


Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 classmethod@ تجعل التابع تابع صنف أي"class method" وبالتالي تمكننا من الوصول إلى الصنف الذي تم فيه تعريف التابع. التابع الذي يتم تعريفه على أنه تابع صف، يستقبل كمعامل أول الصف الخاص به ويعبر عن ذلك ب cls، أي بشكل مشابه لما كنا نفعله في التوابع العادية حينما كنا نمرر للتابع العادي نسخة instance أي (self). إذن هي توابع مرتبطة بالصف وليس بال object. التوابع المعرفة بهذه الطريقة يكون لديها سماحية "access to the state of the class" أي النفاذ إلى حالة الصف (نحن مررنا لها cls أي أنها تشير إلى الصف نفسه وليس نسخة منه) ويمكنها التعديل عليها أيضاً وهذا التعديل ينتقل إلى كل ال object. Static Method@: وهي مشابهة لتلك الموجودة في Java أو C++. الدالة التي نعرفها على أنها ساكة يمكننا الوصول لها من الكلاس نفسه (أي يمكن الوصول لها مباشرة من خلال اسم الكلاس). أو من خلال ال object المأخوذة من الكلاس. عندما يتم إستدعاء التوابع الساكنة من كائن من هذا الكلاس, فإنه لا تتم معاملته بشكل خاص بالنسبة للكائن بل سيبقى كأنك تستدعيها بشكل مباشر من الكلاس. وهذا هو السبب في كونها لاتقبل الوسيط self. التوابع من هذا النوع لاتملك السماحية "access to the state of the class" أي لايمكنها التعديل على حالة الصف. أي أنها لاتعرف شيئ عن حالة الصف class state ولاتستطيع تعديلها أما classmethod يمكنها ذلك. بشكل عام تستخدم class method كنوع من ال factory method (دوال تعيد object (بشكل مشابه لل constructor ) من أجل استخدام معين أنت تريده) أما ال static فتستخدم كأداة للقيام بعمليات معينة. إذا لم يكن لديك معرفة عن factory method يمكنك أن تجدها في هذا المقال: https://wiki.hsoub.com/Design_Patterns/factory_method from datetime import date class Person: def __init__(self, name, age): self.name = name self.age = age # دالة ساكنة لاختبار فيما إذا كان مسناً أم لا @staticmethod def old(age): print("old") return age > 55 #person كلاس ميثود لإنشاء كائن من الصف @classmethod def create(cls, name, year): return cls(name, date.today().year - year) print (Person.old(22)) # True obj=Person.create('km',24) print(obj) # <__main__.Person object at 0x000001C7DC405708> obj.age # 1997
classmethod@ تجعل التابع تابع صنف أي"class method" وبالتالي تمكننا من الوصول إلى الصنف الذي تم فيه تعريف التابع. التابع الذي يتم تعريفه على أنه تابع صف، يستقبل كمعامل أول الصف الخاص به ويعبر عن ذلك ب cls، أي بشكل مشابه لما كنا نفعله في التوابع العادية حينما كنا نمرر للتابع العادي نسخة instance أي (self). إذن هي توابع مرتبطة بالصف وليس بال object. التوابع المعرفة بهذه الطريقة يكون لديها سماحية "access to the state of the class" أي النفاذ إلى حالة الصف (نحن مررنا لها cls أي أنها تشير إلى الصف نفسه وليس نسخة منه) ويمكنها التعديل عليها أيضاً وهذا التعديل ينتقل إلى كل ال object. Static Method@: وهي مشابهة لتلك الموجودة في Java أو C++. الدالة التي نعرفها على أنها ساكة يمكننا الوصول لها من الكلاس نفسه (أي يمكن الوصول لها مباشرة من خلال اسم الكلاس). أو من خلال ال object المأخوذة من الكلاس. عندما يتم إستدعاء التوابع الساكنة من كائن من هذا الكلاس, فإنه لا تتم معاملته بشكل خاص بالنسبة للكائن بل سيبقى كأنك تستدعيها بشكل مباشر من الكلاس. وهذا هو السبب في كونها لاتقبل الوسيط self. التوابع من هذا النوع لاتملك السماحية "access to the state of the class" أي لايمكنها التعديل على حالة الصف. أي أنها لاتعرف شيئ عن حالة الصف class state ولاتستطيع تعديلها أما classmethod يمكنها ذلك. بشكل عام تستخدم class method كنوع من ال factory method (دوال تعيد object (بشكل مشابه لل constructor ) من أجل استخدام معين أنت تريده) أما ال static فتستخدم كأداة للقيام بعمليات معينة. إذا لم يكن لديك معرفة عن factory method يمكنك أن تجدها في هذا المقال: https://wiki.hsoub.com/Design_Patterns/factory_method from datetime import date class Person: def __init__(self, name, age): self.name = name self.age = age # دالة ساكنة لاختبار فيما إذا كان مسناً أم لا @staticmethod def old(age): print("old") return age > 55 #person كلاس ميثود لإنشاء كائن من الصف @classmethod def create(cls, name, year): return cls(name, date.today().year - year) print (Person.old(22)) # True obj=Person.create('km',24) print(obj) # <__main__.Person object at 0x000001C7DC405708> obj.age # 1997- 2 اجابة
-
- 3
-

-
كيف يتصرف إذا أراد حل مشكلة. أعتقد أن هذا أهم أمر. ثم كم ساعة يقضيها على جهازه المحمول في اليوم (أنا أقضي 12 ساعة مثلا). آخر أمر تسألونه عنه هو خبراته. وطبعا يجب أن يكون لديه معرفة في مجال العمل المطلوب منه وليس ضروري أبدا أن يكون ملم به.
