


ريم المهدي
-
المساهمات
127 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو ريم المهدي
-
هي دالة تستخدم لتحويل البيانات من توزيعها الحالي إلى التوزيع الطبيعي او الغاوسي (Gaussian)، يمكن تطبيق الدالة بطريقتين، إما بإستخدام PowerTransformer أو power_transform، لاحظ المثالين التاليين: import numpy as np from sklearn.preprocessing import PowerTransformer pt = PowerTransformer() data = [[1, 2], [3, 2], [4, 5]] print(pt.fit(data)) print(pt.transform(data)) لاحظ قيم البيانات الناتجة بعد عملية التحويل، والان لنرى طريقة تحويل البيانات بالصورة الثانية: import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import power_transform data = [[1, 2], [3, 2], [4, 5]] plt.hist(data) plt.show() في هذه الحالة قمنا بتمثيل القيم في شكل رسم بياني والذي ينتج: الان لاحظ للشكل الناتج بعد تطبيق الدالة: transformed = power_transform(data, method='box-cox') print(transformed) plt.hist(transformed) plt.show() وهنا قد لا يظهر شكل التوزيع الطبيعي بالصورة المطلوبة نسبة لقلة البيانات، لكن عملية التحويل تكون قد تمت وهي التي انتجت الشكل المرفق أعلاه.
-
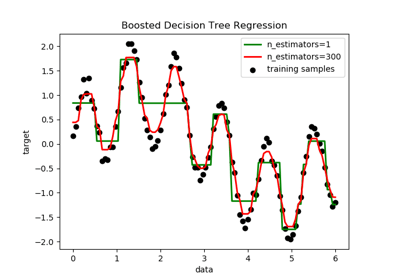
هو من الخوارزميات التي تعتمد على ناتج مجموعة من الخورزميات الأخرى مثل DecisionTreeRegressor وهو عبارة عن الخوارزمية الإفتراضية في هذه الحالة، هذه العملية تتم عن طريق تطبيق الخوارزمية المختارة او النموذج مثلا DecisionTreeRegressor أكثر من مرة على نفس البيانات، الفرق أنه في كل مرة يتدرب فيها النموذج يقوم بتعديل الأوزان حسب الخطأ الناتج من النموذج السابق. import numpy as np import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import AdaBoostRegressor # إنشاء مجموعة البيانات rng = np.random.RandomState(1) X = np.linspace(0, 6, 100)[:, np.newaxis] y = np.sin(X).ravel() + np.sin(6 * X).ravel() + rng.normal(0, 0.1, X.shape[0]) # إنشاء النماذج، الأول هو لشجرة القرارات و الثاني المعتمد على 300 نموذج شجرة قرارات regr_1 = DecisionTreeRegressor(max_depth=4) regr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4), n_estimators=300, random_state=rng) # تدريب النموذجين regr_1.fit(X, y) regr_2.fit(X, y) # توقع نتائج النموذجين y_1 = regr_1.predict(X) y_2 = regr_2.predict(X) # عرض نتائج النموذجين لمعرفة الأفضل plt.figure() plt.scatter(X, y, c="k", label="training samples") plt.plot(X, y_1, c="g", label="n_estimators=1", linewidth=2) plt.plot(X, y_2, c="r", label="n_estimators=300", linewidth=2) plt.xlabel("data") plt.ylabel("target") plt.title("Boosted Decision Tree Regression") plt.legend() plt.show() ناتج تنفيذ البرنامج ينتج الشكل المرفق، لاحظ للإختلاف بإستخدام adaboostregressor والذي ينتج قيم أكثر دقة.
