كل الأنشطة
- الساعة الماضية
-
اعتقد ان المشكلة لديكى فى جزء الحفظ فى قاعدة البيانات فلقد قمتى بالخطأ فى ترتيب ادخال البيانات . cur.execute("INSERT INTO products (ProductName, ExpiryDate, Ingredient) VALUES (%s, %s, %s)", (product_name, ingredient, date_value)) لاحظى انكى يجب ادخال اسم المنتج ثم تاريخ الانتهاء ثم المكونات . ولكنى قد قمتى بالاستبدال . لذلك استبدلى السطر لديكى بهذا السطر . cur.execute("INSERT INTO products (ProductName, ExpiryDate, Ingredient) VALUES (%s, %s, %s)", (product_name,date_value ,ingredient)) واذا لم يحل المشكلة فاعقتد ان المشكلة لديكى فى قاعدة البيانات وللتاكد اكثر يجب ارسال رسالة الخطأ التى تظهر فى منفذ الاوامر لديكى
-
بشمهندس خالد سوال لو سمحت هي مش البرمجه الديناميكيه ده ممكن نستخدمها في خورزميات تاني اوحل حل مشاكل تاني
-
 Scythe Raccoon اشترك بالأكاديمية
Scythe Raccoon اشترك بالأكاديمية -
الأعضاء 17 نشر منذ 32 دقيقة السلام عليكم يظهر معي هذه المشكلة ... POST http://localhost:5000/save_data 500 (INTERNAL SERVER ERROR) لما أريد أخذ داتا من الموقع بواسطة js وحفظها في داتا بيس عن طريق عمل كونكشن بواسطة flask python كيف أقدر أحل المشكلة كود البايثون: @app.route('/save_data', methods=['POST']) def save_data(): try: data = request.get_json() product_name = data['productName'] ingredient = data['ingredient'] date_value = data['date'] cur = mysql.connection.cursor() cur.execute("INSERT INTO products (ProductName, ExpiryDate, Ingredient) VALUES (%s, %s, %s)", (product_name, ingredient, date_value)) mysql.connection.commit() cur.close() return jsonify({"message": "Data saved successfully"}), 200 except Exception as e: print("Exception:", e) return jsonify({"error": str(e)}), 500 كود js: async function confirmSave() { if (confirm("Are you sure you want to save the data?")) { const productName = prompt("Please enter the name of the product:"); if (productName !== null && productName.trim() !== "") { await saveData(productName); } else { alert("Product name cannot be empty."); } } } async function saveData(productName) { const containers = document.querySelectorAll('.container'); let ingredient = ''; let date = ''; let algrency = ''; containers.forEach((container, index) => { const textBox = container.querySelector('.text-box'); const value = textBox.value.trim(); switch(index) { case 0: ingredient = value; break; case 1: date = value; break; case 2: algrency = value; break; } }); // Prepare data to send const postData = { productName: productName, ingredient: ingredient, date: date, }; try { const response = await fetch('/save_data', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(postData) }); if (!response.ok) { throw new Error('Network response was not ok'); } const responseData = await response.json(); console.log(responseData.message); // Log the response message } catch (error) { console.error('Error:', error); } console.log("Product Name:", productName); console.log("Ingredient:", ingredient); console.log("date:", date); console.log("Algrency:", algrency); }
-
 علاء الدين الحطاب اشترك بالأكاديمية
علاء الدين الحطاب اشترك بالأكاديمية -
 من خلال معامل or أو and حسب طبيعة الشروط، فمعامل or يتم تنفيذ الجملة الشرطية إن تحقق أحد الشروط الثلاث، بينما and يجب تحقق جميع الشروط. ففي جافاسكريبت سيكون الأمر كالتالي: function checkAdmission(mathGrade, scienceGrade, historyGrade) { const mathRequirement = 80; const scienceRequirement = 75; const historyRequirement = 70; if (mathGrade >= mathRequirement && scienceGrade >= scienceRequirement && historyGrade >= historyRequirement) { return "مؤهل للقبول في البرنامج"; } else { return "غير مؤهل للقبول في البرنامج"; } } console.log(checkAdmission(85, 80, 75)); console.log(checkAdmission(70, 80, 60)); أما إن كان بخصوص SQL سيفيدك التالي: المعاملات المنطقية في SQL
من خلال معامل or أو and حسب طبيعة الشروط، فمعامل or يتم تنفيذ الجملة الشرطية إن تحقق أحد الشروط الثلاث، بينما and يجب تحقق جميع الشروط. ففي جافاسكريبت سيكون الأمر كالتالي: function checkAdmission(mathGrade, scienceGrade, historyGrade) { const mathRequirement = 80; const scienceRequirement = 75; const historyRequirement = 70; if (mathGrade >= mathRequirement && scienceGrade >= scienceRequirement && historyGrade >= historyRequirement) { return "مؤهل للقبول في البرنامج"; } else { return "غير مؤهل للقبول في البرنامج"; } } console.log(checkAdmission(85, 80, 75)); console.log(checkAdmission(70, 80, 60)); أما إن كان بخصوص SQL سيفيدك التالي: المعاملات المنطقية في SQL- 1 جواب
-
- 1
-

-
 Montaser Shozan اشترك بالأكاديمية
Montaser Shozan اشترك بالأكاديمية -
شكراا لحضرتك جدا
-
وعليكم السلام ورحمة الله وبركاته، باختصار شديد، أعرض لك جميع الاختيارت (ولكن الاختيار الأخير هو الأجدد) لتحويل موقع ويب إلى تطبيق محلي native application لدينا عدة اختيارات، أولها: تطوير تطبيق منفصل لكل من الأندرويد وIOS بلغات البرمجة المخصصة لكل منصة ثانيًا: تطوير تطبيق واحد باستخدام لغات البرمجة الهجينة وسيعمل على كل المنصات (ولكن بالتأكيد سيفقد بعض المزيا) ثالثًا: تطوير تطبيق ويب فيو web view وهو يعرض نفس الموقع ولكن من داخل تطبيق وليس المتصفح هذه النقاط وضحها الزملاء الأفاضل بالتعليقات السابقة. رابعًا: والأحدث توجد نقنية جديدة رائعة ظهرت مؤخرًا، وهي تطبيقات الويب التقدمية PWA Progressive Web Application وهي باختصار: تعديلات تتم على موقع الويب نفسه (أي لا نحتاج لتطوير تطبيقات محلية)، هذه التعديلات تجعل تطبيق الويب يتصرف وكأنه تطبيق محلي، أي - يمكن تثبيته على الجهاز الخاص بك وإظهار أيقونة على سطح المكتب أو شاشة البداية - يمكنه العمل بنافذة مستقلة دون الحاجة إلى المتصفح - يمكنه العمل بدون اتصال بالإنترنت offline - يمكنه الوصول إلى موارد الجهاز مثل الكاميرا والبلوتوث وغيرها - يمكنه إظهار الإشعارات - يمكنه التزامن عند عودة الاتصال، فيقوم بإرسال البيانات إلى الخادم والتي تم تخزينها أثناء الانقطاع والعديد من المزايا الأخرى، التي تجعله يبدو ويتصرف كالتطبيقات المحلية (رغم أنه نفس الموقع ولكن بعد إجراء عدة تعديلات عليه)، وهي تقنية جديدة تنمو سريعًا وتنتشر بشكل خرافي.