- 1 جواب
-
- 1
-
-
يمكنك تعريف أي class بالطريقة التالية، حيث نكتب أولاً الكلمة class ثم اسم الكلاس ثم : ثم نعرف بداخله التابع __init__ الذي يمثل الباني للكلاس، ثم يمكننا تعريف أي تابع آخر نريده class Person: def __init__(self, name,age): self.name = name self.age = age def get_age(self): return self.age p = Person("Ali", 24) print(p.name) print(p.age) print(p.get_age())
- 4 اجابة
-
- 1
-
-
يمكنك ذلك بعدة طرق أسهلها استخدام الدالة join كالتالي: def convert(lst): return (" ".join(lst)) # اختبار التابع l = ['Hsoub', 'Mostaql'] print(convert(l)) # Output: Hsoub Mostaql حيث " " هي التي ستفصل بين الكلمات ويمكنك تغييرها. #تعديل: طريقة أخرى إذا أحببت بدون توابع جاهزة: # تابع التحويل def convert(lst): string=lst[0] # نضع أول كلمة من القائمة في السلسة for word in lst[1:]: # نضيف باقي الكلمات إلى السلسلة string +=' '+ word return string # اختبار التابع l = ['Hsoub', 'Mostaql'] print(convert(l))
- 3 اجابة
-
- 3
-
-
الحل هو أن داتا التدريب من النمط سترنغ ويجب أن تحولها للصيغة العددية : ['-214' '-153' '-58' ..., '36' '191' '-37'] قم بتحويلها إلى النمط العددي، يمكنك استخدام الطريقة التالية: import numpy as np np.array(['1','2','3']).astype(np.float) هذا الخطأ شائع، لأنه غالباً مايتم تخزين الأعداد على شكل String من أجل فعالية التخزين والحجم.
- 1 جواب
-
- 1
-
-
توفر Sklearn القيام بالتوقع الخطي مع التنعيم عن طريق استخدام الكلاس Lasso. يتم استخدامها عبر الموديول linear_model.Lasso كالتالي: sklearn.linear_model.Lasso(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None) الوسطاء: fit_intercept: لجعل المستقيم يتقاطع مع أفضل نقطة على المحور العيني y. copy_X: وسيط بولياني، في حال ضبطه على True سوف يأخذ نسخة من البيانات ، وبالتالي لاتتأثر البيانات الأصلية بالتعديل، ويفيدنا في حالة قمنا بعمل Normalize للبيانات. normalize: وسيط بولياني، في حال ضبطه على True سوف يقوم بتوحيد البيانات (تقييسها) اعتماداً على المقياس n_jobs: لتحديد عدد العمليات التي ستتم بالتوازي (Threads) أي لزيادة سرعة التنفيذ، افتراضياُ تكون قيمته None أي بدون تسريع، وبالتالي لزيادة التسريع نضع عدد صحيح وكلما زاد العدد كلما زاد التسريع (التسريع يتناسب مع قدرات جهازك)، وفي حال كان لديك GPU وأردت التدريب عليها فقم بضبطه على -1. random_state: للتحكم بآلية التقسيم. max_iter: العدد الأقصى للتكرارات. tol: مقدار التسماح في التقارب من القيم الدنيا. float, default=1e-3 positive:عندما يأخذ True تكون المعلاملات كلها موجبه أهم ال attributes: _coef: الأوزان التي حصلنا عليها بعد انتهاء التدريب وهي مصفوفة بأبعاد (,عدد الfeatures). intercept: التقاطع مع المحور y. أهم التوابع: fit(data, truevalue): للقيام بعملية التدريب. predict(data): دالة التوقع ونمرر لها البيانات وتعطيك التوقع لها. score(data, truevalue): لمعرفة مدي كفاءة النموذج ونمرر لها بيانات الاختبار والقيم الحقيقية لها فيقوم بعمل predict للداتا الممررة ثم يقارنها بالقيم الحقيقية ويرد الناتج حسي معيار R Squaerd. يمكن تطبيقه كما يلي: from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.linear_model import Lasso # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=2021) # تطبيق التابع LassoRegression =Lasso(alpha=0.5,random_state=20,solver='auto') LassoRegression.fit(X_train, y_train) #حساب الكفاءه على التدريب والاختبار print('Train Score is : ' , LassoRegression.score(X_train, y_train)) print('Test Score is : ' , LassoRegression.score(X_test, y_test)) #print('Coef is : ' , LassoRegression.coef_) print(LassoRegression.predict(X_test))
- 1 جواب
-
- 2
-
-
SVR هو جزء من موديل support vector machine ويستخدم في مهام التوقع يمكنك استخدامها عبر الموديول sklearn.svm مثل أي نموذج في التعلم الآلي يوجد لديه العديد من المعاملات التي تلعب دوراً أساسيا في عملية تعلم الموديل عبر داتا التدريب لنقوم بالمرور على أهم المعاملات التي يأخذها هذا النموذج. #استدعاء المكتبة: from sklearn.svm import SVR في البداية قمنا باستدعاء المكتبة التي يوجد فيها هذا الموديل #الشكل العام للموديل: SVRModel = SVR(kernel=’rbf’, degree=3, tol=0.001,C=1.0,max_iter=-1,epsilon=0.1,cache_size=200وgamma='auto') أهم البارمتر المستخدمة: البارمتر الأول kernel نوع النواة أو المعادلة المستخدمة تكافئ فكرة تابع التنشيط في الشبكات العصبونية يوجد عدة أنواع ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ ننصح دوما باستخدام rbf لأنها الأفضل. البارمتر الثاني degree وهو في حال أردنا جعل ال regressor غير خطي أي Polynomial نضبطه بالدرجة التي نريدها(default=3). بحال استخدام الkernel=poly فيجب تحديد درجة كثير