
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/07/21 في كل الموقع
-
لدي مجموعة كبيرة من المستندات المتداخلة بحيث كل مستند يحوي بداخله عدّة مستندات أخرى nested. وأحاول الحصول على المستند الأكبر حجماً في هذه المجموعة. من التوثيق وجدت الدالة التالية: db.collection.stats() والتي تعطي متوسط الحجم، ولكن أرغب بالحصول على الحجم الأكبر ضمن هذه المجموعة وليس المتوسط. كيف يمكنني تحقيق ذلك؟2 نقاط
-
ببساطة ال destructor عبارة عن تابع لا يرد أية قيمة ولا يحوي على return ولا نمرر له أي وسيط. يتم تعريفه بأن نكتب ( اسم الصف مسبوق بالإشارة ~ ) ثم فتح قوسين فارغين، و من الممكن أن يحوي تعليمات أو أن لا يحوي. مثال : Class A{ Public : // تعريف باني افتراضي A() { cout<<"A"; } // destructor ~ A() { cout<<" Destructor is call " ; } } لكل صف يتم إنشاؤه يكون هناك destructor افتراضي (يتم تعريفه تلقائياً حتى ولو لم تقم بالتصريح عنه واستدعائه ). مثلاً في حال تم انشاء كائن ضمن دالة وتم تنفيذ محتوى هذه الدالة سيتم استدعاء التابع destructor (وببساطة سيتم حذف أي شيء تم تعريفه ضمن الدالة بعد أن تنفذ). يتم الاستفادة من التابع destructor عندما يكون ضمن الصف حقول معطيات ديناميكية مثل (مؤشرات ، مصفوفات ديناميكية ..إلخ) حيث أننا ضمن جسم التابع نقوم بتحرير المواقع المحجوزة من قبل هذه المتحولات الديناميكية عن طريق استخدام التعليمة delete. مثال : ليكن لدينا الصف dynamic يحتوي على المصفوفة الديناميكية A ،من النمط int و باني افتراضي للتهيئة بالصفر وطريقة لإدخال عناصر المصفوفة و هادم ( destructor). عندئذ يجب استخدام التعليمة delete في الهادم لتحرير المواقع المحجوزة من قبل المصفوفة الديناميكية. #include <iostream> using namespace std; class dynamic { private : int *A ; int size ; public : // البان الافتراضي dynamic (){ cout<<" constructor is called " ; size = 0; A=new int [0]; } //طريقة لادخال عناصر المصوفة void input(s){ size = s; A=new int [size]; for (int i=0;i<size;i++){ cin>>A[i]; } //هادم لتحرير الذاكرة ~dnamic() { Cout<< " destructor is called " ; Delete[]A; } }; int main() { dynamic d //غرض من الصف السابق int n; cin>>n ; //ادخال عدد العناصر d.input(n); return 0 ; } //الخرج constructor is called 5 1 2 55 57 69 destructor is called إذاً تم استدعاء التابع Destructor بعد الانتهاء من تنفيذ جميع تعليمات البرنامج الموضوعة ضمن ال main، ليقوم بتحرير المواقع المحجوزة.1 نقطة
-
استخدم mongoose في node.js، وضمن هيكلية البيانات نسيت تعريف الحقول timestamps، ولكن حسب التوثيق الرسمي وجدت أن الحقل المعرّف الفريد لكل مستند id يحوي بداخله قيمة الوقت والتاريخ لإنشاء كل مستند. ولكن كيف يمكنني استخراج هذه القيم من ObjectID في mogoose. وإجراء استعلام عليها بشكل مشابه للتالي: collection.find({date: {$gt: new Date(2021,1,1)}});1 نقطة
-
return sections::find(1)->bank; هذا الاستعلام يجيب لي القسم والبنوك التابعه له لاكن احيانا مايكون مثلا رقم 1 هو الفرع المطلوب كيف اخلي الاستعلام يصير باسم القسم زي الكود تحت لانه حطيته يطلع خطا return sections::where("section_name","==","البنوك")->bank;1 نقطة
-