-
عملت هذه الخطوات هذا الكود للبايثون: @app.route('/save_data', methods=['POST']) def save_data(): try: data = request.get_json() product_name = data['productName'] ingredient = data['ingredient'] date_value = data['date'] cur = mysql.connection.cursor() cur.execute("INSERT INTO products (ProductName, ExpiryDate, Ingredient) VALUES (%s, %s, %s)", (product_name, ingredient, date_value)) mysql.connection.commit() cur.close() return jsonify({"message": "Data saved successfully"}), 200 except Exception as e: print("Exception:", e) return jsonify({"error": str(e)}), 500 وهذا الكود للجافاسكربت: async function confirmSave() { if (confirm("Are you sure you want to save the data?")) { const productName = prompt("Please enter the name of the product:"); if (productName !== null && productName.trim() !== "") { await saveData(productName); } else { alert("Product name cannot be empty."); } } } async function saveData(productName) { const containers = document.querySelectorAll('.container'); let ingredient = ''; let date = ''; let algrency = ''; containers.forEach((container, index) => { const textBox = container.querySelector('.text-box'); const value = textBox.value.trim(); switch(index) { case 0: ingredient = value; break; case 1: date = value; break; case 2: algrency = value; break; } }); // Prepare data to send const postData = { productName: productName, ingredient: ingredient, date: date, }; try { const response = await fetch('/save_data', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(postData) }); if (!response.ok) { throw new Error('Network response was not ok'); } const responseData = await response.json(); console.log(responseData.message); // Log the response message } catch (error) { console.error('Error:', error); } console.log("Product Name:", productName); console.log("Ingredient:", ingredient); console.log("date:", date); console.log("Algrency:", algrency); } ما هي المشكلة؟
-
السلام عليكم كيف يمكن صياغة دالة شرطية من ثلاثة شروط مثلا اذا اكان العمود a كذا او كذا او كذا فان تكلفتة هي العمود d وشكرا جزيلاً لكل من تفاعل وافاد
- 1 جواب
-
- 2
-
-
 Mohamed Salah83 اشترك بالأكاديمية
Mohamed Salah83 اشترك بالأكاديمية -
 عيسى عودة اشترك بالأكاديمية
عيسى عودة اشترك بالأكاديمية -
 ملهم الحراكي اشترك بالأكاديمية
ملهم الحراكي اشترك بالأكاديمية -
 Firas Nazzal اشترك بالأكاديمية
Firas Nazzal اشترك بالأكاديمية -
هناك مشكلة بالخادم الخاص بـ flask بسبب خطأ 500، هل يظهر خطأ معين في التيرمنال (منفذ الأوامر) الخاص بالخادم؟ وهل الخادم يعمل بشكل صحيح؟ أي قبل إرسال البيانات هل يظهر خطأ معين أم يعمل بشكل سليم؟ أيضًا تأكدي من استيراد مكتبات Flask الصحيحة: from flask import Flask, request, jsonify وتعريف نقطة النهاية POST: @app.route("/save_data", methods=["POST"]) def save_data(): # ... ثم تحليل بيانات JSON من طلب POST: data = request.get_json() ثم التفاعل مع قاعدة البيانات لحفظ البيانات وإرجاع استجابة مناسبة: return jsonify({"message": "Data saved successfully"}) وتأكدي من أنكِ ترسلين طلب POST بدلاً من طلب GET.
-
وعليكم السلام ورحمة الله وبركاته . ان ال HTTP response status code 500 تعنى انه يوجد خطأ فى الخادم اى انه حدث مشكلة لديك فى تنفيذ الكود على الخادم . لذلك تاكد من ارسال البيانات بشكل صحيح و ان تكون الشيفرة الخاصة بحفظ البيانات صحيحة . واذا ما زالت المشكلة موجوده فيجب توفير الكود الخاص بحفظ البيانات لنرى اين توجد المشكلة ونستطيع ان نساعدك
-
 ربما لم تضغط على التبويبة الخاصة بفك الضغط الخاصة ببرنامج WinRAR لديك، لإيجادها، قم بالضغط بالفأرة من خلال الزر الأيمن فوق المجلد الذي ترغب في فك الضغط عنه، ثم اختر الخيار المشار في الصورة، وفي حالة كان للمجلد كلمة سر يجب عليك أن تضعها كي يتم فك الضغط من خلال البرنامج، قم بإرفاق صور توضيحية أكثر في حال لم يعمل معك الأمر.
ربما لم تضغط على التبويبة الخاصة بفك الضغط الخاصة ببرنامج WinRAR لديك، لإيجادها، قم بالضغط بالفأرة من خلال الزر الأيمن فوق المجلد الذي ترغب في فك الضغط عنه، ثم اختر الخيار المشار في الصورة، وفي حالة كان للمجلد كلمة سر يجب عليك أن تضعها كي يتم فك الضغط من خلال البرنامج، قم بإرفاق صور توضيحية أكثر في حال لم يعمل معك الأمر.
-
وعليكم السلام ورحمة الله، دعنا أولًا نتفق على شيء هام جدًا، وهو إذا لديك اختياران كلاهما صحيح، فلا يوجد تفضيل مطلق (أي دائمًا)، بمعنى لا يوجد اختيار هو الأفضل دائمًا، ولكن يوجد اختيار هو الأنسب للحالة التي بين أيدينا، (أؤكد أن الخيارين صحيحان فنحن هنا لا نقارن بين ممارسة صحيحة وأخرى خاطئة). كلتا الشفرتين صحيحتان سواء كصيغة أو كممارسة، نأتي هنا للأنسب، أيهما أنسب؟ هذا يتوقف على الحالة كما وضحت، ففي الكثير من الأحيان يفضل المبرمجون الطريقة الثانية كما وضح مهندس مصطفى @Mustafa Suleiman لأنها طريقة واضحة ومباشرة وخصوصًا إذا يوجد مبتدئين بالفريق فربما لا يعرفون الطريق الأولى. وبالمناسبة الطريقة الأولى مشهورة جدًا في لغات البرمجة وتسمى "العامل الثلاثي" ternary operator ويفضلها الكثير من المبرمجين لأنها رائعة في إعطاء المتغير إحدى قيمتين بناء على شرط معين، فمن يعتاد عليها يدمنها حرفيًا (وأنا واحد منهم)، ولكن هل أستخدمها في كل مكان؟ بالطبع لا ولكن هناك حالات مناسبة لها وحالات أخرى غير مناسبة، من أكبر الفوائد لهذه الطريقة أنها تجنب الوقوع في الأخطاء، انظر للشيفرات التالية .. device = "cuda" if torch.cuda.is_available(): device = "cude" else "cpu": devic = "cpu" هل لاحظت شيئًا؟ لقد حدث خطأ إملائي في اسم المتغير بالسطر الأخير، وهذا سيسبب في مشاكل كبيرة جدًا، لأن بايثون سيعتبر أنك تريد تعريف متغير جديد اسمه devic ولا يعلم أنه تقصد المتغير device، هذه من ضمن فوائد العامل الثلاثي، ولكن كما قلت، يستخدم بحذر. الخلاصة: تعتمد الطريقة على الحالة التي بين يديك، فإذا كان الفريق يحتوي العديد من المبتدئين، فالطريقة الثانية أنسب، أما إذا لديهم خلفية جيدة عن العامل الثلاثي، فالطريقة الثانية ستكون أنسب في حالة إعطاء إحدى قيمتين للمتغير بناء على شرط معين.
- 4 اجابة
-
- 1
-
-
السلام عليكم يظهر معي هذه المشكلة ... POST http://localhost:5000/save_data 500 (INTERNAL SERVER ERROR) لما أريد أخذ داتا من الموقع بواسطة js وحفظها في داتا بيس عن طريق عمل كونكشن بواسطة flask python كيف أقدر أحل المشكلة
- 4 اجابة
-
- 2
-
-
لديك برنامج WinRAR بالفعل وهو البرنامج المسؤول عن التعامل مع الملفات المضغوطة، لفك الضغط عن ملف نضغط عليك بزر الفأرة الأيمن ثم نختر extract here أو فك الضغط هنا ليتم فك ضغط الملف في نفس المكان. ما المشكلة التي تظهر لك؟
-
 Youssef Hany Raghib اشترك بالأكاديمية
Youssef Hany Raghib اشترك بالأكاديمية -
 Amr MansouR9 اشترك بالأكاديمية
Amr MansouR9 اشترك بالأكاديمية -
 Hana Asiri اشترك بالأكاديمية
Hana Asiri اشترك بالأكاديمية - اليوم
-
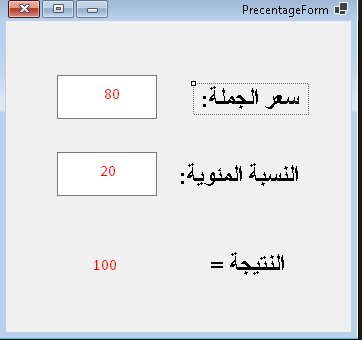
على ما يبدو أنك تريد إظهار سعر البيع بمجرد تغيير سعر الشراء أو النسبة المئوية، في هذه الحالة تحتاج لمعالجة حدث التغير لمربع النص TextChanged لكل من مربعي النص، وكتابة المعادلة الصحيحة لحساب سعر البيع. ولكن يمكنك إضافة زر أوامر Button وكتابة الشيفرات داخله بدلاً من معالجة حدث التغير لمربعات النص. وبالمناسبة يمنكك استخدام أداة أخرى أفضل من مربع النص تسمى NumericUpDown وتستخدم لإدخال قيم عددية فقط، ويتم معرفة القيمة المكتوبة عن طريق الخاصية Value بدلاً من الخاصية Text لمربع النص. إذاً، يفضل إضافة زر أوامر، وتسميته بالشكل الصحيح وليكن btnCalcPrice، ثم النقر عليه مرتين لمعالجة الحدث Click وكتابة الشيفرات التالية // نفترض لديك مربعان نص وأداة عنوان بالأسماء التالية // txtOrigin, txtRatio, lblSalePrice // قراءة سعر الشراء الأصلي من مربع النص الأول decimal originPrice = decimal.Parse(txtOrigin.Text); // قراءة النسبة المئوية من مربع النص الثاني decimal ratio = decimal.Parse(txtRatio.Text); // حساب سعر البيع عن طريق إضافة النسبة المئوية من سعر الشراء إلى سعر الشراء // بفرض سعر الشراء 80، والنسبة 20 فإنه يضيف 20% من سعر الشراء (أي 16 جنيهًا) إلى السعر الأصلي 80، ليصير سعر البيع 96 decimal salePrice = originPrice + (originPrice * ratio / 100); // يتم إظهار سعر البيع في أداة العنوان lblSalePrice.Text = salePrice.ToString(); الآن، اكتب السعر السعر الأصلي، والنسبة، ثم اضغط على الزر ليظهر سعر البيع.
