


Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
أجوبة بواسطة Ahmed Sharshar
-
-
يمكنك ببساطة أستخدام الدالة to_list والتي ستقوم بعمل ما تريد تماما، حيث انها تفصل الصف الى عناصر مختلفة ومنها يمكنك جعلك تلك العناصر في شكل أعمدة.
أنظر الكود التالي للتوضيح:
df2[['Fruit1','Fruit2']] = pd.DataFrame(df2.Fruits.tolist(), index= df2.index) print (df2) Fruit1 Fruit2 0 Apple Orange 1 Apple Orange 2 Apple Orange 3 Apple Orange 4 Apple Orange 5 Apple Orange 6 Apple Orangeكذلك إذا أردت فصل مجوعة من العناصر لكنها ليست في شكل list، كأن تكون العلامة "," هي الفاصل بين العناصر مثلا، يمكنك استخدام الكود التالي:
pd.DataFrame(df["Fruits"].str.split('<delim>', expand=True).values, columns=['Fruit1', 'Fruit2'])
-
 1
1
-
-
يمكنك إستخدام المكتبة itertools بحيث تقوم بعمل عمود جديد عبارة عن مزيج من الأعمدة الأخرى بالشكل الذي تريده.
الكود التالي يوضح كيف يمكن أن تقوم بها:
from itertools import chain dataframe['features'] = dataframe.apply(lambda x: ''.join([*chain.from_iterable((v, f' <{i}> ') for i, v in enumerate(x))][:-1]), axis=1) print(dataframe)
ويكون شكل الخرج هو:
col_1 col_2 col_3 features 0 a name_a age_a a <0> name_a <1> age_a 1 b name_b age_b b <0> name_b <1> age_b 2 c name_c age_c c <0> name_c <1> age_c 3 d name_d age_d d <0> name_d <1> age_d
حيث قمنا بإنشاء العمود features والذي يحتوى شكل البيانات التي تريد.
-
هناك ثلاث طرق داخل pandas يمكن بها إيجاد عدد الصفوف بداخل dataframe وهم:
- len(df.index)
- df.shape[0]
- df[df.columns[0]].count()
وعلى الرغم من أن الثلاث طرق يمكنهم تنفيذ المهمة، الا انهم ليسوا بنفس الكفاءه، أنظر الرسم البياني التالي:
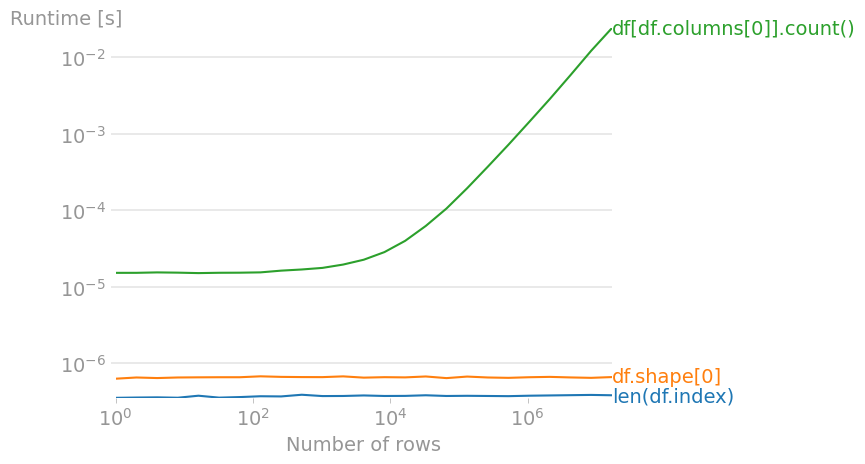
الشكل يوضح الوقت الذي تأخذه كل طريقة في عد الصفوف، نجد أن df[df.columns[0]].count() هي أسوأ طريقة لانه كلما زاد حجم ال dataframe زاد الوقت الذي تأخذه الدالة للعد بشكل كبير.
بينما تعد أفضل طريقة هي len(df.index) وذلك لانها تأخذ أقل وقت أثناء العمل.
-
1
-
يمكننا إستخدام الدالة DataFrame.iterrows والتي تمكننا باستخدام الحلقات التكرارية بداخل dataframe في pandas.
المثال التالي يوضح ما تريد أن تقوم به.
import pandas as pd data = [{'a':1, 'b':2}, {'a':3,'b':4}, {'a':5,'b':6}] df = pd.DataFrame(data) for index, row in df.iterrows(): print(row['a'], row['b']) >>> 1 2 3 4 5 6
-
يمكنك ببساطة إستخدام الدالة GroupBy.sum والتي تقوم بتجميع قيم العناصر وترتيبها تبعا لتلك العناصر، باختصار ، هي تنتج الشكل الذي تريده تماما.
أنظر الكود التالي للتوضيح:
df.groupby(['Fruit','Name']).sum() Out[1]: Number Fruit Name Mangos Ahmed 16 Mike 9 Steve 10 Pinapple Ahmed 35 Tom 87 Tony 15 Banana Ahmed 67 Mike 57 Tom 15 Tony 1-
1
-
-
في pandas توجد الدالة astype() والتي تقوم بالتحويل الى أي نوع من البيانات تريد، ويمكنها تحويل البيانات سواء كانت على الشكل dataframe أو series.
