
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/01/21 في كل الموقع
-
لقد قمت بتحميل npm على خادم الويب، ولكن عندما أقوم بتنفيذ الأمر التالي: sudo npm install يظهر لدي هذا الخطأ: npm ERR! code EINTEGRITY npm ERR! sha512-MKiLiV+I1AA596t9w1sQJ8jkiSr5+ZKi0WKrYGUn6d1Fx+Ij4tIj+m2WMQSGczs5jZVxV339chE8iwk6F64wjA== integrity checksum failed when using sha512: wanted sha512-MKiLiV+I1AA596t9w1sQJ8jkiSr5+ZKi0WKrYGUn6d1Fx+Ij4tIj+m2WMQSGczs5jZVxV339chE8iwk6F64wjA== but got sha512-WXI95kpJrxw4Nnx8vVI90PuUhrQjnNgghBl5tn54rUNKZYbxv+4ACxUzPVpJEtWxKmeDwnQrzjc0C2bYmRJVKg==. (65117 bytes) npm ERR! A complete log of this run can be found in: npm ERR! /home/ubuntu/.npm/_logs/2017-11-29T05_33_52_182Z-debug.log حاولت إزالة الملف package-lock.json ولكن بقيت نفس المشكلة. كيف يمكنني حل هذا الخطأ؟2 نقاط
-
هل يشترط أن تحتوي قناتك ع اليوتيوب فيديوهات من انتاجك الخاص يعني ملكك إذ اردت الربح منها؟ و هل يقبل اليوتيوب ان تنشر فيديوهات ع قناتك حتى ان لم تكن من صنعك -لكنها ليست ملكا ﻷحد- و هل يمكن لغوغل ادسنس ان يقبل قناتك في هذه الحالة و ان تربح منه؟ شكرًا لكم1 نقطة
-
لقد قرأت التوثيق الرسمي في node.js وطبقّت جميع الأوامر على الملفات من خلال المكتبة fs. لكنني لم أجد تابع ضمن هذه المكتبة لنقل الملفات. كيف يمكنني أن أنقل ملف من مكان لآخر ضمن نفس المجلّد أو ضمن مجلّد آخر في node.js ؟1 نقطة
-
كيف اعمل صفحه في موقعي تظهر لكل مشترك في قناتي علي اليوتيوب ومش مهم مسجل عندي في الموقع ولا لأ المهم ان يكون مشترك في القناة ولو مش مشترك تظهر ليه رساله عباره عن زر الاشتراك1 نقطة
-
هو طريقة لتسريع خوارزمية GD وتخفيف التذبذب وهي فعالة من الناحية الحسابية وتأخذ ذاكرة قليلة ومناسبة للمشكلات الكبيرة في التعلم الآلي التي تكون فيها البيانات كبيرة أو عدد الأوزان في الشبكة كبير جداً، تعتمد على حساب متوسط الأوزان الأسية للمشتقات السابقة وتخزينها في متحول v وكذلك حساب متوسط الأوزان الأسية لمربعات المشتقات السابقة ووضعها في متحول s و تقوم أيضاً بالخلط بين الطريقتين. يتم حساب متوسط الأوزان الأسية للمشتقات السابقة عن طريق القوانين: vdw = B1* vdw + (1-B1)*dw vdb = B1*vdb + (1-B1)*db حيث vdw هيي متوسط الأوزان اأاسي لجميع الأوزان في الشبكة. و vdb متوسط الأوزان اأاسي لل bias في الشبكة. و B1 يمثل معدل الاضمخلال الأسي. يتم حساب متوسط الاوزان الاسية لمربعات المشتقات السابقة عن طريق القوانين: Sdw = B2*Sdw + (1-B2)*dw^2 Sdb = B2*Sdb + (1-B2)*db^2 حيث vdw هيي متوسط الأوزان الاسي لجميع الأوزان في الشبكة. و vdb متوسط الأوزان الاسي لل bias في الشبكة. و B2 معدل التضاؤل الأسي. في كيراس يتم استيراده من خلال الموديول: keras.optimizers لاستخدامه في نموذج نمرره للدالة compile بإحدى الطريقتين: model.compile( optimizer=Adam(learning_rate=0.001) ... ) # أو model.compile( optimizer='adam' ... ) # لاحظ أنه في الطريقة الثانية سيستخدم معمل الخطوة الافتراضي # لذا إذا أردت تغييرها استخدم الصيغة الأولى مثال عن طريقه الاستخدام حيث يأخذ adam الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة. # استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import Adam # تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() # تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 بناء الشبكه العصبونيه بطبقه واحده وطبقة خرج ب 10 أصناف model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) #مع معامل تعلم 0.001 adam استخدام model.compile(optimizer=Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) # تدريب الموديل model.fit(X_train,y_train)1 نقطة
