كل الأنشطة
- اليوم
-
 Asmaa Farouk اشترك بالأكاديمية
Asmaa Farouk اشترك بالأكاديمية -
 Mohamed Atef26 اشترك بالأكاديمية
Mohamed Atef26 اشترك بالأكاديمية -
وعليكم السلام ورحمة الله وبركاته. آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.
-
السلام عليكم , كيف يمكنني الحصول على الشهادة بعد اتمام 5 مسارات ورفع جميع الملفات على GitHub.
-
 وليد فهمي اشترك بالأكاديمية
وليد فهمي اشترك بالأكاديمية -
 آلاء خليل اشترك بالأكاديمية
آلاء خليل اشترك بالأكاديمية -
 Jaber Rawashdeh اشترك بالأكاديمية
Jaber Rawashdeh اشترك بالأكاديمية -
 Kareem Hagag اشترك بالأكاديمية
Kareem Hagag اشترك بالأكاديمية -
 عربي اليمن محمد محمد قاسم اسماعيل حسن اشترك بالأكاديمية
عربي اليمن محمد محمد قاسم اسماعيل حسن اشترك بالأكاديمية -
 Kemo Keko اشترك بالأكاديمية
Kemo Keko اشترك بالأكاديمية -
 Fares Elrsaa اشترك بالأكاديمية
Fares Elrsaa اشترك بالأكاديمية -
 Noor Dhia اشترك بالأكاديمية
Noor Dhia اشترك بالأكاديمية -
 الخطأ أنك لم تقم بإنشاء الكود الخاص بفتح وغلق ال nav . هل تريد إستخدام bootstrap أم تقوم بإنشاء كل شئ بشكل يدوي بنفسك ؟ إذا كنت تريد إستخدام bootstrap فيجب أن يكون الهيكل لديك متوافق لما لدى bootstrap هكذا : https://getbootstrap.com/docs/5.3/components/navbar/ أما إذا أردت أن يكون بشكل يدوى فيجب كتابة كود javascript يقوم بهذا الأمر . وإليك الكود بعد التعديل ليتم إستخدام هيكل bootstrap لل nav index.html style.css
الخطأ أنك لم تقم بإنشاء الكود الخاص بفتح وغلق ال nav . هل تريد إستخدام bootstrap أم تقوم بإنشاء كل شئ بشكل يدوي بنفسك ؟ إذا كنت تريد إستخدام bootstrap فيجب أن يكون الهيكل لديك متوافق لما لدى bootstrap هكذا : https://getbootstrap.com/docs/5.3/components/navbar/ أما إذا أردت أن يكون بشكل يدوى فيجب كتابة كود javascript يقوم بهذا الأمر . وإليك الكود بعد التعديل ليتم إستخدام هيكل bootstrap لل nav index.html style.css -
إن المشكلة الأساسية بالفعل في جداول التجزئة (Hash Tables) هي الاصطدامات (Collisions) وأنت محق تماما والطريقة التي استخدمتها في الكود الخاص بك هي مثال جيد للتعليم مثلا والتطبيقات البسيطة ولكنها غير فعالة في التطبيقات الحقيقية لنفس السبب الذي ذكرته وهو أن الكلمات التي تبدأ بنفس الحرف ستتكدس في نفس القائمة المتصلة (Linked List) مما يبطئ البحث بشكل كبير. والآن لنجيب على أسئلتك بالترتيب . ما هي العملية التي تتم على الكلمات لإيجاد الدلو (Bucket) المناسب : هذه العملية تسمى دالة التجزئة (Hash Function) ووظيفتها هي تحويل أي مدخل في حالتنا هنا الكلمة النصية إلى رقم صحيح فريد قدر الإمكان وهذا الرقم هو الذي يحدد فهرس (index) الدلو الذي ستُخزن فيه الكلمة. دالة التجزئة التي استخدمتها بسيطة جداً: short hash = toupper(vocabulary[0]) - 'A' وهي تأخذ الحرف الأول فقط وهذا هو سبب ضعفها فدالة التجزئة الجيدة يجب أن تحقق هدفين رئيسيين: أن تأخذ كل حروف الكلمة في الحسبان بحيث إذا تغير أي حرف في الكلمة، يتغير ناتج الدالة بشكل كبير. أن توزع النواتج بشكل متساوي يجب أن توزع الكلمات على كل ال Buckets المتاحة