الأكواد التالية توضح بعض الأمثلة لهذا:
# التحويل الي int df = df.astype(int) # تحويل العمود a اليint والعمود b الي complex df = df.astype({"a": int, "b": complex}) # التحويل الي float64 s = s.astype(np.float16) # التحويل الي string s = s.astype(str)لكن يجب أن تحذر أثناء استخدامك لها لانها قد تؤدي في بعض الأحيان الى تحويل خاطئ:
>>> s = pd.Series([1, 5, -11]) >>> s 0 1 1 5 2 -11 dtype: int64
لاحظ ماذا يحدث عند التحويل:
>>> s.astype(np.uint8) 0 1 1 5 2 245 dtype: uint8
لأن القيمة -7 صغيرة، قام بعمل خطأ أثناء تحويلها الى uint8 وذلك لان القيم السالبة خارج نطاق uint8 ، لكنه لم يقم باظهار خطأ وانما قام بعمل حساب خاطئ، لذا يجب أن تعرف ما الذي تقوم بتحويله وهل هو مناسب أم لا.
-
1
-
-
في pandas يمكنك إستخدام الدالة to_numeric() لتحويل العناصر الى أرقام.
اذا قمنا بطباعة نوع العناصر التي قمت بانشاءها في مثالك السابق، ستجد أنها من النوع object
>>> s = pd.Series(["5", 6, "7", 8.0, "0.9"]) # mixed string and numeric values >>> s 0 5 1 6 2 7 3 8.0 4 0.9 dtype: object
هنا أنت تريد تحويلها كلها الي قيم عددية، يمكنك أستخدام الكود التالي:
>>> pd.to_numeric(s) 0 5.0 1 6.0 2 7.0 3 8.0 4 0.9 dtype: float64
لاحظ أن نوع العناصر أصبح float64 وهي قيمة عددية.
-
1
-
-
يمكنك عمل دالة بحيث يتم تطبيقها على كل البيانات باستخدام:
s.apply(func, convert_dtype=True, args=())
حيث تقوم بأخذ الدالة وتطبيقها على كل البيانات.
فمثلا لحل المشكلة التي عرضتها يمكنك الإطلاع على الكود التالي:
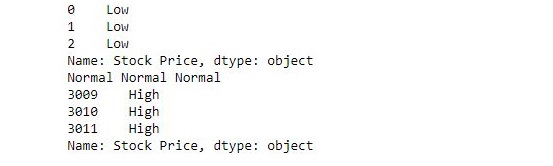
import pandas as pd # قراءه البيانات s = pd.read_csv("stock.csv", squeeze = True) # تعريف الدالة التي تقوم بتصنيف العناصر def fun(num): if num<200: return "Low" elif num>= 200 and num<400: return "Normal" else: return "High" # تطبيق الدالة على البيانات new = s.apply(fun) # طباعة أول 3 قيم print(new.head(3)) # طباعة قيم 3 عناصر عشوائية في المنتصف print(new[1400], new[1500], new[1600]) # طباعة أخر 3 عناصر print(new.tail(3))
لاحظ أن "stock.csv" هو مجرد ملف بيانات يمكنك أستبداله بأي ملف تريد.
عندما قمت بتشغيل الكود كانت هذه هي النتائج:
-
1
-
-
في pandas ، توجد دالة مشابهة ل IN التي توجد في SQL تسمي pd.Series.isin.
من أجل اختيار أو اختبار وجود عناصر داخل dataframe عن طريق السطر الأتى:
something.isin(somewhere)
المثال التالي يوضح استخدام تلك الدالة في حل مشلكتك:
import pandas as pd >>> df country 0 US 1 UK 2 Germany 3 China >>> countries_to_keep ['UK', 'China'] >>> df.country.isin(countries_to_keep) 0 False 1 True 2 False 3 True Name: country, dtype: bool
لاحظ أننا قمنا بإختبار تواجد العناصر التي في countries_to_keep بداخل country، والعناصر الموجودة بداخلها تظهر امامها True وغير الموجودة ب False.
-
في pandas توجد الدالة series.truncate والتى تمكننا من إقتطاع أجزاء محددة من البيانات على شكل dataframe وهي كالتالي:
Series.truncate(before=None, after=None, axis=None, copy=True)
حيث نقوم بتحديد بداية ونهاية الأماكن التي نريد إقتطاعها ، ويمكن استخدامها لتحقيق هدفك كالتالي:
import pandas as pd sr = pd.Series([19.5, 16.8, 22.78, 20.124, 18.1002]) # نقتطع البيانات ما قبل 1 وما بعد 3 sr.truncate(before = 1, after = 3)
ويكون شكل البيانات الخارجة كالتالي:

-
يمكننا استخدام الدالة Series.str.replace() او الدالة replace وذلك لتبديل قيم عناصر محددة بقيم أخرى، والفرق بينها وبين .replace() فقط انها مفيدة في حالة اردت استبدال معلومات على الشكل string.
المثال التالي يوضح كيفية استخدام replace :
# استدعاء المكتبة import pandas as pd # قراءة البيانات data = pd.read_csv("data.csv") # تبديل عناصر في عمود بعناصر أخرى data["Age"]= data["Age"].replace(25.0,20.0) #طباعة البيانات الجديدة print(data)
هنا نقوم باختيار العمود Age وإستبدال بعض القيم العددية فيه من 25 الي 20.