-
يمكن حل هذا السؤال بتعريف مصفوفة بالحروف الكبيرة و إدخال قيمة من المستخدم تمثل ترتيب الحروف التي يجب طباعتها، ولأن المصفوفات تبدأ من 0 يجب أن يتم طرح القيمة المدخلة بواحد ويصبح البرنامج: import java.util.Scanner; public class Main { public static void main(String[] args) { char[] alphabet = {'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'}; Scanner in=new Scanner(System.in); System.out.print("Enter # of character to print:"); System.out.print(alphabet[in.nextInt()-1]); } }
-
هنالك عدد من الأخطاء التي يمكن حلها: 1- تعريف المصفوفة يكون بعد تحديد عدد الصفوف و الأعمدة، 2- الأسماء لا يجب تكرارها في نفس البرنامج، لذا قمت بتعريف r , c بدلاً من row, column اللذان تم إستخدامهما من قبل، مع العلم أنه يمكن إستخدام نفس المتغيرات المعرفة بداخل الحلقة في حلقة أخرى، 3- عمليات الطباعة الأخيرة تكون على مستوى مجموع القيم للصفوف وليس الأعمدة، 4- إستخدام الدالة math.floor هو ما يمكننا من إيجاد قيم أعلى من صفر لملء المصفوفة بالقيم الجديدة، البرنامج المعدل يكون كالتالي: import java.util.Scanner; import static java.lang.Math.*; public class Main { public static void main(String[] args) { Scanner in=new Scanner(System.in); System.out.print("Enter # of rows "); int row =in.nextInt(); System.out.print("Enter # of columns "); int column=in.nextInt(); int matrix[][]=new int[row][column]; for (int r=0;r<matrix.length;r++){ for (int c=0;c<matrix[0].length;c++){ System.out.print("Enter row # "+(r+1)+" and column # "+(c+1)+": "); matrix[r][c]=in.nextInt(); } } System.out.println("Printing User Elements"); for (int r=0;r<matrix.length;r++){ for (int c=0;c<matrix[0].length;c++){ System.out.print(matrix[r][c]+" "); } System.out.println(" "); } System.out.println("Replacing elements with random numbers, done ..."); for (int r=0;r<matrix.length;r++){ for (int c=0;c<matrix[0].length;c++){ matrix[r][c]=((int)Math.floor(Math.random()*100)); } } System.out.println("Printing ..."); for (int r=0;r<matrix.length;r++){ for (int c=0;c<matrix[0].length;c++){ System.out.print(matrix[r][c]+" "); } System.out.println(" "); } int total=0; for (int r=0;r<matrix.length;r++){ for (int c=0;c<matrix[0].length;c++){ total+=matrix[r][c]; } } System.out.println("Printing the total of the elements"); System.out.println("Printing total by row:"); for (int r=0;r<matrix.length;r++){ int subtotal=0; for (int c=0;c<matrix[0].length;c++){ subtotal+=matrix[r][c]; } System.out.println("The sum of row "+(r+1)+" is " +subtotal); } } } قمت بإضافة عدد من عبارات الطباعة ليصبح البرنامج مقروء.
-
المشكلة هي في ضبط شبكة lstm لأنها في هذه الحالة ستخرج كل سلسلة الحالات المخفية hidden states و في شكل البيانات و قبل إستدعاء طبقة dense نريد فقط خرج اخر خطوة زمنية final time step of the hidden state. يمكن تفادي الخطأ بضبط return_sequence=False أو يمكنك مسحها لأن حسب تعريف شبكة lstm قيمتها false: tf.keras.layers.LSTM( units, activation="tanh", recurrent_activation="sigmoid", use_bias=True, kernel_initializer="glorot_uniform", recurrent_initializer="orthogonal", bias_initializer="zeros", unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, return_sequences=False, return_state=False, go_backwards=False, stateful=False, time_major=False, unroll=False, **kwargs )
- 2 اجابة
-
- 1
-

-
إذا كنت تعمل على ويندوز 10 يمكنك تنفيذ البرنامج التالي: import os os.environ['CUDA_VISIBLE_DEVICES'] = '-1' وفي حال كنت تستخدم keras 2 مع ويندوز يمكنك تعديل الكود الأول المذكور في إجابة @Ali Haidar Ahmadإلى: import os os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ['CUDA_VISIBLE_DEVICES'] = '-1'
-
RELU هي إختصار ل Re(ctified) L(inear) (U)nit وهي من أشهر دوال التنشيط المستخدمة، ترجع قيمة 0 في حال كانت القيمة المدخلة أقل من أو تساوي 0 و ترجع نفس قيمة x في حال كانت القيمة أكبر من 0: وبالتالي يمكن كتبتها كالتالي: f(x) = max(0,x) هذه الدالة تتكون من دالتين خطيتين و مع بعضهما تكونان الدالة غير الخطية، وفي حالة القيم المدخلة كانت موجبة لا يوجد حدود للقيم التي تخرجها الدالة فهي تعتمد على مقدار القيمة الموجبة المدخلة. و تعتبر من أسرع الدوال بالمقارنة مع دوال أخرى مثل Sigmoid, Tanh. والان لنتعرف على كيفية التعامل مع relu في tensorflow ، تستخدم relu كعملية في الشبكات العصبية و تستقبل القيم في شكل tensor: y = tf.nn.relu( x ) و تستخدم كأحد طبقات الشبكات العصبية، كما يمكن أيضاً التعامل مع relu بصورة مباشرة كدالة تنشيط و ذلك عن طريق: tf.keras.activations.relu وبالتالي فإن الدالة موجودة في activation module و يمكن إضافتها لأي نموذج بإضافة طبقة كالتالي: model.add( keras.layers.Dense( 25 , activation=tf.keras.activations.relu ) ) لاحظ أن الفرق الأساسي في الطريقتين هو أن الأولى تركز على إنشاء الشبكات العصبية من البداية و في الثانية نتعامل مع الطبقات في نموذج محدد.