-
تمام شكرااا لحضرتك ونا كمان بتفق مع حضرتك جدا ولكن في ناس بتكب بالطريق الاول فا كانت عاوز اشوف الموضع ده
-
بالطبع الطريقة الثانية، فمن الوهلة الأولى تستطيع معرفة وظيفة الكود وآلية عمله. هناك مقولة جيدة، وهي "من الصعب قراءة الكود ومن السهل كتابته". ففي الكود البسيط، الطريقة الأولى أفضل، لكن في المشاريع الحقيقية لكن يكون هناك كود بسيط وصغير، لذا المحافظة على كود قابل للقراءة وليس مختصر أفضل.
- 4 اجابة
-
- 1
-
-
السلام عليكم اي افضل طريق لكتب كود باثيون واي فيه دول يعتبر كود نظيف ده device = "cuda" if torch.cuda.is_available() else "cpu" والا ده device = "cuda" if torch.cuda.is_available(): pass else "cpu": pass اي الفرق بين الثنين دول هل في فرق في السرعه او الذكرا وهكذا يعني
- 4 اجابة
-
- 3
-
-
المشكلة إذن في المنطق البرمجي، فلحساب النسبة المئوية عليك ضرب القيمة بالنسبة المئوية وقسمها على 100. double retailPrice = wholesalePrice * (wholesalePrice / 100));
-
لو سمحتم، كنت أريد أن أقوم بوضع نسبة مئوية مع وضع رقم سعر الجملة وتظهر النتيجة برقم سعر البيع كما في الصورة بلغة سي شارب؟
- 2 اجابة
-
- 2
-
-
مرحباً عمرو , يوجد كتاب اسمه Software Testing: An ISTQB-BCS Certified Tester Foundation Guide بقلم : Brian Hambling، Peter Morgan، Angelina Samaroo، Geoff Thompson يغطي هذه الكتب الأساسيات والمفاهيم الأساسية لاختبارات البرمجيات ويمكن أن توفر لك فهماً جيدا للعمليات اليدوية. أيضاً يوجد مواقع مثل : Ministry of Testing و الذي يوفر مجتمعا كبيرا من محترفي اختبار البرمجيات ويقدم مقالات وموارد مفيدة للمبتدئين والمتقدمين. Software Testing Help : يقدم مقالات ودروسا حول مختلف جوانب اختبار البرمجيات، بما في ذلك الاختبار اليدوي. موقع أكاديمية حسوب , وحسوب IO , والذي يقدمان مقالات متنوعة في البرمجة, ويوجد فريق من المدربين سوف يقوم بالاجابة عليك على أي سؤال كان .
-
 في السيناريوهات العمليّة غالبًا مانحتاج إلى تلخيص النصوص لاستخلاص المعلومات المفيدة من المستندات أو الوثائق المختلفة. بدءًا من المقالات البحثية المُعقّدة وتقارير الأرباح المالية إلى رسائل البريد الإلكتروني الطويلة والمقالات الإخباريّة. ويتطلّب تلخيص النصوص فهمًا دقيقًا للمقاطع الطويلة، والقدرة على تحليل المحتوى المعقد، والكفاءة في صياغة نص متماسك يُلخّص الموضوعات الأساسية للوثيقة الأصلية. خلال هذه المقالة سوف: نبحث عن نص لكي نُنفّذ عملية التلخيص عليه باستخدام تقنيات الذكاء الاصطناعي. نتعرّف على أفضل النماذج الموجودة حاليًّأ لتنفيذ هذه المهمة. نكتب بعض التعليمات البرمجية لتنفيذ ذلك. نُقيّم أداء النماذج باستخدام أدوات تقييم الأداء ذات الصلة بهذه المهمة. النص الذي سنؤدي عليه المهام الموضحة أعلاه هو عبارة عن نص يوضح مجموعة من الاعتبارات والمبادئ الأساسية لتطوير ونشر أنظمة الذكاء الاصطناعي، وقد جلبناه من أحد المواقع يدويًّا من أجل التجريب وتبسيط العمل، لكن في السيناريوهات العمليّة، قد نحتاج إلى استخراج هكذا نصوص من مواقع الويب، وهذا يتطلب استخدام أدوات ومكتبات إضافية أخرى. import textwrap content = """Mozilla's "Trustworthy AI" Thinking Points: PRIVACY: How is data collected, stored, and shared? Our personal data powers everything from traffic maps to targeted advertising. Trustworthy AI should enable people to decide how their data is used and what decisions are made with it. FAIRNESS: We’ve seen time and again how bias shows up in computational models, data, and frameworks behind automated decision making. The values and goals of a system should be power aware and seek to minimize harm. Further, AI systems that depend on human workers should protect people from exploitation and overwork. TRUST: People should have agency and control over their data and algorithmic outputs, especially considering the high stakes for individuals and societies. For instance, when online recommendation systems push people towards extreme, misleading content, potentially misinforming or radicalizing them. SAFETY: AI systems can carry high risk for exploitation by bad actors. Developers need to implement strong measures to protect our data and personal security. Further, excessive energy consumption and extraction of natural resources for computing and machine learning accelerates the climate crisis. TRANSPARENCY: Automated decisions can have huge personal impacts, yet the reasons for decisions are often opaque. We need to mandate transparency so that we can fully understand these systems and their potential for harm.""" نحن الآن جاهزون للبدء بتلخيص هذا النص. لكن دعنا نناقش بداية أبرز التحديات والحلول المرتبطة بتقنيات الذكاء الاصطناعي. التحديات والحلول في الوضع الراهن للذكاء الاصطناعي يتطلّب الوضع الراهن في الذكاء الاصطناعي أن يبقى مهندس الذكاء الاصطناعي يقظًا ومتابعًا لأهم الأعمال والتقنيات والأوراق البحثيّة الجديدة، فكل أسبوع نشاهد العديد من الاختراقات في هذا المجال، فمثلًا التقنيات التي كانت تُستخدم مع مهمةً ما منذ سنة، أصبحت الآن قديمة بكل معنى الكلمة، فربما كنت تستخدم فرضًا نموذج GPT 3 في مشروعك، لكن في لحظة كتابة هذا المقال لدينا GPT 3.5 و GPT 4، وهما نموذجان يُمثلان قفزة هائلة عن GPT 3 وفي المستقبل القريب ستظهر بالتأكيد نماذج أخرى أحدث وأكثر استقرارًا وكفاءة. نستنتج من ذلك أن البيئة الحاليّة للذكاء الاصطناعي هي بيئة ديناميكيّة تتغيّر باستمرار، لذا لن يكون من السهل على المهندسين الجدد المهتمين بهذا المجال مواكبة تلك التطورات السريعة، لذا فالأمر يتطلّب اجتهادًا وصبرًا طويلين، وهذا يتضمّن: التعرّف على النماذج مفتوحة المصدر المتوفرة. معرفة مدى مُلاءمة النماذج للمهام المحددة. مثلًا إذا كنت تعمل على مهام تتضمّن توليد اللغة مثل توليد النص أو تلخيصه، فالأفضل غالبًا هي النماذج التي تعتمد على بنية مُفكك التشفير Decoder من نموذج المحولات Transformers مثل GPT أو CTRL، أو بنيتي مُفكك التشفير والمُشفّر Encoder معًا كما في T5. فهم المعايير والمقاييس المستخدمة لتقييم هذه النماذج فبعض المقاييس مُصمّمة لمهام محددة فقط. معرفة النماذج التي تُحقّق أفضل النتائج على المهمة المطلوبة، وذلك وفقًا للمقاييس والمعايير النموذجيّة للمهمة المدروسة. ضمان التوافق مع الأجهزة المتوفرة، مثلًا ChatGPT لايدعم الآندرويد لحظة كتابة هذا المقال. أما بالنسبة للمهندسين المُنخرطين بالفعل في سوق العمل ويعملون في ظل مواعيد نهائية ضيقة، فربما سيكون من الصعب جدًا عليهم مواكبة أحدث التطورات، والذي يزيد من تعقيد المشكلة هو كثرة المواقع والمجلات والمؤتمرات التي تُنشر فيها أحدث التطورات أو يجري التحدث فيها عن أحدث التطورات، وهذا ما يجعل من الصعب على المهندسين الوصول إلى معلومات شاملة وموحدة. كيف يمكنني معرفة النماذج مفتوحة المصدر المتاحة لمهمة تلخيص النصوص؟ بالعودة لمهمة تلخيص النص التي تحدثنا عنها في بداية المقال مبدئيًّا، نوصي باستكشاف مكتبة HuggingFace التي تتضمّن دليلًا شاملًا للنماذج مفتوحة المصدر مُصنّفةً حسب المهمة، فهي ممتازة كنقطة انطلاق. يمكنك الدخول إلى هذا الرابط على سبيل المثال ورؤية العديد من النماذج الخاصة بهذه المهمة. طبعًا بعض هذه النماذج التي ستراها في القائمة بالتأكيد ستتضمّن نماذج اللغة الكبيرة LLMs، وكما تعلم فهذه النماذج تكون مصممة للأغراض العامة (النماذج اللغوية تُصمّم للتعامل مع العديد من المهام) وليس فقط مهمة تصنيف النص، لذا قد لاترغب بذلك، أو إذا كنت ترغب بذلك (الحل الأفضل)، فيتوجّب عليك تكييفها أو ضبطها Fine-tune على مهمة التلخيص المدروسة إن لم تكن مضبوطة عليها مُسبقًا. لكن في ظل هذا العدد الكبير جدًا من النماذج، قد تنتساءل: ما هي النماذج التي يجب أن أختارها؟ وتزداد الحيرة أكثر بسبب كون هذه النماذج مُدرّبة على أنواع مُختلفة من البيانات، فأحدها ربما يكون مُدرّبًا على تلخيص النشرات الإخباريّة، بالتالي يكون مُدرّبًا على بيانات تتضمّن نشرات أخبار؛ هذا يعني أن هذا النموذج يصلح فقط لتلخيص النصوص الإخباريّة وليس أي نوع آخر، والأسوأ أن بعض النماذج غير معروف ما نوع البيانات المُدرّبة عليها. والإجابة عن هذا السؤال هي "استخدام المقاييس metrics" التي تقيس جودة النموذج بالنسبة للمهمة المطلوبة. كيف يمكننا تقييّم أداء نماذج تلخيص النصوص؟ يمكن أن تكون الخطوات التالية بمثابة إطار عام لتقييم أي نموذج كان بغض النظر عن المهمة المدروسة، أي سواء كانت مهمة تلخيص النص أم غيرها. تجدر الملاحظة أنّه من أجل أن يكون التقييم دقيقًا، يجب علينا اختبار أداء النموذج على أكثر من مجموعة بيانات، لكن من أجل البساطة، سنجرّب حاليًا على مجموعة بيانات واحدة فقط. ابحث عن مجموعة بيانات معياريّة (نموذجيّة) تُستخدم في تقييم النموذج المدروس وفقًا للمهمة المطلوبة. طبعًا عندما نقول نموذجيّة أو معياريّة، فهذا يعني أنها مُعتمدة وموثوقة وصالحة وخالية من التحيزات (إلى أكبر حد ممكن) وذات جودة عالية، وذلك لتتماشى مع مبادئ الاستخدام المسؤول للذكاء الاصطناعي. على سبيل المثال يكمن استخدام موقع Paper with code، فهو يوفر أفضل النماذج ومجموعات البيانات التي يُجري الباحثون تقييماتهم عليها. مثلًا هنا يمكنك أن تجد أبرز المجموعات المناسبة لمهمة تلخيص النص (فمجموعات البيانات التي ستراها في الرابط وفي الموقع عمومًا هي مجموعات بيانات معياريّة). التعرّف على المقاييس المُستخدمة لتقييم المهمة المطروحة. طبعًا هناك مقاييس مُحددة لكل مهمة، وقد يكون مقياسًا ما صالحًا لمهمة واحدة أو عدة مهام. إجراء التقييم باستخدام مقياس واحد أو أكثر، وعلى مجموعة بيانات واحدة أو أكثر (يُفضّل أكثر من واحدة). العثور على مجموعات البيانات كما ذكرت في الفقرة السابقة؛ أفضل طريقة هي الذهاب إلى موقع Papers With Code، فهو موقع موثوق تٌنشر فيه أبرز الأوراق البحثيّة في الذكاء الاصطناعي مع مستودعات الشيفرات البرمجية المرتبطة بها. اذهب أولاً إلى الموقع ثم إلى انتقل لقسم Datasets، ثم ابحث عن "Text Summarization" ثم انتقل إلى قسم Datasets واضغط على "توسيع أو See all" ومن هناك تظهر جميع مجموعات البيانات ذات الصلة مع إمكانية فرزها أو تصفيتها وفق رغبتك. في حالتنا نريد أن نفرزها حسب عدد مرات الاقتباس cite. نختار الآن مجموعة البيانات الأكثر اقتباسًا والتي غالبًا ماتكون الأكثر شعبية، وهي مجموعة بيانات "CNN/DailyMail" في وقت كتابة هذه المقالة. لاداعي لتحميل مجموعة البيانات حاليًّا، وإنما سنراجع المعلومات المُتعلقة بمجموعة البيانات هذه والموجودة على موقع Papers With Code، وذلك من أجل الخطوة التالية. تجدر الملاحظة إلى أن مجموعة البيانات هذه متاحة أيضًا على Huggingface. الآن عليك التحقق من 3 أشياء: الترخيص license: مجموعة البيانات مُرخصة من معهد ماساتشوستس للتكنولوجيا MIT، أي يمكننا استخدامها لكل من المشاريع التجارية والشخصية. الأوراق البحثية الأحدث على هذه البيانات: وذلك لمعرفة فيما إذا كانت الأوراق البحثية التي تستخدم هذه البيانات حديثة أم قديمة. لمعرفة ذلك نفرز الأوراق تنازليًّا. في حالتنا فإن الأوراق التي تستخدم هذه البيانات حديثة (من عام 2023)، وهذا مانرغب به! مدى توفر المعلومات المتعلقة بأصل مجموعة البيانات وعملية جمعها وشفافية الأساليب (مدى صراحة وشمولية توثيق الأساليب المستخدمة لجمع ومعالجة وتنظيم مجموعة البيانات) المستخدمة في إنشائها: مجموعة البيانات مُنشئة من قبل شركة IBM بالشراكة مع جامعة مونتريال، وذلك عظيم! فهذه مصادر موثوقة تلتزم بهذه المتطلبات. دعونا الآن نستكشف المقاييس المُستخدمة في تقييم أداء النماذج على مجموعة البيانات هذه. تقييم النماذج في هذه المرحلة يجب علينا استكشاف المقاييس التي يُشاع استخدامها من قبل الباحثين في تقييّم نماذج التلخيص على مجموعات البيانات. طبعًا يُفترض أن يكون لديك فهم نظري لمهمة تلخيص النص، وإلا فلن تكون قادرًا على فهم هذه المقاييس. هناك نوعان مختلفان لمهمة تلخيص النص (يمكن اعتبار كل نوع بمثابة مهمة فرعيّة)، النوع الأول هو "تلخيّص النص التجريدي Abstractive Text Summarization" والثاني "تلخيّص النص الاستخراجي Extractive Text Summarization" في النوع الأول يكون الهدف هو تلخيص النص من حيث المعنى، وهذا يعني أن يكون لدينا جمل جديدة، أما في النوع الثاني فيكون عبارة عن استخلاص مقتطفات بسيطة من النص. بالنسبة لمجموعة البيانات التي سنعمل عليها (مقالات CNN)، فهي مرتبطة بالنوع الأول. نلاحظ هنا العديد من المصطلحات وهي ROUGE-1 و ROUGE-2 و ROUGE-3، وهي المقاييس الشائعة لهذه المهمة الفرعية، كما نلاحظ العديد من النماذج ونتائجها وفقًا لهذه المقاييس الثلاث، وهو ما نحتاجه. الآن إذا قارنا بين هذه النماذج وفقًا للمقياس الأول، فنلاحظ أن أول 3 نماذج نتائجها متقاربة، حيث نلاحظ أن جميعها تقترب من 50 وهي قيمة واعدة وفقًا لمقياس ROUGE. اختبار النموذج بعد أن تعرّفنا على المقاييس التي يجب أخذها بعين الاعتبار لتقييم النماذج ورؤيتنا لأفضل ثلاثة منها، يمكننا الانتقال إلى مرحلة اختبار النماذج. تجدر الملاحظة أن هذه النماذج يُفضّل أن تُشغّل على وحدة معالجة الرسومات GPU لكونها تنفذ المهام بصورة متزامنة لتحسين الأداء (وبعضها قد لا يعمل إلا عليها)، لكن يمكن أن يكون بعضها قادرًا على العمل على وحدات CPU وبأداء مقبول. دعونا نختار نموذج Pegasus من بين تلك الخيارات، والأمر الذي يجعل اختيارنا موفقًا هو أن هذا النموذج جرى تدريبه على مجموعة بيانات CNN التي نعمل معها بالنسبة لمهمة "استخلاص النص التجريدي". بعد ذلك لنكتب الكود التالي بلغة البرمجة بايثون والذي يستخدم إطار عمل باي توش PyTorch للغة بايثون ومكتبة Transformers من Hugging Face ونموذج Pegasus لتلخيص النصوص: # We start by installing the transformers library %pip install transformers sentencepiece بعد ذلك علينا الوصول إلى نموذج Pegasus من مكتبة المحولات (مكتبة Huggingface): from transformers import PegasusForConditionalGeneration, PegasusTokenizer import torch # Set the seed, this will help reproduce results. Changing the seed will # generate new results from transformers import set_seed set_seed(248602) # We're using the version of Pegasus specifically trained for summarization # using the CNN/DailyMail dataset model_name = "google/pegasus-cnn_dailymail" # If you're following along in Colab, switch your runtime to a # T4 GPU or other CUDA-compliant device for a speedup device = "cuda" if torch.cuda.is_available() else "cpu" # Load the tokenizer tokenizer = PegasusTokenizer.from_pretrained(model_name) # Load the model model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device) # Tokenize the entire content batch = tokenizer(content, padding="longest", return_tensors="pt").to(device) # Generate the summary as tokens summarized = model.generate(**batch) # Decode the tokens back into text summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] # Compare def compare(original, summarized_text): print(f"Article text length: {len(original)}\n") print(textwrap.fill(summarized_text, 100)) print() print(f"Summarized length: {len(summarized_text)}") compare(content, summarized_text) عند تنفيذ الكود سنحصل على تلخيص النص الأصلي content المكون من 1427 حرفًا، وكما تلاحظ يحتوي التلخيص summarized_text على 320 حرفًا فقط ويركز على العبارات والجمل الهامة في النص الأصلي. Article text length: 1427 Trustworthy AI should enable people to decide how their data is used.