الحدود. البارمتر الثالث tol عدد يمثل نقطة إيقاف التعلم بحال تجاوز هذه القيمه فيتوقف svr. البارمتر الرابع C معامل التنعيم أفضل القيم للتجريب 0.1,0.001,10,1 البارمتر الخامس max_iter العدد الأقصى للتكرارت إذا وضعت -1 فأنه يأخذ الحد الأعلى ويفضل ذلك epsilon: ضمن هذا المقدار لن يتم تطبيق أي penalty على تابع التكلفة. أي هي هامش للسماحية بدون تطبيق penalty. افتراضياً default=0.1. cache_size: تحديد حجم ال kernel cache وافتراضياً 200 MB. gamma: معمل النواة وهي إما {‘scale’, ‘auto’}أو float وتكون افتراضياً 'default=’scale. طبعا قمت بشرح الشكل العام للموديل ولكن عن طريقة استخدامه سهل جداً فقط بعد أن تقوم بتقسيم الداتا إلى X_train, y_train,X_test,. y_test تسطيع كتابة الأتي لعملية التدريب: SVRM = SVR(kernel=’rbf’, degree=3, tol=0.001,C=1.0,max_iter=-1) SVRM.fit(X_train, y_train) حيث الدالة fit يوجد ضمنها جميع العمليات الداخلية لعملية التدريب يوجد دالة أخرى تستخدم لغرض التنبؤ كالاتي. #حساب القيم المتوقعة: y_pred = SVRM.predict(X_test) حيث قمنا بالتنبؤ بقيم التصنيف لداتا الاختبار نستطيع حساب دقة الموديل أو كفاءته على التدريب والاختبار عن طريق التابع score ويكون وفق الشكل #حساب الكفاءه على التدريب والاختبار: print('Train Score is : ' , SVRM.score(X_train, y_train)) print('Test Score is : ' , SVRM.score(X_test, y_test)) مثال: from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.svm import SVR # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=44) # تطبيق التابع SVRM = SVR(C = 1.0 ,epsilon=0.1,kernel = 'rbf') SVRM.fit(X_train, y_train) # عرض النتائج print('SVRM Train Score is : ' , SVRM.score(X_train, y_train)) print('SVRM Test Score is : ' , SVRM.score(X_test, y_test))
- 1 جواب
-
- 3
-
-
توفر Sklearn القيام بالتوقع الخطي مع التنعيم عن طريق استخدام الكلاس Ridge. يتم استخدامها عبر الموديول linear_model.Ridge كالتالي: sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None) الوسطاء: fit_intercept: لجعل المستقيم يتقاطع مع أفضل نقطة على المحور العيني y. copy_X: وسيط بولياني، في حال ضبطه على True سوف يأخذ نسخة من البيانات ، وبالتالي لاتتأثر البيانات الأصلية بالتعديل، ويفيدنا في حالة قمنا بعمل Normalize للبيانات. normalize: وسيط بولياني، في حال ضبطه على True سوف يقوم بتوحيد البيانات (تقييسها) اعتماداً على المقياس n_jobs: لتحديد عدد العمليات التي ستتم بالتوازي (Threads) أي لزيادة سرعة التنفيذ، افتراضياُ تكون قيمته None أي بدون تسريع، وبالتالي لزيادة التسريع نضع عدد صحيح وكلما زاد العدد كلما زاد التسريع (التسريع يتناسب مع قدرات جهازك)، وفي حال كان لديك GPU وأردت التدريب عليها فقم بضبطه على -1. random_state: للتحكم بآلية التقسيم. max_iter: العدد الأقصى للتكرارات. tol: مقدار التسماح في التقارب من القيم الدنيا. float, default=1e-3 solver: ال Optimezer المستخدم. solver{‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’}, default=’auto’ alpha: هو معامل التنعيم ويأخذ قيم من الصفر إلى n، و كلما زادت القيمة زاد تأثير التنعيم. default=1.0. أهم ال attributes: _coef: الأوزان التي حصلنا عليها بعد انتهاء التدريب وهي مصفوفة بأبعاد (,عدد الfeatures). intercept: التقاطع مع المحور y. أهم التوابع: fit(data, truevalue): للقيام بعملية التدريب. predict(data): دالة التوقع ونمرر لها البيانات وتعطيك التوقع لها. score(data, truevalue): لمعرفة مدي كفاءة النموذج ونمرر لها بيانات الاختبار والقيم الحقيقية لها فيقوم بعمل predict للداتا الممررة ثم يقارنها بالقيم الحقيقية ويرد الناتج حسي معيار R Squaerd. يمكن تطبيقه كما يلي: from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.linear_model import Ridge # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=2021) # تطبيق التابع RidgeRegression = Ridge(alpha=0.5,random_state=20,solver='auto') RidgeRegression.fit(X_train, y_train) #Calculating Details print('Train Score is : ' , RidgeRegression.score(X_train, y_train)) print('Test Score is : ' , RidgeRegression.score(X_test, y_test)) #print('Coef is : ' , RidgeRegression.coef_) print(RidgeRegression.predict(X_test))
- 1 جواب
-
- 3
-
-
يمكن ذلك باستخدام مكتبة ctime في سي بلس بلس حيث يوجد الداله time تعطي الوقت بعد أعطائها القيمه 0 وبعدها نقول بتحويل الزمن لانه يكون بالثواني إلى يوم والشهر والدقائق والسنه باستخدام الداله ctime #include <iostream> #include <ctime> using namespace std; int main() { // الوقت الحالي time_t now = time(0); // تحويل الوقت الحالي إلى سترنغ char* dt = ctime(&now); cout << "The local date and time is: " << dt << endl; }
- 2 اجابة
-
- 4
-
-