-
المشكلة هي أن الأرقام في bar يتم إسناد datatype بصورة أتوماتيكية في بايثون و بالتالي تصبح القيم int64 و القيم في foo عبارة يتم إسناد النوع object (str) لها. و لاحظ أن إستخدام % يقوم بتعويض القيم من المتغير الأول في مكان %s و نفس الطريقة تنفذ في الثاني، لذلك نحصل على نتيجة مثل: 0 1\n1 2\n2 3\nName: bar, dtype: int64 is 0 a\n1 b\n2 c\nName: foo, dtype: object يمكننا إستخدام عملية الدمج بين عمودين في dataframe بإستخدام + ولكن مع تحويل العمود الذي يحتوي على الأرقام إلى قيم نصية لنسهل عملية الدمج: df["bar"].astype(str) + " is " + df["foo"] والتي يكون خرجها: 0 1 is a 1 2 is b 2 3 is c dtype: object
- 3 اجابة
-
- 1
-
-
هذه المشكلة تظهر في حالة تعاملك مع مكتبة keras أعلى من 2.2.0 يمكنك تنزيل مستوى المكتبة بإستخدام: pip install keras==2.2.0 أو في حالة إستخدام keras==2.5.0rc0 كالتالي: pip install keras==2.5.0rc0 أما في حالة كنت تستخدم colab يمكنك تنفيذ التالي: import keras !pip install keras_applications from keras_applications.imagenet_utils import _obtain_input_shape
- 2 اجابة
-
- 1
-
-
Flatten تستقبل أي tensor بأي شكل (multi-dimensional tensor) و تحوله إلى 1D tensor بالإضافة لعدد العينات. مثلاً إذا كان مدخل الدالة عبارة عن (عدد العينات، 10،20) الناتج سيكون (عدد العينات، 10*20) وبالتالي (عدد العينات، 200). لاحظ المثال التالي و الذي يقوم بتطبيق التسطيح على عدد 32 عينة مكونة من 5 صفوف للطول و 5 أعمدة في العرض و هي عبارة عن صورة ملونة مكونة من 3 قنوات Red, Green, Blue: import numpy as np from tensorflow.keras.layers import * n_samples, H, W, n_channels = 32, 5, 5, 3 # إنشاء قيم كمدخلات للدالة X = np.random.uniform(0,1, (n_samples,H,W,n_channels)).astype('float32') # تطبيق عملية التسطيح بإستخدام طريقتين np_flatten = X.reshape(batch_dim, -1) tf_flatten = Flatten()(X).numpy() #طباعة الشكل الناتج print(np_flatten.shape, tf_flatten.shape) #التأكد من أن الشكل الناتج هو نفسه للطريقتين (tf_flatten == np_flatten).all() # True يمكننا تطبيق التسطيح بإستخدام الدالة flatten أو بإستخدام الدالة reshape في كل من الطريقتين يتم تحويل المدخل إلى (n_samples, H*W*n_channels) وبالتالي يكون الخرج عبارة عن عدد العينات و حاصل ضرب كل من الطول في العرض في عدد القنوات. عادة ما يتم إستخدام flatten مع CNN, RNN,LSTM حسب القيم الممررة و التي توضع قبل عملية نداء الدالة Dense لأنها تستقبل عدد العينات بالإضافة لقيم المدخلات مجموعة في شكل 1D tensor.