<n>values and goals of a system should be power aware and seek to minimize harm.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security. Summarized length: 320 تعمل الأمور بطريقة صحيحة، لكن يبدو أن النص المُلخّص موجزًا جدًا ويحتاج إلى تضمين المزيد من التفاصيل أو السياق. لنرى فيما إذا كان بالإمكان جعل المُلخّص أكثر شمولًا وتفصيلًا. لنقم بإجراء بعض التعديلات على الكود بهدف تغيير طول ومحتوى التلخيص الناتج، بداية لنغير قيمة متغير "البذرة seed" من 248602 إلى 860912 لتوليد نتائج جديدة كما يلي: ملاحظة: نستخدم مفهوم البذور seeds لتهيئة مولّد الأرقام العشوائية، حيث أنّه يحتاج إلى رقم يبدأ به (قيمة أولية) حتى يتمكن من إنشاء رقم عشوائي. افتراضيًّا يستخدم وقت النظام الحالي. set_seed(860912) # Generate the summary as tokens, with a max_new_tokens summarized = model.generate(**batch, max_new_tokens=800) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) ستكون النتيجة على النحو التالي: Article text length: 1427 Trustworthy AI should enable people to decide how their data is used.<n>values and goals of a system should be power aware and seek to minimize harm.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security. Summarized length: 320 يبدو أن الأمر لم ينجح أيضًا. لنحاول تجريب أسلوب فك تشفير يُسمّى "أخذ العينات sampling"، حيث يختار النموذج الكلمة التالية في النص بناءً على توزيعها الاحتمالي الشرطي (أي احتمال اختيار كلمة ما، بالنظر إلى الكلمات السابقة). هنا يكون لدينا مُتغير يسمى "درجة الحرارة temperature" للتحكم في مستوى العشوائية والإبداع في المخرجات المولّدة. هذه المعلمة تُعدّل الاحتمالات قبل أخذ العينات. تؤدي درجة الحرارة المرتفعة إلى زيادة العشوائية (أي ليس من الضروري أن يأخذ الكلمة الأكبر احتمالًا دومًا)، بالتالي مخرجات أكثر تنوعًا وإبداعًا، والعكس من ذلك يجعل عملية أخذ العينات أكثر حتمية ودقة. set_seed(118511) summarized = model.generate(**batch, do_sample=True, temperature=0.8, top_k=0) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) سنحصل الآن على النتيجة التالية: Article text length: 1427 Mozilla's "Trustworthy AI" Thinking Points:.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data. Summarized length: 193 نلاحظ أن الخرج أقصر، لكنه ذو جودة أعلى. ربما إذا رفعنا متغير درجة الحرارة temperature، ستكون النتيجة أفضل. set_seed(108814) summarized = model.generate(**batch, do_sample=True, temperature=1.0, top_k=0) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) هذا هو التخليص الناتج وهو كما تلاحظ أكثر وضوحًا من التلخيص السابق: Article text length: 1427 Mozilla's "Trustworthy AI" Thinking Points:.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security.<n>We need to mandate transparency so that we can fully understand these systems and their potential for harm. Summarized length: 325 دعونا نستخدم الآن طريقة فك تشفير تدعىtop_k`، وهي طريقة تعتمد على أخذ الكلمات k الأعلى احتمالًا (الكلمات المُرشّحة)، ثم الاختيار عشوائيًّا بينها. هذا النهج يهدف إلى السماح للنموذج بأن يكون دقيقًا مع هامش من الإبداع بفضل إدخال العشوائية في الاختيار. والمعلمة k هي معلمة يجب ضبطها بدقة لتحقيق التوازن بين الدقة والإبداع، فمع القيم الكبيرة لها قد يبدو النص بلا معنى وأقل تماسكًا، ومع القيم الصغيرة ستكون النتائج حتميّة وخاليّة من أي إبداع، وقد تتضمّن جملًا مكررة. set_seed(226012) summarized = model.generate(**batch, do_sample=True, top_k=50) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) بعد القيام بالتغييرات السابقة لاحظ التلخيص الناتج: Mozilla's "Trustworthy AI" Thinking Points look at ethical issues surrounding automated decision making.<n>values and goals of a system should be power aware and seek to minimize harm.People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security. Summarized length: 355 دعونا الآن نجرّب نهجًا يدعى top-p أو أخذ عينات النواة Nucleus sampling، وهنا تشير p إلى قيمة حديّة، عند تجاوزها نتوقف عن ترشيح كلمات جديدة. بمعنى أوضح، تُفرز الكلمات تنازليًّا وفقًا لاحتمالاتها، ثم نبدأ باختيار الكلمات واحدة تلو الأخرى حتى يصبح مجموع احتمالاتها أكبر من p، ثم بعد ذلك نختار إحدى الكلمات المُرشحة عشوائيًا. توفّر هذه الطريقة أيضًا التوازن بين العشوائية والحتمية. فقيم p القريبة من 1 تعطي خرجًا أكثر تنوعًا والقيم القريبة من 0 أكثر حتمية. الفرق بينه وبين top_k هو أن عدد الكلمات المُرشّحة يكون ديناميكيًّا وأكثر قابليّة للتكيّف وفقًا للتوزيع الاحتمالي للكلمة التالية على طول مجموعة المفردات. set_seed(21420041) summarized = model.generate(**batch, do_sample=True, top_p=0.9, top_k=50) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) # saving this for later. pegasus_summarized_text = summarized_text سيكون التخليص الآن على النحو التالي: Article text length: 1427 Mozilla's "Trustworthy AI" Thinking Points:.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security.<n>We need to mandate transparency so that we can fully understand these systems and their potential for harm. Summarized length: 325 قد نتساءل ما هي الطريقة الأفضل لفك التشفير. لسوء الحظ، لا توجد طريقة "أفضل" لفك التشفير، ويعتمد اختيار النهج الأفضل على طبيعة البيانات التي تُنشئ مُلخصًا لها ونوع هذه النصوص، وعلى درجة الإبداع و الحتمية التي تريد أن تراها في النص الناتج. وبذلك نكون قد وصلنا إلى نهاية المقالة، حيث تحدّثنا فيها عن مهمة تلخيص النص، وعن كيفية استخدام أحدث النماذج لإنجاز ذلك. ترجمة -وبتصرُّف- للمقال Mozilla AI Guide Launch with Summarization Code Example لصاحبه Melissa Thermidor. اقرأ أيضًا مدخل إلى الذكاء الاصطناعي وتعلم الآلة. تعلم الآلة Machine Learning - الذكاء الاصطناعي. عشرة مشاريع عملية عن الذكاء الاصطناعي. أدوات برمجة نماذج تعلم الآلة.