في الجدول بشكل عشوائي ومتساوي قدر الإمكان لتجنب التكدس في أماكن معينة. وإليك مثال على دالة تجزئة أفضل (Polynomial Rolling Hash) وهذه واحدة من أشهر وأبسط الطرق الفعالة والفكرة هي إعطاء كل حرف في الكلمة وزن مختلف بناءً على موقعه فمثلا نختار رقم أولي وليكن 31 ونمر على حروف الكلمة واحدا تلو الآخر ونحسب قيمة الـ hash كالتالي: hash = (hash * 31 + character_value) % TABLE_SIZE مثال لكلمة "CS50" لنفترض أن حجم الجدول TABLE_SIZE هو 1000. C (قيمته 67): hash = (0 * 31 + 67) % 1000 = 67 S (قيمته 83): hash = (67 * 31 + 83) % 1000 = (2077 + 83) % 1000 = 2160 % 1000 = 160 5 (قيمته 53): hash = (160 * 31 + 53) % 1000 = (4960 + 53) % 1000 = 5013 % 1000 = 13 0 (قيمته 48): hash = (13 * 31 + 48) % 1000 = (403 + 48) % 1000 = 451 % 1000 = 451 إذا كلمة "CS50" سيتم تخزينها في الدلو رقم 451 لاحظ كيف أن كل حرف وموقعه أثر في النتيجة النهائية. ثانيا كيف تتم عملية تقسيم وتوسيع الجدول : هنا يأتي دور الإجابة على سؤالك الأول فالمشكلة في الكود الخاص بك ليست فقط في دالة التجزئة ولكن أيضا في حجم الجدول لديك 26 دلو فقط وهو عدد الحروف الأبجدية وهكذا إذا كان لديك قاموس يحتوي على 140,000 كلمة ففي المتوسط سيكون كل دلو يحتوي على 140,000 / 26 ≈ 5384 كلمة وهذا عدد كبير جدا. زالحل هو ببساطة زيادة عدد ال Buckets فبدلا من 26 دلو يمكننا استخدام عدد أكبر بكثير مثلا 5000 دلو أو أكثر وكلما زاد عدد ال Buckets قل احتمال حدوث الاصطدامات وبالتالي أصبحت القوائم المتصلة (Linked Lists) أقصر بكثير. ولاحظ في دالة التجزئة التي وضحتها لك سابقا الخطوة الأخيرة وهي % TABLE_SIZE (باقي القسمة على حجم الجدول) فإن هذه العملية تضمن أن ناتج الدالة hash سيكون دائما رقم صحيح يقع بين 0 و TABLE_SIZE - 1 وهو ما يمثل فهارس ال Buckets المتاحة في الجدول. إذا تلخيصا لما سبق : لجعل جدول التجزئة الخاص بك فعال لتخزين قاموس ضخم فستحتاج إلى أمرين: زيادة حجم الجدول بشكل كبير أى زيادة ال Buckets وهذا يقلل من احتمالية أن تقع كلمتان مختلفتان في نفس الدلو. استخدام دالة تجزئة قوية فدالة تأخذ كل حروف الكلمة في الحسبان لتوزيع الكلمات بشكل متساو على جميع الBuckets المتاحة. وبهاتين الطريقتين ستحافظ على القوائم المتصلة قصيرة وبالتالي يصبح زمن البحث عن أي كلمة قريبًا جدًا من الزمن الثابت O(1)، وهو الهدف الأساسي من استخدام جداول التجزئة.
-
هذا الموقع هو موقع أكاديمية حسوب . ويتم توفير هنا دورات تعليمية للعديد من المجالات البرمجية باللغة العربية وهي أكاديمة معلومة وتخرج منها العديد من الطلاب العرب والتي تؤهلك مباشرة للعمل بعد التخرج من الدورة . وإليك الدورات المتاحة هنا على الأكاديمية : https://academy.hsoub.com/store/c1-دورات-تعليمية/ وبالإضافة إلى الدورات التعليمية توجد هنا مقالات ودروس وكتب مجانية يمكنك تصفحها وهي تخص العديد من المجالات التقنية والبرمجية . وأيضا يمكنك نشر الأسئلة هنا في العديد من الأقسام في الأكاديمية ويقوم بالإجابة عليك فريق كبير من المدربين هنا على الأكاديمية وأيضا الطلاب والأعضاء الأخرين على الأكاديمية . فهي مجتمع خاص بالعرب في الأسئلة التقنية وغيرها.
