Mohamed Elnemr
-
المساهمات
54 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
1
2 متابعين

إنجازات Mohamed Elnemr
عضو نشيط (3/3)
100
السمعة بالموقع
-
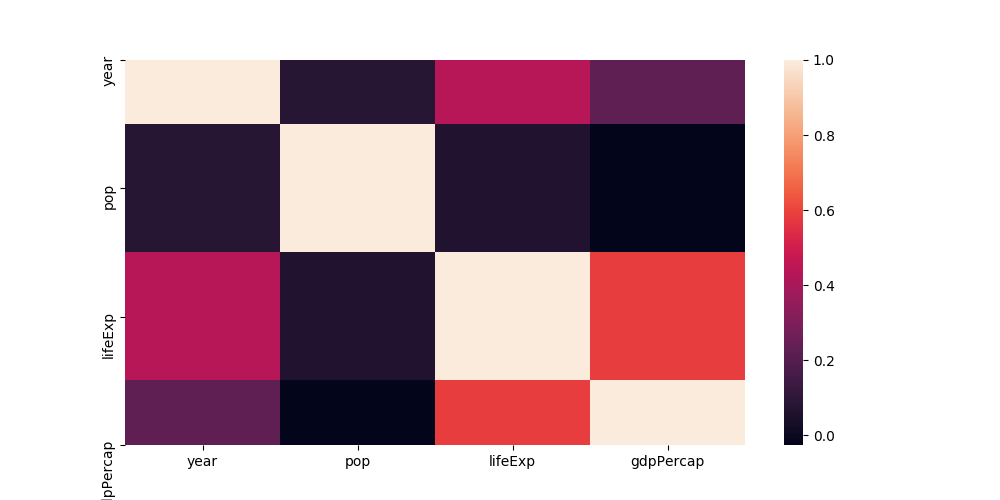
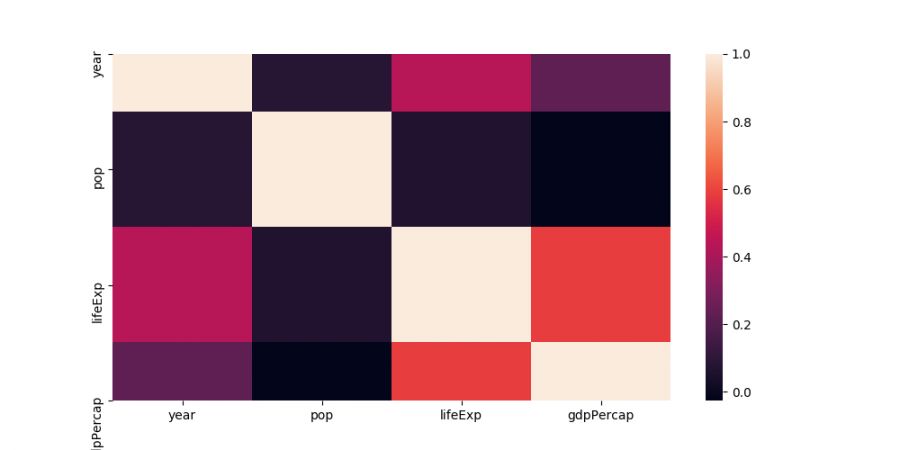
لدي مشكلة عندما أقوم برسم heatmap باستخدام seaborn واظهار الصورة باستخدام matplotK فأنه يقوم بقص نصف الصف الأول وكذلك الأخير من الصورة التي تخرج، مثل هذا المثال: import pandas as pd import seaborn as sns import matplotlib.pyplot as plt data = pd.read_csv('data.csv') plt.figure(figsize=(10,5)) sns.heatmap(data.corr()) plt.show() الصورة الناتجة يكون فيها أول صف وأخر صف مقصوصين من النصف: ما حل تلك المشكلة؟
- 2 اجابة
-
- 1
-

-
أحاول رسم عدة رسومات بيانية بجانب بعضها في matplot، حاولت بالكود التالي لكن لم يفلح: fig = plt.figure() axes = fig.subplots(nrows=2, ncols=2) كيف يمكنني فعل هذا؟
- 2 اجابة
-
- 2
-
-
لدي العديد من البيانات على شكل dataframe، واريد أن أجد طريقة أقوم بعمل إضافة لهم append مرة واحدة عوضاً عن عمل append لكل واحدة مفردها: df.append(df) لنفرض أن لدي dataframes أسماؤهم d1,d2,d3,d4,d5 جربت الطريقة التالية لاضافتهم مرة واحدة لكن لم تفلح: df = rbind(d1,d2,d3,d4,d5) كيف يمكنني فعل هذا؟
- 3 اجابة
-
- 3
-
-
لدي بيانات على الشكل التالي: time result 1 01:00 +52A 2 02:00 +62B 3 03:00 +72C 4 04:00 -82D 5 05:00 -92E وأريد أن أجعلها تظهر على الشكل التالي: time result 1 01:00 52 2 02:00 62 3 03:00 72 4 04:00 82 5 05:00 92 حاولت استخدام الدالة .str.lstrip('+-') لكن يظهر لي الخطأ التالي: TypeError: wrapper() takes exactly 1 argument (2 given) كيف يمكنني عمل هذا؟
- 2 اجابة
-
- 2
-
-
لدي بيانات على الشكل التالي: 1 2 0 April 4.0 1 August 8.0 2 December 12.0 3 February 2.0 4 January 1.0 5 July 7.0 6 June 6.0 7 March 3.0 8 May 5.0 9 November 11.0 10 October 10.0 11 September 9.0 أريد ترتيبهم بناء على قيم العمود رقم 2 تصاعديا، كيف يمكنني فعل هذا؟
- 3 اجابة
-
- 2
-
-
لدي بيانات تحتوى على التاريخ كالتالي: import pandas as pd data = {'start_date': [pd.Timestamp('2021-01-24 13:03:12.050000'), pd.Timestamp('2021-01-27 11:57:18.240000'), pd.Timestamp('2021-01-23 10:07:47.660000')], 'end_date': [pd.Timestamp('2021-01-26 23:41:21.870000'), pd.Timestamp('2021-01-27 15:38:22.540000'), pd.Timestamp('2021-01-23 18:50:41.420000')]} df = pd.DataFrame(data) قمت بعمل عمود لحساب الفرق بين تاريخين كالتالي: df['diff'] = df['end_date'] - df['start_date'] لكنة يظهر لي خانة تدعى "days" عندما يكون الفرق بين التاريخين أكبر من 24 ساعة: start_date end_ date diff 0 2021-01-24 13:03:12.050 2021-01-26 23:41:21.870 2 days 10:38:09.820000 1 2021-01-27 11:57:18.240 2021-01-27 15:38:22.540 0 days 03:41:04.300000 2 2021-01-23 10:07:47.660 2021-01-23 18:50:41.420 0 days 08:42:53.760000 كيف يمكنني حساب الفرق بين الأيام دون ظهور العمود days، بحيث يكون الفرق فقط في شكل ساعات ودقائق؟
- 2 اجابة
-
- 1
-
-
لدي بيانات على شكل dataframe بحيث تحتوى على تواريخ، وكل تاريخ مربوط به حدث أو أكثر أو ليس به أحداث إطلاقا، التواريخ من المفترض أنها لشهر كامل، الا انني عندما أقوم بعمل groupby لجمع عدد الأحداث سوياً في كل تاريخ تابعه لها، يكون عدد التواريخ أقل من 30، وذلك لأن هناك بعض الأيام ليس بها أحداث فيتم إزالتها مباشرة كالتالي: df.groupby(['simpleDate']).size() 09-02-2021 2 09-03-2021 10 09-06-2021 5 09-07-2021 1 لاحظ أن هناك تواريخ في المنتصف تم ازالتها لانها لا تحتوى على أحداث. أريد طباعة تلك التواريخ أيضا بحيث يكون عدد الأحداث بها 0 ولا يتم تجاهلها، كيف يمكنني فعل هذا؟
- 4 اجابة
-
- 2
-
-
أقوم بانشاء بيانات تحتوى على بعض المدن والمكاتب وكذلك مبيعات تلك المكاتب في المدن كالتالي: df = pd.DataFrame({'city': ['Cairo', 'Dohha', 'Riyadh', 'Dubai'] * 3, 'office_id': range(1, 7) * 2, 'sales': [np.random.randint(100000, 999999) for _ in range(12)]}) df.groupby(['city', 'office_id']).agg({'sales': 'sum'}) بحيث تظهر على الشكل التالي: city office_id sales Cairo 2 839507 4 373917 6 347225 Dohha 1 798585 3 890850 5 454423 Riyadh 1 819975 3 202969 5 614011 Dubai 2 163942 4 369858 6 959285 أريد حساب النسبة المئوية لمبيعات كل مكتب في كل مدينة علما أن محصلة المبيعات لكل المكاتب في كل مدينة = 100% كيف يمكنني فعل هذا؟
- 3 اجابة
-
- 2
-
-
أريد أن أعرف الفرق بين الدالة groupby("x").count و groupby("x").size
- 2 اجابة
-
- 1
-
-
قمت بعمل dataframe كالتالي: df = DataFrame(index=['A','B','C'], columns=['D','E']) >>> df D E A NaN NaN B NaN NaN C NaN NaN وأريد وضع قيمة في خانة معينة بناء على مكان الخانة index بحيث تظهر كالتالي: D E A NaN NaN B NaN NaN C 20 NaN كيف يمكنني فعل هذا؟
- 4 اجابة
-
- 2
-
-
أعرف أن هناك طرقاً لطباعة جزء من ال dataframe أو series كأسماء الأعمدة أو أول بضعة صفوف وكذلك أخر بضعة صفوف، لكن أريد أن أقوم بطباعة كافة ال dataframe على الشاشة، كيف يمكنني فعل هذا؟
- 3 اجابة