هي نموذج للتصنيف باستخدام الشبكات العصبونية يتم استخدامها عبر الموديول neural_network.MLPClassifier مثل أي نموذج في التعلم الألي يوجد لديه العديد من المعاملات التي تلعب دورا أساسيا في عملية تعلم الموديل عبر داتا التدريب لنقوم بالمرور على أهم المعاملات التي يأخذها هذا النموذج #استدعاء المكتبة from sklearn.neural_network import MLPClassifier في البداية قمنا باستدعاء المكتبة التي يوجد فيها هذا الموديل #الشكل العام للموديل MLPClassifierModel = MLPClassifier(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) البارمتر الأول activation مثلما نعرف يوجد في الشبكات العصبونية عدة أنواع لتوابع التنشيط أو activation ومن أهمها تابع sigmoid , relu,tanh لن أدخل في تفاصيل كل منها فأي دورة تعلم الآلة أو تعلم عميق تحوي هذه المفاهيم ولكن كنصيحه نقوم بجعل relu لجميع الطبقات ماعدا الأخيره أما الطبقة الأخيره نستخدم sigmod البارمتر الثاني solver هو طريقة الحل أو طريقة الوصول إلى أفضل قيم w,b الأوزران الخاصه بالشبكه العصبونية يوجد أكثر من طريقه مثل sgd ,adam ولكن ننصح باستخدام adam دوما البارمتر الثالث learning_rate هو معامل التعلم وهو يمثل مقدار الخطوه للوصول إلى الأوزران ويمكن تركه costant أي خطوات ثابتة أو adaptive متغيره أما ان تكون طويله أو قصيرة البارمتر الرابع early_stopping التوقف المبكر وهو يأخذ True بحال أردنا أيقاف معامل التعلم عند نقطه بحيث لا يدخل الموديل في مرحلة overfit أي الضبط الزائد وfalse عكس ذلك البارمتر الخامس alpha يمثل معامل التنعيم حيث التنعيم هو طريقة لكي يتخلص الموديل من الضبط الزائد overfit ويلعب alpha دورا مهما في ذلك البارمتر السادس hidden_layer_sizes وهو يمثل عدد الطبقات ماعدا طبقة الدخل والخرج لأنهما لا تعتبرا طبقات مخفيه وعدد الخلايا في كل طبقه حيث الأرقام تدل على عدد الخلايا في الطبقه أما موقع الرقم يدل على الطبقه وعدد المواقع يدل على عدد الطبقات المخفيه فمثلا (10,200,30,4) يوجد أربعة طبقات لأنه يوجد أربع أرقام وكل رقم منها يدل على عدد الخلايا في طبقته مثلا الطبقة الأولى تحوي 10 خلايا طبعا قمت بشرح الشكل العام للموديل ولكن عن طريقة استخدامه سهل جدا فقط بعد أن تقوم بتقسيم الداتا إلى X_train, y_train,X_test, y_test تسطيع كتابة الأتي لعملية التدريب MLPClassifierModel = MLPClassifier(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) MLPClassifierModel.fit(X_train, y_train) حيث الدالة fit يوجد ضمنها جميع العمليات الداخلية لتدريب الشبكه العصبية يوجد دالة أخرى تستخدم لغرض التنبؤ كالاتي: y_pred = MLPClassifierModel.predict(X_test) حيث قمنا بالتنبؤ بقيم التصنيف لداتا الاختبار نستطيع أيضا حساب دقة الموديل أو كفاءته عن طريق التابع score ويكون وفق الشكل: print('MLPClassifierModel Test Score is : ' , MLPClassifierModel.score(X_test, y_test)) حيث قمنا بطباعة قيمتها لكي نرى كفاءة الموديل على بيانات الاختبار وهل هو يعاني من الضبط الزائد overfit أو الضبط الناقص underfit.
- 1 جواب
-
- 2
-
-
في مكتبة sklearn يتطلب الأبعاد (رقم الصف,رقم العمود) ومن المؤكد أن شكل الأبعاد لديك هي (999,) وبالتالي فلن تعمل لأنه يفقد رقم العمود يكون الحل باستخدام الوظيفه reshape من المكتبة numpy لجعلها (999,1) الكود: data=data.reshape((999,1))
- 1 جواب
-
- 2
-
-
في الإصدارات الحديثة من تنسرفلو تم حذف هذه الدالة وأصبح بإمكانك استخدام ال generators مع الدالة Model.fit لذا لديك حلين إما أن تقوم بتثبيت إحدى الإصدارات السابقة مثل 1.15 من تنسرفلو كالتالي: pip install tensorflow==1.15 أو أن تقوم باستخدام الدالة Model.fit : # generetors الشكل العام للتابع في حالة كانت بياناتك ليست fit( x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, **kwargs ) # generetors في حالة كانت بياناتك fit( data_generetors, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, **kwargs ) لكن في الحالة الثانية لن تكون قادراً على استخدام الخاصية validation_data أو validation_split والخواص الأخرى المتعلقة بهم لذا قد يكون الحل الأفضل استخدام إصدار سابق لحل مشكلتك في حال كنت تعتمد validation_generator
- 2 اجابة
-
- 2
-
-
الخطأ هو عدم وجود sklearn في نظامك، ولحل المشكلة يجب تثبيت مكتبة sklearn ويمكنك ذلك عن طريق: أما فتح موجه الأوامر cmd وكتابة التعليمة التالية: pip install -U scikit-learn أو من خلال الكتابة على موجه الأوامر في anconda إن كنت تستخدمها: conda install scikit-learn أو من خلال الكتابة في jupyter notebook: pip install scikit-learn
- 3 اجابة
-
- 3
-
-
