لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/02/21 في كل الموقع
-
الفرق بين cout و printf في c++2 نقاط
-
هناك تحذير يطلع معي Warning : componentWillMount is deprecated and will be removed in the next major version. Use componentDidMount instead. As a temporary workaround, you can rename to UNSAFE_componentWillMount. Please update the following components: Container, Text, TouchableOpacity, Transitioner, View المشروع يعمل بدون مشاكل لكن أريد اصلاح التحذير1 نقطة
-
لدي مصفوفة بسيطة التالي: x = numpy.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) أريد أن أقوم بتحويلها إلى مصفوفة بحجم 5*3 كالتالي: numpy.array([[1, 2, 3, 4, 5] ,[4, 5, 6 ,7, 8], [7, 8, 9, 10, 11]]) حاولت أن أستخدم حلقة for للقيام بهذا الأمر لكن الخطوات لم تكن واضحة بالنسبة لي، كيف يمكنني تطبيق هذا الأمر؟1 نقطة
-
هي دالة خسارة تحسب خسارة بواسون بين القيم الحقيقية والمتوقعة. له الصيغة التالية مع مسائل التصنيف: loss = y_pred - y_true * log(y_pred) توزيع بواسون: هو توزيع احتمالي منفصل، ويعبر عن احتمالية حدوث مجموعة من الأحداث P ضمن فترة زمنية محددة عندما تحدث هذه الأحداث بمعدل وسطي v شرط أن لا تكون متعلقة بزمن حدوث آخر حدث. يكون استخدامها مع مسائل التصنيف (المتعدد) اعتماداً على الصيغة السابقة، وفي كيراس لم يتضمن التوثيق استخدام لها مع مسائل التوقع رغم أنه من الممكن استخدامه مع هذه المسائل عندما تتبع البيانات توزيع بواسون (لكن في هذه الحالة لايتم استخدامها بنفس الصيغة قي الأعلى). يجب أن تقوم بترميز بيانات ال target ترميزاً فئوياً One-Hot. مثال: import tensorflow as tf y_true = [[0, 1, 0], [1, 0, 0]] #تمثل القيم الحقيقية One-Hot مصفوفة من ال y_pred = [[0.01, 0.9, 0], [0.99, 0.0, 0.0]] # مصفوفة القيم المتوقعة p = tf.keras.losses.Poisson() p(y_true, y_pred).numpy()#0.33590174 لاستخدامها مع نموذجك، قم بتمريريها إلى الدالة compile: model.compile( loss=tf.keras.losses.Poisson(), ) # أو model.compile( loss='poisson', ) مثال على مجموعة بيانات راوترز (تصنيف متعدد 46 فئة): # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) #ترميز الفئات المختلفة للبيانات #كما أشرنا One-Hot-Enoding طبعاً يجب أن نستخدم الترميز from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) #أي الفئات target انتهينا من ترميز قيم ال # الآن لنقم بترميز بيانات التدريب import numpy as np #One-Hot قمت بإنشاء تابع يقوم بتحويل بياناتي إلى الترميز # بإمكانك أيضاً استخدام تابع تحويل جاهز