
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/22/21 في كل الموقع
-
لدي هدا النافبار كيف اجعل الروابط تختفي عند تصغير الشاشة خاصة لما اكون بالهاتف وتحل مكانها زر الانسدال <!-- Start Navbar --> <nav class="navbar navbar-expand-lg navbar-ligh " > <a class="navbar-brand" href="login.php" style="color: white">الرئيسية </a> <a class="navbar-brand" href="login.php" style="color: white">تسجيل الدخول </a> <a class="navbar-brand" href="login.php" style="color: white">تسجيل جديد </a> <a class="navbar-brand" href="baridimob.php" style="color: white"> شحن بـ BaridiMob/ ccp/ Paysera </a> </nav>2 نقاط
-
سلام عليكم عندي سؤال : هو ان بعد اتمام من الشرح لا اجد التطبيق العملي او المقصود هو ان لايوجد اختبار كل فترة وفترة او مدرب يحرص على فهم الشرح1 نقطة
-
لدي إطار البيانات التالي: >>> from pandas import * >>> df = DataFrame({'foo':['a','b','c'], 'bar':[1, 2, 3]}) >>> df foo bar 0 a 1 1 b 2 2 c 3 والآن أريد تحويله إلى التالي: bar 0 1 is a 1 2 is b 2 3 is c حاولت أن أقوم بذلك من خلال Pands كالتالي: df['foo'] = '%s is %s' % (df['bar'], df['foo']) لكن الكود السابق يسبب لي مشكلة ويخرج متيجة مختلفة عما أريد: >>> df foo bar 0 0 1\n1 2\n2 3\nName: bar, dtype: int6... 1 1 0 1\n1 2\n2 3\nName: bar, dtype: int6... 2 2 0 1\n1 2\n2 3\nName: bar, dtype: int6... 3 هل يمكن أن أستخدم Numpy لعمل هذا التغير؟ وكيف أقوم بذلك؟1 نقطة
-
من اين اشترى قالب مانجا وردبريس،وبشكل عام من أين أشترى قوالب معينة مثلا عجبنى قالب موقع معين من أين أستطيع شراء مثله1 نقطة
-
بعد إنشاء مصفوفة Numpy وحفظها كـ Django context variable، أتلقى الخطأ التالي عند تحميل صفحة الويب: array([ 0, 239, 479, 717, 952, 1192, 1432, 1667], dtype=int64) is not JSON serializable ماذا الذي يعنيه هذا الخطأ؟ وهل يجب أن أقوم بتغير نوع المصفوفة من خلال مكتبة json حتى أتمكن من التعامل مع هذا الكائن؟1 نقطة
-
لماذا عند عمل arrow function نجعل العنصر const1 نقطة
-
هنا الخطأ يخبرك أنه حقل id يجب أن يحتوي على قيمة وبذلك لا يمكن ان يكون فارغ و يجب أن يكون حقل id عبارة عن Auto Increment بحيث يتم تعبئته تلقائياً , حاول رجاء تغيير الحقل id و جعله auto incement.1 نقطة
-
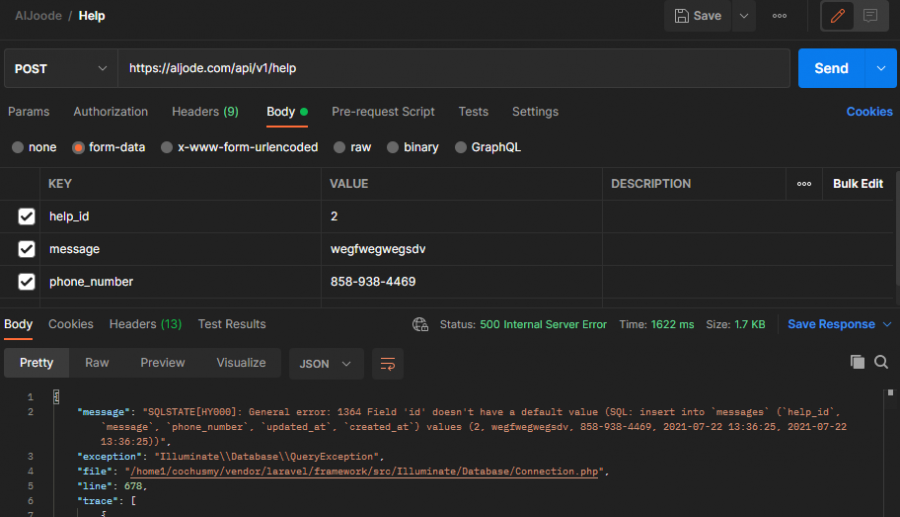
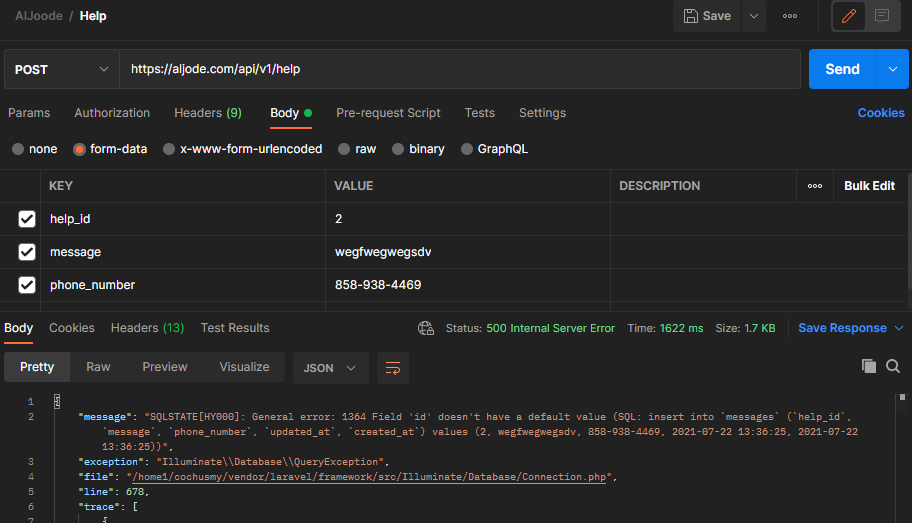
صحيح،شكرا جدا، أعتذر، قمت بتغييرها ونسيت إرجاعها .. الآن ما هي المشكلة؟ مع أنها كانت تعمل بشكل تمام عندما كانت تعمل على ال local
 1 نقطة
1 نقطة -