-
لقد تغيرت الوحدة التي يتم منها استخدام الموديل VGG16 حيث أصبح موجود في applications.vgg16 بدلا من applications لذلك سوف تكون كالأتي: import keras import numpy as np import pandas as pd import matplotlib.pyplot # تصحيح الكود from keras.applications.vgg16 import VGG161 نقطة
-
المشكلة تحدث عند محاولة إدخال خرج طبقة ال RNN الأولى إلى طبقة RNN الثانية. إليك مايلي: طبقات ال RNN بأنواعها المختلفة تعمل في وضعين: الأول يرد كامل الخرج كسلسلة متتابعة من ال timestep وبالتالي يكون الخرج هو مصفوفة tensor ثلاثية الأبعاد (batch_size, timesteps, output_features). أما الوضع الثاني فيرد فقط آخر خرج لكل سلسلة إدخال، وبالتالي يكون الخرج ثنائي الأبعاد (batch_size, output_features). ويتم التحكم بنمط الإخراج باستخدام الوسيط return_sequences الذي يأخذ قيمة بوليانية، في حالة True فيكون الخرج هو الوضع الأول وفي حالة False يكون الوضع الثاني، وافتراضياً يكون False ، أي الوضع الثاني. وكما نعلم أن طبقات الRNN تحتاج كدخل (batch_size, sequence_length, features) وأنت تقوم بتكديس طبقتي RNN وبالتالي خرج الأولى سيكون دخل الثانية لذلك يجب أن يكون خرج الأولى 3D أي يجب أن يكون الوضع الأول. لكن أنت تشغل الوضع الأول وبالتالي سيعطي خطأ، لأنها تحتاج 3D وتعتطيها 2D، لذا لحل المشكلة يجب أن نضبط return_sequences على True. from keras.layers import Dense,Embedding,SimpleRNN from keras.datasets import imdb from keras.preprocessing import sequence from keras.models import Sequential max_features = 1000 maxlen = 20 batch_size = 64 print('Loading data...') (input_train, y_train), (input_test, y_test) = imdb.load_data( num_words=max_features) print(len(input_train), 'train sequences') print(len(input_test), 'test sequences') print('Pad sequences (samples x time)') input_train = sequence.pad_sequences(input_train, maxlen=maxlen) input_test = sequence.pad_sequences(input_test, maxlen=maxlen) print('input_train shape:', input_train.shape) model = Sequential() model.add(Embedding(max_features, 16)) model.add(SimpleRNN(16, return_sequences=True)) model.add(SimpleRNN(16)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(input_train, y_train, epochs=2, batch_size=128, validation_split=0.2) ''' Loading data... 25000 train sequences 25000 test sequences Pad sequences (samples x time) input_train shape: (25000, 20) Epoch 1/2 157/157 [==============================] - 4s 14ms/step - loss: 0.6751 - acc: 0.5501 - val_loss: 0.5692 - val_acc: 0.7026 Epoch 2/2 157/157 [==============================] - 2s 10ms/step - loss: 0.5229 - acc: 0.7427 - val_loss: 0.5801 - val_acc: 0.6912 '''1 نقطة
-