def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss=tf.keras.losses.Poisson(), metrics=['accuracy']) # لاحظ كيف قمنا بتمرير دالة التكلفة إلى النموذج # التدريب history = model.fit(x_train, one_hot_train_labels, epochs=8, batch_size=512, validation_split=0.2) ------------------------------------------------------------------ Epoch 1/8 15/15 [==============================] - 1s 25ms/step - loss: 0.0900 - accuracy: 0.3860 - val_loss: 0.0635 - val_accuracy: 0.5704 Epoch 2/8 15/15 [==============================] - 0s 14ms/step - loss: 0.0608 - accuracy: 0.6000 - val_loss: 0.0558 - val_accuracy: 0.6589 Epoch 3/8 15/15 [==============================] - 0s 15ms/step - loss: 0.0544 - accuracy: 0.6672 - val_loss: 0.0536 - val_accuracy: 0.6667 Epoch 4/8 15/15 [==============================] - 0s 14ms/step - loss: 0.0511 - accuracy: 0.6971 - val_loss: 0.0505 - val_accuracy: 0.7134 Epoch 5/8 15/15 [==============================] - 0s 20ms/step - loss: 0.0481 - accuracy: 0.7221 - val_loss: 0.0487 - val_accuracy: 0.7234 Epoch 6/8 15/15 [==============================] - 0s 19ms/step - loss: 0.0457 - accuracy: 0.7484 - val_loss: 0.0475 - val_accuracy: 0.7529 Epoch 7/8 15/15 [==============================] - 0s 20ms/step - loss: 0.0435 - accuracy: 0.7724 - val_loss: 0.0470 - val_accuracy: 0.7513 Epoch 8/8 15/15 [==============================] - 0s 14ms/step - loss: 0.0421 - accuracy: 0.7906 - val_loss: 0.0465 - val_accuracy: 0.76631 نقطة
-
عندي مشكلة الملف حاولت اني اطلع البيانات بالبوليسي LARVEL ماقاعد يطبع public function viewAny(User $user) { // return true; } @foreach ($post as $post) <table> {{-- @can('View', App\Models\Post::class) <tr> <td>{{$post->body}}</td> </tr> @endcan --}} </table> {{-- {{$post}} --}} @endforeach @can('view-Any', App\Models\Post::class) KKKKKKKKKKKKKKKKKKKKKKKKKKKKK @endcan جربت مايطبع البيانات لما يمر جنب CAN nnn.rar1 نقطة
-
السلام عليكم . كنت اريد ان اعرق كيف استطيع الحصول علي خلفيات متحركة مثل الموجودة في تلك الموقع https://www.tra.org.bh/Media/Interactive_Annual_Reports/2019/en/index.html#page1 للتنبيه انا اسأل عن الخلفية وليس علي الحركية التي يمكن عملها بالJQuery او الCSS1 نقطة
-
الموقع يستخدم قالب svg وهو مصمم خصيصا وهو يتحرك عن طريق css فقط لكن هناك موقع يستخدم لأنشاء هذا النوع من الخلفيات عن طريق برنامج في المتصفح دون برمجة وفي الموقع لديهم خلفيات خرافية svgator او يمكنك رسم ما تريد في figma واستخراجه على شكل svg ثم بامكانه تحريكه ب css وللعلم الأمر سهل جدا وجد ممتع ويتواجد الاف المصادر حول الموضوع1 نقطة