-
الخطأ ظهر نتيجة لتمرير قائمة من القيم (200 في هذه الحالة) إلى دالة التدريب و التي يجب أن تستقبل مدخل واحد يحتوي على 200 صف، لذلك يجب أن تحول قوائم المدخلات إلى مصفوفات، يمكنك ذلك عن طريق إستخدام الدالة numpy.array أو عن طريق numpy.asarray(): import numpy data = numpy.array(data) label = numpy.array(label) أو بالطريقة الثانية: import numpy data = numpy.asarray(data) label = numpy.asarray(label) الفرق بين الطريقتين هو أن الأولى تنشئ نسخة من القائمة و تحولها إلى مصفوفة بينما في الطريقة الثانية تتحول القائمة الأصل إلى مصفوفة. لاحظ أنه يمكنك تنفيذ التحويل أيضاً داخل دالة التدريب كالتالي: import numpy model.fit(numpy.asarray(data),numpy.asarray(label),epochs = 70)
- 2 اجابة
-
- 1
-
-
نقوم بمعالجة البيانات قبل تمريرها للنموذج بعدة طرق منها التطبيع normalizing والتي تقوم بتطبيع القيم لوحدة محددة بإستخدام بيانات الصف (هنالك أيضاً StandardScaler والذي يتعامل مع البيانات بصورة عمودية). يتم تطبيق التطبيع في sklearn إما بإستخدام Normalizer أو preprocessing.normalize اللذان يعطيان نفس الناتج في حال تمرير نفس القيم لكليهما. والناتج يختلف حسب نوع التطبيع المطبق على البيانات و قد ينتج قيم أقل من صفر إذا كانت البيانات الممررة تحتوي على قيم سالبة، لاحظ المثال التالي: from sklearn.preprocessing import Normalizer X = [[4, 1, 2, 2], [-1, -3, -10, -3], [5, 7, 5, 1]] Normalizer(norm='l1').fit_transform(X) والذي ينتج: array([[ 0.44444444, 0.11111111, 0.22222222, 0.22222222], [-0.05882353, -0.17647059, -0.58823529, -0.17647059], [ 0.27777778, 0.38888889, 0.27777778, 0.05555556]]) وهي ايضاً نفس القيم الناتجة في حال إستخدام preprocessing.normalize: import sklearn sklearn.preprocessing.normalize(X, norm='l1') لابد أن تتذكر بالقيام بعمليات معالجة القيم المفقودة قبل مناداة الدالة لانها تنتج خطأ، راجع المثال التالي: from sklearn.preprocessing import Normalizer import numpy as np X = [[4, 1, 2, 2], [1, 3, np.nan, 3], [5, 7, 5, 1]] Normalizer().fit_transform(X) والذي يتنج عنه: ValueError: Input contains NaN, infinity or a value too large for dtype('float64').
- 2 اجابة
-
- 1
-
-
قد تكون المشكلة في التعامل مع البيانات بنوع قوائم وليس مصفوفات وهي النوع التي تستقبل من قبل النموذج عند نداء الدالة fit، يمكنك تحويل بيانات التدريب و التحقق إلى مصفوفات بالطريقة التالية: import tensorflow.keras as keras train_x = np.asarray(train_x) train_y = np.asarray(train_y) validation_x = np.asarray(validation_x) validation_y = np.asarray(validation_y) أو قد يكون هذا الخطأ ناتج من التعامل مع المكتبات القديمة والتي تحتاج إلى ترفيع upgrade، مثلاً بدلاً من مناداة keras بالصورة: import keras والتي تتعامل مع keras الإصدار الأول له، يمكنك مناداة: import tensorflow.keras as keras والتي تتعامل مع الإصدار الثاني لكيراس. نفس الطريقة تنطبق على الدوال المستخدمة مثل sequence.
- 2 اجابة
-
- 1
-
-
الخطأ كما وضح @Ali Haidar Ahmad ناتج لإختلاف النسخ، بالإضافة للحل المقترح يمكنك تطبيق عمليات preprocessing على البيانات بإستخدام keras.preprocessing وبالتالي يحصل توحيد بين مصادر البيانات المختلفة، لاحظ المثال التالي والذي يقوم بإستخدام sequence من preprocessing والتعامل مع tensorflow.python.keras و keras مباشرة: from tensorflow.python.keras.layers import Dense,Embedding,LSTM from tensorflow.python.keras.models import Sequential from keras.preprocessing import sequence from keras.datasets import imdb from keras.optimizers import SGD max_features = 1000 maxlen = 20 batch_size = 64 (input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features) input_train = sequence.pad_sequences(input_train, maxlen=maxlen) input_test = sequence.pad_sequences(input_test, maxlen=maxlen) model =Sequential() model.add(Embedding(max_features, 64)) model.add(LSTM(16)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=SGD(lr=0.01), loss='binary_crossentropy', metrics=['acc']) history = model.fit(input_train, y_train, epochs=2, batch_size=64, validation_split=0.2)
- 2 اجابة
-