لا يمكن قراءة خاصية من التابع where مباشرة على هذا النحو : return sections::where("section_name","==","البنوك")->bank; و في حالة المحاولة سيتم إظهار خطأ يتم فيه إخبارك أن الخاصية bank غير موجودة . قبل ذلك نحتاج تنفيذ الإستعلام الذي قمنا للتو ببناءه عن طريق أحد التوابع get أو first : $first = sections::where("section_name","==","البنوك")->get(); $second = sections::where("section_name","==","البنوك")->first(); الأولى ستقوم بإعادة مجموعة كائنات كل منها يمتلك الخاصية bank و بالتالي و للقراءة منها نحتاج عمل دور على عناصر المجموعة على هذا النحو : foreach($first as $item){ echo $item->bank; } أما بالنسبة للثانية فهي سوف تقوم بإعادة أول كائن يحقق الإستعلام و يمكن قراءة الخاصية مباشرة منه : $second->bank أو : return sections::where("section_name","==","البنوك")->first()->bank;1 نقطة
-
يمكنك استخدام Object.bsonsize مع إجراء حلقة تكرارية على المستندات الموجودة ضمن هذه المجموعة بالشكل التالي: let max_size = 0, doc_id = null; db.test.find().forEach(doc => { const size = Object.bsonsize(doc); if(size > max_size) { max = size; doc_id = doc._id; } }); print(doc_id, max_size); وعندها سيتم طباعة الرقم المعرّف وأعلى حجم للمستند الأكبر الموجود ضمن المجموعة لديك. ولكن ذلك بالتأكيد سيكون له تأثير على الأداء في حالة المجموعات التي تحوي أعداد كبيرة من المستندات لأنه سيتم المرور عليها جميعاً وإجراء شرط المقارنة. كما يمكنك إنشاء مصفوفة وترتيبها ثم أخذ قيمة الحجم بالشكل المختصر التالي: db.docs.find().toArray().map(function(doc) { return {size:Object.bsonsize(doc), _id:doc._id}; }).sort(function(a, b) { return a.size-b.size; }).pop(); والتي ستقوم بطباعة النتيجة التالية: { "size" : 3333, "_id" : "docId..." } وبشكل مماثل يمكنك الحصول على الحجم من خلال خاصية التجميع aggregation والتي تعد الطريقة الأمثل للأداء في حال عدد المستندات الكبير: db.docs.aggregate([ { $match: { 'docs.ids': { $exists: true } }}, { $project: { sizeLargestField: { $size: '$docs.ids' } }}, { $sort: { sizeLargestField: -1 }}, ]) والتي ستقوم بترتيب المستندات من الأكبر حجماً إلى الأصغر وبعدها يمكنك أخذ القيمة الأولى من الناتج.1 نقطة
-
يمكنك استخدام التابع getTimestamp مباشرةً على قيمة الحقل _id وبالتالي سيتم استعادة قيمة التاريخ والوقت حسب timestamp الموجود ضمن هذه القيمة: ObjectId.prototype.getTimestamp = function() { return new Date(parseInt(this.toString().slice(0,8), 16)*1000); } وضمن mongo shell يمكنك تنفيذ الكود التالي: var time = document._id.getTimestamp(); وستظهر لك قيمة الوقت بالشكل التالي في حال قمت بطباعتها: Wed Sep 07 2021 18:37:37 GMT+1000 (AUS Eastern Standard Time) // أو حسب الوقت الموجود أما للمقارنة مع وقت محدد من خلال mongoose في الكود لديك، يمكنك وضع الشرط التالي: document._id.getTimestamp() > new Date("2020-12-12") بحيث يتم استخدام الغرض Date الموجود في الجافاسكريبت. مع إمكانية التحكّم بصيغة الوقت حسب المطلوب.1 نقطة
-
المشكلة تحدث في طبقة التضمين Embedding. هذه الطبقة تأخذ وسيطين على الأقل الأول هو عدد ال tokens (المفردات) الموجودة في بياناتك أي (1 + maximum word index) والثاني هو dimensionality of the embeddings أي أبعاد التضمين. يمكن اعتبار طبقة التضمين قاموس يقوم بربط أعداد صحيحة (كل عدد يمثل كلمة) بأشعة كثيفة. "maps integer indices,(which stand for specific words) to dense vectors" وبالتالي يأخذ كمدخل له عدد صحيح ثم يبحث عن هذا العدد في قاموسه ثم يرد الشعاع المقابل له. Word index --> Embedding layer --> Corresponding word vector أنت ماذا فعلت؟! أنت قمت بتحديد عدد