-
مرحبا لدي الشيفرة التالية import React, { Component, useEffect, useState } from 'react'; import { AppLoading, Font, Permissions } from 'expo'; import AppNavigation from './config/route'; export default class App extends Component { constructor(props) { super(props); this.state = { isReady: false, }; } async componentWillMount() { await Permissions.askAsync(Permissions.LOCATION); } async _getFonts() { await Font.loadAsync({ 'noto-font': require('./assets/fonts/NotoKufiArabic-Regular.ttf'), }); } render() { if (!this.state.isReady) { return ( <AppLoading startAsync={this._getFonts} onFinish={() => this.setState({ isReady: true })} /> ); } return <AppNavigation />; } } ويحدث معي هذا الخطأ عند تشغيل المشروع fontFamily "space-mono" is not a system font and has not been loaded through Font.loadAsync. - If you intended to use a system font, make sure you typed the name correctly and that it is supported by your device operating system.1 نقطة
-
لدي خطأ في مشروع expo react native وقد ظهر فجأة ولم أستطع حله المشروع كان يشتغل دون مشاكل typeError: React.useEffect not a function1 نقطة
-
الرابط المرفق يظهر رسالة 403 forbidden أي أنه ليس لنا صلاحية الاطلاع عليها، هل يمكنك إرفاق صورة أو مقطع للصفحة حتى نتمكن من مساعدك؟ ---إذا كنت تسأل عن مكتبات جاهزة، يوجد بعض المكتبات التي توفر خلفيات متحركة تفاعلية مثل: vantajs.com particles.js و غيرها، يمكنك البحث على الانترنت و ستجد العديد منها. أو يمكنك بناءها بنفسك باستخدام مكتبات مثل: three.js p5.js إذا كان سؤالك عن صور عادية فيمكنك أن تستخدم gif أو video قصير كخلفية1 نقطة
-
أعمل على مشروع بنسخة react native navigation قديمة لكن مؤخرا عند تشغيل المشروع تخرج هذه الرسالة تجبرني على التحديث واذا قمت بالتحديث سأعيد كتابة الشيفرة المتعلقة به هل من حل لتفادي ذلك It appears that you are using old version of react-navigation library. Please update @react-navigation/bottom-tabs, @react-navigation/stack and @react-navigation/drawer to version 5.10.0 or above to take full advantage of new functionality added to react-native-screens1 نقطة
-
مرحبا لدي مشروع react native منشئ عن طريق expo وعندما أقوم بتشغيله أحصل على هذا الخطأ Make sure that you have rebuilt the native code. If the problem persists try clearing the Watchman and packager caches with `watchman watch-del-all && react-native start --reset-cache`."1 نقطة