- 1
-
-
إذا كنت تقصد عدد المعاملات المتاحة التي يمكنك التغيير فيها لأي نموذج يمكن فعل ذلك بإستخدام دالة get_params() والتي تعطي كل المعاملات المتوفرة التي يمكن تمريرها للنموذج و التعديل فيها. reg = RandomForestRegressor() params = reg.get_params() مثلاً هنا إستخدمنا الدالة لمعرفة المعاملات التي يستقبلها reg model والذي هو عبارة عن RandomForestRegressor. كما يمكن أيضاً إستخدام inspect والتي تقوم ايضاً بتوفير المعاملات حتى في حالة عدم إنشاء النموذج: import inspect import sklearn models = [sklearn.linear_model.LinearRegression] for m in models: hyperparams = inspect.signature(m.__init__) print(hyperparams) لاحظ أننا قمنا بنداء inspect للنموذج بإستخدام دالة الconstructor وبالتالي ستخبرنا الدالة constructor عن القيم الموجودة بداخلها، والنتيجة تصبح: (self, fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
-
بالإضافة للأخطاء التي قام بتحديدها @Ali Haidar Ahmad هنالك ثلاث أخطاء أخرى في البرنامج: File "<ipython-input-9-12a8c3b757d3>", line 29 model.fit(x_train, y_train, epochs=5,validation_data=[x_vaild, y_vaild], batch_size=batch_size)) ^ SyntaxError: invalid syntax والذي يظهر نتيجة للقوس الزائد بأخر سطر في البرنامج. ValueError: Input 0 of layer sequential_4 is incompatible with the layer: expected axis -1 of input shape to have value 784 but received input with shape (None, 28, 28) والذي يظهر نتيجة للخلط بين إستخدام x_vaild و x_test في مسألة تحويل شكل البيانات في الأسطر 13-16. عند تعديل الخطأ السابق و تحويل كل x_valid , y_valid إلى x_test, y_test يظهر الخطأ أدناه: ValueError: Input 0 of layer sequential_5 is incompatible with the layer: expected axis -1 of input shape to have value 784 but received input with shape (None, 28, 28) والذي يكون نتيجة لإستخدام x_vaild, y_vaild للتحقق و هما متغيران يأخذان الشكل المخزن في الذاكرة قبل التغيير لقيم x_test, y_test في هذه الحالة يمكننا إستخدام x_train, y_train لعملية التحقق و يصبح شكل البرنامج النهائي كالتالي: import numpy as np import pandas as pd from keras.models import Sequential from keras.layers import Dense , Activation, Dropout from keras.models import Sequential from keras.utils.np_utils import to_categorical from keras.datasets import mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() y_train = to_categorical(y_train) y_vaild = to_categorical(y_vaild) image_size = x_train.shape[1] input_size = image_size * image_size x_train = np.reshape(x_train, [-1, input_size]) x_train = x_train.astype('float32') / 255 x_test = np.reshape(x_test, [-1, input_size]) x_test = x_test.astype('float32') / 255 batch_size = 32 hidden_units = 256 model = Sequential() model.add(Dense(hidden_units, input_dim=input_size)) model.add(Activation('relu')) model.add(Dropout(0.45)) model.add(Dense(hidden_units)) model.add(Activation('relu')) model.add(Dropout(0.45)) model.add(Dense(10)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5,validation_data=(x_train, y_train), batch_size=batch_size)
-
لتتمكن من تفادي هذا الخطأ يمكنك التأكد من الاتي: قم بإستخدام text_to_word_sequence لتحويل النصوص إلى أرقام مقابلة للكلمات، إستخدم pad_sequences لجعل أرقام الكلمات متناسبة الطول، الان يمكنك إستخدام embedding layer والان يمكنك تدريب النموذج بالكلمات المحولة لمتجهات، إذا كنت تستخدم LSTM يمكنك إستخدام GRU بدلاً منه لأنه نموذج أبسط، - إذا لم تزل المشكلة قائمة، يمكنك تحويل الأرقام إلى قيم أقل مساحة بإستخدام tf.keras.backend.set_floatx('float16') بذلك تتحول كل القيم من float64 إلى حجم أصغر float16. - يمكنك أيضاً تقليص حجم العقد في الطبقات الأخيرة من النموذج، ذلك بإضافة dense layer لها عدد عقد أقل. - يمكنك التأكد من حجم المتغير maxlen في pad_sequences، يمكنك مراجعة أطول نص في مجموعة البيانات و بذلك تحدد قيمة ملء العينات الناقصة فقط للحد الأقصى لعدد الكلمات في نص وليس بإستخدام رقم كبير غير مبرر. - يمكنك أيضاً زيادة batch_size للإكثار من حجم العينات المأخوذة في مرة التدريب الواحدة.
