Ali Ahmed55
-
المساهمات
2093 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
14
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Ahmed55
-
 تمام , جدا الف شكراا لحضرتكم
تمام , جدا الف شكراا لحضرتكم -
السلام عليكم هل الاهتمام بالتفاصيل يعد جزءًا مهمًا من كتابة التعليمات البرمجية ؟
- 4 اجابة
-
- 3
-

-
انا عاوز اعرف هل يوجد علاقه مابين Insulin ومابين Glucose وتاثيرهم علي عمود الOutcome ؟ ودي البيانات diabetes_clean1.csv
-
السلام عليكم انا عاوز اعرف لو فيه علاقه مابين عمودين في قاعد بيانات فا اي الرسم البياني الافضل لمهمه دي ؟
- 3 اجابة
-
- 2
-
-
تمام جدا , الف شكراا لحضرتكم
-
تمام , جدا الف شكراا لحضرتكم
-
السلام عليكم هو ممكن باستخدم خورزميات تعلم الاله ان اصنف الصور او اتعرف علي الوجه الا بستخدم التعلم العميق فقط باستخدم الشبكه العصبيه CNNs؟
- 4 اجابة
-
- 3
-
-
تمام , جدا الف شكرااا
-
تمام جدا , الف شكراا لحضرتك
-
تمام , الف شكراا
-
السلام عليكم عند تنظيم بياناتك أو ترتيبها باستخدامPython، متي نحتاج إلى تحويل البيانات الواسعة إلى بيانات طويلة أو طويلة إلى واسعة ؟
- 4 اجابة
-
- 2
-
-
السلام عليكم هلي فيه وظائف في باثيون لمعالجه التحيز ؟ زي في لغه R في وظائف bais انا اقصد التحيز في البيانات
- 4 اجابة
-
- 2
-
-
وكمان هل الافضل ان استخدم الكود ده pregnancy_counts = diabetes[diabetes['Outcome'] == 1].groupby("Age Group")['Pregnancies'].nunique() والا ده pregnancy_counts = diabetes[diabetes['Outcome'] == 1].groupby('Age Group')['Pregnancies'].sum() يعني استخد sum والا nunique ؟
-
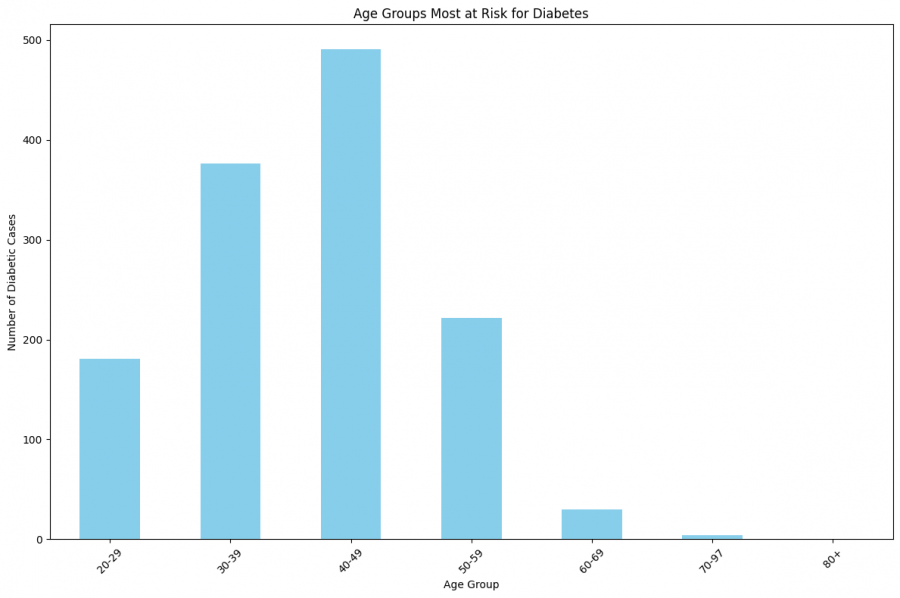
تمام ,لكن انا عاوز اعرف ما هي الفئات العمرية الأكثر عرضة للإصابة يعني ده يظهر في الرسم البياني وكمان متوسط حالات الحمل الفئاء العمري دي و انا عملت الكو ده ظهر الرسم دي انا الصرح مش فهم حاجه يعني هنا الفئاء مابين 40-49 وصل لحد 500 يعني اي ؟ وكمان لم تفيذات الكود ده print(pregnancy_counts) ظهرات النتجيه دي وبرد مش فهم منها حاجه ؟ Age Group 20-29 181 30-39 376 40-49 491 50-59 222 60-69 30 70-97 4 80+ 0 Name: Pregnancies, dtype: int64
-
السلام عليكم انا كتبت الكود لمعرفت ما هي الفئات العمرية الأكثر عرضة للإصابة بمرض السكري بس انا عاوز اعرف كمان عدد حالات الحمل لمريض , يعني 20-29 دي الفئاء الاكثر اصابه بمرض السكري انا بقا عاوز اعرف عدد حالات الحمل في الفترء دي اي ؟ ده الكود bins = [20, 30, 40, 50, 60, 70 , 80 , np.inf] label = ['20-29' , '30-39' , '40-49' , '50-59' , '60-69' , '70-97' , '80+'] diabetes['Age Group'] = pd.cut(diabetes['Age'] , bins=bins , labels=label , right=False) # Count the number of diabetic patients in each age group age_group_counts = diabetes[diabetes['Outcome'] == 1]['Age Group'].value_counts() print(age_group_counts) # Plot the bar chart age_group_counts.plot(kind='bar' , color='skyblue') plt.title("Age Groups Most at Risk for Diabetes") plt.xlabel("Age Group") plt.ylabel("Number of Diabetic Cases") plt.xticks(rotation=45) plt.tight_layout() plt.show() ودي البيانات المستخدم diabetes_clean1.csv
- 3 اجابة
-
- 1
-
-
تمام , الف شكراا لحضرتك
-
السلام عليكم هو اي التحليل الاحصائي ؟
- 2 اجابة
-
- 1
-
-
تمام الف شكراا لحضرتكم
-
تمام , جدا الف شكراا لحضرتكم جدا
-
السلام عليكم هو الpipe الموجود في لغه R هو نفس وظيفه الdef في باثيون ؟
- 4 اجابة
-
- 1
-
-
السلام عليكم هو الDataFrame و الSeries يعتبر نوع من انوع هياكل البيانات ؟
- 3 اجابة
-
- 1
-
-
ايوه صح فعلان المفروض and مش or عشان انا عاوز العمود ده وكمان العمود ده فا الف شكراا لحضرتكم جدا جزاكم الله كل خير الازم الشرطين يتحقيق مش شرط واحد
- 3 اجابة
-
- 1
-
-
السلام عليكم انا هنا عاوز يبدل كل الصفر بقيمه NaN ماعد عمود Pregnancies وكمان عمود الDiabetesPedigreeFunction بس بردو بيغير الاصفر ال قيمه NaN وانا مش عاوز كده ؟ يعني مش ده المنطقي والطبيعه والا اي ؟ for col in diabetes.columns: if col != 'Pregnancies' or col != 'DiabetesPedigreeFunction': diabetes[col] = diabetes[col].replace(0,np.nan) ودي البيانات diabetes_clean.csv
- 3 اجابة
-
- 2
-