في السيناريوهات العمليّة غالبًا مانحتاج إلى تلخيص النصوص لاستخلاص المعلومات المفيدة من المستندات أو الوثائق المختلفة. بدءًا من المقالات البحثية المُعقّدة وتقارير الأرباح المالية إلى رسائل البريد الإلكتروني الطويلة والمقالات الإخباريّة. ويتطلّب تلخيص النصوص فهمًا دقيقًا للمقاطع الطويلة، والقدرة على تحليل المحتوى المعقد، والكفاءة في صياغة نص متماسك يُلخّص الموضوعات الأساسية للوثيقة الأصلية. خلال هذه المقالة سوف: نبحث عن نص لكي نُنفّذ عملية التلخيص عليه باستخدام تقنيات الذكاء الاصطناعي. نتعرّف على أفضل النماذج الموجودة حاليًّأ لتنفيذ هذه المهمة. نكتب بعض التعليمات البرمجية لتنفيذ ذلك. نُقيّم أداء النماذج باستخدام أدوات تقييم الأداء ذات الصلة بهذه المهمة. النص الذي سنؤدي عليه المهام الموضحة أعلاه هو عبارة عن نص يوضح مجموعة من الاعتبارات والمبادئ الأساسية لتطوير ونشر أنظمة الذكاء الاصطناعي، وقد جلبناه من أحد المواقع يدويًّا من أجل التجريب وتبسيط العمل، لكن في السيناريوهات العمليّة، قد نحتاج إلى استخراج هكذا نصوص من مواقع الويب، وهذا يتطلب استخدام أدوات ومكتبات إضافية أخرى. import textwrap content = """Mozilla's "Trustworthy AI" Thinking Points: PRIVACY: How is data collected, stored, and shared? Our personal data powers everything from traffic maps to targeted advertising. Trustworthy AI should enable people to decide how their data is used and what decisions are made with it. FAIRNESS: We’ve seen time and again how bias shows up in computational models, data, and frameworks behind automated decision making. The values and goals of a system should be power aware and seek to minimize harm. Further, AI systems that depend on human workers should protect people from exploitation and overwork. TRUST: People should have agency and control over their data and algorithmic outputs, especially considering the high stakes for individuals and societies. For instance, when online recommendation systems push people towards extreme, misleading content, potentially misinforming or radicalizing them. SAFETY: AI systems can carry high risk for exploitation by bad actors. Developers need to implement strong measures to protect our data and personal security. Further, excessive energy consumption and extraction of natural resources for computing and machine learning accelerates the climate crisis. TRANSPARENCY: Automated decisions can have huge personal impacts, yet the reasons for decisions are often opaque. We need to mandate transparency so that we can fully understand these systems and their potential for harm.""" نحن الآن جاهزون للبدء بتلخيص هذا النص. لكن دعنا نناقش بداية أبرز التحديات والحلول المرتبطة بتقنيات الذكاء الاصطناعي. التحديات والحلول في الوضع الراهن للذكاء الاصطناعي يتطلّب الوضع الراهن في الذكاء الاصطناعي أن يبقى مهندس الذكاء الاصطناعي يقظًا ومتابعًا لأهم الأعمال والتقنيات والأوراق البحثيّة الجديدة، فكل أسبوع نشاهد العديد من الاختراقات في هذا المجال، فمثلًا التقنيات التي كانت تُستخدم مع مهمةً ما منذ سنة، أصبحت الآن قديمة بكل معنى الكلمة، فربما كنت تستخدم فرضًا نموذج GPT 3 في مشروعك، لكن في لحظة كتابة هذا المقال لدينا GPT 3.5 و GPT 4، وهما نموذجان يُمثلان قفزة هائلة عن GPT 3 وفي المستقبل القريب ستظهر بالتأكيد نماذج أخرى أحدث وأكثر استقرارًا وكفاءة. نستنتج من ذلك أن البيئة الحاليّة للذكاء الاصطناعي هي بيئة ديناميكيّة تتغيّر باستمرار، لذا لن يكون من السهل على المهندسين الجدد المهتمين بهذا المجال مواكبة تلك التطورات السريعة، لذا فالأمر يتطلّب اجتهادًا وصبرًا طويلين، وهذا يتضمّن: التعرّف على النماذج مفتوحة المصدر المتوفرة. معرفة مدى مُلاءمة النماذج للمهام المحددة. مثلًا إذا كنت تعمل على مهام تتضمّن توليد اللغة مثل توليد النص أو تلخيصه، فالأفضل غالبًا هي النماذج التي تعتمد على بنية مُفكك التشفير Decoder من نموذج المحولات Transformers مثل GPT أو CTRL، أو بنيتي مُفكك التشفير والمُشفّر Encoder معًا كما في T5. فهم المعايير والمقاييس المستخدمة لتقييم هذه النماذج فبعض المقاييس مُصمّمة لمهام محددة فقط. معرفة النماذج التي تُحقّق أفضل النتائج على المهمة المطلوبة، وذلك وفقًا للمقاييس والمعايير النموذجيّة للمهمة المدروسة. ضمان التوافق مع الأجهزة المتوفرة، مثلًا ChatGPT لايدعم الآندرويد لحظة كتابة هذا المقال. أما بالنسبة للمهندسين المُنخرطين بالفعل في سوق العمل ويعملون في ظل مواعيد نهائية ضيقة، فربما سيكون من الصعب جدًا عليهم مواكبة أحدث التطورات، والذي يزيد من تعقيد المشكلة هو كثرة المواقع والمجلات والمؤتمرات التي تُنشر فيها أحدث التطورات أو يجري التحدث فيها عن أحدث التطورات، وهذا ما يجعل من الصعب على المهندسين الوصول إلى معلومات شاملة وموحدة. كيف يمكنني معرفة النماذج مفتوحة المصدر المتاحة لمهمة تلخيص النصوص؟ بالعودة لمهمة تلخيص النص التي تحدثنا عنها في بداية المقال مبدئيًّا، نوصي باستكشاف مكتبة HuggingFace التي تتضمّن دليلًا شاملًا للنماذج مفتوحة المصدر مُصنّفةً حسب المهمة، فهي ممتازة كنقطة انطلاق. يمكنك الدخول إلى هذا الرابط على سبيل المثال ورؤية العديد من النماذج الخاصة بهذه المهمة. طبعًا بعض هذه النماذج التي ستراها في القائمة بالتأكيد ستتضمّن نماذج اللغة الكبيرة LLMs، وكما تعلم فهذه النماذج تكون مصممة للأغراض العامة (النماذج اللغوية تُصمّم للتعامل مع العديد من المهام) وليس فقط مهمة تصنيف النص، لذا قد لاترغب بذلك، أو إذا كنت ترغب بذلك (الحل الأفضل)، فيتوجّب عليك تكييفها أو ضبطها Fine-tune على مهمة التلخيص المدروسة إن لم تكن مضبوطة عليها مُسبقًا. لكن في ظل هذا العدد الكبير جدًا من النماذج، قد تنتساءل: ما هي النماذج التي يجب أن أختارها؟ وتزداد الحيرة أكثر بسبب كون هذه النماذج مُدرّبة على أنواع مُختلفة من البيانات، فأحدها ربما يكون مُدرّبًا على تلخيص النشرات الإخباريّة، بالتالي يكون مُدرّبًا على بيانات تتضمّن نشرات أخبار؛ هذا يعني أن هذا النموذج يصلح فقط لتلخيص النصوص الإخباريّة وليس أي نوع آخر، والأسوأ أن بعض النماذج غير معروف ما نوع البيانات المُدرّبة عليها. والإجابة عن هذا السؤال هي "استخدام المقاييس metrics" التي تقيس جودة النموذج بالنسبة للمهمة المطلوبة. كيف يمكننا تقييّم أداء نماذج تلخيص النصوص؟ يمكن أن تكون الخطوات التالية بمثابة إطار عام لتقييم أي نموذج كان بغض النظر عن المهمة المدروسة، أي سواء كانت مهمة تلخيص النص أم غيرها. تجدر الملاحظة أنّه من أجل أن يكون التقييم دقيقًا، يجب علينا اختبار أداء النموذج على أكثر من مجموعة بيانات، لكن من أجل البساطة، سنجرّب حاليًا على مجموعة بيانات واحدة فقط. ابحث عن مجموعة بيانات معياريّة (نموذجيّة) تُستخدم في تقييم النموذج المدروس وفقًا للمهمة المطلوبة. طبعًا عندما نقول نموذجيّة أو معياريّة، فهذا يعني أنها مُعتمدة وموثوقة وصالحة وخالية من التحيزات (إلى أكبر حد ممكن) وذات جودة عالية، وذلك لتتماشى مع مبادئ الاستخدام المسؤول للذكاء الاصطناعي. على سبيل المثال يكمن استخدام موقع Paper with code، فهو يوفر أفضل النماذج ومجموعات البيانات التي يُجري الباحثون تقييماتهم عليها. مثلًا هنا يمكنك أن تجد أبرز المجموعات المناسبة لمهمة تلخيص النص (فمجموعات البيانات التي ستراها في الرابط وفي الموقع عمومًا هي مجموعات بيانات معياريّة). التعرّف على المقاييس المُستخدمة لتقييم المهمة المطروحة. طبعًا هناك مقاييس مُحددة لكل مهمة، وقد يكون مقياسًا ما صالحًا لمهمة واحدة أو عدة مهام. إجراء التقييم باستخدام مقياس واحد أو أكثر، وعلى مجموعة بيانات واحدة أو أكثر (يُفضّل أكثر من واحدة). العثور على مجموعات البيانات كما ذكرت في الفقرة السابقة؛ أفضل طريقة هي الذهاب إلى موقع Papers With Code، فهو موقع موثوق تٌنشر فيه أبرز الأوراق البحثيّة في الذكاء الاصطناعي مع مستودعات الشيفرات البرمجية المرتبطة بها. اذهب أولاً إلى الموقع ثم إلى انتقل لقسم Datasets، ثم ابحث عن "Text Summarization" ثم انتقل إلى قسم Datasets واضغط على "توسيع أو See all" ومن هناك تظهر جميع مجموعات البيانات ذات الصلة مع إمكانية فرزها أو تصفيتها وفق رغبتك. في حالتنا نريد أن نفرزها حسب عدد مرات الاقتباس cite. نختار الآن مجموعة البيانات الأكثر اقتباسًا والتي غالبًا ماتكون الأكثر شعبية، وهي مجموعة بيانات "CNN/DailyMail" في وقت كتابة هذه المقالة. لاداعي لتحميل مجموعة البيانات حاليًّا، وإنما سنراجع المعلومات المُتعلقة بمجموعة البيانات هذه والموجودة على موقع Papers With Code، وذلك من أجل الخطوة التالية. تجدر الملاحظة إلى أن مجموعة البيانات هذه متاحة أيضًا على Huggingface. الآن عليك التحقق من 3 أشياء: الترخيص license: مجموعة البيانات مُرخصة من معهد ماساتشوستس للتكنولوجيا MIT، أي يمكننا استخدامها لكل من المشاريع التجارية والشخصية. الأوراق البحثية الأحدث على هذه البيانات: وذلك لمعرفة فيما إذا كانت الأوراق البحثية التي تستخدم هذه البيانات حديثة أم قديمة. لمعرفة ذلك نفرز الأوراق تنازليًّا. في حالتنا فإن الأوراق التي تستخدم هذه البيانات حديثة (من عام 2023)، وهذا مانرغب به! مدى توفر المعلومات المتعلقة بأصل مجموعة البيانات وعملية جمعها وشفافية الأساليب (مدى صراحة وشمولية توثيق الأساليب المستخدمة لجمع ومعالجة وتنظيم مجموعة البيانات) المستخدمة في إنشائها: مجموعة البيانات مُنشئة من قبل شركة IBM بالشراكة مع جامعة مونتريال، وذلك عظيم! فهذه مصادر موثوقة تلتزم بهذه المتطلبات. دعونا الآن نستكشف المقاييس المُستخدمة في تقييم أداء النماذج على مجموعة البيانات هذه. تقييم النماذج في هذه المرحلة يجب علينا استكشاف المقاييس التي يُشاع استخدامها من قبل الباحثين في تقييّم نماذج التلخيص على مجموعات البيانات. طبعًا يُفترض أن يكون لديك فهم نظري لمهمة تلخيص النص، وإلا فلن تكون قادرًا على فهم هذه المقاييس. هناك نوعان مختلفان لمهمة تلخيص النص (يمكن اعتبار كل نوع بمثابة مهمة فرعيّة)، النوع الأول هو "تلخيّص النص التجريدي Abstractive Text Summarization" والثاني "تلخيّص النص الاستخراجي Extractive Text Summarization" في النوع الأول يكون الهدف هو تلخيص النص من حيث المعنى، وهذا يعني أن يكون لدينا جمل جديدة، أما في النوع الثاني فيكون عبارة عن استخلاص مقتطفات بسيطة من النص. بالنسبة لمجموعة البيانات التي سنعمل عليها (مقالات CNN)، فهي مرتبطة بالنوع الأول. نلاحظ هنا العديد من المصطلحات وهي ROUGE-1 و ROUGE-2 و ROUGE-3، وهي المقاييس الشائعة لهذه المهمة الفرعية، كما نلاحظ العديد من النماذج ونتائجها وفقًا لهذه المقاييس الثلاث، وهو ما نحتاجه. الآن إذا قارنا بين هذه النماذج وفقًا للمقياس الأول، فنلاحظ أن أول 3 نماذج نتائجها متقاربة، حيث نلاحظ أن جميعها تقترب من 50 وهي قيمة واعدة وفقًا لمقياس ROUGE. اختبار النموذج بعد أن تعرّفنا على المقاييس التي يجب أخذها بعين الاعتبار لتقييم النماذج ورؤيتنا لأفضل ثلاثة منها، يمكننا الانتقال إلى مرحلة اختبار النماذج. تجدر الملاحظة أن هذه النماذج يُفضّل أن تُشغّل على وحدة معالجة الرسومات GPU لكونها تنفذ المهام بصورة متزامنة لتحسين الأداء (وبعضها قد لا يعمل إلا عليها)، لكن يمكن أن يكون بعضها قادرًا على العمل على وحدات CPU وبأداء مقبول. دعونا نختار نموذج Pegasus من بين تلك الخيارات، والأمر الذي يجعل اختيارنا موفقًا هو أن هذا النموذج جرى تدريبه على مجموعة بيانات CNN التي نعمل معها بالنسبة لمهمة "استخلاص النص التجريدي". بعد ذلك لنكتب الكود التالي بلغة البرمجة بايثون والذي يستخدم إطار عمل باي توش PyTorch للغة بايثون ومكتبة Transformers من Hugging Face ونموذج Pegasus لتلخيص النصوص: # We start by installing the transformers library %pip install transformers sentencepiece بعد ذلك علينا الوصول إلى نموذج Pegasus من مكتبة المحولات (مكتبة Huggingface): from transformers import PegasusForConditionalGeneration, PegasusTokenizer import torch # Set the seed, this will help reproduce results. Changing the seed will # generate new results from transformers import set_seed set_seed(248602) # We're using the version of Pegasus specifically trained for summarization # using the CNN/DailyMail dataset model_name = "google/pegasus-cnn_dailymail" # If you're following along in Colab, switch your runtime to a # T4 GPU or other CUDA-compliant device for a speedup device = "cuda" if torch.cuda.is_available() else "cpu" # Load the tokenizer tokenizer = PegasusTokenizer.from_pretrained(model_name) # Load the model model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device) # Tokenize the entire content batch = tokenizer(content, padding="longest", return_tensors="pt").to(device) # Generate the summary as tokens summarized = model.generate(**batch) # Decode the tokens back into text summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] # Compare def compare(original, summarized_text): print(f"Article text length: {len(original)}\n") print(textwrap.fill(summarized_text, 100)) print() print(f"Summarized length: {len(summarized_text)}") compare(content, summarized_text) عند تنفيذ الكود سنحصل على تلخيص النص الأصلي content المكون من 1427 حرفًا، وكما تلاحظ يحتوي التلخيص summarized_text على 320 حرفًا فقط ويركز على العبارات والجمل الهامة في النص الأصلي. Article text length: 1427 Trustworthy AI should enable people to decide how their data is used.<n>values and goals of a system should be power aware and seek to minimize harm.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security. Summarized length: 320 تعمل الأمور بطريقة صحيحة، لكن يبدو أن النص المُلخّص موجزًا جدًا ويحتاج إلى تضمين المزيد من التفاصيل أو السياق. لنرى فيما إذا كان بالإمكان جعل المُلخّص أكثر شمولًا وتفصيلًا. لنقم بإجراء بعض التعديلات على الكود بهدف تغيير طول ومحتوى التلخيص الناتج، بداية لنغير قيمة متغير "البذرة seed" من 248602 إلى 860912 لتوليد نتائج جديدة كما يلي: ملاحظة: نستخدم مفهوم البذور seeds لتهيئة مولّد الأرقام العشوائية، حيث أنّه يحتاج إلى رقم يبدأ به (قيمة أولية) حتى يتمكن من إنشاء رقم عشوائي. افتراضيًّا يستخدم وقت النظام الحالي. set_seed(860912) # Generate the summary as tokens, with a max_new_tokens summarized = model.generate(**batch, max_new_tokens=800) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) ستكون النتيجة على النحو التالي: Article text length: 1427 Trustworthy AI should enable people to decide how their data is used.