Stochastic Gradient Descent (SGD) Classifier تقوم بعمل Logistic Regression لكن باستخدام خوارزمية التحسين ال Stochastic Gradient Descent. يمكنك استخدامها عبر الموديول: linear_model.SGDClassifier sklearn.linear_model.SGDClassifier(loss='hinge', *, penalty='l2', alpha=0.0001, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, epsilon=0.1, n_jobs=None, random_state=None, learning_rate='optimal', early_stopping=False) الوسطاء: loss: هي دالة التكلفة المستخدمة، وكون المهمة هي مهمة تصنيف نستخدم الدالة الافتراضية دوماً. أي hinge. penalty: وهو نوع التنعيم المستخدم. learning_rate: وهو معامل التعلم (مقدار الخطوة). max_iter: العدد الأقصى للمحاولات. early_stopping: في حال ضبطه على True سيتم تطبيق خاصية التوقف المبكر (لمنع ال Overfitting عندما تنهار الدقة على عينة التطوير مقابل عينة الاختبار). shuffle: لخلط البيانات. verbose: ضبطه على أي قيمة غير الصفر سيعطيك التفاصيل أثناء التدريب. random_state: تتحكم بنظام العشوائية. ال attributes: coef_: الأوزان. intercept_: التقاطع مع المحور y، ضبطه على False يجبر الكلاسيفير على المرور من المبدأ 0،0 لذا يفضل ضبطه على True لإعطاء الحرية للكلاسيفير. n_iter_: عدد المحاولات التي تم تنفيضها خلال التدريب حتى الوصول لمرحلة التقارب من القيم الدنيا. الدوال: fit(X, y): لبدء التدريب على بياناتك. predict(X): لتوقع قيم الدخل اعتماداً على قيم الأوزان. score(X, y): لتقدير مدى كفاءة النموذج. مثال على مجموعة بيانات Iris Data : from sklearn.model_selection import train_test_split from sklearn.linear_model import SGDClassifier from sklearn.metrics import confusion_matrix from sklearn.datasets import load_breast_cancer import seaborn as sns import matplotlib.pyplot as plt # تحميل البيانات Data = load_breast_cancer() X = Data.data y = Data.target # تقسيم البيانات إلى عينات تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=44, shuffle =True) # SGDClassifier تطبيق SGDC = SGDClassifier(penalty='l1',loss='hinge',learning_rate='optimal',random_state=44) SGDC.fit(X_train, y_train) print('SGDC Train Score is : ' , SGDC.score(X_train, y_train)) print('SGDC Test Score is : ' , SGDC.score(X_test, y_test)) # SGDC Test Score is : 0.9414893617021277 print('SGDC loss function is : ' , SGDC.loss_function_) print('SGDC No. of iteratios is : ' , SGDC.n_iter_) # عرض مصفوفة التشتت c = confusion_matrix(y_test, SGDC.predict(X_test)) print('Confusion Matrix is : \n', c) #لرسم المصفوفة sns.heatmap(c, center = True) plt.show()
- 1 جواب
-
- 2
-
-
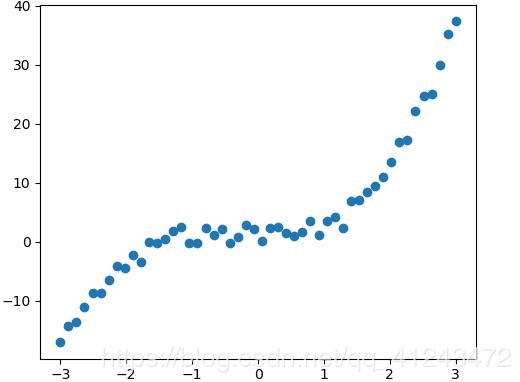
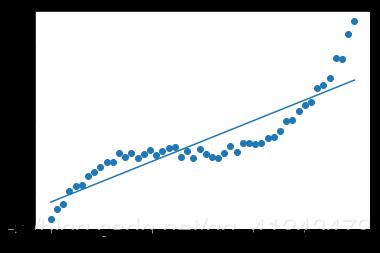
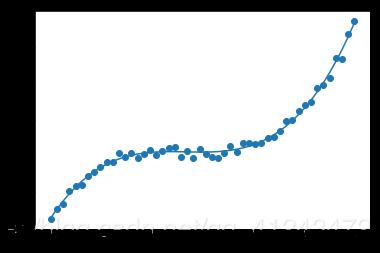
يمكنك استخدامه عبر الموديول: preprocessing.PolynomialFeatures وهو يستخدم مع التوقع الخطي لإعطاء البيانات الصفة اللاخطية، فكما تعلم أن الفرضية المستخدمة مع التوقع الخطي هي معادلة خط مستقيم من الشكل : y=wx+b وبالتالي معادلة مستقيم، وبالتالي في حال البيانات التي لها الشكل التالي لن تكون قادرة على ملاءمتها: حيث سيكون شكل ال Regressor بعد التدريب كالتالي: وبالتالي لملاءمة هكذا نوع من البيانات يجب أن تضيف لبياناتك الصفة اللاخطية وبالتالي تكون معادلة ال Regressor قادراة على ملائمة البيانات بالشكل المطلوب كالتالي: أي يجب أن تكون معادلة ال Regressor كالتالي: y=b+x1+x1^2+,,,,+x1^n للقيام بذلك باستخدام Sklearn: sklearn.preprocessing.PolynomialFeatures(degree=2, include_bias=True) degree: درجة كثير الحدود المطلوبة. include_bias: لتضمين الانحراف bias في العملية. مثال: import numpy as np from sklearn.preprocessing import PolynomialFeatures X = np.arange(4).reshape(2, 2) # تشكيل مصفوفة بقيم عشوائية print(X) ''' array([[0, 1], [2, 3]]) ''' poly = PolynomialFeatures(2) print(poly.fit_transform(X)) # للقيام بعملية التحويل نستدعي هذ التابع ''' array([[1. 0. 1. 0. 0. 1.] [1. 2. 3. 4. 6. 9.]]) '''
- 1 جواب
-
- 2
-
-
تم طرحه أكثر من مرة في المنصة، يمكنك مراجعة الأسئلة السابقة
- 3 اجابة
-
- 1
-
-
يمكن ذلك باستخدام مكتبة pands في البداية نقوم باستيراد المكتبة: import pandas as pd بعد ذلك نقوم بقراءة الملف وفق الرابط url: xls = pd.ExcelFile(url) بعد ذلك نقوم بحساب عدد ال sheet في الملف من خلال تطبيق len على قائمة الأسماء sheet_names، حيث أن xls.sheet_names قائمه تحوي أسماء ال sheet في الملف: namesheet=xls.sheet_names تعريف قائمة فارغة لوضع ال sheet فيها: frames=[] مرور حلقة على عدد ال sheet وقراءة كل شيت باستخدام read_excel من pandas وإضافتها للقائمه frames: for i in range(numsheet): df1 = pd.read_excel(xls,namesheet[i]) frames.append(df1) بعد ذلك نقوم بدمج جميع ال sheet الموجودة في frames باستخدام concat: df = pd.concat(frames) أي شيئ آخر؟
- 1 جواب
-
- 3
-
-