أما اذا اردت استخدام الدالة str.replace فيمكنك استخدامها كالتالي:
# استدعاء المكتبة import pandas as pd # قراءة البيانات data = pd.read_csv("data.csv") # استبدال قيم من عمود معين بقيم أخرى data["country"]= data["country"].str.replace("Egypt", "KSA", case = False) #طباعة البيانات المعدلة print(data)
هنا نقوم باستبدال الكلمة "Egypt" بالكلمة "KSA" من العمود country، لاحظ أن case = False تعني أنه لا يهتم سواء كانت الكلمات بحروف كبيرة capital او حروف صغيرة small
-
1
-
-
بما ان البيانات على شكل dataframe، فانه من المستحب التعامل معها استخدام pandas ، وذلك للتسهيل.
من أجل ترتيب الاسماء بشكل تصاعدي يمكن استخدام الكود التالي:
# استدعاء المكتبة import pandas as pd # قراءة ملف البيانات data = pd.read_csv("data.csv") # ترتيب البيانات بالاسم data.sort_values("Name", axis = 0, ascending = True, inplace = True, na_position ='last') # عرض الترتيب الجديد data
لاحظ انه يجب تغيير اسم ملف البيانات تبعا لاسمه الحقيقي.
كذلك اذا أردت ترتيبه بشكل تنازلي كل ما عليك هو تغيير ascending من true الي false.
لاحظ كذلك ان "Name" هو اسم العمود الذي تريد ترتيبه ويمكنك اختيار اي عمود كما تريد.
-
اذا كنت تستخدم نسخة قديمة من بايثون، ربما عليك استخدام الكود التالي:
import operator x = {0: 1, 2: 3, 4: 5, 2: 2, 0: 0} sorted_x = sorted(x.items(), key=operator.itemgetter(1))وسيكون شكل الخرج كالتالي:
{0: 0, 0: 1, 2: 2, 2: 3, 4: 5}وهنا قمنا بعمل ترتيب لل value بشكل تصاعدي.
للعلم ايضا يمكنك ترتيب ال keys بدلا من ال values اذا اردت بنفس الطريقة كالتالي:
import operator x = {0: 1, 2: 3, 4: 5, 2: 2, 0: 0} sorted_x = sorted(x.items(), key=operator.itemgetter(0))لاحظ ان الفرق الوحيد بين الطريقتين هو تبديل 1 ب 0، حيث تعبر 0 عن keys بينما 1 عن values.
اما اذا كنت تستخدم python 3.7 او احدث،تستطيع استخدام الكود التالي:
>>> x = {0: 1, 2: 3, 4: 5, 2: 2, 0: 0} >>> {k: v for k, v in sorted(x.items(), key=lambda item: item[1])} {0: 0, 0: 1, 2: 2, 2: 3, 4: 5}او باستخدام dict كالتالي:
>>> dict(sorted(x.items(), key=lambda item: item[1])) {0: 0, 0: 1, 2: 2, 2: 3, 4: 5} -
هناك عدة طرق للقيام بتلك المهمة، انظر الطرق التالية:
الطريقة المباشرة، وهي باضافة قيمة value لكل مفتاح key بطريقة مباشرة كالتالي:
dict = {'key1':'Hi', 'key2':'fill_me'} print("Current Dict is: ", dict) # using the subscript notation dict['key2'] = 'for' dict['key3'] = 'me' print("Updated Dict is: ", dict)
ويكون شكل الخرج:
Current Dict is: {'key1': 'hi', 'key2': 'fill_me'} Updated Dict is: {'key3': 'hi', 'key1': 'me', 'key2': 'for'}هنا قمنا باضافة key3 وكذلك تبديل قيمة key2.
استخدام update() : انظر المثال التالي:
dict = {'key1':'old', 'key2':'for'} print("Current Dict is: ", dict) # adding key3 dict.update({'key3':'new'}) print("Updated Dict is: ", dict) # adding dict1 (key4 and key5) to dict dict1 = {'key4':'is', 'key5':'fabulous'} dict.update(dict1) print(dict) # by assigning dict.update(newkey1 ='portal') print(dict)
يكون شكل الخرج كالتالي:
Current Dict is: {'key2': 'for', 'key1': 'old'} Updated Dict is: {'key2': 'for', 'key3': 'new', 'key1': 'old'} {'key4': 'is', 'key2': 'for', 'key5': 'fabulous', 'key3': 'new', 'key1': 'old'} {'key3': 'new', 'newkey1': 'portal', 'key1': 'old', 'key4': 'is', 'key2': 'for', 'key5': 'fabulous'}استخدام العلامة *: تمكننا تلك الطريقة من اضافة قيم قديمة مع قيم جديدة كالتالي:
dict = {'a': 1, 'b': 2} # will create a new dictionary new_dict = {**dict, **{'c': 3}} print(dict) print(new_dict)
ويكون الخرج:
{'b': 2, 'a': 1} {'b': 2, 'c': 3, 'a': 1}
-
يمكن ان تقوم فقط باستخدام الدالة enumerate() بشكل خاطئ، لو انك تريد استخدامها يمكنك تجربة هذا الكود:
months =['January','February','March','April','May','June','July','August','September','October','November','December'] d_months = {} for i, month in enumerate(months): d_months[i+1] = month print(d_months)
يجب ان يظهر الخرج بالشكل التالي:
{1: 'January', 2: 'February', 3: 'March', 4: 'April', 5: 'May', 6: 'June', 7: 'July', 8: 'August', 9: 'September', 10: 'October', 11: 'November', 12: 'December'}
لاحظ اننا استخدمنا i+1 وذلك لاننا نبدأ من المكان 0 ونريد ان نضم اخر شهر لدينا كذلك، لذا فقيمة i+1 =12 وهو عدد الشهور المراد ضمها.