-
td في كل نماذج تعلم الألة يجب أن ننتبه لشيئين أساسين، الأول هو أن النموذج يتعامل مع بيانات ذات طول واحد، أي أن كل عينة يجب أن يكون شكلها نفس شكل بقية العينات في بيانات التدريب و الإختبار. ذلك لأن هيكل النموذج يبنى مرة واحدة و المتغير هو قيم الأوزان المضروبة في القيم الداخلة للنموذج، وهذه تغير في دقة النموذج و ليس شكله. الشئ الثاني هو الإنتباه لشكل البيانات المدخلة مقابل الشكل المتوقع في النموذج، وذلك يعنى ان ننتبه للقيم الممرة في شكل parameters للنموذج. الأن لنقوم بإنشاء النموذج وطباعة ملخصه: model = Sequential() model.add(Embedding(10000, 32)) model.add(SimpleRNN(32)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() Model: "sequential_37" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_12 (Embedding) (None, None, 32) 320000 _________________________________________________________________ simple_rnn_2 (SimpleRNN) (None, 32) 2080 _________________________________________________________________ dense_57 (Dense) (None, 1) 33 ================================================================= Total params: 322,113 Trainable params: 322,113 Non-trainable params: 0 _________________________________________________________________ لاحظ شكل النموذج، يتوقع منك الكلمات المحولة لأرقام صحيحة بأن تحتوي على متجهات ذات 32 لكل قيمة unique أو الرقم الذي يشير للكلمة في مجموعة البيانات. الأن القيمة المتوقعة في حال عدم تحديد شكل المدخل ستكون على هيئة (batch_size, input_length) وبالتالي فإن الطول لكل عينة يجب أن يكون متساوي. دعنا نلقى نظرة على أطوال أول 10 عينات: for i in range(10): print(len(input_train[i])) 218 189 141 550 147 43 123 562 233 130 لاحظ إختلاف القيم عن بعضها، بالتالي يجب أن نقوم بتوحيد أطوالها، ذلك يتم بإستخدام pad_sequences وهي الدالة التي تقوم بحساب أطول عينة و إسناد طولها لبقية العينات (هذا إن لم يتم تحديد طول معين)، وذلك يتم عن طريق وضع أصفار إلى وصول العينة الأقل طولاً للطول المطلوب، لاحظ المثال التالي: from keras.preprocessing.sequence import pad_sequences sequences = [[1, 2, 3, 4], [1, 2, 3], [1]] pad_sequences(sequences) والان الدالة ستقوم بإسناد أصفار لكل مدخل قيمته أقل من 4، لنرى النتائج: array([[1, 2, 3, 4], [0, 1, 2, 3], [0, 0, 0, 1]], dtype=int32)
-
input_shape تتوقع منك إدخال عدد الfeatures أو الأعمدة بالنسبة للبيانات المدخلة بغض النظر عن عدد لعملية التدريب أو الإختبار، أتوقع أن ما تقصده ب 300 هو عدد بيانات التدريب، و الصحيح تمرير عدد الأعمدة، لاحظ شكل البيانات قبل التمرير للنموذج: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() print(train_data.shape, test_data.shape,train_targets.shape,test_targets.shape) والتي تعطي النتيجة التالية: (404, 13) (102, 13) (404,) (102,) بالتالي فإن الرقم 300 لا يمثل حتى عدد العينات المدخلة للتدريب، لكن من هنا يمكننا معرفة عدد الخصائص في البيانات، وهي عبارة عن 13 تستخدم للتفريق بين أسعار المنازل. بذلك 13 هي القيمة الصحيحة التي يجب أن نقوم بتمريرها للنموذج لinput_shape parameter يمكن أن نقوم بمناداتها من شكل البيانات المدخلة للتدريب كما ذكر @Ali Haidar Ahmad أو أن نقوم بتعريفها خارج النموذج في متغير و مناداته كالتالي: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() print(train_data.shape, test_data.shape,train_targets.shape,test_targets.shape) mean=train_data.mean(axis=0) train_data-=mean std=train_data.std(axis=0) train_data/=std test_data -= mean test_data /= std myinput_shape = 13 def build_model(): model=models.Sequential() model.add(layers.Dense(64,activation='relu', input_shape=(myinput_shape,))) model.add(layers.Dense(64,activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop',loss='mse',metrics=['mae']) return model model=build_model() model.fit(train_data,train_targets,epochs=80,batch_size=16,verbose=0) test_mse_score,test_mae_score=model.evaluate(test_data,test_targets) print(test_mae_score)
-
الخطأ هو في شكل البيانات الدالخة للنموذج مع شكل النموذج نفسه، يوجد عدم تطابق ظاهر في شكل البيانات، يمكننا حل هذه المشكلة هو تطبيق نفس ما قمت بفعله في بيانات التدريب على بيانات الإختبار، و المحافظة على نفس شكل الطبقة الأخيرة في النموذج model.add(Dense(2)): import numpy as np import pandas as pd from keras.models import Sequential from keras.layers import Dense , Activation, Dropout from keras.models import Sequential from keras.utils.np_utils import to_categorical from keras.datasets import mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) y_train[y_train<=5]=0 y_train[y_train>5]=1 #تطبيق نفس طريقة بيانات التدريب على بيانات الإختبار y_test[y_test<=5]=0 y_test[y_test>5]=1 y_train=y_train.astype('int64') print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) image_size = x_train.shape[1] input_size = image_size * image_size x_train = np.reshape(x_train, [-1, input_size]) x_train = x_train.astype('float32') / 255 x_test = np.reshape(x_test, [-1, input_size]) x_test = x_test.astype('float32') / 255 print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) batch_size = 32 hidden_units = 256 # y تطبيق على قيم one hot encoding y_train = to_categorical(y_train) y_test = to_categorical(y_test) print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) model = Sequential() model.add(Dense(hidden_units, input_shape=(input_size,))) model.add(Activation('relu')) model.add(Dropout(0.45)) model.add(Dense(hidden_units)) model.add(Activation('relu')) model.add(Dropout(0.45)) model.add(Dense(2)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5, batch_size=batch_size) لاحظ للتعديل كان فقط بإضافة: y_test[y_test<=5]=0 y_test[y_test>5]=1 والتي تقوم بتحويل كل صنف قيمته أقل من أو يساوي 5 إلى 0 و كل القيم غير ذلك إلى 1. ومن ثم قمنا بنداء الدالة to_categorical: y_train = to_categorical(y_train) y_test = to_categorical(y_test) والنموذج يظل كما هو يستخدم categorical_crossentropy كدالة خطأ واخر طبقة في النموذج تحتوي على 2nodes.
-
هو نفس فكرة الخطأ الذي قمت بشرحه هنا وهو يعني عدم تطابق البيانات المدخلة للنموذج مع القيم المتوقعة، في كل عمليات التصنيف يجب تحويل قيم y إلى الترميز المناسب لها حسب دالة حساب الخطأ loss function والتي تقوم بحساب التطابق بين البيانات الحقيقية و المتوقعة من النموذج. يمكنك ترميز البيانات بإستخدام one hot encoding بإستخدام الدالة to_categorical والتي تحول البيانات من بعد واحد لبعدين، مثلا [0,1] تتحول إلى [[1,0],[0,1]] لاحظ أن الأن أصبح لدينا عمودين. في هذه الحالة سيتم إستخدام categorical_crossentropy كدالة لحساب الخسارة loss function و تحديد نفس عدد الأعمدة في أخر طبقة في النموذج. يمكنك تحويل قيم y قبل التقسيم أو بعده كما ذكر @Ali Haidar Ahmad. y = to_categorical(y) و إما إن كانت قيم الy أصلا مقسمة إلى قيم رقمية صحيحة مثلا الارقام من 0 إلى 9 يمكننا إستخدام sparse_categorical_crossentropy.
-
بما أنك إخترت categorical_crossentropy لحساب نسبة الخسارة و من اخر طبقة في النموذج أتوقع أن القيم المصنفة تتبع ل6 أصناف مختلفة، لذا وجب تحويل قيم y إلى الترميز المقابل لها ويمكننا فعل ذلك بإستخدام to_categorical لاحظ للمثال التالي و الذي يقوم بتنفيذ عملية تدريب بإستخدام Conv2D على مجموعة بيانات MNIST وهي بيانات صورية ل10 أصناف تمثل الأرقام من 0 إلى 9: import numpy as np from tensorflow import keras from tensorflow.keras import layers from keras.datasets import mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) x_train = np.reshape(x_train, (-1, 28, 28, 1)) x_test = np.reshape(x_test, (-1, 28, 28, 1)) print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) # y تطبيق على قيم one hot encoding y_train = to_categorical(y_train) y_test = to_categorical(y_test) print(x_train.shape, y_train.shape,x_test.shape, y_test.shape) model = keras.Sequential( [ keras.Input(shape=(28, 28, 1)), layers.Conv2D(32, kernel_size=(3, 3), activation="relu"), layers.MaxPooling2D(pool_size=(2, 2)), layers.Conv2D(64, kernel_size=(3, 3), activation="relu"), layers.MaxPooling2D(pool_size=(2, 2)), layers.Flatten(), layers.Dropout(0.5), layers.Dense(10, activation="softmax"), ] ) model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) model.fit(x_train, y_train,epochs=1, validation_split=0.1) لاحظ مكان التعليق، قمنا بتحويل 1D y values ل 2D وهي عملية one hot encoding وهو التمثيل المقابل لقيم الأصناف لنقوم بعملية التدريب و التأكد.