-
سجلت بحساب خمسات من يومين وشفت هذا الموقع ضمن المواقع الموجودة في خمسات ف عن شو بحكي الموقع وكيف بقدر حقق فائدة منه ... معلش حد يشرح لي كل شي عن هذا الموقع...ومشكورين سلف
- 1 جواب
-
- 1
-

-
الأفضل رؤية الأجابات السابقة التي وضحتها لك ففيها جميع التفاصيل حول الرياضيات المطلوبة . ولكن تلخيصا أهم الفروع المطلوبة هي الاحتمالات والإحصاء، الجبر الخطي و التحليل الرياضي والتفاضل والتكامل.
-
أولا php هي من أسهل اللغات التي يمكنك تعلمها بشكل سريع وأيضا تتوافر بها وظائف كثيرة في مجال العمل الحر ولكن توجد العديد من الملاحظات حولها . فبسبب سهولتها تجد أن أكثر الأشخاص يتعلمونها ولهذا فإن عدد العاملين بها كثير ولهذا هي ذات رواتب ضعيفة نسبيا وأيضا المنافسة فيها ستكون شديدة وصعبة لكثرة الأشخاص الذين يعملون بها . ولهذا إذا أردت أن تتعلم لغة سريعه ف php مناسبة لك ولكن يجب أن تكون قوي ومتمكن بها لتستطيع الحصول على وظيفة بسرعه . أما Node.js و Spring Boot و ASP.NET Core فهي من أشهر اللغات التي يتم العمل بها في الشركات وهي ذات رواتب كبيرة نسبيا وذلك لصعوبة تلك اللغات ويجب التمكن فيها لتستطيع العمل بها ولكن العمل الحر بها قليل وستحتاج إلى خبرة كبيرة لتحصل على عمل حر بنفسك أو يمكنك البحث عن أشخاص كفريق تعملون معا . ولكن يمكنك تعلم لغة ما وبجوارها تتعلم لغة أخرى فهذا الأمر جيد وممتاز وسيعطيك خبرة وأفضلية كبيرة ولكن سيحتاج إلى الكثير من الوقت لهذا يمكنك النظر مدى فراغك وأيضا مسؤولياتك وهل تحتاج إلى عمل في أسرع وقت أم لا . فلو كنت مشغول وتحتاج العمل سريعا في php هي الأفضل لك.
-
الدورة ليست مهتمة بشكل كبير بمجال تحليل البيانات ولكنها تضعك على المسار الصحيح وتوفر لك أساسيات تحليل البيانات . ولو أردت مسار لتعلم تحليل البيانات فيمكنك قراءة الإجابة التالية :
-
ستجد أسفل فيديو الدرس صندوق للتعليقات كما هنا يرجى طرح سؤالك أسفل الدرس وليس هنا حيث هنا قسم الأسئلة العامة ولا نقوم بإجابة الأسئلة الخاصة بمحتوى الدورة أو الدرس، وذلك لمعرفة الدرس الذي توجد به مشكلتك و لمساعدتك بشكل أفضل.