إذا كانت المهمة مهمة توقع كما أشرت، فإنه يتم استخدام MLPRegressor و هو نموذج للتوقع باستخدام الشبكات العصبونية يتم استخدامه عبر الموديول: neural_network.MLPRegressor مثل أي نموذج في التعلم الآلي يوجد لديه العديد من المعاملات التي تلعب دورا أساسيا في عملية تعلم الموديل عبر داتا التدريب لنقوم بالمرور على أهم المعاملات التي يأخذها هذا النموذج #استدعاء المكتبة: from sklearn.neural_network import MLPRegressor في البداية قمنا باستدعاء المكتبة التي يوجد فيها هذا الموديل #الشكل العام للموديل: MLPRegressorModel = MLPRegressor(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) البارمتر الأول activation مثلما نعرف يوجد في الشبكات العصبونية عدة أنواع لتوابع التنشيط أو activation ومن أهمها تابع sigmoid , relu,tanh لن أدخل في تفاصيل كل منها فأي دورة تعلم الآلة أو تعلم عميق تحوي هذه المفاهيم ولكن كنصيحه نقوم بجعل relu لجميع الطبقات ماعدا الأخيره أما الطبقة الأخيره نستخدم sigmod البارمتر الثاني solver هو طريقة الحل أو طريقة الوصول إلى أفضل قيم w,b الأوزران الخاصه بالشبكه العصبونية يوجد أكثر من طريقه مثل sgd ,adam ولكن ننصح باستخدام adam دوما البارمتر الثالث learning_rate هو معامل التعلم وهو يمثل مقدار الخطوه للوصول إلى الأوزران ويمكن تركه costant أي خطوات ثابتة أو adaptive متغيره أما ان تكون طويله أو قصيرة البارمتر الرابع early_stopping التوقف المبكر وهو يأخذ True بحال أردنا أيقاف معامل التعلم عند نقطه بحيث لا يدخل الموديل في مرحلة overfit أي الضبط الزائد وfalse عكس ذلك البارمتر الخامس alpha يمثل معامل التنعيم حيث التنعيم هو طريقة لكي يتخلص الموديل من الضبط الزائد overfit ويلعب alpha دورا مهما في ذلك البارمتر السادس hidden_layer_sizes وهو يمثل عدد الطبقات ماعدا طبقة الدخل والخرج لأنهما لا تعتبرا طبقات مخفيه وعدد الخلايا في كل طبقه حيث الأرقام تدل على عدد الخلايا في الطبقه أما موقع الرقم يدل على الطبقه وعدد المواقع يدل على عدد الطبقات المخفيه فمثلا (10,200,30,4) يوجد أربعة طبقات لأنه يوجد أربع أرقام وكل رقم منها يدل على عدد الخلايا في طبقته مثلا الطبقة الأولى تحوي 10 خلايا طبعا قمت بشرح الشكل العام للموديل ولكن عن طريقة استخدامه سهل جدا فقط بعد أن تقوم بتقسيم الداتا إلى X_train, y_train,X_test, y_test تسطيع كتابة الأتي لعملية التدريب. MLPRegressorModel = MLPRegressor(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) MLPRegressorModel.fit(X_train, y_train) حيث الدالة fit يوجد ضمنها جميع العمليات الداخلية لتدريب الشبكه العصبية يوجد دالة أخرى تستخدم لغرض التنبؤ كالاتي: y_pred = MLPRegressorModel.predict(X_test) حيث قمنا بالتنبؤ بالقيم المتوقعه لداتا الاختبار نستطيع أيضا حساب دقة الموديل أو كفاءته عن طريق التابع score ويكون وفق الشكل: print('MLPRegressorModel Test Score is : ' , MLPRegressorModel.score(X_test, y_test)) حيث قمنا بطباعة قيمتها لكي نرى كفاءة الموديل على بيانات الاختبار وهل هو يعاني من الضبط الزائد overfit أو الضبط الناقص underfit #استدعاء المكتبة from sklearn.neural_network import MLPRegressor #الشكل العام للموديل MLPRegressorModel = MLPRegressor(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) #تدريب الموديل MLPRegressorModel.fit(X_train, y_train) #حساب الدقة على الاختبار print('MLPRegressorModel Test Score is : ' , MLPRegressorModel.score(X_test, y_test)) #حساب القيم المتوقعه y_pred = MLPRegressorModel.predict(X_test)
- 1 جواب
-
- 1
-
-
ربما لأنك تستخدمين المعامل ==. وهو معامل نستخدمه مع ال primitive data types أي مع أنواع البيانات البدائية مثل int و float و double .. إلخ. لكنها لاتصلح للاستخدام مع البيانات من نوع object أي مع الكائنات لأنها في هذه الحالة ستقوم بمقارنة (المرجع) وليس القيمة التي يحملها. يجب استخدام التابع equal.مثلاً: import java.math.BigInteger; public class JavaApplication19 { public static void main(String[] args) { BigInteger x = new BigInteger("15"); // object متغير من النمط BigInteger y = new BigInteger("15"); // object متغير من النمط System.out.println(x.equals(y)); // true System.out.println(x==y); // false } }
- 3 اجابة
-
- 2
-
-
يمكنك فلترة هذا التنبيه، ولن يظهر مرة أخرى باستخدام التعليمات التالية: import warnings warnings.filterwarnings("ignore", message="numpy.ufunc size changed") warnings.filterwarnings("ignore", message="numpy.dtype size changed")
-