هي دالة تكلفة (loss) في كيراس وتنسرفلو ويتم استخدامها مع مسائل التصنيف المتعدد أي عندما يكون لدينا أكثر من فئة (Class label). تتوقع منك مصفوفتين كدخل، واحدة تعبر عن القيم الحقيقية (مصفوفة من الأعداد integer)، والأخرى تعبر عن القيم المتوقعة (float). تعتمد هذه الدالة على المفهوم الشهير في نظرية المعلومات والمعروف ب Cross Entropy أو الإنتروبيا المتقطعة، وهي مقياس لمدى تشابه توزعين احتماليين مختلفين لنفس الحدث وفي ال ML نستخدم هذا التعريف وقانونه لكي نقوم بحساب ال Loss (التكلفة Cost). حيث يكون الخرج الخاص بالشبكة العصبية هو توزيع احتمالي لعدة فئات classes. تابع التنشيط هنا إما Sigmoid أو Softmax فهما تابعي التنشيط الوحيدين المتوافقين مع دالة التكلفة SCCE. الفرق الوحيد بينها وبين CategoricalCrossentropy هو في طريقة تمثيل القيم الحقيقية أو label classes (فئات البيانات)، فهناك نمثلها بأشعة Spare باستخدام الترميز One-Hot أما هنا فلسنا بحاجة للقيام بذلك (ويعتبر هذا الترميز أفضل من ناحية التعقيد الزماني والمكاني كونه لايستهلك دفقات معالجة لافائدة منها كما في ال CCE). أبعاد المدخلات: y_true [batch_size] y_pred [batch_size, num_classes] يتم استيرادها من الموديول: tensorflow.keras.losses مثال: # استيرادها from tensorflow.keras.losses import SparseCategoricalCrossentropy # تشكيل داتامزيفة تعبر عن قيم حقيقية وقيم متوقعة y_true = [2,1,0] # تم تحديد ثلاث أصناف و3 عينات y_pred1 = [[0.1, 0.0,0.9], [0.2, 0.8, 0.0],[0.8, 0.2, 0.0]] # مصفوفة تعبر عن القيم المتوقعة y_pred2 = [[0.0, 0.01,0.99], [0.01, 0.99, 0.0],[0.99, 0.01, 0.0]] # مصفوفة ثانية تعبر عن القيم المتوقعة #SparseCategoricalCrossentropy إنشاء غرض من الكلاس scce = SparseCategoricalCrossentropy() # تمرير القيم الحقيقية والمتوقعة إلى الغرض ليحسب لنا التكلفة scce(y_true, y_pred1).numpy() # 0.18388261 scce(y_true, y_pred2).numpy() # 0.010050405 لاستخدامها ضمن نموذجك كدالة خسارة، نقوم بتمريرها إلى الدالة compile بإحدى الشكلين التاليين، ويمكنك استخدامها ممعيار لنموذجك (لكن في الواقع لا أحد يقوم بذلك): model.compile( loss=tf.keras.losses.SparseCategoricalCrossentropy(), ... ) # أو يمكن تمريرها بسهولة بالشكل التالي model.compile( loss='sparse_categorical_crossentropy', ... ) # لاستخدامها كمعيار model.compile( metrics=['sparse_categorical_accuracy'], ... ) سأقوم بتطبيقها مع مجموعة بيانات routers، حيث أن هذه البيانات لديها 46 فئة (صنف) مختلف: # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) #integer فئات البيانات يجب أن تكون print(train_labels[0:5]) # [3 4 3 4 4] # الآن لنقم بترميز بيانات التدريب import numpy as np #One-Hot قمت بإنشاء تابع يقوم بتحويل بياناتي إلى الترميز # بإمكانك أيضاً استخدام تابع تحويل جاهز def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # لاحظ كيف قمنا بتمرير دالة التكلفة إلى النموذج # التدريب history = model.fit(x_train, train_labels, epochs=8, batch_size=512, validation_split=0.2) # الخرج ''' Epoch 1/8 15/15 [==============================] - 3s 53ms/step - loss: 3.3317 - accuracy: 0.2863 - val_loss: 2.0840 - val_accuracy: 0.5687 Epoch 2/8 15/15 [==============================] - 0s 14ms/step - loss: 1.9193 - accuracy: 0.5986 - val_loss: 1.6421 - val_accuracy: 