السلام عليكم
لدي مشروع عن تحليل بيانات تويتر بلغة البايثون
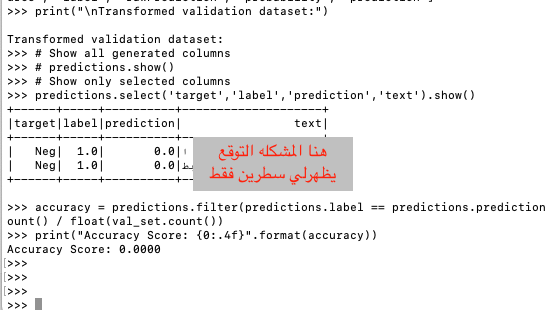
وعندما اعمل run للكود لاتظهرلي من البيانات في اخر فقرة (prediction) سوى سطرين فقط
وكذلك الدقة تظهر 0.00
علما انه عدد اسط بياناتي ٤١
وانا اريد منها ٢٠ سطر فقط
from pyspark.sql import SparkSession
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import Tokenizer,StopWordsRemover,CountVectorizer,IDF,StringIndexer
from pyspark.ml import Pipeline
spark = SparkSession.builder.getOrCreate()
df = spark.read.csv('test_data.tsv', sep='\t', encoding='utf-8', header=False).toDF('target', 'text')
print("Dataset schema:")
df.printSchema()
print("Training dataset:")
df.show(40)
# Print the numbeer of neg and pos tweets
import pandas as pd
print(df.toPandas().groupby(['target']).size())
# Split data into training and validation sets
(train_set, val_set) = df.randomSplit((0.9,0.1), seed=42)
# Arabic stop words
ar_stop_list = open("arabic_stopwords.txt", encoding="utf-8")
stop_words = ar_stop_list.read().split('\n')
# Text Preprocessing
tokenizer = Tokenizer(inputCol='text',outputCol='tokens')
stopwords_remover = StopWordsRemover(inputCol='tokens',outputCol='filtered_tokens').setStopWords(stop_words)
vectorizer = CountVectorizer(inputCol='filtered_tokens',outputCol='raw_features')
idf = IDF(inputCol='raw_features',outputCol='vectorized_features')
label_stringIdx = StringIndexer(inputCol='target',outputCol='label')
pipeline = Pipeline(stages=[tokenizer,stopwords_remover,vectorizer,idf,label_stringIdx])
pipeline_model = pipeline.fit(train_set)
train_df = pipeline_model.transform(train_set)
print("\nNew columns in training dataset:")
print(train_df.columns)
print("\nTransformed training dataset:")
train_df.show()
# For data classification into two classes (neg or pos),
# Fit logistic regression model to the transformed training dataframe
lr = LogisticRegression(maxIter=100, featuresCol='vectorized_features', labelCol='label')
lr_model = lr.fit(train_df)
# Evaluate the model using the validation dataframe
val_df = pipeline_model.transform(val_set)
predictions = lr_model.transform(val_df)
print("\nNew columns in validation dataset:")
print(predictions.columns)
print("\nTransformed validation dataset:")
# Show all generated columns
# predictions.show()
# Show only selected columns
predictions.select('target','label','prediction','text').show()
accuracy = predictions.filter(predictions.label == predictions.prediction).count() / float(val_set.count())
print("Accuracy Score: {0:.4f}".format(accuracy))
arabic_stopwords.txt