-
هي الطبقة المسؤولة عن تحويل القيم المدخلة إلى المتجهات المقابلة لها في vector space، لذلك تلك الطبقة تستقبل الحجم كمدخل، لنقوم بشرح هذا بمثال: import numpy as np from keras.models import Sequential from keras.layers import Embedding input_array = np.random.randint(5, size=(1, 5)) model = Sequential() model.add(Embedding(5, 2, input_length=5)) model.compile('rmsprop', 'mse') model.predict(input_array) بعد إستيراد المكتبات اللازمة، قمنا بتعريف مصفوفة مدخلات input_array والتي تحتوي على صف واحد و 5 أعمدة، و من ثم عرفنا النموذج كsequential model و أضفنا طبقة embedding والتي تأخذ حجم المدخلات input_length (5) بالإضافة للحجم المتوقع للمتجهات المنتجة (2) embedding vector size و بمعدل تمثيلين لكل قيمة مدخلة، قمنا بعد ذلك بتجميع النموذج و من التوقع والناتج كان عبارة عن المتجهات التي تحتوي على تمثيل القيم المدخلة. Embedding شائع الإستخدام في تطبيقات معالجة النصوص، لكن لنقوم بإستخدامه يجب تحويل الكلمات لمقابلها الرقمي، يمكننا فعل ذلك بإسناد قيمة رقمية لكل كلمة مفردة و ذلك لتمريرها للنموذج، لاحظ تمرير 5 كأول قيمة في embedding layer و هي تعني 5 كلمات بدون تكرار. +------------+------------------------------+ | index | Embedding | +------------+------------------------------+ | 0 | [-0.02694855, 0.01748547] | | 4 | [-0.03002046, 0.0154268 ] | | 2 | [-0.02694855, 0.01748547] | | 1 | [-0.02694855, 0.01748547] | | 5 | [-0.02694855, 0.01748547] | +------------+------------------------------+ يمكنك تخيل ناتج الطبقة الأولى كالجدول السابق، حيث كل قيمة رقمية تحولت إلى التمثيل المتجهي المقابل لها.
-
يمكنك إستخدام الدالة clear مع subprocess والتي يمكن تنفيذها في ويندوز، لينيكس، و ماك: import subprocess clear = lambda: subprocess.call('cls||clear', shell=True) clear() أو يمكنك إستخدام الدالة cls المعرفة كالتالي: cls = lambda: print("\033c\033[3J", end='') cls() العبارة \033[H\033[J تقوم بحذف المحتوى من على الشاشة و إرجاع المؤشر إلى أعلى يسار الشاشة. طباعة سطر جديد لمئة مرة متتالية تفهم المفسر أن المبرمج يريد مسح الذاكرة: clear = "\n" * 100 print(clear) في أي وقت تريد تنفيذ عملية المسح يمكن إستدعاء clear، و يمكنك أيضاً كتابة العبارة بطريقة أخرى: cls = lambda: print('\n'*100) cls()
- 4 اجابة
-
- 1
-
-
الحلقات التكرارية تنفذ ما بداخلها إلى إنتهاء القيم المدخلة في الحلقة، إلا في حال كان في الدخل شرط يجب تحقيقه، في هذه الحالة يتم التأكد من الشرط إذا كان يعتمد على قيمة المدخل للحلقة التكرارية: for i in range(1,11): if i == 10: print("test") break print(i) لاحظ في البرنامج المكتوب بالبايثون، الحلقة تبدأ من 1 و تنتهي في 10 (لأن range تنتهي قبل القيمة بواحد) و من ثم داخل الحلقة يوجد شرط إختبار القيمة i إذا كانت تساوي 10 يتم طباعة أي قيمة مثلاً test و إلا فإنه يتم طباعة قيمة i ، لاحظ العبارة break والتي تمنع طباعة الرقم 10 بل توقف الحلقة التكرارية.