0.6221 Epoch 3/8 15/15 [==============================] - 0s 14ms/step - loss: 1.4877 - accuracy: 0.6641 - val_loss: 1.3978 - val_accuracy: 0.6956 Epoch 4/8 15/15 [==============================] - 0s 14ms/step - loss: 1.3094 - accuracy: 0.7072 - val_loss: 1.3088 - val_accuracy: 0.7040 Epoch 5/8 15/15 [==============================] - 0s 14ms/step - loss: 1.1608 - accuracy: 0.7329 - val_loss: 1.2279 - val_accuracy: 0.7234 Epoch 6/8 15/15 [==============================] - 0s 13ms/step - loss: 1.0447 - accuracy: 0.7597 - val_loss: 1.2365 - val_accuracy: 0.7067 Epoch 7/8 15/15 [==============================] - 0s 21ms/step - loss: 0.9647 - accuracy: 0.7750 - val_loss: 1.2022 - val_accuracy: 0.7179 Epoch 8/8 15/15 [==============================] - 0s 12ms/step - loss: 0.9104 - accuracy: 0.7882 - val_loss: 1.1006 - val_accuracy: 0.7390 '''1 نقطة
-
يمكنك استخدام تابع إعادة التسمية rename: const fs = require('fs'); fs.rename(oldPath, newPath, callback) والذي من ضمن خصائصه أنه يمكنك تعريف مسار جديد للملف وعندها سيتم نقل هذا الملف من المسار الموجود فيه إلى المسار الجديد، مثال: var old = '..المسار الحالي للملف/file.txt' var new_path = '..المسار الجديد للملف/file.txt' fs.rename(old, new_path, function (err) { if (err) throw err console.log('success') }) كما يمكنك تحميل واستخدام المكتبة mv، ولكن لا حاجة لأي مكاتب خارجية فهي طريقة بسيطة وسريعة من قبل node.js1 نقطة
-
من الممكن أن تكون المشكلة متعلّقة بال cache ل NPM الموجود لديك، لذلك يمكنك تجربة تنفيذ الأمر التالي أولاً: npm cache verify ثم إعادة تنفيذ أمر التحميل من جديد: npm install والتأكد من إزالة package-lock.json ضمن المشروع كما يمكنك تجربة الأمر التالي: npm cache clean --force وفي حال لم تنفع الأوامر السابقة، في نظام تشغيل ويندوز يمكنك التوجه إلى المسار التالي: Users%username%\AppData\Roaming وإزالة المجلّد npm والمجلّد npm-cache، ثم إعادة تحميل npm من جديد. كما يمكنك البحث عن المشكلة مع نسخة الإصدار لديك على الإصدار الرسمي في github فلقد تمت معالجة المشكلة بأساليب مختلفة حسب النسخة المستخدمة.1 نقطة
-
يمكنك إستعمال هاته الأداة المقدمة من مطوري غوغل لإنشاء و تضمين شيفرة زر الإشتراك في القناة , يمكنك ذلك عن طريق : التصفح إلى صفحة الأداة هنا . قم بطباعة المعرف الخاص بالقناة أو يكفي مجرد إسمها . يمكنك تخصيص نسق العرض و والوضع , كما يمكنك التحكم في عرض عدد المشتركين أو لا. و أخيرا قم بنسخ الكود الذي يتم توليده في مربع النص أسفل الشاشة و لسقه في الكود المصدري لموقعك .1 نقطة
-
العفو يا غالي1 نقطة
-
for i in range(1, 101): if i%2==0: print(i) لم افهم السطر الثاني من الكود لكن انا اعرف ان هذا الكود عمله هو ارجاع الاعداد الزوجيه بين 1 الى 100 ولكن انا كتبت الكود بصيغة اخرى هي كتالي z = 0 while z < 100: z += 2 print(z)1 نقطة
-