-
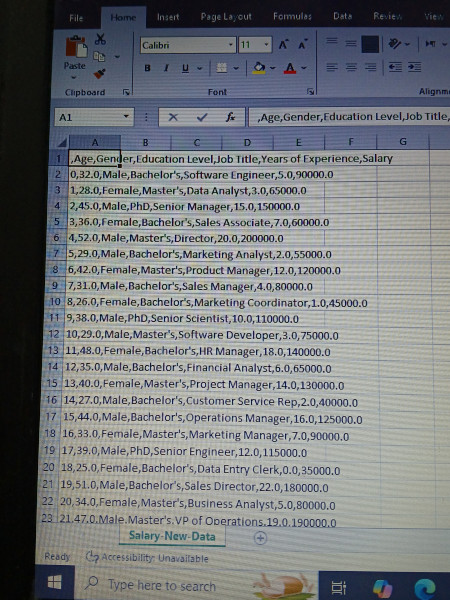
السلام عليكم و رحمة الله وبركاته انا حالياً أتعلم تحليل البيانات و حاليا اتعلم بايثون عندما انتهي من معالجة وتنظيف البيانات واقوم بحفظ الملف بصيغة csv للعمل عليه على power BI تصبح البيانات غير مرتبة وغير قابلة للعمل عليها مع العمل اني اطبق نفس الخطوات الموجودة في الفيديو لكن تحصل هذه المشكلة عندي ولا استطيع إكمال المشروع وسأرفق صورة للبيانات الغير مرتبة في الأسفل ماهي المشكلة؟
- 1 جواب
-
- 1
-
-
تمام يعطيك العافيه معناته المطلوب مني حاليا هو الرياضيات قبل دخول عالم الذكاء الاصطناعي طيب اخر سؤال فقط ممكن تذكر لي ماهي المواضيع او العناوين الاساسية في تعلم الرياضيات عشان احاول ابحث على دورات متخصصه للرياضيات لمدرسين عرب عشان افهم شرح بالعربي بلا شك المصطلحات انجليزيه بعرف لكن الاشكاليه في الشرح الي بيشرح عربي فممكن تذكر لي ماهي المواضيع المطلوب مني تعلمها في الرياضيات عشان ابحث عنها وبارك الله فيك
- 5 اجابة
-
- 1
-
- البارحة
-
في الدورة يتم شرح الأساسيات المطلوبة فقط في الدروس لهذا لن تحتاج إلى دراسة رياضيات خارجية لمتابعة الدروس . ولكنك بالطبع ستحتاج إلى تعلم الكثير من الرياضيات وخصوصا الجبر الخطي للتقدم في المجال وفهم التقنيات المتقدمة في المجال . وإليك الإجابات التالية لكيفية تعلم الرياضيات المتعلقة بالذكاء الإصطناعي : ولكن أغلب الكورسات هي باللغة الإنجليزية وأيضا هذا المجال يحتاج إلى لغة إنجليزية جيدة لتعلمه وحتى للعمل فيه بعد ذلك .
- 5 اجابة
-
- 1
-
-
اشكرك على اجابتك طيب يعني ايش في دورة ادخلها عشان تحاول التبسيط للأسف انا تقريبا لي 15 سنة متخرج من الثانوية فأظن نسيت كل شيء في الرياضيات فهل هناك شيء يساعدوني وطبعا ومايكونش انجليزي لاني لست جيدا في الانجليزي
- 5 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله وبركاته. أولا إن مجال الذكاء الإصطناعي واسع جدا وستأخذ وقتا وجهدا كبيرا لدراسته بشكل جيد وحتى بعد الدراسة سيتوجب عليك التعلم دائما لما يحدث من تطوير مستمر في هذا المجال وبشكل كبير. أى أنه سيحتاج إلى أن توفر وقتا كافايا للدراسة يوميا لتستطيع التقدم فيه. لذلك إذا كنت تريد أو تحب العمل في مجال الذكاء الإصطناعي ولا تمانع من المذاكرة وتخصيص وقت لذلك والإطلاع دائما على التطويرات فيمكنك الإشتراك في دورة الذكاء الإصطناعي فهي جيدة وأيضا إذا كان لديك خبرة سابقة في الجبر الخطي وفي الإحصاء وفي الرياضيات عموما فهذا سيكون جيد ومناسب بالنسبة لك. وهي بالطبع تحتاج إلى شخص ذكي وليس بالضرورة أن يكون عبقري ولكن شخص ذكي يستطيع الفهم بشكل جيد ويتعامل مع الرياضيات وفهمها بشكل جيد لإعتماد المجال بشكل كبير على الرياضيات . أى أنه لو هناك شخص ما لا يحب الرياضيات فسيجد المجال صعب بسبب هذا الأمر. وبما أنك لديك مسؤوليات وأيضا دوام عمل وضغوطات فالأمر يعتمد عليك هل تستطيع توفير وقت ثابت يوميا للدراسة مثلا ساعتين أو أكثر ؟ وكما وضحت لك أن المجال ليس سهلا ويحتاج إلى مجهود ووقت كبير فهنا أنت الأعلم بأمورك وكيفية تنظيمك لوقتك فيمكنك بنفسك الإجابة على هذا السؤال بعد قراءة التفاصيل السابقة التي وضحتها لك. ونعم الدورة بعد إنهائها تستطيع أن تكون شخص مبتدأ في مجال الذكاء الإصطناعي وأن تعمل في شركة أو مشاريع مستقلة لك وهذا لو قمت بإتمامها وإنهائها بفهم جيد لها . وإليك ما ستتعمله في الدورة وما الذي ستؤهلك إليه من خلال الإجابة التالية :
- 5 اجابة
-
- 1
-
-
السلام عليكم لدي 3 أسئله 1- هل ظروفي تناسبني في تعلم دورة الذكاء الاصطناعي هل تحتاج مخ عبقري ولا انسان عادي مثلي مع ضغوطات الحياة انا حاليا بعمر 34 سنة ولدي عائلة وفوق كذا اشتغل بدوام 8 ساعات مسائي وانا صراحه حابب ادخل المجال واخاف ضغوطي الحياتيه تأثر على تركيزي لكن حقيقه عندي همه ان بدي ادخل ؟ 2- انا انسان تخرجت من الثانويه اداري وليس علمي يعني لا درست كيمياء ولا فيزياء وحاليا اعمل كمساعد صيدلي وظيفة متواضعه وبسيطه جدا فأنا ذكرت هذا الكلام لكي أتأكد هل وضعي يسمح بتعلم الذكاء الاصطناعي يعني يحتاج الى مخ تركيز قوي ولا عادي وازيدكم لست جيدا بالانجليزي هههههه الحاله ميئوسة الحمدالله على كل حال ..... حقيقه انا ابغى اتعلم المجال لان هذا الان هو المستقبل وهو ملك الساحة فحقيقه متردد فقط في مسألة الرياضيات واللغه وطبيعة التخصص الذكاء الاصطناعي ؟ 3- وهل دورة الذكاء الاصطناعي في اكاديمية حاسوب كافيه فقط يعني لتوظيف في شركات كبرى وهكذا وبلا شك الارزاق بيد الله بس اقصد من ناحيه كميه العلم والفهم في الدورة ؟ فأرجو الله يسعدكم ويبارك فيكم تجاوبوني جواب يمحي هذا التردد وابدأ وشكرا
- 5 اجابة
-
- 1
-
-
المشكلة ليست في فكرة الـ Hash Table نفسها، بل في دالة التجزئة التي استخدمتها وحجم الجدول الصغير، فالدالة ليست جيدة: short hash = toupper(vocabulary[0]) - 'A'; لأنها تعتمد فقط على الحرف الأول من الكلمة، بالتالي كل الكلمات التي تبدأ بنفس الحرف مثل Apple, Ant, Art, Around وستذهب إلى نفس الـ Bucket أي نفس الخانة في المصفوفة dictionary، وفي اللغة الإنجليزية، هناك حروف تبدأ بها كلمات كثيرة جداً مثل S, T, A وحروف أخرى نادرة كـ X, Z, Q، لذا سيحدث تكتل أي Clustering فبعض الـ Buckets ستحتوي على Linked Lists طويلة جدًا. وعند البحث عن كلمة تبدأ بحرف شائع، ستضطر للمرور على قائمة طويلة، ويصبح أداء البحث يقترب من O(n) في أسوأ الحالات، ويلغي الفائدة من استخدام الـ Hash Table. أيضًا حجم الجدول صغير، فلديك 26 Bucket فقط، وهو عدد قليل جدًا بالنسبة لقاموس ضخم يحتوي على آلاف الكلمات. وبالنسبة للتقسيم فالأفضل للكلمات يعتمد بشكل مباشر على العملية التي تتم على الكلمات أي دالة التجزئة، والجيد منها يعمل على توزيع الكلمات بشكل عشوائي ومتساوٍا قدر الإمكان على جميع الـ Buckets المتاحة، ولفعل ذلك يجب أن تضع في الاعتبار الكلمة بأكملها، وليس فقط الحرف الأول. بيحث نفس الكلمة يجب أن تعطي نفس قيمة الـ Hash في كل مرة، وتعتمد على كل حروف الكلمة وأي تغيير بسيط في الكلمة مثل cat و car يؤدي إلى قيمة Hash مختلفة. وأن توزع الكلمات بشكل متساوٍا على الـ Buckets المتاحة لتجنب التكتل. مثال بسيط للتوضيح مع الوضع في الإعتبار ما سبق، وهي دالة تستقبل مجموع قيم ASCII لكل الحروف في الكلمة. unsigned int hash(const char* word, unsigned int N) { unsigned int sum = 0; for (int i = 0; word[i] != '\0'; i++) { sum += word[i]; } return sum % N; } لكن ما زالت ليس جيدة كفاية، فالكلمتان cat و act لهما نفس الحروف وبالتالي ستحصلان على نفس قيمة الـ Hash وذاك يسمى تصادم - Collision. وذلك ما تم تحسينه في الدالة التالية: unsigned int hash_djb2(const char *word, unsigned int N) { unsigned long hash_value = 5381; int c; while ((c = *word++)) { hash_value = ((hash_value << 5) + hash_value) + c; } return hash_value % N; } توفر قيم مختلفة لكلمتي cat و act، وستوزع الكلمات بشكل ممتاز. بعد الدالة السابقة لم يعد من المنطقي استخدام جدول بحجم 26 فقط، فلو القاموس يحتوي على 140,000 كلمة، فالأفضل استخدام جدول بحجم كبير لتقليل احتمالية التصادمات وجعل القوائم المتصلة قصيرة جدًا. أي بدلاً من تعريف الجدول هكذا: #define ALPHABETS 26 node* dictionary[ALPHABETS] = {NULL}; نقوم بتعريفه بحجم أكبر بكثير، وكقاعدة عامة حجم الجدول يكون عدد أولي قريب من عدد العناصر التي تتوقع تخزينها أو أكبر، لأنّ استخدام عدد أولي يساعد في تحسين التوزيع عند استخدام عملية باقي القسمة %. #define N_BUCKETS 10007 node* dictionary[N_BUCKETS] = {NULL}; وبالتالي بدلاً من حساب الـ Hash بناءًا على الحرف الأول، نستخدم الدالة الجديدة: for (int i = 0; i < n_of_words; i++) { string vocabulary = get_string("Word: "); // بدلاً من // short hash = toupper(vocabulary[0]) - 'A'; unsigned int hash_index = hash_djb2(vocabulary, N_BUCKETS); insert_node(&dictionary[hash_index], vocabulary); }
-
في البداية كل ما تحتاجه بخصوص github هي الأساسيات، والأمر ليس بالصعوبة التي تتصورها، فالأمر يبدوا أنه معقد لكن على العكس تمامًا بعد أن تستوعب الأساسيات. ببساطة، Git نظام للتحكم في الإصدارات Version Control أي هو التقنية أو النظام نفسه، بينما GitHub منصة سحابية أي استضافة للمشاريع باستخدام Git أي منصة سحابية لاستضافة المشاريع. وستقوم بإنشاء مستودع Git محلي على حاسوبك، ثم دفع أي رفع المشروع إلى المستودع البعيد remote على github. وهناك مصطلحات ضرورية وهي: Repository مستودع والمقصود به هو مجلد المشروع. Commit يعني حفظ التغييرات مع رسالة تصف ما قمت به. Branch فرع وهو نسخة موازية لمستودع المشروع تستطيع به إنشاء نسخة منفصلة عن المشروع. Pull Request يعني طلب دمج التغييرات مع ما هو موجود في مستودع المشروع. Clone نسخ المشروع من مستودلجهازك Fork: نسخ مشروع شخص آخر لحسابك وخطوات التثبيت والإعداد لـ GIT على حاسوبك، وستجدها هنا: بجانب الأوامر الأساسية،وهي إنشاء مستودع جديد محلي على حاسوبك: git init git add . git commit -m "first commit" و git push لرفع التغييرات للسحابة على منصة github. وهناك أوامر أخرى من الأفضل الإلمام بها لحين الحاجة:
-
في الواقع العملي لا يتم استخدام المصطلحات العربية بالفعل، اللغة الإنجليزية هي لغة البرمجة، لكن الدارسين بالأكاديمية لغتهم الأولى هي العربية لذا المحتوى موجه لهم في المقام الأول ويتم في معظم الدروس توضيح المصطلح بالإنجليزية أيضًا، وفي حال لم يتم ذكر ذلك، أرجو الاستعانة بموسوعة حسوب وابحث عن المصطلح وستجده بالعربية والإنجليزية. وفي حال واجهت صعوبة في استيعاب مصطلح ما، تستطيع الاستفسار أسفل الدروس وسيتم توضيحه لك، ويجب معرفة المصطلح