-
في التعلم العميق ، ال loss هي القيمة التي تحاول الشبكة العصبية تقليلها: حيث تمثل الفرق بين القيم الحقيقية والتنبؤات. لتقليل هذا الفرق، تتعلم الشبكة العصبية عن طريق ضبط الأوزان بطريقة تقلل من الخسارة.
الدقة accuracy هي عكس ال loss، حيث تمثل مقدار التنبؤات الصحيحية التي حصلنا عليها مقارنة بالقيم الحقيقية، ومع تقليل ال loss نقوم بزيادة ال accuracy.
هناك ثلاثة من البيانات، بيانات للتدريب training set واخري لقياس مدي التقدم الذي نحرزه validation set واخيرا واحدة للاختبار test set.
اما الاولى فهي لتقوم الشبكة بالتعلم عليها، وتكون اكبر حزمة بيانات بين الثلاث انواع، وهنا نستخدم acc لقياس مدي التقدم الذي نحرزه في التعلم بناءا على تلك البيانات، وبالطبيعي فان قيمه acc ستزداد مع الوقت، اذا لم يحدث هذا فان النموذج الذي بنيته بالتاكيد به خطأ ما.
اما الثانية validation set فهي حزمه اخرى لقياس مدي اداء النموذج الخاص بنا حتي نستطيع تحسينه مع الوقت، تكون اصغر من ال training set وقريبه في ححجمها من test set، وفيها نستخدم val_acc لقياس مدى التقدم الذي نحرزه فيها، من الطبيعي كذلك انها ستزداد مع الوقت، لكن مراقبتها مهمة، لانه يجب ان نوقف التعلم اذا توقفت val_acc عن الزيادة حتى لا يحدث over fitting..
-
يمكنك تطبيق بعض طبقات ال dropout كالتالي:
from keras.applications import VGG16 from keras.layers import Dropout from keras.models import Model model = VGG16(weights='imagenet') # خزن اخر طبقة كلها fc1 = model.layers[-3] fc2 = model.layers[-2] predictions = model.layers[-1] # قم بخلق الطبقات التي تريد dropout1 = Dropout(0.85) dropout2 = Dropout(0.85) # قم بزيادة تلك الطبقات وتوصيلها مع ما قبلها وما بعدها x = dropout1(fc1.output) x = fc2(x) x = dropout2(x) predictors = predictions(x) # قم بتشغيل النموذج model2 = Model(input=model.input, output=predictors)
حينها سيصبح شكل النموذج كالتالي:
____________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ==================================================================================================== input_1 (InputLayer) (None, 3, 224, 224) 0 ____________________________________________________________________________________________________ block1_conv1 (Convolution2D) (None, 64, 224, 224) 1792 input_1[0][0] ____________________________________________________________________________________________________ block1_conv2 (Convolution2D) (None, 64, 224, 224) 36928 block1_conv1[0][0] ____________________________________________________________________________________________________ block1_pool (MaxPooling2D) (None, 64, 112, 112) 0 block1_conv2[0][0] ____________________________________________________________________________________________________ block2_conv1 (Convolution2D) (None, 128, 112, 112) 73856 block1_pool[0][0] ____________________________________________________________________________________________________ block2_conv2 (Convolution2D) (None, 128, 112, 112) 147584 block2_conv1[0][0] ____________________________________________________________________________________________________ block2_pool (MaxPooling2D) (None, 128, 56, 56) 0 block2_conv2[0][0] ____________________________________________________________________________________________________ block3_conv1 (Convolution2D) (None, 256, 56, 56) 295168 block2_pool[0][0] ____________________________________________________________________________________________________ block3_conv2 (Convolution2D) (None, 256, 56, 56) 590080 block3_conv1[0][0] ____________________________________________________________________________________________________ block3_conv3 (Convolution2D) (None, 256, 56, 56) 590080 block3_conv2[0][0] ____________________________________________________________________________________________________ block3_pool (MaxPooling2D) (None, 256, 28, 28) 0 block3_conv3[0][0] ____________________________________________________________________________________________________ block4_conv1 (Convolution2D) (None, 512, 28, 28) 1180160 block3_pool[0][0] ____________________________________________________________________________________________________ block4_conv2 (Convolution2D) (None, 512, 28, 28) 2359808 block4_conv1[0][0] ____________________________________________________________________________________________________ block4_conv3 (Convolution2D) (None, 512, 28, 28) 2359808 block4_conv2[0][0] ____________________________________________________________________________________________________ block4_pool (MaxPooling2D) (None, 512, 14, 14) 0 block4_conv3[0][0] ____________________________________________________________________________________________________ block5_conv1 (Convolution2D) (None, 512, 14, 14) 2359808 block4_pool[0][0] ____________________________________________________________________________________________________ block5_conv2 (Convolution2D) (None, 512, 14, 14) 2359808 block5_conv1[0][0] ____________________________________________________________________________________________________ block5_conv3 (Convolution2D) (None, 512, 14, 14) 2359808 block5_conv2[0][0] ____________________________________________________________________________________________________ block5_pool (MaxPooling2D) (None, 512, 7, 7) 0 block5_conv3[0][0] ____________________________________________________________________________________________________ flatten (Flatten) (None, 25088) 0 block5_pool[0][0] ____________________________________________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 flatten[0][0] ____________________________________________________________________________________________________ dropout_1 (Dropout) (None, 4096) 0 fc1[0][0] ____________________________________________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 dropout_1[0][0] ____________________________________________________________________________________________________ dropout_2 (Dropout) (None, 4096) 0 fc2[1][0] ____________________________________________________________________________________________________ predictions (Dense) (None, 1000) 4097000 dropout_2[0][0] ==================================================================================================== Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 ____________________________________________________________________________________________________لاحظ اضافة طبقات ال dropout ،ويمكنك تغيير مكانها كما تريد
-
نعم، لتعلم الخوارزمية انصح بمتابعة كورس او دورة من دورات تعلم البرمجة مثل التي تقدمها حسوب.