Time Series Split هي طريقة لتقسيم الداتا تعتمد على فكرة عنصر تدريب وعنصر اختبار ثم عنصرين تدريب وعنصر اختبار ثم ثلاث عناصر تدريب وعنصر اختبار وهكذا. لنأخذ مثال يوضح Time Series Split بشكل أفضل. في البداية نقوم باستدعاء المكتبات #استدعاء المكتبات import numpy as np from sklearn.model_selection import TimeSeriesSplit قمنا باستدعاء المكتبة numpy لتشكيل الداتا واستدعاء الوظيفه TimeSeriesSplit من الوحدة model_selection في مكتبة sklearn #تشكيل الدخل والخرج: X = np.array([[1, 2], [1, 4], [5, 2], [9, 4], [6, 2], [0, 4]]) y = np.array([1, 2, 3, 4, 5, 6]) حيث X مصفوفة أرقام من 6 أسطر وعمودين و y مصفوفة من 6 اسطر وعمود واحد #TimeSeriesSplit tscv = TimeSeriesSplit(n_splits=5,max_train_size=None) البارمتر الأول n_splits عدد صحيح لتحديد عدد الأجزاء folds وهي افتراضية في sklearn من 3 إلى 5 البارمتر الثاني max_train_size الحجم الأكبر لمجموعة تدريب واحدة for train_index, test_index in tscv.split(X): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] print('X_train \n' , X_train) print('X_test \n' , X_test) print('y_train \n' ,y_train) print('y_test \n' , y_test) print('*********************') بعد ذلك يتم المرور بحلقة حيث يتم استخدام اثنين من الاندكسات في الحلقة للمرور على التدريب والاختبار وتحوي tscv.split(X) بعد ذلك في كل مرور على الحلقة يتم طباعة الاندكسات الخاص بالتدريب والاختبار وبعد ذلك تم تخزين بيانات التدريب والاختبار وبعدها طباعة كل منها في كل محاولة الكود كامل: #استدعاء المكتبات import numpy as np from sklearn.model_selection import TimeSeriesSplit #تشكيل الدخل والخرج X = np.array([[1, 2], [1, 4], [5, 2], [9, 4], [6, 2], [0, 4]]) y = np.array([1, 2, 3, 4, 5, 6]) #TimeSeriesSplit tscv = TimeSeriesSplit(n_splits=5,max_train_size=None) for train_index, test_index in tscv.split(X): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] print('X_train \n' , X_train) print('X_test \n' , X_test) print('y_train \n' ,y_train) print('y_test \n' , y_test) print('*********************') # Machine Learning is everywhere # Written by Ali Ahmed
-
يمكنك استخدام التابع sort الذي له الشكل التالي: list.sort(key = len,reverse=False) key و reverse وسيطان اختياريان. key يمثل تابع لتنفيذ الفرز على أساسه وفي حالتنا سنمرر له التابع len وبالتالي سيتم الفرز على أساس طول كل كلمة. في حال ضبط reverse على True سيكون الترتيب تنازلي. Hsoub = ['ali', 'ml', 'python'] Hsoub.sort(key = len,reverse=True) print(Hsoub) # output: ['python', 'ali', 'ml'] كما يمكنك استخدام هذا التابع لفرز العناصر داخل ال list مهما كان نوعها.
- 2 اجابة
-
- 3
-
-
يمكنك استخدامها عبر الموديول linear_model.LogisticRegression: sklearn.linear_model.LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, n_jobs=None) الوسطاء (غالباً نتركهم على الحالة الافتراضية لكن أنصح باستخدام newton-cg optimizer مع solver ): penalty: لتحديد ال norm المستخدمة في عملية ال penalization (يقصد فيهما نوع عملية التنعيم المستخدمة). ويأخذ القيم التالية: {‘l1’, ‘l2’(default), ‘elasticnet’, ‘none’} ملاحظة: sag و lbfgs و newton-cg يدعمون فقط النوع الثاني l2. elasticnet يدعم فقط saga. tol: مقدار السماحية المسموح بها في الخطأ، أي لكي تخبر النموذج متى يمكنه التوقف عند البحث عن القيمة صغرى بمجرد الوصول إلى هذه القيمة. C: معكوس التنعيم، وكلما كانت أصغر كلما زاد التنعيم. random_state: تتحكم بعملية تقسيم البيانات. max_iter: العدد الأعظمي للتكرارات الممكنة. n_jobs: لتحديد السرعة، ويقبل عدد صحيح: -1: أي أنك تريد التنفيذ على GPU [1,n]: كلما قمت بزيادة الرقم كلما زاد التسريع (يعتمد على قدرات جهازك). Solver: لتحديد خوارزمية التقارب convergence وتكون قيمتها : {‘newton-cg’, ‘lbfgs’ (default), ‘liblinear’, ‘sag’, ‘saga’} sag أو saga في حالة البيانات الكبيرة. liblinear في حالة البيانات الصغيرة. dual: يفضل وضعه على False عندما تكون عدد العينات أكبر من عدد ال features. verbose: لعرض كل التفاصيل أثناء التدريب نضع أي عدد صحيح أكبر من الصفر وإلا نضع 0. ال attributes: coef_: لعرض أوزان التدريب. intercept_: التقاطع مع المحور y وهو قيمة بوليانية، في حال ضبطه على true يتم إخذ أفضل تقاطع مع المحور y. classes_: أسماء الفئات المستخدمة، مثلاً مريض أو غير مريض أي 0 و 1. n_iter_: عدد المحاولات التي قامت بها الخوارزمية. الدوال: score(data, label): لعرض مدى كفاءة المودل. predict(data): لإخراج القيم المتوقعة لدخل معطى. fit(data,label): للقيام بعملية التدريب. مثال على بيانات أمراض سرطان الثدي (مريض|سليم) : # استيراد المكتبات اللازمة from sklearn.datasets import load_breast_cancer # استيراد الداتا from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # تحميل الدات BreastData = load_breast_cancer() data = BreastData.data labels = BreastData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=4, shuffle =True) LogisticR = LogisticRegression(max_iter=110,solver="newton-cg") # حددنا عدد التكرارات ب 110 كحد أقصى LogisticR.fit(X_train, y_train) # بدء التدريب print('train Score is : ' , LogisticR.score(X_train, y_train)) #96% # عرض الدقة على بيانات التدريب print('Test Score is : ' , LogisticR.score(X_test, y_test)) # 91% # عرض الدقة على بيانات الاختبار print('LogisticR Classes are : ' , LogisticR.classes_) # عرض الفئات الموجودة لدينا وهي 0 و 1 أي مريض وسليم print('LogisticR No. of iteratios is : ' , LogisticR.n_iter_) # عرض عدد المحاولات أوالتكرارات print('----------------------------------------------------') # حساب التوقع y_pred = LogisticR.predict(X_test) y_pred_prob = LogisticR.predict_proba(X_test) print('Predicted Value : ' , y_pred[:4]) # عرض القيم المتوقعة بعد قصرها print('Prediction Probabilities Value : ' , y_pred_prob[:4]) # عرض القيم المتوقعة كقيم احتمالية
-
هي أحد طرق تقسيم الداتا هي متل KFold ولكن تختلف عنها بأنها مجموعه من Kfold، ولكن بتنويعات أكبر، ويتم استخدامها في حالة كانت البيانات قليلة جداً وأردنا أن يكون تقييم النموذج دقيق جداً (أشار لذلك فرانسوا كوليت)، لننتقل إلى الكود البرمجي لسهولة الفهم في التطبيق #استدعاء المكتبات: import numpy as np from sklearn.model_selection import RepeatedKFold قمنا باستدعاء المكتبة numpy لتشكيل الداتا، واستدعاء الوظيفه RepeatedKFold من الوحدة model_selection في مكتبة sklearn #تشكيل الداتا الدخل والخرج: X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) y = np.array([11, 22, 33, 44]) حيث X مصفوفة أبعادها 4 أسطر وعمودين وy عمود واحد بأربع أسطر. #RepeatedKFold rkf = RepeatedKFold(n_splits=4, n_repeats=4) البارمتر الأول n_splits عدد صحيح لتحديد عدد الأجزاء folds وهي افتراضية في sklearn من 3 إلى 5. البارمتر الثاني n_repeats وهو نقطة الاختلاف عن KFolds هو عدد صحيح يمثل عدد KFolds. نفس الأمر في Kfolds مرور حلقة حيث يتم استخدام اثنين من الاندكسات في الحلقة للمرور على التدريب والاختبار وتحوي kf.split(X) هذه الاندكسات وهنا عدد المحاولات سوف يكون في مثالنا: n_splits*n_repeats=4*4=16 أي 4 Kfolds وكل kfold يحوي 4 تقسيمات مختلفه في كل مره. نقوم بطباعة الاندكس للتدريب والاختبار في كل محاوله وبعدها تخزين التدريب والاختبار ومن ثم طباعة كل منها: for train_index, test_index in rkf.split(X): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] print('X_train \n' , X_train) print('X_test \n' , X_test) print('y_train \n' ,y_train) print('y_test \n' , y_test) print('*********************') الكود كامل: #استدعاء المكتبات import numpy as np from sklearn.model_selection import RepeatedKFold #تشكيل الداتاالدخل والخرج X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) y = np.array([11, 22, 33, 44]) #RepeatedKFold rkf = RepeatedKFold(n_splits=2, n_repeats=4, random_state=44) for train_index, test_index in rkf.split(X): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] print('X_train \n' , X_train) print('X_test \n' , X_test) print('y_train \n' ,y_train) print('y_test \n' , y_test) print('*********************')
- 1 جواب
-
- 1
-
-
يعتبر البحث الثنائي أفضل من الخطي لأن في البحث الخطي سوف نمرر على كل عنصر لتحقق إذا كان هو أما في البحث الثنائي يتم ترتيب المصفوفه ومن ثم المقارنه مع العدد الذي في الوسط فأذا كان العدد المعطى أكبر من العدد الذي في الوسط نقوم في البحث في النصف الأعلى من المصفوفه أما إذا كان أصغر نقوم بالبحث في النصف الاسفل أما اذا كان يساويه فيكون هو العدد المنشود ويتم تكرار نفس الشي في كل مره حتى نجد العدد: a=[3,2,3,5,6,4,7] x=int(input()) a=sorted(a) start,end=0,len(a) y=-1 while(start<=end): mid=(start+end)//2 if(a[mid]==x): y=mid break if(x>a[mid]): start=mid+1 else: end=mid-1 if(y==-1): print("Number not found") else: print("Number found in index {}".format(y)) في البداية إدخال العدد المراد البحث عنه بعد ذلك ترتيب المصفوفه لأن شرط البحث الثنائي هو ان تكون المصفوفه مرتبه بعد ذلك تعيين قيمة البداية صفر وقيمة النهاية ب طول المصفوفه أعطاء y=-1 وذلك يعني أن العدد في البداية لا يعتبر موجود بعد ذلك حلقه شرط الحلقه يكون دوما البداية أصغر من النهايه بعد ذلك اسناد قيمة الاندكس الذي في الوسط إلى mid بعد ذلك عمليات المقارنه التي ذكرناها في حالة التساوي نقوم بإسناد قيمة mid إلى y في حالة x أكبر من القيمه التي في الوسط هذا يعني أنها أكبر من جميع قيم النصف الأيسر من المصفوفه بالتالي تصبح البداية الجديدة mid+1 في حالة x أصغر من القيمه التي في الوسط هذا يعني أنها أصغر من جميع قيم النصف الأيمن من المصفوفه بالتالي تصبح النهاية الجديدة mid-1 بعد اختلال الشرط نخرج من الحلقه فإذا تغيرت قيمة y هذا يعني أنه موجود ونقوم بطباعة موجود وإذا كان يساوي -1 هذا يعني أنه غير موجود
- 3 اجابة
-
- 2
-