<n>values and goals of a system should be power aware and seek to minimize harm.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security. Summarized length: 320 يبدو أن الأمر لم ينجح أيضًا. لنحاول تجريب أسلوب فك تشفير يُسمّى "أخذ العينات sampling"، حيث يختار النموذج الكلمة التالية في النص بناءً على توزيعها الاحتمالي الشرطي (أي احتمال اختيار كلمة ما، بالنظر إلى الكلمات السابقة). هنا يكون لدينا مُتغير يسمى "درجة الحرارة temperature" للتحكم في مستوى العشوائية والإبداع في المخرجات المولّدة. هذه المعلمة تُعدّل الاحتمالات قبل أخذ العينات. تؤدي درجة الحرارة المرتفعة إلى زيادة العشوائية (أي ليس من الضروري أن يأخذ الكلمة الأكبر احتمالًا دومًا)، بالتالي مخرجات أكثر تنوعًا وإبداعًا، والعكس من ذلك يجعل عملية أخذ العينات أكثر حتمية ودقة. set_seed(118511) summarized = model.generate(**batch, do_sample=True, temperature=0.8, top_k=0) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) سنحصل الآن على النتيجة التالية: Article text length: 1427 Mozilla's "Trustworthy AI" Thinking Points:.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data. Summarized length: 193 نلاحظ أن الخرج أقصر، لكنه ذو جودة أعلى. ربما إذا رفعنا متغير درجة الحرارة temperature، ستكون النتيجة أفضل. set_seed(108814) summarized = model.generate(**batch, do_sample=True, temperature=1.0, top_k=0) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) هذا هو التخليص الناتج وهو كما تلاحظ أكثر وضوحًا من التلخيص السابق: Article text length: 1427 Mozilla's "Trustworthy AI" Thinking Points:.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security.<n>We need to mandate transparency so that we can fully understand these systems and their potential for harm. Summarized length: 325 دعونا نستخدم الآن طريقة فك تشفير تدعىtop_k`، وهي طريقة تعتمد على أخذ الكلمات k الأعلى احتمالًا (الكلمات المُرشّحة)، ثم الاختيار عشوائيًّا بينها. هذا النهج يهدف إلى السماح للنموذج بأن يكون دقيقًا مع هامش من الإبداع بفضل إدخال العشوائية في الاختيار. والمعلمة k هي معلمة يجب ضبطها بدقة لتحقيق التوازن بين الدقة والإبداع، فمع القيم الكبيرة لها قد يبدو النص بلا معنى وأقل تماسكًا، ومع القيم الصغيرة ستكون النتائج حتميّة وخاليّة من أي إبداع، وقد تتضمّن جملًا مكررة. set_seed(226012) summarized = model.generate(**batch, do_sample=True, top_k=50) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) بعد القيام بالتغييرات السابقة لاحظ التلخيص الناتج: Mozilla's "Trustworthy AI" Thinking Points look at ethical issues surrounding automated decision making.<n>values and goals of a system should be power aware and seek to minimize harm.People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security. Summarized length: 355 دعونا الآن نجرّب نهجًا يدعى top-p أو أخذ عينات النواة Nucleus sampling، وهنا تشير p إلى قيمة حديّة، عند تجاوزها نتوقف عن ترشيح كلمات جديدة. بمعنى أوضح، تُفرز الكلمات تنازليًّا وفقًا لاحتمالاتها، ثم نبدأ باختيار الكلمات واحدة تلو الأخرى حتى يصبح مجموع احتمالاتها أكبر من p، ثم بعد ذلك نختار إحدى الكلمات المُرشحة عشوائيًا. توفّر هذه الطريقة أيضًا التوازن بين العشوائية والحتمية. فقيم p القريبة من 1 تعطي خرجًا أكثر تنوعًا والقيم القريبة من 0 أكثر حتمية. الفرق بينه وبين top_k هو أن عدد الكلمات المُرشّحة يكون ديناميكيًّا وأكثر قابليّة للتكيّف وفقًا للتوزيع الاحتمالي للكلمة التالية على طول مجموعة المفردات. set_seed(21420041) summarized = model.generate(**batch, do_sample=True, top_p=0.9, top_k=50) summarized_decoded = tokenizer.batch_decode(summarized, skip_special_tokens=True) summarized_text = summarized_decoded[0] compare(content, summarized_text) # saving this for later. pegasus_summarized_text = summarized_text سيكون التخليص الآن على النحو التالي: Article text length: 1427 Mozilla's "Trustworthy AI" Thinking Points:.<n>People should have agency and control over their data and algorithmic outputs.<n>Developers need to implement strong measures to protect our data and personal security.<n>We need to mandate transparency so that we can fully understand these systems and their potential for harm. Summarized length: 325 قد نتساءل ما هي الطريقة الأفضل لفك التشفير. لسوء الحظ، لا توجد طريقة "أفضل" لفك التشفير، ويعتمد اختيار النهج الأفضل على طبيعة البيانات التي تُنشئ مُلخصًا لها ونوع هذه النصوص، وعلى درجة الإبداع و الحتمية التي تريد أن تراها في النص الناتج. وبذلك نكون قد وصلنا إلى نهاية المقالة، حيث تحدّثنا فيها عن مهمة تلخيص النص، وعن كيفية استخدام أحدث النماذج لإنجاز ذلك. ترجمة -وبتصرُّف- للمقال Mozilla AI Guide Launch with Summarization Code Example لصاحبه Melissa Thermidor. اقرأ أيضًا مدخل إلى الذكاء الاصطناعي وتعلم الآلة. تعلم الآلة Machine Learning - الذكاء الاصطناعي. عشرة مشاريع عملية عن الذكاء الاصطناعي. أدوات برمجة نماذج تعلم الآلة. -
شكراا جدا علي المعلوم ده وشكراا لحضرتك جدا
-
في البداية عليك تحديد هل تريد تشغيل المكتبة على معالج أم كرت الشاشة، وكرت الشاشة يجب أن يكون من نوع nvidia. لأنها تعتمد على CUDA، وهي منصة حوسبة متوازية تم تطويرها بواسطة NVIDIA ومصممة خصيصًا لمعالجات الرسومات (GPUs) من NVIDIA، لذلك لا يمكن تشغيل PyTorch بشكل فعال على كروت شاشة من شركات أخرى مثل AMD أو Intel. وكحل بديل، تتوفر بعض محاكيات CUDA مثل Google Colab و Kaggle Notebooks التي تسمح لك بتشغيل PyTorch على كروت شاشة غير NVIDIA، ولكن أداء تلك المحاكيات أبطأ بكثير من كروت شاشة NVIDIA. وبينما لا ينصح باستخدام CPU لتشغيل PyTorch، إلا أنه ممكن، وسيكون الأداء أبطأ بكثير مقارنة بكروت شاشة NVIDIA. لذا لتثبيت المكتبة على نظام ويندوز لتعمل على المعالج استخدم الأمر: pip3 install torch torchvision torchaudio ولتعمل على CUDA 11.8 استخدم: pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 ولتعمل على CUDA 12.1 استخدم: pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 وتستطيع استيراد المكتبة كالتالي: import torch بالطبع يجب أن تكون CUDA مثبتة على جهازك: https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local وللعلم، PyTorch هي واجهة برمجة تطبيقات Python لمكتبة Torch أي مبنية عليها، وتم إنشاؤها بواسطة Facebook Research، وتم إصدار PyTorch لأول مرة في عام 2016، أي هي نسخة محسنة وبها مزايا أفضل وأسهل في التطوير.
- 4 اجابة
-
- 1
-