اما اذا كنت تبحث عن كتاب فان مرجع مذاكره الخوارزمية والكتاب الافضل لها على الاطلاق هو :
اقتباسIntroduction to Algorithms
لكن هذا الكتاب بالانجليزية، ويمكنك ان تجد له ترجمة.
هذه هي صورة الغلاف الخاصة به:

اما بالعربية فافضل كتاب هو:
اقتباستحليل وتصميم الخوارزميات
وهذه هي صورة الغلاف خاصته:

يمكنك شراء تلك الكتب من المكتبات او اونلاين.
-
1
-
-
الكود التالي يوضح كيف تضيف طبقة او تعدل طبقة والتي يطابق اسمها اسم معين regular expression:
import re from keras.models import Model def insert_layer_nonseq(model, layer_regex, insert_layer_factory, insert_layer_name=None, position='after'): # توضيح الرسم الخاص بالنموذج network_dict = {'input_layers_of': {}, 'new_output_tensor_of': {}} # تعيينالدخل لكل طبقة for layer in model.layers: for node in layer._outbound_nodes: layer_name = node.outbound_layer.name if layer_name not in network_dict['input_layers_of']: network_dict['input_layers_of'].update( {layer_name: [layer.name]}) else: network_dict['input_layers_of'][layer_name].append(layer.name) # تعيين الخرج لكل دخل network_dict['new_output_tensor_of'].update( {model.layers[0].name: model.input}) # نمر على كل الطقات بعد تعيين الدخل model_outputs = [] for layer in model.layers[1:]: # نوضح ال tensor layer_input = [network_dict['new_output_tensor_of'][layer_aux] for layer_aux in network_dict['input_layers_of'][layer.name]] if len(layer_input) == 1: layer_input = layer_input[0] # نقوم باضافة طبقة اذا وافق اسمها اسم معين if re.match(layer_regex, layer.name): if position == 'replace': x = layer_input elif position == 'after': x = layer(layer_input) elif position == 'before': pass else: raise ValueError('position must be: before, after or replace') new_layer = insert_layer_factory() if insert_layer_name: new_layer.name = insert_layer_name else: new_layer.name = '{}_{}'.format(layer.name, new_layer.name) x = new_layer(x) print('New layer: {} Old layer: {} Type: {}'.format(new_layer.name, layer.name, position)) if position == 'before': x = layer(x) else: x = layer(layer_input) network_dict['new_output_tensor_of'].update({layer.name: x}) # نقوم بحفظ الخرج if layer_name in model.output_names: model_outputs.append(x) return Model(inputs=model.inputs, outputs=model_outputs)
-
يمكن استخدام الدالة repeat، عن طريق تحديد عدد المرات التي تريد تكرارها مسبقا، الكود التالي يوضح كيف تقوم بها:
In [1]: import numpy as np In [2]: num_repeats = 5 In [3]: a = np.array([[1, 2], [1, 2]]) In [4]: b = np.dstack([a]*num_repeats) In [5]: b[:,:,0] Out[5]: array([[1, 2], [1, 2]]) In [6]: b[:,:,1] Out[6]: array([[1, 2], [1, 2]]) In [7]: b[:,:,2] Out[7]: array([[1, 2], [1, 2]]) In [8]: b[:,:,3] Out[8]: array([[1, 2], [1, 2]]) In [9]: b[:,:,4] Out[9]: array([[1, 2], [1, 2]]) In [10]: b.shape Out[10]: (2, 2, 3) -
في الواقع لا يوجد فرق بين قيم pi في اي من المكتبات الثلاث، للتاكد جرب الكود التالي:
>>> import math >>> import numpy as np >>> import scipy >>> math.pi == np.pi == scipy.pi True
هنا نحن نقارن بين قيم pi في الثلاث مكتبات والناتج هو true اي انهم جميعهم متساوون.
السبب الوحيد لتوفير نفس قيمه pi في الثلاث مكتبات هي تسهيل استدعائها بغض النظر عن المكتبة التي تقوم باستدعاءها والعمل بها، نظرا لاهمية قيمه ال pi وكثرة استخدامها.