-
كيف ممكن تحقيق التالي ببرنامج سي بلس بلس يكون مخرجاته التالي 1و 23 و 345 و 45671 نقطة
-
لانجيب عن الأسئلة الامتحانية، إذا كان لديك أي سؤال برمجي أو مشكلة نحن جاهزون دوماً1 نقطة
-
يمكنك تثبيت الحزمة mv لكي تقوم بنقل الملفات بكل سهولة npm i mv ويمكنك إستخدامها كالآتي // إستدعاء الحزمة var mv = require('mv'); /* قم بإستبدال * source/file * بالمسار الكامل للملف الذي تريد نقله * واستبدل * dest/file * بالمسار الكامل للوجهة الذي تريد نقل الملف إليها مع اسم الملف */ mv('source/file', 'dest/file', function(err) { // كتابة كود عند وقوع مشكلة هنا }); اما إذا أردت نقل الملفات بدون تثبيت حزم فيمكنك إستخدام هذا الكود var fs = require('fs'); // تحديد الملف المراد نقله var source = fs.createReadStream('source_file'); // تحديد الوجهة المراد النقل إليها var dest = fs.createWriteStream('destination_file'); // نسخ الى المسار الجديد source.pipe(dest); // فك الربط بعد الإنتهاء source.on('end',function() { fs.unlinkSync('source_file'); });1 نقطة
-
شكرا جزيلا على الاهتمام استاذنا الكريم1 نقطة
-
abort_if(Gate::denies('user_access'), Response::HTTP_FORBIDDEN, '403 Forbidden'); هل النظام راح يكمل بعد التحقق ممكن احد يشرج $users = User::with(['roles'])->get(); return view('admin.users.index', compact('users'));1 نقطة
-
PyCharm ليس مسؤول عن التعامل مع SQL إنما ينفذ أكواد Python ويتصل بقاعدة البيانات عبر المخدم المحلي. أرجو متابعة دورة متكاملة تشرح هذه الجزئية، أو ابحث عن مكتبات للتعامل مع قواعد بيانات MySQL في python1 نقطة
-
ما علاقة رخصة شراء Pycharm باستيراد قاعدة البيانات؟ ماذا تقصد بالاستيراد وإلى أين.1 نقطة
-
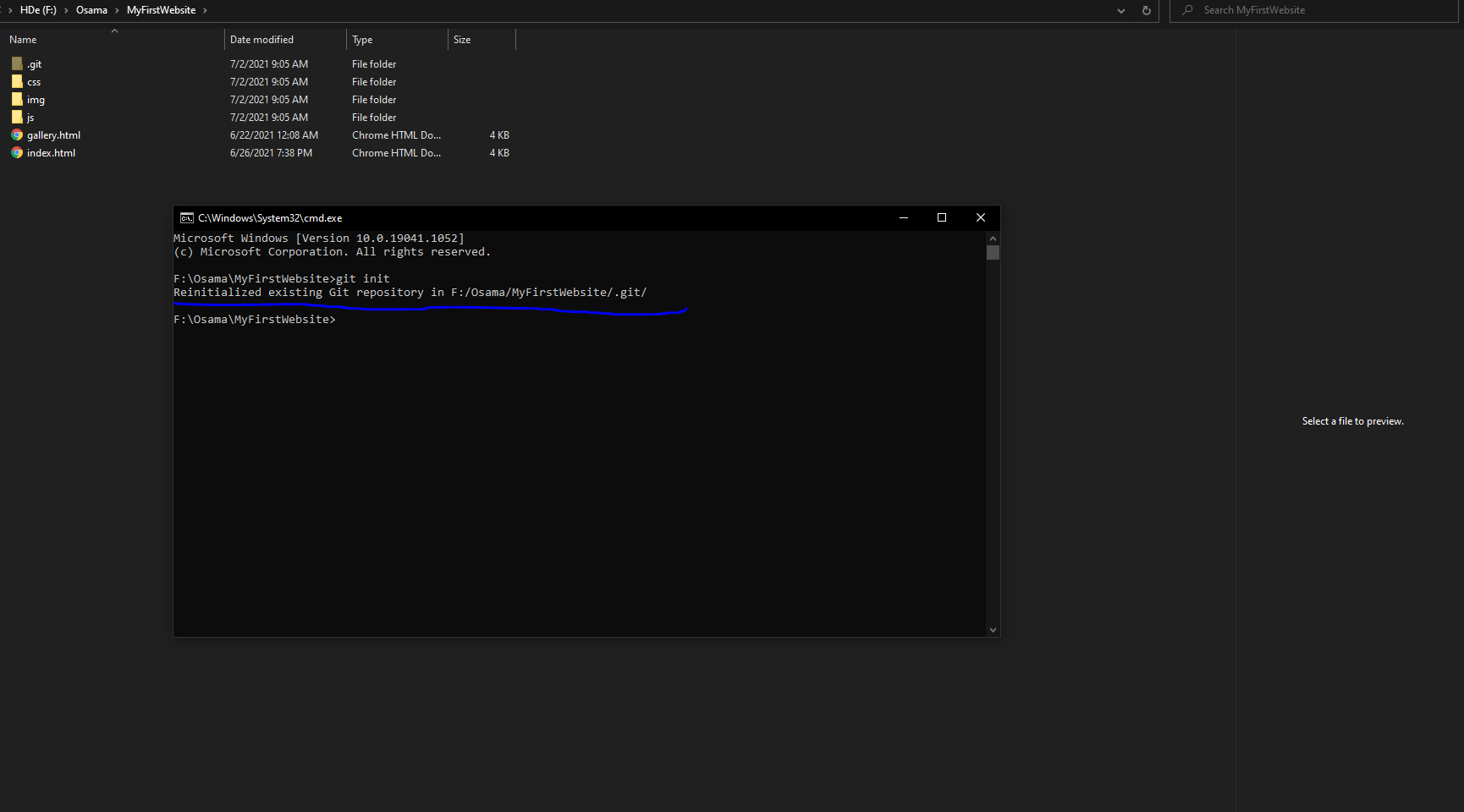
ظهر لى نفس الرسالة
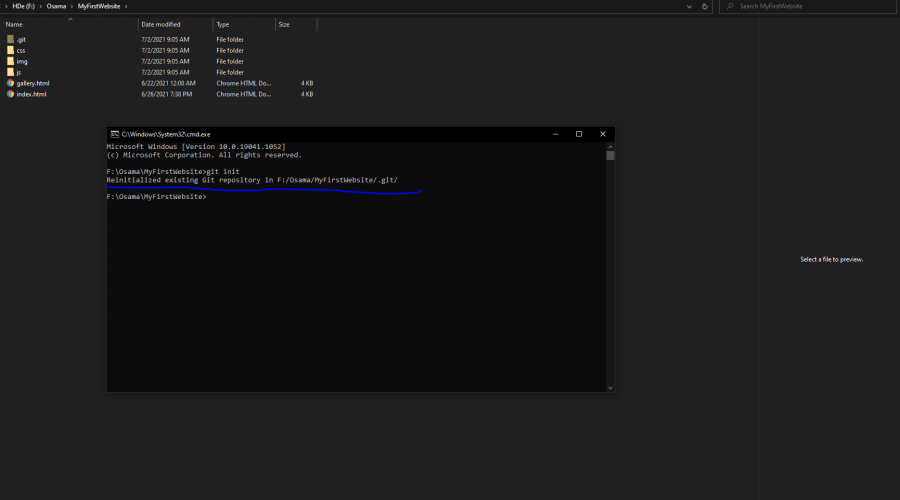 1 نقطة
1 نقطة -
لقد تغيرت الوحدة التي يتم منها استخدام الموديل VGG16 حيث أصبح موجود في applications.vgg16 بدلا من applications لذلك سوف تكون كالأتي: import keras import numpy as np import pandas as pd import matplotlib.pyplot # تصحيح الكود from keras.applications.vgg16 import VGG161 نقطة
-
كدا هيكون للزائر الإختيار ان يشترك او لا انا عايز جزء من الموقع يظهر للمشتركين بس واللي مش مشترك اجباري عليه ان يشترك عشان يظهرله المحتوي1 نقطة
-
بالإضافة لسرعة تنفيذ العمليات المختلفة والكفاءة العالية في التخزين ل numby عن القوائم في python فإن ال numby توفر عليك بعض الأعمال التي ربما تحتاج لمزيد من العمل لتنفيذها من خلال قوائم python مثل الجمع على طول المحور المطلوب numpy.sum(arr, axis, dtype, out) تحويل البيانات من الملفات إلى مصفوفة مباشرة x = numpy.fromfile(file=open("data"), dtype=float).reshape((100, 100, 100)) وهناك أيضاً العديد من المكتبات التي تعمل مع أو تعتمد على ال numby مثل مكتبات ال visualization1 نقطة
-
يمكن حل هذه المشكلة بإستخدام الدالة product في المصفوفات و دالة itertools التي تسمح بالمرور على عناصر المصفوفات واحد تلو الأخر: import numpy as np #إنشاء المصفوفات x = np.array([0, 1, 2]) y = np.array([3, 4, 5]) # إنشاء مصفوفة فارغة لإضافة الناتج فيها لاحقا all = [] # إستخدام الحلقات مع دالة الضرب لإيجاد الناتج و إضافته للمصفوفة for r in itertools.product(x, y): all.append([r[0],r[1]]) np.array(all)1 نقطة
-
بالإضافة إلى ما ذكره @Ali Haidar Ahmad في إجابته يمكننا أيضاً أن نقول هنالك فوارق أخرى بين numpy arrays & lists: المصفوفات لها طول ثابت على عكس القوائم، و في حالة الإضافة للمصفوفة يتم مسح الأصلية و إنشاء واحدة أخرى بنفس الطول + 1. العناصر في القوائم يمكن أن تكون من أنواع مختلفة و لكن العناصر في المصفوفات تكون من نفس النوع، يمكن أن تحتوي عناصر مختلفة لكن لن يتم تنفيذ العمليات الحسابية مثلاً في هذه الحالة. يمكن للمصفوفات التعامل مع العمليات الحسابية و الإحصائية، و العمليات الجبرية و البحث على البيانات الضخمة بصورة أكثر كفاءة و أقل كود. from numpy import arange from timeit import Timer #تحديد عدد البيانات المدخلة Nelements = 10000 #إنشاء قائمة و مصفوفة بنفس الطول x = arange(Nelements) y = range(Nelements) #تعريف دالة الجمع لإستخدامها في قياس المدة الزمنية t_numpy = Timer("x.sum()", "from __main__ import x") t_list = Timer("sum(y)", "from __main__ import y") #طباعة الزمن الناتج من تنفيذ العملية print("numpy: %.3e" % (t_numpy.timeit(Nelements)/Nelements,)) print("list: %.3e" % (t_list.timeit(Nelements)/Nelements,)) البرنامج السابق عبارة عن نموذج يوضح الفرق في سرعة التعامل مع كل من المصفوفات و القوائم التي تصل إلى فرق 10 أضعاف السرعة للمصفوفات مقابل القوائم. numpy: 9.865e-06 list: 1.839e-041 نقطة
-
أول فرق يكمن بالحجم التخزيني، فمصفوفات نمباي تخزن البيانات بشكل أكثر فعالية وتستهلك عدد أقل من البايتات لكل عنصر: import numpy as np import sys # إنشاء قائمة بألفي عنصر l= range(2000) # حجم كل عنصر من عناصر القائمة بالبايت print("Size of each element : ",sys.getsizeof(l),"bytes") # حجم كامل القائمة print("Size of the whole list : ",sys.getsizeof(l)*len(l),"bytes") # إنشاء