادة حجم ال pagefile (جزء محجوز من ال hard disk يستخدم كامتداد لذاكرة الوصول العشوائي (RAM))، حيث أن المشكلة تتعلق بالذاكرة الزائدة "overcommitment". لذا اتبع الخطوات التالية: 1.اضغط زر إبدأ 2.اكتب SystemPropertiesAdvanced 3.اختر Run as administrator 4. Performance --> اختر Settings --> Advanced --> Change 5.قم بإلغاء تحديد "Automatically managing paging file size for all drives" 6.حدد Custom size --> املأ الحجم المناسب 7.اضغط Set --> OK --> exit من "Virtual Memory" و "Performance Options" و "System Properties Dialog" 8.أعد تشغيل النظام الخاص بك أيضاً هناك حل آخر هو التبديل من إصدار 32 بت إلى إصدار 64 بت من Python. حيث أنه يمكن لبرنامج 32 بت ، مثل وحدة المعالجة المركزية 32 بت ، معالجة 4 جيجابايت كحد أقصى من ذاكرة الوصول العشوائي (2 ^ 32). لذلك إذا كان لديك أكثر من 4 غيغابايت من ذاكرة الوصول العشوائي، فلا يمكن لإصدار 32 بت الاستفادة منها. مع إصدار 64 بت من Python (الإصدار المسمى x86-64 في صفحة التحميل) ، تختفي المشكلة.1 نقطة
-
نعم يمكنك ذلك عن طريق تغيير عدد الوسائط التي يقبلها الباني أو عن طريق تغيير نوع بيانات الوسطاء . لاحظ المثال التالي: حيث قمنا بعمل overload للباني Ali. حيث في الاستداعء الأول للباني قمنا باستدعاء الباني ذو الوسيطة الوحيدة (وستتم التهيئة ب 1.1) أما في الاستدعاء الثاني فسيتم تنفيذ الباني ذو الوسيطتين وستتم التهيئة ب 2.5. class Ali { float x; public Ali(float y) { x=y; } public Ali(float y, float m) { System.out.println("Hi"); if(y>m) { x=y; } else { x=m; } } } public class Main { public static void main (String args[]) { Ali t1 = new Ali(1.1); Ali t2 = new Ali(3, 2.5); System.out.println(t1.x); System.out.println(t2.x); } } حيث أننا هنا قمنا بتغيير عدد الوسطاء، ويمكنك أيضاً أن تقوم بتغيير نوع البيانات: class Ali { int x=0; public Ali(int y) { x=y; } float z=0.0; public Ali(float y) { z=y; } } public class Main { public static void main (String args[]) { Ali t1 = new Ali(1.1); // سيؤدي إلى استدعاء الباني الثاني Ali t2 = new Ali(3); // سيؤدي إلى استدعاء الباني الأول } }1 نقطة
-
هذه الطبقة كما يشير اسمها هي طبقة تسطيح (أو تسوية أو إعادة تشكيل) المدخلات. نستخدمها عادة مع النماذج عندما نستخدم طبقات RNN و CNN. ولفهمها جيداً سأشرحها مع المثالين التاليين، الأول مع مهمة تحليل مشاعر imdb أي مع مهمة NLP وسنستخدم طبقات RNN وسنتحتاج إلى الطبقة flatten: from keras.datasets import imdb from keras import preprocessing max_features = 10000 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) # بناء النموذج from keras.models import Sequential from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) # هنا سنتحتاج لإضافة طبقة تسطيح model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2) حسناً هنا قمنا بتسطيح الخرج الناتج من طبقة التضمين Embedding أي قمنا بتسطيح (تحويل) ال 3D tensor التي أنتجتها طبقة التضمين إلى 2Dtensor بالشكل التالي (samples,maxlen * 8)( أي عدد العينات أو الباتشز لايتأثر كما أشرنا في التعريف وإنما يتم إعادة تشكيل الفيتشرز). لقد قمنا هضه العملية لأن الطبقة التي تلي طبقة التضمين هي طبقة من نوع Dense وهي طبقة تستقبل 2D tensor ولاتستقبل 3D وبالتالي وجب علينا تسطيح مخرجات طبقة التضمين. مثال آخر: def lstm_model_flatten(): embedding_dim = 128 model = Sequential() model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen)) model.add(layers.LSTM(128, return_sequences = True, dropout=0.2)) # Flatten layer هنا أيضاً سنحتاج model.add(layers.Flatten()) model.add(layers.Dense(1,activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) model.summary() return model هنا استخدمنا طبقة التسطيح لأن مخرجات طبقة lstm هي 3D كما نعلم وذلك لأننا ضبطنا return_sequences على true، والطبقة التالية هي dense وبالتالي لابد من تسطيح المخرجات بنفس الطريقة. الآن حالة آخرى مع الطبقات التلاففية حيث أنني بنيت نموذج لتصنيف الأرقام المكتوبة بخط اليد: from keras import layers from keras import models from keras.datasets import mnist from keras.utils import to_categorical (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28, 28, 1)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) # بناء النموذج model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) # هنا سنتحتاجها model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) # تدريب النموذج model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=5, batch_size=64) حسناً، إن خرج كل طبقة Conv2D و MaxPooling2D هو 3D Tensor من الشكل (height, width, channels). إن آخر خطوة من بناء الشبكة التلاففية هو إضافة طبقة أو مجموعة طبقات dense وبالتالي تتم تغذية هذه الطبقة بآخر tensor أنتجتها طبقاتنا التلاففية (هنا (64, 3, 3)) وكما ذكرنا فإن dense لاتستقبل 3D وبالتالي يجب تسطيحها، ,وبالتالي هنا سيكون ناتج تسطيح الخرج هو شعاع 1D أبعاده 64*3*3 وهذا ماسوف تتغذى به طبقات ال dense.1 نقطة
-
إن الطبقات التي نقوم باستخدامها في keras و tensorflow هي طبقات تتعامل مع بنية بيانات نسميها tensor (بنية خاصة أكثر كفاءة من بنى المصفوفات العادية)، حيث أن هذه الطبقات صممت بحيث يمكنها أن تستقبل بيانات من نوع numpy.array ثم تحولها تلقائياً إلى tensor. لكن هذه الطبقات لاتتعامل مع القوائم وأنت تمرر لها قائمة وهذا خطأ شائع، لذا يجب أن تحول بياناتك إلى مصفوفة نمباي أولاً وستحل مشكلتك: import numpy data = numpy.array(data) label = numpy.array(label)1 نقطة
-
لقد قمت بتعريف نموذجك مع مخرجين [output1, output2]، لذلك من المتوقع أن يتم عمل ال fitting مع مصفوفتين مختلفتين من ال label. واحدة بحجم (, 119) والأخرى (,2) وهذا مايتوافق مع طبقتي الإخراج Dense لديك. الحل: g = ImageDataGenerator() def generate_data_generator(g, X, Y1, Y2): genX1 = generator.flow(X, Y1, seed=7) genX2 = generator.flow(X, Y2, seed=7) while True: X1i = genX1.next() X2i = genX2 .next() yield X1i[0], [X1i[1], X2i[1]] model.fit_generator(generate_data_generator(generator, x_train, y_train, y_train_gender), steps_per_epoch=len(x_train) / 16, epochs=5)1 نقطة