المفردات بالنص الخاص بك إلى 75000 كلمة فريدة، ثم قمت بتحديد 10000 كلمة في طبقة التضمين وهذا سينتج خطأ لأن الكلمات الموجودة في بياناتك أكثر بكثير وبالتالي لن يجد هذه الكلمات في قاموسه الداخلي وبالتالي ينتج خطأ. لحل المشكلة يجب أن تتم مطابقتهما أي إذا حددت عدد الكلمات التي ستبقى في نصك في مرحلة ال tokenaization ب 75000 فيجب أن تحدد 75000 في طبقة التضمين أيضاً. التصحيح: df_train = pd.read_csv('/content/drive/MyDrive/imdbdataset/Completely_clean_data.csv') df_train.drop(df_train.filter(regex="Unname"),axis=1, inplace=True) df_test = pd.read_csv('/content/drive/MyDrive/imdbdataset/Completely_clean_data_test.csv') df_test.drop(df_test.filter(regex="Unname"),axis=1, inplace=True) max_words = 75000 tokenizer = Tokenizer(num_words=max_words) # fitting tokenizer.fit_on_texts(pd.concat([df_test['review'], df_train['review']])) #max_len=int(df["review_len"].mean()) #231 # do you remember!! train = tokenizer.texts_to_sequences(df_train['review']) test = tokenizer.texts_to_sequences(df_test['review']) train = pad_sequences(train, maxlen=200) test = pad_sequences(test, maxlen=200) print("the shape of data train :",train.shape) print("the shape of data test :",test.shape) # model def modelBiLSTM(): max_words = 75000 #drop_lstm =0.4 embeddings=128 model = Sequential() # الإصلاح model.add(Embedding(max_words, embeddings)) model.add(Bidirectional(LSTM(64, activation='tanh'))) # 2D output model.add(Dense(1, activation='sigmoid')) # binary output return model model=modelBiLSTM() model.summary() # training model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history=model.fit(train, train_label,validation_split=0.12, batch_size=32, epochs=8)1 نقطة
-
يمكن اعتبارها كتحسين لل MSE أو كتطوير لها للتعامل مع حالات معينة، وهي مزيج من ال MSE و MSA. إن ال (MSE) يركز على القيم المتطرفة في مجموعة البيانات، بينما متوسط الخطأ المطلق (MAE) جيد لتجاهل القيم المتطرفة. لكن في بعض الحالات فإن البيانات التي تبدو وكأنها قيم متطرفة، قد لا تشكل مشكلة بالنسبة لك، وأيضاً تلك النقاط من البيانات لا ينبغي أن تحظى بأولوية عالية. وهنا حيث يأتي هوبر لوس. الصيغة الرياضية: كما قلنا فهي مزيج من MSE و MAE مما يعني أنها تربيعية (MSE) عندما يكون الخطأ صغيرًا وإلا فهي MAE. دلتا هنا تعتبر من المعاملات العليا hyperparameter لتحديد نطاق MAE و MSE. من المعادلة نجد أنه عندما يكون الخطأ أقل من دلتا ، يكون الخطأ تربيعيًا وإلا يكون مطلقًا. يمن استخدامها في كيراس بسهولة كالتالي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) #model.compile(optimizer='rmsprop', loss='Huber', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64) """ Epoch 1/8 7/7 [==============================] - 7s 2ms/step - loss: 21.8385 - mae: 22.3385 Epoch 2/8 7/7 [==============================] - 0s 3ms/step - loss: 20.6043 - mae: 21.1043 Epoch 3/8 7/7 [==============================] - 0s 3ms/step - loss: 19.8923 - mae: 20.3920 Epoch 4/8 7/7 [==============================] - 0s 3ms/step - loss: 18.4374 - mae: 18.9368 Epoch 5/8 7/7 [==============================] - 0s 4ms/step - loss: 17.2154 - mae: 17.7146 Epoch 6/8 7/7 [==============================] - 0s 3ms/step - loss: 15.7804 - mae: 16.2756 Epoch 7/8 7/7 [==============================] - 0s 2ms/step - loss: 14.0492 - mae: 14.5466 Epoch 8/8 7/7 [==============================] - 0s 3ms/step - loss: 12.3948 - mae: 12.8905 """