أعتقد أن قمية APP_DEBUG الحالية لديك هي false لتتحصل على معلومات أكثر عن الأخطاء يجب أن تكون true لاحظ الآن الخطأ أصبح أكثر دقة حيث رسالة الخطأ أصبحت: lluminate\Database\QueryException SQLSTATE[HY000]: General error: 1364 Field 'id' doesn't have a default value (SQL: insert into `messages` (`help_id`, `message`, `phone_number`, `updated_at`, `created_at`) values (3, lorem, 5674245, ... حيث يخبرك أن هناك حقل id في جدول messages لا تقوم بتمريره أثناء إنشاء السجل و هذا الحقل ليس nullable و ليس له قيمة إفتراضية. يُمكنك الآن حل المشكلة كما تريد.1 نقطة
-
الطريقة GET تعمل بشكل سليم ( الاتصال بقاعدة البيانات تمام ) ما المقصود ب (محتوى ملف الإعدادات)؟1 نقطة
-
هل بإمكانك توضيح محتوى ملف الإعدادات، لأنه لحد الساعة بهذه المعطيات لا يُمكن إيجاد سبب المشكلة. هل لديك مسار يجلب بيانات من قاعدة البيانات يُمكنك تجربته للتأكد من أن الطريقة get تعمل عند جلب بيانات و للتأكد من الإتصال يعمل1 نقطة
-
ماهي نتيجة الطلب الذي تُرسله لأن الخطأ 500 ليس متعلق بشيء محدد، حتى نستطيع المساعدة يُرجى تفصيل و شرح المشكلة بشكل أكبر1 نقطة
-
في ملف env. قم بتفعيل APP_DEBUG مؤقتا حتى تتحصل على الخطأ الفعلي الذي يؤدي إلى المشكلة1 نقطة
-
يمكنك فتح المسار التالي storage/logs/ ثم فتح الملف بداخل هذا المسار و قراءة ما هي الأخطاء التي تم التعرف عليها و يمكنك حلها , أو مشاركتها معنا , أو أيضا يمكنك فتح ملف error.log على الاستضافة الخاصة بك و قراءة الأخطاء و العمل على حلها. لأنه خطأ 500 Internal Server Error يكون خطأ داخلي ولا يمكن تحديده إلا بالرجوع إلى ملفات logs.1 نقطة
-
المشكلة ليست في ملف .env طالما قمت بكتابة اسم قاعدة البيانات ومعلومات الاتصال بالشكل الصحيح: DB_CONNECTION=mysql DB_HOST=localhost DB_PORT=3306 DB_DATABASE=hello // DB_name DB_USERNAME=root // DB_username DB_PASSWORD= //DB_password تأكد من أن قاعدة البيانات موجودة بنفس الاسم على الاستضافة ومن اسم المستخدم وكلمة المرور للوصول إليها. أما ماتبقى من ملف .env فهو صحيح ولا يتعلّق بالاتصال بقاعدة البيانات. كما يمكنك تشغيل app debug لإمكانية الحصول على معلومات إضافية عن الأخطاء التي تحدث.1 نقطة
-
لما لا يظهر الشكل هنا ارفقت لك الصوره الاصليه حيث لا يظهر الشكل بجانب النص في nav templete 1.zip
.thumb.png.4ecf0c5e46ab4ec322765d5b92ab9b5e.png)
.thumb.png.295becd716a623f9ccd159659e394a3c.png) 1 نقطة
1 نقطة -
الشكل الذي استخدمته عبارة عن أيقونة من مكتبة fonawesome ,لاحظ الكود التالي <span class="navbar-toggler-icon"> <i class="fa fa-bars" aria-hidden="true"></i> </span> اذا المشكلة في مكتبة fontawesome , يبدو ان النسخة التي تملكها في مشروعك فيها نقص بالملفات ولذلك لا تظهر الأيقونة, يمكنك استخدام الطريقة السريعة في تضمين مكتبة fontawesome من خلال استخدام هذا السطر <script src="https://kit.fontawesome.com/597cb1f685.js" crossorigin="anonymous"></script> أرجو منك حذف أسطر التضمين السابقة ووضع هذا السطر هذا فقط1 نقطة
-