-
1
-
-
الحل بسيط، قم بانشاء المصفوفة بعد ذلك استخدم الدالة numpy.delete، لا تقلق فهي لا تقوم بحذف عنصر من المصفوفة فقط استبعاده مؤقتا.
انظر المثال التالي، قم باشناء مصفوفة بالطريقة العادية كالتالي:
import numpy as np x = np.array([0,10,20,30,40,50,60])قم بتحديد العنصر او العناصر التي تريد استبعادها، هنا ان تحدد مكان العناصر التي تريد ازالتها index وليس قيمة العنصر نفسه كالتالي:
exclude = [1, 3, 5]بعد ذلك استخدم الدالة delete كالتالي:
In [4]: np.delete(x, exclude) Out[4]: array([ 0, 20, 40, 60])لاحظ انه تم استبعاد العناصر في الاماكن التي حددناها سابقا [1,3,5] لذا استبعد [10,30,50].
-
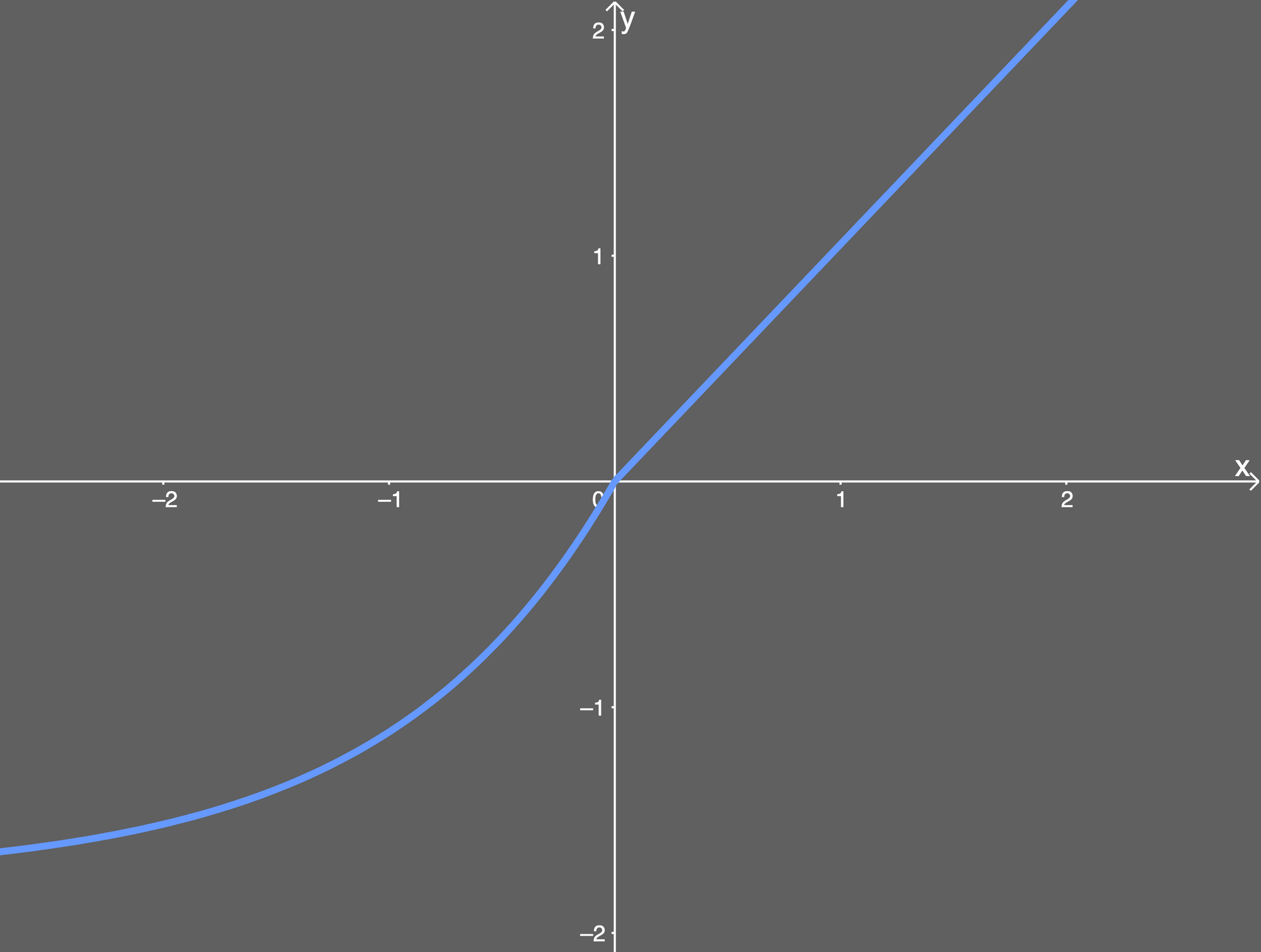
SELU هي دالة تنشيط لها الصيغة الرياضية:
f(x) = { λ.x if x > 0 λ.α(exp(x)-1) if x < 0}حيث ان λ و α ثوابت عددية وتساوي تقريبا
a ≈ 1.6732632423543772848170429916717 λ ≈ 1.0507009873554804934193349852946وترسم بيانيا بالشكل التالي:
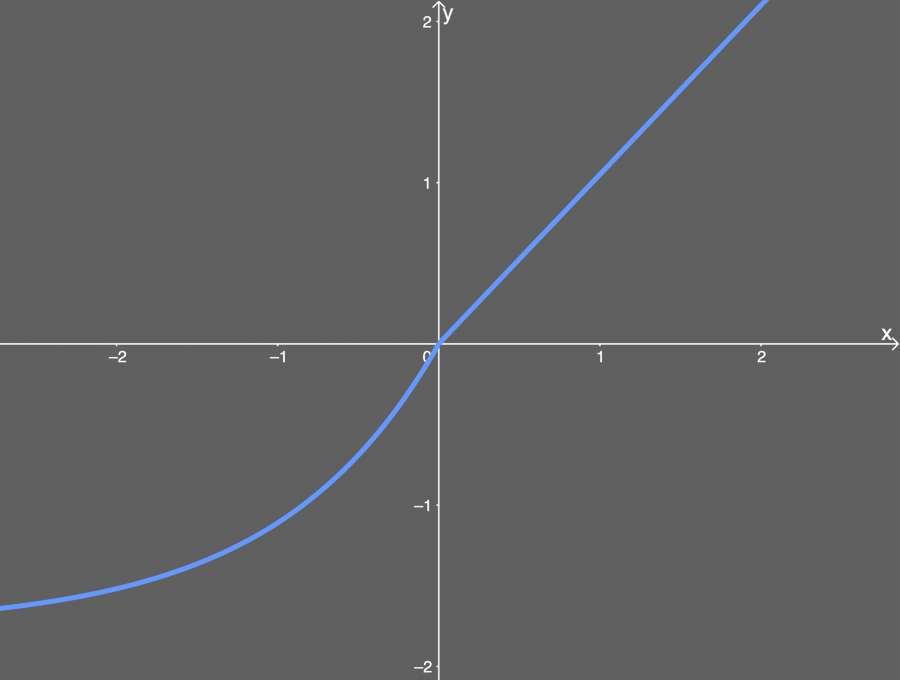
تستطيع ان تلاحظ من الرسم تصرف الدالة، وهي تأخذ شكلا اسيا في القيم الاقل من الصفر بينما تتحول لتصبح خطية في القيم الاكبر من الصفر، وهي تشبه الددالة elu ، فقط باضافة بعض الثوابت.