يمكنك أيضاً إستخدام الدالة reshape للقيام بعملية تحويل شكل inputx: import numpy as np from keras.models import Sequential from keras import layers inputx= np.random.randint(0,40, 4) inputx = inputx.reshape(-1, 4) model = Sequential() model.add(layers.Embedding(input_dim=40, output_dim=32, input_length=4)) model.add(layers.Flatten()) model.add(layers.Dense(units=5, activation='sigmoid')) model.summary() print(model(inputx)) الدالة reshape تقوم بتحويل البيانات من 4 إلى (4,1) يمكنك أيضاً مراجعة شكل النموذج لمعرفة شكل البيانات المدخلة بإستخدام ()model.summary.1 نقطة
-
<select name="food"> @foreach ($items as $item) @if ($loop->last) @isset($selected) <option selected>{{$selected}}</option> @endisset @endif @endforeach </select> الآن، عند اختيار option والضغط على submit شغالة تمام، لكن عند الضغط على submit بدون اختيار option ( يكون ال option ال defualt أول option )، تظهر رسالة خطأ ، لأنه أنا ما عملت select لأي option ف كيف يمكن حل هذه المشكلة؟ باختصار ( أريد عن تشغيل ال form لأول مرة تكون قيمة ال option الأول select )1 نقطة
-
وأخيراااا، الحمد لله، اشتغلت، شكرا جدا جدا1 نقطة
-
هل يمكنك وضع صورة للخطأ أو نص للخطأ الذي يظهر ؟, أو تأكد إسناد قيمة في خاصية value في وسم option بهذا الشكل <select name="food"> <option value="0">الأختيار الأفتراضي</option> @foreach ($items as $item) @if ($loop->last) @isset($selected) <option value="{{$item->id ?? ''}}">{{$selected}}</option> @endisset @endif @endforeach </select> بحيث تقوم بوضع خارج loop وسم option افتراضي وتسند له قيمة معينة و في داخل loop يمكنك تنفيذ كود جلب البيانات , و من ثم إزالة خاصية selected حتى لا يحدث خطأ في عملية أختيار option الافتراضي, و في طبيعة الحال يقوم وسم select باختيار أول option كخيار افتراضي في حالة عدم تحديد أي option كخيار افتراضي عبر خاصية selected.1 نقطة
-
اشتغلت تمام، شكرا جدا على الاقتراح الجميل ( select2 )1 نقطة
-
علامة النسبة المئوية هي شائعة في العديد من لغات البرمجة, ليس فقط في Python , يحدد الباقي عند القسمة على رقمين , لذا في المثال يتم التحقق من الأرقام الزوجية إذا قسمت على 2, فإن الباقي يساوي 0 , فهو عدد زوجي . if i%2==0: تتحقق مما إذا كان الرقم زوجياً. for i in range(1, 101): if i%2==0: print(i) ونتيجة هذا الكود هي 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 94 96 98 1001 نقطة
-
في plugin موجودة تسهل عليك موضوع البحث في dropdown list اسمها select2 اضغط هنا للوصول لرابط الاضافة1 نقطة
-
يجب أن تكون الأبعاد متوافقة مع الطبقة أي يجب أن تكون (1,4) بدلا من (,4). import numpy as np from keras.models import Sequential from keras import layers # إصلاح الكود وتغيير الأبعاد inputx= np.random.randint(0,40, (1,4)) model = Sequential() model.add(layers.Embedding(input_dim=40, output_dim=32, input_length=4)) model.add(layers.Flatten()) model.add(layers.Dense(units=5, activation='sigmoid')) print(model(inputx))1 نقطة
-
هي اختصار لـ Root Mean Squared prop وهي خوارزمية تحسين تستخدم لتسريع خوارزمية gradient descent، وتحسين مسار التدرج. نعلم خوارزمية mini-batch gradient descent تتقدم بشكل أسرع من خوارزمية gradient descent الأساسية ولكن يكون الطريق الذي تسلكه هذه الخوارزمية متذبذب، لذلك لتخفيف هذا التذبذب تقوم هذه الخوارزمية بالتقدم مع الأخذ بعين الاعتبار الـ exponentially weighted average للمشتقات السابقة في الحسبان. يتم في الخطوه الأولى حساب exponentially