بالعريبة والإنجليزية حتى تتمكن من البحث عنه بالرغم من أنّ الإنجليزية أهم بالطبع لكون المصادر أغلبها بالإنجليزية ولن تحتاج العربية إلا في حال شرح أمر ما لشخص آخر أو للفريق وحتى في تلك الحالة يتم استخدام المصطلحات الإنجليزية. وعامًة ستجد مصطلحات متكررة ومستخدمة في أغلب البرمجة ها هي: متغير - Variable: مكان في الذاكرة لتخزين البيانات. نوع البيانات - Data Type: يحدد نوع البيانات التي يمكن تخزينها في المتغير (مثل: نص، عدد صحيح، عدد عشري). عامل - Operator: رمز أو كلمة تستخدم لتنفيذ عملية على البيانات (مثل: + للجمع، - للطرح). تعبير - Expression: مجموعة من المتغيرات والعوامل التي تُرجع قيمة. شرط - Condition: تعبير منطقي يُرجع إما صحيح أو خطأ. جملة - Statement: سطر من التعليمات البرمجية التي تُنفذ مهمة محددة. كتلة - Block: مجموعة من الجمل التي تُنفذ معًا. دالة - Function: مجموعة من التعليمات البرمجية التي تُنفذ مهمة محددة وتُعيد قيمة. معامل - Parameter: قيمة تُمرر إلى دالة عند استدعائها. مصفوفة - Array: مجموعة من البيانات من نفس النوع مخزنة في مكان واحد. حلقة - Loop: تُستخدم لتكرار مجموعة من التعليمات البرمجية عدة مرات. مصفوفة ترابطية - Associative Array / Dictionary: مجموعة من البيانات مخزنة كأزواج من المفتاح والقيمة. كائن - Object: كيان يجمع بين البيانات والوظائف التي تعمل على هذه البيانات. فئة - Class: قالب لإنشاء الكائنات. وراثة - Inheritance: آلية تسمح لفئة ما بوراثة خصائص وصفات فئة أخرى. تعدد الأشكال - Polymorphism: القدرة على استخدام نفس الاسم لوظائف مختلفة في سياقات مختلفة. ملف - File: مجموعة من البيانات المخزنة على وسيط تخزين دائم. استثناء - Exception: حدث غير طبيعي يحدث أثناء تنفيذ البرنامج. معالجة الاستثناءات - Exception Handling: آلية للتعامل مع الاستثناءات ومنع تعطل البرنامج. وبالنسبة للمصطلحات الخاصة ببايثون: وحدة - Module: ملف يحتوي على تعليمات برمجية بايثون يمكن استخدامه في برامج أخرى. حزمة - Package: مجموعة من الوحدات النمطية. قائمة - List: مجموعة مرتبة من العناصر قابلة للتغيير. مجموعة - Tuple: مجموعة مرتبة من العناصر غير قابلة للتغيير. مجموعة - Set: مجموعة غير مرتبة من العناصر الفريدة. قاموس - Dictionary: مجموعة غير مرتبة من أزواج المفتاح والقيمة. تعليمة استيراد - Import Statement: تُستخدم لاستيراد وحدات أو حزم في البرنامج. ديكوريتور - Decorator: دالة تُعدل سلوك دالة أخرى. مولد - Generator: دالة تُعيد سلسلة من القيم. استدعاء ذاتي - Recursion: عندما تستدعي الدالة نفسها داخل تعريفها. تعبير لامبدا - Lambda Expression: دالة مجهولة تُعرّف وتُستخدم في سطر واحد. استيعاب القائمة - List Comprehension: طريقة لإنشاء قائمة جديدة من قائمة موجودة في سطر واحد. استيعاب المجموعة - Set Comprehension: طريقة لإنشاء مجموعة جديدة من مجموعة موجودة في سطر واحد. استيعاب القاموس - Dictionary Comprehension: طريقة لإنشاء قاموس جديد من قاموس موجود في سطر واحد. إدارة الحزم - Package Management: عملية تثبيت وتحديث وإزالة الحزم. بيئة افتراضية - Virtual Environment: بيئة معزولة لتشغيل مشروع بايثون بتبعياته الخاصة.