هذا خطأ شائع يقع فيه المبتدئين، وهو استخدام توابع التنشيط في آخر طبقة من طبقات نماذج التوقع، يجب أن تتذكر دوماً أن مسائل التوقع Regression تكون فيها قيم الخرج قيم مستمرة أي قيم غير محدودة بمجال معين أي ليست كما في ال classifications حيث يكون فيها الخرج قيم متقطعة أي قيم معينة. لذلك لايجب استخدام أحد توابع التنشيط معها ولاسيما توابع التنشيط اللوجستية مثل التابع السيني sigmoid أو حتى tanh. لأن هذين التابعين خرجهما يكون بين ال 0 وال 1 (بالنسبة للسيني) و من 1 لل -1 (بالنسبة لل tanh). وبالتالي إذا استخدمت أحدهما في آخر طبقة سيكون خرج نموذجك قيماً محصورة بمجال محدد وهذا خاطئ لأنه في أي مهمة توقع ولتكن مهمة توقع أسعار المنازل مثلاً، يجب أن يكون الخرج قيماً تنتمي إلى مجال غير محدود (قيم مستمرة) أما إذا استخدمت التابع السيني مثلاً سيكون خرج النموذج من أجل أي عينة قيمة محصورة بالمجال من 0 ل 1 والقيمة الحقيقية قد تكون 100 أو 50 أو 77 أو أو.. وبالتالي سيكون مقدار الخطأ في التوقع كبير جداً. لذا يجب ضبط تابع التنشيط في آخر طبقة على None دوماً. حسناً أنت تتساءل لماذا تابع ال relu يعطيك نتائج جيدة، وهذا صحيح فبالفعل قد يعطيك نتائج جيدة وفي بعض الأحيان قد يعطيك نتائج أفضل من عدم استخدام تابع تنشيط أي None كالمثال التالي، حيث سنستخدم relu والخطأ المطلق mae=2.2152: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) =boston_housing.load_data() mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1, activation='relu')) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) history = model.fit(train_data, train_targets,epochs=7, batch_size=1, verbose=1) ------------------------------------------------- Epoch 1/7 404/404 [==============================] - 1s 967us/step - loss: 338.1444 - mae: 15.1877 Epoch 2/7 404/404 [==============================] - 0s 1ms/step - loss: 21.6941 - mae: 3.1332 Epoch 3/7 404/404 [==============================] - 0s 1ms/step - loss: 17.6999 - mae: 2.8479 Epoch 4/7 404/404 [==============================] - 0s 947us/step - loss: 13.1258 - mae: 2.4018 Epoch 5/7 404/404 [==============================] - 0s 970us/step - loss: 15.7603 - mae: 2.6360 Epoch 6/7 404/404 [==============================] - 0s 1ms/step - loss: 12.1877 - mae: 2.3640 Epoch 7/7 404/404 [==============================] - 0s 965us/step - loss: 9.7259 - mae: 2.2152 أما بدونه mae: 2.3221: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) =boston_housing.load_data() mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1, activation=None)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) history = model.fit(train_data, train_targets,epochs=7, batch_size=1, verbose=1) ----------------------------------------------- Epoch 1/7 404/404 [==============================] - 1s 1ms/step - loss: 280.0789 - mae: 13.5154 Epoch 2/7 404/404 [==============================] - 0s 1ms/step - loss: 19.4468 - mae: 3.0621 Epoch 3/7 404/404 [==============================] - 0s 1ms/step - loss: 17.4921 - mae: 2.9243 Epoch 4/7 404/404 [==============================] - 0s 1ms/step - loss: 14.3356 - mae: 2.6068 Epoch 5/7 404/404 [==============================] - 0s 1ms/step - loss: 12.1125 - mae: 2.4581 Epoch 6/7 404/404 [==============================] - 0s 952us/step - loss: 16.5646 - mae: 2.5852 Epoch 7/7 404/404 [==============================] - 0s 1ms/step - loss: 12.4237 - mae: 2.3221 حسناً كما تلاحظ فإن النتيجة أفضل مع relu، والسبب في أن التابع relu هو تابع خطي خرجه من الشكل: max(x, 0) بحيث من أجل دخل x>0 سيكون خرجه هو x نفسها (أي لاتغيير أي كأننا لم نستخدم تابع تنشيط أي None ) ومن أجل دخل أصغر من الصفر يكون الخرج 0، هذا يعني أنه يسلك سلوك None من أجل الجزء الموجب وكما نعلم فإن أسعار المنازل هي دوماً موجبة وبالتالي استخدام relu سيكون مكافئاً ل None ولكن أفضل لأنه في حالة توقع النموذج قيمة سالبة للنموذج سوف يقصرها على 0 أي إذا توقع -5 سوف يجعلها 0 بسبب تابع ال relu ولهذا السبب كان استخدامه يعطي نتيجة أفضل، لكن هذا لايعني أن استخدامه صحيح وخصوصاً إذا كانت القيم السالبة ضمن مجال التوقع، وأيضاً استخدامه قد يضلل نموذجك قليلاً في الوصول للقيم الصغرى الشاملة لذا أنا أفضل عدم استخدامه.1 نقطة
-
أنت تحاول الوصول إلى ال history من دون أن تقوم بتخزينها، لذا قم بتخزين ال history حيث أن التابع model.fit يعيد History object وهذا الكائن لديه العضو history من النمط dict لذا: ########################## في جزء التدريب###################### # بدلاً من model1.fit(data, label, validation_split=0.2, epochs=13) model2.fit(data, label, validation_split=0.2, epochs=13) model3.fit(data, label, validation_split=0.2, epochs=13) # اكتب history1=model1.fit(data, label, validation_split=0.2, epochs=13) history2=model2.fit(data, label, validation_split=0.2, epochs=13) history3=model3.fit(data, label, validation_split=0.2, epochs=13) ######################### في جزء الرسم ######################### plt.plot(history1.history['val_loss'], 'r', history2.history['val_loss'], 'b', history3.history['val_loss'], 'g')1 نقطة
-
قد تواجهك نفس المشكلة على Windows10 . لذلك أيضاً إذا واجه شخص ما هذه المشكلة في Windows، فيمكن حله من خلال زيادة حجم ال pagefile (جزء محجوز من ال hard disk يستخدم كامتداد لذاكرة الوصول العشوائي (RAM))، حيث أن المشكلة تتعلق بالذاكرة الزائدة "overcommitment". لذا اتبع الخطوات التالية: 1.اضغط زر إبدأ 2.اكتب SystemPropertiesAdvanced 3.اختر Run as administrator 4. Performance --> اختر Settings --> Advanced --> Change 5.قم بإلغاء تحديد "Automatically managing paging file size for all drives" 6.حدد Custom size --> املأ الحجم المناسب 7.اضغط Set --> OK --> exit من "Virtual Memory" و "Performance Options" و "System Properties Dialog" 8.أعد تشغيل النظام الخاص بك أيضاً هناك حل آخر هو التبديل من إصدار 32 بت إلى إصدار 64 بت من Python. حيث أنه يمكن لبرنامج 32 بت ، مثل وحدة المعالجة المركزية 32 بت ، معالجة 4 جيجابايت كحد أقصى من ذاكرة الوصول العشوائي (2 ^ 32). لذلك إذا كان لديك أكثر من 4 غيغابايت من ذاكرة الوصول العشوائي، فلا يمكن لإصدار 32 بت الاستفادة منها. مع إصدار 64 بت من Python (الإصدار المسمى x86-64 في صفحة التحميل) ، تختفي المشكلة.1 نقطة
-
أول فرق يكمن بالحجم التخزيني، فمصفوفات نمباي تخزن البيانات بشكل أكثر فعالية وتستهلك عدد أقل من البايتات لكل عنصر: import numpy as np import sys # إنشاء قائمة بألفي عنصر l= range(2000) # حجم كل عنصر من عناصر القائمة بالبايت print("Size of each element : ",sys.getsizeof(l),"bytes") # حجم كامل القائمة print("Size of the whole list : ",sys.getsizeof(l)*len(l),"bytes") # إنشاء مصفوفة نمباي بألفي عنصر D= np.arange(2000) # حجم كل عنصر بالمصفوفة print("Size of each element: ",D.itemsize,"bytes") # حجم كامل المصفوفة print("Size of the whole array : ",D.size*D.itemsize,"bytes") ''' Size of each element : 48 bytes Size of the whole list : 96000 bytes Size of each element: 4 bytes Size of the whole array : 8000 bytes ''' الفرق الثاني بزمن التنفيذ حيث أن استخدام مصفوفات نمباي يعد أكثر فعالية في زمن التنفيذ، في المثال التالي ستعرض الفرق بزمن تنفيذ العمليات عندما نستخدم مصفوفات نمباي و القوائم: import numpy as np import time # تعريف قائمتين l1 = range (200000) l2 = range(200000) # تعريف مصفوفتين arr1 = np.arange(2000000) arr2 = np.arange(2000000) # حساب الزمن اللازم لمضاعفة عناصر القائمة start = time.time() r = [(x * y) for x, y in zip(l1, l2)] print("Time when we use lists :",(time.time() - start),"sec") #حساب الزمن اللازم لمضاعفة عناصر المصفوفة start = time.time() r = arr1 * arr2 print("Time when we use numpy arrays :",(time.time() - start),"sec") ''' Time when we use lists : 0.04999589920043945 sec Time when we use numpy arrays : 0.0069963932037353516 sec ''' لذا فهي أكثر كفاءة في التخزين والزمن اللازم لإجراء العمليات عليها، ويعود السبب الأساسي لذلك في طريقة تخزين العناصر في نمباي (تخزن العناصر بشكل متجاور على عكس القوائم)1 نقطة
-
يمكنك تنفيذ الجداءالديكارتي باستخدام التابع التالي اعتماداً على الدالة meshgrid في مكتبة نمباي : import numpy as np x = np.array([0, 1, 2]) y = np.array([3, 4, 5]) # تعريف تابع يقوم بعملية الجداء الديكارتي def cartesian(*arrays): g = np.meshgrid(*arrays) coord = [x.ravel() for x in g] p = np.vstack(coord).T return p # استدعاء التابع وطباعة الخرج print(cartesian(x,y)) # الخرج ''' [[0 3] [1 3] [2 3] [0 4] [1 4] [2 4] [0 5] [1 5] [2 5]] '''1 نقطة
-
النمط String لايقبل الإضافة إليه، بحيث أي طريقة يتم استدعاءها على String تنشئ غرض جديد new String وترده وهذا لأن ال String غير قابل للتعديل، ولا يمكنه تغيير حالته الداخلية. أما StringBuilder فيمكنه ذلك باستخدام الطريقة append. وبالتالي يكون التعامل معه أسرع بكثير وأقل كلفة في الذاكرة فهو لايقوم بإنشاء غرض جديد (استهلاك وقت وذاكرة). مثال يبين أهم فرق بينهما: // String استخدام String s=""; for(int i=0;i<5000;i++) s+=String.valueOf(i); // 4828ms //ٍ StringBuilder أما باستخدام ٍStringBuilder sb=new ٍStringBuilder(); for(int i=0;i<5000;i++) sb.append(String.valueOf(i)); // 4ms باستخدام ال String نحتاح إلى 4828ms على جهازي أما باستخدام Builder فقط 4ms وهذا فرق كبير جداً. أي يمكنك استخدام الاثنين لكن ال StringBuilder أكثر كفاءة مهما كانت المهمة سواءاً قراءة ملف أو التعديل عليه.1 نقطة
-
يجب أن تعرف أولاً أن res.send تتكون من res.write res.setHeaders res.end وتقوم send تحدد content type تلقائياً على حسب البيانات المرسلة بينما end لن تقوم بتحديد content type وأيضاً send تقوم بتحديد ال ETag وهو معرف لل http response ويساعد في ال cache وحفظ ال bandwidth هناك بعض الإستخدامات التي يفضل استخدام write ,end معاً بدلاً من send في حالة أن مثلاً البيانات المرسلة كبيرة أو عند محاولة تكرار عملية send فلن تنجح بينما ستنجح من خلال write ,end معاً1 نقطة
-
res.send تستخدم لإرسال الرد للمستخدم /العميل /المتصفح على شكل HTTP res.end تستخدم لإنهاء الإتصال مع إرسال بيانات للمرة الأخيرة )إرسال البيانات اختياري) // الرد بالبيانات res.send([body]) res.end(); res.status(404).end(); send تحدد content type حسب البيانات الممررة مثل html/json حيث يتم التعرف على نمط النص الممرر مكان body في المثال end ممكن أن ترسل على شكل نص فقط ولكن تستعمل فقط لإنهاء الطلبية.1 نقطة
-
تم تقديم عبارة with لأول مرة منذ خمس سنوات، في Python 2.5. تُستخدم with عند العمل مع موارد غير مُدارة "unmanaged resources" مثل file streams Open network connections. Unmanaged memory ومع الأقفال Locks و ال sockets وال subprocesses. يسمح لك بالتأكد من "تنظيف" المورد عند انتهاء تشغيل الكود الذي يستخدمه، حتى إذا تم طرح استثناءات. ففي حال استخدمتها مع الملفات فتتمثل ميزة استخدام عبارة with في ضمان إغلاق الملف بشكل آمن بغض النظر عن كيفية الخروج من الكتل البرمجية المتداخلة الموجودة لديك. بحيث إذا حدث استثناء قبل نهاية الكتلة البرمجية، فسيتم إغلاق الملف بشكل مسبق بواسطة معالج استثناء خارجي. وإذا كانت الكتلة المتداخلة تحتوي على تعليمة return ، أو تعليمة continue أو break، فإن تعليمة with ستغلق الملف تلقائياً في تلك الحالات أيضاً. حيث تضمن عبارة with نفسها بالحصول على الموارد وتحريرها بالشكل المناسب. يكون استخدامها مفيداً عندما يكون لديك عمليتان مترابطتان ترغب في تنفيذهما كزوج، مع وجود كتلة من التعليمات البرمجية بينهما. المثال الكلاسيكي هو فتح ملف ومعالجة الملف ثم إغلاقه وهذا ماسنراه في المثال التالي: # وبدون معالجة للاستثناءات التي قد تحدث with بدون استخدام f = open('path', 'w') f.write('hsoub') f.close() # مع معالجة للاستثناءات التي قد تحدث with بدون استخدام f = open('path', 'w') try: f.write('hsoub') finally: f.close() #with استخدام with open('path', 'w') as file: f.write('hsoub') في أول مثال قد يؤدي حدوث استثناء أثناء استدعاء write إلى عدم إغلاق الملف بشكل سليم مما يؤدي إلى حدوث العديد من الأخطاء في الكود. الطريقة الثانية في المثال أعلاه تهتم بجميع الاستثناءات ولكن استخدام تعليمة with يجعل الكود مضغوطاً وقابل للقراءة بشكل أكبر. وبالتالي ، تساعد العبارة في تجنب الأخطاء والتسريبات من خلال ضمان تحرير المورد بشكل صحيح عند تنفيذ التعليمات البرمجية التي تستخدم المورد بالكامل. ولاحظ أنك لن تحتاج لتعليمة close كما في أول حالتين. يمكنك أيضاً استخدام تعليمة with مع كائنات معرفة من قبلك حيث يمكن استخدامها في الكائنات التي يحددها المستخدم وهذا مفيد بالنسبة لك لأن دعم عبارة with في العناصر الخاصة بك سيضمن عدم ترك أي مورد مفتوحًا أبدًا. لاستخدامها مع الكائنات المعرفة من قبل المستخدم، تحتاج فقط إلى إضافة التوابع __enter __ () و __exit __ () في الكائن، مثال: class wr(object): def __init__(self, file_name): self.file_name = file_name def __enter__(self): self.file = open(self.file_name, 'w') return self.file def __exit__(self): self.file.close() #مع الكائن with استخدام التعليمة with wr('file.txt') as f: f.write('hasoub') إن الكلمة المفتاحية with تشكل باني ل wr، وبمجرد وصول التنفيذ لتعليمة with يتم إنشاء كائن من wr، ثم يقوم بايثون باستدعاء التابع enter الذي يقوم بتهيئة المورد الذي تريد أن تستخدمه في ال object الخاص بك، ويجب أن تقوم طريقة __enter __ () دائمًا بإرجاع واصف للمورد "descriptor"(مقبض للوصول للملف) الذي تم الحصول عليه. يتم استخدام f للإشارة لل descriptor الذي تم الحصول عليه من التابع enter، ويتم وضع الكود البرمجي الذي يستخدم المورد بداخل كتلة with وبمجرد تنفيذ الكود الموجود داخل الكتلة with ، يتم استدعاء طريقة __exit __ () ليتم تحرير جميع الموارد. # وهذا ليس كل شيء عن تعليمة with.1 نقطة
-
هناك العديد من نماذج خططالعمل بعضها يحوي الكثير من التفاصيل والتعقيدات باختصار ماهي أركان خطة العمل الجيدة ؟1 نقطة







.png.ccf7ebceb8918ce3dd529e9519541398.png)
.png.ef2668b5fd44d36f7f796be737bb5063.png)