تلك الدالة ببساطه تقوم بعمل normalization، اي انها تقوم بطرح المتوسط من كل قيمة بعد ذلك تقسم على الانحراف المعياري، وبهذا فان المتوسط يصبح 0 والانحراف المعياري يصبح 1 للاوزان بعد عمل ال normalization وهذا يساعد في عملية التعلم ويجعلها اسهل.
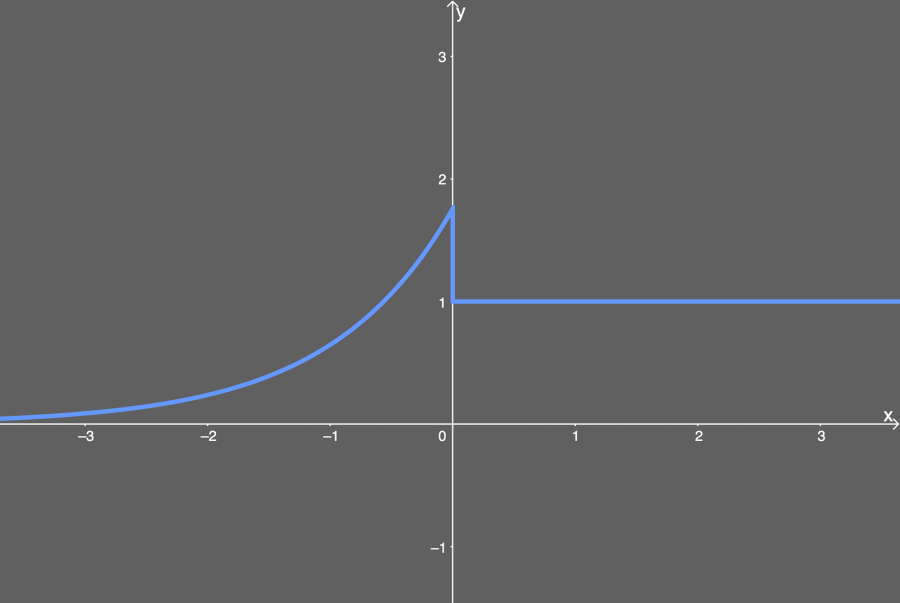
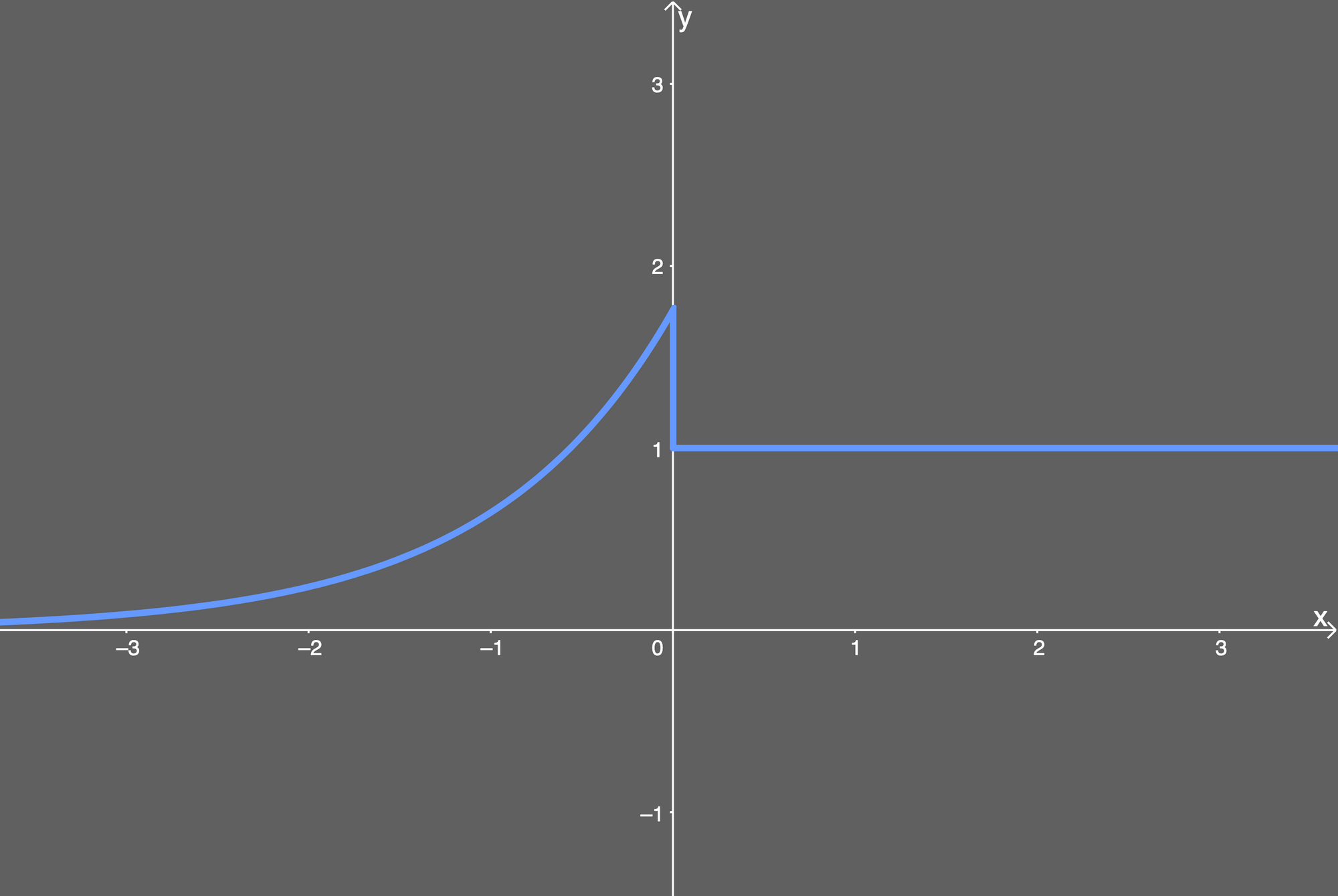
بالنسبة لمشتقتها فهي كالتالي:
f(x) = { λ if x > 0 λ.α(exp(x)) if x < 0}ويمكن تمثيلها بيانيا بالشكل التالي:
مميزاتها:
- بعد تطبيق ال normalization فان هذا يجعل عملية التعلم اسرع بكثير مقارنه بعدم استخدامها.
- لا يمكن ان يحدث اي مشكلة اثناء عملية التعلم.
العيوب:
- تعتبر جديدة نسبيا لذا ليس لها دعم كبير في الاكواد حتى الان
اما عن استخدامها في Keras فيمكنك استخدامها تماما كاي دالة تنشيط اخرى كالتالي:
num_classes = 10 model = tf.keras.Sequential() model.add(tf.keras.layers.Dense(64, kernel_initializer='lecun_normal', activation='selu')) model.add(tf.keras.layers.Dense(32, kernel_initializer