weighted average عن طريق القوانين: Sdw = B2*Sdw + (1-B2)*dw^2 Sdb = B2*Sdb + (1-B2)*db^2 حيث Sdw هيي متوسط الأوزان الأسي لجميع الأوزان في الشبكة. و Sdb متوسط الأوزان الاسي لل bias في الشبكة. و B هي معامل من المعاملات العليا و يسمى الزخم يتراوح من 0 إلى 1 يستخدم لحساب المتوسط الاسي الجديد، وتحدد الوزن بين متوسط القيمة السابقة والقيمة الحالية. بعد ذلك نقوم بتحديث الأوزان كما في gradient descent عن طريق القوانين: w = w - a * dw / sqrt(Sdw) b= b - a * db / sqrt(Sdb) حيث w أوزان الشبكه العصبونية و b تمثل ال bias في الشبكة العصبونية. و dw التغيير في الأوزان و db التغيير في ال bias. و Sdw هيي متوسط الأوزان الاسي لجميع الأوزان في الشبكة. و Sdb متوسط الأوزان الاسي لل bias في الشبكة. و B هي معامل من المعاملات العليا و يسمى الزخم يتراوح من 0 إلى 1 يستخدم لحساب المتوسط الاسي الجديد، فإنها تحدد الوزن بين متوسط القيمة السابقة والقيمة الحالية. أي أن الفرق الوحيد بين Rmsprop و gradient descent هو أنه في GD يتم تعديل الأوزان بالشكل التالي: w = w - a * dw b= b - a * db و Rmsprop نفس الشئ مع قسمة كل من dw,db على جذر exponentially weighted average يتم استيراد RMSprop في keras من خلال الوحدة optimizer لاستخدامه مع النموذج نقوم بتمريره إلى الدالة compile بإحدى الطريقتين: model.compile( optimizer=RMSprop(learning_rate=0.001), ... ) # أو model.compile( optimizer='rmsprop', ... ) #0.001 لاحظ أنه في الطريقة الثانية سيتم استخدام معامل الخطوة الافتراضي وهو # لذا إذا أردت تغييره فعليك باستخدام الطريقة الأولى مثال عملي لطريقة الاستخدام حيث يأخذ RMSprop الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة. # استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import RMSprop # تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() # تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 # بناء الشبكة العصبونية بطبقة واحدة وطبقة خرج ب 10 أصناف. model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) # استخدام compile مع Rmsprop مع معامل تعلم 0.001 model.compile(optimizer=RMSprop(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) # تدريب الموديل model.fit(X_train,y_train)1 نقطة
-
الطريقة الأخرى لحل هذه المشكلة هي إستخدام flatten وهي عبارة الدالة المسؤولة عن تحويل 2D array للصور لمصفوفة ذات بعد واحد بدلا من بعدين بذلك تصبح 28*28 => 1*784. و تضاف flatten لأول طبقة في النموذج (كما يمكن تحديد الشكل المدخل، لكنه اتوماتيكياً يأخذ شكل العينة 2D). والان بعد إستدعاء flatten وإضافتها في أول طبقة في النموذج يصبح البرنامح كالتالي: from keras.models import Sequential from keras import layers import tensorflow as tf from keras.layers import Flatten from tensorflow.keras.datasets import mnist (X_train,y_train),(X_test,y_test)=mnist.load_data() print(X_train.shape,y_train.shape) model = models.Sequential() model.add(Flatten()) model.add(layers.Dense(512, activation='relu')) model.add(layers.Dense(1, activation='softmax')) model.compile(optimizer='Adam',loss='categorical_crossentropy',metrics=['accuracy']) model.fit(X_train,y_train)1 نقطة
-
في البداية قبل تنفيذ عملية التصنيف يمكنك مراجعة شكل البيانات الداخلة و خصوصاً y لانها التي تستخدم في عملية المقارنة بين القيم الحقيقية و المتوقعة من قبل النموذج، بذلك طريقة حساب الدقة للنموذج. لاحظ في البيانات المدخلة أن y لديها 45 صنف مختلف: np.array(np.unique(train_labels, return_counts=True)).T هنالك دالة OneHotEncoder التي تحول القيم الداخلة من أرقام الى التمثيل المقابل لها بإستخدام المصفوفات، راجع البرنامج التالي وهو عبارة عن تحويل 3 قيم فقط كمثال: import pandas as pd y = np.array([0,1,2]).reshape(-1,1) #تعريف القيم from sklearn.preprocessing import OneHotEncoder #مناداة OneHotEncoder من الموديول enc = OneHotEncoder(handle_unknown='ignore') # التعريف enc.fit_transform(y).toarray() #تطبيق عملية التحويل فبالتالي التعديل في برنامج يكون كالتالي: import numpy as np from keras import models from keras import layers from keras.datasets import reuters from sklearn.preprocessing import OneHotEncoder (train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=1000) def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) enc = OneHotEncoder(handle_unknown='ignore') train_labels1 = enc.fit_transform(train_labels.reshape(-1,1)).toarray() test_labels1 = enc.fit_transform(test_labels.reshape(-1,1)).toarray() model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit(x_train, train_labels1, epochs=8, batch_size=512, validation_split=0.2)1 نقطة
-
يمكن حل هذه المشكلة بإستخدام الدالة product في المصفوفات و دالة itertools التي تسمح بالمرور على عناصر المصفوفات واحد تلو الأخر: import numpy as np #إنشاء المصفوفات x = np.array([0, 1, 2]) y = np.array([3, 4, 5]) # إنشاء مصفوفة فارغة لإضافة الناتج فيها لاحقا all = [] # إستخدام الحلقات مع دالة الضرب لإيجاد الناتج و إضافته للمصفوفة for r in itertools.product(x, y): all.append([r[0],r[1]]) np.array(all)1 نقطة
-
هي دالة تكلفة (loss) في كيراس وتنسرفلو ويتم استخدامها مع مسائل التصنيف المتعدد أي عندما يكون لدينا أكثر من فئة (Class label) الصيغة الرياضية: تعتمد هذه الدالة على المفهوم الشهير في نظرية المعلومات والمعروف ب Cross Entropy أو الإنتروبيا المتقطعة، وهي مقياس لمدى تشابه توزعين احتماليين مختلفين لنفس الحدث وفي ال ML نستخدم هذا التعريف وقانونه لكي نقوم بحساب ال Loss (التكلفة Cost). حيث يكون الخرج الخاص بالشبكة العصبية هو توزيع احتمالي لعدة فئات classes. تابع التنشيط هنا إما Sigmoid أو Softmax فهما تابعي التنشيط الوحيدين المتوافقين مع دالة التكلفة CCE. كنصيحة لنتائج أفضل دوماً اعتمد على ال Softmax. عند استخدامك لهذه الوظيفة يجب عليك أن تقوم أولاً بترميز فئات البيانات لديك باستخدام الترميز One-Hot. يتم استيرادها من الموديول: tensorflow.keras.losses مثال: from tensorflow.keras.losses import CategoricalCrossentropy # إنشاء داتا مزيفة لنجرب عليها # قمنا بتشكيل عينتين ولدينا 3 فئات y_true = [[0, 1, 0], [1, 0, 1]] #تمثل القيم الحقيقية One-Hot مصفوفة من ال y_pred = [[0.01, 0.9, 0], [0.77, 0.6, 0.8]] # مصفوفة القيم المتوقعة # CategoricalCrossentropy إنشاء غرض cce =CategoricalCrossentropy() # حساب الخسارة cce(y_true, y_pred).numpy() # 1.0225062 