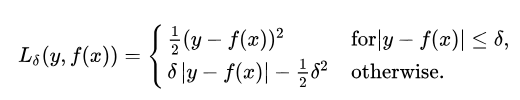 1 نقطة
1 نقطة -
أشهر دالة تكلفة والأفضل مع مسائل التوقع ويمكن استخدامها أيضاً كمعيار لكن من غير الشائع القيام بذلك، وهي تقوم على حساب متوسط الفرق التربيعي بين القيم المتوقعة من النموذج والقيمة الفعلية. ال MSE قوي في التعامل مع القيم المتطرفة في البيانات. الصيغة الرياضية: ال MSE من أجل عينة ما : # من أجل عينة واحدة loss = square(y_true - y_pred) لاستخدامها نقوم بتمررها إلى الدالة compile في نوذجنا كما في المثال: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss=keras.losses., metrics=['mae']) #بالشكل التالي compile هنا استخدمناها كدالة تكلفة وكمعيار عن طريق تمريره إلى الدالة #model.compile(optimizer='rmsprop', loss='mse', metrics=['mse']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64) """ Epoch 1/8 7/7 [==============================] - 1s 2ms/step - loss: 583.3815 - mse: 583.3815 Epoch 2/8 7/7 [==============================] - 0s 2ms/step - loss: 531.9802 - mse: 531.9802 Epoch 3/8 7/7 [==============================] - 0s 3ms/step - loss: 503.3803 - mse: 503.3803 Epoch 4/8 7/7 [==============================] - 0s 3ms/step - loss: 409.2950 - mse: 409.2950 Epoch 5/8 7/7 [==============================] - 0s 2ms/step - loss: 387.9506 - mse: 387.9506 Epoch 6/8 7/7 [==============================] - 0s 3ms/step - loss: 303.1605 - mse: 303.1605 Epoch 7/8 7/7 [==============================] - 0s 2ms/step - loss: 253.2450 - mse: 253.2450 Epoch 8/8 7/7 [==============================] - 0s 3ms/step - loss: 190.7695 - mse: 190.7695 """
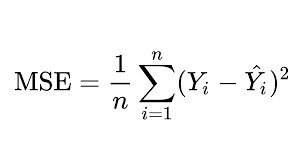 1 نقطة
1 نقطة -
اذا كنت اريد نقل مشرع بالفيجوال ستديو وحجمة جدا كبيير وابي ارسلة لشخص اخر كيف ممكن ارسله ويفتح معه طبيعي ؟ ياليت الخطوات1 نقطة
-
نعم يمكننا ذلك، ففي كيراس تم تعريف ال CosineSimilarity كدالة تكلفة لمهام التوقع. المعادلة الرياضية: loss = -sum(l2_norm(y_true) * l2_norm(y_pred)) يكون الخرج بين ال 1 و -1، بحيث كلما اقتربت القيم من ال -1 يكون التشابه أعظم وكلما اقترب من 1 يكون أقل تشابه وتشير ال 0 إلى حالة التعامد. وهذا مايجعلها قابلة للاستخدام كدالة تكلفة. يمكن استيرادها من الموديول: keras.losses لاستخدامها مع نموذج نمررها للدالة compile كما في المثال التالي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss=keras.losses.CosineSimilarity(axis=1), metrics=['mae']) #model.compile(optimizer='rmsprop', loss='CosineSimilarity', metrics=['mae']) return model # تدريب النموذج model = build_model() model.fit(train_data, train_targets,epochs=8, batch_size=64)1 نقطة
-