='lecun_normal', activation='selu')) model.add(tf.keras.layers.Dense(16, kernel_initializer='lecun_normal', activation='selu')) model.add(tf.keras.layers.Dense(num_classes, activation='softmax')) -
المشكلة بسيطة، فقط مشكلة في شكل البيانات التي تدخل بعد طبقة maxpooling، كل ما عليك هو استبدال:
x = MaxPooling2D(pool_size=(2, 2))
بالسطر التالي:
x = MaxPooling2D((2,2), padding='same')هنا نقوم بعمل padding وذلك من اجل جعل القيم تقبل القسمه /2 ، او بمعني اصح ان نجعل الصوره ذات ابعاد تقبل بانه يمر بها kernel ابعاده 2*2.

اختيار الأسطر التي تحوي على كلمة معينة في باندا pandas
في بايثون
نشر · تم التعديل في بواسطة Ahmed Sharshar
عندما قمت بإختبار حلك الذي قدمته:
أظهر لي هذا الخطأ:
ValueError: cannot mask with array containing NA / NaN valuesإذاً فالحل في حد ذاته ليس خطأً لكن عليك أن تعتبر وجود القيم nan، لذا يمكننا عمل تعديل بسيط ليصبح الكود سليماً كالتالي:
هناك أيضا حل أخر باستخدم str.contains والتي تقوم بالبحث عن كلمة أو جملة معينة داخل dataframe، الكود التالي يؤدي المهمة التي تطلبها كذلك: