

قد يظن البعض أنّ الإحصائيّات تكذب، لكن الحقيقة ليست كذلك. نعم، يتعمّد بعض الأشخاص استخدام أرقام غير حقيقية واستخراج البيانات بانتقاء، لكن معظم الأشخاص يسيئون تفسير البيانات عن طريق الصدفة فقط.

يُعتبر هذا الموضوع مهمًّا لأنّك تقوم بجمع البيانات المتعلّقة بعملك طوال الوقت؛ عن تدفّق الويب web traffic، مصادر الإيرادات revenue sources، أو سلوك الزبائن، ثمّ تقوم باتّخاذ القرارات على أساس فهمك (أو قد يكون سوء فهم) لتلك البيانات.
سأذكر هنا بعض المشاكل الأساسية التي أواجهها باستمرار.
الإحصائيّات لا تخبرك بالقصة كاملة
من السهل أن تختزل مجموعة من البيانات إلى رقم واحد، كما هو الحال مع "المتوسّط" average؛ سهل ولكنّه غير عملي في بعض الأحيان. الأرقام المفردة تكون أكثر فعّالية، فهي تمكّنك من فهم مجموعة كبيرة من البيانات. وهذا الأمر يُعتبر مفيدًا فِعلًا، لكنّه في نفس الوقت يمكن ألّا يعبّر عن الحقيقة.
لنأخذ رباعية Anscombe كمثال، أربعة مخططات تمتلك خصائص إحصائية متطابقة، ومع ذلك تشكّل بوضوح أربع عمليات متباينة:
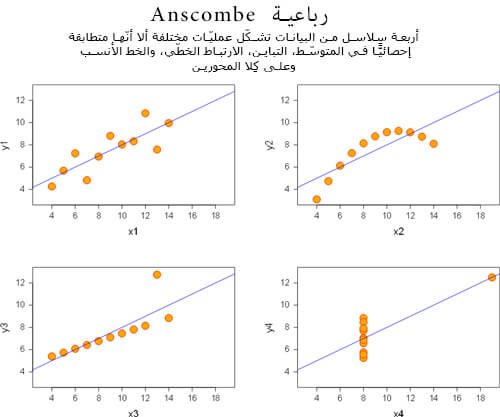
كما هو واضح من المخططات الأربعة أعلاه، الإحصائيّات لا تصِف ما يحدث حقّا مع البيانات. فالمخططات المختلفة نتجت عن إحصائيّات متطابقة.
الحقيقة وراء كل مخطط هي:
- في المخطط الأول: العمليّة هي في الغالب خطّيّة. الخط الأنسب best-fit line ملائم لوصف العلاقة، لكن مع ذلك هنالك أيضًا عوامل أخرى عشوائية في العمل.
- في المخطط الثاني: البيانات مترابطة بصورة مثالية، لكنّها غير خطّيّة. إنّ استخدام إحصائيّات خطّيّة نموذجية يُعتبر أمرًا خاطئًا.
- في المخطط الثالث: البيانات خطيّة بشكل مثالي، مع وجود ناشز outlier واحد. هذا الناشر يتم تجاهله على الأرجح، ويجب أن يمثّل الخط الأنسب best-fit line البيانات الأخرى.
- في المخطط الرابع: البيانات لا تتغير حول المحول السيني باستثناء ناشز واحد والذي ينبغي تجاهله. جميع الأرقام الإحصائية القياسية هي غير مفيدة.
المفاد:
- العمليّات الإحصائية لا يمكن اختزالها إلى رقم واحد.
- تطبيق الإحصائيّات بشكل عشوائي لا يفسّر ما يحدث في الحقيقة.
- المخططات البيانية يمكن أن تساعد في تفسير البيانات.
- المتوسّط قد يكون عديم الفائدة أحيانًا
- لا تستطيع استخدام أداة تحليل دون أن تضطر لاستخدام المتوسّط، كمتوسّط النقرة/اليوم hit/day، متوسّط نسب التحويل conversion ratio، متوسّط حجم التداول transaction size، أو متوسّط الوقت المستغرق في الموقع time on site.
المشكلة هنا هي إنّ المتوسّط ليس عديم الفائدة فحسب، وإنّما مُضلّل. لنأخذ متوسّط الوقت المستغرق في الموقع كمثال والذي يُعتبر كمقياس نموذجي لتحليلات المواقع. إنّ متوسّط الوقت المستغرق في الموقع مهمّ جدًّا في أداة Google Analytics، ويظهر في الجهة العلويّة من لوحة معلومات الموقع، كما موضّح في المثال الحقيقي من مدونتي أدناه:
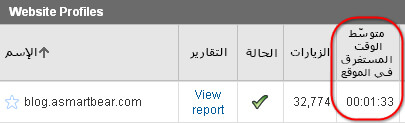
من الجيّد أن يكون الوقت المستغرق في الموقع أطول لأنّ هذا يعني أنّ زوّار الموقع مهتمّون. هل يُعتبر الزمن 1:33 دقيقة جيّدًا؟ هذا هو السؤال الخطأ في الواقع.
سيتضّح الأمر عند تقسيم هذا الرقم إلى عدّة أقسام:
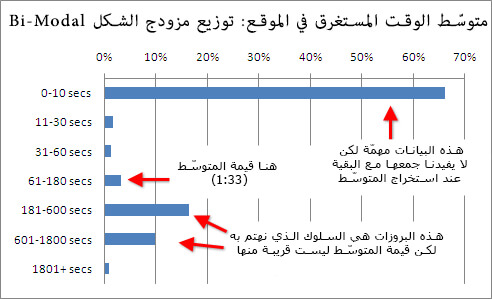
قيمة متوسّط الوقت المستغرق في الموقع المساوية 93 ثانية لا فائدة منها عند محاولة تفسير سلوك المستخدم. الطريقة الصحيحة للتفكير حول الوقت المستغرق في الموقع هي:
- معظم الزوّار يخرج من الموقع bouncing دون النظر إليه حقّا.
- حوالي ثلث الزوّار بقي لفترة كافية لقراءة بعض المقالات.
مع ذلك تبقى طريقتك في تحسين الحالتين 1 و2 مختلفة تمامًا:
- الارتداد bouncing يمكن أن يشير إلى عَوز في مصدر التدفّق traffic source (أي إنّنا جذبنا الأنظار، لكنّها ليست الأنظار الصحيحة)، أو مُشكلة في صفحة الهبوط landing page (أي إنّنا جذبنا الأنظار الصحيحة، لكنّنا فشلنا في استدراجهم إلى قراءة المزيد).
- الحصول على بضع دقائق لتصفّح المدوّنة يُعتبر نجاحًا بالفعل، لكن محاولة جعل شخص ما يبقى لفترة أطول (أي 10 دقائق بدلًا من 5) ربما لا تجدي نفعًا. لذلك السؤال الأنسب هو: كيف نحصل على عدد أكبر من الأشخاص في هذا التصنيف category بدلًا من محاولة زيادة متوسّط الوقت في هذا التصنيف؟
لهذا تعتبر قيمة المتوسّط 1:33 غير مفيدة في وصف الحقيقة. ليس ذلك فحسب، وإنمّا غير مفيدة في معرفة القرار التالي الذي يجب اتّخاذه.
المفاد:
- المتوسّط البسيط عديم المعنى في كثير من الأحيان.
- استخدام رقم واحد لوصف عمليّة ما يمكن أن يزوّر الحقيقة.
- استخدام رقم واحد لوصف عمليّة ما قد يمنعك من تعلّم كيفية التطوير والتحسين للأمثل.
مخاطر "أفضل 10" و"أخرى"
يحب الأشخاص قراءة قوائم "أفضل 10" في جميع المجالات وليس في تقارير تحليلات المواقع فحسب، ويمكن لتلك القوائم أن تكون مفيدة. على سبيل المثال لدّي هنا مخطط لمصادر محركات البحث التي تجلب التدفّق إلى مدونتي:

هنالك العديد من محركات البحث "الأخرى" مثل Ask وAOL، لكن التدفّق الذي يأتي من خلالها قليل جدًّا ويكاد لا يُذكر، لذلك من الأفضل إزالتها من المخطط. المشكلة هنا عندما تكون قيمة "أخرى" ليست بالقليلة التي يمكن تجاهلها. المخطط أدناه هو تقرير حقيقي لاجتماع مجلس الإدارة حضرته السنة الماضية:
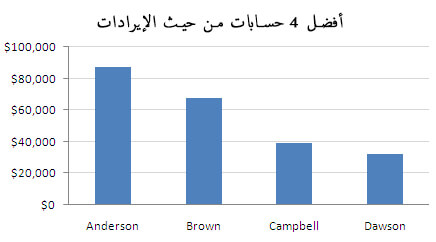
لاحظ المخطط نفسه بعدما تتبعتُ البيانات وقررّتُ إضافة تصنيف "آخرون" إليه.
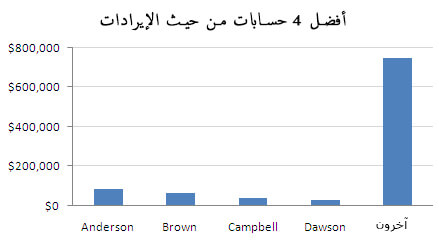
يطلق البعض اسم "الذيل الطويل long tail" على هذا النمط من التوزيع. في هذا النمط هنالك بعض المساهمين الكبار، أكبر بكثير من أي مساهم مفرد آخر، لكن عند جمع كلّ المساهمين الصغار سيصبح تأثيرهم مكافئًا لتأثير المساهمين الكبار، أو حتّى يتفوّق عليه كما في حالتنا هذه.
هنالك عدّة طرق يمكنك اتخاذها عندما تكتشف وجود ذيل طويل في بياناتك. افترض وجود ذيل طويل في خط مبيعات المنتج الخاص بك، كما في شركتيّ iTunes وAmazon اللتين تمتلكان بعض المنتجات الضخمة بالإضافة إلى ذيل طويل يحتوي على الملايين من المنتجات التي تُباع بشكل نادر. فيما يلي أربعة آراء متضاربة حول كيفية التصرّف مع هذه الحالة:
- المنتجات في الذيل الطويل مكلفة جدّا للبيع، لأنّها تتطلب الوصول إلى عدد كبير من الأشخاص الذين يدفعون القليل من المال مقابلها، لذلك لا يمكن اعتبارها مؤثّرة من ناحية الكلفة.
- المنتجات في الذيل الطويل هي الأقل كلفة للبيع، لأنّها تعني الوصول إلى الأسواق لا يستهدفها أحد under-served markets، مما يعني إعلانات رخيصة وزبائن راغبين في الشّراء.
- التعامل بالذيل الطويل يعني إنّنا يجب أن نصبح كلّ شيء من أجل كلّ شخص، وبالتالي نصبح مشتّتين. لنحاول بدلًا من ذلك أن نصبح الرقم واحد في مجال واحد محدّد.
- من الصعب أن نصبح الرقم واحد في جميع المجالات، وفي بعض الأحيان تذهب المكاسب إلى الأشخاص الأغنى، وليس إلى الأشخاص الأذكى أو الأكثر شغفًا. لذلك، بدلًا من منافسة المؤسسات أو الشركات ذات المكانة والسلطة، لنتعامل مع الجزء الآخر من السوق الذي تتجاهله تلك المؤسسات، لكن ليكن الجزء الذي يحتوي على كمية كبيرة من الأعمال الكامنة.
لا يوجد رأي من الآراء السابقة صحيح كليّا. على سبيل المثال تحصل iTunes على معظم عائداتها من المساهمين الكبار (على عكس الاعتقاد الشائع)، لكن الشركات الأخرى مثل Beatport تجني الملايين من الدولارات من الذيل الطويل لأسواق الموسيقى المتخصّصة (الموسيقى الإلكترونية في حالتها).
الشيء الوحيد الخاطئ هو تجاهل عمود "أخرى" في مخططاتك.
المفاد:
- قوائم "أفضل 10" يمكن أن تُخفي بيانات مهمّة.
- تأكد أولًا من أنّك لم تتخلص من معلومات مهمّة عندما تقوم بتصفية البيانات الخاصّة بك.
- أنماط البيانات كالذيل الطويل ليست جيّدة أو سيّئة بحد ذاتها. كما إنّ هنالك عدّة طرق يمكنك استخدامها عندما تتصرف إزاء الحالات المختلفة.
قواعد المقاييس الإحصائية والإحصائيات لا يمكن أن تطبق عشوائيا
لنفترض لديك المخطط التالي (لم نسم البيانات عمدًا):
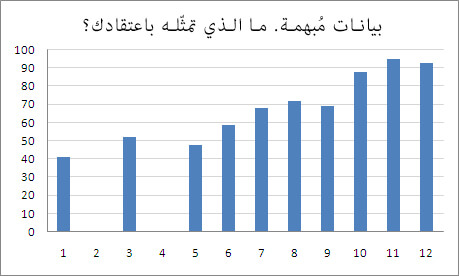
من خلال المخطط نلاحظ أنّ:
- قيمة المتوسّط هي 57.
- القيم بشكل عام تتزايد كلّما اتّجهنا نحو اليمين.
- بعض البيانات مفقودة، أو ربّما ينبغي إهمالها.
مع ذلك تبقى هذه الملاحظات محض افتراضات، وقد تكون خاطئة اعتمادًا على الحالة. لنفترض السيناريوهات التالية:
- قد تكون هذه البيانات هي درجات اختبار لطلّاب في مرحلة ما. في البداية الطلاب يرسبون، وفي منتصف المرحلة تتحسن درجات الطلاب بسبب توظيفهم لمدرّس ما، ثم في نهاية المرحلة يُتقن الطلّاب المادّة. هؤلاء الطلاب يجب تقييمهم بالدرجتين A أو B بسبب التحسّن الواضح والنتائج المستقّرة في اختبارات نهاية السنة الصعبة. لكن يجب أن لا يحصل الطالب على درجة 57؛ متوسّط الدرجات.
- أو يمكن أن تمثّل هذه البيانات نتائج لدراسة أجراها شخص ما حول فعّالية إعلان معيّن. إنّ التقييم "صفر" للموضوعين رقم 2 ورقم 4 هو بيانات حقيقية، ولكنّه يمثّل إشارة سيّئة. يمكن أن يشير هذا التقييم إلى خطأ فادح في الإعلان، قد يكون إعلانًا ضارًّا مثلًا. ما يجب فعله هو البحث والاستفسار من المشاركين في هذه الدراسة لمعرفة سبب الفشل. وبشكل عام، تشّكل قيمة المتوسّط، من ضمنها الأصفار، إشارة مفيدة إلى فعّالية الإعلان ككل. الأمر الذي يدعو للتساؤل هو التحسّن في المراحل اللاحقة، حيث كان من المفترض اختيار المشاركين بشكل عشوائي. من الممكن أن يشير هذا إلى تحيّز في الاختبار نفسه.
من الأمور المثيرة للاهتمام حول النقطة رقم 1 هي إنّه يجب إهمال أغلب البيانات لكي نحصل على قيمة متوسّط مفيدة، والعكس هو الصحيح مع النقطة رقم 2.
بيت القصيد هنا هو إنّ السياق الذي تدور حوله البيانات هو الذي يحدّد طريقة تفسيرها. لذلك لا يمكننا وضع القواعد عشوائيًّا، كأنْ نحدّد البيانات التي يمكن تجاهلها.
المفاد:
- يجب تفسير النتائج اعتمادًا على السياق، لا أن نطّبق الصيغ عشوائيًّا.
- يجب تشكيل نظريّة معيّنة في البداية، ثم ننظر فيما إذا كانت البيانات تدعَم أو تدحض تلك النظرية.
الصيغ ليست بديلا عن التفكير
الإحصائيّات، حالها حال أي أداة أخرى، يمكن أن تكون مفيدة إذا استُخدمت بشكل صحيح، وهي خطيرة إذا استُخدمت بخلاف ذلك. كما في أي خوارزمية؛ البيانات السيّئة تعود عليك بالنتائج السيّئة. أجل، هذا يعني إنّ تحليلات المقاييس metrics analysis هي أصعب مما تبدو عليه، وإنّ عليك أن تستغرق وقتًا في فهم البيانات وأن تبحث مع الآخرين للتحقق من أسلوب تفكيرك.
لكن ما البديل لذلك؟ هل ستفكّر في العمليّات الخاصّة بك بصورة خاطئة ثم تُضّيع وقتك في الحلول غير المنطقيّة؟
المفاد الأخير: بما أنّ المقاييس صعبة وتستغرق وقتًا ومجهودًا لتصحيحها، لا تحاول معايرة والعمل على 100 من المتغيّرات، بل اختر القليل مما تفهمه، تستطيع العمل عليه وتحسينه، عندها تستطيع عمل تغييرات إيجابية وعبقرية في عملك.
هل لديك نصائح أو ملاحظات أخرى؟ أضف تعليقًا في الأسفل وشاركنا بها.
ترجمة وبتصرّف للمقال Avoiding common data-interpretation errors لصاحبه: Jason Cohen.
حقوق الصورة البارزة: Designed by Freepik.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.