- 1 جواب
-
- 1
-
-
هل الشرح باللغة العربية هيأثر عليا لما اطلع سوق العمل وعندي مشكلة في الشرح يعني انا مثلا مش متعود ان ال object اسمه كائن وهكذا مع كثير من الامثلة دا في الحاجات اللي اتشرحتلي قبل كدا بالانجليزي فاي الحل
- 1 جواب
-
- 1
-
-
سلام عليكم. لدي أستفسار بخصوص ال Hash Table: إذا كان لدينا قاموس ضخم (فلنأخذ قاموس اللغة الأنجليزية كمثال) فإن أنسب هيكل بيانات لتخزين القاموس هو ال Hash Table لما يوفر من سرعة ثابتة علي حساب الذاكرة. كالمثال التالي: #include <stdio.h> #include <stdlib.h> #include <string.h> #include <cs50.h> #include <ctype.h> // Global variables #define ALPHABETS 26 #define MAX 35 // Struct node typedef struct node { string word; struct node* next; } node; // Functions prototypes void EXIT(string msg); node* find_tail(node* head); void insert_node(node** head, string word); void print_linked_list(node* head); void free_linked_list(node* head); int main(int argc, string argv[]) { if (argc != 2) { EXIT("Usage: ./dictionary [N of words]\n"); } short n_of_words = atoi(argv[1]); if (!strcmp(argv[1], "0")) { EXIT("No words added\n"); } else if (!n_of_words) { EXIT("Invalid input\n"); } else if (n_of_words > MAX) { printf("%i ", MAX); EXIT("is the max number\n"); } // Hash table starts here node* dictionary[ALPHABETS] = {NULL}; // Take vocabularies & insert them for (int i = 0; i < n_of_words; i++) { string vocabulary = get_string("Word: "); short hash = toupper(vocabulary[0]) - 'A'; insert_node(&dictionary[hash], vocabulary); } // Print & Free dictionary for (int i = 0; i < ALPHABETS; i++) { printf("%c: ", i + 'A'); if (dictionary[i]) { // print current bucket print_linked_list(dictionary[i]); printf("\n"); // free current bucket free_linked_list(dictionary[i]); } else { printf("\n"); } } } // func1: Exit program function void EXIT(string msg) { printf("%s", msg); exit(0); } // func2: To find the tail of a linked list node* find_tail(node* head) { if (!head) { return NULL; } node* temp = head; while (temp->next) { temp = temp->next; } return temp; } // func3: To insert a node to a linked list void insert_node(node** head, string vocabulary) { node* n = malloc(sizeof(node)); if (!n) { return; } n->word = vocabulary; n->next = NULL; if (!*head) { *head = n; return; } find_tail(*head)->next = n; } // func4: To print linked list items void print_linked_list(node* head) { for (node* temp = head; temp; temp = temp->next) { printf("%s ", temp->word); } } // func4: To free linked list void free_linked_list(node* head) { while (head) { node* temp = head->next; free(head); head = temp; } } أعرف أنها طريقة سيئة لتخزين الكلمات؛ إذ أردنا البحث عن كلمة ما في القاموس, فنعم سنختصر الكثير من الوقت لأننا نعلم في أي Bucket سنبحث, لكن ما زال البحث بطئ (أو حتي بنفس البطئ) لأن البرنامج سيضطر للمرور علي عناصر ال Linked List واحدة تلو الأخري. لذلك قاموا بتوسيع الجدول كي تتقسم العناصر أكثر و أكثر (كل هذا علي حساب الذاكرة). هل يمكن لأحدكم أن يشرح لي هذا التقسيم (في مثال القاموس تحديدا). كما أن هناك عملية تتم علي الكلمات كي نجد ال Bucket بنفس الوقت, ما هي هذه العملية.
- 2 اجابة
-
- 1
-
-
 الوظائف يتم طرحها من خلال موقع بعيد والتي بها حالياً وظيفة خدمة العملاء من خلال الرابط التالي https://baaeed.com/companies/hsoub/jobs
الوظائف يتم طرحها من خلال موقع بعيد والتي بها حالياً وظيفة خدمة العملاء من خلال الرابط التالي https://baaeed.com/companies/hsoub/jobs -
تمام هعمل كده وانا شاء الله خير بس حضرتك معندك معلوم ليه ده بيحصل مع العلم ده اول مره تحصل معي المشكله دي اول مره الحمد الله حلت المشكله وكانت من ملفات الكاش والكوكيز في المتصفح والمسحت الملفات دي المشكله اتحلت الحمد الله الف شكراا جدا لحضرتك جزاك الله كل خير
-
 الوظائف لا يتم الإعلان عنها هنا، بل تتم من خلال موقع مستقل أو بعيد، ها هي: https://baaeed.com/companies/hsoub/jobs
الوظائف لا يتم الإعلان عنها هنا، بل تتم من خلال موقع مستقل أو بعيد، ها هي: https://baaeed.com/companies/hsoub/jobs