-
- 1
-
-
أقوم بتحميل بيانات لدي بالشكل التالي: import pandas as pd df = pd.read_csv("D:\\data.csv") df['review'] لكن يظهر لي هذا الخطأ: reviews_new['review'] Traceback (most recent call last): File "<ipython-input-43-ed485b439a1c>", line 1, in <module> reviews_new['review'] File "C:\Users\30216\AppData\Local\Continuum\Anaconda2\lib\site-packages\pandas\core\frame.py", line 1997, in __getitem__ return self._getitem_column(key) File "C:\Users\30216\AppData\Local\Continuum\Anaconda2\lib\site-packages\pandas\core\frame.py", line 2004, in _getitem_column return self._get_item_cache(key) File "C:\Users\30216\AppData\Local\Continuum\Anaconda2\lib\site-packages\pandas\core\generic.py", line 1350, in _get_item_cache values = self._data.get(item) File "C:\Users\30216\AppData\Local\Continuum\Anaconda2\lib\site-packages\pandas\core\internals.py", line 3290, in get loc = self.items.get_loc(item) File "C:\Users\30216\AppData\Local\Continuum\Anaconda2\lib\site-packages\pandas\indexes\base.py", line 1947, in get_loc return self._engine.get_loc(self._maybe_cast_indexer(key)) File "pandas\index.pyx", line 137, in pandas.index.IndexEngine.get_loc (pandas\index.c:4154) File "pandas\index.pyx", line 159, in pandas.index.IndexEngine.get_loc (pandas\index.c:4018) File "pandas\hashtable.pyx", line 675, in pandas.hashtable.PyObjectHashTable.get_item (pandas\hashtable.c:12368) File "pandas\hashtable.pyx", line 683, in pandas.hashtable.PyObjectHashTable.get_item (pandas\hashtable.c:12322) KeyError: 'review' كيف أقوم بحل هذا الخطأ؟
- 3 اجابة
-
- 1
-
-
لدي بيانات على الشكل التالي: df= col1 col2 0 384444683 593 1 384444684 594 2 384444686 596 وأريد تحويلها الى الشكل التالي بحيث أقوم بتحويل ال index الى عمود باسم index: df= index col1 col2 0 0 384444683 593 1 1 384444684 594 2 2 384444686 596 كيف يمكنني فعل هذا؟
- 2 اجابة
-
- 2
-
-
أحاول تشغيل الكود التالي: path = 'data.csv' df = pd.read_csv(path) لكن يظهر لي هذا الخطأ pandas.parser.CParserError: Error tokenizing data. C error: Expected 2 fields in line 3, saw 12 كيف يمكنني التغلب على هذا الخطأ؟
- 3 اجابة
-
- 1
-
-
لدي dataframe كالتالي: df = pd.DataFrame({'a':list('abccbac')}) وأريد أن أقوم بحساب عدد مرات تكرار الحرف a و c و b بحيث تظهر كالتالي: c 3 a 2 b 2 كيف يمكنني فعل هذا؟
- 2 اجابة
-
- 2
-