مصفوفة نمباي بألفي عنصر D= np.arange(2000) # حجم كل عنصر بالمصفوفة print("Size of each element: ",D.itemsize,"bytes") # حجم كامل المصفوفة print("Size of the whole array : ",D.size*D.itemsize,"bytes") ''' Size of each element : 48 bytes Size of the whole list : 96000 bytes Size of each element: 4 bytes Size of the whole array : 8000 bytes ''' الفرق الثاني بزمن التنفيذ حيث أن استخدام مصفوفات نمباي يعد أكثر فعالية في زمن التنفيذ، في المثال التالي ستعرض الفرق بزمن تنفيذ العمليات عندما نستخدم مصفوفات نمباي و القوائم: import numpy as np import time # تعريف قائمتين l1 = range (200000) l2 = range(200000) # تعريف مصفوفتين arr1 = np.arange(2000000) arr2 = np.arange(2000000) # حساب الزمن اللازم لمضاعفة عناصر القائمة start = time.time() r = [(x * y) for x, y in zip(l1, l2)] print("Time when we use lists :",(time.time() - start),"sec") #حساب الزمن اللازم لمضاعفة عناصر المصفوفة start = time.time() r = arr1 * arr2 print("Time when we use numpy arrays :",(time.time() - start),"sec") ''' Time when we use lists : 0.04999589920043945 sec Time when we use numpy arrays : 0.0069963932037353516 sec ''' لذا فهي أكثر كفاءة في التخزين والزمن اللازم لإجراء العمليات عليها، ويعود السبب الأساسي لذلك في طريقة تخزين العناصر في نمباي (تخزن العناصر بشكل متجاور على عكس القوائم)1 نقطة
-
يمكنك تنفيذ الجداءالديكارتي باستخدام التابع التالي اعتماداً على الدالة meshgrid في مكتبة نمباي : import numpy as np x = np.array([0, 1, 2]) y = np.array([3, 4, 5]) # تعريف تابع يقوم بعملية الجداء الديكارتي def cartesian(*arrays): g = np.meshgrid(*arrays) coord = [x.ravel() for x in g] p = np.vstack(coord).T return p # استدعاء التابع وطباعة الخرج print(cartesian(x,y)) # الخرج ''' [[0 3] [1 3] [2 3] [0 4] [1 4] [2 4] [0 5] [1 5] [2 5]] '''1 نقطة
-
في الإصدار الأحدث من numpy 1.8.x ،لديك دالة numpy.meshgrid والتي توفر تنفيذًا أسرع بكثير: دالة numpy.meshgrid() كانت تستخدم لتكون ثنائية الأبعاد فقط ، والآن أصبحت قادرة على ND. في هذا المثال ، ثلاثي الأبعاد: In [115]: %timeit np.array(np.meshgrid([1, 2, 3], [4, 5], [6, 7])).T.reshape(-1,3) 10000 loops, best of 3: 74.1 µs per loop In [116]: np.array(np.meshgrid([1, 2, 3], [4, 5], [6, 7])).T.reshape(-1,3) Out[116]: array([[1, 4, 6], [1, 5, 6], [2, 4, 6], [2, 5, 6], [3, 4, 6], [3, 5, 6], [1, 4, 7], [1, 5, 7], [2, 4, 7], [2, 5, 7], [3, 4, 7], [3, 5, 7]])1 نقطة