وفي حال لم تكن تعرف عدد العينات في كل من المصفوفات المراد تحويل شكلها يمكنك القيام بالتالي: x_train = np.reshape(x_train, (-1, 28, 28, 1)) x_test = np.reshape(x_test, (-1, 28, 28, 1)) والان لاحظ أن البرنامج لن ينفذ و ينتج الخطأ التالي: ValueError: Shapes (60, 1) and (60, 10) are incompatible لتفادي ذلك يجب تحويل مصفوفات y_train, y_test إلى التمثيل المقابل لها في الone hot encoding بإستخدام دالة to_categorical لأن عملية التصنيف إلى 10 أصناف تتتطلب ذلك لاحظ keras.layers.Dense(10): y_train = to_categorical(y_train) y_test = to_categorical(y_test) والان البرنامج يصبح كالتالي: import numpy as np import keras from keras.models import Sequential from keras.layers import Dense , Activation, Dropout from keras.optimizers import Adam ,RMSprop from keras.models import Sequential from keras.utils.np_utils import to_categorical from keras.datasets import mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) x_train = np.reshape(x_train, (-1, 28, 28, 1)) x_test = np.reshape(x_test, (-1, 28, 28, 1)) print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) # y تطبيق على قيم one hot encoding y_train = to_categorical(y_train) y_test = to_categorical(y_test) print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) model = keras.models.Sequential([ keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28,28,1)), keras.layers.MaxPool2D(2,2), keras.layers.Conv2D(64, (3,3), activation='relu'), keras.layers.MaxPool2D(2,2), keras.layers.Flatten(), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10, activation='softmax') ]) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, epochs=20,validation_data=(x_test, y_test), batch_size=60)1 نقطة
-
def count(text): tokens = [] # لتخزين الكلمات في النص بدون تكرار text = text.split() # لتقسيم النص إلى كلمات for word in text: # نمر على كل كلمة بالنص if word not in tokens: # إذا لم تكن الكلمة موجودة مسبقاً نضيفها tokens.append(word) for word in range(0, len(tokens)): #count نمر على كل كلمة فريدة بالنص ونحسب تكرارها باستخدام التابع print(tokens[word], ': ', text.count(tokens[word])) s ='Ali Messi Ali Messi Real Messi FCB FCB' count(s) # استدعاءالتابع1 نقطة
-
جرب: #!/usr/bin/env -S python3 -u1 نقطة
-
جهازك لايفي بالمتطلبات اللازمة لتشغيل البرنامج ... البرنامج يحتاج ذاكرة وصول عشوائي 4GB ونظام Windows10 ومتطلبات أخرى يمكنك مراجعتها بالبحث عن ذلك.1 نقطة
-
يجب أن يتم تحويل نوع العمود ل datatime لكي تستطيع القيام بعملية الترتيب التحويل يتم كالتالي: import pandas as pd df['Birthday']=pd.to_datatime(df['Birthday'])1 نقطة
-
لجعل الكلاس يرث من كلاس آخر, نضع بعد إسم الكلاس قوسين و بداخلهما إسم الكلاس الذي نريده أن يرث منه. في حال كان الكلاس يرث من أكثر من كلاس, يجب وضع فاصلة بين كل كلاسَين نضعهما بين القوسين. تريدين صف ابن يسمى Student سنجعله يرث الصف Person كالتالي: # تعريف الصف الأب class Person: def __init__(self,ID,name,age): self.ID=ID self.name=name self.age=age # تعريف الصف الابن الذي يمثل طالب class Student(Person): def __init__(self,ID,name,age,degree1,degree2,degree3): self.degree1=degree1 self.degree2=degree2 self.degree3=degree3 Person.__init__(self,ID, name, age) # نقوم باستدعاء باني الصف الاب داخل باني الصف الابن def calc_Gpa(self): return (self.degree1+self.degree2+self.degree3)/3 # حساب معدل الطالب في المواد الثلاثة def get_info(self): print("ID :"+str(self.ID)+'\n'+"Name : "+str(self.name)+'\n'+"Age :"+str(self.age)) # اختبار ماقمنا به Leen = Student(55,'Leen',20,100,90,85) print(Leen.calc_Gpa()) print(Leen.get_info())1 نقطة