لاستخدامها في نموذجك: # كالتالي compile لاستخدامه مع النموذج نقوم بتمريره إلى # نقوم أولاً باستيرادها model.compile( loss=tf.keras.losses.CategoricalCrossentropy(), ... ) # أو يمكن تمريرها بسهولة بالشكل التالي model.compile( loss='categorical_crossentropy', ... ) سأقوم بتطبيقها مع مجموعة بيانات routers، حيث أن هذه البيانات لديها 46 فئة (صنف) مختلف: # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=1000) #ترميز الفئات المختلفة للبيانات #كما أشرنا One-Hot-Enoding طبعاً يجب أن نستخدم الترميز from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) # قمنا بعرض فئة أول عينة من بيانات التدريب print('one_hot_train_labels[0]:\n',one_hot_train_labels[0]) ''' one_hot_train_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' # قمنا بعرض فئة أول عينة من بيانات الاختبار print('one_hot_test_labels[0]:\n',one_hot_test_labels[0]) ''' one_hot_test_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' #أي الفئات target انتهينا من ترميز قيم ال # الآن لنقم بترميز بيانات التدريب import numpy as np #One-Hot قمت بإنشاء تابع يقوم بتحويل بياناتي إلى الترميز # بإمكانك أيضاً استخدام تابع تحويل جاهز def vectorize_sequences(sequences, dimension=1000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # بناء الشبكة from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(1000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) # تجميع النموذج model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # لاحظ كيف قمنا بتمرير دالة التكلفة إلى النموذج # التدريب history = model.fit(x_train, one_hot_train_labels, epochs=8, batch_size=512, validation_split=0.2) # الخرج ''' one_hot_train_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] one_hot_test_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] Epoch 1/8 15/15 [==============================] - 1s 26ms/step - loss: 3.3072 - accuracy: 0.2687 - val_loss: 2.0882 - val_accuracy: 0.5598 Epoch 2/8 15/15 [==============================] - 0s 14ms/step - loss: 1.9363 - accuracy: 0.5923 - val_loss: 1.6561 - val_accuracy: 0.6689 Epoch 3/8 15/15 [==============================] - 0s 14ms/step - loss: 1.5366 - accuracy: 0.6684 - val_loss: 1.4629 - val_accuracy: 0.6789 Epoch 4/8 15/15 [==============================] - 0s 13ms/step - loss: 1.3725 - accuracy: 0.7010 - val_loss: 1.3563 - val_accuracy: 0.7067 Epoch 5/8 15/15 [==============================] - 0s 13ms/step - loss: 1.1850 - accuracy: 0.7418 - val_loss: 1.2387 - val_accuracy: 0.7329 Epoch 6/8 15/15 [==============================] - 0s 13ms/step - loss: 1.1154 - accuracy: 0.7538 - val_loss: 1.1835 - val_accuracy: 0.7390 Epoch 7/8 15/15 [==============================] - 0s 12ms/step - loss: 1.0090 - accuracy: 0.7659 - val_loss: 1.1342 - val_accuracy: 0.7524 Epoch 8/8 15/15 [==============================] - 0s 26ms/step - loss: 0.9243 - accuracy: 0.7887 - val_loss: 1.0994 - val_accuracy: 0.7618 '''
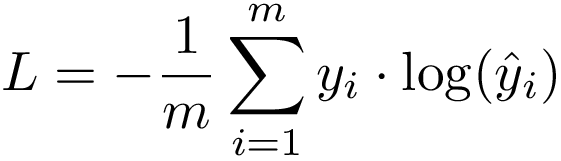 1 نقطة
1 نقطة






